Сжатие речи на основе алгоритма векторного квантования
Министерство образования и науки Украины
Пояснительная записка
к курсовому проекту
по дисциплине «Цифровая обработка сигналов»
на тему: «сжатие речи на основе алгоритма векторного квантования»
2006
Аннотация
В данной курсовой работе представлена разработка алгоритма функционирования системы, обеспечивающей сжатие речи с помощью векторного квантования, и программная реализация алгоритма в системе MATLAB и на языке С.
Приводится исследование влияния на работоспособность системы аддитивных шумов, разработка и исследование программной реализации системы на основе ЦПОС. Разработана система сжатия речи, обеспечивающая сжатие речи до уровня 2400 бит/с и ниже и и подсистема декодирования в реальном времени с помощью алгоритма векторного квантования. Предусмотрены несколько ступеней сжатия. Обеспечена работа системы в двух режимах: дикторо-зависимом и дикторо-независимом. Система реализована в пакете MATLAB и на языке С.
СОДЕРЖАНИЕ
Введение
1. Постановка задачи
2. Описание существующих методов сжатия речи
3. Описание выбранного метода сжатия
4. Разработка программы на MATLab
5. Тестирование на MATLab
6. Системные требования
Заключение
Библиографический список
Приложение А. Текст программы на MATLab
Приложение Б. Текст программы на С
ВВЕДЕНИЕ
При передаче речи по цифровым каналам связи, будь то сотовая или Интернет-телефония, самый важный вопрос - это сколько информации (число бит в единицу времени) придется передавать по каналам, чтобы снабдить пользователя качественной голосовой связью. Ответ на него в каком-то смысле определяет все - стоимость и качество предоставляемых пользователям услуг и аппаратуры, емкость и масштабируемость сети передачи данных и многое другое.
Сжатие речи при ее передаче сокращает объем передаваемых данных, затраты и, благодаря этому, позволяет снижать цены на услуги и привлекать новых пользователей. Именно поэтому рынок цифровой телефонии развивается под непосредственным технологическим диктатом ученых и разработчиков кодеков речи.
Очевидно, что, начиная с каких-то пороговых значений соотношения скорости передачи и доступной емкости каналов, операторы связи имеют достаточную (для развития и своего, и рынка) прибыль. В настоящее время можно сказать, что этот порог уже превышен. Это привело к тому, что расценки на цифровую связь стали более чем конкурентны по сравнению с проводной аналоговой, а благодаря скорому переходу к кодекам речи на скорости порядка 2,4 кбит/с и ниже, цена минуты междугородного разговора может в ближайшие годы снизиться до нескольких центов за минуту.
Сказав про успехи, нельзя не сказать хотя бы пару слов и о недостатках. Качество звучания сжатой речи, что в сотовой, что в Интернет-телефонии оставляет желать лучшего. Некоторые (из тех, кто имеет такой выбор) до сих пор предпочитают аналоговые сотовые сети цифровым, поскольку в последних речь часто звучит механически, случаются посторонние звуки и т. п. - и все из-за сжимающих кодеков речи, так как в остальном цифровые протоколы передачи обеспечивают лучшее качество звучания. В компьютерной телефонии снижению качества, помимо кодеков речи, способствует заметное запаздывание сигнала и ошибки при сборке пакетов. Впрочем, понятно, что если с кодеком на 2,4 кбит/с "узкий" канал справляется с трудом, то на скорости 1,2 кбит/с проблем будет меньше. Да и пропускная способность компьютерных сетей возрастает настолько быстро, что в ближайшей перспективе сетевая задержка снизится в несколько раз. И тогда и у пользователей, и у операторов на первое место могут встать высокие требования именно к низкоскоростным кодекам речи.
