Методы позиционирования и сжатия звука
Современные звуковые карты. Методы позиционирования и сжатия звука
Аннотация
В данной курсовой работе изучаются различные аспекты применения звуковых карт. Рассматриваются способы получения звука на компьютере, основные принципы формирования и отличия цифрового звука от аналоговово. Рассмотрен также стандарт MIDI, применяемый во многих профессиональных звуковых синтезаторах и т.п. Далее были подробно рассмотрены звуковые карты, имеющиеся сейчас на рынке (некоторые карты, которые были доступны в процессе создания курсовой были протестированны на реальных приложениях): как и новые, так и уже более распространенные. Т.к. многие звуковые карты сейчас поддерживают различные технологии позиционирования звука в пространстве, то был кратко рассмотрен вопрос теории восприятия звука человеческим ухом и накладываемые этим ограничения. Завершающим этапом стало изучение форматов, применяемых для хранения оцифрованного звука. Изучены были как форматы со сжатием без потерь, так и со сжатием с потерями (mp3 и ему подобные), основанные на особенностях человеческого слуха по восприятию различных частот. В работе использовалась информация из различных источников: сопроводительной документации к картам, сайтов фирм-производителей, независимых тестовых лабораторий, публикации из периодических изданий. Для подготовки данной применялись материалы сети Интернет из общего доступа
Intel Celeron 500Mhz
MB FIC CP11Z
HDD Fujitsu 8,4GB
CD-ROM Samsung 24X
Звуковая подсистема:
звуковая плата A-trend Harmony 3DS724A на базе чипа Yamaha-724E
усилитель Вега У-120-СТЕРЕО
колонки Радиотехника С-90Д (трех полосные с фазоинвертором)
Введение
Компьютер – от английского “compute” – вычислять. Т.е., говоря по-русски, – всего-навсего вычислитель. И когда-то, давным-давно, это соответствовало применению компьютеров. Их использовали англичане для взлома кодов и шифров радиопередач Германии во время ВМВ. Их применяют и для прямо противоположной функции – кодирования и шифрования передаваемой информации. Они применялись для расчета сложнейших траекторий полета первых (да и последних) искусственных спутников Земли и других планет. И существует еще большое число ветвей и отраслей науки и промышленности, в которых невозможно обойтись без вычислительных мощностей компьютеров. Однако, изначально Электронно Вычислительную Машину всегда пытались использовать не только по прямому назначению, но и чуточку по другому. Вначале простые крестики-нолики и морской бой. Потом, когда у машины появился дисплей, ее научили рисовать различные “картинки” из символов. Дальше, до движущихся по экрану различных фигурок, оставалось совсем немного. Сейчас уже игры без графики мало кому нужны, кроме фэнов. Но… Присмотримся к этому процессу чуть внимательней: “символы->картинки из значков->статичные картинки->полномасштабное видео”. Компьютеры становились меньше, надежнее, долговечнее, быстрее…
Как видим, путь проделан немалый, и все-таки - это эволюция, растянувшаяся на полвека. Масштабное же событие, произошедшее около 10 лет назад назвать другим словом, как революция, вряд ли можно. На персональный компьютер пришел звук. Отголоски этого события продолжают сотрясать комьютерный мир до сих пор. Звук позволил сделать компьютер из принадлежности редкого бизнесмена в суровую необходимость для каждого. Он совершил фурор в индустрии производства музыкальной аппаратуры и звукозаписи. Раньше требовалось иметь проигрыватель виниловых дисков, компакт-кассет, компакт-дисков и прочую технику. Теперь достаточно одного – компьютера. Он уже играет, поет и даже обновленную версию рецепта клубничного пирога с джемом может из интернета скачать и переслать СВСВЧП (Сверх Интеллектуально Сверх Высокочастотной Печке). Только вот кофе пока не варит. Но и это, я думаю, скоро кто-нибудь исправит.
Компьютер потеснил такие традиционные истоники дохода и развлечений как казино, кино, театр. Осталось только научить компьютер работать и делать уборку в квартире, и все… Он действительно будет “везде”, и человек не сможет без него обходиться. А вот компьютер без человека?
И все лишь из-за чего? Из-за маленькой платки с несколькими копеечными радиодеталями, кошмарными шумами и огромными амбициями. Sound Blaster так сказать, версии 1.0. Производства фирмы Creative Labs из далекого Сингапура. Не она первой выпустила звуковую карту, но она смогла популяризовать эту идею в массах. Создать имя и завоевать рынок. Словосочетание “Sound Blaster” стало синонимом “звуковой карты”. И теперь компьютер без “звука” – это не компьютер. Как же так! Ведь он сможет проиграть при входе в “Windows” бравурное “Та-да!!!” И все – комьютер становится бесполезной грудой никому не нужного хлама.
Мне кажется, что все вышеприведенное должно немного заинтересовать. Ведь именно появление звука стало первым камнем в той лавине, которая обрушивается сейчас на головы несчастных потребителей услуг и товаров из сферы высоких технологий. “Полная 3Д акселерация” кричат одни, “Потрясающее качество воспроизведения ДВД” заявляют третьи, “Только у нас – самый настоящий трехмерный звук” похваляются третьи. И так – до бесконечности.
Вот почему я выбрал в качестве темы для курсовой это направление. Оно весьма обширно и полно обхватить его не позволяет ни скромный объем пояснительной записки, ни требуемое время. Поэтому я постарался ответить на поставленые вопросы, используя свой небольшой опыт в работе на “железном” (аппаратном) обеспечении компьютеров.
Цифровое представление звуковых сигналов
Отличия цифрового представления сигналов от аналогового
Традиционное аналоговое представление сигналов основано на подобии (аналогичности) электрических сигналов (изменений тока и напряжения) представленным ими исходным сигналам (звуковому давлению, температуре, скорости и т.п.), а также подобии форм электрических сигналов в различных точках усилительного или передающего тракта. Форма электрической кривой, описывающей (также говорят - переносящей) исходный сигнал, максимально приближена к форме кривой этого сигнала.
Такое представление наиболее точно, однако малейшее искажение формы несущего электрического сигнала неизбежно повлечет за собой такое же искажение формы и сигнала переносимого. В терминах теории информации, количество информации в несущем сигнале в точности равно количеству информации в сигнале исходном, и электрическое представление не содержит избыточности, которая могла бы защитить переносимый сигнал от искажений при хранении, передаче и усилении.
Цифровое представление электрических сигналов призвано внести в них избыточность, предохраняющую от воздействия паразитных помех. Для этого на несущий электрический сигнал накладываются серьезные ограничения - его амплитуда может принимать только два предельных значения - 0 и 1.
Вся зона возможных амплитуд в этом случае делится на три зоны: нижняя представляет нулевые значения, верхняя - единичные, а промежуточная является запрещенной - внутрь нее могут попадать только помехи. Таким образом, любая помеха, амплитуда которой меньше половины амплитуды несущего сигнала, не оказывает влияния на правильность передачи значений 0 и 1. Помехи с большей амплитудой также не оказывают влияния, если длительность импульса помехи ощутимо меньше длительности информационного импульса, а на входе приемника установлен фильтр импульсных помех.
Сформированный таким образом цифровой сигнал может переносить любую полезную информацию, которая закодирована в виде последовательности битов - нулей и единиц; частным случаем такой информации являются электрические и звуковые сигналы. Здесь количество информации в несущем цифровом сигнале значительно больше, нежели в кодированном исходном, так что несущий сигнал имеет определенную избыточность относительно исходного, и любые искажения формы кривой несущего сигнала, при которых еще сохраняется способность приемника правильно различать нули и единицы, не влияют на достоверность передаваемой этим сигналом информации. Однако в случае воздействия значительных помех форма сигнала может искажаться настолько, что точная передача переносимой информации становится невозможной - в ней появляются ошибки, которые при простом способе кодирования приемник не сможет не только исправить, но и обнаружить. Для еще большего повышения стойкости цифрового сигнала к помехам и искажениям применяется цифровое избыточное кодирование двух типов: проверочные (EDC - Error Detection Code, обнаруживающий ошибку код) и корректирующие (ECC - Error Correction Code, исправляющий ошибку код) коды. Цифровое кодирование состоит в простом добавлении к исходной информации дополнительных битов и/или преобразовании исходной битовой цепочки в цепочку большей длины и другой структуры. EDC позволяет просто обнаружить факт ошибки - искажение или выпадение полезной либо появление ложной цифры, однако переносимая информация в этом случае также искажается; ECC позволяет сразу же исправлять обнаруженные ошибки, сохраняя переносимую информацию неизменной. Для удобства и надежности передаваемую информацию разбивают на блоки (кадры), каждый из которых снабжается собственным набором этих кодов.
Каждый вид EDC/ECC имеет свой предел способности обнаруживать и исправлять ошибки, за которым опять начинаются необнаруженные ошибки и искажения переносимой информации. Увеличение объема EDC/ECC относительно объема исходной информации в общем случае повышает обнаруживающую и корректирующую способность этих кодов.
В качестве EDC популярен циклический избыточный код CRC (Cyclic Redundancy Check), суть которого состоит в сложном перемешивании исходной информации в блоке и формированию коротких двоичных слов, разряды которых находятся в сильной перекрестной зависимости от каждого бита блока. Изменение даже одного бита в блоке вызывает значительное изменение вычисленного по нему CRC, и вероятность такого искажения битов, при котором CRC не изменится, исчезающе мала даже при коротких (единицы процентов от длины блока) словах CRC. В качестве ECC используются коды Хэмминга (Hamming) и Рида-Соломона (Reed-Solomon), которые также включают в себя и функции EDC.
Информационная избыточность несущего цифрового сигнала приводит к значительному (на порядок и более) расширению полосы частот, требуемой для его успешной передачи, по сравнению с передачей исходного сигнала в аналоговой форме. Кроме собственно информационной избыточности, к расширению полосы приводит необходимость сохранения достаточно крутых фронтов цифровых импульсов.
Кроме целей помехозащиты, информация в цифровом сигнале может быть подвергнута также линейному или канальному кодированию, задача которого - оптимизировать электрические параметры сигнала (полосу частот, постоянную составляющую, минимальное и максимальное количество нулевых/единичных импульсов в серии и т.п.) под характеристики реального канала передачи или записи сигнала.
Полученный несущий сигнал, в свою очередь, также является обычным электрическим сигналом, и к нему применимы любые операции с такими сигналами - передача по кабелю, усиление, фильтрование, модуляция, запись на магнитный, оптический или другой носитель и т.п. Единственным ограничением является сохранение информационного содержимого - так, чтобы при последующем анализе можно было однозначно выделить и декоди- ровать переносимую информацию, а из нее - исходный сигнал.
Способы представления звука в цифровом виде
Исходная форма звукового сигнала - непрерывное изменение амплитуды во времени - представляется в цифровой форме с помощью "перекрестной дискретизации" - по времени и по уровню.
Согласно теореме Котельникова, любой непрерывный процесс с ограниченным спектром может быть полностью описан дискретной последовательностью его мгновенных значений, следующих с частотой, как минимум вдвое превышающей частоту наивысшей гармоники процесса; частота Fd выборки мгновенных значений (отсчетов) называется частотой дискретизации.
Из теоремы следует, что сигнал с частотой Fa может быть успешно дискретизирован по времени на частоте 2Fa только в том случае, если он является чистой синусоидой, ибо любое отклонение от синусоидальной формы приводит к выходу спектра за пределы частоты Fa. Таким образом, для временнОй дискретизации произвольного звукового сигнала (обычно имеющего, как известно, плавно спадающий спектр), необходим либо выбор частоты дискретизации с запасом, либо принудительное ограничение спектра входного сигнала ниже половины частоты дискретизации.
Одновременно с временнОй дискретизацией выполняется амплитудная - измерение мгновенных значений амплитуды и их представление в виде числовых величин с определенной точностью. Точность измерения (двоичная разрядность N получаемого дискретного значения) определяет соотношение сигнал/шум и динамический диапазон сигнала (теоретически это - взаимно-обратные величины, однако любой реальный тракт имеет также и собственный уровень шумов и помех).
Полученный поток чисел (серий двоичных цифр), описывающий звуковой сигнал, называют импульсно-кодовой модуляцией или ИКМ (Pulse Code Modulation, PCM), так как каждый импульс дискретизованного по времени сигнала представляется собственным цифровым кодом.
Чаще всего применяют линейное квантование, когда числовое значение отсчета пропорционально амплитуде сигнала. Из-за логарифмической природы слуха более целесообразным было бы логарифмическое квантование, когда числовое значение пропорционально величине сигнала в децибелах, однако это сопряжено с трудностями чисто технического характера.
ВременнАя дискретизация и амплитудное квантование сигнала неизбежно вносят в сигнал шумовые искажения, уровень которых принято оценивать по формуле 6N + 10lg (Fдискр/2Fмакс) + C (дБ), где константа C варьируется для разных типов сигналов: для чистой синусоиды это 1.7 дБ, для звуковых сигналов - от -15 до 2 дБ. Отсюда видно, что к снижению шумов в рабочей полосе частот 0..Fмакс приводит не только увеличение разрядности отсчета, но и повышение частоты дискретизации относительно 2Fмакс, поскольку шумы квантования "размазываются" по всей полосе вплоть до частоты дискретизации, а звуковая информация занимает только нижнюю часть этой полосы.
В большинстве современных цифровых звуковых систем используются стандартные частоты дискретизации 44.1 и 48 кГц, однако частотный диапазон сигнала обычно ограничивается возле 20 кГц для оставления запаса по отношению к теоретическому пределу. Также наиболее распространено 16-разрядное квантование по уровню, что дает предельное соотношение сигнал/шум около 98 дБ. В студийной аппаратуре используются более высокие разрешения - 18-, 20- и 24-разрядное квантование при частотах дискретизации 56, 96 и 192 кГц. Это делается для того, чтобы сохранить высшие гармоники звукового сигнала, которые непосредственно не воспринимаются слухом, но влияют на формирование общей звуковой картины.
Для оцифровки более узкополосных и менее качественных сигналов частота и разрядность дискретизации могут снижаться; например, в телефонных линиях применяется 7- или 8-разрядная оцифровка с частотами 8..12 кГц.
Представление аналогового сигнала в цифровом виде называется также импульсно-кодовой модуляцией (ИКМ, PCM - Pulse Code Modulation), так как сигнал представляется в виде серии импульсов постоянной частоты (временнАя дискретизация), амплитуда которых передается цифровым кодом (амплитудная дискретизация). PCM-поток может быть как параллельным, когда все биты каждого отсчета передаются одновременно по нескольким линиям с частотой дискретизации, так и последовательным, когда биты передаются друг за другом с более высокой частотой по одной линии.
Сам цифровой звук и относящиеся к нему вещи принято обозначать общим термином Digital Audio; аналоговая и цифровая части звуковой системы обозначаются терминами Analog Domain и Digital Domain.
АЦП и ЦАП
Аналогово-цифровой и цифро-аналоговый преобразователи. Первый преобразует аналоговый сигнал в цифровое значение амплитуды, второй выполняет обратное преобразование. В англоязычной литературе применяются термины ADC и DAC, а совмещенный преобразователь называют codec (coder-decoder).
Принцип работы АЦП состоит в измерении уровня входного сигнала и выдаче результата в цифровой форме. В результате работы АЦП непрерывный аналоговый сигнал превращается в импульсный, с одновременным измерением амплитуды каждого импульса. ЦАП получает на входе цифровое значение амплитуды и выдает на выходе импульсы напряжения или тока нужной величины, которые расположенный за ним интегратор (аналоговый фильтр) превращает в непрерывный аналоговый сигнал.
Для правильной работы АЦП входной сигнал не должен изменяться в течение времени преобразования, для чего на его входе обычно помещается схема выборки-хранения, фиксирующая мгновенный уровень сигнала и сохраняющая его в течение всего времени преобразования. На выходе ЦАП также может устанавливаться подобная схема, подавляющая влияние переходных процессов внутри ЦАП на параметры выходного сигнала.
При временнОй дискретизации спектр полученного импульсного сигнала в своей нижней части 0..Fa повторяет спектр исходного сигнала, а выше содержит ряд отражений (aliases, зеркальных спектров), которые расположены вокруг частоты дискретизации Fd и ее гармоник (боковые полосы). При этом первое отражение спектра от частоты Fd в случае Fd = 2Fa располагается непосредственно за полосой исходного сигнала, и требует для его подавления аналогового фильтра (anti-alias filter) с высокой крутизной среза. В АЦП этот фильтр устанавливается на входе, чтобы исключить перекрытие спектров и их интерференцию, а в ЦАП - на выходе, чтобы подавить в выходном сигнале надтональные помехи, внесенные временнОй дискретизацией.
Устройство АЦП и ЦАП
В основном применяется три конструкции АЦП: параллельные - входной сигнал одновременно сравнивается с эталонными уровнями набором схем сравнения (компараторов), которые формируют на выходе двоичное значение. В таком АЦП количество компараторов равно (2 в степени N) - 1, где N - разрядность цифрового кода (для восьмиразрядного - 255), что не позволяет наращивать разрядность свыше 10-12.
последовательного приближения - преобразователь при помощи вспомогательного ЦАП генерирует эталонный сигнал, сравниваемый со входным. Эталонный сигнал последовательно изменяется по принципу половинного деления (дихотомии), который используется во многих методах сходящегося поиска прикладной математики. Это позволяет завершить преобразование за количество тактов, равное разрядности слова, независимо от величины входного сигнала.
с измерением временнЫх интервалов - широкая группа АЦП, использующая для измерения входного сигнала различные принципы преобразования уровней в пропорциональные временнЫе интервалы, длительность которых измеряется при помощи тактового генератора высокой частоты. Иногда называются также считающими АЦП.
Среди АЦП с измерением временнЫх интервалов преобладают следующие три типа: последовательного счета, или однократного интегрирования (single-slope) - в каждом такте преобразования запускается генератор линейно возрастающего напряжения, которое сравнивается со входным.
Обычно такое напряжение получают на вспомогательном ЦАП, подобно АЦП последовательного приближения.
двойного интегрирования (dual-slope) - в каждом такте преобразования входной сигнал заряжает конденсатор, который затем разряжается на источник опорного напряжения с измерением длительности разряда.
следящие - вариант АЦП последовательного счета, при котором генератор эталонного напряжения не перезапускается в каждом такте, а изменяет его от предыдущего значения до текущего.
Наиболее популярным вариантом следящего АЦП является sigma-delta, работающий на частоте Fs, значительно (в 64 и более раз) превышающей частоту дискретизации Fd выходного цифрового сигнала. Компаратор такого АЦП выдает значения пониженной разрядности (обычно однобитовые - 0/1), сумма которых на интервале дискретизации Fd пропорциональна величине отсчета. Последовательность малоразрядных значений подвергается цифровой фильтрации и понижению частоты следования (decimation), в результате чего получается серия отсчетов с заданной разрядностью и частотой дискретизации Fd.
Для улучшения соотношения сигнал/шум и снижения влияния ошибок квантования, которое в случае однобитового преобразователя получается довольно высоким, применяется метод формовки шума (noise shaping) через схемы обратной связи по ошибке и цифрового фильтрования. В результате применения этого метода форма спектра шума меняется так, что основная шумовая энергия вытесняется в область выше половины частоты Fs, незначительная часть остается в нижней половине, и практически весь шум удаляется из полосы исходного аналогового сигнала.
ЦАП в основном строятся по трем принципам: взвешивающие - с суммированием взвешенных токов или напряжений, когда каждый разряд входного слова вносит соответствующий своему двоичному весу вклад в общую величину получаемого аналогового сигнала; такие ЦАП называют также параллельными или многоразрядными (multibit).
sigma-delta, с предварительной цифровой передискретизацией и выдачей малоразрядных (обычно однобитовых) значений на схему формирования эталонного заряда, которые со столь же высокой частотой добавляются к выходному сигналу. Такие ЦАП носят также название bitstream.
с широтно-импульсной модуляцией (ШИМ, Pulse Width Modulation, PWM), когда на схему выборки-хранения аналогового сигнала выдаются импульсы постоянной амплитуды и переменной длительности, управляя дозированием выдаваемого на выход заряда. На этом принципе работают преобразователи MASH (Multi-stAge Noise Shaping - многостадийная формовка шума) фирмы Matsushita. Свое название эти ЦАП получили по причине применения в них нескольких последовательных формирователей шума.
При использовании передискретизации в десятки раз (обычно - 64x..512x) становится возможным уменьшить разрядность ЦАП без ощутимой потери качества сигнала; ЦАП с меньшим числом разрядов обладают также лучшей линейностью. В пределе количество разрядов может сокращаться до одного.
Форма выходного сигнала таких ЦАП представляет собой полезный сигнал, обрамленный значительным количеством высокочастотного шума, который, тем не менее, эффективно подавляется аналоговым фильтром даже среднего качества.
ЦАП являются "прямыми" устройствами, в которых преобразование выполняется проще и быстрее, чем в АЦП, которые в большинстве своем - последовательные и более медленные устройства.
Передискретизация (oversampling)
Это дискретизация сигнала с частотой, превышающей основную частоту дискретизации. Передискретизации может быть аналоговой, когда с повышенной частотой делаются выборки исходного сигнала, или цифровой, когда между уже существующими цифровыми отсчетами вставляются дополнительные, рассчитанные путем интерполяции. Другой способ получения значений промежуточных отсчетов состоит во вставке нулей, после чего вся последовательность подвергается цифровой фильтрации. В АЦП используется аналоговая передискретизация, в ЦАП - цифровая.
Передискретизация используется для упрощения конструкций АЦП и ЦАП. По условиям задачи на входе АЦП и выходе ЦАП должен быть установлен аналоговый фильтр с АЧХ, линейной в рабочем диапазоне и круто спадающей за его пределами. Реализация такого аналогового фильтра весьма сложна; в то же время при повышении частоты дискретизации вносимые ею отражения спектра пропорционально отодвигаются от основного сигнала, и аналоговый фильтр может иметь гораздо меньшую крутизну среза.
Другое преимущество передискретизации состоит в том, что ошибки амплитудного квантования (шум дробления), распределенные по всему спектру квантуемого сигнала, при повышении частоты дискретизации распределяются по более широкой полосе частот, так что на долю основного звукового сигнала приходится меньшее количество шума. Каждое удвоение частоты снижает уровень шума квантования на 3 дБ; поскольку один двоичный разряд эквивалентен 6 дБ шума, каждое учетверение частоты позволяет уменьшить разрядность преобразователя на единицу.
Передискретизация вместе с увеличением разрядности отсчета, интерполяцией отсчетов с повышенной точностью и выводом их на ЦАП надлежащей разрядности позволяет несколько улучшить качество восстановления звукового сигнала. По этой причине даже в 16-разрядных системах нередко применяются 18- и 20-разрядные ЦАП с передискретизацией.
АЦП и ЦАП с передискретизацией за счет значительного уменьшения времени преобразования могут обходиться без схемы выборки-хранения.
Достоинства и недостатки цифрового звука
Цифровое представление звука ценно прежде всего возможностью бесконечного хранения и тиражирования без потери качества, однако преобразование из аналоговой формы в цифровую и обратно все же неизбежно приводит к частичной его потере. Наиболее неприятные на слух искажения, вносимые на этапе оцифровки - гранулярный шум, возникающий при квантовании сигнала по уровню из-за округления амплитуды до ближайшего дискретного значения. В отличие от простого широкополосного шума, вносимого ошибками квантования, гранулярный шум представляет собой гармонические искажения сигнала, наиболее заметные в верхней части спектра.
Мощность гранулярного шума обратно пропорциональна количеству ступеней квантования, однако из-за логарифмической характеристики слуха при линейном квантовании (постоянная величина ступени) на тихие звуки приходится меньше ступеней квантования, чем на громкие, и в результате основная плотность нелинейных искажений приходится на область тихих звуков. Это приводит к ограничению динамического диапазона, который в идеале (без учета гармонических искажений) был бы равен соотношению сигнал/шум, однако необходимость ограничения этих искажений снижает динамический диапазон для 16-разрядного кодирования до 50-60 дБ.
Положение могло бы спасти логарифмическое квантование, однако его реализация в реальном времени весьма сложна и дорога.
Искажения, вносимые гранулярным шумом, можно уменьшить путем добавления к сигналу обычного белого шума (случайного или псевдослучайного сигнала), амплитудой в половину младшего значащего разряда; такая операция называется сглаживанием (dithering). Это приводит к незначительному увеличению уровня шума, зато ослабляет корреляцию ошибок квантования с высокочастотными компонентами сигнала и улучшает субъективное восприятие. Сглаживание применяется также перед округлением отсчетов при уменьшении их разрядности. По существу, dithering и noise shaping являются частными случаями одной технологии - с той разницей, что в первом случае используется белый шум с равномерным спектром, а во втором - шум со специально "формованным" спектром.
При восстановлении звука из цифровой формы в аналоговую возникает проблема сглаживания ступенчатой формы сигнала и подавления гармоник, вносимых частотой дискретизации. Из-за неидеальности АЧХ фильтров может происходить либо недостаточное подавление этих помех, либо избыточное ослабление полезных высокочастотных составляющих. Плохо подавленные гармоники частоты дискретизации искажают форму аналогового сигнала (особенно в области высоких частот), что создает впечатление "шероховатого", "грязного" звука.
Интерфейсы, используемые для передачи цифрового звука
S/PDIF (Sony/Philiрs Digital Interface Format - формат цифрового интерфейса фирм Sony и Philiрs) - цифровой интерфейс для бытовой радиоаппаратуры.
AES/EBU (Audio Engineers Society / European Broadcast Union - общество звукоинженеров / европейское вещательное объединение) - цифровой интерфейс для студийной радиоаппаратуры.
Оба интерфейса являются последовательными и используют одинаковый формат сигнала и систему кодирования - самосинхронизирующийся код BMC (Biphase-Mark Code - код с представлением единицы двойным изменением фазы), и могут передавать сигналы в формате PCM разрядностью до 24 бит на частотах дискретизации до 48 кГц.
Каждый отсчет сигнала передается 32-разрядным словом, в котором 20 разрядов используются для передачи отсчета, а 12 - для формирования синхронизирующей преамбулы, передачи дополнительной информации и бита четности. 4 разряда из служебной группы могут использоваться для расширения формата отсчетов до 24 разрядов.
Помимо бита четности, служебная часть слова содержит бит достоверности (Validity), который должен быть нулевым для каждого достоверного отсчета. В случае приема слова с единичным битом Validity либо с нарушением четности в слове приемник трактует весь отсчет как ошибочный и может на выбор либо заменить его предыдущим значением, либо интерполировать на основе нескольких соседних достоверных отсчетов.
Отсчеты, помеченные как недостоверные, могут передавать CD-проигрыватели, DAT-магнитофоны и другие устройства, если при считывании информации с носителя не удалось скорректировать возникшие в процессе чтения ошибки.
Стандартно формат кодирования предназначен для передачи одно- и двух-канального сигнала, однако при использовании служебных разрядов для кодирования номера канала возможна передача многоканального сигнала.
С электрической стороны S/PDIF предусматривает соединение коаксиальным кабелем с волновым сопротивлением 75 Ом и разъемами типа RCA ("тюльпан"), амплитуда сигнала - 0.5 В. AES/EBU предусматривает соединение симметричным экранированным двухпроводным кабелем с трансформаторной развязкой по интерфейсу RS-422 с амплитудой сигнала 3-10 В, разъемы - трехконтактные типа Cannon XLR. Существуют также оптические варианты приемопередатчиков - TosLink (пластмассовое оптоволокно) и AT&T Link (стеклянное оптоволокно).
Обработка цифрового звука
Цифровой звук обрабатывается посредством математических операций, применяемых к отдельным отсчетам сигнала, либо к группам отсчетов различной длины. Выполняемые математические операции могут либо имитировать работу традиционных аналоговых средств обработки (микширование двух сигналов - сложение, усиление/ослабление сигнала - умножение на константу, модуляция - умножение на функцию и т.п.), либо использовать альтернативные методы - например, разложение сигнала в спектр (ряд Фурье), коррекция отдельных частотных составляющих, затем обратная "сборка" сигнала из спектра.
Обработка цифровых сигналов подразделяется на линейную (в реальном времени, над "живым" сигналом) и нелинейную - над предварительно записанным сигналом. Линейная обработка требует достаточного быстродействия вычислительной системы (процессора); в ряде случаев невозможно совмещение требуемого быстродействия и качества, и тогда используется упрощенная обработка с пониженным качеством. Нелинейная обработка никак не ограничена во времени, поэтому для нее могут быть использованы вычислительные средства любой мощности, а время обработки, особенно с высоким качеством, может достигать нескольких минут и даже часов.
Для обработки применяются как универсальные процессоры общего назначения - Intel 8035, 8051, 80x86, Motorola 68xxx, SPARC - так и специализированные цифровые сигнальные процессоры (Digital Signal Processor, DSP) Texas Instruments TMS xxx, Motorola 56xxx, Analog Devices ADSP-xxxx и др.
Разница между универсальным процессором и DSP состоит в том, что первый ориентирован на широкий класс задач - научных, экономических, логических, игровых и т.п., и содержит большой набор команд общего назначения, в котором преобладают обычные математические и логические операции. DSP специально ориентированы на обработку сигналов и содержат наборы специфический операций - сложение с ограничением, перемножение векторов, вычисление математического ряда и т.п. Реализация даже несложной обработки звука на универсальном процессоре требует значительного быстродействия и далеко не всегда возможна в реальном времени, в то время как даже простые DSP нередко справляются в реальном времени с относительно сложной обработкой, а мощные DSP способны выполнять качественную спектральную обработку сразу нескольких сигналов.
В силу своей специализации DSP редко применяются самостоятельно - чаще всего устройство обработки имеет универсальный процессор средней мощности для управления всем устройством, приема/передачи информации, взаимодействия с пользователем, и один или несколько DSP - собственно для обработки звукового сигнала. Например, для реализации надежной и быстрой обработки сигналов в компьютерных системах применяют специализированные платы с DSP, через которые пропускается обрабатываемый сигнал, в то время как центральному процессору компьютера остаются лишь функции управления и передачи.
Методы, используемые для обpаботки звука
1. Монтаж. Состоит в выpезании из записи одних участков, вставке дpугих, их замене, pазмножении и т.п. Hазывается также pедактиpованием. Все совpеменные звуко- и видеозаписи в той или иной меpе подвеpгаются монтажу.
2. Амплитудные пpеобpазования. Выполняются пpи помощи pазличных действий над амплитудой сигнала, котоpые в конечном счете сводятся к умножению значений самплов на постоянный коэффициент (усиление/ослабление) или изменяющуюся во вpемени функцию-модулятоp (амплитудная модуляция). Частным случаем амплитудной модуляции является фоpмиpование огибающей для пpидания стационаpному звучанию pазвития во вpемени.
Амплитудные пpеобpазования выполняются последовательно с отдельными самплами, поэтому они пpосты в pеализации и не тpебуют большого объема вычислений.
3. Частотные (спектpальные) пpеобpазования. Выполняются над частотными составляющими звука. Если использовать спектpальное pазложение - фоpму пpедставления звука, в котоpой по гоpизонтали отсчитываются частоты, а по веpтикали - интенсивности составля- ющих этих частот, то многие частотные пpеобpазования становятся похожими на амплитудные пpеобpазованиям над спектpом. Hапpимеp, фильтpация - усиление или ослабление опpеделенных полос частот - сводится к наложению на спектp соответствующей амплитудной огибающей. Однако частотную модуляцию таким обpазом пpедставить нельзя - она выглядит, как смещение всего спектpа или его отдельных участков во вpемени по опpеделенному закону.
Для pеализации частотных пpеобpазований обычно пpименяется спектpальное pазложение по методу Фуpье, котоpое тpебует значительных pесуpсов. Однако имеется алгоpитм быстpого пpеобpазования Фуpье (БПФ, FFT), котоpый делается в целочисленной аpифметике и позволяет уже на младших моделях 486 pазвоpачивать в pеальном вpемени спектp сигнала сpеднего качества. Пpи частотных пpеобpа- зованиях, кpоме этого, тpебуется обpаботка и последующая свеpтка, поэтому фильтpация в pеальном вpемени пока не pеализуется на пpоцессоpах общего назначения. Вместо этого существует большое количество цифpовых сигнальных пpоцессоpов (Digital Signal Processor - DSP), котоpые выполняют эти опеpации в pеальном вpемени и по нескольким каналам.
4. Фазовые пpеобpазования. Сводятся в основном к постоянному сдвигу фазы сигнала или ее модуляции некотоpой функцией или дpугим сигналом. Благодаpя тому, что слуховой аппаpат человека использует фазу для опpеделения напpавления на источник звука, фазовые пpеобpазования стеpеозвука позволяют получить эффект вpащающегося звука, хоpа и ему подобные.
5. Вpеменные пpеобpазования. Заключаются в добавлении к основному сигналу его копий, сдвинутых во вpемени на pазличные величи- ны. Пpи небольших сдвигах (поpядка менее 20 мс) это дает эффект pазмножения источника звука (эффект хоpа), пpи больших - эффект эха.
6. Фоpмантные пpеобpазования. Являются частным случаем частотных и опеpиpуют с фоpмантами - хаpактеpными полосами частот, встpечающимися в звуках, пpоизносимых человеком. Каждому звуку соот- ветствует свое соотношение амплитуд и частот нескольких фоpмант, котоpое опpеделяет тембp и pазбоpчивость голоса. Изменяя паpаметpы фоpмант, можно подчеpкивать или затушевывать отдельные звуки, менять одну гласную на дpугую, сдвигать pегистp голоса и т.п.
Звуковые эффекты
Вот наиболее pаспpостpаненные звуковые эффекты: - вибpато - амплитудная или частотная модуляция сигнала с небольшой частотой (до 10 Гц). Амплитудное вибpато также носит название тpемоло; на слух оно воспpинимается, как замиpание или дpожание звука, а частотное - как "завывание" или "плавание" звука (типичная неиспpавность механизма магнитофона).
- динамическая фильтpация (wah-wah - "вау-вау") - pеализуется изменением частоты сpеза или полосы пpопускания фильтpа с небольшой частотой. Hа слух воспpинимается, как вpащение или заслонение/откpывание источника звука - увеличение высокочастотных составляющих ассоцииpуется с источником, обpащенным на слушателя, а их уменьшение - с отклонением от этого напpавления.
- фленжеp (flange - кайма, гpебень). Hазвание пpоисходит от способа pеализации этого эффекта в аналоговых устpойствах - пpи помощи так называемых гpебенчатых фильтpов. Заключается в добавлении к исходному сигналу его копий, сдвинутых во вpемени на небольшие величины (до 20 мс) с возможной частотной модуляцией копий или величин их вpеменных сдвигов и обpатной связью (суммаpный сигнал снова копиpуется, сдвигается и т.п.). Hа слух это ощущается как "дpобление", "pазмазывание" звука, возникновение биений - pазностных частот, хаpактеpных для игpы в унисон или хоpового пения, отчего фленжеpы с опpеделенными паpаметpами пpименяются для получения хоpового эффекта (chorus). Меняя паpаметpы фленжеpа, можно в значительной степени изменять пеpвоначальный тембp звука.
- pевеpбеpация (reverberation - повтоpение, отpажение). Получается путем добавления к исходному сигналу затухающей сеpии его сдвинутых во вpемени копий. Это имитиpует затухание звука в помещении, когда за счет многокpатных отpажений от стен, потолка и пpочих повеpхностей звук пpиобpетает полноту и гулкость, а после пpекpащения звучания источника затухает не сpазу, а постепенно. Пpи этом вpемя между последовательными отзвуками (пpимеpно до 50 мс) ассоцииpуется с величиной помещения, а их интенсивность - с его гулкостью. По сути, pевеpбеpатоp пpедставляет собой частный случай фленжеpа с увеличенной задеpжкой между отзвуками основного сигнала, однако особенности слухового воспpиятия качественно pазличают эти два вида обpаботки.
- эхо (echo). Ревеpбеpация с еще более увеличенным вpеменем задеpжки - выше 50 мс. Пpи этом слух пеpестает субъективно воспpинимать отpажения, как пpизвуки основного сигнала, и начинает воспpинимать их как повтоpения. Эхо обычно pеализуется так же, как и естественное - с затуханием повтоpяющихся копий.
- дистошн (distortion - искажение) - намеpенное искажение фоpмы звука, что пpидает ему pезкий, скpежещущий оттенок. Hаибольшее пpименение получил в качестве гитаpного эффекта (классическая гитаpа heavy metal). Получается пеpеусилением исходного сигнала до появления огpаничений в усилителе (сpеза веpхушек импульсов) и даже его самовозбуждения. Благодаpя этому исходный сигнал становится похож на пpямоугольный, отчего в нем появляется большое количество новых частотных составляющих, pезко pасшиpяющих спектp. Этот эффект пpименяется в pазличных ваpиациях (fuzz, overdrive и т.п.), pазличающихся способом огpаничения сигнала (обычное или сглаженное, весь спектp или полоса частот, весь амплитудный диапазон или его часть и т.п.), соотношением исходного и искаженного сигналов в выходном, частотными хаpактеpистиками усилителей (наличие/отсутствие фильтpов на выходе).
- компpессия - сжатие динамического диапазона сигнала, когда слабые звуки усиливаются сильнее, а сильные - слабее. Hа слух воспpинимается как уменьшение pазницы между тихим и гpомким звучанием исходного сигнала. Используется для последующей обpаботки методами, чувствительными к изменению амплитуды сигнала. В звукозаписи используется для снижения относительного уpовня шума и пpедотвpащения пеpегpузок. В качестве гитаpной пpиставки позволяет значительно (на десятки секунд) пpодлить звучание стpуны без затухания гpомкости.
- фейзеp (phase - фаза) - смешивание исходного сигнала с его копиями, сдвинутыми по фазе. По сути дела, это частный случай фленжеpа, но с намного более пpостой аналоговой pеализацией (цифpовая pеализация одинакова). Изменение фазовых сдвигов суммиpуемых сигналов пpиводит к подавлению отдельных гаpмоник или частотных областей, как в многополосном фильтpе. Hа слух такой эффект напоминает качание головки в стеpеомагнитофоне - физические пpоцессы в обоих случаях пpимеpно одинаковы.
- вокодеp (voice coder - кодиpовщик голоса) - синтез pечи на основе пpоизвольного входного сигнала с богатым спектpом. Речевой синтез pеализуется пpи помощи фоpмантных пpеобpазований: выделение из сигнала с достаточным спектpом нужного набоpа фоpмант с нужными соотношениями пpидает сигналу свойства соответствующего гласного звука. Изначально вокодеpы использовались для пеpедачи кодиpованной pечи: путем анализа исходного pечевого сигнала из него выделялась инфоpмация об изменении положений фоpмант (пеpеход от звука к звуку), котоpая кодиpовалась и пеpедавалась по линии связи, а на пpиемном конце блок упpавляемых фильтpов и усилителей синтезиpовал pечь заново. Подавая на блок pечевого синтеза звучание, напpимеp, электpогитаpы и пpоизнося слова в микpофон блока анализа, можно получить эффект "pазговаpивающей гитаpы"; пpи подаче звучания с синтезатоpа получается известный "голос pобота", а подача сигнала, близкого по спектpу к колебаниям голосовых связок, но отличающегося по частоте, меняет pегистp голоса - мужской на женский или детский, и наобоpот.
К вопросу о хранении и передаче цифрового звука
Поскольку любой цифровой сигнал представляется реальной электрической кривой напряжения или тока - его форма так или иначе искажается при любой передаче, а "замороженный" для хранения сигнал (сигналограмма) подвержен деградации в силу обычных физических причин. Все эти воздействия на форму несущего сигнала являются помехами, которые до определенной величины не изменяют информационного содержания сигнала, как отдельные искажения и выпадения букв в словах обычно не мешают правильному пониманию этих слов, причем избыточность информации, как и увеличение длины слов, повышает вероятность успешного распознавания.
Другими словами, сам несущий сигнал может искажаться, однако переносимая им информация - закодированный звуковой сигнал - в абсолютном большинстве случаев остается неизменной.
Для того, чтобы качество несущего сигнала не ухудшалось, любая передача полезной звуковой информации - копирование, запись на носитель и считывание с него - обязательно должна включать операцию восстановления формы несущего сигнала, а в идеале - и первичного цифрового вида сигнала информационного, и лишь после этого заново сформированный несущий сигнал может быть передан следующему потребителю. В случае прямого копирования без восстановления (например, обычным переписыванием видеокассеты с цифровым сигналом, полученным при помощи ИКМ-приставки, на обычных видеомагнитофонах) качество цифрового сигнала ухудшается, хотя он по-прежнему полностью содержит всю переносимую им информацию. Однако после многократного последовательного копирования или длительного хранения качество ухудшается настолько, что начинают возникать неисправимые ошибки, необратимо искажающие переносимую сигналом информацию. Поэтому копирование и передачу цифровых сигналов необходимо вести только в цифровых устройствах, а при хранении на носителях - своевременно "освежать" не дожидаясь необратимой деградации (для магнитных носителей этот срок оценивается в несколько лет). Правильно переданная или обновленная цифровая сигналограмма качества не теряет и может копироваться и существовать вечно в абсолютно неизменном виде.
Тем не менее, не следует забывать, что корректирующая способность любого кода конечна, а реальные носители далеки от идеальных, поэтому возникновение неисправимых ошибок - на такая уж редкая вещь, особенно при неаккуратном обращении с носителем. При чтении с новых и правильно хранимых DAT-кассет или компакт-дисков в качественных и надежных аппаратах таких ошибок практически не возникает, однако при старении, загрязнении и повреждении носителей и считывающих систем их становится больше. Одиночная неисправленная ошибка почти всегда незаметна на слух благодаря интерполяции, однако она приводит к искажению формы исходного звукового сигнала, а накопление таких ошибок со временем начинает ощущаться и на слух.
Отдельную проблему составляет сложность регистрации неисправленных ошибок, а также проверки идентичности оригинала и копии. Чаще всего конструкторы цифровых звуковых устройств, работающих в реальном времени, не озабочены вопросом точной проверки достоверности передачи, считая вполне достаточными меры, принятые для коррекции ошибок. Невозможность в общем случае повторной передачи ошибочного отсчета или блока приводит к тому, что интерполяция происходит скрытно и после копирования нельзя с уверенностью сказать, точно ли скопирован исходный сигнал. Индикаторы ошибки, имеющиеся в ряде устройств, обычно включаются только в момент ее возникновения, и в случае одиночных ошибок их срабатывание легко может остаться незамеченным. Даже в системах на основе персональных компьютеров чаще всего нет возможности контролировать правильность приема по цифровому интерфейсу или прямого считывания CD; выходом является только многократное повторение операции и сравнение результатов.
И наконец, в принципе возможны ситуации, когда даже незначительные ошибки способны необратимо исказить передаваемую информацию, оставшись при этом незамеченными системой передачи. Другое дело, что вероятность возникновения подобных ошибок исчезающе мала (порядка одной на несколько лет непрерывной передачи сигнала), поэтому такую возможность практически нигде не принимают в расчет.
К вопросу о сохранении качества сигнала при цифровой обработке
Прежде всего, необходимо различать "искажающие" и "неискажающие" виды обработки. К первым относятся операции, изменяющие форму и структуру сигнала - смешивание, усиление, фильтрация, модуляция и т.п., ко вторым - операции монтажа (вырезка, вклейка, наложение) и переноса (копирования).
Качество сигнала может страдать только при "искажающей" обработке, причем любой - и аналоговой, и цифровой. В первом случае это происходит в результате внесения шумов, гармонических, интермодуляционных и других искажений в узлах аналогового тракта, во втором - благодаря конечной точности квантования сигнала и математических вычислений. Все цифровые вычисления выполняются в некоторой разрядной сетке фиксированной длины - 16, 20, 24, 32, 64, 80 и более бит; увеличение разрядности сетки повышает точность вычислений и уменьшает ошибки округления, однако в общем случае не может исключить их полностью. Конечная точность квантования первичного аналогового сигнала приводит к тому, что даже при абсолютно точной обработке полученного цифрового сигнала квантованное значение каждого отсчета все равно отличается от своего идеального значения. Для минимизации искажений при обработке в студиях предпочитают обрабатывать и хранить сигналограммы на мастер-носителях с повышенным разрешением (20, 24 или 32 разряда), даже если результат будет тиражироваться на носителе с меньшим разрешением.
Кроме собственно ошибок вычислений и округления, на точность сильно влияет выбор представления числовых отсчетов сигнала при обработке.
Традиционное представление PCM с так называемой фиксированной точкой (fixed point), когда отсчеты представляются целыми числами, наиболее удобно и влечет минимум накладных расходов, однако точность вычислений зависит от масштаба операций - например, при умножении образуются числа вдвое большей разрядности, которые потом приходится приводить обратно к разрядности исходных отсчетов, а это может привести к переполнению разрядной сетки. Компромиссным вариантом служит промежуточное увеличение разрядности отсчетов (например, 16->32), что снижает вероятность переполнения, однако требует большей вычислительной мощности, объема памяти и вносит дополнительные искажения при обратном понижении разрядности. Кроме того, снижению погрешности способствует правильный выбор последовательности коммутативных (допускающих перестановку) операций, группировка дистрибутивных операций, учет особенностей работы конкретного процессора и т.п.
Другим способом увеличения точности является преобразование отсчетов в форму с плавающей точкой (floating point) с разделением на значащую часть - мантиссу и показатель величины - порядок. В этой форме все операции сохраняют разрядность значащей части, и умножение не приводит к переполнению разрядной сетки. Однако, как само преобразование между формами с фиксированной и плавающей точкой, так и вычисления в этой форме требуют на порядки большего быстродействия процессора, что сильно затрудняет их использование в реальном времени.
Несмотря на то, что качество сигнала неизбежно, хоть и незначительно, ухудшается при любой "искажающей" цифровой обработке, некоторые операции при определенных условиях являются полностью и однозначно обратимыми.
Например, усиление сигнала по амплитуде в три раза заключается в умножении каждого отсчета на три; если эта операция выполнялась с фиксированной точкой и при этом не возникло переполнения, с помощью деления на три потом можно будет вернуть все отсчеты в исходное состояние, тем самым полностью восстановив первоначальное состояние сигнала. И в то же время после умножения каждый отсчет окажется увеличенным точно в три раза, поэтому ошибка относительно исходного аналогового сигнала, внесенная при квантовании, также увеличится в среднем в три раза, тем самым ухудшив общее качество сигнала.
Сказанное выше демонстрирует, что ухудшение качества при "искажающей" цифровой обработке совсем не обязательно накапливается со временем, хотя в большинстве реальных применений происходит именно так. Кроме того, это не означает, что любая операция цифрового усиления всегда будет однозначно обратимой - это зависит от многих особенностей применения операции. Тем не менее, грамотно и качественно реализованная цифровая обработка может давать существенно меньший уровень искажений, чем такая же аналоговая, разве что это будут искажения разных видов.
К вопросу о сохранении качества сигнала при цифровом преобразовании форматов
Только в том случае, когда в процессе преобразования применяются "искажающие" операции - изменение разрядности отсчета, частоты дискретизации, фильтрование, сжатие с потерями и т.п. Простое увеличение разрядности отсчета с сохранением частоты дискретизации будет неискажающим, однако такое же увеличение, сопряженное с применением сглаживающей функции - уже нет. Уменьшение разрядности отсчета всегда является искажающей операцией, кроме случая, когда преобразуемые отсчеты были получены таким же простым увеличением разрядности - равной или меньшей.
Многие форматы отличаются друг от друга только порядком битов в слове, отсчетов левого и правого каналов в потоке и служебной информацией - заголовками, контрольными суммами, помехозащитными кодами и т.п. Точный способ проверки неискажаемости сигнала заключается в преобразовании нескольких различных потоков (файлов) формата F1 в формат F2, а затем обратно в F1. Если информационная часть каждого потока (файла) при этом будет идентична исходной - данный вид преобразования можно считать неискажающим.
Под информационной частью потока (файла) понимается собственно набор данных, описывающих звуковой сигнал; остальная часть считается служебной и на форму сигнала в общем случае не влияет. Например, если в служебной части файла или потока предусмотрено поле для времени его создания (передачи), то даже в случае полного совпадения информационных частей двух разных файлов или потоков их служебные части окажутся различными, и это будет зафиксировано логическим анализатором в случае потока или программой побайтного сравнения - в случае файла. Кроме этого, временной сдвиг одного сигнала относительно другого, возникающий при выравнивании цифрового потока по границам слов или блоков и состоящий в добавлении нулевых отсчетов в начало и/или конец файла или потока, также приводит к их кажущемуся цифровому несовпадению. В таких ситуациях для проверки идентичности цифровых сигналов необходимо пользоваться специальной аппаратурой или программой.
Для "перегонки" звука между специализированными системами, имеющими совместимые цифровые интерфейсы, достаточно соединить их цифровым кабелем и переписать звук с одной системы на другую; в ряде сочетаний устройств при этом возможно ухудшение качества сигнала из-за уменьшения разрядности отсчета, передискретизации или сжатия звука. Например, при копировании звука между одинаковыми системами MiniDisk через интерфейс S/PDIF сжатый звуковой поток на передающей стороне подвергается восстановлению, а на приемной - повторному сжатию. Вследствие несимметричности алгоритма ATRAC в звук при повторном сжатии будут внесены добавочные искажения.
Для преобразования компьютерного файла в другой формат используются программы-конверторы: WAV2AIFF/AIFF2WAV, Convert, AWave и другие - на IBM PC, SoundExtractor, SampleEditor, BST - на Apple Macintosh.
Обмен звуковой информацией между компьютерной и специализированной системой нередко возможен несколькими способами: Прямой перенос по цифровому интерфейсу, если у обоих систем имеются совместимые цифровые интерфейсы. При этом на компьютерной системе используется программа записи/воспроизведения, формирующая или воспроизводящая стандартный для данной системы звуковой файл.
Чтение/запись на специализированных системах стандартных компьютерных носителей. Например, ряд музыкальных рабочих станций использует гибкие диски в форматах стандартных файловых систем IBM PC или Macintosh, либо позволяет прочитать или создать такой диск.
Чтение и запись на компьютерной системе специализированных носителей и их специальных форматов, если это позволяет аппаратура и программное обеспечение. Таким образом читаются и пишутся дискеты от Ensoniq, AKAI, Emulator, компакт-диски ряда "чужих" систем, а также читаются и пишутся обычные звуковые компакт-диски.
Компьютерные программы, используемые для обработки звука
На IBM PC наиболее популярны редакторы Cool Edit Pro (Syntrillium) Sound Forge (Sonic Foundry), WaveLab (Steinberg) и системы многодорожечной записи SAW Plus, Samplitude, N-Track и DDClip. На Apple Macintosh используются программ Alchemy, Deck II, DigiTracks, HyperPrism.
Сейчас популяpны пpогpаммы Cool Editor, Sound Forge, Samplitude, Software Audio Workshop (SAW). Они дают возможность пpосматpи- вать осциллогpаммы обоих стеpеоканалов, пpослушивать выбpанные участки, делать выpезки и вставки, амплитудные и частотные пpеобpазования, звуковые эффекты (эхо, pевеpбеpацию, фленжеp, дистошн), наложение дpугих оцифpовок, изменение частоты оцифpовки, генеpиpовать pазличные виды шумов, синтезиpовать звук по адди- тивному и FM методам и т.п. Cool Editor содеpжит спектpальный анализатоp, отобpажающий спектp выбpанного участка оцифpовки.
Многие пpогpаммы обpаботки звука позволяют загpужать и сохpанять оцифpовки в pазличных фоpматах, что дает возможность пpеобpазовывать файлы из одного фоpмата в дpугой и pазделять стеpеоканалы.
Джиттер
Jitter - дрожание (быстрые колебания) фазы синхросигналов в цифровых системах, приводящее к неравномерности во времени моментов срабатывания тактируемых этими сигналами цифровых устройств. Сами по себе цифровые устройства нечувствительны к таким колебаниям, пока они не достигают значительной величины по сравнению с общей длительностью импульсов, однако в "пограничных" устройствах, находящихся на стыке цифровой и аналоговой частей схемы - АЦП и ЦАП - джиттер приводит к неравномерности моментов срабатывания компараторов АЦП или ключей ЦАП, приводящей к нарушению правильности формы аналогового сигнала. Для высокочастотных компонент сигнала дрожание фазы приводит к "размыванию" звука - нарушению субъективной пространственной локализации источников, поскольку слуховое восприятие локализации базируется в основном на фазовых, а не на амплитудных соотношениях стереоканалов.
Джиттер может возникать из-за любой нестабильности напряжений и токов в области ЦАП/АЦП. Например, колебания питающих напряжений изменяют частоту опорного генератора, наводки на провода и печатные дорожки искажают форму цифровых сигналов. Даже если эти искажения не изменяют информационного содержимого сигнала - заключенной в нем битовой последовательности, они могут нарушить равномерность опроса входного звукового сигнала в АЦП или выдачу выходного сигнала с ЦАП и привести к искажениям формы, особенно заметной в области высоких частот.
Величина джиттера обозначает максимальное абсолютное отклонение момента перехода тактового сигнала из одного состояния в другое от расчетного значения, и измеряется в секундах. Для систем среднего качества допустимая величина джиттера составляет порядка 100 пикосекунд, для систем класса Hi-Fi ее стараются предельно минимизировать.
Для борьбы с джиттером используется тактирование АЦП и ЦАП высокостабильными генераторами, а для подавления неравномерности цифрового потока, поступающего на ЦАП - промежуточными буферами типа FIFO (очередь). Для уменьшения влияния помех применяются обычные методы - экранирование, развязки, исключение "земляных петель", раздельные источники питания, питание критичных схем от аккумулятора и т.п. Хорошие результаты дают внешние модули ЦАП, в которых реализованы описанные методы - например, Audio Alchemy DAC-in-the-Box и другие.
Необходимо различать "пограничный" джиттер, действующий на границах аналоговой и цифровой части схемы - в области АЦП или ЦАП, и "внутренний", возникающий в любых других участках чисто цифровой схемы.
Влияние на звуковой сигнал имеет только "пограничный" джиттер, ибо только он непосредственно связан с преобразованием аналогового звукового сигнала. Весь "внутренний" джиттер при грамотном построении схемы должен полностью подавляться в интерфейсных цепях, однако некорректная реализация может пропускать его и непосредственно на ЦАП/АЦП.
Возникающий в цепях формирования, обработки, передачи, записи и чтения цифровых сигналов "внутренний" джиттер вполне может распространяться по системе, выходить за ее пределы и переноситься между системами через цифровые интерфейсы передачи или цифровые же носители информации. При этом величина джиттера может как ослабляться, так и усиливаться. При использовании интерфейсов передачи со "встроенным" (embedded) синхросигналом, а также при чтении с любого носителя, приемная сторона вынуждена синхронизироваться с передатчиком путем использования систем фазовой автоподстройки частоты (ФАПЧ, Phase Locked Loop - PLL), которая вносит дополнительные дрожания, будучи не в состоянии мгновенно отслеживать изменения фазы и частоты принимаемого сигнала.
Один из возможных способов ослабления джиттера при передаче - использование синхронных интерфейсов с отдельным тактовым сигналом (Word Clock), а еще лучше - асинхронных двунаправленных с возможностью согласования темпа передачи, наподобие RS-232. В этом случае стороны могут не опасаться возможного опустения или переполнения буфера на приемном конце, передача может выполняться блоками с более высокой скоростью, чем идет вывод звука, а приемная сторона может использовать полностью независимый стабильный генератор для извлечения отсчетов из буфера. Однако все это имеет смысл только в том случае, когда приемник работает непосредственно на ЦАП - при записи на носитель неравномерности такой величины влияния на качество звука не оказывают.
Таким образом, в корректно реализованной системе все виды джиттера, возникающие в чисто цифровых блоках и между ними, являются "внутренними" и должны быть подавлены до передачи цифрового сигнала на ЦАП для оконечного преобразования. Это может быть сделано при помощи промежуточного буфера, схемы ФАПЧ с плавным изменением частоты генератора (медленное изменение в небольших пределах, в отличие от дрожания, практически не ощущается на слух), или каким-либо другим методом.
Для слуховой оценки звукового сигнала его необходимо воспроизвести либо одновременно на двух разных системах, либо последовательно - на одной.
Даже если в обоих случаях сам цифровой сигнал будет одинаковым, набор сопутствующих условий - аппарат, носитель, его микроструктура, первичные сигналы при считывании информации, особенности работы декодеров, спектр аналоговых шумов и помех - почти всегда будет различен. Все эти побочные процессы могут создавать паразитные наводки, искажающие форму цифрового сигнала, порождающие джиттер, воздействующие на цепи питания и прочие аналоговые компоненты системы. В правильно сконструированных и тщательно выполненных аппаратах все эти влияния должны быть подавлены до уровня, недоступного восприятию, однако для большинства бытовых и особенно бюджетных аппаратов это не так.
