Суперскалярні мікропроцесори
Зміст
Вступ
Суперскалярні мікропроцесори
1.Структурний паралелізм мікропроцесорів
2.Структурні конфлікти та причини їхнього виникнення
3. Конфлікти за даними
4. Архітектура СМП
5. Основні прийоми підвищення швидкодії в СМП
6 .Напрямок розвитку суперскалярної архітектури
Висновок
Література
Вступ
Тема реферату «Суперскалярні мікропроцесори» з дисципліни «Мультімікропроцесорні системи».
Мультімікропроцесорні системи (ММПС) - це системи, що мають два й більше компонент, які можуть одночасно виконувати команди. Підпорядкованими процесорами можуть бути спецпроцесори, розраховані на виконання певного типу завдання або процесори широкого застосування. Спецпроцесори - співпроцесори, процесори вводу-виводу.
Суперскалярні мікропроцесори (далі – СМП) ─ це такі мікропроцесори, система команд яких не містить ніяких вказівок на паралельну обробку усередині мікропроцесора (мал. 1).
Ідея розвитку СМП - побудова можливо більшої кількості паралельних структур при збереженні традиційних послідовних програм, тобто компілятори й апаратури. МП самі, без участі програміста, забезпечують завантаження паралельно працюючих функціональних пристроїв у мікропроцесорі.
мікропроцесор конфлікт суперскалярна архітектура
1.Структурний паралелізм мікропроцесорів
Конвеєрна організація виконання команд. Конфлікти й способи їхнього усунення
Сучасні процесори містять 10 і більше обробних пристроїв, кожне з яких представляє із себе конвеєр. Ефективне завантаження кожного пристрою забезпечується або апаратурами процесора або компілятором, на вхід якого надходить послідовність команд. Основний метод проектування процесорів полягає в сполученні операцій, тобто в певний момент часу процесор виконує 2 і більше операції. Цей метод досягається шляхом впровадження структурного паралелізму й конвеєризації.
При структурному паралелізмі: сполучення операцій досягається шляхом відтворення в декількох копіях апаратної структури.
При конвеєризації: поділ виконує команди, що, на дрібні частини (щабля), і виділення для кожного щабля окремого функціонального блоку апаратури.
Розглянемо наступні щаблі:
Вибірка команди (1);
Декодування (2);
Виконання (3);
Звертання до пам'яті (4);
Запам'ятовування результату (5).
При конвеєрній обробці виникають ситуації, що перешкоджають виконанню наступної команди (конфлікти) :
Структурні конфлікти. Виникають, коли апаратні засоби не можуть підтримувати всі можливі комбінації виконуваних команд у режимі одночасного виконання зі сполученням.
Конфлікти за даними. Виконання наступної команди залежить від результату виконання попередньої команди.
Конфлікти по керуванню. Виникають у випадку виконання команд умовного й безумовного переходів, що змінюють стан програмного лічильника.
2. Структурні конфлікти. Причини їхнього виникнення
Способи мінімізації
Такі конфлікти виникають у машинах з функціональними пристроями, конвеєризованими не повністю. Час роботи такого пристрою - кілька тактів синхронізації конвеєра. У цьому випадку послідовні команди не можуть надходити на даний пристрій у кожному такті.
Недостатнє дублювання деяких ресурсів, що приводить також до припинення конвеєра (приклад - наявність тільки одного порту запису в регістровий файл, але при певних обставинах може знадобитися дві записи в регістровий файл за один такт).
Наявність однієї пам'яті для команд і даних ( немає роздільної кеш-пам'яті команд і кеш-пам'яті даних). Коли одна команда містить звертання до пам'яті за даними, вона буде конфліктувати із вибіркою більше пізньої команди з пам'яті.
При виконанні четвертої команди на першому етапі відразу виникає конфлікт при звертанні до пам'яті, тому що перша команда здійснює звернення до пам'яті, а перша команда повинна здійснювати вибірку коду операції з пам'яті. У цьому випадку здійснюється припинення конвеєра на один такт (stall), виникає так званий "конвеєрний міхур" тому що він проходить по всьому конвеєрі, але не виконує ніякої корисної роботи.
3. Конфлікти за даними
Конфлікти цього типу виникають у тому випадку, коли застосування конвеєрної обробки може змінити порядок обігу за операндами так, що він буде кардинально відрізнятися від порядку проходження операндів при послідовному виконанні команд.
Таблиця 1
-
ADD R1,R2, R3
1
2
3
4
5
sub> R4, R1, R5
1
2
3
4
5
AND R6, R1, R7
1
2
3
4
5
OR R8,R1, R9
1
2
3
4
5
XOR R10,R1,R11
1
2
3
4
5
Приклад: відповідно до вищенаведеної таблиці всі команди, що випливають за АDD, використають її результат, але для такого конвеєрного виконання команда sub> прочитає неправильний результат, тому що команда додавання ще не встигла записати результат виконання.
