Организация Web-доступа к базам данных с использованием SQL-запросов
УПРАВЛЕНИЕ ОБРАЗОВАНИЯ АДМИНИСТРАЦИИ ЛЕНИНСКОГО РАЙОНА
Организация Web-доступа к базам
данных с использованием SQL-запросов.
Исполнитель: ВОЛКОВ Константин Владимирович
ученик 11Б класса МСОШ № 175
Руководители: ФЕДОРОВ Леонид Николаевич
директор Информационно-методического центра
Управления образования администрации Ленинского района
МОКРЯНСКИЙ Дмитрий Георгиевич
методист Информационно-методического центра
Управления образования администрации Ленинского района
Екатеринбург
2000
Cодержание
|
Введение. 1. Причины и история создания языка запросов SQL. 1.1. Реляционные базы данных. Общие понятия. 1.2. Взаимодействие SQL и СУБД. 1.3. Стандарты SQL. Сегодняшнее состояние. 2. Технологии, обеспечивающие, web доступ к базам данных. 2.1. Принципы работы SQL-сервера. 2.2. Таблицы SQL. 2.2.1. Структура запросов SQL. 2.2.2. Запросы с использованием единственной таблицы SQL. 2.2.3. Запросы с использованием нескольких таблиц SQL. 2.2.4 Модификация данных в таблицах SQL. 2.3. Обзор основных SQL-серверов. 2.3.1. SQL-сервер Oralce. 2.3.2. Microsoft SQL сервер. 2.3.3. MySQL – сервер. 2.4. Принципы работы web-серверов. 2.4.1. Web-сервер. Понятие, функции, характеристики. 2.4.2. Трехзвенная архитектура клиент-сервер. 2.4.3. Архитектура Internet/Intranet. 2.4.4. Обзор серверных программ для различных ОС. 2.4.5. Стандарты, облегчающие создание Web-узлов. 2.4.6. Web-технологии. 2.4.7. Web-сервер Apache. 2.4.8. Web-сервер Jigsaw. Web-сервер Netscape Enterprise. Microsoft Internet Information Server. 2.5. Организация пользовательского интерфейса для доступа к базам данных. 3. База данных Информационно-методического центра "Сведения об образовательных учреждениях". 4. Вопросы безопасности и санкционирования доступа к базам данных. 5. Перспективы развития сетевых баз данных. 6. Список литературы. Приложения (Листинг программ). |
3 6 6 8 8 13 14 15 16 20 35 55 64 67 70 72 74 74 74 75 77 78 79 80 81 82 87 89
95
100 104 106 |
Введение
Базы данных выполняют функцию систематизации знаний. На основе этой систематизации могут создаваться новые знания. Так или иначе, любая база данных служит человеку именно для описания происшедших в прошлом событий и на основе знания этих событий помогает принять то или иное решение на будущее. База знаний может быть построена как мультимедийный справочник или как набор текстов и файлов другого формата, проиндексированных по определенным признакам в базе данных.
База данных – это, прежде всего, хранилище объектов данных, т.е. набора возможных понятий или событий, описываемых базой данных, с возможностью поиска этих объектов по признакам. Неотъемлемой чертой базы данных является возможность связывания объектов между собой. Базой данных можно считать не только таблицы, индексирующие файлы со знаниями разных форматов, но и сами эти файлы, потому, что они являются не типизированными хранилищами знаний в такой базе данных.
Итак, в базах знаний мы накапливаем опыт прошлого. Потом человек может сам принять решение на основе этого опыта (типичный случай с мультимедийным справочником) или поставить задачу перед базой данных по поиску решения согласно сложившейся ситуации (найти закон, поясняющий правило оформления таможенной декларации и т.п.). Так происходит в программах справочного характера. Как частный случай баз данных, можно рассматривать различные структурированные файлы, например, словари для переводчиков, форматы файлов RTF, DOC, книги Microsoft Excel, файлы с письмами для почтовых Internet-программ и т.д., жизненно важные функции баз данных, в которых реализуются за счет внутренних функций программ работающих с ними. Базы данных могут применяться как вспомогательное средство, позволяющее реализовать какую-то полезную функцию. Например, хранение настроек программы, Internet-адресов для рассылки рекламы и т.д.
Структура информационных систем.
Для построения информационных систем применяются базы данных, созданные вокруг ядра базы данных. Работа с базой данных происходит, как правило, в многопользовательском режиме, т.е. программа должна быть сетевой. В связи с этим, необходимо обеспечить разделение прав доступа различным пользователям к данным, правильность завершения транзакций, т.е. ссылочную целостность, ограничения и другие правила, реализуемые через встроенные средства сервера базы данных. К тому же, должна быть обеспечена приемлемая производительность информационной системы. В центре всей информационной системы стоит сервер базы данных. Он обеспечивает низкоуровневый доступ к таблицам базы данных, в которых и хранится информация об объектах базы данных. Ядром информационной системы в простейшем случае могут выступать несколько функций, реализованных в программе программистом.
В современном мире чаще всего применяется сервер приложений для реализации ядра информационной системы. В распределенной вычислительной системе сервер приложений берет на себя функцию распределения нагрузки между серверами, которые в общем случае могут работать под разными операционными системами, или находится в разных географически местах. Сервер приложений – это мостик между программами-клиентами и одним или несколькими серверами базы данных. За счет сервера приложений можно снизить нагрузку на приложения пользователя и реализовать сложные правила объектной модели базы данных, которые трудно или нерационально реализовывать на стороне сервера базы данных. В результате, сервер приложений снижает трафик между сервером базы данных и компьютером клиента, повышая общую производительность информационной системы. Исходя из сказанного ранее, на приложение пользователя остается только реализация интерфейса. Такая структура информационной системы называется многозвенной, а приложение пользователя – тонким клиентом. Надо отметить, что в общем случае серверы приложений могут посылать команды друг другу, и взаимодействовать, таким образом, самым рациональным способом с географически удаленными серверами баз данных. Например, для получения отчета с большим количеством вычисляемых полей, нет необходимости делать несколько запросов к удаленной базе данных через Internet, если это может сделать сервер приложений, находящийся в непосредственной близости от сервера базы данных. Он и пошлет в ответ готовый отчет.
Таким образом, только информационная система, построенная по принципу многозвенности, может удовлетворять наиболее полным образом условиям наивысшей производительности при полной коммуникабельности и распределенности вычислений. Система, построенная из нескольких отдельных модулей, выполняющих ряд определенных задач, к тому же, может быть проще модифицируемой.
Необходимые функции базы данных.
Первой и самой важной функцией базы данных, является функция хранения информации. Информация должна хранится упорядоченно для более быстрого и понятного пользователю доступа к ней. Упорядоченность информации в базе данных, помимо удобств доступа, может привести к значительному сокращению аппаратных ресурсов, необходимых для ее обслуживания. Упорядоченность достигается путем нормализации.
Здесь мы вплотную подошли ко второй функции базы данных – ввод информации. Какую информацию будет вводить пользователь? Хорошая база данных построена из главного документа, справочников, из которых пользователь вводит информацию и нескольких полей для ручного ввода, например, текстов назначения платежа в платежных поручениях и суммы. База данных должна заполняться средствами, наиболее полно автоматизирующими этот процесс. При этом плохим тоном являются:
ввод информации об одном объекте разными способами или в разных местах;
ввод одной и той же информации в нескольких местах;
ввод информации разрозненно, без поддержания общей структуры объекта.
Одной из основных функций базы данных является автоматизация. Под автоматизацией, как правило, понимают автоматическое создание выходных документов и пересчет данных, например печать накладной, счета фактуры и протокола согласования цен в складской программе для исходящей накладной.
Далее, нужно вспомнить о системах принятия решений. Информационная система должна позволять создавать статистические отчеты в реальном режиме времени о состоянии описываемого в базе данных процесса. Эта функция удобна для руководителей подразделений, которые могут прогнозировать поведение описываемой системы на основе статистических данных, полученных из базы данных.
Собственно, описанные выше функции информационной системы являются «джентльменским набором», которого достаточно в большинстве случаев. Из дополнительных функций необходимо упомянуть возможность поиска по нескольким взаимосвязанным характеристикам.
В единой информационной системе необходима возможность идентификации пользователя с целью ограничения доступа пользователя к определенным частям базы данных и введения информации о создателе документа и лиц, редактировавших его. Это придаст пользователям ощущение ответственности за выполняемые действия.
Хорошая информационная система должна легко расширяться при необходимости добавления в нее новых возможностей. Расширяемость подразумевает элементы объектной ориентированности, встроенные в базу данных. Настраивая эти объекты, возможно вносить незначительные изменения в структуру базы данных, что продляет срок морального устаревания всей информационной системы. Одним из факторов расширяемости является возможность сочленять разнородные базы данных в единый комплекс. Такая возможность сейчас реализуется через дополнительные модули, которые по своей сути являются серверами приложений, или правильное построение базы данных по классическим реляционным законам. Последний случай затрудняется тем, что некоторые серверы базы данных не могут выполнить один SQL запрос к разным базам данных, тем более находящимся в географической удаленности друг от друга.
Еще одна удобная функция в базе данных – это сквозное прохождение по документам.
Описанные выше функции в разных реализациях информационных систем имеют специфические черты, ориентированные на конкретное прикладное применения.
Причины и история создания языка запросов SQL.
Реляционные базы данных. Общие понятия.
Любую структуру данных можно преобразовать в простую двумерную таблицу. Такое представление является наиболее удобным и для пользователя, и для машины, - подавляющее большинство современных информационных систем работает именно с такими таблицами. Базы данных, которые состоят из двумерных таблиц, называются реляционными.
Основная идея реляционного подхода состоит в том, чтобы представить произвольную структуру данных в виде простой двумерной таблицы или, как говорят, нормализовать структуру.
Из всех систем баз данных реляционные относятся к самым распространенным в мире. Эти системы способны разрешить многие из тех проблем, которые усложняли работу с нереляционными продуктами прежних поколений. Программисты и администраторы таких баз данных были вынуждены тщательно изучать, как структурирована информация и как она представлена в базе данных, что значительно усложнило разработку этих приложений и модификацию самих программ. Реляционные системы способны работать на более высоком уровне. Все операции с данными реализуются программой, называемой DBMS (система управления базой данных Обращаться к ней можно только с помощью операторов языка высокого уровня. Хотя некоторые продукты по-прежнему поддерживают работу в терминах своих собственных языков, язык SQL (Standard Query Language) стал тем технологическим стандартом, на базе которого созданы все, более или менее известные, реляционные продукты.
Язык для взаимодействия с БД SQL появился в середине 70-х и был разработан в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structered English Query Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД, но на самом деле уже являлся полным языком БД, содержащим помимо операторов формулирования запросов и манипулирования БД средства определения и манипулирования схемой БД. В языке отсутствовали средства синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД.
В основе современных реляционных баз данных (и стандарта SQL) лежит несколько правил и принципов:
Все значения данных состоят из простых типов данных. В SQL отсутствуют массивы, указатели, векторы и другие сложные типы данных.
Все данные в реляционной базе данных
изображаются в форме двумерных таблиц
(на языке математики – «отношений»).
Каждая таблица содержит некоторое
число строк (в том числе 0), называемых
«картежами» и один или несколько
столбцов, называемых «атрибутами». Все
строки в таблице имеют одну и ту же
последовательность столбцов, в которых
записаны различные значения, однако
наборы значений в столбцах отличаются.
На
рисунке 1 приведена простейшая таблица
такого типа.
После того как данные введены в БД, можно сравнивать значения в различных столбцах (в том числе и для разных таблиц) или объединять строки, в которых найдено совпадение. Это позволяет соотносить между собой строки и производить очень сложные операции обработки над всеми данными, находящимися в базе.
Все операции определяются только логикой, а не положением строки в таблице. Например, можно запросить все строки, со значением 2 и не возможно запросить первую или, третью или пятую строку. Строки в реляционной базе данных расположены в произвольном порядке. Он не обязательно соответствует тому порядку, в котором они были занесены или в котором хранятся на диске.
Поскольку невозможно определить строку по ее положению (порядку в таблице), необходимо иметь один или несколько столбцов с уникальным значением для идентификации каждой строки. Эти столбцы называются первичными ключами таблицы.
В примере на рис. 1 это первый столбец.
|
ID |
Имя |
Телефон |
Город |
|
2 |
Иван И. Иванов |
555-001 |
Москва |
|
1 |
Константин В. Волков |
555-330 |
Екатеринбург |
|
3 |
Василий В. Грабер |
555-607 |
Санкт-Петербург |
Рисунок 1
Одним из преимуществ реляционного подхода к построению БД – отсутствие необходимости заботится о таких деталях, как способы представления данных или их физическое размещение в самой базе. Старые иерархические и сетевые базы данных, в которых приходилось иметь дело с подобными вопросами реализации, имели громоздкую структуру и были сложными в управлении.
1.2. Взаимодействие SQL и СУБД.
Увеличение объема и структурной сложности хранимых данных, расширение круга пользователей информационных систем привели к широкому распространению наиболее удобных и сравнительно простых для понимания реляционных (табличных) СУБД. Для обеспечения одновременного доступа к данным множества пользователей, нередко расположенных достаточно далеко друг от друга и от места хранения баз данных, созданы сетевые мультипользовательские версии СУБД. В них тем или иным путем решаются специфические проблемы параллельных процессов, целостности (правильности) и безопасности данных, а также санкционирования доступа.
SQL стал унифицированным средством общения и стандартным языком манипулирования с базами данных, обладающим средствами для реализации перечисленных выше возможностей. После появления на рынке двух пионерских СУБД – SQL/DS (1981 год) и DB2 (1983 год) – он приобрел статус стандарта де-факто для профессиональных реляционных СУБД. В 1987 году SQL стал официальным международным стандартом языка баз данных, а в 1992 году вышла вторая версия этого стандарта.
Важной отличительной чертой SQL является его независимость от компьютерной среды (операционной системы и архитектуры). Такой язык назвали SQL – это аббревиатура структурированного языка запросов (Structured Query Language). SQL является инструментом, предназначенным для обработки и чтения информации, содержащейся в компьютерной базе данных.
При создании языка запросов нового поколения разработчики старались сделать его простым и легким в освоении инструментом для обращения к БД. В итоге SQL стал слабо структурированным языком, особенно по сравнению с такими языками, как С или Pascal, и в то же время достаточно мощным и относительно легким для изучения.
1.3. Стандарты SQL. Сегодняшнее состояние.
Одним из наиболее важных шагов на пути к признанию SQL на рынке стало появление стандартов на этот язык. Обычно при упоминании стандарта SQL имеют в виду официальный стандарт, утвержденный Американским институтом национальных стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартам (International Standards Organization— ISO). Однако существуют и другие важные стандарты SQL, включая SQL, реализованный в системе DB2 компании IBM, и стандарт X/OPEN для SQL в среде UNIX.
Работа над официальным стандартом SQL началась в 1982 году, когда ANSI поставил перед своим комитетом ХЗН2 задачу по созданию стандарта языка реляционных баз данных. Вначале в комитете обсуждались достоинства различных предложенных языков. Однако поскольку к тому времени SQL уже стал фактическим стандартом, комитет ХЗН2 остановил свой выбор на нем и занялся стандартизацией SQL.
Разработанный в результате стандарт в большой степени был основан на диалекте SQL системы DB2, хотя и содержал в себе ряд существенных отличий от этого диалекта. После нескольких доработок, в 1986 году стандарт был официально утвержден как стандарт ANSI номер Х3.135, а в 1987 году — в качестве стандарта ISO. Затем стандарт ANSI/ISO был принят правительством США как федеральный стандарт США по обработке информации (FIPS — Federal Information Processing Standard). Этот стандарт, незначительно пересмотренный в 1989 году, обычно называют стандартом “SQL-89”, или “SQLI”. Когда в данном реферате я упоминаю «стандарт ANSI/ISO”, то подразумеваю SQLI, который в настоящее время лежит в основе большинства коммерческих продуктов.
Многие из членов комитетов по стандартизации ANSI и ISO представляли фирмы-поставщики различных СУБД, в каждой из которых был реализован собственный вариант SQL. Как и диалекты человеческого языка, диалекты SQL были в основном похожи друг на друга, однако несовместимы в деталях. Во многих случаях комитет просто обошел существующие различия и не стандартизировал некоторые части языка, определив, что они реализуются по усмотрению разработчика. Этот подход позволил объявить большое число реализаций SQL совместимыми со стандартом, однако сделал сам стандарт относительно слабым.
Чтобы заполнить эти пробелы, комитет ANSI продолжил свою работу и создал проект нового, более жесткого стандарта SQL2. В отличие от стандарта 1989 года, проект SQL2 предусматривал возможности, выходящие за рамки таковых, уже существующих в реальных коммерческих продуктах. А для следующего за ним стандарта SQL3 были предложены еще более глубокие изменения. В результате предложенные стандарты SQL2 и SQL3 оказались более противоречивыми, чем исходный стандарт. Стандарт SQL2 прошел процесс утверждения в ANSI и был окончательно принят в октябре 1992 года. В то время, как первый стандарт 1986 года занимает не более ста страниц, официальный стандарт SQL2 содержит около шестисот.
Вопреки стандарту SQL2, во всех существующих на сегодняшний день коммерческих продуктах поддерживаются собственные диалекты SQL. Более того, поставщики СУБД включают в свои продукты новые возможности и расширяют собственные диалекты SQL, чем еще больше отдаляют их от стандарта. Однако ядро SQL стандартизировано довольно жестко. Там, где это можно было сделать, не ущемляя интересы клиентов, поставщики СУБД привели свои продукты в соответствие со стандартом SQL-89, то же самое постепенно произошло и с SQL2.
Хотя стандарт ANSI/ISO наиболее широко распространен, он не является единственным стандартом SQL. Европейская группа поставщиков X/OPEN также приняла SQL в качестве одного из своих стандартов для «среды переносимых приложений» на основе UNIX. Стандарты группы X/OPEN играют важную роль на европейском компьютерном рынке, где основной проблемой является переносимость приложений между компьютерными системами различных производителей. К несчастью, стандарт X/OPEN отличается от стандарта ANSI/ISO.
Кроме того, компания IBM включила SQL в свою спецификацию Systems Application Architecture (архитектура прикладных систем) и пообещала, что все ее продукты, очевидно, будут переведены на этот диалект SQL. Хотя данная спецификация и не оправдала надежд на унификацию линии продуктов компании IBM, движение в сторону унификации SQL в IBM продолжается. Система DB2 остается основной СУБД компании IBM для мэйнфреймов. Однако компания выпустила реализацию DB2 и для OS/2 (собственной операционной системы для персональных компьютеров), и для линии серверов и рабочих станций RS/6000, работающих под управлением UNIX. Таким образом, диалект DB2 языка SQL является мощным стандартом де-факто.
В технологии баз данных существует важная область, которую не затрагивают официальные стандарты. Это способность к взаимодействию с другими базами данных — методы, с помощью которых различные БД могут обмениваться информацией (как правило, по сети). В 1989 году несколько поставщиков сформировали консорциум SQL Access Group специально для решения этой проблемы. В 1991 году консорциум опубликовал спецификацию RDA (Remote Database Access — удаленный доступ к базам данных). Эта спецификация тесно связана с протоколами OSI, которые не смогли завоевать широкого признания, поэтому она оказывает на рынок незначительное влияние. Прозрачность взаимодействия между различными базами данных остается иллюзорной мечтой.
Тем не менее, второй стандарт от SQL Access Group имеет на рынке больший вес. В результате настойчивых требований компании Microsoft, консорциум SQL Access Group включил в стандарт SQL интерфейс вызовов функций. Полученная спецификация CLI (Call Level Interface), основанная на разработках компании Microsoft, увидела свет в 1992 году. В этом же году была опубликована собственная спецификация ODBC (Open Database Connectivity — взаимодействие с открытыми базами данных) компании Microsoft, основанная на стандарте CLI. Благодаря рыночной силе Microsoft и благословению, полученному «открытым стандартом» от SQL Access Group, ODBC оказался стандартом де-факто для интерфейсов доступа к базам данных на персональных компьютерах. Весной 1993 года компании Apple и Microsoft объявили о соглашении относительно поддержки ODBC в MacOS и Windows, что закрепило за этой спецификацией статус стандарта в обеих популярных средах с графическим пользовательским интерфейсом.
Появление стандарта SQL вызвало довольно много восторженных заявлений о переносимости SQL и использующих его приложений. На самом деле пробелы в стандарте SQL-89 и различия между существующими диалектами SQL достаточно значительны, и при переводе приложения под другую СУБД его всегда приходится модифицировать. Эти отличия, большинство из которых устранено в стандарте SQL2, включают в себя:
Коды ошибок. В стандарте SQL-89 не определены коды, которые возвращают операторы SQL при возникновении ошибок, и в каждой из коммерческих реализаций используется собственный набор таких кодов. В стандарте SQL2 определены стандартные коды ошибок.
Типы данных. В стандарте SQL-89 определен минимальный набор типов данных, однако, в нем отсутствуют некоторые из наиболее распространенных и полезных типов, например символьные строки переменной длины, дата и время, а также денежные единицы. В стандарте SQL2 упомянуты эти типы данных, однако, отсутствуют «новые» типы данных, такие как графические и мультимедийные объекты.
Системные таблицы. В стандарте SQL-89 умалчивается о системных таблицах, в которых содержится информация о структуре самой базы данных. Поэтому каждый поставщик создавал собственные системные таблицы, и их структура отличается даже в четырех реализациях SQL компании IBM. Системные таблицы стандартизированы в SQL2.
Интерактивный SQL. В стандарте определен только программный SQL, используемый прикладной программой, но не интерактивный SQL. Например, оператор select, предназначенный для выполнения запросов к базе данных в интерактивном режиме, в стандарте отсутствует.
Программный интерфейс. В первом стандарте определен абстрактный способ использования SQL в программах, написанных на таких языках программирования, как COBOL, FORTRAN и другие. Этот способ не используется ни в одном коммерческом продукте, а в существующих программных интерфейсах имеются значительные отличия. В стандарте SQL2 определен интерфейс встроенного SQL для популярных языков программирования, но не интерфейс вызова функций.
Динамический SQL. В стандарте SQL-89 не описаны элементы SQL, необходимые для разработки приложений общего назначения, таких как генераторы отчетов и программы создания и выполнения запросов. Однако эти элементы, известные под названием динамический SQL, имеются почти во всех СУБД и в различных системах значительно отличаются. В SQL2 входит стандарт динамического SQL.
Семантические отличия. Поскольку некоторые элементы определены в стандартах как зависящие от реализации, может возникнуть ситуация, когда в результате выполнения одного и того же запроса в двух совместимых СУБД будут получены два различных набора результатов. Отличия результатов обусловлены различиями в обработке значений null, разными агрегатными функциями и несовпадением процедур удаления повторяющихся строк.
Последовательность сравнения. В стандарте SQL-89 не упоминаются последовательности сравнения (сортировки) символов, хранящихся в базе данных. Результаты запроса с сортировкой будут отличаться при выполнении этого запроса на персональном компьютере (с кодировкой ASCII) и на мэйнфрейме (с кодировкой EBCDIC). Стандарт SQL2 позволяет программе или пользователю указывать требуемую последовательность сортировки.
Структура базы данных. В стандарте SQL-89 определен SQL, который используется уже после того, как база данных была открыта и подготовлена к работе. Детали наименования баз данных и первоначального подключения к ним сильно отличаются и несовместимы. Стандарт SQL2 в некоторой степени унифицирует этот процесс, но не может полностью ликвидировать все отличия.
Вопреки перечисленным различиям, в начале 90-х годов стали появляться коммерческие программы, реализующие переносимость приложений между различными СУБД. Однако в таких программах для каждой из поддерживаемых СУБД требуется специальный конвертер, который генерирует код в соответствии с определенным диалектом SQL, выполняет преобразование типов данных, транслирует коды ошибок и т.д. «Прозрачная» переносимость между различными СУБД, использующими SQL, является основной целью стандарта SQL2 и протокола ODBC. Однако повсеместный, «прозрачный» и унифицированный доступ к базам данных SQL остается делом будущего.