Речь представляет собой колебания сложной формы, зависящей от произносимых слов, тембра голоса, интонации, пола и возраста говорящего. Спектр речи весьма широк (примерно от 50 до 10000 Гц), но для передачи речи в аналоговой телефонии когда-то отказались от составляющих, лежащих вне полосы 0,3-3,4 кГц, что ухудшило восприятие ряда звуков (например, шипящих, существенная часть энергии которых сосредоточена в верхней части речевого спектра), но мало затронуло разборчивость. Ограничение частоты снизу (до 300 Гц) также ухудшает восприятие из-за потерь низкочастотных гармоник основного тона. А в цифровой телефонии к влиянию ограничения спектра добавляются еще шумы дискретизации, квантования и обработки, дополнительно зашумляющие речь.
Решающими в выборе полосы 0,3-3,4 кГц были экономические соображения и нехватка телефонных каналов. Потребности пользователей в каналах сделали тогда вопросы качества речи второстепенными.
Для совместимости по полосе с распространенными аналоговыми сетями в цифровой телефонии отсчеты аналоговой речи приходится брать согласно теореме Котельникова с частотой 8 кГц - не меньше двух отсчетов на 1 Гц полосы. Правда, в цифровой телефонии существует принципиальная возможность использовать спектр речи за пределами полосы 0,3-3,4 кГц и тем самым повысить качество, но эти методы не реализуются, так как они вычислительно пока еще очень сложны. Впрочем, кое-что появляется: уже разработаны универсальные кодеки для компьютерной телефонии и мультимедиа, способные передавать не только речь, но и музыку. При полосе исходного сигнала до 6 кГц и тактовой частоте отсчетов около 16 кГц сжатый цифровой сигнал требует для передачи канал в 12 кбит/с.
Озвученная речь, представляющая большую трудность для сжатия, образуется с помощью звуковых связок человека. Скорость их периодических колебаний задает так называемую частоту основного тона (ОТ) - энергию голосового тракта человека, который представляет собой объемный резонатор. Голосовой тракт формирует спектральную окраску речи или, другими словами, ее формантную структуру. Другое название голосового тракта - синтезирующий фильтр - нам более удобно, так как математическое описание речеобразования обычно ведется в терминах линейной фильтрации. Тогда, условно, речевой сигнал можно разделить на две составляющие, отвечающие за (1) ОТ (возбуждение фильтра) и (2) голосовой тракт (формантная структура сигнала). Соответственно, большинство на сегодня используемых алгоритмов, так или иначе, решают один вопрос - как наиболее эффективно выделить и сокращенно описать обе составляющие.
1 ПОСТАНОВКА ЗАДАЧИ
Необходимо разработать систему сжатия речи, обеспечивающую сжатие речи до уровня 2400 бит/с и ниже с помощью алгоритмов векторного квантования. Предусмотреть несколько ступеней сжатия. Обеспечить работу системы в двух режимах: дикторо-зависимом и дикторо-независимом. Реализовать систему в пакете MATLAB и подсистему декодирования в реальном времени с помощью ЦПОС TMS320C7711/5402.
2 ОПИСАНИЕ СУЩЕСТВУЮЩИХ МЕТОДОВ СЖАТИЯ РЕЧИ
Многие методы сжатия речевых сигналов основаны на линейном предсказании речи. В частности, линейное предсказание используется при сжатии речи по методу АДИКМ. Стандарт G726, определяющий алгоритмы АДИКМ, устанавливает для данного типа сжатия речевых сигналов нижнюю скорость передачи 16 Кбит/с .
Дальнейшее снижение скорости передачи возможно при использовании схем анализ-синтез речи, учитывающих особенности цифровой модели формирования речи. Применяют два варианта таких схем – без обратной связи и с обратной связью.
На рисунке 2.1 (а) приведена схема сжатия речи без обратной связи, основанная на анализе по методу линейного предсказания и синтезе речевого сигнала. Здесь речевой сигнал s[n] разбивается на сегменты длительностью 20-39 мс. На каждом из сегментов с помощью устройства оценивания (УО) определяются коэффициенты линейного инверсного фильтра-анализа Ф1 десятого порядка. Кроме этого, на этапе сжатия с помощью выделения основного тона (ОТ) и анализатора тон-шум (Т-Ш) определяются соответствующие параметры функции возбуждения. В кодере выполняется кодирование коэффициентов фильтра и параметров функции возбуждения, которые затем передаются по каналу связи или сохраняются в памяти.
