Статистическое моделирование (работа 1)
Содержание
Введение
Выборочный метод
Статистическая оценка законов распределения
Основные свойства точечных оценок
Оценка математического ожидания и дисперсии по выборке
Доверительные интервалы
Методы получения оценок
Метод максимального правдоподобия
Распределение хи-квадрат
Литература
Введение
Когда приходится изучать не единичные, а массовые случайные явления, необходимо прибегать к статистическим методам исследования. Эти методы предназначены для выявления закономерностей там, где на первый взгляд нет ничего, кроме совокупности отдельных фактов, наблюдений, измерений. Теория вероятностей и математическая статистика являются науками о методах количественного анализа массовых случайных явлений.
В теории вероятностей по заданным вероятностям некоторых событий и функциям распределения случайных величин определяются вероятности и функции распределения других событий и случайных величин.
Естественно спросить: откуда известны исходные вероятности и распределения, как их найти? Одних априорных рассуждений для этого, как правило, недостаточно, необходимы опыт, специальные испытания. Математическая статистика и разрабатывает методы, позволяющие по результатам испытаний делать определённые выводы о вероятностях и распределённых случайных величин и событий.
Целью каждой науки является обнаружение некоторых общих закономерностей, позволяющих предвидеть течение явлений природы и выбирать рациональные пути поведения в исходных ситуациях. Во многих случаях для обнаружения общих закономерностей необходимо провести большое число наблюдений и измерений; как следствие нужны методы обработки совокупности таких наблюдений. Эти методы также разрабатывает математическая статистика.
Первые работы по математической статистике появились в 18ом веке и были связаны со статистикой народонаселения, изучением продолжительности жизни и вопросами страховании. Позже в конце 18ого начало 19ого века в связи с астрономическими задачами начались серьёзные исследования по теории ошибок измерений. Биологические изыскания послужили толчком для постановки многочисленных вопросов, которые привели в начале 20го века к выделению математической статистки в отдельную науку. Сейчас в связи с общим бурным развитием науки и проникновением количественных методов буквально во все отрасли знаний интерес к математической статистике возрос, возникли новые задачи и методы. Математическая статистика находится в стадии дальнейшего развития и её прогресс продолжается.
Известно, что каждое распределение определяется тем или иным числом параметров: закон Пуассона зависит только от одного параметра – математического ожидания; нормальный закон – от двух – математического ожидания и дисперсии исследуемой случайной величины.
Если мы хотим использовать эти законы, например распределения Пуассона, в инженерных задачах, нам нужно оценить параметр, то есть найти его численное значение, в данном случае – численное значение математического ожидания.
Традиционный естественный способ нахождения параметра заключается в обследовании некоторого множества значений соответствующей случайной величины. Это множество обычно называется выборкой; элементы множества – выборочными значениями случайной величины; количество элементов – объёмом выборки. На основании изучения выборки мы делаем некоторые выводы о всей совокупности возможных значений случайной величины. Эта совокупность называется генеральной. В результате обследования выборки и использования соответствующих статистических правил можно получить численную оценку значения параметра. Оценка параметра – это некоторая функция от выборочных значений случайной величины. В нашем случае в качестве оценки параметра – математического ожидания можно использовать среднее арифметическое выборочных значений. Отметим, что оценка является случайной величиной. Таким образом, параметр – постоянная величина заменяется значением случайной величины, полученной по результатам выборки на основании некоторого правила.
Если мы рассмотрим ещё одну выборку такого же объёма, то численное значение оценки будет несколько иным, так как состав нашей выборки случаен. Это ещё раз иллюстрирует тот факт, что с помощью оценки величина параметра определяется с некоторой ошибкой. Узловым для математической статистики является вопрос, как далеко могут отклонятся величины оценок, вычисление по выборке, от соответствующих истинных значений параметров.
В рассмотренном случае нужно по выборке оценить математическое ожидание случайной величины, распределённой по закону Пуассона. Как это сделать? Можно использовать: 1) среднее арифметическое 2) наиболее часто встречающееся выборочное значение случайной величины; 3) средний член вариационного ряда.
Какая из этих оценок лучше? И что значит лучшая оценка? Каким требованиям она должна удовлетворять? Ответы на эти вопросы даёт математическая статистика.
Вторая задача – проверка статистических гипотез. Это могут быть гипотезы о законе распределения, о равенстве двух математических ожиданий или дисперсий различных распределений. Проверка статистических гипотез также производится на основе анализа выборки ограниченного объёма.
Можно предположить что некоторая случайная величина распределена по закону Пуассона. Эта гипотеза нуждается в проверке. Частоты (оценки вероятностей), полученные в результате обработки выборки, могут несколько отличаться от вероятностей, определённых на основании распределения Пуассона. Причина расхождения может заключаться в том, что неправильна гипотеза о законе распределения. Однако не исключение и другая причина: объём выборки весьма мал, а при таком объёме выборки полученные различия между частотами и вероятностями могут наблюдать и при истинности предположения о законе распределения. Принять наилучшее решение в данном случае помогают методы математической статистики.
