Вибірковий метод визначення попиту
Контрольна робота
Вибірковий метод визначення попиту
Опитування та інші види спостережень, застосовувані у маркетинговому дослідженні, можуть бути суцільними або вибірковими. Суцільне cпостереження переважно обмежується рамками фірми і використовується порівняно нечасто. Основним способом отримання даних, особливо про споживачів, є вибірковий метод. Вибірковий метод — це метод статистичного дослідження, за якого узагальнюючі показники сукупності, що вивчається, встановлюються за деякою її частиною, як правило, на основі положень випадкового відбору. За такого методу обстеженню підлягає порівняно невелика частина всієї досліджуваної сукупності (до 5—10 %, зрідка до 15—25 %). При цьому статистична сукупність, яка підлягає вивченню і з якої здійснюється відбір частини одиниць, називається генеральною сукупністю. Відібрана з генеральної сукупності деяка частина одиниць, що підлягає обстеженню, називається вибірковою сукупністю, або вибіркою. Прикладом використання вибіркових спостережень є оцінка можливості проникнення на ринок з допомогою вибірки з фірм-виробників.
Переваги вибіркового методу полягають у тому, що його використання дає змогу краще організувати спостереження, забезпечує проведення дослідження у стисліші терміни, з мінімальними затратами праці і витратами коштів. За дотримування умов випадковості і досить великої кількості спостережень він дає змогу, використовуючи отримані дані, з достатньою для практики точністю робити висновки про характеристики генеральної сукупності. Проте отримані з матеріалів вибіркового спостереження статистичні показники звичайно не збігаються з відповідними характеристиками генеральної сукупності. Це відхилення називається помилкою спостереження і складається з двох частин: помилки репрезентативності (представництва) та помилки вимірювання (реєстрації).
Помилка репрезентативності характеризує розмір розбіжностей між величинами показників, отриманих у вибірковій і генеральній сукупності за умови однакової точності поодиноких спостережень. Вона властива саме вибірковим спостереженням і виникає, коли вибірка нерепрезентативна, тобто не представляє генеральну сукупність у потрібному аспекті. Така помилка має три складові. Це:
систематична (тенденційна) помилка — виникає через недосконалість або порушення правил формування вибіркової сукупності і призводить до зсуву результатів обстеження (незсуненість — одна з вимог вибіркового обстеження, яка досягається правильною організацією його);
випадкова помилка — пов’язана з недостатньо рівномірним представленням у вибірковій сукупності всіх категорій елементів генеральної сукупності. Уникнути таких похибок за вибіркового обстеження принципово неможливо, але теорія вибіркового методу базується на математичній основі, яка дає змогу обчислити й регулювати їх розмір;
помилка, що виникає через недоступність окремих елементів вибірки або у разі відмови відповідати на запитання, яке треба враховувати під час спостережень.
Виникнення помилок вимірювання пояснюється тим, що вимірюється не зовсім те, що було потрібно (так, людина може збрехати, відповідаючи на певне запитання). Такі помилки властиві як суцільному, так і вибірковому спостереженню. Вони пов’язані з неправильною організацією спостереження, неправильно обраною технікою вимірювання, недосконалістю вимірювальних приладів, недостатньою кваліфікацією спостерігачів, неточністю підрахунків тощо. Слід зазначити, що за вибіркового спостереження помилка вимірювання звичайно значно менша, ніж за суцільного, оскільки техніка вимірювання може бути розроблена і здійснена ретельніше за рахунок використання більш кваліфікованих і підготовлених кадрів. Тому навіть коли час і можливості дозволяють виконати повне обстеження всіх елементів сукупності, перевагу може бути віддано отриманню інформації з допомогою вибірки саме з метою підвищення точності результатів. Але цього можна досягти лише у разі додержання правил наукової організації вибіркового дослідження.
