Базові алгоритми обслуговування черг
БАЗОВІ АЛГОРИТМИ ОБСЛУГОВУВАННЯ ЧЕРГ
1. Загальна характеристика розподілу канальних ресурсів
Задача розподілу канальних ресурсів між потоками розв’язується шляхом організації черг і встановленням певного порядку обслуговування поставлених у чергу пакетів. Як було зазначено в лекції 1, порядок обробки поставлених у чергу пакетів визначає частоту їхнього обслуговування, а отже, і кількість канальних ресурсів, які надаються даному потоку.
Черги й алгоритм їхньої обробки є інструментами управління перевантаженнями, коли мережний пристрій не встигає передавати пакети на вихідний інтерфейс в тому темпі, в якому вони надходять. Якщо причиною перевантаження є процесорний блок мережного пристрою, то для тимчасового збереження неопрацьованих пакетів використовується вхідна черга, тобто черга, зв'язана з вхідним інтерфейсом. У випадку, коли причина перевантаження полягає в обмеженій швидкості вихідного інтерфейса (а вона завжди обмежена швидкістю протоколу), то пакети тимчасово зберігаються у вихідній черзі.
За своєю суттю, чергами є області пам'яті комутатора або маршрутизатора, де групуються пакети з однаковими пріоритетами передачі. Алгоритм обслуговування черги визначає порядок, у якому відбувається передача пакетів з цієї черги. Задача застосування всіх алгоритмів зводиться до того, щоб забезпечити найкраще обслуговування трафіка з більш високим пріоритетом за умови, що і пакетові з низьким пріоритетом гарантується відповідна увага.
Алгоритм обслуговування черг як механізм забезпечення QoS має задовольняти таким вимогам.
1. Алгоритм обслуговування черг із підтримкою QoS повинен мати засіб диференціювання пакетів і засіб визначення рівня обслуговування кожного пакета.
2. Алгоритм має гарантувати якість обслуговування пакетів шляхом розподілення ресурсів для кожного окремого потоку трафіка або за допомогою визначення відносного пріоритету потоків.
3. Алгоритм обслуговування черг із підтримкою QoS має забезпечувати захист і рівномірну обробку всіх потоків трафіка з однаковим пріоритетом (наприклад, трафіка, що доставляється без гарантій).
4. Додатковими вимогами до алгоритму обслуговування черг є легкість реалізації і підтримка управління доступом для потоків, що потребують гарантованого надання ресурсів.
Механізми обслуговування черг можна класифікувати за такими ознаками (рис. 1): реалізований принцип розподілу ресурсів (без розподілу ресурсів, пріоритетний розподіл шляхом застосування однойменного обслуговування, пропорційний розподіл шляхом кругового обслуговування черг і рівномірний розподіл шляхом реалізації максимінної схеми); надання гарантій за будь-якими параметрами мережного з'єднання (у термінах смуги пропускання або гарантованої затримки); принцип формування черг (формування черг за потоками або за класами); режим виконання (розподілений на процесорах VIP-плат або нерозподілений на центральному процесорі маршрутизатора).
Найчастіше в маршрутизаторах і комутаторах застосовуються такі алгоритми обробки черг:
- алгоритм FIFO;
- пріоритетне обслуговування (Priority Queuing, PQ);
- справедливе обслуговування (Fair Queuing, FQ);
- обслуговування на основі класу (Class Based Queuing, CBQ);
- зважене справедливе обслуговування (Weighted Fair Queuing, WFQ);
- зважене справедливе обслуговування на основі класу (Class Based WFQ, CBWFQ);
- обслуговування з малою затримкою (Low Latency Queuing, LLQ);
- зважене кругове обслуговування (Weighted Round-Robin, WRR) і його модифікації;
- кругове обслуговування з дефіцитом (Deficit Round-Robin, DRR) і його модифікації.