Технологии, обеспечивающие сетевой доступ к базам данных
Всемирная Паутина недаром так быстро завоевала широкую популярность среди пользователей Internet, в мире бизнеса, науки, политики и т. д. Основные достижения Web – это простота опубликования информации в сети, удобство и сравнительная унифицированность доступа к документам, наличие на сегодняшний день достаточно развитых средств поиска. Однако в целом способы представления, хранения и поиска информации в WWW относятся к категории информационно-поисковых систем (ИПС). Хотя хранилища данных в узлах Web иногда называют базами данных, этот термин в данном случае можно использовать только в самом широком смысле. Исторически ИПС применялись для хранения слабоструктурированной и редко изменяемой информации. Базы данных в узком смысле – это хранилища структурированной, изменяемой информации, причем информация в базе данных должна всегда находиться в согласованном состоянии.
С равным успехом можно хвалить и ругать Web. Можно хвалить Всемирную Паутину за то, что, не выходя из дома, вы можете побывать в любой точке земного шара и посмотреть, что же там происходит. Можно ругать Web за то, что трудно найти действительно актуальную информацию (обычно она устаревшая), за то, что хранилища информации содержат очень много «мусора», опубликованного непонятно из каких соображений. Но в любом случае интерфейс действительно удобен.
Ситуация с базами данных кардинально отличается. Именно базы данных содержат основные знания человечества. В конце двадцатого века с появлением технологии баз данных мы накопили больше информации, чем за всю предыдущую историю. Вся беда в том, что доступ к базам данных (даже к тем, которые содержат полностью открытую информацию) ограничен. Чтобы получить интересующую его информацию, пользователь должен иметь физический доступ к соответствующей СУБД, быть в курсе модели данных, знать схему базы данных и, наконец, уметь пользоваться соответствующим языком запросов. Что касается языка запросов, то проблему частично решает протокол ODBC, позволяющий направлять ограниченный набор операторов SQL (с промежуточной обработкой соответствующим драйвером ODBC) к произвольному серверу баз данных. Но это только частичное решение, поскольку оно никак не помогает пользователю понять схему базы данных (даже в терминах SQL) и, конечно, не способствует созданию унифицированного интерфейса конечного пользователя (нельзя же заставить всех работать в строчном режиме на языке SQL).
Итак, мы имеем удобные средства разработки распределенных в Internet гипермедийных документов, простые, удобные, развитые и унифицированные интерфейсы для доступа к информации WWW. Кроме того, мы имеем большое количество ценных баз данных, управляемых разнородными СУБД, а также желание сделать эти базы доступными всем людям (в случае публичных баз данных) или членам территориально-распределенной корпорации (в случае корпоративных баз данных). Возникает естественное желание скрестить эти две технологии и обеспечить доступ к базам данных в интерфейсе Web. Еще два года назад существовали только идеи такого скрещивания и не очень тщательно разработанные подходы к реализации. На сегодняшний день такие механизмы уже существуют и используются.
Принципы работы SQL-сервера
S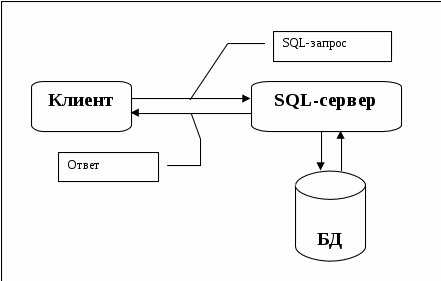
QL
является инструментом,
предназначенным для обработки и чтения
данных, содержащихся в компьютерной
базе данных. SQL
(структурированный язык запросов) как
следует из названия, является языком
программирования, который
применяется для организации взаимодействия
пользователя с базой данных. На самом
деле SQL
работает только с базами данных одного
определенного типа, называемых
реляционными.
Рисунок 2.1
На рисунке 2.1 изображена схема работы SQL. Согласно этой схеме, в вычислительной системе имеется база данных, в которой хранится важная информация. Если БД относится к сфере бизнеса, то в ней может храниться информация о материальных ценностях, выпускаемой продукции, объемах продаж и зарплате. В базе данных на персональном компьютере может храниться информация о выписанных чеках, телефонах и адресах или информация, извлеченная из более крупной вычислительной системы. Компьютерная программа, которая управляет базой данных, называется системой управления базой данных, или СУБД.
Если пользователю необходимо прочитать данные из базы данных, он запрашивает их у SQL с помощью СУБД. SQL обрабатывает запрос, находит требуемые данные и посылает их пользователю. Процесс запрашивания данных и получения результата называется запросом к базе данных: отсюда и название — структурированный язык запросов.
Однако это название не совсем соответствует действительности. Cегодня SQL представляет собой нечто гораздо большее, чем простой инструмент создания запросов, хотя именно для этого он и был первоначально предназначен. Несмотря на то, что чтение данных по-прежнему остается одной из наиболее важных функций SQL, сейчас этот язык используется для реализации всех функциональных возможностей, которые СУБД предоставляет пользователю, а именно:
Организация данных. SQL дает пользователю возможность изменять структуру представления данных, а также устанавливать отношения между элементами базы данных.
Чтение данных. SQL дает пользователю или приложению возможность читать из базы данных содержащиеся в ней данные и пользоваться ими.
Обработка данных. SQL дает пользователю или приложению возможность изменять базу данных, т.е. добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся в ней данные.
Управление доступом. С помощью SQL можно ограничить возможности пользователя по чтению и изменению данных и защитить их от несанкционированного доступа.
Совместное использование данных. SQL координирует совместное использование данных пользователями, работающими параллельно, чтобы они не мешали друг другу.
Целостность данных. SQL позволяет обеспечить целостность базы данных, защищая ее от разрушения из-за несогласованных изменений или отказа системы.
Таким образом, СУБД является достаточно мощным средством для взаимодействия с SQL.
Основными объектами реляционной базы данных являются:
(TABLE) Таблица
Прямоугольная таблица, состоящая из СТРОК и СТОЛБЦОВ. Задать таблицу – значит указать, из каких столбцов она состоит.
(ROW) Строка
Запись, состоящая из полей – столбцов. В каждом поле содержится его значение, либо значение NULL – «пусто». Строк в таблице может быть сколько угодно. Физический порядок их расположения друг относительно друга неопределен.
(COLUMN) Столбец
Каждый столбец в таблице имеет собственные имя и тип.
Таблицы SQL
В реляционной базе данных информация организована в виде таблиц, разделённых на строки и столбцы, на пересечении которых содержатся значения данных. Используемые в языке SQL для запросов сочетания ключей (CREATE TABLE my_table – создание таблицы с названием my_table) получили название «предложение». Таблицы создаются в SLQ с помощью предложения CREATE TABLE. Предложение CREAT TABLE специфицирует имя базовой таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов. CREAT TABLE – выполняемое предложение. Если SQL-серверу дать запрос CREATE TABLE, система построит таблицу, которая сначала будет пустой: она будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Информация в таблицу вставляется при помощи предложения команды INSERT
Структура запросов SQL.
Все запросы на получение практически любых данных из одной или нескольких таблиц выполняются с помощью единственного предложения SELECT.
В синтаксических конструкциях для обращения к БД используются следующие обозначения:
звездочка (*) для обозначения «все» – употребляется в обычном для программирования смысле, т.е. «все случаи, удовлетворяющие определению»;
квадратные скобки ([]) – означают, что конструкции, заключенные в эти скобки, являются необязательными (т.е. могут быть опущены);
фигурные скобки ({}) – означают, что конструкции, заключенные в эти скобки, должны рассматриваться как целые синтаксические единицы, т.е. они позволяют уточнить порядок разбора синтаксических конструкций, заменяя обычные скобки, используемые в синтаксисе SQL;
многоточие (…) – указывает на то, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз;
прямая черта (|) – означает наличие выбора из двух или более возможностей. Например, обозначение ASC|DESC указывает, можно выбрать один из терминов ASC или DESC; когда же один из элементов выбора заключен в квадратные скобки, то это означает, что он выбирается по умолчанию (так, [ASC]|DESC означает, что отсутствие всей этой конструкции будет восприниматься как выбор ASC);
точка с запятой (;) – завершающий элемент предложений SQL;
запятая (,) – используется для разделения элементов списков;
пробелы ( ) – могут вводиться для повышения наглядности между любыми синтаксическими конструкциями предложений SQL;
жирные прописные латинские буквы и символы – используются для написания конструкций языка SQL и должны (если это специально не оговорено) записываться в точности так, как показано-……..;
строчные буквы используются для написания конструкций, которые должны заменяться конкретными значениями, выбранными пользователем, причем для определенности отдельные слова этих конструкций связываются между собой символом подчеркивания (_);
термины «таблица» и «столбец» заменяют (с целью сокращения текста синтаксических конструкций) термины «имя_таблицы», «имя_столбца», …, соответственно;
термин «таблица» - используется для обобщения таких видов таблиц, как базовая_таблица, представление или псевдоним; здесь псевдоним служит для временного (на момент выполнения запроса) переименования и (или) создания рабочей копии базовой_таблицы (представления).
Предложение SELECT (выбрать) имеет следующий формат:
подзапрос [UNION [ALL] подзапрос] …
[ORDER BY {[таблица.]столбец | номер_элемента_SELECT} [[ASC] | DESC]
[,{[таблица.]столбец | номер_элемента_SELECT} [[ASC] | DESC]] …;
и позволяет объединить (UNION) а затем упорядочить (ORDER BY) результаты выбора данных, полученных с помощью нескольких «подзапросов». При этом упорядочение можно производить в порядке возрастания – ASC (ASCending) или убывания DESC (DESCending), а по умолчанию принимается ASC.
В этом предложении подзапрос позволяет указать условия для выбора нужных данных и (если требуется) их обработки
SELECT
(выбрать) данные из указанных столбцов и (если необходимо) выполнить перед выводом их преобразование в соответствии с указанными выражениями и (или) функциями
FROM
(из) перечисленных таблиц, в которых расположены эти столбцы
WHERE
(где) строки из указанных таблиц должны удовлетворять указанному перечню условий отбора строк
GROUP BY
(группируя по) указанному перечню столбцов с тем, чтобы получить для каждой группы единственное агрегированное значение, используя во фразе SELECT SQL-функции SUM (сумма), COUNT (количество), MIN (минимальное значение), MAX (максимальное значение) или AVG (среднее значение)
HAVING
(имея) в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора групп
и имеет формат
SELECT [[ALL] | DISTINCT]{ * | элемент_SELECT [,элемент_SELECT] …}
FROM {базовая_таблица | представление} [псевдоним]
[,{базовая_таблица | представление} [псевдоним]] …
[WHERE фраза]
[GROUP BY фраза [HAVING фраза]];
Элемент_SELECT – это одна из следующих конструкций:
[таблица.]* | значение | SQL_функция | системная_переменная
где значение – это:
[таблица.]столбец | (выражение) | константа | переменная
Синтаксис выражений имеет вид
( {[ [+] | - ] {значение | функция_СУБД} [ + | - | * | ** ]}… )
а синтаксис SQL_функций – одна из следующих конструкций:
{SUM|AVG|MIN|MAX|COUNT} ( [[ALL]|DISTINCT][таблица.]столбец )
{SUM|AVG|MIN|MAX|COUNT} ( [ALL] выражение )
COUNT(*)
Фраза WHERE включает набор условий для отбора строк:
WHERE [NOT] WHERE_условие [[AND|OR][NOT] WHERE_условие]…
где WHERE_условие – одна из следующих конструкций:
значение { = | <> | < | <= | > | >= } { значение | ( подзапрос ) }
значение_1 [NOT] BETWEEN значение_2 AND значение_3
значение [NOT] IN { ( константа [,константа]… ) | ( подзапрос ) }
значение IS [NOT] NULL
[таблица.]столбец [NOT] LIKE 'строка_символов' [ESCAPE 'символ']
EXISTS ( подзапрос )
Кроме традиционных операторов сравнения (= | <> | < | <= | > | >=) в WHERE фразе используются условия BETWEEN (между), LIKE (похоже на), IN (принадлежит), IS NULL (не определено) и EXISTS (существует), которые могут предваряться оператором NOT (не). Критерий отбора строк формируется из одного или нескольких условий, соединенных логическими операторами:
AND
когда должны удовлетворяться оба разделяемых с помощью AND условия;
OR
когда должно удовлетворяться одно из разделяемых с помощью OR условий;
AND NOT
когда должно удовлетворяться первое условие и не должно второе;
OR NOT
когда или должно удовлетворяться первое условие или не должно удовлетворяться второе,
причем существует приоритет AND над OR (сначала выполняются все операции AND и только после этого операции OR). Для получения желаемого результата WHERE условия должны быть введены в правильном порядке, который можно организовать введением скобок.
При обработке условия числа сравниваются алгебраически – отрицательные числа считаются меньшими, чем положительные, независимо от их абсолютной величины. Строки символов сравниваются в соответствии с их представлением в коде, используемом в конкретной СУБД, например, в коде ASCII. Если сравниваются две строки символов, имеющих разные длины, более короткая строка дополняется справа пробелами для того, чтобы они имели одинаковую длину перед осуществлением сравнения.
Наконец, синтаксис фразы GROUP BY имеет вид
GROUP BY [таблица.]столбец [,[таблица.]столбец] … [HAVING фраза]
GROUP BY инициирует перекомпоновку формируемой таблицы по группам, каждая из которых имеет одинаковое значение в столб-цах, включенных в перечень GROUP BY. Далее к этим группам применяются агрегирующие функции, указанные во фразе SELECT, что приводит к замене всех значений группы на единственное значение (сумма, количество и т.п.).
С помощью фразы HAVING (синтаксис которой почти не отличается от синтаксиса фразы WHERE)
HAVING [NOT] HAVING_условие [[AND|OR][NOT] HAVING_условие]…
можно исключить из результата группы, не удовлетворяющие заданным условиям:
значение { = | <> | < | <= | > | >= } { значение | ( подзапрос )
| SQL_функция }
{значение_1 | SQL_функция_1} [NOT] BETWEEN
{значение_2 | SQL_функция_2} AND {значение_3 | SQL_функция_3}
{значение | SQL_функция} [NOT] IN { ( константа [,константа]… )
| ( подзапрос ) }
{значение | SQL_функция} IS [NOT] NULL
[таблица.]столбец [NOT] LIKE 'строка_символов' [ESCAPE 'символ']
EXISTS ( подзапрос )
2.2.2. Запросы с использованием единственной таблицы.
Выборка без использования фразы WHERE
Простая выборка
Запрос выдать название, статус и адрес поставщиков
SELECT Название, Статус, Адрес
FROM Поставщики;
дает результат, приведенный на рис. 2.2,а.
При необходимости получения полной информации о поставщиках, можно было бы дать запрос
SELECT ПС, Название, Статус, Город, Адрес, Телефон
FROM Поставщики;
или использовать его более короткую нотацию:
SELECT *
FROM Поставщики;
Здесь «звездочка» (*) служит кратким обозначением всех имен полей в таблице, указанной во фразе FROM. При этом порядок вывода полей соответствует порядку, в котором эти поля определялись при создании таблицы.
Еще один пример. Выдать основу всех блюд:
SELECT Основа
FROM Блюда;
дает результат, показанный на рис. 2.2,б.
|
а) |
б) |
в) |
||
|
Название |
Статус |
Адрес |
Основа |
Основа |
|
Овощи |
Кофе |
|||
|
Мясо |
Крупа |
|||
|
СЫТНЫЙ |
Рынок |
Сытнинская, 3 |
Овощи |
Молоко |
|
ПОРТОС |
Кооператив |
Садовая, 27 |
Рыба |
Мясо |
|
ШУШАРЫ |
Совхоз |
Новая, 17 |
Рыба |
Овощи |
|
ТУЛЬСКИЙ |
Универсам |
Тульская, 3 |
Мясо |
Рыба |
|
УРОЖАЙ |
Коопторг |
Песчаная, 19 |
Молоко |
Фрукты |
|
ЛЕТО |
Агрофирма |
Пулковское ш.,8 |
Молоко |
Яйца |
|
ОГУРЕЧИК |
Ферма |
Укмерге, 15 |
… |
|
|
КОРЮШКА |
Кооператив |
Нарвское ш., 64 |
Кофе |
Рисунок 2.2
Исключение дубликатов
В предыдущем примере был выдан правильный, но не совсем удачный перечень основных продуктов: из него не были исключены дубликаты. Для исключения дубликатов и одновременного упорядочения перечня необходимо дополнить запрос ключевым словом DISTINCT (различный, различные), как показано в следующем примере:
SELECT DISTINCT Основа
FROM Блюда;
Результат приведен на рис. 2.2,в.
Выборка вычисляемых значений
Из синтаксиса фразы SELECT видно, что в ней может содержаться не только перечень столбцов таблицы или символ *, но и выражения.
Например, если нужно получить значение калорийности всех продуктов, то можно учесть, что при окислении 1 г углеводов или белков в организме освобождается в среднем 4.1 ккал, а при окислении 1 г жиров – 9.3 ккал, и выдать запрос:
SELECT Продукт, ((Белки+Углев)*4.1+Жиры*9.3)
FROM Продукты;
результат которого приведен на рис. 2.3,а.
|
а) |
Б) |
в) |
||||
|
Продукт |
Продукт |
Продукт |
||||
|
Говядина |
1928.1 |
Говядина |
Калорий = |
1928.1 |
Зелень |
118.9 |
|
Судак |
1523. |
Судак |
Калорий = |
1523. |
Помидоры |
196.8 |
|
Масло |
8287.5 |
Масло |
Калорий = |
8287.5 |
Морковь |
349.6 |
|
Майонез |
6464.7 |
Майонез |
Калорий = |
6464.7 |
Лук |
459.2 |
|
Яйца |
1618.9 |
Яйца |
Калорий = |
1618.9 |
Яблоки |
479.7 |
|
Сметана |
3011.4 |
Сметана |
Калорий = |
3011.4 |
Молоко |
605.1 |
|
Молоко |
605.1 |
Молоко |
Калорий = |
605.1 |
Кофе |
892.4 |
|
Творог |
1575. |
Творог |
Калорий = |
1575. |
Судак |
1523. |
|
Морковь |
349.6 |
Морковь |
Калорий = |
349.6 |
Творог |
1575. |
|
Лук |
459.2 |
Лук |
Калорий = |
459.2 |
Яйца |
1618.9 |
|
Помидоры |
196.8 |
Помидоры |
Калорий = |
196.8 |
Говядина |
1928.1 |
|
Зелень |
118.9 |
Зелень |
Калорий = |
118.9 |
Сметана |
3011.4 |
|
Рис |
3512.1 |
Рис |
Калорий = |
3512.1 |
Рис |
3512.1 |
|
Мука |
3556.7 |
Мука |
Калорий = |
3556.7 |
Мука |
3556.7 |
|
Яблоки |
479.7 |
Яблоки |
Калорий = |
479.7 |
Сахар |
4091.8 |
|
Сахар |
4091.8 |
Сахар |
Калорий = |
4091.8 |
Майонез |
6464.7 |
|
Кофе |
892.4 |
Кофе |
Калорий = |
892.4 |
Масло |
8287.5 |
Рисунок 2.3
Фраза SELECT может включать не только выражения, но и отдельные числовые или текстовые константы. Следует отметить, что текстовые константы должны заключаться в апострофы ('). На рис. 2.3,б приведен результат запроса:
SELECT Продукт, 'Калорий =', ((Белки+Углев)*4.1+Жиры *9.3)
FROM Продукты;
А что произойдет, если какой-либо член выражения не определен, т.е. имеет значение NULL и каким образом появилось такое значение?
Если при загрузке строк таблицы в какой-либо из вводимых строк отсутствует значение для какого-либо столбца, то СУБД введет в такое поле NULL-значение. NULL-значение «придумано» для того, чтобы представить единым образом «неизвестные значения» для любых типов данных. Действительно, так как при вводе данных в столбец или их изменении СУБД запрещает ввод значений не соответствующих описанию данных этого столбца, то, например, нельзя использовать пробел для отсутствующего значения числа. Нельзя для этих целей использовать и ноль: нет месяца или дня недели равного нулю, да и для чисел ноль не может рассматриваться как неизвестное значение в одном месте и как известное – в другом. При выводе же NULL-значения на экран или печатающее устройство его код воспроизводится каким-либо специально заданным символом или набором символов: например, пробелом (если его нельзя перепутать с текстовым значением пробела) или сочетанием –0-.
С помощью специальной команды можно установить в СУБД один из режимов представления NULL-значений при выполнении числовых расчетов: запрет или разрешение замены NULL-значения нулем. В первом случае любое арифметическое выражение, содержащее неопределенный операнд, будет также иметь неопределенное значение. Во втором случае результат вычислений будет иметь численное значение (если это значение попадает в диапазон представления соответствующего типа данных).
Например, при выполнении запроса
SELECT ПР, Цена, К_во, (Цена * К_во)
FROM Поставки;
и разных «настройках» СУБД могут быть получены разные результаты:
|
ПР |
Цена |
К_во |
(Цена*К_во) |
ПР |
Цена |
К_во |
(Цена*К_во) |
|
9 |
-0- |
-0- |
-0- |
9 |
-0- |
-0- |
0. |
|
11 |
1.5 |
50 |
75. |
11 |
1.5 |
50 |
75. |
|
12 |
3. |
10 |
30. |
12 |
3. |
10 |
30. |
|
15 |
2. |
170 |
340. |
15 |
2. |
170 |
340. |
Использование BETWEEN
С помощью BETWEEN … AND … (находится в интервале от … до …) можно отобрать строки, в которых значение какого-либо столбца находятся в заданном диапазоне.
Например, выдать перечень продуктов, в которых значение содержания белка находится в диапазоне от 10 до 50:
-
Результат:
SELECT Продукт, Белки
FROM Продукты
WHERE Белки BETWEEN 10 AND 50;
Продукт
Белки
Майонез
31.
Сметана
26.
Молоко
28.
Морковь
13.
Лук
17.
Можно задать и NOT BETWEEN (не принадлежит диапазону между), например:
-
Результат:
SELECT Продукт, Белки, Жиры
FROM Продукты
WHERE Белки NOT BETWEEN 10 AND 50
AND Жиры 100;
Продукт
Белки
Жиры
Говядина
189.
124.
Масло
60.
825.
Яйца
127.
115.
BETWEEN особенно удобен при работе с данными, задаваемыми интервалами, начало и конец которых расположен в разных столбцах.
Для примера воспользуемся таблицей «минимальных окладов» (табл. 2.4), величина которых непосредственно связана со студенческой стипендией. В этой таблице для текущего значения минимального оклада установлена запредельная дата окончания 9 сентября 9999 года.
|
Миноклад |
Начало |
Конец |
|
2250 |
01-01-1993 |
31-03-1993 |
|
4275 |
01-04-1993 |
30-06-1993 |
|
7740 |
01-07-1993 |
30-11-1993 |
|
14620 |
01-12-1993 |
30-06-1994 |
|
20500 |
01-07-1994 |
09-09-9999 |
Рисунок 2.4
Если, например, потребовалось узнать, какие изменения минимальных окладов производились в 1993/94 учебном году, то можно выдать запрос
SELECT Начало, Миноклад
FROM Миноклады
WHERE Начало BETWEEN '1-9-1993' AND '31-8-1994'
и получить результат:
-
Начало
Миноклад
01-12-1993
14620
01-07-1994
20500
Отметим, что при формировании запросов значения дат следует заключать в апострофы, чтобы СУБД не путала их с выражениями и не пыталась вычитать из 31 значение 8, а затем 1994.