В восстанавливающем устройстве (рисунок 2.1 а) сначала происходит декодирование коэффициентов фильтра и параметров функции возбуждения, а затем выполняется синтез речевого сигнала S^[n]. Для этого в зависимости от значения признака тон-шум (ТШ) на вход фильтра-синтеза Ф2 подается сигнал либо с выхода генератора тона (ГТ), либо с выхода генератора шума (ГШ). В технике связи устройство, выполняющее сжатие и восстановление речевых сигналов по приведенной схеме, называют вокодером. Для кодирования периода основного тона используют 6 бит, для коэффициентов усиления - 5 бит, для признака тон/шум – 1 бит, для коэффициента усиления – 5 бит, для коэффициентов линейного предсказания – 8-10 бит. С учетом того, что для каждого сегмента речи оценивается 10 коэффициентов предсказания, получим 97-117 бит на один сегмент. Скорость передачи при длительности сегмента 30 мс составит примерно 3000 бит/секунду.
В системе, изображенной на рисунке 2.1 б), параметры возбуждения (частота основного тона, признак тон/шум, форма сигнала возбуждения) формируются без учета их влияния на качество синтезированной речи, поэтому восстановленная речь как механическая и не обеспечивает узнаваемости голоса.
а)
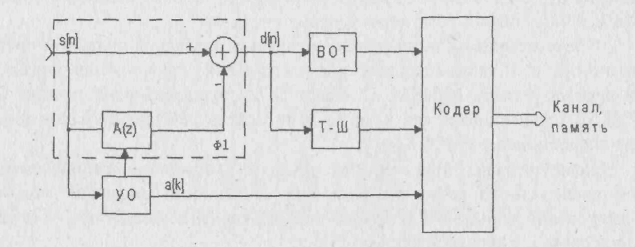
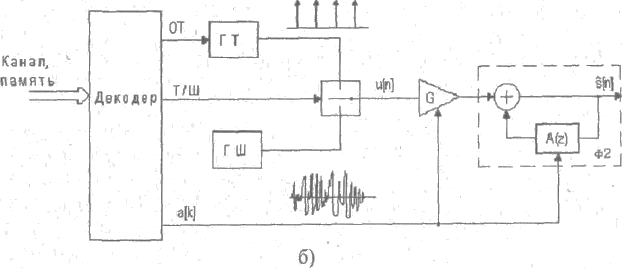
Рисунок 2.1 - Сжатие речевых сигналов в схеме без обратных связей
Для повышения натуральности речи используется схема анализа-синтеза с обратной связью (рисунок 2.2). В этой схеме возбуждающая последовательность формируется путем минимизации ошибки восстановления речевого сигнала, т.е. разности между исходным речевым сигналом s[n] и восстановленным сигналом S[n]. Восстановленный речевой сигнал формируется с помощью фильтров Ф1 и Ф2, на вход которых подается сигнал с выхода генератора функции возбуждения (ФВ). Фильтр Ф1 учитывает квазипериодические свойства вокализованных участков речи, а фильтр Ф2 моделирует формантную структуру речи. Инверсный фильтр, соответствующий фильтру Ф1, является фильтром долговременного предсказания, а инверсный фильтр, соответствующий фильтру Ф2, называется фильтром кратковременного предсказания.