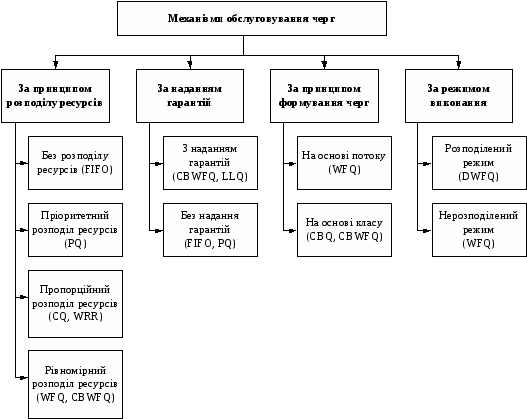
Рисунок 1 – Класифікація механізмів обслуговування черг
2. Механізм обслуговування черг FIFO
обслуговування алгоритм черга комутатор
FIFO (First In – First Out, "першим прийшов – першим пішов") є найпростішим механізмом обслуговування черг, відповідно до якого пакети передаються на вихід у тому порядку, в якому вони надійшли на вхід.
Цей механізм є алгоритмом обробки черг за замовчуванням у всіх пристроях з комутацією пакетів. Незаперечною його перевагою є простота реалізації і відсутність потреби в конфігуруванні. Головний недолік – неможливість диференційованої обробки пакетів різних потоків. Усі пакети знаходяться у загальній черзі на рівних правах – і пакети чутливого до затримок мовного трафіка, і пакети нечутливого до затримок, але дуже інтенсивного трафіка резервного копіювання, тривалі пульсації якого можуть надовго затримати мовний пакет. Іншими словами механізм FIFO не здатний забезпечити рівномірне обслуговування потоків трафіка з однаковим пріоритетом і захистити їх від потоків з нерівномірною інтенсивністю, він допускає перевагу потоків високої інтенсивності над всіма іншими потоками трафіка. Отже, черги FIFO необхідні для нормальної роботи мережних пристроїв, але їх недостатньо для підтримки диференційованої якості обслуговування. Черги FIFO за замовчуванням застосовуються для інтерфейса зі швидкістю вище 2 Мбіт/с (наприклад, Ethernet).
3. Механізм пріоритетного обслуговування черг PQ
Механізм пріоритетного обслуговування черг припускає наявність чотирьох вихідних підчерг – підчерги з високим, середнім, звичайним і низьким пріоритетом обслуговування. Належність потоку трафіка до кожної з чотирьох черг визначається мережним адміністратором. Пакети, що знаходяться у черзі з високим пріоритетом обслуговування, передаються першими. Коли ця черга виявляється порожньою, починається передача пакетів наступної за пріоритетом обслуговування черги і т.д. Відзначимо, що передача пакетів черги із середнім пріоритетом обслуговування не почнеться доти, доки не будуть обслуговані всі пакети черги з вищим пріоритетом. Механізм пріоритетного обслуговування черг PQ підтримує класифікацію пакетів у залежності від вхідного інтерфейса, простого або розширеного списку доступу на підставі IP-адреси, розміру пакета і аплікації, що згенерувала цей пакет. Слід зазначити, що некласифікований трафік за замовчуванням належить до черги зі звичайним пріоритетом обслуговування. У межах черги пакети обробляються відповідно до механізму FIFO. Обмежений розмір буферної пам'яті мережного пристрою вимагає, щоб черги пакетів, що очікують обслуговування, мали деяку граничну довжину. Звичайно за замовчуванням усім пріоритетним чергам надаються однакові буфери, але багато пристроїв дозволяють адміністраторові призначати кожній черзі буфер індивідуального розміру. Пріоритетне обслуговування черг забезпечує високу якість обслуговування для пакетів із черги з найвищим пріоритетом. Якщо середня інтенсивність їхнього надходження в пристрій не перевершує пропускної здатності вихідного інтерфейса (і продуктивності внутрішніх блоків самого пристрою), то пакети вищого пріоритету завжди отримують ту пропускну здатність, що їм потрібна. Рівень затримок пакетів з найвищим пріоритетом також мінімальний. Що ж стосується інших класів пріоритетів, то якість їхнього обслуговування буде нижчою, ніж у пакетів найвищого пріоритету, причому рівень зниження заздалегідь передбачити досить важко. Це залежить від інтенсивності трафіка з найвищим пріоритетом. Пріоритетне обслуговування пакетів потрібно в мережах, де передача трафіка, необхідного для розв’язання критично важливих задач, має бути здійснена навіть за умови повного домінування трафіка з найвищим пріоритетом в моменти перевантаження мережі. Тому пріоритетне обслуговування зазвичай застосовується в тому випадку, коли в мережі є один клас трафіка, наприклад, мовний трафік, чуттєвий до затримок, але його інтенсивність невелика, так що його обслуговування не занадто знижує якість передачі пакетів іншого трафіка. Отже, головною перевагою пріоритетного обслуговування є відносна простота в реалізації і висока якість обслуговування трафіка з найвищим пріоритетом. Основні недоліки полягають у такому:
- необхідність ретельного контролю трафіка на етапі доступу в мережу з метою належного надання пріоритету;
- відсутність верхньої межі для кожного з рівнів пріоритету;
- високий ризик подавлення низькопріоритних потоків потоками з найвищим пріоритетом.