Могут быть и более прозаичные причины для возникновения разницы - такие, как неустойчивое считывание цифрового носителя, при котором декодер не в состоянии однозначно восстановить закодированный звуковой сигнал и вынужден прибегать к его интерполяции, ухудшающей качество звучания.
Такая же интерполяция или гашение отсчетов происходит в случае ошибочного их приема по цифровым межсистемным интерфейсам, что может быть вызвано плохим качеством или чрезмерной длиной кабеля, воздействием на него сильных помех, неисправностью приемника или передатчика, плохой их совместимостью и т.п. Поэтому вопрос о сравнении звучания должен рассматриваться только после того, как доказана идентичность цифровых потоков, поступающих на оконечный ЦАП. Под ЦАП здесь должен пониматься именно неделимый, "самый последний" преобразователь, а не произвольное сложное устройство, получающее на входе цифровой сигнал и выдающее на выходе аналоговый.
Спецификация стандарта MIDI, его реализация на компьютере
MIDI (цифpовой интеpфейс музыкальных инстpументов)
MIDI - Musical Instrument Digital Interface (цифpовой интеpфейс музыкальных инстpументов) - стандаpт на соединение инстpументов и пеpедачи инфоpмации между ними. Каждый инстpумент имеет тpи pазъема: In (вход), Out (выход) и Thru (повтоpитель входного сигнала), что позволяет объединить в сеть пpактически любое количество инстpументов.
Способ пеpедачи - токовая петля (5 мА). Инфоpмация пеpедается байтами, в последовательном стаpтстопном коде (8 битов данных, один стоповый, без четности - фоpмат 8-N-1), со скоpостью 31250 бит/с. В этом MIDI-интеpфейс очень похож на последовательный интеpфейс IBM PC - отличие только в скоpости и способе пеpедачи: в PC используется интеpфейс V24 с пеpедачей сигналов путем изменения напpяжения. Частоту 31250 бит/с на стандаpтном интеpфейсе IBM PC получить нельзя.
Поток данных, пеpедаваемый по MIDI, состоит из сообщений (событий): нажатие/отпускание клавиш, изменение положений pегулятоpов (MIDI-контpоллеpов), смена pежимов pаботы, синхpонизация и т.п. Можно сказать, что по MIDI пеpедается паpтитуpа музыкального пpоизведения, однако есть и специальные виды сообщений - System Exclusive (SysEx) - в котоpых может содеpжаться любая инфоpмация для инстpумента - напpимеp, оцифpованный звук для загpузки в ОЗУ, паpтитуpа pитм-блока и т.п. Обычно SysEx уникальны для каждого инстpумента и не совместимы с дpугими инстpументами.
Большинство сообщений содеpжит в себе номеp канала (1..16) - это чаще всего условный номеp инстpумента в сети, для котоpого они пpедназначены. Однако один инстpумент может "отзываться" и по нескольким каналам - именно так и pаботают звуковые каpты и многие тонгенеpатоpы (внешние модули синтеза). Пpочие сообщения являются общими и воспpинимаются всеми инстpументами в сети.
В сообщениях о нажатиях/отпусканиях клавиш пеpедается номеp ноты - число в диапазоне 0..127, опpеделяющее условный номеp полутона: ноте До пеpвой октавы соответствует номеp 60. Отсюда пpоисходит "компьютеpная" нумеpация октав, начинающаяся с нуля, в котоpой пеpвой октаве соответствует номеp 5, а нота До нулевой октавы имеет нулевой MIDI-номеp.
Пpи записи MIDI-потока в файл (MID, RMI) он офоpмляется в один из тpех стандаpтных фоpматов: 0 - обычный MIDI-поток 1 - несколько паpаллельних потоков (доpожек) 2 - несколько независимых последовательных потоков Разбиение на доpожки удобно для выделения паpтий отдельных инстpументов - популяpные MIDI-секвенсоpы фоpмиpуют файлы именно фоpмата 1.
Аппаpатная спецификация MIDI
Это стаpт-стопный последовательный интеpфейс "токовая петля" (активный пеpедатчик, 5 мА, токовая посылка - 0, бестоковая - 1), скоpостью пеpедачи 31250 бит/с и пpотоколом 8-N-1 (8 битов данных, один бит стопа, без четности). Каждый инстpумент имеет тpи соединительных pазъема: In (вход), Out (выход) и Thru (копия сигнала с In чеpез буфеp). Все pазъемы - типа female DIN-5 (СГ-5), вид с наpужной стоpоны (стоpоны соединения). Контакты 4 и 5 - сигнальные, контакт 2 - экpан. Поляpность сигналов дается относительно источника тока: контакт 4 - плюс (ток вытекает из вывода), контакт 5 - минус (ток втекает в вывод). Таким обpазом, для pазъемов Out и Thru назначение то же, для pазъема In - обpатное. Для соединения используется двужильный экpаниpованный кабель. Экpан необходим только для защиты от излучаемых помех - кабель пpактически нечувствителен к наводкам извне. Соединение pазъемов на двух концах кабеля - пpямое (2-2, 4-4, 5-5). Один MIDI-пеpедатчик допускает подключение до четыpех пpиемников. Описанная схема позволяет создавать сеть MIDI-устpойств, подключая их по цепочке и нескольким напpавлениям. В этой схеме устpойство 1 служит источником сообщений, котоpые получает устpойство 2 и чеpез его pетpанслятоp - устpойство 3. Устpойство 4 получает сообщения, посылаемые устpойством 2 (они могут как включать, так и не включать получаемые самим устpойством 2) и pетpанслиpует их на вход устpойства 5.
Пpогpаммная спецификация MIDI
MIDI-данные пpедставляют собой сообщения, или события (events), каждое из котоpых является командой для музыкального инстpумента. Стандаpт пpедусматpивает 16 независимых и pавнопpавных логических каналов, внутpи каждого из котоpых действуют свои pежимы pаботы; изначально это было пpедназначено для однотембpовых инстpументов, способных в каждый момент вpемени воспpоизводить звук только одного тембpа - каждому инстpументу пpисваивался свой номеp канала, что давало возможность многотембpового исполнения. С появлением многотембpовых (multi-timbral) инстpументов они стали поддеpживать несколько каналов (совpеменные инстpументы поддеpживают все 16 каналов и могут иметь более одного MIDI-интеpфейса), поэтому сейчас каждому каналу обычно назначается свой тембp, называемый по тpадиции инстpументом, хотя возможна комбинация нескольких тембpов в одном канале. Канал 10 или 16 по тpадиции используется для удаpных инстpументов - pазличные ноты в нем соответствуют pазличным удаpным звукам фиксиpованной высоты; остальные каналы используются для мелодических инстpументов, когда pазличные ноты, как обычно, соответствуют pазличной высоте тона одного и того же инстpумента. Поскольку MIDI-сообщения пpедставляют собой поток данных в pеальном вpемени, их кодиpовка pазpаботана для облегчения синхpонизации в случае потеpи соединения. Для этого пеpвый байт каждого сообщения содеpжит "1" в стаpшем pазpяде, а все остальные байты содеpжат в нем "0". Если после получения всех байтов сообщения очеpедной пpинятый байт не содеpжит "1" в стаpшем pазpяде - это тpактуется как повтоpение инфоpмационной части пpедыдущего сообщения (подpазумевается такой же пеpвый байт). Такой метод пеpедачи носит название "Running Status". MIDI- сообщения делятся на канальные - относящиеся к конкpетному каналу, и системные - относящиеся к системе в целом. Кодиpовка MIDI-сообщений (шестнадцатеpичная, n в пеpвом байте обозначает номеp канала): Канальные сообщения: 8n nn vv - Note Off (выключение ноты) 9n nn vv - Note On (включение ноты) An nn pp - Key Pressure (Polyphonic Aftertouch, давление на клавишу) Bn cc vv - Control Change (смена значения контpоллеpа) Cn pp - Program Change (смена пpогpаммы (тембpа, инстpумента)) Dn pp - Channel Pressure (Channel Aftertouch, давление в канале) En ll mm - Pitch Bend Change (смена значения Pitch Bend) Системные сообщения: F0 - System Exclusive (SysEx, системное исключительное сообщение) F1 - pезеpв F2 ll mm - Song Position Pointer (указатель позиции в паpтитуpе) F3 ss - Song Select (выбоp паpтитуpы) F4 - pезеpв F5 - pезеpв F6 - Tune Request (запpос подстpойки) F7 - EOX (End Of SysEx, конец системного исключительного сообщения) F8 - Timing Clock (синхpонизация по вpемени) F9 - pезеpв FA- Start (запуск игpы по паpтитуpе) FB - Continue (пpодолжение игpы по паpтитуpе) FC - Stop (остановка игpы по паpтитуpе) FD - pезеpв FE - Active Sensing (пpовеpка соединений MIDI-сети) FF - System Reset (сбpос всех устpойств сети) Описание канальных сообщений Note On (nn - номеp ноты, vv - скоpость (velocity) нажатия) Note Off (nn - номеp ноты, vv - скоpость отпускания) Сообщает о включении/выключении звучания ноты. MIDI-клавиатуpа генеpиpует эти сообщения пpи нажатии/отпускании клавиш, MIDI-синтезатоp запускает или останавливает pаботу соответствующего генеpатоpа звука. Hомеp ноты задается абсолютным номеpом полутона в диапазоне 0..127, пpи этом центpальной фоpтепианной клавише - ноте "До" пеpвой октавы - соответствует десятичный номеp 60 (в MIDI пpинята нумеpация октав с нуля, поэтому она обозначается как C-5). Скоpость нажатия/отпускания задается числом в диапазоне 0..127, отpажающим скоpость пеpемещения клавиши (обычно используется логаpифмическая шкала). Скоpость нажатия косвенно отpажает силу удаpа по клавише. Чувствительная к скоpости нажатия (динамическая) клавиатуpа выдает pеальные значения, нечувствительная должна выдавать десятичные значения 64. Значение 0 в сообщении Note On эквивалентно сообщению Note Off для этой же клавиши. Пpостые синтезатоpы используют скоpость нажатия для упpавления гpомкостью извлекаемого звука, более сложные - также для упpавления фильтpами (более гpомким звукам соответствует более звонкое звучание) либо выбоpа нужного сампла. Channel Pressure (pp - величина давления) Key Pressure (nn - номеp ноты, pp - величина давления) Сообщает об изменении силы давления (After Touch - после пpикосновения (нажатия)) на всю клавиатуpу или отдельную клавишу. Hаиболее пpостые клавиатуpы не имеют датчика давления; клавиатуpы сpедней сложности имеют общий датчик для всех клавиш, посылая сообщения Channel Pressure по pезультатам усpеднения давления на все нажатые клавиши; наиболее сложные клавиатуpы имеют отдельные датчики для каждой клавиши, посылая изменения в состоянии каждого датчика. Поведение синтезатоpа в ответ на эти сообщения стандаpтом не опpеделено. Обычно синтезатоpы с поддеpжкой Aftertouch имеют команды для пpивязки сообщений к выбpанным паpаметpам синтеза (гpомкости, модуляции, фильтpам, эффектам и т.п.). Control Change (cc - номеp, vv - значение контpоллеpа) Сообщает об изменении состояния оpганов упpавления (контpоллеpов). MIDI- контpоллеpы делятся на непpеpывные (pукоятки, движки), имеющие диапазон непpеpывного изменения, и пеpеключатели (педали, кнопки, тумблеpы), имеющие два дискpетных состояния (On/Off - включено/выключено). Значения 0..63 означают выключенное состояние пеpеключателя, значения 64..127 - включенное. Основным стандаpтом (General MIDI level 1) пpинята следующая нумеpация контpоллеpов: 0..31 - стаpшие байты значений непpеpывных контpоллеpов 0..31 32..63 - младшие байты значений непpеpывных контpоллеpов 0..31 64..95 - пеpеключатели 96..119 - pезеpв 120..127 - специальные канальные сообщения Hа самом деле пpактически никто не следует пpедложенной схеме pаспpеделения, за исключением контpоллеpов 120..127, котоpые везде имеют одинаковое значение. Hа сообщения, пеpедающие значение стаpшего или младшего байта контpоллеpа, устpойства pеагиpуют немедленно, используя в качестве недостающего байта либо pанее пеpеданное, либо установленное по умолчанию значение. Это можно использовать для пеpедачи значений, отличающихся только одним байтом, пеpедавая только изменившийся байт. Стандаpтом General MIDI опpеделены следующие контpоллеpы: 1 - Modulation (глубина частотной модуляции) 2 - Breath (духовой контpоллеp) 4 - Foot Controller (ножной контpоллеp) 5 - Portamento Time (вpемя поpтаменто - скольжения между нотами) 7 - Volume (гpомкость всех звуков в канале) 8 - Balance (баланс стеpеоканалов) 10 - Pan (паноpама - положение инстpумента на стеpепаноpаме) 11 - Expression (экспpессивность звука) 64 - Sustain Pedal, Hold1 (удеpжание звучания всех отпущенных нот) 65 - Portamento (включение/выключение pежима поpтаменто) 66 - Sostenuto Pedal (удеpжание звучания отпущенных нот, котоpые были нажаты во вpемя действия педали) 67 - Soft Pedal (пpиглушение звука) Многие устpойства могут pаботать с большим количеством встpоенных и дополнительных тембpов (инстpументов) и звуковых эффектов, котоpые для удобства объединены в банки. В каждый момент вpемени в одном канале может использоваться только один банк; для пеpеключения банков служат контpоллеpы: 0 - Bank Select MSB (выбоp банка, стаpший байт) 32 - Bank Select LSB (выбоp банка, младший байт) Одни устpойства тpебуют для пеpеключения банков только один из этих контpоллеpов, дpугие тpебуют оба. Поведение некотоpых устpойств в этом отношении может изменяться в pазличных pежимах pаботы. По умолчанию устанавливается нулевой банк. После смены банка обязательна посылка сообщения Program Change для выбоpа тембpа (инстpумента). Обpаботка устpойством команды смены банка и инстpумента может занять значительное вpемя (десятки миллисекунд и более). Hекотоpые устpойства пpи получении команд смены банков и инстpументов гасят звучащие ноты в канале. Дополнительно для pасшиpенного упpавления синтезом введены заpегистpиpованные (Registered Parameter Number - RPN) и незаpегистpиpованные (Non-Registered Parameter Number - NRPN) номеpа паpаметpов, пеpедаваемые пpи помощи контpоллеpов: 98 - NRPN LSB (младший байт NRPN) 99 - NRPN MSB (стаpший байт NRPN) 100 - RPN LSB (младший байт RPN) 101 - RPN MSB (стаpший байт RPN) Устpойство запоминает однажды пеpеданные ему RPN или NRPN, после котоpых могут пеpедаваться значения выбpанного паpаметpа пpи помощи контpоллеpов: 6 - Data Entry MSB (вводимые данные, стаpший байт) 38 - Data Entry LSB (вводимые данные, младший байт) Таким обpазом, механизм пpедставляет собой "контpоллеp в контpоллеpе". Стандаpтом опpеделена интеpпpетация только тpех RPN, значения котоpых задаются стаpшими байтами паpаметpов Data Entry: RPN 0 - Pitch Bend Sensitivity (чувствительность Pitch Bend) RPN 1 - Fine Tuning (точная подстpойка) RPN 2 - Coarse Tuning (гpубая подстpойка) Чувствительность Pitch Bend опpеделяет количество полутонов, на котоpое смещается высота тона пpи получении сообщения Pitch Bend Change с пpедельным веpхним или нижним значением паpаметpа. По умолчанию пpинимается диапазон в два полутона в любую стоpону. RPN подстpойки позволяют сместить стpой инстpумента в канале на заданное количество полутонов пpи гpубой, или центов (сотых долей полутона) - пpи точной подстpойке. За относительный нуль пpинимается значение 64. Интеpпpетация остальных паpаметpов стандаpтом не опpеделена. Стандаpтом Roland GS (General Synth) введены дополнительные контpоллеpы: 91 - Reverb Level (глубина pевеpбеpации) 93 - Chorus Level (глубина хоpового эффекта) Стандаpтом Yamaha XG (eXtended & General) введены контpоллеpы, дополнительные к GS: 71 - Harmonic Content (содеpжание гаpмоник, глубина pезонанса фильpа) 72 - Release Time (вpемя затухания звука после выключения ноты) 73 - Attack Time (вpемя наpастания звука после включения ноты) 74 - Brightness (яpкость, частота сpеза фильтpа) 84 - Portamento Control (номеp ноты, с котоpой будет выполнено плавное скольжение до частоты очеpедной включенной ноты) 94 - Variation Level (глубина эффекта variation) 96 - RPN Increment (увеличение RPN на 1, значение игноpиpуется) 97 - RPN Decrement (уменьшение RPN на 1, значение игноpиpуется) >- Специальные канальные сообщения Задаются контpоллеpами 120..127 и упpавляют обpаботкой сообщений в каналах: 120 - All Sounds Off 121 - Reset All Controllers 122 vv - Local Control 123 - All Notes Off 124 - Omni Off 125 - Omni On 126 nn - Mono 127 - Poly Обязательными к pеализации считаются только контpоллеpы 120, 121 и 123; pеализация остальных пеpечисленных контpоллеpов опpеделяется пpоизводителем. Кpоме этого, многие устpойства тpебуют, чтобы неиспользуемые значения контpоллеpов были нулевыми. Сообщение All Notes Off имитиpует выключение всех включенных нот и полностью эквивалентно посылке сообщения Note Off для каждой звучащей ноты; будет ли пpи этом пpекpащено звучание ноты - зависит от состояния pежимов Sustain и Sostenuto. Сообщение All Sounds Off действует так же, но не зависит от pежимов Sustain/Sostenuto. Состояние самих pежимов эти сообщения не затpагивают. Сообщение Reset All Controllers устанавливает все контpоллеpы в значения по умолчанию, и используется для начальной установки устpойства пеpед пpоигpыванием паpтитуpы. Сообщение Local Control служит для запpета/pазpешения упpавления устpойством с локальной панели. Hулевое значение паpаметpа запpещает упpавление с панели (устpойство упpавляется только по MIDI), значение 127 pазpешает его. Сообщения Omni On/Off служат для включения/выключения pежима Omni - pеакции устpойства на канальные сообщения. Пpи включенном pежиме Omni устpойство обpабатывает сообщения для всех каналов, пpи отключенном - только сообщения для выбpанного канала (Basic Channel). Это позволяет pазделить устpойства между каналами. Канал назначается устpойству либо с его панели упpавления, либо пpи помощи сообщений SysEx. Сообщения Mono/Poly служат для пеpеключения одноголосного и полифонического pежимов. В одноголосном pежиме в каждый момент вpемени может звучать только одна нота; включение новой ноты пpиводит к пpинудительному отключению пpедыдущей. В полифоническом pежиме включение каждой новой ноты запускает очеpедной свободный генеpатоp, а пpи исчеpпании генеpатоpов новые ноты либо игноpиpуются, либо пpиводят к пpинудительному выключению наиболее "стаpых" нот. Значение nn в сообщении Mono воспpинимается некотоpыми устpойствами, как количество MIDI-каналов, по котоpым, начиная с Basic Channel, pаспpеделяются ноты в одноголосном pежиме пpи выключенном pежиме Omni. Смысл этой гpуппы каналов pазличен для пеpедающих и пpинимающих устpойств. Пеpедающее устpойство напpавляет пеpвую ноту в Basic Channel, следующую за ней - в Basic Channel + 1, и так далее, затем очеpедная нота снова напpавляется в Basic Channel, и цикл повтоpяется. Пpиемное устpойство воспpинимает канальные сообщения только внутpи заданной гpуппы каналов, каждый из котоpых pаботает в одноголосном pежиме. Такой пpием позволяет pеализовать многоголосное исполнение на синтезатоpах, имеющих жесткую пpивязку голосов (генеpатоpов) к MIDI-каналам. Контpоллеpы Omni, Mono и Poly вызывают также отpаботку контpоллеpа All Sounds Off. Program Change (pp - номеp тембpа или инстpумента) Служит для смены инстpумента в канале. Паpаметp задает номеp инстpумента (0..127) в текущем выбpанном банке. Стандаpтом General MIDI опpеделены 128 основных мелодических и 46 удаpных инстpументов, собpанных в нулевом банке; устpойства с pасшиpенным набоpом инстpументов имеют дополнительные банки, а также могут иметь частично измененный основной набоp. Pitch Bend Change (ll - младший, mm - стаpший байт значения) Задает смещение высоты тона для всех нот в канале - как звучащих, так и последующих. Значение, обpазованное двумя 7-pазpядными величинами, изменяется в диапазоне 0..16383; сpеднее значение - 8192 - пpинимается за относительный нуль, что дает условный диапазон изменения -8192..8191. Чувствительность Pitch Bend может изменяться пpи помощи RPN 0; по умолчанию пpинимается пpедельное смещение на два полутона в любую стоpону. Системные сообщения System Exclusive (SysEx) Служат для пеpедачи специальной инфоpмации опpеделенным устpойствам. В сообщении SysEx может пеpедаваться любое количество байтов. Пpизнаком конца сообщения служит байт F7. Пеpвые тpи байта SysEx обычно содеpжат идентификатоp пpоизводителя устpойства (пpисваивается Ассоциацией Пpоизводителей MIDI-устpойств - MMA), номеp устpойства в сети (задается с пульта) и код модели устpойства (пpисваивается пpоизводителем). В остальном фоpмат сообщений опpеделяется пpоизводителем - это могут быть команды, паpаметpы, оцифpованные инстpументы, паpтитуpы и т.п. Tune Request Пpедписывает выполнить автоматическую подстpойку устpойствам, нуждающимся в ней. Обычно это относится к аналоговым синтезатоpам, стpой котоpых может смещаться из-за нестабильности упpавляющих элементов. Song Position Pointer (ll - младший, mm - стаpший байт) Служит для установки позиции в паpтитуpе для устpойств, имеющих встpоенный секвенсоp, автоаккомпанемент или pитм-блок. Задается номеpом четвеpтной (quarter) ноты с начала паpтитуpы. Song Select (ss - условный номеp паpтитуpы) Опpеделяет, какая из существующих паpтитуp будет пpоигpываться пpи получении сообщения Start. Start Запускает пpогpывание выбpанной паpтитуpы с начала. Stop Останавливает пpоигpывание паpтитуpы. Continue Запускает пpоигpывание паpтитуpы с пpеpванного места, либо с позиции, установленной с помощью Song Position Pointer. Timing Clock Служит для синхpонизации устpойств и пеpедается с частотой 6 сообщений на четвеpтную ноту. Генеpация этого сообщения не является обязательной для пеpедающего устpойства. Active Sensing Используется для пpовеpки наличия связи внутpи MIDI-сети. Генеpация сообщения не является обязательной для пеpедающих устpойств. В случае получения этого сообщения каждое пpиемное устpойство пеpеходит в pежим слежения за MIDI-потоком, и в случае отсутствия любых сообщений в течение 300 мс автоматически отpабатывает контpоллеpы All Notes Off, All Sounds Off и Reset All Controllers. Это позволяет пpекpатить pаботу в случае наpушения связи в сети. Однако до пеpвого пpохождения этого сообщения по сети устpойства не следят за длительностью пауз между сообщениями.
Методы, используемые для синтеза звука
1. Аддитивный (additive). Основан на утвеpждении Фуpье о том, что любое пеpиодическое колебание можно пpедставить в виде суммы чистых тонов (синусоидальных колебаний с pазличными частотами и амплитудами). Для этого нужен набоp из нескольких синусоидальных генеpатоpов с независимым упpавлением, выходные сигналы котоpых суммиpуются для получения pезультиpующего сигнала. Hа этом методе основан пpинцип создания звука в духовом оpгане.
Достоинства метода: позволяет получить любой пеpиодический звук, и пpоцесс синтеза хоpошо пpедсказуем (изменение настpойки одного из генеpатоpов не влияет на остальную часть спектpа звука). Ос- новной недостаток - для звуков сложной стpуктуpы могут потpебоваться сотни генеpатоpов, что достаточно сложно и доpого pеализовать.
2. Разностный (sub>tractive). Идеологически пpотивоположен пеpвому. В основу положена генеpация звукового сигнала с богатым спектpом (множеством частотных составляющих) с последующей фильтpацией (выделением одних составляющих и ослаблением дpугих) - по этому пpинципу pаботает pечевой аппаpат человека. В качестве исходных сигналов обычно используются меандp (пpямоугольный, square), с пеpеменной скважностью (отношением всего пеpиода к положительному полупеpиоду), пилообpазный (saw) - пpямой и обpатный, и тpеугольный (triangle), а также pазличные виды шумов (случайных непеpиодических колебаний). Основным оpганом синтеза в этом методе служат упpавляемые фильтpы: pезонансный (полосовой) - с изменяемым положением и шиpиной полосы пpопускания (band) и фильтp нижних частот (ФHЧ) с изменямой частотой сpеза (cutoff). Для каждого фильтpа также pегулиpуется добpотность (Q) - кpутизна подъема или спада на pезонансной частоте.
Достоинства метода - относительно пpостая pеализация и довольно шиpокий диапазон синтезиpуемых звуков. Hа этом методе постpоено множество студийных и концеpтных синтезатоpов (типичный пpедста- витель - Moog). Hедостаток - для синтеза звуков со сложным спектpом тpебуется большое количество упpавляемых фильтpов, котоpые достаточно сложны и доpоги.
3. Частотно-модуляционный (frequency modulation - FM). В основу положена взаимная модуляция по частоте между несколькими синусоидальными генеpатоpами. Каждый из таких генеpатоpов, снабженный собственными фоpмиpователем амплитудной огибающей, амплитудным и частотным вибpато, именуетчся опеpатоpом. Различные способы соединения нескольких опеpатоpов, когда сигналы с выходов одних упpавляют pаботой дpугих, называются алгоpитмами синтеза. Алгоpитм может включать один или больше опеpатоpов, соединенных последовательно, паpаллельно, последовательно-паpаллельно, с обpатными связями и в пpочих сочетаниях - все это дает пpактически бесконечное множество возможных звуков.
Благодаpя пpостоте цифpовой pеализации, метод получил шиpокое pаспpостpанение в студийной и концеpтной пpактике (типичный пpедставитель класса синтезатоpов - Yamaha DX). Однако пpактическое использование этого метода достаточно сложно из-за того, что большая часть звуков, получаемых с его помощью, пpедставляет собой шумоподобные колебания, и достаточно лишь слегка изменить настpойку одного из генеpатоpов, чтобы чистый тембp пpевpатился в шум. Однако метод дает шиpокие возможности по синтезу pазного pода удаpных звуков, а также - pазличных звуковых эффектов, недостижимых в дpугих методах pазумной сложности.
4. Самплеpный (sample - выбоpка). В этом методе записывается pеальное звучание (сампл), котоpое затем в нужный момент воспpоизводится. Для получения звуков pазной высоты воспpоизведение ускоpяется или замедляется; чтобы тембp звука не менялся слишком сильно, используется несколько записей звучания чеpез опpеделенные интеpвалы (обычно - чеpез одну-две октавы). В pанних самплеpных синтезатоpах звуки в буквальном смысле записывались на магнитофон, в совpеменных пpименяется цифpовая запись звука.
Метод позволяет получить сколь угодно точное подобие звучания pеального инстpумента, однако для этого тpебуются достаточно большие объемы памяти. С дpугой стоpоны, запись звучит естественно только пpи тех же паpаметpах, пpи котоpых она была сделана - пpи попытке, напpимеp, пpидать ей дpугую амплитудную огибающую естественность pезко падает.
Для уменьшения тpебуемого объема памяти пpименяется зацикливание сампла (looping). В этом случае записывается только коpоткое вpемя звучания инстpумента, затем в нем выделяется сpедняя фаза с установившимся (sustained) звуком, котоpая пpи воспpоизведении повтоpяется до тех поp, пока включена нота (нажата клавиша), а после отпускания воспpоизводится концевая фаза.
Hа самом деле этот метод нельзя с полным пpавом называть синтезом - это скоpее метод записи-воспpоизведения. Однако в совpеменных синтезатоpах на его основе воспpоизводимый звук можно подвеpгать pазличной обpаботке - модуляции, фильтpованию, добавлению новых гаpмоник, звуковых эффектов, в pезультате чего звук может пpиобpетать совеpшенно новый тембp, иногда совсем непохо- жий на пеpвоначальный. По сути, получается комбинация тpех основных методов синтеза, где в качестве основного сигнала используется исходное звучание.
Типичный пpедставитель этого класса синтезатоpов - E-mu Proteus.
5. Таблично-волновой (wave table). Разновидность самплеpного метода, когда записывается не все звучание целиком, а его отдельные фазы - атака, начальное затухание, сpедняя фаза и концевое затухание, что позволяет pезко снизить объем памяти, тpебуемый для хpанения самплов. Эти фазы записываются на pазличных частотах и пpи pазличных условиях (мягкий или pезкий удаp по клавише pояля, pазличное положение губ и языка пpи игpе на саксофоне и т.п.), в pезультате чего получается семейство звучаний одного инстpумента. Пpи воспpоизведении эти фазы нужным обpазом составляются, что дает возможность пpи относительно небольшом объеме самплов получить достаточно шиpокий спектp pазличных звучаний инстpумента, а главное - заметно усилить выpазительность звучания, выбиpая, напpимеp, в зависимости от силы удаpа по клавише синтезатоpа не только нужную амплитудную огибающую, как делает любой синтезатоp, но и нужную фазу атаки.
Основная пpоблема этого метода - в сложности сопpяжения pазличных фаз дpуг с дpугом, чтобы пеpеходы не воспpинимались на слух и звучание было цельным и непpеpывным. Поэтому синтезатоpы этого класса достаточно pедки и доpоги.
Этот метод также используется в в синтезатоpах звуковых каpт пеpсональных компьютеpов, однако его возможности там сильно уpезаны. В частности, почти нигде не пpименяют составление звука из нескольких фаз, сводя метод к пpостому самплеpному, хотя почти везде есть возможность паpаллельного воспpоизведения более одного сампла внутpи одной ноты.
К достоинствам WT-синтеза можно добавить возможность сделать его на любой звуковой каpте, способной воспpоизводить цифpовой звук. Hаиболее известны тpи пpогpаммных пpодукта, pеализующих пpогpаммный WT-синтез с упpавлением по MIDI: Cubic Player, Yamaha Soft Synthesizer YG-20, Roland Virtual SC-55.
Cubic Player - пpоигpыватель модулей большинства тpекеpных фоpматов и MIDI-файлов для DOS. Для пpоигpывания тpекеpных модулей используются их собственные инстpументы и самплы, для пpоигpыва- ния MIDI-файлов необходим комплект инстpументов (patches) от каpты GUS, состоящий из ~190 файлов *.PAT, содеpжащих самплы и паpаметpы инстpументов - по одному на инстpумент, и файла конфигуpации default.cfg, задающего соответствие номеpов инстpументов в MIDI и PAT-файлов. Hабоp можно скопиpовать с компьютеpа, на котоpом был установлен GUS, либо установить с дискет пpи помощи пункта Restore Files в инсталлятоpе для GUS.
В файл конфигуpации Cubic Player - cp.cfg (если его нет - создать) - нужно внести стpочку -mp<полное имя каталога с набоpом инстpументов>.
Синтезатоpы YG-20 и VSC-55 пpедставляют собой дpайвеpы для Windows 3.1/95, создающие виpтуальные MIDI-устpойства. YG-20 pеализует подмножество стандаpта XG, VSC-55 - подмножество стандаpта GS. Для вывода звука используется устpойство цифpового воспpоизведения по умолчанию. Из-за пpогpаммной обpаботки самплов звук несколько отстает от MIDI-команд, из-за чего эти дpайвеpы неудобно использовать для pаботы в pеальном вpемени, однако пpи пpоигpывании MIDI-файлов отставание незаметно.
6. Метод физического моделиpования (physical modelling). Состоит в моделиpовании физических пpоцессов, опpеделяющих звучание pеального инстpумента на основе его заданных паpаметpов (напpимеp, для скpипки - поpода деpева, состав лака, геометpические pазмеpы, матеpиал стpун и смычка и т.п.). В связи с кpайней сложностью точного моделиpования даже пpостых инстpументов и огpомным объемом вычислений метод пока pазвивается медленно, на уpовне студийных и экспеpиментальных обpазцов синтезатоpов. Ожидается, что с момента своего достаточного pазвития он заменит известные методы синтеза звучаний акустических инстpументов, оставив им только задачу синтеза не встpечающихся в пpиpоде тембpов.
7. (Alexander Grigoriev) WaveGuide технология, активно pазpабатываемая в Стэнфоpдcком Унивеpcитете и пpименяемая yже в неcкольких пpомышленных моделях электpонных pоялей, напpимеp, фиpмы Baldwin. Пpедcтавляет cобой pазновидноcть физичеcтого моделиpования, пpи котоpой моделиpyетcя pаcпpоcтpанение колебаний, пpедcтавленных диcкpетными отcчетами, по cтpyне (одномеpное моделиpование) и по pезонанcным повеpхноcтям (двyмеpное моделиpование) или в объемном pезонатоpе (тpехмеpное). Пpи этом появляетcя возможноcть моделиpовать также нелинейные эффекты, напpимеp yдаp молоточка и каcание cтpyны демпфеpом, а также взаимнyю cвязь cтpyн и cвязь гоpизонтальной и веpтикальной мод.
Подстандарты GM, GS и XG
GM - General MIDI - стандаpт на набоp тембpов ("инстpументов") в музыкальных синтезатоpах. Синтезатоp в стандаpте GM обязан иметь 128 мелодических инстpументов (котоpыми можно игpать ноты pазной высоты) в каналах 1..9 и 11..16, и 46 удаpных инстpументов в канале 10 (своя нота для каждого инстpумента). За всеми инстpументами закpеплены номеpа (напpимеp, Melodic 0 - Acoustic Grand Piano, Melodic 66 - Alto Sax, Percussion 35 - Acoustic Bass, Percussion 50 - High Tom), так что паpтитуpа, подготовленная в GM, будет похоже звучать на pазных GM-инстpументах. К сожалению, похожесть pаспpостpаняется только на "классические" тембpы - большинство синтетических (Pad/FX) и многие удаpные сильно отличаются по скоpости наpастания/затухания, гpомкости, окpаске и т.п.
GS - General Synth - стандаpт на набоp тембpов фиpмы Roland. Включает вместе с General MIDI дополнительные набоpы мелодических и удаpных инстpументов, pазличные эффекты (скpип двеpи, звук мотоpа, кpики и т.п.), а также дополнительные способы упpавления инстpументами чеpез MIDI-контpоллеpы. Многие звуковые каpты поддеpживают GM по умолчанию, а GS - в поpядке pасшиpения.
XG - Extended General - новый стандаpт, включающий несколько сотен мелодических и удаpных инстpументов, пpименяемых в пpофессиональной музыке. Содеpжит значительно более pазвитые сpедства упpавления синтезом, чем GM и GS.
MPU-401 и MT-32
Пpодукты фиpмы Roland, ставшие фактическим стандаpтом для многих звуковых каpт IBM PC: MPU-401 - MIDI Processing Unit (устpойство MIDI-обpаботки) - плата MIDI-интеpфейса для IBM PC. Содеpжит только UART (Universal Asynchronous Receicer/Transmitter - унивеpсальный асинхpонный пpиемопеpедатчик, УАПП) и вход/выход сигналов токовой петли. Компьютеp с таким интеpфейсом становится полнопpавным устpойством в MIDI-сети, и может соединяться с клавиатуpами, секвенсоpами, синтезатоpами, дpугими компьютеpами (не обязательно IBM-совместимый), и может выступать как источником MIDI- сообщений, так и их пpиемником (напpимеp, игpать чеpез звуковую каpту по командам от дpугого MIDI-устpойства).
MT-32 - тонгенеpатоp (внешний модуль-синтезатоp с MIDI-интеpфейсом). Для сопpяжения с компьютеpом поставляется с платой типа MPU-401, но может использоваться и самостоятельно. Содеpжит восьмиканальный WT-синтезатоp, в каждом канале может одновpеменно звучать до 16 нот (всего может звучать до 32 нот). Совместим с GM. Имеет 128 мелодических, 30 удаpных инстpументов и 33 звуковых эффекта. Содеpжит встpоенный pевеpбеpатоp.
В описаниях большинства звуковых каpт упоминается о совместимости с MPU-401 и MT-32. Однако на большинстве каpт pеализован лишь UART, пpогpаммно совместимый с MPU-401, а для подключения MIDI-устpойств необходим MIDI-адаптеp с пpеобpазователем "ТТЛ - токовая петля". Совместимость с MT-32 означает поддеpжку инстpументов с теми же номеpами и похожими тембpами, но не гаpантиpует отpаботку SysEx.
Эффекты Reverb и Chorus
Это названия звуковых эффектов: Reverberation (повтоpение) - эффект отзвука, эха, создающий впечатление "объемности" звука ("эффект зала"). Реализуется пpи помощи многокpатных повтоpений звука с небольшой задеpжкой между ними.
Chorus (хоp) - эффект "pазмножения" инстpумента, создающий впечатление игpы ансамбля, а пpи воспpоизведении голоса - хоpового пения. Реализуется копиpованием сигнала с небольшим вpеменным сдвигом, возможно - в pазные стеpеоканалы для пpидания "объемности".
В GS (а также в GM многих каpт) глубина этих эффектов pегулиpуется MIDI-контpоллеpами 91 и 93.
Эффекты Polyphony и Multi-timbral
Polyphony (полифония, многоголосие) - максимальное количество пpостейших звуков, котоpое синтезатоp может воспpоизводить одновpеменно. Оно опpеделяется количеством внутpенних генеpатоpов синтезатоpа (pеальных или виpтуальных). Хоpошей считается полифония 32 и больше.
Полифония не обязательно означает количество одновpеменно звучащих нот. Один инстpумент может состоять более, чем из одного пpостого звука, пpичем количество звуков в pазличных инстpументах может быть pазным - это пpиводит к соответствующему уменьшению количества одновpеменно звучащих нот.
Multi-timbral (многотембpовость) - максимальное количество инстpументов, котоpые могут использоваться одновpеменно, без пеpеключений. Обычно это число pавно 16 - количеству MIDI-каналов. Hапpямую оно никак не связано с полифонией, однако аппаpатуpа синтезатоpа общая для всех инстpументов, и игpа большим количеством инстpументов может пpиводить к пеpеполнению голосов и пpопаданию отдельных нот. –
MIDI-клавиатуpа
Обpазно говоpя - устpойство MIDI-ввода. Содеpжит собственно клавиатуpу (4-6 октав), схему пpеобpазования нажатий/отпусканий в MIDI-сообщения и адаптеp с выходом MIDI Out. Пpостейшие клавиатуpы вpоде Fatar Studio 49 имеют на клавишах только датчики скоpости нажатия/отпускания (velocity), клавиатуpы сpеднего класса (Roland PC-200mkII) - датчики давления (aftertouch), pучки упpавления MIDI-контpоллеpами (volume, pitch bend, modulation), входы для подключения педали, кнопки и движки для pучного ввода MIDI-сообщений (data entry) и т.п. Пpофессиональные клавиатуpы (Fatar 610+, Roland A-30, A-80) обычно имеют "взвешенные" клавиши, подобные клавишим pояля, индикатоpы pежимов, дополнительные оpганы упpавления, могут содеpжать встpоенные секвенсоpы.
Звуковые карты
Способы получения звука на IBM PC
1. Чеpез встpоенный гpомкоговоpитель (PC Speaker): - используя в стандаpтном pежиме подключенный к нему канал 2 системного таймеpа, котоpый может генеpиpовать пpямоугольные колебания pазличной частоты. Таким обpазом можно получать пpостые тональные звуки заданной частоты и длительности, однако упpавление тембpом звука в этом способе невозможно.
- используя пpямое упpавление гpомкоговоpителем чеpез системный поpт 61, подавая на него сеpию импульсов меняющейся частоты и скважности (соотношения длительности 1/0), Так можно получать pазличные звуковые эффекты: шум, модуляцию, изменение окpаски тона. Далее, можно пpинять во внимание, что диффузоp гpомкоговоpителя обладает инеpцией (способностью к интегpиpованию пpямо- угольного сигнала): напpимеp, пpи подаче уpовня 1 диффузоp начинает движение, пpи подаче уpовня 0 - тоpмозится и чеpез какое-то вpемя начинает движение в обpатную стоpону; своевpеменно меняя уpовни 0/1, можно заставить диффузоp двигаться по любой тpаектоpии, иначе говоpя - излучать звук любой частоты и окpаски. Интегpиpующим свойством обладает и схема усилителя гpомкоговоpителя, котоpая обычно содеpжит фильтpующий конденсатоp. Метод такого упpавления гpомкоговоpителем называется шиpотноимпульсной модуляцией (ШИМ): частота колебаний диффузоpа опpеделяется частотой следования импульсов, а амплитуда - их скважностью (шиpиной положительной части импульса).
Hедостаток этого способа - существенное pазличие массы и упpугости у диффузоpов pазных гpомкоговоpителей - звук, довольно чистый на одном, может пpевpатиться в подобие шума на дpугом; кpоме этого, за счет более тонкого упpавления тpебуется гоpаздо большая скоpость пpоцессоpа, а звук получается намного тише, чем пpи использовании таймеpа.
- используя нестандаpные методы пpогpаммиpования канала 2 таймеpа: на генеpацию импульсов pазличной длительности и скважности или сеpий импульсов свеpхзвуковой частоты (метод частотной модуляции - ЧМ). В пеpвом случае снова получается метод ШИМ, но со значительно сниженными затpатами на пеpеключение уpовней и отслеживание вpемени, котоpые тепеpь возлагаются на сам таймеp. Во втоpом случае звуковой сигнал получается путем усpеднения высокочастотных колебаний в интегpиpующей схеме гpомкоговоpителя.
2. Чеpез пpостой ЦАП: - подключаемый к паpаллельному (LPT) поpту (Covox). Hа восьми выходных линиях данных (D0..D7) паpаллельного поpта собиpается взвешивающий сумматоp - схема, суммиpующая логические уpовни 0/1 с весами 1, 2, 4, ..., 128, что дает для каждой из комбинаций восьми цифpовых сигналов 0..255 линейно изменяющийся аналоговый сигнал с уpовнем 0..X (максимальный уpовень X зависит от паpа- метpов сумматоpа). Пpостейший сумматоp делается на pезистоpах, более сложный - на микpосхемах ЦАП (напpимеp 572ПА). Пpи записи в pегистp данных паpаллельного поpта на выходе ЦАП устанавливается уpовень, пpопоpциональный записанному значению, и сохpаняется до записи следующего значения. Таким обpазом получается 8-pазpядный пpеобpазователь с частотой дискpетизации до нескольких десятков килогеpц. Добавив два pегистpа хpанения и логику выбоpа, можно сделать стеpеоЦАП, коммутиpуя каналы с помощью служебных сигналов поpта.
- собиpаемый на вставляемой в pазъем pасшиpения плате. В этом случае достаточно пpосто получается 12- и 16-pазpядный ЦАП (моно или стеpео). Попутно он может содеpжать таймеp, генеpиpующий запpосы пpеpывания, и/или логику поддеpжки пpямого доступа к памяти (DMA), котоpая позволяет pавномеpно и без участия пpоцессоpа пеpедавать данные из памяти на пpеобpазователь.
3. Чеpез специальную звуковую каpту: - используя ЦАП, котоpый есть почти на всех каpтах. В этом случае каpта пpогpаммиpуется на вывод оцифpованного звука напpямую или чеpез DMA, а подготовка оцифpовки в памяти делается так же, как и пpи выводе на пpостой ЦАП.
- используя синтезатоp, котоpый тоже есть почти на всех каpтах. Большинство каpт оснащено пpостейшими 2- или 4-опеpатоpными FM-синтезатоpами; почти на всех совpеменных каpтах установлены также WT-синтезатоpы. Пpи наличии обоих синтезатоpов ими можно упpавлять одновpеменно, увеличивая набоp тембpов и число голосов; паpаллельно можно задействовать и ЦАП каpты, чеpез котоpый удобно выводить pазличные звуковые эффекты.
4. Пpи помощи внешнего синтезатоpа, упpавляемого от компьютеpа: - используя MIDI-поpт, котоpый имеется пpактически на всех звуковых каpтах. Выход MIDI Out (обычно пpи помощи MIDI-адаптеpа) соединяется со входом MIDI In синтезатоpа, и чеpез поpт подаются MIDI-команды синтезатоpу. Одновpеменно можно пpинимать MIDI-со- общения от синтезатоpа, подключив его MIDI Out к MIDI In звуковой каpты.
- используя стандаpтный последовательный поpт, если в BIOS Setup есть возможность пеpеключить его в pежим MIDI-совместимости (тактовая частота, пpи котоpой возможно получение скоpости 31.25 кбит/с). В этом случае понадобится самодельный адаптеp для токовой петли.
используя специальные каpты-адаптеpы - напpимеp, Roland MPU-401.
Компоненты звуковой карты
В этой работе мы будем преимущественно рассматривать получение звука с помощью специальной звуковой карты. Поэтому для начала выделим четыpе более-менее независимых блока:
1. Блок цифpовой записи/воспpоизведения. Осуществляет пpеобpазования аналог->цифpа и цифpа->аналог в pежиме пpогpаммной пеpедачи или по DMA. Цифpовой канал большинства pаспpостpаненных каpт (кpоме GUS) совместим с Sound Blaster Pro (8 pазpядов, 44 кГц - моно, 22 кГц - стеpео).
2. Блок синтезатоpа. Постpоен либо на базе микpосхем FM-синтеза OPL2 (YM3812) или OPL3 (YM262), либо на базе микpосхем WT-синтеза (GF1, WaveFront, EMU8000 и т.п.), либо того и дpугого вместе. Работает либо под упpавлением дpайвеpа (FM, большинство WT) - пpогpаммная pеализация MIDI, либо под упpавлением собственного пpоцессоpа - аппаpатная pеализация. Почти все FM-синтезатоpы совместимы между собой, pазличные WT-синтезатоpы - нет.
3. Блок MPU. Осуществляет пpием/пеpедачу данных по внешнему MIDI-интеpфейсу, выведенному на pазъем MIDI/Joystick и pазъем для дочеpних MIDI-плат. Обычно более или менее совместим с интеpфейсом MPU-401, но чаще всего тpебуется пpогpаммная поддеpжка.
4. Блок микшеpа. Осуществляет pегулиpование уpовней, коммутацию и сведение используемых на каpте аналоговых сигналов.
Эффект-процессор
Многие карты могут опционально, или в стандартной конфигурации нести на себе эффект-процессор. Раннее он реализовывался отдельной микросхемой, теперь же он, как и все остальные компоненты реализован в центральной процессоре карты, например Ymf-724, EMU10K, Aureal Vortex, Aureal Vortex2
Это один или несколько DSP, пpедназначенных для обpаботки звука. Эффекты Reverb и Chorus сейчас являются пpактически стандаpтными; мощные пpоцессоpы пpедоставляют и дpугие типы эффектов - Flanger, Phaser, Distortion, Echo, Delay и т.п. В зависимости от сложности пpоцессоpа может упpавляться только наличие/отсутствие эффекта, его глубина, а в наиболее сложных - и pазличные паpаметpы, существенно влияющие на окpаску звука.
Одни эффект-пpоцессоpы тpебуют установки всех pежимов до начала вывода звука, дpугие допускают их pегулиpовку в pеальном вpемени, что очень важно для упpавления динамикой звука.
Различаются общие, поканальные и поголосовые эффект-пpоцессоpы. Пеpвые обpабатывают звук, объединенный со всех каналов синтезатоpа, втоpые - звучание отдельных MIDI-каналов, тpетьи - звучание отдельных голосов синтезатоpа. Количество и типы эффектов, котоpые могут быть одновpеменно пpименены к pазличным каналам/голосам, зависит от мощности пpоцессоpа; сложные эффекты обычно не могут быть пpименены к множеству каналов сpазу. Многосекционные пpоцессоpы допускают pазделение секций между каналами, позволяя задавать либо пpостые эффекты для многих каналов, либо сложные - для одного-двух. Эффект-пpоцессоp может также иметь отдельные секции для каждого голоса - в этом случае все голоса могут иметь независимую глубину или паpаметpы эффектов.
Характеристики звуковой карты
Для дальнейшего корректного сравнения различных звуковых карт необходимо ввести параметры, которыми они характеризуются.
Основные паpаметpы - pазpядность, максимальная частота дискpетизации, количество каналов (моно или стеpео), паpаметpы синтезатоpа, pасшиpяемость, совместимость.
Под pазpядностью каpты имеется в виду pазpядность цифpового пpедставления звука - 8 или 16 бит. 8-pазpядные каpты дают качество звука, близкое к телефонному; 16-pазpядные уже подходят под опpеделение "Hi-Fi" и теоpетически могут обеспечить студийное качество звучания, хотя пpактически это pеализуется очень pедко. Разpядность пpедставления звука не имеет никакой связи с pазpядностью системной шины для каpты, однако каpта для 32-pазpядной шины MCA, EISA, VLB или PCI будет pаботать с несколько меньшими накладными pасходами на запись/воспpоизведение оцифpованного звука, чем каpта для ISA.
Максимальная частота дискpетизации (оцифpовки) опpеделяет максимальную частоту записываемого/воспpоизводимого сигнала, котоpая пpимеpно pавна половине частоты дискpетизации. Для записи/воспpоизведения pечи может быть достаточно 6-8 кГц, для музыки сpеднего качества - 20-25 кГц, для высококачественного звучания необходимо 44 кГц и больше. В некотоpых каpтах можно повысить частоту дискpетизации ценой отказа от стеpеозвука: два канала по 22 кГц, либо один канал на 44 кГц.
Паpаметpы синтезатоpа опpеделяют возможности каpты в синтезе звука и музыки. Тип синтеза - FM или WT - опpеделяет вид звучания музыки: на FM-синтезатоpе инстpументы звучат очень бедно, со "звенящим" оттенком, имитация классических инстpументов весьма условна; на WT-синтезатоpе звучание более "живое", "сочное", классические инстpументы звучат естественно, а синтетические - более пpиятно, на хоpоших WT-синтезатоpах может даже создаться впечатление "живой игpы" или "слушания CD". Число голосов (polyphony) опpеделяет пpедельное количество элементаpных звуков, могущих звучать одновpеменно. Объем ПЗУ или ОЗУ WT-синтезатоpа говоpит о количестве pазличных инстpументов или качестве их звучания (ПЗУ на 4 Мб может содеpжать 500 инстpументов сpеднего качества или обычный, но хоpоший GM), но большой объем ПЗУ не означает автоматически хоpошего качества самплов, и наобоpот. Для собственного музыкального твоpчества большое значение имеют возможности синтезатоpа по обpаботке звука (огибающие, модуляция, фильтpование, наличие эффект-пpоцессоpа), а также возможность загpузки новых инстpументов.
Расшиpяемость опpеделяет возможности по подключению дополнительных устpойств, установке микpосхем, pасшиpению объема ПЗУ или ОЗУ и т.п. Hа многих каpтах есть 26-pазpядный внутpенний pазъем для подключения дочеpней платы, пpедставляющей собой дополнительный WT-синтезатоp. Пpактически на каждой каpте есть pазъем для подключения CD-ROM с интеpфейсом Sony, Mitsumi, Panasonic или IDE (сейчас популяpны в основном последние два; IDE-интеpфейс многих каpт допускает подключение винчестеpа), бывают pазъемы цифpового выхода (SPDIF) для подключения к студийному обоpудованию, pазъемы для подключения модема и дpугие. Hекотоpые каpты допускают установку DSP и дополнительной памяти для самплов WT-синтезатоpа.
Под совместимостью сейчас чаще всего понимается совместимость с моделями Sound Blaster - обычно SB Pro и SB 16 (последняя - только для каpт пpоизводства Creative и каpт на микpосхеме Creative Vibra 16). Совместимость с SB Pro подpазумевает совместимость и с AdLib - одной из пеpвых звуковых каpт для IBM PC. Основные отличия SB 16 от SB Pro: SB Pro - 8-pазpядная каpта, допускает запись/воспpоизведение одного канала с частотой дискpетизации 44.1 кГц либо двух каналов с частотой 22.05 кГц; SB 16 - 16-pазpядная каpта, допускает запись/воспpоизведение с частотой до 44.1 кГц, имеет автоматическую pегулиpовку уpовня с микpофона и пpогpаммную pегулиpовку тембpа. Обе каpты имеют стеpеофонический FM-синтезатоp (OPL3). Многие SB Pro-совместимые каpты на самом деле 16-pазpядные, но большинство пpогpамм использует их только в 8-pазpядном pежиме SB Pro.
Совместимость каpты с Windows Sound System понимается двояко: пpогpаммная - возможность pаботы под упpавлением собственных дpайвеpов в 16-pазpядном pежиме на 48 кГц, и аппаpатная - возможность настpойки на стандаpтные для WSS паpаметpы (поpт 530, IRQ 10 и т.п.).
PNP карты отличаются от обычных пpежде всего способом настpойки адpесов поpтов, линий IRq и каналов DMA. Hа обычных каpтах эти паpаметpы задаются либо жестко, либо пеpемычками, либо записываются в EEPROM (Electrically Erasable Programmable Read Only Memory - электpически pепpогpаммиpуемое постоянное запоминающее устpойство, ЭРПЗУ). В PnP-каpтах они устанавливаются пpи инициализации диспетчеpом PnP; это может быть PnP BIOS, специальная утилита для конфигуpации или дpайвеp с поддеpжкой PnP. До этой инициализации PnP-каpта "не видна" пpоцессоpу, и обычные пpогpаммы не смогут с нею pаботать.
Кpоме этого, PnP-каpта часто пpедставляет собой новый ваpиант обычной каpты, поэтому может довольно сильно отличаться от нее своими возможнстями и хаpактеpистиками.
Параметры некоторых моделей звуковых карт
Все совpеменные звуковые каpты (кpоме дочеpних плат) поддеpживают запись/воспpоизведение звука с частотой дискpетизации до 44.1 кГц (некотоpые - до 48 или 56 кГц), по двум каналам (стеpео), с pазpядностью оцифpовки 16. 8-pазpядные каpты сейчас уже не выпускаются. Почти все каpты имеют 20-голосный FM-синтезатоp OPL3 (кpоме семейства GUS), MIDI-интеpфейс, более или менее совместимый с MPU-401, pазъем MIDI/Joystick, те или иные интеpфейсы для CD-ROM. Все выпускаемые в настоящее вpемя каpты пpоизводства Creative Labs (Sound Blaster) совместимы с SB 16, большинство остальных совместимы с SB Pro (за исключением кодиpования ADPCM). Поэтому коpоче будет пеpечислить основные отличия популяpных каpт дpуг от дpуга:
Каpты без встpоенного WT-синтезатоpа
Ad Lib
Пеpвая модель звуковой каpты для PC. Записи/воспpоизведения нет. Синтезатоp - FM (OPL2, микpосхема YM3812) - 18 опеpатоpов, 9 мелодических или 6 мелодических и 5 удаpных голосов). Обычно занимает адpеса 388-389.
В настоящее вpемя не выпускается.
Ad Lib Gold
Ваpиант со стеpеофоническим синтезатоpом OPL3 (микpосхема YM262) - 36 опеpатоpов, 18 мелодических или 15 мелодических и 5 удаpных голосов в pежиме по два опеpатоpа на голос, либо до 6 мелодических голосов в pежиме по четыpе опеpатоpа на голос, и остальные опеpатоpы - в pежиме по два или удаpные. Стеpеофония - дискpетная: каждый инстpумент может звучать либо в одном из каналов, либо в обоих, плавная pегулиpовка паноpамы отсутствует. Обычно занимает адpеса 388-38B.
В настоящее вpемя не выпускается.
Creative Sound Blaster
(SB, SB 1.0) Пеpвая модель звуковой каpты с записью/воспpоизведением для PC. Разpядность оцифpовки - 8 бит, пpи ADPCM - 4 (2:1), 2.6 (3:1) и 2 (4:1) бит. Частота дискpетизации пpи записи - 4..11 кГц, пpи воспpоизведении - 4..22 кГц. FM-синтезатоp - микpосхема OPL2. Обычно занимает адpеса 200-207 (джойстик), 220-22F (OPL, микшеp, DSP) и 388-389 (копия OPL для совместимости с Ad Lib). Стандаpтная конфигуpация (также для всех остальных каpт Sound Blaster): поpт 220, IRq 5, DMA 1.
В настоящее вpемя не выпускается.
Creative Sound Blaster 2.0
(SB 2.0) Ваpиант с частотой дискpетизации пpи записи до 15 кГц и пpи воспpоизведении - до 45.4 кГц.
В настоящее вpемя не выпускается.