Существуют и другие не менее важные задачи математической статистики, такие, например как планирование эксперимента, установление статистических зависимостей между случайными событиями.
1. Выборочный метод
Генеральная и выборочная совокупность
Одним из фундаментальных понятий математической статистики является неопределяемое понятие генеральной совокупности. Под генеральной совокупностью понимают множество качественно однородных элементов (объектов, изделий) самой различной природы. Рассмотрим возможные типы этих совокупностей.
Конечная и реально существующая, например генеральная совокупность всех людей Украины в фиксированный момент времени.
Бесконечная и реально существующая, например множество действительных чисел, лежащих между нулем и единицей.
Воображаемая (гипотетическая) конечная или бесконечная: Например, повторные непрекращающиеся бросания игральной кости дают последовательность элементов из бесконечной несуществующей генеральной совокупности.
Вторым основным понятием математической статистики является понятие выборочной совокупности (выборки).
Пусть требуется изучить элементы некоторой генеральной совокупности относительно какого-либо количественного признака, характеризующего эти элементы. Это можно сделать, производя сплошное обследование всех элементов совокупности относительно интересующего нас признака. Однако на практике сплошное обследование применяется сравнительно редко. Для генеральной совокупности, содержащей большое число элементов, сплошное обследование будет экономически невыгодно или вообще физически невозможно. Если обследование объекта связано с его уничтожением (например при проверке качества минных взрывателей) или потребует больших материальных затрат (например запуск современной ракеты), то проводить сплошное обследование практически не имеет смысла. В такой ситуации случайно отбирают из генеральной совокупности ограниченое число объектов и изучают их.
Таким образом, выборочной совокупностью или просто выборкой объёма n будем называть совокупность n объектов, отобранных из интересующей нас генеральной совокупности.
2. Статистическая оценка законов распределения
Если выборка объёма n из генеральной совокупности представительна, то элементы с одинаковыми значениями варианты будут приблизительно одинаково часто встречаться как в выборке, так и в генеральной совокупности. В этом случае естественно принять распределение X в выборке за приближенное распределение ее в генеральной совокупности, тоесть считать дискретное распределение выборки F>n>(x) приближением к теоретической функции распределения F(x). Пример приближения показан на рисунке
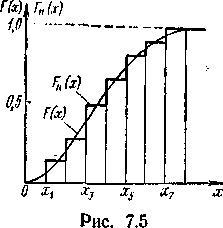
Основанием для такого приближения является так называемая основная теорема математической статистики, доказанная В.И. Гливенко
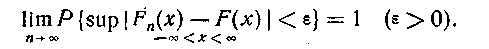
Из этой теоремы следует, что при n→∞ с вероятностью, равной единице, верхняя граница отклонения |F(x)−F(x)| на всей оси x стремится к нулю. Тем самым гарантируется равномерное приближение F>n> (x) к F(x) на всей оси x. Таким образом, исследуя функцию Fn (x), мы можем по ней приближено оценить теоретическую функцию распределения случайной величины.
3. Основные свойства точечных оценок
Для того чтобы оценка >
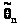 >
имела практическую ценность, она должна
обладать следующими свойствами.
>
имела практическую ценность, она должна
обладать следующими свойствами.
1. Оценка >
>
параметра
называется несмещенной,
если ее математическое ожидание равно
оцениваемому параметру
, т.е.
М>>=
>
 >
.(22.1)
>
.(22.1)
Если равенство (22.1) не выполняется,
то оценка >
>
может либо завышать значение
(М>>>>>
), либо занижать его (М>><
>
>
) . Естественно в качестве приближенного
неизвестного параметра брать несмещенные
оценки для того, чтобы не делать
систематической ошибки в сторону
завышения или занижения.
2. Оценка >
>
параметра
называется состоятельной
, если она подчиняется закону больших
чисел, т.е. сходится по
вероятности к оцениваемому
параметру при неограниченном возрастании
числа опытов (наблюдений ) и, следовательно,
выполняется следующее равенство:
>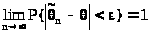 >,(22.2)
>,(22.2)
где > 0 сколько угодно малое число.
Для выполнения (22.2) достаточно,
чтобы дисперсия оценки стремилась к
нулю при >
 >,
т.е.
>,
т.е.
>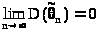 >(22.3)
>(22.3)
и кроме того, чтобы оценка была несмещенной. От формулы (22.3) легко перейти к (22.2) , если воспользоваться неравенством Чебышева.
Итак, состоятельность оценки означает, что при достаточно большом количестве опытов и со сколько угодно большой достоверностью отклонение оценки от истинного значения параметра меньше любой наперед заданной величины. Этим оправдано увеличение объема выборки.