4. Зважені черги, що настроюються
Механізм CQ (Custom Queuing, CQ, "черга, що настроюється" або "звичайна черга") надає адміністратору можливість вручну задати розподіл ресурсів, тобто розподілити смугу пропускання. Іноді CQ називають також механізмом замовленого резервування ресурсів. Механізм CQ обробляє кожну непорожню чергу в режимі кругового обслуговування (Round Robin), усякий раз передаючи з цієї черги певну кількість пакетів, яка додатково настроюється. Замовлене обслуговування черг дозволяє гарантувати надання певної частини смуги пропускання трафіка, необхідному для виконання критично важливих задач, у той же час не забуваючи і про інший трафік мережі. Механізм замовленого обслуговування черг CQ підтримує класифікацію пакетів у залежності від вхідного інтерфейса, простого або розширеного списку доступу на підставі IP-адреси, розміру пакета та аплікації, що згенерувало цей пакет. Відповідно до механізму CQ трафік можна розподілити за 16 чергами (рис. 2). Крім цього, існує додаткова нульова системна черга, яка призначена виключно для обробки високопріоритетних пакетів, таких, як пакети підтримки з'єднання і управляючих пакетів. Ця черга є пріоритетною і її пакети передаються першими. Трафік користувачів не може оброблятися в системній черзі.
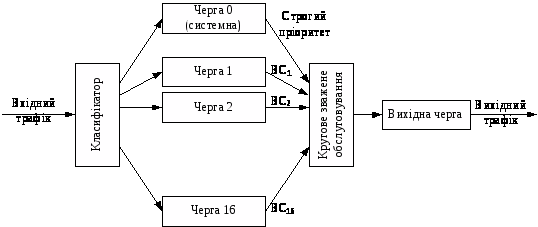
Рисунок 2 – Механізм замовленого обслуговування черг CQ
У рамках CQ черги 1–16 обслуговуються за круговим принципом, починаючи з першої. З кожною чергою пов'язаний свій лічильник байт (Byte Count, BC), який визначає кількість байтів, що має бути передана з цієї черги, перш ніж перейти до наступної. Пакети з черги передаються доти, поки не перевищиться значення лічильника байт або черга не виявиться порожньою. Після цього система переходить до наступної непорожньої черги. Відзначимо, що якщо значення лічильника байт було перевищено, пакет, що передається в поточний момент часу, передається повністю. Наприклад, якщо значення лічильника байтів дорівнюватиме 100, а розмір пакета –1024 байта, то щораз при обслуговуванні даної черги маршрутизатор передаватиме 1024, а не 100 байт.
Припустимо, що розмір пакетів трьох різних протоколів дорівнює 500, 300 і 100 байт відповідно. Для того, щоб рівномірно розподілити смугу пропущення між трьома протоколами, ви можете спробувати встановити значення лічильника байтів для кожної черги рівним 200. Слід зазначити, що подібне рішення, проте, не приведе до розподілу смуги пропускання в пропорції 33/33/33. Коли маршрутизатор обслуговує першу чергу, він передає щораз 500-байтовий пакет інформації; другу чергу – 300-байтовий пакет; третю чергу –два 100-байтових пакета. Отже, дійсний розподіл смуги пропускання здійснюється в пропорції 50/30/20. До такого непередбачуваного результату призвело занадто мале значення лічильника байтів.