Найбільш поширений спосіб відбору одиниць сукупності для дослідження базується на принципі однакових можливостей потрапляння у вибірку кожної одиниці генеральної сукупності. Завдяки цьому виключається створення вибіркової сукупності тільки за рахунок одного типу елементів. Це дає змогу уникнути систематичних помилок і здійснювати кількісне оцінювання помилки репрезентативності.
За вибіркового методу використовуються переважно два основних види узагальнюючих показників: відносна величина альтернативної ознаки та середня величина кількісної ознаки.
Відносна величина альтернативної ознаки характеризує частку (питому вагу) одиниць у статистичній сукупності, які відрізняються від усіх інших одиниць цієї сукупності тільки наявністю досліджуваної ознаки.
Середня величина кількісної ознаки — це узагальнена характеристика ознаки, яка має різні значення в окремих одиницях статистичної сукупності.
У генеральній сукупності частка одиниць, що мають досліджувану ознаку, називається генеральною часткою, а середня величина цієї ознаки — генеральною середньою. У вибірковій сукупності частку досліджуваної ознаки називають вибірковою часткою, або частістю, а її середню величину — вибірковою середньою.
Основне завдання вибіркового дослідження полягає у тому, щоб на основі характеристик вибіркової сукупності (частості або середньої) отримати з певною вірогідністю висновки про частку або середню генеральної сукупності.
Як правило, організація вибіркового обстеження складається з таких елементів:
визначення цільової величини у вигляді запланованого вимірювання цільової частини генеральної сукупності (наприклад, частки домогосподарок певного регіону, що користуються пральними машинами);
вибір інформаційної основи вибіркового спостереження (наприклад, певні статистичні матеріали), визначення структури вибірки (наприклад, кількість людей певного віку з певним рівнем прибутку) та способу відбору одиниць з генеральної сукупності;
визначення способів (одного чи більше) отримання інформації для визначення цільової величини (наприклад, спостереження або відповіді на запитання);
визначення методу аналізу результатів вибіркового спостереження та оцінювання точності дослідження.
Необхідною умовою організації вибіркового спостереження є попереднє вивчення генеральної сукупності, оцінювання її однорідності, поділ за головними ознаками та визначення необхідної кількості спостережень. Результати вибіркового обстеження відображаються у термінах імовірності настання деякої події із зазначенням (оскільки усі вибіркові методи пов’язані з похибками) деякого рівня вірогідності того, що отриманий результат є правильним і знаходиться у прийнятних межах.
Способи відбору одиниць з генеральної сукупності
У статистиці залежно від завдань дослідження та специфіки об’єкта, що вивчається, застосовуються різні способи формування вибіркових сукупностей.
Головною умовою здійснення вибіркового обстеження є уникнення систематичних (тенденційних) похибок. Вони виникають у разі невиконання принципів рівних можливостей потрапляння у вибірку для кожної одиниці генеральної сукупності.
Способи відбору визначаються правилами формування вибіркової сукупності. Найчастіше використовуються такі вибірки: власне-випадкові, або прості випадкові; механічні; типові (розшаровані, районовані); територіальні та цільові.
Власне-випадкова вибірка полягає у тому, що вибіркова сукупність створюється в результаті випадкового відбору окремих одиниць з генеральної сукупності. Для добору елементів сукупності проводять жеребкування або використовують псевдовипадкові числа. Реалізація цього способу потребує попередньої підготовки до формування вибірки (наприклад, нумерації кожної одиниці генеральної сукупності). У разі великих за обсягом сукупностей ручне її проведення може бути досить трудомістким.
Власне-випадкова вибірка може здійснюватися за схемою повторного або безповторного відбору. Вибір схеми відбору залежить від характеру досліджуваного об’єкта. У разі безповторного відбору чисельність генеральної сукупності у процесі вибірки скорочується. За повторного відбору кожна одиниця, яка потрапила у вибірку, після її дослідження має повернутися у генеральну сукупність, де їй надається така сама можливість знову потрапити у вибірку. Так, у разі вивчення споживацького попиту населення не виключена повторна реєстрація незадоволеного попиту того самого покупця у декількох магазинах міста.
