Построение систем распознавания образов
 ÌÈÍÈÑÒÅÐÑÒÂÎ
ÎÁÐÀÇÎÂÀÍÈß ÓÊÐÀÈÍÛ
ÌÈÍÈÑÒÅÐÑÒÂÎ
ÎÁÐÀÇÎÂÀÍÈß ÓÊÐÀÈÍÛ
ДОНЕЦКИЙ ГОСУДАРСТВЕННЫЙ ИНСТИТУТ ÈÑÊÓÑÑÒÂÅÍÍÎÃÎ ÈÍÒÅËËÅÊÒÀ
О С Н О В Ы П О С Т Р О Е Н И Я
С И С Т Е М Р А С П О З Н А В А Н И Я
О Б Р А З О В
Ч а с т ь 1
(К у р с л е к ц и й)
Óòâåðæäåíî :
çàñåäåíèè êàôåäðû íà ðàñïîçíàâàíèÿ îáðàçîâ
Ïðîòîêîë ¹ 3 îò 23.11.97
1 9 9 7
Настоящее учебное пособие представляет собой первую часть курса лекций по "Основам построения систем распознавания образов", читаемых студентам специальности "Программное обеспечение вычислительной техники и автоматизированных систем управления" в VI - VII ñåìåñòðàõ îáó÷åíèÿ â Äîíåöêîì Ãîñóäàðñòâåííîì èíñòèòóòå èñêóññòâåííîãî èíòåëëåêòà.
Причинами подготовки и выпуска специального курса лекций явились:
1.Îòñóòñòâèå îòðàáîòàííîãî è äîñòóïíîãî ó÷åáíèêà èíæåíåðíîé íàïðàâëåííîñòè ïî ñîçäàíèþ ñèñòåì ðàñïîçíàâàíèÿ.
2.Äåôèöèò êíèã ñîîòâåòñòâóþùåé òåìàòèêè äëÿ îðãàíèçàöèè ñàìîñòîÿòåëüíîé ðàáîòû ñòóäåíòîâ.
3.Íåîáõîäèìîñòü îáîáùåíèÿ îòäåëüíûõ âçãëÿäîâ àâòîðà, äîñòàòî÷íî ïðîäîëæèòåëüíîå âðåìÿ ñïåöèàëèçèðîâàâøåãîñÿ â îáëàñòè ñîçäàíèÿ ñèñòåì ðàñïîçíàâàíèÿ.
Одновременно с курсом лекций в настоящее учебное пособие помещены вопросы практических занятий по изучаемым темам и методические указания к лабораторным работам.
Составитель доц. Л.А. Белозерский
Ответственный за выпуск В.В. Гончаров
С О Д Е Р Ж А Н И Е
Т е м а 1 Ðàñïîçíàâàíèå îáðàçîâ â æèçíè ÷åëîâåêà (Ââåäåíèå)...……
Ë Å Ê Ö È ß 1.1 Ðàñïîçíàâàíèå â áèîëîãè÷åñêèõ è òåõíè÷åñêèõ ñèñòåìàõ.
1.1.1. Всеобъемлющий характер действия механизмов распознавания ..............................................................................................
1.1.2. Краткая история вопроса появления технических систем автоматического распознавания и методов их создания............................................................................................………
Л Е К Ц И Я 1.2 Òåðìèíîëîãèÿ è îòëè÷èòåëüíûå îñîáåííîñòè ñèñòåì ðàñïîçíàâàíèÿ ...................................................................……….
1.2.1. Основные определения...........................................……………….
1.2.2. Ñèñòåìû ðàñïîçíàâàíèÿ................................................…………..
Т е м а 2 Çàäà÷è, ðåøàåìûå â ïðîöåññå ñîçäàíèÿ ñèñòåì ðàñïîçíàâàíèÿ
Л Е К Ц И Я 2.1. Проблематика задач создания систем распознавания на описательном уровне ...............……………………
Л Е К Ц И Я 2.2. Формулировка задач создания систем распознавания и методы их решения .........................…………………
Л Е К Ц И Я 2.3. Формулировка задач создания систем распознавания и методы их решения (продолжение) ……………….
Т е м а 3 Классификация систем распознавания
Л Е К Ц И Я 3.1 Принципы классификации и типы систем распознавания………………………………………………………….
Л Е К Ц И Я 3.2 Принципы классификации и типы систем ðàñïîçíàâàíèÿ (ïðîäîëæåíèå) ….....................……………………….
Ò å ì à 4 Îïòèìèçàöèÿ ýâðèñòè÷åñêèõ âûáîðîâ ïðè ñîçäàíèè ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ
Ë Å Ê Ö È ß 4.1 Îïòèìèçàöèÿ àëôàâèòà êëàññîâ è ñëîâàðÿ ïðèçíàêîâ
4.1.1. Уточнение назначения и цели создания СР .......……………….
4.1.2. Âçàèìîñâÿçü ðàçìåðíîñòè àëôàâèòà êëàññîâ è ýôôåêòèâíîñòè ÑÐ ………………………………………………………………………
Ë Å Ê Ö È ß 4.2 Îïòèìèçàöèÿ àëôàâèòà êëàññîâ è ñëîâàðÿ ïðèçíàêîâ (ïðîäîëæåíèå) ….……………..............................................
4.2.1.Взаимосвязь размерности вектора признаков и эффективности СР…………………………………………………………………………
4.2.2.Формализация задачи оптимального взаимосвязанного выбора
àëôàâèòà êëàññîâ è ñëîâàðÿ ïðèçíàêîâ ………….…………………….
Ôîðìàëèçàöèÿ èñõîäíûõ äàííûõ .. . . ....... .....……… .
4.2.2.2.Âûèãðûø ðàñïîçíàâàíèÿ è îïòèìèçàöèÿ àëôàâèòà êëàññîâ è ñëîâàðÿ ïðèçíàêîâ â óñëîâèÿõ îãðàíè÷åíèé ……..
Т е м а 5 Ìîäåëèðîâàíèå ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ - ìåòîäîëîãèÿ èõ ñîçäàíèÿ è îïòèìèçàöèè
Ë Å Ê Ö È ß 5.1 Ââåäåíèå â ìîäåëèðîâàíèå .....................................
5.1.1. История вопроса ......................................................……………..
5.1.2 Îñíîâíûå îïðåäåëåíèÿ ............................................……………
Ë Å Ê Ö È ß 5.2 Ìîäåëèðîâàíèå ñëîæíûõ ñèñòåì è ïðèìåíåíèå ìîäåëåé
5.2.1. Принципы построения модели сложной системы ...………….
5.2.2. Моделирование сложных систем и опытно-теоретический метод их испытаний ........................……………………………………
Ë Å Ê Ö È ß 5.3 Ìåòîä ñòàòèñòè÷åñêèõ èñïûòàíèé (ìåòîä Ìîíòå-Êàðëî)………………………………………………………………….
5.3.1.Основное определение .............................................…………….
5.3.2.Принципы получения случайных величин на ЭВМ …………
Ë Å Ê Ö È ß 5.4 Ìåòîä ñòàòèñòè÷åñêèõ èñïûòàíèé (ïðîäîëæåíèå)
5.4.1.Моделирование независимых случайных событий ……………
5.4.2.Способы получения случайных чисел с заданным законом распределения ..........................................................……………………
Ë Å Ê Ö È ß 5.5 Ìîäåëü ñèñòåìû ðàñïîçíàâàíèÿ îáðàçîâ ................
5.5.1.Моделирование распознаваемого объекта ........…………………
Ë Å Ê Ö È ß 5.6. Ìîäåëü ñèñòåìû ðàñïîçíàâàíèÿ îáðàçîâ (ïðîäîëæåíèå)……………………………………………………………
5.6.1.Моделирование средств определения характеристик объектов распознавания.........................................................……………………....
5.6.2.Моделирование каналов связи ...............................………………
Ë Å Ê Ö È ß 5.7. Ìîäåëèðîâàíèå àëãîðèòìà ðàñïîçíàâàíèÿ .............
5.7.1.Модель алгоритма распознавания объектов (явлений, процессов) ....................................................................................................
5.7.2.Модуль оценки эффективности системы распознавания ……..
5.7.3.Модуль управления моделью системы распознавания …………
Ë Å Ê Ö È ß 5.8 Îïûòíî-òåîðåòè÷åñêèé ìåòîä â çàäà÷àõ ñîçäàíèÿ ñèñòåì ðàñïîçíàâàíèÿ .............................................……………………
5.8.1.Использование принципов опытно-теоретического метода при моделировании СР .........................................……………………………
5.8.2. Моделирование в задачах создания и оптимизации систем распознавания..................................................................…………………
ЛАБОРАТОРНЫЕ РАБОТЫ..................................................................
ВОПРОСЫ ПРАКТИЧЕСКИХ ЗАНЯТИЙ ...................................…...
ËÈÒÅÐÀÒÓÐÀ................................................….........................................
Т е м а 1
Распознавание в биологических и технических
системах
Л Е К Ц И Я 1.1
Распознавание образов в жизни человека
( Введение)
1.1.1. Âñåîáúåìëþùèé õàðàêòåð äåéñòâèÿ ìåõàíèçìîâ ðàñïîçíàâàíèÿ.
Распознавание образов (а часто говорят - объектов, сигналов, ситуаций, явлений или процессов) - самая распространенная задача, которую человеку приходится решать практически ежесекундно от первого до последнего дня своего существования. Для этого он использует огромные ресурсы своего мозга, которые мы оцениваем таким показателем как число нейронов, равное 1010.
Можно даже не утруждая себя примерами (мы рассмотрим их ниже) заметить, что похожие действия наблюдаются в биологии, в живой природе, а иногда даже в неживой. Кроме того, распознавание постоянно встречается в технике. А если это так, то, очевидно, следует считать механизм распознавания всеобъемлющим.
С более общих позиций можно утверждать, и это вполне очевидно, что в повседневной деятельности человек постоянно сталкивается с задачами, связанными с принятием решений, обусловленных непрерывно меняющейся окружающей обстановкой. В этом процессе принимают участие: органы чувств, с помощью которых человек воспринимает информацию извне; центральная нервная система, осуществляющая отбор, переработку информации и принятие решений; двигательные органы, реализующие принятое решение. Но в основе решений этих задач лежит, в чем легко убедиться, распознавание образов.
В своей практике люди решают разнообразные задачи по классификации и распознаванию объектов, явлений и ситуаций (мгновенно узнают друг друга, с большой скоростью читают печатные и рукописные тексты, безошибочно водят автомобили в сложном потоке уличного движения, осуществляют отбраковку деталей на конвейере, разгадывают коды, древнюю египетскую клинопись и т.д.).
Рассмотрим некоторые примеры всепроникающего механизма распознавания образов человеком в природе и обществе.
1.Вы легко узнаете издалека своего знакомого (но задайтесь вопросом: как?) Обратите внимание на слабую зависимость результатов распознавания от дальности, если конечно мы еще видим отдельные элементы и движения.
2.Предположим Вам нужен для изучения или повторения такой раздел математики, как интегральное исчисление. Ваши действия :
а) распознаете по корешкам обложек справочник на книжной полке;
(на фоне других книг - прочитывая, распознавая названия при последовательном просмотре или по внешнему виду, хранимому Вами в памяти по предшествующему пользованию этим справочником)
б) листаете и распознаете страницу справочника с оглавлением; (по опыту знаете, что оглавление располагается в начале или в конце книги)
в) распознаете тексты заголовков оглавления; (читаете);
г) распознаете среди всех заголовков необходимый Вам (сравниваете прочитанный со смысловым содержанием интересующего Вас раздела)
д) распознаете соответствующую этому заголовку страницу; (зная, что в оглавлении против найденного раздела печатается интересующий номер страницы)
е) листаете справочник и распознаете по нумерации страниц необходимый номер;
(сравниваете запомненный номер с номерами открываемых ñòðàíèö) è ò.ä., è ò.ï.
Обратите внимание, во-первых, на то, сколько знаний, хранящихся в Вашей памяти используется. Во-вторых, здесь, как и в предыдущих примерах, можно задаться многочисленными вопросами по поводу того, как это Вы сами все осуществляете, и не найти ответа.
В рассмотренном примере мы уже должны были заметить, что помимо “чистого” распознавания в нем присутствуют наши действия, но при этом любому действию предшествует распознавание. А любое выполненное действие влечет за собой новый этап распознавательной деятельности.
3.Вот может быть более очевидный пример из военного дела. Обратите в нем внимание на сочетание распознавания и действий, являющихся управлением.
Представьте себя в роли летчика в кабине самолета-истребителя. Вы взлетаете, набираете высоту, готовитесь и начинаете выполнять боевую задачу. Прежде всего:
-îáíàðóæèâàåòå (òî åñòü, ðàñïîçíàåòå) â çîíå îáçîðà öåëü-ñàìîëåò ïðîòèâíèêà;
-èäåòå íà ñáëèæåíèå;
-íà îñíîâå èìåþùèõñÿ çíàíèé î ñâîåì ñàìîëåòå êàê îðóæèè - ðàñïîçíàåòå ìîìåíò, êîãäà ïðîèçâåñòè ïóñê ðàêåòû ïî îáíàðóæåííîé öåëè;
-ïðîèçâîäèòå ïóñê;
или:
-ðàñïîçíàåòå, ÷òî ïðîòèâíèê îïåðåäèë Âàñ è ïðîèçâåë ïî âàøåìó ñàìîëåòó ïóñê ðàêåòû;
-ðàñïîçíàåòå ñðåäè áîëüøîãî íàáîðà òàêòè÷åñêèõ ïðèåìîâ â âàøåé ïàìÿòè íåîáõîäèìûé ïðèåì äëÿ óïðàâëåíèÿ ñàìîëåòîì â öåëÿõ ïðîâåäåíèÿ ïðîòèâîðàêåòíîãî ìàíåâðà;
-ïðîèçâîäèòå ìàíåâð.
-ðàñïîçíàåòå, ÷òî ìàíåâð óäàëñÿ (åñëè íå óäàëñÿ è åñòü âîçìîæíîñòü- ïîâòîðÿåòå) - è ñàìè àòàêóåòå ïðîòèâíèêà;
Затем:
-ðàñïîçíàåòå, ÷òî ãîðþ÷åå íà èñõîäå èëè - çàäà÷à âûïîëíåíà - óõîäèòå íà ïîñàäêó;
-ðàñïîçíàåòå ïîñàäî÷íóþ ïîëîñó - îñóùåñòâëÿåòå ïîñàäêó.
Вот далеко не полный и подробный перечень этапов распознавания и действий. Но если сами действия понятны и очевидны, то предшествующее им распознавание требует осмысливания соответствующего механизма. И прежде всего, каждый этап описанных последовательности - это действия на основе знаний, хранящихся в памяти.
4. Ðàññìîòðèì ïðèìåð èç îáëàñòè ýêîíîìèêè. Ðóêîâîäèòåëü ýêîíîìè÷åñêîãî ðåãèîíà ïî ýêîíîìè÷åñêèì ïîêàçàòåëÿì õîçÿéñòâåííîé äåÿòåëüíîñòè îáíàðóæèâàåò (ðàñïîçíàåò) óõóäøåíèå ïðîäîâîëüñòâåííîãî îáåñïå÷åíèÿ îáëàñòè, ãîðîäà è ò.ï.
Обратившись к другой группе экономических показателей, он распознает, что лежит в основе такого нежелательного явления (например, отсутствие горючего для автотранспорта). В итоге принимается решение о дополнительных договорах на бензин или дизельное топливо с поставщиками или, найдя новых поставщиков, организует отправку железнодорожного состава цистерн или автозаправщиков для доставки и т.д.
5. Åùå îäèí âîåííûé ïðèìåð èç îáëàñòè îáîðîíû, ãäå ÷åëîâåê íå âûïîëíÿåò íè ðàñïîçíàþùåé ôóíêöèè, íè ôóíêöèè óïðàâëåíèÿ. ÑÏÐÍ (ñèñòåìà ïðåäóïðåæäåíèÿ î ðàêåòíîì íàïàäåíèè), íàõîäÿñü â ðåæèìå êðóãëîñóòî÷íîãî áîåâîãî äåæóðñòâà àâòîìàòè÷åñêè îáíàðóæèâàåò â íåêîòîðûé ìîìåíò âðåìåíè (òî åñòü, ðàñïîçíàåò) ÊÎ (êîñìè÷åñêèé îáúåêò) è çàâÿçûâàåò åãî òðàåêòîðèþ. Íà ýòîé îñíîâå àâòîìàòè÷åñêè îïðåäåëÿåòñÿ íå ÿâëÿåòñÿ ëè ýòîò ÊÎ áàëëèñòè÷åñêîé ðàêåòîé (ðàñïîçíàåòñÿ ïî ïîïàäàíèþ ïðîëîíãèðîâàííîé âî âðåìÿ ïîëåòà ÊÎ òî÷êè åãî ïàäåíèÿ íà îáîðîíÿåìóþ òåððèòîðèþ, íà òåððèòîðèþ ñòðàíû). Åñëè óêàçàííîå óñëîâèå âûïîëíèëîñü ÑÏÐÍ äàåò ñèãíàë òðåâîãè íà ñðåäñòâà ïðîòèâîäåéñòâèÿ , íàïðèìåð ñèñòåìó ïðîòèâîðàêåòíîé îáîðîíû (ÏÐÎ). Ñèñòåìà ÏÐÎ, â ñâîþ î÷åðåäü, îáÿçàíà àâòîìàòè÷åñêè ïî äàííûì ÑÏÐÍ îáíàðóæèòü (ðàñïîçíàòü ) èíòåðåñóþùóþ öåëü, ðàñïîçíàòü, íàïðèìåð, ÷òî ýòî ñëîæíàÿ áàëëèñòè÷åñêàÿ öåëü ÑÁÖ (áîåâàÿ ÷àñòü Á× +ëîæíûå öåëè ËÖ), ðàñïîçíàòü Á× ñðåäè ËÖ, ïðîèçâåñòè ïóñê ïðîòèâîðàêåòû è ò.ä., è ò.ï.
6.Теперь примеры из области биологии.
Семечко растения распознает достаточность температуры окружающей среды, достаточность влаги, питательных веществ - и включает механизм роста.
Росянка распознает насекомое, севшее на ее лепестки и резко закрывается как ловушка для последующего переваривания пищи.
Подсолнечник распознает, где расположено солнце, и поворачивает свое соцветие в его сторону.
Комар распознает человека и пьет его кровь.
Лягушка распознает и ловит комара.
Удав распознает и ловит лягушку. и т.д.
И здесь также мы задаемся уже знакомым нам вопросом: как?
7. Ñîâñåì óæå óòðèðîâàííûé ñëó÷àé èç òåõíèêè: äâåðíîé çàìîê ðàñïîçíàåò ñâîé êëþ÷ è ðàçðåøàåò îòêðûòü ïîìåùåíèå.
В последнем примере человек, как создатель, знает все.
Таким образом, приведенные примеры показывают, что распознавание в природе, обществе, в жизни человека, в технике - всеобъемлюще. Но при этом мы отмечаем, что ответов на поставленные вопросы, когда речь касается распознающей деятельности человека в большинстве случаев мы не найдем. До настоящего времени полные представления о способностях живых организмов в распознавании многих явлений и объектов отсутствуют. В то же время, создавая технические системы, способные заменить его, человек высказывает гипотезы, продвигающие его к знанию распознающей деятельности в природе, что позволяет ему успешно решать стоящие задачи. Рассматриваемый курс “Основы построения систем распознавания образов” и должен научить пониманию того, что лежит в основе современных гипотез распознавательной деятельности и как на этой основе упомянутые задачи решаются.
1.1.2. Краткая история вопроса появления технических систем автоматического распознавания и методов их создания
Длительное время вопросы распознавания рассматривались человеком лишь с позиций методов биологии и психологии. При этом целью изучения являлись в основном качественные характеристики, не позволяющие вскрыть и точно описать соответствующий механизм. Если и получались числовые характеристики, то они, как правило, были связаны с изучением рецепторов, таких как органы зрения, слуха, осязания. Что же касалось характеристик принятия решений, то до их математической оценки дело не доходило. И только кибернетика позволила ввести в изучение психологического процесса распознавания образов, лежащего в основе принятия любых решений, количественные методы, что открыло принципиально новые возможности в исследовании и проектировании автоматических систем распознавания. Только кибернетика позволила ввести в область распознавания, как явления природы, математические представления. В этом можно увидеть в частности реализацию взглядов Галилея, который утверждал:
“Книга природы написана на языке математики. И тот, кто хочет прочесть ее, должен изучать этот язык”.
Исторически сложилось, что многие задачи такого класса, как распознавание метеоосадков; распознавание авиационной ситуации в районе аэропорта авиадиспетчером; распознавание полосы посадки летчиком в сложных условиях, человек, как правило, решает эффективно, то есть с необходимым качеством. Этим и объясняется исторически появившаяся необходимость использования человека в качестве элемента или звена сложных автоматических систем.
Примечательно то, что в процессе указанной деятельности человека число принимаемых решений по результатам распознавания ситуаций конечно, в то время как число состояний внешней среды, оцениваемых в процессе самого распознавания и приводящих к указанным решениям, может быть бесконечным.
Это можно видеть на примере машинистки, печатающей под диктовку. Из бесчисленного множества вариантов произношения одного и того же звука она выбирает только один, всегда ударяя по одной, определенной клавише пишущей машинки. В результате она безошибочно печатает слова, независимо от их искажения при устном произнесении.
К принятию такого конечного числа решений человек подготовлен всем своим жизненным опытом. Поэтому принятие идеологии автоматизации указанных процессов, замены человека как звена автоматических систем привело к тому, что человечество прежде всего научилось строить автоматы, способные реагировать на множество изменений характеристик внешней среды некоторым ограниченным числом рациональных решений (реакций) исполнительных органов этих автоматов. Это не значит, что были найдены механизмы, лежащие в основе человеческих и природных способностей распознавания, но главные особенности этих способностей, лежащие на поверхности представлений, созданные автоматы во многих случаях хорошо имитировали.
Например, автомат, управляющий технологическим процессом выпуска некоторой продукции, реагирует на случайные изменения качества ее путем регулирования количества той или иной компоненты исходного материала, режима работы и т.п., но только при достижении определенного уровня этих изменений. То есть, реакция осуществляется не на любое изменение, а на множество их, совокупность.
В результате человечество пришло к ситуации, когда распознающие устройства могут повышать, например, эффективность систем связи (распознавая сигналы в шумах), помогают устанавливать объективный диагноз заболеваний (распознавая всегда однозначно в отличии от человека симптомы-признаки заболеваний), дают возможность осуществлять автоматический контроль сложных технических систем и вовремя вмешиваться и проводить их ремонтно-восстановительные работы и т.д.
Создание устройств, которые выполняют функции распознавания различных объектов, во многих случаях открывает возможность замены человека как элемента сложной системы специализированным автоматом. Такая замена позволяет значительно расширить возможности различных систем, выполняющих сложные информационно-логические задачи. Заметим здесь, что качество работ, выполняемых человеком на любом рабочем месте зависит от квалификации, опыта, добросовестности, состояния. В то же время автомат его заменяющий действует однообразно и обеспечивает всегда одинаковое качество, если он исправен.
Но не только указанная замена и освобождение человека от выполнения рутинных операций является причиной создания и поиска путей создания ряда систем распознавания. В некоторых случаях человек вообще не в состоянии решать эту задачу со скоростью, задаваемой обстоятельствами, не зависимо от качеств и психологического состояния принимающего решение (Например: противоракетный маневр самолета в сложных метеоусловиях; вывод из рабочего режима АЭС и т.п.). Автомат же с такими задачами может легко справляться.
Итак, основные цели замены человека в задачах распознавания сводятся к следующим:
1) Îñâîáîæäåíèå ÷åëîâåêà îò îäíîîáðàçíûõ ðóòèííûõ îïåðàöèé äëÿ ðåøåíèÿ äðóãèõ áîëåå âàæíûõ çàäà÷.
2) Ïîâûøåíèå êà÷åñòâà âûïîëíÿåìûõ ðàáîò.
3) Ïîâûøåíèå ñêîðîñòè ðåøåíèÿ çàäà÷.
В течение достаточно продолжительного времени проблема распознавания привлекает внимание специалистов в области прикладной математики, а затем и информатики. Так можно, в частности, отметить работы Р.Фишера, выполненные в 20-х годах и приведшие к формированию дискриминантного анализа, как одного из разделов теории и практики распознавания. В 40-х годах А.Н.Колмогоровым и А.Я.Хинчиным поставлена задача о разделении смеси двух распределений.
Наиболее плодотворными явились 50-60-е годы ХХ века. В это время на основе массы работ появилась теория статистических решений. В результате этого появления найдены алгоритмы, обеспечивающие отнесение нового объекта к одному из заданных классов, что явилось началом планомерного научного поиска и практических разработок. В рамках кибернетики начало формироваться новое научное направление, связанное с разработкой теоретических основ и практической реализации устройств, а затем и систем, предназначенных для распознавания объектов, явлений, процессов.
Новая научная дисциплина получила название “Распознавание образов”.
Таким образом, базой для решения задач отнесения объектов к тому или иному классу послужили, как это отмечается сегодня, результаты классической теории статистических решений. В ее рамках строились алгоритмы , обеспечивающие на основе экспериментальных измерений параметров (признаков), характеризующих этот объект, а также некоторых априорных данных, описывающих классы, определение конкретного класса, к которому может быть отнесен распознаваемый объект.
В последующем математический аппарат теории распознавания расширился за счет применения:
-ðàçäåëîâ ïðèêëàäíîé ìàòåìàòèêè;
-òåîðèè èíôîðìàöèè;
-ìåòîäîâ àëãåáðû ëîãèêè;
-ìàòåìàòè÷åñêîãî ïðîãðàììèðîâàíèÿ è ñèñòåìîòåõíèêè.
(Системотехника - научное направление, охватывающее проектирование, создание, испытания и эксплуатацию сложных систем).
К середине 70-х годов определился облик распознавания как самостоятельного научного направления, появилась возможность создания нормальной математической теории распознавания. В этом нам придется убедиться, а также приобрести необходимые навыки, прослушав курс “Основы построения систем распознавания образов”.
Первая отечественная работа в области распознавания образов - работа основоположника современной теории информации Харкевича Александра Александровича - “Опознавание образов” .”Радиотехника” т.14,15. 1959 г.
Наши отечественные ученые, внесшие существенный вклад в эту дисциплину:
В.М.Глушков, В.С.Михалевич, В.С.Пугачев, НП.Бусленко, Ю.И.Журавлев, Я.З.Цыпкин, А.Г.Ивахненко, М.А.Айзерман, Э.М.Браверман, М.М.Бонгард, В.Н.Вапник, Г.П.Тартаковский, В.Г.Репин, Л.А.Растригин, А.Л.Горелик и др.
Зарубежные ученые:
1-й Ф.Розенблатт - 1957г , Персепторон - простейшая модель мозга, решающая задачи распознавания.
Р.Гонсалес, У.Гренандер, Р.Дуда, Г.Себестиан, Дж.Ту, К.Фу, П.Харт.
Л Е К Ц И Я 1.2
Терминология и отличительные особенности систем распознавания
1.2.1. Основные определения
В силу чисто исторических причин класс задач распознавания связан с понятием “образа”. В свое время не обратили внимания, что в заимствованном из англоязычных работ термине “pattern recognition” òåðìèí “pattern”, êðîìå çíà÷åíèÿ “îáðàç”, èìååò åùå çíà÷åíèå “ìîäåëü”, ñòèëü”, “ðåæèì”, “çàêîíîìåðíîñòü”, “îáðàç äåéñòâèÿ”.  ñîâðåìåííîì ðàñïîçíàâàíèè è îñîáåííî èñêóññòâåííîì èíòåëëåêòå åãî óïîòðåáëÿþò â ñàìîì øèðîêîì ñìûñëå, èìåÿ â âèäó, ÷òî “îáðàç” - ýòî íåêîòîðîå ñòðóêòóðèðîâàííîå ïðèáëèæåííîå (îáðàòèòå âíèìàíèå - “ïðèáëèæåííîå”!) îïèñàíèå (ýñêèç) èçó÷àåìîãî îáúåêòà, ÿâëåíèÿ èëè ïðîöåññà.
То есть, частичная определенность описания является принципиальным свойством образа.
Основное назначение описаний (образов) - это их использование в процессе установления соответствия объектов, то есть при доказательстве их идентичности, аналогичности, подобия, сходства и т.п., которое осуществляется путем сравнения (сопоставления). Два образа считаются подобными, если удается установить их соответствие. Можно, в частности, считать, что имеет место соответствие, если достигнута их идентичность.
Сопоставление образов представляет собой основную задачу распознавания и играет существенную роль в информатике в целом. Эта задача возникает, в частности, в различных разделах искусственного интеллекта, например в понимании естественного языка компьютером, символьной обработке алгебраических выражений, экспертных системах, преобразовании и синтезе программ ЭВМ.
Теперь отметим следующий важный момент, что в различных задачах образу придается различный смысл. Это определяется часто тем, какие характеристики объекта входят в описание образа, какой аппарат используется для представления этих характеристик. Именно отсюда и можно понять, почему образ является приближенным описанием объекта. Чем большее число свойств и качеств объекта отражено на принятом языке в образе рассматриваемого объекта, тем полнее это описание, тем полнее этот образ характеризует описываемый объект. Однако в любом случае мы имеем дело с описанием, а не с самим объектом, который всегда богаче описания. Итак, любой образ представляется некоторым набором признаков. Поэтому вполне допустимо наряду с выражением “распознавание образов” применять выражение “отождествление некоторых наборов описаний объектов”.
* * *
Достаточно наглядно и теоретически и практически понимается различие между объектом и образом, если рассмотреть различия между картиной (художественное полотно), являющейся плоским объектом, и таким ее изображением как фотографическое или компьютерное, введенное телекамерой или сканером.
Простота примера состоит в том, что как картина, так и ее изображение на пленке или в телевизионном кадре записи - двумерны. Вводя соответствующие системы координат, представим их так
f(a,b) - объект;
g(x,y) - изображение объекта.
Общепринято объект обозначать буквой f, а èçîáðàæåíèå -g.
Заметим сразу, что изображение может выступать как образ картины в том числе в автоматической системе распознавания, будучи введенным в компьютер для прямого сопоставления с другими изображениями. Но при этом обратим внимание и на то, что изображение здесь - это уже не сам объект.
Можно понять, что идеальная изображающая система - это такая система, для которой в любой точке пространства выполняется равенство f = g. На практике почти не существует таких систем. Функциональные связи между f и g всегда подлежат экспериментальному определению.
Для понимания сути вопроса рассмотрим простейшую оптическую систему получения фотографий картины, нарисованной на двухмерном экране. Здесь мы имеем дело с объектом, лежащем в плоскости, и таким же плоским изображением.
В данном примере распределения f и g имеют одну и ту же размерность, поскольку они являются пространственным распределением интенсивности света или его цвета в плоскости.
Фотография формируется квантами света, отраженного от картины, прошедшего через линзовую систему фотоаппарата и попавшего на фотопленку. Такое формирование изображения приводит к потери качества за счет искажений и несовершенства приемного устройства, и следовательно, в этом случае f и g не равны друг другу. И только если известен закон потери качества, то можно провести компенсацию искажений путем соответствующей обработки изображения.
Другим примером могут быть двухмерные изображения g распределения f радиационного препарата в организме человека, полученные с помощью гамма-камеры, поворачивающейся последовательно на определенные углы относительно пациента. Здесь надо избавиться от иллюзии того, что полученные детали изображения соответствуют областям интереса врача-диагноста. Дело в том, что рассмотренное визуализированное изображение - это не распределение активности поглощения в теле пациента, а распределение интенсивностей только в элементах изображения.
То есть, изображение g есть некоторое представление (описание) объекта f, которое, хотя и располагается в том же месте, но может иметь отличия не только качественные, но и такие количественные как размеры. В данном случае приходится констатировать, что процессы в гамма-камере, с помощью которой производится регистрация исходных данных, на сегодняшний день не имеют математического описания, позволяющего связать объект с его изображением. Это еще раз заставляет подчеркнуть, что врач не видит изменений интенсивности поглощения гамма-излучения в теле пациента, а только - распределение интенсивностей на изображении, полученном с помощью системы регистрации. А отсутствие математического описания связей изображения и процесса не позволяет строго трактовать результаты медицинского наблюдения. Остается надеяться только на опыт врача.
Разумно считать, что объект и его изображение физически совпадают и связаны друг с другом соотношениями, характеризующими конкретный метод визуализации, хотя в ряде случаев могут иметь отличающиеся размеры.
Таким образом, в общем случае не существует идеального (1:1) соответствия между информацией, содержащейся в какой-либо точке с координатами (a, b), и информацией, соответствующей точке (x, y). В принципе информацию от каждой точки объекта можно “рассеять” по всем точкам изображения. Однако в любом полезном методе визуализации главный вклад в каждую точку (a, b) будет давать отдельная конкретная точка (x, y). Другие, соседние точки будут вносить меньшее количество информации, причем уменьшение указанного вклада происходит достаточно резко по мере удаления от основной точки с координатами (x, y). Эти выводы известны как принцип близости, а распределение по изображению некоторой точки из пространства объекта может зависеть как от значения поля в точке объекта, так и от поля в точках, расположенных около этой точки и удаленных на бесконечное расстояние от нее.
Какая же существует физическая связь между пространством объекта и пространством изображения?
В плоскость изображения попадает информация исходя из наличия информации в плоскости объекта, а также в зависимости от того, какой кодирующий носитель информации используется в данном методе визуализации (фотография формируется за счет переноса фотонов, яркостная картина УЗИ - за счет рассеяния продольных ультразвуковых волн, степень поглощения радиационных препаратов - путем счета испущенных g-квантов, рентгенограмма - за счет линейного затухания рентгеновских квантов и т.п.).
Введем функцию h(x,y,a,b), которая описывает пространственные связи для точечного процесса, то есть процесса, который отличен от нуля лишь в точке с координатами (a' ,b' ). Тогда зарегистрированное изображение будет иметь вид:
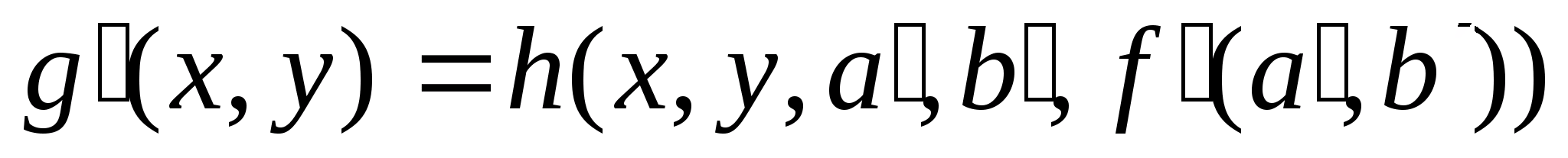
Здесь зависимость распределения изображения от амплитуды сигнала точечного источника учтена введением в функцию h пятого аргумента.
Рассмотрим теперь сигнал от второго точечного объекта, расположенного там же, где и первый:
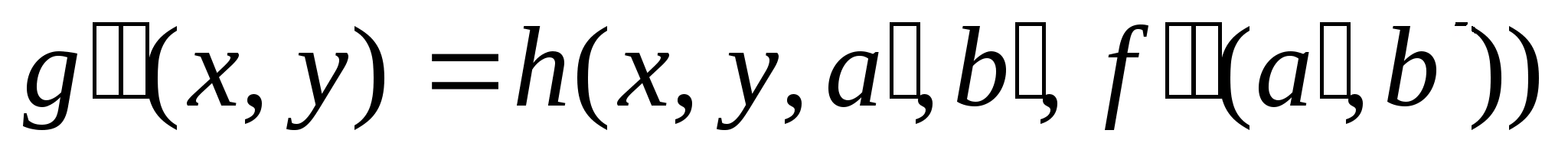
Согласно принципу суперпозиции излученные энергии сигналов суммируются:
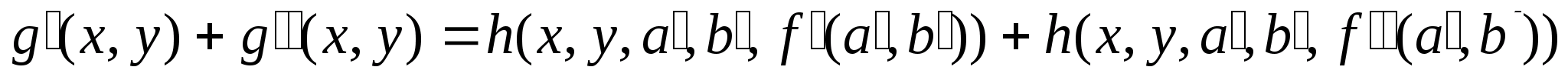
Это - нелинейная суперпозиция в силу нелинейности слагаемых в правой части равенства. В итоге, как видим, суммированию измеряемых распределений в плоскости изображения не соответствует сложение функций в плоскости объекта.
Если же система линейна, то
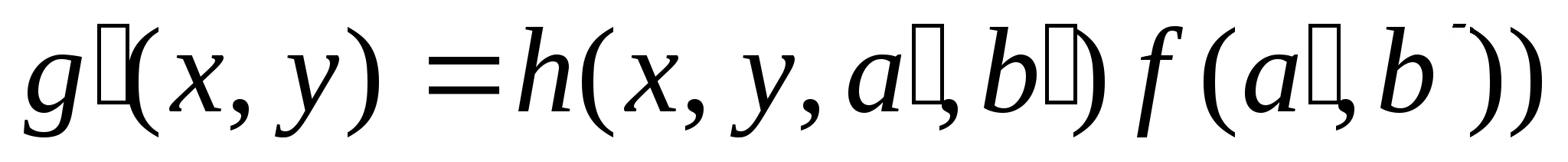
а суперпозиция будет иметь следующий вид
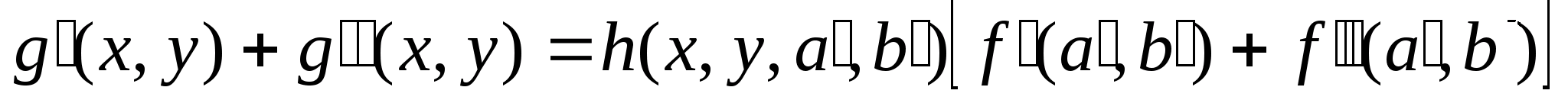
То есть, в случае линейности системы сложение функций в плоскости объекта приводит к суммированию распределений в плоскости изображения с точностью до единственной функции преобразования h.
Математически последнее является очень важным упрощением, так как линейность в рассматриваемых задачах предполагается всегда в первом приближении, даже когда это, строго говоря, не соответствует действительности.
Теперь можно перейти к обобщенным соотношениям, связывающим пространства объекта и его изображения. Для нелинейной системы визуализации имеем:
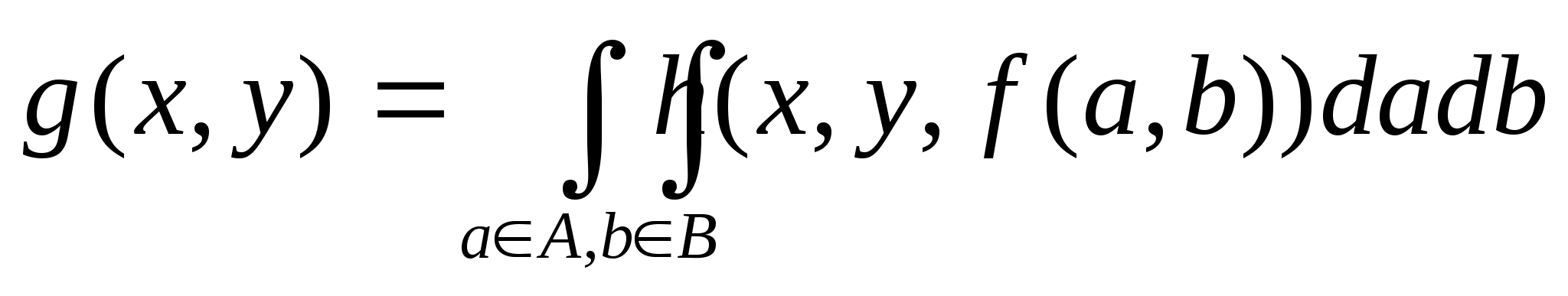
а для линейной
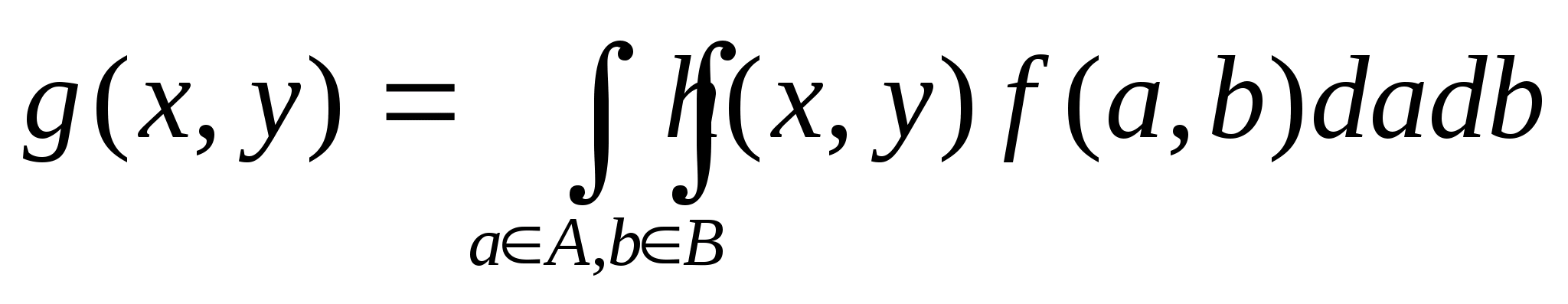
Функция h, используемая для связи распределений f и g, называется функцией отклика точечного источника (ФОТИ). Зависимость ее от всех четырех пространственных координат определяет ФОТИ как пространственно-зависимую. Если же точечный процесс одинаков для всех точек плоскости объекта, то h - пространственно-инвариантна. При этом h зависит лишь от разности координат (x-a,y-b). Для пространственно-инвариантной системы
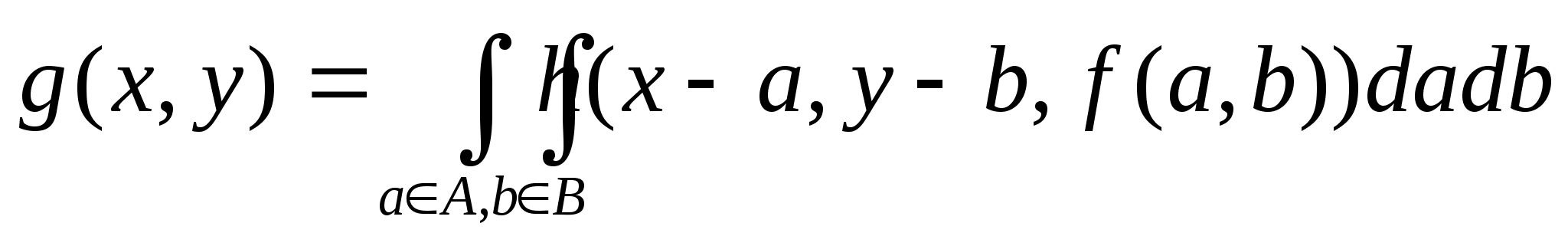
при этом для линейной пространственно-инвариантной системы
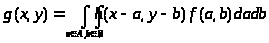
Последнее выражение известно как интеграл свертки, согласно которому распределение по изображению представляет собой свертку распределения по объекту с ФОТИ. Именно функция h описывает процесс переноса информации от объекта в пространство изображения и характеризует все геометрические искажения, присущие процессу визуализации.
Окончательное упрощение обобщенных соотношений, описывающих процесс формирования изображений, получается в том случае, когда свойства системы в двух перпендикулярных направлениях не коррелируют друг с другом. Это означает, что двухмерную ФОТИ можно представить в виде произведения двух одномерных ФОТИ. Так для пространственно-зависимой системы имеем
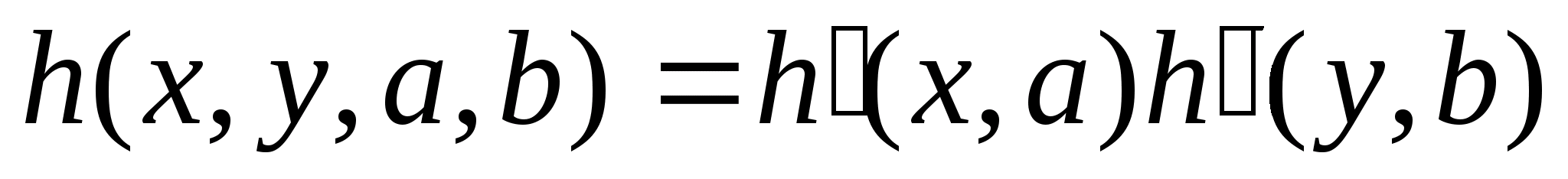
а для пространственно-инвариантной
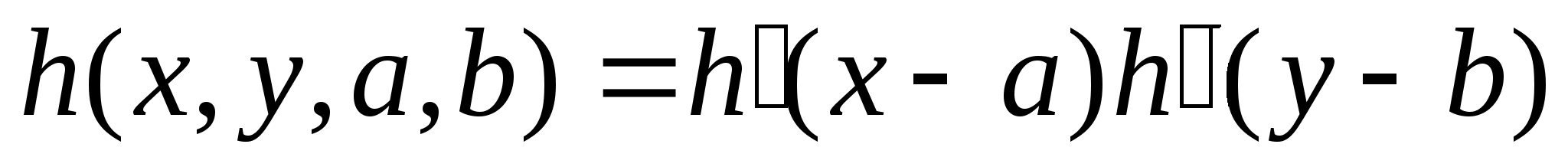
Это свойство системы называется разделимостью.
В итоге для линейной, пространственно-инвариантной разделимой системы получаем