Так как >
>
- случайная величина, значение которой
изменяется от выборки к выборке, то меру
ее рассеивания около математического
ожидания
будем характеризовать дисперсией D>>.
Пусть >
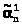 >
и >
>
и >
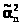 >
- две несмещенные оценки параметра ,
т.е. M>>=
и M>>=
, соответственно D >
>
и D>>и,
если D >
>
< D>>,
то в качестве оценки принимают >
>.
>
- две несмещенные оценки параметра ,
т.е. M>>=
и M>>=
, соответственно D >
>
и D>>и,
если D >
>
< D>>,
то в качестве оценки принимают >
>.
3. Несмещенная оценка >
>,
которая имеет наименьшую дисперсию
среди всех возможных несмещенных оценок
параметра ,
вычисленных по выборкам одного и того
же объема , называется
эффективной оценкой.
На практике при оценке параметров не всегда удается удовлетворить одновременно требованиям 1, 2, 3. Однако выбору оценки всегда должно предшествовать ее критическое рассмотрение со всех точек зрения. При выборке практических методов обработки опытных данных необходимо руководствоваться сформулированными свойствами оценок.
4. Оценка математического ожидания и дисперсии по выборке
Наиболее важными характеристиками случайной величины являются математическое ожидание и дисперсия. Рассмотрим вопрос о том, какие выборочные характеристики лучше всего оценивают математическое ожидание и дисперсию в смысле несмещенности, эффективности и состоятельности.
Теорема 23.1.
Арифметическая средняя >
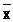 >,
вычисленная по n независимым наблюдениям
над случайной величиной ,
которая имеет математическое ожидание
M
= ,
является несмещенной оценкой этого
параметра.
>,
вычисленная по n независимым наблюдениям
над случайной величиной ,
которая имеет математическое ожидание
M
= ,
является несмещенной оценкой этого
параметра.
Доказательство.
Пусть >
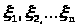 >-
n
независимых наблюдений над случайной
величиной .
По условию M
= ,
а т.к. >
>-
n
независимых наблюдений над случайной
величиной .
По условию M
= ,
а т.к. >
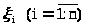 >
являются случайными величинами и имеют
тот же закон распределения, то тогда >
>
являются случайными величинами и имеют
тот же закон распределения, то тогда >
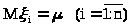 >.
По определению средняя арифметическая
>.
По определению средняя арифметическая
>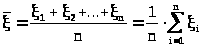 >.(23.1)
>.(23.1)
Рассмотрим математическое ожидание средней арифметической. Используя свойство математического ожидания, имеем:
>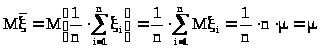 >,
>,
т.е. >
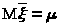 >.
В силу (22.1) >
>
является несмещенной оценкой.
>.
В силу (22.1) >
>
является несмещенной оценкой.
Теорема 23.2.
Арифметическая средняя >
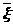 >,
вычисленная по n независимым наблюдениям
над случайной величиной ,
которая имеет M
=
и >
>,
вычисленная по n независимым наблюдениям
над случайной величиной ,
которая имеет M
=
и >
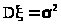 >,
является состоятельной оценкой этого
параметра.
>,
является состоятельной оценкой этого
параметра.
Доказательство.
Пусть >
>
- n
независимых наблюдений над случайной
величиной .
Тогда в силу теоремы 23.1 имеем M
= >
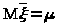 >.
>.
Для средней арифметической >
>
запишем неравенство Чебышева:
>
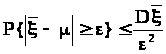 >
.
>
.
Используя свойства дисперсии 4,5 и (23.1), имеем:
>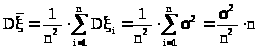 >,
>,
т.к. по условию теоремы >
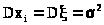 >.
>.
Следовательно,
>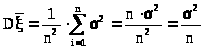 >
.(23.2)
>
.(23.2)
Итак, дисперсия средней арифметической в n раз меньше дисперсии случайной величины . Тогда
>
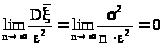 >,
>,
поэтому
>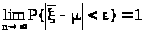 >,
>,
а это значит, что >
>
является состоятельной оценкой.
Замечание:
1. Примем без доказательства
весьма важный для практики результат.
Если
N (a, ),
то несмещенная оценка >
>
математического ожидания a
имеет минимальную дисперсию, равную >
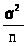 >,
поэтому >
>
является эффективной оценкой параметра
а.
>,
поэтому >
>
является эффективной оценкой параметра
а.
Перейдем к оценке для дисперсии и проверим ее на состоятельность и несмещенность.
Теорема 23.3. Если случайная выборка состоит из n независимых наблюдений над случайной величиной с
M
=
и D
= >
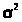 >,
то выборочная дисперсия
>,
то выборочная дисперсия
>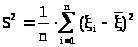 >
(23.3)
>
(23.3)
не является несмещенной оценкой D - генеральной дисперсии.