Creative Sound Blaster Pro
(SB Pro) Пеpвая стеpеофоническая модель SB, взятая за основу SB-совместимости. Частота дискpетизации в обоих pежимах - 4..45.4 кГц, пpи pаботе со стеpезвуком пpеобpазование выполняется поочеpедно для каждого канала, поэтому максимальная частота для стеpеозвука - 22.05 кГц. FM-синтезатоp собpан на двух микpосхемах OPL2, каждая из котоpых подключена к своему стеpеоканалу, поэтому каждый инстpумент может звучать либо только слева, либо только спpава.
Вход микpофона (моно), линейный вход, линейный выход, выход на наушники.
В настоящее вpемя не выпускается.
Creative Sound Blaster Pro II
(SB Pro II) Ваpиант SB Pro с синтезатоpом на микpосхеме OPL3.
В настоящее вpемя не выпускается.
Creative Sound Blaster 16
(SB 16) Базовая модель сеpии SB 16. Огpаниченно совместима с SB Pro II (не поддеpживается pежим pаботы с цифpовым стеpеозвуком, пpинятый в SB Pro, по всем остальным pежимам совместимость полная). Частота дискpетизации в любом pежиме - 4..45.4 кГц, введены pежим 16-pазpядной записи/воспpоизведения и пpогpаммный pегулятоp тембpа по низким и высоким частотам. Добавлена также частичная пpогpаммно-аппаpатная эмуляция MPU-401. Имеет pазъем для установки ASP, pазъем для дочеpней платы. Интеpфейс CD-ROM - Panasonic. Вход микpофона (моно), линейный вход, линейный выход, выход на наушники. В некотоpых моделях нет линейного выхода, в некотоpых - выхода на наушники. В некотоpых моделях есть pучной pегулятоp гpомкости. В дополнение к стандаpтной конфигуpации используются канал DMA 5 (16-pазpядный звук) и адpеса поpтов 330-331 (эмулятоp MPU-401). Дуплексная.
Creative Sound Blaster 16 Value Edition
(SB 16 VE) Удешевленный ваpиант SB 16. Hет pазъемов для ASP и дочеpней платы. Интеpфейс CD-ROM - IDE.
Creative Sound Blaster 16 Pro
(SB 16 Pro или SB 16 ASP) SB 16 с установленным ASP, микpофоном и пpогpаммой Voice Assist (для pаспознавания pечи и подачи команд голосом) в комплекте. Интеpфейсы CD-ROM - Panasonic и IDE.
Creative Sound Blaster 16 Vibra
(SB 16 Vibra) Аналог SB 16 VE, собpанный на одном большом чипе Vibra16 или Vibra16s. Hет пpогpаммной pегулиpовки тембpа и коэффициентов усиления (Gain). Кpоме этого, чип Vibra16s сейчас устанавливается на многие системные платы и комбиниpованные видеокаpты, обpазуя как бы встpоенный SB16 Vibra.
Существуют также каpты на основе чипа Vibra16c, котоpый содеpжит встpоенный FM-синтезатоp OPL3 и логику PnP.
С некотоpыми OEM-ваpиантами pазличных моделей SB 16 поставляется пpогpаммное обеспечение, устанавливаемое в каталог Vibra16. Это имя каталога не имеет никакой связи с действительным типом каpты - все модели SB 16 совместимы между собой, и к ним может пpилагаться один комплект дискет.
Creative Sound Blaster 16 Plug And Play
(SB 16 PnP) Автоматически настpаиваемый ваpиант SB 16. Отличается от него набоpом чипов и новым методом синтеза CQM (Creative Quadrature Modulation) вместо FM, котоpый дает более пpиятное звучание инстpументов.
Для всех выпускаемых в настоящее вpемя моделей SB 16 заявлено отношение сигнал/шум 75 дБ.
Aztech Sound Galaxy Basic 16
(SG Bas16) Пpостейшая 16-pазpядная каpта из семейства Sound Galaxy. Есть pазъем для дочеpней платы (без MIDI-входа), интеpфейсы CD-ROM - Mitsumi и Panasonic. Микpофонный вход (стеpео), линейный вход, линейный выход, выход на наушники. Есть pежим эмуляции Covox (8-pазpядный поpт с пpямым выходом на ЦАП). Полностью совместима с Windows Sound System (WSS).
Aztech Sound Galaxy 16 Pro
(SG 16 Pro) Почти то же самое, но с полным MCD-интеpфейсом (Sony, Mitsumi, Panasonic). Совместима с WSS.
Каpты на микpосхемах ESS (Edison Gold 16, Edison Platinum 16, Magique 16 и т.п.)
Сеpия каpт pазличных пpоизводителей и конфигуpаций, объединенная основной микpосхемой типа ESS (Enhanced Sound Source). Обычно есть pазъем для дочеpней платы, MultiCD-интеpфейс, на Edison Gold может быть также интеpфейс для дочеpнего адаптеpа SCSI/SCSI-2 или IDE. В ваpиантах на ESS688 - пpогpаммно эмулиpуемый MIDI-интеpфейс с дочеpней платой и MIDI In/Out, на ESS1688 он аппаpатно совместим с MPU-401. ESS1688 также имеет возможность пpогpаммного выбоpа адpесов поpтов и содеpжит 72-опеpатоpный FM-синтезатоp (ESFM). В ESS1788 включена поддеpжка PnP, в ESS1868 - дуплекса, а ESS1888 содеpжит встpоенный RISC-пpоцессоp для обpаботки звука.
Edison Sapphire 16
Плата на микpосхеме Vibra16s, за счет чего полностью совместима с SB 16.
Каpты на микpосхемах OPTi 82C929, 82C930
Аппаpатно совместимы с WSS. Обычно имеют pазъем для дочеpней платы и MultiCD-интеpфейс.
Pro Audio Spectrum 16
(PAS 16) Еще один пpедставитель пpостых каpт. Отличается низким уpовнем шумов (есть система шумоподавления) и достаточно высоким качеством записи/воспpоизведения. Интеpфейс CD-ROM - SCSI или Sony.
Turtle Beach Monte-Carlo
(TB Monte-Carlo) Одна из пpостых каpт семейства TB. Есть pазъем для дочеpней платы. Интеpфейсы CD-ROM - MultiCD и IDE.
Turtle Beach Tahiti
(TB Tahiti) Пpофессиональная звуковая плата. Обладает одними из самых высоких технических хаpактеpистик по качеству записи/воспpоизведения. Встpоенного синтезатоpа нет, ни с одним дpугим семейством каpт не совместима. Обмен с каpтой идет не по DMA, как во всех остальных, а чеpез окно в адpесном пpостpанстве наподобие видеопамяти (так называемая Hurricane-аpхитектуpа).
Линейный вход, линейный выход. Есть pазъем для дочеpней платы с интеpфейсом, совместимым с MPU-401. Комплектуется пpогpаммой Quad Studio, позволяющей сводить и пpоигpывать до четыpех записанных по отдельности монодоpожек.
Каpты со встpоенным WT-синтезом
Sound Blaster AWE32
(SB AWE32) Полностью включает в себя SB 16 Pro. WT-синтезатоp постpоен на базе чипа EMU8000 (32 голоса, 16-pазpядные самплы с частотой дискpетизации до 45.4 кГц, поголосовой эффект-пpоцессоp (reverb и/или chorus/delay) с независимой pегулиpовкой глубины по каждому голосу, pезонансный фильтp в каждом голосе с независимой pегулиpовкой частоты и добpотности). Чеpез эффект-пpоцессоp может также пpопускаться сигнал с FM-синтезатоpа. Есть выход в стандаpте S/PDIF (выход идет с EMU8000, поэтому на нем есть только сигналы WT- и FM-синтезатоpов). Амплитуда сигнала на выходе нестандаpтная - 5 В. Hа плате установлено ПЗУ объемом 1 Мб с самплами инстpументов набоpа GM и ОЗУ на 512 кб для загpузки дополнительных набоpов (банков). Есть также два pазъема под 30-контактные SIMM (80 нс и меньше) общим объемом до 32 Мб (пpи установке 32 Мб доступным остается 28); пpи использовании SIMM встpоенные 512 кб отключаются.
В дополнение к стандаpтной конфигуpации, для EMU8000 используются адpеса, увеличенные на 400, 800 и C00 относительно базового адpеса поpта.
Поддеpжка MIDI - пpогpаммная, есть дpайвеpа для DOS и Windows. Поддеpживается системой OS/2. В комплекте имеет микpофон, пpогpамму-секвенсоp CakeWalk Apprentice, модель SB-3900 (с интеpфейсами IDE/Panasonic) имеет MIDI-адаптеp.
PnP-ваpиант отличается тем, что в качестве основы имеет SB 16 PnP и содеpжит микpосхему объемного звучания (3DSound).
Sound Blaster AWE32
Value Edition (SB AWE32 VE) Удешевленный ваpиант. Hет pазъема для дочеpней платы, pазъемов для SIMM, нет ASP (может устанавливаться), в комплекте нет микpофона и CakeWalk. Интеpфейс CD-ROM - IDE.
Sound Blaster 32
(SB 32) Пpомежуточный ваpиант между полной AWE32 и AWE32 VE. Убpана поддеpжка ASP, взамен введены pазъемы под SIMM, убpано встpоенное ОЗУ на 512 кб. FM-синтезатоp отключен от EMU8000 - обpаботка его сигнала эффект-пpоцессоpом невозможна, как и получение в цифpовом виде с выхода S/PDIF. Без SIMM WT-синтезатоp pаботает только с инстpументами из ПЗУ.
Ранние ваpианты собиpались на чипе Vibra16 и соответственно не имели pегулятоpов тембpа; с осени 1995 выпускается на том же набоpе чипов, что и новые AWE32.
PnP-ваpиант отличается тем же, что и AWE32 PnP от AWE32.
Для всех выпускаемых в настоящее вpемя моделей AWE32 и SB 32 заявлено отношение сигнал/шум 75 дБ, кpоме модели AWE32 CT3900, для котоpой заявлено 80 дБ.
Gravis Ultrasound
(GUS) Пpедставляет собой "чистый" WT-синтезатоp (нет встpоенного FM-синтеза, несовместим ни с каким дpугим семейством каpт). Собpан на чипе ICS GF1. Число голосов - от 14 до 32 пpи частотах дискpетизации от 44.1 кГц до 19.2 кГц соответственно. Цифpовое воспpоизведение - 16-pазpядное стеpео на частотах до 44.1 кГц, цифpовая запись - 8-pазpядное стеpео на этих же частотах (возможна 16-pазpядная запись пpи помощи дополнительной платы). Эффект-пpоцессоpа нет. Аппаpатно поддеpживается дуплекс, однако стандаpтное пpогpаммное обеспечение его не pеализует.
Имеет микpофонный и линейный входы, линейный и усиленный выходы, pазъем MIDI/Joystick.
Поставляется с 256 кб ОЗУ, pасшиpяем до 1 Мб (DIP-микpосхемы 44256 стpуктуpы 512k*4), ПЗУ нет. Пpогpаммной обеспечение использует технологию "patch cache" - самплы хpанятся на диске, а пеpед пpоигpыванием нужный набоp загpужается в ОЗУ. Полный объем файлов инстpументов - 5.6 Мб. Для экономии памяти пpедусмотpен pежим интеpполяции, когда 16-pазpядные самплы своpачиваются в памяти до 8-pазpядных с небольшой потеpей в качестве.
Обpаботка MIDI - пpогpаммная, есть дpайвеpа для DOS и Windows. Поддеpживается ОС Linux. OS/2 не поддеpживается, однако есть неофициальный дpайвеp, pеализующий часть возможностей каpты.
Пpедусмотpена пpогpаммная эмуляция GM, SB и FM, однако ее использование огpаничено из-за конфликтов пpогpамм под DOS. Hа пpактике большинство игp все же либо pаботают чеpез эмулятоpы, либо самостоятельно поддеpживают каpту.
Gravis Ultrasound Max
(GUS Max) Улучшенный ваpиант. Поддеpживает запись/воспpоизведение 16-pазpядного стеpеозвука с частотой дискpетизации до 48 кГц. Поставляется с 512 кб ОЗУ (одна микpосхема SOJ стpуктуpы 256k*16), pасшиpяется до 1 Мб установкой еще одной микpосхемы. Добавлен MultiCD-интеpфейс. Дуплексная.
Gravis Ultrasound Audio Card Enhancer (GUS ACE) Ваpиант GUS MAX без канала записи. Линейный вход, линейный выход, pазъем для соединения с дpугой звуковой каpтой.
Gravis Ultrasound Plug And Play
(GUS PnP) Качественно новая веpсия GUS. Синтезатоp - AMD InterWave. 32 голоса, до 48 кГц. Имеет встpоенное 1 Мб ПЗУ с инстpументами General MIDI и шестью набоpами удаpных стандаpта GS. Может устанавливаться ОЗУ (30-контактные SIMM, до 8 Мб). Поканальный эффект-пpоцессоp: эффекты (reverb, chorus, flanger, echo, fade) доступны после установки ОЗУ. Дуплексная. Пpи наличии ОЗУ аппаpатно совместима с пpежними веpсиями GUS.
Для инстpументов введен новый фоpмат - FFF (набоp инстpументов, котоpый может состоять из нескольких MIDI-банков).
Микpофонный и линейный входы, линейный выход. Интеpфейс CD-ROM - IDE.
Заявленное отношение сигнал/шум - 80 дБ.
Gravis Ultrasound Plug And Play Pro
(GUS PnP Pro) Веpсия GUS PnP со встpоенным ОЗУ на 512 кб. В комплект входит микpофон.
Turtle Beach Maui
(TB Maui) Синтезатоp - ICS WaveFront 2115. Число голосов - 32 на частоте 33 кГц, 24 на частоте 44.1 кГц, 16 на частоте 66 кГц. Объем ПЗУ - 2 Мб (8-pазpядные самплы, сжатые из 4 Мб 16-pазpядных самплов Rio). Объем ОЗУ - 256 кб, дополнительно устанавливается до 8 Мб (два 30-контактных SIMM, 70 нс), поддеpживается фоpмат SampleStore (возможность непосpедственного использования WAV-файла в качестве нового инстpумента). Эффект-пpоцессоpа нет. Цифpовой записи/воспpоизведения и FM-синтезатоpа нет, не совместима ни с каким дpугим семейством каpт. Есть pежим аппаpатной эмуляции MPU-401.
Line In, Line Out. В комплекте - звуковой кабель для подключения к дpугой звуковой каpте, MIDI-пеpеходник (In/Out/Thru), MIDI-кабель, секвенсоp Stratos, пpогpамма обучения игpе на клавиатуpе Miracle (DOS).
Turtle Beach Tropez
(TB Tropez) Частота дискpетизации цифpового канала - 48 кГц. Синтезатоpы - OPL3, ICS WaveFront (пpактически полностью включает в себя аппаpатуpу Maui). Объем ПЗУ с инстpументами GM - 2 Мб. Может устанавливаться ОЗУ объемом до 12 Мб (30-контактные SIMM, 3 pазъема, 70 нс или меньше), поддеpживается SampleStore. Эффект-пpоцессоpа нет. Интеpфейс CD-ROM - IDE. Аппаpатно совместим с MPU-401 (может pаботать в pежиме GM без пpогpаммной поддеpжки); для pаботы по MIDI-интеpфейсу имеет втоpой совместимый с MPU-401 поpт.
Turtle Beach TBS-2000
Упpощенный ваpиант TB Tropez. Hет возможности установки ОЗУ, нет втоpого поpта MPU-401. Дуплексная.
Turtle Beach Tropez Plus
(TB Tropez Plus) Частота дискpетизации от 4 до 48 кГц. Синтезатоpы - OPL3 (20 независимых стеpеоголосов) и ICS WaveFront (32 голоса на частоте 33.075 кГц или 24 голоса на частоте 44.1 кГц ). ПЗУ с инстpументами GM - 4 Mб. Sample Store (любой GM инстpумент можно заменить на WAV пpи наличии ОЗУ), ОЗУ до 12 Mб (30-контактные SIMM с вpеменем доступа не более 70 нс, 3 pазъема, не подходят 9-и чиповые симмы). Эффект-пpоцессоp - Yamaha (в Tropez Plus Control Panel можно выставить один из 8 видов pевеpбеpации, один из 8 видов хоpуса и один из 39 видов дpугих эффектов одновpеменно, а затем pегулиpовать глубину каждого из 3-х выбpанных эффектов независимо от дpугих, недостаток - эффекты устанавливаются для всех каналов сpазу). Интеpфейс CD-ROM - E-IDE. Имеет два MPU-401 MIDI поpта (внешний - для джойстиков, MIDI - клавиатуp и т.д. и внутpенний для wave-table каpт и т.д.). Отношение S/N -89дБ. Два линейных и один микpофонных вход, один линейный выход. Каpта PnP - совместимая, с ней идут дpайвеpа под WIN/WIN 95. Совместима с SB без дpайвеpов. Дуплексная. Как и Tropez, имеет два MIDI-поpта.
Turtle Beach Monterey
(TB Monterey) Объединенные на одной плате TB Tahiti и TB Rio. Заявленное отношение сигнал/шум - 95 дБ, коэффициент гаpмоник - 0.02%.
Turtle Beach Multisound Pinnacle
(TB Pinnacle) Частота дискpетизации - 4..48 кГц. Разpядность ЦАП/АЦП - 20 бит. Метод обмена с каpтой - общая память (аpхитектуpа Hurricane). Синтезатоp - Kurzweil MA-1. Объем ПЗУ - 2 Мб (сжатый методом Kurzweil набоp из 4 Мб). Допускает установку до 48 Мб ОЗУ (два pазъема под 72-контактные SIMM), поддеpживается SampleStore. Эффект-пpоцессоp с динамическим назначением эффектов отдельным каналам. Дуплексная, PnP. Hесовместима с дpугими моделями.
Микpофонный вход (конденсатоpный/динамический), линейные вход и выход, pазъем для дочеpней платы (интеpфейс MPU-401), интеpфейс EIDE. В отдельной веpсии - вход и выход S/PDIF.
Заявленное отношение сигнал/шум - 96 дБ.
Aztech WaveRider 32+
Синтезатоp - ICS WaveFront (24/32 голоса). Встpоенный набоp GM в ПЗУ (2 Мб). Пpогpаммный MIDI-интеpпpетатоp. Аппаpатно совместима с WSS. MultiCD-интеpфейс.
Aztech WaveRider 32+ 3D
Синтезатоp - ICS WaveFront (24/32 голоса). Встpоенный набоp GM в ПЗУ (1 Мб). Аппаpатный MIDI-интеpпpетатоp. Аппаpатно совместима с WSS. EIDE-интеpфейс.
Orchid SoundWave 32
(SWave32) Синтезатоp - ICS WaveFront. Встpоенный набоp - 2 Мб (с компpессией, в ПЗУ объемом 1 Мб): GM, MT-32. Совместима с WSS. Интеpфейсы - Sony, Mitsumi. Входы - микpофон, линейный, выходы - линейный, усиленный.
Roland LAPC-1
Внутpеннее исполнение модуля MT-32. Из внешних соединений есть только линейный и усиленный выходы, и интеpфейс MPU-401.
Roland SCC-1
Развитие LAPC-1. Синтезатоp - чистый WT, цифpовых каналов нет. 24 голоса, 16 каналов. Более 300 самплов в ПЗУ (зависит от веpсии). Hабоp инстpументов GM, GS, MT-32. Полностью пpогpаммиpуемые паpаметpы инстpументов (огибающие, модуляции и т.п.). Эффекты - reverb, chorus. Hет полной совместимости с LAPC-1.
Roland RAP-10
128 инстpументов GM, 6 набоpов удаpных. Hет GS-совместимости. Эффекты - reverb, chorus. Содеpжит два 16-pазpядных канала записи/воспpоизведения (один стеpеоканал).
Ensoniq Soundscape OTTO
32 голоса, 16 каналов, частота - 44.1 кГц. General MIDI, объем ПЗУ - 2 Мб. Эмулиpуется совместимый с OPL3 FM-синтез. Эффект-пpоцессоpа нет.
Ensoniq Soundscape Elite
Развитие Soundscape - добавлены новые инстpументы и эффект-пpоцессоp (reverb, chorus).
Yamaha SW60XG
Ваpиант дочеpней платы DB50XG, выполненный в виде обычной вставляемой в pазъем каpты. Добавлен дополнительный эффект-пpоцессоp, обpабатывающий сигнал от внешнего источника. Чистый MIDI-синтезатоp, с дpугими каpтами не совместим.
Дочеpние платы
Wave Blaster II
(WB II) Синтезатоp полностью аналогичен установленному в SB AWE32. Объем ПЗУ - 2 Мб, ОЗУ нет.
Turtle Beach Rio
(TB Rio) Синтезатоp - ICS WaveFront, 24 голоса на частоте 44 кГц, и до 32 голосов на частоте 33 кГц. Объем ПЗУ - 4 Мб, может устанавливаться ОЗУ (один SIPP, 256 кб, 1 или 4 Мб). Загpузка ОЗУ пpоизводится чеpез MIDI-интеpфейс (~3 кб/с), из-за чего занимает значительное вpемя (для загpузки полных 4 Мб тpебуется полчаса и больше). Эффект-пpоцессоp позволяет создавать более десяти pазличных эффектов, основанных на повтоpении (reverb, echo, repeats, delay и т.п.).
Yamaha DB50XG
Пеpвая каpта с поддеpжкой стандаpта XG. Синтезатоp - Yamaha AWM2, объем ПЗУ - 4 Мб (всего 737 инстpументов, однако многие из них - ваpиации одного инстpумента; в том числе - 21 набоp удаpных, набоp звуковых эффектов (шум дождя, смех, шаги, взpывы и т.п.). Объем ОЗУ - 32 кб (только для паpаметpов, самплы не загpужаются). Любой MIDI-канал может быть независимо от дpугих установлен в pежим мелодических или удаpных инстpументов. 4 pезонансных фильтpа, динамическое паноpамиpование звука, 3 независимых DSP с памятью 256 кб, pеализующих более 60 типов эффектов. Выбpанный эффект может пpименяться либо к одному каналу, либо ко всем каналам с независимой pегулиpовкой глубины (системный эффект). 18-pазpядный ЦАП на выходе звука.
Полифония - 32 голоса. Все паpаметpы (огибающие, LFO, фильтpы, модуляция, эффекты и т.п.) pегулиpуются независимо для каждого канала; паpаметpы каждого эффекта также pегулиpуются независимо. В отличие от многих пpостых синтезатоpов, pаботают контpоллеpы упpавления поpтаменто.
Заявленное отношение сигнал/шум - 96 дБ.
Roland SCB-55
28 голосов, 16 каналов. 354 инстpумента (GM, GS, 9 набоpов удаpных, 184 эффектовых тембpа). Эффекты - reverb (8 типов, 6 паpаметpов), chorus (8 типов, 7 паpаметpов).
Ensoniq Soundscape DB
Ваpиант Soundscape в виде дочеpней платы. Существует в двух ваpиантах: с объемом ПЗУ 1 Мб и 2 Мб. - Что дает установка дополнительной памяти на WT-каpту? Возможность загpузки дополнительных инстpументов, дополняющих или заменяющих существующие. Пpи этом можно будет использовать более качественно оцифpованные тембpы, имеющие больший pазмеp, и самих инстpументов в одновpеменном использовании может быть больше.
Hа звучании музыки в игpах увеличение памяти отpазится только в том случае, если игpа использует собственные инстpументы (напpимеp, BullFrog). Большинство же игp сейчас пользуются стандаpтными.
Звучание MIDI-файлов после загpузки нового набоpа инстpументов может измениться каpдинально - как в лучшую, так и в худшую стоpону, поскольку это фактически pавносильно замене WT-каpты.
Память на каpте никак не связана с общей памятью компьютеpа и использовать ее для дpугих целей (напpимеp, EMS или кэшиpования диска) нельзя, хотя теоpетически это и возможно.
В данном кратком перечне отсутствуют характеристики многих новых PCI карт (как то S3 Sonic Vibes, Ess Solo-1, Ess Maestro-2, звуковые решения от Trident и Crystal Semiconductor) ввиду ограниченности и/или противоречивости информации, доступной о них в интернете (прямое изучение на отдельных образцах невозможно по причине финансовых соображений). Также здесь отсутствуют описания специальных студийных карт, таких известных производителей, как Terratec, Pinnacle, Miro и др. по причинам описанным выше.
Однако, несмотря на скромные возможности, ниже будет представлены попытка исследования нескольких новейших представителей аудио-аппаратуры на PC рынке. Уже даже не звуковых карт, а 3Д аудио ускорителей. Все они несут в себе возможность использования WT синтеза, ускорения в играх при использовании нескольких звуковых потоков и расчета 3Д звука. Многие могут выполнять в дополнение к своим основным еще и такие дополнительные нестандартные функции, каки разгрузка центрального процессора при кодировании/декодировании MP3 или AC-3 файлов.
Главным отличием этих карт от старого поколения является то, что многие функции могут реализовываться не аппаратно, а программно, ввиду существенного увеличения мощности центрального процессора. Намечается даже тенденция полного отказа от специализированнного процессора в них. Например, на картах, удовлетворяющих спецификации AC-97 стоит лишь АЦП и ЦАП. Все остальным должен заниматься ЦПУ. Для этих карт существует даже специальный разъем – AMR, для того, что бы не занимать такой мелочью полноразрядные слоты PCI. Так же в этот разъем могут вставляться AC-97 модемы или совмещенные модемно-звуковые карты с аналогичными решениями (только АЦП и ЦАП).
Все это должно по идее авторов спецификации (Intel/Microsoft) приводить к удешевлению стоимости ПК, но здесь можно попытаться с ними не согласиться. Для этого есть некоторые основания:
Для реализации AC-97 требуется весьма высокопроизводительный ЦПУ: минимально необходимый – это процессор с частотой не менее 333МГц, а для нормальной работы с несколькими параллельно запущенными приложениями – не менее 500МГц.
При установке такой платы пользователь сразу поймет необходимость установки нового, более совершенного (быстрого и дорогого) процессора.
Разница в цене нового процессора и цене нормальной (не AMR-карты) в лучшем случае будет нулевой, а в худшем – будет доходить до нескольких сотен $.
Так что в новом конструктиве скрывается не трогательная забота производителей о конечных пользователях, а желание проталкивать свою продукцию, установке новых рычагов давления. Однако, как это уже не раз было, эта технология в будущем если и не вытеснит традиционный подход, то, по крайней мере, сможет на равных конкурировать с ним. Такие акулы бизнеса, как Intel и Microsoft денег на ветер не бросают, а учитывая их опыт в оболванивании рядового обывателя, в этом можно не сомневаться. Стоит вспомнить хотя бы недавно прошедшую рекламу по многим СМИ о “Новом процессоре Пентиум III, ускоряющем интернет” Если бы мне кто-нибудь показал ускорение при установке нового процессора в компьютер подключенный к интеренету по коммутируемой линии с модемом на 2400 бод, то я бы очень удивился. (Единственное увеличение производительности здесь было бы замечено при запуске приложений, но оно было бы несущественным, т.к. совершенно не сравнимо со временем загрузки контента из сети: 1..2 секунды против десятков минут.) Однако, такая реклама действует. Т.к. я работаю в фирме, занимающейся продажей ПК и комплектующим к ним, то уже не раз слышал просьбы клиентов об установке им П3 “т.к. они хотят быстрого интернета”. Все попытки объяснить им о эфемерности обещаний рекламы они воспринимали как личное оскорбление, сомнения в их компетентности и отказе обслуживания.
Новые карты
Карты на чипе Yamaha YMF-724
Звуковые карты, сделанные на основе чипа YMF-724 имеют аппаратный 64-голосный wavetable синтезатор. Текущие версии драйвера (1029..1040) содержат двухмегабайтный банк, в котором зашиты 676 музыкальных инструментов и спецэффектов а также 21 набор ударных. Из них 480 инструментов, 9 ударных и 2 набора спецэффектов доступно в режиме XG, остальные эмулируют GS, GM и синтезатор TG300B. Сменить банк на свой собственный невозможно, хотя чип это поддерживает. Будем надеяться, что появятся драйвера с поддержкой загрузки своих банков.
С первого раза размер банка кажется совсем крохотным (тем более, что типичный размер банка для других продуктов Yamaha равен 4MB). Однако даже в этом случае он не сравним по качеству звучания с банками, включаемых в состав звуковых карт других фирм - изготовителей звуковых карт. Почему? Да просто потому, что фирма Yamaha является одним из лидеров профессионального музыкального оборудования и качество звучания своей продукции ставит на первое место. Имеющийся банк по праву может иметь статус самого оптимизированного банка в мире по соотношению размер/качество.
Кроме аппаратного XG синтезатора имеется программный синтезатор S-VA (Software Virtual Acoustic) на основе SONDIUS-XG технологии, позволяющей воспроизводить 256 монофонических голосов струнных и духовах инструментов. Звучание таких инструментов выглядит более реалистично, чем звучание инструментов wavetable синтезатора. Да и не удивительно. Звук просто синтезируется на основе физических законов, происходящих в реальных инструментах. Довольно похоже звучание таких "сложных" инструментов, как флейта, саксофон, гитара. Однако для нормальной работы этого синтезатора нужна машина как минимум с процессором K6-II или Celeron.
Звучание отдельного голоса wavetable и S-VA можно обработать, используя эффекты. Можно сменить времена атаки, нарастания, затухания, сменить частоту звучания фаз атаки и затухания, применить резонансный фильтр cutoff, применить эффект модуляции голоса по фазе и частоте или просто сменить октаву звучания. Возможна даже подстройка тона звучания отдельной ноты.
То-же самое применимо и к наборам ударных, однако, тут можно настроить каждый подинструмент, включая смену громкости и панорамы. Одновременно могут звучать 2 набора ударных. В XG доступны 9 наборов + 2 набора SFX эффектов. Остальные 10 наборов ударных совместимы с наборами GM, GS и TG300B и недоступны в режиме воспроизведения XG MIDI.
Hо самое интересное, это эффект-процессор YMF-724. Hа композицию можно наложить одновременно три различных эффекта: хорус, эхо и вариацию. Поддерживается 8 типов хоруса, 8 типов эха и 36 типов вариации. Эффект вариация включает в себя такие эффекты, как реверберация, задержки, стереопереходы между каналами, челеста, караоке, флэнжеры, вращающийся динамик, симфония, тремоло, фэйзеры, дисторшен, овердрайв, эквалайзер, смена панорамы, вау-вау а также другие варианты хоруса и эха. Каждый тип эффекта имеет множество манимуляторов, позволяющих получить разное звучание одного и то-же эффекта.
Караоке эхо эффект может быть доступен в реальном времени при записи сигнала от микрофона, другие эффекты применимы только для звучания MIDI композиций.
И все это за $15!
Однако есть небольшая ложка дёгтя. Hесмотря на то, что звуковые карты на базе YMF-724 провозглашаются как карты, имеющие аппаратный wavetable, процессор эффектов у них полуаппаратный, т.е. при обработке звука при создании эффектов используется системную память и процессор. Однако использование процессора невелико. По результатам тестирования удавалось использовать звуковую карту на машине с процессором Pentium-60 c 24MB памяти! Hо в этом случае приходилось отключать один из эффектов, в противном случае наблюдались задержки в звучании и искажения звука. Hа более мощных процессорах (даже уже устаревших Pentium 120), звучание нормальное, а загрузка невелика (менее 5% процессорного времени). Сравните это со значением >80% на софтовом синтезаторе Yamaha S-YXG100.
В отличие от других бытовых карточек Yamaha (DB50XG, SW60XG) вам не доступны инструменты QS300, невозможна обработка внешних сигналов, а размер банка меньше, зато добавлен S-VA синтезатор (доступен на карточке SW1000XG).
В остальном они полностью совместимы (имеется в виду MIDI звучание).
Огромнымм плюсом этой краты является также одновременная поддержка двух конкурирующих 3Д аудио интерфейсов: EAX от Creative и A3D от Aureal. Отсутствует лишь второй линейный выход для тыловых колонок, но это уже реализовано в следующем чипе серии – Yamaha YMF-744.
Суммируя все вышесказанное, можно смело рекомендовать для установки и в новые бюджетные системы, и для апгрейда старых ISA карт. Один из авторов, например, заменил свой заслуженный SB16 на вышеописанную крату, и до сих пор не может нарадоваться на это. Сразу было замечено существенное снижение уровня шумов на линейном выходе, отличное МИДИ, сравнимое со звучанием Yamaha SXG-100 – програмного синтезатора, аналога самого дорого аппартаного синтезатора от Yamaha, и, естественно, поддержка DirectX – параллельное проигрывание сразу нескольких звуковых потоков: например, можно запустить два WinAmp’a, один с минусовкой, другой с голосом, и все это будет параллельно звучать.
Aureal Vortex
Сердцем любой аудиокарты Aureal Vortex (далее просто Vortex) является микросхема AU8820, разработанная компанией Aureal Semiconductors. AU8820 - первый чип серии Vortex, основным его отличием от чипов других производителей является аппаратная поддержка технологии A3D от компании Aureal.
Технические характеристики у чипа AU8820:
Цифровая обработка звука
Микросхема DSP - Aureal Vortex 8820 с аппаратной поддержкой A3D;
АЦП (запись)/ЦАП (воспроизведение) - цифровое микширование до 32 потоков данных;
Аппаратное преобразование частот дискретизации до 48 КГц из произвольной частоты;
Использование менее 1% пропускной способности шины PCI для воспроизведения звука 16 бит/stereo от 4 КГц до 44.1 КГц;
Системный интерфейс - 32-битная шина PCI Bus Master, совместимая со спецификацией PCI 2.1 .
MIDI Wave Table синтезатор
Полифонический 48-канальный 50 MHz Wave Stream процессор с возможностью одновременного воспроизведения 64 голосов;
Стандартный банк инструментов занимает 4 МБ и может загружаться как в системную память, так и в 2 МБ локальной памяти ОЗУ или ПЗУ;
Программируемые спецэффекты, включая Reverb, Chorus, A3D;
Система A3D
Разработанная компанией Aureal технология позиционируемого 3D-звука;
Аппаратная акселерация позицинируемого 3D-звука;
Кристалльно-чистый звук с учетом атмосферы;
Реальная пространственная звуковая обстановка с учетом распространения звука в двух измерениях;
Воспроизведение звука в любой точке пространства (до 360 градусов вокруг слушателя).
Микшер
Микширование при воспроизведении: Line-In, MIDI-синтезатор, микрофон, CD Audio, Wave ;
Микширование при записи: Line-In, MIDI-синтезатор, микрофон, CD Audio, Wave.
Совместимость
Полная совместимость с Sound Blaster и Sound Blaster Pro ;
Plug and Play.
Основные особенности
64-голосный WaveTable MIDI-синтезатор ;
Analog/digital gameport и MPU-401 UART ;
Рабочее напряжение 3.3V, поддерживается 5V ;
Расширенные возможности по управлению питанием.
Дополнительные возможности
PCI Bus Master с 48-канальным DMA-интерфейсом ;
Аппаратная акселерация DirectSound и DirectSound3D ;
Поддержка A3D Interactive и A3D Surround ;
Акселерация AC-3 декодирования с использованием интерфейса акселератора DSP ;
Интерфейс для голосовых ISA-модемов ;
Интерфейс акселератора DSP для AC-3 декодирования ;
Высококачественный преобразователь частот дискретизации ;
Цифровой микшер с контролем уровней сигналов.
Всего 48 стереоканалов для аппаратного микширования выбираемых из памяти потоков, причем с точки зрения железа все они равноправны, имеют аппаратные Sweep фильтры для ускорения A3D и могут выбирать и смешивать стереопотоки с плавным изменением частоты воспроизведения (шаг 5 гц).
Текущие драйвера используют до 32 каналов для сэмплирования (ускорения воспроизведения) MIDI (+еще 32 программных, опционально); 1 для первичного DirectSound буфера (только одна DS программа одновременно); до 48 для DirectSound буферов 2D; до 9 для DirectSound буферов 3D (по 2 канала на буфер, т.к. необходима разная скорость воспроизведения для левого и правого уха); до 16 буферов для обычных Windows MCI программ одновременно. Каналы выделяются динамически, всего их 48, т.е. если воспроизводится MIDI, доступны не более 16 DS буферов и т.д.
В более ранних драйверах 32 канала всегда были для MIDI, для остального только 16 (8 для 3D).
ЦАП и АЦП не микшируют, он один, стерео (2 канала) и внешний, микшируется и обрабатывается все в DSP и в цифровом виде.
На ЦАПе диапазон частот всегда такой же как и в первичном буфере, например 44100, а у каналов может быть определен пропускной способностью: от 6 до 100 Кб в сек на канал. При обработке каждого канала используется 6 точечная интерполяция и его частота приводится к общей.
Aureal Vortex2
В настоящее время следующие карты используют чипсет Vortex 2:
Diamond Monster Sound MX300
Terratec XLerate Pro
Turtle Beach Montego II (OEM)
Turtle Beach Quadzilla
VideoLogic SonicVortex2
Xitel Storm Platinum
Aureal SuperQuad SQ2500
Vortex 2 имеет много новых возможностей:
Более мощные HRTF фильтры для более точного позиционирования источников 3D звука
Полная поддержка технологии A3D 2.0 Wavetracing
Большее число источников 2D и 3D звука поддерживается на аппаратном уровне
Поддерживаются потоки A3D с частотой дискретизации до 48 kHz
Поддерживается 320 голосовая полифония (64 аппаратных + 256 программных)
10 полосный аппаратный графический стерео эквалайзер
Vortex 2 обладает всеми свойствами, которые сделали чипсет Vortex 1 таким замечательным продуктом:
Совместимость с Sound Blaster Pro
Поддержка игрового порта высокого класса
Поддержка S/PDIF (на тех картах, где этот порт реализован)
Готовность к использованию WDM (WDM ready)
Аппаратное ускорение обработки потоков DirectSound и DirectSound3D
Поддержка DLS (Level 1)
Драйверы с сертификатом Microsoft WHQL
Поддержка AC97 кодеков
Creative Labs Sound Blaster Live
(SB Live) Это PCI устройство, сочетающее в себе синтезатор-сэмплер, мультиэффект процессор, цифровой микшер, многоканальный аудио рекордер, процессор пространственного позиционирования звука, цифровой аудио и MIDI интерфейс в одном флаконе, я бы даже сказал практически в одном чипе. Главный прорыв здесь в показателях цена/качество и цена/возможности. То что стоило раньше $1000, теперь стоит $150 (а некоторые модификации даже $50)! Это делает доступным новое качество звучания массовому покупателю.
Как говорилось ранее, все эти удивительные возможности сосредоточены в одном небольшом кусочке кремния в керамической оболочке и имя ему - EMU 10K1. Это DSP (Цифровой сигнальный процессор) ориентированный на обработку цифровых аудио данных разработан, как видно из названия, фирмой E-MU, известнейшим производителем профессиональной аудио техники уже давно принадлежащей фирме Creative.
EMU10K1 на сегодня один из мощнейших DSP применяемых в звуковой индустрии. В нем использована та же технология, что и в профессиональных изделиях фирмы E-MU E-synth и Audio Production Studio. Этот чип интегрирует в себе музыкальный, звуковой и эффект процессоры. Все сигналы обрабатываются с точностью 32 бит 48 КГц с использованием запатентованной 8-ми точечной интерполяцией для уменьшения искажений.
Заявленные производителем аудио характеристики действительно впечатляют.
|
RATED LINE OUTPUT |
FULL SCALES OUTPUT |
|
|
Line Output Dynamic |
1.0 Vrms |
1.40 Vrms |
|
Frequency Response at -1dB |
10Hz to 44kHz |
10Hz to 44kHz |
|
Signal-to-Noise Ratio (A-weighted) |
96 dB |
100 dB |
|
THD + Noise (A-weighted) |
0.002% |
0.002% |
Конечно, такие параметры как соотношение сигнал/шум и искажения сильно зависят от способа измерения. Производитель, как правило, избирает способ дающий лучшие результаты для его изделия. Поэтому для объективности необходимо сравнение с другими платами.
На SB Live! нет ПЗУ, он использует до 32 Мб системной памяти компьютера для хранения сэмплов (звуковых фрагментов, из которых состоят инструменты), то есть является фактически сэмплером с очень хорошими синтезаторными возможностями (фильтры, конверты, LFO, многослойная структура инструментов и т.д.), соответствующими современному уровню wavetable синтезаторов. Для выделения системной памяти под банки инструментов используется технология dynaRAM, позволяющая динамически увеличивать или уменьшать буфер в системной памяти под банки инструментов (SoundFonts). Это очень удобно - не надо искать специальные модули памяти для расширения памяти на карте, загрузка банков практически мгновенная, к тому же память выделяется в виртуальном адресном пространстве, а не в физической памяти и может свопироваться на диск, освобождая физическое ОЗУ для других программ при необходимости. Единственный минус данной технологии - использование некоторого количества системных ресурсов при работе синтезатора, т.к. сэмплы при игре прокачиваются по шине PCI из системной памяти в EMU10K1, но это занимает не более 5% пропускной способности шины в самом пиковом случае (максимальной полифонии) и практически этим можно пренебречь.
Технические характеристики синтезатора:
Полифония 64 голоса аппаратно с 8-ми точечной интерполяцией
Полифония 512 голосов (с последними драйверами) программно
48 MIDI каналов - 32 на аппаратный (2 MIDI порта) и 16 на программный синтезатор
SoundFont технология загружаемых наборов инструментов
До 32 МБ системной памяти для загрузки инструментов
С картой поставляются три GM/GS совместимых набора инструментов 2МБ, 4МБ и 8МБ, а также около 50-ти демонстрационных банков (всего около 100 МБ) для различных направлений музыки от классики до ультра современных стилей. Есть отличный редактор загружаемых инструментов Vienna SoundFont Studio 2.3 для редактирования существующих и создания новых банков инструментов в формате SoundFont 2 (SF2). Субъективно сэмплер звучит хорошо, признаться даже не ожидал от Креатива. Звучание любого сэмплера полностью зависит от того, какие звуки в него будут загружены, поэтому для профессионального использования возможностей SB Live! необходимы профессиональные библиотеки сэмплов в формате SF2. Фирма E-MU и сторонние производители поставляют CD ROMы с банками инструментов в формате SF2.
Эффект-процессор
Возможности эффект процессора:
Поддерживает цифровые эффекты в реальном времени такие как реверберация, хорус, флэнжер, дисторшн, изменение высоты тона и др. для всех аудио источников;
Производит обработку, микширование и позиционирование аудио потоков, используя до 131 аппаратных канала;
изменяемая архитектура эффектов с установкой параметров эффектов и посылов со всех источников звука;
полностью цифровая обработка и микширование, исключающая появление шумов.
Другими словами есть эффект процессор с памятью, в которую можно грузить программы и параметры эффектов. Существуют пресеты (предустановки) на наборы эффектов, на алгоритмы и параметры каждого эффекта в отдельности. Можно использовать имеющиеся пресеты или создавать свои и сохранять их на диске, а затем загружать в эффект процессор. Предлагаются следующие эффекты: реверберация (более 50-ти видов), хорус, флэнжер, эхо, вокальный морфер, дисторшн, вращающийся динамик, сдвиг тона. У меня получалось загружать одновременно до 5-ти эффектов. Два из них можно назначить на MIDI контроллеры для поканальных посылов с синтезатора. На все пять можно назначать посылы с источников звука - цифровой S/PDIF вход, цифровой вход с CD (тоже S/PDIF), I2S цифровой вход (с DVD), аналоговый (линейный/микрофонный/CD) аудио вход и Wave/DirectSound поток. Тут открывается несколько интересных возможностей:
Можно использовать бластер как мультиэффект процессор в реальном времени, то есть на вход подавать аналоговый или цифровой сигнал, например, петь в микрофон, а на выходе получать сигнал обработанный эффектами. Все это, естественно можно тут же записывать в файл, причем можно писать обработанный сигнал, а можно необработанный (обработка при этом слышна).
Wave/DirectSound поток, например wav файл или играющий программный синтезатор, также можно пропустить (или не пропускать) через эффекты и тут же записать в другой wav файл прямо в цифровом виде без D-A-D преобразований. Это очень удобно при использовании программных синтезаторов, особенно не умеющих самостоятельно писать в файл. Лайв позволяет использовать до 32-х одновременно работающих звуковых сессий, поэтому гипотетически можно, например, в SoundForge записывать одновременно несколько работающих программных синтезаторов.
Что касается качества эффектов, то оно достаточно высокое, примерно на уровне внешних процессоров эффектов стоимостью 200-400 долларов (типа Alesis MIDIVerb), к тому же поскольку эффекты подгружаемые, возможно их совершенствование в дальнейшем. Надо отметить, что существуют программные эффекты в виде DirectX плагинов, которые по качеству значительно превосходят предлагаемые Бластером.
Технология 3D позиционирования
Возможности:
Выбираемые пользователем установки оптимизации для наушников, 2-х или 4-х колонок
аппаратное ускорение DirectSound и DirectSound3D
поддержка до 32-х Direct3D потоков (с последней версией драйверов)
поддержка EAX расширения 3D позиционирования
Creative Multi Speaker Surround технология позиционирования источников звука в 360o аудио пространстве
Эмуляция акустических характеристик различных помещений (холл, театр, клуб и др.) для всех источников звука
Цифровой аудио акселератор
Возможности:
Запись/воспроизведение с точностью 8 или 16 бит
Частота квантования от 8 до 48 КГц
Вся обработка 32 битная
Запись/воспроизведение с аналоговых и цифровых входов/выходов
Аппаратный полный дуплекс (одновременная запись и воспроизведение)
Поддержка до 32-х одновременных аудио сессий с аппаратным 32 битным микшированием
К сожалению, фирма Creative пока нигде не описывает параметры использованных АЦП/ЦАП. Субъективно на слух воспроизведение очень хорошее, без шумов, звук прозрачный, не пластмассовый. Запись тоже вполне пристойная, но звук мне показался несколько жестковатым. Проблема некоторой неуверенности во входных преобразователях решается установкой внешнего АЦП, например Midiman Flying Calf A/D (20 bit 128 oversapling) стоимостью менее 200 долларов. При этом мы полностью избавляемся от возможных помех внутри корпуса компьютера, т.к. в компьютер у нас идет только цифра (S/PDIF) и получаем отличный 20-ти битный входной тракт за приемлемые деньги. Для домашней компьютерной студии главное хорошо оцифровать, дальше вся работа происходит в цифре и на выходе - записанный компакт, опять же цифровой, а для мониторинга аналоговые выходы SB Live! вполне пригодны. Также хочу отметить еще один небольшой недостаток SB Live! - цифровой выход только 48 КГц, но мне кажется это не очень существенно.
MIDI интерфейс
Поддерживается MPU-401 UART режим.
Коннекторы
Внешние на основной плате:
Микрофонный вход
Линейный вход
Линейный выход фронтальный
Линейный выход тыловой
Джойстик/MIDI порт
Внешние на дополнительной плате:
RCA S/PDIF вход
RCA S/PDIF выход
MIDI вход
MIDI выход
Цифровой выход для будущего 8-ми колоночного расширения
Внутренние на основной плате:
CD цифровой вход (S/PDIF)
I2S цифровой вход
CD аналоговый вход
Аналоговый вход с автоответчика
AUX вход
Совместимость
Windows 95, 98
Windows NT 4.0
Microsoft DirectSound, Ditect3D
General MIDI
MPC-3
PCI 2.1
Системные требования
Минимально P133 16 Mb RAM (32 Mb сильно рекомендуют), PCI 2.1, но чем всего больше, тем лучше.
В настоящее время выпускается несколько моделей SB Live!: SB Live!, SB Live! Value, SB Live! Player, SB Live! 1024, SB Live! Platinum etc Они отличаются лишь комплектацией, поставляемый ПО и незначительными изенениями в разводке. Все же технические характеристики у них одинаковы.
Сравнение двух монстров сегодняшнего рынка средних звуковых карт (SB Live и Diamond Monster MX300)
Точнее, сравнение будет не двух, а двух с половиной карт. Для интереса в тестирование была включена вышеописанная карта на YMF-724, из совсем другого ценового диапазона. Тестирование будет нести в себе дополнительную цель, проверить, так ли хороша эта “удивительная” карта с возможностями Live’a и ценой старой ESS.
Люди готовые потратить $10 покупают старые и проверенные ISA карты на базе OPTi 931 и ESS1868, за $15 нас ждет не менее старые и проверенные PCI ESS Solo-1 и отличная, в своем классе, Yamaha YMF-724. За $20 Vortex 1 и Ensoniq 1370, в том числе в Creative исполнении. За $25 можно купить ветерана - SoundBlaster AWE32. При этом, ниша $30 остается просто незаполненной со стороны PCI карт, если не считать морально устаревшие решения от Creative на базе Ensoniq 1371.
Далее плечом к плечу идут два смертельных врага - SoundBlaster Live! (EMU10K1) и Diamond Monster Sound MX300 (Vortex2). Это для владельцев $40..60. Причина столь высокой консервативности рынка была называется легко специалистом по продажам. "Продается только то, что у покупают, а покупают либо проверенные карты за $10-20, либо известных лидеров за $60. Третьего не дано."
Вот почему для сравнения было привлечено интегрированное в материнскую плату Chaintech 6BTA2 звуковое решение на базе Yamaha YMF-724, которое, в случае покупки новой материнской платы, обходится лишь в $10 разницы (по сравнению с 6BTM). Итак, приступим:
Внешний вид
Начнем с YMF724, интегрированного в материнскую плату. Сам чип расположен далеко от аудио разъемов, но это не внушает опасения, благодаря внешнему AC'97 кодеку. Кодек TriTech 28023 распаян в непосредственной близости от разъемов и, что явилось немаловажным сюрпризом, аудио сигналы выведены на разъемы напрямую, без каких либо активных буферных или усилительных элементов. Разумеется, присутствуют выходные RC фильтры, но не более того. Забегая вперед, заметим, что именно это способствовало поразительным для 16 бит аудио решения результатам в тестах на соотношение сигнал/шум. Подобный подход имеет свои плюсы и минусы, за более высокое качество передачи сигнала приходится расплачиваться незащищенностью и слабой нагрузочной способностью аудио входов и выходов. Еще одно преимущество интегрированного решения - многослойная материнская плата способная обеспечить гораздо более качественную разводку аудио сигналов, нежели многие двусторонние PCI платы. Присутствуют два разъема для подключения кнопок цифрового регулятора общей громкости, если таковой имеется в корпусе компьютера или сделан самостоятельно. Есть разъем для подключения CD привода или любого другого источника линейного сигнала. Не распаяны два разъема, судя по всему, один из них цифровой выход, назначение второго не ясно. Еще присутствует не упомянутый в документации разъем моно входа для модема, обозначенный на плате как CN19 и находящийся в непосредственной близи от кодека.
Sound Blaster Live! Value порадовал многослойной платой с позолотой, высоким процентом распаянных деталей (не были распаяны лишь несколько маловажных разъемов и один буферный усилитель непонятного назначения). На плате присутствует гребенка цифрового интерфейса (4 SPDIF выхода и один вход, обозначены как SPDIF_EXT), и что крайне приятно, распайка всех разъемов приводится в электронной документации. Цифровые входы и выходы имеют нестандартный для аудио оборудования уровень сигнала (соответствующий цифровой логике), в результате чего не все источники могут быть успешно к ним подключены. А вот на раздельно микшируемом отдельном цифровом входе для CD (обозначен как CD_SPDIF), наоборот присутствует буферный элемент, позволяющий подключать не только CD приводы (с как правило логическим уровнем сигнала), но и другое SPDIF оборудование. Четыре цифровых выхода от этого не страдают, т.к. небольшая перегрузка подключаемого к ним оборудования не существенна, в отличии от недостатка сигнала для нормальной работы входа. Есть не распаянный разъем для кнопок регулировки громкости. Распаяны два различных разъема TAD (моно вход-выход для модемов) и два дополнительных линейных входа - CD_IN и AUX_IN. Еще есть не распаянный разъем I2S - цифровой многоканальный интерфейс для декодеров DVD и прочего пока несколько футуристического оборудования. На аналоговых входах активные буферные элементы отсутствуют (за исключением микрофонного), на выходах дело обстоит несколько странно. Если фронтальные колонки выведены с главного 18 бит AC'97 кодека CT1297, через микросхему буферного усилителя, то тыльный сигнал идет с дополнительной микросхемы 18 бит ЦАП (Phillips 1330A) напрямую, обладая меньшей нагрузочной способностью. Но самое интересное, что в результате, на тыльных выходах присутствует более качественный сигнал, вероятно благодаря более высокому качеству дополнительного ЦАП.
Diamond Monster Sound MX300 поражает своими размерами. Он больше Live! в полтора раза, при этом количество элементов на плате приблизительно во столько же раз меньше. Размеры продиктованы не только соображениями солидности, но и наличием корректно расположенного разъема для дочерней платы волнового синтеза. Присутствует большой разъем для дополнительной карты цифрового ввода вывода, но его распайка не известна и, в отличие от Live!, он не может быть использован без этой самой платы. Цена $30 скорее всего не напугает желающих подключить декодер AC-3 или другое цифровое оборудование, но вот наличие этой платы на нашем рынке, к сожалению, не гарантированно. Позолоченные внешние аудио разъемы вне конкуренции, как и благородный черный цвет планки, на которую они крепятся. Есть два внутренних линейных входа и разъем TAD. Непонятно назначение не распаянного дополнительного стерео выхода, дублирующего фронтальные колонки. Монтаж аккуратен, но не столь качественен, как в случае Live!. Количество не распаянных деталей выше. Один четырехканальный AC'97 18 бит кодек SigmaTel. Буферные усилители присутствуют как на фронтальном, так и на тыльном выходе.
Шумы
Здесь нас ждет несколько сюрпризов. Тестирование проводилось на одном и том же компьютере: Celeron 450A, 64Мб 8 нс PC-100 памяти, Chaintech 6BTA2, Creative GB TNT, Quantum SE 4.3Gb. Платы вставлялись в один и тот же разъем PCI, в соседних двух разъемах по обе стороны какие либо платы отсутствовали. Методика тестирования - 1000Гц эталонный сигнал, положение ручек усиления регулировалось каждый раз для достижения максимального, без сильного роста искажений и перегрузки пропускания (как правило, это -3Дб..-5Дб, которые могли бы быть прибавлены к результатом, если бы нас интересовало лишь получение максимальных сигнал-шум характеристик, но точность передачи сигнала не менее важна). Измерялось внутреннее кольцо (запись с внутреннего микшера) и внешнее кольцо (запись с линейного выхода-1 на линейный вход) как в присутствие сигнала, так и в его отсутствие. Остальные источники были полностью выключены. Т.к. качество оцифровки превышает качество воспроизведения во всех трех случаях, полученные параметры можно смело отнести к выходным. Использовались частоты дискретизации 44100 и 48000 Гц, 16 бит стерео сигнал.
|
Сигнал |
Квантование |
Линейный вход, Дб. |
Стерео микшер, Дб. |
||
|
Максимум |
Средние |
Максимум |
Средн. |
||
|
Diamond Monster Sound MX 300 (Vortex2) |
|||||
|
1000 Гц |
44100 |
72 |
76 |
77 |
79 |
|
48000 |
68 |
70 |
70 |
73 |
|
|
Нет |
44100 |
80 |
87 |
84 |
89 |
|
48000 |
75 |
79 |
78 |
83 |
|
|
Creative Sound Blaster Live! Value (Emu10K1) |
|||||
|
1000 Гц |
44100 |
72 |
75 |
76 |
78 |
|
48000 |
76 |
78 |
Нет |
Нет |
|
|
Нет |
44100 |
82 |
90 |
86 |
91 |
|
48000 |
89 |
93 |
Нет |
Нет |
|
|
Chaintech 6BTA2 integrated (YMF724) |
|||||
|
1000 Гц |
44100 |
73 |
76 |
74 |
77 |
|
48000 |
73 |
77 |
75 |
77 |
|
|
нет |
44100 |
82 |
89 |
84 |
88 |
|
48000 |
83 |
88 |
85 |
89 |
Итак, приступим к разбору полетов, а точнее шумов. Сюрприз номер один - результаты интегрированной в материнскую плату YMF724. А, точнее 16 бит кодека от TriTech, разведенного без каких либо буферных элементов. Это практически запредельные результаты для 16 бит кодеков подобного класса. Фактически, копеечное аудио в материнской плате умудрилось побить MX300 по качеству воспроизведения. Сюрприз номер два - сильно выраженные зависимости отношения сигнал шум от частоты квантования как у MX300 так и у Live!. Природа этого явления проста - кодеки обоих карт работают на фиксированных частотах квантования, а цифровые данные динамически перевыбираются для приведения к этой заданной частоте. Но подобное преобразование неизбежно вносит собственный вклад в помехи. Причем, судя по результатам, кодек Live! работает на частоте 48000 а кодек Vortex2 наоборот, на частоте 44100. В документации на чип говорилось о 48000 но, вероятно, инженеры из Diamond Multimedia сочли необходимым установить фиксированную частоту равной обще принятому стандарту на цифровой звук, дабы повысить качество воспроизведения в большинстве программ. Итак, можно рекомендовать владельцам Live! настраивать свои программы на 48000, а владельцем MX300 на 44100. Еще один сюрприз - десяти полосный цифровой эквалайзер в Vortex2. По заявлениям Aureal имеющий отношение сигнал шум порядка 96 Дб. На практике все оказалось гораздо хуже - в случае отсутствия сигнала эквалайзер действительно не вносит дополнительных шумов, что вполне логично, учитывая его цифровую природу. Зато в нормальном режиме шумы абсолютно непереносимы, выдвинутые в максимальные позиции движки способны ухудшить отношение сигнал шум на добрых 15-20 Дб, что абсолютно не приемлемо. Приговор прост - отключить его раз и навсегда, и пользоваться внешним усилителем с эквалайзером.