За механічної вибірки генеральна сукупність механічно поділяється на рівновеликі групи і з кожної з них лише один елемент потрапляє у вибірку. Кількість елементів у кожній групі дорівнює n/N, де n — обсяг вибірки, а N — обсяг генеральної сукупності. Якщо елементи генеральної сукупності впорядковано за суттєвою ознакою, тобто ознакою, яка повністю визначає поведінку досліджуваного показника, то у вибірку має відбиратись елемент, який знаходиться всередині кожної групи (це дає змогу уникнути систематичної помилки вибірки). Якщо ж елементи генеральної сукупності впорядковано за нейтральною ознакою, то з першої групи можна взяти будь-який елемент, а з інших добираються ті, що відповідають порядковому номеру елемента, відібраного з першої групи. Доведено, що механічна вибірка за точністю результату близька до власне-випадкової, а здійснити її (у разі неавтоматизованого добору елементів) простіше.
Якщо стикаються з досить неоднорідною інформацією (прикладом такої неоднорідності може слугувати неоднорідність населення), то використовують типову вибірку, яка передбачає попередню структуризацію генеральної сукупності. За такої вибірки генеральна сукупність спочатку поділяється на однорідні типові групи, а потім з кожної групи проводиться незалежний індивідуальний відбір елементів у вибіркову сукупність.
Важливою особливістю типової вибірки є те, що вона може дати точніші порівняно з іншими способами відбору одиниць у вибіркову сукупність результати. Оскільки похибка типової вибірки визначається середньою з групових дисперсій, то репрезентативність такої вибірки забезпечується поділом генеральної сукупності на якісно однорідні групи. Якщо групи об’єднують однорідні елементи, а групові середні помітно різні, варіація ознаки в групах буде значно меншою, ніж в цілому по сукупності. У такому разі середня з групових дисперсій буде меншою за дисперсію по сукупності, а отже, й похибка типової вибірки порівняно з власне-випадковою буде менша. Забезпечити більшу точність типової вибірки можна обґрунтованим вибором ознаки поділення генеральної сукупності, кількості груп, обсягів кожної з них і способів відбору. Зменшення варіації ознаки за поділу сукупності можливе лише у тому разі, коли ознака поділення корелює з ознакою, характеристики якої оцінюються. Чим щільніший зв’язок між ознаками, тим помітніше зменшення похибки.
Якісно однорідні групи за типової вибірки можуть утворюватися як в результаті спеціально проведеного типового групування одиниць генеральної сукупності, так і в результаті використання тих, що вже є, у тому числі й тих, що склалися природно. Так, у разі вивчення споживацького попиту на певній території магазини, що продають товар, попит на який досліджується, можуть групуватися за їх типом (універмаги, магазини культтоварів та ін.).
У більшості випадків використовуються типові вибірки з неоднаковою кількістю елементів. Проте з кожної типової групи можна відібрати кількість одиниць, пропорційну їх чисельності, тобто використовувати пропорційний типовий відбір.
За визначення статистичних показників типової вибірки не можна застосовувати відповідні стандартні функції Excel. Це пов’язане з тим, що такі функції призначені для обчислення показників вибірки, всі елементи якої входять до однієї групи, а в типовій вибірці треба обчислювати статистичні показники по варіаційному ряду, в якому дані об’єднано (згруповано) за значенням ознаки та підраховано кількість випадків повторення кожного з них. Тому середня вибірки та дисперсія середньої розраховуються як зважені показники за такими формулами:
x>cep >= x>і> f>і> / f>і >,
2 = (x>і> – x>cep>)2 f>і> / f>і> ,
де x>і> — значення ознаки в і-й групі;
f>і> — кількість елементів, що входять до цієї групи.