Фильтр долговременного предсказания описывается передаточной функцией
P>L>(z) = 1- A>L>(z), (2.1)
где A>L>(z)-az^-t и t - задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания d>K>[n], то в соответствии с (2.1) ошибка долговременного предсказания d>Д{>[n] будет равна:
d>Д>[n] = d>K>[n] - ad>K>[n-T] (2.2)
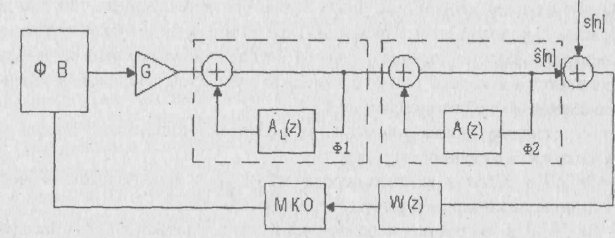
Рисунок 2.2 - Сжатие речевых сигналов в схеме анализ-синтез
Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности S[n] ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рисунок 2.2) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой. Фильтр W(z) учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рисунке 2.2, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
Существует несколько различных способов формирования функции возбуждения: многоимпульсное, регулярно-импульсное и векторное (кодовое) возбуждение. Соответствующие алгоритмы представляют много-импульсное (MLPC), регулярно-импульсное (RPE-LPC) и линейное предсказание с кодовым возбуждением (code excited linear prediction - CELP). MLPC использует функцию возбуждения, состоящую из множества нерегулярных импульсов, положение и амплитуда которых выбирается так, чтобы минимизировать ошибку восстановления. Алгоритм RPE-LPC является разновидностью MLPC, когда импульсы имеют регулярную расстановку. В этом случае оптимизируется амплитуда и относительное положение всей последовательности импульсов в пределах сегмента речи. CELP представляет способ, который основывается на векторном квантований. В соответствии с этим способом из кодовой книги возбуждающих последовательностей выбирается квазислучайный вектор, который минимизирует квадрат ошибки восстановления. Кодовая книга используется как на этапе сжатия речевого сигнала, так и на этапе его восстановления. Для восстановления сегмента речевого сигнала необходимо знать номер соответствующего вектора возбуждения в кодовой книге, параметры фильтров A\.(z) и A(z), коэффициент усиления СУ. Восстановление речевого сигнала по указанным параметрам выполняется в декодере только с помощью элементов, входящих в верхнюю часть схемы, изображенной на рисунке 2.2.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефонной связи;
VCELP со скоростью передачи 7,95 Кбит/с (vector sum excited linearprediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
LD-CELP (low-delay CELP) одобрен стандартом МККТТ G.728. Вданном стандарте достигается небольшая задержка примерно 0,625 мс(обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией АL(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP).
На рисунке 2.3,а изображена обобщенная схема сжатия речевого сигнала с помощью алгоритмов векторного квантования.
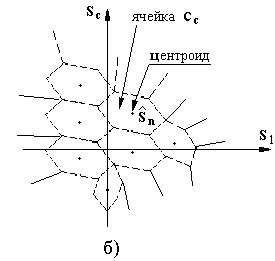
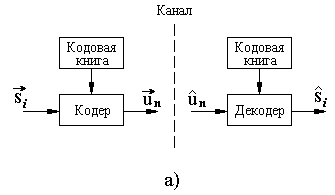
Рисунок 2.3 – Векторное квантование
Входной вектор s>i> представляет собой вектор признаков речевого сигнала (например, спектральных),
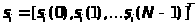 .
.
Кодер отображает
входной вектор
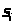 в выходной символ u>n>,
n
= 1, 2, …, L
с помощью кодовой книги. Кодовая книга
содержит L
векторов
в выходной символ u>n>,
n
= 1, 2, …, L
с помощью кодовой книги. Кодовая книга
содержит L
векторов
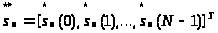 ,
n
= 1, 2, …, L.
,
n
= 1, 2, …, L.
Предположим,
что канал не имеет шумов, т.е.
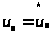 .
.
Векторный
квантователь функционирует следующим
образом. Входной вектор
сравнивается с каждым вектором из
кодовой книги. В результате из кодовой
книги выбирается вектор
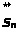 ,
ближайший к вектору
,
и в канал передается символ u>n>,
представляющий адрес найденного кодового
вектора. На приемной стороне с помощью
полученного адреса u>n>
восстанавливается вектор признаков
речевого сигнала
,
ближайший к вектору
,
и в канал передается символ u>n>,
представляющий адрес найденного кодового
вектора. На приемной стороне с помощью
полученного адреса u>n>
восстанавливается вектор признаков
речевого сигнала
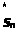 ,
на основе которого синтезируется речевой
процесс. В такой интерпретации векторное
квантование, по сути, является
распознаванием образов, где вектор
представляет собой входной образ,
кодовая книга соответствует базе
эталонов.