Для выявления всех значений минимальных окладов, которые существовали в 1993/94 учебном году, можно сформировать запрос
SELECT *
FROM Миноклады
WHERE Начало BETWEEN '1-9-1993' AND '31-8-1994'
OR Конец BETWEEN '1-9-1993' AND '31-8-1994'
-
Миноклад
Начало
Конец
7740
01/07/1993
30/11/1993
14620
01/12/1993
30/06/1994
20500
01/07/1994
09/09/9999
Наконец, для получения минимального оклада на 15-5-1994:
-
Результат:
SELECT Миноклад
FROM Миноклады
WHERE '15-05-1994' BETWEEN Начало AND Конец
Миноклад
14620
Использование IN
Выдать сведения о блюдах на основе яиц, крупы и овощей
SELECT *
FROM Блюда
WHERE Основа IN (Яйца Крупа Овощи);
Результат:
|
БЛ |
Блюдо |
В |
Основа |
Выход |
Труд |
|
1 |
Салат летний |
З |
Овощи |
200. |
3 |
|
3 |
Салат витаминный |
З |
Овощи |
200. |
4 |
|
16 |
Драчена |
Г |
Яйца |
180. |
4 |
|
17 |
Морковь с рисом |
Г |
Овощи |
260. |
3 |
|
19 |
Омлет с луком |
Г |
Яйца |
200. |
5 |
|
20 |
Каша рисовая |
Г |
Крупа |
210. |
4 |
|
21 |
Пудинг рисовый |
Г |
Крупа |
160. |
6 |
|
23 |
Помидоры с луком |
Г |
Овощи |
260. |
4 |
Рассмотренная форма IN является в действительности просто краткой записью последовательности отдельных сравнений, соединенных операторами OR. Предыдущее предложение эквивалентно такому:
SELECT *
FROM Блюда
WHERE Основа=Яйца OR Основа=Крупа OR Основа=Овощи;
Использование LIKE
Выдать перечень салатов
-
Результат:
SELECT Блюдо
FROM Блюда
WHERE Блюдо LIKE 'Салат%';
Блюдо
Салат летний
Салат мясной
Салат витаминный
Салат рыбный
Обычная форма «имя_столбца LIKE текстовая_константа» для столбца текстового типа позволяет отыскать все значения указанного столбца, соответствующие образцу, заданному «текстовой_константой». Символы этой константы интерпретируются следующим образом:
символ _ (подчеркивание) – заменяет любой одиночный символ,
символ % (процент) – заменяет любую последовательность из N символов (где N может быть нулем),
все другие символы означают просто сами себя.
Следовательно, в приведенном примере SELECT будет осуществлять выборку записей из таблицы Блюда, для которых значение в столбце Блюдо начинается сочетанием 'Салат' и содержит любую последовательность из нуля или более символов, следующих за сочетанием 'Салат'. Если бы среди блюд были «Луковый салат», «Фруктовый салат» и т.п., то они не были бы найдены. Для их отыскания надо изменить фразу WHERE:
WHERE Блюдо LIKE '%салат%'
или при отсутствии различий между малыми и большими буквами (такую настройку допускают некоторые СУБД):
WHERE Блюдо LIKE '%Салат%'
Это позволит отыскать все салаты.
Вовлечение неопределенного значения (NULL-значения)
Если при загрузке данных не введено значение в какое-либо поле таблицы, то СУБД поместит в него NULL-значение. Аналогичное значение можно ввести в поле таблицы, выполняя операцию изменения данных. Так, при отсутствии сведений о наличии у поставщиков судака и моркови в столбцы Цена и К_во соответствующих строк таблицы Поставки вводится NULL и там будет храниться код NULL-значения, а не 0, 0. Или пробел. (Отметим, что в распечатке таблицы Поставки в этих местах расположен пробел, установленный в СУБД для представления NULL-значения при выводе на печать).
В этом случае для выявления названий продуктов, отсутствующих в кладовой, шеф-повар может дать запрос
-
Результат:
ПР
SELECT DISTINCT ПР
FROM Наличие
WHERE К_во IS NULL;
2
9
Естественно, что для выявления продуктов, существующих в кладовой, следует дать запрос
SELECT DISTINCT ПР
FROM Наличие
WHERE К_во IS NOT NULL;
Использование условий
столбец IS NULL и столбец IS NOT NULL
вместо, например,
столбец = NULL и столбец < NULL
связано с тем, что ничто – и даже само NULL-значение – не считается равным другому NULL-значению. (Несмотря на это, два неопределенных значения рассматриваются, однако, как дубликаты друг друга при исключении дубликатов, и предложение SELECT DISTINCT даст в результате не более одного NULL-значения.)
Выборка с упорядочением
Простейший вариант этой фразы – упорядочение строк результата по значению одного из столбцов с указанием порядка сортировки или без такого указания. (По умолчанию строки будут сортироваться в порядке возрастания значений в указанном столбце.)
Например, выдать перечень продуктов и содержание в них основных веществ в порядке убывания содержания белка
|
SELECT Продукт, Белки, Жиры, Углев FROM Продукты ORDER BY Белки DESC; |
Продукт |
Белки |
Жиры |
Углев |
|
Судак |
190. |
80. |
0. |
|
|
Говядина |
189. |
124. |
0. |
|
|
Творог |
167. |
90. |
13. |
|
|
Яйца |
127. |
115. |
7. |
|
|
Кофе |
127. |
36. |
9. |
|
|
Мука |
106. |
13. |
732. |
При включении в список ORDER BY нескольких столбцов СУБД сортирует строки результата по значениям первого столбца списка пока не появится несколько строк с одинаковыми значениями данных в этом столбце. Такие строки сортируются по значениям следующего столбца из списка ORDER BY и т.д.
Например, выдать содержимое таблицы Блюда, отсортировав ее строки по видам блюд и основе:
-
Результат:
SELECT *
FROM Блюда
ORDER BY В Основа;
БЛ
Блюдо
В
Основа
Выход
Труд
21
Пудинг рисовый
Г
Крупа
160.
6
20
Каша рисовая
Г
Крупа
210.
4
18
Сырники
Г
Молоко
220.
4
. . .
16
Драчена
Г
Яйца
180.
4
28
Крем творожный
Д
Молоко
160.
4
. . .
26
Яблоки печеные
Д
Фрукты
160.
3
7
Сметана
З
Молоко
140.
1
8
Творог
З
Молоко
140.
2
2
Салат мясной
З
Мясо
200.
4
6
Мясо с гарниром
З
Мясо
250.
3
1
Салат летний
З
Овощи
200.
3
. . .
Кроме того, в список ORDER BY можно включать не только имя столбца, а его порядковую позицию в перечне SELECT. Благодаря этому возможно упорядочение результатов на основе вычисляемых столбцов, не имеющих имен.
Например, запрос
SELECT Продукт, ((Белки+Углев)*4.1+Жиры*9.3)
FROM Продукты
ORDER BY 2;
позволит получить список продуктов, показанный на рис.2.3,в – переупорядоченный по возрастанию значений калорийности список рис.2.3,а.
Агрегирование данных
SQL-функции
В SQL существует ряд специальных стандартных функций (SQL-функций). Кроме специального случая COUNT(*) каждая из этих функций оперирует совокупностью значений столбца некоторой таблицы и создает единственное значение, определяемое так:
COUNT
число значений в столбце,
SUM
сумма значений в столбце,
AVG
среднее значение в столбце,
MAX
самое большое значение в столбце,
MIN
самое малое значение в столбце.
Для функций SUM и AVG рассматриваемый столбец должен содержать числовые значения.
Следует отметить, что здесь столбец – это столбец виртуальной таблицы, в которой могут содержаться данные не только из столбца базовой таблицы, но и данные, полученные путем функционального преобразования и (или) связывания символами арифметических операций значений из одного или нескольких столбцов. При этом выражение, определяющее столбец такой таблицы, может быть сколь угодно сложным, но не должно содержать SQL-функций (вложенность SQL-функций не допускается). Однако из SQL-функций можно составлять любые выражения.
Аргументу всех функций, кроме COUNT(*), может предшествовать ключевое слово DISTINCT (различный), указывающее, что избыточные дублирующие значения должны быть исключены перед тем, как будет применяться функция. Специальная же функция COUNT(*) служит для подсчета всех без исключения строк в таблице (включая дубликаты).
Функции без использования фразы GROUP BY
Если не используется фраза GROUP BY, то в перечень элементов_SELECT можно включать лишь SQL-функции или выражения, содержащие такие функции. Другими словами, нельзя иметь в списке столбцы, не являющихся аргументами SQL-функций.
Например, выдать данные о массе лука (ПР=10), проданного поставщиками, и указать количество этих поставщиков:
|
Результат: |
||
|
SELECT SUM(К_во),COUNT(К_во) FROM Поставки WHERE ПР = 10; |
||
|
SUM(К_во) |
COUNT(К_во) |
|
|
220 |
2 |
Если бы для вывода в результат еще и номера продукта был сформирован запрос
SELECT ПР,SUM(К_во),COUNT(К_во)
FROM Поставки
WHERE ПР = 10;
то было бы получено сообщение об ошибке. Это связано с тем, что SQL-функция создает единственное значение из множества значений столбца-аргумента, а для «свободного» столбца должно быть выдано все множество его значений. Без специального указания (оно задается фразой GROUP BY) SQL не будет выяснять, одинаковы значения этого множества (как в данном примере, где ПР=10) или различны (как было бы при отсутствии WHERE фразы). Поэтому подобный запрос отвергается системой.
Правда, никто не запрещает дать запрос
SELECT 'Кол-во лука =',SUM(К_во),COUNT(К_во)
FROM Поставки
WHERE ПР = 10;
-
Результат:
'Кол-во лука ='
SUM(К_во)
COUNT(К_во)
Кол-во лука =
220
2
Отметим также, что в столбце-аргументе перед применением любой функции, кроме COUNT(*), исключаются все неопределенные значения. Если оказывается, что аргумент – пустое множество, функция COUNT принимает значение 0, а остальные – NULL.
Например, для получения суммы цен, средней цены, количества поставляемых продуктов и количества разных цен продуктов, проданных коопторгом УРОЖАЙ (ПС=5), а также для получения количества продуктов, которые могут поставляться этим коопторгом, можно дать запрос
SELECT SUM(Цена),AVG(Цена),COUNT(Цена),
COUNT(DISTINCT Цена),COUNT(*)
FROM Поставки
WHERE ПС = 5;
и получить
|
SUM(Цена) |
AVG(Цена) |
COUNT(Цена) |
COUNT(DISTINCT Цена) |
COUNT (*) |
|
6.2 |
1.24 |
5 |
4 |
7 |
В другом примере, где надо узнать «Сколько поставлено моркови и сколько поставщиков ее поставляют?»:
SELECT SUM(К_во),COUNT(К_во)
FROM Поставки
WHER ПР = 2;
будет получен ответ:
-
SUM(К_во)
COUNT (К_во)
-0-
0
Наконец, попробуем получить сумму массы поставленного лука с его средней ценой («Сапоги с яичницей»):
|
Результат: |
|
|
SELECT (SUM(К_во) +AVG(Цена)) FROM Поставки WHERE ПР = 10; |
|
|
SUM(К_во)+AVG(Цена) |
|
|
220.6 |
Фраза GROUP BY
Мы показали, как можно вычислить массу определенного продукта, поставляемого поставщиками. Предположим, что теперь требуется вычислить общую массу каждого из продуктов, поставляемых в настоящее время поставщиками. Это можно легко сделать с помощью предложения
SELECT ПР, SUM(К_во)
FROM Поставки
GROUP BY ПР;
Результат показан на рис. 2.5,а.
|
а) |
б) |
в) |
г) |
||||||
|
ПР |
ПС |
ПР |
Цена |
К_во |
ПР |
ПР |
|||
|
9 |
0 |
1 |
9 |
-0- |
-0- |
1 |
370 |
9 |
0 |
|
11 |
150 |
3 |
9 |
-0- |
-0- |
2 |
0 |
11 |
150 |
|
12 |
30 |
5 |
9 |
-0- |
-0- |
3 |
250 |
12 |
30 |
|
15 |
370 |
1 |
11 |
1.50 |
50 |
4 |
100 |
15 |
70 |
|
1 |
370 |
5 |
11 |
-0- |
-0- |
5 |
170 |
1 |
370 |
|
3 |
250 |
6 |
11 |
-0- |
-0- |
6 |
220 |
3 |
250 |
|
5 |
170 |
8 |
11 |
1.00 |
100 |
7 |
200 |
5 |
70 |
|
6 |
220 |
1 |
12 |
3.00 |
10 |
8 |
150 |
6 |
140 |
|
8 |
150 |
3 |
12 |
2.50 |
20 |
9 |
0 |
8 |
150 |
|
7 |
200 |
6 |
12 |
-0- |
-0- |
10 |
220 |
7 |
200 |
|
2 |
0 |
1 |
15 |
2.00 |
170 |
11 |
150 |
2 |
0 |
|
4 |
100 |
3 |
15 |
1.50 |
200 |
12 |
30 |
4 |
100 |
|
13 |
190 |
2 |
1 |
3.60 |
300 |
13 |
190 |
13 |
190 |
|
14 |
70 |
7 |
1 |
4.20 |
70 |
14 |
70 |
14 |
70 |
|
16 |
250 |
2 |
3 |
-0- |
-0- |
15 |
370 |
16 |
250 |
|
17 |
50 |
7 |
3 |
4.00 |
250 |
16 |
250 |
17 |
50 |
|
10 |
220 |
. . . |
17 |
50 |
10 |
220 |
Рисунок 2.5
Фраза GROUP BY (группировать по) инициирует перекомпоновку указанной во FROM таблицы по группам, каждая из которых имеет одинаковые значения в столбце, указанном в GROUP BY. В рассматриваемом примере строки таблицы Поставки группируются так, что в одной группе содержатся все строки для продукта с ПР = 1, в другой – для продукта с ПР = 2 и т.д. (см. рис. 2.5,б). Далее к каждой группе применяется фраза SELECT. Каждое выражение в этой фразе должно принимать единственное значение для группы, т.е. оно может быть либо значением столбца, указанного в GROUP BY, либо арифметическим выражением, включающим это значение, либо константой, либо одной из SQL-функций, которая оперирует всеми значениями столбца в группе и сводит эти значения к единственному значению (например, к сумме).
Отметим, что фраза GROUP BY не предполагает ORDER BY. Чтобы гарантировать упорядочение по ПР результата рассматриваемого примера (рис. 2.5,в) следует дать запрос
SELECT ПР, SUM(К_во)
FROM Поставки
GROUP BY ПР
ORDER BY ПР;
Наконец, отметим, что строки таблицы можно группировать по любой комбинации ее столбцов. Так, по запросу
SELECT Т, БЛ, COUNT(БЛ)
FROM Заказ
GROUP BY Т, БЛ;
можно узнать коды и количество порций блюд, заказанных отдыхающими пансионата (32 человека) на каждую из трапез следующего дня:
-
Т
БЛ
COUNT(БЛ)
1
3
18
1
6
14
1
19
17
1
21
15
…
Использование фразы HAVING
Фраза HAVING (рис. 2.3) играет такую же роль для групп, что и фраза WHERE для строк: она используется для исключения групп, точно так же, как WHERE используется для исключения строк. Эта фраза включается в предложение лишь при наличии фразы GROUP BY, а выражение в HAVING должно принимать единственное значение для группы.
Например, выдать коды продуктов, поставляемых более чем двумя поставщиками:
|
SELECT FROM Поставки GROUP BY ПС HAVING COUNT(*) 2; |
Результат: |
ПР |
|
9 |
||
|
11 |
||
|
12 |
||
2.2.3. Использование запросов с использованием нескольких таблицы.
О средствах одновременной работы с множеством таблиц
Затрагивая вопросы проектирования баз данных, мы выяснили, что базы данных – это множество взаимосвязанных сущностей или отношений (таблиц) в терминологии реляционных СУБД. При проектировании стремятся создавать таблицы, в каждой из которых содержалась бы информация об одном и только об одном типе сущностей. Это облегчает модификацию базы данных и поддержание ее целостности. Но такой подход тяжело усваивается начинающими проектантами, которые пытаются привязать проект к будущим приложениям и так организовать таблицы, чтобы в каждой из них хранилось все необходимое для реализации возможных запросов. Типичен вопрос: как же получить сведения о том, где купить продукты для приготовления того или иного блюда и определить его калорийность и стоимость, если нужные данные «рассыпаны» по семи различным таблицам? Не лучше ли иметь одну большую таблицу, содержащую все сведения базы данных ПАНСИОН ?
Даже при отсутствии средств одновременного доступа ко многим таблицам нежелателен проект, в котором информация о многих типах сущностей перемешана в одной таблице. SQL же обладает великолепным механизмом для одновременной или последовательной обработки данных из нескольких взаимосвязанных таблиц. В нем реализованы возможности «соединять» или «объединять» несколько таблиц и так называемые «вложенные подзапросы». Например, чтобы получить перечень поставщиков продуктов, необходимых для приготовления Сырников, возможен запрос
SELECT Продукт, Цена, Название, Статус
FROM Продукты, Состав, Блюда, Поставки, Поставщики
WHERE Продукты.ПР = Состав.ПР
AND Состав.БЛ = Блюда.БЛ
AND Поставки.ПР = Состав.ПР
AND Поставки.ПС = Поставщики.ПС
AND Блюдо = 'Сырники'
AND Цена IS NOT NULL;
-
Продукт
Цена
Название
Статус
Яйца
1.8
ПОРТОС
Кооператив
Яйца
2.
КОРЮШКА
Кооператив
Сметана
3.6
ПОРТОС
Кооператив
Сметана
2.2
ОГУРЕЧИК
Ферма
Творог
1.
ОГУРЕЧИК
Ферма
Мука
0.5
УРОЖАЙ
Коопторг
Сахар
0.94
ТУЛЬСКИЙ
Универсам
Сахар
1.
УРОЖАЙ
Коопторг
Он получен следующим образом: СУБД последовательно формирует строки декартова произведения таблиц, перечисленных во фразе FROM, проверяет, удовлетворяют ли данные сформированной строки условиям фразы WHERE, и если удовлетворяют, то включает в ответ на запрос те ее поля, которые перечислены во фразе SELECT.
Следует подчеркнуть, что в SELECT и WHERE (во избежание двусмысленности) ссылки на все (*) или отдельные столбцы могут (а иногда и должны) уточняться именем соответствующей таблицы, например, Поставки.ПС, Поставщики.ПС, Меню.*, Состав.БЛ, Блюда.* и т.п.
Очевидно, что с помощью соединения несложно сформировать запрос на обработку данных из нескольких таблиц. Кроме того, в такой запрос можно включить любые части предложения SELECT, рассмотренные в главе 2 (выражения с использованием функций, группирование с отбором указанных групп и упорядочением полученного результата). Следовательно, соединения позволяют обрабатывать множество взаимосвязанных таблиц как единую таблицу, в которой перемешана информация о многих типах сущностей. Поэтому начинающий проектант базы данных может спокойно создавать маленькие нормализованные таблицы, так как он всегда может получить из них любую «большую» таблицу.
Кроме механизма соединений в SQL есть механизм вложенных подзапросов, позволяющий объединить несколько простых запросов в едином предложении SELECT. Иными словами, вложенный подзапрос – это уже знакомый нам подзапрос (с небольшими огра-ничениями), который вложен в WHERE фразу другого вложенного подзапроса или WHERE фразу основного запроса.
Для иллюстрации вложенного подзапроса вернемся к предыдущему примеру и попробуем получить перечень тех поставщиков продуктов для Сырников, которые поставляют нужные продукты за минимальную цену.
SELECT Продукт, Цена, Название, Статус
FROM Продукты, Состав, Блюда, Поставки, Поставщики
WHERE Продукты.ПР = Состав.ПР
AND Состав.БЛ = Блюда.БЛ
AND Поставки.ПР = Состав.ПР
AND Поставки.ПС = Поставщики.ПС
AND Блюдо = 'Сырники'
AND Цена = ( SELECT MIN(Цена)
FROM Поставки X
WHERE X.ПР = Поставки.ПР );
Результат запроса имеет вид
-
Продукт
Цена
Название
Статус
Яйца
1.8
ПОРТОС
Кооператив
Сахар
0.94
ТУЛЬСКИЙ
Универсам
Мука
0.5
УРОЖАЙ
Коопторг
Сметана
2.2
ОГУРЕЧИК
Ферма
Творог
1.
ОГУРЕЧИК
Ферма
Здесь с помощью подзапроса, размещенного в трех последних строках запроса, описывается процесс определения минимальной цены каждого продукта для Сырников и поиск поставщика, предлагающего этот продукт за такую цену.
Запросы, использующие соединения
Декартово произведение таблиц
Так как декартово произведение n таблиц – это таблица, содержащая все возможные строки r, такие, что r является сцеплением какой-либо строки из первой таблицы, строки из второй таблицы, … и строки из n-й таблицы (а мы уже научились выделять с помощью SELECT любое подмножество реляционной таблицы), то осталось лишь выяснить, можно ли с помощью SELECT получить декартово произведение. Для получения декартова произведения нескольких таблиц надо указать во фразе FROM перечень перемножаемых таблиц, а во фразе SELECT – все их столбцы.
Так, для получения декартова произведения Вид_блюд и Трапезы надо выдать запрос
SELECT Вид_блюд.*, Трапезы.*
FROM Вид_блюд, Трапезы;
Получим таблицу, содержащую 5 х 3 = 15 строк:
-
В
Вид
Т
Трапеза
З
Закуска
1
Завтрак
З
Закуска
2
Обед
З
Закуска
3
Ужин
С
Суп
1
Завтрак
С
Суп
2
Обед
С
Суп
3
Ужин
Г
Горячее
1
Завтрак
Г
Горячее
2
Обед
Г
Горячее
3
Ужин
Д
Десерт
1
Завтрак
Д
Десерт
2
Обед
Д
Десерт
3
Ужин
Н
Напиток
1
Завтрак
Н
Напиток
2
Обед
Н
Напиток
3
Ужин
В другом примере, где перемножаются таблицы Меню, Трапезы, Вид_блюд, Блюда:
SELECT Меню.*, Трапезы.*, Вид_блюд.*, Блюда.*
FROM Меню, Трапезы, Вид_блюд, Блюда;
образуется таблица (рис 2.6), содержащая 21 х 3 х 5 х 33 = 10395 строк.
Эквисоединение таблиц
Если из декартова произведения убрать ненужные строки и столбцы, то можно получить актуальные таблицы, соответствующие любому из соединений.
|
Меню |
Трапезы |
Вид_блюд |
Блюда |
|||||||||
|
Т |
В |
БЛ |
Т |
Трапеза |
В |
Вид |
БЛ |
Блюдо |
В |
Основа |
Выход |
Труд |
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
1 |
Салат летний |
З |
Овощи |
200. |
3 |
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
2 |
Салат мясной |
З |
Мясо |
200. |
4 |
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
3 |
Салат витаминный |
З |
Овощи |
200. |
4 * |
|
. . . |
||||||||||||
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
12 |
Суп молочный |
С |
Молоко |
500. |
3 |
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
13 |
Бастурма |
Г |
Мясо |
300. |
5 |
|
. . . |
||||||||||||
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
32 |
Кофе черный |
Н |
Кофе |
100. |
1 |
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
33 |
Кофе на молоке |
Н |
Кофе |
200. |
2 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
1 |
Салат летний |
З |
Овощи |
200. |
3 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
2 |
Салат мясной |
З |
Мясо |
200. |
4 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
3 |
Салат витаминный |
З |
Овощи |
200. |
4 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
4 |
Салат рыбный |
З |
Рыба |
200. |
4 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
5 |
Паштет из рыбы |
З |
Рыба |
120. |
5 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
6 |
Мясо с гарниром |
З |
Мясо |
250. |
3 * |
|
. . . |
Рисунок 2.6
Очевидно, что отбор актуальных строк обеспечивается вводом в запрос WHERE фразы, в которой устанавливается соответствие между:
кодами трапез (Т) в таблицах Меню и Трапезы (Меню.Т = Трапезы.Т),
кодами видов блюд (В) в таблицах Меню и Вид_блюд (Меню.В = Вид_блюд.В),
номерами блюд (БЛ) в таблицах Меню и Блюда (Меню.БЛ = Блюда.БЛ).