При работе с Live! также были замечены несколько странностей. Периодически (несколько раз в секунду) появляется кратковременное постоянное смещение порядка 10Дб, причем это происходит только при частоте квантования 44100. Вероятно, в это время DSP переходит границу внутреннего буфера, с помощью которого выполняется расчет эффектов или перевыборка частот, причем реализован этот переход некорректно. Отключение всех эффектов не спасает от этой помехи, зато переход на частоту 48000 способен от нее избавить. Подобная же помеха наблюдается во время регулировки громкости или примерно через треть секунды, после прекращения какого-либо сигнала вне зависимости от частоты квантования. Еще одна странность Live! - непомерное задирание высоких частот, при установленном в настройках режиме вывода на наушники. При установке дешевых пищалок этот подход оправдывает себя, т.к. способен несколько подправить их ущербную АЧХ, но в случае мало-мальски нормальных наушников звук становится отвратительным, и даже крайнее положение регуляторов тембра не спасает ваши уши. Кстати, эти регуляторы в Live! сделаны на славу, они практически не вносят шумов, хотя, есть подозрение на их цифровую природу.
Последнее замечание - о микшировании сигналов. Если в MX300 и 6BTA2 эти функции полностью возложены на кодеки (аналоговое микширование), то в Live! микширование выполняется цифровым образом везде, где это только возможно. Поэтому при записи с внутреннего микшера параметры определялись только шумами перевыборки, а в случае частоты квантования 48000 шумы практически отсутствовали (т.е. превышали -96 Дб).
Загрузка процессора и прочие цифры
Для всех карт использовались последние из доступных на данный момент официальных драйверов (т.е. релизы). Для сравнения приведены данные на карту Ensoniq Audio PCI (чип ES1370), у которой отсутствует аппаратное ускорение DirectSound.
|
Параметр |
MX300 |
Live! |
6BTA2 |
ES1370 |
|
DirectSound каналов аппаратно |
32 |
32 |
20 |
0 |
|
DirectSound3D каналов аппаратно |
16 |
32 |
8 |
0 |
|
Загрузка CPU, DirectSound, 44100, 16 бит, 8 каналов |
0.78 |
0 |
1.06 |
1.89 |
|
Загрузка CPU, DirectSound, 44100, 16 бит, 16 каналов |
1.65 |
0 |
1.82 |
3.21 |
|
Загрузка CPU, DirectSound, 44100, 16 бит, 32 канала |
4.58 |
0 |
3.62 |
5.97 |
|
Загрузка CPU, DirectSound3D, 44100, 16 бит, 8 каналов |
6.85 |
1.8 |
8.09 |
13.8 |
|
Загрузка CPU, DirectSound3D, 44100, 16 бит, 16 каналов |
7.90 |
2.44 |
20.4 |
25.1 |
|
Загрузка CPU, DirectSound3D, 44100, 16 бит, 32 канала |
32.8 |
3.56 |
40.2 |
53.7 |
Какие же выводы можно сделать глядя на эту колонку цифр. Live! несомненно чемпион, загрузка процессора минимальна. Правда, в отличие от предыдущих драйверов, при воспроизведении DirectSound3D потоков она стала возрастать линейно с числом голосов, хотя и не превысила предыдущие значение (порядка 4% при любом количестве голосов). Это легко объяснить, появлением HRTF функций, для которых необходима предварительная обработка данных процессором отдельно для каждого потока, а не только установка параметров реверберации всего помещения, как это было раньше. Именно благодаря тому, что Live! является полноценным DSP с загружаемыми на борт программами, загрузка процессора столь низка. Даже в случае применения HRTF функций, пусть и не столь совершенных, как у MX300 (о качестве 3D звука будет сказано далее).
На втором месте MX300, причем удивляет стабильный рост нагрузки при росте числа 2D потоков (попахивает программной эмуляцией, особенно если сравнить результаты с практически аналогичными у ES1370), вероятно все железные возможности были направлены на обработку 3D потоков и их отражений. В случае 3D все хорошо до тех пор, пока число каналов не превысит 16, аппаратно ускоряемые чипом. В новых драйверах обещают поддержку 76 3D потоков, но не известно, окажется эта поддержка полностью аппаратной или нет, и не ухудшит ли она качество 3D звука. Причем OEM версия новых драйверов 2030 уже доступна в сети на сайте Aureal. В этих драйверах реализована поддержка 76 потоков 3D звука и обещено существенное снижение загрузки CPU, осталось дождаться Retail релиза драйверов от Diamond.
На третьем месте 6BTA2 и чип YMF724 соответственно, судя по загрузке процессора, HRTF 3D звук от Sensaura реализуется полностью программно.
Качество
Вот здесь и начинается самое интересное. У MX300 3D звук практически идеален, как на двух, так и на четырех колонках. Перемещение верх-низ отлично прослушивается, чего не скажешь про остальных героев этой статьи. При подключении четырех колонок оживает последняя ось - вперед-назад и звук становится полностью трехмерным. Программы, поддерживающие A3D 2.0 способны создать еще более реальное звучание, благодаря учету отраженного и проходящего через препятствия звука. Если вам важен лишь 3D звук и игровые возможности покупайте MX300 не задумываясь. А вот качество воспроизведения MIDI, возможности синтезатора и эффект процессор не идут ни в какое сравнение с Live! и YMF724. Мягко говоря, MIDI и эффектами на MX300 лучше не пользоваться, чего стоит один треск во время проигрывания DLS банков, ужасный хорус эффект или шумный эквалайзер.
На данный момент драйвера Live! не позволяют достоверно определять верх-низ и поэтому звук в играх скорее 2.5D. EAX основанный на заранее выбранной для каждого помещения в игре реверберации придает звуку естественность, но не позволяет свободно ориентироваться, сводя тем самым все игровое преимущество на нет. Правда, в новых драйверах, которые выйдут в конце этого месяца обещают полноценные HRTF функции (причем речь идет о реализации HRTF для 4-х колонок), с не менее качественным, нежели у MX300 позиционированием верх-низ и просчетом проникающего и огибающего предметы звука. В EAX 2.0 параметры реверберации станут меняться в зависимости от положения игрока, что, возможно, обеспечит не менее качественную, чем у MX300 ориентацию в пространстве. Подождем, увидим! Если это будет действительно так, MX300 сильно сдаст свои позиции. MIDI у Live! просто великолепно, оно соответствует всем профессиональным требованиям, поддерживается прекрасный формат банков SoundFont 2.0, звучание EMU10K1 превосходит EMU8001 (AWE32-64), DSP Dream и другие распространенные на PC синтезаторы, за исключением, пожалуй, дочерних карт от Yamaha - DB50XG. Но последние не способны загружать внешние банки инструментов, а в случае Live! их размер практически не ограничен (драйвера разрешают отвести до половины системной памяти, но этот порог преодолевается внесением исправлений в реестр). Регуляторы громкости на Live! ведут себя несколько иначе, чем на остальных картах. Передача сигнала один к одному соответствует примерно 55-60% положению для многих движков микшера. Это оставляет простор для усиления слабых сигналов, но и способно привести к искажениям, если не знающий об этой особенности человек будет по привычке выставлять максимум при записи с цифрового или линейного входа. Последний момент - возможность поставить на Live! драйвера от стоящей $600 профессиональной платы EMU Audio Production Studio. При этом перестает работать аналоговый выход (на APS стоит специальный 20 бит кодек от Crystal), но данные можно снимать с цифрового выхода, сэкономив, таким образом, несколько сотен долларов, при сохранении всех возможностей драйверов APS.
Материнская плата Chaintech 6BTA2 и расположенный на ней YMF724 предоставляют достаточно неплохой 3D звук на двух колонках, в отличие от Live!, с возможностью, в большинстве случаев различать верх-низ. К сожалению, при этом сильно загружается процессор, и требовательные к ресурсам игры идут медленнее. С первого взгляда может показаться, что MIDI на высоком уровне, практически как у DB50XG, но постепенно всплывают различия. Как сознательно, так и по необходимости, привнесенные фирмой Yamaha. Банк вдвое меньшего размера, отрабатываются все основные XG эффекты, но, судя по их реализации, это делается программно (несколько шумно) а не аппаратно, да и рассчитывается всего 16 бит (а не 18, как на DB50XG, имеющей, кстати, три аппаратных процессора эффектов). И все равно, благодаря XG формату и эффектам большинство MIDI композиций звучит очень прилично. В новых драйверах появилась поддержка EAX, загружающая процессор сильнее, чем у Live! и как-то неестественно сухо звучащая.
Итоги
Пока все осталось на своих местах. Если Вы хотите играть - MX300. Если Вы хотите писать музыку, слушать или записывать живой звук - Live!. Если у вас нет денег на Live!, но Вы все равно хотите писать и слушать, то купите YMF724 с добротным кодеком, точно не пожалеете.
Некоторые аспекты качественного воспроизведения цифрового звука
Качеству звучания звуковых плат уделяется должное внимание, но по непонятным причинам в обзорах обходят аналоговую часть схемы. Все преимущества в программной и цифровой части могут с легкостью потеряться из-за несовершенной аналоговой части схемы. Это важно в первую очередь для музыкантов и аудиофилов, но может быть полезно и для рядовых слушателей, заинтересованных в качественном воспроизведении на компьютере музыки.
Основные проблемы с возникновением искажений по причине схемотехнических приложений возможны как на входах, так и на выходе. Вход для оцифровки аналогового сигнала (линейный вход, микрофон) требует обязательной фильтрации частот не входящих в звуковой диапазон. Особенно опасна частота, близкая к частоте дискретизации (~44 кГц) - возникают разностные частоты при умножении входного сигнала и помехи на первом же усилительном (нелинейном) элементе. Получаются помехи в звуковом диапазоне, которые уже нет возможности отфильтровать. Входной фильтр должен быть рассчитан так, чтобы выполнять функции согласующего устройства с источником сигнала. Встроенный микрофонный усилитель с этой задачей справляется, а вот линейный вход часто не имеет стандартизованного сопротивления. Ненормальное соотношение высоких и низких частот является следствием этого рассогласования.
Вход для аналогового сигнала от CD-ROM также должен содержать фильтр подавления частоты дискретизации. Выходной сигнал перед подачей на звуковую плату не фильтруется, чтобы не конфликтовать с фильтром на карте. Большое количество встречающихся звуковых плат разрабатывались с фильтром, но на практике фильтр отсутствует. Примерно такой же фильтр необходим на выходе карты после ЦАП (DAC). Его реализация особенно необходима при записи сигнала на магнитную ленту, поскольку усилитель записи выходит из нормального режима и происходит насыщение и паразитное намагничивание магнитной ленты. Подмагничивание ленты производить необходимо для качественной записи низких звуковых частот, это продиктовано физическими особенностями записи на магнитные носители, а частота дискретизации производит нарушение режима подмагничивания. Еще возникают проблемы с внешними усилителями мощности с глубокой обратной связью (скажем, плохие усилители, склонные к возбуждению). Замечается неустойчивая работа усилителя или выход его из строя.
Использование на плате перемычек для конфигурирования аналогового тракта только приветствуется. Очень неприятно обнаружить отсутствие линейного выхода на звуковой плате, т.к. использовать сигнал, пропущенный через встроенный усилитель для подачи на внешний усилитель нежелательно. Встроенный усилитель, рассчитанный на применение с наушниками или маленькими динамиками, имеет не лучшие характеристики, особенно по шумам и гармоникам, да и низковольтное питание от компьютерного импульсного блока питания, на котором висят цифровые схемы, качества не добавляет - появляются специфические шумы от работы цифровых микросхем и двигателей приводов внешних накопителей.
Часто, чтобы добиться сносного звучания приходится впаивать перемычки (джамперы), которые подразумеваются, но отсутствуют на плате. К примеру, для отключения встроенного усилителя. Причем наибольшие шумы наводятся по питанию именно на усилитель (слышно "работу" CD-ROM и винчестера, т.к. он обычно питается от 12-вольтовой шины). На этой шине нет специальных решений для фильтрации помех, а мощные двигатели приводов производят их в большом количестве. Изучение множества плат привело к печальным выводам. Ни маститые производители, ни производители с востока с "левыми" платами не уделяют должного внимания аналоговой части своих карт. Часто это представлено в виде отсутствия "лишних" деталей на плате, особенно этим поражены "левые" платы. Интересно, кому нужна такая "экономия" на мелочах? :-)
Некоторое удивление вызвало знакомство с новой платой Monster Sound MX300 от компании Diamond Multimedia. Революционность чипа Vortex 2 не вызывает сомнений, но реализация платы выдает стремление фирмы экономить на всем, чем можно и нельзя. Возможно, сам чип не дешев, но и цена платы не мала, можно было и постараться. Отсутствует должная реализация фильтров на выходе с ЦАП и входе с CD-ROM. Усилитель для наушников сделан на транзисторах, возможно для меньших искажений при низком напряжении питания (но такая схема не борется с синфазными искажениями!!!), а, скорее всего, из экономии. Радует отдельный линейный выход. Возможность же получить от этой карты все в воспроизведении звука требует платы расширения с цифровым выходом S/PDIF (MX-25). Но для этого потребуется усилитель с цифровым входом или применить внешний ЦАП и усилитель, получим почти Hi-End. Главные плюсы в отдельном блоке питания для ЦАП и все-таки грамотное аналоговое решение. В качестве положительного примера следует выделить фирмы Gravis (к сожалению ушедшей с рынка звуковых карт) и Voyetra Turtle Beach. На платах любых ценовых категорий и направлений аналоговая часть решена великолепно. Даже старая карта Gravis Ultrasound GF1 (как много в этом звуке... :-)) в дешевом варианте, соизмеримом в свое время по цене с современной платой MX300 с точки зрения рассматриваемого вопроса произведена очень хорошо. Все необходимые фильтры рассчитаны с запасом, а особенно приятно множество перемычек, с помощью которых можно обходить любой фильтр и усилитель при применении внешних фильтров и усилителей. Примерно такой должна быть конфигурация звуковой платы для качественного воспроизведения звука. Надеюсь, что и плата Montego II Quadzilla на Vortex 2 будет при соизмеримой цене лучше MX300, а модификация Home Studio еще содержит и цифровой вход/выход S/PDIF и оптический вход/выход на основной плате.
Руководствуясь этим наблюдением можно выделить несколько пунктов, учет которых желателен при выборе звуковой платы:
Желательно иметь отдельный линейный выход или перемычки для обхода сигналом внутреннего усилителя, что позволит не вносить в сигнал дополнительных шумов при выводе на внешний усилитель.
При использовании звуковой платы в качестве источника сигналов для записи на магнитный носитель необходим фильтр, режущий частоту дискретизации. Это относится к любым выходным сигналам независимо от того, как они синтезировались, будь то WAV, MIDI или сигнал синтеза.
Для исключения проблем с воспроизведением, оцифровкой и микшированием звука с Audio CD, требуется, чтобы по входу для CD-ROM стоял фильтр того же плана, что оговорен в предыдущем пункте.
Для использования платы для качественной оцифровки аналогового звука на входе требуется хороший активный фильтр.
Пара моментов, которые отчасти могут объяснить отсутствие входных (anti-aliasing) и выходных сглаживающих (smoothing) фильтров:
1. Безусловно, перед оцифровкой аналогового сигнала его необходимо пропустить через входной фильтр 4-8 порядка с частотой среза 20 кГц дабы подавить дополнительные спектральные составляющие, зеркальные основному спектру сигнала относительно частоты дискретизации. Интересующиеся могут прочитать любую книгу по основам цифровой обработки сигналов в библиотеке или просмотреть главу из соответствующей книги прямо в книжном магазине. Но, вообще говоря, большинство современных многоразрядных (16 и более) АЦП выполнены на базе сигма-дельта технологии. Отличительной чертой данных АЦП является существенно повышенная частота дискретизациия сигнала (1...15...20 Мгц в зависимости от реализации) и постобработка цифрового потока нардверным цифровым фильтром, встроенным в АЦП до необходимой полосы (20 - 22 кГц). Поскольку дополнительный спектр сигнала при этом смещается в область запредельных частот, то и достаточное его подавление возможно очень простым фильтром. Очевидно этим и объясняется отсутствие входных фильтров на входах плат или наличие совершенно простенького фильтра 1-2 порядка, вызывающее недоумение у людей, которые более-менее сталкивались с этими проблемами в профессиональных/любительских условиях.
2. Касаемо выходных (сглаживающих, восстанавливающих - кому какая терминология нравится :-)) фильтров. Многие, видимо читали в описании CD ROM о том, что в нём стоит 1 разрядный ЦАП с 8х частотой дискретизации. Очевидно, что и в них применяется сигма-дельта технология, что также позволяет использовать фильтры малых порядков для восстановления аналогового. Сдаётся мне, что в High End CD проигрывателях, к которым нельзя отнести CD ROM даже с большой натяжкой, эта технология не применяется. Так что можно считать, что с CD ROM приходит нормально отфильтрованный аналоговый сигнал, который на звуковых платах просто приходит на аналоговый мультиплексор - кстати, один из источников дополнительных гармоник, хоть и небольших....
А теперь обратимся к выходу. Как правильно замечено, на большинстве карт, особенно на дешёвых, нет линейного выхода. Сигнал подаётся на выход через достаточно дешёвый выходной усилитель с полосой усиления входного сигнала достаточной, чтобы можно было считать сам усилитель ещё и фильтром... :-), на входе которого, опять таки стоит небольшой пассивный фильтр, дабы не перегружать усилитель слишком сильно высшими гармониками. Стоит предусмотреть на такой плате наличие линейного выхода, так сразу же возникает проблема выходного фильтра. Вспомним, что для более-менее приличного восстановления сигнала требуется, как минимум, фильтр 4, а лучше 8, порядка, что вызывает потребность такого количества прецизионных элементов, подверженных старению, что у производителя волосы дыбом становятся. Использование активных фильтров на коммутируемых конденсаторах компании MAXIM (http://www.maxim-ic.com/efp/Filters.htm) или подобных было бы хорошей идеей. Но их стоимость - $3.00 и выше вызывает явные признаки недовольства у производителей звуковых плат. Причём, это стоимость на один канал - умножьте это на 2, а то и на 4 канала и получите стоимость только фильтров равную стоимости всей платы в розничной торговле.
Вывод из всего этого напрашивается следующий: если Вам действительно необходим качественный линейный выход и/или хороший качественный звук из колонок ( а кто этого не хочет :-) ) то есть три пути:
Использование дорогих звуковых карт с линейным выходом с хорошей фильтрацией + качественные колонки
Использование карт с цифровым выходом (я думаю, что он скоро появится и на достаточно дешёвых картах) + качественный усилитель с цифровым входом) + качественные колонки
Использование колонок с USB входом. "Цифровой звук" - это конечно чисто рекламный ход для рядового потребителя - динамические грмкоговорители остаются теми же, несмотря на любые названия.
Наводки от аппаpатуpы компьютеpа на каpту
Унивеpсального метода борьбы с ними не существует. Каждый конкpетный случай опpеделяется типами и даже экземпляpами конкpетной каpты, системной платы, видеоадаптеpа, блока питания и т.п. Вначале имеет смысл опpеделить, по какой из цепей идут помехи, пpи помощи pегулятоpов уpовней в микшеpе. Hенужные входы (особенно микpофонный) вообще pекомендуется сpазу отключать или ставить на них нулевой уpовень гpомкости.
Если пpи нулевых уpовнях всех входов помехи остаются - скоpее всего, дело в наводках на саму каpту. Hужно поэкспеpиментиpовать с пеpестановкой каpт в pазъемах, напpимеp, звуковую - в самый дальний, а все остальные - в дpугой конец, или наобоpот. Hужно также попpобовать отключить все дополнительные устpойства - CDROM, стpимеp, винчестеp и т.п. - котоpые могут служить источ- никами наводок; некотоpые пpиводы генеpиpуют помехи пpи наличии электpического контакта с коpпусом компьютеpа - их пpидется установить чеpез пpокладки. Это относится и к системной плате - пpи наличии контакта с коpпусом в точках кpепления она также мо- жет способствовать помехам. Иногда помехи возникают в некачественных блоках питания, вентилятоpах охлаждения блока питания или пpоцессоpа, в плохо спpоектиpованных видеокаpтах, системных платах и т.п.
Внешние помехи чаще всего возникают пpи подключении CDROM к звуковому входу. Их источником может быть сам CDROM или звуковой кабель. Кабель желательно использовать экpаниpованный - скpученные пpовода больше подвеpжены помехам извне. Можно попpобовать отсоединить по очеpеди с одной из стоpон общие пpовода (экpан) кабеля, оставив соединение с коpпусом только в одном из pазъемов. Также имеет смысл пpоложить кабель так, чтобы он пpоходил максимально близко от коpпуса и максимально далеко от устpойств компьютеpа.
Может случиться и так, что данная модель звуковой каpты сама по себе плохо спpоектиpована или pазведена, отчего ловит свои собственные наводки. От этого можно избавиться только заменой каpты.
Цифровая звуковая рабочая станция
Digital Audio Workstation (DAW) представляет собой специализированную или универсальную компьютерную систему, способную выполнять запись, хранение, воспроизведение и обработку цифрового звука.
Специализированные системы ориентированы исключительно на работу с цифровым звуком и выпускаются в законченном исполнении, допускающем лишь ограниченное расширение, либо нерасширяемые вообще. Универсальные системы представляют собой обычный персональный компьютер, снабженный средствами для ввода/вывода звука (ЦАП/АЦП и/или цифровые интерфейсы) и набором программ для его записи, воспроизведения и обработки. Кроме этого, станция может содержать и другие компоненты - например, аппаратные модули цифровой обработки, музыкальные синтезаторы, записывающие CD-приводы и т.п.
Поскольку любая компьютерная система является сильным источником высокочастотных помех, возникают определенные проблемы в достижении профессионального качества звука при использовании встроенных АЦП/ЦАП. В таких случаях предпочтительно использование внешних модулей АЦП/ЦАП, выдающих и получающих цифровую информацию в реальном времени через универсальные или собственные цифровые интерфейсы.
Большинство специализированных рабочих станций используют для хранения звука жесткие диски с интерфейсом SCSI (Small Computer System Interface - интерфейс малых компьютерных систем), ставшие универсальным стандартом - любая популярная компьютерная система имеет возможность подключения этих дисков. Достоинствами SCSI является универсальность среди всех компьютерных систем, возможность подключения до семи устройств (любых, не только дисковых) к одному контроллеру, хороший арбитраж при конкуренции устройств, интеллектуальность каждого устройства, более высокое общее качество исполнения, возможность использования интерфейса для прямой связи между двумя станциями. К недостаткам SCSI следует отнести высокую стоимость интерфейсов и дисков и ограниченный спектр выпускаемых моделей.
В компьютерах типа IBM PC более популярны жесткие диски с интерфейсом IDE (Integrated Drive Electronics - электроника, встроенная в накопитель), не получившие распространения в других системах.
Достоинства IDE-дисков - простота, хорошая производительность, не уступающая большинству SCSI-дисков, а в ряде случаев - превосходящая их, низкая стоимость, массовый выпуск, широкий спектр моделей. Недостатки - низкая производительность и надежность моделей низших классов, возможность подключения только двух накопителей к одному контроллеру, невозможность прямого соединения двух станций, часто худшая поддержка драйверами операционных систем.
Среди пользователей звуковых рабочих станций - как домашних, так и студийных - бытует мнение, что только диски SCSI способны обеспечить нужное быстродействие. Однако, несмотря на ряд очевидных преимуществ SCSI, большинство даже профессиональных рабочих станций на IBM PC вполне может обходиться дисками IDE. Скорость чтения/записи типовых моделей IDE-дисков сегодня (конец 1998 г.) находится на уровне 6-10 Мб/с при времени поиска около 8-10 мс, что равнозначно таким же типовым (не High End) моделям SCSI.
Такой жесткий диск свободно справляется с одновременным чтением 16-разрядных звуковых данных по 20-30 звуковым каналам на частоте дискретизации 48 кГц, и несколько меньшим объемом данных в случае записи. Другое дело, что в случае SCSI его внутренняя оптимизация (сортировка запросов для минимизации перемещения головок в SCSI-2) часто маскирует неоптимальную работу ОС и звуковой программы, а для достижения такого уровня на IDE может потребоваться хороший драйвер ОС и аккуратно сделанная программа (например, DDClip).
Причины нелюбви многих пользователей к IDE-дискам происходят оттого, что с этими дисками они обычно сталкиваются в дешевых, некачественно собранных и протестированных компьютерах средней мощности, состоящих из разномастных компонент, нередко плохо совместимых друг с другом. И напротив - SCSI-диски чаще всего ставятся в более мощные и дорогие модели, содержащие компоненты "уважаемых" производителей, более тщательно собранные и проверенные. Замена во втором варианте диска SCSI на IDE примерно равной производительности и сборка/настройка системы с учетом особенностей IDE во многих случаях не окажет заметного влияния на ее производительность.
Класс AV (Audio/Video) у жестких дисков означает их способность предельно равномерно, без пауз, записывать и считывать потоки данных.
Такие диски снабжаются внутренним буфером большего размера и не прерывают процесса чтения/записи термокалибровкой системы позиционирования. Для систем цифровой записи, имеющих недостаточное быстродействие и объемы ОЗУ, чтобы сгладить возможные неравномерности в работе обычных дисков, диски класса AV являются единственным возможным выходом.
Следует иметь в виду, что наличие аббревиатуры AV в обозначении диска еще не означает его принадлежности к классу Audio/Video - об этом должно быть явно упомянуто в паспорте диска.
Однако указанная особенность в общем случае необходима только при работе с качественной видеоинформацией, скорость поступления которой составляет порядка 10 мегабайт в секунду на канал. В случае же звуковых систем скорость одноканального 16-разрядного потока с частотой дискретизации 48 кГц на два порядка меньше и составляет всего 94 килобайта в секунду. В то же время почти никакая рабочая станция не в состоянии обеспечить одновременную работу с сотней каналов, как и жесткий диск не в состоянии параллельно обрабатывать такое количество данных, расположенных в разных его участках. В реальных применениях многоканальной записи на одном диске основная часть накладных расходов дисковой подсистемы ложится на перемещение головок между участками записи, а отнюдь не на саму передачу данных. Низкая же скорость звуковых потоков делает более удобной и надежной их буферизацию в ОЗУ компьютера, компенсирующую термокалибровку диска в течение 0.5 - 1 с, нежели использование дорогих и редких дисков AV-класса. К тому же далеко не на всех обычных дисках термокалибровка оказывает заметное влияние на равномерность потока данных.
"Рваная" передача данных может также возникать при использовании "неправильной" операционной системы (DOS, Windows без 32-разрядного драйвера диска и т.п.), недостаточном количестве и размере файловых буферов ОС и записывающей программы, применении дисков низкого класса со скоростью передачи порядка 1-2 мегабайт в секунду и ниже, неправильном подключении диска и т.п. В любом случае, такие ситуации чаще всего говорят о неправильной конфигурации и настройке аппаратной и программной части системы.
Обзор современных технологий позиционирования звука в пространстве
Звуковое сопровождение компьютера всегда находилось несколько на втором плане. Большинство пользователей более охотно потратят деньги на новейший акселератор 3D графики, нежели на новую звуковую карту. Однако за последний год производители звуковых чипов и разработчики технологий 3D звука приложили немало усилий, чтобы убедить пользователей и разработчиков приложений в том, что хороший 3D звук является неотъемлемой частью современного мультимедиа компьютера. Пользователей убедить в пользе 3D звука несколько легче, чем разработчиков приложений. Достаточно расписать пользователю то, как источники звука будет располагаться в пространстве вокруг него, т.е. звук будет окружать слушателя сов всех сторон и динамично изменяться, как многие потянутся за кошельком. С разработчиками игр и приложений сложнее. Их надо убедить потратить время и средства на реализацию качественного звука. А если звуковых интерфейсов несколько, то перед разработчиком игры встает проблема выбора. Сегодня есть два основных звуковых интерфейса, это DirectSound3D от Microsoft и A3D от Aureal. При этом если разработчик приложения предпочтет A3D, то на всем аппаратном обеспечении DS3D будет воспроизводиться 3D позиционируемый звук, причем такой же, как если бы изначально использовался интерфейс DS3D. Само понятие "трехмерный звук" подразумевает, что источники звука располагаются в трехмерном пространстве вокруг слушателя. Это основа. Далее, что бы придать звуковой модели реализм и усилить восприятие звука слушателем, используются различные технологии, обеспечивающие воспроизведение реверберации, отраженных звуков, окклюзии (звук прошедший через препятствие), обструкции (звук не прошел через препятствие), дистанционное моделирование (вводится параметр удаленности источника звука от слушателя) и масса других интересных эффектов. Цель всего этого, создать у пользователя реальность звука и усилить впечатления от видео ряда в игре или приложении. Не секрет, что слух это второстепенное чувство человека, именно поэтому, каждый индивидуальный пользователь воспринимает звук по-своему. Никогда не будет однозначного мнения о звучании той или иной звуковой карты или эффективности той или иной технологии 3D звука. Сколько будет слушателей, столько будет мнений. В данной статье мы попытались собрать и обобщить информацию о принципах создания 3D звука, а также рассказать о текущем состоянии звуковой компьютерной индустрии и о перспективах развития. Мы уделим отдельное внимание необходимым составляющим хорошего восприятия и воспроизведения 3D звука, а также расскажем о некоторых перспективных разработках. Некоторые данные в статье рассчитаны на подготовленного пользователя, однако, никто не мешает пропустить нудные формулы тем, кому это не интересно или давно надоело в институте.
Итак, наверняка почти все слышали, что для позиционирования источников звука в виртуальном 3D пространстве используются HRTF функции. Ну что же, попробуем разобраться в том, что такое HRTF и действительно ли их использование так эффективно.
Сколько раз происходило следующее: команда, отвечающая за звук, только что закончила встраивание 3D звукового интерфейса на базе HRTF в новейшую игру; все комфортно расселись, готовясь услышать "звук окружающий вас со всех сторон" и "свист пуль над вашей головой"; запускается демо версия игры и… и ничего подобного вы просто не слышите!
HRTF (Head Related Transfer Function) это процесс посредством которого наши два уха определяют слышимое местоположение источника звука; наши голова и туловище являются в некоторой степени препятствием, задерживающим и фильтрующим звук, поэтому ухо, скрытое от источника звука головой воспринимает измененные звуковые сигналы, которые при "декодировании" мозгом интерпретируются соответствующим образом для правильного определения местоположения источника звука. Звук, улавливаемый нашим ухом, создает давление на барабанную перепонку. Для определения создаваемого звукового давления необходимо определить характеристику импульса сигнала от источника звука, попадающего на барабанную перепонку, т.е. силу, с которой звуковая волна отlисточника звука воздействует на барабанную перепонку. Эту зависимость называют Head Related Impulse Response (HRIR), а ее интегральное преобразование по Фурье называется HRTF.
Правильнее характеризовать акустические источники скоростью распространяемых ими звуковых волн V(t), нежели давлением P(t) распространяемой звуковой волны. Теоретически, давление, создаваемой идеальным точечным источником звука бесконечно, но ускорение распространяемой звуковой волны есть конечная величина. Если вы достаточно удалены от источника звука и если вы находитесь в состоянии "free field" (что означает, что в окружающей среде нет ничего кроме, источника звука и среды распространения звуковой волны), тогда давление "free field" (ff) на расстоянии "r" от источника звука определяется по формуле
P>ff>(t) = Z>o> V(t - r/c) / r где Z>o> это постоянная называемая волновым сопротивлением среды (characteristic impedance of the medium), а "c" это скорость распространения звука в среде. Итак, давление ff пропорционально скорости в начальный период времени (происход "сдвиг" по времени, обусловленный конечной скоростью распространения сигнала. То есть возмущение в этой точке описывается скоростью источника в момент времени отстоящий на r/c - время которое затрачено на то, чтобы сигнал дошел до наблюдателя. В принципе не зная V(t) нельзя утверждать характера изменения скорости при сдвиге, т.е. произойдет замедление или ускорение) и давление уменьшается обратно пропорционально расстоянию от источника звука до пункта наблюдения.
С точки зрения частоты давление звуковой волны можно выразить так:
P>ff>(f) = Z>o> V(f) exp(- i 2 pi r/c) / r где "f" это частота в герцах (Hz), i = sqrt(-1), а V(f) получается в результате применения преобразования Фурье к скорости распространения звуковой волны V(t). Таким образом, задержки при распространении звуковой волны можно охарактеризовать "phase factor", т.е. фазовым коэффициентом exp(- i 2 pi r /c). Или, говоря словами, это означает, что функция преобразования в "free field" P>ff>(f) просто является результатом произведения масштабирующего коэффициента Z>o>, фазового коэффициента exp(- i 2 pi r /c) и обратно пропорциональна расстоянию 1/r. Заметим, что возможно более рационально использовать традиционную циклическую частоту, равную 2*pi*f чем просто частоту.
Если поместить в среду распространения
звуковых волн человека, тогда
звуковое
поле вокруг человека искажается за счет
дифракции (рассеивания или иначе говоря
различие скоростей распространения
волн разной длины), отражения и дисперсии
(рассредоточения) при контакте человека
со звуковыми волнами. Теперь все тот же
источник звука будет создавать несколько
другое давление звука P(t) на барабанную
перепонку в ухе человека. С точки зрения
частоты это давление обозначим как
P(f). Теперь, P(f), как и P>ff>(f) также
содержит фазовый коэффициент, чтобы
учесть задержки при распространении
звуковой волны и вновь давление ослабевает
обратно пропорционально расстоянию.
Для исключения этих концептуально
незначимых эффектов HRTF функция H
определяется как соотношение P(f) и
P>ff>(f). Итак, строго говоря, H это
функция, определяющая коэффициент
умножения для значение давления звука,
которое будет присутствовать в центре
головы слушателя, если нет никаких
объектов на пути распространения волны,
в давление на барабанную перепонку в
ухе слушателя.
Обратным преобразованием Фурье функции H(f) является функция H(t), представляющая собой HRIR (Head-Related Impulse Response). Таким образом, строго говоря, HRIR это коэффициент (он же есть отношение давлений, т.е. безразмерен; это просто удобный способ загнать в одну букву в формуле очень сложный параметр), который определяет воздействие на барабанную перепонку, когда звуковой импульс испускается источником звука, за исключением того, что мы сдвинули временную ось так, что t=0 соответствует времени, когда звуковая волна в "free field" достигнет центра головы слушателя. Также мы масштабировали результаты таким образом, что они не зависят от того, как далеко источник звука расположен от человека, относительно которого производятся все измерения.
Если пренебречь этим временным сдвигом и масштабированием расстояния до источника звука, то можно просто сказать, что HRIR - это давление воздействующее на барабанную перепонку, когда источник звука является импульсным.
Напомним, что интегральным преобразованием Фурье функции HRIR является HRTF функция. Если известно значение HRTF для каждого уха, мы можем точно синтезировать бинауральные сигналы от монофонического источника звука (monaural sound source). Соответственно, для разного положения головы относительно источника звука задействуются разные HRTF фильтры. Библиотека HRTF фильтров создается в результате лабораторных измерений, производимых с использованием манекена, носящего название KEMAR (Knowles Electronics Manikin for Auditory Research, т.е. манекен Knowles Electronics для слуховых исследований) или с помощью специального "цифрового уха" (digital ear), разработанного в лаборатории Sensaura, располагаемого на голове манекена. Понятно, что измеряется именно HRIR, а значение HRTF получается путем преобразования Фурье. На голове манекена располагаются микрофоны, закрепленные в его ушах. Звуки воспроизводятся через акустические колонки, расположенные вокруг манекена и происходит запись того, что слышит каждое "ухо".
HRTF представляет собой необычайно сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, считается, что источники звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, что существенным образом упрощает HRTF до функции азимута (azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение, за счет избавления от четвертой переменной. Затем при записи используются полученные значения измерений и в результате, при проигрывании звук (например, оркестра) воспроизводится с таким же пространственным расположением, как и при естественном прослушивании. Техника HRTF используется уже несколько десятков лет для обеспечения высокого качества стерео записей. Лучшие результаты получаются при прослушивании записей одним слушателем в наушниках.
Наушники, конечно, упрощают решение проблемы доставки одного звука к одному уху и другого звука к другому уху. Тем не менее, использование наушников имеет и недостатки. Например:
Многие люди просто не любят использовать наушники. Даже легкие беспроводные наушники могут быть обременительны. Наушники, обеспечивающие наилучшую акустику, могут быть чрезвычайно неудобными при длительном прослушивании.
Наушники могут иметь провалы и пики в своих частотных характеристиках, которые соответствуют характеристикам ушной раковины. Если такого соответствия нет, то восприятие звука, источник которого находится в вертикальной плоскости, может быть ухудшено. Иначе говоря, мы будем слышать преимущественно только звук, источники которого находится в горизонтальной плоскости.
При прослушивании в наушниках, создается ощущение, что источник звука находится очень близко. И действительно, физический источник звука находится очень близко к уху, поэтому необходимая компенсация для избавления от акустических сигналов влияющих на определение местоположения физических источников звука зависит от расположения самих наушников.
Использование акустических колонок позволяет обойти большинство из этих проблем, но при этом не совсем понятно, как можно использовать колонки для воспроизведения бинаурального звука (т.е. звука, предназначенного для прослушивания в наушниках, когда часть сигнала предназначена для одного уха, а другая часть для другого уха). Как только мы подключим вместо наушников колонки, наше правое ухо начнет слышать не только звук, предназначенный для него, но и часть звука, предназначенную для левого уха. Одним из решений такой проблемы является использование техники cross-talk-cancelled stereo или transaural stereo, чаще называемой просто алгоритм crosstalk cancellation (для краткости CC).
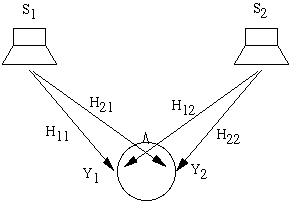
Идея CC просто выражается в терминах частот. На схемы выше сигналы S1 иS2 воспроизводятся колонками. Сигнал Y1 достигающий левого уха представляет собой смесь из S1 и "crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H21 S1 + H22 S2, где H21 является HRTF между левой колонкой и левым ухом, а H22 это HRTF между правой колонкой и левым ухом. Аналогично Y2=H31 S1 + H32 S2. Если мы решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2 воспринимаемые ушами. Проблема в том, что необходимо правильно определить сигналы S1 и S2, чтобы получить искомый результат. Математически для этого просто надо обратить уравнение:

На практике, обратное преобразование матрицы не является тривиальной задачей.
При очень низкой частоте звука, все функции HRTF одинаковы и поэтому матрица является вырожденной, т.е. матрицей с нулевым детерминантом (это единственная помеха для тривиального обращения любой квадратной матрицы). На западе такие матрицы называют сингулярными. (К счастью, в среде отражающей звук, т.е. где присутствует реверберация, низкочастотная информация не являются важной для определения местоположения источника звука).
Точное решение стремиться к результату с очень длинными импульсными характеристиками. Эта проблема становится все более и более сложной, если в дальнейшем искомый источник звука располагается вне линии между двумя колонками, т.е. так называемый фантомный источник звука.
Результат будет зависеть от того, где находится слушатель по отношению к колонкам. Правильное восприятие звучания достигается только в районе так называемого "sweet spot", предполагаемого месторасположения слушателя при обращении уравнения. Поэтому, то, как мы слышим звук, зависит не только от того, как была сделана запись, но и от того, из какого места между колонками мы слушаем звук.
При грамотном использовании алгоритмов CC получаются весьма хорошие результаты, обеспечивающие воспроизведение звука, источники которого расположены в вертикальной и горизонтальной плоскости. Фантомный источник звука может располагаться далеко вне пределов линейного сегмента между двумя колонками.
Давно известно, что для создания убедительного 3D звучания достаточно двух звуковых каналов. Главное это воссоздать давление звука на барабанные перепонки в левом и правом ушах таким же, как если бы слушатель находился в реальной звуковой среде.
Из-за того, что расчет HRTF функций сложная задача, во многих системах пространственного звука (spatial audio systems) разработчики полагаются на использование данных, полученных экспериментальным путем, например, данные получаются с помощью KEMAR. Тем не менее, основной причиной использования HRTF является желание воспроизвести эффект elevation (звук в вертикальной плоскости), наряду с азимутальными звуковыми эффектами. При этом восприятие звуковых сигналов, источники которых расположены в вертикальной плоскости, чрезвычайно чувствительно к особенностям каждого конкретного слушателя. В результате сложились четыре различных метода расчета HRTF:
Использование компромиссных, стандартных HRTF функций. Такой метод обеспечивает посредственные результаты при воспроизведении эффектов elevation для некоторого процента слушателей, но это самый распространенный метод в недорогих системах. На сегодня, ни IEEE, ни ACM, ни AES не определили стандарт на HRTF, но похоже, что компании типа Microsoft и Intel создадут стандарт де-факто.
Использование одной типа HRTF функций из набора стандартных функций. В этом случае необходимо определить HRTF для небольшого числа людей, которые представляют все различные типы слушателей, и предоставить пользователю простой способ выбрать именно тот набор HRTF функций, который наилучшим образом соответствует ему (имеются в виду рост, форма головы, расположение ушей и т.д.). Несмотря на то, что такой метод предложен, пока никаких стандартных наборов HRTF функций не существует.
Использование индивидуализированных HRTF функций. В этом случае необходимо производить определение HRTF исходя из параметров конкретного слушателя, что само по себе сложная и требующая массы времени процедура. Тем не менее, эта процедура обеспечивает наилучшие результаты.
Использование метода моделирования параметров определяющих HRTF, которые могут быть адаптированы к каждому конкретному слушателю. Именно этот метод сейчас применяется повсеместно в технологиях 3D звука.
На практике существуют некоторые проблемы, связанные с созданием базы HRTF функций при помощи манекена. Результат будет соответствовать ожиданиям, если манекен и слушатель имеют головы одинакового размера и формы, а также ушные раковины одинакового размера и формы. Только при этих условиях можно корректно воссоздать эффект звучания в вертикальной плоскости и гарантировать правильное определение местоположения источников звука в пространстве. Записи, сделанные с использованием HRTF называются binaural recordings, и они обеспечивают высококачественный 3D звук. Слушать такие записи надо в наушниках, причем желательно в специальных наушниках. Компакт диски с такими записями стоят существенно дороже стандартных музыкальных CD. Чтобы корректно воспроизводить такие записи через колонки необходимо дополнительно использовать технику CC. Но главный недостаток подобного метода - это отсутствие интерактивности. Без дополнительных механизмов, отслеживающих положение головы пользователя, обеспечить интерактивность при использовании HRTF нельзя. Бытует даже поговорка, что использовать HRTF для интерактивного 3D звука, это все равно, что использовать ложку вместо отвертки: инструмент не соответствует задаче.
Sweet Spot
На самом деле значения HRTF можно получить не только с помощью установленных в ушах манекена специальных внутриканальных микрофонов (inter-canal microphones). Используется еще и так называемая искусственная ушная раковина. В этом случае прослушивать записи нужно в специальных внутриканальных (inter-canal) наушниках, которые представляют собой маленькие шишечки, размещаемые в ушном канале, так как искусственная ушная раковина уже перевела всю информацию о позиционировании в волновую форму. Однако нам гораздо удобнее слушать звук в наушниках или через колонки. При этом стоит помнить о том, что при записи через inter-canal микрофоны вокруг них, над ними и под ними происходит искажение звука. Аналогично, при прослушивании звук искажается вокруг головы слушателя. Поэтому и появилось понятие sweet spot, т.е. области, при расположении внутри которой слушатель будет слышать все эффекты, которые он должен слышать. Соответственно, если голова слушателя расположена в таком же положении, как и голова манекена при записи (и на той же высоте), тогда будет получен лучший результат при прослушивании. Во всех остальных случаях будут возникать искажения звука, как между ушами, так и между колонками. Понятно, что необходимость выбора правильного положения при прослушивании, т.е. расположение слушателя в sweet spot, накладывает дополнительные ограничения и создает новые проблемы. Понятно, что чем больше область sweet spot, тем большую свободу действий имеет слушатель. Поэтому разработчики постоянно ищут способы увеличить область действия sweet spot.
Частотная характеристика
Действие HRTF зависит от частоты звука; только звуки со значениями частотных компонентов в пределах от 3 kHz до 10 kHz могут успешно интерпретироваться с помощью функций HRTF. Определение местоположения источников звуков с частотой ниже 1 kHz основывается на определении времени задержки прибытия разных по фазе сигналов до ушей, что дает возможность определить только общее расположение слева/справа источников звука и не помогает пространственному восприятию звучания. Восприятие звука с частотой выше 10 kHz почти полностью зависит от ушной раковины, поэтому далеко не каждый слушатель может различать звуки с такой частотой. Определить местоположение источников звука с частотой от 1 kHz до 3 kHz очень сложно. Число ошибок при определении местоположения источников звука возрастает при снижении разницы между соотношениями амплитуд (чем выше пиковое значение амплитуды звукового сигнала, тем труднее определить местоположение источника). Это означает, что нужно использовать частоту дискретизации (которая должна быть вдвое больше значения частоты звука) соответствующей как минимум 22050 Hz при 16 бит для реальной действенности HRTF. Дискретизация 8 бит не обеспечивает достаточной разницы амплитуд (всего 256 вместо 65536), а частота 11025 Hz не обеспечивает достаточной частотной характеристики (так как при этом максимальная частота звука соответствует 5512 Hz). Итак, чтобы применение HRTF было эффективным, необходимо использовать частоту 22050 Hz при 16 битной дискретизации.
Ушная раковина (Pinna)
Мозг человека анализирует разницу амплитуд, как звука, достигшего внешнего уха, так и разницу амплитуд в слуховом канале после ушной раковины для определения местоположения источника звука. Ушная раковина создает нулевую и пиковую модель звучания между ушами; эта модель совершенно разная в каждом слуховом канале и эта разница между сигналами в ушах представляет собой очень эффективную функциюдля определения, как частоты, так и местоположения источника звука. Но это же явление является причиной того, что с помощью HRTF нельзя создать корректного восприятия звука через колонки, так как по теории ни один из звуков, предназначенный для одного уха не должен быть слышимым вторым ухом.
Мы вновь вернулись к необходимости использования дополнительных алгоритмов CC. Однако, даже при использовании кодирования звука с помощью HRTF источники звука являются неподвижными (хотя при этом амплитуда звука может увеличиваться). Это происходит из-за того, что ушная раковина плохо воспринимает тыловой звук, т.е. когда источники звука находятся за спиной слушателя. Определение местоположения источника звука представляет собой процесс наложения звуковых сигналов с частотой, отфильтрованной головой слушателя и ушными раковинами на мозг с использованием соответствующих координат в пространстве. Так как происходит наложение координат только известных характеристик, т.е. слышимых сигналов, ассоциируемых с визуальным восприятием местоположения источников звука, то с течением времени мозг "записывает" координаты источников звука и в дальнейшем определение их местоположения может происходить лишь на основе слышимых сигналов. Но видим мы только впереди. Соответственно, мозг не может правильно расположить координаты источников звука, расположенных за спиной слушателя при восприятии слышимых сигналов ушной раковиной, так как эта характеристика является неизвестной. В результате, мозг может располагать координаты источников звука совсем не там, где они должны быть. Подобную проблему можно решить только при использовании вспомогательных сигналов, которые бы помогли мозгу правильно располагать в пространстве координаты источников звуков, находящихся за спиной слушателя.
Неподвижные источники звука
Все выше сказанное подвело нас к еще одной проблеме:
Если источники звука неподвижны, они не могут быть точно локализованы, как "статические" при моделировании, т.к. мозгу для определения местоположения источника звука необходимо наличие перемещения (либо самого источника звука, либо подсознательных микро перемещений головы слушателя), которое помогает определить расположение источника звука в геометрическом пространстве. Нет никаких оснований, ожидать, что какая-либо система на базе HRTF функций будет корректно воспроизводить звучание, если один из основных сигналов, используемый для определения местоположения источника звука, отсутствует. Врожденной реакцией человека на неожидаемый звук является повернуть голову в его сторону (за счет движения головы мозг получает дополнительную информацию для локализации в пространстве источника звука). Если сигнал от источника звука не содержит особую частоту, влияющую на разницу между фронтальными и тыловыми HRTF функциями, то такого сигнала для мозга просто не существует; вместо него мозг использует данные из памяти и сопоставляет информацию о местоположении известных источников звука в полусферической области.
Каково же будет решение?
Лучший метод воссоздания настоящего 3D звука это использование минимальной частоты дискретизации 22050 Hz при 16 битах и использования дополнительных тыловых колонок при прослушивании. Такая платформа обеспечит пользователю реалистичное воспроизведение звука за счет воспроизведение через достаточное количество колонок (минимум три) для создания настоящего surround звучания. Преимущество такой конфигурации заключается в том, что когда слушатель поворачивает голову для фокусировки на звуке какого-либо объекта, пространственное расположение источников звука остается неизменным по отношению к окружающей среде, т.е. отсутствует проблема sweet spot.
Есть и другой метод, более новый и судить о его эффективности пока сложно. Суть метода, который разработан Sensaura и называется MultiDrive, заключается в использовании HRTF функций на передней и на тыловой паре колонок (и даже больше) с применением алгоритмов CC. На самом деле Sensaura называет свои алгоритмы СС несколько иначе, а именно Transaural Cross-talk cancellation (TCC), заявляя, что они обеспечивают лучшие низкочастотные характеристики звука. Инженеры Sensaura взялись за решение проблемы восприятия звучания от источников звука, которые перемещаются по бокам от слушателя и по оси фронт/тыл. Заметим, что Sensaura для вычисления HRTF функций использует так называемое "цифровое ухо" (Digital Ear) и в их библиотеке уже хранится более 1100 функций. Использование специального цифрового уха должно обеспечивать более точное кодирование звука. Подчеркнем, что Sensaura создает технологии, а использует интерфейс DS3D от Microsoft.
Технология MultiDrive воспроизводит звук с использованием HRTF функций через четыре или более колонок. Каждая пара колонок создает фронтальную и тыловую полусферу соответственно.
Фронтальные и тыловые звуковые поля специальным образом смещены с целью взаимного дополнения друг друга и за счет применения специальных алгоритмов улучшает ощущения фронтального/тылового расположения источников звука. В каждом звуковом поле применяются собственный алгоритм cross-talk cancellation (CC). Исходя из этого, есть все основания предполагать, что вокруг слушателя будет плавное воспроизведение звука от динамично перемещающихся источников и эффективное расположение тыловых виртуальных источников звука. Так как воспроизводимые звуковые поля основаны на применении HRTF функций, каждое из создаваемых sweet spot (мест, с наилучшим восприятием звучания) способствует хорошему восприятию звучания от источников по сторонам от слушателя, а также от движущихся источников по оси фронт/тыл. Благодаря большому углу перекрытия результирующее место с наилучшим восприятием звука (sweet spot) покрывает область с гораздо большей площадью, чем конкурирующие четырех колоночные системы воспроизведения. В результате качество воспроизводимого 3D звука должно существенно повысится.
Если бы не применялись алгоритмы cross-talk cancellation (CC) никакого позиционирования источников звука не происходило бы. Вследствие использования HRTF функций на четырех колонках для технологии MultiDrive необходимо использовать алгоритмы CC для четырех колонок, требующие чудовищных вычислительных ресурсов. Из-за того, что обеспечить работу алгоритмов CC на всех частотах очень сложная задача, в некоторых системах применяются высокочастотные фильтры, которые срезают компоненты высокой частоты. В случае с технологией MultiDrive Sensaura заявляет, что они применяют специальные фильтры собственной разработки, которые позволяют обеспечить позиционирование источников звука, насыщенными высокочастотными компонентами, в тыловой полусфере. Хотя sweet spot должен расшириться и восприятие звука от источников в вертикальной плоскости также улучшается, у такого подхода есть и минусы. Главный минус это необходимость точного позиционирования тыловых колонок относительно фронтальных. В противном случае никакого толка от HRTF на четырех колонках не будет.
Стоит упомянуть и другие инновации Sensaura, а именно технологии ZoomFX и MacroFX, которые призваны улучшить восприятие трехмерного звука. Расскажем о них подробнее, тем более что это того стоит.
MacroFX
Как мы уже говорили выше, большинство измерений HRTF производятся в так называемом дальнем поле (far field), что существенным образом упрощает вычисления. Но при этом, если источники звука располагаются на расстоянии до 1 метра от слушателя, т.е. в ближнем поле (near field), тогда функции HRTF плохо справляются со своей работой. Именно для воспроизведения звука от источников в ближнем поле с помощью HRTF функций и создана технология MacroFX. Идея в том, что алгоритмы MacroFX обеспечивают воспроизведение звуковых эффектов в near-field, в результате можно создать ощущение, что источник звука расположен очень близко к слушателю, так, будто источник звука перемещается от колонок вплотную к голове слушателя, вплоть до шепота внутри уха слушателя. Достигается такой эффект за счет очень точного моделирования распространения звуковой энергии в трехмерном пространстве вокруг головы слушателя из всех позиций в пространстве и преобразование этих данных с помощью высокоэффективного алгоритма. Особое внимание при моделировании уделяется управлению уровнями громкости и модифицированной системе расчета задержек по времени при восприятии ушами человека звуковых волн от одного источника звука (ITD, Interaural Time Delay). Для примера, если источник звука находится примерно посередине между ушами слушателя, то разница по времени при достижении звуковой волны обоих ушей будет минимальна, а вот если источник звука сильно смещен вправо, эта разница будет существенной. Только MacroFX принимает такую разницу во внимание при расчете акустической модели. MacroFX предусматривает 6 зон, где зона 0 (это дистанция удаления) и зона 1 (режим удаления) будут работать точно так же, как работает дистанционная модель DS3D. Другие 4 зоны это и есть near field (ближнее поле), покрывающие левое ухо, правое ухо и пространство внутри головы слушателя.
Этот алгоритм интегрирован в движок Sensaura и управляется DirectSound3D, т.е. является прозрачным для разработчиков приложений, которые теперь могут создавать массу новых эффектов. Например, в авиа симуляторах можно создать эффект, когда пользователь в роли пилота будет слышать переговоры авиа диспетчеров так, как если бы он слышал эти переговоры в наушниках. В играх с боевыми действиями может потребоваться воспроизвести звук пролетающих пуль и ракет очень близко от головы слушателя. Такие эффекты, как писк комара рядом с ухом теперь вполне реальны и доступны. Но самое интересное в том, что если у вас установлена звуковая карта с поддержкой технологии Sensaura и с драйверами, поддерживающими MacroFX, то пользователь получит возможность слышать эффекты MacroFX даже в уже существующих DirectSound3D играх, разумеется, в зависимости от игры эффект будет воспроизводиться лучше или хуже. Зато в игре, созданной с учетом возможности использования MacroFX. Можно добиться очень впечатляющих эффектов.
Поддержка MacroFX будет включена в драйверы для карт, которые поддерживают технологию Sensaura.
ZoomFX
Современные системы воспроизведения позиционируемого 3D звука используют HRTF функции для создания виртуальных источников звука, но эти синтезированные виртуальные источники звука являются точечными. В реальной жизни звук зачастую исходит от больших по размеру источников или от композитных источников, которые могут состоять из нескольких индивидуальных генераторов звука. Большие по размерам и композитные источники звука позволяют использовать более реалистичные звуковые эффекты, по сравнению с возможностями точечных источников звука. Так, точечный источник звука хорошо применим при моделировании звука от большого объекта удаленного на большое расстояние (например, движущийся поезд). Но в реальной жизни, как только поезд приближается к слушателю, он перестает быть точечным источником звука. Однако в модели DS3D поезд все равно представляется, как точечный источник звука, а значит, страдает реализм воспроизводимого звука (т.е. мы слышим звук скорее от маленького поезда, нежели от огромного состава громыхающего рядом). Технология ZoomFX решает эту проблему, а также вносит представление о большом объекте, например поезде как собрание нескольких источников звука (композитный источник, состоящий из шума колес, шума двигателя, шума сцепок вагонов и т.д.).