Доказательство.
Пусть >
>
- n
независимых наблюдений над случайной
величиной .
По условию >
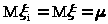 >
и >
>
и >
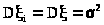 >
для всех >
>
для всех >
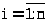 >.
Преобразуем формулу (23.3) выборочной
дисперсии:
>.
Преобразуем формулу (23.3) выборочной
дисперсии:
>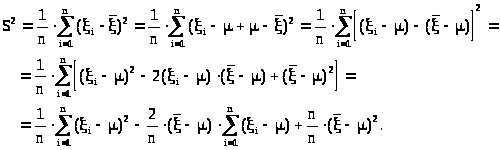 >
>
Упростим выражение
>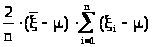 >.
>.
Принимая во внимание (23.1), откуда
>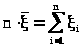 >
>
можно записать
>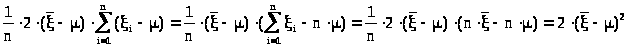 >
>
Тогда
>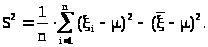 >
>
Теперь рассмотрим >
 >
- математическое ожидание выборочной
дисперсии:
>
- математическое ожидание выборочной
дисперсии:
>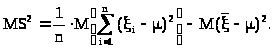 >
>
Используя определение дисперсии, получаем:
>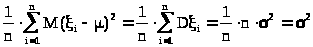 >
>
и>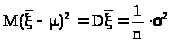 >
в силу (23.2), следовательно,
>
в силу (23.2), следовательно,
>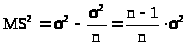 >,(23.4)
>,(23.4)
т.е. выборочная дисперсия является смещенной оценкой дисперсии генеральной совокупности.
Замечание 2. Оценку (23.4) можно исправить так, чтобы она стала несмещенной
>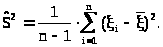 >(23.5)
>(23.5)
Обычно оценку >
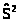 >
называют исправленной
выборочной дисперсией.
Действительно,
>
называют исправленной
выборочной дисперсией.
Действительно,
>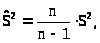 >
>
тогда
>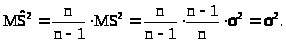 >
>
Дробь >
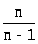 >
называют поправкой Бесселя.
При малых n поправка Бесселя значительно
отличается от 1. При n > 50 практически
нет разницы между >
>
называют поправкой Бесселя.
При малых n поправка Бесселя значительно
отличается от 1. При n > 50 практически
нет разницы между >
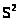 >
и >
>
.
>
и >
>
.
Замечание
3. Можно показать, что
оценки >
>
и >
>
являются состоятельными и не являются
эффективными.
Несмещенной, состоятельной и
эффективной оценкой >
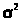 >
является оценка
>
является оценка
>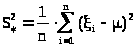 >(23.6)
>(23.6)
в случае, когда математическое ожидание известно
.
5. Доверительные интервалы
Изучавшиеся ранее оценки
неизвестного параметра являются
точечными: мы
старались судить о значении неизвестного
числа или вектора
по значению оценки >
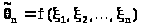 >,
принятом ею, как только известна
статистическая выборка (>
>,
принятом ею, как только известна
статистическая выборка (>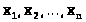 >).
Однако, поскольку оценка сама является
случайной величиной, её выборочное
значение заведомо не совпадает с
константой .
Имея в виду это обстоятельство,
предпочтительнее стремиться указывать
не точное значение оцениваемого
параметра, а некоторый интервал,
содержащий в себе значение параметра.
Границы такого интервала должны
определяться доступной нам информацией
- выборкой из генеральной совокупности,
то есть они сами случайны, и поэтому
есть смысл говорить о вероятности того,
что значение параметра находится внутри
интервала.
>).
Однако, поскольку оценка сама является
случайной величиной, её выборочное
значение заведомо не совпадает с
константой .
Имея в виду это обстоятельство,
предпочтительнее стремиться указывать
не точное значение оцениваемого
параметра, а некоторый интервал,
содержащий в себе значение параметра.
Границы такого интервала должны
определяться доступной нам информацией
- выборкой из генеральной совокупности,
то есть они сами случайны, и поэтому
есть смысл говорить о вероятности того,
что значение параметра находится внутри
интервала.
Определение 24.1.
Пусть генеральная совокупность
описывается случайной величиной ,
распределение которой зависит от
скалярного параметра .
Пусть, далее, >
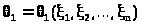 >
и >
>
и >
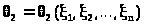 >
две функции выборки такие, что всегда
>
>
две функции выборки такие, что всегда
>
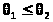 >
и
>
и
>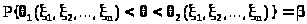 >.
>.
(>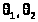 >)
со случайными границами называют
доверительным
интервалом для неизвестного параметра
с доверительной вероятностью .
>)
со случайными границами называют
доверительным
интервалом для неизвестного параметра
с доверительной вероятностью .
Число называют уровнем значимости интервала.