Такой скорректированный запрос
SELECT Меню.*, Трапезы.*, Вид_блюд.*, Блюда.*
FROM Меню, Трапезы, Вид_блюд, Блюда
WHERE Меню.Т = Трапезы.Т
AND Меню.В = Вид_блюд.В
AND Меню.БЛ = Блюда.БЛ;
позволит получить эквисоединение таблиц Меню, Трапезы, Вид_блюд и Блюда:
|
Т |
В |
БЛ |
Т |
Трапеза |
В |
Вид |
БЛ |
Блюдо |
В |
Основа |
Выход |
Труд |
|
1 |
З |
3 |
1 |
Завтрак |
З |
Закуска |
3 |
Салат витаминный |
З |
Овощи |
200. |
4 |
|
1 |
З |
6 |
1 |
Завтрак |
З |
Закуска |
6 |
Мясо с гарниром |
З |
Мясо |
250. |
3 |
|
1 |
Г |
19 |
1 |
Завтрак |
Г |
Горячее |
19 |
Омлет с луком |
Г |
Яйца |
200. |
5 |
|
. . . |
||||||||||||
|
3 |
Г |
16 |
3 |
Ужин |
Г |
Горячее |
16 |
Драчена |
Г |
Яйца |
180. |
4 |
|
3 |
Н |
30 |
3 |
Ужин |
Н |
Напиток |
30 |
Компот |
Н |
Фрукты |
200. |
2 |
|
3 |
Н |
31 |
3 |
Ужин |
Н |
Напиток |
31 |
Молочный напиток |
Н |
Молоко |
200. |
2 |
Естественное соединение таблиц
Легко заметить, что в эквисоединение таблиц вошли дубликаты столбцов, по которым проводилось соединение (Т, В и БЛ). Для исключения этих дубликатов можно создать естественное соединение тех же таблиц:
SELECT Т, В, БЛ, Трапеза, Вид, Блюдо, Основа, Выход, Труд
FROM Меню, Трапезы, Вид_блюд, Блюда
WHERE Меню.Т = Трапезы.Т
AND Меню.В = Вид_блюд.В
AND Меню.БЛ = Блюда.БЛ;
Реализация естественного соединения таблиц имеет вид
|
Т |
В |
БЛ |
Трапеза |
Вид |
Блюдо |
Основа |
Выход |
Труд |
|
1 |
З |
3 |
Завтрак |
Закуска |
Салат витаминный |
Овощи |
200. |
4 |
|
1 |
З |
6 |
Завтрак |
Закуска |
Мясо с гарниром |
Мясо |
250. |
3 |
|
1 |
Г |
19 |
Завтрак |
Горячее |
Омлет с луком |
Яйца |
200. |
5 |
|
… |
||||||||
|
3 |
Г |
16 |
Ужин |
Горячее |
Драчена |
Яйца |
180. |
4 |
|
3 |
Н |
30 |
Ужин |
Напиток |
Компот |
Фрукты |
200. |
2 |
|
3 |
Н |
31 |
Ужин |
Напиток |
Молочный напиток |
Молоко |
200. |
2 |
Композиция таблиц
Для исключения всех столбцов, по которым проводится соединение таблиц, надо создать композицию
SELECT Трапеза, Вид, Блюдо, Основа, Выход, Труд
FROM Меню, Трапезы, Вид_блюд, Блюда
WHERE Меню.Т = Трапезы.Т
AND Меню.В = Вид_блюд.В
AND Меню.БЛ = Блюда.БЛ;
имеющую вид
|
Трапеза |
Блюдо |
Вид |
Основа |
Выход |
Труд |
|
Завтрак |
Салат витаминный |
Закуска |
Овощи |
200. |
4 |
|
Завтрак |
Мясо с гарниром |
Закуска |
Мясо |
250. |
3 |
|
Завтрак |
Омлет с луком |
Горячее |
Яйца |
200. |
5 |
|
. . . |
|||||
|
Ужин |
Драчена |
Горячее |
Яйца |
180. |
4 |
|
Ужин |
Компот |
Напиток |
Фрукты |
200. |
2 |
|
Ужин |
Молочный напиток |
Напиток |
Молоко |
200. |
2 |
Тета-соединение таблиц
В базе данных ПАНСИОН трудно подобрать несложный пример, иллюстрирующий тета-соединение таблиц. Поэтому сконструируем такой надуманный запрос:
SELECT Вид_блюд.*, Трапезы.*
FROM Вид_блюд, Трапезы
WHERE Вид Трапеза;
позволяющий выбрать из полученного декартова произведения таблиц Вид_блюд и Трапезы лишь те строки, в которых значение трапезы «меньше» (по алфавиту) значения вида блюда:
-
В
Вид
Т
Трапеза
З
Закуска
1
Завтрак
С
Суп
1
Завтрак
С
Суп
2
Обед
Н
Напиток
1
Завтрак
Соединение таблиц с дополнительным условием
При формировании соединения создается рабочая таблица, к которой применимы все операции: отбор нужных строк соединения (WHERE фраза), упорядочение получаемого результата (ORDER BY фраза) и агрегатирование данных (SQL-функции и GROUP BY фраза).
Например, для получения перечня блюд, предлагаемых в меню на завтрак, можно сформировать запрос на основе композиции:
SELECT Вид, Блюдо, Основа, Выход, 'Номер –', БЛ
FROM Меню, Трапезы, Вид_блюд, Блюда
WHERE Меню.Т = Трапезы.Т
AND Меню.В = Вид_блюд.В
AND Меню.БЛ = Блюда.БЛ
AND Трапеза = ’Завтрак’;
-
Вид
Блюдо
Основа
Выход
'Номер –'
БЛ
Закуска
Салат витаминный
Овощи
200.
Номер -
3
Закуска
Мясо с гарниром
Мясо
250.
Номер -
6
Горячее
Омлет с луком
Яйца
200.
Номер -
19
Горячее
Пудинг рисовый
Крупа
160.
Номер -
21
Напиток
Молочный напиток
Молоко
200.
Номер -
31
Напиток
Кофе черный
Кофе
100.
Номер -
32
Соединение таблицы со своей копией
В ряде приложений возникает необходимость одновременной обработки данных какой-либо таблицы и одной или нескольких ее копий, создаваемых на время выполнения запроса.
Например, при создании списков студентов (таблица Студенты) возможен повторный ввод данных о каком-либо студенте с присвоением ему второго номера зачетной книжки. Для выявления таких ошибок можно соединить таблицу Студенты с ее временной копией, установив в WHERE фразе равенство значений всех одноименных столбцов этих таблиц кроме столбцов с номером зачетной книжки (для последних надо установить условие неравенства значений).
Временную копию таблицы можно сформировать, указав имя псевдонима за именем таблицы во фразе FROM. Так, с помощью фразы
FROM Блюда X, Блюда Y, Блюда Z
будут сформированы три копии таблицы Блюда с именами X, Y и Z.
В качестве примера соединения таблицы с ней самой сформируем запрос на вывод таких пар блюд таблицы Блюда, в которых совпадает основа, а название первого блюда пары меньше (по алфавиту), чем номер второго блюда пары. Для этого можно создать запрос с одной копией таблицы Блюда (Копия):
SELECT Блюдо, Копия.Блюдо, Основа
FROM Блюда, Блюда Копия
WHERE Основа = Копия.Основа
AND Блюдо < Копия.Блюдо;
или двумя ее копиями (Первая и Вторая):
SELECT Первая.Блюдо, Вторая.Блюдо, Основа
FROM Блюда Первая, Блюда Вторая
WHERE Первая.Основа = Вторая.Основа
AND Первая.Блюдо < Вторая.Блюдо;
Получим результат вида
-
Первая.Блюдо
Вторая.Блюдо
Основа
Морковь с рисом
Помидоры с луком
Овощи
Морковь с рисом
Салат летний
Овощи
Морковь с рисом
Салат витаминный
Овощи
Помидоры с луком
Салат витаминный
Овощи
Помидоры с луком
Салат летний
Овощи
Салат витаминный
Салат летний
Овощи
Бастурма
Бефстроганов
Мясо
Бастурма
Мясо с гарниром
Мясо
Бефстроганов
Мясо с гарниром
Мясо
Вложенные подзапросы
Виды вложенных подзапросов
Вложенный подзапрос – это подзапрос, заключенный в круглые скобки и вложенный в WHERE (HAVING) фразу предложения SELECT или других предложений, использующих WHERE фразу. Вложенный подзапрос может содержать в своей WHERE (HAVING) фразе другой вложенный подзапрос и т.д. Нетрудно догадаться, что вложенный подзапрос создан для того, чтобы при отборе строк таблицы, сформированной основным запросом, можно было использовать данные из других таблиц (например, при отборе блюд для меню использовать данные о наличии продуктов в кладовой пансионата).
Существуют простые и коррелированные вложенные подзапросы. Они включаются в WHERE (HAVING) фразу с помощью условий IN, EXISTS или одного из условий сравнения ( = | < | < | <= | | = ). Простые вложенные подзапросы обрабатываютя системой «снизу вверх». Первым обрабатывается вложенный подзапрос самого нижнего уровня. Множество значений, полученное в результате его выполнения, используется при реализации подзапроса более высокого уровня и т.д.
Запросы с коррелированными вложенными подзапросами обрабатываются системой в обратном порядке. Сначала выбирается первая строка рабочей таблицы, сформированной основным запросом, и из нее выбираются значения тех столбцов, которые используются во вложенном подзапросе (вложенных подзапросах). Если эти значения удовлетворяют условиям вложенного подзапроса, то выбранная строка включается в результат. Затем выбирается вторая строка и т.д., пока в результат не будут включены все строки, удовлетворяющие вложенному подзапросу (последовательности вложенных подзапросов).
Следует отметить, что SQL обладает большой избыточностью в том смысле, что он часто предоставляет несколько различных способов формулировки одного и того же запроса. Поэтому во многих примерах данной главы будут использованы уже знакомые нам по предыдущей главе концептуальные формулировки запросов. И несмотря на то, что часть из них успешнее реализуется с помощью соединений, здесь все же будут приведены их варианты с использованием вложенных подзапросов. Это связано с необходимостью детального знакомства с созданием и принципом выполнения вложенных подзапросов, так как существует немало задач (особенно на удаление и изменение данных), которые не могут быть реализованы другим способом. Кроме того, разные формулировки одного и того же запроса требуют для своего выполнения различных ресурсов памяти и могут значительно отличаться по времени реализации в разных СУБД.
Простые вложенные подзапросы
Простые вложенные подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, что иллюстрируется в следующем примере: выдать название и статус поставщиков продукта с номером 11, т.е. помидоров.
|
Результат: |
||
|
SELECT Название, Статус FROM Поставщики WHERE ПС IN ( SELECT ПС FROM Поставки WHERE ПР = 11 ); |
Название |
Статус |
|
СЫТНЫЙ |
рынок |
|
|
УРОЖАЙ |
коопторг |
|
|
ЛЕТО |
агрофирма |
|
|
КОРЮШКА |
кооператив |
При обработке полного запроса система выполняет прежде всего вложенный подзапрос. Этот подзапрос выдает множество номеров поставщиков, которые поставляют продукт с кодом ПР = 11, а именно множество (1, 5, 6, 8). Поэтому первоначальный запрос эквивалентен такому простому запросу:
SELECT Название, Статус
FROM Поставщики
WHERE ПС IN (1, 5, 6, 8);
Подзапрос с несколькими уровнями вложенности можно проиллюстрировать на том же примере. Пусть требуется узнать не поставщиков продукта 11, как это делалось в предыдущих запросах, а поставщиков помидоров, являющихся продуктом с номером 11. Для этого можно дать запрос
SELECT Название, Статус
FROM Поставщики
WHERE ПС IN
( SELECT ПС
FROM Поставки
WHERE ПР IN
( SELECT ПР
FROM Продукты
WHERE Продукт = 'Помидоры' ));
В данном случае результатом самого внутреннего подзапроса является только одно значение (11). Как уже было показано выше, подзапрос следующего уровня в свою очередь дает в результате множество (1, 5, 6, 8). Последний, самый внешний SELECT, вычисляет приведенный выше окончательный результат. Вообще допускается любая глубина вложенности подзапросов.
Тот же результат можно получить с помощью соединения
SELECT Название, Статус
FROM Поставщики, Поставки, Продукты
WHERE Поставщики.ПС = Поставки.ПС
AND Поставки.ПР = Продукты.ПР
AND Продукт = 'Помидоры';
При выполнении этого компактного запроса система должна одновременно обрабатывать данные из трех таблиц, тогда как в предыдущем примере эти таблицы обрабатываются поочередно. Естественно, что для их реализации тебуются различные ресурсы памяти и времени, однако этого невозможно ощутить при работе с ограниченным объемом данных в иллюстративной базе ПАНСИОН.
Использование одной и той же таблицы во внешнем и вложенном подзапросе
Выдать номера поставщиков, которые поставляют хотя бы один продукт, поставляемый поставщиком 6.
-
Результат:
SELECT DISTINCT ПС
FROM Поставки
WHERE ПР IN
( SELECT ПР
FROM Поставки
WHERE ПС = 6);
ПС
1
3
5
6
8
Отметим, что ссылка на Поставки во вложенном подзапросе означает не то же самое, что ссылка на Поставки во внешнем запросе. В действительности, два имени Поставки обозначают различные значения. Чтобы этот факт стал явным, полезно использовать псевдонимы, например, X и Y:
SELECT DISTINCT X.ПС
FROM Поставки X
WHERE X.ПР IN
( SELECT Y.ПР
FROM Поставки Y
WHERE Y.ПС = 6 );
Здесь X и Y – произвольные псевдонимы таблицы Поставки, определяемые во фразе FROM и используемые как явные уточнители во фразах SELECT и WHERE. Напомним, что псевдонимы определены лишь в пределах одного запроса.
Вложенный подзапрос с оператором сравнения, отличным от IN
Выдать номера поставщиков, находящихся в том же городе, что и поставщик с номером 6.
-
Результат:
SELECT ПС
FROM Поставщики
WHERE Город =
( SELECT Город
FROM Поставщики
WHERE ПС = 6 );
ПС
1
4
6
В подобных запросах можно использовать и другие операторы сравнения (<, <=, <, = или ), однако, если вложенный подзапрос возвращает более одного значения и не используется оператор IN, будет возникать ошибка.
Коррелированные вложенные подзапросы
Выдать название и статус поставщиков продукта с номером 11.
SELECT Название, Статус
FROM Поставщики
WHERE 11 IN
( SELECT ПР
FROM Поставки
WHERE ПС = Поставщики.ПС );
Такой подзапрос отличается от обычного тем, что вложенный подзапрос не может быть обработан прежде, чем будет обрабатываться внешний подзапрос. Это связано с тем, что вложенный подзапрос зависит от значения Поставщики.ПС а оно изменяется по мере того, как система проверяет различные строки таблицы Поставщики. Следовательно, с концептуальной точки зрения обработка осуществляется следующим образом:
Система проверяет первую строку таблицы Поставщики. Предположим, что это строка поставщика с номером 1. Тогда значение Поставщики.ПС будет в данный момент имеет значение, равное 1, и система обрабатывает внутренний запрос
( SELECT ПР
FROM Поставки
WHERE ПС = 1 );
получая в результате множество (9, 11, 12, 15). Теперь система может завершить обработку для поставщика с номером 1. Выборка значений Название и Статус для ПС=1 (СЫТНЫЙ и рынок) будет проведена тогда и только тогда, когда ПР=11 будет принадлежать этому множеству, что, очевидно, справедливо.
Далее система будет повторять обработку такого рода для следующего поставщика и т.д. до тех пор, пока не будут рассмотрены все строки таблицы Поставщики.
Подобные подзапросы называются коррелированными, так как их результат зависит от значений, определенных во внешнем подзапросе. Обработка коррелированного подзапроса, следовательно, должна повторяться для каждого значения извлекаемого из внешнего подзапроса, а не выполняться раз и навсегда.
Рассмотрим пример использования одной и той же таблицы во внешнем подзапросе и коррелированном вложенном подзапросе.
Выдать номера всех продуктов, поставляемых только одним по-ставщиком.
|
Результат: |
|
|
SELECT DISTINCT X.ПР FROM Поставки X WHERE X.ПР NOT IN ( SELECT Y.ПР FROM Поставки Y WHERE Y.ПС <> X.ПС ); |
X.ПР |
|
17 |
Действие этого запроса можно пояснить следующим образом: «Поочередно для каждой строки таблицы Поставки, скажем X, выделить значение номера продукта (ПР), если и только если это значение не входит в некоторую строку, скажем, Y, той же таблицы, а значение столбца номер поставщика (ПС) в строке Y не равно его значению в строке X».
Отметим, что в этой формулировке должен быть использован по крайней мере один псевдоним – либо X, либо Y.
Запросы, использующие EXISTS
Квантор EXISTS (существует) – понятие, заимствованное из формальной логики. В языке SQL предикат с квантором существования представляется выражением EXISTS (SELECT * FROM …).
Такое выражение считается истинным только тогда, когда результат вычисления «SELECT * FROM …» является непустым множеством, т.е. когда существует какая-либо запись в таблице, указанной во фразе FROM подзапроса, которая удовлетворяет условию WHERE подзапроса. (Практически этот подзапрос всегда будет коррелированным множеством.)
Рассмотрим примеры. Выдать названия поставщиков, поставляющих продукт с номером 11.
|
Результат: |
|
|
SELECT Название FROM Поставщики WHERE EXISTS ( SELECT * FROM Поставки WHERE ПС = Поставщики.ПС AND ПР = 11 ); |
Название |
|
СЫТНЫЙ |
|
|
УРОЖАЙ |
|
|
КОРЮШКА |
|
|
ЛЕТО |
Система последовательно выбирает строки таблицы Поставщики, выделяет из них значения столбцов Название и ПС, а затем проверяет, является ли истинным условие существования, т.е. су-ществует ли в таблице Поставки хотя бы одна строка со значением ПР=11 и значением ПС, равным значению ПС, выбранному из таблицы Поставщики. Если условие выполняется, то полученное значение столбца Название включается в результат.
Предположим, что первые значения полей Название и ПС равны, соответственно, 'СЫТНЫЙ' и 1. Так как в таблице Поставки есть строка с ПР=11 и ПС=1, то значение 'СЫТНЫЙ' должно быть включено в результат.
Хотя этот первый пример только показывает иной способ формулировки запроса для задачи, решаемой и другими путями (с помощью оператора IN или соединения), EXISTS представляет собой одну из наиболее важных возможностей SQL. Фактически любой запрос, который выражается через IN, может быть альтернативным образом сформулирован также с помощью EXISTS. Однако обратное высказывание несправедливо.
Выдать название и статус поставщиков, не поставляющих продукт с номером 11.
|
Результат: |
||
|
SELECT Название, Статус FROM Поставщики WHERE NOT EXISTS ( SELECT * FROM Поставки WHERE ПС = Поставщики.ПС AND ПР = 11 ); |
Название |
Статус |
|
ПОРТОС |
кооператив |
|
|
ШУШАРЫ |
совхоз |
|
|
ТУЛЬСКИЙ |
универсам |
|
|
ОГУРЕЧИК |
ферма |
Функции в подзапросе
Теперь, после знакомства с различными формулировками вложенных подзапросов и псевдонимами легче понять текст и алгоритм реализации запроса на получение тех поставщиков продуктов для Сырников, которые поставляют эти продукты за минимальную цену:
SELECT Продукт, Цена, Название, Статус
FROM Продукты, Состав, Блюда, Поставки, Поставщики
WHERE Продукты.ПР = Состав.ПР
AND Состав.БЛ = Блюда.БЛ
AND Поставки.ПР = Состав.ПР
AND Поставки.ПС = Поставщики.ПС
AND Блюдо = 'Сырники'
AND Цена = ( SELECT MIN(Цена)
FROM Поставки X
WHERE X.ПР = Поставки.ПР );
Естественно, что это коррелированный подзапрос: здесь сначала определяется минимальная цена продукта, входящего в состав Сырников, и только затем выясняется его поставщик.
На этом примере мы закончим знакомство с вложенными подзапросами, предложив попробовать свои силы в составлении ряда запросов, с помощью механизма таких подзапросов:
Выдать названия всех мясных блюд.
Выдать количество всех блюд, в состав которых входят помидоры.
Выдать блюда, продукты для которых поставляются агрофирмой ЛЕТО.
Объединение (UNION)
Для SQL это означает, что две таблицы можно объединять тогда и только тогда, когда:
они имеют одинаковое число столбцов, например, m;
для всех i (i = 1, 2, …, m) i-й столбец первой таблицы и i-й столбец второй таблицы имеют в точности одинаковый тип данных.
Например, выдать названия продуктов, в которых нет жиров, либо входящих в состав блюда с кодом БЛ = 1:
|
Результат: |
Продукт |
|
SELECT Продукт FROM Продукты WHERE Жиры = 0 UNION SELECT Продукт FROM Соста WHERE БЛ = 1 |
Майонез |
|
Лук |
|
|
Помидоры |
|
|
Зелень |
|
|
Яблоки |
|
|
Сахар |
Из этого простого примера видно, что избыточные дубликаты всегда исключаются из результата UNION. Поэтому, хотя в рассматриваемом примере Помидоры, Зелень и Яблоки выбираются обеими из двух составляющих предложения SELECT, в окончательном результате они появляются только один раз.
Предложением с UNION можно объединить любое число таблиц (проекций таблиц). Так, к предыдущему запросу можно добавить (перед точкой с запятой) конструкцию
UNION
SELECT Продукт
FROM Продукты
WHERE Ca < 250
позволяющую добавить к списку продуктов Масло, Рис, Мука и Кофе. Однако тот же результат можно получить простым изменением фразы WHERE первой части исходного запроса
WHERE Жиры = 0 OR Ca < 250
Реализация операций реляционной алгебры предложением SELECT
С помощью предложения SELECT можно реализовать любую операцию реляционной алгебры.
Селекция (горизонтальное подмножество) таблицы создается из тех ее строк, которые удовлетворяют заданным условиям. Пример:
SELECT *
FROM Блюда
WHER Основа = 'Молоко'
AND Выход 200;
Проекция (вертикальное подмножество) таблицы создается из указанных ее столбцов (в заданном порядке) с последующим исключением избыточных дубликатов строк. Пример:
SELECT DISTINCT Блюдо, Выход, Основа
FROM Блюда;
Объединение двух таблиц содержит те строки, которые есть либо в первой, либо во второй, либо в обеих таблицах. Пример:
SELECT Блюдо, Основа, Выход
FROM Блюда
WHER Основа = 'Овощи'
UNION
SELECT Блюдо, Основа, Выход
FROM Блюда
WHER В = 'Г';
Пересечение двух таблиц содержит только те строки, которые есть и в первой, и во второй. Пример:
SELECT БЛ
FROM Состав
WHERE БЛ IN
( SELECT БЛ
FROM Меню);
Разность двух таблиц содержит только те строки, которые есть в первой, но отсутствуют во второй. Пример:
SELECT БЛ
FROM Состав
WHERE БЛ NOT IN
( SELECT БЛ
FROM Меню);
Здесь опущено лишь достаточно нудное описание редко встречаемой операция деления, которая также может быть реализована предложением SELECT с коррелированными вложенными подзапросами.
Резюме
Знакомство с возможностями предложения SELECT показало, что с его помощью можно реализовать все реляционные операции. Кроме того, в предложении SELECT выполняются разнообразные вычисления, агрегирование данных, их упорядочение и ряд других операций, позволяющих описать в одном предложении ту работу, для выполнения которой потребовалось бы написать несколько страниц программы на алгоритмических языках Си, Паскаль или на внутренних языках ряда распространенных СУБД.
Например, пусть требуется получить калорийность и стоимость тех блюд, для которых:
есть все составляющие их продукты;
калорийность не превышает 400 ккал;
стоимость не превышает 1.5 рубля, а результат надо упорядочить по возрастанию калорийности блюд в рамках их видов.