,
на основе которого синтезируется речевой
процесс. В такой интерпретации векторное
квантование, по сути, является
распознаванием образов, где вектор
представляет собой входной образ,
кодовая книга соответствует базе
эталонов.
В качестве
меры расстояния между входными векторами
и векторами из кодовой книги обычно
используется сумма квадратов отклонений
s>i>(k)
и
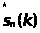 :
:
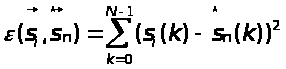 (2.3)
(2.3)
Кодовая книга
(база эталонов) создается путем разделения
N
- мерного пространства признаков на L
непрерывающихся ячеек (областей) (рисунок
2.3,а). Каждая ячейка ассоциируется C>n>
с вектором-эталоном
.
Если входной вектор
принадлежит ячейке C>n>,
то квантователь назначает этому вектору
символ u>n>,
который представляет собой адрес
вектора-эталона данной ячейки (центроида).
В простейшем
случае, если вектор
представляет собой блок отсчетов
речевого сигнала, рассмотренная схема
квантования является обобщением
импульсной кодовой модуляции (ИКМ), и
называется векторной ИКМ. В векторной
ИКМ (ВИКМ) число битов, приходящихся
один отсчет речевого сигнала определяется
по формуле
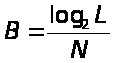 (2.4)
(2.4)
ВИКМ имеет
преимущество перед различными видами
ИКМ [ 1 ], если
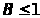 .
.
Процесс
проектирования кодовой книги, который
связан с обучением, может быть реализован
двумя способами. В первом случае кодовая
книга разрабатывается на основе алгоритма
К-средних. Рекомендуется, чтобы обучающая
выборка содержала по 40 примеров векторов
признаков для каждого кодового вектора.
Вычислительную сложность разработки
кодовой книги можно снизить, если
определенным образом структурировать
кодовую книгу. Действительно, так как
в процессе построения кодовой книги
выполняется поиск среди L
векторов-эталонов, то упорядочение
книги может привести к сокращению
времени поиска. Для ускорения поиска
часто применяют бинарные деревья [2].
Сложность вычислений можно уменьшить,
если в кодовой книге отдельно хранить
нормализованные векторы
и масштабный коэффициент G
(коэффициент усиления).
Во втором случае кодовая книга создается с помощью алгоритма обучения, в соответствии с которым положение центроидов на каждом шаге уточняется по рекуррентной формуле
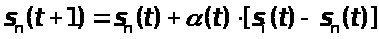 ,
(2.5)
,
(2.5)
где t
– номер шага; α - коэффициент обучения,
α ~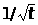 .Формула
уточняет положение только того центроида,
для которого входной вектор
.Формула
уточняет положение только того центроида,
для которого входной вектор
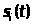 оказался ближайшим.
оказался ближайшим.
Выражение (2.5) соответствует правилу обучения состязательных нейронных сетей, в частности, правилу Кохонена. Подробнее см. в [2].
Существует различные схемы сжатия речи c помощью алгоритмов векторного квантования. Большинство из них основано на схеме “анализ-синтез”. Применяют два варианта таких схем – без обратной связи и с обратной связью [1]. В основе каждой из схем лежит модель синтеза речи на основе коэффициентов линейного предсказания [1]. В соответствии с этой моделью речь может быть получена путем подачи специальным образом подобранного возбуждающего сигнала на вход линейного фильтра, который моделирует резонансные частоты голосового тракта. Передаточная функция фильтра описывается уравнением
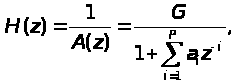 (2.6)
(2.6)
где G - коэффициент усиления, a>i> - коэффициенты линейного предсказания, P - порядок предсказателя.
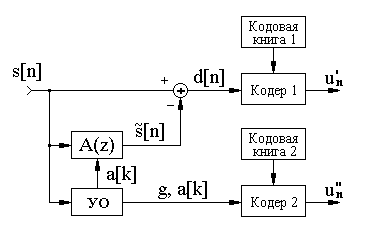
Возможная структурная схема системы низкоскоростного кодирования речи с помощью алгоритмов векторного квантования изображена на рисунке 2.2.