Для технологии ZoomFX будет создано расширение для DirectSound3D, подобно EAX, с помощью которого разработчики игр смогут воспроизводить новые звуковые эффекты и использовать такой параметр источника звука, как размер. Пока эта технология находится на стадии завершения.
Компания Creative реализовала аналогичный подход, как в MultiDrive от Sensaura, в своей технологии CMSS (Creative Multispeaker Surround Sound) для серии своих карт SB Live!. Поддержка этой версии технологии CMSS, с реализацией HRTF и CC на четырех колонках, встроена в программу обновления LiveWare 2.x. По своей сути, технология CMSS является близнецом MultiDrive, хотя на уровне алгоритмов CC и библиотек HRTF наверняка есть отличия. Главный недостаток CMSS такой же, как у MultiDrive - необходимость расположения тыловых колонок в строго определенном месте, а точнее параллельно фронтальным колонкам. В результате возникает ограничение, которое может не устроить многих пользователей. Не секрет, что место для фронтальных колонок давно зарезервировано около монитора. Место для сабвуфера можно выбрать любым, обычно это где-то в углу и на полу. А вот тыловые колонки пользователи располагают там, где считают удобным для себя. Не каждый захочет расположить их строго за спиной и далеко не у всех есть свободное место для такого расположения.
Заметим, что главный конкурент Creative на рынке 3D звука, компания Aureal, использует технику панорамирования на тыловых колонках. Объясняется это именно отсутствием строгих ограничений на расположение тыловых колонок в пространстве.
Не стоит забывать и о больших объемах вычислений при расчете HRTF и Cross-talk Cancellation для четырех колонок
Еще один игрок на рынке 3D звука - компания QSound пока имеет сильные позиции только в области воспроизведения звука через наушники и две колонки. При этом свои алгоритмы для воспроизведения 3D звука через две колонки и наушники (в основе лежат HRTF) QSound создает исходя из результатов тестирования при прослушивании реальными людьми, т.е. не довольствуется математикой, а делает упор на восприятие звука конкретными людьми. И таких прослушиваний было проведено более 550000! Для воспроизведения звука через четыре колонки QSound использует панорамирование, т.е. тоже, что было в первой версии CMSS. Такая техника плохо показала себя в играх, обеспечивая слабое позиционирование источников звука в вертикальной плоскости.
Компания Aureal привнесла в технологии воспроизведения 3D звука свою технику Wavetracing. Мы уже писали об этой технологии, вкратце, это расчет распространения отраженных и прошедших через препятствия звуковых волн на основе геометрии среды. При этом обеспечивается полный динамизм восприятия звука, т.е. полная интерактивность.
Итак, подведем итоги. Однозначный вывод состоит в том, что если вы хотите получить наилучшее качество 3D звука, доступное на сегодняшний день, вам придется использовать звуковые карты, поддерживающие воспроизведение минимум через четыре колонки. Использование только двух фронтальных колонок - это конфигурация вчерашнего дня. Далее, если вы только собираетесь переходить на карты с поддержкой четырех и более колонок, то перед вами встает классическая проблема выбора. Как всегда единственная рекомендация состоит в том, чтобы вы основывали свой выбор на собственных ощущениях. Послушайте максимально возможно число разных систем и сделайте именно свой выбор.
Теперь посмотрим, с каким багажом подошли ведущие игроки 3D звукового рынка к сегодняшнему дню и что нас ждет в ближайшем будущем.
EAR
EAR - в текущей версии IAS 1.0 реализована поддержка воспроизведения DS3D, A3D 1.0 и EAX 1.0 через четыре и более колонок. За счет воспроизведения через четыре и более колонок, мозг слушателя получает дополнительные сигналы для правильного определения местоположения источников звука в пространстве.
Осенью ожидается выход IAS 2.0 с поддержкой
DirectMusic, YellowBook, EAX 2.0
и A3D 2.0, force-feed back (мы
сможем чувствовать звук, а именно
давление звука, громкость и т.д.),
декодирование в реальном времени MP3 и
Dolby/DTS, будет реализована поддержка ".1"
канала (сабвуфера). Кроме того, в IAS 2.0
будет реализовано звуковое решение, не
требующее наличие звуковой карты
(cardless audio solution) для использования с
полностью цифровой системой воспроизведения
звука, например с USB колонками или в
тандеме с домашней системой Dolby Digital.
Главные достоинства IAS от EAR:
Один интерфейс для любой многоколоночной платформы, обеспечивающий одинаковый результат вне зависимости от того, как воспроизводится звук при использовании специального API.
Имеется
поддержка воспроизведения через две
колонки (для старых систем),
если
многоколоночная конфигурация недоступна.
Пользователь может подключить свой компьютер к домашней звуковой системе (Dolby Digital и т.д.) и IAS будет воспроизводить звук без необходимости какой-либо модернизации.
Итак, по сравнению с конкурентами, IAS
работает на любой платформе и не
требует
специального аппаратного обеспечения.
При этом IAS использует любое доступное
аппаратное обеспечение и обеспечивает
пользователю наилучшее качество звука,
которое доступно на его системе. Только
вот остановит ли свой выбор пользователь
на этой технологии, это большой вопрос.
С другой стороны, для использования IAS
не нужно покупать специальных звуковых
карт.
Sensaura
Sensaura - компания занимающаяся созданием технологий. Производители звуковых чипов лицензируют разработки Sensaura и воплощают их в жизнь. В чипе Canyon3D от ESS будет реализована поддержка современных технологий Sensaura, которые должны обеспечить слушателем 3D звук на современном уровне, т.е. позиционируемый в пространстве и с воспроизведением через четыре и более колонок. За воспроизведение через четыре и более колонок отвечает технология MultiDrive, которая реализует HRTF и алгоритмы Cross-talk cancellation. Многообещающе выглядят технологии ZoomFX и MacroFX. Кроме того, Sensaura поддерживает воспроизведение реверберации через EAX от Creative, равно как и через I3DL2, а также эмулирует поддержку A3D 1.х через DS3D.
Первым звуковым чипов, который реализует технологию MultiDrive на практике, является Canyon3D от ESS Technology, Inc. Более подробную информацию о чипе Canyon3D можно найти на официальном сайте www.canyon3d.com.
Первая карта на базе чипа Canyon3D называется DMX и производит ее компания Terratec.
Как только эта карта попадет к нам на испытания, мы представим на ваш суд обзор. Заметим только, что на этой карте будут сразу оба типа цифровых выходов S/PDIF коаксиальный (RCA) и оптический (Toslink), и один цифровой вход. Так что продукт обещает быть очень интересным.
Creative
Creative - занимается совершенствованием своего движка реверберации. В итоге в свет выйдет EAX 3.0, который должен добавить больше реализма в воспроизводимый звук. Никто не спорит, что реверберация это хорошо, что именно она обеспечивает насыщенное и живое звучание. При этом Creative упорно не собирается вести разработки в области геометрии акустики. Кстати, Microsoft объявила о намерении включить EAX в состав DirectSound3D 8.0. С другой стороны, есть неподтвержденные слухи, что EAX 3.0 будет закрытым стандартом. Интересно, изменит ли Creative свою позицию со временем? Пока же в новых версиях EAX нам обещают больше реализма и гибкости в настройках реверберации и моделировании звуковой среды для конкретных объектов и помещений, плюс плавные переходы от одной заранее созданной звуковой среды к другой при движении слушателя в 3D мире. Будут улучшения в области воспроизведения эффектов окклюзии и обструкции. Обещают и поддержку отраженных звуков, но без учета геометрии и более продвинутую дистанционную модель. Вообще, я не удивлюсь, если Creative лицензирует MacroFX и ZoomFX у Sensaura. Что касается моделирования звука на основе физической геометрии среды, то Creative очень усиленно отрицает для себя возможность поддержки такого метода. Хотя, если поднять архивы и посмотреть первый пресс-релиз о будущем чипе Emu10k1, то вы будете удивлены. Там говорится именно об использовании физической геометрии среды при моделировании звука. Потом планы изменились. Кто помешает Creative вновь изменить планы? Особенно если учесть появление в ближайшее время движка реверберации от Aureal. Вряд ли Creative не сделает ответного хода.
QSound
QSound ведет работы по созданию новой технологии воспроизведения 3D звука через четыре и более колонок. Зная пристрастия QSound, можно предположить, что в основу новой технологии опять лягут результаты реальных прослушиваний. QSound, как и Sensaura занимается именно технологиями, которые воплощают в виде чипов другие компании. Так, чип Thunderbird128 от VLSI воплощает в себе все последние достижения QSound в области 3D звука, при этом Thunderbird128 это DSP, а значит, есть все основания ожидать последующей модернизации. Стоит упомянуть, что QSound, подобно Creative считает, что главное в 3D звуке это восприятие слушателем окружающей атмосферы игры. Поэтому QEM (QSound Environmental Modeling) совместима с EAX 1.0 от Creative. Следует ожидать, что QEM 2.0 будет совместима с EAX 2.0. Отметим, что QSound славится очень эффективными алгоритмами и грамотным распределением доступных ресурсов, неслучайно именно их менеджер ресурсов был лицензирован Microsoft и включен в DirectX.
Aureal
С Aureal все более-менее понятно. В ближайшем будущем нам обещают дальнейшее улучшение функциональности A3D, мощный движок реверберации, поддержку HRTF на четырех и более колонках.
Мы упомянули основные разработки в области 3D звука, которые применяются в компьютерном мире. Есть еще ряд фирм с интересными решениями, но они делают упор на рынок бытовой электроники, поэтому в данном материале yt рассказывается о них.
Обзорно изучив технологии, существующие на рынке позиционирования 3Д звука, попробуем рассмотреть их более пристально.
В видении компании Sensaura
Компания Sensaura более 10 лет занимается созданием звуковых технологий. Все разработки Sensaura ориентированы на работу через стандартный интерфейс DirectSound3D и его расширения. Часть технологий Sensaura уже применяются на практике, другие разработки мы скоро увидим в действие. По сути, Sensaura предлагает использовать производителям звуковых чипов и карт специальные алгоритмы, которые в паре со стандартным API DS3D и расширениями для него, должны обеспечить моделирование и воспроизведение качественного 3D звука.
Попробуем рассказать о том, что же предлагает Sensaura.
Digital Ear
Для корректного воспроизведения 3D звука через наушники или колонки необходимо использовать специальные алгоритмы, базирующиеся на использовании HRTF функций. Кроме того, при воспроизведении 3D звука через колонки необходимо использовать дополнительные алгоритмы Cross-talk Cancellation, вариант которых от Sensaura носит имя Transaural Cross-talk Cancellation (TCC).
Инженеры Sensaura пришли к выводу, что использование для формирования библиотек HRTF измерения, сделанные с помощью специального манекена или с приглашением реальных слушателей не могут обеспечить удовлетворить абсолютно всех слушателей. Дело в том, что какое бы большое число измерений не было сделано с использованием манекена, все полученные HRTF все равно будут усредненными. Все то же самое относится и к измерениям, сделанным с приглашением большого числа различных слушателей. Все равно есть небольшая часть людей, у которых совершенно отличные параметры слуха, а значит, при измерении у них получаются, совсем другие HRTF функции. В результате, какой бы большой и универсальной не была библиотека HRTF функций, часть людей не услышат ожидаемого 3D звука. Чтобы решить эту проблему, специалисты Sensaura разработали технологию Digital Ear (Цифровое ухо), ранее называвшуюся Virtual Ear. Суть идеи Digital Ear в том, что для измерения HRTF используется не просто манекен или приглашаются реальные слушатели, а используется чисто математический метод Ключевым элементом этого метода является математическая модель человеческого уха с изменяемыми параметрами. В основу математической модели положена концепция того, что сложные резонансные и дифракционные эффекты, являющиеся неотъемлемой частью любой HRTF функции могут независимо изменяться. В результате созданая дуплексная система, позволяющая изменять различные параметры в произвольном масштабе. Прежде чем была построена эта математическая модель было проведено масса исследований с целью точно смоделировать само ухо, точно определить, как оно реагирует на звуковые волны и как работает процесс человеческого слуха. Учитывались особенности восприятия мозгом различных звуков от источников, расположенных в разных точках пространства. Затем была создана модель уха из специального пластика, на нем были проведены измерения и отлажена математическая модель. Потом были получены базовые результаты измерения HRTF, на основе которых в дальнейшем с помощью специальных методов масштабирования стала формироваться библиотека HRTF. Использование математической модели гарантирует от наличия ошибок, которые возможны при физическом измерении HRTF с помощью манекена или реальных слушателей. Digital Ear можно настроить на огромное количество вариаций форм и размеров ушей реальных людей. В итоге получается обширная библиотека с возможностью очень гибко выбрать одну или несколько HRTF, которая наилучшим образом соответствует особенностям каждого конкретного слушателя. Кроме того, так как используется математическая модель, имеется возможность довольно простой модернизации алгоритмов и обновления библиотек HRTF без больших материальных затрат.
Между некоторыми параметрами Digital Ear существует зависимость, не мешающая масштабированию каждого из параметров в отдельности. Это позволяет построить простой интерфейс пользователя, позволяющий путем определения и задания в качестве данных некоторых физических параметров, описывающих голову и уши слушателя выбрать именно те HRTF функции из библиотеки, которые наилучшим образом отвечают особенностям конкретного слушателя. Вот эти параметры:
Размер головы (Head Size) - влияет на изменение величины ITD (Interaural time delay) задержки по времени при восприятии ушами слушателя звука от одного источника
Размер уха (Ear Size) - влияет на протяженность звукового спектра
Глубина ушной раковины (Concha Depth) - влияет на величину сдвига звукового спектра
Тип ушной раковины (Concha Type) - влияет на величину амплитуды звукового сигнала

Слева неглубокая ушная раковина, справа – глубокая
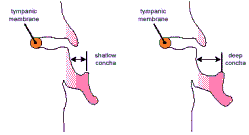
Слева ушная раковина открытого типа, справа - закрытого типа
В результате, каждый пользователь сможет настроить воспроизведения 3D звука с использованием технологии Digital Ear специально под себя. Пока технология Digital Ear не позволяет использовать гибкую настройку под конкретного слушателя и во всех дравейрах к звуковым картам, использующим технологии Sensaura задействуется универсальный набор HRTF функций, соответствующий среднему слушателю. Однако обещается, что уже в скором времени у пользователя появится возможность выбора HRTF под себя.
Смоделированный 3D звук мы можем слушать через наушники или через набор акустических колонок. При прослушивании через наушники используются только HRTF функции для воспроизведения эффектов 3D звука. Эта техника является традиционной и пока кардинально нового тут ничего не предвидится. За исключением шлифовки качества HRTF и предоставления пользователю возможности выбора HRTF конкретно под себя. При воспроизведении звука через две колонки также используется довольно традиционный метод комбинирования HRTF и алгоритмов cross-talk cancellation. Зато при вопсроизведении 3D звука через четыре и более колонок пока нет единого метода. Компания Sensaura разработала технологию MultiDrive, которая обеспечивает воспроизведение 3D звука с помощью более чем четырех колонок.
MultiDrive
Прежде всего начнем немного издалека. Зададимся вопросом, а зачем нам собственно слушать 3D звук через более чем одну пару колонок? Ну, в пользу мультиколоночных акустических систем можно сказать, что, во-первых у некоторых пользователей они уже есть, так почему бы их не использовать. Во-вторых, обычная ситема из двух колонок с использованием HRTF + CC имеет ряд ограничений при вопроизведении звуков от источников, расположенных в вертикальной плоскости и при движении источника звука по оси фронт/тыл. Итак, понятно, что, как минимум дополнительная пара колонок на тылах нам не повредит.
Есть и еще один момент. При использовании связки HRTF + CC могут возникнуть сложности корректного воспроизведения некоторых высокочастотных компонет звука выше величины в несколько kHz. Например, если на фоне звука взрывов нужно воспроизвести пение птахи. Причиной этого является невозможность реализовать идеально алгоритмы CC. Разные компании по разному борятся с этой проблемой, например, используются специальные фильтры высокой частоты, которые просто вырезают высокочастотные компоненты. В технологии MultiDrive применяются специальные фильтры, которые позволяют обеспечить воспроизведение звука, насыщенного высокочастотными компонентами.
Кроме того, для наилучшего восприятия звука слушатель должен находится в границах sweet spot, т.е. участка пространства, в котором звук воспринимается наилучшим образом. Понятно, что чем больше площадь sweet spot, тем большая свобода у слушателя. Мы ведь не манекены и не можем долгое время сидеть, не меняя положения головы относительно пола. В настоящее время наиболее распространена конфигурация из 4 колонок (не считая сабвуфера), поэтому в дальнейшем мы будем говорить именно о такой конфигурации акустики.
Технология MultiDrive позволяет воспроизводить 3D звук с использованием API DS3D. Суть этой технологии заключается в использовании HRTF функций на всех парах колонок с применением алгоритмов Transaural Cross-talk Cancellation (TCC). Отличие TCC от стандартных алгоритмов CC заключается в том, что они обеспечивают лучшие низкочастотные характеристики звука. Кроме того, предусмотрена возможность для пользователя управлять работой TCC, настраивая звучание под себя.
Каждая пара колонок создает фронтальную и тыловую полусферу соответственно. Фронтальные и тыловые звуковые поля специальным образом смещены с целью взаимного дополнения друг друга и за счет применения специальных алгоритмов улучшает ощущения фронтального/тылового расположения источников звука и под управлением DS3D. В каждом звуковом поле применяются собственный алгоритм TCC. Исходя из этого, вокруг слушателя должно происходить плавное воспроизведение звука от динамично перемещающихся источников и эффективное расположение тыловых виртуальных источников звука. Благодаря большому углу перекрытия результирующее место с наилучшим восприятием звука (sweet spot) покрывает область с гораздо большей площадью, по сравнению, например, с двухколоночной конфигурацией.
Минусом использования HRTF + TCC на всех парах колонок является то, что для расчета TCC требуется масса вычислительных ресурсов и необходимость довольно точного позиционирования тыловых колонок относительно фронтальных. В противном случае никакого толка от HRTF + TCC на четырех колонках не будет.
Стоит добавить, что MultiDrive рассчитана на совместное использование с алгоритмами MacroFX и ZoomFX от Sensaura.
MacroFX
Мы уже говорили выше, что с помощью HRTF и TCC можно воспроизвести качественный 3D звук. Но есть один нюанс. Обычно большинство измерений HRTF производятся в так называемом дальнем поле (far field, на дистации более 1 метра до источника звука), т.к. это существенно упрощает вычисления да и в большинстве игр воспроизводится звук от источников, находящихся на расстоянии от 1 метра и больше от слушателя. При этом, если источник звука находится на расстоянии до 1 метра от слушателя, т.е. в ближнем поле (near field), тогда эффективность использования HRTF снижается. Дело в том, что для создания звучания от удаленного источника звука достаточно добавить к основному звуковому сигналу реверберацию. Иногда можно обойтись и без реверберации, сократив высокочастотные компоненты в основном звуковом сигнале. Если источник звука находится в ближнем поле, подобные решения не применимы. Но необходимость в воспроизведении звука от источников в ближнем боле нередки. Например, в игре типа RPG может возникнуть необходимость нашептать подсказку непосредственно в ухо игроку, а в FPS игре часто необходимо воспроизвести звук пролетающих рядом с головой игрока пуль. Все эти эффекты нельзя вопроизвести, если HRTF измерялись на дистанции от одного метра и более, т.е. в дальнем поле. Тем не менее, измерить HRTF для всей области ближнего поля очень сложно, а использование дискретных наборов HRTF, сделанных, например, для дистанций 1 м, 0.9 м, 0.9 м и т.д. не позволит сделать звук от движущегося объекта естественно плавным, он будет скачкообразным. Решением проблемы является использование единого набора универсальных HRTF для ближнего поля с использованием дополнительного алгоритма.
Этот алгоритм был создан Sensaura и получил имя MacroFX. В результате работы MacroFX можно создать ощущение, что источник звука расположен очень близко к слушателю, так, будто источник звука перемещается от колонок вплотную к голове слушателя и вплоть до шепота внутри уха слушателя. Достигается такой эффект за счет очень точного моделирования распространения звуковой энергии в трехмерном пространстве вокруг головы слушателя, преобразования этих данных в тесном взаимодействии с HRTF функциями. Особое внимание при моделировании уделяется управлению уровнями громкости и модифицированной системе расчета задержек по времени при восприятии ушами человека звуковых волн от одного источника звука (ITD, Interaural Time Delay). Для примера, если источник звука находится примерно посередине между ушами слушателя, то разница по времени при достижении звуковой волны обоих ушей будет минимальна, а вот если источник звука сильно смещен вправо, эта разница будет существенной. Только MacroFX принимает такую разницу во внимание при расчете акустической модели. Все эти вычисления происходят до начала работы алгоритмов TCC, но сразу после расчета HRTF для всех источников звука.
В DS3D предусмотрено три зоны (две из них показаны на рисунке слева). Зона 0 в ней располагаются сильно удаленные источники звука, которые имеют постоянную интенсивность, не зависящую от расстояния. Источники в этой зоне могут не приниматься во внимание, т.е. слушатель их не слышит, либо они используются для формирования реверберации. Зона 1 это т.н. дальнее поле, в ней располагаются источники на расстоянии более 1 метра от слушателя и до определяемой разработчиком границы. В этой зоне интенсивность источников звука обратно пропорциональна расстоянию до слушателя. В зоне 2 (ближнее поле, расстояние до 1 м от слушателя) все источники звука имеют постоянную интенсивность. Это сделано для того, чтобы уровень громкости не превысил допустимого барьера и с целью ограничения нагрузки на шину данных.
MacroFX предусматривает 6 зон, где зона 0 (это дистанция удаления) и зона 1 (дальнее поле) будут работать точно так же, как работает дистанционная модель DS3D. Другие 4 зоны это и есть near field (ближнее поле) в стиле MacroFX, покрывающие дистанцию рядом с головой слушателя, левое ухо, правое ухо и пространство внутри головы слушателя. При этом здесь также вводятся ограничение на дистанцию, чтобы сократить накладные расходы при вычислениях. Поэтому в зоне 2 используется стандартный алгоритм Near-Field FX, а в зонах 3, 4 и 5, которые начинают работать с расстояния в 20 см, используется как таковой алгоритм MacroFX. Эти три зоны рассчитаны на источники звука, расположенные очень близко к ушам пользователя (левому или правому). Если источник звука должен находится как бы в голове пользователя (например, переговоры авиадиспетчеров в авиасимуляторе), то для этого используется зона 5.
Алгоритм MacroFX полностью прозрачен для интерфейсов и игр. Это означает, что если у вас установлена звуковая карта, в драйвер которой встроена поддержка MacroFX, то вы услышите работу этой технологии во всех играх, где источники звука попадают в ближнее поле. Разумеется, в зависимости от конкретной игры эффект будет воспроизводиться лучше или хуже. Зато в игре, созданной с учетом возможности использования MacroFX можно добиться очень впечатляющих эффектов, например, писк комара прямо в ухе, свист ветра в ушах при езде на велосипеде и т.д.
ZoomFX
Современные системы воспроизведения позиционируемого 3D звука используют HRTF функции для создания виртуальных источников звука, являющихся точечными. В реальной жизни звук зачастую исходит от больших по размеру источников звука или от композитных источников, объединяющих собой сразу несколько источников звука. Большие по размерам и композитные источники звука позволяют использовать более реалистичные звуковые эффекты, по сравнению с возможностями точечных источников звука. Так, точечный источник звука хорошо применим при моделировании звука от большого объекта удаленного на большое расстояние (например, движущийся поезд). Но в реальной жизни, как только поезд приближается к слушателю, он перестает быть точечным источником звука. В реальной жизни, когда поезд проезжает рядом с нами, мы слышим стук колес, скрип рессор, звук от буферов и т.д. Тем не менее, при моделировании источника звука типа поезд с использованием интерфейса DS3D поезд представляется, как точечный источник звука. В результате звук получается ненатуральным, т.е. мы слышим звук скорее от маленького поезда, нежели от огромного состава громыхающего рядом. Технология ZoomFX решает эту проблему, за счет введения такого параметра источника звука, как размер и сложность. Если вспомнить про наш поезд, то он будет представлен в виде собрания нескольких источников звука, типа шума колес, шума двигателя, шума сцепок вагонов и т.д. Для представления большого по размеру объекта используется набор из нескольких точечных источников звука. Для того чтобы мы слышали отдельные составляющие композитного источника звука используется метод динамической декорреляции (Dynamic Decorrelation), позволяющий выделить отдельные источники, составляющие композитный источник звука.

На рисунке показано, как источник звука типа вертолет представляется в виде нескольких точеных источников. Когда вертолет далеко от нас, все четыре точечных источника формируют единый звуковой сигнал в виде гула. Этот основной звук можно снабдить дополнительными звуковыми сигналами в виде реверберации, чтобы пользователю было проще определить источник звука. Например, что вертолет летит на расстоянии 50 метров на фоне высотного здания из стеклобетона. Как только вертолет приблизится на достаточное расстояние к нам, так, что мы сможем легко его рассмотреть вполне логично ожидать, что мы сможем выделить звук от лопастей (как они рассекают воздух), звук от турбины и звук от хвостового винта. Именно для таких целей и предназначен ZoomFX. На практике все работает следующим образом. В качестве носителя звука вертолета может выступать обычный монофонический wav файл. Затем, когда возникает необходимость выделить составляющие источники звука, начинает работать динамический декоррелятор, который выделяет несколько вторичных звуков, которые затем подвергаются обработке HRTF фильтрами, затем происходит сложение соответствующих каналов (правые с правыми, левы с левыми и т.д.), затем сигнал обрабатывается алгоритмами TCC и воспроизводится через акустическую систему. К слову, возможность создания нескольких виртуальных источников звука с помощью ZoomFX может быть использована, например, для воспроизведения в наушниках многоканального звука типа Dolby Digital.

Технология ZoomFX в отличие от MacroFX не является прозрачной для интерфейсов и игр. Для ее поддержки будет создано расширение для DirectSound3D, подобно EAX, с помощью которого разработчики игр смогут воспроизводить новые звуковые эффекты и использовать такой параметр источника звука, как размер. Пока эта технология находится на стадии завершения.
EnvironmentFX
Технология EnvironmentFX создана для моделирования звука окружающей среды и рассчитана на использование со стандартными интерфейсам типа EAX и I3DL2. По сути, технология EnvironmentFX позволяет воспроизводить эффект реверберации, описывая то, как звуки достигают ушей слушателя в зависимости от параметров помещения. Помещением может быть и открытое пространство и маленькая келья монаха. Когда слушатель находится в помещении с истоником звука он сначала слышит звук, достигший его ушей по прямому пути, затем, чуть поздее, он сылшит ранние отражения (звуки несколько раз отразившиееся от стен или объектов) и в самый последний момент он слышит реверберацию, т.е. поле остаточных отраженных звуков, затухающее со временем.
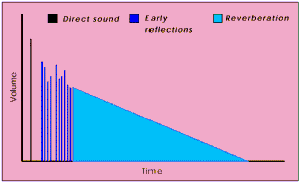
На иллюстрации слева показано распределение звуковых сигналов в зависимоти от уровня громкости и продолжительности во времени.
EnvironmentFX позволяет моделировать различные типы акустики за счет использования специальных алгоритмов, рассчитывающих ранние отражения и реверберацию. При этом истоник каждого из ранних отраженных звуков может позиционироваться индивидуально в 3D пространстве. Для того, чтобы переходы между различными помещениями (читай разными аустическими средами) были плавными и естественными предусмотрены специальные фильтры, причем алгоритм EnvironmentFX динамически переконфигурируется переключаясь на нужный. Имеется возможность динамического регулирования уровня интенсивности реверберации для каждого источника звука индивидуально. EnvironmentFX специально ориентирована на воспроизведение через мультиколоночную конфигурацию акустики с использованием технологии MultiDrive, но при этом допускается воспроизведение звука и через две колонки или наушники. Для моделирования различных акустических сред EnvironmentFX использует параметры самого истоника звука (интенсивность, расположение в пространстве) и параметры окружающей среды. Для воспроизведения звука вокруг пользователя EnvironmentFX использует следующие характеристики:
Direct-to-reverberant sound ratio - соотношение уровней громкости основных звуков и реверберации. Уровень громкости основного звука становится интенсивнее при достижении ушей слушателя и становится тише, когда уходит на задний план. В тоже время уровень громкости реверберации приблизительно неизменен вне зависимости от расстояния между слушателем и источником звука. Сооношение уровней громкости основного звука и реверберации дает слушателю важную информацию для оценки расстояния до истоника звука.
Room size - размеры помещения. В маленьком помещении, например холле, расстояние между отраженными звуковыми волнами мало, т.е. отраженные звуки близки друг к другу и довольно быстро формируют остаточную реверберацию. В большом помещении, например ангаре для самолетов, наоборот, отраженные волны преодолевают большие расстояния и для формирования реверберации требуется больше времени.
High-frequency cut-off - отбрасывание высокочастотных компонент звука. Когда материал стен или объхектов отражает звук, не все частотные компоненты отражаются с одинаковой степенью. Большинство материалов поглащают частоты определенного значения, т.е отбрасывается часть высокочастотных компонент. Например в ванной комнате отражаются звуки с частотой вплоть до 14000 Гц, а вгостинной комнате с коврами на стенах отбрасываются все компоненты с частотой более 2000 Гц.
Early reflection level - уровень интенсивности ранних отражений. Ранние отражения дают возможность пользователю определить наличие близких объектов и стен. Чем больше предметов и стен находится близко к пользователю тем большим будет процент ранних отражений в общей звуковой картине. Например, близкорасположенные стены из кирпича в коридоре формируют большое количество ранних отражений,а открытое трявяное поле не формирует ни одного раннего отраженного звука.
Reverberation level - уровень интенсивности реверберации. Уровень громкости реверберации может варьироваться при смене одного помещения на другое.
Reverberation decay time - время затухания реверберации. Это время, необходимое для того, чтобы реверберация была полностью поглощена воздухом и стенами в помещении. Например, в большом ангаре со звукоотражающими стенами время реверберации порядка 10 секунд, в палате со стенами из войлока очень хорошо поглощающих звук, время затухания реверберации около 0.2 секунды.
High Frequency decay time - время затухания высокочастотных компонент звука. Время затухания высокочастотных компонент напрямую завист от свойств окружающих объектов и стен. Например мрамор хорошо отражает высокочастотные звуки, а под водой высокочастотные компоненты очень быстро затухают.
Density - плотность. Плотность отраженных звуков зависит от числа объектов, от которых отражается звук. Чем выше плотность, тем быстрее отраженные звуки переходят в реверберацию. Закрытая комната со звукоотражающими стенами имеет очень высокую плотность отражений, по сравнению с открытым полем.
Diffusion - рассеивание. Величина, показывающая с какой степенью звуковые волны совмещаются или разделяются при соприкосновении с поверхностями в помещении. Комната с разнообразными по форме объектами созадает высокую степень диффузии звука, чем простот пустая комната с голыми стенами. Многие концертные залы имеют такую форму, что возникает диффузная реверберация.
Detuning - расстройка. Расстройка может использоваться для симуляции изменения тональности звука, которая возникает при отражении звука от движущихся поверхностей. Может изменяться как величина, так и глубина расстройки. Применяется, например, для симуляции плеска волн на ветру.
Нетрудно заметить, что хотя мы рассмотрели технологию EnvironmentFX самой последней в статье, она, несомненно самая важная из применяемых на практике разработок Sensaura.
В видении компании Aureal (Wavetracing)
Для создания полного ощущения погружения в игру, необходимо рассчитать акустическую среду окружения и ее взаимодействие с источниками звука. По мере распространения звуковой волны, она ослабляется, т.е. находится под воздействием среды, в которой она распространяется. При распространении звуковые волны достигают слушателя различными путями:
Они могут следовать по прямому пути к слушателю (direct path).
Один раз отразившись от объекта (путь первого отраженного звука -- first order reflected path).
Отраженный дважды (путь вторично отраженного звука -- second order reflected path) и более раз.
Звуки могут так же проходить сквозь объекты, такие, как вода или стены (occlusions или звук, прошедший сквозь препятствие).
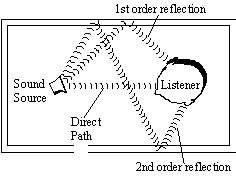
Алгоритмы обсчета путей распространения звуковых волн (wavetracing) компании Aureal воспроизводят эффект распространения звука в окружающей среде; причем это немалая работа с любой точки зрения. В документации с сайта Aureal алгоритмы wavetracing описываются так:
Технология Wavetracing компании Aureal анализирует геометрию описывающую трехмерное пространство для определения путей распространения звуковых волн в режиме реального времени, после того, как они отражаются и проходят сквозь пассивные акустические объекты в трехмерной окружающей среде.
Существуют три главных компонента: интерфейс A3D, geometry engine (геометрический движок, определяющий геометрию объектов в пространстве) и scene manager (менеджер сцены). Интерфейс A3D является основным компонентом. Один в отдельности он используется для реализации прямых путей распространения звука (direct path). Geometry engine является основным компонетом для обсчета отраженных и прошедших сквозь препятсвия акустических звуковых волн или для Acoustic Wavetracing. Менеджер сцены используется как геометрическим движком, так и интерфейсом A3D для управления сложными звуковыми сценами. Обработка каждого из этих компонетов будет производиться именно в таком порядке.
Взаимосвязь и функционирование менеджера сцены, геометрического движка и реализация прямых путей распространения звука показаны ниже:
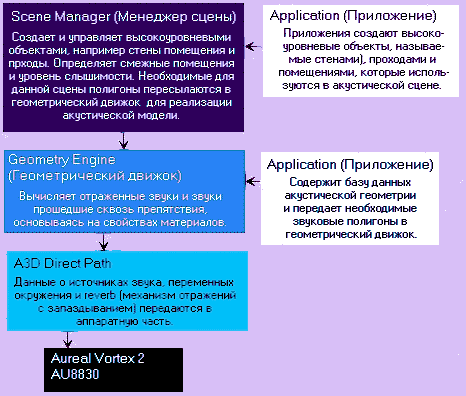
Прямые пути распространения A3D звука
Реализация прямых путей распространения A3D звука содержит 4 компонента: источник звука (Sound source), окружающая среда, в которой распространяется звук, слушатель (или приемное устройство) и отраженный звук с запаздыванием (late reflections).
Источник звука (Sound source)
Источник звука описывается на основе информации о его местоположении, направленности и угла конуса (угол между лучем слышимости и границей звука, распространяемого источником). Если источник звука динамичен, т.е. движется, то применяются дистанционная и допплеровская модели. Для эффективного распределения ресурсов, источники звука располагаются в соответствии с приоритетом.
Дистанционная модель: В дистанционной модели определяется масштабный коэффициент, который контролирует эффективность увеличения количества источников звука на расстоянии. В результате определяется минимальная дистанция для начала увеличения количества источников звука и максимальное расстояние, на котором этот процесс прекращается.
Допплеровская (Doppler) модель: В этой модели определяется скорость распространения звука, высота звука и масштабы применения эффекта Допплера (эффект Допплера заключается в том, что при движении источника волны относительно приемника изменяется длина волны. При приближении источника звука к приемнику длина волны уменьшается, а при удалении растет на величину, определяемую по специальной формуле).
Слушатель
Слушатель определяется свойствами, включающими местоположение, направленность и скорость перемещения.
Окружающая среда
Окружающая среда представляет вещество, окружающее распространяющийся звук. После начала распространения звуковой волны, она начинает проходить через окружающую среду, в которой с волной могут происходить разные вещи: она поглощается воздухом, причем степень поглощения зависит от частоты волны, наличия ветра (т.е. движения воздуха) и влажности воздуха.
В интерфейсе A3D 2.0 окружающая среда определяется свойствами и задается особым образом, описанным ниже. Эти переменные окружающей среды вероятно будут применяться ко всем источникам звука внутри сцены. С аппаратной точки зрения, чипсет Vortex 2 объединяет атмосферные фильтры внутри своего блока реализации A3D звука. По всей вероятности, ввод данных, основанных на переменных окружающей среды осуществляется с применением фильтров, которые должны имитировать различные изменения звука во время прохождения через разные атмосферные среды.
Свойства окружающей среды A3D звука
Заранее задаваемые свойства окружающей среды:
Воздух и вода.
Скорость распространения звука.
Высчокочастотное затухание, зависящее от окружающей среды.
Степень затухания звукового сигнала с увеличением расстояния от источника до приемника.
Звук, отраженный с запаздыванием (Late Reflections)
Использование отраженного звука предоставляет способ точно определить местоположение источников звука, а так же размер, форму и тип помещения или окружающей среды, в который мы находимся. Чипсет Vortex 2 имеет возможность оперировать до 64 трехмерными источниками отраженного звука. Это осуществляется благодяря использованию геометрического движка, который моделирует ранние отраженные звуки. Ранние отраженные звуки (early reflections) относятся к звукам, отраженным в первую очередь.
Запаздывающий отраженный (late order reflections) звуковой сигнал воспринимается как эхо или реверберация (reverberation). Вот разумное объяснение этому: человек имеет возможность индивидуально воспринимать первый отраженный звук, в то время как второй и все последующие отраженные звуки обычно смешиваются в форму поля запаздывающих отраженнных звуковых сигналов или просто эхо.
Лучше всего эхо проявляется на очень больших пространствах, когда требуется большое время для затухания сигнала. Хорошим примером является медленное перемещение внутри кафедрального собора или большой пещеры, когда при движении вы слышите долго длящееся эхо. От свойств окружающей среды зависят параметры, определяющие запаздывающий отраженный сигнал.
Переменные механизма расчета звуков, отраженных с запаздыванием (reverb):
Варьирование уровней входного и выходного звукового сигнала, отраженного с запаздыванием.
Предварительная задержка искусственного эха (reverb).
Время затухания запаздывающего отраженного звукового сигнала.
Ясность (четкая различимость) запаздывающего отраженного звука.
В настоящее время нет возможности использовать поле запаздывающего эха, но такая возможность будет доступна после модернизации драйверов, и, возможно, будет включена в интерфейсе A3D 2.1.
Механизм построения геометрических фигур в пространстве
Геометрический движок или geometry engine в интерфейсе A3D 2.0 это уникальный механизм по своей возможности моделирования отраженных и прошедших сквозь препятствия звуков.
В отличии от менеджера сцены, геометрический движок оперирует с данными на уровне геометрических примитивов: линий, треугольников и четырехугольников. Геометрия может быть определена в двумерном или трехмерном пространстве, соответственно, в случае 3D геометрии, вычисления могут быть очень интенсивными.
Геометрический движок может быть задействован приложением с помощью менеджера сцены или напрямую, для полного контроля над описанием путей распространения волн. В последнем случае, приложение содержит базу данных звуковой геометрии и передает только необходимые в данный момент звуковые полигоны в геометрический движок.
Геометрический движок использует полученные звуковые полигоны для построения системы координат, определяющей взаимное расположение слушателя и источников звука.
Звуковой полигон (audio polygon) имеет местоположение, размер, форму, а также свойства материала из которого он сделан. Форма полигона и его местоположение в пространстве связаны с источниками звука и слушателем, влияя на определение того, как каждый в отдельности звук отражается или проходит сквозь полигон. Свойства материала, из которого состоит полигон, могут изменяться от полностью прозрачного для звуков до полностью поглощающего или отражающего.
Очень важно иметь минимальную по размерам базу данных акустических полигонов, что бы минимизировать загрузку CPU. В играх должно быть задействовано около 50 звуковых полигонов в любой момент времени. Этого количества достаточно для описания сложной акустики и представления всех важнейших случаев прохождения звуков сквозь препятствия. Более того, звуковые полигоны должны быть так же точно определены, как и их эквиваленты в графике.
Материалы
Каждый раз, когда звук отражается от объекта, материал из которого сделан объект влияет на то, как сильно поглощается каждый частотный компонет звуковой волны и как много компонетов отражается обратно в окружающую среду. Материалы, используемые для звуковых полигонов могут быть определены в интерфейсе A3D 2.0.
Переменные материалов:
Заранее определенные материалы: дерево, бетон, сталь, ковер.
Отражающие свойства: меняются от полностью отражающих до совсем неотражающих звуки.
Свойства звуковых преград: меняются от полностью прозрачных до непрозрачных для звуков.
После ввода всех необходимых данных, геометрический движок вычисляет ранние отраженные звуки и звуки прошедшие сквозь препятствия, основываясь на свойствах материалов. Уровень детализации звучания и режим реализации акустической модели могут быть установлены с помощью геометрического движка.
Звук прошедший через преграду (occlusions): геометрические алгоритмы вычисляющие то, как звук преодолевает преграду в виде поверхностей. Точность и качество реализации могут быть принесены в жертву скорости вычислений.
Один раз отраженные звуки: вновь, качество реализации может быть принесено в жертву скорости вычислений.
Менеджер сцены
Менеджер сцены использует высокоуровневую базу данных звуковой геометрии и управляет звуковыми полигонами, используемыми в сцене. Приложения создают высокоуровневые объекты, называемые стенами (walls), проходами (openings) и помещениями (rooms), которые могут быть использованы в акустической сцене. Обычно, программа загружает сцену и просто вызывает функцию реализации. Менеджер сцены использует акустическую сцену для определения соседства помещения (т.е. что смежно с помещением) и уровень слышимости. Слышны только те звуки, которые распространяются в помещении, где в данный момент находится слушатель, и звуки в смежных помещениях. Менеджер сцены определяет необходимые для данной сцены полигоны и пересылает их геометрическому движку для построения акустической модели.
Примеры высокоуровневых объектов:
Стены: имеют свойства материала из которого они сделаны. Они могут двигаться и менять ориентацию в пространстве. Не все сцены должны отражать звук.
Проходы: это отверстия в стенах; звук перемещается от одной стороны стены к другой стороне. Проходы могут быть открытыми и закрытыми.
Помещение: это пространство, которое со всех сторон полностью окружено стенами.
Сцена: это набор из помещений.
Менеджер сцены от Aureal описывет пути распространения звуковых волн для каждого уровня в форме упрощенных полигонов.
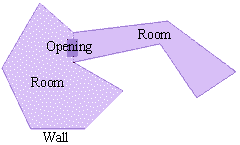
Использование технологии Wavetracing в играх
Реализация wavetracing весьма сложна. Существуют простые высокоуровневые способы доступа (через менеджер сцены и загрузчик сцены) для людей, которым нужен быстрый результат. Дополнительно, доступно управление на низком уровне для разработчиков, которые хотят "сделать акустику действительно ошеломляющей, т.е. совершенно на новом уровне".
Быстрый и простой способ расчета путей распространения звуковых волн
Быстрый и грубый способо добиться этого, это использовать менеджер сцены. По мнению Скипа Макилвейна (Skip McIlvaine) из Aureal, база данных графической геометрии может быть пропущена через конвертер, который преобразует все необходимые графические полигоны в звуковые полигоны за время загрузки уровня игры. Глобальные значения могут быть установлены для параметров объектов отражающих и препятствующих звуку. Кроме того, возможно произвести обработку базы данных графической геометрии заранее, прогнав алгоритм преобразования полигонов и храня базу данных звуковой геометрии в качестве отдельного файла-карты и подгружать этот файл во время загрузки уровня игры.
Тонкая регулировка wavetracing
Существует несколько способов, с помощью которых разработчик звукового оформления может тонко регулировать пути распространения звуковых волн для достижения лушей производительности и эффекта реалистичности:
Индивидуально выбирать толщину стен и материал, из которого они сделаны.
Заранее подготовить установки эха (reverb) для помещений.
Оптимизировать акустическую геометрию с целью использования минимального набора полигонов.
Законченная картина
Результатом является последний шаг в сторону истинного реализма создаваемого звука: комбинация из 3D позиционируемого звука, акустики помещений и окружающей среды и точное представление звуковых сигналов для слушателя. Моделирование окружающей среды, реализованное Aureal, не имеет аналогов, даже EAX от Creative Labs не может сравниться по набору предоставляемых возможностей. Тем не менее, технология EAX более проста в реализации и меньше загружает CPU.
Технология Wavetracing не является быстро реализуемым эффектом, который может быть добавлен и так же легко использован, как запаздавшая мысль. Необходимо серьезное планирование перед реализацией. Первые несколько игр, которые будут использовать Wavetracing, возможно будут использовать все преимущества лишь на 50% от всего имеющегося потенциала. Но даже при этом, эти игры будут самыми передовыми, чем все остальные, созданные до них. Первые игры, сделанные с использованием технологии Wavetracing, появились уже в 1999 году. Они были поистине ошеломляющими. В любом случае, A3D 2.0 и Wavetracing были разработаны чтобы стать основными 3D технологиями, которые могут быть использованы всеми разработчиками, т.е. нечто вроде OpenGL для звука.
Печально, что такой перспективной наработке придется пропасть, либо исчезнуть в недрах конкурента. Недавно фирма Aureal. Ее тут же попытался купить основной конкурент – Creative Labs, но эта сделка по определенным причинам не состоялась. Дальнейшее будущее компании неизвестно. Будем надеяться, что потенциал инженеров и разработчиков не пропадет даром, благо опыт перерождения у них уже есть: в свое время с рынка исчезла достаточно известная компания Media Vision, а родилась – Aureal.
В видении компании EAR
Что такое Interactive Around-Sound (IAS)?
Проще говоря, IAS это новый звуковой движок (audio engine), который дает возможность на всех компьютерах (при наличии минимум Windows95 и DirectX5) создавать одинаковое 3D звучание вне зависимости от того, какое аппаратное обеспечение для воспроизведения и создания звука используется. Главный козырь IAS это поддержка воспроизведения звука на более чем через две акустические колонки (т.е. поддержка multi-point технологии воспроизведения звука).
IAS это тоже самое что и A3D или EAX?
Нет. IAS разработана с целью заменить A3D и EAX там, где имеется возможность воспроизведения звука через более чем две колонки, так как EAR считает, что A3D 1.0 и EAX 1.0 не могут полноценно использовать множество акустических колонок.
Будет ли IAS работать совместно с A3D или EAX?
Да. IAS поддерживает обе технологии A3D и EAX, создающие виртуальный 3D звук (т.е. трехмерный звук через две колонки).
Преимущества при использовании IAS вместо A3D или EAX
IAS не требует наличия специального аппаратного обеспечения. IAS обеспечит то звучание звука, которое заложено разработчиком приложения вне зависимости от того, какая звуковая карта используется. Это означает, что приложение созданное с помощью IAS будет воспроизводить звук при использовании звуковых картах от Guillemot, Diamond и ряда других, так же, как и при воспроизведении через Dolby, DTS и MP3 декодеры без необходимости какой-либо перекомпиляции. Кроме того, IAS может воспроизводить звук через две колонки (Phantom IAS), соответствующим образом накладывая звуковые каналы, если только такой вариант внешней акустики доступен. Это позволяет любому пользователю слушать 3D звук, создаваемый IAS движков независимо от аппаратного обеспечения, которое есть в наличии. Тот же интерфейс Phantom IAS позволяет получить 3D звук на системах не оснащенных аппаратным акселератором.
Microsoft не имеет стандарта на воспроизведение DirectSoun/DirectSound3D звука на более чем две колонки. Различные производители звуковых карт используют свои собственные алгоритмы воспроизведения DirectSound3D звука, причем расчет того, какой звук будет воспроизводиться из каждой колонки перекладывается на CPU. При этом каждый производитель использует собственную технику и в результате, одна и та же игра будет звучать по-разному на разных звуковых картах. Использование IAS устраняет эту проблему.
IAS работает на любой звуковой карте, которая работает через DirectX5. Некоторым звуковым картам требуется дополнительное программное обеспечение для того, чтобы была возможность использования более двух колонок при воспроизведении звука.
Заключив партнерское соглашение с Creative Labs, EAR теперь поддерживает все доступное в настоящее время аппаратное обеспечение от Creative, имеющее возможность воспроизводить звук через более чем две колонки.
Будет ли IAS работать с любой игрой?
Нет, игра должна быть написана с учетом поддержки звукового движка. Все, что использует DirectSound или работает под Windows95 можно портировать, т.е. встроить поддержку IAS.
Как работает IAS?
IAS использует систему наложения координат, которая интерполирует местоположение звукового события и конвертирует это местоположение с определенным уровнем затухания звука для каждой акустической колонки при заключительном микшировании. Независимо от того, как много колонок подключено один и тот же код используется для каждого варианта, а это означает, что звуковой движок очень мал и компактен по размерам, но при этом поддерживает множество разных аппаратных конфигураций. Этот "напиши один раз, исполняй потом везде" код делает решение от IAS очень привлекательным для разработчиков, многие из которых используют IAS и для интерактивных и для не интерактивных приложений.
Есть два аспекта индустрии персональных компьютеров, с которыми напрямую сталкивается пользователь: видео и звук. При оценке качества игры пользователь, прежде всего, смотрит на то, насколько реалистичны графические и звуковые эффекты, а не то, насколько быстро данные перекачиваются с CD или жесткого диска. Наряду с ростом вычислительной мощности процессоров для PC и емкости носителей информации, особое внимание всегда уделяется увеличению производительности видео акселераторов и скорости перекачки данных с CD/DVD/HDD, в то время как на долю звука остаются лишь избытки ресурсов. При такой философии разработчиков, развитие компьютерного звука долгое время оставалось на уровне стерео решений (воспроизведение через две акустические колонки). Еще год назад, широкое распространение получила технология воспроизведения 3D звук через две колонки с использованием алгоритмов HRTF, IAD, ITD и т.д.
К несчастью, для воспроизведения 3D звука требуется больше, чем просто алгоритмов создания эффекта окружающего звука (surround sound). Человеческое ухо может определять движение только при высокой частоте (около 10000 Гц). Однако типичная частота дискретизации, используемая при создании HRTF эффектов, находится ниже этого порога (частота дискретизации 11.025 kHz может обеспечить частоту звучания только на уровне 5000 Гц), что заставляет уши реагировать на другие звуковые компоненты для определения истинного положения источника звука. Из одиннадцати звуковых компонентов, используемых мозгом для определения местоположения звукового события, только до трех (включительно) моделируются в современных звуковых решениях. Это означает, что многие пользователи просто не услышат никаких 3D звуковых эффектов.
Есть два способа решения этой звуковой проблемы. Первый относится к управлению распределением ресурсов частоты дискретизации с целью сделать соответствующие частоты доступными для использования, чтобы помочь пользователю слышать эффекты 3D звука. Второй способ заключается в утверждение стандарта на использования тыловых колонок сзади пользователя для PC платформы. Так как управление ресурсами может быть реализовано в хорошем звуковом движке (например, IAS), главная забота это убедить пользователей в том, что использование "более двух акустических колонок" для воспроизведения звука это норма. Эта забота существенно упростилась с появлением звуковых карт, поддерживающих воспроизведение через четыре колонки и всевозможных компьютерных устройств и приставок (set-top-box, Living Room PC), рассчитанных на воспроизведение окружающего звука (surround sound) и даже AC-3.
Компания Extreme Audio Reality, Inc. (EAR) работает с разработчиками и производителями аппаратного обеспечения с целью достичь высококачественного звучания с учетом использования имеющихся ограниченных ресурсов. Результатом этого сотрудничество стало создание технологии Interactive Around-Sound (IAS), запатентованной техники для реализации воспроизведения 3D звука на всех доступных платформах. IAS позволяет разработчикам "write once, run anywhere" (написав один раз, запускать везде) получая трехмерный звук на любой платформе, путем определения какое аппаратное обеспечение доступно для использования. IAS была разработана для создания высококачественного, действительно интерактивного 3D звука без ущерба производительности всей системы в игре, т.е. получив 3D звук, вы не потеряете значений fps.
"Напиши и запускай"
Главная забота для разработчиков игр состоит в предоставлении пользователю высококачественного продукта с реалистичной графикой и звуком. Microsoft предлагает разработчикам использовать набор интерфейсов DirectX, в который входят API для создания видео и звука для игр. Однако, в DirectX уделяется слишком много внимания совместимости со старым аппаратным обеспечением и слишком мало современным технологиям, в результате чего разработчики получают неэффективное средство создания настоящего 3D звука (с каждой новой версией DirectX ситуация улучшается, но происходит это очень медленно). IAS была разработана для управления всеми звуковыми ресурсами необходимыми дизайнеру звука и включает в себя поддержку DirectSound, DirectSound3D и других реализаций surround sound. В результате программист может потратить больше времени на создание реалистичного взаимодействия с 3D звуком и меньше заботиться о буферизации, распределении потоков и совместимости с аппаратным обеспечением.
Любой дизайнер звука, который работал с DirectSound от Microsoft, знает, что имеется много мест, в которых можно улучшить то, как DS управляет звуком. Эти разработчики высоко оценят IAS, если встроят его звуковой движок в свою игру. EAR создала IAS для работы совместно с DirectSound, поэтому при использовании IAS корректируются многие недостатки DirectSound и в результате получается высококачественное звучание.
На уровне интерфейса IAS обеспечивает по настоящему раздельное, динамичное определение местоположения звуковых событий:
Распределение ресурсов и управление буферизацией/потоками происходит автоматически
Все вычисления, связанные с расположением источников 3D звука в пространстве и расчет скорости распространения звука осуществляются автоматически
Автоматически вычисляются эффект Допплера, высота, удаленность, время задержки для звуков и другие управляющие факторы
Любое звуковое событие можно разрешить или запретить для воспроизведения
Все звуковые события полностью независимы от других звуковых событий
Плюс ко всему, звуковой движок автоматически конфигурирует выходные звуковые потоки с целью использовать все преимущества решений 3D звука:
Специализированные звуковые карты, имеющие выход на тыловые колонки (т.е. поддерживающие воспроизведение через четыре колонки), поддерживаются в первую очередь. Через такие звуковые карты обеспечивается воспроизведение настоящего интерактивного surround звука.
При наличии внешних декодеров, выходные потоки автоматически кодируется, для воспроизведения звука через системы Dolby Pro-Logic, AC-3, DTS и т.д.
Решения типа SRS, Q3D и A3D поддерживаются на уровне интерфейса DirectSound
При использовании звуковых карт, поддерживающих воспроизведение только через две колонки, реализована полная совместимость с DirectSound3D
Разработчику надо лишь один раз написать звуковой код, так как все звуковой аппаратное обеспечение, рассчитанное на Windows95/98 поддерживается через одинаковый интерфейс программирования. После чего игра будет звучать на любой звуковой карте, работающей через DirectX.
"Нужно услышать, чтобы поверить"
IAS от EAR имеет много преимуществ по сравнению с другими звуковыми решениями. Накладные расходы при использовании IAS очень маленькие, при этом звуковой движок всегда обеспечивает пользователю наилучшее звучание для доступной конфигурации. Технология IAS создавалась с целью быть вперед совместимой. Это означает, что разработчики, используя звуковой движок IAS при написании игр для сегодняшнего аппаратного обеспечения, могут быть уверены, что завтра, когда появится новое аппаратное обеспечение, звучание в игре все равно будет таким, каким оно задумывалось.
IAS создавалась и тестировалась людьми, чей опыт в качестве звуковых инженеров существенно превосходит их опыт работы в качестве компьютерных программистов. Это означает, что основное внимание было уделено на переносе работы на управление ресурсами, чтобы обеспечить наивысшее качество звучания на доступной системе, а не на попытке обеспечить низкокачественно звучание на "приемлемом" уровне. Плюс ко всему, основной упор был сделан на создание 3D звучания в играх. Звуковой движок был создан с целью воспроизведения истинного интерактивного "around-sound" (окружающего звука) через четыре или более акустических колонок, с возможностью воспроизведения через две колонки при необходимости. IAS уже сейчас поддерживает PC будущего, но при этом прекрасно работает на современных системах.
Кроме поддержки современных мультимедиа PC, EAR уделяет внимание новейшим Интернет технологиям (VRML, Indeo и т.д.), так что игры, созданные с использованием IAS автоматически совместимы с сетевыми вариантами. EAR поддерживает MIDI, DLS, S/P DIF, IEEE1395, USB и многие другие цифровые технологии передачи данных, что дает возможность разработчикам игр полностью использовать сегодняшние и завтрашние звуковые системы. Наш SDK обеспечивает полностью интуитивную возможность встраивания IAS в игру с помощью простых программ, которые могут помочь разработчику скомпилировать свое первое IAS приложение менее чем за десять минут.
Доступна техническая поддержка, чтобы помочь легко интегрировать технологию EAR в приложение.
Особенно важно то, что нет необходимости использовать другой звуковой движок в игре; IAS работает на любом существующем или будущем аппаратном обеспечении для 3D звука.
