Автоматическое распараллеливание программ для распределенных систем. Статическое построение расширенного графа управления
Аннотация
В дипломной работе рассматриваются задачи, связанные с технологией автоматического распараллеливания программ.
В первой ее части обсуждаются этапы развития компьютерной науки в области параллельных вычислений, существующие архитектурные и теоретические решения.
Вторая часть содержит описание проекта разработки системы автоматического распараллеливания программ на языке Fortran77, частью которого является данная дипломная работа.
Третья часть посвящена одному из этапов автоматического распараллеливания – созданию внутреннего представления программы, соответствующего проблематике решаемой задачи. Реализация этого этапа является задачей данной дипломной работы.
В четвертой части приведено описание программного кода дипломной работы, осуществляющего решение поставленной задачи.
В приложении содержится один из примеров, использованных при тестировании программы дипломной работы, и распечатка результатов его обработки.
Оглавление
Введение 4
1. Система автоматического распараллеливания. 11
1.1 Назначение системы. 11
1.2 Схема работы системы автоматического распараллеливания. 12
1.3 Постановка задачи дипломной работы. 14
2. Создание внутреннего представления программы. 15
2.1 Разбор исходного текста. Система Sage++. 15
2.2 Внутреннее представление программы высокого уровня. 19
2.3 Расширенный граф управления. Вспомогательные структуры. 20
3. Построение расширенного графа управления. 24
3.1 Ограничения на входную программу. 24
3.2 Описание классов. 24
3.3 Алгоритмы. 30
Заключение. 35
Библиография. 36
Приложение. 37
Введение
Определим параллельный компьютер как множество процессорных устройств, которые могут согласованно работать над решением вычислительных задач. Это определение является достаточно широким, чтобы в него можно было включить параллельные суперкомпьютеры с сотнями или тысячами процессоров, объединенные в сети рабочие станции, многопроцессорные рабочие станции. Параллельные компьютеры представляют интерес из-за возможности объединения вычислительных ресурсов (процессоров, памяти и др.) для решения важных счетных задач. Если раньше параллелелизм относился к несколько экзотическим областям науки, то дальнейшее изучение направлений развития архитектуры компьютеров, сетевых технологий и конечных приложений коренным образом изменило это представление. Использование параллельных вычислений стало повсеместным, а параллельное программирование – центральным направлением в индустрии программного обеспечения.
Параллелелизм: направления развития
Несмотря на постоянно увеличивающееся быстродействие компьютеров, нельзя ожидать, что они станут достаточно быстрыми для удовлетворения всех потребностей всевозможных задач вычислительного характера. Напротив, история компьютерной науки показывает, что как только новейшие архитектурные технологии начинают справляться с требованиями уже существующих приложений, очень скоро появляются новые приложения, вызывающие необходимость дальнейшего их развития. И если раньше основным побуждающим фактором создания передовых вычислительных разработок являлись задачи математического моделирования сложных систем - погодные и климатические явления, электронные цепи, производственные процессы, различные физические и химические процессы, то сейчас не меньшее значение приобрели коммерческие приложения, обрабатывающие большие объемы информации: программное обеспечение для проведения видеоконференций, медицинской диагностики, параллельные СУБД, системы виртуальной реальности.
Производительность компьютера напрямую зависит от времени, необходимого для совершения простейшей операции, и количества таких операций, совершаемых одновременно. Это время, в свою очередь, ограничено тактовой частотой процессора, – для которой существует некоторый предел, обусловленный физическими законами. Таким образом, ускорения процессоров недостаточно для дальнейшего увеличения вычислительной мощности. Хотя рост производительности компьютеров от их создания до наших дней описывается экспоненциальным законом (от нескольких десятков операций с плавающей точкой в секунду для первых ЭВМ в 1940-х до десятков миллиардов в 1990-х), наиболее значительным достижением представляется их эволюция от последовательной архитектуры к параллельной.
Другим важным направлением развития, несомненно, сильно изменившим взгляд на вычислительные процессы, является большое увеличение возможностей сетей, соединяющих компьютеры. Резко возросшая пропускная способность, высокая надежность, защищенность передаваемой информации и другие успехи в этом направлении позволяют разрабатывать приложения, использующие физически распределенные ресурсы как части одной системы. Такие приложения могут, например, использовать процессорное время множества удаленных компьютеров, обращаться к распределенным базам данных, осуществлять рендеринг одновременно на нескольких графических станциях.
Таким образом, можно сделать вывод о бесспорной необходимости использования принципов параллелелизма при решении задач, требующих большого объема вычислений (в том числе в реальном времени), а также о существовании позволяющих использовать такой подход архитектурных и сетевых решений.
Модели параллельного программирования
Основой модели компьютера фон Неймана является процессор, способный выполнять последовательность инструкций. Кроме различных арифметических операций, эти инструкции могут специфицировать адрес данных в памяти для чтения или записи, адрес следующей инструкции. И хотя вполне возможно создавать программы в рамках этой модели при помощи машинных языков, такой метод слишком сложен для большинства приложений. Поэтому на практике применяется технология модульного проектирования, при которой сложные программы конструируются из более простых компонентов, и в этих компонентах используются такие элементы абстракции высокого уровня, как структуры данных, циклы и процедуры. Несколько более высоким уровнем абстракции является технология объектно-ориентированного программирования. Высокоуровневые языки, такие, как Fortran, Pascal, Ada, C, C++, предоставляют возможность разработки ПО в рамках этих технологий с автоматической компиляцией текста в исполняемый код.
Параллельное программирование привносит дополнительный уровень сложности: если мы станем программировать на низком уровне, не только резко увеличится количество инструкций по сравнению с последовательной программой, но и придется подробно распределять задания между, возможно, тысячами процессоров, и координировать миллионы межпроцессорных обменов. Таким образом, модульность можно назвать одним из основных требований к параллельному ПО. Поскольку большинство существующих алгоритмов ориентировано на однопроцессорные системы, очевидна необходимость при разработке новых алгоритмов учитывать особенности одновременного выполнения многих операций: параллельность – неотъемлемое требование к алгоритмам, реализуемым в параллельном ПО. Постоянное увеличение количества процессоров в параллельных компьютерах приводит нас к выводу, что программы, рассчитанные на фиксированное число CPU, равно как и программы, предназначенные для выполнения на одном компьютере, нельзя считать приемлемыми. Следовательно, мы можем к списку требований добавить расширяемость – “эластичность” к увеличению числа процессоров, на которых выполняется программа. Если все параллельные вычислительные системы классифицировать по способу организации доступа к памяти, то можно выделить две группы: системы с общей памятью – каждый процессор (вычислительный узел) имеет непосредственный доступ к запоминающему устройству, и системы с распределенной памятью – каждый узел имеет отдельное ЗУ. Во 2-м случае обмены данными требуют достаточно высоких накладных расходов, и если для мультипроцессорных компьютеров доступ к данным другого процессора может потребовать в 10 – 1000 раз больше времени, чем к своим, то для сетевых распределенных систем порядок может быть намного выше. В связи с этим, к параллельным алгоритмам и программам предъявляется также требование локальности – оптимальное с точки зрения расходов на межпроцессорные коммуникации распределение данных.
Рассмотрим несколько моделей параллельного программирования. Простейшая модель опирается на два понятия: задача и канал. При этом параллельное вычисление состоит из одной или более задач, выполняющихся одновременно, их количество может меняться в процессе выполнения программы. Каждая задача включает в себя последовательную программу и локальную область памяти, что, фактически, является виртуальной машиной фон Неймана. В дополнение к этому, задача имеет набор входных и выходных портов, определяющих ее интерфейс с окружением. Кроме чтения и записи в локальную память, задача может: посылать сообщения в свои выходные порты, принимать сообщения через свои входные порты, создавать новые задачи (приостанавливаясь до их завершения), прекращать свое выполнение. Операция посылки сообщения асинхронная, т.е. она завершается сразу независимо от реакции принимающей стороны, операция приема – синхронная, т.е. она вызывает приостановку задачи, пока сообщение не станет доступным. Пары входных/выходных портов могут быть соединены очередями сообщений, которые называются каналами. Каналы могут создаваться и удаляться во время выполнения программы, ссылки на каналы (порты) можно включать в сообщения, так что соединения достаточно динамичны. Задачи могут быть отображены на физические процессоры различными способами (в частности, все задачи на одном процессоре) без изменения семантики программы.