Для этого можно дать запрос, показанный на рис. 2.7, позволяющий получить искомый результат в виде таблицы
|
Вид |
Блюдо |
||||
|
Горячее |
Помидоры с луком |
калорий - |
244.6 |
0.44 |
руб |
|
Горячее |
Бефстроганов |
калорий - |
321.3 |
0.53 |
руб |
|
Горячее |
Драчена |
калорий - |
333.9 |
0.33 |
руб |
|
Горячее |
Каша рисовая |
калорий - |
339.2 |
0.27 |
руб |
|
Горячее |
Омлет с луком |
калорий - |
354.9 |
0.36 |
руб |
|
Десерт |
Яблоки печеные |
калорий - |
170.2 |
0.30 |
руб |
|
Десерт |
Крем творожный |
калорий - |
394.3 |
0.27 |
руб |
|
Закуска |
Салат летний |
калорий - |
155.5 |
0.32 |
руб |
|
Закуска |
Салат витаминный |
калорий - |
217.4 |
0.37 |
руб |
|
Закуска |
Творог |
калорий - |
330.0 |
0.22 |
руб |
|
Закуска |
Мясо с гарниром |
калорий - |
378.7 |
0.62 |
руб |
|
Напиток |
Кофе черный |
калорий - |
7.1 |
0.05 |
руб |
|
Напиток |
Компот |
калорий - |
74.4 |
0.14 |
руб |
|
Напиток |
Кофе на молоке |
калорий - |
154.8 |
0.11 |
руб |
|
Напиток |
Молочный напиток |
калорий - |
264.9 |
0.34 |
руб |
|
Суп |
Суп молочный |
калорий - |
396.6 |
0.22 |
руб |
SELECT Вид, Блюдо, 'калорий –',
(SUM(INT((Белки+Углев)*4.1+Жиры*9.3)*Вес/1000)),
(SUM(Стоимость/К_во*Вес/1000)+MIN(Труд/100)),’руб’
FROM Блюда, Вид_блюд, Состав, Продукты, Наличие
WHERE Блюда.БЛ = Состав.БЛ
AND Состав.ПР = Продукты.ПР
AND Состав.ПР = Наличие.ПР
AND Блюда.В = Вид_блюд.В
AND БЛ NOT IN
( SELECT БЛ
FROM Состав
WHERE ПР IN
( SELECT ПР
FROM Наличие
WHERE К_во = 0))
GROUP BY Вид, Блюдо
HAVING SUM(Стоимость/К_во*Вес/1000+MIN(Труд/100)) < 1.5
AND SUM(((Белки+Углев)*4.1+Жиры*9.3)*Вес/1000) < 400
ORDER BY Вид, 4;
Рисунок 2.7
Такой результат, нестрого говоря, строился следующим образом.
FROM. Эта фраза инициирует создание в рабочей памяти таблицы, являющейся декартовым произведением таблиц Блюда, Вид_блюд, Состав, Продукты и Наличие.
WHERE. Эта фраза нужна для преобразования полученного декартова произведения в естественное соединение и удаления из последнего строк с кодами блюд, не обеспеченных продуктами. Естественное соединение образуется путем вычеркивания строк, где не совпадают: код блюда из таблицы Блюда с кодом блюда из таблицы Состав, код продукта из таблицы Состав с кодом продукта из таблицы Продукты и т.д. Обеспеченность блюда всеми продуктами проверяется с помощью последовательности подзапросов. Внутренний подзапрос выдает перечень кодов продуктов, которых нет в кладовой пансионата. Следующий подзапрос выдает коды тех блюд, в состав которых должны входить «отсутствующие» продукты. И, наконец, из естественного соединения вычеркиваются строки с кодами полученных блюд (точнее оставляются строки «Где код блюда не принадлежит перечню кодов блюд, полученному в подзапросе».
SELECT. Из полученного соединения удаляются столбцы, не используемые в выражениях SELECT или других фразах. Если в списке SELECT есть выражения (константы), то для хранения их значений формируются дополнительные столбцы и инициируются операции по их заполнению. В рассматриваемом примере будут сохранены столбцы Вид, Блюдо, Белки, Углев, Жиры, Вес, Стоимость, К_во и созданы дополнительные столбцы для формирования и хранения значений стоимости и калорийности составляющих каждого блюда, а также для хранения текстовых констант 'калорий –' и 'руб'. Обратите внимание на прием, использованный при суммировании стоимостей продуктов, входящих в состав блюда, и стоимости его приготовления (Труд): можно ли заменить MIN на MAX или AVG?
GROUP BY. Отредактированное естественное соединение группируется по видам блюд и их названиям. Создаются группы горячих блюд, десертов и т.д., а внутри каждой группы создаются подгруппы строк со сведениями о продуктах, относящихся к конкретному блюду группы.
SELECT. Каждая подгруппа строк, полученная на предыдущем шаге, преобразуется в единственную строку для результата. В нее заносится вид блюда (общий для всех подгрупп группы), название блюда (общее для всех строк подгруппы), две текстовых константы ('калорий –' и 'руб') и две суммы. Последние формируются путем суммирования тех значений дополнительных столбцов, которые принадлежат подгруппе.
HAVING. Сформированные строки, не удовлетворяющие условиям фразы HAVING
SUM(Стоимость/К_во*Вес/1000+MIN(Труд/100)) < 1.5 и
SUM(((Белки+Углев)*4.1+Жиры*9.3)*Вес/1000) < 400
исключаются из результата предыдущего шага.
ORDER BY. Результат шага 6 упорядочивается в соответствии со списком фразы ORDER BY для получения окончательного результата. Сначала строки группируются по видам блюд (в алфавитном порядке), а затем – по значению элемента данных, указанного на четвертом месте фразы SELECT, т.е. по калорийности.
Конечно, рассмотренный запрос весьма сложен, но попробуйте написать на любом знакомом вам языке программу, реализующую те же действия, и оцените сложность ее написания и отладки.
2.2.4. Модификация данных в таблицах SQL.
Особенности и синтаксис предложений модификации
Модификация данных может выполняться с помощью предложений DELETE (удалить), INSERT (вставить) и UPDATE (обновить). Подобно предложению SELECT они могут оперировать как базовыми таблицами, так и представлениями. Однако по ряду причин не все представления являются обновляемыми. Пока зафиксируем этот факт, отложив описание представлений и особенностей их обновления до главы 5, но будем помнить, что термин «представление» относится только к обновляемым представлениям.
Предложение DELETE имеет формат
DELETE
FROM базовая таблица | представление
[WHERE фраза];
и позволяет удалить содержимое всех строк указанной таблицы (при отсутствии WHERE фразы) или тех ее строк, которые выделяются WHERE фразой.
Предложение INSERT имеет один из следующих форматов:
INSERT
INTO {базовая таблица | представление} [(столбец [,столбец] …)]
VALUES ({константа | переменная} [,{константа | переменная}] …);
или
INSERT
INTO {базовая таблица | представление} [(столбец [,столбец] …)]
подзапрос;
В первом формате в таблицу вставляется строка со значениями полей, указанными в перечне фразы VALUES (значения), причем i-е значение соответствует i-му столбцу в списке столбцов (столбцы, не указанные в списке, заполняются NULL-значениями). Если в списке VALUES фразы указаны все столбцы модифицируемой таблицы и порядок их перечисления соответствует порядку столбцов в описании таблицы, то список столбцов в фразе INTO можно опустить. Однако не советуем этого делать, так как при изменении описания таблицы (перестановка столбцов или изменение их числа) придется переписывать и INSERT предложение.
Во втором формате сначала выполняется подзапрос, т.е. по предложению SELECT в памяти формируется рабочая таблица, а потом строки рабочей таблицы загружаются в модифицируемую таблицу. При этом i-й столбец рабочей таблицы (i-й элемент списка SELECT) соответствует i-му столбцу в списке столбцов модифицируемой таблицы. Здесь также при выполнении указанных выше условий может быть опущен список столбцов фразы INTO.
Предложение UPDATE также имеет два формата. Первый из них:
UPDATE (базовая таблица | представление}
SET столбец = значение [, столбец = значение] …
[WHERE фраза]
где значение – это
столбец | выражение | константа | переменная
и может включать столбцы лишь из обновляемой таблицы, т.е. значение одного из столбцов модифицируемой таблицы может заменяться на значение ее другого столбца или выражения, содержащего значения нескольких ее столбцов, включая изменяемый.
При отсутствии WHERE фразы обновляются значения указанных столбцов во всех строках модифицируемой таблицы. WHERE фраза позволяет сократить число обновляемых строк, указывая условия их отбора.
Второй формат описывает предложение, позволяющее производить обновление значений модифицируемой таблицы по значениям столбцов из других таблиц. К сожалению в ряде СУБД эти форматы отличаются друг от друга и от стандарта. Для примера приведем один из таких форматов:
UPDATE {базовая таблица | представление}
SET столбец = значение [, столбец = значение] …
FROM {базовая таблица | представление} [псевдоним],
{базовая таблица | представление} [псевдоним]
[,{базовая таблица | представление} [псевдоним]] …
[WHERE фраза]
Здесь перечень таблиц фразы FROM содержит имя модифицируемой таблицы и тех таблиц, значения столбцов которых используются для обновления. При этом, естественно, таблицы должны быть связаны между собой в WHERE фразе, которая, кроме того, служит для указания условий отбора обновляемых строк модифицируемой таблицы.
В значениях, находящихся в правых частях равенств фразы SET, следует уточнять имена используемых столбцов, предваряя их именем таблицы (псевдонима).
Предложение INSERT
Вставка единственной записи в таблицу
Добавить в таблицу Блюда блюдо:
Шашлык (БЛ – 34, Блюдо – Шашлык, В – Г, Основа – Мясо, Выход – 150)
при неизвестной пока трудоемкости приготовления этого блюда.
INSERT
INTO Блюда (БЛ, Блюдо, В, Основа, Выход)
VALUES (34, 'Шашлык', 'Г', 'Мясо', 150);
Создается новая запись для блюда с номером 34, с неопределенным значением в столбце Труд.
Порядок полей в INSERT не обязательно должен совпадать с порядком полей, в котором они определялись при создании таблицы. Вполне допустима и такая версия предыдущего предложения:
INSERT
INTO Блюда (Основа, В, Блюдо, БЛ, Выход)
VALUES ('Мясо', 'Г', 'Шашлык', 34, 150);
При известной трудоемкости приготовления шашлыка (например, 5 коп) сведения о нем можно ввести с помощью укороченного предложения:
INSERT
INTO Блюда
VALUES (34, 'Шашлык', 'Г', 'Мясо', 150, 5);
в котором должен соблюдаться строгий порядок перечисления вводимых значений, так как, не имея перечня загружаемых столб-цов, СУБД может использовать лишь перечень, который определен при создании модифицируемой таблицы.
В предыдущих примерах проводилась модификация стержневой сущности, т.е. таблицы с первичным ключом БЛ. Почти все СУБД имеют механизмы для предотвращения ввода не уникального первичного ключа, например, ввода «Шашлыка» под номером, меньшим 34. А как быть с ассоциациями или другими таблицами, содержащими внешние ключи?
Пусть, например, потребовалось добавить в рецепт блюда Салат летний (БЛ = 1) немного (15 г) лука (ПР = 10), и мы воспользовались предложением
INSERT
INTO Состав (БЛ, ПР, Вес)
VALUES (1, 10, 15);
Подобно операции DELETE операция INSERT может нарушить непротиворечивость базы данных. Если не принять специальных мер, то СУБД не проверяет, имеется ли в таблице Блюда блюдо с первичным ключом БЛ = 1 и в таблице Продукты – продукт с первичным ключом ПР = 10. Отсутствие любого из этих значений породит противоречие: в базе появится ссылка на несуществующую запись. Проблемы, возникающие при использовании внешних ключей, подробно рассмотрены в литературе, а здесь отме-тим, что все «приличные» СУБД имеют механизмы для предотв-ращения ввода записей со значениями внешних ключей, отсутст-вующих среди значений соответствующих первичных ключей.
Вставка множества записей
Создать временную таблицу К_меню, содержащую калорийность и стоимость всех блюд, которые можно приготовить из имеющихся продуктов. (Эта таблица будет использоваться шеф-поваром для составления меню на следующий день.)
Для создания описания временной таблицы можно, например, воспользоваться предложением CREATE TABLE
CREATE TABLE К_меню
( Вид CHAR (10),
Блюдо CHAR (60),
Калор_блюда INTEGER,
Стоим_блюда REAL);
а для ее загрузки данными – предложение INSERT с вложенным подзапросами:
INSERT
INTO К_меню
SELECT Вид, Блюдо,
INT(SUM(((Белки+Углев)*4.1+Жиры*9.3) * Вес/1000)),
(SUM(Стоимость/К_во*Вес/1000) + MIN(Труд/100))
FROM Блюда, Вид_блюд, Состав, Продукты, Наличие
WHERE Блюда.БЛ = Состав.БЛ
AND Состав.ПР = Продукты.ПР
AND Состав.ПР = Наличие.ПР
AND Блюда.В = Вид_блюд.В
AND БЛ NOT IN
( SELECT БЛ
FROM Состав
WHERE ПР IN
( SELECT ПР
FROM Наличие
WHERE К_во = 0))
GROUP BY Вид, Блюдо
ORDER BY Вид, 3;
В этом запросе предложение SELECT выполняется так же, как обычно, но результат не выводится на экран, а копируется в таблицу К_меню. Теперь с этой копией можно работать как с обычной базовой таблицей (Блюда, Про-дукты,…), т.е. выбирать из нее даннные на экран или принтер, обновлять в ней данные и т.п. Никакая из этих операций не будет оказывать влияния на исходные данные (например, изменение в ней названия блюда Салат летний на Салат весенний не приведет к подобному изменению в таблице Блюда, где сохранится старое название). Так как это может привести к противоречиям, то подобные временные таблицы уничтожают после их использования. Поэтому программа, обслуживающая шеф-повара, должна исполнять предложение DROP TABLE К_меню после того, как будет закончено составление меню.
Использование INSERT…SELECT для построения внешнего соединения
Рассмотренное в естественное соединение двух таблиц не включает тех строк какой-либо из них, для которых нет соответствующих строк в другой таблице. Например, если в таблицу Блюда были занесены под номером 34 сведения о Шашлыке, а рецепт его приготовления не был занесен в таблицу Рецепты, то при загрузке их естественного соединения в таблицу Временная:
CREATE TABLE Временная
( Вид CHAR (8),
Блюдо CHAR (60),
Рецепт CHAR (560));
INSERT
INTO Временная
SELECT Вид, Блюдо, Рецепт
FROM Блюда, Рецепты, Вид_блюд
WHERE Блюда.БЛ = Рецепты.БЛ
AND Блюда.В = Вид_блюд.В;
в ней не окажется строки с Шашлыком (в таблице Рецепты не обнаружен код 34, и строка с этим кодом исключена из результата).
Следовательно, в некотором смысле можно считать, что при обычном соединении теряется информация для таких несоответствующих строк. Однако иногда (как и в приведенном примере) может потребоваться способность сохранить эту информацию. В этом случае можно воспользоваться так называемым внешним соединением:
INSERT
INTO Временная
SELECT Вид, Блюдо, Рецепт
FROM Блюда, Рецепты, Вид_блюд
WHERE Блюда.БЛ = Рецепты.БЛ
AND Блюда.В = Вид_блюд.В;
INSERT
INTO Временная
SELECT Вид, Блюдо, «???»
FROM Блюда, Вид_блюд
WHERE Блюда.В = Вид_блюд.В
AND БЛ NOT IN
( SELECT БЛ
FROM Рецепты);
В результате будет создана базовая таблица
|
Вид |
Блюдо |
Рецепт |
|
Закуска |
Салат летний |
Помидоры и яблоки нарезать… |
|
Закуска |
Салат мясной |
Вареное охлажденное мясо, … |
|
. . . |
||
|
Напиток |
Кофе черный |
Кофеварку или кастрюлю спо… |
|
Напиток |
Кофе на молоке |
Сварить черный кофе, как … |
|
Горячее |
Шашлык |
??? |
где первые 33 строки соответствуют первому INSERT и представляют собой проекцию естественного соединения таблиц Блюда и Рецепты по кодам блюд (БЛ), включающую три столбца. Последняя строка результата соответствует второму INSERT и сохраняет информацию о блюде Шашлык, рецепт котого пока не введен в таблицу Рецепты.
Заметим, что для внешнего соединения нужны два отдельных INSERT…SELECT. Однако тот же результат можно получить и одним INSERT…SELECT, используя фразу UNION, объединяющую предложения SELECT из двух INSERT:
INSERT
INTO Временная
SELECT Вид, Блюдо, Рецепт
FROM Блюда, Рецепты, Вид_блюд
WHERE Блюда.БЛ = Рецепты.БЛ
AND Блюда.В = Вид_блюд.В
UNION
SELECT Вид, Блюдо, «???»
FROM Блюда, Вид_блюд
WHERE Блюда.В = Вид_блюд.В
AND БЛ NOT IN
( SELECT БЛ
FROM Рецепты);
Предложение UPDATE
Обновление единственной записи
Изменить название блюда с кодом БЛ=5 на Форшмак, увеличить его выход на 30 г и установить NULL-значение в столбец Труд.
UPDATE Блюда
SET Блюдо = 'Форшмак', Выход = (Выход+30), Труд = NULL
WHERE БЛ = 5;
Обновление множества записей
Утроить цену всех продуктов таблицы поставки (кроме цены кофе – ПР = 17).
UPDATE Поставки
SET Цена = Цена * 3
WHERE ПР <> 17;
Обновление с подзапросом
Установить равной нулю цену и К_во продуктов для поставщиков из Паневежиса и Резекне.
UPDATE Поставки
SET Цена = 0, К_во = 0
WHERE ПС IN
(SELECT ПС
FROM Поставщики
WHERE Город IN ('Паневежис', 'Резекне'));
Обновление нескольких таблиц
Изменить номер продукта ПР = 13 на ПР = 20.
UPDATE Продукты UPDATE Состав
SET ПР = 20 SET ПР = 20
WHERE ПР = 13; WHERE ПР = 13;
UPDATE Поставки UPDATE Наличие
SET ПР = 20 SET ПР = 20
WHERE ПР = 13; WHERE ПР = 13;
К сожалению в единственным запросе невозможно обновить более одной таблицы, а так как код продукта входит в четыре таблицы, то пришлось выдать четыре сходных запроса. Это может привести к противоречию базы данных (нарушению целостности по ссылкам), поскольку после выполнения первого предложения таблицы Состав, Поставки и Наличие ссылаются на уже несуществующий продукт. База становится непротиворечивой только после выполнения четвертого запроса.
О конструировании предложений модификации
Для тех, кто достаточно хорошо понял предложение SELECT, несложно овладеть конструированием предложений DELETE, INSERT и UPDATE. Но в процессе такого конструирования следует учитывать, что:
Если в WHERE фразе предложений DELETE и UPDATE используется вложенный подзапрос, то во фразе FROM этого подзапроса не должна упоминаться таблица, из которой удаляются (в которой обновляются) строки. Аналогично, в подзапросе предложения INSERT не должна упоминаться таблица, в которую загружаются данные.
Так, SQL отвергнет предложение
INSERT
INTO Выбрано
SELECT (33), Т, БЛ
FROM Выбрано
WHERE СМ = 17;
позволяющее ввести информацию о том, что отдыхающий, сидящий на 33-м месте, выбирает тот же набор блюд, что и отдыхающий, сидящий на 17-м месте. Ввод придется осуществить через какую-либо промежуточную таблицу, например, таблицу Выбор:
DELETE
FROM Выбор;
INSERT
INTO Выбор (СМ, Т, БЛ)
SELECT (33), Т, БЛ
FROM Выбрано
WHERE СМ = 17;
INSERT
INTO Выбрано
SELECT СМ, Т, БЛ
FROM Выбор;
Составляя предложения модификации данных, необходимо все время помнить о сохранении непротиворечивости базы данных. Об этом упоминалось ранее и подробно говорилось в литературе.
Предложение DELETE
Удаление единственной записи
Удалить поставщика с ПС = 7.
DELETE
FROM Поставщики
WHERE ПС = 7;
Если таблица Поставки содержит в момент выполнения этого предложения какие-либо поставки для поставщика с ПС = 7, то такое удаление нарушит непротиворечивость базы данных. К сожалению нет операции удаления, одновременно воздействующей на несколько таблиц. Однако в некоторых СУБД реализованы механизмы поддержания целостности, позволяющие отменить некорректное удаление или каскадировать удаление на несколько таблиц.
Удаление множества записей
Удалить все поставки.
DELETE
FROM Поставки;
Поставки – все еще известная таблица, но в ней теперь нет строк. Для уничтожения таблицы надо выполнить операцию DROP TABLE Поставки.
Удалить все мясные блюда.
DELETE FROM Блюда
WHERE Основа = 'Мясо';
Удаление с вложенным подзапросом
Удалить все поставки для поставщика из Паневежиса.
DELETE
FROM Поставки
WHERE ПС IN
(SELECT ПС
FROM Поставщики
WHERE Город = 'Паневежис');
Предложение INSERT
Вставка единственной записи в таблицу
Добавить в таблицу Блюда блюдо:
Шашлык (БЛ – 34, Блюдо – Шашлык, В – Г, Основа – Мясо, Выход – 150)
при неизвестной пока трудоемкости приготовления этого блюда.
INSERT
INTO Блюда (БЛ, Блюдо, В, Основа, Выход)
VALUES (34, 'Шашлык', 'Г', 'Мясо', 150);
Создается новая запись для блюда с номером 34, с неопределенным значением в столбце Труд.
Порядок полей в INSERT не обязательно должен совпадать с порядком полей, в котором они определялись при создании таблицы. Вполне допустима и такая версия предыдущего предложения:
INSERT
INTO Блюда (Основа, В, Блюдо, БЛ, Выход)
VALUES ('Мясо', 'Г', 'Шашлык', 34, 150);
При известной трудоемкости приготовления шашлыка (например, 5 коп) сведения о нем можно ввести с помощью укороченного предложения:
INSERT
INTO Блюда
VALUES (34, 'Шашлык', 'Г', 'Мясо', 150, 5);
в котором должен соблюдаться строгий порядок перечисления вводимых значений, так как, не имея перечня загружаемых столб-цов, СУБД может использовать лишь перечень, который определен при создании модифицируемой таблицы.
В предыдущих примерах проводилась модификация стержневой сущности, т.е. таблицы с первичным ключом БЛ. Почти все СУБД имеют механизмы для предотвращения ввода не уникального первичного ключа, например, ввода «Шашлыка» под номером, меньшим 34. А как быть с ассоциациями или другими таблицами, содержащими внешние ключи?
Пусть, например, потребовалось добавить в рецепт блюда Салат летний (БЛ = 1) немного (15 г) лука (ПР = 10), и мы воспользовались предложением
INSERT
INTO Состав (БЛ, ПР, Вес)
VALUES (1, 10, 15);
Подобно операции DELETE операция INSERT может нарушить непротиворечивость базы данных. Если не принять специальных мер, то СУБД не проверяет, имеется ли в таблице Блюда блюдо с первичным ключом БЛ = 1 и в таблице Продукты – продукт с первичным ключом ПР = 10. Отсутствие любого из этих значений породит противоречие: в базе появится ссылка на несуществующую запись. Проблемы, возникающие при использовании внешних ключей, подробно рассмотрены в литературе, а здесь отме-тим, что все «приличные» СУБД имеют механизмы для предотв-ращения ввода записей со значениями внешних ключей, отсутст-вующих среди значений соответствующих первичных ключей.
Предложение UPDATE
Обновление единственной записи
Изменить название блюда с кодом БЛ=5 на Форшмак, увеличить его выход на 30 г и установить NULL-значение в столбец Труд.
UPDATE Блюда
SET Блюдо = 'Форшмак', Выход = (Выход+30), Труд = NULL
WHERE БЛ = 5;
Обновление множества записей
Утроить цену всех продуктов таблицы поставки (кроме цены кофе – ПР = 17).
UPDATE Поставки
SET Цена = Цена * 3
WHERE ПР <> 17;
Обновление с подзапросом
Установить равной нулю цену и К_во продуктов для поставщиков из Паневежиса и Резекне.
UPDATE Поставки
SET Цена = 0, К_во = 0
WHERE ПС IN
(SELECT ПС
FROM Поставщики
WHERE Город IN ('Паневежис', 'Резекне'));
Обновление нескольких таблиц
Изменить номер продукта ПР = 13 на ПР = 20.