Стараясь иметь как можно более достоверные выводы, границы доверительного интервала выбирают таким образом, чтобы доверительная вероятность была как можно ближе к 1.
Схематически процесс построения доверительного интервала можно описать следующим образом.
Пусть >
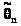 >
- несмещенная оценка параметра .
>
- несмещенная оценка параметра .
Выберем доверительную вероятность . Значение выражения « как можно ближе к 1» относительно, оно находится вне границ математики и определяется лицом, производящим статистические исследования. Обычно выбирают равным 0,9; 0,95; 0,99.
Пусть, далее, можно найти такое число > 0, что
>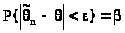 >.(24.1)
>.(24.1)
Записав (24.1) в виде
>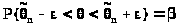 >,
>,
видим, что интервал (>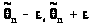 >)
является доверительным интервалом для
параметра
с уровнем значимости
.
>)
является доверительным интервалом для
параметра
с уровнем значимости
.
Практически вопрос о построении
доверительного интервала связан с
возможностью нахождения распределения
оценки >
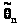 >,
а это, в свою очередь, зависит от
распределения генеральной совокупности.
>,
а это, в свою очередь, зависит от
распределения генеральной совокупности.
Пример 24.1. Построение доверительного интервала для математического ожидания нормальной генеральной совокупности при известной дисперсии.
Пусть генеральная совокупность распределена по нормальному закону с параметрами (2), где 2 (дисперсия) известно. Мы уже знаем, что наилучшей в смысле несмещенности, состоятельности и эффективности оценкой неизвестного математического ожидания нормального закона является выборочное среднее
>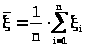 >.
>.
В продвинутом курсе теории
вероятностей доказывается, что нормальное
распределение обладает свойством
устойчивости
: если независимые случайные величины
распределены нормально с параметрами
(>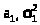 >)
и (>
>)
и (>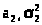 >)
соответственно, то их сумма
+
распределена нормально с параметрами
(>
>)
соответственно, то их сумма
+
распределена нормально с параметрами
(>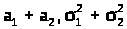 >).
>).
Используя это утверждение в
нашем случае, заключаем, что>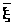 >распределена
нормально с параметрами (>
>распределена
нормально с параметрами (>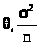 >),
а нормированное выборочное среднее >
>),
а нормированное выборочное среднее >
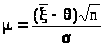 >
подчинено нормальному закону с параметрами
(0,1).
>
подчинено нормальному закону с параметрами
(0,1).
Это означает, что
>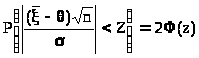 >,
где >
>,
где >
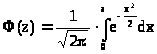 >.
>.
Функция Ф(z) нам уже встречалась, её значения табулированы.
Выберем теперь доверительную
вероятность
и обозначим >
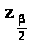 >корень
уравнения Ф(>>)
= />2>.
>корень
уравнения Ф(>>)
= />2>.
После этого рассмотрим равенства
>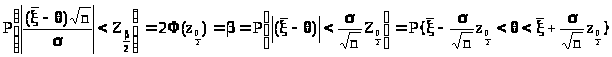 >,
которые свидетельствуют о том, что
интервал
>,
которые свидетельствуют о том, что
интервал
>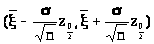 >
>
является доверительным для параметра с доверительной вероятностью ( и уровнем значимости ).
Приведем часть из таблицы значений
>
>
(прил. 2) для некоторых наиболее
употребительных значений .
Таблица 24.1 (Зависимость >
>
от доверительной вероятности)
|
|
0,9 |
0,925 |
0,95 |
0,99 |
|
> |
1,65 |
1,78 |
1,96 |
2,89 |
Обозначим >
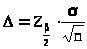 >
половину ширины доверительного интервала.
>
половину ширины доверительного интервала.
Замечаем, что:
при фиксированной доверительной вероятности ширина доверительного интервала уменьшается с ростом числа наблюдений n как величина порядка >
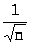 >
( при увеличении, например, числа
наблюдений в 100 раз ширина интервала
уменьшится в 10 раз);
>
( при увеличении, например, числа
наблюдений в 100 раз ширина интервала
уменьшится в 10 раз);поскольку Ф(z) возрастает с ростом z, то увеличение доверительной вероятности, при всех прочих постоянных параметрах, приводит к расширению доверительного интервала.
Пример 24.2. Желая
узнать, сколько часов в неделю дети
проводят у телевизора, социологическая
служба обследовала 100 учеников некого
города, в результате чего оказалось,
что в среднем это число равно >
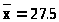 >.
Из прошлой практики известно, что
стандартное отклонение (>
>.
Из прошлой практики известно, что
стандартное отклонение (>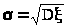 >)
генеральной совокупности равно 6 (часов).
Найдем доверительный интервал с
доверительной вероятностью 0,95 для числа
часов в неделю, проводимых ребенком у
телевизора.