Модель Message Passing, вероятно, является сегодня наиболее распространенной. В этой модели программа также создает набор задач, каждая из которых содержит локальные данные, и идентифицируется уникальным именем. Задачи могут передавать и принимать сообщения для\от именованной задачи. Таким образом, рассматриваемая модель представляет собой лишь сокращенную версию модели задача/канал – отличие только в механизме передачи данных. Однако на практике большинство message-passing систем при старте программы создают фиксированное количество одинаковых задач и не позволяют создавать или уничтожать задачи во время выполнения. Т.е. эти системы фактически реализуют модель SPMD - “одна-программа-много-данных”, в которой все задачи выполняют одну и ту же последовательную программу над разными данными.
В модели “Общая память” задачи разделяют общее адресное пространство, в котором они производят чтение и запись асинхронно. Для контроля доступа к разделяемой памяти используются различные механизмы, например, блокировки и семафоры. Преимущество этой модели с точки зрения программиста заключается в отсутствии понятия владельца данных, и, кроме того, отсутствии необходимости обменов между задачей-производителем данных и задачей-потребителем.
Другая часто используемая модель, параллелелизм данных, называется так из-за использования параллелелизма, возникающего при выполнении некоторой операции над многими элементами некоторой структуры данных (например, массива). Поскольку каждая операция над каждым элементом данных может быть представлена как независимая задача, грануляция вычислений мала и концепция локальности не возникает. Однако, компиляторы, реализующие эту модель, часто требуют от программиста информацию о распределении данных между процессорами. Такой компилятор может затем транслировать программу в представление SPMD, автоматически создавая код для осуществления необходимых обменов.
Рассмотренные модели параллельного программирования предоставляют программисту возможность разработки ПО, удовлетворяющего требованиям к параллельным программам. Параллельные языки, созданные на базе традиционных (таких как Fortran, C), или являющиеся их расширением, в той или иной степени реализуют эти модели, оставляя, однако, за программистом проблему выбора параллельного алгоритма и решение задач, связанных с оптимизацией распределения данных, минимизацией расходов на коммуникационные обмены и многих других.
Автоматические средства разработки параллельного ПО.
История эволюции средств разработки ПО показывает, что в ее процессе решается несколько задач:
реализация новых языков программирования;
переработка алгоритмов анализа исходного текста программы с целью генерации наиболее оптимального исполняемого кода;
максимальное упрощение процесса разработки ПО и др.
В последнее время необходимость в облегчении работы программиста стала, возможно, наиболее актуальной из-за резко возросшего спроса на программные продукты во всех областях деятельности: время, необходимое на создание работоспособной, максимально свободной от ошибок программы, превратилось чуть ли не в самый значительный параметр. Перерождение тройки «редактор-компилятор-компоновщик» в среду разработки, последующая ее визуализация, и дальнейшее превращение в систему «быстрой разработки программ» позволило программисту сосредоточиться на оптимизации алгоритма, избавив от рутинных действий по созданию исполняемого кода из исходного текста и даже от многих этапов собственно программирования - примером может служить занимающая много времени работа по созданию пользовательского интерфейса.
Разработка параллельного ПО - задача на порядок сложнее, поэтому от средств такой разработки требуется вся помощь, которую они могут предоставить. Программист должен работать в тесном сотрудничестве со своей средой, как получая от нее подсказки, так и предоставляя ей необходимую информацию о структуре программы и обрабатываемых данных в случае невозможности автоматического принятия решения. Одним из подходов к такой разработке может быть написание программы на привычном последовательном языке, с дальнейшей ее трансляцией в текст соответствующего расширенного языка - уже параллельного. Такой метод, во-первых, позволяет осуществлять разработку машинно-независимого продукта - генерация исполняемого кода производится компилятором целевой архитектуры, а, во-вторых, предлагает неплохое решение проблемы существования большого количества уже написанных последовательных программ. Подобные средства разработки носят название «исходный код - в исходный код трансляторы».
Алгоритм работы такой системы может быть следующим:
анализ исходной программы на последовательном языке с целью выяснения скрытого в ней параллелелизма;
один или более пробных запусков программы под средой (или в присутствии блока анализа времени выполнения) для получения более полной информации об ее структуре и оценке времени последовательного выполнения;
выбор оптимального с точки зрения системы варианта распараллеливания и оценка времени параллельного выполнения, основанная на параметрах некоторой целевой архитектуры, заданных пользователем;
выдача результатов – величина полученного ускорения и причины невозможности распараллеливания некоторых участков с предоставлением пользователю возможности вмешаться в процесс и дать необходимые инструкции; этот этап продолжается, пока не будет достигнут удовлетворяющий пользователя вариант или он не прекратит дальнейший анализ;
генерация текста на целевом параллельном языке и выдача подробного отчета о результатах распараллеливания.
Разработка параллельного ПО является очень трудоемкой задачей из-за сложности определения скрытого параллелелизма, возможности внесения некорректного, нарушающего семантику программы, ложного параллелелизма, и из-за необходимости учитывать большое число факторов, влияющих на конечную производительность программы. Автоматические средства разработки параллельных продуктов и распараллеливания готовых последовательных предоставляют возможность существенно облегчить этот процесс.
Анализ последовательной программы
Одной из первых задач, возлагаемых на автоматический распараллеливатель программ, является анализ исходной последовательной программы с целью сбора максимального количества необходимой для распараллеливания информации об ее структуре. Данные, полученные на этом этапе, в совокупности с результатами работы блока динамического анализа являются основой дальнейшей деятельности системы.
Задача статического анализа исходной программы может быть условно разделена на два этапа:
трансляция текста программы в некоторое внутреннее представление и построение структур, отражающих последовательность работы программы и используемые в ней данные;
поиск возможных вариантов распараллеливания с выбором оптимального и определение «узких» участков, препятствующих распараллеливанию.
Рассмотрим несколько более подробно 1-й этап, поскольку решение связанных с ним задач является темой данной дипломной работы. Внутреннее представление программы необходимо для возможности ее анализа независимо от исходного последовательного языка, т.е. оно является точным переложением текста программы, записанным в терминах, понятных системе. Кроме того, оно должно быть достаточным для последующей генерации текста параллельной программы на целевом языке. После создания такого представления, необходимо подняться на такой уровень абстракции, который позволит исследовать алгоритм программы с требуемой точки зрения. Иными словами, надо построить структуры данных, содержащих всю программу в приемлемом для последующего анализа виде, расширенные для возможности хранения и обработки результатов работы других блоков распараллеливателя.
1. Система автоматического распараллеливания
Данная дипломная работа является частью проекта разработки системы автоматического распараллеливания программ на языке Fortran77. Система состоит из нескольких функциональных блоков, каждый из которых реализует один или более этапов построения параллельной программы, сохраняющей семантику заданной последовательной программы. Фиксированный интерфейс обмена данными между ними позволяет производить независимую модификацию каждого блока. Таким образом, система может развиваться в сторону дальнейшего увеличения ее интеллектуальности в принятии решений о возможности распараллеливания входной программы и поиска наиболее эффективных вариантов ее преобразования.
1.1 Назначение системы
Представляемая система предназначена для распараллеливания программ, написанных на языке Fortran77. Использование этого языка как основного при разработке научных и инженерных приложений на протяжении многих лет привело к образованию большого числа программ, необходимость в которых сохраняется и сегодня. Автоматическая трансляция накопившегося последовательного кода в параллельный позволит использовать новые архитектурные возможности при существенно меньших по сравнению с повторной реализацией затратах. Формируемый системой отчет о принятых в процессе распараллеливания решениях может служить основой рекомендаций по модификации исходного кода с целью достичь наиболее эффективного результата.
Второй аспект применения – разработка параллельного ПО на основе Fortran77. Достоинство такого подхода заключается в использовании привычного языка программирования и передаче системе распараллеливания обязанностей по оценке эффективности реализации алгоритмов с точки зрения параллельного выполнения.