Якщо в рамках виділеного бюджету неможливо точно визначити склад певної групи (наприклад, у випадку, коли це потребує проведення суцільної вибірки), то використовують територіальну вибірку. Основною ідеєю її є те, що елементи вибірки можуть бути ідентифіковані у межах певного району й можна скласти список цих районів. У маркетингових дослідженнях методи територіальної вибірки найчастіше застосовуються в опитуванні домогосподарств. Часто така вибірка є єдиним способом отримання ймовірної вибірки на великій території з недостатньо визначеними елементами. Може застосовуватися й техніка «зосередження», що полягає у створенні невеликих осередків проведення вибіркових досліджень. Це має місце у пробному маркетингу (наприклад, коли необхідно оцінити можливі обсяги продажу у регіональному масштабі за запуску у виробництво нового продукту або нової маркетингової програми). Вплив техніки «зосередження» на похибку вибірки можна оцінити лише тоді, коли відомі кореляційні залежності між елементами кожного осередку. Оскільки у пробному маркетингу дуже складно провести кореляцію всередині осередку, то й неможливо визначити ступінь точності проведених досліджень.
Цільова вибірка полягає у систематичному відборі елементів з метою залучення до дослідження достатньої кількості елементів кожного основного типу. Але використання результатів такої вибірки обмежується неможливістю оцінити помилку вибірки в якийсь об’єктивний спосіб. До неї вдаються за вивчення реакції ринку на новий виріб або на модернізацію старого, коли ймовірнісна вибірка потребує великих витрат. При цьому робиться припущення, що смаки споживачів більш-менш ідентичні, принаймні, всередині однієї групи.
Помилка вибірки
Після проведення певної кількості спостережень отримують розподілення результатів (вибіркових оцінок) того самого істинного рівня (наприклад, низки характеристик населення). Це вибіркове розподілення підлягає законові нормального розподілення, якщо вибірка достатньо велика. Оскільки істинний рівень може не збігатися з рівнем вибіркових характеристик, необхідно брати до уваги похибку вибірки. У цьому разі можна знайти ступінь вірогідності вибіркових характеристик.
У математичній статистиці значення середньої похибки визначається за формулою
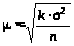 ,
,
де 2 — дисперсія вибіркової сукупності;
n — чисельність одиниць вибіркової сукупності;
k — коефіцієнт, який для повторного відбору дорівнює одиниці, а для безповторного — 1 – n/N, де N — чисельність генеральної сукупності.
Середня похибка вибірки використовується для визначення межі відхилень характеристик вибірки від характеристик генеральної сукупності. Суттєвим є твердження, що ці відхилення не будуть більші за значення, яке в статистиці називається граничною помилкою вибірки, лише з певним ступенем імовірності.
Гранична помилка вибірки пов’язана із середньою похибкою вибірки співвідношенням
= t,
де t — коефіцієнт кратності помилки.
Значення коефіцієнта кратності помилки залежить від того, з якою довірчою ймовірністю (надійністю) слід гарантувати результати вибіркового обстеження. Для його визначення користуються таблицею значень інтеграла ймовірностей нормального закону розподілення. В економічних дослідженнях звичайно обмежуються значеннями t, що не перевищують двох-трьох одиниць:
|
Кратність помилки |
Імовірність (надійність) |
Кратність |
Імовірність (надійність) |
Кратність |
Імовірність (надійність) |
|
0,1 |
0,0797 |
1,5 |
0,8664 |
2,6 |
0,9907 |
|
0,5 |
0,3829 |
2,0 |
0,9545 |
3,0 |
0,9973 |
|
1,0 |
0,6827 |
2,5 |
0,9876 |
4,0 |
0,999937 |
При цьому вибір тієї чи іншої довірчої імовірності залежить від того, з яким ступенем вірогідності слід гарантувати результати вибіркового обстеження (найчастіше спираються на ймовірність 0,9545, за якої t дорівнює 2).