>)
генеральной совокупности равно 6 (часов).
Найдем доверительный интервал с
доверительной вероятностью 0,95 для числа
часов в неделю, проводимых ребенком у
телевизора.
Поскольку
= 0,95, из табл. 24.1 находим >
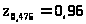 >,
и границы интервала доверия будут
такими:
>,
и границы интервала доверия будут
такими:
>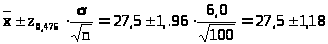 >,
>,
интервал доверия имеет вид (26.32; 28.68).
Теперь поставим вопрос иначе: сколько детей надо обследовать с тем, чтобы среднее число часов в неделю, проводимых ребенком у телевизора, отклонилось от его оценки не более чем на 0,5 ч. с вероятностью 0,95?
В такой постановке речь идет о нахождении числа n таким, чтобы выполнялось равенство
>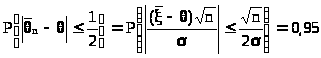 >
,
>
,
откуда >
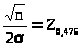 >
или n
= (2Z>0.475>)2.
>
или n
= (2Z>0.475>)2.
В условиях примера n = (261,96)2 553.
Разумеется, при больших значениях n ширина доверительного интервала уменьшится.
Заметим, что по сравнению с первоначальной задачей ширина интервала уменьшилась в 1,18/0,5 = 2,36 раз, количество необходимых испытаний увеличилось в (2,36)2 = 5,57 раз ( 553 отличается в третьем знаке от 100 5,57).
Пример 24.3. Построение доверительного интервала для математического ожидания нормальной генеральной совокупности при неизвестной дисперсии.
Снова рассмотрим генеральную совокупность , распределенную нормально с параметрами (2), однако теперь считаем дисперсию 2 неизвестной.
Обозначим >
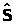 >
стандартное выборочное квадратичное
отклонение
>
стандартное выборочное квадратичное
отклонение
>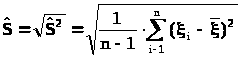 >.
>.
В курсах теории вероятностей доказывается, что случайная величина
>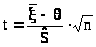 >
>
подчиняется так называемому закону распределения Стьюдента с n - 1 степенью свободы и её плотность имеет вид
>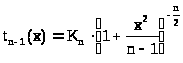 >,
>,
где К>n> некоторая нормирующая константа.
Созданы таблицы , дающие возможность вычислять вероятности вида
>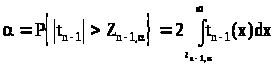 >
>
(см. прил. 4).
Ввиду вышесказанного, получаем равенства:
>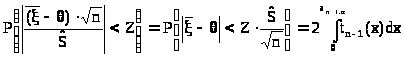 >,
>,
из которых видно, что выбрав Z как корень уравнения
>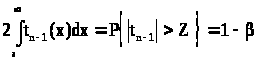 >
>
( обозначим этот корень >
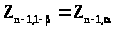 >),
приходим к доверительному интервалу
для
вида
>),
приходим к доверительному интервалу
для
вида
>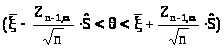 >.
>.
Пример 24.4. Рассмотрим
вопрос о построении доверительного
интервала для неизвестного количества
времени в течение недели, проводимого
ребенком у экрана телевизора, сохранив
все данные примера 24.2, считая теперь,
что 6ч. есть оценка выборочного
среднеквадратического отклонения, >
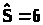 >.
>.
По таблице распределения Стьюдента
(см. приложение 4) находим >
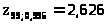 >,
границы интервала будут
>,
границы интервала будут
>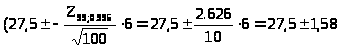 >,
>,
а сам интервал (25,92; 29,08).
Замечаем, что интервал стал шире, что объясняется уменьшением объема имеющейся информации из-за незнания ещё одного параметра генеральной совокупности.
6. Методы получения оценок
До сих пор мы считали, что оценка неизвестного параметра известна и занимались изучением ее свойств с целью использования их при построении доверительного интервала. В этом параграфе рассмотрим вопрос о способах построения оценок.
Методы правдоподобия
Пусть требуется оценить неизвестный
параметр >
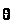 >,
вообще говоря, векторный, >
>,
вообще говоря, векторный, >
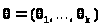 >.
При этом предполагается, что вид функции
распределения известен с точностью до
параметра >
>,
>.
При этом предполагается, что вид функции
распределения известен с точностью до
параметра >
>,
>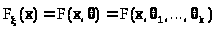 >.
>.
В таком случае все моменты
случайной величины
становятся функциями от >
>:
>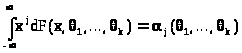 >.
>.
Метод моментов требует выполнения следующих действий:
Вычисляем k «теоретических» моментов
>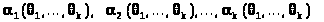 >.
>.