1.2 Схема работы системы автоматического распараллеливания
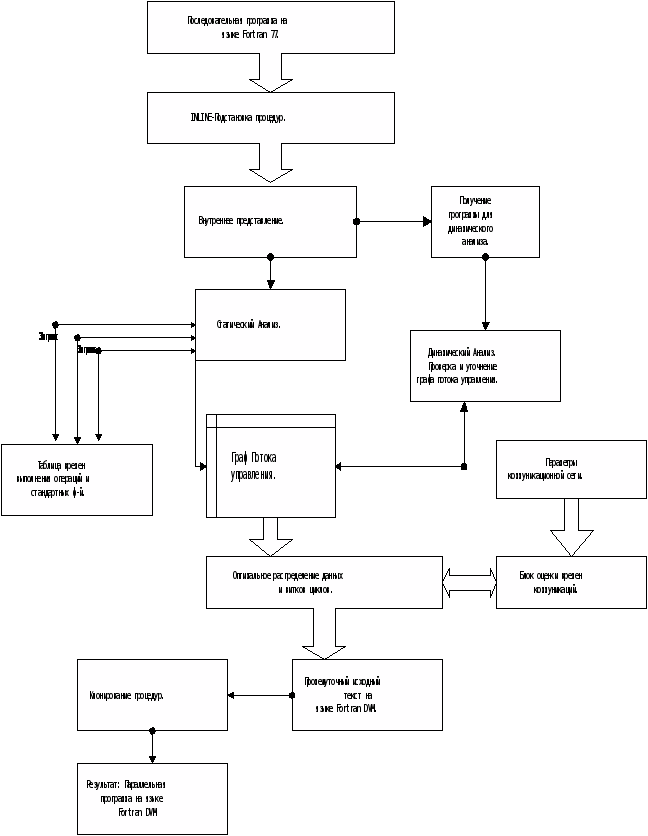
На вход системы автоматического распараллеливания (САР) подается текстовый файл с программой на Fortran77. Она должна, во-первых, быть правильной с точки зрения языка, и, во-вторых, удовлетворять накладываемым системой ограничениям.
Первый шаг – разбор текста средствами библиотеки Sage++, в результате которого образуется файл с внутренним представлением исходной программы.
Задача блока INLINE-подстановки процедур САР заключается в модификации структуры исходной программы с целью привести ее к виду, облегчающему дальнейший анализ и повышающему его точность. В результате его работы образуется файл с внутренним представлением программы, состоящей только из главного модуля, в котором все вызовы подпрограмм заменены их телами. Если исходная программа не содержит процедур, пользователь может не использовать этот блок.
Внутреннее представление без вызовов процедур поступает на вход двух блоков. Первый – блок статического анализа. Его задачей является статическое построение расширенного графа потока управления программы и некоторых вспомогательных структур данных.
Блок подготовки программы для динамического анализа также получает внутреннее представление. Его назначение – создание версии программы для последующей обработки блоком динамического анализа.
Задача блока динамического анализа – дополнение графа управления данными, полученными при выполнении программы в его присутствии. Кроме того, на этом шаге некоторые результаты статического анализа могут быть скорректированы.
Следующий этап – поиск оптимального распределения вычислений и данных между узлами вычислительной сети. Анализ производится на основе информации о возможности распараллеливания тех или иных участков программы, полученной на предыдущих шагах.
Задача учета затрат на доступ к удаленным данным, на перераспределение данных в процессе выполнения программы и т.п. решается осуществлением запросов к блоку оценки времен коммуникаций.
Следующий блок производит модификацию внутреннего представления с целью реализовать выбранный вариант распараллеливания.
Задача блока клонирования процедур заключается в выделении во внутреннем представлении переработанной программы процедур, их оформлении и вставки соответствующих операторов вызова. Пользователь может не использовать функции этого блока, если считает это целесообразным.
Далее на основе результирующего внутреннего представления происходит генерация текста программы на FortranDVM.
1.3 Постановка задачи дипломной работы
Задачей дипломной работы является реализация следующих функций блоков САР:
Статическое построение расширенного графа потока управления программы и сопровождающих его структур (блок №2);
Экспорт данных в файлы для блока распределения вычислений и данных (блок №2);
Чтение из файлов директив FortranDVM, сформированных блоком распределения, и соответствующая им модификация внутреннего представления программы (блок №7).
2. Создание внутреннего представления программы
Для программ, назначение которых заключается в анализе и обработке других программ, основным параметром является текст исходной программы. В отличие от параметров простых типов, такой сложно организованный параметр требует предварительного анализа с целью обеспечить возможность получения из него необходимой для решаемой задачи информации. И поскольку для большинства приложений такого рода доступа к входной программе на уровне символов в текстовом файле недостаточно, возникает задача перевода текста программы в некоторую структуру, отражающую его в виде законченных языковых конструкций – идентификаторов, типов, структур данных, операторов, управляющих конструкций и др. Иными словами, необходимо произвести разбор исходного текста – parsing. Однако в некоторых случаях этого недостаточно и для решения поставленных задач требуется подняться на более высокий уровень абстракции. Следовательно, встает вопрос о создании некоего высокоуровнего представления программы, отражающего специфику конкретной задачи.
2.1 Разбор исходного текста. Система Sage++
Первоочередной задачей на этапе создания внутреннего представления программы, написанной на некотором языке, является разбор исходного текста. В результате такого анализа должна быть доступна информация о порядке выполнения операторов программы с учетом использованных в ней языковых конструкций, нарушающих последовательный характер их выполнения – ветвления, безусловные переходы, циклы, обращения к подпрограммам, операторы прекращения выполнения программы и т.п. Несмотря на то, что для строго типизированных языков программирования анализ операторов объявления может дать полную информацию о константах, переменных и их типах, представляется существенным дополнением наличие таблиц типов и имен. Все перечисленные возможности предоставляет свободно распространяемая библиотека Sage++, разработанная в Иллинойском университете..
“Sage++ является попыткой предложить объектно-ориентированный инструментарий для построения систем обработки программ на языках Fortran77, Fortran90, C и C++. Sage++ предназначен для разработчиков, проводящих исследования в следующих областях: построение распараллеливающих компиляторов, средств анализа производительности и оптимизаторов исходного кода” [2].
Библиотека Sage++ реализована в виде иерархии классов C++, которые позволяют получить доступ к дереву разбора, таблице имен и таблице символов для каждого файла, входящего в исходное приложение. Классы объединены в пять семейств: “Проекты и файлы” – хранят информацию обо всех файлах приложения, “Операторы” – ссылаются на базовые операторы языков, “Выражения” – указывают на выражения, содержащиеся внутри операторов, “Символы” – определенные в программе идентификаторы, “Типы” – сопоставленные с каждым идентификатором и выражением типы. Библиотека обеспечивает средства как всестороннего изучения исходной программы, так и различной ее модификации – добавление к ней новых файлов, создание и изменение операторов, входящих в файлы, вставка и модификация содержащихся в операторах выражений и др. Рассмотрим основные возможности Sage++, представляющие для нас интерес в рамках первого аспекта.
Перед началом анализа программы необходимо создать и сохранить на диске Sage++-представления каждого входящего в ее состав файла специальной утилитой из пакета Sage++. После этого надо создать текстовый файл проекта со списком имен полученных файлов.
Для получения доступа к данным проекта существует класс SgProject:
SgProject(char *proj_file_name) - конструктор, proj_file_name - имя файла проекта;
int numberOfFiles() – количество файлов в проекте;
SgFile &file(int i) – i-й файл проекта.
Класс SgFile представляет файл, входящий в исходное приложение:
SgStatement *firstStatement() – указатель на первый оператор файла;
SgSymbol *firstSymbol() – указатель на первый элемент таблицы имен файла;
SgType *firstType() - указатель на первый элемент таблицы типов файла.
Каждый определенный в файле идентификатор содержится в таблице имен и представляется объектом одного из наследников класса SgSymbol:
int variant() – тэг, определяющий класс символа;
int id() - уникальный номер символа в таблице ;
char *identifier() - текстовое представление символа
SgType *type() - тип символа;
SgStatement *declaredInStmt() - оператор объявления;
SgSymbol *next() - указатель на следующий элемент таблицы.
После выяснения тэга подлежащего анализу идентификатора можно при помощи соответствующей ему глобальной функции получить указатель на объект класса-наследника SgSymbol, содержащего специфические для этого идентификатора данные. Примерами таких производных классов могут служить:
SgVariableSymb – переменная программы;
SgConstantSymb - константа;
SgFunctionSymb - процедура, функция или главная программа.
С каждым идентификатором и выражением соотнесен его тип – скалярный или сложный, представленный объектом класса SgType или одного из его наследников:
int variant() - тэг типа, соответствующий либо скалярному типу, либо классу-наследнику;
int id() - уникальный номер типа в таблице типов;
SgType *baseType() - указатель на базовый тип для сложных типов;
SgType *next() – указатель на следующий элемент таблицы типов.