UPDATE Продукты UPDATE Состав
SET ПР = 20 SET ПР = 20
WHERE ПР = 13; WHERE ПР = 13;
UPDATE Поставки UPDATE Наличие
SET ПР = 20 SET ПР = 20
WHERE ПР = 13; WHERE ПР = 13;
К сожалению в единственным запросе невозможно обновить более одной таблицы, а так как код продукта входит в четыре таблицы, то пришлось выдать четыре сходных запроса. Это может привести к противоречию базы данных (нарушению целостности по ссылкам), поскольку после выполнения первого предложения таблицы Состав, Поставки и Наличие ссылаются на уже несуществующий продукт. База становится непротиворечивой только после выполнения четвертого запроса.
О конструировании предложений модификации
Для тех, кто достаточно хорошо понял предложение SELECT, несложно овладеть конструированием предложений DELETE, INSERT и UPDATE. Но в процессе такого конструирования следует учитывать, что:
Если в WHERE фразе предложений DELETE и UPDATE используется вложенный подзапрос, то во фразе FROM этого подзапроса не должна упоминаться таблица, из которой удаляются (в которой обновляются) строки. Аналогично, в подзапросе предложения INSERT не должна упоминаться таблица, в которую загружаются данные.
Так, SQL отвергнет предложение
INSERT
INTO Выбрано
SELECT (33), Т, БЛ
FROM Выбрано
WHERE СМ = 17;
позволяющее ввести информацию о том, что отдыхающий, сидящий на 33-м месте, выбирает тот же набор блюд, что и отдыхающий, сидящий на 17-м месте. Ввод придется осуществить через какую-либо промежуточную таблицу, например, таблицу Выбор:
DELETE
FROM Выбор;
INSERT
INTO Выбор (СМ, Т, БЛ)
SELECT (33), Т, БЛ
FROM Выбрано
WHERE СМ = 17;
INSERT
INTO Выбрано
SELECT СМ, Т, БЛ
FROM Выбор;
Составляя предложения модификации данных, необходимо все время помнить о сохранении непротиворечивости базы данных. Об этом упоминалось ранее и подробно говорилось в литературе.
2.3. Обзор основных SQL-серверов.
2.3.1. SQL-сервер Oracle.
Общая характеристика продуктов Oraсle
Все продукты Oracle (СУБД, средства разработки, средства для конечного пользователя, сетевые компоненты) являются открытыми, масштабируемыми и программируемыми. Они позволяют разрабатывать приложения, как уровня небольшой рабочей группы, так и уровня огромного предприятия с тысячами пользователей, террабайтными базами, размещенными в различных зданиях и даже странах.
Средства Oracle позволяют надежно защитить эти данные, обеспечить их целостность и непротиворечивость. Продукты Oracle работают более чем на ста вычислительных платформах (компьютер + операционная система), поддерживают все основные промышленные сетевые протоколы и графические оконные среды. Это позволяет с минимальными затратами переносить готовые приложения с одной платформы на другую. Например, разработав приложение на однопроцессорном персональном компьютере с MS Windows, Вы можете далее выполнять его на Unix – машинах, больших IBM машинах, SMP и MPP архитектурах, высоко надежных и кластерных архитектурах.
При повышении нагрузки на приложение, можно заменить сервер на более мощный, добавить еще один сервер, вынести часть обработки в другой узел и т. д. Если клиент работал через терминал, а затем решил перейти к архитектуре клиент – сервер или даже переместился в другой город, он сможет продолжать работать с теми же БД Oracle. Все это не потребует модификации кода приложений.
С помощью средств Oracle можно реализовать оперативную обработку (OLTP – системы), системы поддержки принятия решений (DSS – системы) и системы накопления и анализа больших объемов данных (Data Warehouse и OLAP – системы). Oracle поддерживает все основные стандарты:
FIPS 127-2, ANSI X3-135.1992 – для БД;
NCSC TDI C2, B1, ITSEC F – C2/E3, F – B1/B3 – по защите данных;
OSI, DNSIX (MaxSix), SNMP – для сети;
ODBC, TSIG, X/Open, DCE, DDE, OLE, OCX, VBX – для взаимодействия приложений.
Классификация продуктов Oracle
Все многообразие продуктов фирмы Oracle можно разделить на следующие группы:
Oracle7 Server – ядро СУБД и дополнительные компоненты ядра (опции). Они необходимы для хранения, поиска, извлечения, обработки и администрирования данных;
инструментальные средства разработки приложений. Это, в первую очередь, набор средств разработчика Developer/2000, а также прекомпиляторы с языков 3GL и библиотека CALL-интерфейса;
средства автоматизации проектирования и разработки (CASE-средства) – Designer/2000;
средства для конечных пользователей. Это набор средств Descoverer/2000, офисная система Oracle Office, средства хранения и обработки текстов Text Server (c Context и CoAutor);
средства для анализа данных и создания OLAP (online analyse processing) приложений – Express – продукты;
средства для обеспечения работы продуктов Oracle в компьютерной сети. Это SQL*Net с драйверами различных сетевых протоколов, средства управления сетью, кодирования данных, преобразования протоколов;
средства для взаимодействия с пакетами других фирм. Это шлюзы по данным (Transparent Gateway) к различным СУБД и процедурные шлюзы; ODBC драйвер, Oracle Objects for OLE, универсальный пакет связи Oracle Glue;
продукты для рабочих групп – Workgroup/2000. К этой группе относится нерасширяемое ядро Oracle для персональных компьютеров, однопользовательский персональный Oracle, средства разработки небольших приложений-Oracle Power Objects. Продукты для рабочих групп отличаются компактностью, простотой установки и использования, а так же низкими ценами;
готовые прикладные системы – Oracle Applications. Среди них наиболее известными являются: Oracle Financial – финансовые, Oracle Manufacturing – управление производством, Oracle Human Resources – кадры, бухгалтерия;
новые направления. К этой группе можно отнести продукты для работы с мультимедиа (Media Server, Media Net, Media Objects), средства для работы с БД по медленным и ненадежным сетям (радиомодемы, телефоны, сотовая связь) – Oracle Mobile Agents, средства для работы с БД по Internet (WWW Viewer и WWW сервер).
Oracle7 Server
Универсальный сервер Oracle позволяет хранить и обрабатывать самые разные типы данных. Кроме привычных структурированных данных (числа, строки, дата, время) можно работать с неструктурированными данными, такими как тексты, многомерные пространственные данные, изображения, видео, аудио. При этом Oracle обеспечивает надежность хранения и быстроту доступа к этим данным, а так же возможность создания приложений, работающих со всеми этими данными в комплексе.
Сегодня Oracle – это реляционная СУБД, поддерживающая язык SQL и его расширения для работы с различными типами данных, а так же механизм транзакций. Особенности архитектуры Oracle Server обеспечивают очень высокое быстродействие системы в многопользовательском режиме. Оригинальный механизм многоверсионной записи позволяет получать согласованные результаты при выполнении запросов без блокировки данных. Автоматически выполняется блокировка данных на уровне записи при модификации данных. Это позволяет увеличивать число пользователей системы без снижения ее производительности.
Встроенные оптимизаторы запросов, использование алгоритмов хеширования, битовых индексов и B-деревьев, возможность тонкой настройки СУБД на возможности среды эксплуатации также позволяют обеспечить очень высокое быстродействие. Дополнительная компонента ядра Parallel Query Option позволяет ускорить работу существующих приложений за счет использования возможностей многопроцессорных машин. Эта компонента резко снижает время выполнения отдельного запроса, загрузки данных, построения индекса и т. д. За счет разбиения операций (например, оператора Select) на части и выполнения этих частей параллельно на разных процессорах. Увеличение числа процессоров с 1 до 10 позволяет ускорить выполнение запроса в 8 раз, что очень важно для работы с очень большими БД.
Компоненты Oracle Parallel Server позволяет СУБД Oracle и приложениям работать на МРР и кластерных архитектурах. Наиболее часто кластер реализуется на базе компьютеров фирм DЕC, Sequent, HP, Sun, IBM (RS 6000). При этом все машины кластера могут работать с одной и той же БД (что ускоряет и распараллеливает работу), а при выходе из строя одного из узлов кластера, другие узлы аккуратно отработают отказ и возьмут на себя дальнейшую обработку данных. Использование Oracle на кластере компьютеров позволяет относительно недорого обеспечить высоконадежное и быстрое решение задач.
Oracle Server позволяет реализовать как односерверную, так и многосерверную архитектуру БД. В случае многосерверной архитектуры узлы могут отстоять на большое расстояние, размещаться на разных ОС и компьютерах, связываться по разным сетевым протоколам. На основе многосерверной архитектуры Oracle позволяет реализовать как распределенную базу данных, так и репликацию.
Компонента Distributed Option позволяет приложению работать с распределенной БД так же, как с локальной. Автоматически реализуемый протокол 2х-фазной фиксации позволяет одновременно модифицировать данные в разных узлах БД. Узлы всегда находятся в согласованном состоянии, однако для этого требуется постоянное наличие связи между узлами. Механизм репликации не требует постоянного наличия связи между узлами. Через заданные промежутки времени или при восстановлении связи, изменения, сделанные в данном узле, будут отрабатываться в копиях таблиц в других узлах. Можно реализовать не только простую репликацию (изменения распространяются от таблицы – мастер к копиям), но и сложную репликацию (когда в узлах хранятся копии одной и той же таблицы и их можно одновременно обновлять).
Сложную репликацию реализует компонента Advance Replcation Option, она же помогает задать механизм разрешения возникающих коллизий. Oracle Server имеет средства для реализации Backup копии Вашей базы, готовой быстро вступить в действие при уничтожении основной базы.
2.3.2. Microsoft SQL сервер.
Microsoft SQL Server для Windows NT является основным средством обработки больших объемов информации. Новая версия SQL Server значительно расширена для повышения производительности СУБД, упрощения администрирования, повышения надежности и скорости обработки данных.
Обзор продукта
Сейчас организации становятся все более динамичными. Это необходимо для быстрой реакции на меняющиеся условия ведения бизнеса. Все более активно идет процесс децентрализации принятия решений, а стремление повысить продуктивность принятия решений ведет к упрощению процедур реализации различного рода идей. Для создания средств поддержки подобного рода изменений организации обращаются к технологиям распределенной обработки информации. Эти технологии позволяют размещать данные как можно ближе к пользователям, которым информация необходима для принятия важных решений.
|
История развития SQL Server |
||||
|
|
SQL Server 6.0 |
SQL Server следующие версии |
||
|
NT Server |
NT Server |
Cairo |
||
|
Симметричная архитектура сервера (SMP) Графические средства администратора Унифицированная регистрация в сети Расширенные хранимые процедуры Интеграция с эл. Почтой SQL Object Manager Service Manager RPC для доступа к БД Performance monitor ANSI89 Level 1 |
Тиражирование данных Параллельная обработка БД Сканирование, индексирование, создание и восстановление страховых копий, загрузка Поддержка очень больших БД Оптимизатор, опережающее чтение, управление блокировками Распределенное управление OLE automation ODBC курсоры Расширения языка ANSI92 (95.1) X/A (95.1) |
Унифицированное хранение данных Параллельные запросы Distributed joins Доступ к данным OLE Проверка версий, блокировка на уровне записи Защита средствами Cairo, каталоги Пользовательские функции Интеграция с репозитарием объектов |
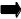
Microsoft SQL Server 6.0 –специально разработана для удовлетворения требований, предъявляемых системами распределенной обработки данных (таких как тиражирование данных, параллельная обработка, поддержка больших баз данных (БД) на относительно недорогих аппаратных платформах, сохраняющая простоту управления и использования). Сервер имеет средства удаленного администрирования и управления операциями, организованные на базе объектно- ориентированной распределенной среды управления. Новые возможности, такие как OLE Automation и средства программирования административных задач на языке Visual Basic for Applications, обеспечивают интеграцию с приложениями, работающими на ПК. По-прежнему Microsoft уделяет очень большое внимание соответствию своих продуктов существующим промышленным стандартам, что отразилось в расширенной поддержке ANSI SQL и ODBC.
Microsoft SQL Server 6.0 входит в состав семейства Microsoft BackOffice, объединяющего пять серверных приложений, разработанных для совместного функционирования в качестве интегрированной системы. Она позволяет пользователям повысить производительность процесса принятия решений средствами систем, базирующихся на архитектуре клиент-сервер. Кроме того, Microsoft SQL Server 6.0 завершает линию средств разработки, включающих Microsoft Access, Visual FoxPro®, Visual Basic и Visual C++™.
2.3.3. MySQL-сервер.
MySQL – компактный многопоточный сервер баз данных. MySQL характеризуется большой скоростью, устойчивостью и легкостью в использовании.
MySQL был разработан компанией TcX для внутренних нужд, которые заключались в быстрой обработке очень больших баз данных. Компания утверждает, что использует MySQL с 1996 года на сервере с более чем 40 БД, которые содержат 10,000 таблиц, из которых более чем 500 имеют более 7 миллионов строк.
MySQL является идеальным решением для малых и средних приложений. Исходные тексты сервера компилируются на множестве платформ. Наиболее полно возможности сервера проявляются на Unix-серверах, где есть поддержка многопоточности, что дает значительный прирост производительности. На текущий момент MySQL все еще в стадии разработки, хотя версии 3.22 полностью работоспособны.
MySQL-сервер является бесплатным для некоммерческого использования. Иначе необходимо приобретение лицензии, стоимость которой составляет 190 EUR.
Возможности MySQL.
MySQL поддерживает язык запросов SQL в стандарте ANSI 92, и кроме этого имеет множество расширений к этому стандарту, которых нет ни в одной другой СУБД.
Краткий перечень возможностей MySQL:
1.Поддерживается неограниченное количество пользователей, одновременно работающих с базой данных.
2.Количество строк в таблицах может достигать 50 млн.
3.Быстрое выполнение команд. Возможно MySQL самый быстрый сервер из существующих.
4.Простая и эффективная система безопасности.
MySQL – очень быстрый сервер, но для достижения этого разработчикам пришлось пожертвовать некоторыми требованиями к реляционным СУБД.
В MySQL отсутствуют:
1.Поддержка вложенных запросов, типа SELECT * FROM table1 WHERE id IN (SELECT id FROM table2). Утверждается, что такая возможность будет в версии 3.23.
2.Не реализована поддержка транзакций. Взамен предлагается использовать LOCK/UNLOCK TABLE.
3.Нет поддержки внешних (foreign) ключей.
4.Нет поддержки триггеров и хранимых процедур.
5.Нет поддержки представлений (VIEW). В версии 3.23 планируется возможность создавать представления.
По словам создателей именно пункты 2-4 дали возможность достичь высокого быстродействия. Их реализация существенно снижает скорость сервера. Эти возможности не являются критичными при создании Web-приложений, что в сочетании с высоким быстродействием и малой ценой позволило серверу приобрести большую популярность.
2.4. Принципы работы web-серверов.
2.4.1. Web-сервер. Понятие, функции, характеристики.
Web-сервер – это программное обеспечение, отвечающее за прием запросов браузеров, поиск указанных файлов и возращение их содержимого.
В настоящее время в мире разработано и широко применяется несколько десятков программ, реализующих эти функции. Практически для каждой операционной системы существует целый ряд таких программ. Некоторые из них являются независимыми от операционной системы и могут использоваться одновременно в разных ОС. Но в подавляющем большинстве Web-серверы ориентированы на применение только в одной операционной системе. Среди них есть как коммерческие программы, так и распространяемые бесплатно. Иногда функции Web-сервера являются только частью функций, заложенных разработчиками в программу. Кроме минимального набора выполняемых задач, определяющих основные функции Web-сервера, большинство программ содержит в себе много дополнительных возможностей. К ним относятся ограничение прав доступа к отдельным документам, возможность криптографической защиты передаваемых и принимаемых данных, создания на одном компьютере нескольких Web-серверов с разными доменными именами, использования нестандартных портов входа для сервера. Кроме этого от Web-серверов часто требуется поддержка работы с системами управления базами данных и языками Perl и Java. Кроме набора функций, существенное влияние на выбор Web-сервера оказывают простота настройки и удобство в администрировании. Немаловажное значение для высоко посещаемых серверов имеет также быстрота ответа программы на запрос клиента. На сегодняшний день (по данным обзора Netcraft Web Server Survey) бесспорным лидером среди Web-серверов является бесплатно распространяемый сервер Apache. В пятерку лидеров входят также серверы Microsoft Internet Information Server, Netscape, NCSA и WebSite.
2.4.2. Трехзвенная архитектура клиент-сервер.
Обыкновенно для небольших организаций разработчики применяют двухзвенную архитектуру клиент-сервер, когда с рабочих станций осуществляется удаленный доступ к базе данных, и не более того. В самых простых, примитивных системах даже не используются возможности, предоставляемые пользователям РСУБД (Распределения Управления Базами данных), какие, как триггеры и сохраненные процедуры; и хотя разработчики именуют подобные системы клиент-серверами, они имеют весьма мало общего с истинными распределенными приложениями. Более того, идеология «толстого клиента» принуждает к установке на рабочих местах весьма дорогостоящих Wintel-компьютеров, способных произвести все основные вычисления обмен данными с удаленным сервером. Операция производится сквозь толстый многоуровневые слой провайверов, которые должны быть установлены на персональной рабочей станции и лицензированы их разработчиками для каждого рабочего места. Иногда получается совершенно нелепая вещь: если пропускная способность сети не достаточно велика или или недостаточно эффективно организован поток прохождения транзакций, то быстродействующие процессоры клиентских машин совершенно бездействуют; в противном же случае, наоборот, сервер базы данных «задыхается» и не успевает ответить каждому из многочисленных и буквально долбящих его, как дятлы, клиентов. При числе одновременно работающих клиентов более 30 необходимо переходит на трехзвенную архитектуру. В трехзвенной архитектуре всю логику работы с сервером можно возложить на специальный сервер приложения, а разделенные на отдельные фрагменты приложения уменьшают нагрузку на и на машину-клиента, и на сервер, перенося соответствующие операции на специальный сервер. Серверная часть приложения лучше защищена, а сами приложения могут либо непосредственно адресоваться к другим серверным приложениям, либо маршрутизировать запросы к ним (рис. 2.8).
2.4.3. Архитектура Internet/Intranet.
Достоинства этой архитектуры (рис 2.9) сводятся к достоинствам соответствующей части системы клиент-сервер.
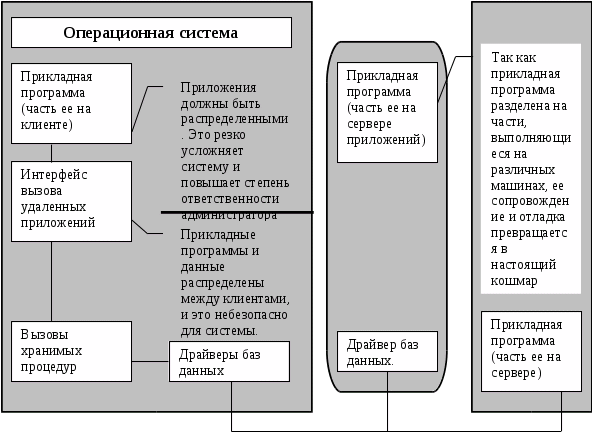
Клиент
Сервер приложений
Сервер баз данных
Рисунок 2.8. Трехзвенная схема работы клиент-сервер.
Клиентская часть
Прикладная программа доступна с любого компьютера, на котором инсталлирован браузер. Пользователю нет необходимости изучать интерфейс прикладной программы, потому что он всегда преобразуется к стандарту HTML-странички. Это помогает снизить затраты на обучение. Кроме того, пользователя совершенно не заботят особенности хардверной платформы и операционной системы, поскольку он имеет дело только с браузером, который умеет делать все.
Серверная часть
Приложения доступны
любому пользователю сети Internet/Intranet,
имеющему право образаться к ним. Поскольку
все операции по сопровождению и
усовершенствованию системы производятся
на сервере, то пропадает необходимость
сопровождать и модернизировать части
приложения, находящиеся на машинах-клиентах.
Такая конфигурация способна обеспечить
работу десятка т
ысяч
или даже миллиона пользователей, являясь
идеальной архитектурой для унаследования
программ.
Рисунок 2.9. Универсальная схема клиент-сервер для сетей Internet/Intranet.
2.2.4. Обзор серверных программ для различных ОС.
Сегодня выпускаются Web-серверы для всех основных платформ, в том числе различных версий UNIX, Windows NT, IntranetWare фирмы Novell (дополнительный компонент NetWare 4.x), OS/2 Warp, Mac OS и даже Windows 95. Web-серверы стали доступными для массового пользователя.
Функции Web-серверов не ограничиваются пересылкой статических HTML-страниц. Java и сопутствующие языки составления сценариев представляют собой идеальную платформу разработки для Web. Во все рассмотренные продукты, за исключением Apache и ICSS, входят средства для работы с прикладными программами Java, размещенными на сервере. Ряд Web-серверов предусматривают собственные API (Application Programming Interface), а некоторые из них снабжены широко известным интерфейсом Netscape Server API (NSAPI).
Наибольшее распространение среди этих серверов получил метод программирования для Web с применением языков сценариев. Фирмы Microsoft и Netscape включили в свои пакеты даже объектно-ориентированные инструменты для быстрой разработки программ (rapid applications development – RAD), рассчитанные на серьезных разработчиков.
Web-серверы все чаще выпускаются в виде комплексов функциональных средств, встраиваемых в ОС. Универсальность сетей на базе TCP/IP означает, что в интрасети допустимо применение различных типов серверов – например, подключение сервера UNIX к сети Windows NT, - но данный подход может оказаться не самым эффективным с точки зрения использования ресурсов.
Благодаря Web-браузерам для администрирования сервера вовсе не обязательно всегда находиться в непосредственной близости от него. В большинстве продуктов имеются функции дистанционного администрирования через Web-браузер.
Чем больше число Web-узлов, участвующих в обмене конфиденциальной информацией, тем острее необходимость в надежной защите и шифровании данных. Самая распространенная форма обеспечения безопасности, применяемая на Web-серверах, - простая аутентификация, во время которой каждый пользователь должен сообщить свой идентификатор и пароль. Средствами для базовой аутентификации снабжены все рассмотренные серверы. Разработчики некоторых серверов пошли дальше, позволив ограничивать доступ по IP-адресу и имени узла.
Для защиты от непрошеных посетителей можно подвергнуть информацию процедуре шифрования. На Web-серверах для шифрования данных служит протокол защиты на уровне гнезд – Secure Sockets Layer (SSL). Для организации защищенного, шифрованного канала связи между сервером и браузером по протоколу SSL выполняется проверка подлинности сертификата. Учреждения уполномоченные выдавать сертификаты, скажем VeriSign, за плату сертифицируют серверы при помощи протокола SSL.
2.4.5. Стандарты, облегчающие создание Web-узлов.
Трудности Web-дизайнеров ныне не ограничиваются написанием программ на JavaScript, подключающих пользователей к версиям одного и того же узла для браузера Netscape или Microsoft. Пользователи мобильных вычислительных устройств (например, персональных цифровых помощников), также получившие доступ к Web, нуждаются в наличии быстро работающих текстовых версий узлов, в то время как разработчики стараются создавать богатые графикой Web-страницы, быстро отображаемые лишь при наличии скоростных каналов.
Web-дизайнерам остается лишь надеяться, что одна из организаций, занимающихся установлением стандартов, например Консорциум World Wide Web (W3C), предложит способ, благодаря которому не придется создавать отдельных версий Web-узлов для каждого типа клиентов.
Между тем стандарт прозрачного выбора типа информационного наполнения существует, причем еще с 1989 года. Проблема в том, что полностью его не поддерживает почти ни один Web-сервер.
Функция выбора типа информационного наполнения является частью протокола HTTP. Она же используется для отправки пользователям загружаемых шрифтов, предусмотренных спецификацией Cascading Style Sheets 2.0.
Известны лишь два Web-сервера, полностью поддерживающих эту функцию, - Apache и Jigsaw. В частности, функция выбора типа информационного наполнения используется на Web-узле для локализации: сервер автоматически устанавливает язык текста согласно данным, полученным от браузера пользователя. Узел поддерживает несколько языков, но не содержит ссылок для выбора одного из них, поскольку этого не требуется.