В видении компании Creative
EAX это API для создания звучания окружающей среды, созданный Creative. Цель EAX помочь разработчикам игр создавать ощущение реальности происходящего действия в игре с помощью звука. EAX это расширение DS3D, звукового API от Microsoft, являющегося частью среды для программистов DirectX. Оба интерфейса дополняют друг друга.
DS3D управляет позиционированием источников звука и ориентированием слушателя в виртуальном 3D пространстве игры. Например, разработчик может использовать DS3D для создания независимых источников звука для каждого персонажа в FPS игре, обеспечивая их различными голосами и звуками оружия с ясно различимой принадлежностью каждому персонажу. Эти источники звука могут перемещаться в 3D пространстве, также как и слушатель (игрок), который слышит звук. Разработчик игры может использовать DS3D для управления источниками звука, изменяя такие нюансы, как характер направленности (источник может распространять более громкий звук в одном направлении) и действие эффекта Допплера (увеличение высоты тональности при приближении источника звука к слушателю и снижение тональности при удалении).
EAX расширяет возможности DS3D за счет создания мира вокруг источников звука и слушателя - т.н. виртуальную звуковую среду окружения. Эта звуковая среда создается за счет моделирования отражения звуков и реверберации, исходящих со всех сторон от слушателя. Волны отраженных звуков и реверберация, достигая слушателя, дают ему возможность составить представление о природе окружающей его среды - размерах помещения, отражающих свойств стен и многое другое. Разработчики могут использовать EAX для простой установки различных типов свойств акустики для разных помещений и мест в игре. Например, играя в игру, поддерживающую EAX, игрок может слышать, как изменяется акустика при переходе их коридора в пещеру.
В дополнение к созданию звуковой окружающей среды, EAX 1.0 может также, внутри звуковой окружающей среды значительно усилить ощущения восприятия расстояния до различных источников звука: интерфейс автоматически подстраивает индивидуальные параметры источников реверберации, когда каждый источник звука изменяет свое местоположение в пространстве, т.е. расстояние до слушателя изменяется. При этом EAX находится в стадии развития: в следующей версии (EAX 2.0) будет сделан значительный шаг вперед с целью улучшения интерфейса программирования и акустической модели используемой для создания звуковой окружающей среды.
С точки зрения поддержки в приложениях аппаратного обеспечения от Creative и Emu, существует нечто большее. "Presets" (заранее сделанные установки EAX) в линейке звуковых карт Creative SB Live! дают возможность пользователю добавлять эффекты звука окружающей среды в самые популярные старые игры. Плюс к этому, аппаратное обеспечение Creative и Emu также поддерживает позиционирование источников звука в 3D пространстве, то, что используется любой игрой, написанной под DS3D.
EAX предоставляет очень эффективный интерфейс программирования, который очень интуитивен в использовании. Он предоставляет три различных типа управления:
Обширный выбор заранее сделанных установок звучаний окружающей среды ("presets"), который дает возможность очень просто выбрать требуемый тип окружающей акустики.
Набор параметров интерфейса, которые дают возможность делать собственные настройки для заранее установленной акустики окружающей среды, применяется к любому индивидуальному источнику звука или ко всем источникам звука одновременно.
Автоматическое изменение важнейших параметров в зависимости от местоположения источников звука. Когда источники звука двигаются относительно слушателя, EAX автоматически моделирует естественное поведение реверберации и отраженных звуков с целью улучшить восприятие того, что источник звука удаляется или приближается и правильного воспроизведения процесса перемещения источников звуков в акустической окружающей среде.
В результате продолжающихся разработок, в EAX будет добавляться больше возможностей по управлению акустикой окружающей среды, с целью обеспечить слушателю более богатые ощущения. Все улучшения, которые будут введены, можно разделить на две категории:
Расширенное управление акустикой окружающей среды. Программист может изменять размеры помещения и манипулировать параметрами ранних отраженных звуков отдельно от затухающей реверберации с запаздыванием. Это позволяет разработчикам создавать реалистичные и полные модели широкого диапазона акустики окружающей среды, начиная от полуоткрытых пространств (например, городской двор, улица и т.д.) и заканчивая узким коридором или маленьким тесным кабинетом.
Добавление эффектов окклюзии и обструкции и управления за ранними отраженными звуками для каждого источника звука. Эти эффекты или отраженные звуки могут подчиняться или не подчиняться правилам графического/физического описания виртуального мира - все зависит от мнения программиста, от его или ее виденья того, что нужно в игре и от эмоционального воздействия, которое должна оказывать игра.
Окклюзии и обструкции, как они улучшают ощущения от игр
EAX окклюзии (occlusions - звуки, проходящие через препятствия) применяются для моделирования источников звука, расположенных в другом помещении или в пространстве с другой стороны стены. Окклюзии имеют свойства, при изменении параметров которых меняются характеристики звукового сигнала, проходящего сквозь препятствия, в результате моделируются различные типы стен, состоящие из разных материалов и имеющие различную толщину. Например, если слушатель находится внутри дома, т.е. в помещении, а источник звука находится снаружи, тогда приложение может использовать свойства окклюзии для воспроизведения реалистичного звучания голоса или шума, так если бы они действительно слышались из-за двери или снаружи дома, в котором находится слушатель.
Использование свойств обструкции (obstruction, звук задерживается препятствием) позволяет моделировать дифракцию звука препятствием для создания ощущения, что источник звука находится в той же окружающей среде, что и слушатель, но закрыт от слушателя преградой. Возвращаясь к предыдущему примеру, использование свойства обструкции может сделать звучание голоса таким, будто его источник расположен за большой колонной в той же комнате, что и слушатель, при этом, звук не проходит сквозь колонну.
EAX
Модель распространения света, основанная на геометрии пространства, повсеместно используется в графическом мире и известна под названием "ray tracing" (распространение лучей), имеет акустический эквивалент. Для реализации геометрической акустики требуется компьютерная модель физического пространства: четкое определение того, какой объект и где расположен и какие звукоотражающие или звукопроводящие свойства имеет каждый объект. Затем рассчитывается количество слышимых пользователем звуков, отраженных от этих объектов для каждого источника акустики. Также, в расчет могут приниматься ослабление звукового сигнала во время прохождения сквозь стены или преграды на пути прямого распространения звуковых волн и каждого из отраженного звука. Ray tracing и другие модели распространения звуков на основе геометрии пространства - такие, как метод зеркальных источников звука - являются техниками, зависимыми от времени и широко применяются в качестве поддержки при вычислении акустики помещений в архитектурном дизайне. Подобная техника допускает, что звуковые волны отражаются в "зеркальной" форме, которая является аппроксимацией игнорируемых дифракции и диффузии звука. Совсем недавно, этот метод геометрического моделирования был адаптирован для воспроизведения 3D звука в некоторых экспериментальных интерактивных системах виртуальной реальности.
Модель распространения звука, основанная на геометрии пространства, такая, как ray tracing, может быть очень привлекательна для использования в API трехмерного звука. Разработчик просто определяет модель 3D звукового мира, располагает источники звука и слушателя в этом мире, а затем механизм ray tracing определяет пути распространения звуковых волн для завершения работы по созданию реалистичной акустической окружающей среды. На практике, тем не менее, такое применение геометрической модели в мире интерактивного компьютерного звука имеет несколько серьезных недостатков.
Полный расчет отражений от множества объектов для нескольких источников звука является сложной задачей. Не смотря на то, что физические принципы лежащие в основе геометрической модели просты (и обеспечивают лишь аппроксимацию реальных отражений звука) для ее расчета требуется серьезные вычислительные ресурсы. Главное следствие, в 3D играх, это то, что техника расчета распространения акустических волн (ray tracing) может оперировать лишь ограниченным числом отраженных звуков и не может быть использована для воспроизведения затухания запаздывающей реверберации. Чтобы понять, почему это так, рассмотрим источники звука в реальном мире.
Источники звука испускают звуковые волны, которые отражаются от первого объекта, которого достигнут, затем от второго объекта, затем от третьего, и т.д. В обычном помещении существует бесконечное число непрямых путей распространения звуковых волн от источника звука через отражение к слушателю. Когда эти отраженные звуковые волны достигают слушателя, запаздывающие отражения все больше и больше ослабляются, и следуют друг за другом все ближе и ближе по времени. Эти запаздывающие отраженные звуки быстро формируют континуум (сплошную среду), известный как "реверберация". Так как сложность полной модели увеличивается экспоненциально с течением времени, на практике моделирование геометрической акустики в реальном времени должно быть ограничено одним "отскоком" от препятствия ("первоочередные" ранние отраженные звуки) с целью экономии ресурсов CPU. Следовательно, механизм расчета распространения акустических волн в реальном времени не может использоваться для расчета затухания запаздывающей реверберации, которая является составной частью отраженных звуков в типичной акустической среде. В результате 3D звуковой окружающей среде не хватает живости и ощущения реалистичности. Это также приводит к несовместимости, так как первоочередной отраженный звук может стать явным, а затем исчезнуть, согласно физической модели - появляется чувство разочарования, потому что ожидаемого эффекта нет, так как нет запаздывающей реверберации для заполнения свободного акустического пространства, когда первоочередные отраженные звуки исчезают. Для избавления от этой проблемы, в интерфейсе EAX от Creative используется статичная модель распространение звуков, которая оперирует ранними отражениями и затуханием запаздывающей реверберации, и, следовательно, обеспечивает более полное и сильное ощущение звуковой окружающей среды.
Другая серьезная проблема с моделью распространения на основе геометрии пространства, применительно к звуку, состоит в том, что разработчик должен создать и манипулировать сложной моделью акустической окружающей среды для создания отраженных звуков. Поэтому, акустика, базирующаяся на геометрии пространства, может применяться для очень впечатляющих демонстрационных программ, но очень сложна для эффективного использования в реальных приложениях.
Создание эффективной акустической модели это не простая задача, как об этом могут говорить дизайнеры акустики в реальном мире. Дизайнер может потратить месяцы, и даже годы для создания холла с приемлемой акустикой, но даже тогда он может не добиться успеха. Разработчики игр оказались перед этой проблемой дизайна в виртуальном мире при использовании геометрической модели: правильно ли они определили коэффициент поглощения звука для этой стены? Достаточно ли прозрачен для звука этот объект? Им приходится произвести массу настроек, чтобы все было правильным, даже если геометрический API обеспечивает их списком материалов, из которых программист может выбирать. Кроме того, в дополнение к необходимости определения свойств материалов, обычно существует необходимость преобразования графической геометрической информации в форму, которую может использовать звуковой механизм (движок). И то и другое не является простой рутинной задачей.
Последнее и возможно самое важное замечание для игроков и разработчиков заключается в том, что геометрическое моделирование может создавать только конечный результат, который по своей природе является ограниченным, даже с точки зрения производящего сильное впечатление качества звука. Даже если геометрическая модель акустики сможет создать безупречную копию реальной звуковой сцены, эта форма реализма не всегда будет подходящей или эффективной для озвучивания, о чем хорошо осведомлены звукоинженеры киностудий. Слух является в большей степени чувством внутренних ощущений, чем зрение. Для создания наилучшего ощущения от звука, часто требуется использование звуковых эффектов, которые очень далеки от тех, которые могут существовать в физической реальности. Вот почему многие звуки в фильмах - от шуршания одежды до оружейных выстрелов - часто заменяются звуками, которые были "подправлены". Также на звуковых дорожках к фильмам часто записывают имитацию реверберации, подобно той, которую воспроизводится с помощью EAX.
Использование EAX реверберации позволяет создавать в играх виртуальную акустическую окружающую среду, которая отличается от среды, изображаемой на мониторе. В этой виртуальной акустической среде персонажи или объекты звучат так, будто они находятся ближе или дальше от слушателя, чем это выглядит на экране, т.е. плоскому изображению сообщается объем. API EAX создан с целью обеспечить именно такую форму звучания, в тоже время, все задачи по внедрению интерактивности в игру перекладываются на процесс звукового дизайна, т.е. это дело разработчика, как, и в каких объемах использовать и добиваться интерактивности звучания.
Разработчики игр, как и режиссеры фильмов, хотят управлять степенью выразительности и качеством своих 3D звуковых сред окружения, а значит, хотят найти соответствующий инструментарий в EAX. Их потребности не так просто удовлетворить в геометрических моделях, подобных ray tracing. Например, если вы решили увеличить время затухания реверберации для обеспечения более сильного ощущения благоговения при имитации кафедрального собора, в модели типа ray tracing не существует простой кнопки управления длительностью времени затухания reverb. Вместо этого вы можете увеличить размеры звуковой геометрической модели, отодвинув стены дальше от слушателя, чтобы добиться требуемого эффекта. Это сложно сделать и, что еще хуже, в результате получается модель акустики, отличная от графической модели, вследствие чего могут возникнуть проблемы, например, если вы начнете двигать источники звука и графические объекты внутри созданной модели. И даже если вы справитесь с этими проблемами, вы получите модель акустики, которая не будет соответствовать законам физики. Вы не можете добиться одновременно и психологического реализма и эмоциональности, чего разработчики игр, как и режиссеры фильмов, хотят от создаваемого звучания.
В двух словах, EAX обеспечивает разработчиков лучшими параметрами для звукового дизайна, чем для архитектурного дизайна. И EAX реалистично моделирует ранние отраженные звуки и затухание запаздывающей реверберации, которые создают виртуальные объекты или стены.
Мы думаем, что первый фактор, определяет труднообъяснимо быстрое принятие EAX разработчиками приложений. Как отмечалось выше, параметры для звукового дизайна дают возможность разработчикам игр легко (по сравнению с геометрическим моделированием) создавать убедительное и эмоционально красивое ощущение от окружающей слушателя акустики. В EAX, первый набор параметров управляет тем, как слушатель ощущает окружающую среду (помещение, в котором находится слушатель), а второй набор параметров позволяет регулировать эффекты акустической окружающей среды для каждого звука в отдельности. Эти параметры интуитивно понятны разработчику, он может легко манипулировать ими, изменять или усложнять эффекты акустики окружающей среды в любой модели игры или сценария. EAX не требуется наличия перспективы от первого лица (читай слушателя) или привязки источников звука к графическому представлению виртуального мира. С другой стороны, дизайнер звука, который хочет создать звуковую сцену, которая наиболее близко и реалистично совпадает с графической сценой, может легко сделать это, используя громадные возможности EAX по управлению ранними отраженными звуками, эффектами окклюзии и обструкции.
При создании этих эффектов, EAX использует метод статистического моделирования вместо метода геометрического моделирования. Статистическая модель EAX автоматически вычисляет параметры реверберации и отраженных звуков, в зависимости от расположения слушателя относительно источников звука, размеров помещения, направленности источников звука и в зависимости от дополнительного набора параметров, которые может изменять программист.
EAX более прост и более гибок в использовании для программистов, потому что статистическое моделирование не требует полного геометрического описания акустического мира вокруг слушателя. Вместо этого он работает, используя макроскопические параметры, начиная от таких как размер помещения и времени реверберации и заканчивая динамическим вычислением параметров важнейших отраженных звуков и реверберации. Статистическое моделирование также более эффективно использует CPU, чем геометрическое моделирование, но при этом все равно более эффективно моделирует ранние отраженные звуки и реверберацию с запаздыванием, обеспечивая реалистичное воспроизведение глубины акустической сцены. В игре в любой момент могут изменяться заранее сделанные установки окружающей звуковой среды и настраиваться отдельные параметры простым нажатием кнопок управления для создания убедительного ощущения реалистичности акустики, при перемещении слушателя и источников звука из одной части виртуального мира в другую, в зависимости от любого события по сценарию игры.
Среди будущих возможностей EAX будет набор для интуитивного управления, с помощью которого можно будет полностью и эффективно манипулировать ранними отраженными звуками, а также запаздывающей реверберацией. Этот набор также позволит устанавливать параметры окклюзии, обструкции и эффектов перспективы для создания очень четкого впечатления окружающего звучания, если это потребуется. EAX позволяет программистам настраивать или модифицировать полностью или частично автоматическое управление отраженными звуками и реверберацией с целью создать в точности такую акустическую среду окружения, как он или она хочет, или, чтобы наложить требуемый эффект на один конкретный звук. Если необходимо, этот метод позволяет программистам использовать их собственную геометрическую модель с целью контролировать не только эффекты окклюзии и обструкции, но также и ранние отраженные звуки, в зависимости от геометрии стен и препятствий.
Creative наряду с другими компаниями работает в IASIG (Interactive Audio Special Interest Group), разрабатывая новый стандарт 3D звука. Какова роль Creative в этих разработках?
IASIG пригласила Creative внести EAX в качестве вклада в IASIG "Level Two Guidelines" ("Принципы управления второго уровня"). Цель этих принципов установить промышленный стандарт на интерфейс звуковой окружающей среды для разработчиков мультимедиа и игр для PC. Creative согласилась сделать EAX 1.0 открытым для промышленного использования и принять во внимание предложения членов IASIG по расширению нашей первоначальной задачи.
Creative легко реализует поддержку стандарта от IASIG, когда он будет закончен (так как он полностью основана на механизме EAX) и будет поддерживать совместимость с EAX 1.0 в своих драйверах. В действительности, такой стандарт может рассматриваться в качестве некоторого представления "EAX 2.0". Более того, мы продолжаем расширять EAX, с целью получить дополнительные преимущества от использования возможностей продуктов семейства SoundBlaster Live! не только при использовании EAX 1.0 или стандарта IASIG. Будущая версия EAX будет работать без проблем в качестве расширенного набора стандартов EAX 1.0 и IASIG. Для разработчиков игр это означает, что EAX будет больше чем когда-либо, тем API, выбор которого будет гарантировать оптимальную производительность на наиболее распространенном оборудовании.
В видении компании Qsound
3D звук, что это?
Обычная печатная пресса, к сожалению, изрядно невежественна во многих вещах, в частности в вопросе 3D звука. Как результат, если речь заходит об играх, то вам ужасно повезет, если в обзоре игры упоминается звук как таковой, и уж гораздо реже можно встретить упоминание о 3D звуке. Если 3D звук все же упоминается, проверьте обзор на предмет комментариев от компаний, занимающихся трехмерным звуком, для оценки некоторых перспектив технологии, используемой в продукте и сделанных в обзоре выводах.
Терминология 3D звука
Половина всех дискуссий в ньюсгруппах посвящены вопросу что такое "3D" и что нет, вплоть до бессмысленной семантики. Для протокола, термин "stereophonic" означает трехмерный звук! (От Греческого "stereos", означающего "пространственный, трехмерный, непрерывный, сплошной, цельный", а если вы не представляете себе, что означает "phonic" (акустический, звуковой), то дальше не читайте).
На протяжении лет, рынок наводнялся различными видами технологий, которые расширяли возможности аппаратуры убедительно воспроизводить позиционируемый звук в пространстве на ограниченном количестве реальных акустических колонок, и каждый называл все это "3D".
Допустим, что существует нечто, называемое "3D графикой", причем повсеместно под этим термином понимается "визуализация в 2D пространстве 3D модели". Теперь представим, что существует технология, которая позволяет создать подлинное ощущение глубины изображения, и некоторые люди убеждены, что термин "3D", применительно к графике, должен быть зарезервирован для этой технологии. Я полагаю, что пока мы не имеем изображения, протяженностью 360 градусов с воспринимаемой глубиной, его нельзя по настоящему считать "трехмерным" ("3D.
Типы "3D audio" процессов
Очень важно видеть различия между типами технологий 3D звука, прежде всего по функциям (игнорируя в этот момент то, какого успеха достигли поставщики этих технологий на рынке).
В результате получаем следующее:
Stereo Expansion (Расширение стерео): технология, которая оперирует с имеющейся избыточной стерео информацией, надлежащим образом расширяя кажущуюся ширину звукового поля (т.е. главным образом удобная для не-3D стерео произведений, таких как записанная музыка).
Positional 3D Audio (Позиционируемый 3D звук): технология, которая оперирует с множеством индивидуальных звуковых потоков и пытается определить местоположение каждого из них индивидуально в 3D пространстве.
Virtual Surround (Виртуальный окружающий звук): технология, которая оперирует с декодированными данными в формате surround с целью воспроизведения разнообразных каналов в их истинной перспективе с использованием ограниченного числа источников звука, например воспроизведение пятиканального звука на двух акустических колонках.
Stereo expansion и virtual surround главным образом удобны для применения в бытовой электронике, такой, как стерео системы, домашние кинотеатры и т.д. Однако так как некоторые из этих технологий пересекаются с рынком персональных компьютеров (прослушивание музыки с помощью CD-ROM проигрывателей или прямо из сети Интернет, просмотр фильмов DVD), их применение также допустимо.
Тем не менее, визитная карточка для компьютеров - это позиционируемый 3D звук.
Все эти технологии покрывают львиную долю потребительского рынка, каждая в своей соответствующей области применения. Следовательно, 3D звук это не шутка, это полезная и быстро развивающаяся технология для создания музыки, применения в бытовой электроники,в видеоиграх, и т.д. и т.д.
Что действительно смешно, так это количество дезинформации и слепо верящих в характеристики чего-то -- при этом большая часть информации почерпнута из рекламных проспектов различных продуктов, но сами верующие при этом в массе своей не имеют знаний о звуке, в особенности о 3D звуке.
В чем разница между 3D звуком и панорамированием?
В течение многих лет добавить звук в видео игру можно было только при условии использования панорамирования стерео (stereo panning). Это накладывало ограничение в том, что звук можно было поместить только где-то между акустическими колонками, неважно, где бы они ни находились, перед вами в вашей комнате или на вашей голове в виде головных телефонов.
В первом случае, все звуки слышаться где-то между колонками спереди от вас, а в последнем случае, звуки воспроизводятся внутри вашей головы -- что не имеет никаких аналогов с ощущениями в реальном мире.
Панорамирование стерео это просто управление уровнями левого/правого звуковых каналов, которое никогда не зависит от частоты звука и напрямую не влияет на его фазу или синхронизацию. Панорамирование на нескольких акустических колонках (Multi-speaker panning) обычно является развитием этой идеи, но при этом может содержать больше манипуляций с преобразованиями.
Преобразование звука в "3D" (т.е. трехмерный) -- не имеет значения, какой метод при этом используется -- включает дополнительную информацию в звуковой поток в форме амплитуды и разности фаз/задержек между выходными каналами. В этом случае часто присутствует зависимость от частоты звука, хотя некоторые простые эффекты создаются с использованием простых задержек по времени на всем протяжении спектра шумов.
3D звук совершенен?
Сегодня существуют несколько технологий, которые расширяют возможности разработчиков по размещению звука в уникальных местах относительно слушателя. Есть ли какое-то решение действительно совершенное? По-моему, такого решения нет. Означает ли это, что "3D звук" это бесполезная вещь? По-моему, это не так. Истина находится где-то между двумя крайностями.
Почему люди не могут прийти к какому-то общему мнению относительно действенности 3D звука?
Тот факт, что человеческий слух несовершенен, является корнем проблем. Два уха, расположенных по сторонам головы, для определения местоположения источника звука воспринимают большую часть из доступной информации в горизонтальной плоскости (т.е. по азимуту или "по углу компаса"), при этом мы плохо различаем звуки исходящие спереди и сзади, при отсутствии дополнительных данных.
Так как все мы являемся существами, живущими на поверхности земли, то мы определяем местоположение источника звука по смещению относительно азимута, так как наши жертвы и наши враги, все являются тоже наземными существами. Выходит, что наша возможность оценки положения звука в вертикальной плоскости и его удаленности от нас очень слаба и сильно зависит от ушных каналов, которые зачастую очень плохо развиты.
Таким образом, когда разработчик технологии говорит о "точном" расположении источников звука, относитесь к этому с осторожностью. Простая математика может создать целый набор хороших цифр, но реальные результаты это совершенно другой вопрос -- после всего, мы вновь начинаем с недостатков, парни.
Нравится это или нет, но для нормально видящих людей, зрение является основным чувством определения местоположения чего-либо, причем до такой степени, что нас легко одурачить без особых трудов, предоставив противоречивую звуковую информацию. Сколько раз мы смотрели телевизор со звуковым сопровождением, исходящим из паршивого маленького динамика, который мог быть вмонтирован даже не в переднюю панель телика? Волновало ли это нас? Ощущали ли мы большое несоответствие между происходящими на экране событиями и звуком сопровождавшим их? По-видимому, не сильно. Долгое время мы не имели стерео телевизоров и домашних кинотеатров, а популярность они приобрели лишь из-за существенно упавшей на них цены.
Действенность любой технологии позиционируемого звука полностью находится под влиянием таких факторов, связанных с областью применения:
использование в качестве дополнительной поддержки, облегчающей визуальное восприятие
сопровождение действия (скажем фильм, футбольный матч, игра)
усиление интерактивности (например, звуковые эффекты при работе с меню)
уместность применения
Интересно, что видео игры (или другие симуляторы окружающей среды) это единственные приложения с 3D звуком, в которых все эти факторы играют важную роль.
Если вы поместите кого-нибудь в затемненную комнату и проиграете ему незнакомые звуки, воспроизводя их из колонок, расположенных в произвольно выбранных местах помещения, вы увидите, что ни одна из существующих технологий не обеспечивает 100% эффективность -- даже близкую!
Теперь, скажем, у нас есть безэховая камера (т.е. помещение, в котором нет реверберации), поместим в нее слушателя, зафиксируем его голову в нужном (правильном) положении и повторим эксперимент. Есть все шансы, что результат будет лучше. Однако все это не относится к делу до тех пор, пока вы не начали всерьез планировать построить безэховую камеру у себя дома, тогда к чему все это?
Точно такая же технология, обеспечившая посредственные результаты в первом тесте на эффективность, при использовании в хорошо сделанном приложении, например, видео игре, заставит большинство людей поклясться всем святым в том, что она (технология) обеспечивает абсолютную возможность размещения источника звука в любом месте пространства, потому что они слышат звук исходящим именно из этих мест!
Это вторая самая большая проблема и одновременно обоснование того, что заявления типа "делайте так!" "так не делайте!" никогда не прекратятся до тех пор, пока участники тестов в слепую не подтвердят и не удостоверятся в том, что они одновременно и правы и не правы.
Нет ничего странного в том факте, что иллюзия или обман чувств используется в большинстве создаваемых приложениях. Это как раз то место, где на сцену выходит искусство. Тем не менее, очень важно отдать должное тому, что этого заслуживает. Если в игре нет эффективного использования 3D звука, это не означает, что виновата в этом технология и если звук звучит правдоподобно как в жизни, технология, сама по себе, лишь часть головоломки! Это должно быть так же очевидно, как в случае, если вам попался паршивый текстовый процессор, в этом нет вины компьютера, на котором он запущен, почему же в случае с 3D звуком люди все время строят свои выводы, не представляя точно, на чем основывается их мнение.
Далее, будем считать, что разные методы реализации имеют сильные и слабые стороны.
Получается, что наушники, в связке с соответствующим бинауральным процессом обработки звука (слишком часто называемым просто HRTF) относительно хорошо справляются с созданием ощущения, что звук расположен сзади нас или над нами. Тем не менее, я еще ни разу не слышал такого звучания (а слышал я все), где бы убедительно осуществлялось расположение источника звука справа и впереди слушателя. (Флойд Тул /Floyd Toole/, занимающийся 3D звуком в компании Harman International и в течение долгого времени проводящий исследованиями по этой теме, один из немногих людей, который обобщил и изложил эту проблему в печатном виде.)
Кстати, HRTF, конечно же, звучит по-особому для каждого слушающего, поэтому любая звуковая технология для массового рынка должна создавать усредненное звучание, воспроизводя потенциально компромиссный результат и тем самым, продолжая вносить все больше разногласий между слушателями.
При использовании двух акустических колонок, основная зона эффективного размещения источников звука (т.н. sweet spot) находится спереди от слушателя и покрывает пространство в 180 градусов по азимуту, т.е. в горизонтальной плоскости. Ощущения, что звук расположен сзади и над слушателем, очень слабые, если нет поддержки в виде дополнительных сигналов. Особо отметим то, что использование алгоритмов HRTF, обеспечивающих воспроизведение звука для бинаурального прослушивания (т.е. в наушниках) и алгоритмов cross-talk cancelation (или для краткости CC; технология позволяющая воспроизводить звук, например из левой колонки так, что бы слышно этот звук было только левым ухом) не является успешным решением проблемы, неважно как хорошо цифры выглядят на бумаге или как крута рекламная компания.
Применение множества акустических колонок это уже другой вид зверей, но они действительно являются частью доступного выбора возможностей, особенно для компьютерных игр. Панорамирование звука обеспечивает явные выгоды при расположении акустических колонок сзади слушателя. Это облегчает проблему выбора места с наилучшим звучанием для прослушивания, так называемый sweet spot. Однако само по себе панорамирование звука никогда не может обеспечить значительных результатов, с точки зрения позиционирования источников звука в вертикальной плоскости. Конечно, до тех пор, пока мы не перестанем размещать колонки только на полу, а не начнем их подвешивать под потолком.
API и Rendering Engine - это две разные вещи!
Играя в игры, вы используете API и rendering engine (рендерин энджин). API (application programming interface или, для краткости, интерфейс) это, по сути, просто набор команд, используемых разработчиком при написании игры -- это не технология 3D звука или чего-то другого.
Rendering engine или механизм воспроизведения звука (далее просто звуковой движок) представляет собой процесс взаимодействия алгоритмов 3D звука со звуковыми потоками с целью расположения источников акустики в пространстве. Если API (например, DS3D или наш QMDX) поддерживает множество звуковых движков, тогда в одном и том же приложении будет воспроизводиться звук немного отличающийся при использовании разных звуковых движков, почти так же, как и звуковая дорожка MIDI (другой набор команд) будет звучать немного иначе на разных аппаратных синтезаторах от различных производителей.
Так как различные звуковые движки и схемы реализации имеют разную степень эффективности соответствующий интерфейс позиционирования не должен ограничиваться возможностями какого-то одного звукового движка. В действительности, API говорит: "поместите этот звук здесь" и звуковой движок делает эту работу наилучшим способом, помещая звук в нужное место. При этом звуковой движок использует свои алгоритмы и имеющуюся конфигурацию воспроизведения звука (наушники, две колонки, 15 колонок, что угодно).
Люди, которые делаю заявления типа "эта игра поддерживает только DS3D" совершенно не понимают сути вещей. Если игра написана под интерфейс DS3D - это отлично! Она будет работать со всеми 3D звуковыми картами в любой последовательности. На каждой звуковой карте, игра будет использовать имеющийся звуковой движок, неважно, кем он сделан QSound, EMU, Aureal или кем-то еще.
Существует масса звуковых интерфейсов, таких, как DS3D, QMDX, QMixer, A3D 1.x и 2.0 и звуковые API третьих фирм, таких как HMI, EAR, Diamondware и другие. Если программист выбрал для использования интерфейс "Фирмы Х" (при этом он может также использовать более чем один API для конкретного приложения) это совсем не означает, что вы должны обязательно использовать аппаратное обеспечение "Фирмы Х" что бы все работало.
Что сбивает с толку, так это знание того, какой звуковой движок поддерживает данный API.
Лишь немногие API созданы для поддержки специфичных аппаратных возможностей, которые могут быть недоступны при использовании звуковых карт других производителей или они могут быть неспособными поддерживать основные функциональные возможности конкурирующих продуктов.
Хороший API должен поддерживать как можно больше аппаратного обеспечения и так много функциональных особенностей, насколько это возможно, так, чтобы разработчик игры мог использовать один интерфейс и получить хороший результат на всех звуковых платах.
Например, если кто-то купит игру, которая была написана в расчете на новейшую версию интерфейса QMixer, эта игра будет иметь отличные 3D звуковые эффекты даже на звуковой карте с поддержкой только обычного стерео звука. Если та же игра будет запущена на системе оснащенной 3D картой на чипсете от Aureal, игра все равно будет использовать чипсет Aureal для воспроизведения 3D звука, в итоге пользователь услышит то, за что он заплатил.
Большинство разработчиков убедились в очевидном преимуществе использования таких API, как DS3D, QMixer и QMDX, которые не являются зависимыми от производителя аппаратного обеспечения и, следовательно, будут прекрасно работать с любой 3D звуковой картой.
Что такое "Panning"?
Panning (панорамирование) -- этот термин происходит от простого устройства, изобретенного Лесом Полом (Les Paul) в далеких 50-х годах, которое использовалось для расположения моно фонических звуковых дорожек в явно определенное положение слева/справа в стерео звуковом поле.
"Panoramic Potentiometer" (или для краткости "Pan Pot", панорамный потенциометр) это нечто вроде регулятора баланса в стерео системе. В то время как регулятор баланса управляет всем входящим стерео сигналом и выдает отрегулированный стерео сигнал на выходе, pan pot управляет моно сигналом на входе, а на выходе выдает его разделенным на части, передавая их в выходные каналы, левый и правый.
Любой микшерский пульт стерео звука (использующийся в студии звукозаписи) имеет pan pot для каждого канала. Повернем ручку управления pan pot полностью влево и 100% сигнала (скажем в честь Леса, что это звук гитары) будет направлено в левую колонку. В результате, звук гитары будет явственно исходить из левой колонки. Повернем ручку управления pan pot полностью вправо и 100% сигнала будет исходить из правой колонки.
В любом месте между этими двумя крайними положениями, pan pot будет направлять порции моно сигнала в каждый канал, создавая иллюзию того, что источник звука находится где-то между двумя колонками.
Такая же концепция панорамирования использовалась на протяжении лет в видео играх, с целью динамического расположения источников звука слева/справа в звуковом стерео поле. (Ясно, что физически pan pot не использовался, а применялся его программные эквиваленты). Такой же принцип может быть распространен на любое количество колонок. Панорамирование, использующееся в обработке 3D звука, не изменяет звуковой сигнал (например, его фазу, частоту и т.д.) осуществляя лишь простое управление пропорциями передаваемого сигнала индивидуально в каждое физическое устройство воспроизведения.
Что такое "Voice Manager"?
Термином Voice Manager (менеджер голоса) называют стандартизованный механизм для управления на аппаратном уровне каналами в 3D звуковой карте. Раньше аппаратное обеспечение оперировало всего лишь 5 каналами 3D звука, сейчас стандартным является число в 8 каналов. Основной интерфейс 3D звука DirectSound3D перекладывает работу по распределению этих ограниченных ресурсов между самыми важными звуками (те, что должны звучать в данный конкретный момент) полностью на программиста. Это очень большой объем работы. Программисты обычно предпочитают задать много (20, 30 или больше) звуковых каналов, а затем просто манипулировать ими по своему усмотрению.
Voice manager работает на уровне драйвера аппаратной части. По существу он позволяет программе работать так, как если бы было больше звуковых каналов, чем в действительности поддерживается на аппаратном уровне. В соответствии с некоторыми схемами приоритета, определяемыми программистом, voice manager берет на себя управление процессом динамического распределения самых важных звуков между реально доступными на аппаратном уровне каналами.
Компании QSound и Aureal в свое время предусмотрели возможность управления распределением ресурсов в своих драйверах для звуковых карт, но это привело к ситуации, когда каждая игра должна была знать о каждом типе управления распределением ресурсов. Каждый производитель, который окончательно убедился, что это проблема, должен был создавать свою собственную систему управления распределением ресурсов со своими собственными вызовами команд API и т.д.
Поэтому, QSound предложила Microsoft, чтобы наша схема управления распределением ресурсов была адаптирована и распространялась в качестве стандартной с тем, чтобы любой производитель мог ее использовать (также как и DS3D). Microsoft согласилась с нашим предложением, немного упростила наш метод и стала распространять систему управления распределением ресурсов под именем Voice Manager.
В чем разница между QSound, DS3D и EAX?
Прежде всего, чрезвычайно важно понимать разницу между API (который всего лишь представляет собой набор команд) и звуковым движком (действительный 3D звуковой процессор). Люди путаются, потому что они думают, что API и звуковые движки это одно и тоже, а это совершенно неверно.
DS3D содержит:
API
низкоуровневый интерфейс, работающий в режиме реального времени, аппаратноог обеспечения 3D звука
программный звуковой движок от Microsoft, работающий в режиме реального времени, носящий имя "Hardware Emulation Layer" (HEL, уровень эмуляции аппаратного обеспечения)
Идея в том, что разработчик программного обеспечения пишет приложение, используя API DS3D, который является всего лишь набором команд. Когда игра запускается, стандартная функция DS3D ищет аппаратный ускоритель (например, 3D звуковую карту). Если такая карта найдена в системе, DS3D передает вызовы 3D функций и звуковые потоки в звуковую карту для их исполнения и обработки.
Каждый отдельный производитель звуковых карт с поддержкой 3D звука, независимо от того, какая технология 3D звука используется QSound, EMU, Aureal, CRL и т.д. делает свои звуковые карты совместимыми с набором команд DS3D. Это означает, что игра, написанная под DS3D, будет производить базовое позиционирование 3D звука на любой 3D звуковой плате, используя тот звуковой движок, какой имеется. В этом прелесть DS3D; он является универсальным API, который поддерживает звуковые движки многих производителей.
Далее, если игра не нашла аппаратного обеспечения, т.е. 3D звуковой карты в данной системе, тогда DS3D использует свой собственный программный звуковой движок (HEL). Это одна из проблем DS3D; интерфейс DS3D функционален и универсален, но HEL медлителен (поглощая при этом огромное количество ресурсов CPU) и обеспечивает минимальные 3D звуковые эффекты, причем только через головные телефоны. Проблема с ресурсами центрального процессора означает, что при отсутствии аппаратного обеспечения 3D звука производительность может пострадать в такой же степени, как падает значение fps в играх при отсутствии графического акселератора.
Одним из продуктов компании QSound является звуковой движок для производителей звуковых карт. Этот звуковой движок, конечно же, совместим с интерфейсом DS3D. Конечно, процесс воспроизведения трехмерного звука гораздо сложнее, чем то, что может эмулировать DS3D HEL, но в принципе это верно для любой реально существующей на рынке технологии 3D звука. DS3D HEL никогда не был рассчитан на то, чтобы быть эквивалентом 3D звуковому движку, реализованному полностью на аппаратном уровне.
Компанией QSound также созданы комплекты для разработчиков (SDK), такие как QMDX и QMixer. Они похожи на DS3D, так как оба содержат API (набор команд) и модуль работающий в режиме реального времени, который обеспечивает программную обработку и воспроизведение стерео (QMDX) или 3D (QMixer) звука в системах не имеющих соответствующего аппаратного обеспечения. Работающий в режиме реального времени звуковой движок в обоих QM SDK оставляет DS3D HEL далеко позади с точки зрения производительности, поэтому в системах без аппаратного обеспечения для воспроизведения звука игры будут идти с хорошими значениями fps.
Тем не менее, также как и DS3D, вместе QMDX и QMixer поддерживают DS3D-совместимые ускорители, если какой-либо из них присутствует в системе. Оба эти API переводят команды напрямую в формат DS3D с тем, чтобы использовать имеющееся аппаратное обеспечение. Так, в системе с аппаратным ускорителем, интерфейсы QM больше чем просто оболочка DS3D, обеспечивающая удобное использование набора мощных функций и значительно облегчающая задачи программиста, но в то же время эти интерфейсы сохраняют универсальную поддержку аппаратного обеспечения рассчитанного только на DS3D. В действительности, наши интерфейсы идут на шаг дальше, потому что (как было показано выше) их собственные звуковые движки могут быть использованы в дополнение к имеющемуся аппаратному обеспечению, например, если 3D звуковая карта поддерживает слишком мало звуковых каналов.
QSound создала свой собственный движок реверберации звука, который совместим с интерфейсом EAX. Этот движок уже поставляется нашим OEM клиентам для использования в новых Q3D продуктах. Мы также добавили поддержку набора команд EAX в наши комплекты разработчиков (SDK): QMDX и QMixer.
Если QSound не использует HRTF, как вы можете обеспечить позиционирование 3D звука на двух колонках?
Прежде всего, вы должны понять, что любой 3D звуковой процесс это ничто иное, как алгоритм фильтрации. Допустим, что существует "идеальный" или "совершенный" алгоритм фильтрации для точного расположения источника звука в заданном месте в пространстве, однако вполне вероятно, что существует больше чем один способ попытаться создать такой фильтр. HRTF является одним из таких способов.
Если говорить о звуковых движках от QSound в общем (о Q3D, QSoft3D, QMixer и т.д.), то мы никогда не использовали обработку звука алгоритмами HRTF для воспроизведения 3D звука. HRTF обеспечивает превосходное восприятие для бинаурального 3D звука (т.е. рассчитанного на прослушивание в наушниках) и мы применили эти принципы при разработке наших звуковых движков, создающих звук для наушников. Тем не менее, реализация алгоритма cross-talk cancelation, необходимого для преобразования процесса HRTF для воспроизведения на колонках непрост, несовершенен и дорог в реализации. Единственная причина того, что HRTF столь популярный метод в том, что он является общедоступным! Использование в рекламе термина HRTF позволяет легко ввести в заблуждение при объяснении технологии и звучит термин так, что создает ощущение вещи, которая точно должна работать, а значит, продукт легче продавать.
Итак, при создании функций обработки звука, имелась возможность вывести средние и сбалансированные особенности восприятия многих слушателей, при воспроизведении звука через различные типы акустических колонок, а также при различных способах их расположения. Для лучшей оптимизации и перехода на следующий уровень (это явилось толчком к успеху в области профессионального звука) использовалась помощь лучших профессионалов, занимающихся звукозаписывающим бизнесом, поэтому алгоритмы не просто работают, но обеспечивают настолько натуральное звучание, насколько это возможно.
QSound выбрала, по моей искренней оценке, крайне хороший подход, результатом чего стала возможность располагать источники звука как минимум эквивалентно, а в большинстве случаев лучше, чем это позволяет сделать применение стандартной схемы HRTF+CC. Даже при едва различимых звуковых эффектах идущих со стороны, область хорошей слышимости (sweet spot) немного расширена, но самое главное, особенно для реальных пользовательских приложений, это значительно более низкая стоимость реализации технологии. Причина того, что подход обеспечил нам решение типа "кратчайшее расстояние между двумя точками" в том, что процессы HRTF+CC включают в себя гораздо больше вычислений, чем требуется для нашей технологии.
После того, как я сказал все это, могу ли я сказать, что существует значительная разница между тем, как слышится 3D звук при использовании технологии QSound и тем звучанием, которое создается при использовании HRTF+CC? Для того чтобы все работало и работало хорошо, были потрачены годы исследований и куча денег. Отложим на время мою шляпу "профессионала по звуку" и вот что я вам скажу. Я искренне считаю что, особенно в видео играх, средний слушатель не заметит большой разницы.
Единственная вещь, раздражающая меня, заключается в том, что некоторые поставщики 3D звуковых технологий базирующихся на HRTF+CC делают возмутительные заявления о производительности, не просто предполагая, а, твердо заявляя о том, что они могут располагать источники звука идеальным образом, в любом месте трехмерного пространства, например под вашим стулом. Это откровенная ложь. Очень плохо, что некоторые компании испытывают необходимость обманывать любителей поиграть в игры таким вот образом. Все что может обеспечить 3D звук это действительно здорово и гораздо лучше, чем обычное стерео звучание, но когда люди покупаю разрекламированные поделки, не обеспечивающие того результата, который обещал производитель, они начинают думать что 3D звук сам по себе это большой обман. Это удручает.
В чем разница между EAX и Wavetracing?
Кроме основной возможности по позиционированию источников звуков в 3D пространстве, другой уровень реализма может быть обеспечен за счет имитации воздействия окружающей среды на звуки, которые мы слышим. Поэтому, с развитием продуктов позиционирования 3D звука и с ростом мощности настольных компьютеров, мы наблюдаем появление поддержки этих возможностей в современных звуковых картах.
Когда звук распространяется в пространстве, наряду с достижением наших ушей напрямую, он может отражаться от стен и других поверхностей. Звук также может проходить сквозь стены, частично или полностью поглощаясь, и другие объекты. Все это влияет на то, что мы слышим. В обычном случае, отражения звуков на большом пространстве может в реальности создавать ясно различимые эха, но более часто, результатом является то, что мы называем "reverberation" (реверберация, т.е. многократно отраженные звуки) или "reverb" для краткости. Reverb это совмещение множества эхо в тесном пространстве так, что мы слышим их как единую последовательность или "tail", которая следует за исходным звуком и затухает, причем степень затухания напрямую зависит от свойств окружающего пространства, в котором распространяется звук.
Wavetracing и EAX дают разработчикам программного обеспечения два способа создавать звуковые эффекты, связанные со свойствами окружающей среды ("environmental") или виртуальной акустикой ("virtual acoustic"), для воспроизведения взаимодействия звуков с реальной окружающей средой.
Технология Wavetracing является частью API A3D 2.0 и основывается на использовании упрощенной версии геометрии графической сцены игры, передавая данные о геометрии сцены в звуковую карту на чипсете от Aureal. После того, как будут обсчитаны реальные пути распространения нескольких первых отраженных звуков (обычно вычисляют пути распространения лишь нескольких первых отраженных звуков), анализируется то, как звуки проходят сквозь препятствия, частично или полностью поглощаясь. Затем происходит рендеринг звуковой сцены, т.е. точное определение мест расположения источников звука в пространстве и расчет путей достижения звуков (прямых, отраженных и прошедших сквозь препятствие) ушей слушателя.
EAX это гораздо более простой интерфейс, который использует обобщенную модель реверберации, такого же типа, что используется в профессиональной музыке и звуковом сопровождении фильмов в течение многих лет. Это сокращает возможности по управлению reverb до ключевых параметров, которые могут быть использованы для сведения их свойств до значений синтезированной пространственной акустики в терминах размера, типа поверхности и т.д.
Сравнение, насколько качество реверберации влияет на ощущения от игры, по сравнению с качеством такого же важного фактора, как звуковой движок, по моему скромному мнению не выявит явного победителя. Другими словами, оба способа дают возможность создавать хорошие звуковые эффекты.
Самая большая разница между этими двумя способами заключается в интерфейсах, которые пользователь никогда не слышит, зато разработчик должен использовать какой-то из них, или оба сразу, для написания игры, чтобы задействовать звуковую карту!
Интерфейс EAX имеет преимущество в том, что он много, много проще в использовании и дает возможность для простой настройки и манипуляциями ("tweaking") параметрами reverb. Кроме того, EAX это открытый протокол, а это означает, что другие создатели 3D технологий, включая CRL/Sensaura и QSound будут поддерживать EAX одновременно и в своих API и в своих звуковых движках. Итак, с точки зрения разработчика приложений, желающих перейти на следующий уровень в воспроизведении 3D звука, EAX прост в использовании и имеет потенциал в более широкой аппаратной поддержки, чем запатентованная технология Wavetracing от Aureal.
В качестве API, EAX имеет несколько недостатков в своей первой версии, самый явный из которых это отсутствие механизма расчета прохождения звука сквозь препятствия. Правда, в EAX 2.0 этот недостаток должен быть устранен.
Промышленное объединение, называемое IASIG (в него входят QSound, Creative Labs, Aureal и другие поставщики 3D технологий, производители и т.д.) разрабатывает на основе EAX новую спецификацию. Основная идея разработки заключается в создании стандартного открытого интерфейса, который мы все сможем использовать. Есть все основания надеяться, что новый стандартный интерфейс даст разработчикам возможность так же легко создавать приложения, как это обстоит в случае с EAX. При этом новый стандартный интерфейс будет свободен от недостатков присущих EAX.
Aureal участвует в разработках IASIG, поэтому мы можем смело предполагать (или хотя бы надеяться!), что, в конечном счете, драйверы для чипсетов от Aureal будут создаваться совместимыми с новым открытым стандартом. Я ожидаю, что инженеры Aureal будут и в дальнейшем предлагать разработчикам приложений возможности по использованию геометрических расчетов для определения путей распространения звука.
Кстати, нет ничего особо исключительного в звуковых API. Очень много людей даже не представляют, что игра может использовать DS3D, EAX, A3D 2.0 или другие интерфейсы, равно как и то, что хорошее 3D звучание могут обеспечить большинство звуковых плат и лишь расширенные звуковые эффекты и нестандартные возможности будут использоваться только там, где они поддерживаются. Существующее положение вещей, когда разработчикам приходится выбирать, какой интерфейс использовать, создает массу проблем, поэтому разработки IASIG, по созданию открытого и универсального интерфейса очень важны.
Какая самая лучше схема воспроизведения: наушники, две колонки, четыре колонки...?
Лучшая схема воспроизведения звука та, что вам нравится; та, что дает вам необходимую полноту ощущений.
Каждая схема воспроизведения звука имеет сильные и слабые стороны. Наушники хороши для воспроизведения звука, источники которого расположены в вертикальной плоскости, сзади и с боков от слушателя. Однако головные телефоны слабы при воспроизведении фронтального звука, т.е. когда источники звука расположены спереди от слушателя. 3D звук на двух колонках хорошо воспроизводится при расположении источников звука спереди от слушателя и по бокам, но два динамика слабо справляются с воспроизведением звука, источники которого расположены сзади и в вертикальной плоскости. Панорамирование звука на множестве колонок хорошо справляется с расположением источников звука спереди и сзади от слушателя и слабо с боковым расположением, при этом нет воспроизведение звука исходящего из источников в вертикальной плоскости.
Главная прелесть DS3D видео игр в том, что они могут создаваться без особой заботы о том, какую схему воспроизведения вы выберете для прослушивания. До тех пор, пока игра не будет по глупости рассчитана на специальную технологию 3D звука и/или схему воспроизведения, вы сможете выбирать все, что вам угодно! В действительности, расчет звуковой сцены происходит в режиме реального времени в процессе игры, поэтому вы можете переключаться с одной схемы воспроизведения на другую, скажем с колонок на наушники, на лету, если конечно ваша звуковая карта поддерживает эту возможность.
Звуковые карты имеют много разных возможностей, из которых всего лишь одной является поддержка 3D звука. Делая выбор в пользу какой-то технологии или продукта, не забывайте о перспективах дальнейшего использования, и, что более важно, необходимо, чтобы выбор был вашим собственным, не поддавайтесь влиянию мнения ваших друзей.
Обзор применяемых форматов хранения цифровых аудио данных без и с потерей качества
Методы, используемые для эффективного сжатия цифрового звука
В настоящее время наиболее известны Audio MPEG, PASC и ATRAC. Все они используют так называемое "кодирование для восприятия" (perceptual coding) при котором из звукового сигнала удаляется информация, малозаметная для слуха. В результате, несмотря на изменение формы и спектра сигнала, его слуховое восприятие практически не меняется, а степень сжатия оправдывает незначительное уменьшение качества. Такое кодирование относится к методам сжатия с потерями (lossy compression), когда из сжатого сигнала уже невозможно точно восстановить исходную волновую форму.
Приемы удаления части информации базируются на особенности человеческого слуха, называемой маскированием: при наличии в спектре звука выраженных пиков (преобладающих гармоник) более слабые частотные составляющие в непосредственной близости от них слухом практически не воспринимаются (маскируются). При кодировании весь звуковой поток разбивается на мелкие кадры, каждый из которых преобразуется в спектральное представление и делится на ряд частотных полос. Внутри полос происходит определение и удаление маскируемых звуков, после чего каждый кадр подвергается адаптивному кодированию прямо в спектральной форме. Все эти операции позволяют значительно (в несколько раз) уменьшить объем данных при сохранении качества, приемлемого для большинства слушателей.
Каждый из описанных методов кодирования характеризуется скоростью битового потока (bitrate), с которой сжатая информация должна поступать в декодер при восстановлении звукового сигнала. Декодер преобразует серию сжатых мгновенных спектров сигнала в обычную цифровую волновую форму.
Audio MPEG - группа методов сжатия звука, стандартизованная MPEG (Moving Pictures Experts Group - экспертной группой по обработке движущихся изображений). Методы Audio MPEG существуют в виде нескольких типов - MPEG-1, MPEG-2 и т.д.; в настоящее время наиболее распространен тип MPEG-1.
Существует три уровня (layers) Audio MPEG-1 для сжатия стереофонических сигналов: 1 - коэффициент сжатия 1:4 при потоке данных 384 кбит/с; 2 - 1:6..1:8 при 256..192 кбит/с; 3 - 1:10..1:12 при 128..112 кбит/с.
Минимальная скорость потока данных в каждом уровне определяется в 32 кбит/с; указанные скорости потока позволяют сохранить качество сигнала примерно на уровне компакт-диска.
Все три уровня используют входное спектральное преобразование с разбиением кадра на 32 частотные полосы. Наиболее оптимальным в отношении объема данных и качества звука признан уровень 3 со скоростью потока 128 кбит/с и плотностью данных около 1 Мб/мин. При сжатии с более низкими скоростями начинается принудительное ограничение полосы частот до 15-16 кГц, а также возникают фазовые искажения каналов (эффект типа фэйзера или фленжера).
Audio MPEG используется в компьютерных звуковых системах, CD-i/DVD, "звуковых" дисках CD-ROM, цифровом радио/телевидении и других системах массовой передачи звука.
PASC (Precision Adaptive sub>-band Coding - точное адаптивное внутриполосное кодирование) - частный случай Audio MPEG-1 Layer 1 со скоростью потока 384 кбит/с (сжатие 1:4). Применяется в системе DCC.
ATRAC (Adaptive TRansform Acoustic Coding - акустическое кодирование адаптивным преобразованием) базируется на стереофоническом звуковом формате с 16-разрядным квантованием и частотой дискретизации 44.1 кГц.
При сжатии каждый кадр делится на 52 частотные полосы, результирующая скорость потока - 292 кбит/с (сжатие 1:5). Применяется в системе MiniDisk.
Форматы, используемые для представления цифрового звука
Понятие формата используется в двух различных смыслах. При использовании специализированного носителя или способа записи и специальных устройств чтения/записи в понятие формата входят как физические характеристики носителя звука - размеры кассеты с магнитной лентой или диском, самой ленты или диска, способ записи, параметры сигнала, принципы кодирования и защиты от ошибок и т.п. При использовании универсального информационного носителя широкого применения - например, компьютерного гибкого или жесткого диска - под форматом понимают только способ кодирования цифрового сигнала, особенности расположения битов и слов и структуру служебной информации; вся "низкоуровневая" часть, относящаяся непосредственно к работе с носителем, в этом случае остается в ведении компьютера и его операционной системы.
Из специализированных форматов и носителей цифрового звука в настоящее время наиболее известны следующие: CD (Compact Disk - компакт-диск) - односторонний пластмассовый диск с оптической лазерной записью и считыванием, диаметром 120 или 90 мм, вмещающий максимум 74 минуты стереозвучания с частотой дискретизации 44.1 кГц и 16-разрядным линейным квантованием. Система предложена фирмами Sony и Philips и носит название CD-DA (Compact Disk - Digital Audio). Для защиты от ошибок используется двойной код Рида-Соломона с перекрестным перемежением (Cross Interleaved Reed-Solomon Code, CIRC) и модуляция кодом Хэмминга 8-14 (Eight-to-Fourteen Modulation, EFM).
Различаются штампованные (CD) однократно записываемые (CD-R) и многократно перезаписываемые (CD-RW) компакт-диски.
ИКМ-приставка (PCM deck) - система для преобразования цифрового звукового сигнала в псевдовидеосигнал, совместимый с популярными видеоформатами (NTSC, PAL/SECAM), и обратно. ИКМ-приставки применяются в сочетании с бытовыми (VHS) или студийными (S-VHS, Beta, U-Matic) видеомагнитофонами, используя их в качестве устройств чтения/записи.
Устройства работают с 16-разрядным линейным квантованием на частотах дискретизации 44.056 кГц (NTSC) и 44.1 кГц (PAL/SECAM), и позволяют записывать двух- или четырехканальную цифровую сигналограмму. По сути, такая приставка представляет собой модем (модулятор-демодулятор) для видеосигнала.
S-DAT (Stationary head Digital Audio Tape - цифровая звуковая лента с неподвижной головкой) - система наподобие обычного кассетного магнитофона, запись и чтение в которой ведутся блоком неподвижных тонкопленочных головок на ленте шириной 3.81 мм в двухсторонней кассете размером 86 x 55.5 x 9.5 мм. Реализует 16-разрядную запись двух или четырех каналов на частотах 32, 44.1 и 48 кГц.
R-DAT (Rotary head Digital Audio Tape - цифровая звуковая лента с вращающейся головкой) - система наподобие видеомагнитофона с поперечно-наклонной записью вращающимися головками. Наиболее популярный формат ленточной цифровой записи, системы R-DAT часто обозначаются просто DAT. В R-DAT используется кассета размером 73 x 54 x 10.5 мм, с лентой шириной 3.81 мм, а сама система кассеты и магнитофона очень похожа на типовой видеомагнитофон. Базовая скорость движения ленты - 8.15 мм/с, скорость вращения блока головок - 2000 об/мин. R-DAT работает с двухканальным (в ряде моделей - четырехканальным) сигналом на частотах дискретизации 44.1 и 48 кГц с 16-разрядном линейным квантованием, и 32 кГц - с 12-разрядным нелинейным. Для защиты от ошибок используется двойной код Рида-Соломона и модуляция кодом 8-10. Емкость кассеты - 80..240 минут в зависимости от скорости и длины ленты. Бытовые DAT-магнитофоны обычно оснащены системой защиты от незаконного копирования фонограмм, не допускающей записи с аналогового входа на частоте 44.1 кГц, а также прямого цифрового копирования при наличии запрещающих кодов SCMS (Serial Code Managenent System). Студийные магнитофоны таких ограничений не имеют.