Пример производного от SgType класса – SgArrayType, объект которого создается для каждого определенного в программе массива. Основные члены этого класса:
int dimension() - размерность массива;
SgExpression *sizeInDim(int i) - выражение, характеризующее длину по i-му измерению.
Каждый файл программы разбит на операторы, для представления которых используется класс SgStatement и его производные:
int variant() - тэг оператора;
int id() - уникальный номер оператора;
int lineNumber() - номер строки в исходном тексте;
SgExpression *expr(int i) - i-е выражение, входящее в оператор (i = 0,1,2);
SgStatement *lexNext() - следующий в лексическом порядке оператор;
SgStatement *lexPrev() - предыдущий в лексическом порядке оператор;
SgStatement *controlParent() - охватывающий управляющий оператор;
SgStatement *lastNodeOfStmt() – для операторов, не являющихся листом дерева разбора, возвращает указатель на последний оператор поддерева.
Аналогично другим классам Sage++ тэг объекта SgStatement позволяет определить класс-потомок SgStatement, соответствующий рассматриваемому оператору. В каждом из них существуют данные и методы, специфические для представляемого этим классом оператора. Эти классы объединены в несколько семейств:
заголовочные операторы;
операторы объявления;
управляющие операторы;
исполняемые и другие операторы.
Примеры классов, относящихся к этим семействам.
Заголовочные:
SgProgHedrStmt – заголовок программы (Fortran);
SgProcHedrStmt – заголовок подпрограммы (Fortran);
SgBlockDataStmt – оператор блока данных (Fortran).
Операторы объявления:
SgVarDeclStmt – оператор объявления переменной;
SgParameterStmt – оператор объявления констант (Fortran);
SgImplicitStmt – оператор Implicit (Fortran).
Управляющие:
SgForStmt – цикл FOR;
SgIfStmt - оператор ветвления If-Then-Else (Fortran), if (C);
SgLogIfStmt - оператор логического If (Fortran);
SgArithIfStmt - оператор арифметического If (Fortran).
Исполняемые и другие:
SgAssignStmt - оператор присваивания (Fortran);
SgCallStmt - оператор Call (Fortran);
SgContinueStmt - оператор Continue;
SgControlEndStmt - обозначает конец одного из основных блоков (напр. ENDIF);
SgReturnStmt - оператор Return;
SgGotoStmt - оператор Goto.
Большинство операторов программы содержат некоторые выражения. Класс SgExpression является базовым для выражений всех видов:
int variant() - тэг вида выражения;
SgExpression *lhs() - левое поддерево выражения;
SgExpression *rhs() - правое поддерево выражения;
В отличие от иерархии классов, порождаемой SgStatement, не вводится подкласс для каждой операции, находящейся в корне дерева разбора выражения. Основные бинарные операции, такие, как стандартные арифметические, идентифицируются только тэгом. Листья дерева могут иметь собственные классы, например:
SgValueExp - представляет значение одного из базовых типов;
SgVarRefExp - ссылка на переменную или на массив;
SgArrayRefExp - ссылка на элемент массива;
SgFunctionCallExp - вызов функции.
Разработчиками Sage++ предлагается следующий алгоритм разбора исходной программы. Производится последовательный перебор файлов, входящих в проект. Начиная с указателя SgStatement* SgFile:: firstStatement() осуществляется обход операторов текущего файла. При этом анализируется оператор, входящие в него выражения, тело(а) – для операторов, содержащих таковое (например, управляющей группы). Переход на следующий оператор реализуется кодом cur_stmt=cur_stmt->lastNodeOfStmt()->lexNext() для операторов, не являющихся листом дерева разбора, и cur_stmt=cur_stmt->lexNext() для остальных (где cur_stmt – указатель на текущий оператор). Использование рекурсивного подхода к просмотру дерева представляется достаточно естественным.
2.2 Внутреннее представление программы высокого уровня
Представление подлежащей обработке программы в виде, предлагаемом Sage++, или подобном ему дает разработчику широчайшие возможности для извлечения всей необходимой ему информации о программе. Следующим этапом проектирования системы обработки программ является определение набора знаний об исходной программе, специфического для решаемой задачи. При этом возникают две стороны переработки внутреннего представления программы: получение на его основе новых данных, и объединение излишне подробной информации в более крупные блоки. Иными словами, нужно подняться на более высокий уровень абстракции и разработать соответствующее ему представление программы. Рассмотрим интересующую нас предметную область – автоматическое распараллеливание программ и определим требования к представлению программы, продиктованные особенностями этой области.
Распределение вычислений и данных является одним из основных шагов в процессе создания параллельного приложения. Существует два подхода к решению этой проблемы: доменная декомпозиция, при которой основное внимание уделяется распределению относящихся к задаче данных, и функциональная декомпозиция – сначала распределяются вычисления, а затем относящиеся к ним данные. Поскольку в нашем проекте системы автоматического распараллеливания выбрана вторая методика, вид внутреннего представления определяется, в первую очередь, удобным для анализа способом хранения вычислений.
Носителями вычислений программы являются входящие в ее состав операторы. Однако, с точки зрения распараллеливания интересны не столько конкретные операторы, сколько участки программы, состоящие из последовательно выполняющихся операторов, целиком подлежащие какому-то из видов исполнения - параллельному или последовательному, а также порядок следования этих участков. Объединяя группу операторов в один элемент высокоуровнего представления программы, следует агрегировать в нем некоторую информацию, относящуюся к этим операторам. В нашем случае такой информацией является:
Количество вычислительных операций в блоке – арифметические операции и стандартные функции. Эти данные требуются для оценки времени выполнения блока.
Наличие операторов некоторых типов. Например, присутствие в блоке операторов ввода\вывода препятствует его параллельному выполнению.
Список обращений к переменным и массивам с разделением по типу обращения – чтение или модификация. Этот список нужен при поиске в блоке зависимостей по данным, а также для корректного распределения данных между элементами вычислительной сети.
Список переменных специального вида и их характеристики. Примером могут служить редукционные переменные.
Линейная последовательность выполнения описанных блоков операторов может быть нарушена одной из следующих конструкций: цикл, ветвление, безусловный переход. Для них должны существовать элементы специальных типов, отражающих их особенности. В этих элементах необходимо предусмотреть возможность хранения относящихся к ним данным. Для цикла это может быть, в частности, количество итераций, для ветвления – вероятность перехода по каждой из веток и др.
2.3 Расширенный граф управления. Вспомогательные структуры
Классической структурой для описания последовательности выполнения операторов программы является граф потока управления. Разработанное в данной дипломной работе представление программы выполняет те же функции, только в качестве его элементов используются блоки более высокого уровня. Такое представление – назовем его расширенным графом потока управления программы - в совокупности с некоторыми вспомогательными структурами содержит в себе всю информацию, необходимую для следующих в цикле работы блоков системы распараллеливания.
В процессе обработки исходной программы реализованным в дипломной работе блоком автоматического распараллеливателя производится построение следующих структур, образующих вместе высокоуровневое представление программы:
расширенный граф управления;
список циклов программы;
таблица символов программы.
Рассмотрим устройство основной структуры – графа управления. Граф состоит из блоков, соответствующих логическим элементам представления, и дуг, отражающих отношение между ними.
Типы блоков:
Линейный участок. Объединяет в себе непрерывную группу операторов, выполняющихся последовательно один за другим.
Цикл. Представляет циклы программы.
Ветвление. Соответствует условным операторам программы.
Слияние. Это блок, в котором сходятся ветви развилки. Строгое соответствие блоков ветвления и слияния обеспечивает возможность изучения находящихся между ними элементов как единого целого.
Отношение между двумя блоками может двух типов:
второй блок выполняется сразу после первого;
второй блок содержится внутри первого - такой тип отношения может быть только между блоком-циклом и первым блоком из его тела.
Для облегчения дальнейшего описания структуры графа и его визуального представления, введем следующие названия для типов отношений между блоками:
если второй блок следует за первым, будем говорить, что он “находится справа” от первого, соответственно первый блок “находится слева” от второго;
если второй блок содержится внутри первого, будем говорить, что он “находится снизу” от первого, при этом первый “находится сверху” от второго.
Дуги, представляющие описанные отношения, будем называть ссылками вправо, влево, вниз, вверх.
Блок ветвления требует наличие двух вправо – по числу возможных ветвей. Соответственно, блок слияния всегда имеет две входящие слева ссылки. Для осуществления всевозможных вариантов обхода графа требуются также использования обратных дуг – вверх и\или влево.