Насправді досить велике значення лічильників байтів також може призвести до досить небажаного розподілу смуги пропускання. Якщо всім трьом чергам надати значення лічильника байтів, яке дорівнює 10 Кбайт, то, незважаючи на те, що пакети кожного з протоколів обслуговуватимуться швидко в момент обробки черги, відповідної цьому протоколові, може пройти досить багато часу, перш ніж ця черга обслуговуватимуться знову. У розглянутому нами випадку одним з найбільш оптимальних рішень є установка значень лічильників байтів черг таким, що дорівнюють 500, 600 і 500 байт відповідно, що приведе до розподілу смуги пропускання в пропорції 31:38:31.
Отже, задача розподілу смуги пропускання в заданих пропорціях між декількома потоками зводиться до визначення коректного значення лічильника байтів. Для розрахунку такого значення лічильника байтів BC пропонується такий алгоритм.
Нехай потрібно
розподілити смугу пропускання між
трьома чергами в пропорції
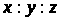 з огляду на те, що розміри пакетів, що
надходять у кожну з цих черг, складають
з огляду на те, що розміри пакетів, що
надходять у кожну з цих черг, складають
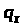 ,
,
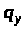 ,
,
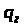 відповідно.
відповідно.
Крок 1. Розраховуються
допоміжні змінні
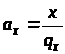 ,
,
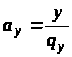 ,
,
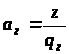 .
.
Крок 2. Отримані значення
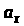 ,
,
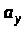 ,
,
 нормалізуються й округляються у більший
бік до найближчого цілого числа
нормалізуються й округляються у більший
бік до найближчого цілого числа
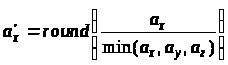 ,
,
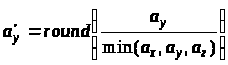 ,
,
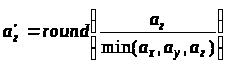 .
.
Крок 3. Розраховуються значення лічильників байтів
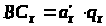 ,
,
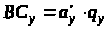 ,
,
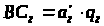 .
.
Крок 4. Розраховується
розподіл смуги між чергами, який
забезпечується отриманими значеннями
лічильників байтів
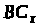 ,
,
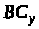 ,
,
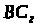 :
:
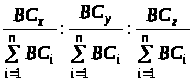 ,
,
де
 – загальна кількість черг. У даному
прикладі
=3.
– загальна кількість черг. У даному
прикладі
=3.
Крок Якщо отриманий
розподіл значно відхиляється від
заданого (),
то необхідно повернутися до кроку 2 і
помножити коефіцієнти пропорції
кількості пакетів з кожної черги, що
мають передаватися за один раз,
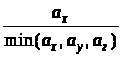 ,
,
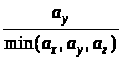 ,
,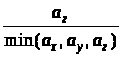 (до операції округлення) на деяке
спеціальне число. Це число підбирається,
виходячи з міркувань максимального
наближення коефіцієнтів пропорцій до
цілих чисел, хоча воно не обов'язково
має бути цілим.
(до операції округлення) на деяке
спеціальне число. Це число підбирається,
виходячи з міркувань максимального
наближення коефіцієнтів пропорцій до
цілих чисел, хоча воно не обов'язково
має бути цілим.
5. Алгоритм організації черг на основі класу CBQ
Алгоритм CBQ (Class-Based Queuing) забезпечує ієрархічний розподіл ресурсів і цікавий у першу чергу ієрархічним підходом в організації черг.
У рамках CBQ смуга пропускання каналу поділяється між декількома класами трафіка в заздалегідь заданих співвідношеннях, причому кожному з класів у період перевантаження гарантується певна частка загальної смуги. За відсутності перевантаження смугу пропускання, яку виділено для одного класу трафіка і яка не використовується ним цілком, можна розділити між іншими класами, інтенсивність надходження яких перевищує виділену їм смугу. У рамках CBQ використовується два планувальника: загальний планувальник (general scheduler) і планувальник розподілу ресурсів (link-sharing scheduler), між якими проводиться строге розмежування (рис. 3).