Р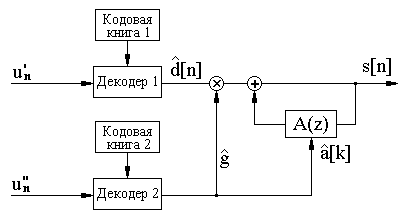
исунок
2.4 – Низкоскоростное кодирование речи
Процедура кодирования речи сводится к следующему:
- оцифрованный речевой сигнал s[n] нарезается на сегменты длительностью 20 мс (при fg=8 КГц в каждом сегменте будет по 160 выборок);
- для каждого сегмента вычисляются с помощью устройства оценивания (УО) параметры фильтра линейного предсказания и определяется ошибка предсказания d[n], соответствующая функции возбуждения;
- функция возбуждения и параметры фильтра линейного предсказания кодируются с помощью отдельных векторных квантователей и передаются в канал.
Процедура декодирования заключается в пропускании восстановленного сигнала возбуждения через синтезирующий фильтр (2.4), параметры которого переданы одновременно с функцией возбуждения.
Приведенное описание процессов кодирования и декодирования речи не является исчерпывающим, оно объясняет лишь принцип действия кодера. Практические схемы намного сложнее, и это связано в основном со следующими двумя моментами.
Во-первых, на рисунке 2.2 изображена схема без обратной связи. Лучшего качества синтезируемой речи можно добиться в схемах с обратной связью [1]. Однако такие схемы сложнее.
Во-вторых, описанная выше схема, использует кратковременное предсказание и не обеспечивает в достаточной степени устранения избыточной речи. Поэтому в дополнение к кратковременному предсказанию используется еще и долговременное предсказание [1]. Выходной сигнал фильтра кратковременного предсказания используется для оценивания параметров фильтра долговременного предсказания – задержки τ и коэффициента предсказания a:
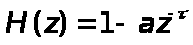
При оценке качества кодирования и сопоставлении различных кодеров оцениваются разборчивость речи и качество синтеза речи (качество звучания). Для оценки разборчивости речи используется метод ДРТ (диагностический рифмованный текст). В этом методе подбираются пары близких по звучанию слов, отличающиеся отдельными согласными (“кол-гол-пол”), которые многократно произносятся рядом дикторов, и по результатам испытаний оценивается доля искажений [3,4].
Для оценки качества звучания используется критерий ДМП (диагностическая мера приемлемости) [4]. Испытания заключаются в чтении несколькими дикторами, мужчинами и женщинами, ряда специально подобранных фраз, которые прослушиваются на выходе тракта связи рядом экспертов-слушателей, выставляющих свои оценки по 5-балльной шкале. Результатом является средняя оценка мнений (MOS).
Обратим внимание на следующий факт. Если кодовая книга создается на обучающих данных, принадлежащих только одному диктору, тоне следует ожидать, что она будет обеспечивать хорошее качество звучания для другого диктора. Соответственно, кодовая книга, полученная в лабораторных условиях, не обеспечит того же качества звучания при записи речи в шумовой обстановке, например, в салоне автомобиля. Для построения дикторо-независимой системы необходимо проектировать кодовую книгу на речевых сигналах различных дикторов.
3 ОПИСАНИЕ ВЫБРАННОГО МЕТОДА СЖАТИЯ
Разработанные за последние 20 лет методы кодирования обеспечивают хорошее качество (разборчивость, натуральность звучания, повышенную возможность опознавания говорящего) при передаче речи в цифровой форме по узкополосным каналам связи. На практике широкое применение нашли кодеры с линейным предсказанием при многоимпульсном возбуждении и при возбуждении от кода.
Наиболее совершенным алгоритмом (с точки зрения качества) является алгоритм с векторным квантованием.