Таким образом, у каждого блока может быть до шести исходящих из него дуг, имеющих номер, классифицирующий представляемое ею отношение:
– 1-я ссылка вправо
– 2-я ссылка вправо
– ссылка вниз
– ссылка вверх
– 1-я ссылка влево
– 2-я ссылка влево
Каждый элемент графа помимо ссылок на соседей содержит общую для всех типов информацию:
уникальный номер;
тип блока;
уровень, характеризующий глубину вложенности;
флаг возможности параллельного исполнения;
количество каждой из возможных вычислительных операций;
ссылки на 1-й и последний операторы блока.
Специфические данные:
для циклов - уникальный номер цикла;
для ветвлений – вероятность перехода по каждой из ветвей.
Количество операций определяется следующим образом:
линейный блок - общее их количество во всех входящих в него операторов;
блок цикла - сумма операций во всех входящих в его тело блоков;
блок ветвления – сумма слагаемых вида: число операций в i-й ветви * вероятность перехода по ней;
блок слияния не имеет операций;
если блок цикла входит в состав некоторого вышестоящего, то его слагаемое образуется как произведение числа операций в нем и количества итераций.
Приведем схему фрагмента некоторой программы и соответствующий ей граф.
ЛИН1
DO 1 … (1)
ЛИН2
DO 1 … (2)
IF … THEN
ЛИН3
ELSE
ЛИН4
ENDIF
1 CONTINUE
DO 2 … (3)
ЛИН5
2 CONTINUE
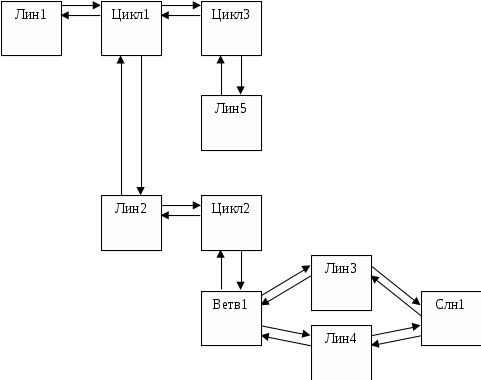
Основными элементами программы, подлежащими изучению на предмет возможности распараллеливания, являются циклы. Такой подход представляется достаточно естественным, поскольку во многих приложениях основная вычислительная нагрузка находится именно в циклах. Примерами могут служить реализации всевозможных численных методов. Очевидная нецелесообразность размещения всей специфической для циклов информации в узлах графа, а также существование этапов изучения циклов программы без учета их расположения в графе повлекли за собой разработку дополнительной структуры данных – списка циклов. Он представляет собой двунаправленный линейный список, в котором каждому циклу соответствует уникальный элемент, содержащий следующие данные:
Уникальный номер цикла. Служит для связи с расширенным графом.
Уровень вложенности – соответствует аналогичному полю из графа.
Ссылка на идентификатор счетчика цикла.
Начальное, конечное выражения счетчика, шаг цикла.
Количество итераций (витков) цикла.
Списки переменных и элементов массивов, используемых на чтение и на модификацию.
Список редукционных переменных.
Ссылки на оператор заголовка цикла и на оператор его завершения.
Все используемые в графе и списке циклов идентификаторы переменных и массивов объединяются в таблицу имен – третью составляющую нашего представления программы. Для каждого идентификатора хранится следующая информация:
Тэг вида идентификатора – переменная или массив.
Тип идентификатора.
Строка имени.
Размерность и длина по каждому измерению – для массива.
Ссылка на соответствующий элемент таблицы имен низкоуровнего представления.
Описанные структуры образуют представление исходной последовательной программы достаточно высокого уровня абстракции, соответствующего проблематике рассматриваемой нами предметной области. Оно позволяет хранить всю необходимую для распределения вычислений и данных информацию о программе, сокращая при этом количество функциональных блоков до минимума.
3. Построение расширенного графа управления
Выполнение задач дипломной работы осуществлялось на языке C++ с использованием библиотеки Sage++ 2.0. В данном пункте приведены описания классов, составляющих программный код дипломной работы, использованные в их наиболее существенных методах алгоритмы, а также условия, которым должна удовлетворять входная программа для успешной ее обработки системой в целом, и реализованным в дипломной работе блоком в частности.
3.1 Ограничения на входную программу
Первое требование к входной программе заключается в ее корректности с точки зрения синтаксиса и семантики Fortran77. Заключенные в ней ошибки, не определенные на этапе разбора текста средствами Sage++, могут привести к непредсказуемым результатам.
Общим для всей системы ограничением является также ее достаточно высокая чувствительность к плохой структурированности программы, а именно:
в программе не должны присутствовать операторы прекращения выполнения;
запрещены операторы перехода, за исключением выхода из тела цикла на первый за концом цикла оператор по условию.
Другим существенным требованием является запрет на использование COMMON-областей.
Ограничения, накладываемые в данной дипломной работе:
выражения в заголовках циклов (начальное, конечное, шаг) могут быть только линейными относительно некоторой переменной, т.е. иметь вид C1*V+C0, где C1 и C0 – константы, V - переменная;
индексные выражения в обращениях к массивам должны удовлетворять тому же условию;
отсутствие аппарата поиска зависимостей по данным влечет необходимость вставки пользователем комментария “DEPENDENCE” в теле цикла, содержащего зависимость.
3.2 Описание классов
В рамках дипломной работы реализовано два набора классов:
Классы, выполняющие построение внутреннего представления, экспорт данных для блока распределения вычислений и данных, последующий импорт результатов работы этого блока и генерацию текста на FortranDVM.
Классы, используемые в блоке распределения вычислений и данных. Выполняют импорт внутреннего представления и воссоздают его структуру, а также производят экспорт результатов работы этого блока.
Рассмотрим назначение классов 1-го набора и их наиболее важные члены.
1) Класс cSourceProgramSg – представляет исходную последовательную программу. Обработка входной программы должна начинаться с создания объекта этого класса.
cSourceProgramSg (char *projfile) – конструктор класса, projfile – имя файла проекта Sage++; в этом конструкторе происходит открытие проекта, разбор входящего в него файла исходной программы, создание незаполненных графа, списка циклов и таблицы символов.
SgStatement *FirstSt () – 1-й оператор программы.
SgStatement *LastSt () - последний оператор программы.
cProgramGraphSg *PrgGraph () – граф программы.
cLoopListSg *LpList () – список циклов.
cSymbolTabSg *SymTab () – таблица символов.
void PrepareConsts () – замена в теле программы обращений к константам на их значения.
void PrepareLoops () – конвертация циклов программы к виду DO-ENDDO.
void BuildLoopList () – построение списка циклов.
void BuildProgGraph () – построение графа программы.
void PrintLoopList (ostream&) – вывод в поток списка циклов для просмотра.
void PrintProgGraph (ostream&) – вывод графа.
void PrintSymbolTab (ostream&) – вывод таблицы имен.
void ExportData (char*) – экспорт данных в файлы.
void ImportData (char*) – импорт данных из файлов;
void Unparse (char*) – генерация результирующего текста в файле, имя которого определяется параметром метода.
При экспорте данных в файлы образуются следующие файлы:
filename.gr – узлы графа;
filename.gri – индексный файл;
filename.lp – список циклов;
filename.st – таблица символов, где filename – параметр метода ExportData(char*).
2) Класс cProgramGraphSg – представляет расширенный граф программы.
cProgramGraphSg (cSymbolTabSg*, cLoopListSg*) – конструктор класса, создает пустой граф управления. Параметры – таблица символов и список циклов, на которые будет ссылаться граф.
cLoopListSg *LpList () – список циклов, используемый графом.
cSymbolTabSg *SymTab () – таблица имен, используемая графом.
cProgramGraphNodeSg *CurNode () – текущий узел.
int IsStart () – является ли текущий узел начальным.
int GoStart (), GoDown (), GoUp (), GoLeft1 (), GoLeft2 (),
GoRight1 (), GoRight2 (), GoId (long int) – переместить указатель на текущий узел соответственно на 1-й узел, вниз, вверх, влево по 1-й ссылке, влево по 2-й ссылке, вправо по 1-й ссылке, вправо по 2-й ссылке, на узел с заданным номером. Возвращает 1 при удачном переходе, 0 в противном случае..
void CountOpers () – подсчет числа операций для каждого узла графа.
void ExportData (ofstream&, ofstream&) – экспорт графа и индексной информации в потоки.
void ImportData (ifstream&) – импорт данных от блока распределения вычислений, подлежащих вставке в граф;
void Build (SgStatement*, SgStatement*, int, int) – построение графа.
void Unparse () – произвести вставку добавленных в граф данных во внутреннее представление Sage++;
3) Класс cProgramGraphNodeSg – представляет узел графа управления.
cProgramGraphNodeSg () – конструктор класса, создает новый узел.
