Элементарные методы сортировки
Элементарные методы сортировки
В качестве нашей первой экскурсии в область алгоритмов сортировки, мы изучим некоторые «элементарные» методы которые хорошо работают для небольших файлов или файлов специальной структуры. Существует несколько причин, по которым желательно изучение этих простых методов. Во-первых, они дают нам относительно безболезненный способ изучить терминологию и основные механизмы работы алгоритмов сортировки, что позволяет получить необходимую базу для изучения более сложных алгоритмов. Во-вторых, для многих задач сортировки бывает лучше использовать простые методы, чем более сложные алгоритмы. И, наконец, некоторые из простых методов можно расширить до более хороших методов или использовать их для улучшения более сложных.
В некоторых программах сортировки лучше использовать простые алгоритмы. Программы сортировки часто используются только один раз (или несколько раз). Если количество элементов, которые нужно отсортировать не велико (скажем меньше чем 500 элементов), то может статься, что использование простого алгоритма будет более эффективно, чем разработка и отладка сложного алгоритма. Элементарные методы всегда пригодны для маленьких файлов (скажем меньших, чем 50 элементов); маловероятно, что сложный алгоритм было бы разумно использовать для таких файлов, если конечно не нужно сортировать большое количество таких файлов.
Как
правило, элементарные методы, которые
мы будем обсуждать, производят около
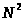 операций
для сортировки N
произвольно взятых элементов. Если N
достаточно мало, то это может и не быть
проблемой, и если элементы распределены
не произвольным образом, то эти алгоритмы
могут работать даже быстрее, чем сложные.
Однако следует запомнить то, что эти
алгоритмы не следует использовать для
больших, произвольно упорядоченных
файлов, с одним единственным исключением
для алгоритма оболочечной сортировки,
который часто используется во многих
программах.
операций
для сортировки N
произвольно взятых элементов. Если N
достаточно мало, то это может и не быть
проблемой, и если элементы распределены
не произвольным образом, то эти алгоритмы
могут работать даже быстрее, чем сложные.
Однако следует запомнить то, что эти
алгоритмы не следует использовать для
больших, произвольно упорядоченных
файлов, с одним единственным исключением
для алгоритма оболочечной сортировки,
который часто используется во многих
программах.
Правила Игры
Перед тем, как рассматривать какой-либо конкретный алгоритм, было бы полезно изучить терминологию и некоторые основные соглашения об алгоритмах сортировки. Мы будем изучать алгоритмы для сортировки файлов записей содержащих ключи. Ключи, которые являются только частью записи (часто очень маленькой их частью), используются для управления процессом сортировки. Целью алгоритма сортировки является переорганизация записей в файле так, чтобы они располагались в нем в некотором строго определенном порядке (обычно в алфавитном или числовом).
Если сортируемый файл целиком помещается в память (или целиком помещается в массив), то для него мы используем внутренние методы сортировки. Сортировка данных с ленты или диска называется внешней сортировкой. Главное отличие между ними состоит в том, что при внутренней сортировке любая запись легко доступна, в то время как при внешней сортировке мы можем пользоваться записями только последовательно, или большими блоками. Большинство алгоритмов сортировки, которые мы рассмотрим – внутренние.
Обычно,
главное, что будет нас интересовать в
алгоритме – это время его работы. Первые
четыре алгоритма, которые мы рассмотрим,
для сортировки N элементов имеют время
работы пропорциональное
,
в то время как более сложные алгоритмы
используют время пропорциональное
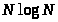 .
(Можно показать, что никакой алгоритм
сортировки не может использовать менее,
чем
сравнений между ключами.) После изучения
простых методов мы рассмотрим более
сложные методы, время работы которых
пропорционально
.
(Можно показать, что никакой алгоритм
сортировки не может использовать менее,
чем
сравнений между ключами.) После изучения
простых методов мы рассмотрим более
сложные методы, время работы которых
пропорционально
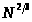 и методы использующие бинарные свойства
ключей для уменьшения общего времени
работы до N.
и методы использующие бинарные свойства
ключей для уменьшения общего времени
работы до N.
Количество используемой дополнительной памяти алгоритма сортировки – это еще один важный фактор, который мы будем принимать во внимание. Вообще говоря, методы сортировки делятся на три типа:
методы сортировки, которые сортируют без использования дополнительной памяти, за исключением, возможно, небольшого стека и / или массива;
методы, которые используют для сортировки связанные списки и поэтому используют N дополнительных указателей хранящихся в памяти;
и методы, которые нуждаются в дополнительной памяти для хранения копии сортируемого файла.