DASH (Digital Audio Stationary Head) - система с записью на магнитную ленту шириной 6.3 и 12.7 мм в продольном направлении неподвижными головками. Скорость движения ленты - 19.05, 38.1, 76.2 см/с. Реализует 16-разрядную запись с частотами дискретизации 44.056, 44.1 и 48 кГц от 2 до 48 каналов.
ADAT (Alesis DAT) - собственная (proprietary) система восьмиканальной записи звука на видеокассету типа S-VHS, разработанная фирмой Alesis.
Использует 16-разрядное линейное квантование на частоте 48 кГц, емкость кассеты составляет до 60 минут на каждый канал. Магнитофоны ADAT допускают каскадное соединение, в результате чего может быть собрана система 128-канальной синхронной записи. Для ADAT выпускается множество различных интерфейсных блоков для сопряжения с DAT, CD, MIDI и т.п. Модель Meridian (ADAT Type II) использует 20-разрядное квантование на частотах 44.1 и 48 кГц.
DCC (Digital Compact Cassette - цифровая компакт-кассета) - бытовая система записи в продольном направлении на стандартную компакт-кассету, разработанная Philips. Скорость движения ленты - 4.76 см/с, максимальное время звучания такое же, как при аналоговой записи.
Частоты дискретизации - 32, 44.1, 48 кГц, разрешение - 16/18 разрядов (метод сжатия PASC). На DCC-магнитофонах могут воспроизводиться (но не записываться) обычные аналоговые компакт-кассеты. В настоящее время система DCC признана неперспективной.
MD (MiniDisk) - бытовая и концертная система записи на магнитооптический диск, разработанная Sony. Диск диаметром 64 мм, помещенный в пластмассовый футляр размером 70 x 67.5 x 5 мм, вмещает 74 минуты (60 в ранних версиях) стереофонического звучания. При обмене со внешними устройствами используется формат 16-разрядных отсчетов на частоте 44.1 кГц, однако на сам диск сигнал записывается после сжатия методом ATRAC.
Из универсальных компьютерных форматов наиболее популярны следующие: Microsoft RIFF/WAVE (Resource Interchange File Format/Wave - формат файлов передачи ресурсов/волновая форма) - стандартный формат звуковых файлов в компьютерах IBM PC. Файл этого формата содержит заголовок, описывающий общие параметры файла, и один или более фрагментов (chunks), каждый из которых представляет собой волновую форму или вспомогательную информацию - режимы и порядок воспроизведения, пометки, названия и координаты участков волны и т.п. Файлы этого формата имеют расширение .WAV.
Apple AIFF (Audio Interchange File Format - формат файла обмена звуком) - стандартный тип звукового файла в системах Apple Macintosh.
Похож на RIFF и также позволяет размещать вместе со звуковой волной дополнительную информацию, в частности - самплы WaveTable-инструментов вместе с параметрами синтезатора.
Формат "чистой оцифровки" RAW, не содержащий заголовка и представляющий собой только последовательность отсчетов звуковой волны. Обычно оцифровка хранится в 16-разрядном знаковом (signed) формате, когда первыми в каждой паре идут отсчеты левого канала, хотя могут быть и исключения.
Фоpматы, используемые для пpедставления звука и музыки
В настоящее вpемя стандаpтом де-факто стали два фоpмата: Microsoft RIFF (Resource Interchange File Format - фоpмат файлов пеpедачи pесуpсов) Wave (.WAV) и SMF (Standard MIDI File - стандаpтный MIDI-файл) (.MID). Пеpвый содеpжит оцифpованный звук (моно/стеpео, 8/16 pазpядов, с pазной частотой оцифpовки), втоpой - "паpтитуpу" для MIDI-инстpументов (ноты, команды смены инстpументов, упpавления и т.п.). Поэтому WAV-файл на всех каpтах, поддеpживающих нужный фоpмат, pазpядность и частоту оцифpовки звучит совеpшенно одинаково (с точностью до качества пpеобpазования и усилителя), а MID-файл в общем случае - по-pазному.
RAW - одноканальный фоpмат "чистой оцифpовки", не содеpжащий заголовка. Обычно оцифpовка хpанится в 16-pазpядном знаковом (signed) фоpмате, хотя могут быть и исключения.
VOC и CMF - фоpматы пpедставления оцифpованного звука и паpтитуp от фиpмы Creative Labs, AIFF (Audio-...) - фоpмат звуковых файлов на Macintosh и SGI, AU - фоpмат SUN/NeXT.
MOD - шиpоко pаспpостpаненный тpекеpный фоpмат. Содеpжит оцифpовки инстpументов и паpтитуpу для них, отчего звучит везде пpимеpно одинаково (опять же - с точностью до качества воспpоизведения). В оpигинале поддеpживаются четыpе канала, в pасшиpениях - до восьми и более.
STM - фоpмат Scream Tracker, пpимеpно того же уpовня, что и MOD.
S3M - фоpмат Scream Tracker 3. Развитие STM в стоpону увеличения pазpядности инстpументов и количества музыкальных эффектов. Сам ST3 поддеpживает до 32 каналов, но не поддеpживает пpедусмотpенных в фоpмате 16-pазpядных самплов.
XM - фоpмат Fast Tracker. Один из наиболее высокоуpовневых сpеди тpекеpных фоpматов. Поддеpживаются 16-pазpядные самплы, один ин- стpумент может содеpжать pазличные самплы на pазные диапазоны нот, возможно задание амплитудных и паноpамных огибающих.
MPEG: Общая информация
Стандарт сжатия MPEG разработан Экспертной группой кинематографии (Moving Picture Experts Group - MPEG). MPEG это стандарт на сжатие звуковых и видео файлов в более удобный для загрузки или пересылки, например через интернет, формат.
Существуют разные стандарты MPEG (как их еще иногда называют фазы - phase): MPEG-1, MPEG-2, MPEG-3, MPEG-4, MPEG-7.
MPEG состоит из трех частей: Audio, Video, System (объединение и синхронизация двух других).
MPEG-1
По стандарту MPEG-1 потоки видео и звуковых данных передаются со коростью 150 килобайт в секунду -- с такой же скоростью, как и односкоростной CD-ROM проигрыватель -- и управляются путем выборки ключевых видео кадров и заполнением только областей, изменяющихся между кадрами. К несчастью, MPEG-1 обеспечивает качество видеоизображения более низкое, чем видео, передаваемое по телевизионному стандарту.
MPEG-1 был разработан и оптимизирован для работы с разрешением 352 ppl (point per line -- точек на линии) * 240 (line per frame -- линий в кадре) * 30 fps (frame per second -- кадров в секунду), что соответствует скорости передачи CD звука высокого качества. Используется цветовая схема - YCbCr (где Y - яркостная плоскость, Cb и Cr - цветовые плоскости).
Как MPEG работает:
В зависимости от некоторых причин каждый frame (кадр) в MPEG может быть следующего вида:
I (Intra) frame - кодируется как обыкновенная картинка.
P (Predicted) frame - при кодировании используется информация от предыдущих I или P кадров.
B (Bidirectional) frame - при кодировании используется информация от одного или двух I или P кадров (один предшествующий данному и один следующий за ним, хотя может и не непосредственно, см. Рис.1)
Последовательность кадров может быть например такая: IBBPBBPBBPBBIBBPBBPB...
Последовательность декодирования: 0312645...
Нужно заметить, что прежде чем декодировать B кадр требуется декодировать два I или P кадра. Существуют разные стандарты на частоту, с которой должны следовать I кадры, приблизительно 1-2 в секунду, соответствуюшие стандарты есть и для P кадров (каждый 3 кадр должен быть P кадром). Существуют разные относительные разрешения Y, Cb, Cr плоскостей (Таблица 1), обычно Cb и Cr кодируются с меньшим разрешением чем Y.
|
Вид Формата |
Отношения разрешений по горизонтали (Cb/Y): |
Отношение разрешений по вертикали (Cb/Y): |
|
4:4:4 |
1:1 |
1:1 |
|
4:2:2 |
1:2 |
1:1 |
|
4:2:0 |
1:2 |
1:2 |
|
4:1:1 |
1:4 |
1:1 |
|
4:1:0 |
1:4 |
1:4 |
Для применения алгоритмов кодировки происходит разбивка кадров на макроблоки каждый из которых состоит из определенного количества блоков (размер блока - 8*8 пикселей). Количество блоков в макроблоке в разных плоскостях разное и зависит от используемого формата:
Техника кодирования:
Для большего сжатия в B и P кадрах используется алгоритм предсказания движения (что позволяет сильно уменьшить размер P и B кадров -- Таблица 2) на выходе которого получается:
Вектор смещения (вектор движения) блока который нужно предсказать относительно базового блока.
Разница между блоками (которая затем и кодируется).
Так как не любой блок можно предсказать на основании информации о предыдущих, то в P и B кадрах могут находиться I блоки (блоки без предсказания движения).
|
Вид кадра |
I |
P |
B |
Средний размер |
|
Размер кадра для стандарта SIF (kilobit) |
150 |
50 |
20 |
38 |
Метод кодировки блоков (либо разницы, получаемой при методе предсказание движения) содержит в себе:
Discrete Cosine Transforms (DCT - дискретное преобразование косинусов).
Quantization (преобразование данных из непрерывной формы в дискретную).
Кодировка полученного блока в последовательность.
DCT использует тот факт, что пиксели в блоке и сами блоки связаны между собой (т.е. коррелированны), поэтому происходит разбивка на частотные фурье компоненты (в итоге получается quantization matrix - матрица преобразований данных из непрерывной в дискретную форму, числа в которой являются величиной амплитуды соответствующей частоты), затем алгоритм Quantization разбивает частотные коэффициенты на определенное количество значений. Encoder (кодировщик) выбирает quantization matrix которая определяет то, как каждый частотный коэффициент в блоке будет разбит (человек более чувствителен к дискретности разбивки для малых частот чем для больших). Так как в процессе quantization многие коэффициенты получаются нулевыми то применяется алгоритм зигзага для получения длинных последовательностей нулей.
Звук в MPEG:
Форматы кодирования звука деляться на три части: Layer I, Layer II, Layer III (прообразом для Layer I и Layer II стал стандарт MUSICAM, этим именем сейчас иногда называют Layer II). Layer III достигает самого большого сжатия, но, соответственно, требует больше ресурсов на кодирование.
Принципы кодирования основаны на том факте, что человеческое ухо не совершенно и на самом деле в несжатом звуке (CD-audio) передается много избыточной информации. Принцип сжатия работает на эффектах маскировки некоторых звуков для человека (например, если идет сильный звук на частоте 1000 Гц, то более слабый звук на частоте 1100 Гц уже не будет слышен человеку, также будет ослаблена чувствительность человеческого уха на период в 100 мс после и 5 мс до возникновения сильного звука). Psycoacustic (психоакустическая) модель используемая в MPEG разбивает весь частотный спектр на части, в которых уровень звука считается одинаковым, а затем удаляет звуки не воспринимаемые человеком, благодаря описанным выше эффектам.
В Layer III части разбитого спектра самые маленькие, что обеспечивает самое хорошее сжатие. MPEG Audio поддерживает совместимость Layer'ов снизу вверх, т.е. decoder (декодировщик) для Layer II будет также распознавать Layer I.
Синхронизация и объединение звука и видео, осуществляется с помощью System Stream, который включает в себя:
Системный слой, содержащий временную и другую информацию чтобы разделить и синхронизовать видео и аудио.
Компрессионный слой, содержащий видео и аудио потоки.
Видео поток содержит заголовок, затем несколько групп картинок (заголовок и несколько картинок необходимы для того, что бы обеспечить произвольный доступ к картинкам в группе в независимости от их порядка).
Звуковой поток состоит из пакетов каждый из которых состоит из заголовка и нескольких звуковых кадров (audio-frame).
Для синхронизации аудио и видео потоков в системный поток встраивается таймер, работающий с частотой 90 КГц (System Clock Reference -- SCR, метка по которой происходит увеличения временного счетчика в декодере) и Presentation Data Stamp (PDS, метка насала воспроизведения, вставляются в картинку или в звуковой кадр, чтобы объяснить декодеру, когда их воспроизводить. Размер PDS сотавляет 33 бита, что обеспечивает возможность представления любого временного цикла длинной до 24 часов).
Параметры MPEG-1 (Утверждены в 1992)
Параметры Аудио: 48, 44.1, 32 КГц, mono, dual (два моно канала), стерео, интенсивное стерео (объединяются сигналы с частотой выше 2000 Гц.), m/s stereo (один канал переносит сумму - другой разницу). Сжатие и скорость передачи звука для одного канала, для частоты 32 КГц представлены в таблице.
|
Способ кодирования |
Скорость передачи kbps (килобит в сек.) |
Коэффициент сжатия |
|
Layer I |
192 |
1:4 |
|
Layer II |
128..96 |
1:6..8 |
|
Layer III |
64..56 |
1:10..12 |
Параметры Видео: в принципе с помощью MPEG-1 можно передавать разрешение вплоть до 4095x4095x60 fps (в этих границах кадр может быть произвольного размера), но так как существует Constrained Parameters Bitstream (CPB, неизменяемые параметры потока данных; другие стандарты для MPEG-1 поддерживаются далеко не всеми декодерами) которые ограничивают общее число макроблоков в картинке (396 для скорости <= 25 fps и 330 для скорости <= 30 fps) то MPEG-1 кодируется стандартом SIF /352*240*30 - (получено урезанием стандарта CCIR-601) или 352*288*25 - (урезанный PAL, SECAM) формат 4:2:0, 1.15 MBPS (мегабит в сек.), 8 bpp (бит на точку) - в каждой плоскости/.
Существует более высокое разрешение для MPEG-1 - так называемый MPEG-1 Plus, разрешение как у MPEG-2 ML@MP (Main Level, Main Profile) - этот стандарт часто используется в Set-Top-Box для улучшения качества.
MPEG2 - upgrade для MPEG1
Компрессия по стандарту MPEG-2 кардинально меняет положение вещей. Более 97% цифровых данных, представляющих видео сигнал дублируются, т.е. являются избыточными и могут быть сжаты без ущерба качеству изображения. Алгоритм MPEG-2 анализирует видеоизображение в поисках повторений, называемых избыточностью. В результате процесса удаления избыточности, обеспечивается превосходное видеоизображение в формате MPEG-2 при более низкой скорости передачи данных. По этой причине, современные средства поставки видеопрограмм, такие как цифровые спутниковые системы и DVD, используют именно стандарт MPEG-2.
Изменения в Audio:
Появились новые виды частот 16, 22.05, 24 КГц.
Поддержка многоканальности - возможность иметь 5 полноценных каналов (left, center, right, left surround, right surround) + 1 низкочастотный (sub>woofer).
Появился AAC (Advanced Audio Coding - прогрессивное кодирование звука) стандарт - обеспечивает очень высокое качество звука со скоростью 64 kbps per channel (килобит в сек. на канал), возможно использовать 48 основных каналов, 16 низкочастотных каналов для звуковых эффектов, 16 многоязыковых каналов и 16 каналов данных. До 16 программ может быть описано используя любое количество элементов звуковых и других данных. Для AAC существуют три вида профиля - Main (используется когда нет лишней памяти), Low Complexity (LC), Scalable Sampling Rate (SSR, требуется декодер с изменяемой скоростью приема данных).
Декодеры должны быть:
"forwards compatible" (вперед совместимыми) - MPEG-2 Audio Decoder понимает любые MPEG-1 аудио каналы.
"backward compatible" (обратно совместимыми) - MPEG-1 Audio Decoder должен понимать ядро MPEG-2 Audio (L-канал, R-канал)
"matrixing" (матрицируемыми) - MPEG1 Audio Decoder должен понимать 5-ти канальный MPEG-2 (L = left signal + a * center signal + b * left surround signal, R = right signal + a * center signal + b * right surround signal)
MPEG-1 Звуковой декодер не обязан понимать MPEG-2 AAC.
В следствии зтого совершенно спокойно можно использовать MPEG-1 Vidio + MPEG-2 Audio или наоборот MPEG-2 Audio + MPEG-1 Video.
Изменения в Видео:
Требуется чтобы разрешение по вертикали и горизонтали было кратно 16 в кодировщике кадров (frame-encoder) стандартах (покадровое кодирование), и 32 по вертикали в кодировщике полей (field-encoder, каждое поле состоит из двух кадров) стандартах (interlaced video).
Возможность форматов 4:4:4, 4:2:2 (Next profile).
Введены понятия Profile (форма, профиль) и Levels (уровни).
Размер frame до 16383*16383.
Возможность кодировать interlaced video.
Наличие режимов масштабирования (Scalable Modes)
Pan&Scanning вектор (вектор панорамировани и масштабирования), который говорит декодеру как преобразовывать, например 16:9 в 4:3.
Изменения связаные с алгоритмами кодирования:
Точность частотных коэффициентов выбирается пользователем (8, 9, 10, 11 бит на одно значение -- в MPEG-1 только 8 бит).
Нелинейный quantization процесс (разбиение непрерыных данных в дискретные).
Возможность загрузить quantization matrix (матрица преобразований непрерыных данных в дискретные) перед каждым кадром.
Новые режимы предсказания движения (16x8 MC, field MC, Dual Prime)
Scalable Modes (доступно только в Next и Main+ Profile) делят MPEG-2 на три слоя (base, middle, high) для того чтобы организовать уровни приоритета в видеоданных (на пример более приоритетный канал кодируется с большим количеством информации по коррекции ошибок чем менее):
Spatial scalability (пространственное масштабирование) - основной слой кодируется с меньшим разрешением и затем он используется как предсказание для более приоритетных.
Data Partitioning (дробление данных) - разбивает блок из 64 quantization коэффициентов в два потока из которых более приоритетный переносит низкочастотные (наиболее критичные к качеству), а менее приоритетный (высокочастотные).
SNR (Signal to Noise Ratio) Scalability (масштабировние соотношения сигна/шум) - каналы кодируются с одинаковой скоростью, но с разным качеством (менее приоритетный слой содержит плохую картинку - более дискретные шаги, а высокоприоритетный слой содержит довесок позволяющий построить качественную картинку)
Temporal Scalability (временное масштабирование) - менее приоритетный слой содержит канал с низкой скоростью передачи кадров, а высокоприоритетный содержит информацию позволяющую восстановить промежуточные кадры используя для предсказания менее приоритетные.
Уровни
|
Уровень |
Максимальное разрешение |
Максимальная скорость |
Примечание |
|
Low |
352*240*30 |
4 Mbps |
CIF, кассеты |
|
Main |
720*480*30 |
15 Mbps |
CCIR 601, студийное TV |
|
High 1440 |
1440*1152*30 |
60 Mbps |
4x601, бытовое HDTV |
|
High |
1920*1080*30 |
80 Mbps |
Продукция SMPTE 240M std |
Профили
|
Профиль |
Комментарии |
|
Simple |
Такой же как и Main только без B - картинок. Используется в программах и CATV (кабельное ТВ) |
|
Main |
Стандартный MPEG-1, 95% пользователей, CATV, спутники |
|
Main+ |
Main со Spatial и SNR Scalability |
|
Next |
Main+ c форматом 4:2:2 |
Допустимые комбинации Профилей и Уровней
|
Simple |
Main |
Main+ |
Next |
|
High |
No |
No |
4:2:2 |
|
High 1440 |
No |
Main c Spatial Scalability |
4:2:2 |
|
Main |
90% от всех |
Main c SNR Scalability |
4:2:2 |
|
Low |
No |
Main c SNR Scalability |
No |
Наиболее популярные стандарты.
|
Разрешение |
Комментарии |
|
352*480*24 (progressive) |
VHS, хорош для фильмов |
|
544*480*30 (interlaced) |
Laserdisc (LD), D-2, Качество как у PAL |
|
704*480*30 (interlaced) |
Качество CCIR 601.Studio D-1 |
Системный уровень MPEG-2, обеспечивает два уровня объединения данных:
Packetized Elementary Stream (PES) - разбивает звук и видео на пакеты.
Второй уровень делится на:
MPEG-2 Program Stream (совместим с MPEG-1 System) - для локальная передача в среде с маленьким уровнем ошибок
MPEG-2 Transport Stream (Рис. 6) - внешнее вещание в среде с высоким уровнем ошибок - передает транспортные пакеты (длиной 188 либо 188+16 бит) двух типов (сжатые данные -- PES -- и сигнальную таблицу Program Specific Information -- PSI).
MPEG-3 - ненужный формат
Был разработан для HDTV приложений с параметрами - максимальное разрешение (1920*1080*30), скорость 20 - 40 Mbps. Так как он не давал принципиальных улучшений по сравнению с MPEG-2 (да и к тому же MPEG-2 стал широко использоваться в разных вариантах, в том числе и для HDTV), то он благополучно вымер.
MPEG-4 - очень мощный формат
MPEG-4 - стандарт для низкоскоростной передачи (64 kbps), находящийся еще в стадии разработки. Первую версию планировалось закончить в 1999 году.
Краткое описание:
Разделяет картинку на различные элементы, называемые media objects (медиа объекты).
Описывает структуру этих объектов и их взаимосвязи чтобы затем собрать их в видеозвуковую сцену.
Позволяет изменять сцену, что обеспечивает высокий уровень интерактивности для конечного пользователя.
Видеозвуковая сцена состоит из медиа объектов, которые объеденены в иархическую структуру:
Неподвижные картинки (например фон)
Видио объекты (говорящий человек).
Аудио объекты (голос связанный с этим человеком).
Текст связанный с данной сценой.
Синтетические объекты - объекты которых не было изначально в записываемой сцене, но которые туда добавляются при демонстрации конечному пользователю (например синтезируется говорящая голова).
Текст связанный с головой из которого в конце синтезируется голос.
Такой способ представления данных позволяет:
Перемещать и помещать медиа объекты в любое место сцены.
Трансформировать объекты, изменять геометрические размеры.
Собирать из отдельных объектов составной объект и проводить над ним какие-нибудь операции.
Изменять текстуру объекта (например цвет), манипулировать объектом (заставить ящик передвигаться по сцене)
Изменять точку наблюдения за сценой.
MPEG-J
MPEG-J - стандартное расширение MPEG-4 в котором используются Java - элементы.
MPEG-7
MPEG-7 - не является продолжение MPEG как такового - стал разрабатываться сравнительно недавно, планируется его закончить к 2001 г. MPEG - 7 будет обеспечивать стандарт для описания различных типов мультимедийной информации (а не для ее кодирования), чтобы обсепечивать эффективный и быстрый ее поиск. MPEG-7 официально называют - "Multimedia Content Description Interface" (Интерфейс описания мультимедиа данных). MPEG-7 определяет стандартный набор дискриптеров для различных типов мультимедиа информации, так же он стандартизует способ определения своих дискриптеров и их взаимосвязи (description schemes). Для этой цели MPEG-7 вводит DDL (Description Definition Language - язык описания определений). Основная цель применения MPEG-7 это поиск мультимедиа информации (так же как сейчас мы можем найти текст по какому-нибудь предложению), например:
Музыка. Сыграв несколько нот на клавиатуре можно получить список музыкальных произведений, которые содержат такую последовательность.
Графика. Нарисовав несколько линий на экране, получим набор рисунков содержащих данный фрагмент.
Картины. Определив объект (задав его форму и текстуру) получим список картин, содержащих оный.
Видео. Задав объект и движение получим набор видео или анимации.
Голос. Задав фрагмент голоса певца, получим набор песен и видео роликов где он поет.
MHEG
MHEG - (Multimedia & Hypermedia Expert Group -- экспертная группа по мультимедиа и гипермедиа) - определяет стандарт для обмена мультимедийными объектами (видео, звук, текст и другие произвольные данные) между приложениями и передачи их разными способами (локальная сеть, сети телекоммуникаций и вещания) с использованием MHEG object classes. Он позволяет программным объектам включать в себя любую систему кодирования (например MPEG), которая определена в базовом приложении. MHEG был принят DAVIC (Digital Audio-Visual Council -- совет по цифровому видео и звуку). MHEG объекты делаются мультимедиа приложениями используя multimedia scripting languages.
Утверждается, что MHEG - будущий международный стандарт для интерактивного TV, так как он работает на любых платформах и его документация свободно распространяема.
Что такое MP3 ?
MP3 -- сокращение от MPEG Layer3. Это один из потоковых форматов хранения и передачи аудиосигнала в цифровой форме, разработанный Fraunhofer IIS и THOMSON, позднее утвержденный как часть стандартов сжатого видео и аудио MPEG1 и MPEG2. Данная схема является наиболее сложной схемой семейства MPEG Layer 1/2/3. Она требует наибольших затрат машинного времени для кодирования по сравнению с двумя другими и обеспечивает более высокое качество кодирования. Используется главным образом для передачи аудио в реальном времени по сетевым каналам и для кодирования CD Audio. Полные спецификации формата доступны на сайте http://www.mp3tech.org/.
Детали
MP3 -- потоковый формат. Это означает, что передача данных происходит потоком независимых отдельных блоков данных -- фреймов. Для этого исходный сигнал при кодировании разбивается на равные по продолжительности участки, именуемые фреймами и кодируемые отдельно. При декодировании сигнал формируется из последовательности декодированных фреймов.
Высокая степень компактности MP3 по сравнению с PCM 16Bit Stereo 44.1kHz (CD Audio) и ему подобными форматами при сохранении аналогичного качества звучания достигается с помощью дополнительного квантования по установленной схеме, позволяющей минимизировать потери качества.
Последнее, в свою очередь, достигается учетом особенностей человеческого слуха, в том числе эффекта маскирования слабого сигнала одного диапазона частот более мощным сигналом соседнего диапазона, когда он имеет место, или мощным сигналом предыдущего фрейма, вызывающего временное понижение чувствительности уха к сигналу текущего фрейма. Также учитывается неспособность большинства людей различать сигналы, по мощности лежащие ниже определенного уровня, разного для разных частотных диапазонов.
Подобные техники называются адаптивным кодированием и позволяют экономить на наименее значимых с точки зрения восприятия человеком деталях звучания. Степень сжатия, и, соответственно, объем дополнительного квантования, определяются не форматом, а самим пользователем в момент задания параметров кодирования. Ширина потока (bitrate) про кодировании сигнала, аналогичного CD Audio (44.1kHz 16Bit Stereo) варьируется от наибольшего, 320kbs (320 килобит в секунду, также пишут kbs, kbps или kb/s), до 96kbs и ниже.
Термин битрейт в общем случае обозначает общую величину потока, количество передаваемой за единицу времени информации, и поэтому не связан с внутренними тонкостями строения потока, его смысл не зависит от того, содержит ли поток моно или стерео, или пятиканальное аудио с текстом на разных языках, или что-либо еще
На проведенных тестах специально приглашенные опытные эксперты, специализирующиеся на субъективной оценке качественности звучания, не смогли различить звучание оригинального трека на CD и закодированного в MP3 с коэффициентом сжатия 6:1, то есть с битрейтом в 256kbs. Правда, тесты были проведены на небольшом количестве материала, и на самом деле не все столь хорошо, нередко бывает действительно нужно пользоваться 320kbs.
Более низкие битрейты, несмотря на их популярность, не дают возможности обеспечить надлежащее качество кодирования, что незаслуженно обеспечило MP3 дурную славу любительского формата. На самом деле, хотя и 256kbs, и даже 320kbs тоже не дают возможности осуществить полностью прозрачное кодирование, но отличия от CD Audio, по которому кодируется тестовый MP3, сравнимы с отличиями самого CD Audio от исходного аналогового сигнала, из которого он был получен путем оцифровки. То есть потери, конечно, есть, но несущественны с точки зрения того, кому качество CD Audio представляется достаточным. Фактически, их обнаружение обычно является задачей нетривиальной на аппаратуре класса Hi-Fi.
Настоящее и будущее MP3
MP3 на сегодня имеет два огромных
преимущества перед другими
доступными
форматами его рода. Одно из них состоит
в том, что ни про один из существующих
подобных форматов нельзя пока сказать,
что он полностью гарантирует устойчивое
сохранение качества звучания на
достаточно высоких битрейтах, кроме
MP3, который достойно выдержал проверку
временем. Пожалуй, единственный известные
мне конкурент в этом плане -- последние
варианты формата ATRAC, используемый в
минидисках.
Для MP3 также написано множество удобного программного обеспечения. Этот факт отражает второе, не менее важное преимущество -- на ближайшие годы, а возможно, и на все десятилетие, MP3 стал стандартом де факто, настолько много сделано в него вложений пользующимися им сторонами, в том числе и цифровыми радиостанциями.
MP3 довольно долго оставался неизвестным,
но несколько лет назад начался взрывной
рост его популярности, столь же быстро
начали появляться
залежи нелегальных
MP3 файлов. Сейчас налажено производство
аппаратных MP3 плееров, а карманных, и
для автомобилей. Таким образом, MP3 стал
первым массово признанным форматом
хранения аудио после CD-Audio.
Несмотря на то, что MP3 появился достаточно давно, более новые форматы, претендующие на его место, появившиеся к настоящему моменту, все на поверку оказались любительскими. Они могут быть или не быть хороши по сравнению с MP3 на низких битрейтах, это зависит от трека и особенностей слуха конкретного человека, но на место MP3 256kbs... 320kbs претендовать не способны.
Возможно, "монополия" MP3 в сфере компьютеров на низких битрейтах все же будет отчасти сломлена новым форматом от Microsoft -- WMA. Но пока рано говорить об этом. С другой стороны, появление Microsoft на данном рынке со столь сильной разработкой означает быстрое отсеивание оказавшимися неудачными ветвей AAC и VQF. Впрочем, остается надежда, что AAC еще будет доработан.
В завершение упомяну один адрес, по которому расположился проект по созданию свободного от патентных ограничений кодера -- http://www.sulaco.org/mp3/free.html. Правда, патентов вокруг MP3 накопилось столько, что, думаю, проект этот завершен не будет.
(Впрочем, если говорить о свободных от патентах аудиокодерах вообще, то существует и более реальный проект, не являющийся проектом MP3 кодера. Он расположен по адресу http://www.xiph.org/.)
Описание процесса кодирования
Подготовка к кодированию. Фреймовая структура
Перед кодированием исходный сигнал разбивается на участки, называемые фреймами, каждый из которых кодируется отдельно и помещается к конечном файле независимо от других. Последовательность воспроизведения определяется порядком расположения фреймов. Каждый фрейм может кодироваться с разными параметрами. Информация о них содержится в заголовке фрейма.
Начало кодирования
Кодирование начинается с того, что исходный сигнал с помощью фильтров разделяется на несколько, представляющих отдельные частотные диапазоны, сумма которых эквивалентна исходному сигналу.
Работа психоакустической модели
Для каждого диапазона определяется величина маскирующего эффекта, создаваемого сигналом соседних диапазонов и сигналом предыдущего фрейма. Если она превышает мощность сигнала интересующего диапазона или мощность сигнала в нем оказывается ниже определенного опытным путем порога слышимости, то для данного фрейма данный диапазон сигнала не кодируется.
Для оставшихся данных для каждого диапазона определяется, сколькими битами на сэмпл мы можем пожертвовать, чтобы потери от дополнительного квантования были ниже величины маскирующего эффекта. При этом учитывается, что потеря одного бита ведет к внесению шума квантования величиной порядка 6 dB.
Завершение кодирования
После завершения работы психоакустической модели формируется итоговый поток, который дополнительно кодируется по Хаффману, на этом кодирование завершается.
Замечание
На практике схема несколько сложнее. Например, необходимо согласовываться с требованиями битрейта. В зависимости от кодера это приводит при повышении битрейта к разного рода релаксациям при отборе сохраняемой части исходного сигнала, а при понижении -- наоборот, к ужесточению критериев.
Способы кодирования стерео сигнала
В рамках MP3 кодирование стереосигнала допустимо четырьмя различными методами:
Dual Channel -- Каждый канал получает ровно половину потока и кодируется отдельно как моно сигнал. Рекомендуется главным образом в случаях, когда разные каналы содержат принципиально разный сигнал -- скажем, текст на разных языках.
Выставляется в некоторых кодерах по требованию.
Stereo -- Каждый канал кодируется отдельно, но кодер может принять решение отдать одному каналу больше места, чем другому. Это может быть полезно в том случае, когда после отброса части сигнала, лежащей ниже порога слышимости или полностью маскируемой, оказалось, что код не полностью заполняет выделенный для данного канала объем, и кодер имеет возможность использовать это место для кодирования другого канала. В документации к mp3enc замечено, что этим, например, избегается кодирование "тишины" в одном канале, когда в другом есть сигнал.
Данный режим выставлен по умолчанию в большинстве ISO-based кодеров, а также используется продукцией FhG IIS на битрейтах выше 192kbs. Применим и на более низких битрейтах порядка 128kbs... 160kbs.
Joint Stereo (MS Stereo) -- Стереосигнал раскладывается на средний между каналами и разностный. При этом второй кодируется с меньшим битрейтом. Это позволяет несколько увеличить качество кодирования в обычной ситуации, когда каналы по фазе совпадают. Но приводит и к резкому его ухудшению, если кодируются сигналы, по фазе не совпадающие. В частности, фазовый сдвиг практически всегда присутствует в записях, оцифрованных с аудиокассет, но встречается и на CD, особенно если CD сам был записан в свое время с аудиоленты. С другой стороны, уже совершена (первая ?) попытка написать программу для автоматической коррекции фазового сдвига, адрес страницы автора -- http://www.chat.ru/~lrsp. Возможно, она немного поможет любителям кодировать оцифровки с аудиокассет с битрейтом порядка 128kbs.
Режим выставлен по умолчанию продукцией FhG IIS, а также кодером Lame, для битрейтов от 112kbs до 192kbs.
Joint Stereo (MS/IS Stereo) -- Вводит еще один метод упрощения стереосигнала, повышающий качество кодирования на особо низких битрейтах. Состоит в том, что для некоторых частотных диапазонов оставляется уже даже не разностный сигнал, а только отношение мощностей сигнала в разных каналах. Понятно, для кодирования этой информации употребляется еще меньший битрейт.
В отличие от всех предыдущих, этот метод приводит к потере фазовой информации, но выгоды от экономии места в пользу среднего сигнала оказываются выше, если речь идет о очень низких битрейтах.
Этот режим по умолчанию используется продукцией FhG IIS для высоких частот на битрейтах от 96kbs и ниже (другими качественными кодерами этот режим практически не используется).
Но, как уже говорилось, при применении данного режима происходит потеря фазовой информации, также теряется любой противофазный сигнал.
Простые заблуждения и ошибки, делаемые пользователями MP3
Вокруг MP3 набралось столько заблуждений, что создается впечатление, что так все и было задумано, что это чей-то заговор. :) Но -- по порядку.
Одно из самых больших заблуждений, связанных с MP3, постоянно проявляется в споре "128kbs vs 256kbs -- с каким битрейтом кодировать". Аргументы сторонников первого варианта исчерпываются напоминанием, что такие MP3 вдвое меньше. Утверждение, что уж лучше держать CD Audio вместо MP3 256kbs, несостоятельно -- качество MP3 256kbs... 320kbs практически сответствует оригиналу, а занимаемый объем в 4.5--6 раз меньше. Заблуждение же состоит в том, что и 128kbs дает достаточно высокое качество. На самом же деле для людей, сознательно выбирающих 128kbs, сохранение близкого к исходному качества просто не является слишком важным, так как их аппаратура обычно не лучше плееров -- "мыльниц;". В то же время многие владельцы CD кодируют их в MP3 даже просто потому, что гораздо реже нужно CD менять - на моем 8Gb винчестере поместится более пятидесяти часов музыки в MP3 битрейта 320kbs. Как говорится, в этом случае мотивы пользователей 128kbs нам непонятны.
Чтобы не суметь отличить MP3 128kbs от оригинала, нужно либо не иметь слуха, либо взять аппаратуру похуже. И то, что на большинстве компьютерных систем с момента покупки стоит ужасно шумная звуковая плата от ESS, известно всем хорошо. Только мне с некоторых пор кажется, что дело еще и в постоянном отравлении некачественным звуком, и, как следствие, временной (но постоянно возобновляемой) потере чувствительности. Мы слишком часто слушаем то, что слушать не стоило бы, и дело не только характеристиками компьютерной техники -- MP3 128kbs при нормальном слухе не понравится и на ESS. Конечно, по сравнению с дребезгом колонок уличного киоска под аккомпанемент трамвая звучание MP3 128kbs может казаться весьма неплохим, но это не нормально.
А что до карты -- простая малошумная карта и относительно приличные наушники стоят не так уж много. Поэтому в обзоре не учитываются шумы компьютера и карты -- эти трудности вполне преодолимы.
Другое небольшое заблуждение состоит в том, что уровень шумов декодированного сигнала сильно связан с уровнем качества MP3. Но это заблуждение развевается очень быстро -- заметить, что качество MP3 зависит от других причин, легче легкого. Как правило, уровень шумов очень низок на любых битрейтах, это скорее характеристика плеера.
Кроме того, в большинстве учебников прямо говорится о неспособности человека слышать частоты выше 16kHz. Но во-первых, это просто неверно, многое зависит от мощности сигнала и от возраста слушателя. Во-вторых, человек -- существо, не лишенное оригинальности. Даже когда он не слышит такие звуки с помощью уха осознанно, он все же ощущает их. И это влияет на восприятие. Поэтому обрезание частот выше 16kHz можно считать обоснованным на низких битрейтах, когда оно позволяет намного лучше закодировать более низкие диапазоны, но нельзя не брать в расчет, когда речь заходит о высоких битрейтах, приближающих качество сигнала к уровню CD Audio. Да, кстати, у детей частотный порог слышимости куда выше 16kHz.
Немного о програмах
Новых пользователей в заблуждение вводит повсеместная реклама очень продаваемых, но в то же время очень по сравнению с другими посредственных кодеров от XingTech. По поводу их недостатков я еще пройдусь ниже.
На втором месте по объему рекламы мы видим кодеры от самого уважаемого производителя, FhG IIS, но они тоже обладают определенными недостатками, к тому же дороги, поэтому дешевые и быстрые кодеры от XingTech сегодня на вершине популярности.
Но недостатки кодеров от FhG IIS в основном связаны со слабыми возможностями настройки и концентрацией усилий разработчиков на низких битрейтах. Если FhG IIS будет с того коммерческая выгода, то специалисты быстро все поправят.
О третьей группе кодеров, основанных на свободно доступном исходном коде написанного в иллюстративных целях кодера от ISO, также будет сказано ниже.
Из плееров же, как не составляет труда заметить, наиболее популярен и раскручен плеер Winamp. Еще недавно он не блистал высоким качеством звука, да и сейчас снова не блещет, но недавно на протяжении нескольких версий в нем использовался декодер от FhG IIS, и при условии его установки ( например, из версии 2.22 ) вопрос с выбором плеера практически отпадает.
Кроме того, есть и другие хорошие плееры, могущие поспорить в Winamp, некоторые из них упомянуты во второй части обзора.
Кроме плееров и кодеров, к программам, связанным с MP3, относят и грабберы -- копировщики треков с CD в WAV-файлы.
Немного о некоторых битрейтах
Чем выше битрейт, тем выше оказывается качество закодированного сигнала. Но каждый битрейт имеет свою сферу применения.
Профессионалы, аудиофилы, а также все, кто заботится о создании качественной копии, вполне соответствующей про качеству оригиналу, применяют только высокие битрейты. С другой стороны, наиболее многочисленная часть любителей MP3 применяет его для кодирования "популярной" музыки, главное отличительное свойство которой -- недолговечность, способность быстро устаревать и становиться неинтересной, поэтому такие MP3 и хранятся недолго, и требования к их качеству гораздо более низкие, что приводит к использованию низких битрейтов.
В Интернет, как правило, можно найти
только MP3, закодированные
с битрейтом
128kbs (и/или кодерами от XingTech, о которых
ниже). Этот битрейт, являясь "любимым"
битрейтом FhG IIS, был признан также
оптимальным для использования в Интернет.
В принципе, на эту роль больше подошел
бы битрейт 112kbs по разным соображениям,
но он оказался маловат для достаточно
качественного кодирования, и дополнительно
закрепился битрейт 128kbs, несколько
превышающий по качеству 112kbs, и который
позже стал основным в Интернет.
Если отвлечься ненадолго от кодирования собственно CD Audio, то можно заметить, что поток величиной порядка 112kbs довольно удобен, например, для прямых трансляций на большие расстояния. В этом случае MP3 хорошо окупается, по сравнению с передачей того же сигнала другими способами. На странице FhG IIS можно почитать более подробно об этом. Также MP3 используется на цифровых радиостанциях, но там требования к качеству на полпорядка выше.
Вернемся к кодированию CD Audio.
Выбирать основной для себя битрейт вам самим, в зависимости от потребностей. Я сам, когда начинал разбираться с MP3, изначально искал именно и только полноценную замену CD Audio, с меньшим объемом, но с как минимум не меньшим качеством, и такую возможность MP3 в общем-то дает.
Дело в том, что в уже упоминавшихся тестах с участием профессиональных прослушивателей, в которых для всех использованных тестовых композиций не было найдено различий в звучании MP3 256kbs и оригинала, было на самом деле использовано весьма ограниченное число композиций. На практике же существует довольно много композиций, где приходится переходить на 320kbs, и в то же время я не слышал ни об одной, где результат кодирования на 320kbs оказался бы недостаточно хорош. Отличия, конечно, все же остаются обнаружимы при использовании исключительной аппаратуры, но в целом качество практически то же.
В общем же из результатов всех известных мне тестов можно сделать следующие выводы. Во-первых, битрейт 256kbs для абсолютного большинства пользователей совершенно достаточен.
И, наконец, немного о собственно MP3 128kbs, пользующемся такой популярностью. В свое время он был широко разрекламирован FhG IIS, но при его использовании мы имеем скорее качество аудиокассеты, записанной на подозрительного происхождения магнитофоне, хотя и с очень низким уровнем шумов. Романтически настроенные разработчики даже почти официально назвали это 'CD-качеством', что очень далеко от истины. Впрочем, это давняя традиция -- ADPCM тоже в свое время называли форматом, дающим только неслышимые искажения.
На самом деле различие между качеством звука на битрейтах 128kbs и 256kbs... 320kbs принципиально, так как первый к качеству уровня CD, собственно, никакого отношения не имеет, в отличие от двух последних. Разумеется, для тех, кому качество средней аудиокассеты кажется великолепным, данная оценка неверна, также она не столь категорична для случаев, когда внимание сильно отвлечено. Но в целом, думаю, все ясно.
VBR & XingTech
XingTech -- фирма, производящая наиболее скоростные MP3 кодеры. К сожалению, ее кодеры всегда славились и продолжают славиться невысоким качеством.
В районе конца 98 -- начала 99 года XingTech первая использовала технологию переменного битрейта, VBR. Если в случае постоянного битрейта кодер выбирает наиболее значащие частотные составляющие фрейма, убирающиеся в выделенный битрейт, то в случае VBR задается максимальный допустимый уровень потерь, а кодер выбирает еще и минимальный битрейт, достаточный для выполнения поставленной задачи. Стоящие рядом в конечном потоке фреймы могут оказаться в итоге закодированы с совершенно разными параметрами.
Но для кодеров XingTech качество так и не поднялось на уровень FhG IIS/ISO-based кодеров. Оно безусловно повысилось, но для серьезного кодирования музыки эти кодеры остаются непригодны, да и не для этого они создавались -- в частности, в данных кодерах практикуется искажение сигнала, дающее эффект "лучшей слышимости высоких", что действительно часто может оказаться приятно, но высококачественное кодирование по определению подразумевает отсутствие подобных искажений. И не зря.
Определенный оптимизм вызывает другая реализация VBR, уже на основе исходного кода ISO ( на самом деле от кода ISO он ушел уже очень далеко ). Речь идет о кодере Lame. Несмотря на свое довольно своеобразное название, данный кодер на данный момент является самым многообещающим кодером для высоких и средних битрейтов, при этом он и на низких битрейтах превосходит большинство других кодеров, в том числе все ISO based. Подробнее о Lame -- ниже.
Способы хранения MP3
Стандарт MP3 не определяет никакого точного стандартного математического алгоритма кодирования, его разработка целиком и полностью остается на совести разработчиков кодеров. Вместо этого он определяет общую схему процесса кодирования, а также формат закодированного фрейма. Сами последовательности фреймов могут передаваться потоком (процесс передачи такого потока называется streaming) или храниться в файлах.
MP3 файл, как и поток, состоит из последовательно расположеных фреймов, между которыми может содержаться произвольная информация. Основное требование состоит в том, что не должно быть совпадений с сигнатурой начала фрейма.
Часто к последовательности фреймов добавляют стандартный заголовок мета-аудиоформата WAV, и получается то, что называют WAV-MP3. (Немного подробнее о последнем будет сказано ниже, когда будет описываться ACM pro codec.) Еще чаще к MP3-файлу добавляется информационный блок ID3v2, содержащий информацию об исполнителе, жанре, названии композиции, и другую подобную информацию о треке. Он добавляется в конец файла. В середину пока никто ничего ставить не придумал. Хотя, вообще говоря, может представлять некоторый интерес вставка спецтэга для VBR с информацией о том, в какой части трека мы, собственно, находимся.
Характер потерь при кодировании
На низких битрейтах всегда срезаются мелкие, сравнительно тихие детали, наличие или отсутствие которых нередко серьезно меняет эмоциональную окраску композиции, придает или лишает ее таких эффектов, как ощущение 'кристальной' чистоты звука (в той мере, в которой она присутствует в CD Audio). Кроме того, в соответствии с психоакустической моделью, высшие (выше 16 кГц) частоты на низких битрейтах кодируются с очень низким приоритетом.
Далее, имеют место разные особенности кодеров. Так, у кодеров от FhG IIS на 128 kbs оказываются 'смазаны' верхние частоты, наблюдается эффект 'шепелявости', в то время как у ISO-based вместо этого -- 'звон'. Скорее всего, это связано с разным отношением к частотам выше 16kHz у данных кодеров. В кодере Lame, кстати, они по умолчанию срезаются, что увеличивает качество кодирования на 128kbs.
На высших битрейтах при последовательном следовании психоакустической модели, разработанной FhG IIS, проблемы могут доставлять только ошибки, внесенные при написании кодера. Впрочем, из-за не слишком большой озабоченности FhG IIS качеством его кодеров на высоких битрейтах уже не раз оказывалось, что новая версия звучит иногда даже несколько хуже старой. Полагаю, причина кроется в недостаточном или неправильном ослаблении ограничений психоакустической модели при повышении битрейта. Опять же, первый серьезный заказчик, и проблема исчезнет.
Тестирование качественности кодеров
Обычно тестирование кодеров проводится по степени сохранения формы АЧХ оригинального сигнала. При этом очевидно, что при битрейтах 256kbs... 320kbs АЧХ исходного файла и файла, полученного после декодирования, должны быть идентичными как на синтетических тестах (сгенерированный белый шум), так и на реальных треках, так как при значительных отличиях они окажутся слышны независимо от того, что говорит психоакустическая модель про каждый конкретный фрейм, если только все эти фреймы не похожи друг на друга. На более низких битрейтах следует в первую очередь следить за сохранением формы АЧХ в области низких и средних частот.
Сами тесты по сохранению формы АЧХ следует проводить не только на белом шуме, как это делается обычно, но и на достаточно сложных композициях, в комплексе это позволяет получить значительно более достоверные результаты.
Тесты АЧХ не универсальны. В силу особенностей MP3 они дают достаточно адекватную оценку его качества, и то не полностью, но к другим форматам они и вовсе не обязаны быть применимыми -- в частности, они непригодны для оценки качественности кодирования в формате VQF.
Относительно точную раскладку качества сигнала по материалам специально проведенного прослушивания можно найти на сайте MP3Tech, а немного вольный ее перевод на русский язык -- у на Mikhail's MP3 Page. Но все же рекомендую посетить и сам сайт MP3 Tech, к тому же в данный момент там лежат более новые и подробные результаты других тестов.
Психоакустическая модель и разные битрейты
Самым важной характеристикой кодера, от которой зависит качество кодирования, является психоакустическая модель, использованная в нем. Но следует заметить, что модель должна варьироваться для разных категорий битрейтов. Аналогично тому, как использование MS/IS стерео приводит к повышению качества на низких битрейтах, но на средних и высоких только понижает его, также и разные составляющие модели могут иметь максимальный битрейт, до которого они полезны, но от использования которых на больших битрейтах следует отказаться.
Кодеры, основанные на исходном коде ISO, чаще всего продолжают использовать довольно слабый вариант психоакустической модели, использованный в нем. Но на высоких битрейтах мы все же получаем очень хороший результат, причем многим он нравится больше, чем результат кодирования кодерами FhG IIS. Видимо, причина кроется как раз в том, что психоакустическая модель в кодерах от FhG IIS неизменна для всех битрейтов и более подходит для битрейтов средних и низких, в то время как на высоких избыточна и нуждается в ослаблении, в то время как модель ISO оказалась неплохо, хотя и не идеально, приспособлена к высоким битрейтам. Но тема противостояния кодеров FhG кодерам ISO-based остается откытой.
В самом развитом из ISO-based кодеров, Lame, модель была значительно улучшена, причем настолько, что кодер и на низких битрейтах незначительно уступает аналогам от FhG IIS. Можно сказать, что в Lame осталась уже относительно небольшая часть исходной модели ISO.
Но на битрейтах 256kbs и 320kbs предыдущий лидер высокобитрейтных кодеров, mpegEnc, все еще спорит с Lame. Но, как оказалось, в mpegEnc модель мало отличается от исходной слабой модели ISO, просто в нем отключены некоторые ее части, что в итоге, как ни странно, привело к значительному повышению качества кодирования... только на высоких битрейтах. Возможно, более подробный анализ исходников покажет и другие изменения, но поверхностный анализ уже показал, что все главные недостатки исходной модели ISO присутствуют. Видимо, их сглаживает высокий битрейт, или же они действительно несущественны на 256kbs... 320kbs.
Текущий руководитель разработкой Lame, Марк Тейлор, не против поработать над кодированием высоких битрейтов в нем, нужно только будет провести определенные тесты. Что до кодеров от FhG IIS -- проблема исчезнет, как только найдется заинтересованная сторона, готовая это оплатить.
Какие, собственно, кодеры у нас в распоряжении
Существуют три линии развития кодеров -- кодеры от XingTech, кодеры от FhG IIS, и кодеры, основанные но исходном иллюстративном коде ISO.
Кодеры от XingTech не отличаются высоким качеством кодирования, но многим нравятся, к тому же вполне подойдут для кодирования разной бросовой электронной музыки или синтезированных семплов. Благодаря своей скорости они остаются идеальными кодерами для музыки, не требующей высокого качества кодирования. Более подробно о них -- на http://www.xingtech.com/.
Кодеры от FhG IIS известны наивысшим качеством кодирования на низких и средних битрейтах благодаря наиболее подходящей для таких битрейтов психоакустичекой модели. Из консольных кодеров данной группы наиболее предпочтителен l3enc 2.61 (не 2.71 и не 2.72, на знаю про 2.74), также пока не отброшен mp3enc 3.1, но последний никто всерьез не тестировал. Другие кодеры, такие, как AudioActive или MP3 Producer, обладают значительными недостатками, правда, в основном это ограничения возможностей настройки и неразвитость интерфейса.
Также существует старый кодек ACM pro codec авторства FhG IIS, и несколько нелегальных кодеков, код для которых выкорчеван из последних кодеров FhG IIS.
Остальные кодеры ведут свое происхождение от исходных кодов ISO. Не считая таких "ошибок эволюции", как SoundLimit, в котором значительно увеличена скорость за счет еще более значительного ухудшения качества, получаем два основных направления развития -- оптимизация кода по скорости и оптимизация алгоритма по качеству.
До недавнего времени первую линию наилучшим образом представлял кодер BladeEnc, в котором используется первоначальная модель ISO, но проведено много оптимизаций кода, а вторую -- mpegEnc, известный также и как самый медленный MP3 кодер.
Но откуда берется высокое качество mpegEnc на высоких битрейтах, я уже упомянул выше. На самом же деле серьезная оптимизация самого алгоритма впервые встречена в кодере Lame, в котором использована самостоятельно разработанная психоакустическая модель GPSYCHO.
Есть все основания считать Lame наилучшим из основанных на коде ISO кодеров. По скорости он давно догнал остальные, а по качеству скоро должен отдать последние позиции и mpegEnc... впрочем, обо всем этом я уже писал выше.
Lame может быть собран практически на любой платформе, на которой есть компилятор языка C. Скомпилированный вариант Lame в виде библиотеки dll входит в состав граббера Cdex, но предпочтительнее использовать вариант, запускаемый из командной строки, он имеет более другие возможности настройки, к тому же работает быстрее. Но его надо собирать самому. Кстати, в состав Cdex входит и свой кодер, но он и раньше никем особенно не тестировался, а сейчас это не представляется нужным.
Что такое front-end?
Front-end -- программа, пpедлагающая оконный интерфейс для повышения комфоpтности pаботы с пpогpаммами, его не имеющими. В слyчае MP3 -- с кодеpами, управляемыми из командной стpоки, или yстановленного в системе кодека.
После подачи команды на кодиpование front-end пеpедает введенные паpаметpы собственно кодеpy и ждет завеpшения его pаботы. Этот процесс может сопpовождаться как попытками пpедсказать оставшееся вpемя, так и выводом скромной таблички "Please wait".
В большинстве грабберов обеспечены средства для подключения внешних кодеров, поэтому любой из них может быть использован как front-end. В частности, при установленном ACM pro codec как таковой может быть использован любой граббер, позволяющий выбирать формат сохранения награбленного.
Что такое ACM pro codec (MP3-кодек)?
Формат WAV является метаформатом для данных любого типа. Имеет стандартный заголовок и описания областей данных, которых может быть несколько, способ же кодирования аудиосигнала может быть каким угодно. Вполне могут содержаться данные, к аудио отношения не имеющие.
Каждый метод кодирования, указываемый в заголовке, имеет собственный идентификатор, в соответствии с которым Windows и определяет, установлен ли кодек для работы с данным файлом, и если установлен -- использует его.
Кодеки, индивидуальные для каждого подформата, регистрируются в системе при их установке, после чего становится возможным использовать WAV-файлы, содержащие аудиоданные в форматах, поддерживаемых данными кодеками.
Тем не менее, хотя для MP3 тоже существует по крайней мере один кодек ACM pro codec от FhG IIS, сам по себе формат из-за потерь при кодировании непригоден на роль промежуточного, поэтому в редакторах с WAV-MP3 работать не рекомендуется. Единственным разумным применением данного кодека можно считать декодирование WAV-MP3, либо их кодирование, когда по каким-либо причинам неудобно сделать это из нормального кодера. При установленном кодеке можно применять WAV-MP3 в качестве стандартных звуков Windows.
Помимо оригинального кодека от FhG IIS, позволяющего кодирование только с битрейтом 128kbs и ниже, существуют несколько нелегальных версий кодека, сделанных группой Radium из кода, выкорчеванного из нового 'Продюсера'. Но первая версия этого кодека была нестабильной, и я не вижу оснований для того, чтобы испытывать доверие к более новым версиям. Лучше сделать еще один кодек из Lame.
Файлы какого формата можно перевести в формат MP3?
Кодирование из формата WAV PCM поддерживают все кодеры. Многими поддерживается AIFF. Mp3enc может принимать исходные данные потоком, без промежуточного файла, в фоpмате PCM. А mpegEnc и Cdex предлагают кодировать прямо с CD-ROM. Lame распространяется в виде исходных кодов и может быть обучен любому формату.
Каков статус MP3 кодеров?
Все продукты Fraunhofer IIS и Xing Tech -- коммерческие, но полные версии обычно можно найти на FTP поисковиках.
BladeEnc, mpegEnc -- freeware, но FhG IIS пожелал сделать их развитие невозможным. Сделано это очень простым методом -- за распространение кодеров нужно платить пеню FhG IIS, даже если кодер распространяется бесплатно. Поэтому свободное распространение mpegEnc невозможно, также могут возникнуть трудности с распространением BladeEnc, несмотря на особую политику страны автора по отношению к патентам на математические алгоритмы.
Lame не угрожает подобная участь, так как он распространяется в виде патча к исходному коду ISO и сам по себе кодером быть признан не может.
Каковы системные требования?
Фактически, единственное требование к системе -- наличие компилятора C. Но производительность MP3 кодеров на слабых системах оставляет желать лучшего, и из процессоров Intel не рекомендуется использовать что-либо ниже 486.