SgStatement *poSt1, *poSt2, *poSt3 – принимают значения после построения графа.
Для линейного участка: poSt1 – 1-й оператор блока, poSt2 – последний оператор.
Для цикла: poSt1 – оператор заголовка цикла, poSt2 – оператор, завершающий цикл (ENDDO)
Для ветвления: poSt1 – IF, poSt2 – ELSE, poSt3 – ENDIF.
int Level – уровень вложенности, внешнему уровню соответствует 0.
int IsParal – признак возможности распараллеливания.
long int LoopId – для элементов типа “цикл” содержит номер соответствующего цикла из списка.
float Ver1, Ver2 – для элементов типа “ветвление” вероятность перехода соответственно по 1-й и 2-й ветви.
float Opers[df_OPERS_COUNT] – массив, в каждом элементе которого содержится количество соответствующих индексу элемента операций в блоке. Например, Opers[0] - число сложений, Opers[1] – вычитаний.
long int Id () – уникальный номер узла.
int NodeType () – тэг типа узла.
long int ExportData (ofstream&) – экспорт узла в файловый поток, возвращает количество записанных байт.
void ImportData (ifstream&) – импорт данных из файлового потока.
void Unparse () – произвести вставку добавленных в узел данных во внутреннее представление Sage++.
4) Класс cLoopListSg – представляет список циклов программы.
cLoopListSg (cSymbolTabSg*) – конструктор класса, создает пустой список циклов, параметр – таблица символов, на которую будет ссылаться список.
cSymbolTabSg *SymTab () – таблица символов, используемая списком.
cLoopListNodeSg *CurNode () – указатель на текущий элемент списка.
int GoStart (), GoEnd (), GoRight (), GoLeft (), GoId (long int) – переместить указатель на текущий узел соответственно на 1-й узел, последний узел, влево, вправо, на узел с заданным номером. Возвращает 1 при удачном переходе, 0 в противном случае.
void Analyse () – произвести необходимый анализ элементов списка.
void Build (SgStatement*, SgStatement*, int) – построить список.
void ExportData (ofstream&) – экспорт списка в файловый поток.
5) Класс cLoopListNodeSg – представляет элемент списка циклов.
cLoopListNodeSg () – конструктор класса, создает новый элемент.
long int Id () – номер элемента.
SgStatement *poSt1, *poSt2 – ссылки соответственно на оператор заголовка цикла и на оператор завершения цикла.
cSymbolSg *poCounterSym – ссылка на переменную-счетчик цикла.
cExpressionSg *poStartExpr, *poEndExpr, *poStepExpr – начальное, конечное выражения счетчика и выражение шага цикла.
long int IterNum – количество итераций цикла.
int Level – уровень вложенности.
int IoOp, GotoOp – флаги наличия в теле цикла операторов ввода\вывода и операторов перехода за тело цикла.
cVarListElemSg *LVar[df_MAX_LRVAR_COUNT], *RVar[df_MAX_LRVAR_COUNT] – списки обращений к переменным и элементам массивов на модификацию и на чтение соответственно.
sReduct RedVar[df_MAX_REDVAR_COUNT] – список редукционных переменных, содержащихся в теле цикла.
void AnalyseHead (cSymbolTabSg *) – произвести анализ заголовка цикла.
void AnalyseBodyVars (cSymbolTabSg*) – произвести анализ обращений к переменным и элементам массивов в теле цикла.
void AnalyseRedVars (cSymbolTabSg*) – произвести поиск редукционных переменных в теле цикла.
void AnalyseIoOp () – определить присутствие в теле цикла операций ввода\вывода.
void AnalyseGotoOp () – определить присутствие в теле цикла операторов перехода за тело цикла.
long int ExportData (ofstream&) – экспорт элемента в файловый поток, возвращает количество записанных байт.
6) Класс cSymbolTabSg – представляет таблицу символов. Реализована в виде двунаправленного списка элементов класса cSymbolSg.
cSymbolTabSg () – конструктор класса, создает пустую таблицу.
cSymbolSg *FirstSym () – указатель на 1-й элемент списка.
void ExportData (ofstream&) – экспорт таблицы в файловый поток.
7 ) Класс cSymbolSg – представляет элемент таблицы символов.
cSymbolSg () – конструктор класса, создает новый элемент.
long int Id () – уникальный номер элемента.
SgSymbol *poSgSym – ссылка на соответствующий элемент таблицы символов Sage++.
int Variant () – тэг вида элемента: переменная или массив.
int Type – код типа.
char *Name – строка имени.
int Dim () – размерность (для массива).
int DimLen (int i) – длина по i-му измерению (для массива).
cSymbolSg *LinkRight () – следующий в списке элемент.
cSymbolSg *LinkLeft () – предыдущий в списке элемент.
long int ExportData (ofstream&) – экспорт элемента в файловый поток.
int operator == (cSymbolSg&), operator != (cSymbolSg&)
8) Класс cExpressionSg – представляет выражение. Текущая реализация класса позволяет хранить только выражения вида c1*V+c0, где c1,c0 – константы, V – переменная.
cExpressionSg (SgExpression*, cSymbolTabSg*) – конструктор класса, параметрами являются подлежащее разбору выражение, представленное объектом Sage++, и таблица символов, которая будет дополнена входящим в состав выражения идентификатором.
int Variant () – тэг вида выражения.
cSymbolSg *poVariable – ссылка на переменную выражения.
int IntC0 (), IntC1 () – значения констант, приведенные к типу int.
float RealC0 (), RealC1 () – аналогично, float.
double DoubleC0 (), DoubleC1 () – аналогично, double.
long int ExportData (ofstream&) – экспорт выражения в файловый поток.
int operator == (cExpressionSg&), operator != (cExpressionSg&)
9) Класс cArrayRefSg – представляет ссылку на элемент массива.
cArrayRefSg (SgArrayRefExp*, cSymbolTabSg*) – конструктор класса, параметрами являются подлежащая разбору ссылка на элемент массива, представленная объектом Sage++, и таблица символов, в которую будут добавлены входящие в ссылку переменные и имя массива.
SgArrayRefExp *poSgArrRef – исходный объект Sage++.
cSymbolSg *poSym – идентификатор массива.
int sub>scrNum – количество индексных выражений в ссылке.
cExpressionSg* sub>scrList [df_MAX_DIM] – массив индексных выражений.
long int ExportData (ofstream&) – экспорт в файловый поток.
int operator == (cArrayRefSg&)
int operator != (cArrayRefSg&)
10) Класс cVarListElemSg – представляет элемент списка обращений к переменным и массивам.
cVarListElemSg (SgVarRefExp*, cSymbolTabSg*), cVarListElemSg (SgArrayRefExp*, cSymbolTabSg*) – конструкторы класса, 1-й для разбора обращения к переменной, параметрами являются ссылка на переменную, представленная объектом Sage++, и таблица символов, в которую будут добавлены идентификаторы; 2-й для разбора ссылки на массив, параметры имеют тот же смысл.
int Variant () – тэг вида элемента (ссылка на переменную или на массив).
cSymbolSg *poSym – идентификатор переменной для ссылки 1-го вида.
cArrayRefSg *poArr – ссылка на массив для 2-го вида.
long int ExportData (ofstream&) – экспорт в файловый поток.
int operator == (cVarListElemSg&)
int operator != (cVarListElemSg&).
Для каждого из описанных классов существует его аналог во втором наборе, имеющий такое же имя за исключением постфикса “Sg”. В классах-аналогах отсутствуют методы для построения структур и конструкторы разбора. Корректная инициализация объектов этих классов производится только за счет введенных методов импорта из файлового потока. В классе cProgramGraphNode добавлены члены-данные для хранения директив FortranDVM, формирование которых осуществляет блок распределения вычислений и данных, и методы для их вставки, а также реализован экспорт этих комментариев в файл.