Стабильность – еще одна немаловажная характеристика методов сортировки. Метод сортировки называется стабильным, если он сохраняет относительных порядок следования записей с одинаковыми ключами. Например, если алфавитный список группы сортируется по оценкам, то стабильный метод создает список, в котором фамилии студентов с одинаковыми оценками будут упорядочены по алфавиту, а нестабильный метод создаст список в котором, возможно, исходный порядок будет нарушен. Большинство простых методов стабильны, в то время как большинство хорошо известных сложных методов – нет. Если стабильность необходима, то она может быть достигнута посредством добавления к ключу небольшого индекса перед сортировкой или посредством удлинения, каким-либо образом, ключа. Стабильность с легкостью принимается за норму; к нестабильности люди относятся с недоверием. На самом же деле, лишь немногие методы достигают стабильности без использования дополнительного времени или места.
Следующая программа, для сортировки трех записей, предназначена для иллюстрации основных соглашений, которые мы будем использовать. В частности, главная программа любопытна тем, что она работает только для N=3; смысл в том, что любая программа сортировки может быть сведена к процедуре sort3 этой программы.
Три оператора присвоения, каждый из которых сопровождается оператором if, на деле реализуют операцию «обмена». Мы вставляем ее непосредственно в программный код вместо использования вызова процедуры, поскольку они являются основой многих алгоритмов и часто попадают внутрь цикла.
Чтобы сконцентрироваться на алгоритмических вопросах, мы будем работать с алгоритмами, которые просто сортируют массивы целых в численном порядке. В общем, очень легко адаптировать такие алгоритмы для практического использования, включающего в себя работу с большими ключами или записями. В основном программы сортировки работают с записями двумя способами: либо они сравнивают и сортируют только ключи, либо передвигают записи целиком. Большинство алгоритмов, которые мы изучим можно применять, посредством их переформулировки в терминах этих двух операций, для произвольных записей. Если сортируемые записи довольно большие, то обычно пытаются избежать передвижения их посредством «косвенной сортировки»: при этом сами записи не переупорядочиваются, а вместо этого переупорядочивается массив указателей (индексов), так, что первый указатель указывает на самый маленький элемент и так далее. Ключи могут храниться либо с записями (если они большие), либо с указателями (если они маленькие). Если необходимо, то после сортировки записи можно упорядочить. Это описано дальше.
Программа sort3 использует даже более ограниченный доступ к файлу: это три операции вида «сравнить две записи и обменять их, если нужно, чтобы поместить запись с меньшим ключом на первое место». Программы, ограниченные такими операциями интересны, поскольку они подходят для реализации на аппаратном уровне. Мы изучим их более подробно позднее.
Все примеры программ используют для сортировки глобальный массив. Это не означает, что такой подход лучше или хуже чем передача массива как параметра. Все зависит от точки зрения и конкретного алгоритма. Массив сделан глобальным только потому, что тогда примеры становятся короче и понятней.
Сортировка выбором
Один из самых простых методов сортировки работает следующим образом: находим наименьший элемент в массиве и обмениваем его с элементом находящимся на первом месте. Потом повторяем процесс со второй позиции в файле и найденный элемент обмениваем со вторым элементном и так далее пока весь массив не будет отсортирован. Этот метод называется сортировка выбором, поскольку он работает, циклически выбирая наименьший из оставшихся элементов, как показано на рисунке 1. При первом проходе символ пробела уходит на первое место, обмениваясь с буквой ‘П’. На втором проходе элемент ‘В’ обменивается с элементом ‘Р’ и так далее.
Следующая программа дает полную реализацию этого процесса. Для каждого i от 1 до N-1, она обменивает наименьший элемент из a [i..N] с a[i]:
По мере продвижения указателя i слева направо через файл, элементы слева от указателя находятся уже в своей конечной позиции (и их больше уже не будут трогать), поэтому массив становится полностью отсортированным к тому моменту, когда указатель достигает правого края.
Этот метод – один из простейших, и он работает очень хорошо для небольших файлов. Его «внутренний цикл» состоит из сравнения a[i]<a[min] (плюс код необходимый для увеличения j и проверки на то, что он не превысил N), что вряд ли можно еще упростить.
Кроме того, хотя сортировка выбором является методом «грубой силы», он имеет очень важное применение: поскольку каждый элемент передвигается не более чем раз, то он очень хорош для больших записей с маленькими ключами.
Сортировка вставкой
Метод сортировки вставкой, почти столь же прост, что и сортировка выбором, но гораздо более гибкий. Этот метод часто используют при сортировке карт: берем один элемент и вставляем его в нужное место среди тех, что мы уже обработали (тем самым оставляя их отортированными).
Рассматриваемый элемент вставляется в позицию посредством передвижения большего элемента на одну позицию вправо и затем размещением меньшего элемента в освободившуюся позицию, как показано на рисунке 2. Так ‘И’ при третьем шаге меньше всех остальных отсортированных элементов, поэтому мы «топим» его в начало массива. ‘М» больше ‘И’ но меньше всех остальных, поэтому мы помещаем его между ‘И’ и ‘П’, и так далее.