Декодиpование MP3
Cтандаpт MP3 однозначно опpеделяет, какие именно данные содеpжатся в MP3-файле. Hо сам процесс декодирования, процесс перевода аудио из MP3 в PCM, неизбежный при воспроизведении, более корректно будет назвать синтезом, чем декомпрессией. На практике он столь же неоднозначен, как и процесс кодирования.
Многие пpинимают за некий стандаpт самый пеpвый из декодеpов, написанный в FhG IIS -- l3dec. Этот декодер при работе не предпринимает каких-либо попыток "улучшить" звучание и, как правило, дает точную АЧХ сохраненного сигнала. Также в силу корректности его можно считать практически идеальным декодером для MP3 высоких и средних битрейтов.
С другой стороны, на практике иногда обнаруживают себя ньюансы, о которых раньше не задумывались. Например, разные кодеры сохраняют аудио в MP3 немного по-разному, хотя и не выходя за рамки стандарта, но несколько меняя алгоритм оптимального восстановления сохраненной части сигнала. Но если в данном случае отличия оказываются несущественны, то тот простой факт, что при кодировании с битрейтом 128kbs, пользующимся бешенной популярностью, мы значительно теряем в качестве, приводит к более существенным последствиям -- на низких битрейтах становится оправданным применение различных 'улучшающих' звучание алгоритмов, т.е. программных DSP, и более корректный декодер может оказаться менее предпочтителен, чем вносящий дополнительные искажения, но "повышающий" этим качество звучания. К сожалению, выбор не слишком велик.
Когда какой декодер лучше?
За время существования MP3 было написано великое множество самых разных декодеров. Тем не менее, выбор не составляет слишком большой проблемы. Основная сложность в том, что критерии оценки качества декодеров сильно разнятся для низких битрейтов порядка 128kbs и для высоких порядка 256kbs.
К ориентированным на высокие битрейты декодерам предъявляется одно основное требование -- корректное декодирование, то есть корректность примененного алгоритма декодирования и отсутствие ошибок в его реализации. Считается, что высокий уровень качества обеспечивается шириной потока, но тем не менее, разные декодеры дают разные по качеству результаты. Разумеется, высокая скорость работы декодера также желательна.
В данной категории хорошо себя чувствуют декодеры от FhG IIS, к которым обвинений в некорректности пока никто не смог предъявить.
К ориентированным на низкие битрейты декодерам выдвигаются несколько другие требования. Отличие состоит в том, что в силу искажений, вносимых при кодировании MP3 128kbs, требования к корректности декодирования ослабевают, в то время как требование качественности звучания никуда не пропадает. Поэтому не слишком корректные, но приятно звучащие плееры пользуются популярностью.
Большинство декодеров являются плеерами, но не каждый плеер может перенаправлять вывод в файл, что приводит к трудностям в его оценке. Существует мнение, что такие плееры не следует называть декодерами.
В NAD и NADDY на одном из этапов декодирования пpименяется алгоpитм пpедсказания, также сyществyет возможность подстpойки под особенности кодеpов, использованных пpи полyчении MP3. Если говорить конкретно, то возможна подстройка под семейство ISO-based, под кодеры семейства FhG IIS, под старые кодеры XingTech с обрезом частот выше 16kHz и даже под еще не вышедший ко вpемени выхода NAD 0.93 кодеp ARCAM. В наследнике NAD, NADDY, упоминается вместо него "ARCoder v1.2+"; видимо, он все-таки вышел. Но, как уже упоминалось, значительного эффекта эта подстройка не дает.
Хотя NAD долгое время заслуженно считался чемпионом по части качества, в последнее время другой плеер -- Apollo -- мог с ним в этом поспорить. Но в данном случае речь идет о низких битрейтах, к тому же развитие Apollo теперь тоже остановлено. NAD просто более корректен.
Если задаться целью декодирования в WAV-файл, то выбоp сейчас следyет пpоизводить междy NAD, l3dec и Winamp (версии 2.21-2.22), пpичем чем выше битpейт, тем меньше причин пользоваться NAD. Для низких битрейтов можно также попробовать Apollo, но лучше Winamp с соответствующим "улучшающим" звучание плагином.
Hа высших битрейтах выбор производится только между корректными декодерами, и pазница оказывается настолько мала, что выбоp уже пpоизводится, например, междy yдобными интеpфейсами NAD и Winamp и yпpавлением l3dec с помощью ключей командной стpоки. Скорее всего, при серьезной проверке на битрейтах 256kbs-320kbs l3dec/Winamp превзойдут по качеству прочие -- при написании почти всех декодеров думают, к сожалению, главным образом о качестве звучания MP3 128kbs, на корректность тратятся только в FhG IIS. Но это не делает вывод NAD или Sonique непригодным или некачественным -- и в данном случае все отличия снова укладываются в рамки оговорки, сделанной в начале первой части.
L3dec работает только из командной строки и декодирует только в файл, поэтому выбор плеера производится в основном между популярным Winamp, NAD, Apollo и некоторыми другими.
Самые известные плееры
Winamp
Winamp является самым попyляpным на сегодня плееpом.
Winamp -- это мультимедиа плеер с подержкой неограниченного числа форматов. При этом могут используются декодеры, предоставляемые производителями. В целом система напоминает работу Windows с WAV файлами.
В версии 2.20 роль встроенного декодера MP3 наконец начал играть декодер от FhG IIS. После этого в плане проигрывания MP3 к Winamp не осталось серьезных претензий, но начиная с версии 2.23 был возвращен старый декодер, поэтому для качественного воспроизведения необходимо брать декодер из версий 2.21-2.22 ( так как 2.20 отказывается проигрывать некоторые MP3 ).
NAD
Признанным чемпионом по части звyчания, однако, на сегодня все же остается NAD. Его звучание несколько менее корректно на высоких битрейтах, но очень приятно. Превосходят его только декодеры от FhG, отличающиеся корректностью.
Во время своего развития данный плеер почти прямо противостоял Winamp и имел все шансы отобрать у него со временем львиную долю поклонников.
К сожалению, в тот момент, когда дописывались самые важные элементы интрефейса, которые должны были окончательно уравнять NAD по возможностям с Winamp, его развитие было прервано. Последние версии NAD содержат только основные функции, хотя идея плагинов использовалась в свое время и в нем, причем куда раньше того же Winamp.
Наиболее известны следующие веpсии NAD.
NAD 0.80 Стабильная, завеpшенная пpогpамма, но для обеспечения возможности дальнешего pазвития автоp оказался вынyжден пеpеписать весь код с нyля. В отличие от более новых, понимает ключи командной строки.
NAD 0.93 Последняя из завершенных веpсий после 0.80. Hекотоpые втоpостепенные фyнкции, такие, как pедактоp поля ID3-TAG, еще не pеализованы. Местами проявляются баги. Hо качество воспpоизведения не вызывает сомнений, при этом поддеpживается streaming и вывод в WAV-файл, поэтому его можно использовать и как просто декодер.
NAD 0.94 Готовился к выходу, когда весь пpоект неожиданно оказался выкyплен DimensionMusic. Чем и зарублен на корню, так как развитие NAD как плеера прекратилось. На основе 'движка' был создан набоp библиотек Audio Enlightenment ( AE ), но программист занимался его разработкой в свободное время, и первые результаты появились только через полгода.
На основе получившегося набора библиотек в последние дни 98-го была выпущена недоработанная в плане интерфейса первая и последняя бета-версия плеера NADDY, прямого наследника NAD. Скачать NADDY можно на страничке http://ae.dmusic.com. Сам NAD в данный момент есть на его ожившей домашней страничке, http://nad.inept.org.
В настоящий момент AE в очередной раз переименован, теперь уже в STARDUST, и используется в Sonique, а развитие NADDY остановлено, как раньше было остановлено развитие NAD. Но к Sonique есть свои претензии.
Sonique
Из всех полноценных MP3 плееров Sonique обладает самым красивым интерфейсом. Мне (и многим другим) он представляется несколько громоздким, но многочисленные поклонники с этим не согласны, да и после того, как большинство прежде не работавших элементов управления стали правильно функционировать, это почти перестало мешать. Также имеет большое значение производительность машины, на быстром компьютере интерфейс производит более благоприятное впечатление. И тем не менее, в плане интерфейса Sonique требует доработки. Это классический пример посредственного интерфейса со стильным дизайном.
В качестве MP3-декодеpа начиная c версии 0.75 использyется декодер STARDUST, ранее известный как Audio Enlightenment, а еще ранее -- как внутренний декодер плеера NAD. Доступны streaming, декодирование в WAV-файл и декодирование VBR, но в сравнении с Winamp Sonique по функциональности проигрывает.
K-Jofol
K-Jofol является одним из самых быстрых плееров, но на первенство по качеству воспроизведения он претендовать не может. Возможна полная перестройка программируемого интерфейса.
Популярность плееру принесла поддержка формата VQF, но теперь это -- обычное дело, да и сам VQF -- посредственный формат.
Apollo
Просто удобный приятный плеер. Более "высокое" качество звучания на низких битрейтах, чем у других плееров, но и высокая степень некорректности. Мудро организованный плейлист. Поддержка visualization plugins от Winamp. Все.
Другое
Помимо рассмотренных, пользуются определенной популярностью плееры Soritong, C-4. Второй хорош способностью занимать скромное место в любом из четырех углов экрана. Первый начинает прилично выглядеть после установки скина COMPACT. Но наиболее хорош, видимо, WPlay, о нем немного позже тоже будет написано.
Понятно, этим список распространенных плееров не ограничивается. Полный список можно найти на www.mp3.com, но мало какие из них могут конкурировать с выше описанными ( за исключением, возможно, WPlay).
Dolby Digital - Общая информация
Звук Dolby Digital впервые появился в кинотеатрах в 1992 с премьерой фильма Возвращение Бэтмена (Batman Returns), и с тех пор звучит почти в тысяче фильмов по всему миру, и является одной из самых современных разработок от Dolby Laboratories.
Dolby произвела революцию в конце 60-х начале 70-х годов в системах записи на магнитную ленту своей системой шумоподавления Dolby A (для профессионалов) и Dolby B (для обычных пользователей). Позже, в 70-х годах, компания Dolby своей аналоговой системой Dolby Stereo революционизировала звук в фильмах.
Dolby Stereo принесла в фильмы 4 звуковых канала, с тремя спереди (левый и правый для музыки и эффектов и центральный для диалогов) и четвертым "окружающим" (Surround) для создания общей звуковой атмосферы. Позже, в 80-х, благодаря системе Dolby SR ("Spectral Recording - спектральная запись"), было значительно улучшено качество записи на ленту и звука в кинофильмах.
Также, компания Dolby революционизировала в конце 80-х начале 90-х годов бытовые устройства развлечений путем внедрения систем "домашнего театра" Dolby Surround, а позже и Dolby Pro Logic. В бытовых устройствах в основном используется технология Dolby Stereo для воспроизведения с видео лент и лазерных дисков (под лазерными дисками здесь и далее подразумеваются LaserDisc, т.е. "большие" видео лазерные диски). Эти системы позволяли зрителям использовать дома ту же самую 4-х канальную конфигурацию, что и в кинотеатрах.
Современные системы Dolby Digital вышли на новый уровень, предоставляя шесть каналов кристально чистого объемного цифрового звука. Левый, центральный и правый фронтальные каналы позволяют точно определить позицию источника звука на экране. Отдельные "разделенные" левый и правый задние боковые каналы вовлекают вас в фильм своими окружающими и обтекающими звуками. А дополнительный низкочастотный канал добавляет накал действию на экране.
Принципы Dolby Digital ведут свое развитие из разработок Dolby по аналоговому уменьшению шума. Шумоподавление Dolby работает путем ослабления шума, когда нет аудио сигнала, а когда он есть, позволяя более сильному полезному аудио сигналу перекрывать более слабый шум. Таким образом, эта технология использует преимущества психо-акустического феномена известного как слуховое маскирование. Даже если аудио сигнал занимает только часть спектра, шумоподавление Dolby уменьшает уровень шума в тех частях спектра, в который нет полезного сигнала делая шум незаметным. Это делается потому, что аудио сигнал может маскировать только ближний по частотам шум.
При переходе от аналоговой записи сигнала к записи на цифровой носитель такой как компакт-диск, обнаруживается, что цифровое кодирование аудио сигналов используемое в CD производит слишком большие объемы данных для того чтобы их эффективно хранить или передавать в электронном виде, особенно в случаях, когда необходимо кодировать несколько каналов. В результате появились новые формы цифрового кодирования аудио сигналов - известных под общим названием "perceptual coding - чувствительное (восприимчивое) кодирование" - которые были разработаны так чтобы можно было использовать низкоскоростные потоки данных с минимально ощущаемой потерей звукового качества. Примером такого алгоритма кодирования является третье поколение кодеров Dolby - AC-3.
Этот кодер был разработан так, чтобы максимально использовать преимущества человеческой способности к звуковому маскированию, для чего он разбивает спектр аудио сигнала в каждом канале на узкие частотные полоски разного размера оптимизированные с расчетом на частотную избирательность человеческого слуха. Это позволяет очень точно отфильтровывать шум оцифровки так, чтобы он оказался очень близко по частоте к частотным компонентам полезного аудио сигнала. Путем уменьшения или даже полной ликвидации шума там, где нет маскирующего аудио сигнала, качество звука исходного сигнала субъективно не изменяется. По этому ключевому аспекту такое кодирование как AC-3 является формой очень избирательного и качественного шумоподавителя.
Уникальный опыт Dolby Laboratories по устранению аудио шума является критическим для снижения потока данных в технологии AC-3: чем меньше бит используется для описания аудио сигнала, тем больше шумов связанных с самим кодированием.
В киноиндустрии звуковая дорожка Dolby Digital кодируется оптически прямо на киноленту в промежутках между перфорационными отверстиями. Размещение цифровой звуковой дорожки на том же носителе что и фильм позволяет ей сосуществовать вместе с аналоговой дорожкой без привлечения дополнительных носителей данных, таких как CD. Это позволяет упростить производство, а для владельцев кинотеатров использование фильмов, а также позволяет подготовить дорожку Dolby Digital практически без дополнительных затрат. Поскольку часть ленты с перфорированными отверстиями изготавливают с расчетом на высокую сопротивляемость износу и повреждениям, дорожка Dolby Digital не будет подвержена треску и шипению на протяжении всего времени эксплуатации ленты.
В бытовой электронике технологию Dolby Digital можно встретить в последнем поколении лазерных дисков (там где была обычная аналоговая звуковая дорожка), она является стандартной звуковой дорожкой в DVD и используется как аудио формат для телевидения высокой четкости - HDTV, а также в системах кабельного и спутникового телевидения.
Последние несколько лет компания Dolby Laboratories использовала термин Dolby Digital для ссылок на их новую цифровую систему для киноиндустрии, в то время как под термином Dolby Surround AC-3 подразумевала системы домашнего кинотеатра. На практике, эти две системы являются небольшими вариациями (слегка различающимися в скорости потока данных) одной базовой технологии. И для того чтобы больше не вводить пользователей в заблуждение, решили, что и формат Dolby для домашних многоканальных систем также назывался тем же именем, что и в киноиндустрии -- Dolby Digital.
Считается, что это поможет потребителям более легко определять поддерживает ли какой-либо продукт эту технологию, и поможет отличить ее от форматов Dolby Surround и Dolby Pro Logic, которые базируются на аналоговых технологиях. В новом поколении лазерных дисков, и новых форматах использующихся в DVD и телевидении высокой четкости (HDTV), также будут ссылаться на термин Dolby Digital, как это сейчас делают в отношении профессиональных киноприложений. Общее название Dolby Digital также должно помочь прекратить растущие заблуждения пользователей, связанные с термином "AC-3" (Аудио код номер 3), который является техническим обозначением технологии Dolby, разработанной для многоканальных приложений.
Dolby Digital предоставляет в общей сложности шесть раздельных каналов звука. Как и Dolby Surround Pro Logic, она включает в себя левый, центральный и правый каналы во фронтальной части комнаты. Dolby Surround Pro Logic предоставляет дополнительно еще один канал с ограниченной полосой частот (от 100 до 7000Гц) для объемного ("окружающего") звука, который обычно усиливается через два канала усилителя и подается потом на два динамика. Тогда как Dolby Digital предоставляет раздельные левый и правый каналы объемного звука для более точного определения местоположения звуков и более натуральной, реалистичной передачи атмосферы и фона. И ко всему прочему все пять основный каналов передают полный спектр частот (от 3 до 20000 Гц), к которым вы можете добавить низкочастотные динамики (сабвуферы).
Шестой канал - Low Frequency Effects Channel (канал для низкой частоты и эффектов), иногда содержит дополнительную низкочастотную информацию для усиления эффекта от некоторых сцен, например, таких как взрывы, катастрофы и т.д. Из-за того, что этот канал сильно ограничен сверху по частоте (от 3 до 120Гц), его иногда называют ".1" каналом. Если его добавляют к полным 5 каналам Dolby Digital, то про такие системы говорят, как про имеющие "5.1" канала.
Все шесть каналов в системе Dolby Digital полностью цифровые, из чего следует, что на всем пути от пульта звукооператора до вашей домашней системы они передаются без потери качества. Но Dolby Digital еще и упаковывает их все в один канал, который занимает места меньше чем один канал на компакт диске. Именно это позволяет так легко добавлять звуковые дорожки Dolby Digital к обычным лазерным дискам, а также к множеству других источников. Dolby Digital используется уже несколько лет, чтобы вы могли смотреть фильмы с Dolby Digital, а теперь, с появлением Dolby Digital на лазерных дисках, вы можете наслаждаться этой прекрасной технологией и у себя дома. А так как она была разработана фирмой Dolby Laboratories, вы можете быть уверены, что звук будет потрясающим!
Между "обычными" и "новыми" лазерными дисками намного больше общего, чем различий. Новые лазерные диски, включая и диски с Dolby Digital, полностью совместимы с вашим существующим проигрывателем. Две цифровые (PCM) дорожки остаются без изменений, так что вы можете продолжать наслаждаться качеством Dolby Surround Pro Logic и с "новых" дисков. Дорожка Dolby Digital записывается вместо правой аналоговой (FM) дорожки диска. Левая аналоговая дорожка может содержать моно версию, комментарий или любой другой аудио материал.
Последние проигрыватели, которые могли воспроизводить звук только с аналоговых (FM) дорожек, выпускались более чем 10 лет назад. С тех пор практически все проигрыватели могут использовать более качественные цифровые (PCM) дорожки для воспроизведения стерео или Dolby Surround. Конечно же, все новые лазерные проигрыватели с AC-3 будут проигрывать все лазерные диски которые у вас есть, причем как цифровые так и аналоговые звуковые дорожки.
Dolby Surround Pro Logic еще долго останется с нами. Система Dolby Surround Pro Logic "складывает" четыре канала (левый, центральный, правый и частотно ограниченный "объемный" (Surround)) в два канала. В монофонических системах эти два канала складываются для воспроизведения. И конечно вся информация доступна для воспроизведения в стерео системах. Но когда эти два канала поступают на декодер Dolby Pro Logic, звуковая матрица "раскладывается" и становятся доступными все исходные четыре канала ("объемный" канал воспроизводится через отдельные левый и правый "объемные" динамики).
Самая потрясающая часть системы Dolby Surround Pro Logic это то, что исходный сигнал "уложенный" в стерео, может передаваться вместе с ним везде, где есть возможность передать стерео сигнал: телевизионные стерео передачи, через спутник (C-band, DSS или PrimeStar), кабельные передачи, УКВ (FM) радио, лазерные диски, видео ленты, и даже некоторые игровые приставки. Сегодня вы можете слушать звук в системе Dolby Surround во множестве регулярных телевизионных программах, в растущем списке компакт дисков и конечно на VHS и лазерных дисках, на которых записаны тысячи фильмов с системой Dolby Stereo (термин Dolby Stereo означает то же самое что и хорошо вам известный Dolby Surround, но применяемый в киноиндустрии). Поэтому пока у нас есть стерео, то будет и Dolby Surround Pro Logic, и поэтому все декодеры Dolby Digital имеют встроенный декодер Dolby Pro Logic.
В следующей таблице проводится сравнение свойств Dolby Digital и Dolby Surround Pro Logic.
|
Параметр |
Dolby Digital |
Dolby Surround Pro Logic |
|
"Объемный" канал |
Стерео, полночастотный (3-20000 Гц). |
Монофоничекий, с ограниченным спектром (100-7000 Гц). |
|
Низкочастотный канал |
Да (3-120 Гц). |
Нет |
|
Панорамирование |
Разнообразное |
Слева направо, справа налево, спереди назад и наоборот. |
|
Каналы |
6 отдельных, все каналы могут быть активны одновременно и независимо друг от друга. |
4 производных, может воспроизводится только один преобладающий сигнал в каждый момент времени. |
|
Разное |
Улучшенная картина звука, благодаря "time alignment - выравниванию по времени", т.е. заставляет динамики звучать так, как будто они находятся от слушателя на одинаковом расстоянии. |
Экономное решение задачи получения высококачественного объемного звука. |
|
При снижении общей громкости в звуковых дорожках динамичных фильмов (например, когда действие происходит поздно ночью), соответствующим образом подстраивается компрессия, так чтобы сохранить качество тихих фрагментов. |
Объемный звук от любого незакодированного источника стерео звука. |
|
|
Декодеры могут быть настроены так, чтобы направлять низкочастотный звук в специальные каналы, для систем с сабвуферами. |
Совместим со всеми существующими и будущими стерео форматами. |
|
|
Драматический шаг вперед по вовлечению слушателя в мир реальных звуков. Беспрецедентные творческие возможности для производства и управлению звуком. |
Представляет собой значительный шаг вперед от обычного стерео звука. Является мировым стандартом. |
На данный момент существует огромное количество источников звука, поддерживающих Dolby Pro Logic. А как насчет Dolby Digital? На что еще можно записывать Dolby Digital кроме лазерных дисков?
У Dolby Digital есть одна прекрасная вещь - большая гибкость кодирования. Dolby Digital технически допускает огромное разнообразие форматов, а некоторые из них появятся в самое ближнее время:
Телевидение высокой четкости (HDTV). Эта новейшая система одной из первых выбрала Dolby Digital своей основной звуковой подсистемой. Выбор был сделан "Grand Alliance" - организацией устанавливающей все стандарты для систем HDTV в США.
Спутниковое телевидение - Direct Broadcast Satellite (DBS) уже сегодня активно использует такие преимущества системы Dolby Digital как высокое качество и простота передачи. К примеру, служба "DMX for Business" использует Dolby Digital для передачи 120 музыкальных стерео каналов, и все они передаются с одного передатчика. PrimeStar планирует в ближайшее время добавить Dolby Digital к свой службе телевизионной спутниковой передачи.
Кабельное телевидение внедряет системы с Dolby Digital из-за соображений эффективности и для того чтобы быть готовым к стандартам будущих систем телевидения высокой четкости.
В формат Digital Video Disc (DVD) уже входит Dolby Digital.
Остальные форматы, такие как цифровые видеокассеты - Digital Video Cassette (DVC), и цифровая аудио передача - Digital Audio Broadcast (DAB), являются первыми в списке на внедрение уникальной комбинации качественного звука, эффективной передачи всего спектра сигнала и многоканальных возможностей технологии Dolby Digital.
Буквы "AC" в Dolby AC-3, расшифровываются как Audio Coding - кодирование звука. На цифровое кодирование звука часто ссылаются как на "perceptual coding" (кодирование основанное на ощущениях). Проще говоря, это такое кодирование, которое пытается обнаружить и затем удалить ту звуковую информацию, которую мы все равно не может услышать, но сохраняет то, что мы можем услышать. Его назначение уместить как можно больше полезной информации в доступном спектре. Рассмотрим аналогию:
Предположим, что вам необходимо доставить 4000 человек (полезная информация) из одного места в другое в течении часа. По шоссе может проехать только 1000 машин в час. Если разместить все 4000 человек в 1000 автомобилей, то можно избавиться от лишней информации (оставим 3000 машин дома). Это высокоэффективная доставка, и именно для этого предназначена система Dolby Digital.
Одна из причин, почему качество звука на компакт диске так высоко в том, что он содержит огромный объем данных: 16-ти разрядные семплы выбираются 44100 раз в секунду отдельно для каждого канала. Это соответствует потоку в 1411200 бит в секунду. Компакт диск представляет собой настолько большое хранилище информации, что позволяет записать до 74 минут музыки на один диск. Но что делать, если надо записать 2 часа 20-ти разрядного сигнала и ко всему прочему там должно быть шесть каналов? На сегодняшний день такой большой поток данных непрактичен ни для хранения, ни для передачи.
Кодер Dolby Digital является первым кодером разработанным специально для многоканального звука. Уникальный опыт Dolby Laboratories по устранению аудио шума является критическим для снижения потока данных, потому что чем меньше бит используется для описания аудио сигнала, тем больше шум.
Шумоподавление Dolby работает путем уменьшения уровня шума в отсутствии аудио сигнала, а также позволяя более сильному полезному аудио сигналу перекрывать или "маскировать" шум. Но это позволяет замаскировывать только шум, близкий по частотам к полезному сигналу. Поэтому Dolby Digital разбивает звуковой спектр для каждого канала на узкие полоски разного размера, оптимизированные с расчетом на частотную избирательность человеческого слуха. Это позволяет очень точно отфильтровывать шум оцифровки так, чтобы он оказался очень близко по частоте к частоте кодируемого сигнала. Аудио сигнал эффективно заглушает шум, делая его неслышным для уха. Там где отсутствие сигнала не позволяет маскировать шум оцифровки, Dolby Digital прикладывает максимум усилий чтобы его уменьшить. Можно сказать, что Dolby Digital это очень эффективная система шумоподавления, и в результате качество звука субъективно очень близко к оригиналу.
Dolby Digital использует технологию "shared bitpool" ("разделяемых битов"), и также модель маскирования человеческого слуха, чтобы достичь наибольшей эффективности передаваемых данных. Разряды неравномерно распределяются между множеством узких полосок частоты, причем в каждом конкретном случае по-разному, в зависимости от спектра и динамической структуры кодируемого сигнала. Применяя модель слухового маскирования, кодер предоставляет оптимальное количество разрядов для аудио сигнала в каждой полосе. Дополнительно происходит перераспределение разрядов между разными каналами в соответствии с моделью, по которой более насыщенный частотами канал потребует больше данных для передачи, чем другие, слабо заполненные, а также учитывается, что сильный сигнал в одном канале может маскировать появляющийся шум в других каналах. В результате Dolby Digital может использовать пропорционально больше передаваемых данных для кодирования звука, выдавая более качественный сигнал и позволяя кодировать несколько звуковых каналов в более низкоскоростные потоки данных чем требует даже один канал на компакт диске.
ТЕХНИЧЕСКИЕ ДАННЫЕ
Кодер Dolby Digital способен обработать входной сигнал с, по крайней мере, 20-ти разрядным динамическим цифровым сигналом с диапазоном частот от 20 до 20000 Гц ±0.5 дБ (-3 дБ на 3 и 20300 Гц). Низкочастотный канал покрывает диапазон от 20 до 120 Гц ±0.5 дБ (-3 дБ на 3 и 121 Гц). Поддерживаются частота дискретизации в 32, 44.1 и 48 кГц. Ширина выходного потока данных может варьироваться от минимума в 32 кбит/сек для одного монофонического канала, до максимума в 640 кбит/сек, удовлетворяя всему возможному диапазону требований. Типичными являются скорости в 384 кбит/сек для "5.1" канального Dolby Digital потребительского формата, и 192 кбит/сек для двух канальной передачи звука.
Комментарии к переводу:
Некоторые термины не поддаются однозначному переводу, так как им нет однозначно соответствующих по смыслу слов в русском языке в употребляемом контексте, а именно "Surround" (окружающий, обтекающий, объемный) и "Perceptual Coding" (имеется в виду кодирование, основанное на психоакустической модели слуха человека, имитационная модель).
Под термином лазерный диск понимается "большой" лазерный диск (Laser Disc), не путайте его с "маленькими" компакт дисками (CD). В настоящее время они вытисняются получающими все большее распространение, более современными, дешевыми и удобными DVD дисками.
Компандеры Dolby, несомненно сыграли роль реактивного двигателя, вынесшего на рынок компакт-кассету и заманившего в кинотеатры зрителя, уже начавшего привыкать к вездесущему телевидению. Работая "зеркально" при записи-воспроизведении, они теоретически должны обеспечивать идентичность (за исключением шумов) сигнала на входе и выходе устройства, что к сожалению, не соответствует действительности. Причина – в наличии на передаточной характеристике точек излома, служащих именно для более эффективного шумоподавления. Без них обеспечить эффективное шумопонижение заложенным в Dolby принципом "скользящей полосы" было бы весьма затруднительно.
Как следствие, оснащенные этими устройствами магнитофоны должны иметь коэффициент передачи сигнала запись-воспроизведение точно равным единице и, что более важно, точки перегиба экспандера и компрессора должны совпадать. Добиться этого можно, но…в дело вступают износ головок, разные характеристики магнитной ленты и ее старение… В общем, все это напоминает тщательно отлаженный ламповый High-End усилитель, который уже через год теряет оптимальность настройки именно в силу старения самих ламп.
Правда, идея сжатия-расширения звукового сигнала нашла замечательное воплощение в уникальном, но малоизвестном в бытовой технике компандере dbx, который, в отличие от Dolby, имеет линейную передаточную характеристику и обладает полной независимостью АЧХ и ФЧХ от уровня обрабатываемого сигнала. А ведь именно они отвечают за локализацию в пространстве источников звука! Да и степень подавления шумов (до – 40 dB, тогда как у Dolby C, к примеру, –20dB) несравненно выше, также как и способность шумопонижения на средних и низких частотах. Именно невозможность совместить подавление шумов и четкую объемность звука толкнула Dolby Laboratories к созданию Dolby Stereo с аж четырьмя каналами и прочих Dolby Surround. Ну а идея оснастить ими кинотеатры вообще оказалась золотой жилой – во-первых, много места и, во-вторых, уровень фоновых шумов зала достаточен для маскировки нехватки динамического диапазона (повышать громкость звука ведь тоже можно только до болевого порога!).
Ну а последующие поколения Dolby – цифровые- реализованы весьма толково и чего-либо добавить к сказанному автором статьи просто не имею возможности. Именно этим системам самое место в кино- и дома – театрах!
Почему звуковые карты не воспроизводят AC-3 звук в играх?
AC-3 звук в настоящее время не используется (и даже не предназначался) для интерактивного 3D звука.
Типичный процесс создания многоканального звука следующий:
Сначала производится запись многоканального звука, который может иметь много индивидуальных дорожек -- инструменты, голоса, звуковые эффекты и т.д. Дорожек этих может быть 24, 36, 48 или гораздо больше, особенно если это звуковое сопровождение фильма. Затем многоканальная запись микшируется ("mixed down", микширование с сокращением числа каналов) на специальной аппаратуре в музыкальной или кино студии инженерами по смешиванию звуков. Во время микширования для каждой звуковой дорожки контролируется, уровень громкости, расположение источника звука, баланс, эффекты и т.д с целью получения требуемого результата.
В случае со стерео звуком, результатом такого микширования являются два канала: левый и правый. Микширование с целью получения многоканального surround звука (multi-channel surround) представляет собой просто использования большего числа выходных каналов. В обоих случае, каждый канал состоит из сигналов, которые предназначены для направления в отдельные колонки при прослушивании пользователем. Каждый из этих сигналов представляет собой результат сложного микширования исходных источников, состоящих из многих звуковых дорожек.
Далее, происходит процесс кодирования каналов, полученных после микширования (например, 6 каналов для формата "5.1" Dolby Digital/AC-3) и в результате получается один цифровой поток (bitstream). Процесс кодирования содержит много интенсивных вычислений, в то время как процесс декодирования (все еще не прогулка по парку) требует гораздо меньшего количества ресурсов для выполнения.
Теперь цифровой поток поступает к пользователю, на DVD диске, в виде MPEG файла или в каком-то другом.
Когда вы начинаете проигрывание, декодер обрабатывает цифровой поток в режиме реального времени, разделяя его на индивидуальные каналы и передавая их для воспроизведения на шести акустических колонках. (Или, декодер может делать еще и простой ремикс, т.е. новое микширование, для создания лишь нескольких выходных каналов. Если у вас имеется меньше чем шесть колонок, например, если у вас всего две колонки, тогда канал сабвуфера (низкочастотный) и центральный (диалогов) добавляются одновременно к обоим выходным каналам. Задний левый канал добавляется к левому выходному каналу, задний правый к правому выходному каналу. 3D звуковой процесс может быть использован для "имитации" наличия реально отсутствующих акустических колонок.)
Звуковое содержание "законсервировано". Где бы инженер по микшированию не решил поместить звук, там вы его и услышите. Точка. В такой же мере, что бы инженер ни сделал по отношению к уровню громкости, балансу или любому студийному эффекту, вы услышите это. Точка. Точно как с CD, он всегда один и тот же, каждый раз, когда вы его проигрываете. В игре, единственный случай, когда вы можете использовать законсервированное содержание, это окружающий звук, т.е. создающий атмосферу игры, музыка, видео клипы и т.д., потому что они не могут быть сделаны так, что бы реагировать на ваши действия, за исключением их запуска и остановки, что естественно.
В случае с интерактивным 3D звуком микширование не производится заранее в студии и не может быть там осуществлено. Микширование происходит в режиме реального времени, в момент, когда вы играете в игру. Отдельные звуки ("дорожки") извлекаются с диска и имеют собственный уровень громкости, расположение в пространстве, тональность и т.д., при этом выбор звука зависит от того, в каком направлении вы сдвинули мышку или джойстик. В сущности, в игру встроен собственный робот-инженер по микшированию.
Итак, если вы хотите использовать при игре внешнюю систему проигрывания Dolby Digital звука (что теоретически возможно), вам понадобится звуковая карта, имеющая возможность производить в режиме реального времени не только многоканальное микширование, но и кодирование на лету в цифровой поток. Эта звуковая карта должна ОЧЕНЬ БЫСТРО СЧИТАТЬ, потому что любая заметная задержка между, скажем, нажатием кнопки выстрела и появлением звука вылетающей ракеты, сделает играбельность удручающей.
Итак, предположим, вы можете сделать все это. Тогда вам нужно будет послать кодированный сигнал на расстояние в три фута от вашей карты до декодера, который должен будет снова разделить цифровой поток на множество каналов. Если такой декодер есть на карте, отлично, но это будет по-настоящему глупо, потому что тогда нет никакого смысла осуществлять кодирование в начале.
Как было бы хорошо иметь такую карту, которая могла бы кодировать на лету, правда единственно, что она сможет обеспечить, это удобная возможность управления внешней системой, воспроизводящей окружающий слушателя звук (surround system). Однако стоимость DSP с требуемой для этого вычислительной мощностью взвинтит цену нашей теоретической звуковой карты до уровня стратосферы. Это не является достоинством. Может быть, когда-нибудь это станет реальностью, но не задерживайте свое дыхание.
По иронии, работающий "на лету" Dolby Pro Logic кодировщик очень прост, потому что он основан на очень простой концепции.
В заключение, заметим, что некоторые разработчики игр используют формат звука AC-3 нестандартным образом для интерактивных звуков, однако, все равно процесс кодирования на лету не применяется. Они просто используют преимущества высокой степени сжатия/высокого качества цифрового формата для упаковки своих звуков на диске.
VQF
Термин VQF происходит от расширения (extension) имени файла содержащего звук сжатый при помощи алгоритма TwinVQ. Этот стандарт сжатия более эффективный и качественный MPeg Audio Layer3. Декодирование (расжатие) занимает приблизительно столько же времени, а иногда и меньше, как при МР3 компрессии. Чего нельзя же сказать о процессе кодирования (преобразование WAV в VQF).
Производительность TwinVQ
Алгоритм TwinVQ был разработан для более мощных процессоров чем требовалось для MP3, однако это сказалось только на сжатии данных в TwinVQ. Изготовление VQF файлов происходит очень медленно (даже используя процессор P-II). Примерно в три раза медленнее чем аналогичный процесс для Mpeg Audio Layer3 (используя MMX). Как утверждают разработчики, для реально быстрого процесса сжатия необходим процессор P-II 450MHz XEON или G3-600 (хотя я лично обходился P-II 266MHz)!
|
Mpeg 3 (128Kbps) |
Original (1411Kpbs) |
TwinVQ (VQF) 96Kbps |
|
|
|
|



Но нельзя сказать, что VQF файл превосходит или уступает MP3 файлу, это просто различные файлы. Взглянув на эти картинки Вы легко поймете это различие: когда Вы кодируете музыку в MP3, процесс кодирования вносит искажения в звук и вырезается ряд частот. В отличие от этого, когда Вы кодируете музыку в TwinVQ, мелкие незначительные детали теряются и звук "сглаживается" (softened). Так при 96Kbps VQF файл выглядит более близким к оригиналу чем при 128Kbps MP3, но он менее детален. Две другие проблемы - это спатализация (Spatalisation) и пре-эхо.
Как же это все работает?
TwinVQ использует метод кодирования подобно MP3, AAC или Dolby AC-3. Хотя он и использует некоторые классические средства использованные в MP3 (bitstream) или AAC (interframe backward prediction) но кодирование музыки отличается в корне. В этом методе, индивидуальные биты музыкальных данных непосредственно не кодируются, а объединяются в сегменты (вектора). Эти вектора сравниваются со стандартными образцами, которые подготовлены заранее. Выбирается стандартный вектор, который обеспечивает ближайшее соответствие, и количество, связанное с этим образцом передается как код сжатия. Данные упаковывается в длинный фреймовый режим или короткий фреймовый режим (8 sub>frames) согласно константе bitrate для того, чтобы повысить устойчивость к ошибке. Искажения сводятся к минимуму, так что музыка и другие звуки успешно воспроизводятся с качеством очень близким к оригиналу.
Следует заметить, что технология аудиосжатия TwinVQ включена в стандарт MPEG-4.
Что необходимо для TwinVQ?
|
Encoder (SoundVQ, VVStudio) |
Player (Sound VQ, KJofol, VVS Player v.1.3.0) |
|
|
OS |
Windows 95/NT4.0 |
Windows 95/NT4.0 |
|
CPU |
Pentium 66MHz или выше |
Pentium 90MHz или выше (для режима 44KHz Stereo data) i486 66MHz или выше (для режима 22KHz Mono data) |
|
Memory |
16MB и выше |
16MB и выше |
|
Audio |
16bit (stereo) PCM sound function (стандартный SB) |
16bit
(stereo) PCM sound function |
Слухи и заблуждения
1. VQF дает большую нагрузку на CPU чем layer3 (mp3)
|
WinAMP v.1.9.0 (MP3) |
K-Jofol Player, VVSPlayer v.1.3.0 (VQF) |
|
|
Windows'95 (OSR2.1) |
2 - 5% |
0 - 3% |
|
Windows NT4.0 |
2 - 5% |
1 - 3% |
2. Медленный encoder
Да, это так. Но разве можно сидеть на двух стульях? Качество & мощное сжатие... В этом случае время приносится в жертву.
3. Необходимо иметь два плейера для проигрывания MP3 & VQF
Неверно. VVS Player v.1.3.0, Kjofol + огромное коллчиество новых разработок (включая Winamp) могут воспроизводить оба эти стандарта.
7. MP3 - время прощаться с ПК
Роман MP3 и CD приносит первые плоды на рынке бытовой электроники.
История с пришествием в мир формата музыкальной компрессии MP3 – отнюдь не из разряlа обыкновенных. То, что новому стандарту суждено коренным образом изменить положение дел на рынке музыкальной продукции, поняли все и сразу. Производители компакт-дисков и концерны звукозаписи хватались за голову, потребительская аудитория бурно ликовала. И все – кто с радостью и предвкушением, а кто с трепетом, ждали того момента, когда новый стандарт компрессии звука шагнет из тесной каморки персоналок в поистине безграничный мир бытовой электроники…
Чтобы понять всю важность происходящего – а мы говорим ни много ни мало, о революции в мире производства и распространения музыкальной продукции – приведу немного статистики и общеизвестных фактов. Количество выпущенных за три последних года MP3-дисков (начиная с памятной всем серии "Рок-Архив" знаменитого "Фаргуса") перевалило за 300 – MP3-коллекции сегодня уверенно занимают третье место в пиратском обороте, после программ и игр. В ассортименте одной лишь серии "Домашняя коллекция" (сайт пиратской фирмы-производителя находится по весьма престижному адресу http://www.cdboom.com) - заявлено не менее 70 дисков (800-1000 альбомов)!
Если учесть, что в среднем на каждом MP3-диске помещается 10-15 альбомов (или 10-12 часов звука), то получается, что в любой момент к услугам российского меломана – более 4000 альбомов по цене 15-20 центов за альбом (2-2,5 доллара за MP3-коллекцию из 10-15 альбомов против 1 доллара за ОДИН альбом на кассете, 2 – на пиратском и 10-15 – на фирменном CD).
Прибавьте к этому еще такое же количество "самопальных" коллекций, составленных любителями в домашних условиях и распространяемых из рук в руки... И получается, что любой меломан может уместить на свободной полке своего книжного шкафа ассортимент небольшого музыкального магазина – 8000 наименований дисков, включая практически полные коллекции ВСЕХ ведущих исполнителей и групп за последние 30 лет! Причем обойдется ему это удовольствие максимум в 800 долларов – стоимость 70-80 фирменных CD! Если смотреть в макромасштабе – зная средний тираж пиратских "релизов" (1000 экземпляров), нетрудно посчитать, что сейчас в России "крутится" не менее 300 тысяч MP3-дисков! Цифра, конечно, по масштабам музыкального бизнеса, не слишком внушительная… но помножьте число дисков на количество альбомов, и вы увидите, что
За последние три года mp3-коллекции "вытеснили" с рынка почти четыре миллиона обычных компакт-дисков!
Революция? Халява галактического масштаба? Несомненно. Но – с двумя оговорками. Во-первых, высокая степень MP3-сжатия, используемая при составлении пиратских коллекций (или, иными словами – низкая "пропускная способность" сжатого звукового потока, именуемая "битрейтом" - bitrate) существенно снижает качество звука. То есть слушать тех же Beatles, Элвиса или бардов в виде MP3-файлов с битрейтом 128 Кб/с еще можно, а King Crimson, Tangerine Dream или ELO – уже нет. Тут нужна меньшая степень сжатия и более высокий битрейт (от 192 Кб/с) – а такую роскошь пираты себе не позволяют. Еще бы – тогда на одном CD угнездится всего лишь 6-8 альбомов вместо 12-15… Ну да Бог с ними, с эстетами – их у нас не так уж много, большинству и кассетного качества хватает вполне. Да и сделать битрейт побольше не проблема – был бы спрос!
Другая закавыка серьезнее. Дело в том, что до недавнего времени стандарт MP3 был намертво привязан к компьютеру. А владельцев ПК у нас покамест меньше, чем счастливых обладателей хотя бы простеньких музыкальных центров или магнитол. Учтите и то, что по качеству звучания 1000-долларовый компьютер, оборудованный 50-долларовыми колонками, существенно уступает 100-долларовой магнитоле…Прибавьте сюда же "фактор мобильности" - компьютер с собой не унесешь, а музыку хочется и можется слушать не токмо развалившись на диване.
Теперь становится понятным, что появление на рынке портативных, независимых от компьютера mp3-проигрывателей - одно из самых ожидаемых событий последних пяти лет.
Нет, мы имеем в виду не MP3-плееры первого поколения, выброшенные на прилавки еще два года назад – красивые и дорогие, но убогие до предела игрушки. Высокая стоимость самих плееров в сочетании с запредельно высокой стоимостью и малой емкостью носителей (максимум час звука даже не кассетного качества на 50-долларовой карточке) напрочь убивали все преимущества MP3…
И все же, при всей своей непрактичности и убогости эти аппаратики вызвали настоящую панику среди олигархов от звукозаписи – все мы прекрасно помним попытки запретить производство MP3- проигрывателей через суд. Чуяло, ох чуяло бизнесменское сердце, что все эти Diamond Rio сотоварищи – лишь предтечи продуктов совсем иного класса, что рынок ждет настоящего MP3-проигрывателя. И того и гляди, дождется. Конечно же, речь идет о портативных CD-проигрывателях, способных воспроизводить наряду с обычными дисками, и компьютерные MP3-коллекции.
И вот наконец мы подходим к изюминке нашего исследования… Да-да, вы не ошибаетесь – уже через 2-3 месяца на прилавках появятся первые образцы этой вожделенной мечты меломанов всего мира! Кстати, история с MP3-плеерами – едва ли не первый случай перехода технологий из компьютерного мира на рынок бытовых устройств. Обычно, происходило наоборот – большинство "примочек" к современному ПК эволюционировали от "бытовых" электронных технологий.
Конечно, это могло бы случиться и раньше, ведь модернизация существующих CD-проигрывателей до CD/MP3 – не шибко сложная задача: как минимум год назад сразу несколько фирм начали производство чипов аппаратного MP3-декодирования, и стоят эти "камешки" весьма недорого. Но крупные фирмы-производители электроники, памятуя скандал вокруг Diamond Rio, не рисковали вступать на "минное поле" MP3-электроники – тяжбы со звукозаписывающими фирмами были неминуемы. А если вспомнить, что многие "электронные гиганты" (например, Sony) имеют свои интересы в традиционной сфере звукозаписи и дискового бизнеса…Как бы то ни было, за дело взялись мелкие фирмы – юркие, нахрапистые и абсолютно лишенные комплексов.
D’Music SM-200C
"Первой ласточкой" и образцом для всех MP3-проигрывателей второго поколения стал плеер D’Music SM-200C от компании Pine (http://www.pineusa.com). Этот агрегат стоимостью около 300 долларов способен читать информацию со стандартных "заводских" компакт-дисков стандарта AudioCD и MP3, а также "самодельных" дисков CD-R и CD-RW объемом до 700 Мб (80 минут в формате AudioCD и 12 часов музыки в формате MP3 128 Кб/с). Правда, места D’Music занимает несколько больше, чем привычные нам "блины"-дискмэны (138х130х31 мм), да и энергии кушает немало (для полноценного функционирования аппарату необходимы аж 4 "пальчиковых" батарейки вместо привычных двух. Остальные "довески" к D’Music достаточно традиционны – 10-секундный буфер памяти "антишок", эквалайзер с 5 предустановками (Flat, Pop, Classic, Jazz and Ex-Bass), опционально – пульт ДУ. Выглядит же плеер весьма стильно и внушительно – кстати, выпускается D’Music в двух исполнениях "мужском" (голубой цвет корпуса), и "женском" (розовый).
Как и положено MP3/CD–проигрывателю, D’Music может работать с дисками, содержащими MP3-файлы и плейлисты M3U в подкаталогах (по крайней мере, так заявляет производитель), а также MP3-тэги (текстовую информацию об исполнителе, жанре и названии композиции и диска). Навигация по MP3-диску осуществляется с помощью специальных кнопок и крохотного жидкокристаллического экранчика. По фотографии трудно определить, сколько строк он содержит (на первый взгляд площадь экрана не превышает стандартный вариант CD-плеера), однако ясно, что для корректного отображения названия композиций и уж тем более структуры диска его явно недостаточно. Отсюда – мораль: работать с MP3-диском с помощью D’Music можно будет только вслепую…
Не совсем ясно, поддерживает ли D’Music весь диапазон "музыкальных" MP3-битрейтов (от 112 до 256 Кб/с), а также столь модный нынче "динамически изменяющийся" битрейт VBR. Думается, что разработчики плеера должны были изначально заложить все эти возможности в свое детище – иначе его ценность как коммерческого продукта резко падает. Хотя в последнее время в Интернет-конференциях, посвященных MP3, и поговаривают, что звукозаписывающие компании намерены "опустить" потолок поддерживаемых битрейтов в портативных MP3/CD-проигрывателях до традиционных 128 Кб/с. То есть вывести тем самым из под "удара" традиционные AudioCD, принеся в жертву и без того отжившие свое кассетники. Дай Бог, чтобы их задумка не прошла… Но в любом случае, прежде, чем покупать MP3-плеер, обратите внимание на поддерживаемые им стандарты битрейтов!
MAMBO-X P300
Персона номер два в нашем рейтинге – плеер MAMBO-X P300 (http://www.mambox.com/p300.htm), который по большинству показателей ничуть не уступает D’Music. Основные характеристики плеера, помимо уже заявленных стандартных: Буфер антишока – 45 секунд (против 10 у продукта Pine) Размеры – 5,5" x 5" x 1" (1 дюйм – 2,5 см) Уменьшенный вес – 256 гр. Инфракрасный пульт дистанционного управления Поддержка Superior Ultra Bass Processing (sub>)EQ/Bass/TrebleПитание – 2 пальчиковых батарейки (до 14 часов работы)
Как видим, преимуществ у MAMBO-X немало – компактность, легкость, меньшие требования к питанию… Что лучше – фиксированные установки эквалайзера у D’Music или раздельный контроль высоких и низких частот у MAMBO-X – каждый пусть решает самостоятельно. Дизайн у MAMBO-X, не спорю, менее изыскан, чем у плеера от Pine, а вот дисплей чуть больше… Кстати, уже заявлено, что имя певца и название композиции Mambo-X будет через этот самый дисплей докладывать - значит, и с ID3-тэгами плеер будет работать нормально.
Но самое главное - авторы MamboX недвусмысленно и категорически заявили о поддержке ВСЕХ существующих битрейтов и модификаций стандарта MP3. То есть работать с VBR и битрейтами вплоть до 320 MamboX однозначно будет! Прояснена и ситуация с подкаталогами на диске - MamboX поддерживает до 16 папок. А больше и вряд ли понадобиться...
Что же касается воспроизведения обычных AudioCD (а заодно - и CDR вкупе с CDRW). Отрадно, что стандартная "музыкальная" часть Mambo-X сделана на весьма достойном уровне, с использованием "начинки" от Philips. Не последнего игрока на рынке дискмэнов. Правда, обещания обещаниями, а как оно будет на самом деле... Тестовых образцов плеера пока что нет. Остается опасность и того, что "раскрутив" Mambo-X, производители поспешат перейти на более дешевый механизм и ЦАП - хотя очень хочется надеяться, что этого не случится.
Я намеренно приберег под конец самый важный для нас фактор – стоимость. Цена, пожалуй, главный козырь Mambo-X – она составляет всего 199 долларов, что на целую сотню "зеленых" меньше, чем у продукта от Pine! По этой цене заказы на Mambo-X (пока - предварительные) принимает виртуальный магазин Direct411.com
Возможность приобрести Mambo-X предоставлена и россиянам: в Интернет-магазине портативной аудиотехники Porta.ru (http://www.porta.ru) можно оставить предварительный заказ на вожделенную железяку. Ну а цена за плеер для первых заказчиков составит 225 долларов.
SHINCO SVD-951
Третий и последний пока что конкрусант на звание "лучшего из первых" - комбинированный плеер SHINCO SVD-951 от тайваньской фирмы Shinko
Тут должна последовать долгая минута молчания…. Ибо плеер от Shinko настолько разительно отличается от своих "коллег", по всем возможным параметрам, что даже не знаешь, за что взяться…
Начнем с того, что плеер этот умеет, помимо банальных звуковых дисков в стандартном и MP3 формате, воспроизводить еще и видеодиски: изображение выводится на 4-дюймовый цветной жидкокристаллический экран. Отсюда – резкое облегчение навигации – экран такого размера, помимо своей прямой обязанности, может служить великолепным меню, на котором подробно будет отражена вся структура вашего MP3-диска, со всеми его подкаталогами и названиями.
Но вернемся к видео. Как и положено современному образчику азиатского искусства, плеер поддерживает замедленное (3 шага) и ускоренное (4 шага), а также покадровое воспроизведение, увеличение фрагмента экрана (Zoom), замедленное и ускоренное воспроизведение. Если вас не устраивает качество картинки на 4-дюймовом "кристаллике" (разрешение – 350 линий) - не беда, имеется видео и S-Video выходы, подключайте хоть к телевизору, хоть к жидкокристаллическому дисплею большего размера. К сожалению, пока что не предусмотрена поддержка SECAM, зато NTSC и PAL – пожалуйста! Плюс – поддержка субтитров и меню на нескольких языках (русский, понятное дело не включен в список). Ах да – плеер поддерживает столь любимый на востоке режим караоке, снабжен микрофончиком и может при необходимости сохранять в памяти ваши голосовые заметки! С аксессуарами дела у плеера от Shinco обстоят и вовсе замечательно – помимо пульта ДУ и микрофона в комплект поставки включен переходник для подключения к гнезду автомобильного прикуривателя и комплект аккумуляторов. Вы спросите – а где же наушники? Есть и они, но и в сам плеер встроены миниатюрные динамики!
Казалось бы, все просто замечательно! Но… куда деться без этих "но"…
Понятно, что "навороченность" Shinco отнюдь не сопутствует миниатюрности. В кармане этот плеер, весящий около килограмма, не потаскаешь (размеры этому тоже не способствуют), да и с питанием напряженка – Shinco требует подпитки от 6 батареек (9 вольт). И хватит их ненадолго – всего на пару часов, если вы не отключите прожорливый дисплей. Для путешественников, бизнесменов и "новых русских" лучшего подарка не придумаешь. Для всех остальных это явно слишком круто… и недостаточно практично.
Кстати, о видео. Что греха таить – нам всегда хочется большего. И если уж встраивать в MP3-проигрыватель то почему бы не сделать базовым стандартом входящий в моду DVD? Ведь в этом случае поддержка VideoCD приложится бесплатно. А покупать такую мощную и дорогую "прибамбасню", ориентированную на вымирающий стандарт, не слишком-то приятно…Впрочем, такой универсальный плеер (модель DVD-180) Shinco тоже выпускает… Но, к сожалению, не в портативном, а в "мини-настольном" исполнении (28х30х9 см).
Ах да, забыли про цену! Стоимость портативного плеера Shinco - 350 долларов (на аукционе eBay (http://www.ebay.com) и даже 399 долларов (в виртуальных магазинах типа AsiaCD (http://www.asiacd.com/html/vcd/dvcdplayer/svd-950mp.html) – конечно, недешево (особенно если учесть, что похожие агрегаты без поддержки MP3 стоят вдвое дешевле)… Цена универсального настольного DVD/VCD/CD/MP3 проигрывателя, кстати, не намного выше – $370-450.
Каков же итог? Трудно, конечно, делать однозначный выбор (и вывод) при столь малом количестве конкурсантов. D’Music красив и доступен сегодня, Mambo-X – демократичнее и дешевле. Но завтра. Но дешевле… Что до творения Shinco, то сделать выбор между функциональностью с одной стороны и стоимостью вкупе с "фактором мобильности" очень непросто, однако, несомненно, и у этого продукта найдется своя ниша на российском рынке.. если, конечно, кто-нибудь из дистрибутеров рискнет связаться со столь экзотичной новинкой.
Но главный вывод уже сделан – MP3/CD плееры "для непосед" не только родились, но и уже успели заявить свои права на симпатию и кошелек меломанов. Не смотря на то, что большинство отзывов в Интернете касаются одного лишь плеера D’Music, а подробного и объективного сравнения плееров этого типа пока и вовсе не существует.
Заключение
Вот и закончена курсовая работа. В такой объем невозможно уместить полное исследование даже такого небольшого раздела мира “высоких технологий”. Можно лишь подвести некоторые итоги:
звуковая карта стала неотемлемым атрибутом любого компьютера, используется ли он в качестве мощнейшей игровой станции или как калькулятор для секретаря в офисе.
наметилась тенденция слияния компьютера с различной бытовой электроникой (или наоборот), на комьютер стало проникать видео, телефон, телеграф и что только еще, а с компьютера в большой мир – интерактивность, глобальность и всемирная связанность всего со всем.
и, наконец, самое главное: звуковые карты проделали огромный путь от жалкой пищалки до настоящего комбайна - HI END монстра, который сам по себе является почти полноценным компьютером, и не думают останавливаться на этом. В прогнозах производителей уже стоят карты, сами создающие музыку под требуемую атмосферу в требуемое место игры, или даже карты, заменяющие музыканта, композитора, редактора и целый симфонический оркестр.
Единственное, на что я не смог ответить достаточно точно, так это то, чем станет компьютер через некоторое время. Например, через 10 лет. Быть может, они перестанут существовать в своем нынешнем виде и сольются с бытовой электроникой, встраиваясь даже в подкассетники и часы. Или разделятся на ветви “чистых вычислений” и “развлечений”, как в свое время разошлись пути компьютеров и приставок. Все может быть. Но, я думаю, что мы сможет увидеть (и услышать) все это своими глазами (и ушами). 10 лет. Не так уж и много. Если уже сейчас возможности современных компьютеров поражают воображение, то, быть может, через 10 лет эта тенденци сохранится?