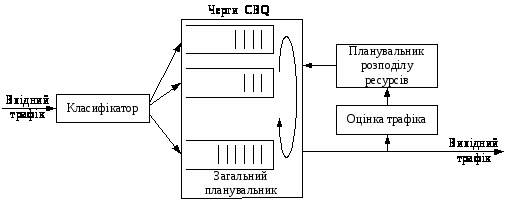
Рисунок 3 – Механізм CBQ
Вхідний трафік класифікується і розділяється на кілька черг відповідно до заздалегідь заданих правил фільтрації. Загальний планувальник (як правило, це WRR) визначає, з якої черги обслуговуватиметься наступний пакет. Черга вибирається виходячи з того, щоб гарантувати кожному класу трафіка щонайменше задану частку від сумарної пропускної здатності каналу (гарантована смуга). У рамках окремих черг використовується механізм FIFO.
Вихідний трафік контролюється шляхом оцінки часу між сусідніми пакетами одного класу трафіка. На підставі цієї інформації трафік класифікується як такий, що перевищує ліміт (over-limit), як такий, що укладається в ліміт (under-limit) або як такий, що залишився (at-limit). Трафік вважається як таким, що перевищує ліміт, якщо смуга, яку він використовує більше, ніж йому гарантується, відповідно трафік є таким, що укладається в ліміт, якщо він використовує смугу менше йому гарантованої.
Якщо черга якого-небудь класу трафіка виявиться порожньою, планувальник розподілу ресурсів розділить гарантовану даному класові смугу між іншими класами. У випадку виникнення перевантаження, планувальник розподілу ресурсів переводить клас, що перевищив ліміт, у розряд пасивного і загальний планувальник тимчасово не обслуговує пакети з цієї черги.
Як уже відзначалося вище, у CBQ застосовується ієрархічний підхід до розподілу ресурсів (hierarchical link-sharing). Для окремого класу трафіка в CBQ створюється своя черга, причому існують різні варіанти побудови критеріїв класифікації, наприклад, класифікація може базуватися на аплікації, яка згенерувала пакет, або на адресах відправника й одержувача. Приклади відповідних схем поділу ресурсів наведені на рис. 4. На рис. 4 для кожного класу трафіка зазначена частка сумарної смуги пропускання, гарантована даному класові в умовах перевантаження. Виділення якому-небудь класові 0% означає, що в період перевантаження даному класові не гарантується передача.
Приклад ієрархічного розподілу ресурсів наведений на рис. 5
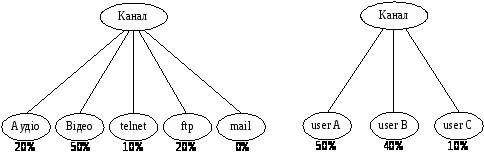
Рисунок 4 – Приклади розподілу ресурсів з використанням різних критеріїв класифікації трафіка
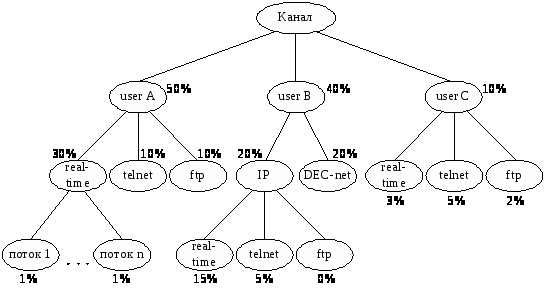
Рисунок 5 – Приклад ієрархічного розподілу ресурсів
Механізм обслуговування CBQ є дуже розповсюдженим, він реалізований у Packet Filter (pf) у сімействі операційних систем BSD.
Розглянемо приклад. Нехай маємо таку структуру черг:
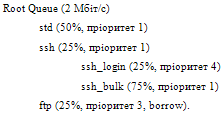
Тут Root Queue – коренева черга – займає всю смугу пропускання каналу (2 Мбіт/с). Коренева черга має три дочірні черги std, ssh і ftp, яким надається 50%, 25% і 25% від сумарної смуги відповідно. Черга ssh у свою чергу має дві дочірні підчерги: ssh_login і ssh_bulk, що поділяють смугу, яку виділено для ssh, в співвідношенні 1:3 (25% і 75%).