Этот процесс реализован в следующей программе. Для каждого i от 2 до N, подмассив a [1..i] сортируется посредством помещения a[i] в подходящую позицию среди уже отсортированных элементов:
Также как и при сортировке выбором, в процессе сортировки элементы слева от указателя i находятся уже в сортированном порядке, но они не обязательно находятся в своей последней позиции, поскольку их еще могут передвинуть направо чтобы вставить более маленькие элементы встреченные позже. Массив становится полностью сортированным когда указатель достигает правого края.
Однако имеется еще одна важная деталь: программа insertion не всегда работает, поскольку while может проскочить за левый край массива, когда v – самый меньший элемент массива. Чтобы исправить ситуацию, мы помещаем «сторожевой» ключ в a[0], делая его, по крайней мере, не больше, чем самый маленький ключ массива. Сторожевые элементы повсеместно используются в ситуациях подобных этой для предотвращения дополнительной проверки (в данном случае j>0), что почти всегда помогает во внутренних циклах.
Пузырьковая сортировка
Элементарный метод сортировки, который часто дают на вводных занятиях – это пузырьковая сортировка: Стоящие рядом элементы массива обмениваются местами, до тех пор, пока встречаются неотсортированные пары. Реализация этого метода дана ниже.
Чтобы поверить в то, что она на самом деле работает, может потребоваться некоторое время. Для этого заметьте, что когда во время первого прохода мы встречаем максимальный элемент, мы обмениваем его с каждым элементом справа от него пока он не окажется в крайней правой позиции. На втором проходе мы помещаем второй максимальный элемент в предпоследнюю позицию и так далее. Пузырьковая сортировка работает также как и сортировка выбором, хотя она и делает гораздо больше работы на то, чтобы переместить элемент в его конечную позицию.
Характеристики простейших сортировок
Свойство
1 Сортировка
выбором использует около
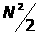 сравнений и N обменов.
сравнений и N обменов.
Свойство
2 Сортировка
вставкой использует около
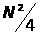 сравнений и
сравнений и
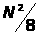 обменов в среднем, и в два раза больше
в наихудшем случае.
обменов в среднем, и в два раза больше
в наихудшем случае.
Свойство
3 Пузырьковая
сортировка использует около
сравнений и
обменов в среднем и наихудшем случаях.
Свойство 4 Сортировка вставкой линейна для «почти сортированных» файлов.
Свойство 5 Сортировка выбором линейна для файлов с большими записями и маленькими ключами.
Сортировка файлов с большими записями
Очень часто бывает возможно (и желательно) сделать так, чтобы при сортировке файла состоящего из N элементов любом методом было бы сделано только N операций обмена полной записи посредством косвенной адресации к элементам массива (используя массив индексов или указателей), а саму реорганизацию делать после.
Более конкретно: если массив a [1..N] содержит большие записи, то мы предпочтем использовать массив указателей p [1..N] для того, чтобы знать, где находится очередной элемент массива a, и для произведения псевдообмена. Ниже приведена программа сортировки вставкой с использованием массива указателей:
Для предотвращения излишнего контроля в цикле, в программе опять используются «сторожевые» элементы.
Изначально, индексы идут по порядку. Потом порядок индексов начинает меняться так, чтобы массив a, прочитанный по порядку чтения индексов был упорядочен.
Для этого мы можем использовать следующую процедуру, которая физически упорядочивает записи файла используя при этом N перестановок:
Сортировка Шелла
Сортировка вставкой работает медленно потому, что она обменивает только смежные элементы. Оболочечная сортировка является простейшим расширением сортировки вставкой, которая увеличивает скорость работы алгоритма за счет того, что позволяет обменивать элементы находящиеся далеко друг от друга.
Основная идея алгоритма состоит в том, чтобы отсортировать все группы файла состоящие из элементов файла отстоящих друг от друга на расстояние h. Такие файлы называются h-сортированными. Когда мы h-сортируем файл по некоторому большому h, мы передвигаем его элементы на большие растояния. Это облегчает работу сортировки для меньших значений h. Процесс заканчивается когда h уменьшается до 1.
Приведенная программа использует последовательность… 1093, 364, 121, 40, 13, 4, 1. Могут существовать и другие последовательности – одни лучше, другие хуже.
Свойство 6 Оболочечная сортировка никогда не делает более чем N1.5 сравнений для вышеуказанной последовательности h.
Подсчет распределения
Во многих случаях мы знаем, что значения ключей в файле лежат в каких либо пределах. В этих ситуациях применим алгоритм, именуемый подсчет распределения. Здесь приведена программа для этого простого алгоритма.