3.3 Алгоритмы
Реализованные в дипломной работе классы блока статического построения расширенного графа управления программы и вспомогательных структур данных содержат большое число членов-методов, решающих задачи разной сложности. Остановимся на деталях реализации некоторых из них.
На самом внешнем уровне программы построения и экспорта всех структур находится функция main(). Ее основное содержание заключается в следующих строках:
cSourceProgramSg TestProg(projfile);
TestProg.PrepareAll();
TestProg.BuildAll();
TestProg.PrintAll(cout);
TestProg.ExportData(trgfile);
В первую очередь создается объект класса cSourceProgramSg, параметром конструктора которого является имя файла-проекта Sage++. Далее вызываются методы этого класса:
PrepareAll() – предварительная обработка Sage++ представления исходного приложения;
BuildAll() – построение всех структур;
PrintAll(cout) – вывод в поток cout построенных структур для просмотра;
ExportData(trgfile) – экспорт данных в файлы.
void cSourceProgramSg::PrepareAll()
Вызывает методы того же класса:
PrepareConsts(); - подготовка констант.
PrepareLoops(); - подготовка циклов.
void cSourceProgramSg::PrepareConsts()
Осуществляет замену обращений к константам их значениями. Алгоритм:
Просмотр таблицы имен Sage++ и составление списка объявленных констант и их значений.
Обход всех операторов программы и поиск во входящих в них выражениях использования каждой из констант.
При положительном результате поиска, производится рекурсивный обход дерева разбора выражения с заходом только в те ветки, в которых используются константы. Вместо листа, соответствующего константе, строится новое выражение – значение константы, и оно возвращается на предыдущий уровень рекурсии, для остальных листьев возвращается исходное выражение. Вернувшись из рекурсивного вызова, заменяем всю ветку возвращенной. После этого текущее поддерево анализируется на возможность его вычисления. Если удается – вместо этого поддерева возвращается вычисленное значение.
При таком алгоритме, например, выражение 2*N+M+t, где N=100, M=5, будет заменено выражением 205+t.
void cSourceProgramSg::PrepareLoops().
Приводит все циклы программы к виду DO-ENDDO. Просматривает операторы программы. Для найденных циклов применяет метод Sage++, выполняющий такое преобразование.
void cSourceProgram::BuildAll().
BuildLoopList(); - построение списка циклов.
BuildProgGraph(); - построение графа.
void cSourceProgram::BuildLoopList().
LpList()->Build(FirstSt(), LastSt(), 0); - построение списка циклов.
LpList()->Analyse(); - анализ построенного списка.
void cLoopListSg::Build(SgStatement *first_line, SgStatement *last_line, int cur_lev).
Этот метод производит последовательный просмотр операторов в промежутке от first_line до last_line включительно с обеих сторон. При обнаружении оператора-заголовка цикла, осуществляется добавление к списку циклов нового элемента, в качестве его уровня вложенности принимается значение cur_lev. Затем метод вызывает себя со следующими параметрами: следующий оператор после обнаруженного заголовка цикла – first_line, оператор завершения найденного цикла – last_line, cur_lev+1 – для cur_lev в новом вызове. После возвращения из рекурсивного вызова просмотр продолжается с оператора завершения найденного цикла. Метод добавления нового элемента к списку цикла устроен так, что текущий указатель списка перемещается на вновь добавленный.
void cLoopListSg::Analyse().
Для каждого элемента списка:
AnalyseHead(SymTab()); - анализ заголовка.
AnalyseBodyVars(SymTab()); - анализ обращений к переменным и массивам в теле.
AnalyseRedVars(SymTab()); - поиск редукционных переменных.
AnalyseIoOp(); - поиск операторов ввода\вывода.
AnalyseGotoOp(); - анализ операторов перехода.
void cLoopListSg::AnalyseRedVars(cSymbolTabSg*).
В нашей задаче переменная считается редукционной, если выполнены следующие условия:
перем = {перем} {операция} {выражение}, или (1)
перем =min/max({выражение} {перем}), или (2)
IF ({перем}{.GT.|.LT.}{выражение})
{перем}={выражение} (3)
{операция}="+"|"*" (4)
где {выражение} не содержит {перем}, а также {перем} нигде больше не используется в данном цикле. Условие (3) есть другая реализация условия (2). Также необходимо обнаруживать редукционные переменные в выражениях вида:
{перем}={выражение}{операция}{перем}{операция}{выражение} (5), где выполняются те же условия, что и в (1)-(4), но при этом {операция} стоящая по обе стороны {перем} одинакова и если {операция} ="+", то {выражения} не содержат операций умножения и деления.
void cSourceProgramSg::BuildProgGraph().
PrgGraph()->Build(FirstSt(), LastSt(), 0, sy_DIR_RIGHT1); - построение графа.
PrgGraph()->Analyse(); - анализ построенного графа.
void cProgramGraphSg::Analyse().
CountOpers();
void cProgramGraphSg::Build (SgStatement *first_line, SgStatement *last_line, int cur_lev, int cur_dir).
Для идентификации каждого из возможных направлений добавления новых элементов определены константы:
sy_DIR_RIGHT1, sy_DIR_RIGHT2, sy_DIR_DOWN
Добавление нового звена в некотором направлении осуществляется при помощи методов cProgramGraphSg::AddNewRight1 ();
cProgramGraphSg::AddNewRight2 ();
cProgramGraphSg::AddNewRightFull (); - специальное добавление для блока слияния;
cProgramGraphSg::AddNewDown ();
При этом текущий указатель графа перемещается на новый блок.
Поскольку в графе отсутствует заглавное звено, первый узел графа строится особым образом независимо от указанного направления.
Алгоритм работы метода (рекурсивный):
Перемещение текущего указателя списка циклов на первый элемент.
Запомнить номер текущего элемента графа в переменной node1.
Начать цикл прохода с first_line.
switch
Если текущий оператор – заголовок цикла
Если перед этим прошли какое-то количество операторов, т.е. надо добавить линейный блок, определяем направление добавления следующим образом:
Если еще ничего не добавляли и cur_dir == sy_DIR_DOWN
Добавить вниз.
Иначе
Если ничего не добавляли и cur_dir == sy_DIR_RIGHT2
Добавить вправо2.
Иначе
Добавить вправо1.
{такой анализ связан с тем, что когда мы добавляем 1-е звено в данном вызове метода, мы должны учитывать переданное направление; в остальных случаях добавление блоков на одном уровне происходит вправо1}
Запомнить номер текущего (только что добавленного) элемента в node1.
Заполнить блок информацией.
{теперь надо добавить блок для найденного цикла}
Определить направление аналогично и добавить.
Заполнить блок информацией.
Добавить в него информацию из текущего элемента списка циклов и сдвинуться в списке вправо.
Вызвать рекурсивно Build с телом найденного цикла, cur_lev+1, sy_DIR_DOWN.
Установить указатель текущего оператора на конец цикла (ENDDO).
Если текущий оператор – заголовок ветвления
Проверка на необходимость добавления линейного блока – аналогично.
Добавить блок развилки в нужном направлении – аналогично.
Запомнить номер текущего блока (развилка) в переменной node2.
Заполнить блок информацией.
Добавить слияние.
Запомнить номер текущего блока (слияние) в переменной node3.
Вернуться влево (на развилку).
Вызвать Build с телом 1-й ветви, cur_lev, sy_DIR_RIGHT1.
Перейти на блок node2.
Вызвать Build с телом 2-й ветви, cur_lev, sy_DIR_RIGHT2.
Перейти на блок node3 (далее надо добавлять после слияния).
Установить указатель текущего оператора на конец ветвления (ENDIF).
Если текущий оператор – логический IF
Аналогично, только второй ветви нет.
Если текущий оператор – IF-ELSEIF
Аналогично, только ELSEIF обрабатывается как новый IF-THEN.
Конец switch
Если текущий оператор == last_line
Закончить цикл просмотра
Проверка на наличие линейного участка – аналогично.
Перейти на блок node1 (тот, на котором были перед вызовом).
Заключение
Реализованные в дипломной работе классы C++ выполняют следующие функции, соответствующие ее задачам:
построение расширенного графа потока управления программы, списка циклов и таблицы используемых идентификаторов;
экспорт этих структур в файлы;
предоставление блоку распределения вычислений и данных методов доступа к сохраненным структурам;
дополнение внутреннего представления программы директивами FortranDVM, сформированными блоком распределения вычислений и данных.
Общий объем разработанного программного кода – около 4500 строк на языке C++.