У рамках CBQ можливе введення пріоритетів. Черги одного рівня ієрархії і рівного пріоритету обслуговуються за круговим принципом (WRR). Черга, що має вищий пріоритет, обслуговується першою. У даному прикладі спочатку обслуговується черга ftp (пріоритет 3), потім черги з пріоритетом 1 – std і ssh за круговим принципом. Коли обслуговуватиметься черга ssh, спочатку вилучаються пакети з ssh_login (пріоритет 4), потім з ssh_bulk (пріоритет 1). Пріоритети черг різного рівня ієрархії (ftp і ssh_login) не порівнюються. Запис borrow для черги ftp означає, що цій черзі дозволено запозичати ресурси (смугу пропускання), які виділені для інших черг цього ж рівня ієрархії, але ними не використовуються. Розглянута черга конфігурується на інтерфейсі fxp0 за допомогою наступних команд:

Тут записи ecn і red означають, що в цих чергах працюють механізми боротьби з перевантаженнями ECN і RED.
6. Максимінна схема рівномірного розподілу ресурсів
З метою забезпечення рівномірного обслуговування використовується максимінна схема рівномірного розподілу ресурсів (max-min fair-share allocation scheme). Основними її правилами є такі:
• ресурси розподіляються в порядку підвищення вимог;
• користувач не може отримати обсяг ресурсів, який перевищує його потреби;
• ресурси розподіляються рівномірно між користувачами з незадоволеними вимогами.
Розглянемо приклад. Припустимо, що загальний обсяг доступного ресурсу дорівнює 14 одиницям. Вимоги до ресурсу користувачів А, В, С, D та Е складають 2, 2, 3, 5 і 6 одиниць, відповідно. Розподіл ресурсу починається з джерела з найменшими вимогами, який одержує обсяг ресурсу, що дорівнює відношенню всього запасу ресурсу до загальної кількості користувачів. Отже, у розглянутому нами випадку користувачам А і В буде надано 14/5=2,8 одиниць ресурсу (рис. 6). Однак вимоги користувачів А і В складають усього лише 2 одиниці ресурсу. У цьому випадку надлишковий ресурс обсягом 1,6 одиниць (по 0,8 одиниць з кожного користувача) рівномірно розподіляється між трьома іншими користувачами. Отже, користувачі С, D та Е одержують по 2,8 + (1,6/3) = 3,33 одиниць ресурсу (рис. 7). Наступним за обсягом висунутих вимог до ресурсів є користувач С. Вимоги користувача С на 0,33 одиниці менше обсягу ресурсів, що йому пропонується. Надлишковий ресурс обсягом 0,33 одиниці рівномірно розподіляється між користувачами D і Е, кожний з яких одержує по 3,33 + (0,33/2)=3,5 одиниці ресурсу (рис. 8).

Рисунок 6 – Розподіл ресурсів для користувачів А і В
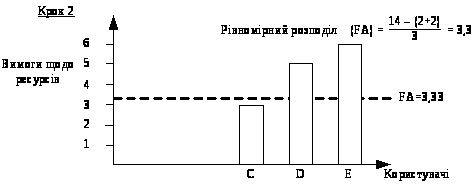
Рисунок 7 – Розподіл ресурсів для користувача С
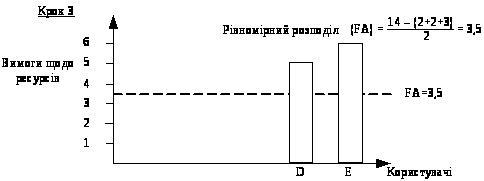
Рисунок 8 – Розподіл ресурсів для користувачів D та E
У загальному випадку
обсяг ресурсів, наданий
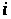 -му
користувачеві, розраховується за
формулою:
-му
користувачеві, розраховується за
формулою:
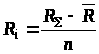 ,
,
де
 – сумарний запас ресурсів;
– сумарний запас ресурсів;
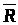 – обсяг уже розподілених ресурсів;
– обсяг уже розподілених ресурсів;
 – кількість користувачів,
яким ще потрібні ресурси.
– кількість користувачів,
яким ще потрібні ресурси.
Як видно з рис. 6 – 8, вимоги користувачів А та В задовольняються в повному обсязі, тому що вони не перевищують значення, отриманого в результаті рівномірного розподілу ресурсів між усіма користувачами. На кроці 2 цілком задовольняються вимоги користувача С. А запити користувачів D і Е залишаються незадоволеними.