Учитывая рассмотренное, легко понять, что, наблюдая изображение, мы не можем считать его точным представлением распределения по объекту. Это можно заметить путем внимательного рассмотрения изображения и сравнения его с объектом или явлением. Причина - несовершенства системы визуализации.
Именно поэтому в теории обработки изображений большое внимание уделяется методам исключения соответствующих искажений, получившим название обращение свертки (Вытекает из рассмотрения хотя бы последнего интеграла свертки!).
В соответствующих задачах интеграл свертки рассматривается с учетом искажения изображений шумами. Так для линейных систем полное представление о задаче создает выражение
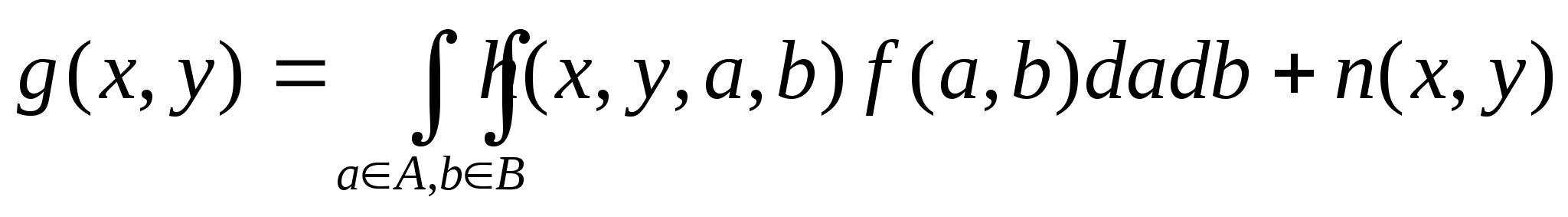
где n(x,y) - распределение шума в изображении.
* * *
Теперь сконцентрируем внимание на следующем важном термине распознавания образов - “класс”. Здесь, прежде всего, обратим внимание на то, что как человек, так и автомат принимают решение на основе отождествления совокупности конкретных значений характеристик объектов или явлений не просто друг с другом, а обычно с некоторым классом, в который объединяются объекты или явления, имеющие общие свойства (например: характеристики выхода из строя агрегатов и систем той же АЭС - класс опасных отказов или класс отказов, требующих определенного технического вмешательства, но неопасных).
Таким образом, классы - это объединения объектов (явлений), отличающиеся общими свойствами, интересующими человека.
Всегда, имея в виду цель распознавания, в конечном итоге принятое решение об отнесении объекта к тому или иному классу определяет реакцию соответствующей системы на данную входную ситуацию однозначно.
Таким образом, в самых общих чертах распознавание можно определить как соотнесение объектов или явлений на основе анализа их характеристик, представляющих образы этих объектов, с одним из нескольких, заранее определенных классов.
И следует обратить внимание на то, что термин “распознавание” в равной мере относится как к процессам восприятия и познания, свойственным человеку и живым организмам, так и к техническим попыткам человека реализовать “электронные” или “вычислительные” аналоги этих процессов, то есть к решению задач в рамках предмета распознавания как раздела информатики.
1.2.2. Системы распознавания
До этого мы говорили о проблеме распознавания в целом, о теории, о возможности замены человека автоматом. Теперь сосредоточим внимание на практическом применении соответствующих знаний. При этом обратим внимание и на то, что те практические реализации методов распознавания , о которых в этих случаях шла речь, носят название систем распознавания (СР).
Здесь необходимо подчеркнуть, что именно центральную задачу распознавания образов представляет построение на основе систематических теоретических и экспериментальных исследований эффективных вычислительных средств (объединяемых в понятии “системы распознавания”) для отнесения описаний с объектов, явлений, процессов к соответствующим классам.
Широкий круг задач, возлагаемых на такие системы, определяется приведенным нами определением самого понятия “распознавание” и включает выяснение по разнородной, часто неполной, нечеткой, искаженной и косвенной информации факта, обладают ли изучаемые объекты, явления, процессы, ситуации фиксированным конечным набором свойств, позволяющим отнести их к определенному классу. Сюда входят как непосредственно задачи распознавания и классификации, так и такие задачи, в результате решения которых на основе распознавания требуется выяснить, в какой области из конечного числа областей будут находиться некоторые процессы через определенный промежуток времени.
Отсюда понятно, что к задачам распознавания должны относиться задачи технической и медицинской диагностики, геологического прогнозирования, прогнозирования свойств химических соединений, распознавания свойств динамических и статических объектов в сложной фоновой обстановке и при наличии активных и пассивных помех, прогнозирования урожая, обнаружения лесных пожаров, управления производственными процессами.
Разработки систем распознавания, начатые с 50-х годов, исчисляются тысячами. Сегодня уже трудно назвать такую отрасль науки и сферы производства, где СР не используются или не будут. При этом применение методов распознавания в ряде направлений науки и техники оказывает обратное влияние на эти направления, поистине революционизирующее влияние.
Рассмотрим некоторые применения.
1) Ñèñòåìû òåõíè÷åñêîé äèàãíîñòèêè.
Их внедрение - важнейший фактор повышения эффективности использования машин и технологического оборудования, резкого сокращения расходов на эксплуатацию.
Исторически сложившаяся тенденция усложнения, а значит удорожания машин постоянно увеличивает затраты на эксплуатацию. Выход - переход к системам технической диагностики (распознавания состояния машин), например, безразборный поиск неисправностей. В результате вместо планово-предупредительного ремонта - ремонт по фактической необходимости. Например, в инструкции по эксплуатации автомобиля предусмотрены плановые технические обслуживания через 500 км, 1000 км, 2000 км и т.д. Если же его оснастить системами распознавания состояний, то от плановых ТО можно было бы отказаться заменив их обслуживанием отдельных узлов и систем по необходимости.
2) Ìåäèöèíñêàÿ äèàãíîñòèêà.
Автоматизированные системы диагностики в медицине - путь увеличения
- широты и глубины охвата симптомов;
( рассчитывать только на память врача во всех ситуациях очень трудно. Лучше функцию памяти отдать компьютеру)
-оперативности;
(компьютер обеспечит почти мгновенный результат)
-достоверности.
(диагноз компьютера не зависит от внешних факторов, как это случается с человеком)
3) Ñåëüñêîå õîçÿéñòâî.
Области применения здесь:
-ðàñïîçíàâàíèå ðàçìåðîâ óðîæàÿ ïî äàííûì êîñìè÷åñêèõ íàáëþäåíèé;
-óìåíüøåíèå ðó÷íîãî òðóäà ïðè ñîðòèðîâêå ïëîäîâ ïî ôîðìå, öâåòó è ðàçìåðàì è ò.ï.
4) Âîåííîå äåëî.
Сложные системы вооружения:
-автоматический функциональный контроль технического состояния систем и ввод резервирующих;
-роботы, обслуживающие фазированные антенные решетки радаров.
На основе рассмотренного можно уже ответить на вопрос, что же представляет собой СР.
В первом приближении:
“СР - это автоматическое вычислительное устройство, предназначенное для распознавания образов (каких? можно уже не повторяться).
Заметим, что это очень поверхностное определение. Сегодня физически СР это и вычислительная машина как один составляющий элемент СР;
-это и такие часто более дорогостоящие технические средства, как средства обнаружения распознаваемых объектов (например, патологических изменений того или иного органа человека);
-это и средства измерений параметров обнаруженных объектов (без них не получить признаков распознавания);
-это и математическое обеспечение, в составе которого: методы и алгоритмы обработки измерительной информации; методы и алгоритмы определения признаков распознавания; методы и алгоритмы непосредственно распознавания объектов, явлений , процессов ( построения решающих правил отнесения объектов к тому или иному классу); методы и алгоритмы в некотором смысле оптимального управления процессом распознавания; методы и алгоритмы оценки эффективности СР как на стадии проектирования, так и в процессе ее функционирования;
-наконец, для больших систем это и коллектив подготовленных специалистов обеспечивающих жизненный цикл существования системы.
Рассмотрим подробнее отдельные элементы.
а) Средства обнаружения распознаваемых объектов.
К ним в разных областях применения относятся:
в медицине:
-рентгеновские аппараты;
-аппараты УЗИ;
-ЯМР-томографы;
-энцефалографы;
-рентгеновские томографы;
-кардиографы и т.д.
в военном деле:
-радиолокаторы;
-оптические (лазерные) локаторы;
-лазерные дальномеры;
-приемники гамма-излучения;
-сонары - ультразвуковые локаторы.
Средства обнаружения представляют дорогостоящую часть СР. Но этим дорогостоящая часть СР не ограничивается.
б) Средства сопряжения.
Для сопряжения средств обнаружения с ЭВМ необходимы специальные электронные устройства аппаратного интерфейса. Эти составные части СР также достаточно дорогостоящи.
в)Средства измерений параметров распознаваемых объектов,явлений, процессов.
Средства измерений часто входят в состав обнаружителей (РЛС - измерение дальностей, углов, Рс/Рш).
г) Методы и алгоритмы обработки измерительной информации
Часто для получения признаков распознавания или параметров , которые их обусловливают необходима специальная математическая обработка (пример, для РЛС - определение дальностей целей по временной задержке сигналов, угловых координат по разности фаз, коэффициентов лобового сопротивления целей по координатам и их производным и т.п.).
Сам процесс назначения признаков - творческий процесс, говорят - эвристический, зависящий от человека.
д) Методы и алгоритмы принятия решения о принадлежности объектов распознавания.
е) Методы и алгоритмы оптимального управления распознаванием.
ж) Методы и алгоритмы оценки эффективности распознавания.
Как алгоритмы принятия решений, так и управление распознаванием, так и оценка эффективности определяются сложностью систем распознавания и представляют концентрированное применение комплекса математических операций соответствующего назначения.
з) Э В М
Наконец, ЭВМ. Это обязательный элемент современной СР. Вся обработка измерений с целью выделения признаков распознавания, вся математика классификации, управления и оценки эффективности выполняется ЭВМ. Само развитие теории и методов распознавания обязано появлению ЭВМ.
и) Коллектив подготовленных специалистов.
Такая составляющая на первый взгляд не имеет отношения к системе. Однако без коллектива подготовленных специалистов трудно обойтись в больших системах, решения которых чрезвычайно ответственны. В таких системах оценка эффективности - это показатель, которым пользуются с момента создания СР и до конца ее существования. При этом пользуются этим показателем специалисты, а не система. А сама необходимость такого использования связана с тем, что в процессе работ появляется возможность повысить эффективность СР за счет получения новых данных и уточнения параметров системы в результате анализа специалистами конкретного случая распознавания с последующим уточнением этими специалистами имеющихся параметров. То есть, система в течение своей жизни (говорят - “жизненного цикла”) изменяется (динамизм системы).
Таким образом, СР - сложная динамическая система, состоящая в общем случае из коллектива подготовленных специалистов и совокупности технических средств получения и переработки информации, обеспечивающих на основе специально сконструированных алгоритмов решение задачи классификации соответствующих объектов, явлений или процессов.
После того, как описан состав и функции элементов СР, для завершения общих представлений о проблеме распознавания можно провести и некоторые поверхностные сравнения технических СР и такой совершенной СР, как человек.
Так рецепторы человека, к которым мы относим зрительные, слуховые, осязательные, обонятельные и вкусовые рецепторы - это средства обнаружения, а иногда и измерения характеристик распознаваемых объектов, явлений, процессов. Тут аналогия полнейшая.
Далее на пути оперирования с информацией у технических СР стоит устройство сопряжения с ЭВМ. Естественными аналогами его являются биологические средства связи человеческих рецепторов с мозгом, выполняющим роль ЭВМ.
Но это, пожалуй, - все, что мы сегодня знаем наверняка. И вопросов здесь больше, чем ответов:
-êàêèå ôóíêöèè âûïîëíÿþò ðåöåïòîðû â ÷àñòè ïåðâè÷íîé îáðàáîòêè ðåçóëüòàòîâ îáíàðóæåíèÿ îáúåêòîâ, ÿâëåíèé;
-êàêîâû õàðàêòåðèñòèêè ëèíèé ïåðåäà÷è äàííûõ îò ðåöåïòîðîâ ê ìîçãó êàê ÖÂÑ;
-êàêèå ïðèçíàêè âûäåëÿåò ñèñòåìà îáðàáîòêè;
-êàêèå àëãîðèòìû èñïîëüçóåò ìîçã äëÿ ðåøåíèÿ çàäà÷è êëàññèôèêàöèè, îïòèìàëüíîãî óïðàâëåíèÿ ïðîöåññîì ðàñïîçíàâàíèÿ;
-êàê ÷åëîâåêó óäàåòñÿ èçáàâèòüñÿ îò ñïåöèôè÷íîñòè, ñâîéñòâåííîé òåõíè÷åñêèì ÑÐ è ò.ä.
В процессе нашего дальнейшего изучения предмета Вы сами поставите еще много нерешенных в этом плане вопросов. А их разрешение чрезвычайно важно для построения быстродействующих и высокоэффективных технических СР, помогающих человеку в его повседневной практике.
Достижение соответствующих целей - задачи XXI века.
Òåìà 2
Çàäà÷è, ðåøàåìûå â ïðîöåññå ñîçäàíèÿ ñèñòåì ðàñïîçíàâàíèÿ.
Л Е К Ц И Я 2.1.
Проблематика задач создания систем распознавания на описательном уровне
При изучении первой темы мы уже создали представления о проблеме распознавания в целом. Казалось бы, можно было бы теперь сразу перейти к теоретическому осмысливанию составляющих этой проблемы. Однако какие это составляющие, как они соотносятся друг с другом в общей постановке проблемы, этого пока не было возможности выделить.
Поэтому, прежде чем перейти к формальной постановке соответствующих задач, постараемся рассмотреть их и осмыслить на описательном уровне.
Итак, мы уже знаем, что распознавание образов в технике - необходимый элемент процесса механизации и автоматизации машин, устройств и систем для
-замены человека там, где используется тяжелый физический труд;
-реализации быстрых реакций в управлении там, где нет времени на раздумье;
-замены человека в так называемых рутинных операциях, то есть, повторяющихся действиях, не требующих умственных усилий.
Уже протяжении 4-х десятков лет эти потребности реализовывались в таких конкретных на приложениях, как создание специалзированных роботов, техническая и медицинская диагностика, метеопрогноз, формализованная оценка общественных, экономических и социальных явлений и процессов. На это, начиная с 50-х годов, были направлены усилия научной и инженерной мысли.
В результате сопоставления конкретных решений и разработок оказалось, что несмотря на многообразие и особенности приложений, задачи создания систем распознавания имели много общего, не зависящего от указанной специфики.
Вот почему для выработки методических подходов теории распознавания имело смысл выделять общие повторяющиеся приемы, а их число естественно должно быть ограниченным и легко объединяемым в задачи. Сами же эти задачи должны были явиться ключевыми для создания любой системы распознавания. В результате оказалось, что найденный методический подход к построению систем распознавания образов инвариантен к предметной области.
Постараемся осмыслить эту инвариантность построения СР , рассмотрев простые реализации систем.
А. Распознавание стороной А самолетов стороны В (этот пример мы будем часто использовать в последующем, постепенно его усложняя).
Здесь фактически требуется создать автоматическую систему, обеспечивающую стороне А решение указанной задачи.
Понятно, что цель создания такой системы - оборона стороны А от возможного нападения, а следовательно - предотвращение возможного ущерба.
Первое, с чего естественно начать эту работу - провести изучение и анализ всей возможной информации об авиации стороны В и собрать необходимые данные.
Как эта информация может быть получена:
-из открытой печати (часто многие характеристики самолетов не скрываются);
-из разведданных;
-из экспериментальных наблюдений самолетов стороны В и измерений их характеристик (например, с помощью РЛС);
-из экспериментальной обработки данных, полученных по макетам и моделям соответствующих самолетов стороны В
(наземные стенды или электродинамические расчеты); и т.д.
Какие это характеристики? Это - численность экипажей, высоты полета, крейсерские скорости, дальности полета, число двигателей и т.д.
Рассматриваемое изучение позволит обнаружить в том числе и способы, которые применяет или предполагает применять сторона В для преодоления противовоздушной обороны (ПВО) стороны А и которые будут ухудшать возможности распознавания. Например, США по программе Стелс разработали бомбардировщик-невидимку для радиолокационных средств - В1).
Таким образом мы должны получить все мыслимые и существующие характеристики самолетов (признаки).
Второй шаг, логично следующий из проведенного изучения - на основе знания тактико-технических характеристик средств противодействия стороне В, имеющихся у стороны А, и знаний авиации стороны В можно выделить ситуации применения ее, существенно отличающиеся по возможному ущербу и по возможности его предотвращения.
Это фактически соответствует разделению самолетов стороны В на классы, для каждого из которых стороне А известно, что нужно предпринять.
В результате может оказаться, что классов 3 (А1- бомбардировщики, А2 - штурмовики ,А3 - истребители), а средств противодействия - 2 (S1 - ЗУР, S2 - истребители с их вооружением).
При этом наиболее эффективно их распределить следующим образом:
А1 - S1
А2 - S2
А3 - S1
то есть, классы А1 и А3 с точки зрения противодействия желательно объединить в один класс.
Если же средств противодействия - 3 (S1- ЗУР для больших высот, S2 - ЗУР маловысотные, S3 - истребители с их вооружением), то классы можно не объединять, а использовать стратегию
А1 - S1
А2 - S2
А3 - S3
Третий шаг по созданию системы распознавания самолетов стороны В - выбор измерителей.
Для обозначенных классов авиации из анализа имеющихся у стороны А средств наблюдения за самолетами (РЛС, ОЛС и т.п.) и полного перечня признаков соответствующих самолетов, полученных на первом нашем этапе разработки (например, крейсерские скорости, высоты полета, длины фюзеляжей, размахи крыльев, число двигателей и т.п.) выделить такие, которые могут быть определены по данным имеющихся средств измерений.
Здесь возможны и разочарования: может не оказаться таких средств измерений. Тогда принимается решение о их создании.
Итак, по каждому самолету мы имеем № характеристик - признаков. Но это еще ничего не дает нам для решения задачи. Мы не знаем, как разделить самолеты, пользуясь этими признаками по классам.
Для этого и нужен 4-й шаг - àïðèîðíîå îïèñàíèå êëàññîâ. Òî åñòü, íåîáõîäèìî íà ÿçûêå âûáðàííûõ ïðèçíàêîâ îïèñàòü êàæäûé êëàññ ñàìîëåòîâ èëè òàêòè÷åñêèõ ñïîñîáîâ èõ ïðèìåíåíèÿ.
При этом в описании каждого класса должны содержаться сведения:
- о наличии или отсутствии признаков качественного характера (тип двигателя, наличие постановщика помех, тип помех и т.п.);
- о диапазонах или законах распределения признаков, имеющих количественное выражение.
Следует заметить, что все выбранные признаки должны получить соответствующее содержание (свое) для каждого класса.
На этом подготовительный этап работы заканчивается .
Теперь, если с помощью выбранных средств наблюдений за воздушными целями обнаружен неизвестный самолет и измерены (оценены) его признаки, то сопоставление полученных апостериорных данных (по результатам проведенных опытных измерений) с априорными (доопытным описанием классов) позволяет произвести его распознавание (отнесение к соответствующему классу А1,А2 самолетов стороны В).
Здесь априорные данные - доопытное признаковое описание классов;
апостериорные данные - послеопытный набор признаков классифицируемого самолета.
Рассмотрим вторую возможную реализацию СР.
Б. Распознавание заболеваний сердца. Требуется построить такого рода автоматическую систему.
1-й шаг создания такой системы - изучение всей информации о заболеваниях сердца.
На первый взгляд эта задача кажется более легкой, чем распознавание самолетов, так как все сведения носят открытый характер. Однако обольщаться здесь не следует. В процессе пристального ее изучения может обнаружиться, что некоторые стороны изучения явления человечеству пока еще неизвестны.
В результате мы должны иметь здесь все возможные характеристики заболеваний (признаки):
-çóáöû êàðäèîãðàìì;
-ïîâåäåíèå ïóëüñà;
-ïîâåäåíèå àðòåðèàëüíîãî äàâëåíèÿ è ò.ï.
2-й шаг - изучение всего арсенала средств лечения заболеваний и разделения их по классам, для которых известно, что нужно конкретно предпринимать для лечения (По самолетам мы также добивались разделения их по классам).
В результате может оказаться, что:
-число средств лечения (S>1>, S>2>...) больше числа классов заболеваний (А>1>, А>2>,....); тогда их просто комплексируют или принимают решение о дополнительном распознавании противопоказаний;
-некоторые классы требуют одинаковых средств лечения (например, хирургическое вмешательство); тогда классы объединяют.
3-й шаг - из анализа имеющегося арсенала средств медицинской диагностики (кардиограф, фонокардиограф, УЗИ, рентген, анализ крови и т.д., и т.п.) и признаков классов заболеваний выделяют те признаки, которые реально определить имеющимися средствами ( Здесь возможны и решения о создании новых специальных средств диагностики).
Заметим, что те же действия предпринимались и для измерения признаков самолетов стороны В.
4-й шаг - на языке отобранных признаков описывается аналогично самолетам каждый класс заболеваний сердца, то есть, составляется перечень значений признаков каждого класса.
При этом для каждого класса должны быть выделены сведения:
-î íàëè÷èè èëè îòñóòñòâèè ïðèçíàêîâ êà÷åñòâåííîãî õàðàêòåðà;
-î äèàïàçîíàõ èëè çàêîíàõ ðàñïðåäåëåíèÿ ïðèçíàêîâ, èìåþùèõ êîëè÷åñòâåííîå âûðàæåíèå.
Здесь также следует заметить, что все выбранные признаки должны получить соответствующее содержание (свое) для каждого класса.
Теперь, если с помощью выбранных средств диагностики состояний сердца оценены признаки, характеризующие его деятельность, то сопоставление полученных апостериорных данных (по результатам опытных измерений) с априорными (доопытным описанием классов) позволяет произвести распознавание конкретного класса заболеваний или отсутствие заболеваний вообще.
Эти два примера показали, что подходы к построению систем распознавания практически ничем не отличаются, несмотря на специфику самих создаваемых систем.
В результате мы получили общие представления о последовательности решения и составляющих задачи создания системы распознавания. В результате отмечаем, что несмотря на различие предметных областей подходы к построению СР - одинаковы. Система распознаваний заболеваний сердца строилась также, как и система распознавания самолетов, но заменить ее она не позволяет. Точно также СР самолетов не может применяться для решения задач распознавания заболеваний сердца.
Системы распознавания объектов (явлений), создаваемые человеком всегда узко специализированы в отличии от его собственных природных возможностей.
Что же касается общего подхода к построению любой системы, то теперь, если у нас имеется некоторая совокупность объектов или явлений, которые необходимо распознавать (классифицировать), на основе обобщения действий при создании СР в 2-х рассмотренных примерах мы знаем, что последовательность решения соответствующих задач следующая:
-в соответствии с выбранным принципом совокупность объектов или явлений подразделяется на ряд классов (говорят: назначается алфавит классов);
-разрабатывается совокупность признаков (говорят: словарь);
-на языке словаря признаков описывается каждый класс;
-выбираются и (или) создаются средства определения признаков;
-на вычислительных средствах реализуется алгоритм сопоставления апостериорных и априорных данных и принимается решение о результатах распознавания.
В то же время, несмотря на выполненное определение последовательности действий, проведенное рассмотрение не позволяет ответить на следующие вопросы:
-как лучше производить разбиение объектов (самолеты, заболевания и пр.) по классам;
-как накапливать и обрабатывать априорную информацию;
-из каких соображений выбирать признаки;
-как описывать классы на языке признаков;
-на основе каких методов сравнивать априорную и апостериорную информацию;
-когда и как появляется вся система распознавания.
Все эти вопросы являются предметом рассмотрения в пределах читаемого курса. Мы будем их детализировать все более глубоко по мере освоения предмета.
На последний вопрос следует дать предварительный ответ до того, как мы проведем упомянутое углубленное изучение. Система должна появляться с самого начала изучения вопроса. Этот вариант ее должен представлять собой модель-прообраз будущей системы распознавания. Сейчас мы должны понять только одно - без такой модели создание СР чаще всего невозможно вообще. Без нее мы не сможем выбрать ни набор классов, ни перечень признаков, ни средства измерений их, ни решающие правила, обеспечивающие в комплексе, во взаимосвязи требуемое качество решений о принадлежности. Это обусловлено тем, что полная информация для создания СР на момент начала ее создания всегда отсутствует и без экспериментальной отработки всего процесса принятия решений не всегда ясно, какая информация может вообще потребоваться. Поэтому модель должна позволить методом последовательных приближений внутренней структуры системы к требуемой достигнуть желаемого результата. В то же время вопросы моделирования СР не могут быть рассмотрены на нынешнем уровне полученных знаний. Поэтому моделирование СР - предмет дальнейшего изучения курса "Основ построения систем распознавания образов"
Итак, главные выводы:
1. Задачи, решаемые в процессе создания систем распознавания, инвариантны относительно предметной области, имеют много общего, основываются на едином методологическом подходе.
2. Каждая система распознавания индивидуальна и предназначается только для одного вполне конкретного вида объектов или явлений.
Если найдена сфера применения распознавания, то соответствующая система должна разрабатываться заново с учетом новых специфических свойств объектов (явлений), определяющих как систему измерений характеристик, так и словарь признаков, алфавит классов и алгоритм принятия решений.
3. СР должна создаваться методом последовательных приближений внутренней структуры на ее математической модели по мере накопления необходимой информации.
Теперь, после того как мы на качественном уровне рассмотрели проблематику распознавания, можно провести дополнительную детализацию и определить последовательность задач создания соответствующих систем.
Л Е К Ц И Я 2.2
Формулировка задач создания систем
распознавания и методы их решения
ЗАДАЧА № 1
Определение полного перечня признаков (параметров), характеризующих объекты или явления, для которых данная система разрабатывается.
В решении этой задачи - главное найти все признаки, характеризующие существо распознаваемых объектов (явлений). Любые ограничения, любая неполнота, как мы в последующем убедимся, приводят к ошибкам или полной невозможности правильной классификации объектов (явлений).
Можем себе представить такую неполноту в уже рассмотренной нами задаче распознавания самолетов как использование одного признака - потолок высоты полета самолетов. В результате - бомбардировщики не удастся отличать от истребителей ( при создании бомбардировщиков стремятся к обеспечению максимально возможной высоты полета, а при создании истребителей добиваются, чтобы они могли уничтожать бомбардировщики).
Реально даже целая группа признаков может оказаться неэффективной.
Поэтому для решения 1-ой задачи создания СР необходимо найти все возможные признаки, описывающие объекты распознавания, с тем, чтобы при оценке эффективности решений системы не возвращаться к этой задаче, обнаружив ограниченность выбранных признаков на последующих этапах разработки.
Но чтобы назначать признаки распознавания, необходимо, во-первых, понять, что не существует способов их автоматической генерации. На сегодня это под силу только человеку. Поэтому говорят, что выбор признаков - эвристическая операция. Во-вторых, выбор признаков можно осуществлять, имея представление об их общих свойствах. С этих позиций достаточно принять, что признаки могут подразделяться на:
-детерминированные;
-вероятностные;
-логические;
-структурные.
А. Детерминированные признаки - это такие характеристики объектов или явлений, которые имеют конкретные и постоянные числовые значения.
Примерами детерминированных признаков могут быть, например, ТТХ бомбардировщиков и истребителей США (таблицы № 1, 2).
Числовые значения признаков по каждому из самолетов можно интерпретировать как координаты точек, представляющих каждый самолет в 11-мерном пространстве признаков.
Необходимо иметь в виду, что в задачах распознавания с детерминированными признаками ошибки измерения этих признаков не играют никакой роли, если, например, точность измерений такого признака, как размах крыльев самолета значительно выше (например, 1 мм), чем различие этого признака у разных классов самолетов (например, 10 м).
Представить такую систему, где используются детерминированные признаки не так трудно:
-распознавание принадлежности самолета, данные которого получены разведкой или из открытой печати и не привязаны к классам (бомбардировщик- А>1>, истребитель-А>2> и т.п.);
-распознавание на конвейере деталей по отличию геометрических характеристик, если ошибки измерений существенно меньше разметов этих деталей.
Распознавание осуществляется путем сравнения полученных размеров с имеющимися в базе данных характеристиками деталей.
Б. Вероятностные признаки - это характеристики объекта (явления), носящие случайный характер.
С такими признаками в основном и имеют дело в природе и технике.
Отличаются эти признаки тем, что в силу случайности соответствующей величины признак одного класса может принимать значения из области значений других классов, каждый из которых подлежит распознаванию в системе.
Таблица № 1
|
Характеристики |
Ò è ï û ñ à ì î ë å ò î â |
|||
|
В-1А |
В-52 |
В-57А |
FB-111 |
|
|
Экипаж (чел.) |
4 |
6 |
2 |
2 |
|
Vmax (êì\÷) при H=15 êì |
2330 |
1020 |
935 |
2330 |
|
Vmin (êì\÷) при H=0.3 êì |
1200 |
500 |
500 |
1350 |
|
Потолок (м) |
15240 |
15000 |
13750 |
20000 |
|
Бомб.нагрузка (т) |
22 |
34 |
14 |
16 |
|
Макс.взлетная масса (т) |
180 |
221 |
25 |
45 |
|
Размах крыльев (м) |
42 |
56 |
19 |
21 |
|
Длина самолета (м) |
44 |
48 |
20 |
22 |
|
Кол-во двигателей |
4 |
8 |
2 |
2 |
|
Тяга двигателей (т) |
13.6 |
7.7 |
3.3 |
9.2 |
|
Дальность полета (км |
11000 |
20000 |
4380 |
6600 |
Таблица ¹ 2
|
Характериcòèêè |
Т и п ы с а м о л е т о в |
||||
|
F - 4 E Фантом |
F - 105 E Тандер-чиф |
F - 15 Игл |
F - 100 D Супер-сейбр |
Хантер |
|
|
Экипаж (чел.) |
2 |
2 |
1 |
1 |
1 |
|
V>max > (êì\÷) при H =15 êì |
2330 |
2230 |
2655 |
1400 |
1000 |
|
V>min >(êì\÷) ïðè H =0.3 (êì) |
1470 |
1400 |
1470 |
1220 |
1150 |
|
Потолок (м) |
19000 |
15000 |
21000 |
15000 |
17000 |
|
Бомб.нагр. (т) |
7.2 |
6.4 |
- |
3.4 |
0.9 |
|
Макс.взлетн. масса (т) |
26 |
24 |
25 |
18 |
11 |
|
Размах крыльев (м) |
12 |
11 |
14 |
11 |
10 |
|
Длина самолета (м) |
18 |
21 |
19 |
12 |
13 |
|
Кол-во двигателей |
2 |
1 |
2 |
1 |
1 |
|
Тяга двигателей (т) |
5.4 |
12 |
10.9 |
5.3 |
4.5 |
|
Дальность полета (км) |
885 |
760 |
1100 |
860 |
560 |
Если признак не может принять значений в области соответствующих значений для других классов, то, следовательно, имеем дело не с вероятностным, а с тем же детерминированным признаком. Это как раз подчеркивает, почему вероятностные системы являются системами более общего порядка.
Для того, чтобы можно было в условиях случайности говорить о возможности распознавания, следует потребовать, чтобы вероятности наблюдения значений признака в своем классе были как можно больше, чем в чужих. В противном случае данный признак не позволит построить СР, использующую описание классов на его основе. Эффективность его недостаточна для достоверного решения и необходимо искать другие признаки, имеющие большую разделительную способность.
Вспомним из теории вероятностей, чем характеризуется случайная величина - законом распределения вероятностей. То есть, точно так же законом распределения должен характеризоваться каждый вероятностный признак.
Вспомним и то, что в качестве законов распределения вероятностей в теории вероятностей выступают интегральная функция F(x) - интегральный закон или плотность распределения вероятностей (ПРВ) - дифференциальный закон f(x). При этом связь между ними:
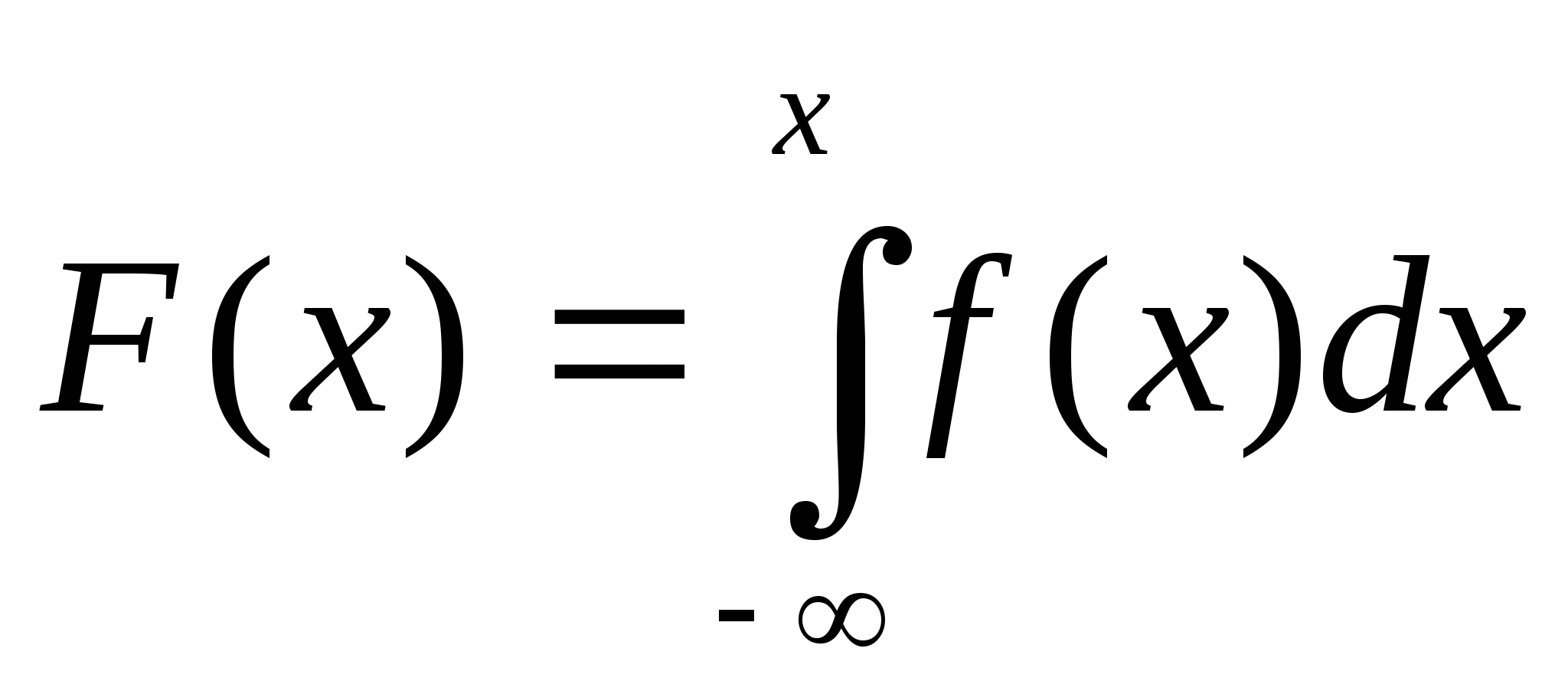
Вспомним, что самый распространенный в природе закон распределения - нормальный или Гауссов - имеет ПРВ
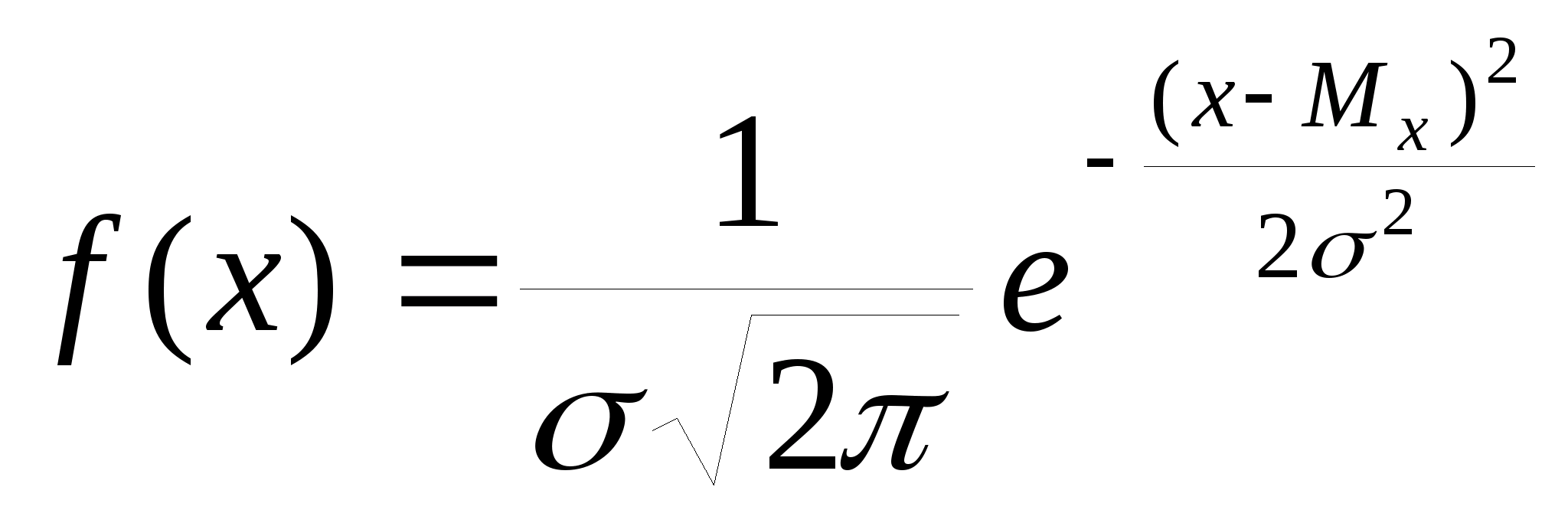
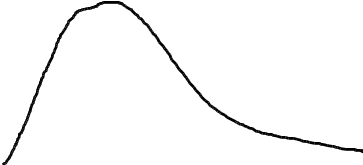
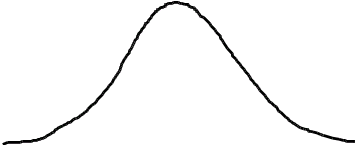
Если предположить, что какой-либо вероятностный признак (например, размах крыльев, измеренный каким-либо средством измерений с ошибками) распределен по нормальному закону, то для 3-х условных классов, отличающихся размахами крыльев, распределения этого параметра будут выглядеть, как показано на рис.2.1.
Из рис. 2.1 видно, что если для неизвестного самолета мы с помощью упомянутого средства измерений определили размах крыльев Lкр с естественной случайной ошибкой , то с определенной вероятностью это измерение может быть отнесено к каждому из классов. Однако, легко заметить, что если это значение лежит ближе к одному из центров рассеяния (например, Mx1), то вероятность отнесения его к соответствующему распределению, а значит и классу, максимальная.
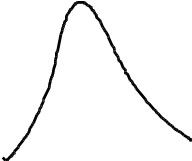


 f(L>êð>)
f(L>êð>)


M>x>1 M>x>2 M>x>3 L>êð>
Рис.2.1
Примеры вероятностных признаков распознавания:
-среднее значение мощности сигнала радиолокатора, отраженного от самолета (причина - изрезанность круговой диаграммы рассеяния сигнала радиолокатора самолетом и электронные и атмосферные шумы в том же радиолокационном диапазоне);
-размер листа растения (причины - отличия в питании, освещенности, влаги и т.п.);
-размер патологического изменения какого-либо органа человека (причины - различные стадии заболевания при его обнаружении, различные ракурсы и сечения наблюдений образования и т.п.) и т.д.
В. Логические признаки распознавания - это характеристики объекта или явления, представленные в виде элементарных высказываний об истинности (“да”, "нет” или “истина”, “ложь”).
Эти признаки, как мы понимаем, не имеют количественного выражения, то есть являются качественными суждениями о наличии, либо об отсутствии некоторых свойств или составляющих у объектов или явлений.
Примеры логических признаков:
-наличие ТРД на самолете ;
-боль в горле пациента ;
-кашель ;
-насморк ;
-растворимость реактива и т.д.
Здесь по каждому признаку можно сказать только то, что он есть, либо его нет.
К логическим можно отнести также такие признаки, у которых не важна величина, а лишь факт попадания или непопадания ее в заданный интервал. (например, крейсерская скорость самолета больше или меньше 2000 км/ч).
Г. Структурные признаки - непроизводные (то есть, элементарные, не производимые из других элементарных признаков) элементы (символы), примитивы изображения объекта распознавания.
Появление структурных признаков обязано возникновению проблемы распознавания изображений с ее специфическими особенностями и трудностями.
Примеры структурных признаков:
а)для изображения прямоугольника:
- горизонтальный отрезок прямой;
- вертикальный отрезок прямой.
б) для любого изображения на экране дисплея:
-пиксел.
Забегая далеко вперед в изложении материала, следует отметить, что традиционно для описания изображений использовались разложения его в ряды по ортогональным функциям (ряды Фурье, полиномы Эрмита, Лежандра, Чебышева, разложения Карунена-Лоэва и др.).
Структурное описание в отличии от разложений:
-понятнее (физичнее) для человека, решающего задачу распознавания объекта;
-приемлемо и для компьютерной реализации при распознавании;
-свободно от трудоемкости вычислений и потерь информации, свойственных разложениям.
Оказывается, что оперируя ограниченным числом атомарных (непроизводных) элементов (примитивов), можно получить описание разнообразных объектов. То есть, для отличающихся объектов можно иметь набор одинаковых непроизводных элементов. Но для того, чтобы описание можно было бы выполнить, наряду с определением непроизводных элементов должны вводиться правила комбинирования, определяющие способы построения объекта из упомянутых непроизводных элементов. В результате два одинаковых непроизводных элемента различных объектов могут быть соединены друг с другом по разным правилам. Это и будет их отличать.
В целом для описания какого-либо объекта непроизводные элементы объединяются в цепочки (предложения) по своему, характерному только для этого объекта, набору правил.
В результате связей из непроизводных элементов (структурных признаков) образуется объект, аналогично тому, как предложения языка строятся путем соединения слов, в свою очередь состоящих из букв. В этом структурные методы проявляют аналогию с синтаксисом естественного языка. Отсюда структурные признаки носят еще название лингвистических или синтаксических.
( Пример - код Фримена).
* * *
Таким образом, мы рассмотрели очень подробно 1-ую задачу создания систем распознавания - определение полного перечня признаков (параметров), характеризующих объекты или явления, для которых данная система разрабатывается. Главные выводы:
1) Выбор, назначение признаков распознавания - эвристическая операция, зависящая от творчества, изобретательности разработчика.
2) Состав признаков , выбираемых на этом этапе, должен быть как можно более разносторонним и полным, независимым от того, можно или нельзя эти признаки получить.
3) Выбор признаков должен осуществляться в группах детерминированных, вероятностных, логических и структурных.
Л Е К Ц И Я 2.3
Формулировка задач создания систем
распознавания и методы их решения
( продолжение)
ЗАДАЧА № 2
Первоначальная классификация объектов (явлений), подлежащих распознаванию, составление априорного алфавита классов.
Нам уже знакома на описательном уровне эта задача: необходимо выбрать (назначить) классы объектов (явлений) распознавания. Решение ее осуществляется наиболее часто эвристически, как и выбор признаков распознавания, а логика ее решения следующая:
1-е - определяется, какие решения могут приниматься по результатам распознавания либо человеком, либо автоматической системой управления объектом (цель распознавания).
2-е - на основе определенной выше цели формулируются требования к системе распознавания, позволяющие выбрать принцип классификации.
3-е - составляется априорный алфавит классов объектов (явлений).
Предположим по результатам некоторого метода медицинской диагностики состояния печени человека необходимо принимать решения о методе лечения (см.1-й пункт в рассмотренной последовательности решения задачи априорной классификации - цель). Насколько серьезно принятие такого решения, учитывая возможность хирургического вмешательства, я надеюсь, понятно.
Тогда, очевидно, что требованием к системе (см.2-й пункт последовательности) - надежное (с высокой вероятностью) диагностирование каждого заболевания печени.
Следовательно, в априорный алфавит классов (см.3-й пункт рассмотренной последовательности) необходимо включить все возможные заболевания печени, а их - 11. То есть, классов распознаваемых заболеваний печени, диагностируемых некоторой гипотетической системой распознавания должно быть 11. Для более четкого понимания назовем эти классы:
1.Острый гепатит.
2.Хронический гепатит.
3.Жировая инфильтрация.
4.Цирроз.
5.Киста простая.
6.Киста паразитарная.
7.Абсцесс.
8.Опухоль.
9.Метастазы.
10.Гематома.
11.Конкременты.
Заметим, что, кроме ситуации, предложенной рассмотренной задачи, возможны и другие, когда количество классов, по которым надежно распознаются некоторые объекты (явления), заранее неизвестно и должно определяться самой системой распознавания. Эта задача называется задачей кластеризации, в которой можно отказаться уже от эвристического подхода. Однако решение здесь достигается при выборе некоторых общих правил кластеризации, которые задает разработчик системы.
ЗАДАЧА № 3
Разработка априорного словаря признаков распознавания.
Решая задачу №1, мы должны были найти все возможные признаки распознавания заданных объектов или явлений. Точно также при решении задачи ¹2 îïðåäåëèëñÿ ñîñòàâ êëàññîâ.
Теперь, располагая соответствующим перечнем и априорным алфавитом классов, необходимо провести анализ возможностей измерения признаков или расчета их по данным измерений, выбрать те из них, которые обеспечиваются измерениями, а также в случае необходимости разработать предложения и создать новые средства измерений для обеспечения требуемой эффективности распознавания.
Таким образом, главное содержание рассматриваемой задачи построения СР - создание словаря, обеспечиваемого реально возможными измерениями.
Однако, хороший или плохой набор признаков распознавания, получился в результате указанных действий разработчика СР, можно понять, выполнив испытания системы распознавания в целом и оценив эффективность распознавания. Но системы распознавания на указанном этапе разработки еще не существует. В то же время, как мы заметили, появилась необходимость оценки эффективности. И рассматривая очередные задачи создания СР, мы обнаружим, что рассматриваемая задача остается актуальной на протяжении всех последующих этапов создания системы распознавания (описание классов, выбор алгоритма распознавания). Только методом последовательных приближений удается добиться выбора словаря признаков, обеспечивающего желаемое качество решений.
Выходом из создавшегося положения является возможность создания на данном этапе математической модели системы. Математические модели СР и используются для реализации указанных последовательных приближений, о чем упоминалось на описательном уровне при рассмотрении задач построения систем распознавания.
ЗАДАЧА № 4
Описание классов априорного алфавита на языке априорного словаря признаков.
Априорное описание классов - наиболее трудоемкая из задач в процессе создания системы распознавания, требующая глубокого изучения свойств объектов распознавания, а также и наиболее творческая задача.
В рамках этой задачи необходимо каждому классу поставить в соответствие числовые параметры детерминированных и вероятностных признаков, значения логических признаков и предложения, составленные из структурных признаков-примитивов.
Значения этих параметров описаний можно получить из совокупности следующих работ и действий:
-специально поставленные экспериментальные работы или --экспериментальные наблюдения;
-результаты обработки экспериментальных данных;
-математические расчеты;
-результаты математического моделирования;
-извлечения из литературных источников.
Что же такое описание класса на языке признаков? Рассмотрим это отдельно для детерминированных, вероятностных, логических и структурных признаков.
Если признаки распознаваемых объектов - детерминированные, то описанием класса может быть точка в №-мерном пространстве детерминированных признаков из априорного словаря, сумма расстояний которой от точек, представляющих объекты данного класса, минимальна.
Легко себе представить такой эталон, вернувшись к рассмотренным нами таблицам ТТХ самолетов. Здесь мы имеем дело с 11-мерным пространством признаков. Каждая координата - это одна какая-нибудь характеристика, например “экипаж”. Если рассматривать только одну координату “экипаж”, то точкой эталона для истребителей будет - 1, для бомбардировщиков - 4. Это точки, суммы расстояний которых от всех истребителей и всех бомбардировщиков, представляющих эти два класса, минимальны.
Точно также это можно сделать по всем 11 координатам (т.е. “потолок”, “размах крыльев”, ”бомбовая нагрузка “ и т.д.), в результате чего будем уже иметь дело с точками эталонов в 11-мерном пространстве.
Если признаки распознавания - логические, то для описания каждого класса необходимо прежде всего иметь полный набор элементарных логических высказываний A,B,C, входящих в состав априорного словаря. Но это только признаки. Для описания классов этого недостаточно. Еще необходимо установить соответствие между набором значений приведенных признаков A,B,C и классами W>1>, W>2>,...W>m>.
Так для простоты понимания и без притязаний на медицинскую достоверность возьмем такой пример: необходимо распознавать два заболевания - обычная простуда и ангина (W>1>,W>2>), а в качестве логических признаков выберем
А - повышенная температура (А=0 - нет, А=1 - да);
В - насморк (В=0 - нет, В=1 - да);
С - нарывы в горле (С=0 - нет, С=1 - да).
Тогда так называемое булево соотношение между классом W>1> (обычное простудное заболевание) и значениями признаками (а эти значения - бинарные) выглядит так
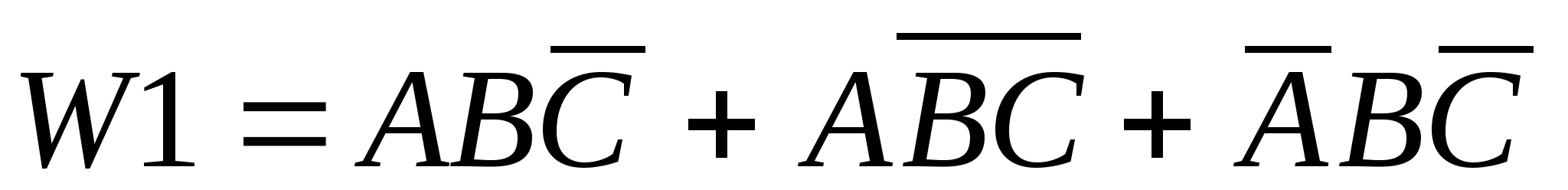
Здесь умножение, как вы знаете, соответствует логическому “И”, а сложение - “ИЛИ”.
Точно также для второго класса заболеваний получим следующее описание
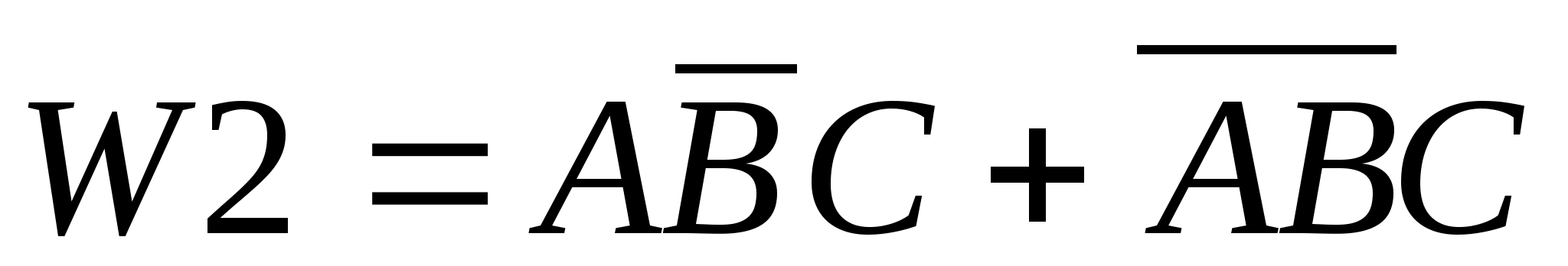
Подробнее здесь мы эти вопросы не рассматриваем, так как логическим системам в дальнейшем курсе уделим достаточное внимание.
Если распределение объектов распознавания, представляемых числовыми значениями их признаков по областям соответствующего пространства вероятностное, то для описания классов необходимо определить характеристики этих распределений. А из теории вероятности известно, что это
-ôóíêöèè ÏÐÂ f>i> (x>1>,x>2>,....,x>n>), ãäå x>1>.....x>n> - âåðîÿòíîñòíûå ïðèçíàêè, I - íîìåð êëàññà;
-P(W>i>) - априорная вероятность того, что объект, случайно выбранный из общей совокупности, окажется принадлежащим к классу W>i>.
Как получить ПРВ классов системы распознавания?  ðàñïîðÿæåíèè ðàçðàáîò÷èêà ÑÐ - òðè ñïîñîáà:
-ýêñïåðèìåíòàëüíîå îïðåäåëåíèå ïî ñòàòèñòè÷åñêèì äàííûì;
-òåîðåòè÷åñêèé âûâîä;
-ìîäåëèðîâàíèå.
То же касается априорной вероятности класса P(W>i>).
Если признаки распознавания - структурные, то описанием каж-дого класса должен быть набор предложений (цепочек из непроизводных элементов с правилами соединения). Каждое из предложений класса - характеристика структурных особенностей объектов этого класса. Пример - код Фримена.
ЗАДАЧА № 5
Выбор алгоритма классификации, обеспечивающего отнесение распознаваемого объекта или явления к соответствующему классу.
Непосредственное решение задачи распознавания на основе использования словаря признаков и алфавита классов объектов или явлений фактически заключается в разбиении пространства значений признаков распознавания на области D>1>,D>2>,...,D>n>, соответствующие классам W>1>,W>2>,...,W>n> (вспоминаем определение “образа”).
Указанное разбиение должно быть выполнено таким образом, чтобы обеспечивались минимальные значения ошибок отнесения классифицируемых объектов или явлений к “чужим” классам.
Результатом такой операции является отнесение объекта, имеющего набор признаков X>1>,X>2>,....,X>n> (точка в n-мерном пространстве), к классу W>i>, если указанная точка лежит в соответствующей классу области признаков - D>i>.
Разбиение пространства признаков можно представлять как построение разделяющих функций f>i>(x>1>,x>2>,....,x>n>) ìåæäó ìíîæåñòâàìè (îáëàñòÿìè) ïðèçíàêîâ Di, ïðèíàäëåæàùèì ðàçíûì êëàññàì.
Упомянутые функции должны обладать следующим свойством:
-åñëè
îáúåêò, èìåþùèé âåêòîð ïðèçíàêîâ
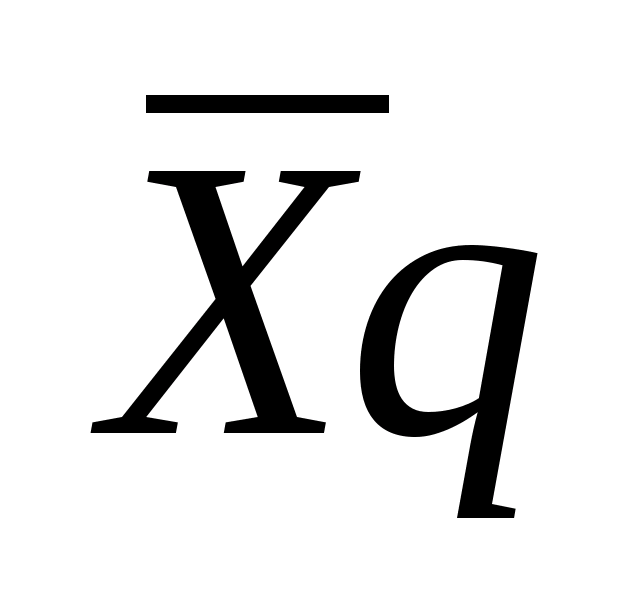 ôàêòè÷åñêè îòíîñèòñÿ
ê êëàññó
ôàêòè÷åñêè îòíîñèòñÿ
ê êëàññó
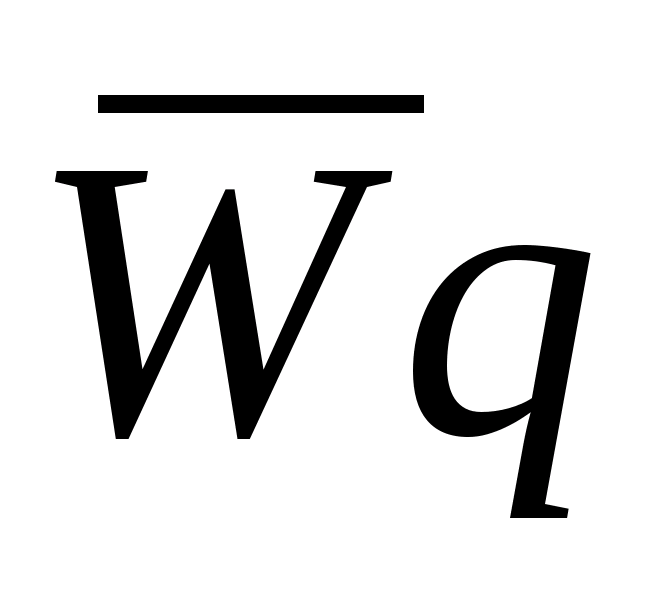 ,
то значение разделяющей функции
,
то значение разделяющей функции
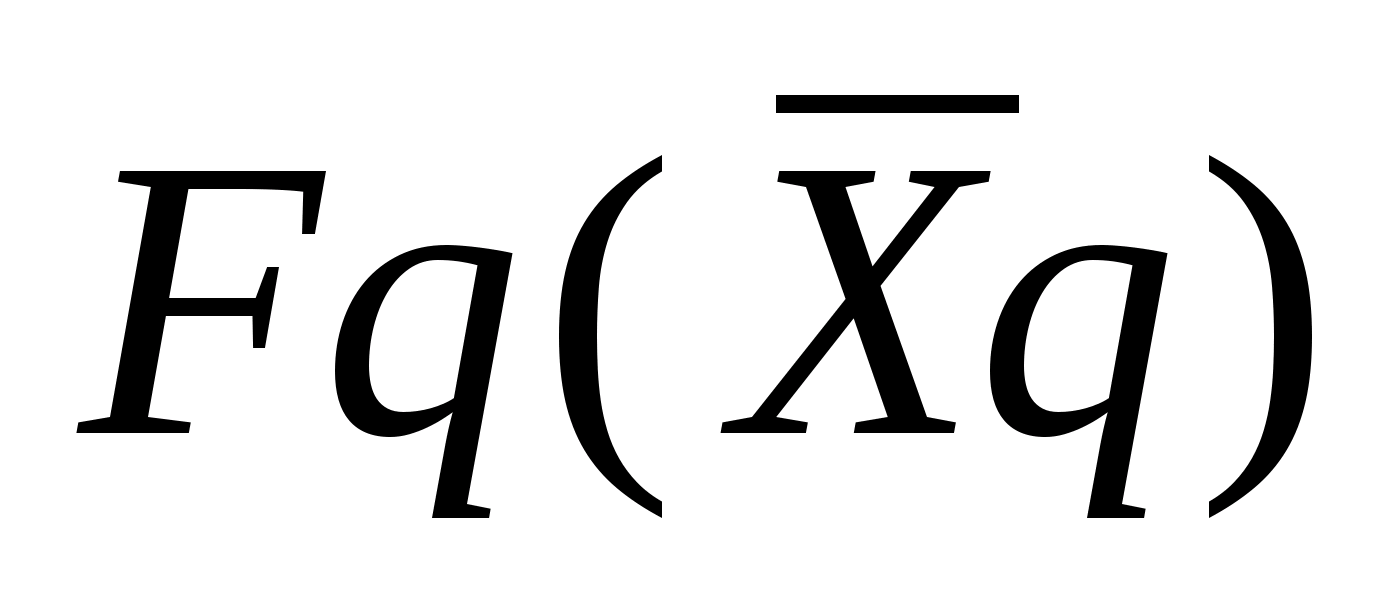
должно
быть большим, чем значение ее для класса
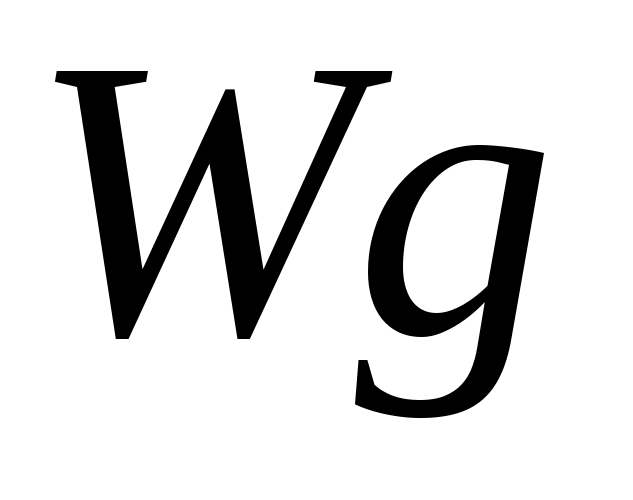 -
-
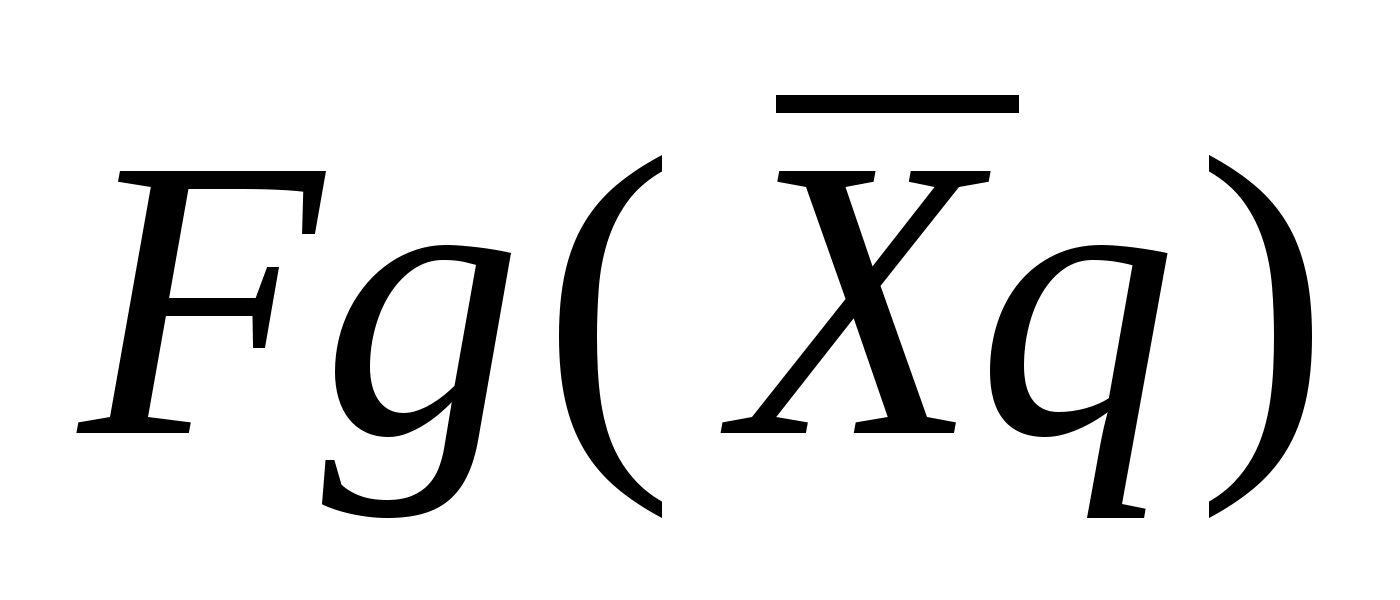 (çäåñü èíäåêñ q - îçíà÷àåò íîìåð êëàññà,
ê êîòîðîìó ïðèíàäëåæèò âåêòîð ïðèçíàêîâ).
(çäåñü èíäåêñ q - îçíà÷àåò íîìåð êëàññà,
ê êîòîðîìó ïðèíàäëåæèò âåêòîð ïðèçíàêîâ).
Отсюда легко определить выражение решающей границы между областями D>i>, соответствующим классам W>i>:
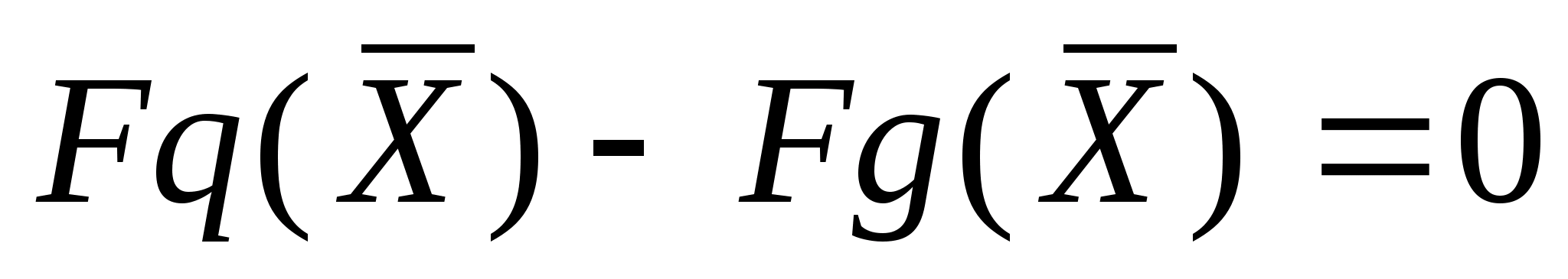
Для двух распознаваемых классов разбиение двумерного пространства выглядит так (ðèñ 2.2). Ôèçè÷åñêè ðàñïîçíàâàíèå îñíîâûâàåòñÿ íà ñðàâíåíèè çíà÷åíèé òîé èëè èíîé ìåðû áëèçîñòè ðàñïîçíàâàåìîãî îáúåêòà ñ êàæäûì êëàññîì. Ïðè ýòîì åñëè çíà÷åíèå âûáðàííîé ìåðû áëèçîñòè (ñõîäñòâà) L äàííîãî îáúåêòà w ñ êàêèì-ëèáî êëàññîì W>g> достигает экстремума относительно значений ее по другим классам, òî åñòü
то принимается
решение о принадлежности этого объекта
классу W>g>,
òî åñòü w W>g>.
W>g>.
Надеюсь понятно, что если мера близости не имеет экстремума, то мы находимся на границе, где не можем отдать предпочтение ни одному из классов.