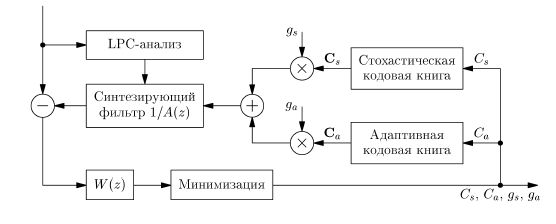
Рисунок 3.1 – Структурная схема кодирования
Речевой сигнал S разделяется на кадры длительностью в 20 мс. В каждом кадре с использованием алгоритма линейного предсказания (LPC) определяются параметры синтезирующего фильтра 1/А(z), после чего методом анализа через синтез находятся параметры сигнала возбуждения, минимизирующие взвешенный сигнал ошибки. Сигнал возбуждения представляется наборами индексов векторов извлекаемых из стохастической и адаптивной кодовых книг а также наборами соответствующих им коэффициентов усиления. При кодировании сигнала возбуждения кадр разбивается на 4 подкадра по 5 миллисекунд. В каждом подкадре кодируются и передаются индексы (9 бит на индекс), коэффициенты усиления. В целом кадр кодируется 144 битами из которых 40 бит отводятся на кодирование коэффициентов усиления с использованием скалярного квантования.
При использовании векторного квантования для каждого из двух коэффициентов усиления производилось объединение четырех значений, полученных для подкадров одного кадра, в один четырехмерный вектор. В результате этого для каждого кадра формировались два вектора коэффициентов усиления для квантования которых использовались различные кодовые книги. Формирование кодовых книг выполнялось на основе обучающей выборки размером 16 000 векторов, с использованием которой для каждого из векторов были построены по две кодовые книги размером 64 и 128 эталонных векторов (длина кодового слова 6 и 7 бит соответственно). При таких размерах кодовых книг количество бит, отводимых на кодирование коэффициентов усиления, сокращается соответственно на 28 и 26 бит на кадр.
Обучающая выборка формировалась в результате обработки речевого материала от двенадцати дикторов (5 женщин и 7 мужчин) общей продолжительностью 8 минут. Для построения кодовых книг использовался алгоритм К средних с начальными условиями, полученными использованием Диагностической Меры Приемлемости (DAM) путем прослушивания 12 фонетически сбалансированных 6-слоговых предложений, произносимых дикторами, не участвовавшими в формировании обучающей выборки. Качестов звучания оценивалось бригадой из 10 слушателей. По результатам оценки вычислялась средняя оценка мнений (процент предпочтений).
Таким образом, использование векторного квантования коэффициента усиления позволяет без ущерба качества звучания понизить скорость до 2,4 Кбит/сек.
4 Разработка программы на MATLAB
Входные файлы должны быть 16-разрядные .WAV файлы, с частотой дискретизации в 8 кГц. Программное обеспечение большинства звуковых плат поддерживает этот формат файла.
Описание некоторых функций.
1) Функция Speech_process - моделирование вокодера, включая анализ, передачу, синтез, и графический интерфейс пользователя (GUI).
2) Функция COR - вычисление автокорреляции задержки.
Вычисление коэффициентов автокорреляции последовательности данных:
idim
C(i) = SUM rar(k) * rar(k-i) , где i = 0, ..., n
k=i+1
c0 = C(0)
3) Функция LSPDECOD - независимый LSP декодер;
4) Функция DECODHAM - расшифровывает кодируемое ключевое слово в получателе. Исправляет одиночные ошибки или обнаруживает многократные ошибки (проверка по чету).
5) Функция VDECODE - создает стохастический вектор возбуждения по индексу кодовой книги. Формирует LPC возбуждение.
6) Функция WAVHDR - создает заголовок файла для 16-разрядного, 8 кГц, моно 7) Функция ZEROFILT - нерекурсивный фильтр. Фильтр осуществлен в прямой реализации.