2.4.6. Web-технологии.
HTML-страницы системы World Wide Web бывают динамические и статические. Средства, наращивающие функциональные возможности Web и позволяющие создавать динамические HTML-страницы, подразделяются на расширения серверной части и расширения клиентской части. Расширения серверной части – это программы, позволяющие повысить функциональность Web-серверов. Расширения клиентской части – это программы, позволяющие наращивать функциональные возможности браузеров. Расширения серверной части можно подразделить на следующие три категории:
Расширения, использующие обычный CGI. Common Gateway Interface (общий шлюзовой интерфейс), или CGI, был первым интерфейсом, позволившим создавать приложения, наращивающие функциональность Web-серверов. CGI-программы обладают наибольшей переносимостью между Web-серверами. Сервер общается с CGI-приложением через стандартные ввод и вывод операционной системы, а также переменные окружения. CGI-программы могут быть написаны на любом языке программирования, вплоть до языка командного интерпретатора операционной системы. Недостатком CGI является необходимость загружать при каждом запросе большую программу, что может привести к истощению ресурсов сервера и происходит достаточно медленно.
Расширения, использующие гибридный CGI. Использование гибридного CGI позволяет сохранить свойственную CGI переносимость, избавившись от присущих ему недостатков. Идея заключается в использование маленькой CGI-программы и некоторого процесса-партнера. CGI-программа получает данные от Web-сервера и передает их процессу-партнеру, который выполняет всю обработку. Процесс-партнер (например, демон в UNIX) загружается один раз при загрузке операционной системы и общается с CGI-программой при помощи межпроцессных коммуникаций.
Расширения, использующие API. В настоящее время широкое распространение получили Web-сервера, предоставляющие программам-расширениям сервера специальные API-интерфейсы. Программы-расширения, использующие API, должны быть созданы в виде разделяемых библиотек (например, DLL, Dynamic Link Library в среде Windows). Они исполняются в адресном пространстве Web-сервера. Очевидно, что расширения такого типа значительно экономнее по отношению к системным ресурсам, чем CGI-программы. Недостатками этого способа являются его небезопасность (ошибка в такой программе может привести к выходу из строя всего сервера) и низкая переносимость API-приложений между разными Web-серверами (т.к. разные сервера могут использовать разные API). Наиболее распространенными API-интерфейсами Web-серверов являются NSAPI фирмы Netscape и ISAPI компании Microsoft.
Ниже представлен список Web-серверов разных фирм-производителей.
ServerWatch и WebCompare
Netcraft Web Server Survey
Russian Web Survey
Apache http://www.apache.org
Russian Apache
AOL Server
Alibaba
Amiga Web Server
Boa
CERN httpd
Common Lisp Hypermedia Server
EMWAC HTTP server
GoServe
Internet Connection Secure Servers http://www.icss.raleigh.ibm./icsserver/.
Java Web Server
JAWS Adaptive Web Server
Jigsaw http://www.w3.org
Lotus Domino Web Server http://www.lotus.com.
MacHTTP
Internet Information Server http://www.microsoft.com/iis.
NCSA HTTPD
Netscape FastTrack http://www.netscape.com.
Netscape Enterprise http://www.netscape.com.
Novell Web Server http://www.novell.com.
Open Market Web Server
Oracle Web Application Server
Phttpd
Plexus
Purveyor WebServers
Roxen Challenger
RushHour
Sky Light
Stronghold
thttpd
The NetPublisher Server
Web-серверы для Macintosh
Web Commander http://www.luckman.com.
Web Server4D
WebSite Professoinal http://software.ora.com.
WebStar http://www.starnine.com.
WebQuest Web Server
ZBServer
Zeus Server
Рассмотрим более подробно наиболее популярные из них.
2.4.7. Web-сервер Apache.
Этот Web-сервер является самым распространенным в мире среди серверов для операционной системы Unix. Причин такой популярности много. Прежде всего, это возможность свободно получить его как с основного сервера проекта Apache, так и с «зеркал», расположенных во многих странах мира, в том числе и России. Имеется подробная документация по настройке и администрированию, включая FAQ. В рамках данного проекта ведется подробный учет и исправление найденных ошибок, чему посвящено несколько страниц сервера. Многие разработчики модифицируют код Apache, внося дополнительные функции, и предлагают для свободного распространения свои разработки. В частности, имеются версии Apache, в которые добавлены функции по работе с русскоязычными документами с учетом различных кодировок кириллицы.
Russian Apache это
программный продукт, за основу которого
был взят популярный HTTP-сервер Apache. К
нему была добавлена функциональность,
необходимая для корректной поддержки
нескольких кодировок кириллицы
одновременно, что потребовало внесени
добавлений в основной код Apache.
2.2.8. Web-сервер Jigsaw.
Увеличение значимости технологии Java в области серверного ПО подготовил почву для появления Web-сервера на этом языке. Продукт, созданный совместными усилиями ряда разработчиков, носит название Jigsaw. В создании сервера приняли участие десятки ученых – специалистов повычислительной технике, связанных с консорциумом World Wide Web Consortium и с Массачусетским технологическим институтом Он относится к категории свободно распространяемого программного обеспечения. Хотя Jigsaw 2.0 и представляет собой полнофункциональный Web-сервер, его основная цель – показать в действии такие высокоэффективные серверные технологии, как HTTP 1.1, сервлеты и распределенные публикации, которые столь активно пытается пропагандировать W3C.
Jigsaw сервер, полностью написанный на Java. Это поможет ускорить его установку на таких операционных системах, как Windows 95, NT, OS/2 и Solaris. По этой же причине он обладает следующими характеристиками:
Расширяемость
Мобильность
Объектно-ориентированная разработка
Jigsaw будет работать на любой платформе, поддерживающей Java, без изменений; он состоит из ядра и модулей расширения, можно добавлять и свои собственные модули. При написании кода применен объектно-ориентированный подход все ресурсы являются объектами. В противовес большинству существующих серверов, которые рассматривают ресурсы либо как CGI-скрипты, либо как файлы, Jigsaw допускает доступ к любому объекту через HTTP или другой допустимый протокол.
Цель Jigsaw продемонстрировать новые возможности протоколов (таких, как HTTP/1.1.или PISC) и обеспечить платформу для экспериментирования в области серверного программного обеспечения. Java обладает возможностями, облегчающими решение этой задачи. Переносимость Java-кода может быть использована в будущих экспериментах с концепцией мобильного кода.
Среди самых интересных возможностей сервера можно назвать сервлеты Java – приложения, которые исполняются на сервере, а результат их работы отображается на настольном компьютере. Поскольку сервлеты сохраняют пользовательское соединение с сервером, администраторы узлов могут опросить посетителей, предоставить им динамический доступ к базе данных и позволить совместно работать с документами.
Кроме того, Jigsaw 2.0 активно использует HTTP 1.1 – стандарт, который теперь поддерживает проблемная группа Internet Engineering Task Force. Сейчас браузеры отключаются, ожидая ответа на серверные запросы. HTTP 1.1 позволяет одновременно обрабатывать несколько серверных запросов. HTTP 1.1 может поддерживать подготовку Web-публикаций, предоставляя пользователям возможность редактировать файлы через свои браузеры так, что их исправления не перекрываются друг с другом.
Кроме того, определенные усилия в направлении использования технологии Java на серверной стороне предпринимает группа разработчиков Apache Group.
Будущий дополнительный модуль сервера Apache, о котором идет речь, свяжет между собой HTTP-сервер Apache и виртуальную Java-машину, так что пользователи смогут запускать любые серверные приложения, основанные на интерфейсе прикладного программирования Servlet API. Таким образом, Java сможет превратиться в серверный язык программирования, что позволит свести к минимуму проблемы с производительностью клиентских Java-приложений. Кроме того, этот модуль сможет выполнять функции связующего ПО, объединяющего продукты различных разработчиков, считают создатели Apache.
2.2.9. Web-сервер Netscape Enterprise.
Enterprise Server является типичным Web-сервером и, как все подобные серверы, управляет размещением Web-страниц, но помимо этого он может использоваться как сервер приложения, обеспечить мощную платформу для запуска прикладных программ, к которым можно обращаться пользователям навигатора, и связываться с реляционными базами данных или наследуемыми системами. Enterprise Server 2.0 обеспечивает следующие возможности.
Публикация содержимого и управление. Совместно с Netscape Navigator Gold Enterprise Server 2.0 облегчает доступ пользователей сетей Intranet к содержимому Web-сервера, которое может состоять из различного набора мультимедийных средств. Enterprise Server 2.0 является наиболее быстрым Web-сервером, доступным на обеих платформах: UNIX и Windows NT. В нем содержитcя автоматическая технология кэширования, поддержка симметричных мультипроцессорных систем, популярных HTTP-расширений, эффективное управление памятью и процессами, позволяющее реентерабельно выполнять программный код, запущенный на выполнение многими браузерами в контексте одного процесса в отличие от многих копий процессов программ CGI.
Интегрированный полнотекстовый поиск. Все содержимое, управляемое Enterprise Server, может автоматически индексироваться и становиться доступным для полнотекстового поиска, Поддерживается инкрементная индексация документов, многократные произвольные наборы и поддержка для многих типов документов, таких, как Adobe PDR.
Встроенное управление версиями. Enterprise Server 2.0 способен управлять версиями сохраняемых документов. Каждый раз, когда документ модифицируется, создается новая версия, но все старые версии также доступны. Enterprise Server 2.0 сравнивает любые две версии и может возвратиться обратно к предыдущей версии в любое время. Группы людей могут работать с одним и тем же документом, используя особенности блокировок, которые позволяют одному человеку проверять документ и не дават ь возможности другим изменять его, пока проверка не закончена.
Автокаталогизация на отдельных серверах. Enterprise Server 2.0 может автоматически сформировать содержательный каталог и потом управлять им. Этот каталог облегчает просмотр содержимого Web по автору, дате создания и т. д. Эта возможность реализована для одиночных серверов по сравнению с полнофункциональным каталогом-сервером, описанным ниже.
Среда разработки приложений. Enterprise Server 2.0 позволяет создавать интерактивные Web-страницы и прикладные программы, которые динамически генерируют информацию для реляционных баз данных, наследуемых систем или реализуют программную логику таким образом, чтобы часть приложения выполнялась на сервере, а часть – на клиенте. Использование Java и JavaScript позволяет при этом добиться платформенной независимости.
Java-сервер приложений. Enterprise Server 2.0 имеет встроенную Java-машину, позволяя вставлять в Web страницы и прикладные программы Java-апплсты, используя язык программирования Java. Быстродействующие Java-расширения могут выполняться на сервере «на лету» и обращаться к внешним С++/С-библиотекам. Код, написанный на Java, является кросс-платформенным, так что прикладная программа может быть выполнена на любой операционной системе, которая функционирует на серверах, без того, чтобы вносить в программы какие бы то ни было изменения.
JavaScript-ннтерпретатор. JavaScript может быть вставлен в HTML-документы и выполняться автоматически на Enterprise Server 2.0 с целью оживления или индивидуализации отдельных документов или для перемещения данных из реляционной базы данных или системы наследства в текущий документ. JavaScript также является кросс –платформенным средством, так что может выполняться на всех серверах и в любых операционных системах, которые поддерживают Java, без всяких изменений в программе. JavaScripts, выполняемый на сервере, может даже создавать JavaScripts, который будет выполняться в навигаторе, как только документ будет перемещен к пользователю.
Реляционный уровень доступа к базам данных. JavaScript, выполненный на Enterprise Server 2.0, может обращаться к любой реляционной системе базы данных, включая CA/Ingres, Informix, Microsoft, Oracle и Sybase. ODBC-подцержка также включена. JavaScript внутри HTML-документов может читать данные из реляционных таблиц базы данных или изменять данные в таблицах.
Интерфейсы NSAPI, CGI и WinCGI. Через быстродействующий локальный интерфейс NSAPI, промышленный стандарт CGI и Windows-специфический интерфейс WinCGI Enterprise Server 2.0 может легко адаптироваться к любым пользовательским платформам и расширять функциональные возможности программистов, применяющих общие среды разработки типа C++, Peri и Visual Basic.
Сервис управления. В дополнение к родному HTML-базированному управлению сервером, которое используют все серверы SuiteSpot, Enterprise Server 2.0 также включает поддержку SNMP, так что вы можете контролировать состояние и действия сервера из любой SNMP-базированной системы управления. HTML-интерфейс управления сервером делает возможным удаленное управление сервером из сети через навигатор. Enterprise Server 2.0 также поддерживает возврат предыдущей версии конфигурации как процесс с одним шагом.
Служба безопасности. Enterprise Server 2.0 обеспечивает полную поддержку для протокола защиты SSL3.0 (включая установление подлинности сервера и пользователя через Х.509-сертификаты), двухстороннее шифрование и целостность данных. Enterprise Server 2.0 позволяет администратору устанавливать привилегии управления доступом для пользователей и документов., Используя Х.509-сертификаты, можно проверить имена и пароли пользователя, домены, его хосты, IP-адреса и принадлежность к определенным группам.
LiveWire-возможности. Enterprise Server 2.0 включает продукт LiveWire, который описан ниже.
Orion и будущие реализации
Реализация Enterprise Server следующих поколений, объединенных ныне под кодовым именем Orion, расширит возможности Enterprise Server как основной компоненты SuiteSpot, позволяя корпорациям развернуть более продвинутое содержание Intranet и прикладных программ, функционирующих в сети и являющихся функциями сети. Ниже перечислены некоторые из областей, где намечается расшить функциональные возможности будущих реализаций Orion.
Программируемые Web-страницы. Netscape обеспечит средства для программирования Web-страниц, разбивая их на части, составляющие статическое и динамическое содержание. В дополнение к полнотекстовому поиску, управлению версиями и быстродействующей публикации HTTP Web-ресурсы будут обеспечивать новые функциональные возможности в нескольких областях.
• Обработка форматов. Enterprise Server автоматически будет обработывать содержание в ряде форматов, включая преобразования к другим форматам, типа HTML. Поддерживаемые форматы будут включать Adobe PDF, Microsoft RTF, Word и др. Netscape будет также поддерживать индексацию и каталогизацию других форматов и документов.
• Управление метаданными и поиск. Пользователям будет предоставлена возможность работы с метаданными типа заголовка, ключевых слов, имени автора, даты создания и формата документа. Благодаря этому можно будет выполнять гибкие запросы в соответствии с теми параметрами, которые заданы в метаданных.
• Заказные представления(виды). Пользователи смогут генерировать заказные представления(виды) содержимого отдельных областей и каталогов Web. Например, они смогут отображать все документы размером больше 10 Кбайт или, например, все документы, содержащие «Южная Америка» в их заголовках.
Услуги каталога. Будет поддерживаться Lightweight Directory Access Protocol (LDAP), который будет использоваться для сохранения информации о пользователе, параметрах управления доступом и информации о конфигурации сервера.
• Услуги агента. Встроенная машина обслуживания агентов даст возможность пользователям и администраторам создавать агентов, которые могут быть выполнены на станции. Эти агенты способны взаимодействовать с Web. Простой агент мог бы наблюдать за некоторым документом, который будет изменен, и затем отправлять по почте пользователям этого документа копию новой версии. Более сложный агент мог бы анализировать содержание Web каждые полчаса и посылать пользователю электронную почту, содержащую связи с документами в базе, авторизированными любым из пяти других пользователей, которые содержат ключевые слова «Альфа-проект». Агенты могут быть вызваны, например, когда новые документы начинают читаться или когда их кто-нибудь изменяет.
Репликация. Репликация, или способность автоматически или явно копировать содержание одного сервера на другой, и в конечном счете способность разрешать конфликты между точными копиями, автоматически будет заложена в новые версии. Согласование первоначально произойдет на уровне файла, в последующих версиях Netscape добавит поддержку для уровня поля replication. Это сделает возможным использование одного сервера как организационного сервера, а другого – как производственного сервера или позволит копировать содержание центрального сервера по филиалам в разрезе тех сведений, которые там нужны.
Сервис разработки приложений. В новых реализациях будут расширены возможности открытой сетевой среды Netscape ONE, обеспечивая изощренный интерфейс пользователя API и библиотеки классов для Java и JavaScript. Пользовательским приложениям, например, не составит труда провести полнотекстовый поиск или выполнить запросы к метаданным, зарегистрировать новую версию документа, и его автора. Также дату создания документа, преобразовать формат документа, создать заказное представление (вид) всех документов в интеллигентной программируемой среде Web (Smart programmable content store) и копировать документ из одного сервера в другой. Netscape будет поддерживать интеграцию Java, JavaScript и встроенные в сервер средства LiveConnect. Более мощными реляционными возможностями доступа к базе данных и более эффективным выполнением виртуальной Java-машины будут расширены услуги разработки приложений, обеспечиваемых в Enterprise Server 2.0,.
Сервис управления. В дополнение к использованию встроенной машины каталога LDAP Enterprise Server 2.0 будет управляем через общие системы управления, включая CA/Unicenter, HP OpenView, IBM/Tivoli TME и Sun Solstice.
Служба безопасности. Netscape добавит более сложный список управления доступом (ACL) по модели, интегрированной с услугами каталога LDAP и интеллигентной программируемой средой Web. Все аспекты управления ресурсами Web и операций будут подчинены многоуровневому управлению доступом, включая поиски документа, полно текстовые поиски, metadata-запросы, управление версиями, преобразование форматов, заказные представления (виды) и агенты.
Рисунок 2.10. Схема работы пользовательских приложений на WEB.
Microsoft Internet Information Server.
Выход новой Windows NT 4.0 – огромный шаг в строну интеграции этой операционной системы и сетей Microsoft в Internet. Отныне стало возможно построение всех традиционных сервисов Internet: серверов Web, новостей, почтовых серверов, брандмауэров – на серверах под управлением Windows NT.
Начиная с версии 4.0 в состав Windows NT входит мощьный Web Internet Information Server (IIS), который реализует также серверы FTP и Gopher. Продукт прост в установке и администрировании. Удобный механизм виртуальных каталогов позволяет физически располагать страницы Web на разных компьютерах (что бывает полезно из соображении безопасности), при этом администратор достаточно легко может манипулировать ими.
Входящий в состав продукта Internet Information Manager позволяет настраивать все серверы web в организации, создавать области с конфиденциальной информацией, разрешая доступ к ним отдельным пользователям или группам пользователей. IIS позволяет писать Internet-приложения, используя CGI (Common Gateway Interface). Встроенная поддержка SSL (Secure Sockets Layer) позволяет шифровать трафик между сервером web и клиентом.
Для разработчиков существует открытый Internet Server API (ISAPI), позволяющий создавать приложения, работающие по протоколу HTTP под управлением ISS. ISAPI является реализацией серверной части технологии Active X. Написанные с использованием ISAPI программы работают гораздо быстрее, чем программы, написанные при помощи CGI. Применяя Internet DataBase Connector, на сервере Web можно размещать таблицы различных СУБД, поддерживающие стандарт ODBC (рис. 2.11).
Еще одна составная часть Windows NT 4.0 – Search Server, позволяющий автоматически создавать индексы и производить поиск по ключевым словам на файл-серверах, серверах Web, любых компьютерах внутри компании или где-либо в Internet. Автоматическое обновление информации сервером поиска позволяет сохранять актуальными индексы сводя скорость поиска к минимуму.
Все сервисы IIS имеют собственные счетчики в Perfomance Monitor, позволяющие в реальном времени отслеживать нагрузку на них объем передаваемых данных и т.п. Эти же статистические данные можно получить при помощи протокола SNMP.
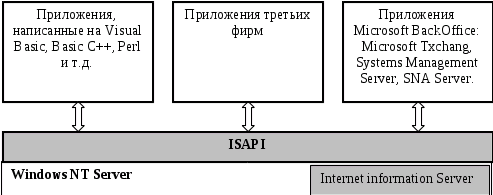
Рисунок 2.11. Взаимодействие через интерфейс ISAPI
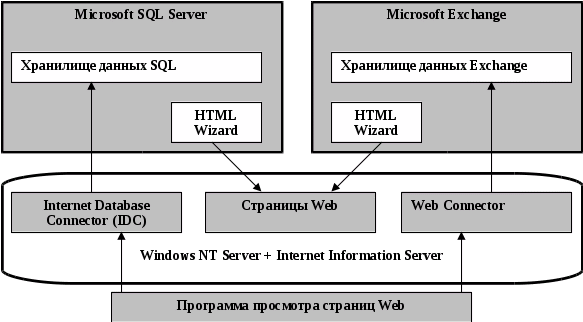
Рисунок 2.12. Ресурсы, доступные из браузеров.
2.5. Организация пользовательского интерфейса для доступа к базам данных.
Многие организации используют электронные базы данных для поддержки своих рабочих процессов. Часто это системы на одного – двух пользователей, выполненные с использованием dbf – ориентированных средств разработки: Clipper, Dbase, FoxPro, Paradox, Access. Обычно используется ряд таких баз, независимых друг от друга. Если информация, хранимая в таких БД, представляет интерес не только для непосредственных пользователей, то для ее дальнейшего распространения используются бумажные отчеты и справки, созданные базой данных.
С появлением локальных сетей, подключением таких сетей к Интернет, созданием внутрикорпоративных, сетей, появляется возможность с любого рабочего места организации получить доступ к информационному ресурсу сети. Однако, при попытке использовать существующие БД возникают проблемы связанные с требованием к однородности рабочих мест (для запуска «родных» интерфейсов), сильнейшим трафиком в сети (доступ идет напрямую к файлам БД), загрузкой файлового сервера и невозможностью удаленной работы (например, командированных сотрудников). Решением проблемы могло бы стать использование унифицированного интерфейса WWW для доступа к ресурсам организации.
Технология World Wide Web получила столь широкое распространение из-за простоты своего пользовательского интерфейса. Принцип «жми на то, что интересно», лежащий в основе гипертекста, интуитивно понятен. В технологиях WWW все ключевые понятия просматриваемого документа: слова, картинки – имеют возможность «раскрыться» новым документом, развивающим это понятие. Такой способ представления информации называется «гипертекстом», а документы, представленные в таком виде – «гипертекстовыми документами». Для описания этих документов используется специальный язык – язык описания гипертекстовых документов или HTML (HyperText Markup Language).
Из этих предпосылок возникает задача преобразования накопленных данных в гипертекстовые документы WWW, задача поддержки актуальности преобразованной структуры. Другими словами, задача предоставления WWW – доступа к существующим базам данных.
Основные понятия
Использование технологий WWW для обеспечения доступа к каким-либо информационным ресурсам подразумевает существование следующих компонентов:
IP-сети с поддержкой базового набора услуг по передаче данных с единой политикой нумерации и маршрутизации, работающим сервисом имен DNS.
В
ыделенного
информационного сервера – WWW-сервера,
обеспечивающего предоставление
гипертекстовых документов через IP –
сеть в ответ на запросы WWW – клиентов.
Рисунок 2.13
Передаваемые гипертекстовые документы оформляются в стандарте HTML – языке описания гипертекстовых документов. Эти документы могут либо храниться в статическом виде (совокупность файлов на диске), либо динамически компоноваться в зависимости от параметров запроса специальным программным обеспечением. Для динамической компоновки HTML-документов, WWW-сервер использует специальным образом оформленные программы- CGI-программы (Common Gate Interface)
Сценарии
В состав специфики конкретной БД входят как технологические основы, такие как тип СУБД, вид интерфейсов, связи между таблицами, ограничения целостности, так и организационные решения, связанные с поддержкой актуальности баз данных и обеспечением доступа к ней.
При обеспечении WWW-доступа к существующим БД, возможен ряд путей – комплексов технологических и организационных решений. Практика использования WWW-технологии для доступа к существующим БД предоставляет широкий спектр технологических решений, по разному связанных между собой – перекрывающих, взаимодействующих и т.д. Выбор конкретных решений при обеспечении доступа зависит от специфики конкретной СУБД и от ряда других факторов, как то: наличие специалистов, способных с минимальными издержками освоить определенную ветвь технологических решений, существование других БД, WWW-доступ к которым должен осуществляться с минимальными дополнительными затратами и т.д.