 X>1>
o o o o
X>1>
o o o o
xx x o o o
x o o F>2>(X>1>,X>2>) > F>1>(X>1>,X>2>)
x x x o o o o
x o o o o o
x x x x x o o o o o
F>1>(X>1>,X>2>)>F>2>(X>1>,X>2>) x o
x x x x x x x o o
x x x x x x
x x x x x
 X>2>
X>2>
Рис.2.2
В алгоритмах распознавания, использующих детерминированные ïðèçíàêè â êà÷åñòâå ìåðû áëèçîñòè, èñïîëüçóåòñÿ ñðåäíåêâàäðàòè÷åñêîå ðàññòîÿíèå ìåæäó äàííûì îáúåêòîì w è ñîâîêóïíîñòüþ îáúåêòîâ (w>1>,w>2>,....,w>n>), представляющих (описывающих) каждый класс. Так äëÿ ñðàâíåíèÿ ñ êëàññîì W>g> это выглядит так
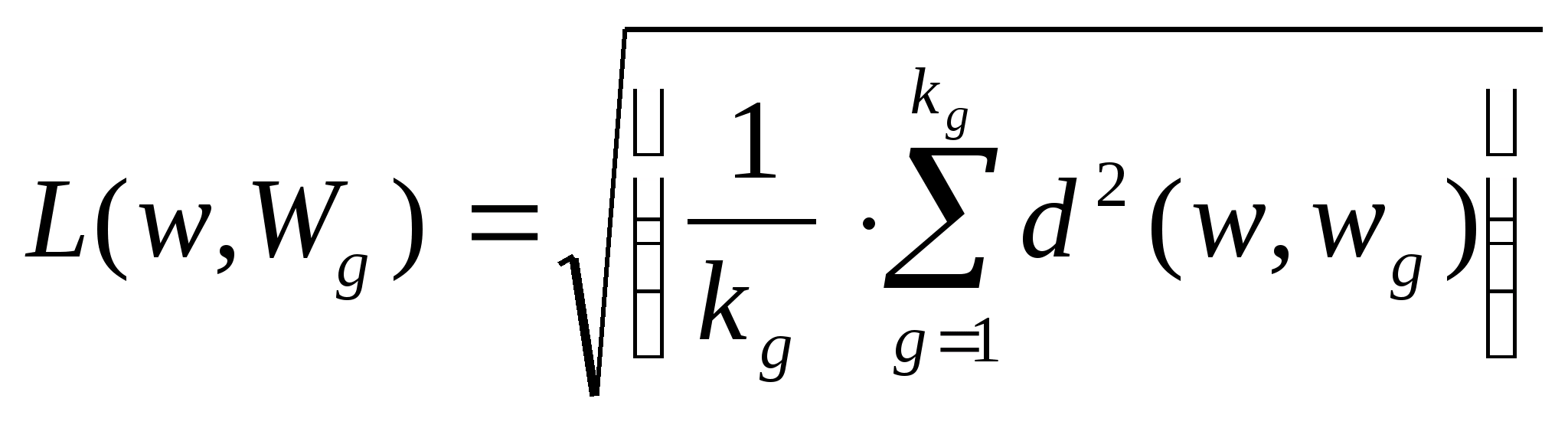
где k>g> - êîëè÷åñòâî îáúåêòîâ, ïðåäñòàâëÿþùèõ W>g>-й класс.
При этом в качестве методов измерений расстояния между объектами d(w,w>g>) могут использоваться любые методы (творческий процесс здесь не ограничивается).
Так, если сравнивать непосредственно координаты (признаки), то
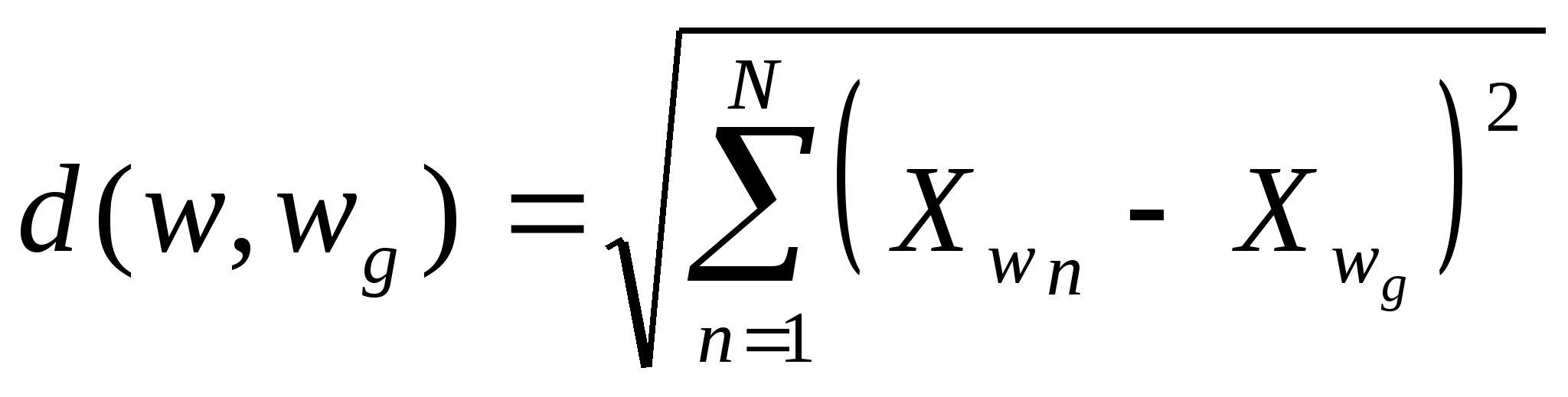
где N - ðàçìåðíîñòü ïðèçíàêîâîãî ïðîñòðàíñòâà.
Если сравнивать угловые отклонения, то рассматривая вектора, составляющими которых являются признаки распознаваемого объекта w и класса w>g>, будем иметь:
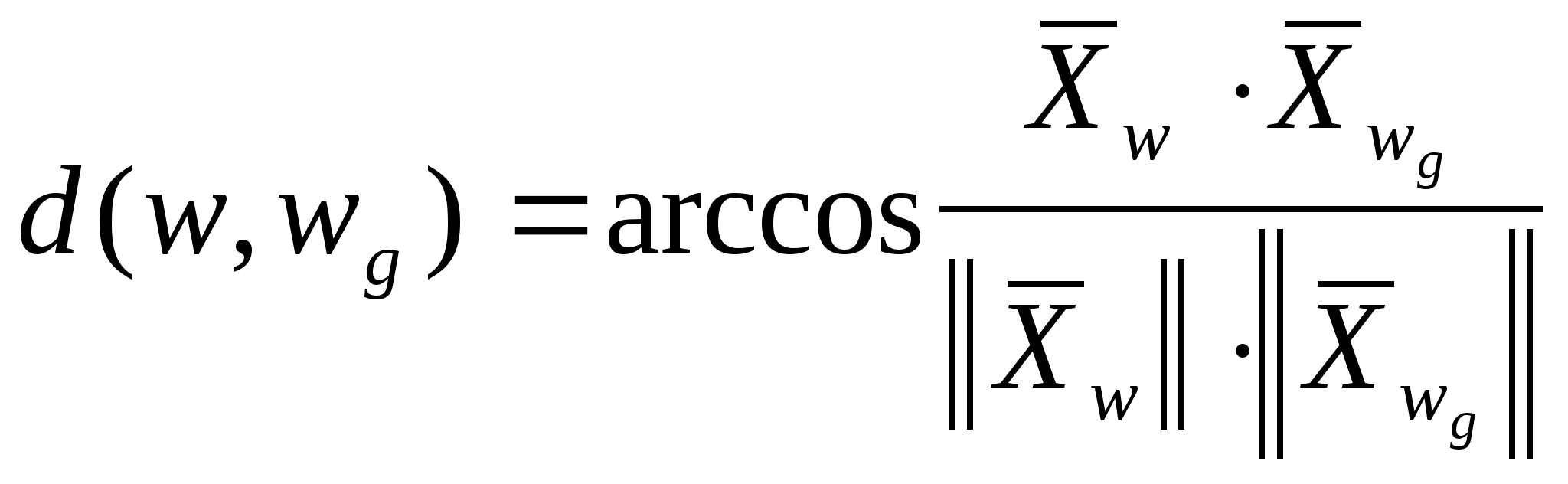
где ||X>w>|| и ||X>wg>|| - нормы соответствующих векторов.
В алгоритме распознавания, использующем детерминированные признаки можно учитывать и их веса V>j> (устанавливать степень доверия или важности). Тогда рассмотренное среднеквадратическое расстояние принимает следующий вид:
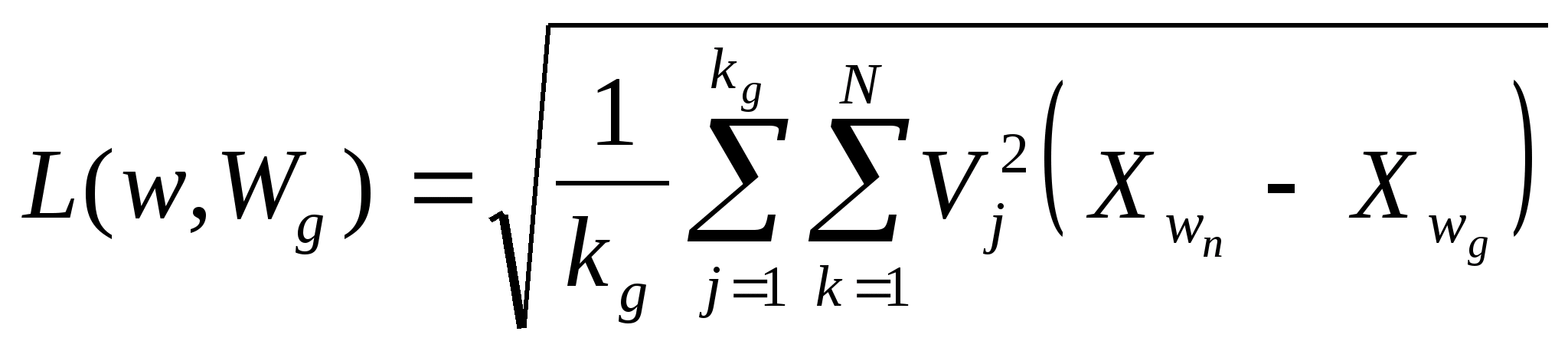
В алгоритмах распознавания, использующих вероятностные признаки, в качестве меры близости используется риск, связанный с решением о принадлежности объекта к классу W>i>, где i - íîìåð êëàññà. (i=1,2,..,m.).
Описания классов, как мы недавно рассмотрели
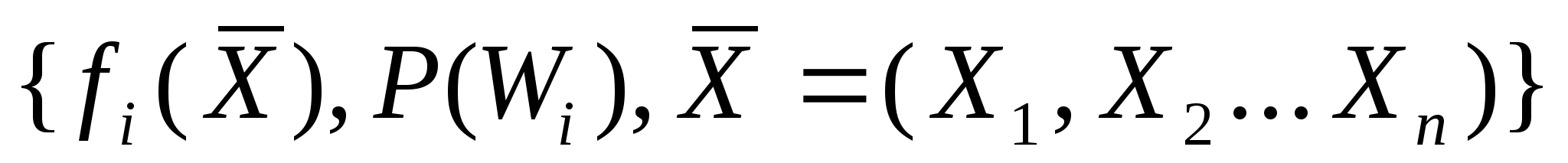
В рассматриваемом случае к исходным данным для расчета меры близости относится платежная матрица вида:
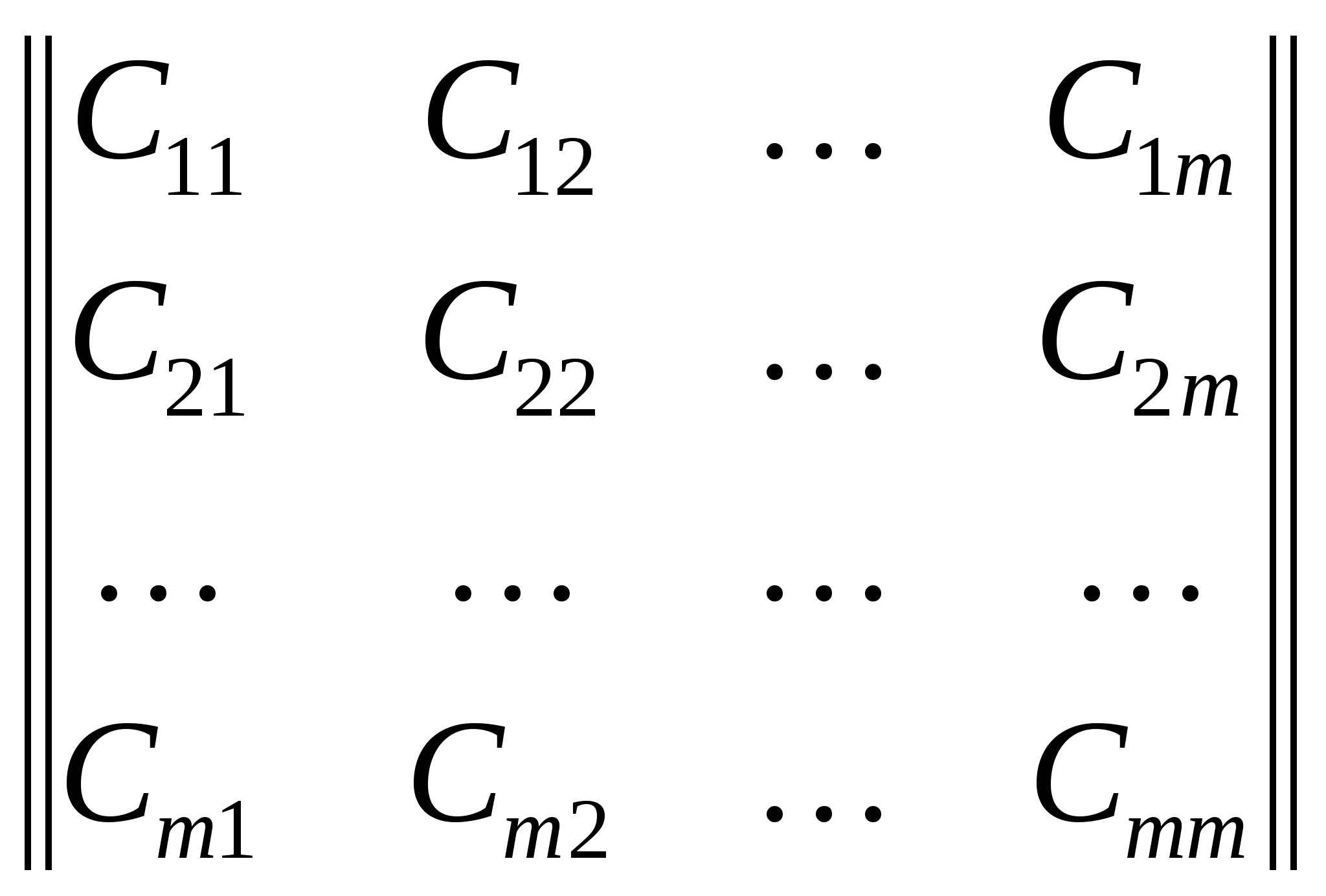
Здесь на главной диагонали - потери при правильных решениях. Îáû÷íî ïðèíèìàþò Ñ>ii>=0 или C>ii><0.
По обеим сторонам от главной диагонали - потери при ошибочных решениях. В каждой системе эти потери свои, свойственные только ей. Однако назначение их - творчество разработчика системы распознавания.
Если
вектор признаков распознаваемого
объекта w -
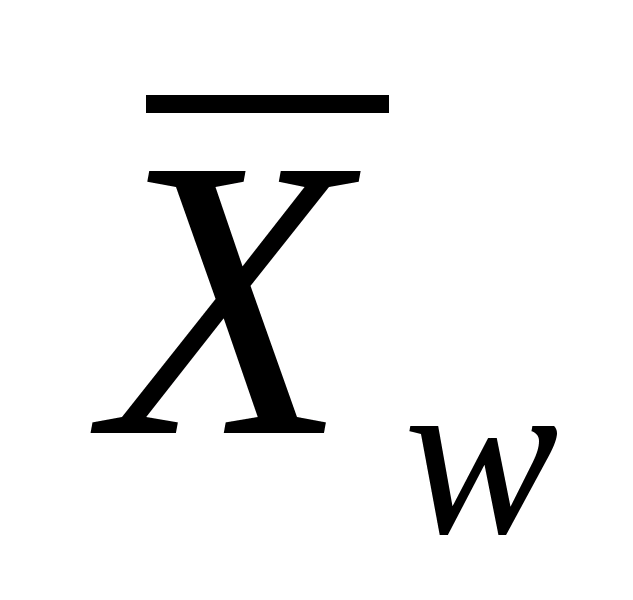 ,
то ðèñê,
ñâÿçàííûé ñ ïðèíÿòèåì ðåøåíèÿ î
ïðèíàäëåæíîñòè ýòîãî îáúåêòà ê êëàññó
W>g>, когда на самом деле он может
принадлежать классам W>1>,W>2>,...,W>m>,
наиболее
öåëåñîîáðàçíî îïðåäåëÿòü êàê
ñðåäíåå çíà÷åíèå ïîòåðü
,
то ðèñê,
ñâÿçàííûé ñ ïðèíÿòèåì ðåøåíèÿ î
ïðèíàäëåæíîñòè ýòîãî îáúåêòà ê êëàññó
W>g>, когда на самом деле он может
принадлежать классам W>1>,W>2>,...,W>m>,
наиболее
öåëåñîîáðàçíî îïðåäåëÿòü êàê
ñðåäíåå çíà÷åíèå ïîòåðü
С>1g>, C>2g>,...,C>mg>> >,
то есть, потерь, стоящих в g-ом столбце платежной матрицы.
Тогда этот средний риск можно записать как определение МОЖ
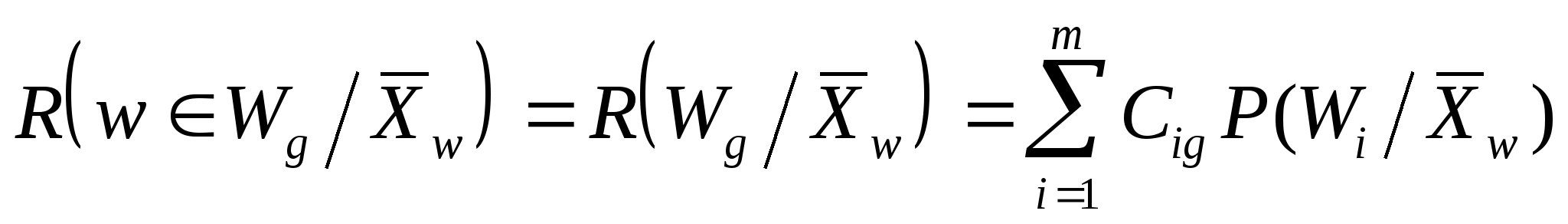
Здесь P(W>i>/X>w>)
-
àïîñòåðèîðíàÿ âåðîÿòíîñòü òîãî,
÷òî wW>i>.
Для исходных данных, а именно описаний классов эта вероятность легко может быть определена в соответствии с теоремой гипотез или по формуле Байеса
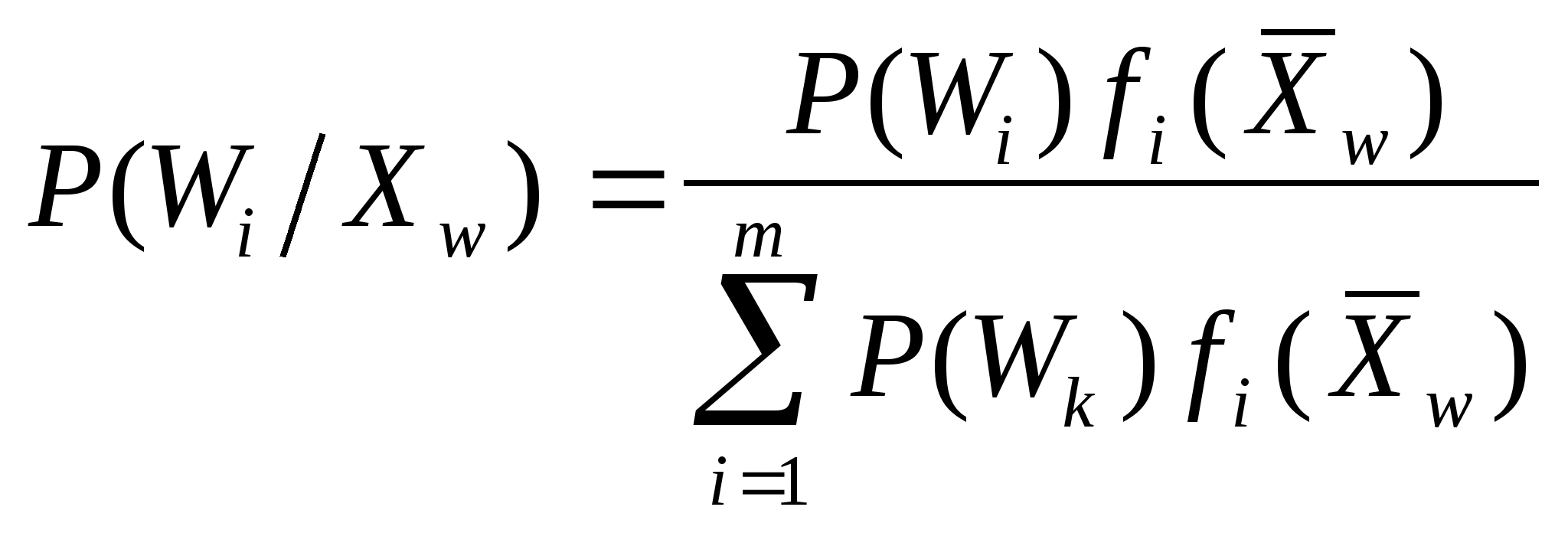
Вероятности и плотности, входящие в формулу - ни что иное как характеристики описания классов в вероятностной системе.
Для алгоритмов, основанных на логических признаках, понятие “мера близости” не имеет смысла. Вспомним упрощенный пример, рассмотренный нами для логических признаков заболеваний (простой простуды и ангины).
Имея значения признаков А,B,C, достаточно подставить их в булевы соотношения между классами и признаками, чтобы сразу получить результат как истинность или ложность булевой функции описания того или иного класса.
Действительно, пусть признаки приняли следующие значения:
-Ïîâûøåííàÿ òåìïåðàòóðà: A=1
-Íàñìîðê: B=0
-Íàðûâû â ãîðëå: C=1
Тогда подстановка их в булевы соотношения даст следующий результат:
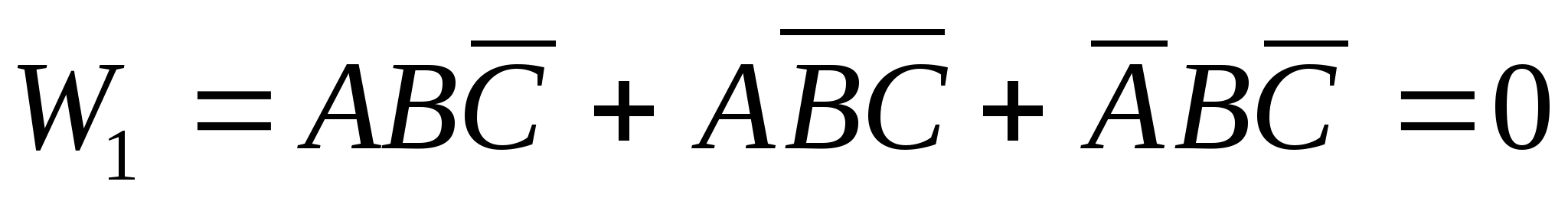
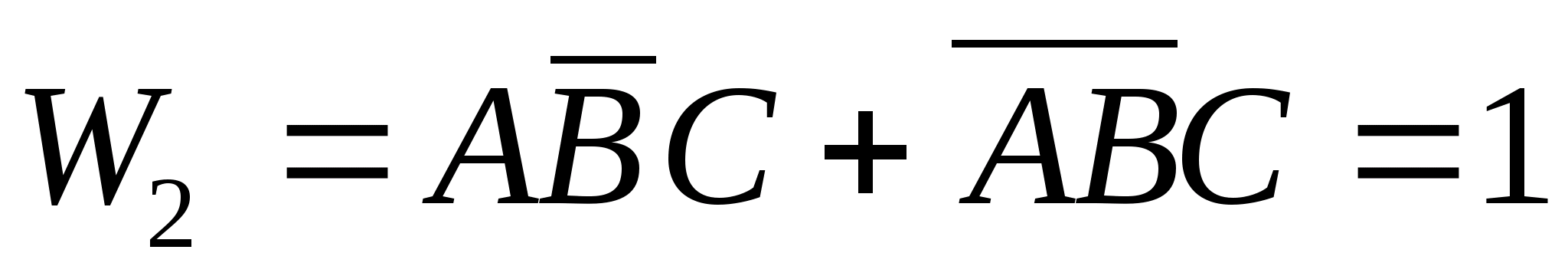
То есть, истинным является второе соотношение, соответствующее распознаванию ангины как диагностируемого класса из двух заболеваний.
Для алгоритмов, основанных на структурных (лингвистических) признаках, понятие “меры близости” более специфично.
С учетом того, что каждый класс описывается совокупностью предложений, характеризующих структурные особенности объектов соответствующих классов, распознавание неизвестного объекта осуществляется идентификацией предложения, описывающего этот объект, с одним из предложений в составе описания какого-либо класса.
При этом идентификация может подразумевать наибольшее сходство предложения, описывающего распознаваемый объект с предложениями из наборов описания каждого класса.
Рассмотрев задачу №5 , мы фактически завершили рассмотрение круга задач создания СР. В то же время уже отмечалось, что создание СР осуществляется последовательными приближениями по мере получения дополнительной информации. В этом ряду последовательных приближений главную роль играют признаки распознавания. От эффективности их набора зависит, эффективность системы в целом. В процессе совершенствования системы указанный набор пополняется, неэффективные признаки исключаются. Поэтому одной из задач создания СР должна быть и задача перехода от априорного словаря признаков к рабочему. То же касается и априорного алфавита классов.
ЗАДАЧА № 6
Определение рабочего алфавита классов и рабочего словаря признаков системы распознавания.
Настоящая задача на уровне разработки, прошедшей этапы решения задач 1 - 5, ïî êðàéíåé ìåðå óæå ìîæåò áûòü ïîñòàâëåíà, òàê êàê â ðåçóëüòàòå âûïîëíåíèÿ ïðåäøåñòâóþùèõ çàäà÷ ñîçäàíà ñèñòåìà ðàñïîçíàâàíèÿ ïåðâîãî ïðèáëèæåíèÿ (àïðèîðíûé àëôàâèò êëàññîâ è àïðèîðíûé ñëîâàðü ïðèçíàêîâ, âûáðàí àëãîðèòì ðàñïîçíàâàíèÿ).
Суть стоящей задачи - разработка такого (рабочего) алфавита классов и такого (рабочего) словаря признаков, которые обеспечили бы максимальное значение показателя эффективности распознавания. То есть, из априорного словаря мы должны выбрать признаки, позволяющие при всех имеющихся ограничениях на их получение (измерение) доставить максимум вероятности правильной классификации объектов (явлений) и (или) минимальные вероятности ошибочных классификаций создаваемой системой. Такой выбор не может не предполагать оценку указанных показателей до того, как создана система.
Указанное существо задачи заставляет снова обратить внимание на возможность получения оценки эффективности системы распознавания путем ее моделирования. Об этом мы говорили при создании априорного словаря признаков. К этому мы вернемся при специальном рассмотрении вопросов моделирования систем распознавания.
Что же касается приемов, обеспечивающих отбор в процессе оптимизации систем распознавания, то они являются также предметом отдельного рассмотрения.
Ò å ì à 3
Êëàññèôèêàöèÿ ñèñòåì ðàñïîçíàâàíèÿ
Л Е К Ц И Я 3.1
Принципы классификации и типы систем распознавания
Ïðè ðàññìîòðåíèè çàäà÷, ðåøàåìûõ â ïðîöåññå ñîçäàíèÿ ñèñòåì ðàñïîçíàâàíèÿ (òåìà 2) , ìû ãîâîðèëè î ïðèçíàêàõ îáúåêòîâ (ÿâëåíèé), î ñïîñîáàõ èõ ïîëó÷åíèÿ â ïðîöåññå ðàáîòû ÑÐ, îá èñïîëüçîâàíèè àïðèîðíîé èíôîðìàöèè, íå çàòðàãèâàÿ âîïðîñîâ âçàèìîñâÿçåé â ñèñòåìå. Èíîãäà òîëüêî óïîìèíàëè îá ýòîì .
 òî æå âðåìÿ, ÷òîáû ëåã÷å, ñîçíàòåëüíåå ðåøàòü çàäà÷ó âûáîðà ïðèçíàêîâ (à ýòî, êàê ìû ïîìíèì, - ïðîöåññ ýâðèñòè÷åñêèé), à òàêæå äëÿ ïëàíèðîâàíèÿ èñïîëüçîâàíèÿ êàê àïðèîðíîé èíôîðìàöèè (îïèñàíèå êëàññîâ), òàê è àïîñòåðèîðíûõ äàííûõ (èçìåðåíèÿ ïî äàííîìó íåèçâåñòíîìó ïîäëåæàùåìó êëàññèôèêàöèè îáúåêòó) ýòè âçàèìîñâÿçè íåîáõîäèìî õîðîøî ïðåäñòàâëÿòü.
Однако, как оказывается, упоминаемые взаимосвязи могут принимать различные формы, иметь свои особенности. Простое перечисление здесь не подходит. Поэтому представляется необходимым классифицировать сначала сами системы распознавания. Это позволит понять взаимосвязи в них и решать те задачи, о которых мы сейчас говорили.
Начнем с уточнения того, что такое классификация. Классификация - это распределение предметов, явлений по классам, îòäåëàì, ðàçðÿäàì â çàâèñèìîñòè îò èõ îáùèõ ñâîéñòâ.
В основе классификации лежат определенные принципы.
Для классификации СР будем использовать следующие принципы:
1.Однородность информации для описания ðàñïîçíàâàåìûõ îáúåêòîâ èëè ÿâëåíèé.
2.Способ получения апостериорной информации.
3.Количество первоначальной априорной информации.
4.Характер информации о признаках распознавания.
А. Рассмотрим 1-й принцип.
(Однородность информации)
Здесь под однородностью следует понимать - различную или единую физическую природу информации (признаков).
По этому принципу СР делятся на:
-ïðîñòûå;
-ñëîæíûå.
Простые СР характеризуются единой физической природой признаков. Например:
1) только масса - для систем распознавания жетонов, монет в автоматах таких, как междугородный телефон, турникет метро;
2) геометрические размеры - для таких СР, как всякого рода замки.
Ясно, что для простых систем распознавания не обязательно иметь компьютер. Достаточно их реализовать в виде механических или электромеханических устройств. Хотя компьютерные реализации в принципе не противопоказаны, если наряду с этой в системе решаются и другие более достойные задачи.
Сложные СР характеризуются физической неоднородностью признаков.
В рассмотренном нами в теме ¹ 2 ïåðå÷íå ïðèçíàêîâ ñàìîëåòîâ òàêàÿ íåîäíîðîäíîñòü ïðîñìàòðèâàåòñÿ íåâîîðóæåííûì ãëàçîì. Òàì èìåëè:
-è ÷èñëåííîñòü ýêèïàæåé;
-è âûñîòû ïîëåòà;
-è âçëåòíûé âåñ;
-è ãåîìåòðè÷åñêèå ðàçìåðû è ò.ä.
Точно также в медицинской практике для диагностики может оказаться необходимым привлекать:
-è òåìïåðàòóðó;
-è äàííûå àíàëèçà êðîâè;
-è äàííûå êðîâÿíîãî äàâëåíèÿ;
-è êàðäèîãðàììû è ò.ï.
Конечно, простота всегда предпочтительнее. Хорошо иметь всего 1 - 2 ïðèçíàêà è ïðè ýòîì æåëàòåëüíî îäíîðîäíûõ, ÷òîáû ðåøàòü çàäà÷ó êîìïüþòåðíîãî ðàñïîçíàâàíèÿ, íàïðèìåð, çàáîëåâàíèé ïå÷åíè. Íî íå âñåãäà, êàê è â ýòîì ñëó÷àå, òàê ïîëó÷àåòñÿ. Ñðàâíèòå ðàñïîçíàâàíèÿ êëþ÷à çàìêîì è ðàñïîçíàâàíèå ïðåñòóïíèêà ïî ñëîâåñíîìó ïîðòðåòó (íàáîðó ïðèçíàêîâ).
Б. Второй принцип классификации СР.
(Способ получения апостериорной информации).
По этому принципу сложные системы ( а мы уже знаем, что они собой представляют) распознавания делятся на:
-îäíîóðîâíåâûå;
-ìíîãîóðîâíåâûå.
На рис. 1 изображена одноуровневая система распознавания.
Здесь:
И>1>, И>2>,.....,И>n> - разнородные по физической природе измерители.
АО - априорное описание классов распознаваемых объектов;
АК - алгоритм классификации;
САУ- система автоматического управления (алгоритм) распознаванием.
Многоуровневые сложные системы распознавания отличаются от одноуровневых тем, что не все признаки от разнородных физических измерителей используются непосредственно для решения задачи распознавания.
Здесь на основе объединения признаков нескольких измерителей и соответствующей обработки могут быть получены вторичные признаки, которые могут как использоваться в АК, так и сами в свою очередь служить основой для объединения. То есть, получаем 2-й, 3-й и др. уровни признаков, определяющие многоуровневость СР. Причем подсистемы, которые осуществляют объединение признаков, в свою очередь могут представлять собой также устройства распознавания (локальные СР).
Схема здесь в целом подобна предыдущей (для одноуровневой системы), а отличается лишь усложнением связей от признаков к АК.(Рис.2)
 W
W







È 1 È 2 ............................. È n







X11 X12 .... X1k X21 X22 .... X2p Xn1 Xn2 .... Xnr


A K





 Ñ
À Ó
Ñ
À Ó
Ðåøåíèå î ïðèíàäëåæíîñòè

A O
Ðèñ. 1
W






È 1 È 2 ......................... È n
X11 X12 .... X1k X21 X22 ....X2p Xn1 Xn2 . Xnr







A
B
C

D


À Ê

 Ñ
À Ó
Ñ
À Ó
À Î Ðåøåíèå î ïðèíàäëåæíîñòè
Ðèñ. 2
Таким образом:
в одноуровневых СР информация о признаках распознаваемого объекта (апостериорная информация) формируется непосредственно на основе обработки прямых измерений;
в многоуровневых СР информация о признаках формируется на основе косвенных измерений как результат функционирования вспомогательных распознающих устройств (пример: измерение дальности радиолокатором по времени задержки излученного импульса).
В. Третий принцип классификации.
(Количество первоначальной априорной информации).
Здесь вопрос касается того, достаточно или недостаточно априорной информации для определения априорного алфавита классов, построения априорного словаря признаков и описания каждого класса на языке этих признаков в результате непосредственной обработки исходных данных.
Соответственно этому СР делятся на:
-ñèñòåìû áåç îáó÷åíèÿ;
-îáó÷àþùèåñÿ (ÎÑÐ) è ñàìîîáó÷àþùèåñÿ ñèñòåìû (ÑÑÐ).
Сразу заметим, что многоуровневые сложные СР однозначно нельзя разделить на указанные классы, так как каждая из локальных СР, входящих в их состав, сама может представлять как систему без обучения, так и систему обучающуюся или самообучающуюся.
Системы без обучения.
Для построения таких систем необходимо располагать полной первоначальной априорной информацией. Предыдущие, рассмотренные нами схемы СР фактически изображали такие системы.
Обучающиеся системы.
Итак, судя по предыдущему рассмотрению, для обучающихся систем мы должны иметь дело с ситуацией, когда априорной информации не хватает для описания распознаваемых классов на языке признаков . (Возможны случаи, когда информации хватает, однако делать упомянутое описание нецелесообразно или трудно).
Исходная информация для обучающихся СР (ОСР) представляется в виде набора объектов w>1>, w>2>,....,w>l> ,распределенных по m классам:
(w>1> ,w>2> ,...,w>r> ) W>1>
(w >r+1> ,w >r+2> ,...,w>q> ) W>2>
..................
(w>g+1> ,w>g+2> ,...,w>l> ) W>m>
Цель обучения и ее достижение заключаются для ОСР в определении разделяющих функций
F>i>(X>1> ,X>2> ,.....,X>n>),
где i = 1,2,....,m (номер класса).
Определение этой функции осуществляется путем многократного предъявления системе указанных объектов (из набора w>1>,w>2>,....,w>l> ) с указанием, какому классу они принадлежат.
То есть, на стадии формирования ОСР работают с “учителем”, осуществляющим указание о принадлежности предъявленного для обучения объекта. И прежде, чем система будет применяться, должен пройти этап обучения.
О разделяющих функциях мы уже вели речь, когда рассматривали задачи построения систем распознавания. Теперь мы вернулись к этому понятию, определив СР, в которых указанные функции применяются.
Мы и еще раз вернемся к этому понятию, когда будем рассматривать математическую сторону вопроса определения разделяющей функции.
Теперь же мы уже в состоянии изобразить ОСР (Рис. 3).
Y - учитель;
ОО - обучающие объекты;
АРФ - алгоритм построения разделяющих функций;
ТС - под общим названием “Технические средства”
объединены измерители признаков распознавания;
АО - априорное описание классов распознаваемых об’ектов;
АК - алгоритм классификации;
САУ - система автоматического управления (алгоритм) распознавания;
w - неизвестные, распознаваемые объекты.
Ïóíêòèðíûå ëèíèè íà ðèñóíêå ñîîòâåòñòâóþò âçàèìîñâÿçÿì â ïðîöåññå îáó÷åíèÿ.

W




 Ò
Ñ ÎÁÎ Ó
Ò
Ñ ÎÁÎ Ó



À Ð Ô
À Î

 Ñ
À Ó
Ñ
À Ó
 À
Ê
À
Ê


Ðåøåíèå î ïðèíàäëåæíîñòè
Ðèñ. 3
Л Е К Ц И Я 3.2
Принципы классификации и типы систем распознавания
(Продолжение)
Самообучающиеся системы.
В отличии от систем без обучения и систем, обучающихся с учителем, для самообучающихся систем характерна недостаточность информации для формирования не только описаний классов, но даже алфавита классов. То есть, определен только словарь признаков распознавания. Однако для организации процесса обучения задается все-таки некоторый набор правил, в соответствии с которым система сама вырабатывает классификацию.
Для ССР также, как для ОСР существует период обучения, характерно наличие периода самообучения, когда ей предъявляются объекты обучающей последовательности. Только при этом не указывается принадлежность их к каким-либо классам.
Соответствующая функциональная схема ССР приведена на рис.4.
Здесь дополнительно к обозначениям рис.2,3 имеем:
ОС - объекты самообучения;
ПК - правила классификации;
АФК - алгоритм формирования классов.
Примером самообучающейся системы может быть система разделения на классы промышленных предприятий для сравнительного анализа эффективности их функционирования. При этом в качестве правил классификации могут быть указания либо о равенстве объемов выпускаемой продукции, либо о равенстве численности рабочих и т.п.).
В другой широко применяемой терминологии ССР - это система автоматического кластерного анализа или таксономии (taxis - порядок, nomos - закон).
Завершая рассмотрение классификации СР по количеству первоначальной априорной информации, заметим, что СР, в которых недостаточно информации для назначения словаря признаков, не существует. Без этого не создается никакая система.
W




 Ò
Ñ ÎÁÑ
Ò
Ñ ÎÁÑ




À Ô Ê Ï Ê
À Î


 Ñ À Ó
Ñ À Ó

À Ê

Ðåøåíèå î ïðèíàäëÅÆíÎñòè
Ðèñ. 4
Г. Четвертый принцип классификации.
(Характер информации о признаках распознавания).
С характеристикой информации о признаках распознавания мы уже имели дело при изучении задач создания СР. В соответствии с ее отличительными особенностями СР подразделяются на
-äåòåðìèíèðîâàííûå;
-âåðîÿòíîñòíûå;
-ëîãè÷åñêèå;
-ñòðóêòóðíûå (ëèíãâèñòè÷åñêèå);
-êîìáèíèðîâàííûå.
Подытоживая пройденное, отметим характерные особенности этих систем, а именно: метод решения задачи распознавания и метод априорного описания классов.
Детерминированные системы.
а) Метод решения задачи распознавания: èñïîëüçîâàíèå ãåîìåòðè÷åñêèõ ìåð áëèçîñòè;
б) Метод априорного описания классов: êîîðäèíàòû âåêòîðîâ-ýòàëîíîâ ïî êàæäîìó èç êëàññîâ èëè êîîðäèíàòû âñåõ îáúåêòîâ, ïðèíàäëåæàùèõ êëàññàì (íàáîðû ýòàëîíîâ ïî êàæäîìó êëàññó).
Вероятностные системы.
а) Метод решения задачи распознавания: âåðîÿòíîñòíûé, îñíîâàííûé íà âåðîÿòíîñòíîé ìåðå áëèçîñòè (ñðåäíèé ðèñê);
б) Метод априорного описания классов: âåðîÿòíîñòíûå çàâèñèìîñòè ìåæäó ïðèçíàêàìè è êëàññàìè.
Логические системы.
а) Метод решения задачи распознавания: ëîãè÷åñêèé, îñíîâàííûé íà äèñêðåòíîì àíàëèçå è èñ÷èñëåíèè âûñêàçûâàíèé;
б) Метод априорного описания классов: ëîãè÷åñêèå ñâÿçè, âûðàæàåìûå ÷åðåç ñèñòåìó áóëåâûõ óðàâíåíèé, ãäå ïðèçíàêè - ïåðåìåííûå, êëàññû - íåèçâåñòíûå âåëè÷èíû.
Структурные (лингвистические) системы.
а) Метод решения задачи распознавания: ãðàììàòè÷åñêèé ðàçáîð ïðåäëîæåíèÿ, îïèñûâàþùåãî îáúåêò íà ÿçûêå íåïðîèçâîäíûõ ñòðóêòóðíûõ ýëåìåíòîâ ñ öåëüþ îïðåäåëåíèÿ åãî ïðàâèëüíîñòè.
б) Метод априорного описания классов: ïîäìíîæåñòâà ïðåäëîæåíèé, îïèñûâàþùèõ îáúåêòû êàæäîãî êëàññà.
Комбинированные системы.
а) Метод решения задачи распознавания: ñïåöèàëüíûå ìåòîäû âû÷èñëåíèÿ îöåíîê;
б) Метод априорного описания классов: òàáëè÷íûé, ïðåäïîëàãàþùèé èñïîëüçîâàíèå òàáëèö, ñîäåðæàùèõ êëàññèôèöèðîâàííûå îáúåêòû è èõ ïðèçíàêè (äåòåðìèíèðîâàííûå, âåðîÿòíîñòíûå, ëîãè÷åñêèå).
Комбинированные системы требуют отдельного рассмотрения для понимания принципов их построения, что мы и сделаем в нашем курсе после определенной подготовки.
В целом рассмотренная классификация СР может быть представлена следующей схемой (рис.5)
После проведенной классификации возвратимся для дополнительного рассмотрения функциональных схем СР. И обратим внимание именно на термин "достаточное" или "недостаточное" количество информации. С этой меркой мы походили к разделению СР на два большие класса: СР без обучения, обучающиеся и самообучающиеся СР. То есть, для СР без обучения имели дело с полной информацией, а для ОСР - с неполной (нет описания классов на языке признаков), а для ССР - еще с большей неполнотой (отсутствует даже алфавит классов).
Однако заметим, что само понятие “неполнота информации” - качественное, относительное. Для СР без обучения при прочих равных условиях этой информации просто больше. Это означает, что результативность СР при имеющемся объеме априорной информации значительно выше, чем имеем в той ситуации, которая требует создания ОСР. О результативности СР, для которой невозможно априорно назначит алфавит классов говорить вообще нельзя. Что же касается примененного здесь выражения "результативность значительно выше", то из последующего изучения курса будет понятно, что этому казалось бы опять-таки качественному утверждению соответствуют вполне конкретные количественные показатели.

Ñ Ð


Ïðîñòûå Ñëîæíûå








 Áåç îáó÷åíèÿ
Ñ îáó÷åíèåì Ñ ñàìîîáó÷åíèåì
Áåç îáó÷åíèÿ
Ñ îáó÷åíèåì Ñ ñàìîîáó÷åíèåì












Äåòåðìèíè
ðîâàííûå Âåðîÿòíîñòíûå Ëîãè÷åñêèå Ñòðóêòóðíûå



Êîìáèíèðîâàííûå
Ðèñ. 5
Таким образом, отсюда следует, что информацией никогда пренебрегать не стоит. Поэтому при построении как ОСР, ССР и просто СР необходимо всегда использовать принцип обратной связи для расширения объема информации. То есть, результаты решения задачи распознавания неизвестных объектов после апостериорного подтверждения правильности их классификации необходимо использовать для уточнения описания классов в простых СР без обучения и для дополнительного обучения в ОСР и ССР.
Для решения таких задач приведенные схемы СР должны быть дополнены соответствующими функциональными связями дообучения.
* * *
Классификация СР была бы неполной, если бы мы не коснулись экспертных систем, стоящих несколько в стороне от приведенной методологии построения изучаемых нами классических СР.
Как вы уже знаете, эти системы основываются на методах искусственного интеллекта.
Классические решения задач распознавания основываются на моделировании математико-алгоритмических функций (уравнения, системы уравнений) детерминированных или стохастических систем с точным определением области применения, значений параметров, диапазонов сигналов, интервалов времени, частотных диапазонов и т.п. Эти задачи опираются на надежные, точно научно обоснованные знания. В них реализуются новые и оригинальные достижения высококвалифицированных специалистов, имеющих в то же время узкую специализацию. Однако такие специалисты достаточно редки. Это и побуждает создавать экспертные системы, основанные на представлении неалгоритмического, логического, декларативного характера, нечеткого и слабо формализованного знания в виде множества фактов и правил, причинно-следственных связей.
Указанные знания при этом могут быть как заслуживающими доверия и опробированными многочисленными независимыми применениями, так и сомнительными.
Экспертные системы распознавания - это специализированные автоматы обработки знаний для интерактивного и кооперативного решения проблем распознавания на естественном профессиональном языке со способностями приобретения, хранения и представления знаний в форме алгоритмических программ с одной стороны и неалгоритмических фактов и правил, с другой стороны.
Изучение экспертных систем - это отдельный предмет с его методами и подходами.
Ò å ì à 4
Îïòèìèçàöèÿ ýâðèñòè÷åñêèõ âûáîðîâ ïðè ñîçäàíèè ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ
Л е к ц и я 4.1
Оптимизация алфавита классов и словаря признаков
4.1.1. Уточнение назначения и цели создания СР
Как нами уже установлено, процесс распознавания включает такую последовательность операций:
- прием на входе СР образа распознаваемого объекта;
-cîïîñòàâëåíèå àïîñòåðèîðíîé èíôîðìàöèè ïîñòóïèâøåãî îáúåêòà ñ èìåþùèìñÿ â ÑÐ àïðèîðíûì îïèñàíèåì êëàññîâ âñåõ îáúåêòîâ, ïîäëåæàùèõ ðàñïîçíàâàíèþ (îáúåêòîâ, íà êîòîðûå ðàññ÷èòàíà ñèñòåìà);
- принятие решения об отнесении объекта, образ которого был принят, к одному из классов.
Ïðàâèëî, ñîãëàñíî êîòîðîìó îáúåêòó, îáðàç êîòîðîãî ïðèíÿò, ñòàâèòñÿ â ñîîòâåòñòâèå íàèìåíîâàíèå êëàññà, íàçûâàåòñÿ ðåøàþùèì ïðàâèëîì.
 ëèòåðàòóðå øèðîêî ðàñïðîñòðàíåíî ìíåíèå, ÷òî ñóòü ïðîáëåìû ðàñïîçíàâàíèÿ è ñîñòîèò â îïðåäåëåíèè òàêîãî ðåøàþùåãî ïðàâèëà. Òî åñòü, öåíòðàëüíîé çàäà÷åé ÷àñòî ñ÷èòàåòñÿ íàõîæäåíèå â ïðèçíàêîâîì ïðîñòðàíñòâå òàêèõ ãðàíèö, êîòîðûå íåêîòîðûì îïòèìàëüíûì îáðàçîì (íàïðèìåð, ïî êðèòåðèþ ìèíèìóìà îøèáîê ðàñïîçíàâàíèÿ) ðàçäåëÿþò ýòî ïðîñòðàíñòâî íà îáëàñòè, ñîîòâåòñòâóþùèå êëàññàì.
При этом нами четко установлено, что в зависимости от объема àïðèîðíîé èíôîðìàöèè âîçìîæíî äâà ïîäõîäà ê îïðåäåëåíèþ ðåøàþùèõ ïðàâèë (ãðàíèö ìåæäó êëàññàìè â ïðèçíàêîâîì ïðîñòðàíñòâå):
1. Непосредственное предварительное определение при достаточном количестве априорной информации (СР без обучения).
2.Постепенное уточнение в ходе работы СР по назначению при наборе достаточного количества информации (обучающиеся СР).
Каждый их подходов основан на том, что априорный словарь признаков и алфавит классов известны. При отсутствии априорного алфавита êëàññîâ ïðèìåíÿåòñÿ ïîäõîä, ðåàëèçóåìûé â ñàìîîáó÷àþùåéñÿ ÑÐ. Îäíàêî ïðè ýòîì çàðàíåå äîëæíû áûòü èçâåñòíû ñëîâàðü ïðèçíàêîâ è , êðîìå
того, набор некоторых правил назначения классов в процессе самообучения. Решающие правила здесь определяются как итог нахождения алфавита классов.
Исторически сложилось, что первые теоретические и прикладные работы в области распознавания основывались на полной определенности àëôàâèòà êëàññîâ è ñëîâàðå ïðèçíàêîâ. Ïðè ýòîì ïðîáëåìà ðàñïîçíàâàíèÿ ñâîäèëàñü îáû÷íî ê ïðîáëåìå îïòèìàëüíîãî â íåêîòîðîì ñìûñëå îïðåäåëåíèÿ ðåøàþùèõ ïðàâèë , ðåøàþùèõ ãðàíèö ìåæäó êëàññàìè.
Широкая практика создания СР в последующие годы (особенно в военных приложениях) и дальнейшее развитие теории распознавания убедительно показали, что приведенное отношение устарело. При построении реальных СР даже при известных признаках и классах приходится решать сложную и дорогостоящую задачу разработки, ввода и использования специальных измерительных средств и комплексов таких средств с ЭВМ. Эти средства и комплексы оказываются главным элементом в получении признаков распознавания.
При этом реализация решающего правила - это алгоритмическая задача, решение которой отодвигается на второй план сложностью и ценой задачи создания измерительных средств.
Кроме того, для логических и структурных СР о поиске решающих правил вообще не может быть и речи. Они известны. В логических СР - ýòî ïðàâèëà îïðåäåëåíèÿ íåèçâåñòíûõ â áóëåâûõ óðàâíåíèÿõ, â ñòðóêòóðíûõ - ïðàâèëà îïðåäåëåíèÿ ïðàâèëüíîñòè êîíñòðóêöèè ïðåäëîæåíèÿ. Ýòîò ôàêò ïîýòîìó è ÿâëÿåòñÿ äîïîëíèòåëüíûì äîêàçàòåëüñòâîì ïåðâîñòåïåííîé âàæíîñòè çàäà÷è îïðåäåëåíèÿ ïðèçíàêîâ è êëàññîâ.
В результате представляется возможным сформулировать назначение любой СР.
Назначение СР - получение информации, необходимой для принятия решения о принадлежности неизвестных объектов (явлений) к тому или иному классу.
Такое определение наиболее плодотворно для сложных систем.
Оно заставляет сосредоточить усилия в создании СР на главном направлении.
(Примером главенства информации могут служить медицинские СР, геологические, метеорологические, криминалистические, системы контроля космического пространства страны).
Но и принятие решений о принадлежности - íå ñàìîöåëü. Ïîýòîìó âòîðîé ìîìåíò, íà êîòîðûé íàì íåîáõîäèìî îáðàòèòü âíèìàíèå äî ïåðåõîäà ê òåîðåòè÷åñêèì îïèñàíèÿì ðàññìàòðèâàåìûõ â ýòîé òåìå çàäà÷, - ýòî íåîáõîäèìîñòü ïîíèìàíèÿ òîãî, ÷òî ëþáàÿ ÑÐ ÿâëÿåòñÿ ÷àñòüþ êàêîé-ëèáî ñèñòåìû óïðàâëåíèÿ ( àâòîìàòè÷åñêîé èëè àâòîìàòèçèðîâàííîé).
Отсюда легко формируется цель создания СР.
Цель создания СР - обеспечение высокой эффективности принимаемых решений в управлении.
Приведенные определения позволяют более критично отнестись к тому факту, что информация, которая лежит в основе принятия решений и обеспечивает достижение цели распознавания, основывается на эвристическом методе ее получения.
Из рассмотрения содержания задач построения СР следует, что словарь признаков распознавания и алфавит классов формируются человеком на основе его знаний, опыта, интуиции. В то же время ответственность за решения может быть очень велика.
Поэтому очень важно найти объективные методы оценки такого рода человеческой деятельности.
На это мы и направим последующий анализ.
Взаимосвязь размерности алфавита классов и эффективности СР
Мы пока еще не затрагивали вопросов такой взаимосвязи, хотя как алфавит классов, так и словарь признаков определили и имеем представление о их выборе. Однако, обсуждение вопросов составления словаря признаков и выбора алфавита классов никак не затрагивало их взаимосвязи. В то же время мы понимаем, что наличие связей двух явлений, объектов, процессов вообще достаточно часто позволяет выяснить некоторые ограничения составляющих. Попытаемся их поискать для таких объектов, как словарь признаков и алфавит классов.
Оказывается, что отмеченные особенности и приведенные определения назначения и цели создания СР уже определяют взаимосвязи между классами и принимаемыми решениями.
Рассмотрим, какие же это взаимосвязи, в чем их существо. Очевидно, главное, что накладывает на них отпечаток - это необходимость достижения высокой эффективности решений.
Отсюда можно утверждать, что в управлении высокая эффективность решений достигается:
1)Увеличением числа классов в принятом алфавите, то есть, повышением степени детализации распознаваемых объектов (явлений) по назначению и характеру. При этом чем детальнее классификация, тем легче предпринять адекватное управление. ( Вполне понятно, что распознать просто отказ двигателя автомобиля менее привлекательно, чем указать на выход из строя клапана или масляного насоса).
2)Повышением точности определения признаков распознавания, а значит снижением возможности ошибочных решений, часто опасных для управления (снижение ошибок классификации).
Так, если ошибки измерения координат падающего КО большие, то можно как ошибочно самоуспокоиться, предполагая точку падания за пределами интересующей нас зоны ответственности, так и ошибочно объявить тревогу и даже вызвать панику.
В то же время увеличение числа классов в любой задаче, как можно понять только из соображений здравого смысла
( в дальнейшем мы это опишем более строго математически) не всегда просто, а иногда оказывается и невозможно.
Но существует одна ситуация, когда это увеличение всего на один класс бесспорно важно. Так для того, чтобы результаты распознавания были более приемлемы для последующего управления, приходится дополнительно к имеющимся m классам вводить (m+1)-ый, когда отказываются от распознавания, а значит и от управления. Отказ от управления лучше, чем управление при ошибочности распознанной ситуации (если это возможно по назначению системы).
Теперь постараемся понять имеющиеся связи, рассматривая отношения между числом классов и ошибками распознавания. Для удобства рассматриваем одномерный случай (вместо вектора признаков без ущерба для задачи, но для ясности физических представлений, имеем один признак.
Пусть заданы три класса объектов W>1>, W>2>, W>3>
- распределениями вероятностей f(x/W>1>), f(x/W>2> ), f(x/W>3> ), ãäå x - âåðîÿòíîñòíûé ïðèçíàê ðàñïîçíàâàíèÿ ;
- априорными вероятностями P(W>1>), P(W>2>), P(W>3>);
- матрицей потерь при решениях
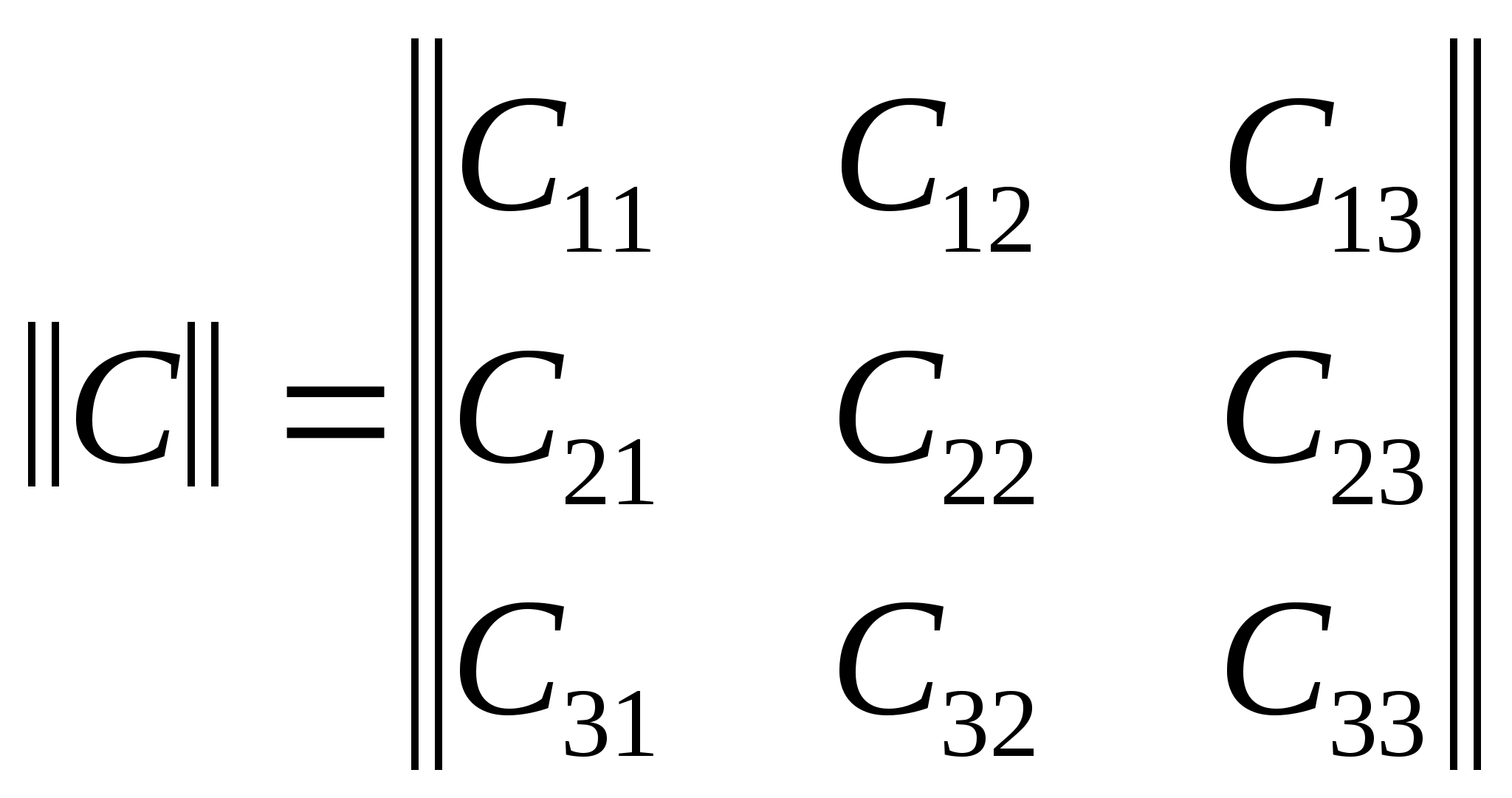
Теперь поймем, что если априорная вероятность отнесения объекта к i-му классу, в то время как он принадлежит к j-му классу (то есть, априорная вероятность ошибки) равна
P(Wi /Wj ),
то среднее значение платы за ошибочную классификацию всех m объектов в системе распознавания определяется как условное МОЖ потерь (зависимость от Wj
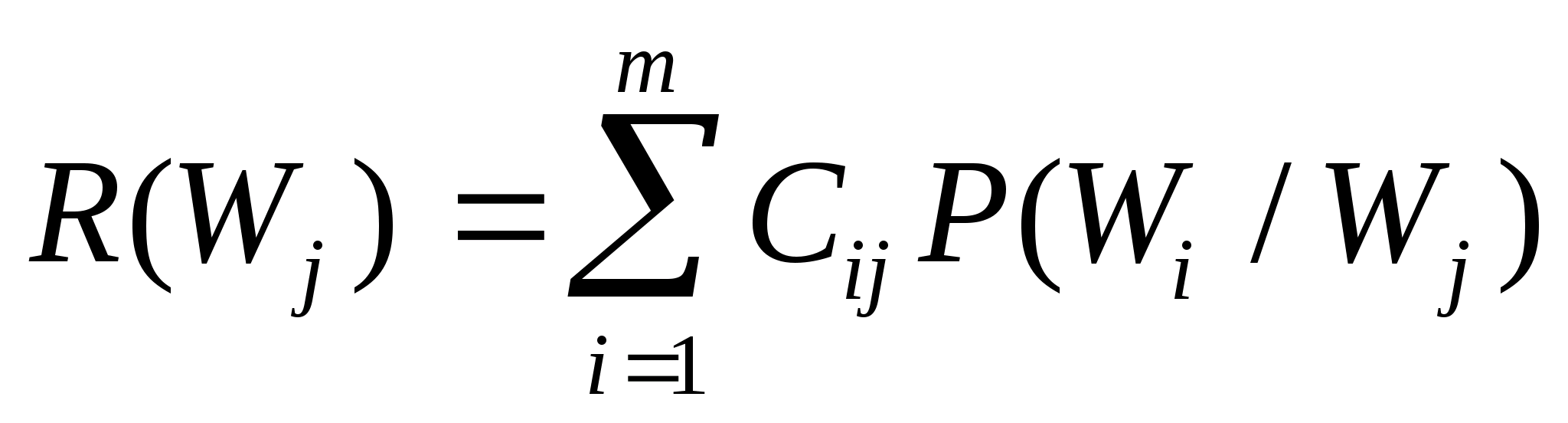
В целом средние потери классификации (то есть, потери по всем классам) определяются как среднее
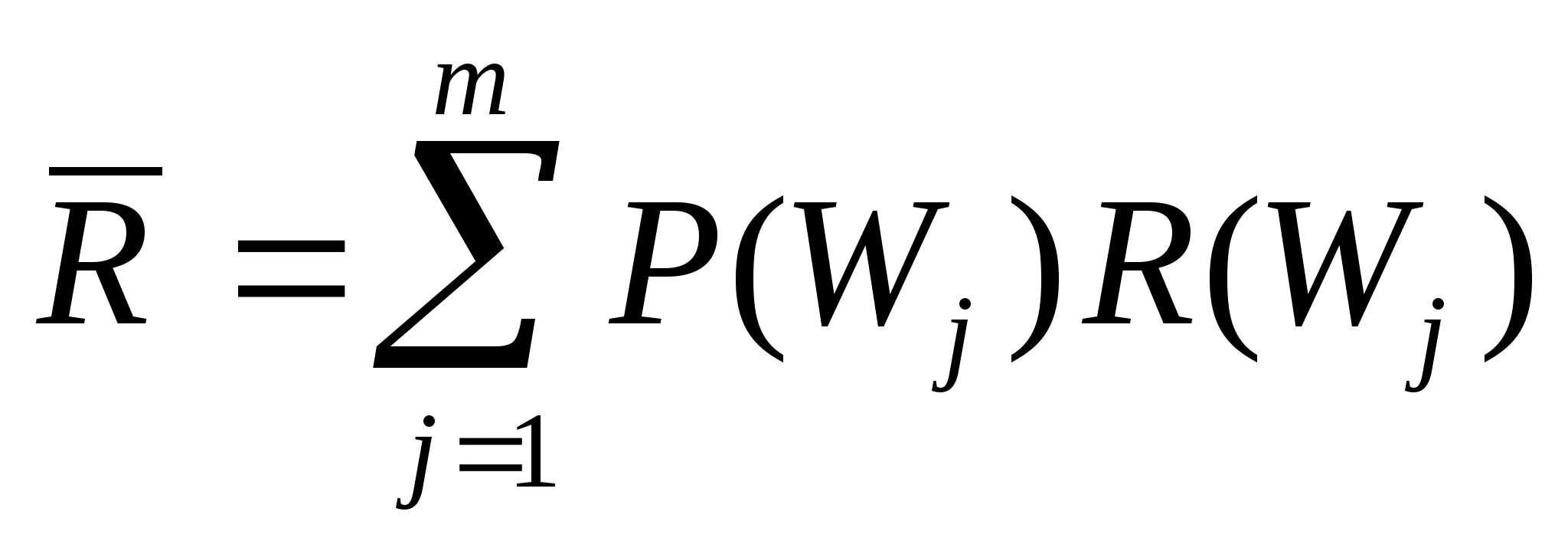
Остается определить вероятность P(Wi /Wj ), так как априорное описание классов напрямую не дает ее значений.
Изобразим ситуацию классификации в
рассматриваемом нами примере в виде
функций ПРВ параметра распознавания
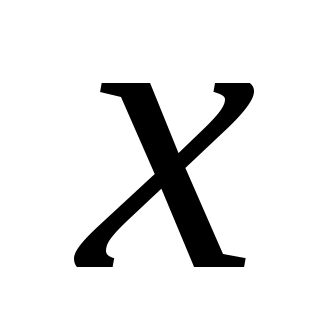 для трех классов (Рис 4.1.1)
для трех классов (Рис 4.1.1)
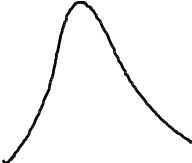
 f(x/W>i>)
f(x/W>i>)



 f(x/W>1>)
f(x/W>2>)
f(x/W>3>)
f(x/W>1>)
f(x/W>2>)
f(x/W>3>)