Ця проблема вирішується з використанням схемних рішень, називаних пересиланням даних (просування, обхід або закоротка). У цьому випадку результат операції АЛУ знову подається на вхід АЛУ. Якщо апаратури виявляє, що попередня операція записує свій результат у регістр, що є джерелом для наступної операції, то логічні схеми керування вибирають як входи результат, що надходить по ланцюгах обходу, а не значення, прочитане з регістрового файлу. Така техніка обходів може бути узагальнена й використана не тільки для АЛУ, але й для інших функціональних пристроїв у мікропроцесорі.
Конфлікти за даними класифікуються в такий спосіб:
- читання після читання (RAR). Залежність відсутня. Порядок виконання команд не важливий;
- читання після запису (RAW). j-я команда намагається прочитати результат i-й команди перш, ніж i-я запише цей результат. Усувається механізмом обходу;
- запис після читання (WAR).j-я команда намагається записати в приймач перш, ніж його вміст считається i-й командою, у результаті i-я команда може некоректно одержати нове значення;
- запис після запису (WAW). j-я команда намагається записати операнд перш, ніж буде записаний результат i-й. Виникає в конвеєрах при записі з багатьох щаблів, або що дозволяють виконуватися наступній команді, коли попередня припинена.Конфлікти за даними, що приводять до припинення конвеєра.Приклад послідовності команд, яка приводить до такого рода конфликтів приведен в таблиці 2.
Таблиця 2
|
LW R1,32,(R6) |
1 |
2 |
3 |
4 |
5 |
||||
|
ADD R4,R1,R7 |
1 |
2 |
6 |
3 |
4 |
5 |
|||
|
sub> R5,R1,R8 |
1 |
6 |
2 |
3 |
4 |
5 |
|||
|
AND R6,R1,R7 |
6 |
1 |
2 |
3 |
4 |
5 |
Команда LW (завантаження регістра 1 з пам'яті за адресою, що перебуває в регістрі 6) має затримку, що не усувається механізмом обходу. Це така ж ситуація (міхур), як і для структурного конфлікту . Для даного випадку використається апаратури внутрішніх блокувань конвеєра.
4. Архітектура СМП
Для перерахованих вище типів МП існують поняття статичної й динамічної послідовності команд.
Статична - це впорядкована послідовність команд у пам'яті мікропроцесора.
Динамічна - безліч послідовностей інструкцій у порядку їхнього виконання, що відповідає динаміці налагодження програми. Динамічна структура програми може бути змінена, при незмінній статичній структурі. Це й дає підвищення ступеня паралельності виконання команд. При виконанні програми мікропроцесор як би просуває за статичною структурою програми вікно виконання. Команди в цьому вікні можуть виконуватися паралельно, якщо між ними немає залежності.
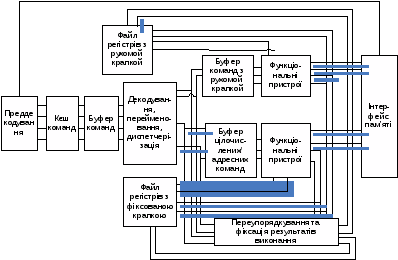
Малюнок 1. Архітектура суперскалярного мікропроцесора
5. Основні прийоми підвищення швидкодії в СМП
Передвиборка команд і пророкування переходів
Блок передвиборки команд витягає з пам'яті декілька команд за один такт мікропроцесора й тому особливі вимоги пред'являються до пропускної здатності інтерфейсу мікропроцесор-пам'ять. Для цього застосовуються багаторівневі роздільні кеш-пам'яті дані й кеш-пам'яті команд.
У блоці пророкування переходів використаються або додаткові біти в коді операції або переддекодування при виборі з кеш-пам'яті.
Декодування команд, перейменування ресурсів і диспетчеризація
На цьому етапі визначаються істотні залежності й переборюються несуттєві, виробляється розподіл команд по буферах функціональних пристроїв.
Для подолання зайвих залежностей, що виникають у результаті обмеженості логічних ресурсів, комірок пам'яті, регістрів використається механізм динамічного відображення логічних ресурсів на фізичні ресурси мікропроцесора.
Коли команда створює нове значення для фізичного ресурсу, він одержує ім'я. Дана процедура називається перейменуванням регістрів. Існують два основних способи перейменування:
1 - фізичний файл регістрів більше логічного. Зі списку вільних фізичних регістрів береться один і йому зіставляється відповідне логічне ім'я. Якщо список вільних регістрів порожній, диспетчеризація команд припиняється до моменту появи вільних фізичних регістрів.