Якщо в формулу для визначення підставити конкретний вміст , то для обчислення граничної помилки можна буде використати такі вирази:
у разі альтернативної ознаки
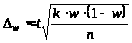 ,
,
де w — вибіркова частка, яка визначається з відношення одиниць, які мають досліджувану ознаку, до загальної чисельності одиниць вибіркової сукупності;
у разі кількісної ознаки
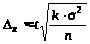 ,
,
де 2 — дисперсія кількісної ознаки у вибірці.
Визначення розміру вибірки
У разі організації вибіркових досліджень важливо визначити, наскільки великим має бути обсяг вибірки. Для загальної відповіді на це питання слід знати:
витрати на проведення вибіркового дослідження;
витрати на отримання наближених оцінок;
ступінь мінливості процесу;
ступінь надійності результатів, необхідний для прийняття подальших рішень.
Обминаючи вартісні фактори, розмір оптимальної вибірки можна визначити, базуючись на формулі граничної похибки. Приміром, за безповторного відбору для середньої кількісної ознаки необхідна чисельність обчислюється так:
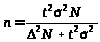 ,
,
де n — чисельність одиниць вибірки;
N — обсяг генеральної сукупності;
t — коефіцієнт кратності помилки (або коефіцієнт довіри);
2 — дисперсія;
— гранична (задана) помилка середньої (звичайно вибирається рівною 10 % від значення середньої).
Нехай для обстеження, що має на меті виявити потреби у певному товарі тривалого використання в регіоні, де мешкає 10 тис. сімей, необхідно провести анкетування.
Умовно приймаємо, що в кожній квартирі проживає одна сім’я і на неї виділяється одна анкета. Припустимо, що попередніми дослідженнями встановлено, що середній розмір покупки та дисперсія становлять відповідно 17 і 150 грн. Виходячи з того, що гранична помилка не повинна перевищувати 10 % від середньої і що результати обстеження необхідно гарантувати з довірчою імовірністю, не меншою 0,954, чисельність вибірки має становити
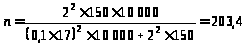 .
.
Ясна річ, деяка частина анкет не повертається (припустимо, практика показує, що приблизно кожна п’ята), тому треба збільшити кількість анкет до 255. Отже, можемо зробити висновок, що необхідно включити у вибірку щонайменше кожну 40-у квартиру.
Технологію визначення розміру вибірки pозглянемо на прикладі вибору магазинів для вивчення на деякій території споживацького попиту на певний товар.
Для цього на окремому робочому листі Excel слід створити список усіх магазинів, що торгують товаром, попит на який вивчається (рис. 2.3.7).
Заголовок списку мусить мати такі поля: номер магазину, тип (наприклад, універмаг і культтовари), місцезнаходження, загальний товарообіг, товарообіг по товару, частка продажу товару в товарообігу магазину.
Оформлення заголовка списку магазинів
|
A |
B |
C |
D |
E |
F |
|
|
1 |
ВИЗНАЧЕННЯ ОБСЯГУ ВИБІРКИ |
|||||
|
2 |
Номер магазину |
Тип магазину |
Адреса |
Загальний товарообіг |
Товарообіг по товару |
Частка продажу товару ( %) |
|
3 |
У цей список щодо кожного магазину заноситься інформація у перші п’ять стовпців (A, B, C, D, E). У клітину F3 заводиться формула =D3/E3*100 і копіюється на всі рядки списку.
Оскільки типова вибірка дає найточніші, порівняно з іншими способами відбору одиниць у вибіркову сукупність, результати, то відбір конкретних магазинів бажано проводити окремо для кожного типу магазинів. Тому список магазинів треба відразу впорядкувати за типом магазинів, а всередині цієї впорядкованості — за часткою продажу товару (команда Дані/Сортування).