a b X
Рис. 4.1.1
Если теперь определить области возможного разброса параметра распознавания каждого класса как G>i> ,то легко определить записанную нами вероятность ошибки так
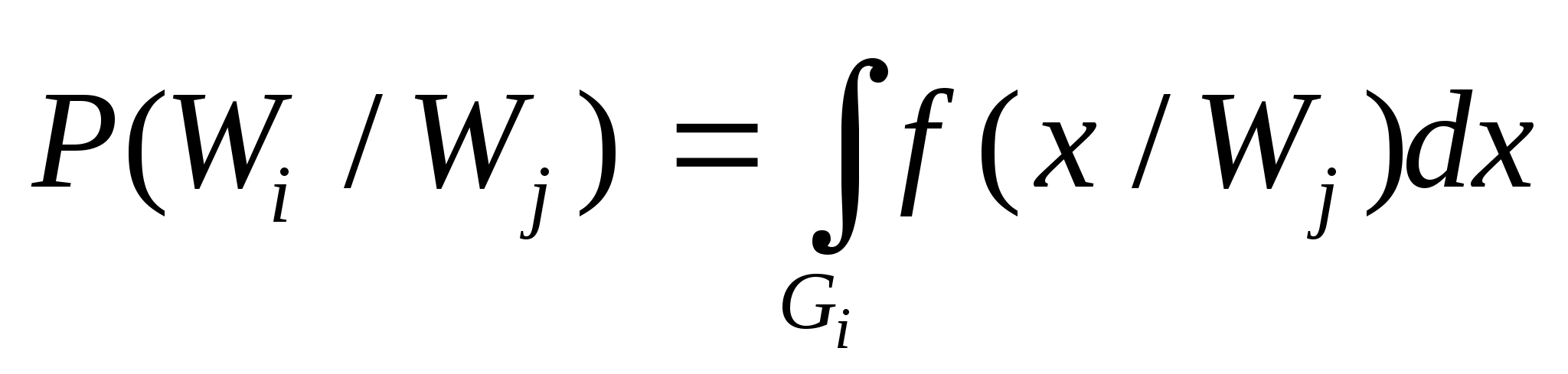
Обозначим указанные области Gi на рисунке. Здесь эти области в силу одномерности случая должны представлять собой отрезки. Поэтому достаточно указать границы
а - граница между 1-ым и 2-ым классами;
b - граница между 2-ым и 3-им классами
Соответственно отрезки:
1-го класса ]- ¥ +a];
2-го класса ]+a +b];
3-го класса ]+b + ¥[ .
Теперь можно записать в соответствии с приведенной формулой условные риски ошибочных решений
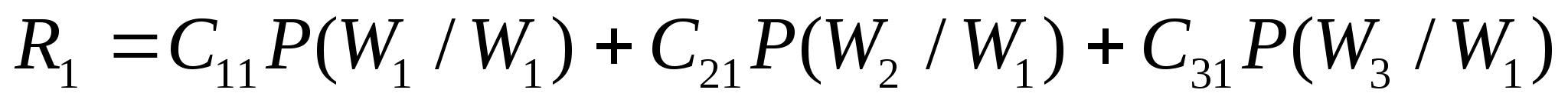
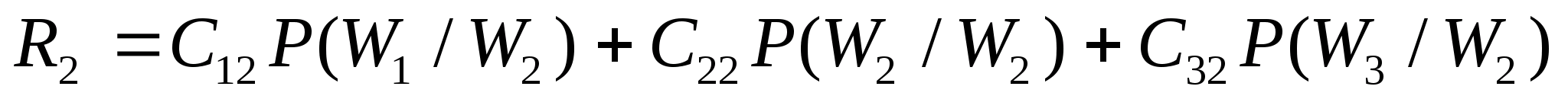
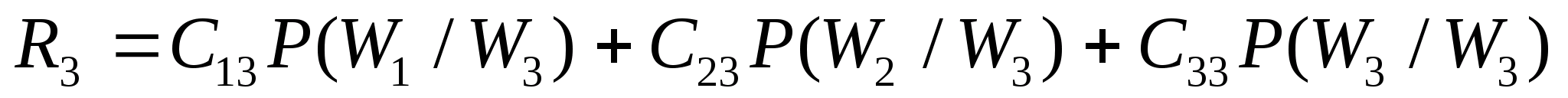
Отсюда средний риск ошибочных решений в системе распознавания (то есть, риск ошибочной классификации всех классов):
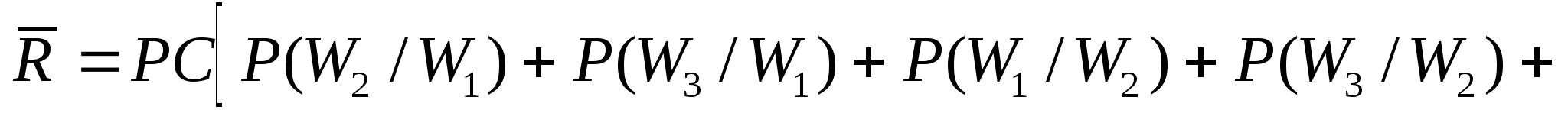
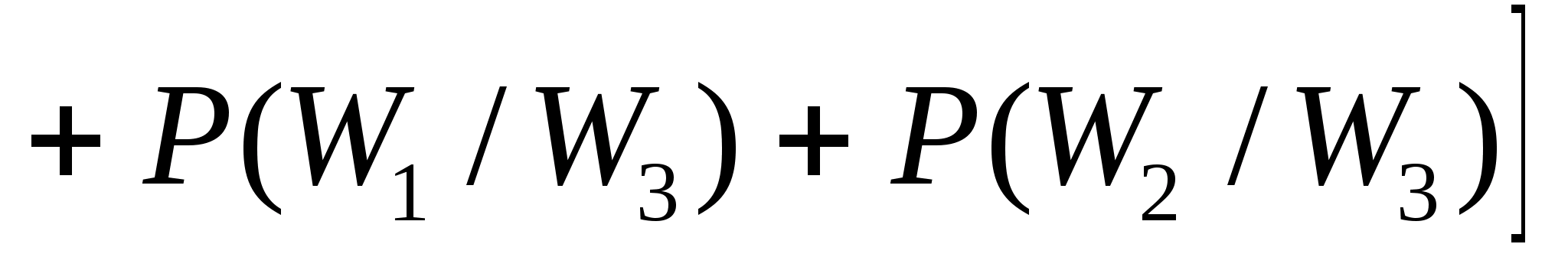
Для простоты рассмотрения принимаем С>ii> = 0, C>ij> = C, P>i> = P и, пользуясь рисунком, получим
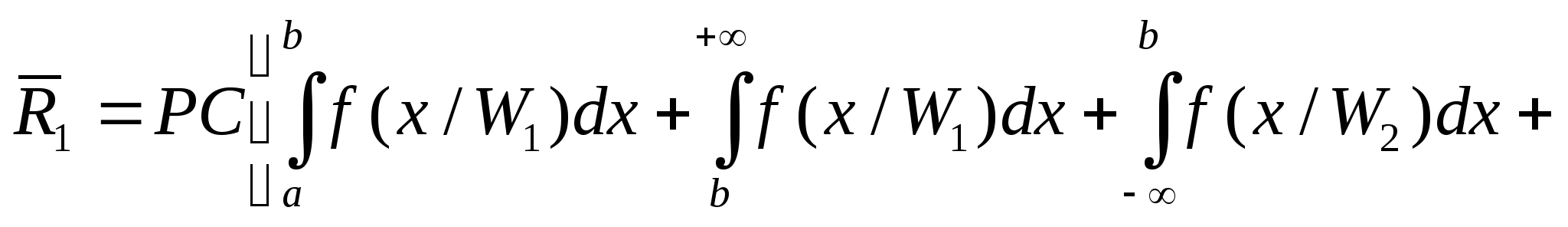
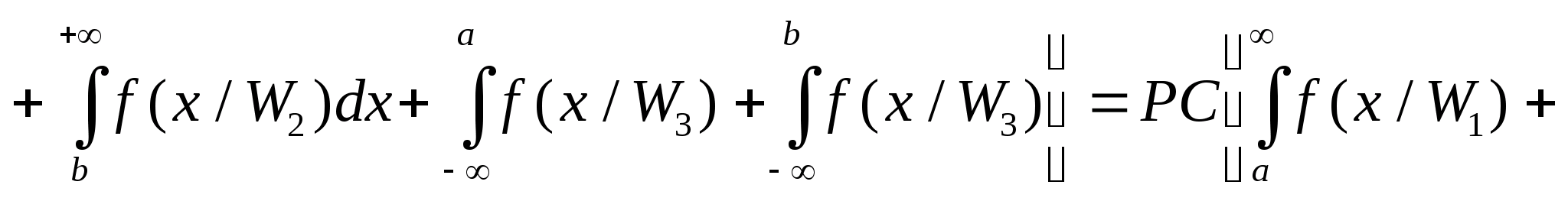
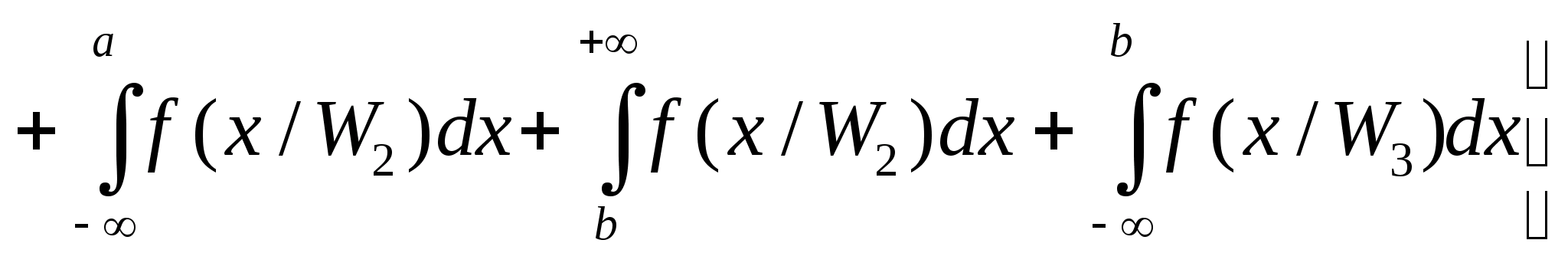
Здесь обозначен средний риск индексом "1", так как теперь рассмотрим вторую ситуацию, для которой постараемся уменьшить число классов, объединяя первый и второй классы в один - четвертый.
Определим по правилам теории вероятностей ПРВ четвертого класса по ПРВ первого и второго классов
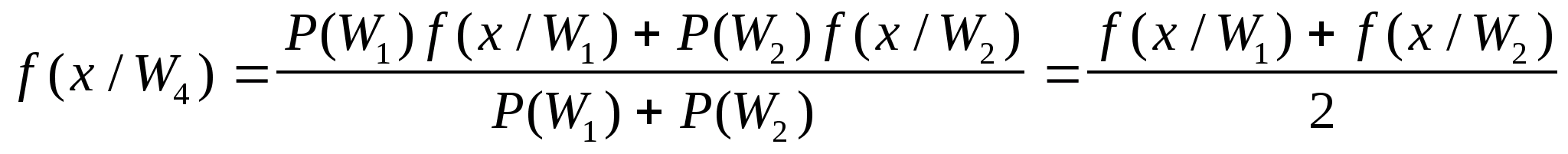
До этого мы упрощали представление вероятностей и плат за ошибки для трех классов. Добавим к этому и четвертый класс
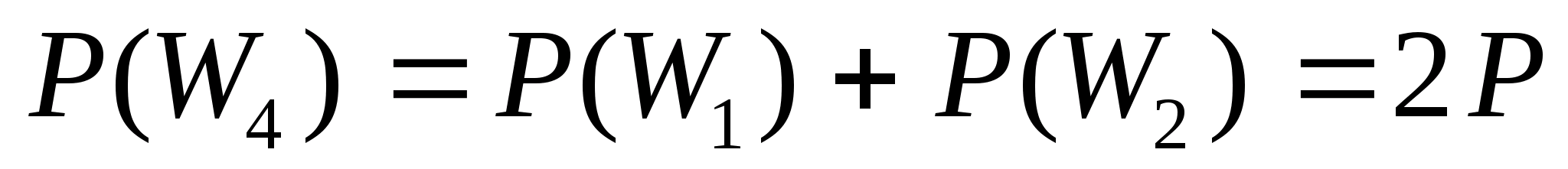
C>44>=0; C>14> =C>41> = C.
На рисунке ПРВ классов изобразим ПРВ четвертого класса (пунктир).
Теперь можно записать, как и в первом случае (три класса), условные риски ошибочных решений для оставшихся 3-го и 4-го классов

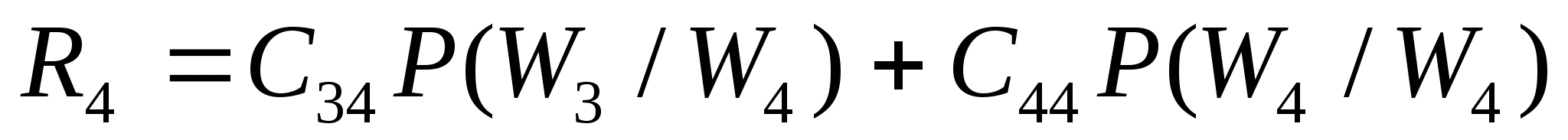
(Условные риски R>1> и R>2> здесь отсутствуют, так как ïðîèçîøëî îáúåäèíåíèå 1-ãî è 2-ãî êëàññîâ â 4-ûé. Êðîìå òîãî, ìàòðèöà ïëàò çà îøèáêè ñ ó÷åòîì ÷åòâåðòîãî êëàññà ïðèíÿëà ñíà÷àëà ñëåäóþùèé âèä
а затем из нее за счет того же объединения исключили столбцы и строки, имевшие индексы "1" и "2". В результате получили:
Средний риск для случая двух оставшихся классов W>3> и W>4> обозначим индексом "2" и также, как для первого случая, после простых преобразований получим
 .
.
Теперь, если подставим сюда вместо ПРВ f(x/W>4>) его выражение, определенное уже нами, то получим
Наконец мы можем сравнить средний риск R>1 > и R>2>
__ __
R>1> > R>2>
Вывод:
При заданном признаковом пространстве и прочих равных óñëîâèÿõ óìåíüøåíèå ÷èñëà êëàññîâ ïðèâîäèò ê ìåíüøåíèþ îøèáîê ðàñïîçíàâàíèÿ.
Следствие:
При увеличении числа классов для уменьшения среднего риска (через уменьшение вероятности ошибочных решений) необходимо включать в состав словаря признаков такие, которые имеют меньший разброс.
Действительно, для рассмотренного нами одномерного случая по приведенному рисунку можно проследить, что вероятности ошибочных решений снижаются, если распределения имеют меньший разброс. То есть, при этом опять-таки уменьшается риск ошибочных решений в системе и тем самым достигается большая эффективность, но теперь уже без уменьшения числа классов.
Л е к ц и я 4.2
Оптимизация алфавита классов и словаря признаков
(продолжение)
4.2.1. Взаимосвязь размерности вектора признаков и эффективности СР
Из предположений, возникающих в связи с приведенным следствием изучения вопроса уменьшения числа классов, можно заключить, что увеличение числа признаков должно приводить к повышению эффективности СР, так как рано или поздно в составе вектора может появиться такой признак, разброс которого минимален. Это качественное утверждение является достаточно важным в построении систем распознавания и поэтому требует строгого доказательства.
Итак, докажем, что с увеличением числа признаков вероятность правильного распознавания неизвестных объектов также увеличивается.
Рассмотрим такое доказательство, допуская, что
- для каждого k-го признака распознавания существует некоторая вероятность такого события A>k>, когда решение о принадлежности объектов к W>i> классу принимается однозначно.
-ïðèçíàêè ðàñïîçíàâàíèÿ íåçàâèñèìû ìåæäó ñîáîé.
Независимость признаков означает и независимость событий A>k> (событий принятия однозначных решений о принадлежности).
Обратимся к теории вероятностей. Вероятность наступления двух совместных или несовместных событий A>1 > и A>2>
P (A>1> + A>2> ) = P (A>1> ) + P (A>2> ) - P (A>1> A>2> )
Отсюда для трех событий получим
P (A>1> + A>2> + A>3> ) = P [A>1>+ (A>2> + A>3> )] = P (A>1> ) + P (A>2> + A>3> ) - P [A>1> (A>2> + A>3> )] = P (A>1> ) + P (A>2> ) + P (A>3> ) - P (A>2>A>3> ) - P (A>1>A>2> + A>1>A>3> ) =
=P (A>1> ) + P (A>2> ) + P (A>3> ) - P (A>2 >A>3> ) -[ P(A>1>A>2> ) + P (A>1>A>3> ) - P (A>1>A>2>A>3> )]
или
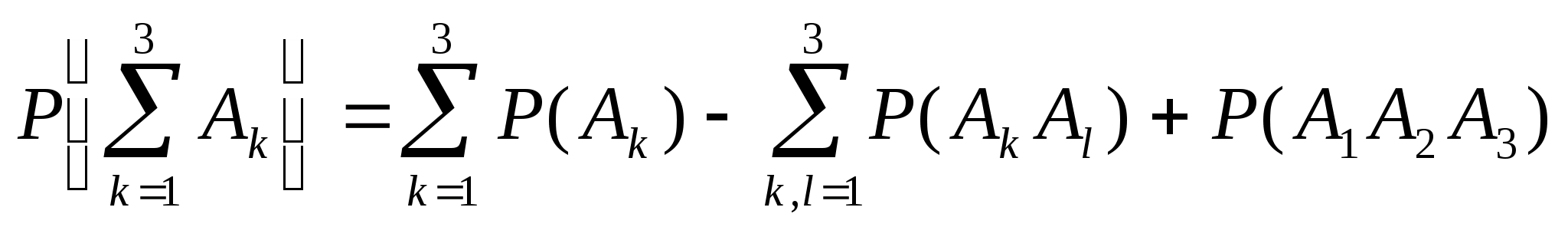
Точно также для четырех событий
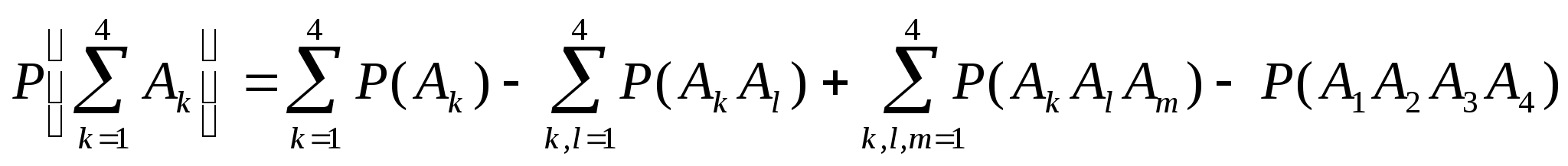
Теперь образуем разность между вероятностями суммы 4-х и 3-х событий, состоящих в рассматриваемом нами случае в принятии однозначного решения о принадлежности по 4-м и 3-м признакам распознавания соответственно:
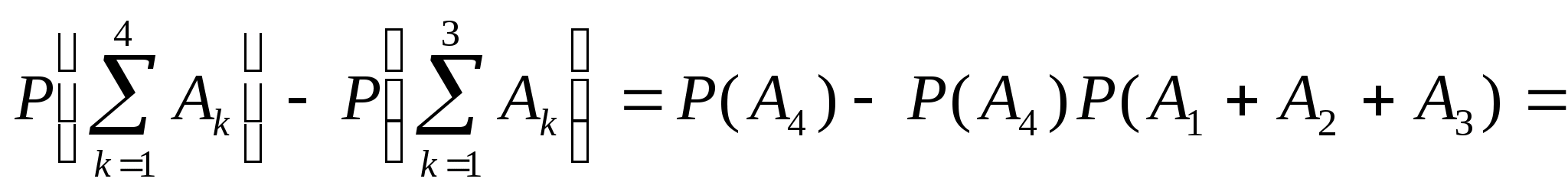
=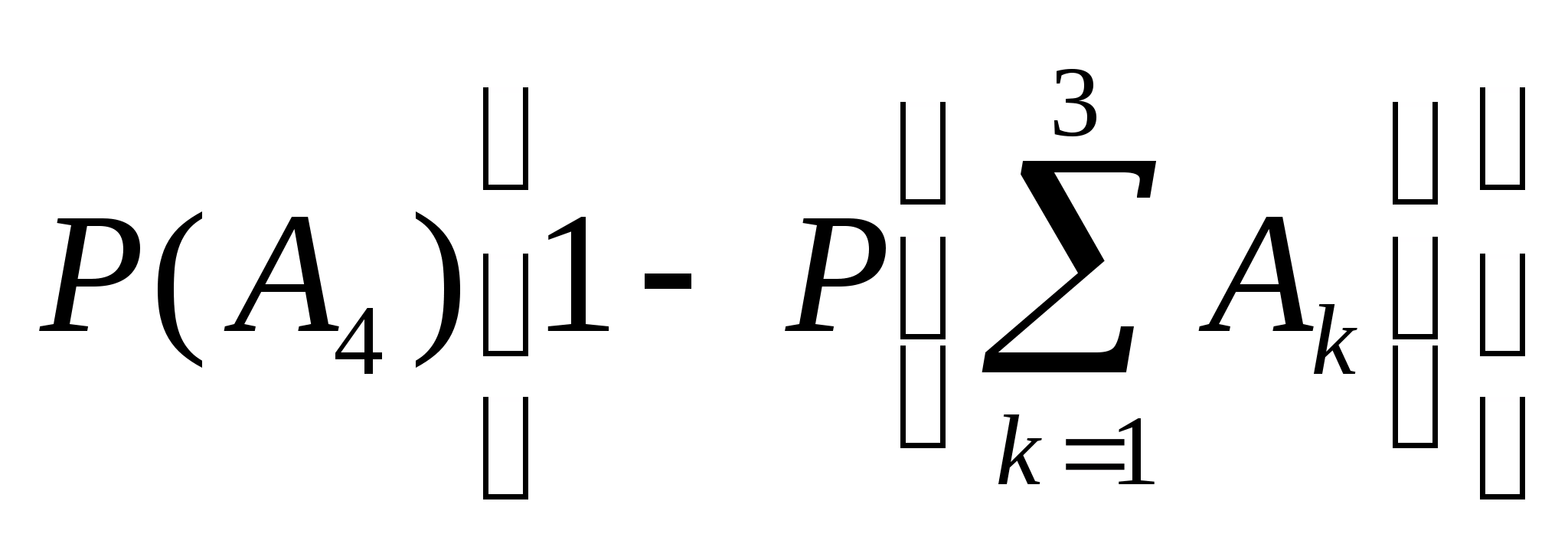
(Наиболее просто эту разность получить, не доводя уменьшаемое до êîíå÷íîãî âèäà
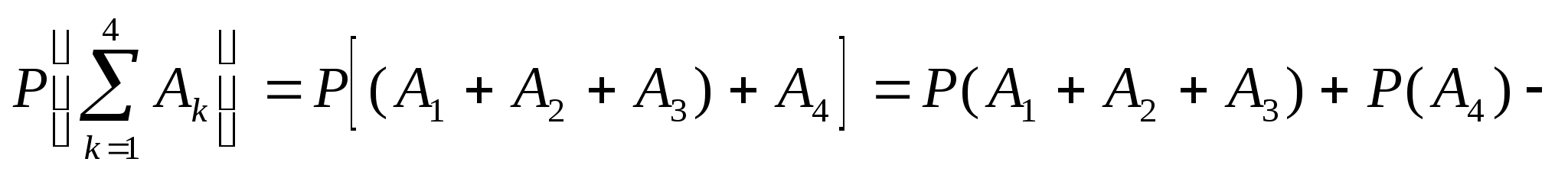
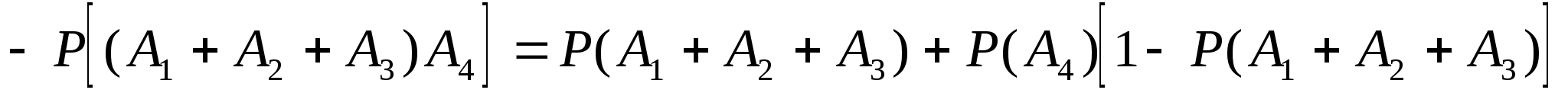
Теперь по индукции можно записать:
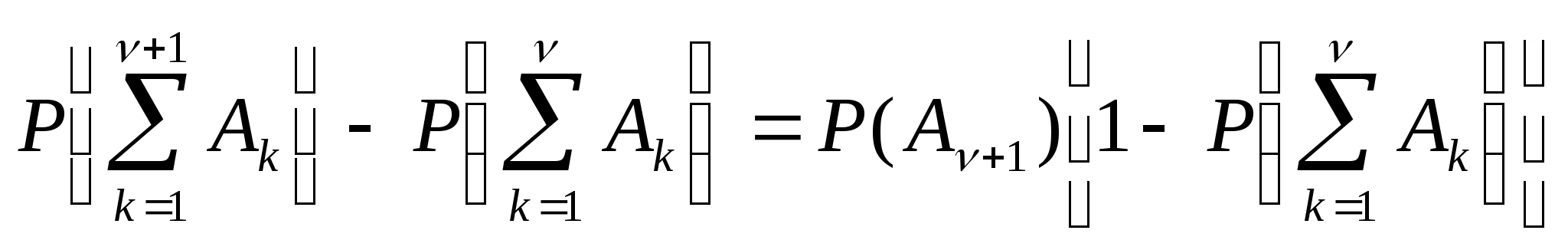
Из приведенного выражения следует, что если не достигнута предельная вероятность правильного распознавания, то есть:

то при любом n имеем
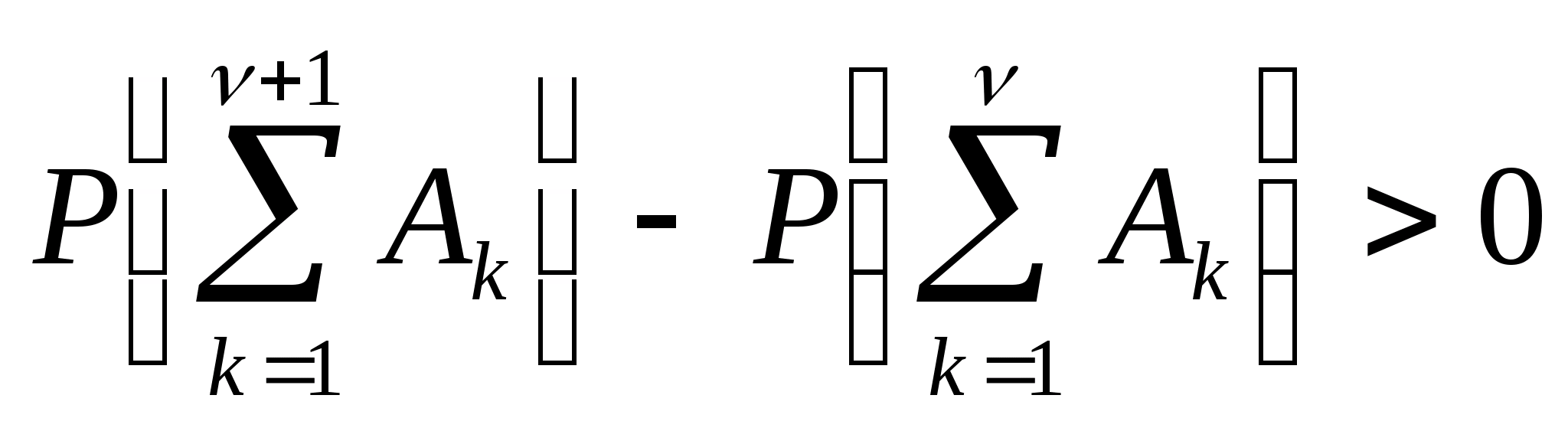
Это является доказательством возрастания вероятности при увеличении числа признаков.
Таким образом, последовательность
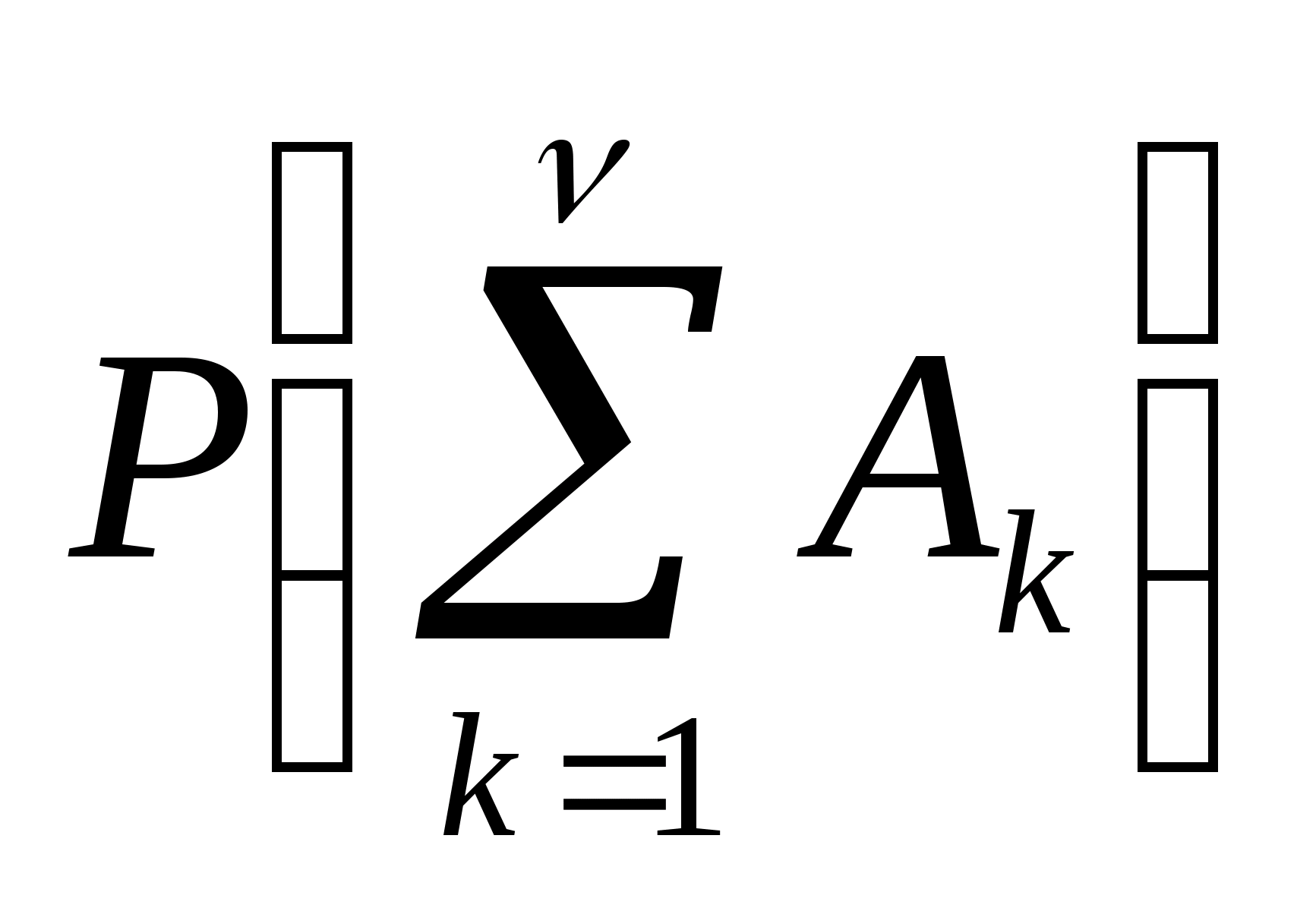
при
 является монотонно возрастающей, а
значит и сходящейся, так как предел
возрастания
-
“1”.
является монотонно возрастающей, а
значит и сходящейся, так как предел
возрастания
-
“1”.
Для сходящейся последовательности
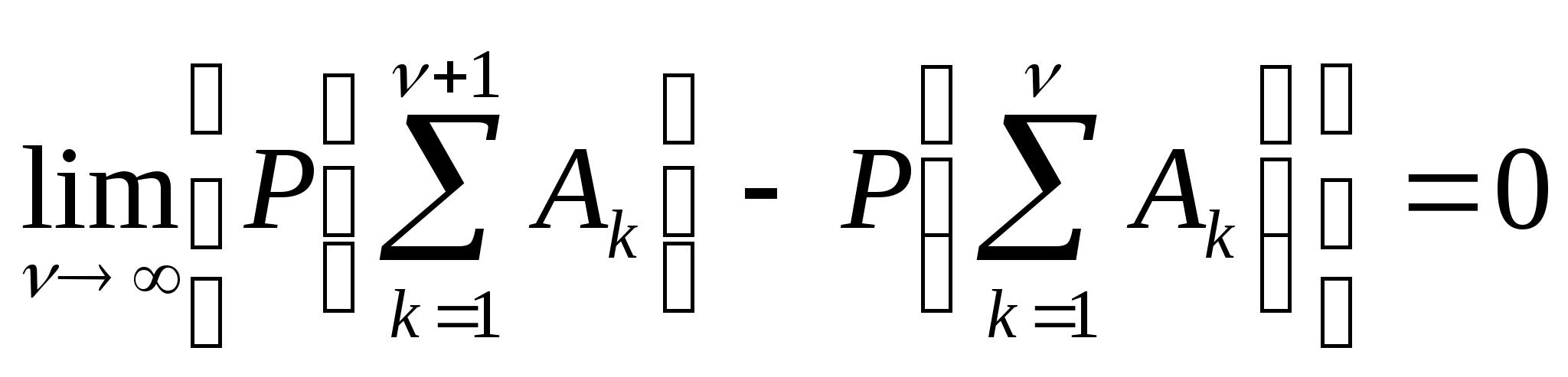
а значит
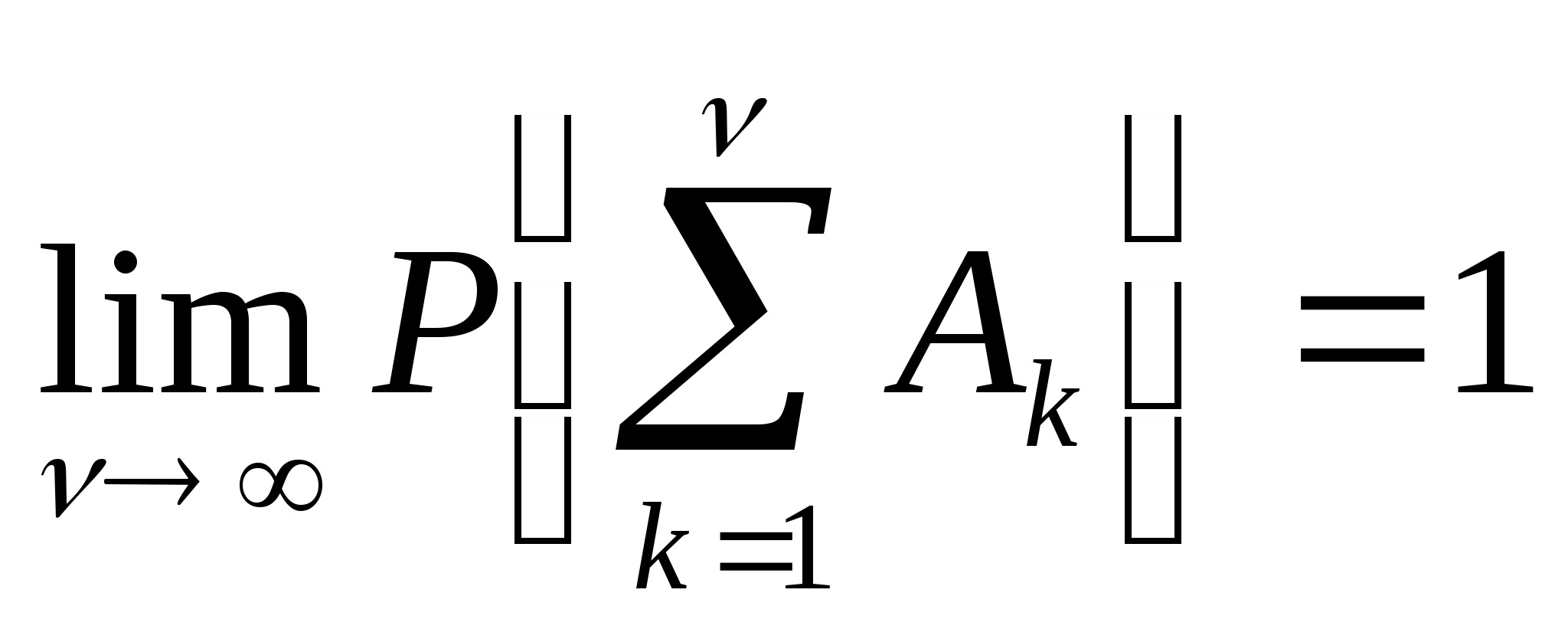
что и требовалось доказать.
Следствие:
Снижение эффективности распознавания за счет увеличения числа классов может быть скомпенсировано увеличением размерности вектора признаков.
Заметим, что мы вели доказательство для независимых признаков.  ñëó÷àå çàâèñèìûõ ïðèçíàêîâ (êîððåëèðîâàííûõ) íàäåæäà íà ïîâûøåíèå ýôôåêòèâíîñòè îñíîâûâàåòñÿ íà íàëè÷èè ñâÿçåé, ïðèâîäÿùèõ ê ëó÷øåé ðàçäåëèìîñòè êëàññîâ (Ýòî ìîæíî ïîêàçàòü íà ïðèìåðå äâóìåðíîãî ïðîñòðàíñòâà ïðèçíàêîâ, êîòîðîìó ñîîòâåòñòâóþò íåïåðåêðûâàþùèåñÿ ýëëèïñû ðàññåÿíèÿ).
4.2.2. Формализация задачи оптимального взаимосвязанного выбора алфавита классов и словаря признаков
Решая задачу повышения эффективности СР за счет увеличения размерности вектора признаков, мы не обращали внимания на то, что указанное увеличение - это часто возрастание числа технических средств измерений, каждое из которых обеспечивает определение одного или группы признаков. Значит при этом растут расходы на построение СР. А ðåñóðñû ÷àñòî îãðàíè÷åíû.
Поэтому в условиях ограниченных ресурсов на создание СР только некоторый компромисс между размерами алфавита классов и объемом рабочего словаря признаков обеспечивает решение задачи оптимальным образом. Для обеспечения этого компромисса требуется предварительная формализация задачи. Начнем с общей формулировки задачи.
4.2.2.1. Формализация исходных данных
Пусть задано множество объектов или явлений
W ={w>1> , w>2> ,....,w>l> };
(например, W=самолеты, а w>1> -пассажирский самолет Òó-154 , w>2> - военно-транспортный самолет АН-12, w>3> - истребитель МИГ-29 и т.д.).
Введем множество из r âîçìîæíûõ âàðèàíòîâ ðàçáèåíèÿ ýòèõ îáúåêòîâ W íà êëàññû (âàðèàíòû àëôàâèòà êëàññîâ)
A ={A>1>, A>2>, ..., A>r>}
(например, A>1> - 2 класса - пассажирские, военные (m>1> =2); A>2> -5 классов - истребители, бомбардировщики, штурмовики, пассажирские, военно- транспортные (m>2> =5) )
Таким образом, с учетом возможного отказа от решений в каждом âàðèàíòå ìíîæåñòâî îáúåêòîâ W ïîäðàçäåëÿåòñÿ íà ñâîå ÷èñëî êëàññîâ:
в варианте A>1> - на (m>1> +1) классов;
в варианте A>2> - на (m>2> +1) классов;
...........................................................
в варианте A>r> - на (m>r> +1) классов.
Иными словами здесь мы располагаем r алфавитами классов.
В соответствии с вариантом алфавита классов (A>s>) исходные объекты (явления) разбиваются на m>s> "решающих" классов
W = {W(1/A>s> ), W(2/A>s> ), W(3/A>s> ),....... , W(m>s> /A>s> )},
где естественно "1", "2",..... - номера классов; A>s> - вариант алфавита классов, где s=1,2,....,r.
Например:
W(1/A>s> ) = {W>1> ,W>2> ,..W>k> }; W(2/A>s> ) = { W>k>+1 ,W>k>+2 ,..,W>l> }
и т.д.
Таким образом, мы располагаем подмножествами классифицированных объектов.
Если при этом располагаем априорным словарем признаков
_
X = { x>1> , x>2> , ..., x>n> },
и притом размеры указанных подмножеств классифицированных объектов таковы, что соответствующие выборки признаков представительны (в каждом классе достаточное в статистическом смысле число объектов),то тогда тем или иным способом может быть проведено описание каждого из классов на языке этого словаря.
В детерминированном случае это достаточно просто. Каждый класс имеет свои эталоны со своими характеристиками как наборами параметров, представляющих собой признаки распознавания:
X>ik> [W(j/A>s> )],
__
где i = 1,n - число признаков распознавания;
__
j = 1,m - ÷èñëî êëàññîâ;
___
k = 1,N>эj> - число эталонов в j-том классе.
При статистическом подходе (вероятностные признаки и вероятностная СР) описание это:
- априорные вероятности классов P[W(i/A>s> )];
_
- функции условных ПРВ f{X/[W(i/A>s> )]};
Если же объем выборок объектов по подмножествам недостаточен для непосредственного описания классов, то эти описания, как мы знаем, могут быть получены с помощью процедуры обучения.
Наличие описаний классов уже позволяет определять решающие правила (решающие границы), использование которых обеспечивает минимизацию ошибок при распознавании неизвестных объектов.
Если бы не было ограничений на величину ресурсов, ассигнуемых на построение СР, а именно на создание измерительных средств, предназначенных для определения признаков, то можно было бы считать, что как алфавит классов, так и словарь признаков определены и можно приступать к построению системы.
Реально при создании сложных систем не бывает без указанных ограничений. При этом, когда речь идет об ограничениях, это не обязательно финансовые ограничения. Достаточно часто в качестве таковых могут выступать ограничения на быстродействие, память и т.п.
4.2.2.2.Выигрыш распознавания и оптимизация алфавита классов и словаря признаков в условиях ограничений
В условиях ограничений на создание или использование средств измерений (а равно - средств получения признаков распознавания) оказывается естественной невозможность использования всех признаков. Поэтому для формирования рабочего словаря признаков вводится вектор, совпадающий по мощности с вектором признаков X:
_
V ={v>1> ,v>2> ,...,v>n> },
компоненты которого v>j >ðàâíû 1, åñëè äàííûé ïðèçíàê àïðèîðíîãî ñëîâàðÿ èñïîëüçóåòñÿ â ðàáî÷åì è 0 â ïðîòèâíîì ñëó÷àå. Ýòîò âåêòîð íîñèò íàçâàíèå âåêòîðà îòáîðà.
Располагая стоимостями измерения каждого j-го признака С>j> , имеем общие затраты на реализацию априорного словаря признаков
С>апр>
=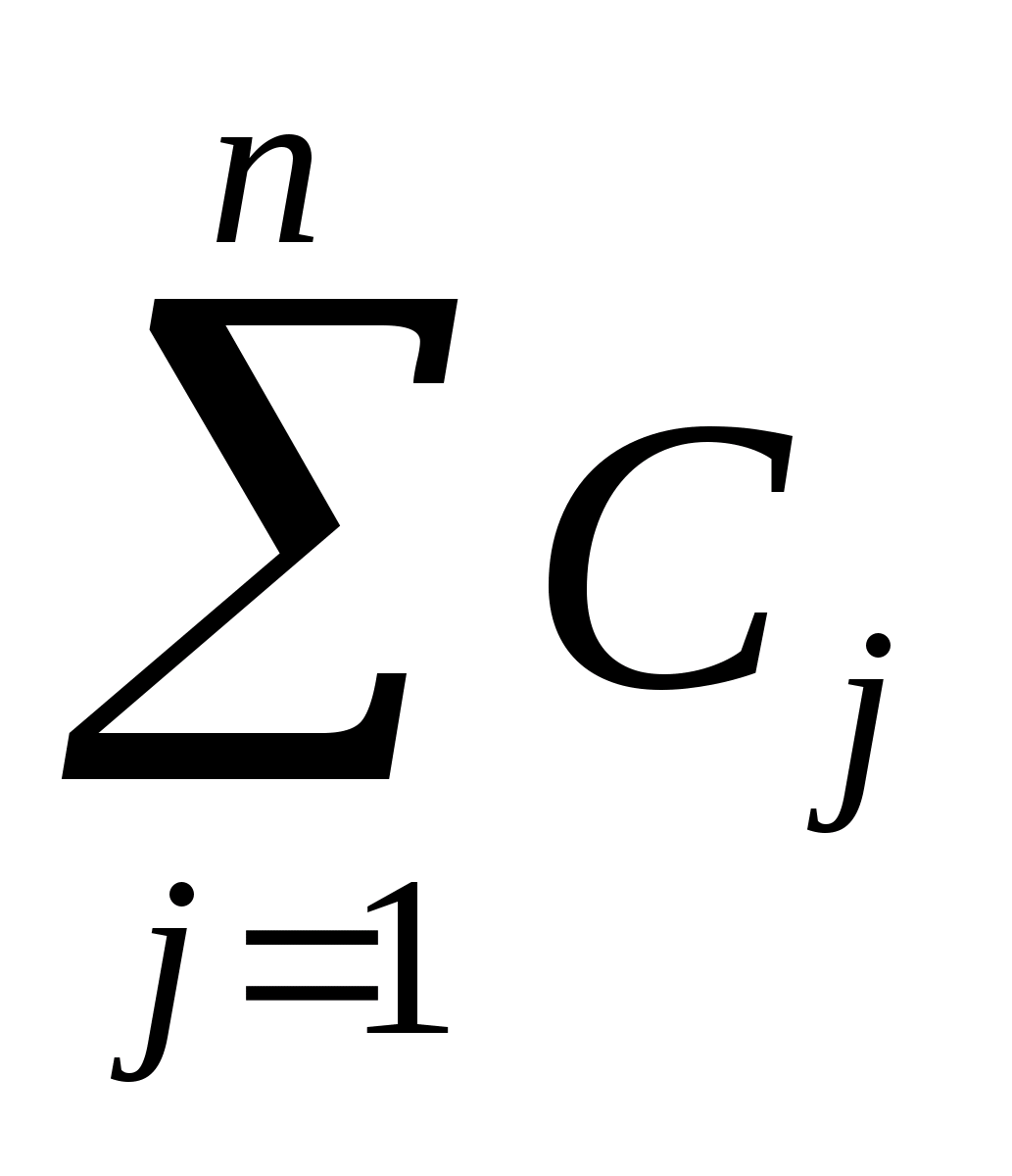
Для рабочего словаря будем иметь
С>раб>
=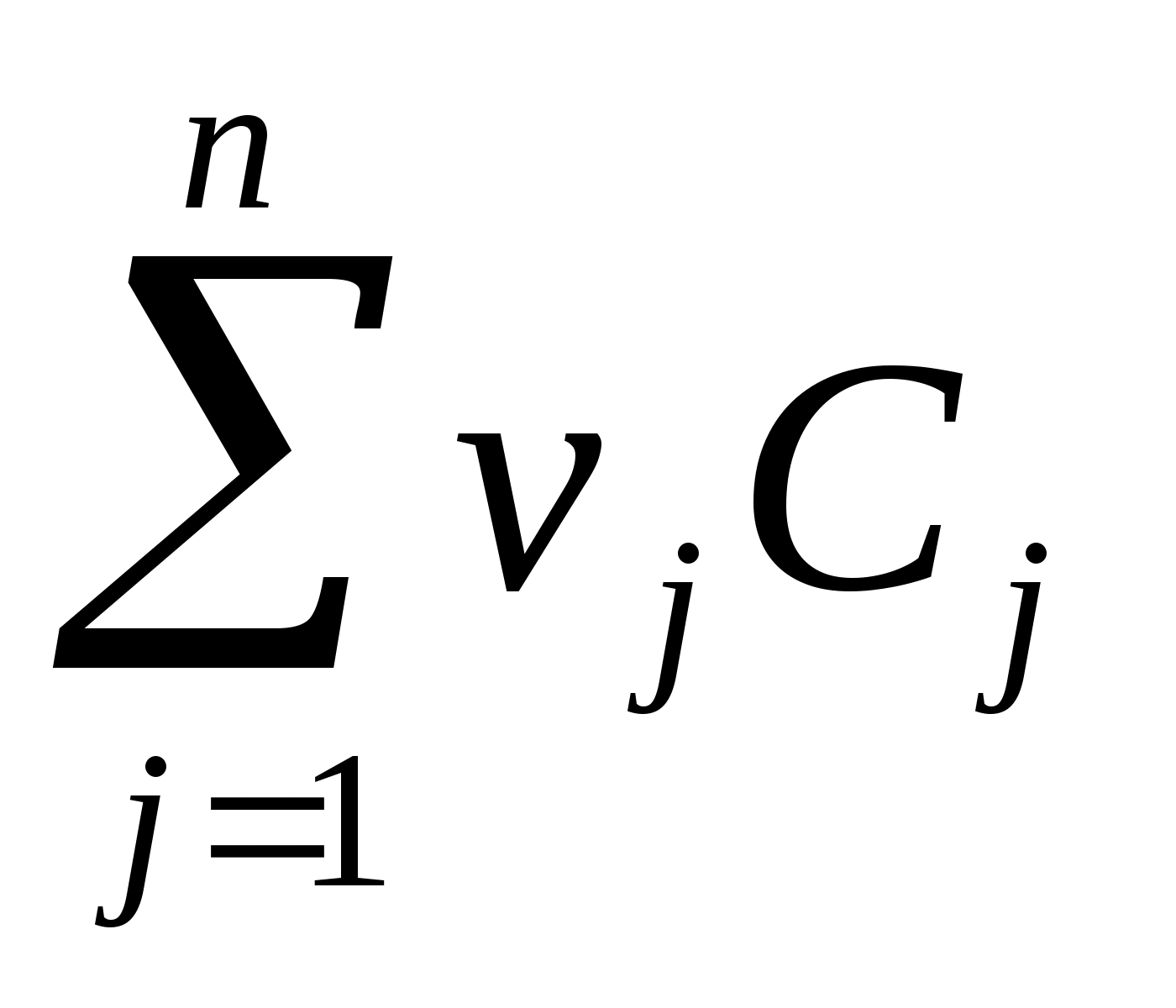
При наличии конкретной величины ассигнованных ресурсов (C>0> ) на создание СР ограничения, о которых идет речь, формализуются в виде следующего неравенства
С>0>
>=
Если в конечном итоге интересоваться вектором отбора, то возникает следующая экстремальная задача:
в пределах выделенных ассигнований на создание СР (C>0>) åîáõîäèìî íàéòè òàêîå ïðîñòðàíñòâî ïðèçíàêîâ, ïðè êîòîðîì îáåñïå÷èâàåòñÿ ìàêñèìàëüíîå çíà÷åíèå íåêîòîðîãî êðèòåðèÿ ýôôåêòèâíîñòè ÑÐ.
Здесь речь идет не только о словаре признаков, но и об алфавите, учитывая выясненную связь между ними. Действительно, если мы будем уменьшать число признаков, то придется уменьшить и число классов.
Обращая внимание на тот факт, что без критерия эффективности такая задача не решается, введем его.
В соответствующей литературе приводится несколько требований, которыми следует руководствоваться при выборе показателя эффективности:
1) показатель эффективности должен характеризовать систему как единое целое.
2) показатель эффективности должен обеспечивать возможность получения количественной оценки с требуемой достоверностью.
3) область изменения показателя эффективности должна иметь четко очерченные границы.
На поверхности понимания стоящей перед нами задачи в качестве åäèíîãî ïîêàçàòåëÿ äëÿ âñåé ñèñòåìû ëåæèò âåðîÿòíîñòü ïðàâèëüíîãî ðàñïîçíàâàíèÿ.
Однако, такой выбор несколько расходится с пониманием цели создания СР - выработкой управляющих решений. Поэтому и критерий должен характеризовать выигрыш, достигаемый от принятия решения как ответных действий на распознавание.
Составляющими такого выигрыша от применения СР являются частные выигрыши от отнесения неизвестного объекта к тому или иному классу.
Обозначим такую составляющую в i-ом классе s-ого варианта алфавита классов так:
G>s> [W(i/A>s> )].
Что же такое "выигрыш"? Что можно выиграть в управляющем решении?
Рассмотрим в общем виде два примера:
1) В экономике по результатам распознавания ситуации может быть принято такое решение, которое обеспечит максимальную прибыль. А может быть и такое решение, которое даст меньшую прибыль или вообще никакой, не говоря уже о возможных убытках. Поэтому понятно, что здесь величина выигрыша зависит от того, насколько не только правильно, но и детально распознана ситуация. Если класс, к которому она отнесена достаточно широк, то трудно ожидать большого выигрыша. Если же детализация очень подробная, что соответствует большему числу распознаваемых классов, то можно ожидать большую отдачу от принятого решения.
2) В военном деле мы можем иметь дело с отнесением к классу опасных не только боевых частей (БЧ) ракет, но и ложных целей (ЛЦ), их имитирующих. При этом вынуждены будем обстрелять (а это и есть решение по результатам распознавания) и БЧ и каждую ЛЦ. В этом случае мы имеем проигрыш, измеряемый ценой ПР и затратами на их пуски. Если же мы все-таки часть ЛЦ распознаем и отнесем к соответствующему классу, то сэкономим часть противоракет ПР. Если же все ЛЦ отделим от БЧ баллистических ракет (БР), то выигрыш будет максимальным.
Таким образом, в каждом конкретном случае выигрыш специфичен. Но чем он больше, тем лучше.
При таких качественных рассуждениях, хотя и правильных, назначение и подсчет выигрышей не поддается точным выводам и оценкам. Эта задача всегда индивидуальная, носит эвристический характер и требует творчества конструктора при максимальном учете факторов, влияющих на результат. Так или иначе выигрыш для каждого класса, обеспечивающий соответствующее решение, должен быть назначен.
Принимая во внимание зависимость выигрыша от ряда случайных факторов распознавания, в качестве оценки эффективности необходимо использовать единый показатель, получаемый как математическое ожидание составляющих:
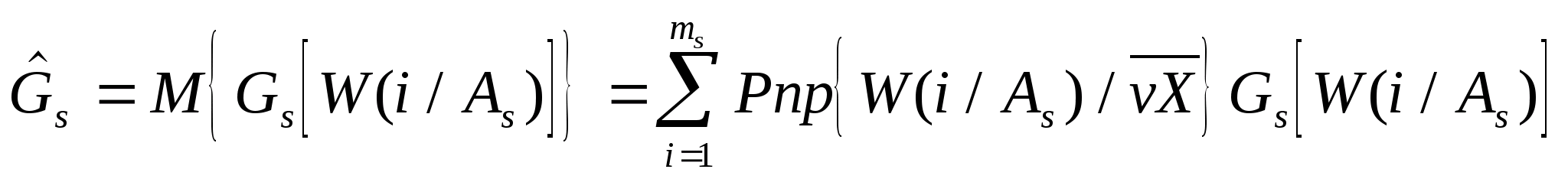
где -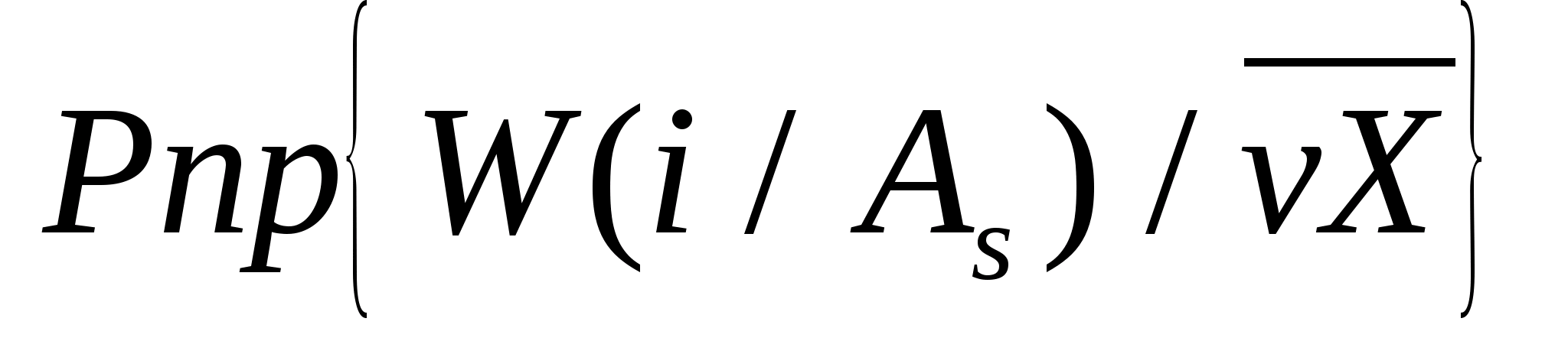 -
апостериорная вероятность правильного
отнесения объекта к W>i> -му классу
(то есть, после измерения вектора
признаков и их отбора).
-
апостериорная вероятность правильного
отнесения объекта к W>i> -му классу
(то есть, после измерения вектора
признаков и их отбора).
Теперь сформулированная нами задача может быть формализована следующим образом:
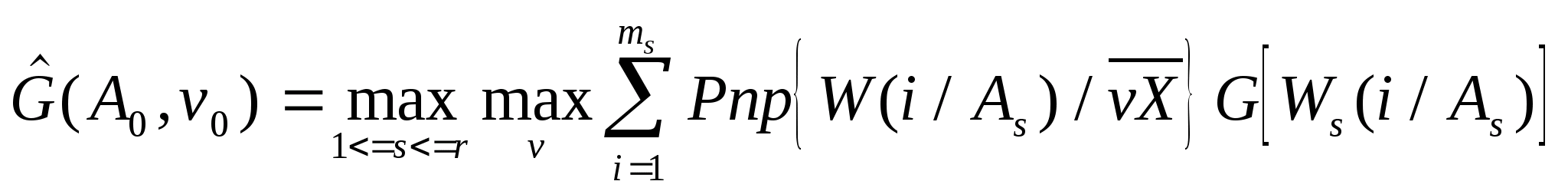
при C>0>
>=
Здесь A>0> ,v>0> - искомое решение, обеспечивающее выбор варианта разбиения на классы (алфавит классов) и определения рабочего словаря признаков.
Таким образом, общая постановка проблемы создания СР объектов или явлений заключается в определении оптимального алфавита классов и рабочего словаря признаков при наилучшем решающем правиле в условиях ограничений на построение системы измерений признаков распознавания.
Т е м а 5
Моделирование систем распознавания образов - методология их создания и
оптимизации
Л Е К Ц И Я 5.1
Введение в моделирование
5.1.1. История вопроса
История моделирования начинается фактически с истории математики, а также с появления графического и пластического искусств, известных нам по памятникам ранних цивилизаций. Так элементы математического моделирования существовали уже в период зарождения математики. Одним из первых примеров четко сформулированной математической модели является теорема Пифагора (VI век до нашей эры).
Рассмотрим компьютерную реализацию теоремы Пифагора в ее наиболее простой интерпретации
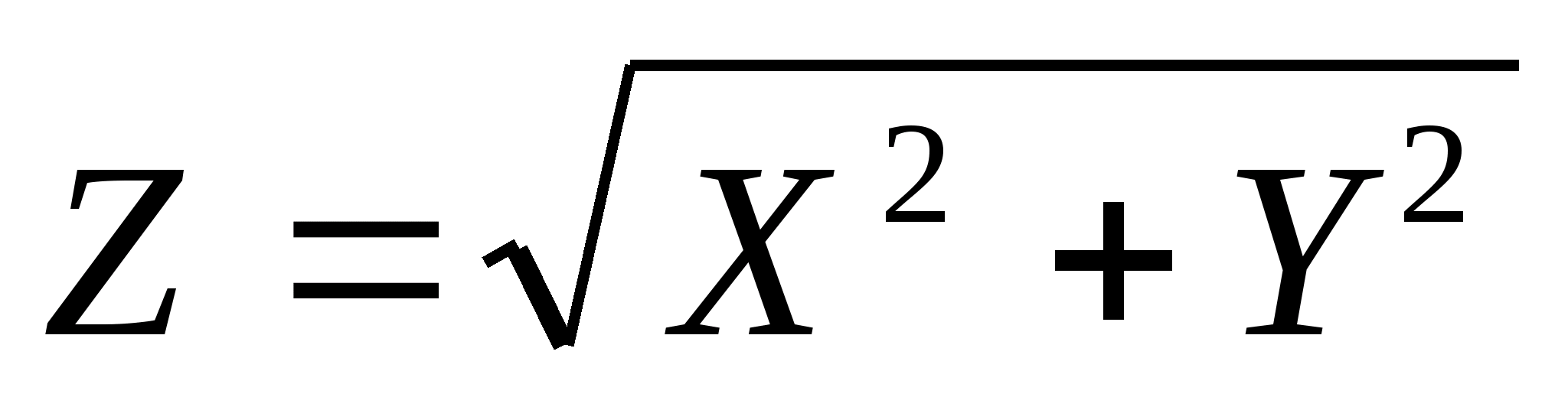
Известно, что эта проверенная жизнью зависимость может использоваться в расчетах как строительных конструкций, так и в машиностроении, так и в определении кратчайшего пути по карте и на местности и т.п.
Если теперь на входе компьютерной программы задавать переменные X и Y как катеты треугольника, например, реальной строительной конструкции, имея желание получить интересующий разработчика размер гипотенузы этой конструкции то в результате расчета будем иметь значения Z, найденные фактически в результате моделирования указанной природной зависимости.
Теорема Пифагора возглавляет длинный список классических примеров математических моделей, среди которых
-законы движения Ньютона (XVII в);
-полиномы Эйлера (XVIII в);
-волновые уравнения Максвелла (XIX в);
-теория относительности Эйнштейна (XX в).
Характеризуя существо математического моделирования, следует определить математическую модель как абстрактное математическое представление отображаемого объекта, явления, процесса .
Графические и пластические искусства в отличие от математики возглавили ряд методов, получивших название аналогового моделирования.
Аналоговые модели следует определить как отображение предметов, процессов, явлений посредством аналогичного представления.
Классическими примерами аналоговых моделей могут служить глобус, рельефные карты, модели солнечной системы в виде тел на проволочных орбитах, модели молекулярных соединений в виде атомных структур, а также аэродинамические трубы, аналоговые модели систем автоматического регулирования, представляемые элементарными звеньями (интегрирующее, инерционное и т.д.) и т.п.
С появлением вычислительных машин стало очевидно, что математические и аналоговые модели могут быть запрограммированы, например, для их исследований. Это явилось знаменательным в истории развития моделирования. С этого момента моделирование получило мощное средство, оказавшее существенное влияние на его совершенствование, развитие, усложнение и охват различных сторон деятельности человека.
Значимость происшедшего скачка достаточно убедительно характеризует такой пример первых проб компьютерной реализации моделей. В начале 50-х годов в университете Дж. Гопкинса в США был построен имитатор воздушного боя, состоявший из механических элементов. Каждый вариант боя проигрывался на нем вручную несколькими участниками и длился 3 часа.
Оказалось, что результаты при этом обусловливались рядом случайных факторов, а не искусством игроков.
Несколько позже рассмотренная аналоговая модель была формализована в математическую и запрограммирована на ЭВМ ЮНИВАК 1103А. В итоге время реализации одного варианта моделирования уменьшилось почти в 10000 раз. Эффект, достигнутый при переходе к ЭВМ, был феноменальным.
Использование ЭВМ сделало возможным создание таких моделей, которые не могли быть реализованы на базе аналоговой техники или с помощью ручного счета. При этом стала очевидной и возможность решения огромного числа вариантов поставленной задачи.
После второй мировой войны моделирование с использованием вычислительной техники применялось главным образом для решения военных задач:
-в военных играх;
-в исследованиях боевых операций;
-в испытаниях и исследованиях сложных систем вооружения.
В то же время постепенно моделирование находило все большее применение во всех невоенных областях человеческой деятельности:
-в физических и технических науках;
-в коммерческой деятельности;
-в медицине;
-в юриспруденции;
-в библиотечном деле;
-в социальных науках.
Было показано практически, что моделирование с помощью вычислительной техники применимо к любому предмету и явлению, которые могут быть описаны количественно и представлены в виде математических соотношений.
Комплексы разнообразной аппаратуры, связанные в единую целесообразно функционирующую систему посредством управляющей ЭВМ или действий обслуживающего персонала, можно встретить сегодня как на металлургических и химических предприятиях, так и в медицинских учреждениях или в исследовательских лабораториях.
Усложнение аппаратуры влечет за собой усложнение ее проектирования и производства. Нужно отметить, что организация деятельности многочисленных участников процесса разработки, упорядочение использования технологического и испытательного оборудования и т.д. превратились в ХХ веке в тяжелые системотехнические проблемы.
В настоящее время непрерывно растет число вновь создаваемых сложных систем. Это вызывается как потребностями, возникающими вследствие значительных трудностей осуществления процесса управления разросшейся экономикой, увеличением масштабов предприятий крупного производства, а также достижениями в области автоматизации и вычислительной техники.
Наиболее характерные особенности сложных систем - это наличие большого количества разнородных элементов, объединенных в систему для достижения единой цели, сложные взаимно переплетающиеся связи, развитая система математического обеспечения, предназначенная для обработки огромных информационных потоков .
Сложные системы характеризуются множеством состояний. Каждое из них определяется конкретным набором входных параметров. Изменение входного состояния или значений параметров, характеризующих поведение отдельных элементов системы, приводит к изменению выходных параметров системы и ее состояний.
Множество параметров, характеризующих каждый из элементов и систему в целом, а также наличие сложных функциональных зависимостей между ними, затрудняет формализацию с целью описания поведения таких систем. На практике редко удается получить полное математическое описание поведение сложной системы в общем виде.
Уникальность и дороговизна сложных систем практически исключает традиционные эмпирические методы их проектирования путем “доводки” аппаратуры на серии опытных образцов. В ряде случаев сложную систему вообще не успевают испытать в течение всего периода эксплуатации. При этом проверка в аварийных ситуациях, как правило, оказывается вообще невозможна (АЭС в аварийных ситуациях).
Если в качестве выхода из создавшегося положения использовать расчеты систем с привлечением ЭВМ, то здесь, во-первых, приходится сталкиваться не только с неоднозначностью состояний систем, но и с их сложностью и нелинейностью. До уровня инженерных расчетов доводится обычно только анализ линейных стационарных или нелинейных безынерционных систем. Приходится идти на их упрощения. Обычно использование аналитических методов расчета выходных показателей системы позволяет понять ее закономерности разработчику. Однако для сложных систем возможности аналитических методов крайне ограничены сложностью математического описания узлов и блоков, а также достоверностью априорного определения факторов, которые наиболее существенно влияют на динамику исследуемой системы.
Во-вторых, частные данные (то есть, для отдельных состояний), получаемые в процессе длинных математических выкладок и вычислений, не имеют, к тому же, наглядной физической интерпретации. Это затрудняет:
-выявление первопричин окончательного поведения системы -может потребоваться проведение повторных аналитических выводов и расчетов; только полный объем вычислений по системе в целом характеризует ее исследуемый вариант);
-убеждение заказчика, не являющегося специалистом в области математических методов анализа, в эффективности предлагаемой системы.
Таким образом, при исследовании сложных систем как часто невозможен натурный эксперимент, так и крайне ограничены возможности аналитических и численных расчетов.
Выходом из создавшегося положения явилась организация натурных экспериментов составных частей создаваемой системы в тесной связи с экспериментами на ЭВМ с запрограммированной структурой исследуемой системы, называемой моделью.
Сочетание неполного натурного эксперимента с экспериментом на указанной модели получило название опытно-теоретического метода испытаний сложных систем.
В основе этого метода - создание на ЭВМ модели системы, позволяющей не только получить выходные показатели, но и исследовать взаимные связи процессов, элементов и поведение сложной системы в различных условиях эксплуатации при изменяемых значениях параметров и переменных.
5.1.2. Основные определения
Термин “моделирование” имеет в литературе много различных толкований. Наиболее приемлемым на взгляд многих авторов является такое определение:
моделирование есть метод изучения системы путем ее замены более удобной для экспериментальных исследований системой, называемой моделью и сохраняющей наиболее существенные черты оригинала.
И как дополнение можно использовать следующее определение:
моделирование есть общий метод изучения объекта путем исследования замещающей его модели с переносом получаемой информации на изучаемый объект.
Отправной точкой при построении модели технической системы следует считать описание.
Описание - совокупность сведений об исследуемой системе и условиях, при которых необходимо провести исследования.
Описание представляется в виде:
-схем;
-текстов;
-формул;
-таблиц экспериментальных данных;
-характеристик внешних воздействий è îêðóæàþùåé ñèñòåìó âíåøíåé ñðåäû.
Описание задает предполагаемый алгоритм работы системы и может формально рассматриваться как некоторая функция внешних воздействий.
В качестве примера можно без достаточной детализации рассмотреть описание модели системы распознавания речи.
Здесь, во-первых, исходя из того, что описание - это сведения о системе и условиях ее применения, нужно более точно определить систему распознавания речи, Например:
“Система распознавания речевых команд управления подъемом стекол автомобиля в процессе его эксплуатации”.
Для такой системы описание модели должно включать:
-схему речевого аппарата человека и теоретические положения речеобразования;
-описание условий речевого управления (шумы двигателя, шумы окружающей среды и т.д.);
-характеристики микрофона, как датчика сигналов, воспринимающего команду (зависимость выходных сигналов от звукового давления во всем диапазоне частот, например, в виде таблиц);
-характеристики сигналов управления (мощность, направленность, удаленность от микрофона);
-характеристики канала приема электрических сигналов на входе преобразователя “аналог-цифра” компьютера (чувствительность, дискретность, точность и т.п.);
-математические зависимости, применяемые для обработки принятого сигнала с целью получения признаков распознавания и классификации;
-способ преобразования результатов распознавания в команды управления;
-характеристики канала передачи команд управления;
-требования к величинам сигналов управления двигателями подъема стекол. и т.д. и т.п. )
Модель воспроизводит описание системы с большими или меньшими упрощениями, зависящими от намерений исследователя, возможностей вычислительных средств, имеющихся в его распоряжении и времени, отпускаемого на проведение испытаний.
При этом должен достигаться разумный компромисс между точностью воспроизведения моделью характеристик системы и сложностью необходимых для этого мер и средств.
Другими словами (основываясь на рассмотрении описания системы как функции внешних воздействий) , при моделировании производится аппроксимация функции-описания более простой и удобной для машинного представления функцией-моделью .
Аналогия между построением модели и аппроксимацией позволяет использовать для наглядности представлений аппроксимацию функции w(x) на некотором отрезке [a,b] линейной комбинацией
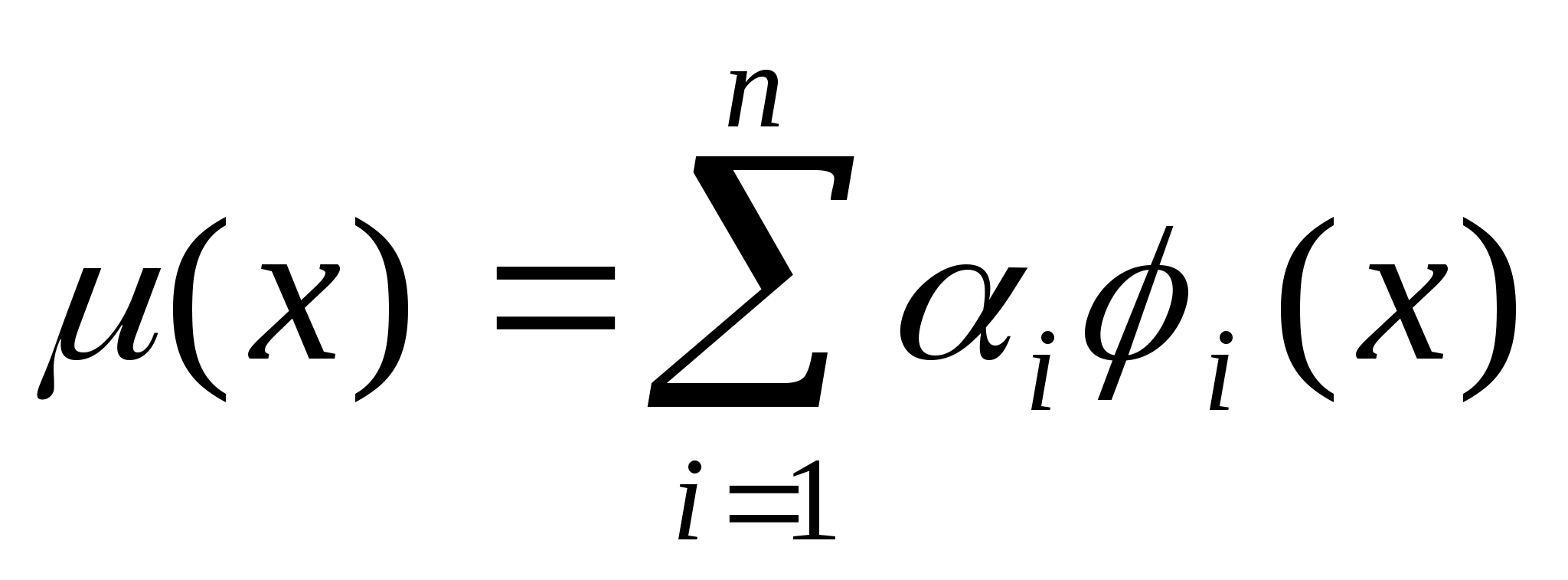
Здесь
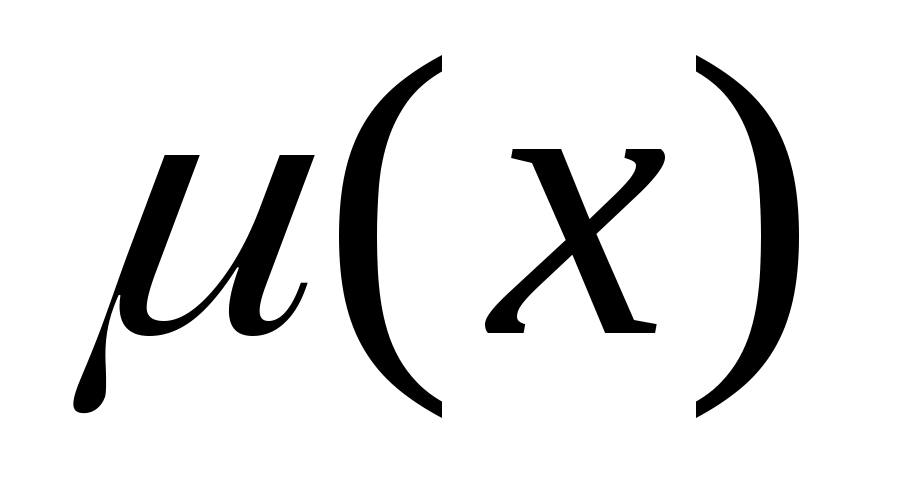 - модель функции-описания w(x) характеризуется
- модель функции-описания w(x) характеризуется
n параметрами (числовыми коэффициентами a>i> );
j >i> (x) - íåêîòîðûå âîçìîæíûå ïðîñòûå ôóíêöèè, çàäàííûå íà òîì æå îòðåçêå [a,b].
Теперь, исходя из характеристики модели (см. выше положение о том, что модель воспроизводит систему с упрощениями), варьируя параметрами a>i> , необходимо получить наилучшее или удовлетворяющее исследователя (в некотором смысле) приближение функции-модели к функции-описанию.
Обычно для оценки точности описания и модели пользуются более удобной для вычисления мерой
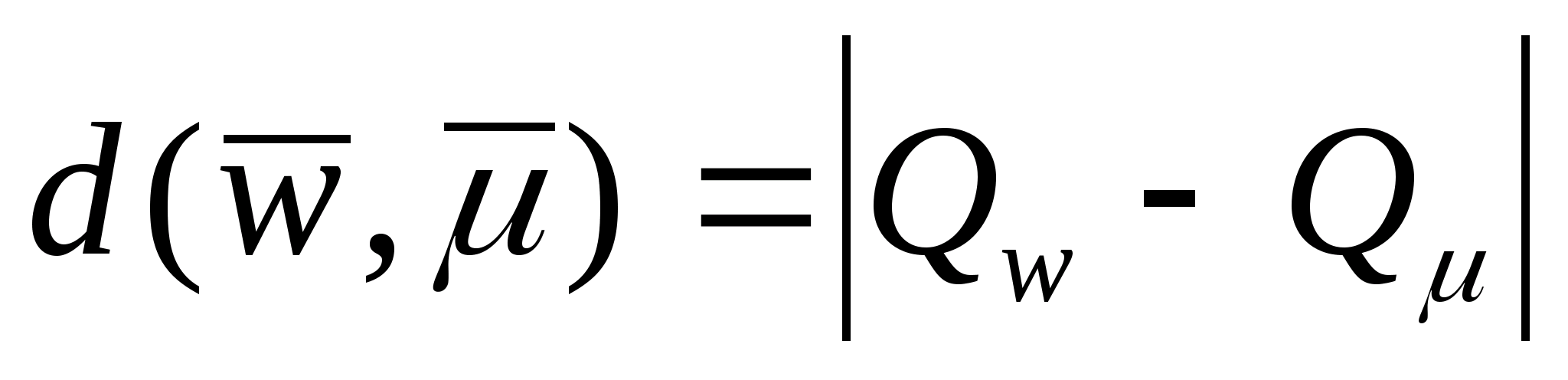
где Q>w> - скалярный показатель, который намереваются получить при исследовании системы (например, производительность, надежность, пропускная способность); Q>m> - скалярный показатель, соответствующий Q>w>, но полученный при анализе модели m.
При этом описание w(x) и модель m(x) отождествлены с векторами w и m некоторого многомерного пространства.
Если
при этом описание полностью характеризует
систему и ее состояния и существует
некоторое взаимно-однозначное
преобразование