2- фізичний файл регістрів дорівнює логічному файлу , але є один буфер, що використається для встановлення порядку виконання команд при перериваннях . Команди містяться в кінець буфера й після виконання її результат заноситься в заздалегідь певний елемент черги. Якщо команда досягла кінця буфера й була вже виконана, її результат міститься в регістровий файл, а сама команда вилучається. Не виконана команда перебуває в буфері до одержання необхідного їй операнда. Коли буфер заповнюється, диспетчеризація призупиняється.
Виконання команд
Після формування для кожної команди впорядкованих трійок (коду операції, операнда-источника, операнда-приймача) і розміщення їх у буферах, наступає фаза динамічної перевірки готовності значень операндів для виконання команди.
Команда готова, як тільки готові операнди, але є ряд обмежень, пов'язаних з доступністю фізичних ресурсів (виконавчі пристрої, комутатори й порти регістрових файлів) і переупорядкуванням буфера. Для організації вікна виконання використаються різні методи:
1- Одна черга - перейменування регістрів не потрібно й доступність операндів відзначається бітом резервування в кожному регістрі. Регістр резервується, що коли модифікує його команда призначається на виконання й звільняється коли команда виконана;
2- Кілька черг - кожна черга організується для команд одного типу, команди роботи з FPU, робота з АЛУ, робота з пам'яттю;
3- Використання станції, що резервує. Вона складається з елементів, кожний з яких містить:
- код операції;
- найменування першого операнда;
- сам перший операнд;
- ознака доступності першого операнда;
- найменування другого операнда;
- сам другий операнд;
- ознака доступності другого операнда;
- найменування регістра результату.
Коли команда виконується, то найменування результату рівняється з операндом у результуючій станції, і, у випадку порівняння, установлюється ознака доступності результату. Коли в команди доступні всі операнди, дозволяється її виконання.
6 .Напрямок розвитку суперскалярної архітектури
При всіх перевагах суперскалярної архітектури принаймні дві обставини обмежують ефективність її використання.
По-перше, є обмеження на ступінь паралелізму на рівні команд, навіть якщо застосовується сама зроблена техніка суперскалярних обчислень. Перше обмеження виникає з умовних переходів. Друге з того, що розмір вікна виконання ( число активних команд, які можуть виконуватися паралельно) обмежує можливий програмі паралелізм, тому що не розглядається паралельне виконання команд, що перебувають на відстані, що перевищує розмір вікна.
По-друге, складність СМП зростає як кількість паралельна команд, що виконують, і навіть швидше. Орієнтовно межею є запуск на паралельне виконання 7-8 команд СМП.
Альтернативою суперскалярній обробці є використання довгого командного слова (VLIW). Використання цього методу припускає завдання в командному слові сукупності паралельно виконуваних команд. Підготовкою таких програм повинен займатися компілятор.
Переваги VLIW полягають у наступному:
- компілятор може більш ефективно досліджувати залежності між командами й вибирати паралельно виконуючі, чим це робить апаратури;
- є більш простий пристрій керування й можна мати більше високу тактову частоту.
Недоліки VLIW наступні :
- наявність команд розгалуження, які залежать від динаміки обчислень;
- VLIW - реалізація вимагає великого регістра пам'яті імен, багатовхідних регістрових файлів, великої кількості перехресних зв'язків.
Висновок
Крім VLIW-реалізації є перехід до мультипроцесорного виконання, коли вводиться кілька лічильників команд. Для цього необхідно наявність распаралелюючих компіляторів з мов високого рівня.
Література
1. Ю-Чжен Лю, Г.Гибсон Микропроцессоры семейства 8086/8088 М.: Радио и связь, 1987.
2. Б.В.Шевкопляс Микропроцессорные структуры. Инженерные решения М.: Радио и связь, 1990
3. В.Шевкопляс Микропроцессорные структуры. Инженерные решения. Дополнение первое. М.: Радио и связь, 1993
4. М.Гук Аппаратные средства IBM PC С.Петербург Питер 2000
5. В.Корнеев А.Киселев Современные микропроцессоры Санкт-Петербург БХВ – Петербург 2003
6. Локазюк В.М. и др Микропроцессоры и микроЭВМ в производственных системах Киев Издательский центр Академия 2002
7. Гуржий А.М. и др Архитектура принципы функционирования и управления ресурсами IBM PC Харьков 2003
8. В.В.Сташин А.В. Урусов О.Ф. Мологонцева Проектирование цифровых устройств на однокристальных микроконтроллерах Л. Энергоатомиздат
9. Под ред.А.Д.Викторова Руководство пользователя по сигнальным микропроцессорам семейства ADSP-2100 Санкт- Петербургский государственный электротехнический университет. Санкт- Петербург 1997
10. М.Предко Руководство по микроконтроллерам в 2-х томах М: Постмаркет, 2001