По выборке >
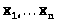 >
строим k
одноименных выборочных моментов. В
излагаемом контексте это будут моменты
>
строим k
одноименных выборочных моментов. В
излагаемом контексте это будут моменты
>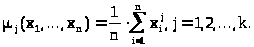 >
>
Приравнивая «теоретические» и одноименные им выборочные моменты, приходим к системе уравнений относительно компонент оцениваемого параметра
>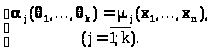 >(25.1)
>(25.1)
Решая полученную систему (точно или приближенно), находим исходные оценки >
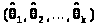 >.
Они, конечно, являются функциями от
выборочных значений >
>.
Они, конечно, являются функциями от
выборочных значений >
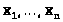 >.
>.
Мы изложили порядок действий, исходя из начальных - теоретических и выборочных - моментов. Он сохраняется при ином выборе моментов, начальных, центральных или абсолютных, который определяется удобством решения системы (25.1) или ей подобной.
Перейдем к рассмотрению примеров.
Пример 25.1. Пусть
случайная величина
распределена равномерно на отрезке [
;
] , где >
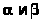 >
- неизвестные параметры. По выборке (>>)
объема n из распределения случайной
величины .
Требуется оценить
и
.
>
- неизвестные параметры. По выборке (>>)
объема n из распределения случайной
величины .
Требуется оценить
и
.
Решение.
В данном случае распределение определяется плотностью
>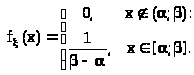 >
>
1) Вычислим первые два начальных «теоретических» момента:
>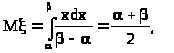 >
>
>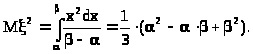 >
>
2) Вычислим по выборке два первых начальных выборочных момента
> >
>
3) Составим систему уравнений
>
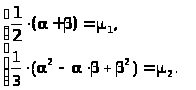 >
>
4) Из первого уравнения выразим через
>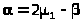 >
>
и подставим во второе уравнение, в результате чего придём к квадратному уравнению
>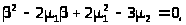 >
>
решая которое, находим два корня
> >.
>.
Соответствующие значения таковы
> >.
>.
Поскольку по смыслу задачи должно выполнятся условие < , выбираем в качестве решения системы и оценок неизвестных параметров
> >.
>.
Замечая, что >
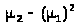 >есть
не что иное, как выборочная дисперсия
>
>есть
не что иное, как выборочная дисперсия
>
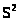 >,
получаем окончательно
>,
получаем окончательно
> >.
>.
Если бы мы выбрали в качестве
«теоретических» моментов математическое
ожидание и дисперсию, >
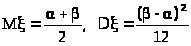 >,
то пришли бы к системе (с учетом неравенства
< )
>,
то пришли бы к системе (с учетом неравенства
< )
>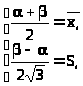 >
>
которая линейна и решается проще предыдущей. Ответ, конечно, совпадает с уже полученным.
Наконец, отметим, что наши системы всегда имеет решение и при том единственное. Полученные оценки, конечно, состоятельны, однако свойствам несмещенности не обладают.
7. Метод максимального правдоподобия
Изучается, как и прежде, случайная
величина ,
распределение которой задается либо
вероятностями её значений >
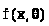 >,
если
дискретна, либо плотностью распределения
>
>,
если
непрерывна, где >
>-
неизвестный векторный параметр. Пусть
(>>)
- выборка значений .
Естественно в качестве оценки >
>,
если
дискретна, либо плотностью распределения
>
>,
если
непрерывна, где >
>-
неизвестный векторный параметр. Пусть
(>>)
- выборка значений .
Естественно в качестве оценки >
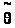 >
взять то значение параметра, при котором
вероятность получения уже имеющейся
выборки максимальна.
>
взять то значение параметра, при котором
вероятность получения уже имеющейся
выборки максимальна.
Выражение
>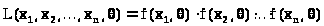 >
>
называют функцией правдоподобия, она представляет собой совместное распределение или совместную плотность случайного вектора с n независимыми координатами, каждая из которых имеет то же распределение (плотность), что и .
В качестве оценки неизвестного
параметра >
>
берется такое его значение >
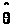 >,
которое доставляет максимум функции
>
>,
которое доставляет максимум функции
>
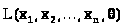 >,
рассматриваемой как функции от >
>
при фиксированных значениях >
>.
Оценку >
>
называют оценкой максимального
правдоподобия. Заметим,
что >
>
зависит от объема выборки n
и выборочных значений >
>
>,
рассматриваемой как функции от >
>
при фиксированных значениях >
>.
Оценку >
>
называют оценкой максимального
правдоподобия. Заметим,
что >
>
зависит от объема выборки n
и выборочных значений >
>
>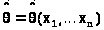 >,
>,
и, следовательно, сама является случайной величиной.
Отыскание точки максимума функции
>
>представляет
собой отдельную задачу, которая
облегчается, если функция дифференцируема
по параметру >
>.
В этом случае удобно вместо
функции >
>рассматривать
её логарифм, поскольку точки экстремума
функции и её логарифма совпадают.