N -i
H (z) = SUM b (i) z
I=0
X (t) - > --- (z0) ----- b0 > ------ + ----- > y (t)
| |
Z1 ------ b1 > ------ +
| |
Z2 ------ b2 > ------ +
| |
::
| |
ZN ------ bN > ------ +
5 Тестирование программы на MATLAB
Кодовое представление параметров каждого из сегментов в шестнадцатеричном
виде:
ASCII hex-encoded representation of each set of frame parameters:
855C146BF548AD8EFE03BD2CD2ED0EE6B0A2
291C111D51673E41CD5BF56406582BCC3821
FF5046DBCDE6CE54DE5E67008A20498CAD30
575C908A636E8ED3AF0B46CC023EE29CB0BB
41BE7B8ADC0F9E5758DCDEC0C4C4C3A58CF4
193C70ECF504840F281C5E44082AB4EFB477
442088F484200F070AD21D60DEE9AF841D0E
A8CE80DF01A626049FE934A8C66735331CDD
0F863600A412234C603D33C5C2F632221F94
...
43F33E5F0B5F004800B70A4A5ADB9310067E
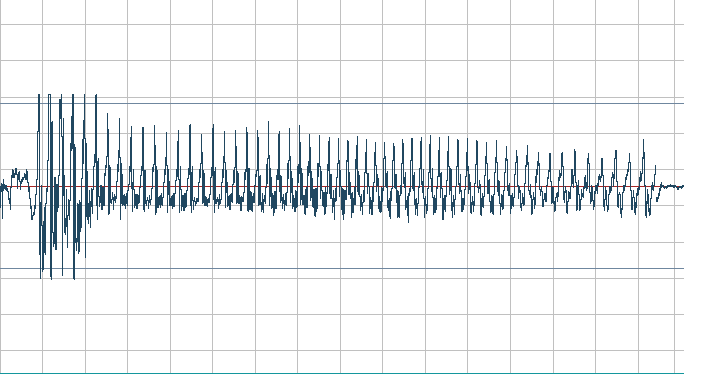
Рисунок 5.1 – амплитудная характеристика звукового файла Five.Wav
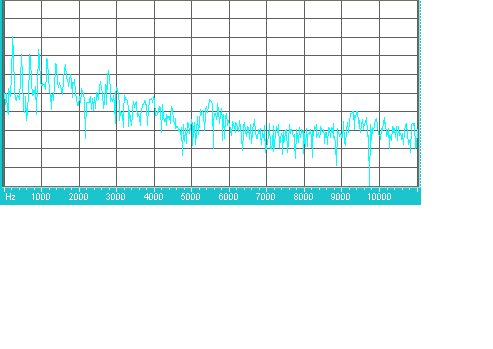
Рисунок 5.2 – частотная характеристика звукового файла Five.Wav
(после окна Хэмминга)
СИСТЕМНЫЕ ТРЕБОВАНИЯ
486DX4-100 или лучше;
16 (рекомендуется) Мбайт;
512 Кб минимум свободного места жесткого диска;
Microsoft Windows v3.1 или выше;
MATLAB для Windows v4.0 или лучше
программное обеспечение также запускается в UNIX и других средах рабочей станции.
Заключение
В данном курсовом проекте с помощью пакета MATLAB был разработан ряд функций, осуществляющих сжатие речи по алгоритму векторного квантования, обеспечивающих сжатие речи до уровня 2400 бит/с и ниже. Предусмотрено несколько ступеней сжатия. Обеспечена работа системы в двух режимах: дикторо-зависимом и дикторо-независимом.
Библиографический список
Бондарев В.Н. Цифровая обработка сигналов: методы и средства/ В.Н. Бондарев, Г. Трестер, В.Н. Чернега.- Харьков: Изд-во Конус, 2001.-398 с.
Бондарев В.Н. Искусственный интеллект/ В.Н. Бондарев, Ф.Г. Аде.- Севастополь: Изд-во СевНТУ, 2002.-616 с.
Рабинер Л.Р Цифровая обработка речевых сигналов/ Л.Р. Рабинер, Р.В. Шафер.- М.: Радио и Связь. 1981.-495 с.
Ратынский М.В. Основы сотовой связи/ М.В. Ратынский; Под ред. Д.Б. Зимина.- М.: Радио и Связь, 1998.- 248 с.
Makhoul J. Vector Qvantization // Speech Coding Proceedings of the IEEE, 1985.- Vol. 73. - N 11.- P.1551-1588.