Нехай
повний список магазинів, що торгують
товаром, попит на який вивчається, займає
52 рядки робочого аркуша. У такому разі
в клітину С53 треба завести формулу
=СЧЕТ(С3:С52), а у клітину F53 — формулу
=ДИСПР(F3:F52). Перша формула дасть змогу
обчислити загальну кількість магазинів,
а друга — дисперсію розподілення частки
продажу товару в цій сукупності магазинів.
Слід звернути увагу на те, що використання
функції ДИСПР передбачає, що її параметри
представляють усю генеральну
сукупність.
Якщо дані представляють тільки вибірку
з генеральної сукупності, то дисперсію
слід обчислювати, використовуючи функцію
ДИСП.
Для полегшення подальшого використання у формулах значень клітин С53 і Е53 (кількості магазинів і дисперсії), цим клітинам і робочому аркушу слід надати імена (наприклад, N, D і СписокМ відповідно). Щоб дати ім’я клітині, можна завести курсор у цю клітину, клацнути мишею в полі імені, набрати там нове ім’я й обов’язково натиснути клавішу Enter. Можна також надавати імена клітинам, використовуючи діалогове вікно Надати ім’я. Для цього необхідно виконати таку послідовність дій:
розташувати курсор в клітині, якій треба надати ім’я;
вибрати команду Вставка/Ім’я/Надати;
у діалоговому вікні Надати ім’я, що з’явиться після цього, набрати нове ім’я у текстовому полі Ім’я;
натиснути на кнопку Додати, а потім — на кнопку ОК.
Для того щоб надати нове ім’я робочому аркушу, треба клацнути правою кнопкою миші на ярлику відповідного робочого аркуша, у контекстному меню вибрати команду Перейменувати, ввести потрібне ім’я і натиснути клавішу Enter.
Для проведення розрахунків на окремому робочому аркуші створюється таблиця.
Коефіцієнт граничної помилки вибираємо виходячи з 10 % рівня помилки середньої від її значення. Сьомий та восьмий рядки робочої таблиці показують межі вибірки, дотримання яких з вибраною ймовірністю гарантуватиме вірогідність результатів вибіркового обстеження. Останній показник у цій таблиці — це частка магазинів (n/N), що мають потрапити у вибірку.
Формули у робочому аркуші для обчислення обсягу вибірки
|
A |
B |
C |
D |
|
|
1 |
ВИЗНАЧЕННЯ ОБСЯГУ ВИБІРКИ |
|||
|
2 |
Середня вибірки (середня частка продажу) |
= СРЗНАЧ (СписокМ! F3:F52) |
||
|
3 |
Гранична помилка середньої |
= 0,1*B2 |
||
|
4 |
Довірча ймовірність (надійність) |
0,9545 |
0,9876 |
0,9973 |
|
5 |
Коефіцієнт кратностi помилки (t) |
2 |
2,5 |
3 |
|
6 |
Обсяг вибiрки (n) |
= B4^2*D*N / ($B3^2 *N + B4^2*D) |
= C4^2*D*N / ($B3^2*N + C4^2*D) |
= D4^2*D*N / ($B3^2*N + D4^2*D) |
|
7 |
Нижня межа вибірки |
= B6-$B3 |
= C6-$B3 |
=D6-$B3 |
|
8 |
Верхня межа вибірки |
= B6+$B3 |
= C6+$B3 |
=D6+$B3 |
|
9 |
Частка вибірки |
= B6/N |
= C4/N |
=D6/N |
У табл. наведено результати обчислень за середньої 16 і трьох значень коефіцієнта довірчої ймовірності (0,9545; 0,9876; 0,9973). Після аналізу отриманих результатів слід вибрати значення довірчої ймовірності та надати відповідній клітині дев’ятого рядка робочого аркуша ім’я ЧасткаВ.