Методы дифференциального исчисления позволяют найти точки, подозрительные на экстремум, а затем выяснить, в какой из них достигается максимум.
С этой целью рассматриваем вначале систему уравнений
>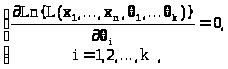 >(25.2)
>(25.2)
решения которой >
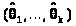 >-
точки, подозрительные на экстремум.
Затем по известной методике, вычисляя
значения вторых производных
>-
точки, подозрительные на экстремум.
Затем по известной методике, вычисляя
значения вторых производных
>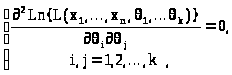 >
>
по знаку определителя, составленного из этих значений, находим точку максимума.
Оценки, полученные по методу максимального правдоподобия, состоятельны, хотя могут оказаться смещенными.
Рассмотрим примеры.
Пример 25.2. Пусть производится некоторый случайный эксперимент, исходом которого может быть некоторое события А, вероятность Р(А) которого неизвестна и подлежит оцениванию.
Решение.
Введем случайную величину равенством
>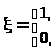 >
>
если событие А не произошло
(произошло событие
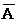 ).
).
Распределение случайной величины задается равенством
>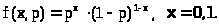 >
>
Выборкой в данном случае будет
конечная последовательность (>>),
где каждое из >
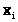 >
может быть равно 0 либо 1.
>
может быть равно 0 либо 1.
Функция правдоподобия будет иметь вид
>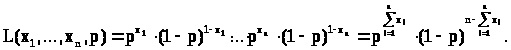 >
>
Найдем точку её максимума по р, для чего вычислим производную логарифма
>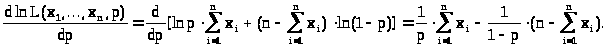 >
>
Обозначим >
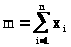 >
- это число равно количеству единиц
«успехов» в выбранной последовательности.
>
- это число равно количеству единиц
«успехов» в выбранной последовательности.
Приравняем полученную производную к нулю
>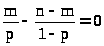 >
>
и решим полученное уравнение
>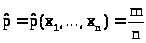 >.
>.
Поскольку производная >
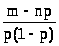 >
меняет знак с «+» на «-» при возрастании
р от 0 до 1, точка >
>
меняет знак с «+» на «-» при возрастании
р от 0 до 1, точка >
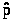 >
есть точка максимума функции L,
а >
>
есть точка максимума функции L,
а >
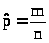 >
- оценка максимального правдоподобия
параметра р. Заметим, что отношение >
>
- оценка максимального правдоподобия
параметра р. Заметим, что отношение >
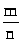 >
есть частота появления события А в
первых n
испытаниях.
>
есть частота появления события А в
первых n
испытаниях.
Поскольку m
есть число «успехов» в последовательности
n
независимых испытаний ( в схеме Бернулли),
то >
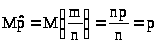 >,
и >
>
- несмещенная оценка. В силу закона
больших чисел Бернулли >
>
стремится по вероятности к р, и оценка
состоятельна.
>,
и >
>
- несмещенная оценка. В силу закона
больших чисел Бернулли >
>
стремится по вероятности к р, и оценка
состоятельна.
Пример 25.3. Построим
оценки неизвестных математического
ожидания и дисперсии нормально
распределенной случайной величины
с параметрами >
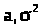 >.
>.
Р е ш е н и е.
В условиях примера случайная величина определяется плотностью распределения
>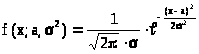 >.
>.
Сразу выпишем логарифм функции правдоподобия
>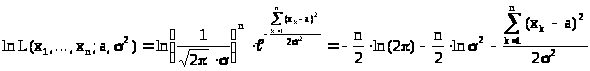 >.
>.
Составим систему уравнений для нахождения экстремальных точек
>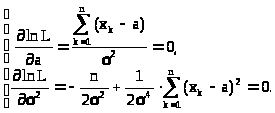 >
>
Из первого уравнения находим >
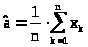 >,
из второго, подставляя найденное значение
a,
находим >
>,
из второго, подставляя найденное значение
a,
находим >
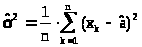 >.
>.
Вычислим вторые производные
функции lnL
в точке (>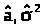 >):
>):
А = >
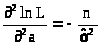 >,В
= >
>,В
= >
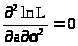 >,С
= >
>,С
= >
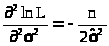 >.
>.
Поскольку определитель
>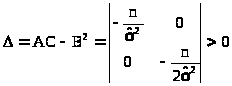 >,
>,
а А < 0, то найденная точка в самом деле точка максимума функции правдоподобия.
Заметим, что оценка >
>
есть выборочное среднее (несмещенная
и состоятельная оценка математического
ожидания), а >
>
- выборочная дисперсия (смещенная оценка
дисперсии).