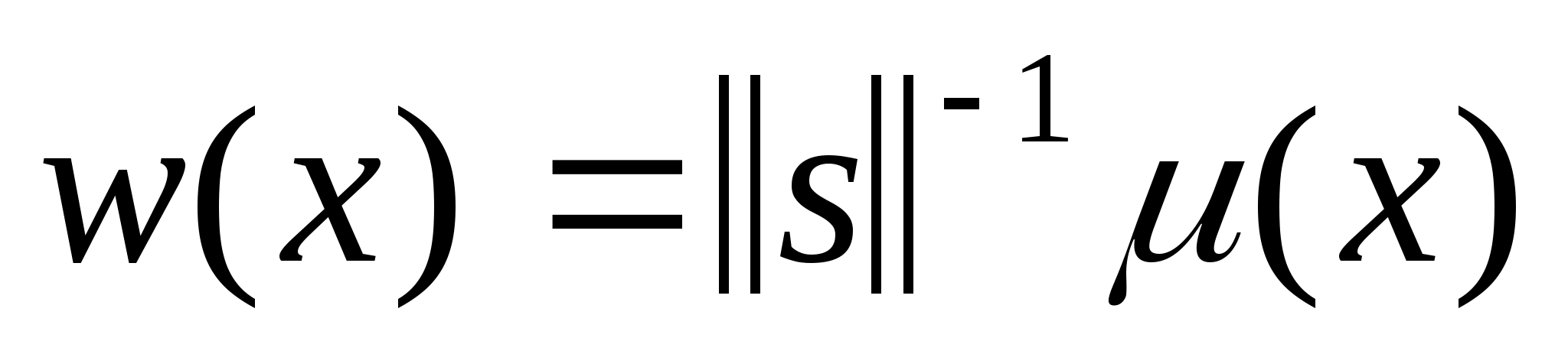
и
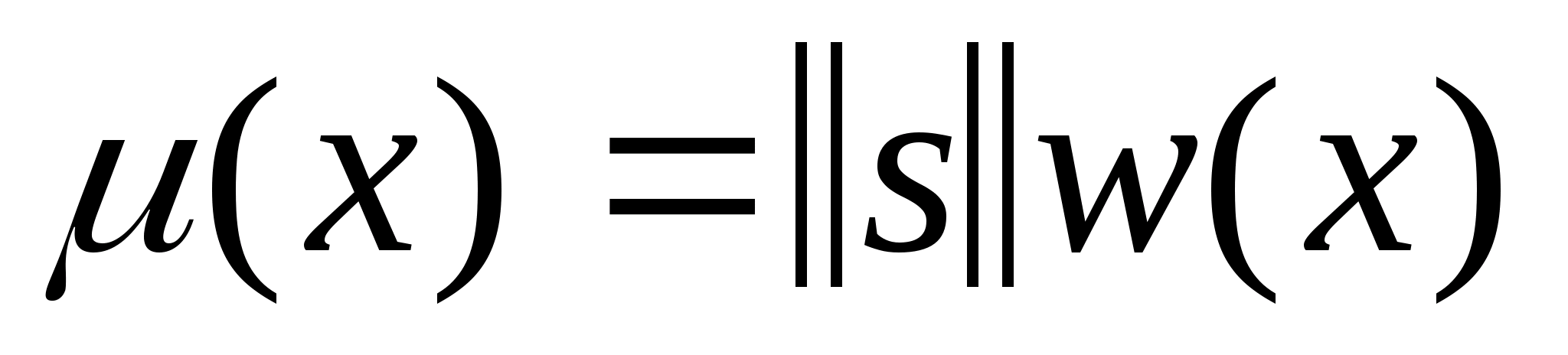
то модель и система (в крайнем случае ее описание) изоморфны.
При выполнении только второго соотношения, то есть при отсутствии обратного преобразования, имеем дело с гомоморфностью.
Л Е К Ц И Я 5.2
Моделирование сложных систем и применение моделей
5.2.1. Принципы построения модели сложной системы
а) Принцип декомпозиции
Прежде всего исходим из того очевидного положения, что сложные системы можно разбить на подсистемы и элементы с иерархической структурой связей. Тогда каждая подсистема, решая конкретную задачу, обеспечивает тем самым достижение общей цели.
С этих позиций, к особенностям сложной системы следует отнести такие:
1)Сложную систему можно расчленить на конечное число подсистем, а каждую подсистему, в свою очередь, - на конечное число более простых субподсистем до тех пор, пока не получим элементы системы ( под элементами системы следует понимать объекты, которые в условиях данной задачи не подлежат расчленению на части) .
2)Элементы сложной системы функционируют во взаимодействии друг с другом.
3)Свойства сложной системы определяются не только свойствами отдельных элементов, но и характером взаимодействия между ними.
На практике стремятся расчленить сложную систему на такую совокупность подсистем, которая наилучшим образом отражала бы работу и функциональное взаимодействие ее элементов. В этом случае и строгое физико-математическое описание становится более доступным.
Использование принципа декомпозиции систем на подсистемы, подсистем на элементы позволяет создать модель сложной системы путем разработки для простых физически элементов их математическое описание и соответствующий алгоритм.
Практическая реализация этого принципа предполагает, что специалисты, изучающие процессы в каждом конкретном элементе, способны на основе экспериментальных и теоретических исследований разработать модели всех элементов и достичь при этом точности, которая необходима для оценки характеристик работоспособности каждого из этих элементов в условиях штатной эксплуатации.
Например, выделив в качестве отдельного элемента системы двигатель постоянного тока, даем возможность специалисту формировать его описание. Так из теории систем автоматического регулирования для такого двигателя описанием является система дифференциальных уравнений
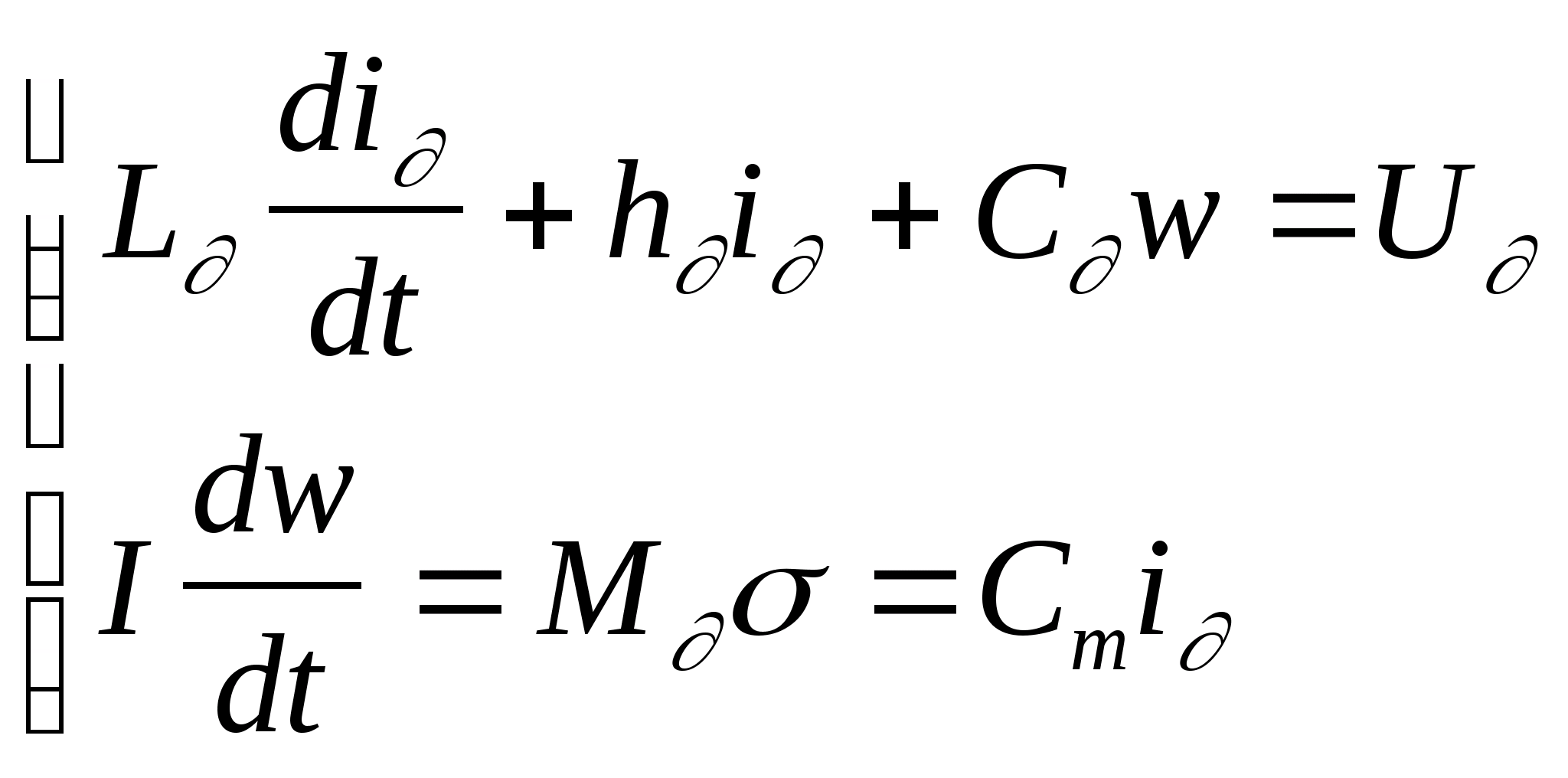
или после упрощения и преобразований
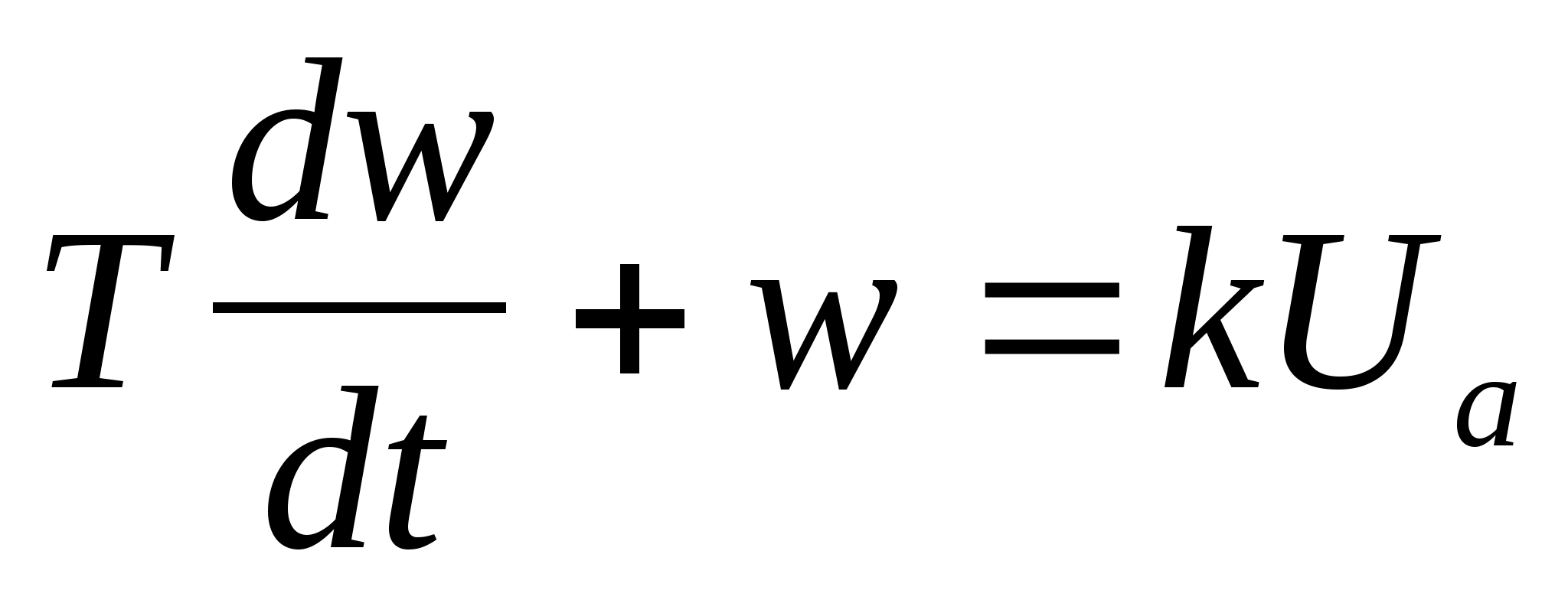 ,
,
где
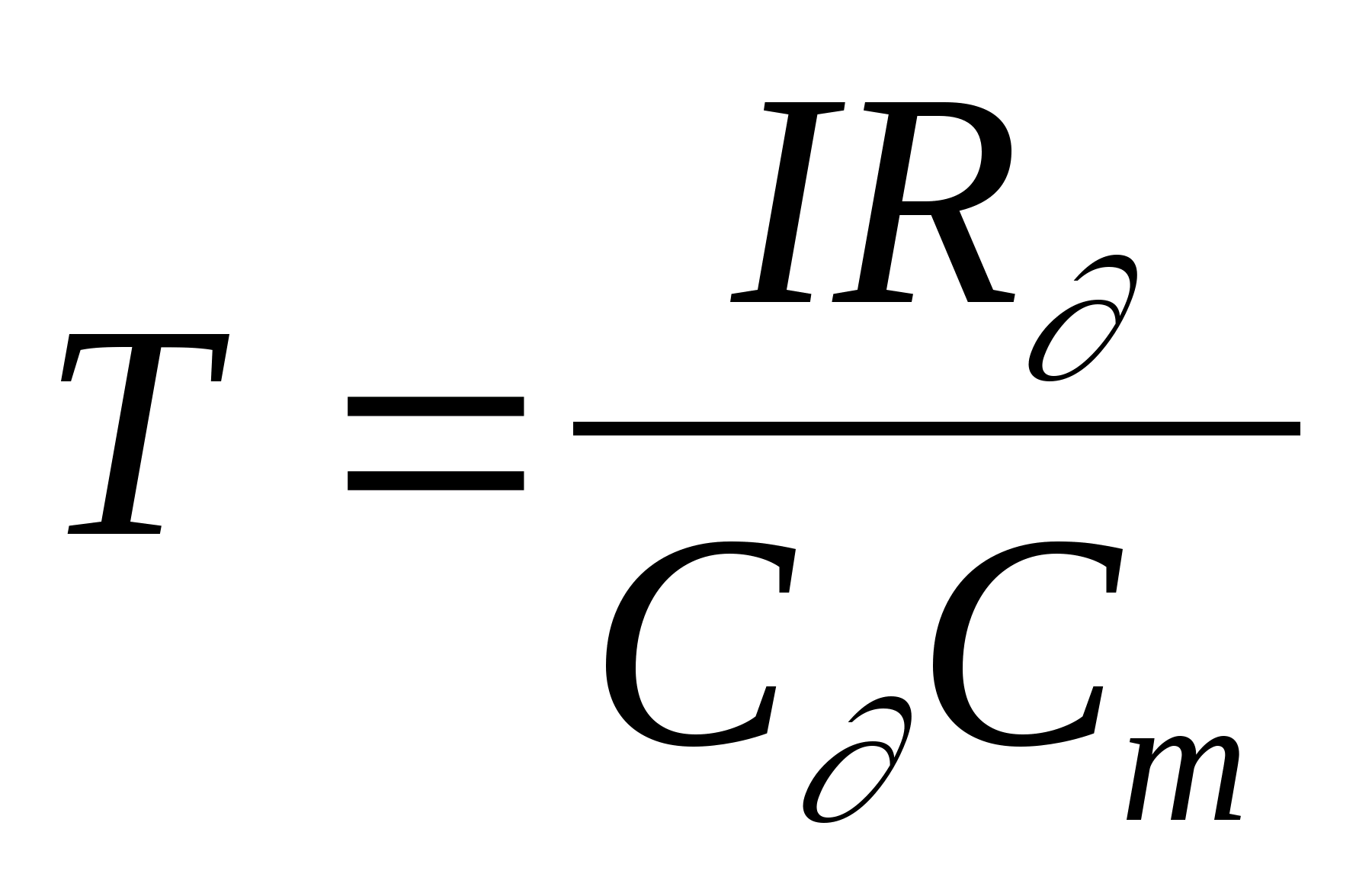 ,
,
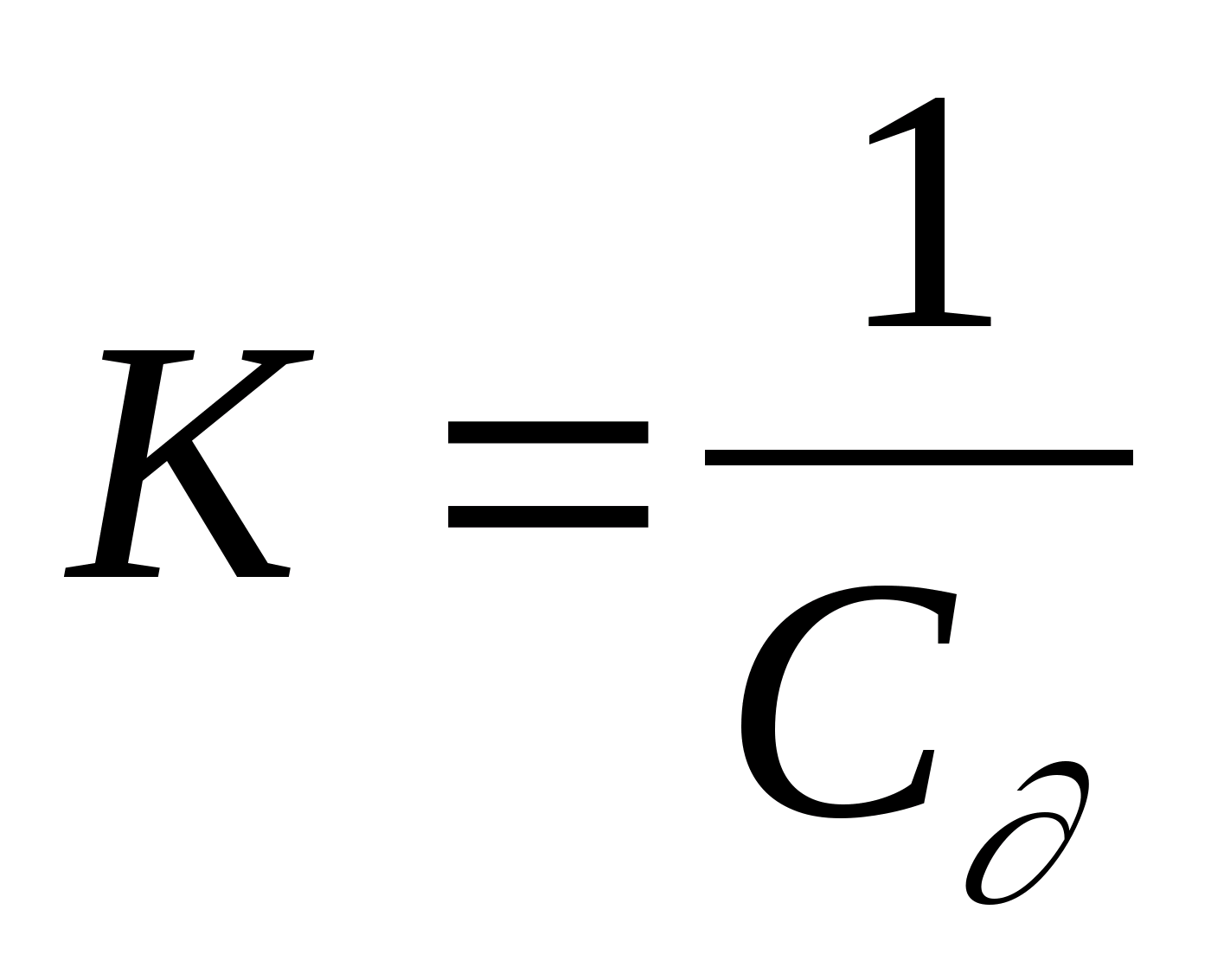
Таким образом субблоки, блоки, элементы сложной системы или удается описать математически с достаточной степенью точности для расчета их текущих состояний, или в результате специальных экспериментальных исследований получить совокупность числовых данных для описания указанных состояний. Эти числовые данные могут быть как непосредственно использованы при компьютерной реализации соответствующих блоков в виде таблиц, описывающих реакцию этих блоков на входные воздействия, так и в виде заменяющих упомянутые таблицы аппроксимирующих их зависимостей. И в том и в другом случаях программирование не вызывает трудностей.
Так или иначе декомпозиция системы, о которой идет речь, дает возможность специалистам создать программно реализуемые алгоритмы функционирования блоков, субблоков, элементов.
Отсюда совокупность моделирующих алгоритмов блоков, субблоков, элементов, разработанных указанным способом, с учетом их взаимодействия определяют алгоритм модели всей системы в целом.
Примерами декомпозиции при создании модели системы распознавания заболеваний внутренних органов человека могут быть варианты разбиения ее на элементы и блоки компьютерной системы, построенной на основе ультразвуковой медицинской диагностики. Структурная схема одного такого варианта при достаточно поверхностной декомпозиции представлена на рис. 5.2.1.


 Ìîäåëü
îòðàæàþùèõ Ìîäåëü
óëüòðàçâó-
Ìîäåëü
îòðàæàþùèõ Ìîäåëü
óëüòðàçâó-
ñâîéñòâ
âíóòðåííå- êîâîãî
ëîêàòîðà,
ãî
îðãàíà ÷åëîâåêà â
ÿâëÿþùåãîñÿ îñ- óëüòðàçâóêîâîì
íîâíûì ýëåìåíòîì
диапазоне волн аппарата УЗИ

Модель алгоритма
обработки изображе-
ний внутреннего ор-
гана

Модель алгоритма
анализа и принятия
ðåøåíèÿ
Рис 5.2.1. Структурная схема варианта декомпозиции системы распознавания
Более детальная декомпозиция позволяет представленные блоки расчленить на субблоки и элементы. Так , например, могут быть детализированы первые два из блоков рассмотренной схемы (Рис.5.2.2).
Точно также могут быть подвергнуты декомпозиции и другие модули структурной схемы, приведенной на рис.5.2.1. В результате появляется возможность для узких специалистов на основе физико-математического описания разработать алгоритмы их и затем комплексировать в общий алгоритм модели системы.
а) Принцип допустимых упрощений
В большинстве случаев, однако, общий алгоритм модели, полученный в результате декомпозиции системы, разработки специалистами алгоритмов элементов и их связей и последующего объединения, является

 Ìîäóëü îïèñàíèÿ Ìîäóëü
îïèñàíèÿ
Ìîäóëü îïèñàíèÿ Ìîäóëü
îïèñàíèÿ
геометрической возможных поло-

 ôîðìû âíóòðåí- æåíèé
ïîòîëîãè-
ôîðìû âíóòðåí- æåíèé
ïîòîëîãè-
него органа ческих образо-
ваний в органе

Модуль описания Модуль описания
положений функцио- геометрических
íàëüíûõ ýëåìåíòîâ
õàðàêòåðèñòèê
âíóòðåííåãî îðãàíà
ïîòîëîãè÷åñêèõ
образований
Модуль выбора
óñëîâèé íàáëþäå-
 íèÿ
âíóòðåííåãî
íèÿ
âíóòðåííåãî
îðãàíà
(ñå÷åíèå)

Модуль описания
звукодинамичес-
ких свойств се-

 ÷åíèÿ
îðãàíà
÷åíèÿ
îðãàíà



 Ìîäóëü îïèñàíèÿ
Ìîäóëü îïèñàíèÿ Ìîäóëü îïèñàíèÿ
Ìîäóëü îïèñàíèÿ
Ìîäóëü îïèñàíèÿ Ìîäóëü îïèñàíèÿ
çâóêîäèíàìè÷åñ- çâóêîäèíàìè÷åñ- çâóêîäèíàìè÷åñ-
êèõ ñâîéñòâ ïà- êèõ ñâîéñòâ êàæ- êèõ ñâîéñòâ ïà-
òîëîãè÷åñêèõ äîãî èç ôóíêöèî- ðåíõèìû âíóòðåí-
 îáðàçîâàíèé
íàëüíûõ ýëåìåíòîâ íåãî îðãàíà
îáðàçîâàíèé
íàëüíûõ ýëåìåíòîâ íåãî îðãàíà


 Модуль формирования ультазвуково-
Модуль формирования ультазвуково-
го изображения сечения органа
на модель алгоритма обработки изображений
Рис.5.2.2. Структурная схема декомпозиции модели отражающих свойств и ультразвукового локатора
только исходным и его еще нельзя положить в основу создания рабочей модели системы. Это определяется его громоздкостью, а также плохой согласованность с вычислительными ресурсами и с требованиями к модели системы.
Такие возможные недостатки исходного алгоритма модели вытекают из различия целей моделирования отдельных элементов и сложной системы в целом.
Причина различия целей состоит в том, что специалисты, разрабатывающие алгоритмы элементов, стремятся к тому, чтобы отразить характеристики этих элементов с максимальной точностью. В результате алгоритмы моделей элементов могут оказаться достаточно сложными, а в итоге
-непомерно возрастает время счета одной реализации функционирования системы в целом;
-уменьшается общее число модельных экспериментов (реализаций) при общем ограничении времени на испытание сложной системы.
И это при том, что всегда существуют более простые реализации элементов по сравнению с предложенными “сходу”. К тому же с точки зрения влияния на конечную точность моделирования системы вклады отдельных элементов могут оказаться несущественными, а значит сами описания алгоритмов их функционирования могут допускать упрощения.
Поэтому модель системы в целом должна строиться на основе компромисса между ожидаемой точностью оценок конечного показателя и сложностью самой модели.
Отсюда путь к созданию рабочей модели системы - поиск компромиссных решений. В основе его лежит анализ допустимых упрощений как исходных алгоритмов моделей элементов, так и алгоритмов их взаимодействия.
При создании рабочей модели системы (разработке алгоритма модели) методики анализа возможных упрощений бывают самыми разными, но смысловое содержание их состоит в том, чтобы обеспечить системные расчеты в отведенное время и достичь при этом заданной точности конечного показателя (например, эффективности для систем распознавания). Естественно, что указанный анализ, направленный на исключение, замену отдельных блоков и субблоков или их корректировку должен предполагать:
-более углубленное аналитическое изучение и представление работы физического аналога;
-экспериментальные исследования физического аналога.
Решения по упрощению многообразны. Все они специфичны и не поддаются обобщению. При этом наиболее конкретная рекомендация по замене может быть дана лишь в отношении блоков, осуществляющих воздействие на исследуемую часть системы. Только в этой ситуации блоки можно однозначно заменить упрощенным эквивалентом, не зависящим от указанной исследуемой части системы. Само собой разумеется, что если при заменах и корректировках не нарушается функциональное взаимодействие блоков и субблоков, то схема сопряжения их в общей модели остается без изменений.
При заменах блоков упрощенным эквивалентом отказываются от точного описания
-либо на основе отдельных исследований на самостоятельной модели (говорят: ”частной” модели) воздействий, данного блока на систему и выбора в качестве замены нового блока формирующего реализации наихудшего воздействия;
-либо при достаточно большом числе факторов, определяющих воздействие, выбором в качестве замены нового блока, формирующего случайное воздействие с заданными характеристиками.
Если, например, в состав некоторой сложной системы входит автоматический электронный измеритель некоторой величины, используемой блоками этой системы, то приходится иметь дело с неизбежными ошибками измерений. Причины ошибок здесь - наличие электронных шумов, вызываемых:
-неравномерной эмиссией электронов (так называемый “дробовой шум) в электровакуумных приборах;
-неравномерностью процессов генерации и рекомбинации носителей тока в полупроводниковых приборах.
При построении модели указанного измерителя возможны:
1)Строгое физико-математическое описание указанных неравномерностей движения носителей тока и их влияния на измеряемую величину ("модель с точностью до носителя").
2)Экспериментальная оценка максимальной ошибки измерения интересующего параметра и замены точного блока всего лишь имитатором постоянной величины максимально возможной ошибки, добавляемой к измерениям.
3)Экспериментальные статистические исследования ошибок измерителя, получение закона распределения вероятностей ошибок и замена точного блока на блок генерации случайных ошибок с заданным законом распределения, добавляемых к “чистым” измерениям.
В технических приложениях моделирования ни "точность до носителя", ни имитация максимальных ошибок не являются удовлетворительным решением. Третий подход к решению задачи встречается наиболее часто. Это связано, особенно в электронике, с наличием большого числа случайных воздействий. Это и каналы связи со случайными шумами. Это и ошибки измерений, носящие случайный характер. Это и точности изготовления деталей и т.д. и т.п.
Отсюда следует, что при соответствующих заменах блоков каждый эксперимент на системной модели должен носить случайный характер.
5.2.2. Моделирование сложных систем и опытно-теоретический метод их испытаний
Рассмотрение истории вопроса появления и развития моделирования показало, что цель создания любой модели - испытания некоторой системы. При этом сегодня речь идет о компьютерной реализации и испытаниях модели системы в условиях, которые или невозможно, или достаточно дорого создать для проведения натурных испытаний реальной системы, или это сопряжено с большими временными затратами.
В то же время из проведенного рассмотрения отличий модели от представляемого ею объекта (процесса, явления) следует, что полностью положиться на результаты моделирования, выступающего в качестве единственного источника получения характеристик указанного объекта (процесса, явления) не представляется возможным.
Отсюда логически вытекает необходимость сочетания моделирования и натурных испытаний для совместного получения показателей соответствующей системы. Соответствующий метод и получил название опытно-теоретического.
Здесь необходимо заметить: когда речь идет о натурных испытаниях системы, подразумевают натурные испытания ее элементов или сокращенного, упрощенного варианта. В противном случае пришлось бы создать систему в целом, не зная заранее, как она будет выполнять те или иные задачи. А если при этом система окажется неспособной выполнить свое назначение и затраты нецелесообразными? Но система создана?! В связи с этим и цель опытно-теоретического метода - избежать нецелесообразных затрат, используя сочетание экспериментальных данных в ограниченном объеме и моделирования - во всей области факторного пространства функционирования системы.
Суть опытно-теоретического метода, обязательно предполагающего создание модели системы, сводится к выполнению следующих положений:
1)Получение для одних и тех же условий достаточного количества реализаций показателей функционирования системы или ее отдельных блоков в натурных испытаниях и на модели.
2)Проведение параметрической доработки модели на основе сравнения результатов натурных экспериментов и моделирования, если структура модели удовлетворительна.
3)Проведение структурной перестройки модели, дополнительный учет отдельных факторов, дополнение связей при наличии остаточной разности между выходными характеристиками после попытки параметрической доработки.
4)Проверка статистической совместимости модели и системы в ряде целенаправленно выбранных точек факторного пространства.
5)На основе выполненной калибровки модели (пункты 1-4) распространение результатов испытаний системы с помощью моделирования на всю область факторного пространства.
Таким образом достигается сначала изоморфность модели и системы, а затем оценка этой системы на модели во всех возможных условиях функционирования.
Упомянутый при этом отказ от создания системы в целом, замена ее испытаний на испытания отдельных узлов, модулей, составляющих и т.п. отражается на построении модели системы. Дело в том, что некоторые результаты испытаний могут позволить, например, отдельные составляющие системы не моделировать, описывая соответствующие физические процессы, не искать для них точных математических описаний для реализации, а воспользоваться полученными экспериментальными данными. Так, можно не моделировать уходы параметров отдельных электронных и электромеханических устройств, приводящие к их отказам, если в результате испытаний получены характеристики надежности этих устройств (вероятность безотказной работы в течение рабочего цикла, наработка на отказ, время безотказной работы). То есть, натурные испытания могут явиться основанием для упрощения модели при сохранении ее изоморфности системе.
Рассмотренный путь упрощения - не единственный. Во-первых, уже упомянутый нами компромиссный характер создания модели системы (между точностью и возможностью реализации) дает в отдельных случаях такие основания. Тогда, как уже упоминалось можно отказаться от некоторых деталей моделирования. Во-вторых, задачи, ставящиеся перед моделью могут быть различными: оценка функционирования системы, оценка взаимодействия системы с другими сложными системами, оценка характеристик системы во всем диапазоне условий функционирования и т.д. Это приводит к тому, что при испытаниях сложных систем имеют дело не с одной единственной моделью. Так по своему назначению модели делятся на частные и системные.
Частные модели - это модели отдельных частей системы (подсистем, узлов, агрегатов), позволяющие при высокой точности моделирования этих частей получить исходные данные для использования в системной модели. В результате системная модель не будет перегружена соответствующими частными задачами, то есть, упростится и сможет стать реализуемой в приемлемое время (например, в реальное время), с приемлемым быстродействием и в допустимом объеме.
Системные модели включают в свой состав элементы, отражающие в той или иной степени работу всех частей системы или напрямую используют отдельные части системы. Они позволяют получить показатели качества всей системы в целом. А так как таких показателей может быть несколько, то и системных моделей может быть несколько. При таком разделении функций исчезает сложность разрабатываемых моделей. Этим, в частности, объясняется деление системных моделей на функциональные и комплексные. И если функциональные модели предназначаются для испытаний функционирования сложной системы в различных ситуациях, то комплексные обеспечивают:
-отработку и отладку программного обеспечения сложной системы;
-оценку характеристик отдельных средств и получение исходных данных для полной оценки системы.
Л Е К Ц И Я 5.3
Метод статистических испытаний
(метод Монте-Карло)
5.3.1. Основное определение
Из рассмотрения принципов построения моделей сложных систем следует, что при упрощениях модели и замене блоков, описывающих, как правило, воздействия на систему и ее части, эксперимент на системной модели сложной системы достаточно часто приобретает случайный характер. Случаен в силу этого и выходной эффект системы от запуска модели к запуску. Для проведения моделирования в таких условиях наиболее приемлемым является метод моделирования, основанный на статистических испытаниях, так называемый метод Монте-Карло.
Приемлемость указанного метода обусловливается тем, что
1)расчет оценок выходных параметров осуществляется с использованием достаточно простых алгоритмов обработки.
2)просто и точно определяется необходимый объем моделирования из условия достижения заданной точности оценок выходных показателей.
3)методика организации экспериментов на модели достаточно проста и хорошо программно реализуема.
В этом легко убедиться на простых примерах. А пока рассмотрим определение.
Метод статистических испытаний (метод Монте-Карло) состоит в решении различных задач вычислительной математики путем построения для каждой задачи случайного процесса с параметрами, равными искомым величинам этой задачи. .
Рассмотрим простейшие примеры.
А. Пусть необходимо определить вероятность P>ч> того, что суммарное число попаданий при стрельбе в “десятку” мишени при 10 выстрелах - четно.
Известно, что если вероятность попадания в “десятку” при одном выстреле равна p , то искомая вероятность согласно биномиальному закону распределения вероятностей вычисляется так:
Здесь
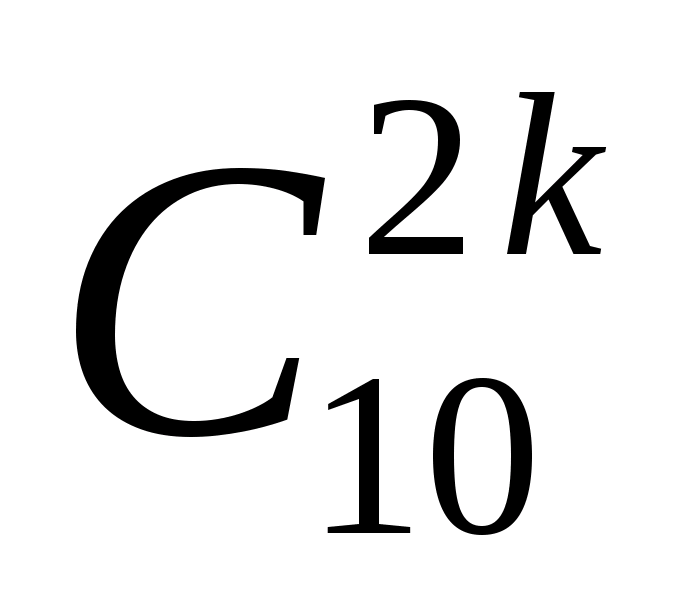 - число сочетаний из 10 по 2k.
- число сочетаний из 10 по 2k.
Если предварительно подсчитать все числа сочетаний при k=0…5 или использовать готовую таблицу сочетаний, то вычисления P>ч> по указанной формуле потребуют 26 операций.
Вместо такого расчета можно было бы экспериментально выполнить N серий стрельб по 10 выстрелов и определить из их числа количество серий n>ч> , в которых число попаданий в “десятку” - четное. Тогда при достаточно большом N имеем
Однако при таком подходе для получения достоверными в оценке Pч двух знаков после запятой потребуется около 10 000 серий по 10 выстрелов.
Оказывается, что ЭВМ позволяет выполнить решение указанной задачи третьим способом.
Как известно многие языки программирования имеют в составе стандартных функций датчик случайных чисел, позволяющий формировать случайную последовательность равномерно распределенных чисел на интервале [0,1].
Поэтому вместо выстрела по мишени достаточно выбрать из датчика указанное число со значением x и проверить выполнение неравенства x<p. Если оно выполнено, то это соответствует попаданию в “десятку” с вероятностью p. Покажем это.
Действительно вероятность попадания случайной величины в интервал [0;p] ðàâíà
 ,
,
где w(x) - ïëîòíîñòü ðàñïðåäåëåíèÿ âåðîÿòíîñòè
В нашем случае имеем дело с равномерным распределение на единичном интервале, то есть w(x) = 1. Поэтом P>0>>;>>ð> = p.
Выбираем теперь серии из 10 чисел x. Если при этом число “попаданий” (выполнения неравенства x<p) будет четным, считаем серию удачной.
При N таким образом имитированных серий получим также, как и в прямом эксперименте со стрельбами
Однако в отличии от этого прямого эксперимента результат будет получен здесь на современной ЭВМ не более чем за 10 с.
Таким образом задача в рассмотренном случае была решена (согласно определению метода Монте-Карло) путем построения случайной последовательности с параметром, равным искомой величине P>ч>. Эта последовательность была построена следующим образом:
-ôîðìèðîâàíèå íà ïåðâîì ýòàïå ðàâíîìåðíî ðàñïðåäåëåííîé ïîñëåäîâàòåëüíîñòè íà èíòåðâàëå [0,1] ;
-ôîðìèðîâàíèå íà âòîðîì ýòàïå íîâîé ñëó÷àéíîé ïîñëåäîâàòåëüíîñòè (N ñåðèé) ãðóïïèðîâêîé ïîëó÷åííûõ íà ïåðâîì ýòàïå çíà÷åíèé â ñåðèè ïî 10;
-ôîðìèðîâàíèå íà òðåòüåì ýòàïå èñêîìîé ñëó÷àéíîé ïîñëåäîâàòåëüíîñòè ïóòåì âûáîðêè èç ïîñëåäîâàòåëüíîñòè ñåðèé âòîðîãî ýòàïà ðàçìåðà N òàêèõ, â êîòîðûõ íåðàâåíñòâî x<p âûïîëíÿåòñÿ ÷åòíîå ÷èñëî ðàç.
Количество серий третьего этапа формирования и определяет частость
которая при N ®¥ стремится к искомой величине P>ч> .
Б.Еще один пример, но из области непосредственного применения метода Монте-Карло к вычислению интегралов.
Пусть необходимо вычислить
При этом будем считать, что 0<=x<=1 и 0<= g(x) <=1 , то есть вся функция лежит в единичном квадрате.
Такое ограничение не влияет на общность задачи, так как любой интеграл заменой переменных и изменением масштаба может быть приведен к рассматриваемому.
 Y
Y