Возможные варианты использования разработанных классов не ограничиваются системой автоматического распараллеливания. Они могут быть полезны также для решения задач, связанных с оптимизацией программ, поиска логических ошибок в их структуре, профилированием и др.
Направления развития блока, связаны, в первую очередь, со снятием ограничений на входную программу и реализацией не вошедших в дипломную работу видов анализа.
Библиография
“Sage++ user’s guide (online)”, May 1995, Version 1.9
“Designing and Building Parallel Programs (Online) v1.3”, © Copyright 1995 by Ian Foster
“The Polaris Internal Representation.” Keith A. Faigin, Jay P. Hoeflinger, David A. Padua, Paul M. Petersen, and Stephen A. Weatherford. International Journal of Parallel Programming, October 1994.
“The Structure of Parafrase-2: An Advanced Parallelizing Compiler for C and Fortran” Constantine Polychronopoulos, Milind B. Girkar, Mohammad R. Haghighat, Chia L. Lee, Bruce P.Leung, Dale A. Schouten. Languages and Compilers for Parallel Computing, MIT Press, 1990
Приложение
В качестве одной из тестовых программ использовалась реализация на языке Fortran77 алгоритма Якоби поиска решения системы линейных уравнений A x = b.
PROGRAM JACOB
PARAMETER (L=8, ITMAX=20)
REAL A(L,L), EPS, MAXEPS, B(L,L)
W = 0.5
MAXEPS = 0.5E - 7
DO 1 I = 1, L
DO 1 J = 1, L
A(I,J) = 0.
B(I,J) = (1. +I+J)*2.3
1 CONTINUE
DO 2 IT = 1, ITMAX
EPS = 0.
DO 21 I = 2, L-1
DO 21 J = 2, L-1
EPS = MAX (EPS, ABS(B(I,J)-A(I,J)))
A(I,J) = B(I,J)
21 CONTINUE
DO 22 I = 2, L-1
DO 22 J = 2, L-1
B(I,J) = (W/4)*(A(I-1,J)+A(I,J-1)+A(I+1,J)+A(I,J+1))+(1-W)*A(I,J)
22 CONTINUE
PRINT *, 'IT = ', IT, ' EPS = ', EPS
IF (EPS .LT. MAXEPS) THEN
GO TO 3
ENDIF
2 CONTINUE
3 OPEN (3, FILE='JACOBI.DAT', FORM='FORMATTED')
WRITE (3,*) B
END
Результат вывода в поток cout структур данных, построенных тестирующей программой.
Building Loop List
Building Loop List - ok
Building Prog Graph
Building Prog Graph - ok
Printing Loop List
Count= 7
Id= 1 Lev= 0 Counter: Id= 1 Name= i Start: 1 End: 8 Step: 1 IterNum: 8
Left vars: Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0 Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: i j
Id= 2 Lev= 1 Counter: Id= 3 Name= j Start: 1 End: 8 Step: 1 IterNum: 8
Left vars: Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0 Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: i j
Id= 3 Lev= 0 Counter: Id= 5 Name= it Start: 1 End: 20 Step: 1 IterNum: 20 Left vars: eps Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0 Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: eps Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0 w Array name= a sub>scr0: 1*i+-1 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+-1 Array name= a sub>scr0: 1*i+1 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+1
Id= 4 Lev= 1 Counter: Id= 1 Name= i Start: 2 End: 7 Step: 1 IterNum: 6
Left vars: eps Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: eps Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0
Id= 5 Lev= 2 Counter: Id= 3 Name= j Start: 2 End: 7 Step: 1 IterNum: 6
Left vars: eps Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: eps Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0
Id= 6 Lev= 1 Counter: Id= 1 Name= i Start: 2 End: 7 Step: 1 IterNum: 6
Left vars: Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: w Array name= a sub>scr0: 1*i+-1 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+-1 Array name= a sub>scr0: 1*i+1 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+1 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0
Id= 7 Lev= 2 Counter: Id= 3 Name= j Start: 2 End: 7 Step: 1 IterNum: 6
Left vars: Array name= b sub>scr0: 1*i+0 sub>scr1: 1*j+0
Right vars: w Array name= a sub>scr0: 1*i+-1 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+-1 Array name= a sub>scr0: 1*i+1 sub>scr1: 1*j+0 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+1 Array name= a sub>scr0: 1*i+0 sub>scr1: 1*j+0
Printing Loop List - ok
Printing Prog Graph
Count= 17
Id= 1 Lev= 0 Type= 1 Opers[4]=2 IsParal=0
Moving right1
Id= 2 Lev= 0 Type= 2 Loopid= 1 Opers[0]=16 Opers[2]=8 Opers[4]=16 IsParal=1
Moving down
Id= 3 Lev= 1 Type= 2 Loopid= 2 Opers[0]=2 Opers[2]=1 Opers[4]=2 IsParal=1
Moving down
Id= 4 Lev= 2 Type= 1 Opers[0]=2 Opers[2]=1 Opers[4]=2 IsParal=0
Moving up
Repeat Id= 3
Moving up
Repeat Id= 2
Moving right1
Id= 5 Lev= 0 Type= 2 Loopid= 3 Opers[0]=36 Opers[1]=24 Opers[2]=12 Opers[3]=6 Opers[4]=13 Opers[5]=1 Opers[6]=6 Opers[7]=6 IsParal=0
Moving down
Id= 6 Lev= 1 Type= 1 Opers[4]=1 IsParal=0
Moving right1
Id= 7 Lev= 1 Type= 2 Loopid= 4 Opers[1]=6 Opers[4]=12 Opers[6]=6 Opers[7]=6 RedVar[0]: var= eps op= 5 IsParal=1
Moving down
Id= 8 Lev= 2 Type= 2 Loopid= 5 Opers[1]=1 Opers[4]=2 Opers[6]=1 Opers[7]=1 RedVar[0]: var= eps op= 5 IsParal=1
Moving down
Id= 9 Lev= 3 Type= 1 Opers[1]=1 Opers[4]=2 Opers[6]=1 Opers[7]=1 IsParal=0
Moving up
Repeat Id= 8
Moving up
Repeat Id= 7
Moving right1
Id= 10 Lev= 1 Type= 2 Loopid= 6 Opers[0]=36 Opers[1]=18 Opers[2]=12 Opers[3]=6 IsParal=1
Moving down
Id= 11 Lev= 2 Type= 2 Loopid= 7 Opers[0]=6 Opers[1]=3 Opers[2]=2 Opers[3]=1 IsParal=1
Moving down
Id= 12 Lev= 3 Type= 1 Opers[0]=6 Opers[1]=3 Opers[2]=2 Opers[3]=1 IsParal=0
Moving up
Repeat Id= 11
Moving up
Repeat Id= 10
Moving right1
Id= 13 Lev= 1 Type= 1 IsParal=0
Moving right1
Id= 14 Lev= 1 Type= 3 Opers[5]=1 IsParal=0
Moving right1
Id= 16 Lev= 1 Type= 1 IsParal=0
Moving right1
Id= 15 Lev= 1 Type= 4 IsParal=0
Moving left1
Repeat Id= 16
Moving left1
Repeat Id= 14
Moving right2
Repeat Id= 15
Moving left2
Repeat Id= 14
Moving left1
Repeat Id= 13
Moving left1
Repeat Id= 10
Moving left1
Repeat Id= 7
Moving left1
Repeat Id= 6
Moving up
Repeat Id= 5
Moving right1
Id= 17 Lev= 0 Type= 1 IsParal=0
Moving left1
Repeat Id= 5
Moving left1
Repeat Id= 2
Moving left1
Repeat Id= 1
Printing Prog Graph - ok
Printing Symbol Table
Id= 1 Name= i
Id= 2 Name= a Dim= 2 DimLen0= 8 DimLen1= 8
Id= 3 Name= j
Id= 4 Name= b Dim= 2 DimLen0= 8 DimLen1= 8
Id= 5 Name= it
Id= 6 Name= eps
Id= 7 Name= w
Printing Symbol Table - ok
Export Data
Export Data - ok
Opers[0] – ‘+’
Opers[1] – ‘-’
Opers[2] – ‘*’
Opers[3] – ‘/’
Opers[4] – ‘:=’
Opers[5] – ‘<’, ‘>’,…
Opers[6] – ABS()
Opers[7] – MAX()
Redop=5 - MIN
Соответствующий распечатке граф.
1
2
5
7
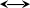
17
3
4
6
10
13
8
9
11
12
14
15
16