Зверніть увагу, що всі користувачі з незадоволеними вимогами (тобто з вимогами, обсяг яких перевищує їх максимінну рівномірну частку), одержують рівні обсяги ресурсів. Максимінна схема рівномірного розподілу ресурсів одержала свою назву в зв'язку з тим, що користувач з незадоволеними вимогами одержує максимум з можливих мінімальних рівномірних часток. Максимінна схема рівномірного розподілу ресурсів, у якій кожному користувачеві призначається певна вага, одержала назву зваженої максимінної схеми рівномірного розподілу ресурсів (weighted max-min fair-share allocation scheme). У відповідності до зваженої максимінної схеми рівномірного розподілу ресурсів кожному користувачеві надається рівномірна частка ресурсів, пропорційна до його ваги. Принцип максимінного рівномірного розподілу ресурсів було покладено в основу узагальненої схеми поділу процесорного часу (Generalized Processor Sharing, GPS). У відповідності зі схемою GPS кожен потік трафіка вміщується у власну логічну чергу, після чого нескінченно малий обсяг даних з кожної непорожньої черги обслуговується за круговим принципом. Необхідність обробки нескінченно малого обсягу даних на кожному колі обумовлена вимогою рівномірного обслуговування всіх непорожніх черг на будь-якому кінцевому часовому інтервалі. Отже, схема GPS є справедливою в будь-який момент часу. Якщо ж усім потокам трафіка призначити вагу, то обсяг даних потоку, який оброблюється за одне коло, буде пропорційний його вазі. Подібне розширення схеми GPS фактично є зваженою максимінною схемою рівномірного обслуговування. Незважаючи на те, що GPS є ідеальним втіленням максимінної схеми рівномірного розподілу ресурсів, цю модель не можна реалізувати на практиці. Це пов'язано з припущенням про нескінченно малий обсяг даних, що обслуговуються, кожного кола.
7. Алгоритм рівномірного обслуговування черг (FQ)
Спробою практичної реалізації схеми GPS є алгоритм рівномірного обслуговування черг (FQ) на основі обчислення порядкового номера пакета, що імітує роботу GPS-сервера, який обслуговує в окремий момент часу 1 байт даних. Алгоритм FQ моделює схему GPS шляхом обчислення порядкового номера кожного отриманого пакета. Власне кажучи, порядковий номер пакета є службовою позначкою, яка визначає відносний порядок обробки пакетів.
Одним з основних понять алгоритму FQ є поняття лічильника циклів (Round Number, RN), значення якого відповідає кількості виконаних циклів побайтового планувальника кругового обслуговування в заданий момент часу. Лічильник циклів безпосередньо визначає значення порядкового номера пакета.
З метою ілюстрації способу моделювання схеми GPS за допомогою алгоритму FQ розглянемо три потоки трафіка – А, В і С, розміри пакетів яких складають 128, 64 і 32 байт, відповідно. Пакети надходять один за іншим на завантажений FQ-сервер у порядку Al, A2, A3, Bl, C1. Першим на FQ-сервер надходить пакет А1, потім –пакет А2 і т.д.
Потік вважається активним (active), якщо хоча б один із пакетів з цього потоку знаходиться в очікуванні обслуговування; у іншому випадку потік вважається пасивним (inactive).
Припустимо, що системою FQ був отриманий пакет А1, який належить пасивному потокові. Повна обробка 128-байтового пакета побайтовим планувальником кругового обслуговування потребує 128 циклів. Якщо на момент одержання пакета А1 значення лічильника циклів дорівнювало 100, то після повної передачі пакета А1 це значення складе 100+128=228. По суті, порядковий номер пакета є номером циклу, в якому здійснюється передача останнього байта пакета. Оскільки в дійсності планувальник за один раз реалізує передачу всього пакета, а не його одного байта, він обслуговує весь пакет незалежно від того, чи зрівнявся лічильник циклів з порядковим номером пакета (рис.9).