Результати обчислення обсягу вибірки
|
A |
B |
C |
D |
|
|
1 |
ВИЗНАЧЕННЯ ОБСЯГУ ВИБІРКИ |
|||
|
2 |
Середня вибірки (середня частка продажу) |
16 |
||
|
3 |
Гранична помилка середньої |
1,6 |
||
|
4 |
Довірча ймовірність |
0,9545 |
0,9876 |
0,9973 |
|
5 |
Коефіцієнт кратностi помилки (t) |
2 |
2,5 |
3 |
|
6 |
Обсяг вибiрки (n) |
33,74 |
38,21 |
41,18 |
|
7 |
Нижня межа вибірки |
32,14 |
36,61 |
39,58 |
|
8 |
Верхня межа вибірки |
35,34 |
39,81 |
42,78 |
|
9 |
Частка вибірки |
0,67 |
0,76 |
0,82 |
Найпростіший спосіб підрахувати кількість магазинів кожного типу полягає у створенні на новому робочому аркуші зведеної таблиці, для чого слід виконати такі дії:
Установити курсор на будь-якій клітині списку магазинів.
Вибрати з меню команду Дані/Зведена таблиця.
На першому кроці Майстра зведених таблиць вибрати режим «у списку або базі даних Microsoft Excel».
На другому кроці просто клацнути по кнопці Далі.
На третьому кроці:
перетягнути поле Тип магазину в область діаграми Колонка;
ще раз перетягнути поле Тип магазину в область діаграми Дані і подвійно клацнути по ньому лівою кнопкою миші;
у діалоговому вікні Обчислення поля зведеної таблиці вибрати операцію Кількість значень і клацнути по кнопці ОК;
завершити формування зведеної таблиці натисканням кнопки Готово.
Таблиця, створювана Майстром зведених таблиць займатиме лише перші три рядки (на рисунку їх подано жирним курсивом).
У четвертий рядок, безпосередньо за останнім рядком зведеної таблиці з метою отримання для кожного типу магазину такого розміру вибірки, щоб вона була пропорційна чисельності даного типу магазину, в клітини В4 та С4 вводяться формули, що обчислюють добуток частки вибірки (ЧасткаВ), яка відповідає вибраній довірчій імовірності і чисельності відповідного типу магазину.
Вигляд зведеної таблиці (перші три рядки) списку магазинів
|
A |
B |
C |
D |
|
|
1 |
Кількість
значень по |
Тип магазину |
||
|
2 |
Культтовари |
Універмаг |
Підсумок |
|
|
3 |
Всього |
41 |
11 |
52 |
|
4 |
Кількість магазинів у вибірці |
= ОКРУГЛ (ЧасткаВ*В3) |
= ОКРУГЛ (ЧасткаВ*С3) |
|
|
5 |
Генератори псевдови-падкових чисел |
= 1 + ЦІЛЕ (В3* СЛЧИСЛ()) |
||
|
6 |
Найпростіший спосіб відбору одиниць у вибіркову сукупність — з допомогою псевдовипадкових чисел. Саме цей спосіб доцільно застосувати для включення у вибірку конкретних магазинів, тобто для визначення опорних магазинів з вивчення споживацького попиту.
Техніка використання псевдовипадкових чисел може бути такою:
рядки таблиці (рис. 2.3.10) закріплюються на екрані. Для цього табличний курсор розміщується у клітині D6 і виконується команда Вікно/Закріпити ділянки;
у клітину В5 уводиться формула, яка завдяки використанню функції СЛЧИС( ) виконуватиме роль генератора випадкових чисел у діапазоні від 1 до кількості магазинів відповідного типу, тобто роль генератора випадкових порядкових номерів магазинів відповідного типу у їх списку. Функція СЛЧИС( ) повертає рівномірно розподілене випадкове число, що більше або дорівнює 0 і менше 1. Нове випадкове число повертається цією функцією кожного разу, коли перераховується робочий аркуш;
після введення формули і натискання клавіші Enter у клітині В5 буде відображено порядковий номер магазину, який може виконувати роль опорного магазину типу «Культтовари». Далі слід змістити табличний курсор у клітину В6, занести туди цей номер і натиснути клавішу Enter (а краще клавішу ). У клітині В5 з’явиться порядковий номер наступного магазину. Кількість повторів цієї операції визначається значенням клітини В4;
після копіювання формули з клітини В5 у клітину С5 аналогічно визначаються опорні магазини типу «Універмаг».