 1
1
y = g(x)
 x
x
1
Рис.5.3.1.
Будем рассматривать две области на плоскости (x,y)
W - область, заданная неравенствами
0<= x <=1
0<= y <=1
w - область, ограниченная кривой y = g(x) и ординатами x=0 и x = 1.
Площадь области W равна единице S1=1, а площадь области w>S>>2> = I.
Зададим в области W равномерное распределение случайных точек. Это означает, что вероятность попадания точки с координатами x>i> , y>i> â îáëàñòü W равна 1, а в некоторую часть этой области - пропорциональна площади этой области независимо от ее расположения внутри W.
Плотность заданного распределения вероятностей f(x,y) = 1
Ïîýòîìó âåðîÿòíîñòü ïîïàäàíèÿ òî÷êè â îáëàñòü w ðàâíà
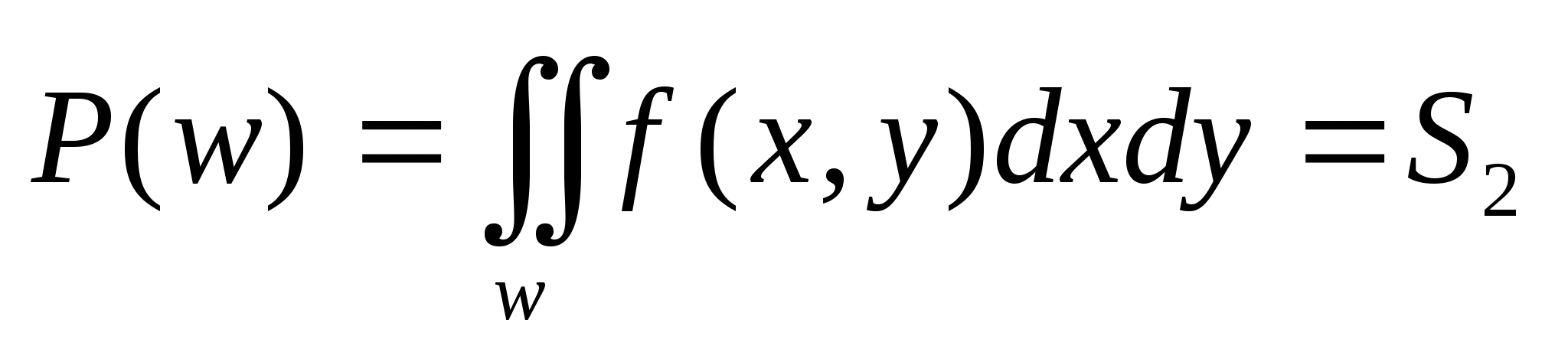
Таким образом, I = S>2>.
Если теперь мы располагаем возможностью имитировать случайные точки с координатами x>i>, y>i> в соответствии с заданной плотностью, то после N испытаний, подсчитав число тех из них (m), которые попали в область w , получим частость
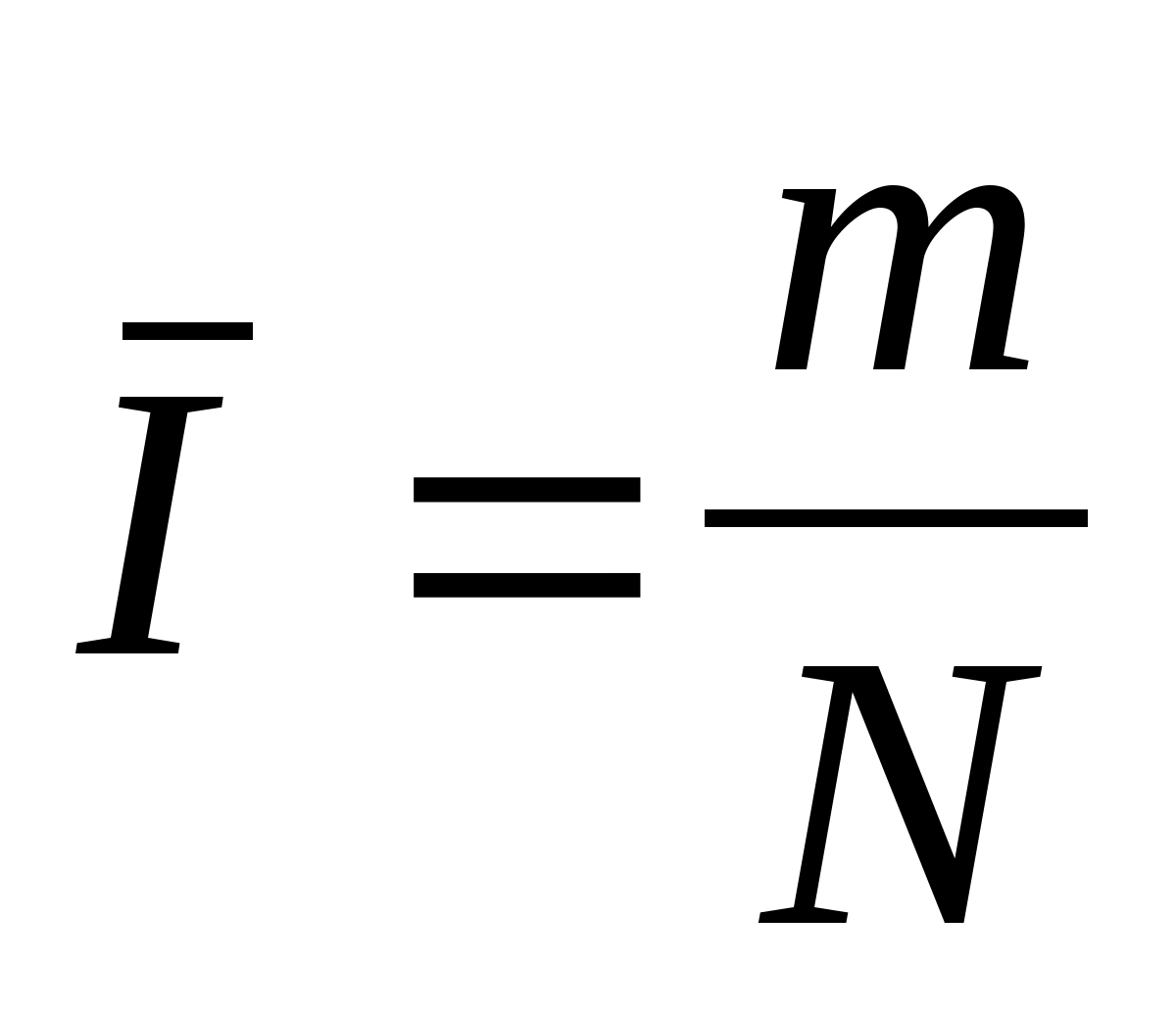
Вспоминаем, что частота при N ®¥ стремится к истинному значению, а в качестве приближенного значения интеграла следует использовать указанную частоту.
Подводя итог рассмотренному примеру с точки зрения введенного определения метода Монте-Карло, отметим, что
-решаемая задача относится к области вычислительной математики;
-для решения задачи формировалась случайная последовательность чисел как выборка значений из последовательности с равномерной плотностью распределения вероятностей, попадающих в область w;
-искомая величина определялась как отнесение числа попаданий в область w к общему числу экспериментов.
Рассмотренных примеров уже вполне достаточно для того, чтобы пояснить данное в начале определение метода статистических испытаний. В то же время следует иметь в виду , что существует большое многообразие задач, для которых метод Монте-Карло является плодотворным, позволяя достигать инженерного результата там, где аналитические методы либо сложны, либо не дают ответа. В этом аспекте необходимо отметить такие области применения, как
-многомерные интегралы;
-теория обнаружения сигналов;
-обращение матриц и решение систем линейных алгебраических уравнений;
-некоторые краевые задачи;
-нахождение собственных значений и собственных функций и др.
5.3.2.Принципы получения случайных величин на ЭВМ
Датой рождения метода Монте-Карло принято считать 1949 г , когда в американском журнале ассоциации статистиков появилась статья Метрополиса и Улама “ Метод Монте-Карло”. Создателями метода считают Дж.Неймана и С.Улама. В Советском Союзе первые статьи о методе относятся к 1955-1956 годам.
Теоретические основы метода Монте-Карло известны уже давно. Более того, некоторые задачи статистики решались с использованием случайных выборок, то есть, фактически этим методом. Но так как моделировать случайные величины вручную - очень трудоемкая работа, широкое применение метода началось с появления вычислительных машин.
Само название “Монте-Карло” происходит от названия города в княжестве Монако, знаменитого своими игорными домами. Все дело здесь в том, что одним из простейших механических устройств для получения случайных величин является рулетка. Простейшая схема ее - вращающийся диск с цифрами, резко останавливающийся для определения цифры, на которую указывает неподвижная стрелка.
Пуская и останавливая рулетку и объединяя получаемые в каждом пуске цифры в группы заданного размера (например, пять), можно составить таблицу случайных цифр (в случае примера группирования - пятизначную). Таблица эта носит название таблицы случайных чисел, хотя правильнее было бы назвать ее таблицей случайных цифр. Самая большая такая таблица (RAND Corporation, 1955 г) содержит 1 000 000 цифр.
Составление таблиц случайных чисел - не такая простая задача. Если мы хотим иметь хорошую таблицу, то придется при разработке ее тщательно проверять, так как любое физическое устройство вырабатывает случайные числа отличающимися по распределению от равномерного.
Ну, а используются такие таблицы либо для ручного счета, что сегодня - редкость, либо при машинном применении приходится поступаться тем, что при вводе соответствующий файл потребует большой памяти в ущерб решаемым при этом задачам.
Для устранения этого недостатка казалось бы легче подключить рулетку к ЭВМ. Однако ясно, что быстродействие такого комплекса генерации случайных чисел будет исключительно низким. Поэтому в качестве генераторов случайных величин чаще используются шумы в электронных лампах. Например, здесь может быть предложен следующий алгоритм. Если за некоторый фиксированный промежуток времени Dt уровень шума превысил заданный порог четное число раз, то в разряд некоторого числа записывается единица, если нечетное - ноль.
Так как количество такого рода генераторов выбирают равным количеству разрядов упомянутого числа в ЭВМ, то во все эти разряды будут записаны нули и единицы. Каждый такт такой логической проверки всех генераторов дает одно полноразрядное число, равномерно распределенное в интервале [0,1].
Недостатки этого метода генерации:
1)Возможны неисправности электронных генераторов шума, приводящие к пропаданию равновероятности нулей и единиц, что требует постоянных проверок и ремонта.
2)Невозможно повторение случайной последовательности чисел, полученной в одном эксперименте, для проверки работы программы ЭВМ.
Поэтому такого рода датчики применяются в специализированных ЭВМ для решения задач методом Монте-Карло.
Для универсальных ЭВМ такие датчики - слишком дорогостоящее оборудование, так как в таких ЭВМ прибегают к расчетам с использованием случайных чисел достаточно редко. Но чтобы не исключить полностью такую возможность здесь лучше использовать так называемые псевдослучайные числа.
Генерация псевдослучайных чисел осуществляет сама машина в соответствии со специальными стандартными функциями, предусматриваемыми в ее математическом обеспечении.
Можно вообще не интересоваться, как эти числа получаются. Указанные стандартные функции неоднократно проверяются разработчиками и качество их гарантируется. Однако сама постановка вопроса “получение псевдослучайных чисел” на ЭВМ вызывает недоумение. Ведь все, что делает машина, должно быть заранее запрограммировано. Поэтому хотелось бы понимать, откуда появляется случайность. Кроме того, без понимания особенностей псевдослучайных последовательностей, хотя бы поверхностного, трудно говорить иногда о их разумном использовании.
Что же такое псевдослучайные числа?
Числа, получаемые по какой-либо формуле и имитирующие значения случайной величины, называются псевдослучайными.
Под словом “имитирующие” подразумевается, что эти числа удовлетворяют ряду требований так, как если бы они были значениями случайной величины.
Первый алгоритм для получения псевдослучайных чисел был предложен Дж.фон Нейманом в 1951 г. Он получил название метода середины квадратов. . Существо его заключается в следующем.
Пусть задано произвольное 4-значное целое число n>1>= 9876.
Возведем его в квадрат и получим 8-значное число n>1>2 = 97535376.
Выберем 4 средние цифры из этого числа и обозначим n>2>= 5353.
Затем снова возведем его в квадрат n>2>2 = 28654609 и выберем 4 средние цифры. В результате получим n>3> = 6546.
Продолжая указанные рекуррентные действия будем иметь
n>4> = 8501; n>5> = 2670; n>6> = 1289 и т.д.
В качестве псевдослучайных значений предлагалось использовать
g>к> = 10 -4 *n >к> ,
то есть:
0.9876; 0.5353; 0.6546; 0.8501; 0.2670; 0.1289 и т.д.
Таков самый простой алгоритм, обладающий отдельными недостатками, на которых не будем задерживать внимание. Главное то, что они заставили в последующем обратиться к более сложным алгоритмам. Но схема получения псевдослучайных чисел осталась фактически неизменной: очередное значение получается из предыдущего или предыдущих.
Рассмотрение теории вопроса и других алгоритмов не входит в планы нашего курса, но нам необходимо знать один важный вывод из соответствующих разделов, имеющий практическое значение:
рекуррентно получаемые псевдослучайные последовательности обладают периодом, величина которого зависит главным образом от разрядности представления чисел в машине.
С точки зрения теории вероятностей - это плохо. Однако там, где длины генерируемых последовательностей удовлетворяют потребителя, появляется такое достоинство как возможность отработки программного обеспечения сложных систем при одних и тех же последовательностях.
Ну, а рекуррентность получения псевдослучайных последовательностей и определенный период позволяют повторять генерацию последовательности любое число раз, что невозможно для физических датчиков случайных чисел и что так важно для отладки специфических программ.
В целом достоинства методов получения псевдослучайных чисел заключаются в следующем:
1) на получение каждого числа затрачивается всего несколько простых операций, в результате чего скорость генерирования случайных чисел имеет тот же порядок, что и скорость работы ЭВМ.
2) программы получения псевдослучайных чисел чрезвычайно компактны в силу простоты рекуррентных соотношений.
3) любое псевдослучайное число может быть легко воспроизведено.
4) последовательность псевдослучайных чисел достаточно один раз аттестовать, а затем постоянно использовать в сходных задачах без опасения изменения характеристик.
Л Е К Ц И Я 5.4
Метод статистических испытаний
(продолжение)
5.4.1. Моделирование независимых случайных событий
Возможность генерации псевдослучайных чисел, равномерно распределенных на интервале [0,1], открывает широкие возможности для статистического моделирования вообще во всех его приложениях.
Наиболее важным в задачах статистических испытаний представляется моделирование независимых случайных событий. Здесь существо задачи состоит в том, что необходимо воспроизвести случайное событие А, наступающее с вероятностью p.
Если для этого воспользоваться квазиравномерной последовательностью, то интересующая вероятность в общем виде может рассматриваться как результат интегрирования соответствующей плотности распределения вероятностей
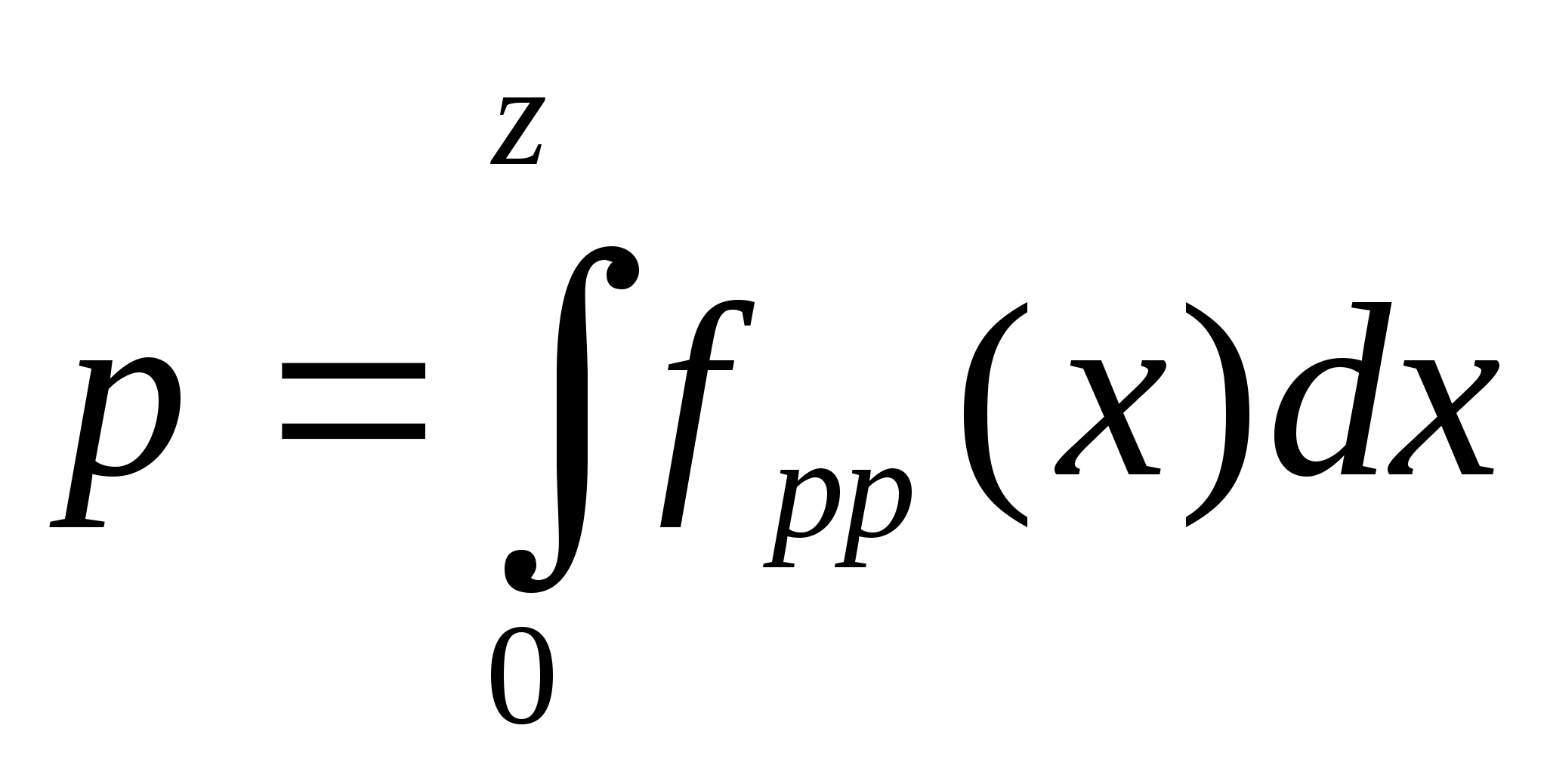
где z - некоторый пока неопределенный предел; f>рр>(x)- плотность вероятностей равномерно распределенных чисел.
Но для равномерного распределения на интервале [a,b] имеем
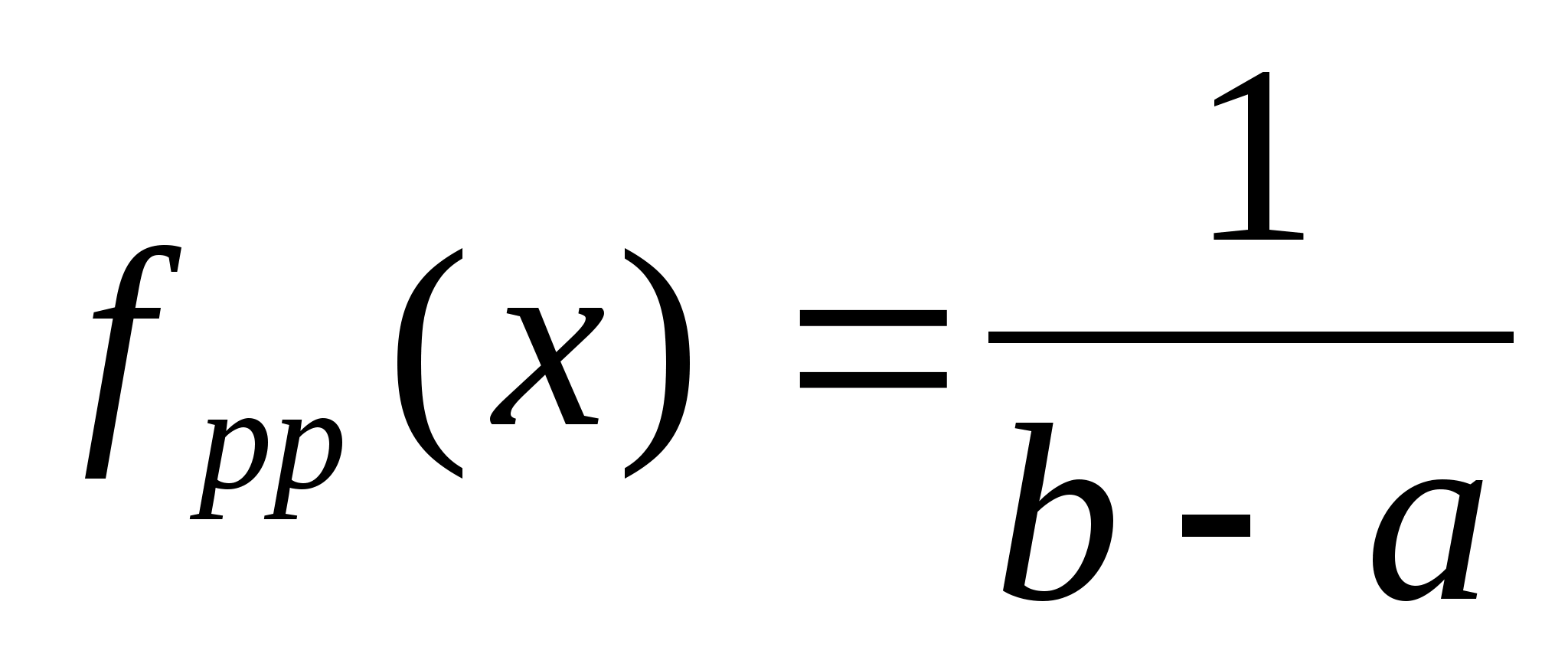
Для чисел равномерных на интервале [0,1] будем иметь
f >рр>(x)= 1 и соответственно
Отсюда очевидно z = p.
Тогда понятно, что реализация события А с вероятностью p осуществляется тогда, когда равномерно распределенные числа на интервале [0,1] попадают в его часть [0,p].
Следовательно, процедура моделирования появления случайного события А должна состоять в генерации случайных чисел R 4i 0 и сравнении их с величиной p : R>i> <= p
Выполнение неравенства соответствует наступлению события А.
Рассмотренные соображения распространяются на моделирование полной группы событий . A>1>,A>2>,…,A>m >, наступающих с вероятностями p>1>,p>2> ,…,p>m>, для которых естественно определено:
p>1> + p>2> +…+ p>m> = 1.
Здесь, используя ту же квазиравномерную последовательность, можем записать условия наступления любого события As из представленной группы:
Тогда действительно:
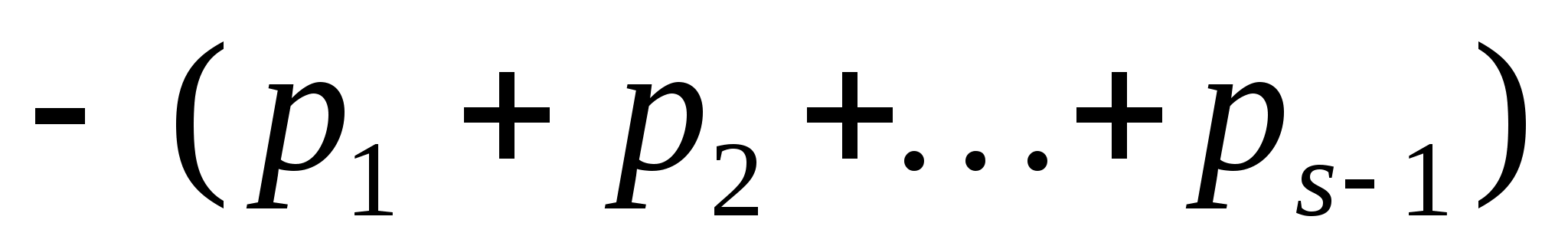
что и требовалось доказать.
Процедура моделирования появления событий A>s >(s=1,m) состоит в рассмотренном случае в генерации последовательности R>i> и проверки попадания ее в интервалы
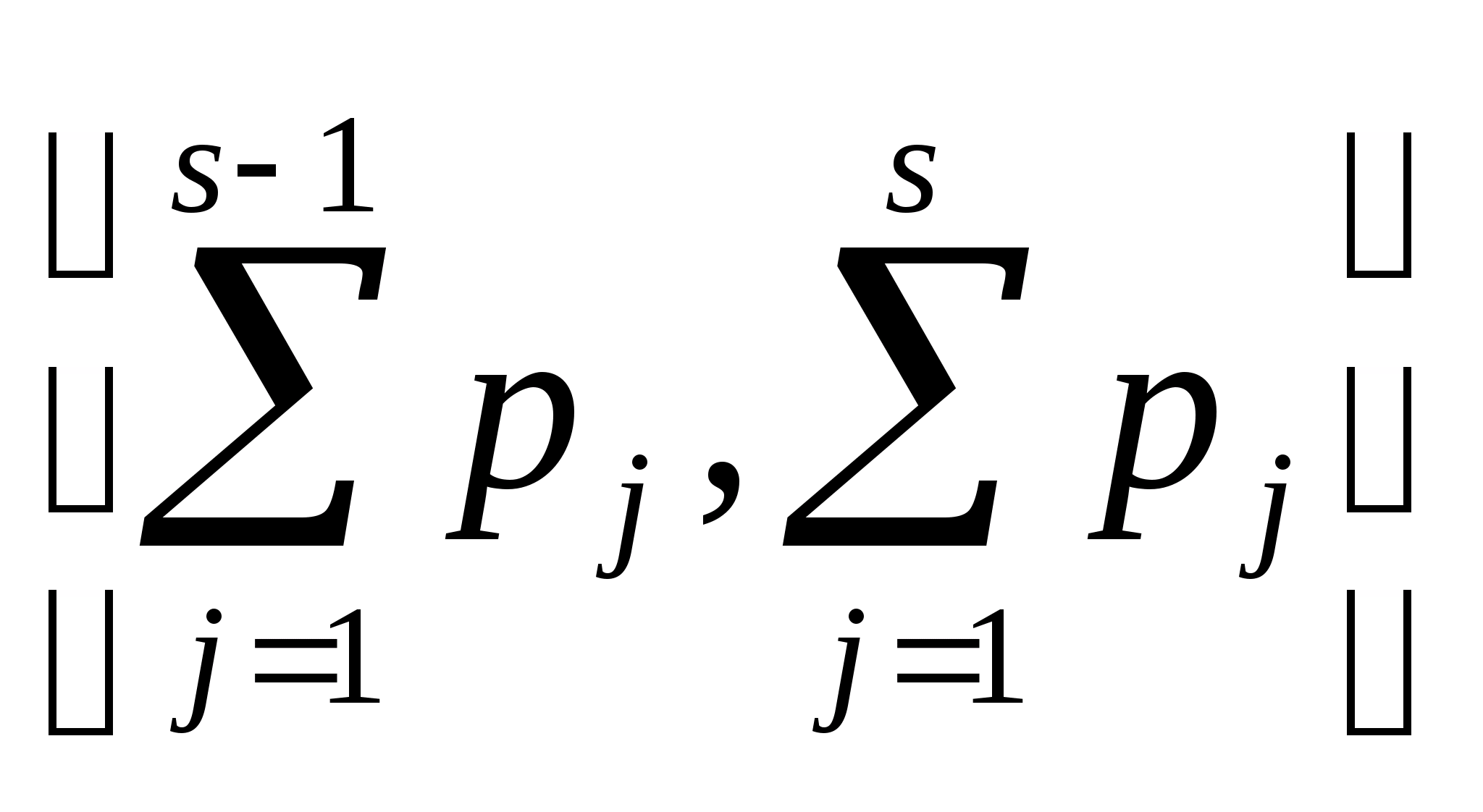
Исходом испытания при этом будет появление того события A>s>, номеру которого соответствует выполненное неравенство, а значит интервал.
5.4.2. Способы получения случайных чисел с заданным законом распределением
Основным соотношением, связывающим случайные числа S>i>, имеющие заданный закон распределения f(x), и числа R>i>, равномерно распределенные на интервале [0,1], является:
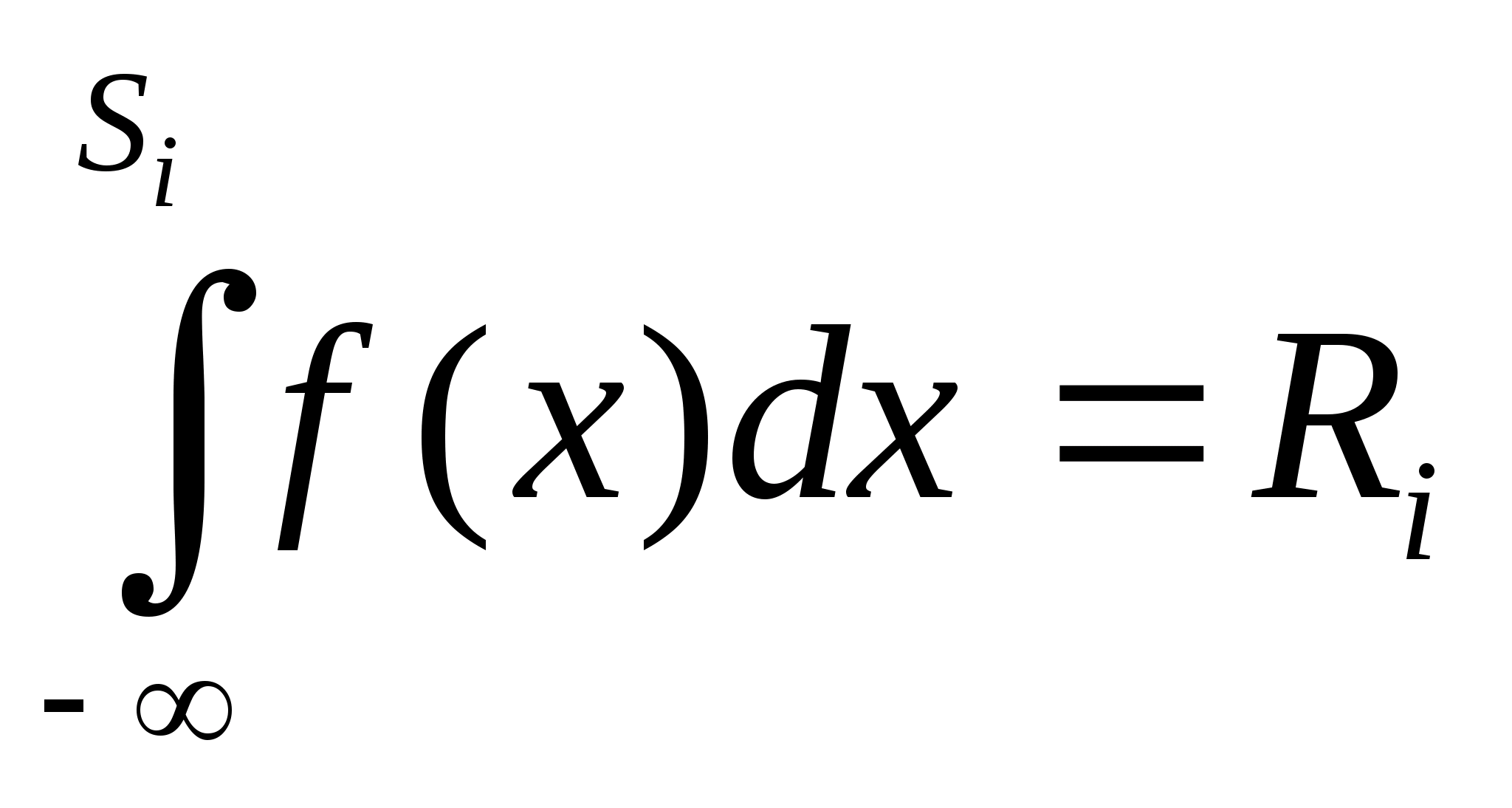
Доказательство справедливости этого соотношения следует из того факта, что
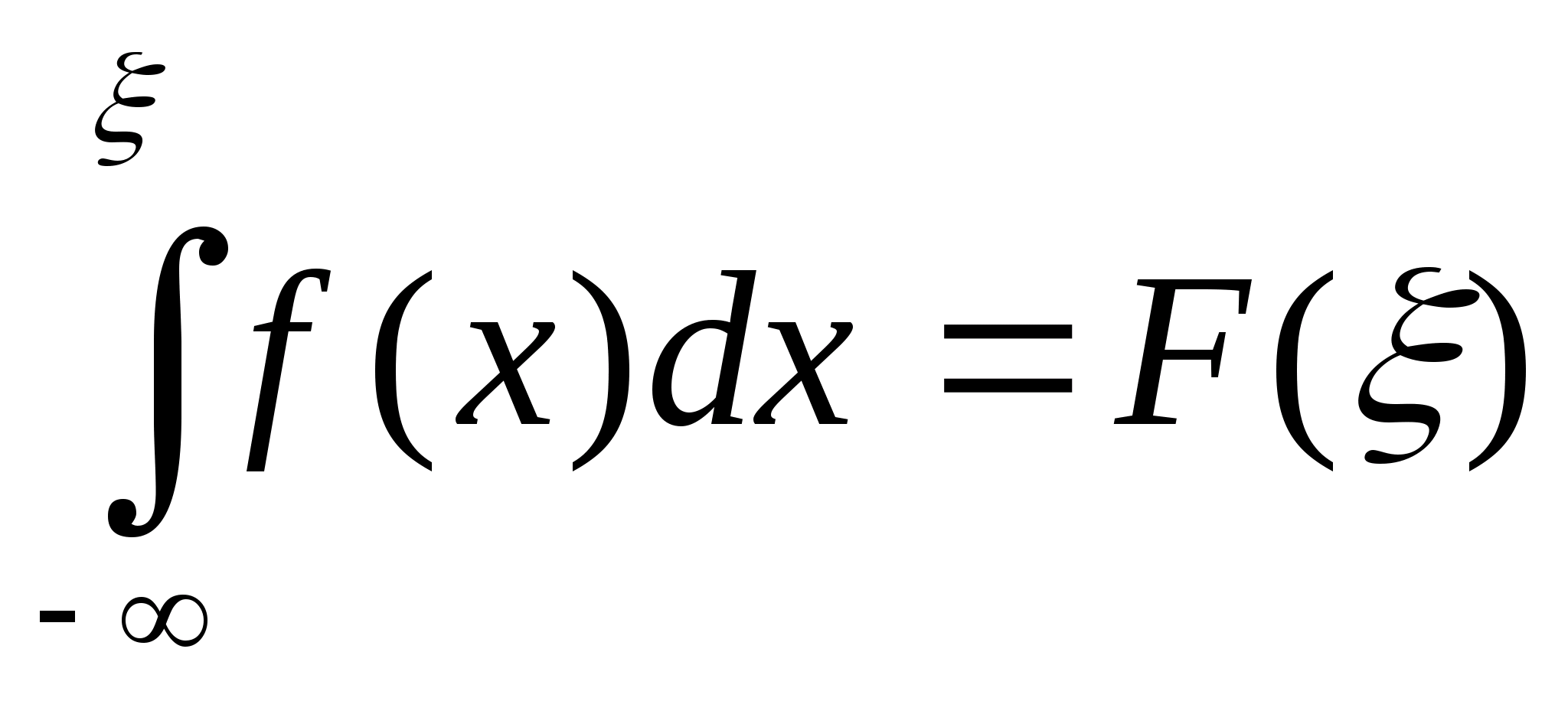
где F(x) - интегральная функция распределения вероятностей, являющаяся однозначной функцией своего аргумента.
При этом F( x) изменяется от 0 до 1 при изменении x от - ¥ до + ¥.
Таким образом, для аргумента, лежащего в интервале - ¥ < x < + ¥, функция 0 < F(x) < 1, что соответствует числам последовательности, равномерно распределенным на интервале [0,1].
Возвращаясь к исходному выражению
заметим, что для получения числа, принадлежащего совокупности {S>i>}, имеющей плотность распределения f(x), необходимо приведенное уравнение разрешить относительно S>i> .
Пусть, например, требуется получить случайные числа с экспоненциальным законом распределения
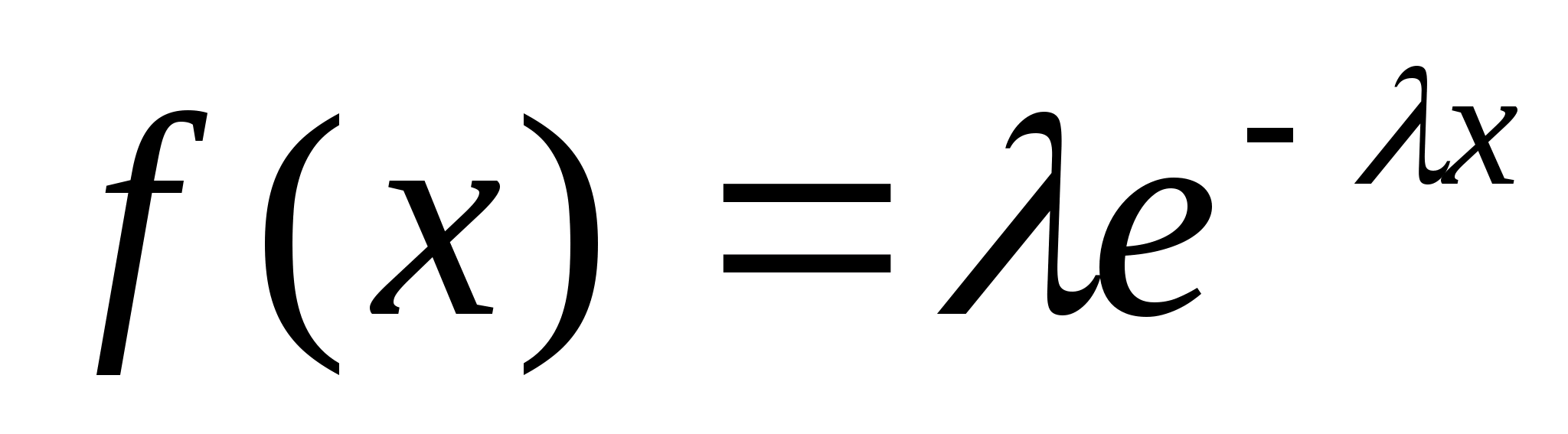
В силу приведенного соотношения преобразования имеем
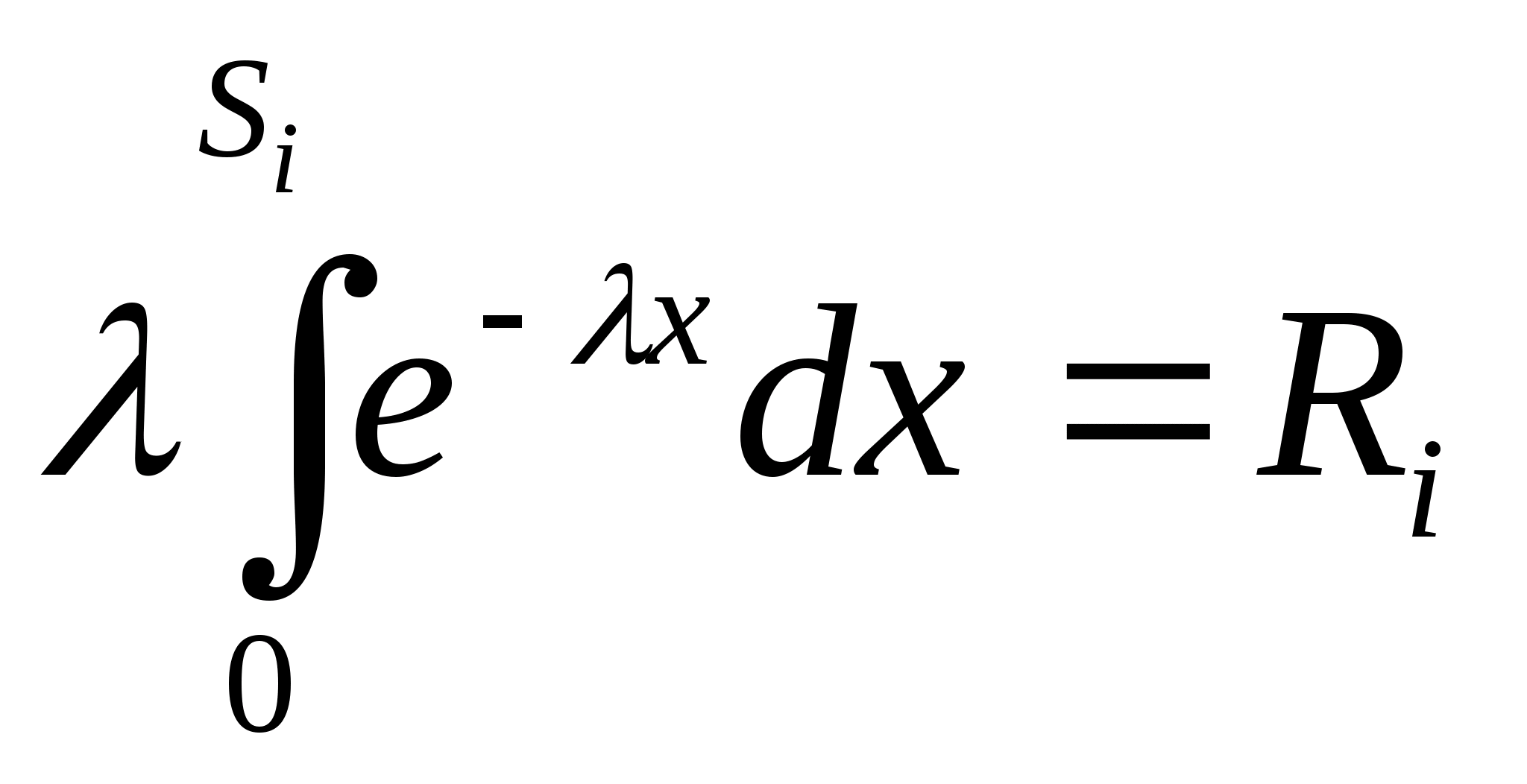
Интегрируя, получим
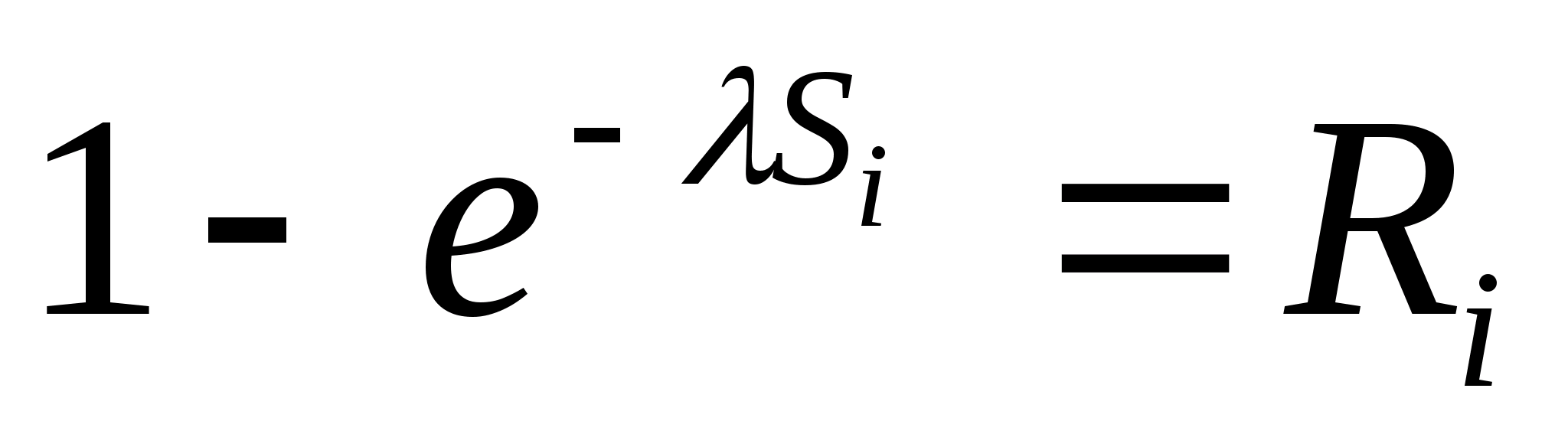
Отсюда
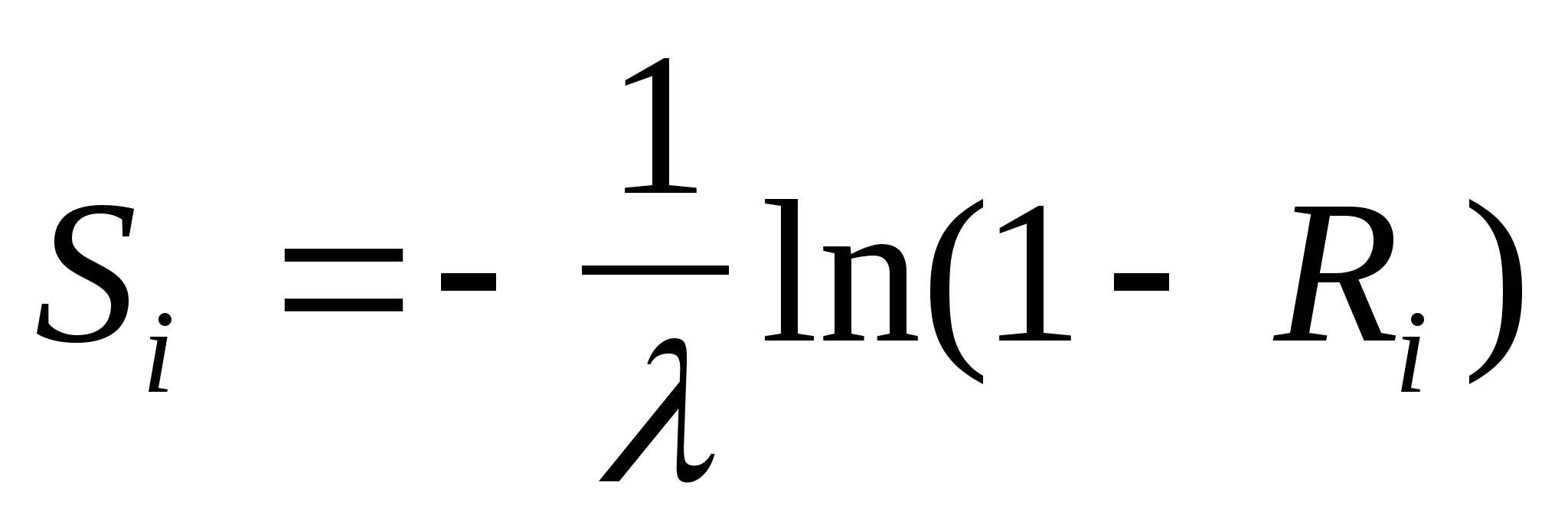
Понятно, что генерация равномерной последовательности значений в интервале [0,1] и подстановка их в полученное выражение обеспечивает генерацию случайной последовательности с экспоненциальным законом распределения вероятностей.
При попытке преобразования равномерного распределения в заданное может оказаться, что разрешить уравнение
относительно Si, как это проделано в примере, весьма трудно. Это случается, например, когда интеграл от f(x) не выражается через элементарные функции или когда плотность f(x) задана только графически.
В такой ситуации для преобразования используется метод Неймана.
Условия для его реализации:
случайная величина x может быть определена на интервале [a,b];
плотность распределения вероятностей f(x) на интервале [a,b] ограничена f(x) <= M>o>.
Разыгрывание (генерация) значений x, распределенных с плотностью вероятностей f(x), осуществляется следующим образом:
1)Генерируем два случайных значения R>1> и R>2> величины равномерно распределенной на интервале [0,1] и получаем случайную точку на графике f(x) с координатами
x’ = a + R>1>*(b - a)
y’ = R>2>* Mo
 y
y
M>o>
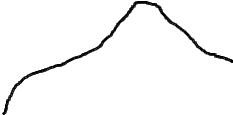

 y’ Ã
y’ Ã
 a x’
b x
a x’
b x
Рис.5.4.1.
2)Если полученная точка лежит под кривой y = f(x), то полагаем, что первое значение случайной величины, соответствующей плотности распределения вероятностей f(x) равно
x>1> = a + R>1>*(b - a) = x’
Если же полученная точка лежит над кривой y =f(x), то пара случайных чисел R>1> и R>2> отбрасывается, выбирается новая R>3> и R>4> и операции пп.1,2 повторяются.
Случайные числа xi, полученные таким образом, имеют плотность распределения вероятностей f(x).
Получение случайных величин, плотность вероятностей которых - нормальный закон, имеет свои особенности.
Основное уравнение преобразования в этом случае имеет следующий вид:
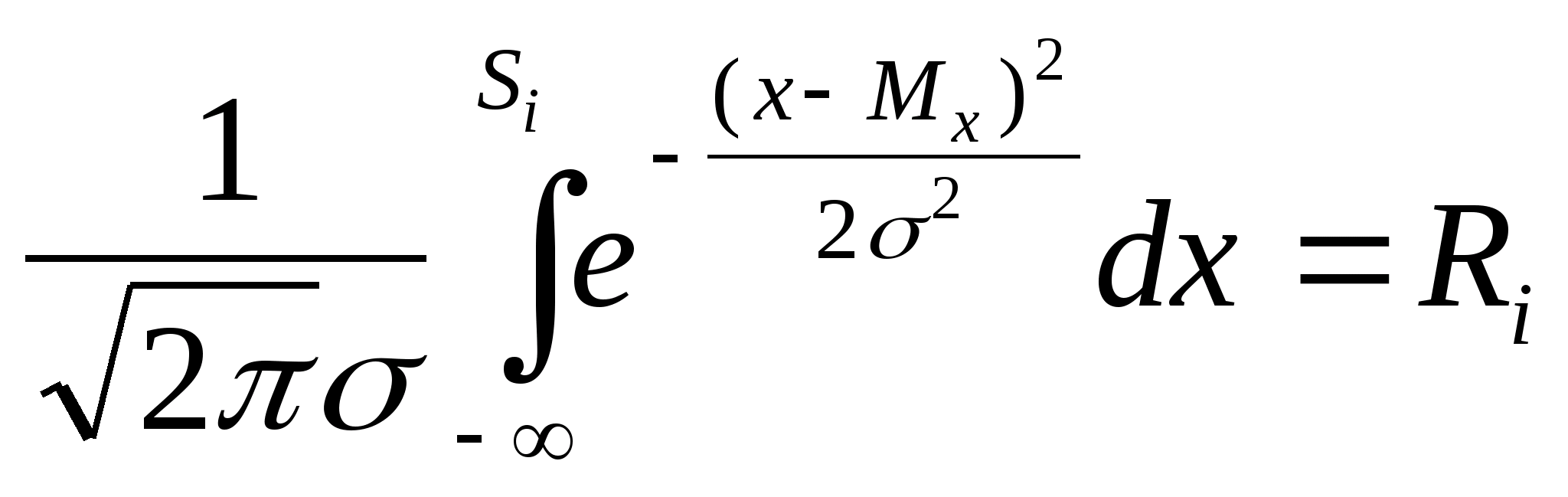
В явном виде оно неразрешимо. Поэтому приходится использовать другой путь. Так согласно центральной предельной теореме теории вероятностей известно, что нормальный закон распределения возникает во всех ситуациях, когда случайная величина может быть представлена в виде суммы достаточно большого числа независимых (или слабо зависимых) элементарных слагаемых, каждое из которых в отдельности мало влияет на сумму. Это дает возможность приближенно моделировать нормальную плотность распределения вероятностей суммированием чисел, равномерно распределенных на интервале [0,1]:
a = g>1> + g>2> + .....+ g>n>
Эта
сумма асимптотически нормальна с МО
 и с СКО
и с СКО 
Но для равномерной плотности распределения
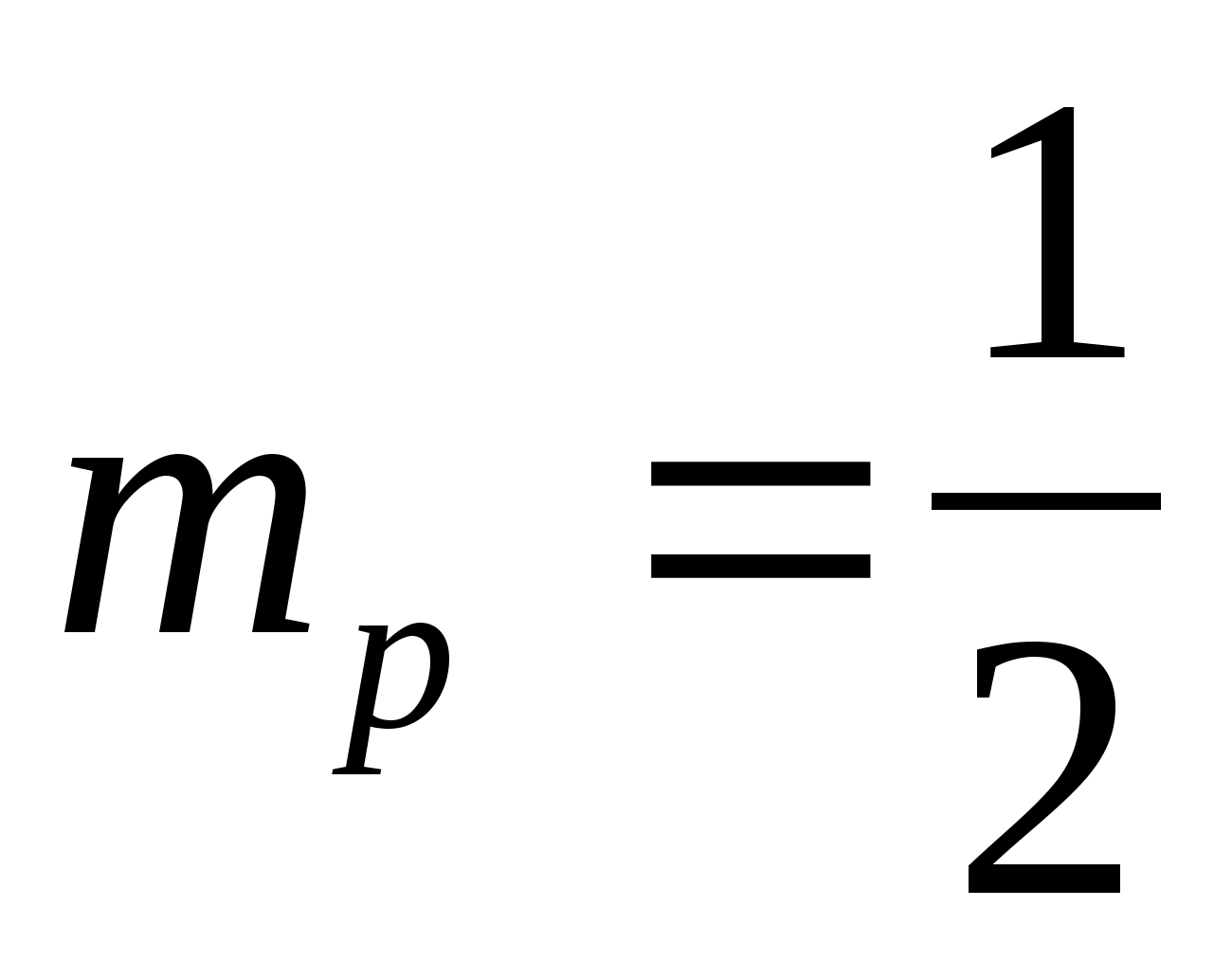 ,
,
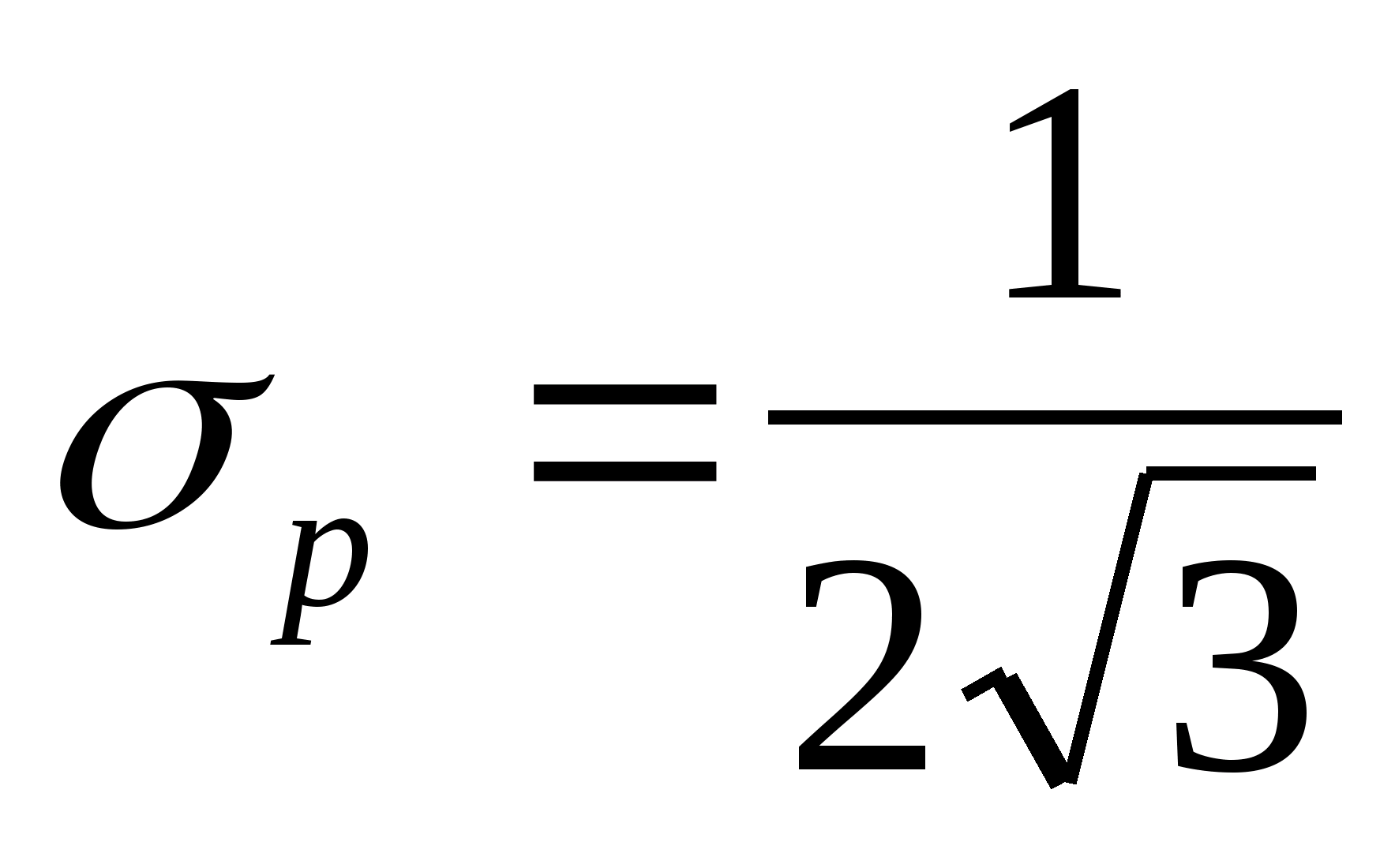
Значит
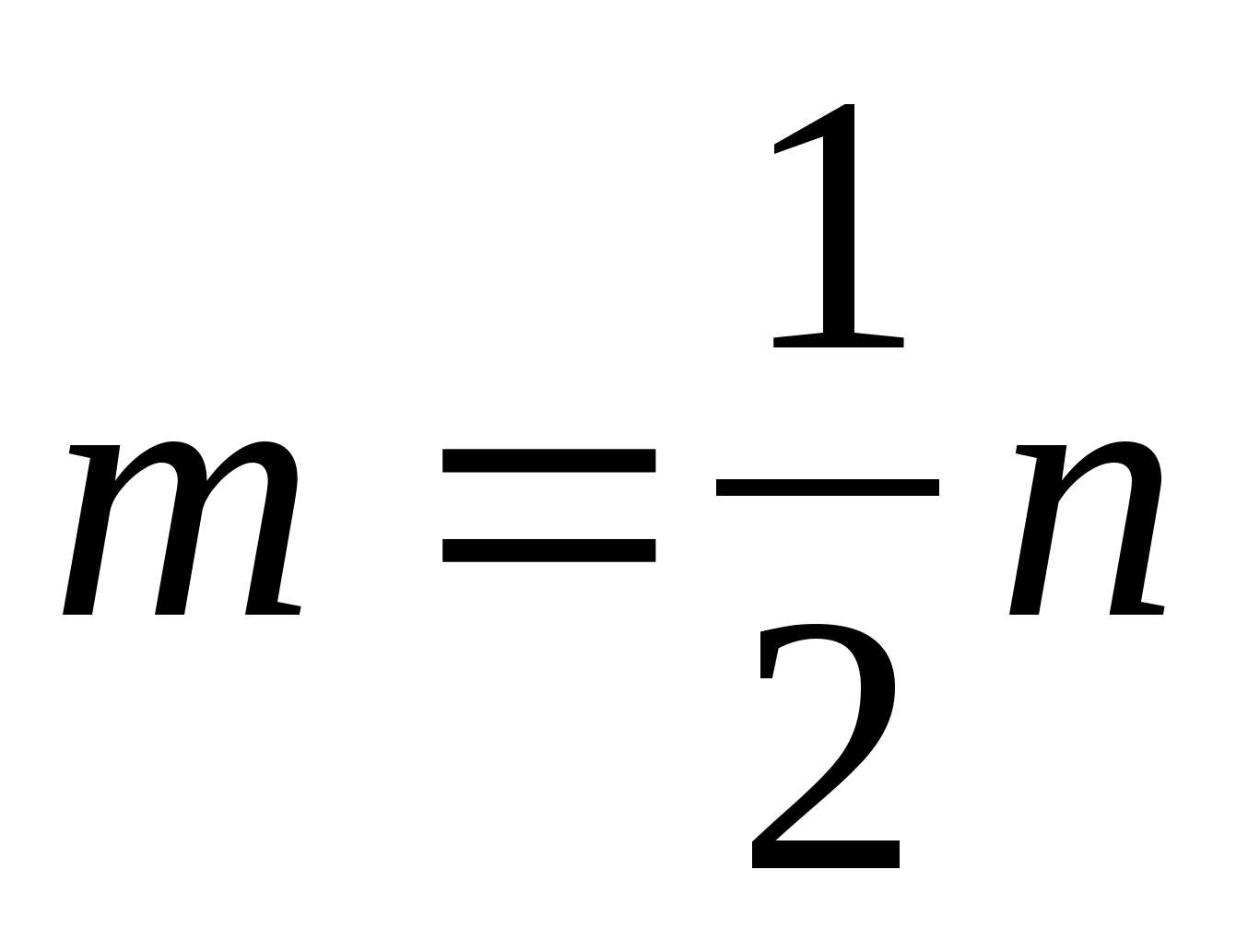 ,
,