Коли система FQ отримає пакет А2, він уже належатиме активному потокові трафіка завдяки наявності в черзі пакета А1 з порядковим номером 228. Порядковий номер пакета А2 дорівнюватиме 228+128=356, оскільки його слід передати після пакета А1. Аналогічно, пакетові A3 призначається порядковий номер 356+128=484. Оскільки пакети В1 і С1 належать пасивним потокам трафіка, їхні порядкові номери дорівнюють 164=(100+64) і 132=(100+32), відповідно (рис. 9). З урахуванням обчислених порядкових номерів пакети будуть обслуговані в такій послідовності: С1,В1, А1, А2, А3.
Отже, порядковий номер
(Sequence Number)
 пакета довжиною
пакета довжиною
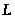 байт, що визначає черговість його
обробки, можна розрахувати за формулою:
байт, що визначає черговість його
обробки, можна розрахувати за формулою:
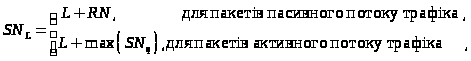 (1)
(1)
де
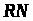 – значення лічильника циклів на момент
надходження пакета (дорівнює порядковому
номерові останнього обслуговуваного
пакета);
– значення лічильника циклів на момент
надходження пакета (дорівнює порядковому
номерові останнього обслуговуваного
пакета);
 – значення найбільшого порядкового
номера пакета, який поставлений в чергу
цього потоку (для активного потоку).
– значення найбільшого порядкового
номера пакета, який поставлений в чергу
цього потоку (для активного потоку).
Лічильник циклів
використовується винятково для розрахунку
порядкового номера пакетів, які належать
новим (пасивним) потокам трафіка.
Порядковий номер пакетів, що належать
активним потокам трафіка, розраховується
з урахуванням найбільшого порядкового
номера пакета з цього потоку, який
поставлений в чергу.
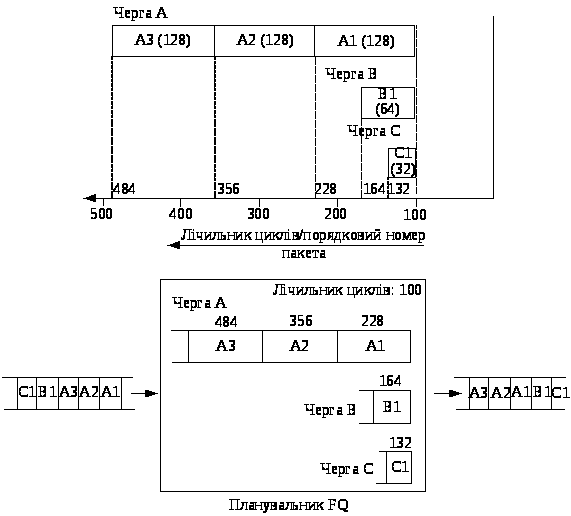
Рисунок 9 – Приклад моделювання побайтового GPS-планувальника кругового обслуговування за допомогою алгоритму FQ
Слід зазначити, що лічильник циклів оновлюється при передачі кожного чергового пакета, при цьому його нове значення дорівнює порядковому номерові пакета, що передається. Отже, якщо 32-байтовый пакет D1, що належить новому потоку, буде прийнятий у момент передачі пакета А1, значення лічильника циклів дорівнюватиме 228, а порядковий номер пакета D1 – 260=(228+32). Оскільки порядковий номер пакета D1 менше порядкових номерів пакетів А2 і A3, він буде переданий раніше за цих пакетів. Зміна в порядку обслуговування пакетів схематично зображена на рис. 10.
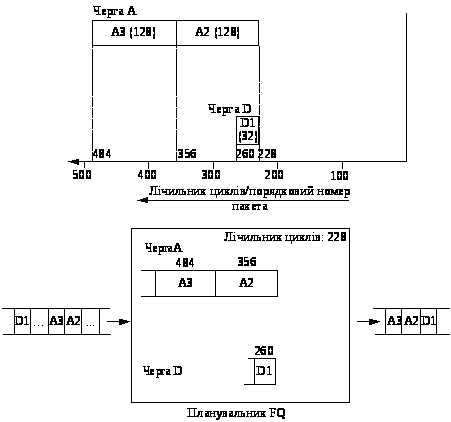
Рисунок 10 – Зміна в порядку обслуговування пакетів, яка викликана надходженням пакета D1 у момент передачі пакета А1