WWW – доступ к существующим базам данных может осуществляться по одному из трех основных сценариев. Ниже дается их краткое описание и основные характеристики.
Однократное или периодическое преобразование содержимого БД в статические документы
В этом варианте содержимое БД просматривает специальная программа, создающая множество файлов – связных HTML-документов (см.рис.2.14 ).
Полученные файлы могут быть перенесены на один или несколько WWW-серверов. Доступ к ним будет осуществляться как к статическим гипертекстовым документам сервера.
Р
исунок
2.14
Этот вариант характеризуется минимальными начальными расходами. Он эффективен на небольших массивах данных простой структуры и редким обновлением, а также при пониженных требованиях к актуальности данных, предоставляемых через WWW. Кроме этого, очевидно полное отсутствие механизма поиска, хотя возможно развитое индексирование.
В качестве преобразователя может выступать программный комплекс, автоматически или полуавтоматически генерирующий статические документы. Программа-преобразователь может являться самостоятельно разработанной программой либо быть интегрированным средством класса генераторов отчетов.
Динамическое создание гипертекстовых документов на основе содержимого БД
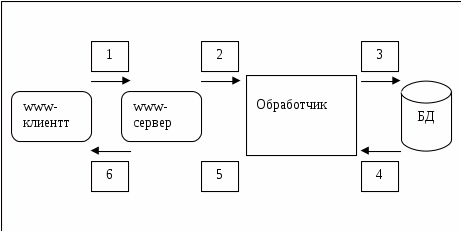
В
этом варианте доступ к БД осуществляется
специальной CGI-программой, запускаемой
WWW-сервером в ответ на запрос WWW –
клиента. Эта программа, обрабатывая
запрос, просматривает содержимое БД и
создает выходной HTML-документ, возвращаемый
клиенту (см.рис.2.15).
Рисунок 2.15
Это решение эффективно для больших баз данных со сложной структурой и при необходимости поддержки операций поиска. Показаниями также являются частое обновление и невозможность синхронизации преобразования БД в статические документы с обновлением содержимого. В этом варианте возможно осуществлять изменение БД из WWW-интерфейсов.
К недостаткам этого метода можно отнести большое время обработки запросов, необходимость постоянного доступа к основной базе данных, дополнительную загрузку средств поддержки БД, связанную с обработкой запросов от WWW – сервера.
Для реализации такой технологии необходимо использовать взаимодействие WWW-сервера с запускаемыми программами CGI – Common Gateway Interface. Выбор программных средств достаточно широк – языки программирования, интегрированные средства типа генераторов отчетов. Для СУБД со внутренними языками программирования существуют варианты использования этого языка для генерации документов.
Создание информационного хранилища на основе высокопроизводительной СУБД с языком запросов SQL. Периодическая загрузка данных в хранилище из основных СУБД
В этом варианте предлагается использование технологии, получившей название «информационного хранилища» (ИХ). Для обработки разнообразных запросов, в том числе и от WWW-сервера, используется промежуточная БД высокой производительности (см. рис.2.16). Информационное наполнение промежуточной БД осуществляется специализированным программным обеспечением на основе содержимого основных баз данных (см. рис.2.17).
Этап 1 – перегрузка данных
Р
исунок
2.16
Этап 2 – обработка запросов
Рисунок 2.1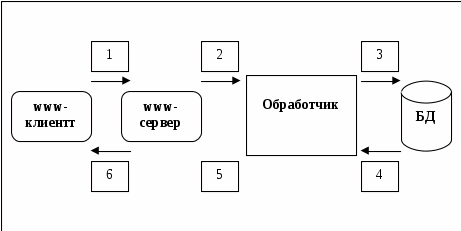
7
Данный вариант свободен ото всех недостатков предыдущей схемы. Более того, после установления синхронизации данных информационного хранилища с основными БД возможен перенос пользовательских интерфейсов на информационное хранилище, что существенно повысит надежность и производительность, позволит организовать распределенные рабочие места.
Несмотря на кажущуюся громоздкость такой схемы, для задач обеспечения WWW-доступа к содержимому нескольких баз данных накладные расходы существенно уменьшаются.
Основой повышения производительности обработки WWW-запросов и резкого увеличения скорости разработки WWW-интерфейсов является использование внутренних языков СУБД информационного хранилища для создания гипертекстовых документов.
Для загрузки содержимого основной БД в информационное хранилище могут использоваться все перечисленные решения (языки программирования, интегрированные средства), а также специализированные средства перегрузки, поставляемые с SQL-сервером и продукты поддержки информационных хранилищ.
База данных Информационно-методического центра «Сведения об образовательных учреждениях»
Назначение и предметная область
База данных предназначена для хранения данных об учебных заведениях города Екатеринбурга и доступна по адресу: http://base.eimc.ru.
|
2 |
№ школы: 109 Полное наименование: Муниципальное образовательное учреждение средняя общеобразовательная школа №109 с углубленным изучением предметов гуманитарно-педагогического цикла Ленинского р-на г. Екатеринбурга Адрес: 620146, г. Екатеринбург, ул. Волгоградская, 37б Телефоны: 28-17-52; 28-76-19; 28-08-05; 28-17-78 (музык школа) Тип компьютерной техники: Pentium 166 – 13 штук, локальная сеть есть
Список профильных классов: Математические, гуманитарные, гуманитарно-педагогические
Список кружков факультативов: «Рукодельница»; 2. «Эстетика быта»; 3. «Мягкая игрушка»; 4. «Театральный»; 5. «Кукольный театр»; 6. «ИЗО»; 7. «Баскетбол»; 8. «Аэробика»; 9. «Музей»; 10. «История ремесла»; 11. «Юный агроном»
Дополнительная информация: 17 лет школа сотрудничает с УРГПУ; 6 лет – с педколледжами; - При школе работает районный центр образовательных технологий; - В музее школы работает постоянно действующая выставка кружковцев школы; - Традицией школы стало проведение ежегодно: интеллектуально марафона, праздника «Золотые россыпи», - в честь победителей конкурсов и т.д.
Интернет сайт: None Электронный адрес: None |
Рисунок 3.1
Анализ запросов показывает, что для наиболее оптимального поиска требуемого ресурса и отображения нужного следует выделить следующие критерии:
№ школы
Полное наименование
Адрес
Телефоны
Тип компьютерной техники
Список профильных классов
Список кружков факультативов
Дополнительная информация
Интернет сайт
Электронный адрес
Пример заполненного по данным критериям ресурса можно увидеть на рисунке 3.1
Web-интерфейс позволяет любому желающему добавить информацию о каком либо учебном заведении, при этом оставив данные о себе. После проверки достоверности информации сотрудниками Информационно методического центра данные помещаются в базу данных. Такая система требует создания дополнительной базы данных содержащей в себе информацию о владельцах информационных ресурсов (внесших их). Эта база должна содержать в себе такие атрибуты, как:
Ф.И.О. владельца
E-mail владельца
Телефон
4. Адрес
5. Дата внесения ресурса в базу данных
Для поддержания связи с владельцем, в обязательные для заполнения поля включены “Ф.И.О.”., “E-mail” или “Телефон”. При не заполнении их в регистрации будет отказано. Содержимое поля “Дата внесения ресурса в базу данных” автоматически генерируется системой.
Проектирование базы данных.
Для организации базы данных «Сведения об учебных заведениях города Екатеринбурга» нам нужно создать две таблицы: «Учреждения» и «Владельцы ресурсов».
СОЗДАТЬ ТАБЛИЦУ Учреждения
ПЕРВИЧНЫЙ КЛЮЧ ( ID )
ПОЛЯ ( ID Целое,
Номер школы Целое,
Полное_наименование Текст,
Адрес Текст,
Телефон Текст,
Тип_компбютерной_техники Текст,
Список_профильных_классов Текст,
Список_кружков_факультативов Текст,
Дополнительная_информация Текст );
СОЗДАТЬ ТАБЛИЦУ Владельцы_ресурсов
ПЕРВИЧНЫЙ КЛЮЧ ( ID )
ПОЛЯ ( ID Целое,
Ф.И.О. Текст,
Текст,
Телефон Текст,
Адрес,
Дата внесения ресурса в базу данных Дата );
Устройство поисковой системы.
Поиск в системе происходит по средствам web-интерфейса. Поисковая форма содержит два поля: “Критерия вывода” и “Фильтр”. Поле “Фильтр” в свою очередь имеет следующие настройки: Вывод всех ресурсов, которые содержат значение поля “Фильтр”, Вывод всех ресурсов, которые не содержат значение поля “Фильтр” и настройка учета или не учета регистра.
Алгоритм поиска выглядит следующим образом:
Определяются настройки фильтра.
Определяется значение “Критерии вывода”.
Каждый ресурс базы имеет свой ID (первичный ключ). Программа обрабатывает столбец, имя которого имеет значение “Критерии вывода” (начиная с ресурса имеющего наименьший ID).
Не учет регистра преобразует при обработке значение атрибута и значение “Фильтра” в строчные буквы.
Если пользователь отметил параметр Вывод всех ресурсов, которые содержат значение поля “Фильтр”, то результатом выполнения программы станет список ресурсов, которые содержат значение “Фильтра”.
Если была выбрана опция Вывод всех ресурсов, которые не содержат значение поля “Фильтр”, то результатом выполнения программы будет обратное п.4 – все, что не содержит значение “Фильтра”.
Администрирование системы.
Одной из главной задач в построении системы – часть ее администрирования. Известно немало случаев, когда пользовательская часть имеет удобный интерфейс, она привлекает больше и больше пользователей и в конечном итоге администрирование этой системы становится практически невозможно. Исходя из этого, нами было уделено не мало внимания на администраторский интерфейс. При построении такого интерфейса главными задачами были:
Удобный интерфейс. Web-интерфейс – это наиболее распространенный и привычный для всех. Использование графических элементов делает работу администратора быстрой и удобной.
Быстрота работы. В нашем случае быстрота работы зависит не от конфигурации компьютера, а от качества связи с сервером, на котором установлена система.
Система регистрации ресурсов.
Устройство системы не предполагает немедленное внесение информации в основную базу данных после ее регистрации. По сути, таблица «Ресурсы» делится на две подтаблицы: основная и временная. После регистрации ресурс попадает во временную таблицу. Цензор просматривает временную таблицу каждые 24 часа. Ресурс может быть перемещен в основную таблицу, удален или оставлен во временной таблице для дальнейшего рассмотрения.
Р
исунок
3.2. Работа поисковой системы.
Вопросы безопасности и санкционирования доступа к базам данных.
Многие считают, что самое главное – это защитить свои (собственные или корпоративные) данные от людей (или запущенных ими программ), не обладающих полномочиями для доступа к этим данным. Конечно, это важно, иногда очень важно, но гораздо чаще данные теряются по вине их владельца. Вспомните, как часто вам приходилось хвататься за голову по той причине, что вы уничтожили еще нужный файл, выкинули из файла нужную часть текста, неправильно обновили запись в базе данных и т.д.
Рассмотрим такой пример. Пусть в базе данных хранятся записи, содержащие характеристики разных марок автомобилей. Каждая запись состоит из трех полей, хранящих название автомобиля, его вес и мощность мотора. Предположим, что некто имеет право изменять содержимое базы данных. С одной стороны, нельзя запретить ему менять значение мощности мотора, поскольку при первоначальном вводе соответствующей записи могла быть допущена ошибка или у автомобиля данной марки мощность мотора действительно изменилась. С другой стороны, если изменить значение мощности ошибочно, то в дальнейшем никаким образом не удастся узнать правильную мощность мотора. Еще неизвестно, что лучше – допустить несанкционированное чтение своих данных другими пользователями или полностью утратить их по причине собственной ошибки.
Свойство хранимых данных, которое заключается в том, что они правильны в соответствии с критериями, установленными владельцем и/или администратором данных, называется целостностью данных. По моему мнению, бессмысленно говорить о безопасности данных в системе, которая не обеспечивает какие-либо средства поддержки целостности.
В файловых системах средства поддержки целостности обычно отсутствуют. Например, владелец файла, содержащего объектный модуль программы, может воспользоваться текстовым редактором и исключить часть модуля. Очень вероятно, что файл перестанет быть целостным.
В современных базах данных дела обстоят несколько лучше (хотя и не идеально). Во-первых, уже во многих СУБД поддерживается понятие домена (множества значений некоторого типа данных). При определении столбца таблицы можно указать домен допустимых значений этого столбца, и после этого система следит за тем, чтобы в столбце содержались только допустимые значения. (Конечно, это не значит, что по ошибке нельзя поместить в поле записи допустимое, но неверное значение.) Во-вторых, для столбца, для таблицы или для нескольких таблиц одновременно можно определить одно или несколько ограничений целостности. Ограничение целостности – это логическое выражение, которое должно быть истинным при целостном состоянии базы данных. Система не допускает выполнения операций обновления базы данных, в результате которых нарушается хотя бы одно ограничение целостности. В-третьих, в некоторых системах появилась поддержка триггеров – хранимых процедур, написанных на процедурном расширении языка SQL (например, PL/SQL в Oracle), которые автоматически вызываются при выполнении специфицированных операций обновления базы данных и служат для поддержания ее целостности.
Такие средства в ряде случаев позволяют избежать серьезных ошибок, связанных с нарушением целостности данных, но, к сожалению, не дают полной гарантии отсутствия ошибок. Например, по-прежнему, полномочный пользователь может неправильно изменить значение мощности мотора в записи марки автомобиля (удовлетворив при этом ограничение домена и все ограничения целостности). Пожалуй, единственную на сегодня возможность избежать потери данных по причине собственной ошибки обеспечивают так называемые темпоральные системы баз данных (примером может служить СУБД Postgres).
В таких системах при любом обновлении записи образуется ее полная копия, а предыдущий вариант продолжает существовать вечно. Даже после удаления записи все накопленные варианты продолжают оставаться в базе данных. Можно потребовать выборку из базы данных любого варианта записи, если указать момент или интервал времени, когда этот вариант был текущим (потому такие базы данных и называются темпоральными). В темпоральных базах данных ошибки пользователей, которые не ловятся системой поддержания целостности, перестают быть фатальными. Всегда можно вернуться к последнему правильному состоянию данных (если, конечно, они находились в правильном состоянии в некоторый известный момент времени).
Кстати, нужно, наверное, заметить, что как обычно случается в программировании, передовой в мире СУБД подход темпоральных баз данных в большой степени основан на старых идеях операционных систем компании Digital RSX и VMS. В этих системах каждое обновление файла приводило к созданию его новой версии, и все предыдущие версии сохранялись до явного уничтожения. Ох, и мороки было чистить залежи своих файлов, когда число версий доходило до сотни. Частенько случалось по ошибке уничтожить именно правильную версию. Темпоральные СУБД не допускают уничтожения существующих вариантов записей, но чтобы не переполнить магнитные диски, приходится время от времени архивировать наиболее старую часть активной порции базы данных.
До сих пор в качестве примера распространенного вида ошибок фигурировал случай, когда неправильно обновлялось индивидуальное поле некоторой записи. Однако часто возникают ситуации, когда совокупные данные записи становятся неверными по той причине, что значения нескольких полей должны изменяться согласованно. Расширим немного пример базы данных марок автомобилей. Пусть каждая запись содержит еще одно поле – класс автомобиля. Например, пусть при весе до 3,5 тонн автомобиль относится к классу B, а при большем весе – к классу С. Конечно, это ограничение целостности, и его можно сформулировать, например, на языке SQL. Конечно, можно определить триггер, который будет автоматически изменять значение класса автомобиля в зависимости от устанавливаемого значения его веса. Но все это ужасно громоздко.
На мой взгляд, более изящное решение подобных проблем обеспечивают системы объектно-ориентированных баз данных (ООБД). В таких системах хранятся не записи данных, а объекты. Каждый объект обладает внутренним состоянием (по-простому, хранит внутри себя запись данных), а также набором методов, т.е. процедур, с помощью которых (и только таким образом) можно обратиться к данным, составляющим внутреннее состояние объекта, и/или изменить их.
В случае ООБД конструирование базы данных состоит в разработке структуры и методов объектов. Поэтому можно написать методы таким образом, чтобы при работе с любым объектом было невозможно нарушить его целостность. Например, ООБД марок автомобилей состояла бы из объектов, внутреннее состояние которых представляло бы собой записи той же структуры, как и раньше, а в число методов входил бы метод «Изменить вес автомобиля». Тогда код этого метода автоматически изменял бы и класс автомобиля при возникновении соответствующего условия. Кстати, заметим, что отсутствовал бы метод «Изменить класс автомобиля», значение класса было бы доступно только по чтению. Ошибочные состояния объектов все равно возможны, поскольку никто не мешает обратиться к методу «Изменить вес автомобиля» с неверными, хотя и правдоподобными параметрами. Как и прежде, единственным способом сохранить возможность доступа к последнему варианту объекта с правильным состоянием является использование техники темпоральных баз данных.
По поводу подхода ООБД существует и ряд критических замечаний. В частности, многих не устраивает, что вместо чисто декларативных ограничений целостности и полудекларативных триггеров, используемых в реляционных системах, в ООБД для поддержания внутренней целостности объектов приходится писать чисто процедурный код. Но у каждого свои пристрастия. Лично мне более близок подход ООБД.
Завершая этот небольшой экскурс в область средств поддержки целостности данных, еще раз заметим, что в любом случае при достаточном старании можно навредить себе больше, чем злоумышленный враг. Заботясь о защите от других, следует подумать, насколько ты защищен от собственных ошибок.
В контексте баз данных термин безопасность означает защиту данных от несанкционированного раскрытия, изменения или уничтожения. SQL позволяет индивидуально защищать как целые таблицы, так и отдельные их поля. Для этого имеются две более или менее независимые возможности:
механизм представлений, рассмотреный в предыдущей главе и используемый для скрытия засекреченных данных от пользователей, не обладающих правом доступа;
подсистема санкционирования доступа, позволяющая предоставить указанным пользователям определенные привилегии на доступ к данным и дать им возможность избирательно и динамически передавать часть выделенных привилегий другим пользователям, отменяя впоследствии эти привилегии, если потребуется.
Обычно при установке СУБД в нее вводится какой-то идентификатор, который должен далее рассматриваться как идентификатор наиболее привилегированного пользователя – системного администратора. Каждый, кто может войти в систему с этим идентификатором (и может выдержать тесты на достоверность), будет считаться системным администратором до выхода из системы. Системный администратор может создавать базы данных и имеет все привилегии на их использование. Эти привилегии или их часть могут предоставляться другим пользователям (пользователям с другими идентификаторами). В свою очередь, пользователи, получившие привилегии от системного администратора, могут передать их (или их часть) другим пользователям, которые могут их передать следующим и т.д.
Привилегии предоставляются с помощью предложения GRANT (предоставить), общий формат которого имеет вид
GRANT привилегии ON объект TO пользователи;
В нем «привилегии» – список, состоящий из одной или нескольких привилегий, разделенных запятыми, либо фраза ALL PRIVILEGES (все привилегии); «объект» – имя и, если надо, тип объекта (база данных, таблица, представление, индекс и т.п.); «пользователи» – список, включающий один или более идентификаторов санкционирования, разделенных запятыми, либо специальное ключевое слово PUBLIC (общедоступный).
К таблицам (представлениям) относятся привилегии SELECT, DELETE, INSERT и UPDATE [(столбцы)], позволяющие соответственно считывать (выполнять любые операции, в которых используется SELECT), удалять, добавлять или изменять строки указанной таблицы (изменение можно ограничить конкретными столбцами). Например, предложение
GRANT SELECT, UPDATE (Труд) ON Блюда TO cook;
позволяет пользователю, который представился системе идентификатором cook, использовать информацию из таблицы Блюда, но изменять в ней он может только значения столбца Труд.
Если пользователь USER_1 предоставил какие-либо привилегии другому пользователю USER_2, то он может впоследствии отменить все или некоторые из этих привилегий. Отмена осуществляется с помощью предложения REVOKE (отменить), общий формат которого очень похож на формат предложения GRANT:
REVOKE привилегии ON объект FROM пользователи;
Например, можно отобрать у пользователя cook право изменения значений столбца
5. Перспективы развития сетевых баз данных
Термин «системы следующего (или третьего) поколения» вошел в жизнь после опубликования группой известных специалистов в области БД «Манифеста систем баз данных третьего поколения». Cторонники этого направления придерживаются принципа эволюционного развития возможностей СУБД без коренной ломки предыдущих подходов и с сохранением преемственности с системами предыдущего поколения.
Частично требования к системам следующего поколения означает просто необходимость реализации давно известных свойств, отсутствующих в большинстве текущих реляционных СУБД (ограничения целостности, триггеры, модификация БД через представления и т.д.). В число новых требований входит полнота системы типов, поддерживаемых в СУБД; поддержка иерархии и наследования типов; возможность управления сложными объектами и т.д.
Одной из наиболее известных СУБД третьего поколения является система Postgres, а создатель этой системы М.Стоунбрекер, по всей видимости, является вдохновителем всего направления. В Postgres реализованы многие интересные средства: поддерживается темпоральная модель хранения и доступа к данным и в связи с этим абсолютно пересмотрен механизм журнализации изменений, откатов транзакций и восстановления БД после сбоев; обеспечивается мощный механизм ограничений целостности; поддерживаются ненормализованные отношения (работа в этом направлении началась еще в среде Ingres), хотя и довольно странным способом: в поле отношения может храниться динамически выполняемый запрос к БД.
Одно свойство системы Postgres сближает ее с объектно-ориентированными СУБД. В Postgres допускается хранение в полях отношений данных абстрактных, определяемых пользователями типов. Это обеспечивает возможность внедрения поведенческого аспекта в БД, т.е. решает ту же задачу, что и ООБД, хотя, конечно, семантические возможности модели данных Postgres существенно слабее, чем у объектно-ориентированных моделей данных.
Хотя отнесение СУБД к тому или иному классу в настоящее время может быть выполнено только условно (например, иногда объектно-ориентированную СУБД O2 относят к системам следующего поколения), можно отметить три направления в области СУБД следующего поколения. Чтобы не изобретать названий, будем обозначать их именами наиболее характерных СУБД.
Направление Postgres. Основная характеристика: максимальное следование (насколько это возможно с учетом новых требований) известным принципам организации СУБД (если не считать упоминавшейся коренной переделки системы управления внешней памятью).
Направление Exodus/Genesis. Основная характеристика: создание собственно не системы, а генератора систем, наиболее полно соответствующих потребностям приложений. Решение достигается путем создания наборов модулей со стандартизованными интерфейсами, причем идея распространяется вплоть до самых базисных слоев системы.
Направление Starburst. Основная характеристика: достижение расширяемости системы и ее приспосабливаемости к нуждам конкретных приложений путем использования стандартного механизма управления правилами. По сути дела, система представляет собой некоторый интерпретатор системы правил и набор модулей-действий, вызываемых в соответствии с этими правилами. Можно изменять наборы правил (существует специальный язык задания правил) или изменять действия, подставляя другие модули с тем же интерфейсом.
В целом можно сказать, что СУБД следующего поколения – это прямые наследники реляционных систем.
6. Список литературы.
Браун М., Ханикатт Д. “HTML 3.2”, К., 1996
Вьюкова Н.И., Галатенко В.А., “Информационная безопасность систем управления базами данных”, СУБД № 1 1996
Грабер М., “Справочное руководство по SQL”, М., 1997
Дейта К. “Введение в системные баз данных”, М., 1999
Дунаев С.Б. “Intranet-технологии.”, М., 1997
Кириллов В.В. “Структуризованный язык запросов (SQL)”, М.,1997
Кузнецов С.Д. “Основы современных баз данных”, К., 1999
Кузнецов С.Д. “Безопасность и целостность или, Худший враг себе - это ты сам”, СПб., 1998
Мейер М. “Теория реляционных баз данных”, М.,1996
ЦНИТ НГУ. “Использование технологий WWW для доступа к базам данных”, Н., 1997
Шпеник М., Следж О. и др. “Руководство администратора баз данных Microsoft SQL Server 7.0”, М., 1999
"SQL Полное руководство" К., 1998