Оброблення результатів опитування
Припустимо, що проведено вибіркове анкетування 10 000 сімей з метою отримати відповіді на такі запитання:
Наскільки населення регіону забезпечене певним виробом?
Який середній вік експлуатації цього виробу?
Яке зношення (середній вік) виробів, що знаходяться в експлуатації?
Нехай з 255 розісланих анкет повернулося 208, з яких виявлено, що 183 сім’ї вже мають зазначений виріб. На викладене в анкеті прохання вказати термін експлуатації виробу отримано такі відповіді: вироби, що використовувалися до 3 років, має 21 сім’я, від 4 до 6 років — мають 47 сімей, від 7 до 9 років — 96 сімей, від 10 років і більше — 19 сімей. Бажання про заміну виробу на сучасніший висловили 137 сімей (рис. 2.3.11).
Ступінь забезпеченості сімей товаром визначається як відношення кількості сімей, що використовують виріб, до загальної кількості отриманих відповідей.
Для визначення середнього «віку» виробів, що має населення, і дисперсії середньої використовуються такі формули:
x>cep >= xf / f,
2 = (x – x>cep>)2 f / f .
Оброблення результатів опитування
|
Термін експлуатації виробу |
Середнє значення терміну експлуатації (x) |
Кількість сімей, що мають виріб (f) |
Загальний
час експлуатації |
(х – х>сер>)2·f |
|
До 3 років |
2 |
21 |
42 |
516 |
|
Від 4 до 6 років |
5 |
47 |
235 |
180 |
|
Від 7 до 9 років |
8 |
96 |
768 |
105 |
|
Від 10 років і більше |
12 |
19 |
228 |
483 |
|
Разом |
183 |
1273 |
1283,65 |
|
|
Кількість сімей, N |
10 000 |
|||
|
Відправлено анкет |
255 |
|||
|
Отримано відповідей, n |
208 |
|||
|
Кількість сімей, що мають виріб |
183 |
|||
|
Кількість сімей, що планують заміну виробу |
137 |
|||
|
Ступінь забезпеченості товаром, w |
88 % |
|||
|
Середній «вік» виробів, що знаходяться в експлуатації, х>сер> |
7 |
|||
|
Середній «вік» спрацьованості виробів, що знаходяться в експлуатації |
9,29 |
|||
|
Дисперсія середнього віку виробів, що знаходяться в експлуатації |
7,01 |
|||
|
Коефіцієнт кратностi помилки, t |
2 |
|||
|
Гранична помилка забезпеченості товаром |
4,5 % |
|||
|
Гранична помилка середнього віку виробів, що знаходяться в експлуатації |
0,36 |
Гранична помилка ступеня забезпеченості сімей товаром обчислюється за формулою для альтернативної ознаки:
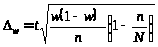 ,
,
де w — ступінь забезпеченості сімей товаром (клітина С14);
n — обсяг вибірки.
Гранична помилка середнього «віку» товару обчислюється (y клітинi С18) за формулою для середнього значення кількісної ознаки:
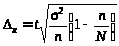 .
.
Отримані результати дозволяють стверджувати:
забезпеченість населення товаром, що вивчається, з імовірністю 0,954 у межах інтервалу від 83,5 % до 92,5 % (88 4,5);
середній «вік» експлуатованих населенням виробів в інтервалі від 6,64 до 7,36 року (7 0,36);
середній термін зношення виробу в інтервалі від 8,34 до 9,06 років (8,7 0,36).