Тогда, если i-ое значение нормальной случайной величины a соответствует i-му эксперименту суммирования n равномерно распределенных чисел, то
a>i> = g>i>>1> + g>i>>2> + .....+ g>i>n
Значит, получение нормально распределенной последовательности {S>i>} с математическим ожиданием m>з> и СКО - s>з> осуществимо путем нормирования и перемасштабирования последовательности {a>i>}, òî åñòü, ïðèâåäåíèÿ åå ê çàäàííûì ÷èñëîâûì õàðàêòåðèñòèêàì:
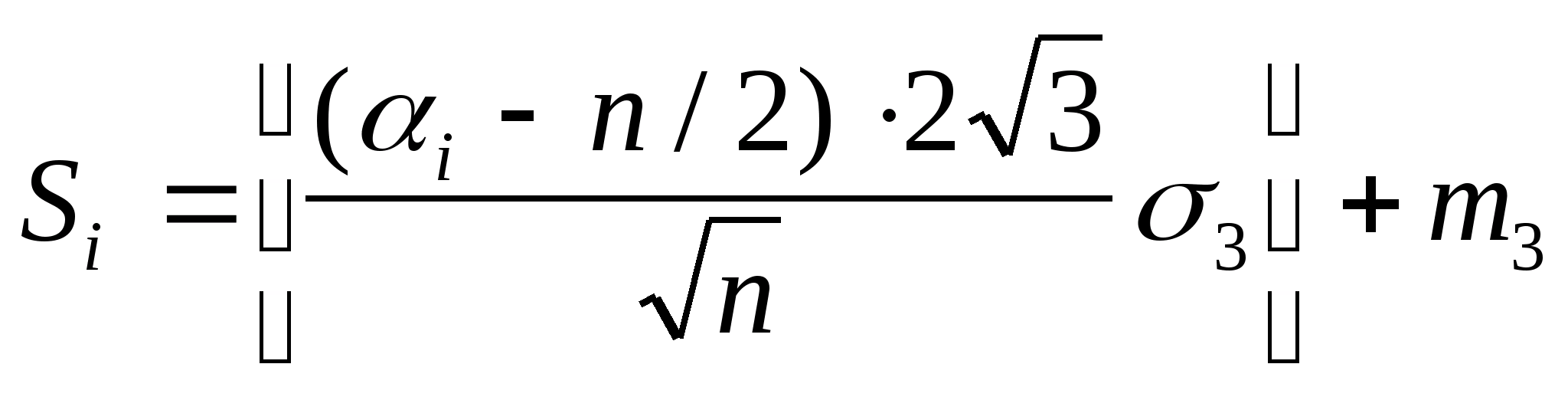
Л Е К Ц И Я 5.5
Модель системы распознавания образов
Теперь после изложения общих представлений о моделировании вообще можно перейти к построению моделей конкретных систем - систем распознавания образов. Поэтому начнем с того, что определим в первом приближении цель моделирования систем распознавания.
Цель компьютерного моделирования систем распознавания - их исследовательские испытания для оценки эффективности распознавания в приемлемые сроки и во всем факторном пространстве представления объектов (явлений, процессов) и возможностей измерителей их характеристик.
Можно было бы предположить, что такое определение касается только сложных СР, в состав которых входят многочисленные и разнородные средства измерений или на информационной основе которых строятся сами системы распознавания. Для таких систем не вызывает сомнения необходимость применения опытно-теоретического метода испытаний. Поэтому для них и должна идти речь о сроках и факторном пространстве применения СР. То есть, к компьютерному моделированию прибегают чаще всего постольку, поскольку не могут в приемлемое время провести натурные испытания СР во всем факторном пространстве поведения объектов (явлений, процессов) и измерителей их характеристик.
И далее, казалось бы, что системы распознавания, для которых натурные испытания достаточно дешевы, а способы моделирования входных воздействий достаточно сложны и неясны, не следует вообще и моделировать. Кажется, что все можно получить в эксперименте.
Если задаться целью, то можно найти настолько простые системы.
Однако в большинстве случаев кажущаяся простота и дешевизна натурных экспериментов (испытаний) при неопределенности методов построения моделей входных воздействий скрывает от испытателя характеристики факторного пространства состояния и поведения объектов распознавания. При этом не удается определить фактическую эффективность, а оцененное значение ее только успокаивает (“ведь оценка получена!”), так как, к сожалению, характеризует только какую-то неопределенную часть факторного пространства, о которой могут быть лишь качественные суждения, а чаще всего и ошибочные.
Поэтому независимо ни от чего попытка разработки изоморфной модели уже ведет к получению дополнительной информации для создания более эффективных систем или для четкого определения области применения созданной системы распознавания.
Отказ от этого подхода приводит к тому, что легко реализуемые экспериментальные применения системы часто не позволяют объяснить причины неожиданно появляющихся отрицательных результатов. И только более полный анализ поведения объектов (явлений, процессов) распознавания, измерителей их характеристик и сопутствующих искажений (что входит в задачи создания соответствующих моделей) выводит из тупиковой ситуации, если, конечно, она расценена как тупиковая.
Решение задач построения компьютерных моделей систем распознавания образов основывается на
-понимании ïðèíöèïîâ êëàññèôèêàöèè è ñòðóêòóðû ñèñòåì ðàñïîçíàâàíèÿ;
-ñïîñîáîâ îïèñàíèÿ êëàññîâ íà ÿçûêå ñëîâàðÿ ïðèçíàêîâ;
-ïîäõîäîâ ê ôîðìàëèçàöèè ïîêàçàòåëåé ýôôåêòèâíîñòè ðàñïîçíàâàíèÿ.
Начиная с декомпозиции, как одного из важнейших принципов построения моделей, можно заметить, что блочный состав моделей систем распознавания грубо уже определяют их схемы, рассмотренные при изучении принципов классификации. Поэтому модель СР первого приближения должна включать следующие основные элементы:
-ðàñïîçíàâàåìûé îáúåêò (ÿâëåíèå, ïðîöåññ);
-òåõíè÷åñêèå ñðåäñòâà (ñðåäñòâà èçìåðåíèé);
-ìíîãîóðîâíåâàÿ (â îáùåì ñëó÷àå) ñèñòåìà îáðàáîòêè èçìåðåíèé;
-àëãîðèòì êëàññèôèêàöèè.
Ну, а так как моделирование систем распознавания, как это было сформулировано выше, преследует целью проведение испытаний и получение оценки выполнения ими задач - эффективности -, то последним венчающим модель элементом в перечисленный состав должен быть включен блок оценки этого показателя (эффективности).
Рассмотрим более подробно все перечисленные элементы модели, стремясь к их детализации и определению принципов компьютерной реализации во взаимодействии друг с другом.
5.5.1. Моделирование распознаваемого объекта
Сложность модели распознаваемого объекта (явления, процесса) определяется полностью степенью физико-химической сложности его самого, условий его наблюдения и степенью доступности необходимых измерений.
Исходя из определения назначения системы распознавания ,- получение информации, необходимой для принятия решения о принадлежности неизвестного объекта (явления, процесса) к тому или иному классу ,- ничего другого не остается, как получить по возможности всю информацию, имеющую отношение к его распознаванию. Незнание или плохое знание описания объекта во всем диапазоне интересующих сторон, свойств, характеристик, факторов поведения не дает оснований надеяться на эффективность получаемых решений.
Заметим, что соответствующая задача (получение всей информации) не противоречит самой первой задаче, с которой начинается создание СР, - определение полного перечня признаков распознавания.
Говоря слова “модель объекта” (а равно “модель явления”, “модель процесса”) условимся, что при этом будем иметь в виду “модель объектов распознавания”, которые могут относиться к различным классам. Но так как в системе в каждом акте ее применения всегда имеют дело с одним неизвестным объектом, подлежащим распознаванию, а также имея в виду, что принципы моделирования всех объектов данной СР одинаковы (различны лишь характеристики), чаще всего используется термин “модель объекта распознавания”.
Исходя из этого определим модель объекта как цифровой имитатор совокупности его свойств, характеристик и состояний. Заметим, что, на первый взгляд, число моделируемых (имитируемых) свойств, характеристик и состояний объекта равно размерности словаря признаков распознавания. Так действительно, если в СР используется один простой признак распознавания, то и моделью соответствующего объекта должно имитироваться поведение этой одной характеристики, одного свойства, одного состояния объекта. Точно также, если СР использует несколько простых признаков, то имитатор объекта должен обеспечивать получение такого же количества характеристик (свойств, состояний) каждого моделируемого объекта. Однако если признак распознавания один, но комбинированный, то цифровой имитатор соответствующего объекта должен выдавать системе столько и таких его характеристик (свойств, состояний), сколько и каких используется для расчета этого комбинированного признака во многоуровневой системе. То есть, размерность вектора имитируемых свойств может быть больше или равна размерности вектора признаков распознавания.
Примеры.
1)Пусть в СР в качестве признака распознавания используется один - масса объекта. Значит моделью каждого из объектов, подлежащих распознаванию, будет в простейшем случае запись в банке данных каждого из них всего одного соответствующего числа в принятой размерности (тонна, килограмм, грамм и т.п.).
2)Пусть в качестве признаков распознавания в СР используются геометрические размеры объекта. Тогда модель каждого объекта, подлежащего распознаванию, будет представлять в простейшем случае три числа в соответствующем банке данных - длина, ширина, высота (м, дм, см, мм).
3)Пусть в СР метеоосадков в качестве признака дождей (а дожди бывают разными хотя бы по интенсивности) используется количество воды, попадающей на определенную поверхность земли. Тогда моделью любого класса дождей может быть всего одно число - количество мм осадков в час (месяц, год).
4)Пусть в СР распознаются звуки по высоте их тона. Тогда моделью каждого звука будет число, характеризующее частоту основного тона его и имеющее размерность - Гц.
5)Пусть в СР распознаются звуки по ряду признаков:
-âûñîòà îñíîâíîãî òîíà;
-íàëè÷èå íèçêî÷àñòîòíîé ìîäóëÿöèè îñíîâíîãî òîíà;
-èçìåíåíèå èíòåíñèâíîñòè.
Тогда модель такого в данном случае сложного явления должна содержать по каждому классу, подлежащему распознаванию, по крайней мере, такие параметры как частота основного тона;
-÷àñòîòà ìîäóëÿöèè;
-èçìåíåíèå àìïëèòóäû îñíîâíîãî òîíà âî âðåìåíè (âèä ìîäóëÿöèè).
Чем сложнее свойства объекта, отражаемые в составе вектора признаков распознавания, тем сложнее модель этого объекта. Так, если для распознавания требуется знание геометрических характеристик объекта более полно, чем для определения длины, ширины и высоты, то такой объект должен уже представляться чертежами его в трех проекциях. Соответствующая модель - внешние контуры указанных проекций, представляемые
-ëèáî â âèäå íàáîðà äèñêðåòíûõ òî÷åê êîîðäèíàò;
-ëèáî â âèäå íàáîðà ïàðàìåòðîâ ñïëàéíîâ, àïïðîêñèìèðóþùèõ óêàçàííûå êîíòóðû;
-ëèáî â âèäå ðàäèàëüíî-êðóãîâûõ ðàçâåðòîê óêàçàííûõ êîíòóðîâ, òî åñòü , âåëè÷èí ðàäèóñ-âåêòîðîâ, èìåþùèõ íà÷àëî â íåêîòîðîì öåíòðå ÷åðòåæà ïðîåêöèè è êîíåö íà ãðàíèöå êîíòóðà.
Так или иначе мы имеем и здесь и в рассмотренных простейших случаях наборы числовых характеристик распознаваемых объектов, которые для каждого из объектов и представляются как его модель.
Утверждая, что чем больше размерность вектора признаков, тем сложнее модель объекта, мы как бы все и усложняем сами вполне сознательно. Действительно формирование словаря признаков, а значит размерности соответствующего вектора, - эвристическая операция. Причем эта задача обычно нацелена на то, чтобы как можно всестороннее охарактеризовать выбранным словарем объект распознавания. Ведь от количества и качества признаков распознавания зависит эффективность классификации. Поэтому получающееся отсюда усложнение модели следует считать естественным состоянием при стремлении к созданию высокоэффективной системы.
Для четкости последующего изложения вопросов построения моделей СР назовем банк данных с числовыми характеристиками распознаваемых объектов, соответствующими признакам распознавания, модулем статических характеристик объектов в составе модели объекта.
Этим модель не исчерпывается.
Следующий важный шаг анализа состава модели объекта (явления, процесса) основывается на представлении о том, как объекты распознавания появляются на входе системы распознавания. Достаточно трудно представить себе системы, на вход которых объекты попадают в строгой очередности. Обычно имеем дело с некоторым вероятностным распределением, то есть, каждый объект или группа достаточно близких объектов, образующих класс, предъявляются СР с конкретной априорной вероятностью.
Изоморфно этому одним из составляющих модель СР модулей должен быть элемент, осуществляющий вероятностный выбор предъявляемого объекта в каждом запуске программы модели распознавания. Таким образом каждый модельный эксперимент по распознаванию при наличии такого модуля должен начинаться со статистической задачи выбора объекта определенного класса, подлежащего в этом эксперименте распознаванию.
Логико-математические принципы построения модуля выбора объекта - это принципы генерации случайных событий методом статистических испытаний (Монте-Карло). При этом, если каждый класс, для которого определена априорная вероятность, представляется одним объектом, то имеем дело с одним датчиком случайных событий (появлений объектов на входе СР). Если же каждый класс содержит несколько однотипных объектов, то соответственно модуль должен иметь и второй датчик случайных событий, заключающихся в появлении на входе системы одного конкретного объекта из набора их (полной группы событий), входящих в имитируемый класс.
В итоге для наиболее общего случая функциональная схема рассмотренной части модели объекта имеет следующее строение (Рис.5.5.1).
Рассмотренная часть модели распознаваемого объекта является достаточной, если мы имеем дело с объектами, явлениями или процессами в статике или если располагаем наблюдениями их для измерения характеристик в фиксированные моменты времени.
Однако чаще всего реальные СР имеют дело с объектами, характеризующимися некоторой кинематикой.
Например, нами рассматривалась такие характеристики звука как высота и громкость, соответствующие признаки которых - частота и амплитуда. В представленном на схеме модуле статических характеристик указанные параметры были бы записаны в виде двух чисел по каждому классу.
Но звук одного тона - это периодический во времени процесс, кинематическая характеристика которого
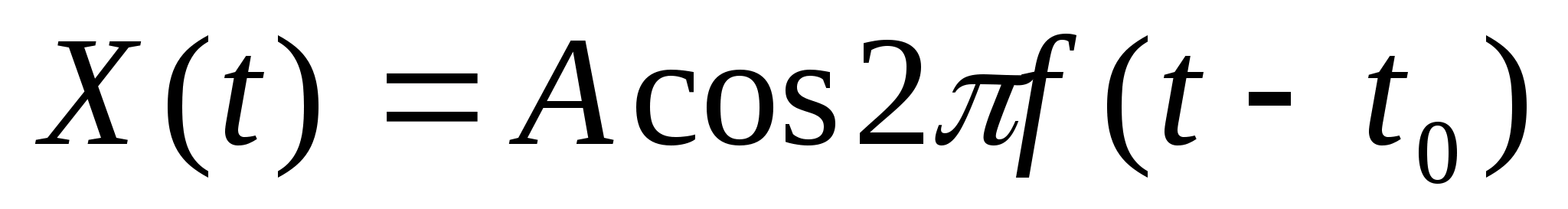 ,
,
где A - амплитуда; f - частота.
Здесь получить интересующие признаки (частоту и амплитуду) по одному мгновенному значению не представляется возможным. Они могут быть определены только путем наблюдений и обработки процесса X(t). А если это так, то в соответствующую модель необходимо ввести модуль, который обеспечивает получение X(t), а значит
-счет времени от некоторого момента начала наблюдений или обработки t>0>;
-расчет кинематики X(t) по приведенной выше зависимости, в
 Ìîäóëü âûáîðà
êëàññà
Ìîäóëü âûáîðà
êëàññà
в соответствии с ап-
риорными вероятнос-
тями появления P(Wi)
№ класса
 Ìîäóëü âûáîðà
îáúåê-
Ìîäóëü âûáîðà
îáúåê-
та заданного класса
из соответствующего
набора
№ класса ( i )
№ объекта

М о д у л ь с т а т и ч е с ê è õ õ à ð - ê î á ú å ê î â



 Ñòàòè÷åñêèå
Ñòàòè÷åñêèå
Ñòàòè÷åñêèå
Ñòàòè÷åñêèå
Ñòàòè÷åñêèå
Ñòàòè÷åñêèå
õàðàêòåðèñòèêè õàðàêòåðèñòèêè ... õàðàêòåðèñòèêè
объектов 1-го îáúåêòîâ 2-ãî îáúåêòîâ m-ãî
класса êëàññà êëàññà
Статические характеристики объекта i-го класса
Рис.5.5.1
Функциональная схема чсти модели объекта
которую и входят статические характеристики - амплитуда и частота.
Здесь счетчик времени - независимая от физического содержания задачи функция
 ,
,
где Dt - принятая в модели дискретность представления исходных сигналов;
k - число тактов моделирования кинематики.
Сам же расчет кинематики определяется объектом и его свойствами.
Рассмотрим еще один пример.
Пусть объект распознавания описан плоским изображением, контур которого в модуле статических характеристик представлен в виде таблицы расстояний от центра тяжести этого изображения с помощью радиально-круговой развертки:
или при выбранной дискретности развертки Dj развертки
Если реально объект распознавания является вращающимся вокруг центра масс с угловой скоростью j>v> , а система распознавания должна получать соответствующие признаки путем обработки измеренных радиальных размеров объекта, то модель объекта должна содержать модуль кинематики. При этом определение исходного радиального размера объекта во времени должно осуществляться путем, по крайней мере, линейного интерполирования значений таблицы статических характеристик. С учетом дискретной во времени имитации радиального размера будем иметь:
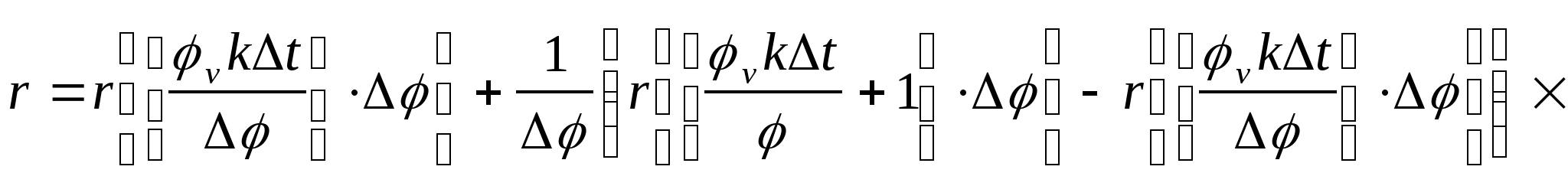
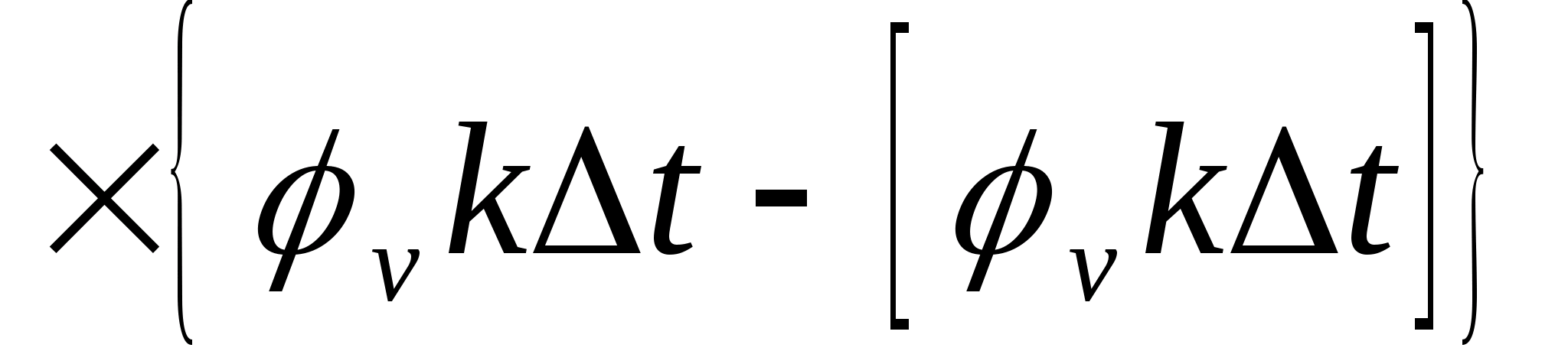
Если вместо статического описания радиально-круговой разверткой тот же плоский объект описан координатами точек контура в прямоугольной системе x,y. Тогда кинематика его при вращении относительно центра масс:
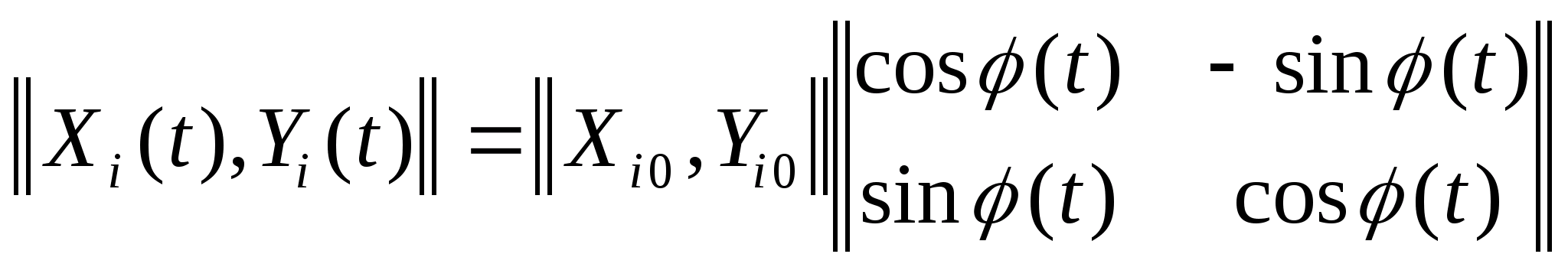
где X>io> ,Y>io> - координаты i-ой точки статического описания объекта;
X>i>(t),Y>i>(t)- координаты i-ой точки в процессе вращения объекта.
Применив указанное преобразование ко всем точкам описания объекта, получим его положение в каждый интересующий момент времени в виде соответствующих положений всех описывающих точек.
Точно также, как и в предыдущем случае, при дискретном счете времени от некоторого момента t>0> áóäåì èìåòü:
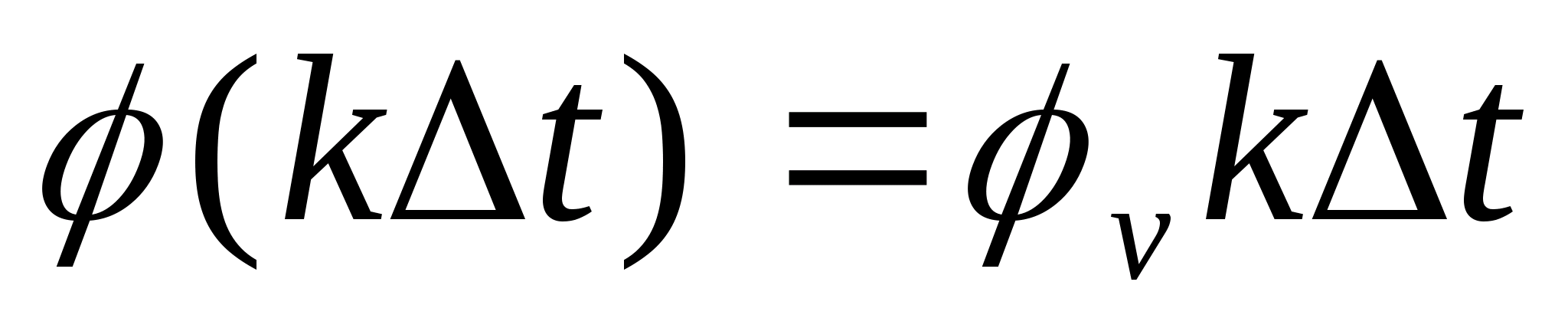
Если же при вращении центр нашей фигуры будет совершать некоторое поступательное движение, то для координат точек ее контура будут:

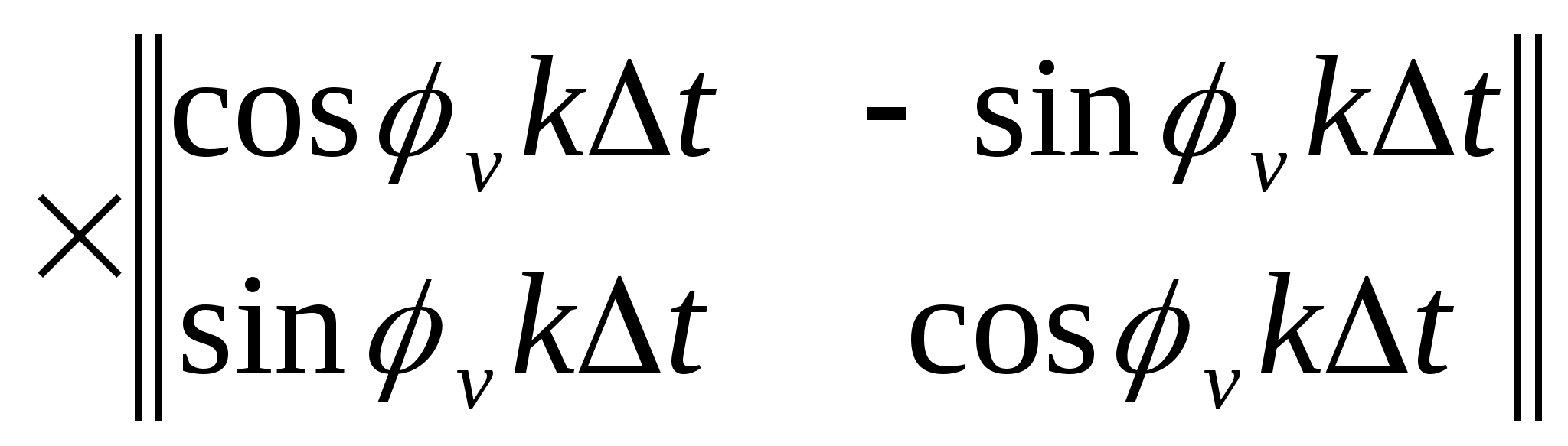
Осуществляя указанные расчеты по статической таблице координат точек контура, будем получать в последовательные моменты времени с дискретностью Dt ïîëíîå ïðåäñòàâëåíèå î äâèæåíèè ðàññìàòðèâàåìîãî îáúåêòà. Ýòî è ÿâëÿåòñÿ ïðàêòè÷åñêèì ðåøåíèåì çàäà÷è åãî ìîäåëèðîâàíèÿ ïðè ãåîìåòðè÷åñêîì îïèñàíèè.
Рассмотрение приведенных примеров показывает, что более сложные физические описания статики распознаваемых объектов (явлений, процессов) приведут к более сложным выражениям для определения их кинематики.
На этом рассмотрение основ построения модели распознаваемого объекта может быть закончено. Типичная функциональная схема его может быть представлена теперь следующим образом (Рис.5.5.2.).
В заключение отметим, что счетчик времени, введенный необходимостью моделирования кинематики объекта, задает темп работы
 Ìîäóëü âûáîðà êëàññà
â ñîîòâåòñòâèè ñ àïðè-
Ìîäóëü âûáîðà êëàññà
â ñîîòâåòñòâèè ñ àïðè-
орными вероятностями появления P(Wi)
¹ êëàññà

Модуль выбора объекта заданного класса
из соответствующего набора
¹ êëàññà (i)
¹ îáúåêòà

М о д у л ь с т а т и ч е с к и х х - к о б ъ е к о в
Ñòàòè÷åñêèå õàðàêòåðèñòèêè
îáúåêòà i-ãî êëàññà

М о д у л ь к и н е м а т и ч е с к и х х а р - к




 Ñóáìîäóëü Ñóáìîäóëü
Субмодуль
Ñóáìîäóëü Ñóáìîäóëü
Субмодуль
счетчика вре- счетчика вре- счетчика време-
мени функцио- мени функцио- ни функцио-
íèðîâàíèÿ ¹1 íèðîâàíèÿ ¹2 íèðîâàíèÿ ¹m


 Ñóáìîäóëü
ðàñ-
Ñóáìîäóëü ðàñ-
Cóáìîäóëü ðàñ-
Ñóáìîäóëü
ðàñ-
Ñóáìîäóëü ðàñ-
Cóáìîäóëü ðàñ-
÷åòà êèíåìàòè- ÷åòà êèíåìàòè- ÷åòà êèíåìàòè-
÷åñêèõ õàðàê- ÷åñêèõ õàðàê- ÷åñêèõ õàðàê-
òåðèñòèê îáú- òåðèñòèê îáú- òåðèñòèê îáú-
åêòà 1-ãî êë. åêòà 2-ãî êë. åêòà m-го кл.
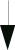
Кинематические характеристики объекта
Рис. 5.5.2.
Функциональная схема модели объекта
âñåé ìîäåëè ñèñòåìû ðàñïîçíàâàíèÿ. ×åðåç âðåìÿ Dt íà âûõîäå ìîäåëè îáúåêòà ïîÿâëÿþòñÿ íîâûå äàííûå î íåì. Ïðè ýòîì îòñ÷åò âðåìåíè íà÷èíàåòñÿ ñ ìîìåíòà çàïóñêà ìîäåëè. Ñàì æå ñ÷åò ïðè ñèíõðîíèçàöèè îò ÝÂÌ îáåñïå÷èâàåò ðàáîòó ìîäåëè, êàê ãîâîðÿò, “â ðåàëüíîì âðåìåíè”. Åñëè æå òàêàÿ ñèíõðîíèçàöèÿ îòñóòñòâóåò, òî î÷åðåäíîé òàêò ìîäåëèðîâàíèÿ îáúåêòà íà÷èíàåòñÿ ïîñëå âûïîëíåíèÿ âñåõ ïðîãðàìì ìîäåëè äî êîíöà.  ýòîì ñëó÷àå ìàñøòàá âðåìåíè ìîæåò áûòü çàìåäëåííûì îòíîñèòåëüíî ðåàëüíîãî èëè óñêîðåííûì. Âñå çàâèñèò îò îáúåìà âû÷èñëèòåëüíûõ îïåðàöèé âñåé ìîäåëè ÑÐ.
Л Е К Ц И Я 5.6.
Ìîäåëü ñèñòåìû ðàñïîçíàâàíèÿ îáðàçîâ
(продолжение)
5.6.1. Ìîäåëèðîâàíèå ñðåäñòâ îïðåäåëåíèÿ õàðàêòåðèñòèê îáúåêòîâ ðàñïîçíàâàíèÿ
Модель измерителей, обеспечивающих определение характеристик для решения задачи распознавания, является логическим продолжением модели объекта , а значит очередным элементом, в составе общей модели системы. Как следует из предыдущих разделов курса сами измерители являются наиболее сложной и, как следствие, дорогостоящей частью системы. Отсюда вполне понятно, что эта сложность отражается и на рассматриваемой модели. Чаще всего причина сложности модели заключается в том, что в составе систем распознавания используются дистанционные измерители, реализующие достаточно сложные по техническому осуществлению физические принципы с вытекающими отсюда последствиями их математического описания. Кроме того, работа измерителей сопровождается ошибками измерений и отказами, что в свою очередь обусловливает усложнение физико-математического описания и алгоритм.
Для того, чтобы выделить принципы построения моделей средств определения характеристик объектов распознавания, прежде всего обратимся к примерам.
Начнем с такого простого случай как распознавание звуков по их высоте. Тогда на выходе модели объекта, а значит на входе модели измерителей, мы имеем дело с дискретным процессом
Естественно потребовать от измерителя определение частоты как параметра распознавания. Тогда задачами такого измерителя, состоящего очевидно из микрофона и усилителя должны быть:
-прием и усиление этого звукового сигнала;
-определение периода принятого гармонического сигнала и по нему частоты.
Последняя задача может выглядеть как рекуррентное сопоставление каждого принятого дискретного значения с предыдущим и обнаружение номера дискрета, когда достигается максимум сигнала. На некотором временном интервале в результате такой обработки будет получено s таких çíà÷åíèé: k>max1> , k>max2> , ....., k>maxs>. Тогда интересующая частота тона определится как
Но оказывается, что при моделировании этим нельзя ограничиться, òàê êàê ðåàëüíûé ñèãíàë èñêàæàåòñÿ øóìàìè èçìåðèòåëüíîãî òðàêòà è îøèáêàìè èçìåðèòåëÿ àìïëèòóäû . Ïðè ýòîì
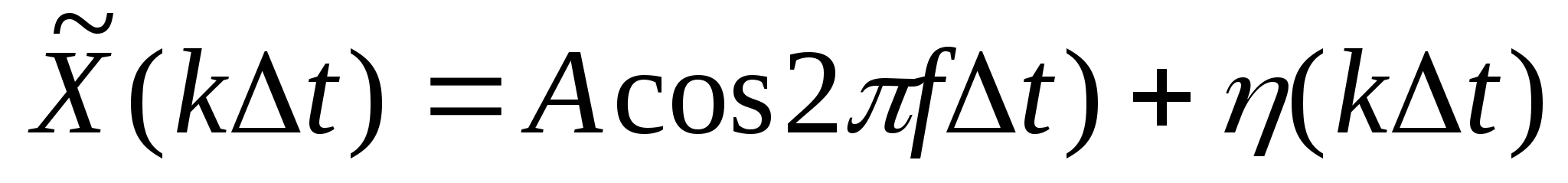
где h(kDt) - íîðìàëüíûé ñëó÷àéíûé ïðîöåññ ñ íóëåâûì ìàòåìàòè÷åñêèì îæèäàíèåì è äèñïåðñèåé D>x>. При этом дисперсия является паспортной характеристикой применяемого измерителя частоты тона звукового сигнала.
Случайная аддитивная составляющая сигнала, входящая в это выражение и обусловливает ошибки определения номеров тактов достижения максимумов сигналом, а значит и ошибку определения частоты. Определить âåëè÷èíó, âåðíåå ïàðàìåòðû, ýòîé îøèáêè ìîæíî, ïðîâåäÿ òåîðåòè÷åñêèé âûâîä çàâèñèìîñòè
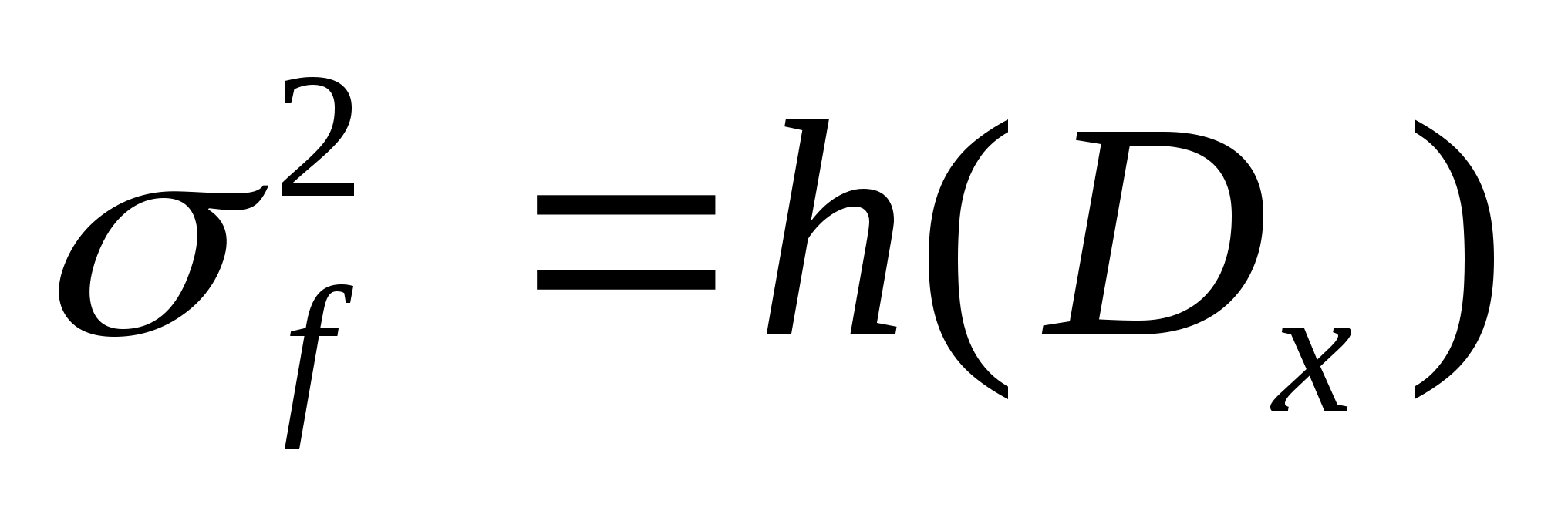
пользуясь рассмотренной связью между частотой и максимумами сигнала. Ýòîãî æå ìîæíî äîñòè÷ü è ÷èñëåííî, ïîëüçóÿñü ìåòîäîì ñòàòèñòè÷åñêèõ èñïûòàíèé (Ìîíòå-Êàðëî). Äëÿ ðåàëèçàöèè åãî ïðèäåòñÿ î÷åâèäíî ãåíåðàöèþ íîðìàëüíîé ñëó÷àéíîé ïîñëåäîâàòåëüíîñòè h(kDt) ñ M>x> = 0 и дисперсией D>x>. Добавляя соответствующее значение последовательности к периодической части сигнала и определяя по приведенному алгоритму значения f>i>, после набора достаточного статистического материала (q реализаций) ïîëó÷èì
 ;
;
Точно так может быть определена и плотность распределения вероятностей интересующих нас ошибок измерений.
Заметим, что с точки зрения построения всей модели измерителя получение параметров ошибок измерения частоты (M>f>, s>f >2 ) èëè ïëîòíîñòè ðàñïðåäåëåíèÿ âåðîÿòíîñòåé â ðàìêàõ ìîäåëè ñàìîãî èçìåðèòåëÿ íå ÿâëÿåòñÿ íåîáõîäèìûì. Ðàññìîòðåííóþ îïåðàöèþ ìîæíî ïðîâåñòè îòäåëüíî. Âûïîëíÿåòñÿ ýòî, êàê ìû óïîìÿíóëè è ïîêàçàëè, ëèáî àíàëèòè÷åñêè, ëèáî ñ èñïîëüçîâàíèåì ìåòîäà Ìîíòå-Êàðëî. Ïðè÷åì êîìïüþòåðíûå ðåàëèçàöèè è òîãî è äðóãîãî ïîäõîäîâ ïðåäñòàâëÿþò ñîáîé ÷àñòíûå ìîäåëè îøèáîê. À ðåçóëüòàòû èõ ðàáîòû äàþò âîçìîæíîñòü âêëþ÷èòü â ìîäåëü èçìåðèòåëÿ ÷àñòîòû óïðîùåííûé ñóááëîê îøèáîê. Ïîñëåäíèé áóäåò ïðåäñòàâëÿòü ñîáîé âñåãî ëèøü äàò÷èê ñëó÷àéíûõ ÷èñåë , ïîñòðîåííûé íà îñíîâå ðåàëèçàöèè ïëîòíîñòè ðàñïðåäåëåíèÿ âåðîÿòíîñòåé îøèáîê îïðåäåëåíèÿ ÷àñòîòû èëè íîðìàëüíîé àïïðîêñèìàöèè ïëîòíîñòè ñ ÷èñëîâûìè õàðàêòåðèñòèêàìè, îïðåäåëåííûìè íà óïîìÿíóòûõ ÷àñòíûõ ìîäåëÿõ .
В качестве второго примера, помогающего нам выяснить принципы построения модели распознавания, рассмотрим измеритель радиального размера такого объекта как вращающийся вокруг своего центра тяжести прямоугольник.
Для простоты и наглядности будем считать, что точка, из которой âåäóòñÿ íàáëþäåíèÿ ýòîãî ïðÿìîóãîëüíèêà è èçìåðÿåòñÿ åãî òåêóùèé ðàäèàëüíûé ðàçìåð ëåæèò â íà÷àëå êîîðäèíàò (0,0). Ïðè ýòîì ðàäèàëüíûì ðàçìåðîì îáúåêòà ñ÷èòàåòñÿ âåëè÷èíà
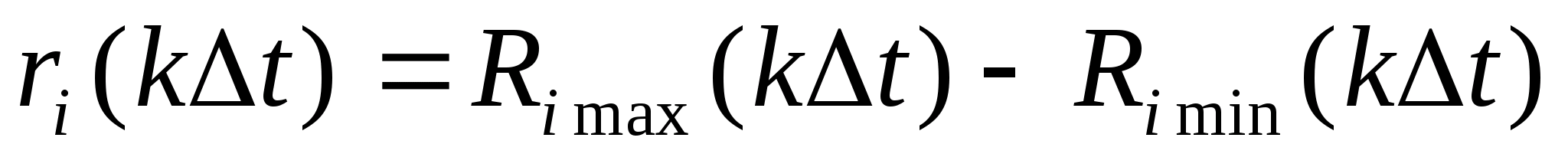
где R>i>> >>max>(kDt), R>i>> >>min>(kDt) - ðàññòîÿíèÿ äî íàèáîëåå óäàëåííîé è áëèæàéøåé ê òî÷êå ñòîÿíèÿ èçìåðèòåëÿ òî÷åê êîíòóðà ïðÿìîóãîëüíèêà (ïåðåñå÷åíèÿ ñ ðàäèóñ-âåêòîðîì íàáëþäåíèÿ).
Из простых алгебраических соображений, решая уравнения по определению точек пересечения прямых, отрезки которых образуют стороны прямоугольника, с прямой радиус-вектора из начала координат, для каждого положения прямоугольника будем иметь соответствующие значения. А как изменяются во времени координаты точек контура прямоугольника в модели объекта, а значит и уравнения отрезков сторон его, мы уже рассмотрели. Понятно, что изложенные принципы позволяют записать строго все математические выражения, составляющие существо такого измерителя и легко программно реализовать при построении модели.
По аналогии с предыдущим примером можно считать, что паспортной характеристикой измерителя радиального размера должна быть либо плотность распределения вероятностей ошибок определения r>i> или числовые характеристики нормального закона, имеющего место как правило при измерениях. И так же, как и в предыдущем примере, модель измерителя радиального размера должна включать модуль датчика случайных чисел, генерирующего аддитивную добавку к r>i> - dr>i> â ñîîòâåòñòâèè ñ óêàçàííûìè äàííûìè. Òî åñòü, èçìåðåííîå â êàæäîì òàêòå ðàáîòû ïðîãðàììû ìîäåëè çíà÷åíèå ðàäèàëüíîãî ðàçìåðà äîëæíî èìåòü ñëó÷àéíóþ äîáàâêó
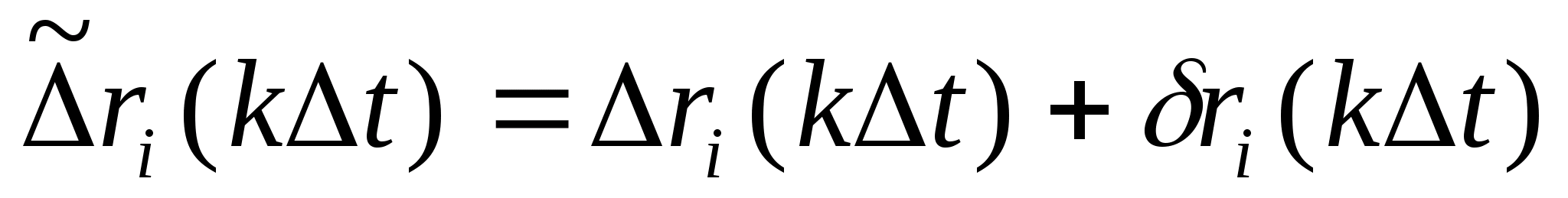
Следует еще раз подчеркнуть, что плотность распределения этой добавки, как случайной величины, должна соответствовать заданной в паспорте для данного измерителя или полученной для него экспериментально в процессе его испытаний.
Таким образом, уже два рассмотренных примера однозначно демонстрируют, что составными частями модели измерителей характеристик объектов распознавания должны быть:
-модули каждого из средств, отличающихся по физическим принципам, алгоритмы измерений которых имеют свое специфическое математическое описание;
-модули датчиков случайных чисел, реализующие случайные добавки к измерениям каждого средства в соответствии с заданными плотностями распределения вероятностей ошибок.
В то же время эти примеры, позволившие сформировать первые представления о модели средств измерений, не достаточно подчеркнули факт того, что измерители чаще всего определяют интересующие характеристики объекта на некотором временном интервале наблюдения, то есть по совокупности сигналов, а не в точке.
Уже в первом примере измерителя частот гармонических сигналов нельзя было обойтись без накопления информации: частота определялась по результатам наблюдения нескольких периодов сигнала X(t).
Точно также во втором примере (вращающийся прямоугольник) скорее всего для решения распознавательных задач мгновенными замерами радиальных размеров ограничиться нельзя. Требования классификации могут заставить нас здесь либо опять-таки измерять период вращения, либо пользоваться в этих целях такими характеристиками как математическое ожидание и среднеквадратический разброс радиального размера объекта:
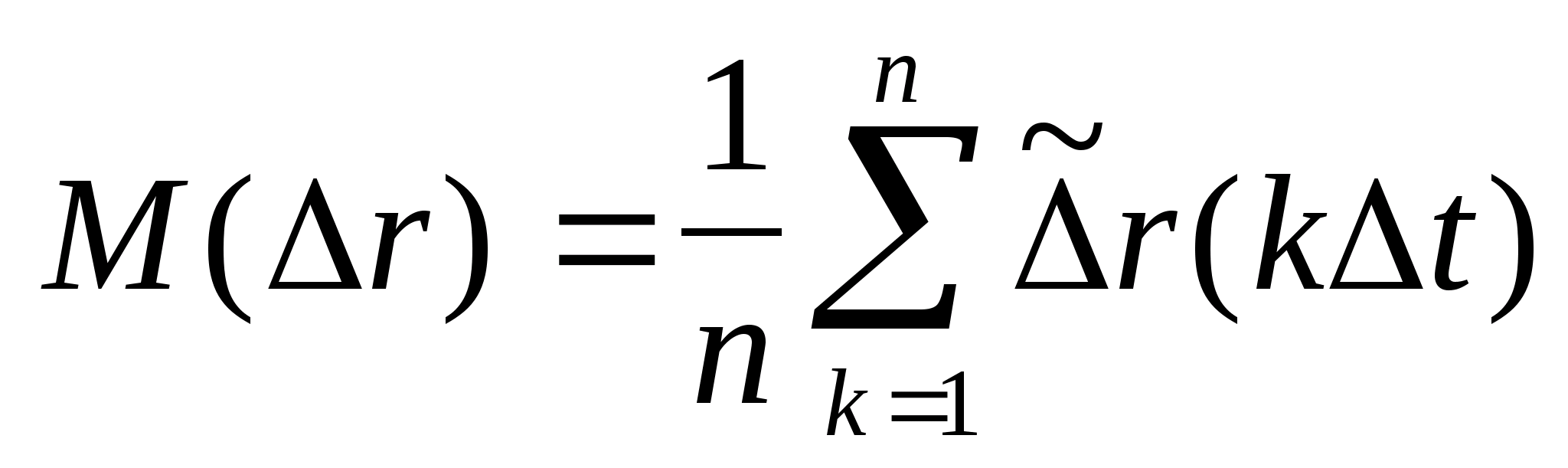
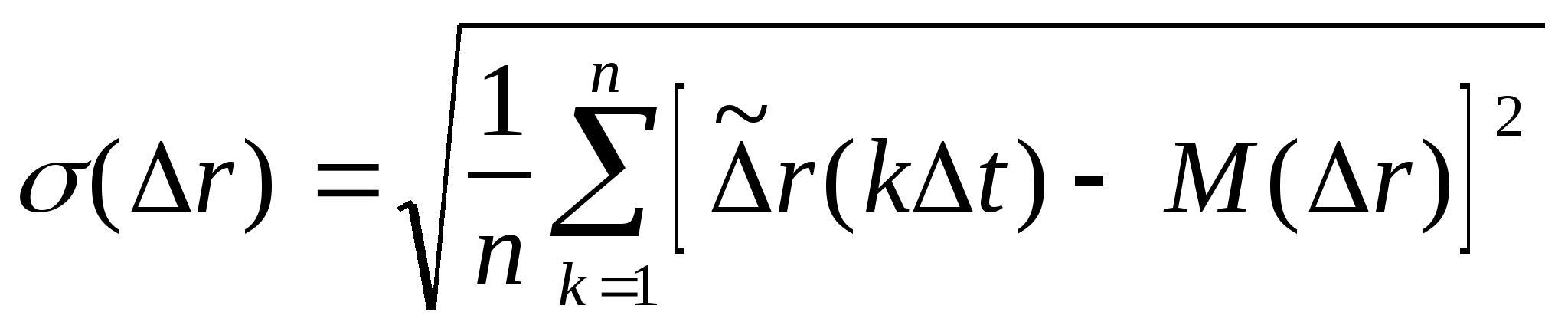
Таким образом, рассмотренные примеры реализации измерителей параметров объекта, а значит и признаков их распознавания, заставляют считать обязательным наличие в составе модели измерителя модуля накопления информации об объекте на некотором интервале времени. Длительность åãî áóäåò åñòåñòâåííî îïðåäåëÿòüñÿ íåîáõîäèìîé òî÷íîñòüþ ïîëó÷àåìûõ îöåíîê, à òàêæå çàâèñèò îò
-типа измерителя, его возможностей обнаружения и устойчивого измерения соответствующего параметра;
-допустимого временного баланса на решение задачи распознавания.
Так радиолокатор начнет измерения радиолокационных характеристик воздушного или космического объекта только после того, как этот объект приблизиться настолько, что соответствующий отраженный сигнал превысит уровень собственных шумов приемного устройства этого радиолокатора.
Датчик температуры начнет ее измерения после достижения ею порога чувствительности его.
Рассмотрев указанные примеры, мы все-таки не охватили другие важные стороны измерителей, на которые должно быть обращено внимание при построении модели. К ним относиться надежность.
Если измеритель вышел из строя или его отказ привел к снижению точности определения параметра распознавания, то ясно, что это приведет к падению эффективности классификации объектов. Следовательно, при моделировании такие ситуации должны быть предусмотрены, а выполнить это достаточно просто, если мы располагаем, например, вероятностью безотказной работы соответствующего средства как паспортной характеристикой. В соответствии с рассмотренным нами методом моделирования случайных событий (метод Монте-Карло) достаточно организовать датчик таких случайных событий как отказ и при выполнении условий выхода из строя запрещать модели измерителя выдавать на выход данные по распознаваемому объекту. Если же отказ приводит только к снижению точности, то в задачи такого модуля должно входить соответствующее изменение характеристик измеренных параметров по сравнению с паспортными.
Проведенное рассмотрение типового состава модели измерителя дает îñíîâàíèÿ ñ÷èòàòü, ÷òî ðåàëüíûå îáúåêòû, ÿâëåíèÿ, ïðîöåññû, ïîäëåæàùèå ðàñïîçíàâàíèþ, à ñîîòâåòñòâåííî è èçìåðèòåëè èõ õàðàêòåðèñòèê, ìîãóò îáëàäàòü øèðîêèì ñïåêòðîì îñîáåííîñòåé. Èìåííî îíè îòðàæàþòñÿ íà ïðèíöèïàõ ïîñòðîåíèÿ ìîäåëè èçìåðèòåëÿ. Ïîýòîìó ðåàëüíî ðàññìàòðèâàåìûå ìîäåëè ìîãóò áûòü è çíà÷èòåëüíî ïðîùå è ñóùåñòâåííî ñëîæíåå. Îäíàêî èçëîæåííûå ïðèíöèïû äàþò îñíîâû ìåòîäîëîãèè, áàçèðóþùåéñÿ íà òùàòåëüíîì àíàëèçå îáúåêòîâ, ÿâëåíèé, ïðîöåññîâ è çàäà÷ èçìåðåíèÿ èõ õàðàêòåðèñòèê, à ïîýòîìó ïîçâîëÿþò íàäåÿòüñÿ íà ó÷åò óêàçàííîé ïðîñòîòû èëè ñëîæíîñòè ïðè ðåàëèçàöèè è îáåñïå÷åíèè èçîìîðôíîãî ïðåäñòàâëåíèÿ ìîäåëåé èçìåðèòåëåé.
5.6.2. Моделирование каналов связи
Немаловажную роль в определении характеристик распознаваемых объектов играют каналы связи. И говоря о том, что главная цель СР - получение информации для решения задач распознавания, указанные каналы можно считать конструктивно присущими таким системам.
В качестве каналов связи могут рассматриваться:
-каналы передачи и приема энергии измерителями, осуществляющими дистанционное измерение характеристик объектов;
-каналы передачи информации измерителя на устройства, осуществляющие ее обработку и использование.
Так, если речь идет об измерителях радиолокационного типа, то здесь каналом названного первого типа является земная атмосфера. Она обладает частотно-избирательными свойствами, пропуская почти без потерь одни волны и задерживая другие. Ослабление и поглощение при этом носит экспоненциальный характер и зависит от протяженности трассы распространения сигналов от радиолокатора до наблюдаемого объекта. Поэтому при достаточно коротких трассах этим ослаблением можно пренебречь. В противном случае любые ослабления сигналов ведут как к снижению дальности наблюдения интересующего объекта, так и к ухудшению точности сопутствующих измерений.
Ионосфера Земли является анизотропной средой, обладающей различными значениями показателя преломления для различных длин волн. В итоге - изменение поляризации, а значит ослабление принимаемого сигнала.
Слоистость атмосферы - причина систематических ошибок измерения óãëîâûõ êîîðäèíàò, äàëüíîñòè è ñêîðîñòè îáúåêòà.
Местные неоднородности атмосферы, обусловленные вихревыми процессами в воздухе, - причина случайных ошибок измерений.
Для ультразвукового локатора, используемого в медицинской аппаратуре УЗИ, слоистость и местные неоднородности тканей человека, частотная зависимость их коэффициента пропускания приводят:
-к затуханию сигнала;
-к поглощению сигнала;
-к рассеянию сигналов;
-к интерференции ультразвуковых колебаний.
Если первые три вызывают неоднородное ослабление отраженного сигнала, несущего информацию о состоянии внутреннего органа человека, то последнее приводят к появлению спекл - шума, затрудняющего наблюдения распознаваемых объектов и являющегося результатом дифракции отраженных от различных неоднородностей сигналов.
Характерно то, что в большинстве случаев исследованию рассматриваемых каналов связи посвящены многочисленные теоретические и экспериментальные работы. При этом достаточно часто указанные воздействия на распространение сигналов измерителей хорошо описываются математически. Для них существуют или теоретические зависимости или в худшем случае эмпирические соотношения, хорошо себя зарекомендовавшие. В каждом конкретном случае канала связи и измерителя эти зависимости и соотношения наполняются своим специфическим содержанием.
Главный вывод из этого рассмотрения - возможность учета искажений информационных сигналов в разрабатываемой модели системы распознавания.
Второй из упомянутых типов каналов передачи информации измерителей - это в большинстве случаев каналы ее ввода в ЭВМ. Здесь главным является, если не учитывать дальность передачи и соответствующее ослабление сигналов, преобразование измеренного значения , представленного в виде тока или напряжения в цифровую форму.
Такое преобразование может осуществляться как стандартными средствами ЭВМ, так и в самом измерителе параметров объектов распознавания.
Речь же о важности выяснения существа указанного преобразования идет потому, что дискретизация всегда вносит ошибки в передаваемый параметр и должна учитываться при моделировании.
Здесь математическое описание достаточно строго и исходит их того, что плотность распределения вероятностей ошибок дискретизации - равномерная с нулевым математическим ожиданием и дисперсией
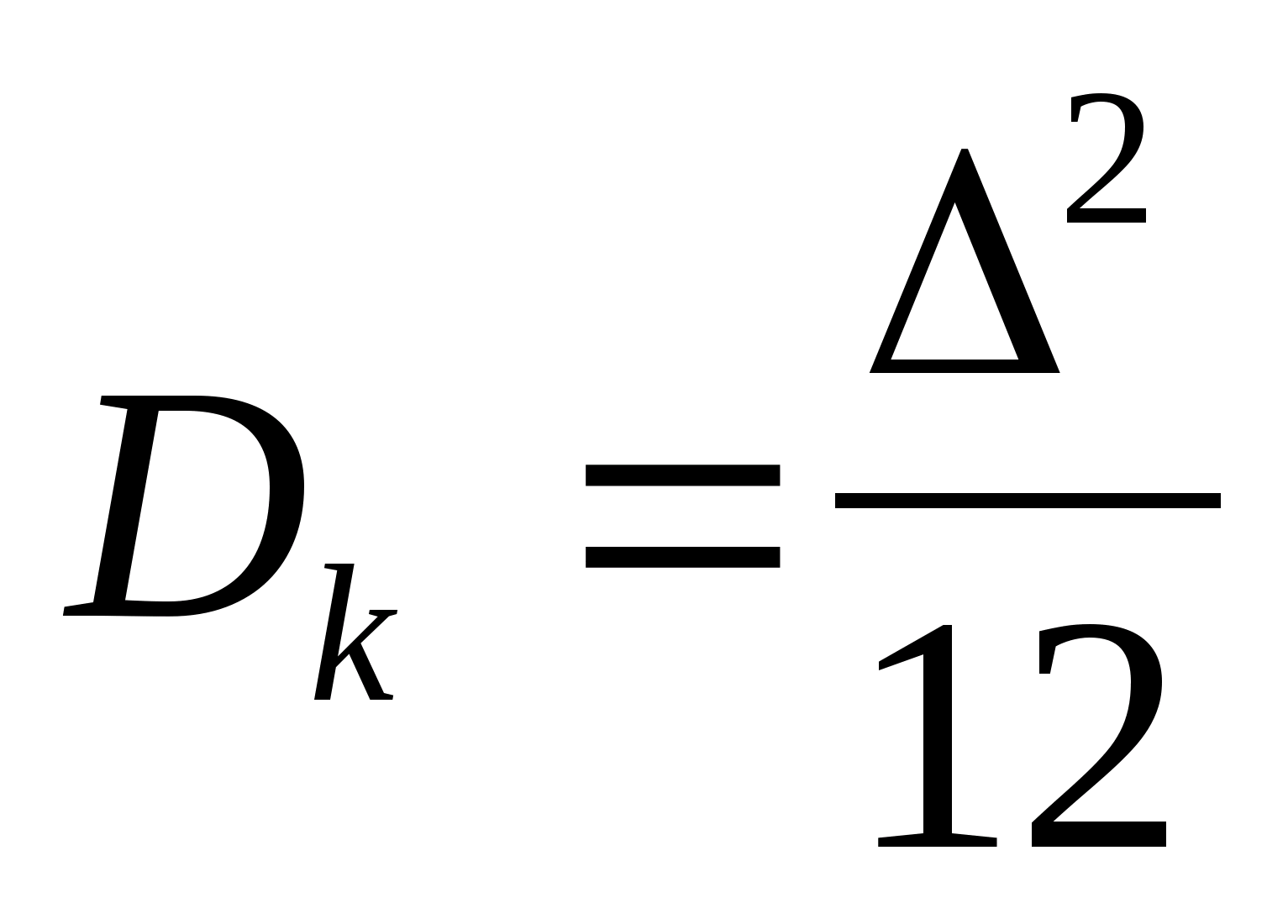
где D - цена младшего разряда преобразования.
Таким образом, рассмотрение показало, что каналы связи, осуществляющие передачу информации зависят главным образом от типа измерителя. Поэтому их включение в модель измерителя в качестве специальных модулей не должно вызывать сомнений.
В итоге типовая функциональная схема модели измерителя может быть представлена следующим образом (Рис.5.6.1).
Динамические характеристики объекта
Модель 1-го измери- Ìîäåëü 2-ãî èçìåðè-
теля òåëÿ

 Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
отказов измери- îòêàçîâ èçìåðè- ....
теля òåëÿ

 Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
начала и продол- íà÷àëà è ïðîäîë-
жительности из- æèòåëüíîñòè èç- ....
мерений ìåðåíèé

Ìîäóëü îöåíêè
Ìîäóëü îöåíêè ....
параметров ïàðàìåòðîâ
 Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
аппаратурных àïïàðàòóðíûõ ....
ошибок îøèáîê

Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
ошибок канала îøèáîê êàíàëà ....
связи ñâÿçè
 Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
Ìîäóëü èìèòàöèè
преобразования ïðåîáðàçîâàíèÿ ....
параметра в циф- ïàðàìåòðà â öèô-
ровой код ðîâîé êîä
Рис.5.6.1. Модель средств измерения характеристик
Л Е К Ц И Я 5.7.
Моделирование алгоритма распознавания
5.7.1. Модель алгоритма распознавания
объектов (явлений, процессов)
О модели алгоритма распознавания следует вести речь в следующих случаях:
1)При программной реализации соответствующего алгоритма не на рабочей ЭВМ, а на ЭВМ, предназначенной только для предварительной его отработки.
2)При отличиях языка программирования модели от языка программирования рабочего алгоритма.
3)При отработке в процессе моделирования принципов построения алгоритма и, в частности, алфавита классов и словаря признаков, а также решающего правила.
4)При различных сочетаниях ситуаций, представленных в пп. 1-3 настоящего перечня.
Если алгоритм системы распознавания реализуется на “своей” ЭВМ в эксплуатационном представлении, то он уже в силу полной изоморфности и аналогичности не представляет собой модель, а является реальной составной частью системы или ее модели (если идет речь о модели системы). В этом случае функциональная схема алгоритма ничем не отличается от схем, приведенных при изучении вопросов их классификации.
Реализация алгоритма распознавания на “своей” ЭВМ совместно с моделью объекта распознавания и средств измерения характеристик представляет собой комбинированную модель СР (реальный программно реализованный алгоритм СР и модели входных воздействий), предназначаемую для оценок:
-правильности функционирования алгоритма СР;
-эффективности системы распознавания, имеющей выбранную структуру и реализацию.
Первая из рассмотренных ситуаций применения моделирования систем распознавания может иметь достаточно широкий спектр задач в процессе создания алгоритма и его отработки, если отсутствуют экономически допустимая возможность его реализации на рабочей ЭВМ или ЭВМ подобного типа.
Точно также существуют условия для возникновения второй ситуации.
Например, желание приспособить готовую программно реализованную СР для другой системы на ЭВМ, где в соответствии с имеющимися требованиями программирование ведется на другом языке или на автокоде, заставляет рассматривать существующую реализацию как модель.
Третья ситуация применения моделей систем распознавания представляется наиболее соответствующей конструирования систем распознавания. В том случае, когда целью моделирования алгоритма является выбор признаков распознавания и алфавита классов, состав модели оказывается наиболее полным по сравнению с другими и поэтому представляющим наибольший интерес.
Главное что отличает такую модель - это наличие модуля описания классов на языке признаков. Забегая вперед, можно заметить, что подобный модуль может быть и принадлежностью рабочего алгоритма СР. Наиболее это очевидно для обучающихся систем распознавания.
Алгоритм функционирования модуля описания классов на языке признаков в максимальной степени интересен для вероятностных систем распознавания. Другие системы имеют более простую и очевидную реализацию.
На начальной стадии модельной отработки вероятностной СР имеем дело с m классами и N признаками распознавания .В дальнейшем их число может быть изменено. Для этого и проводится моделирование.
Òîãäà, êàê èçâåñòíî, îïèñàíèå êàæäîãî èç êëàññîâ ïðåäñòàâëÿåòñÿ òàê:
_
Êëàññ 1 : f(X/W>1>) и P(W>1>)
_
Класс 2 : f(X/W>2>) и P(W>2>)
_
Класс 3 : f(X/W>3>) и P(W>3>)
..............................
_
Класс m : f(X/W>m>) и P(W>m>)
При независимости всех N признаков обычно имеем:
_ _ _ _
f(X/W>1>) = f(X>1>/W>1>)*f(X>2>/W>1>)*....*f(X>N>/W>1>)
_ _ _ _
f(X/W>2>) = f(X>1>/W>2>)*f(X>2>/W>2>)*....*f(X>N>/W>2>)
.......................................
_ _ _ _
f(X/W>m>) = f(X>1>/W>m>)*f(X>2>/W>m>)*....*f(X>N>/W>m>)
Êàê
âèäèì, èñõîäíûìè äàííûìè äëÿ îïèñàíèÿ
êëàññîâ N ïðèçíàêàìè ÿâëÿþòñÿ â ýòîì
ñëó÷àå ÷àñòíûå îïèñàíèÿ êàæäîãî èç
êëàññîâ ïî êàæäîìó ïðèçíàêó
f(X>j>/W>i>), где j = 1,N
Отсюда понятно, что если j-ый признак распознавания имитируется в модели объекта ( а у нас такая имитации будет предусмотрена), то при достаточном количестве запусков модели (числе испытаний) получим в каждом заранее известном классе ряд измерений
{X>jk>} k = 1, N>исп>
Отсюда статистической обработкой может быть получена сначала гистограмма плотности распределения вероятностей
f(X>j>/W>i>)
Затем аппроксимация этой плотности теоретическим непрерывным распределением (например нормальным) дает требуемое частное описание i-го класса по данному j-му признаку. Точно также получаются частные описания всех классов по каждому из признаков. Они и обеспечивают при указанной независимости признаков начальное описание всех классов.
Таким образом, отсюда понятно, что в составе модуля описания классов модели СР должен находиться субмодуль восстановления плотностей распределения вероятностей признаков в каждом из назначенных классов, реализующий рассмотренный алгоритм.
Обратим теперь внимание на то, что число классов и число признаков в соответствии с имеющимися представлениями о создании СР в исходном состоянии должно быть максимально возможным. Число классов - так как всегда есть стремление к максимальной детализации решений. Число признаков - так как их максимуму соответствует максимум вероятности правильной классификации.
В соответствии с этим модель СР может быть использована для оценки результативности увеличения числа признаков, введения новых. Здесь без дополнения ее путем доработок не обойтись. Ну, а все последующие шаги оптимизации СР, обеспечивающей максимум вероятности правильной классификации, связываются, во-первых, с выбором такого числа признаков, которое удовлетворяло бы имеющимся ограничениям на создание средств измерений и обработки информации. Таким образом, здесь уже имеем дело с противоположной тенденцией - ограничением числа признаков (исключением менее эффективных), но при стремлении сохранить достигнутую эффективность на полном их наборе.
Следовательно, во-вторых, в задачи оптимизации должны входить действия по компенсация потерь от уменьшения числа признаков, которые сопровождаются, как мы уже доказали, только уменьшением числа классов в исходном алфавите.
В результате сокращения числа признаков сокращенное описание будет иметь вид:
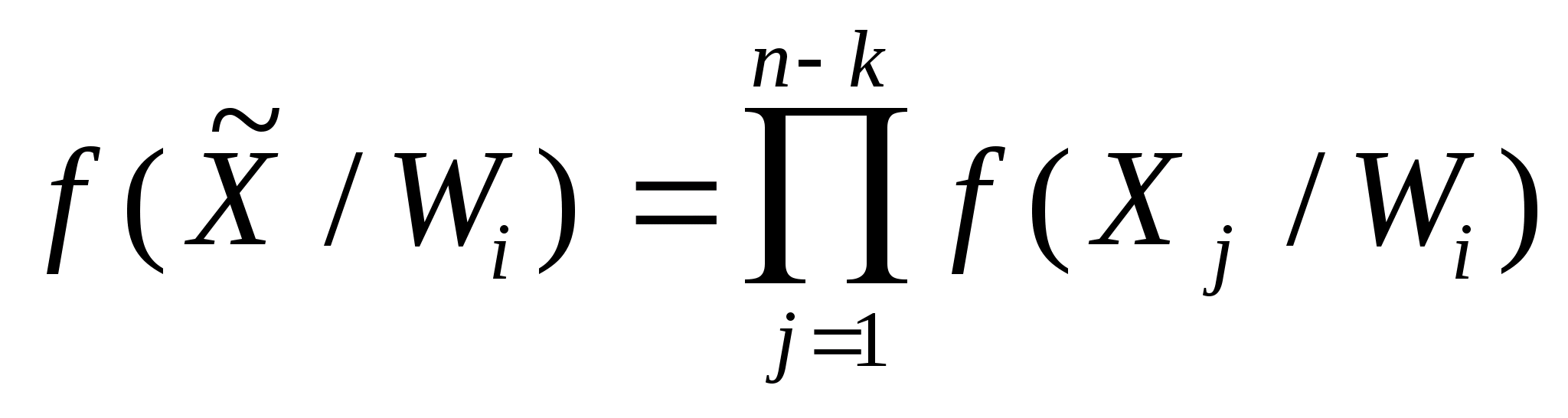
где k - число исключенных признаков распознавания из i-го класса
i = 1,(m-l)
l - число исключенных классов.
Причем здесь предполагается, что после отбора в состав вектора признаков тех, которые удовлетворяют предъявленным ограничениям, производится повторное описание классов .
Когда же есть необходимость уменьшить число классов, то исключаемые из алфавита классы вынужденно объединяются с теми оставшимися в его составе, для которых такое объединение не принесет увеличения числа ошибочных решений в системе. Тогда при объединении, например, двух классов (p-го и q-го) и тот и другой исчезают из алфавита и появляется один новый (m+1)-ый с описанием:
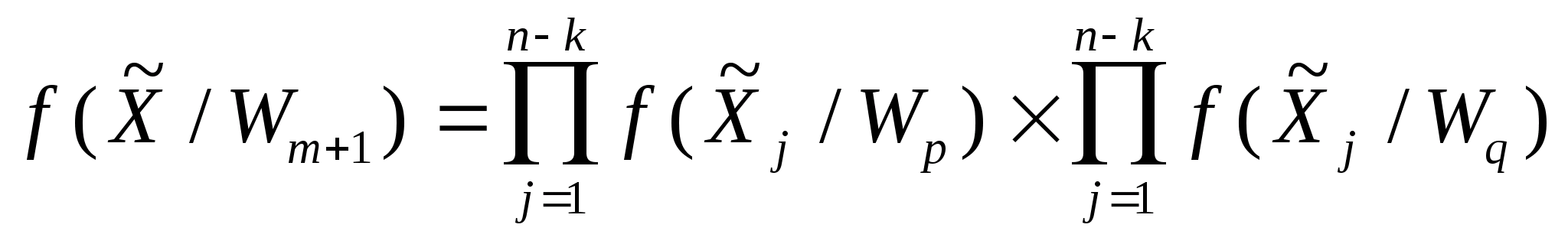
и
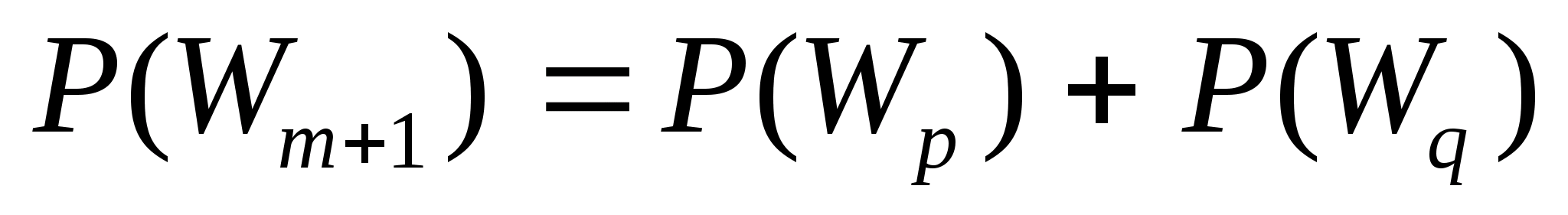
Естественно, что тогда (после исключения) последней алгоритмической функцией в модуле описания классов должна быть функция их перенумерации в новом составе.
Таким образом, последовательность алгоритмических действий модуля описания классов включает:
1)Расчет одномерных плотностей распределения вероятностей каждого из признаков по классам по репрезентативной выборке реализаций измеренных значений (при моделировании объектов и измерителей).
2)Исключение из описаний одномерных плотностей распределения при сокращении размерности вектора признаков.
3)Перекомпоновка плотностей описания классов и априорных вероятностей при сокращении числа классов.
4)Перенумерации классов после объединения отдельных.
Учитывая тот факт, что при имеющихся ограничениях на создание средств измерений и (или) средств обработки приходится варьировать наборами признаков, рассмотренный модуль описания классов должен повторять функции 2-го пункта при каждом новом наборе.
Наличие рассмотренного модуля в составе модели СР предъявляет определенные требования к его окружению. Во-первых, для каждого нового описания классов необходимо в качестве входной информации модуля иметь используемый в данной серии испытаний вектор отбора признаков. При решении задачи объединения классов в качестве входной информации модуля необходимо иметь решение в виде номеров классов, назначенных к объединению. В соответствии с этим модуль обеспечивает:
-повторное описание классов при каждом новом векторе отбора;
-описание объединенных классов после испытаний системы распознавания для одного состава алфавита (перекомпоновка векторов-признаков при их независимости).
Если первая из приведенных задач решается автоматически исключением признаков, то вторая не может быть решена без оценки эффективности СР в данной серии испытаний. То есть, решается после проведения испытаний с данным вариантом алфавита во всем диапазоне допустимых векторов отбора признаков распознавания.
5.7.2. Ìîäóëü îöåíêè ýôôåêòèâíîñòè ñèñòåìû ðàñïîçíàâàíèÿ
Оценка эффективности СР, как это следует из самого понятия “эффективность”, представляется необходимым элементом модели СР в целом, позволяющим ответить на вопрос, каково качество или созданной системы или системы после ее очередных доработок (изменений алфавита классов и словаря признаков распознавания), осуществляемых в процессе оптимизации.
В том случае, когда решение системы зависит от многих факторов, имеющих случайный характер, показателями, характеризующими оптимальность, являются вероятности правильных и ошибочных решений. Отсюда целесообразным для конструкции модели оценки эффективности должен быть субмодуль оценки вероятностей решений системы.
К основным данным для формализации такого субмодуля относятся исходы модельных испытаний. Они представляют собой решения о принадлежности при известной принадлежности классифицируемого объекта в каждом испытании.
Поэтому работа алгоритма субмодуля в рассматриваемой части заключается в фиксации решений и истиной принадлежности объекта в некоторой матрице решений:
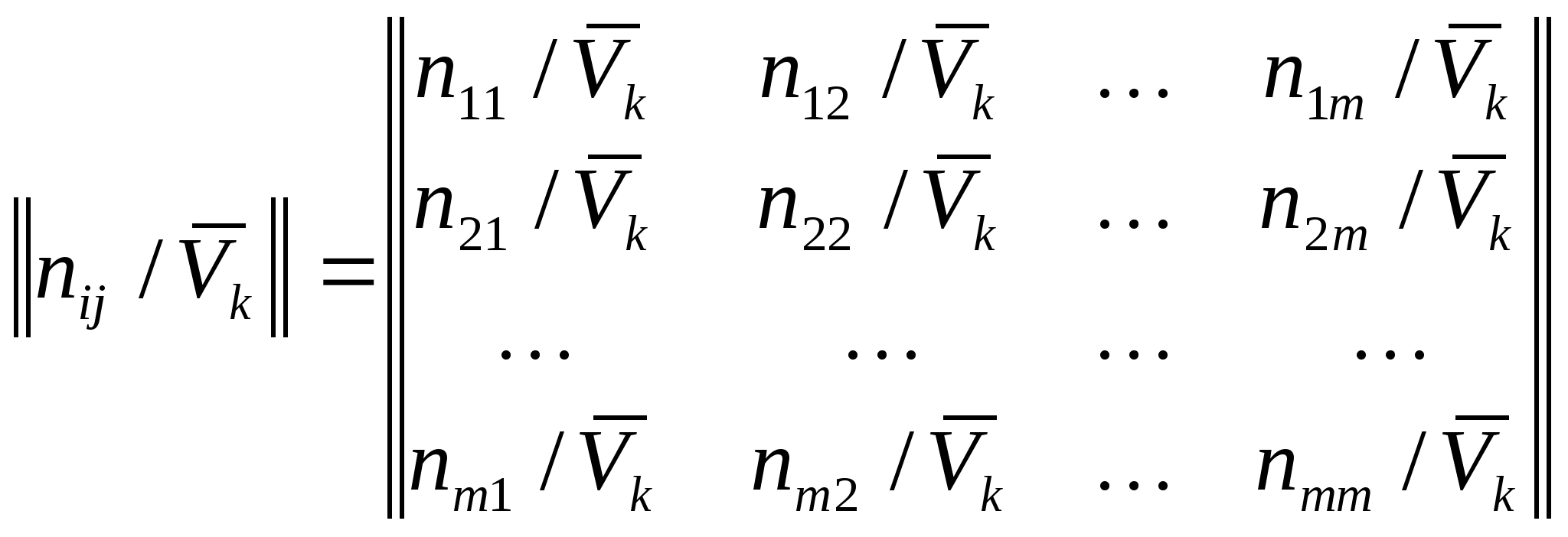
где n>ij>/V>k> - число отнесений объекта j-го класса (известного при организации моделирования) к классу i.
Число таких матриц после испытаний СР для каждого вектора отбора V>k> равно числу таких векторов, удовлетворяющих ограничениям средств на создание или использование систем измерений признаков распознавания. Если же имеем дело с оценкой конкретной структуры системы распознавания, то естественно будем иметь всего одну матрицу для заданного конкретного набора признаков распознавания.
В любом случае эти матрицы легко преобразуются в матрицы вероятностей соответствующих решений (точнее, частот, сходящихся к вероятности с заданной точностью при специально выбранном количестве модельных испытаний).Тогда для алфавита классов A>r> èìååì:
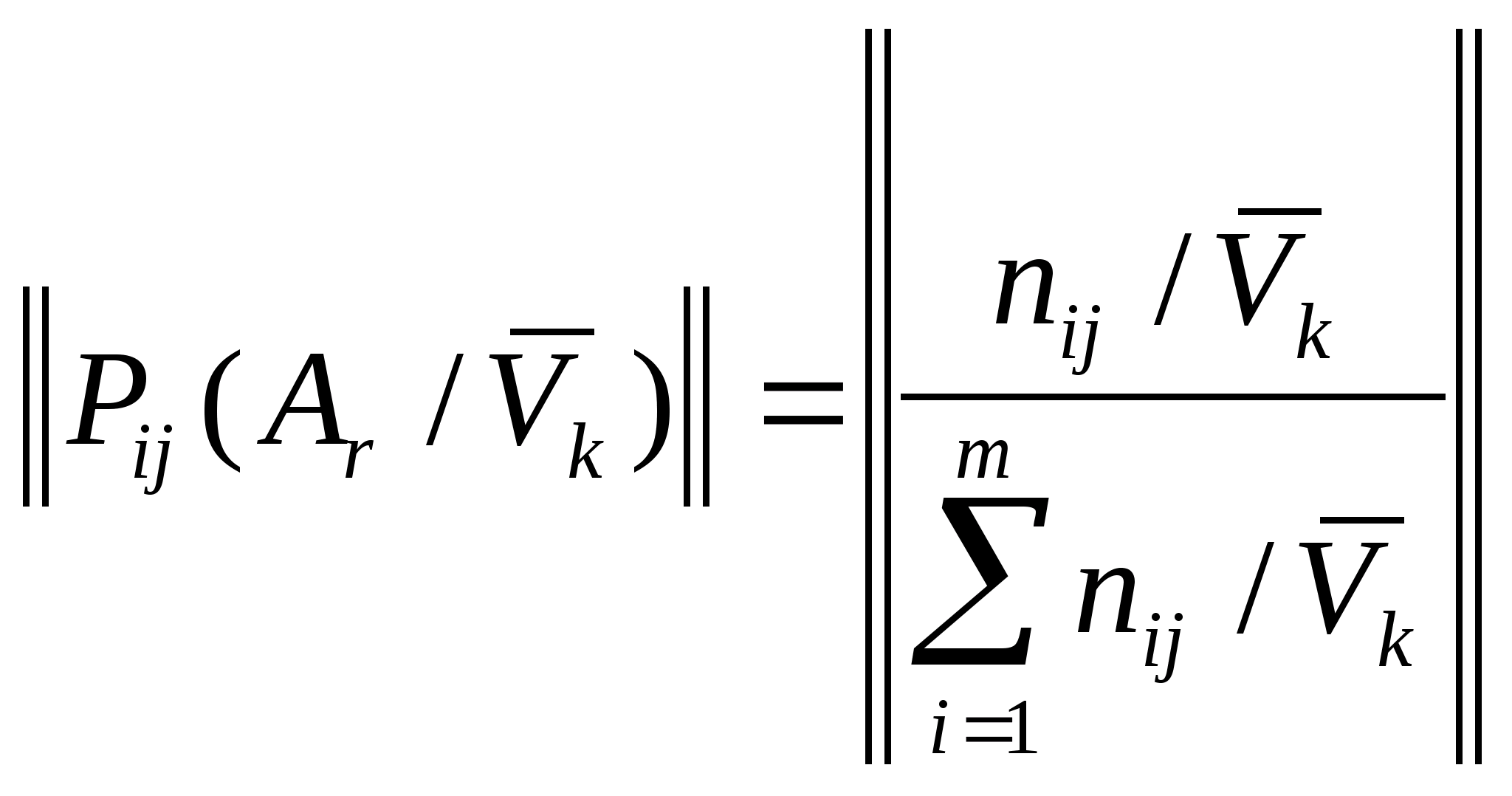
Эта простота конечной оценки показателей функционирования системы как раз и является характерной особенностью метода статистических испытаний (метода Монте-Карло).
Отсюда может быть получена вероятность правильных системных решений в целом (то есть, отнесений ко всем классам алфавита):
>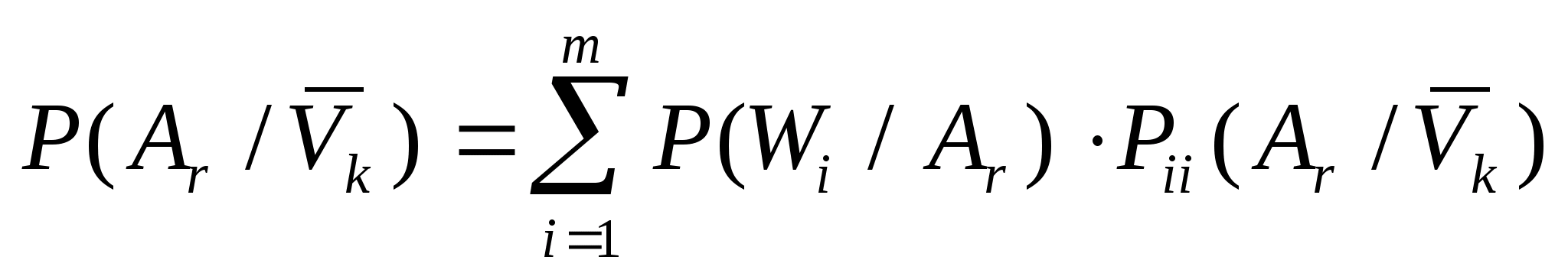 >
>
На этом при оценке эффективности СР с конкретной детерминированной структурой моделирование завершается и рассмотренным субмодулем ограничивается структура модуля оценки эффективности.
Если же существует необходимость оптимизации, то возникает необходимость дополнения модели оценки эффективности субмодулем выбора оптимального набора признаков распознавания. . Его алгоритм очевиден:
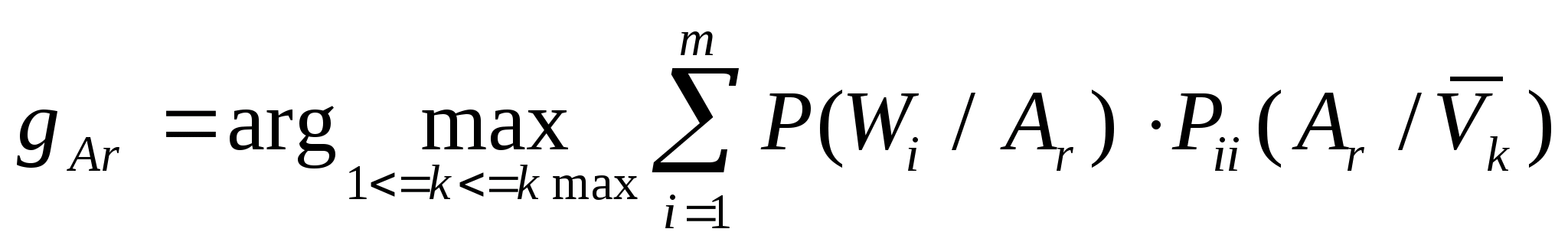
_
То есть, g-ый вектор отбора (V>g>) обеспечивает максимальную вероятность правильных системных решений в алфавите A>r>.
Теперь матрица вероятностей соответсвует любым системным решениям для найденного оптимального набора признаков распознавания. В результате появляется возможность определить в данном алфавите класс g, объекты которого классифицируются в максимальной степени ошибочно.
Соответствующую вероятность находим как ìàêñèìàëüíóþ âåðîÿòíîñòü îøèáêè:
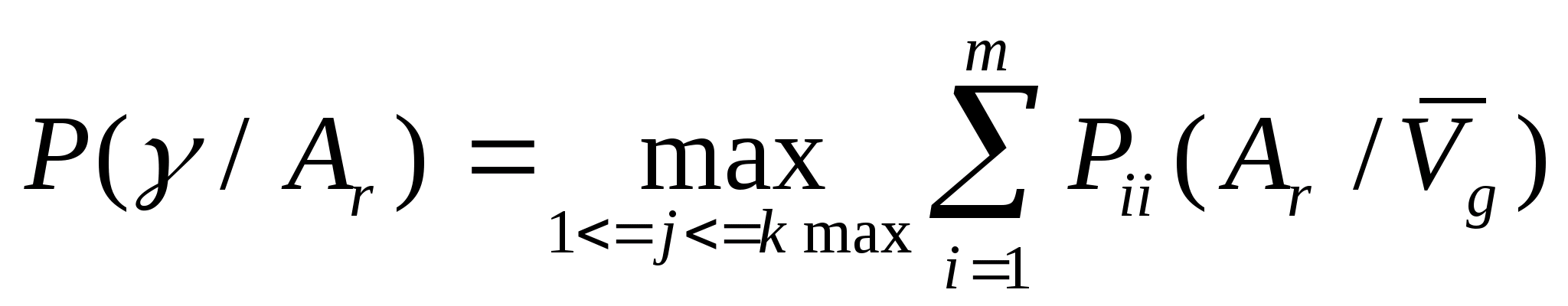
откуда номер упомянутого класса:
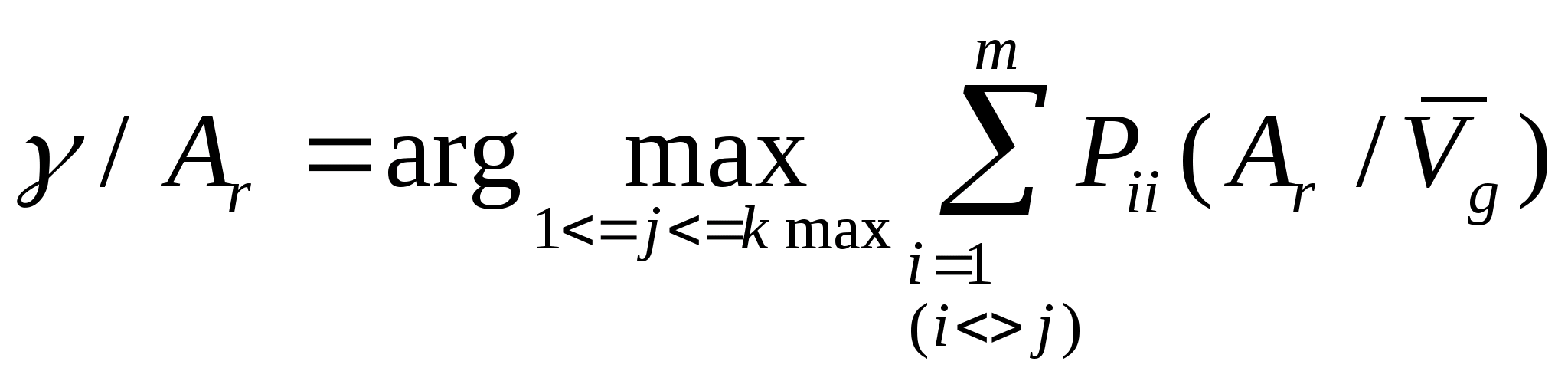
Если теперь задаться порогом вероятности P( g)>зад>, то появляется возможность при P( g/Ar) > P( g)>зад> принять решение о необходимости исключения из алфавита A>r> класса с номером g , эффективность отнесения к которому ниже требуемой (заданной).
Отсюда все операции, связанные с определение такого класса (номера его через вероятность ошибочного отнесения), могут быть объединены в отдельном субмодулем- поиска класса, снижающего эффективность распознавания.
Наконец, та же матрица
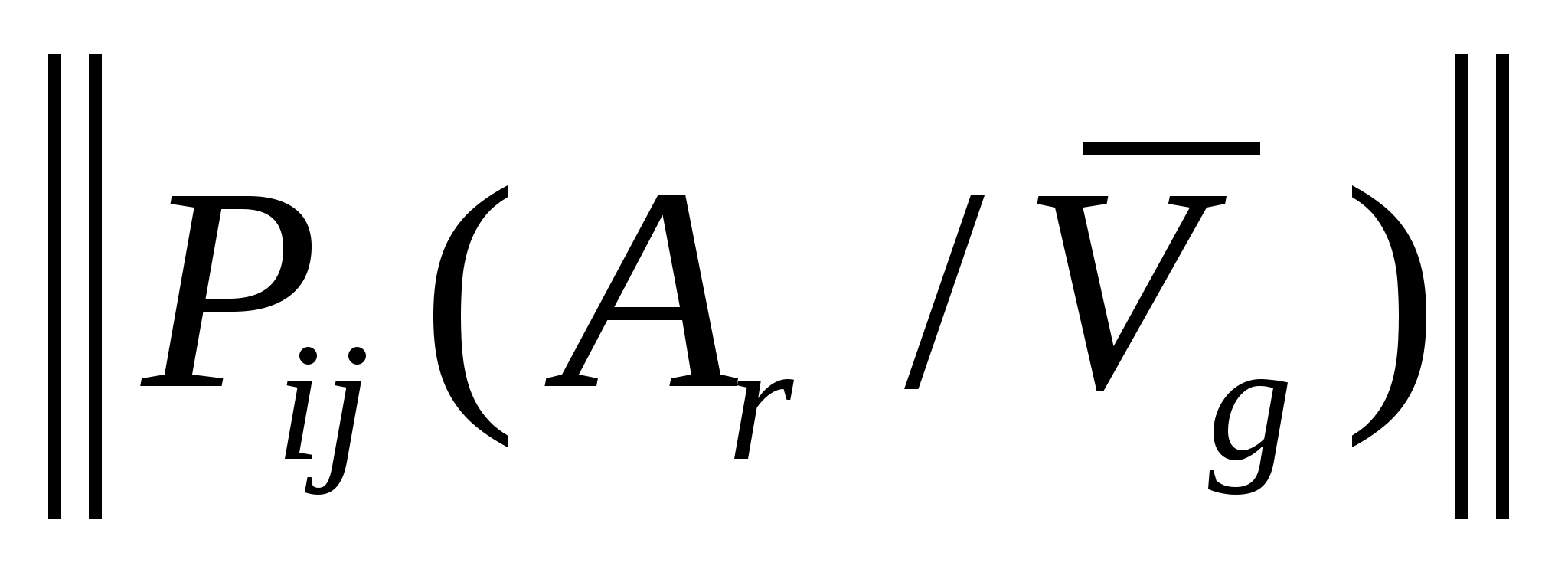
позволяет выделить такой класс, отнесение к которому объектов найденного низкоэффективного класса наиболее целесообразно для повышения эффективности системных решений. Номер такого класса соответствует максимальной вероятности отнесения к нему указанного низкоэффективного класса. То есть:
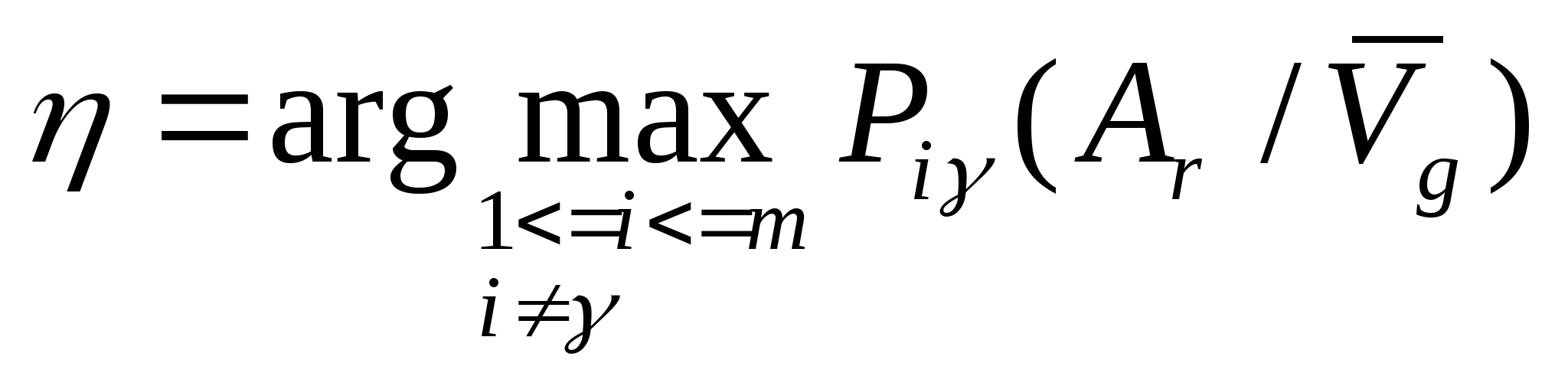
Эти операции можно поручить отдельному субмодулю, выходом которого должны быть номера классов g и h , которые следует объединить в алфавите A>r>, чтобы повысить эффективность СР в целом. Он может быть назван субмодулем определения номеров объединяемых классов.
 ðàññìàòðèâàåìîì ñîñòàâå (Ðèñ.5.7.1.) ìîäóëü îöåíêè ýôôåêòèâíîñòè óäîâëåòâîðÿåò ïîòðåáíîñòÿì êàê îöåíêè êà÷åñòâà ÑÐ, òàê è ïîòðåáíîñòÿì óïðàâëåíèÿ îïòèìèçàöèåé ÑÐ â óñëîâèÿõ îãðàíè÷åíèé ñðåäñòâ íà ñîçäàíèå èçìåðèòåëåé.
Ñàìè ôóíêöèè óïðàâëåíèÿ ìîäåëüþ ÑÐ íåîáõîäèìî îáúåäèíèòü â îòäåëüíîì ìîäóëå.
¹ ðàñïîçíàííîãî êëàññà
Субмодуль оценки № имитируемого
ðåçóëüòàòà ðàñïî- êëàññà
знавания (от модели объекта)
 A>r>
i,j
A>r>
i,j
Ñóáìîäóëü ðàñ÷åòà _
îò ìîäóëÿ ìàòðèöû ðåøåíèé V>k>
óïðàâëåíèÿ (îò ìîäóëÿ óïðàâëåíèÿ)
||
n>ij>/V >k> ||
 Ñóáìîäóëü ðàñ÷åòà
Ñóáìîäóëü ðàñ÷åòà
è õðàíåíèÿ ìàòðèö
íà ìîäóëü âåðîÿòíîñòåé ðå-
óïðàâëåíèÿ øåíèé
|| P>ij> (A>r> /V>k> ) ||
Субмодуль опреде-
ëåíèÿ îïòèìàëüíî-
на модуль го набора призна-
управления ков в алфавите A>r>
 g>Ar>
g>Ar>
Ñóáìîäóëü ïîèñêà
íåýôôåêòèâíî ðàñ-
íà ìîäóëü ïîçíàâàåìîãî
óïðàâëåíèÿ êëàññà
è ìîäóëü P( g/A>r>) è g/A>r>

 îïèñàíèÿ
îïèñàíèÿ
êëàññîâ Ñóáìîäóëü ðåøåíèÿ Ñóáìîäóëü îïðåäå-
îá èñêëþ÷åíèè g-го ëåíèÿ ðàñøèðÿåìî-
класса го класса (h )
Рис.5.7.1. Модуль оценки эффективности
5.7.3. Модуль управления моделью системы распознавания
Из рассмотрения общих принципов моделирования сложных систем, а òàêæå ñîñòàâà è îñîáåííîñòåé ïîñòðîåíèÿ ìîäåëè ÑÐ ñëåäóåò, ÷òî â îáùèõ ÷åðòàõ äèíàìèêà ìîäåëèðîâàíèÿ ñèñòåìû ðàñïîçíàâàíèÿ ïðåäñòàâëÿåò ñîáîé
-многократно повторяющийся ( с каждым пуском программы модели) процесс выбора распознаваемого объекта;
-многократно повторяющийся процесс имитации работы измерителей параметров по каждому моделируемому объекту и штатной обработки полученной информации с целью получения признаков распознавания;
-многократно повторяющийся ( для каждого выбранного объекта распознавания) процесс штатного принятия решения о принадлежности предъявленного объекта;
-статистическую обработку принятых решений в каждом из пусков программы модели как источник определения показателя качества СР в целом.
Первая из приведенных функций, задающая весь процесс функционирования программы модели в каждом пуске, реализуется в виде:
-первоначального пуска программы модели испытателем с исходными требованиями, введенными им предварительно;
-автоматического повторения заданного числа циклов пуска программы для реализации повторений процесса распознавания в соответствии с методологией статистических испытаний;
-своевременной выдачи необходимых исходных данных для ввода в отдельные субмодули модели для организации их работы по заранее введенным и хранимым данным или по результатам выполненной работы другими субмодулями.
Все остальные функции, характеризующие динамику модели СР в целом, должны выполняться автоматически в рассмотренной последовательности. То есть, первая функция объединяет фактически все задачи управления моделью. Выполнение ее логично возложить на отдельный модуль - модуль управления. .
Общее рассмотрение реализации модуля управления позволяет обратить внимание на задачу связи испытателя с моделью системы. При этом ðàññìàòðèâàÿ àëãîðèòìè÷åñêîå ñîäåðæàíèå óæå îïèñàííûõ ìîäóëåé, âõîäÿùèõ â ñîñòàâ ìîäåëè, ìîæíî çàêëþ÷èòü, ÷òî ìîäóëü óïðàâëåíèÿ äîëæåí èìåòü èíòåðôåéñ, ïîçâîëÿþùèé ââîäèòü äëÿ îðãàíèçàöèè ìîäåëèðîâàíèÿ òàêèå èñõîäíûå äàííûå, êàê
-количество статистичесих испытаний (пусков) на модели системы;
-исходный априорный алфавит классов;
-априорные вероятности предполагаемых классов;
-допустимое значение вероятности ошибочной классификации.
Кроме того, тот же интерфейс должен обеспечить представление испытателю по его требованию индикации:
-реализаций измеренных характеристик (признаков) моделируемых объектов;
-поэтапных значений (для каждого алфавита классов и набора признаков распознавания) показателя эффективности системы;
-состава алфавита классов и параметров их описания;
-текущего состояния отбора признаков в рабочий словарь.
Теперь можно детализовать отдельные детали управления. Так модуль óïðàâëåíèÿ äîëæåí îáåñïå÷èâàòü
-автоматическое повторение решений полного объема задач испытаний на модели со сменой вектора отбора признаков распознавания (если заданы ограничения на средства создания и использования средств измерений);
-автоматический переход к анализу эффективности всех вариантов рабочего словаря после завершения испытаний со всеми возможными векторами отбора;
-автоматический переход к выполнению корректировки алфавита классов после выполненного анализа ошибок классификациии;
-автоматическое повторение циклов полного объема испытаний после корректировки алфавита классов.
А отсюда логически вытекает, что задание (генерация) векторов отбора, удовлетворяющих заданным ограничениям, вполне соответствует ôóíêöèÿì óïðàâëåíèÿ. Òî åñòü, ýòà çàäà÷à äîëæíà ðåøàòüñÿ ìîäóëåì óïðàâëåíèÿ, êîòîðûé îáÿçàí èìåòü ñîîòâåòñòâóþùèå èñõîäíûå äàííûå ïî îãðàíè÷åíèÿì âûäåëåííûõ ñðåäñòâ è çàòðàòàì íà ñîçäàíèå èëè ïðèìåíåíèå îòäåëüíûõ èçìåðèòåëåé.
Перечисленные функции должны быть алгоритмически дополнены функцией обучения системы на информации об объектах, имитируемой соответствующим модулем модели. Работа в указанном режиме может осуществляться как при первом пуске модели для первоначального описания классов, так и при любой смене алфавита классов и словаря признаков.
Обобщенная структурная схема модуля управления приведена на рис 5.7.2, а общая структурная схема модели СР без детализации рассмотренных модулей и субмодулей - на рис.5.7.3.

 Îò ìîäóëÿ
Îò ìîäóëÿ
обработки Субмодуль вывода Субмодуль ввода P(W>i>)
õàðàêòåðèñòèê èñõîäíûõ äàííûõ A>r>
èçìåðåíèé îáúåêòà ðàñïîçíà- è óïðàâëåíèÿ îòî- P(g)>з>
âàíèÿ áðàæåíèåì
Îò ìîäóëÿ Ñóáìîäóëü îòîáðà- Ñóáìîäóëü ãåíåðà- _
 æåíèÿ ïðîöåññà
öèè äîïóñòèìûõ V>k>
æåíèÿ ïðîöåññà
öèè äîïóñòèìûõ V>k>


 îöåíêè ýô- ìîäåëèðîâàíèÿ
âåêòîðîâ îòáîðà
îöåíêè ýô- ìîäåëèðîâàíèÿ
âåêòîðîâ îòáîðà
ôåêòèâíî-
ñòè è äð.
Субмодуль управ-
ëåíèÿ îïèñàíèåì Íà
 êëàññîâ ìîäóëü
êëàññîâ ìîäóëü
описания
классов
Ñóáìîäóëü óïðàâ-
ления циклом ис-
ïûòàíèé ñèñòåìû Íà
ìîäóëü
имитации объектов
Субмодуль управ-
ëåíèÿ îöåíêîé ýô-
ôåêòèâíîñòè
На модуль
оценки
эффективности
Рис. 5.7.2. Обобщенная структурная схема модуля управления ìîäåëüþ

 èíôîðìàöèÿ, óïðàâëåíèå
P(g)>з>
èíôîðìàöèÿ, óïðàâëåíèå
P(g)>з>
Ìîäóëü óïðàâëåíèÿ
ìîäåëüþ A>r>
A>r>
V>k>
Модуль имитации
îáúåêòîâ ðàñïîç-
 íàâàíèÿ
íàâàíèÿ
Модуль измерите-
ëåé õàðàêòåðèñòèê
объектов
Модуль отбора
признаков распоз-
навания
 A>r>
A>r>
 Ìîäóëü îïèñàíèÿ Ìîäóëü
ïðèíÿòèÿ
Ìîäóëü îïèñàíèÿ Ìîäóëü
ïðèíÿòèÿ
êëàññîâ ðåøåíèé î ïðè-
íàäëåæíîñòè

 h g
h g
Ìîäóëü îöåíêè
ýôôåêòèâíîñòè
Рис.5.7.3. Общая структурная схема модели СР
Л Е К Ц И Я 5.8
Опытно-теоретический метод в задачах создания систем распознавания
5.8.1. Использование принципов опытно-
теоретического метода при моделировании СР
Назначение опытно-теоретического метода - испытания сложных систем во всем факторном пространстве их функционирования.
Системы распознавания образов являются обычно составной частью сложных технических систем. Поэтому испытания самих сложных систем обеспечивают, как правило, и испытания СР.
Главное, что объединяет информационно системы распознавания и сложные системы, в состав которых они входят, это - объекты распознавания и средства измерений характеристик этих объектов. Причина такого пересечения систем очевидна и состоит в том, что сложные системы обеспечивают принятие решений по определенным объектам (процессам, явлениям), а распознавание этих же объектов (явлений, процессов) всегда направлено на получение дополнительной информации для принятия указанных решений.
Отсюда казалось, что занимаясь системами распознавания, можно было бы не интересоваться опытно-теоретическим методом, отдать его на откуп специалистам-испытателям сложных систем. При этом, если не учитывать неотъемлемое использование в составе СР средств измерений ( а они нужны сложной системе и без задач распознавания), то сама СР не выглядит как сложная.
Однако часто СР разрабатываются либо после создания систем принятия решений, являющихся сложными, либо самостоятельно в расчете на перспективное использование в какой-либо предметной области. То есть, в этих случаях разработчики СР встречаются с тем, что или не располагают изоморфными моделями объектов распознавания и средств измерений (они не были нужны разработчикам сложных систем) или просто лишены этих данных, так как предметная область применения СР еще не определилась. Поэтому и в первом и во втором (после определения предметной области) случаях становится важным для всесторонних оценок характеристик этих систем взгляд с позиций опытно-теоретического метода на упомянутое пересечение систем - объекты распознавания и средства измерения их параметров. Это обращение к опытно- теоретическому методу заставляет разработчиков СР самостоятельно идти по пути создания изоморфных моделей объектов и измерителей. В результате объединение модели СР с упомянутыми моделями уже представляется как сложная система со всеми вытекающими последствиями по ее испытаниям.
Дополнительно к изложенному можно заметить, что в соответствии с приведенными в нашем курсе определением главной задачей СР является получение информации об объекте распознавания. А это как раз и оправдывает объединение программно реализованного алгоритма распознавания с моделями объекта и измерителей при испытаниях системы распознавания.
Само моделирование объектов (явлений, процессов) распознавания почти всегда представляет собой достаточно объемную и сложную задачу. Примером может служить хотя бы разработка модели системы распознавания речевых сообщений. Объект распознавания здесь - это в конечном итоге состояния речевого аппарата человека при производстве колебаний звукового диапазона. Сложность этого аппарата, его динамики не позволяет надеяться на легкое создание безупречной модели. При этом опытно-теоретический метод испытаний остается единственным в достижении высокой достоверности результатов отработки соответствующей СР на модели. А без всесторонних испытаний во всем факторном пространстве применения подобных систем, особенно для принятия решений высокой ответственности, не представляется возможным обойтись. Поэтому здесь создание изоморфных реальному речевому аппарату синтезаторов речи - это одновременно и путь создания эффективных СР.
Можно найти достаточное число примеров из других областей науки и òåõíèêè, êîòîðûå ïîäòâåðäÿò, ÷òî óñòðàíÿòüñÿ îò èñïîëüçîâàíèÿ ïðèíöèïîâ îïûòíî-òåîðåòè÷åñêîãî ìåòîäà ïðè ñîçäàíèè ÑÐ íå òîëüêî íåöåëåñîîáðàçíî, íî è îøèáî÷íî.
Отсюда арсеналом средств разработчика СР при создании моделей объектов и измерителей должны быть следующие принципы опытно-теоретического метода:
1).Построение общей топологии модели СР, включая источники информации, и проведении ее декомпозиции.
2).Распределение задач между моделями и определение состава частных моделей.
3).Выбор и обоснование способов приближения моделей к реальным моделируемым объектам и измерителям их характеристик.
4).Выбор условий проведения и планирование натурных испытаний èíôîðìàöèîííûõ ñðåäñòâ ÑÐ.
5).Обоснование объема экспериментов и проведение натурных испытаний информационных средств СР для оценки степени близости моделей и реальных объектов и измерителей.
6).Проведение параметрической и структурной доработок модели информационных средств СР на основе сравнения в одинаковых условиях результатов реальных испытаний и моделирования.
7).Проверка статистической совместимости моделей и соответствующих информационных средств в выбранных точках факторного пространства состояний объектов распознавания и измерителей их характеристик.
8).Проведение испытаний СР на моделях, определение характеристик качества программно ðåàëèçîâàííûõ àëãîðèòìîâ, ôóíêöèîíàëüíîãî âçàèìîäåéñòâèÿ ýëåìåíòîâ ñèñòåìû è åå ýôôåêòèâíîñòè âî âñåé îáëàñòè ôàêòîðíîãî ïðîñòðàíñòâà.
В целом опытно-теоретический метод подход к испытаниям сложных ñèñòåì è åãî ïðèíöèïû îñíîâûâàþòñÿ íà öåëîì ðÿäå òåîðåòè÷åñêèõ ïîëîæåíèé, ðåøåíèé è âûâîäîâ, êîòîðûå ìîãóò áûòü ðàññìîòðåíû òîëüêî â îòäåëüíîì êóðñå. Íàøà çàäà÷à - ïîêàçàòü ëîãè÷åñêóþ ïðèåìëåìîñòü ýòîãî ïîäõîäà ê ìîäåëèðîâàíèþ ÑÐ è àäðåñîâàòü áóäóùåãî ðàçðàáîò÷èêà ê òàêèì ìàòåðèàëàì, èçëàãàþùèì ñîîòâåòñòâóþùèå ìåòîäû, êàê
1. Н.П.Бусленко. Теория больших систем. М.,”Наука”, 1969.
2. А.С.Шаракшанэ, И.Г.Железнов и др.
Ñëîæíûå ñèñòåìû. Ì.,”Âûñøàÿ øêîëà”, 1977.
3. Г.И.Бутко,Ю.П.Порывкин и др.
Îöåíêà õàðàêòåðèñòèê ñèñòåì óïðàâëåíèÿ ëåòàòåëüíûìè àïïàðàòàìè. Ì.,”Ìàøèíîñòðîåíèå”, 1984.
5.8.2. Моделирование в задачах создания
и оптимизации систем распознавания
После того, как рассмотрены основные принципы построения моделей сложных систем и их испытаний с использованием моделирования, не сложно понять, на каком этапе создания СР может и должна появляться соответствующая модель.
Если обратиться к задачам создания СР, то первая из них - выбор признаков распознавания заданных объектов (явлений, процессов). То есть, в самом начале разработки СР в распоряжении разработчика находится конкретная, вполне определенная предметная область с ее объектами (явлениями, процессами).
Не вызывает сомнений то, что на рассматриваемом этапе уже возможно создание модели объектов (явлений, процессов), подлежащих распознаванию. В то же время соответствующая разработка оказывается в целом ряде случаев достаточно объемной, так как в самом начале работ в априорный словарь признаков включаются все возможные параметры, õàðàêòåðèçóþùèå îáúåêò (ÿâëåíèå, ïðîöåññ). À â ðåçóëüòàòå ïîñëåäóþùåãî ìîäåëèðîâàíèÿ îòäåëüíûå õàðàêòåðèñòèêè ìîãóò îêàçàòüñÿ íåâîñòðåáîâàííûìè â ñâÿçè ñ òåì, ÷òî íå íàéäåòñÿ ñîîòâåòñòâóþùåãî èçìåðèòåëÿ èõ èëè åãî ñîçäàíèå îêàæåòñÿ ýêîíîìè÷åñêè íåâîçìîæíûì.
Поэтому хотя то всестороннее изучение свойств объекта, которое будет в указанном случае проведено, и полезно для представлений возможного развития СР, разработка модели более целесообразной оказывается после анализа и выбора допустимого набора измерительных средств.
Так или иначе построение в выбранном признаковом пространстве модели, изоморфной реальному объекту, представляется достаточно мощным процессом для поиска наиболее эффективных признаков распознавания. Указанный процесс обязывает к глубокому анализу существа распознаваемого объекта.
В результате создания модели объекта появляется возможность очередного шага в построении модели СР в целом - возможность создания и подключения модели средств измерений.
Далее после решения задачи выбора априорного алфавита классов (а это уже следующая задача создания СР) созданный комплекс из двух моделей (объекта и измерителей) позволяет методом статистических испытаний получить описание этих классов. То есть, статистически разыгрывая начальные условия состояния и движения объекта и измерителей его характеристик, получаем статистические данные (плотности распределения вероятностей) по каждому из признаков при их независимости в назначенных классах или совместные описания в более сложных случаях.
Если создается обучающаяся система, то после выбора начальных приближений разделяющих функций классов (а это уже очередной этап создания СР) использование созданных моделей ( объекта и измерителей) обеспечит тем же методом статистических испытаний уточнение параметров указанных разделяющих функций. При этом появляется возможность проверки приемлемости для создаваемой системы различных решающих функций.
Для случая “полной” априорной информации (система без обучения) задача выбора правила классификации также легко решается методом статистических испытаний. Здесь реализуется возможность проверки различных статистических критериев.
Как для обучающейся системы, так и для системы без обучения этап исследования решающих правил уже предполагает, что в состав модели входит модуль оценки эффективности. Без него предусматриваемое сравнение в приведенных случаях невозможно.
Таким образом, на всех этапах (при решении всех задач) создания СР любых типов моделирование оказывается инструментом, избавляющим разработчика от сбора большого объема экспериментальных данных. При этом, конечно, всегда предполагается, что применяемые модели прошли калибровку в рамках опытно-теоретического метода и являются изоморфными реальным аналогам.
В итоге рассмотрения роли и места моделирования в задачах создания систем распознавания образов остается вспомнить, что одно из важнейших направлений разработки - оптимизация эвристических выборов априорного словаря признаков и априорного алфавита классов. Однако в том, что моделирование может обеспечить выбор наиболее эффективных рабочего словаря и рабочего алфавита, уже пришлось убедиться при разработке структурной схемы полной модели СР.
В заключение необходимо обратить внимание на то, что общая структурная схема модели системы распознавания, рассматриваемая для вероятностного описания классов, остается справедливой для детерминированных и логических систем. Конечно внутренняя структура отдельных модулей должна быть подвергнута корректировке. Так в детерминированном случае ошибки измерений становятся несущественными и соответствующий субмодуль можно было бы исключить из модуля измерителя характеристик объекта распознавания. Точно также упрощается модуль описания классов за счет использования набора детерминированных эталонов. Упрощается и модуль классификации. Но в целом вся структура модели остается приспособленной для испытаний детерминированных систем.
Аналогично свои особенности имеет реализация модели логической СР:
-результаты обработки информации измерителей после бинарного квантования должны преобразовываться в логические признаки;
-случайность результатов измерений за счет сопутствующих ошибок трансформируется в реально имеющую место случайность получения того или иного логического признака;
-описание классов выглядит в виде системы булевых функций классов с импликантами в виде произведений логических признаков;
-модуль классификации должен приобрести возможность решения булевых уравнений.
В то же время модуль оценки эффективности в основной своей части äîëæåí ìàëî îòëè÷àòüñÿ îò ìîäóëÿ âåðîÿòíîñòíîé ñèñòåìû, òàê êàê è â ýòîì ñëó÷àå îöåíêè îñíîâûâàþòñÿ íà ìåòîäå Ìîíòå-Êàðëî.
Таким образом, разработанная общая структурная схема модели СР должна играть роль типовой, содержание модулей которой корректируется в зависимости от назначения системы и характеристик признаков распознавания.

Ë À Á Î Ð À Ò Î Ð Í Û Å Ð À Á Î Ò Û
Ï Î Ê Ó Ð Ñ Ó
"Îñíîâû ïîñòðîåíèÿ ñèñòåì
ðàñïîçíàâàíèÿ îáðàçîâ"
Лабораторная работа №1 по курсу “Основы построения систем распознавания образов”
Èññëåäîâàíèå ãåîìåòðè÷åñêèõ ìåð áëèçîñòè ðàñïîçíàâàåìûõ îáúåêòîâ è êëàññîâ
I. Öåëü ðàáîòû
Целью лабораторной работы является практическое освоение методов компьютерной реализации геометрических мер близости, применяемых для принятия решений в детерминированных системах распознавания.
II. Çàäà÷è ëàáîðàòîðíîé ðàáîòû
1. Разработка алгоритма принятия решения в детерминированной системе распознавания на основе использования известных геометрических мер близости.
2. Программная реализация разработанного алгоритма.
3. Ввод заданных описаний 3-х классов на языке 11-и предложенных признаков распознавания (таблицы 1-3 - варианты заданий).
4. Отладка программы.
5. Выполнение контрольных распознаваний неизвестных объектов по векторам их признаков (таблица 4).
6. Сравнение принятых решений об отнесении неизвестных объектов к заданным классам по различным мерам близости.
III. Òðåáîâàíèÿ ê âûïîëíåíèþ çàäà÷.
1. Число классов распознавания - 5-10.
2. Размерность вектора признаков - до 20.
3. Число эталонов описания классов - 5-10.
4. Язык программирования - Паскаль, Си.
5. Программно должно быть предусмотрено использование для принятия решения всех введенных эталонов описания классов и их усредненных описаний.
6.Лабораторная работа должна быть оформлена в соответствии с установленным порядком.
IV. Ìåòîäè÷åñêèå óêàçàíèÿ
1. В качестве геометрических мер близости при детерминированном описании распознаваемых объектов и классов использовать
а) Эвклидово расстояние между объектами, описанными на языке
признаков
б) Угловое расстояние между векторами признаков распознаваемого объекта и эталона
в) Сумму модулей разности координат (признаков) объекта и эталона .
2. Решение о принадлежности объекта, представленного вектором Xw, к одному из классов принимается согласно правилам принятия решений в детерминированных системах.
Ïðèìå÷àíèå: Îïèñàíèå êëàññîâ k ýòàëîíàìè ìîæåò áûòü ïðåîáðàçîâàíî ê îïèñàíèþ îäíèì ýòàëîíîì. Ýòî îñóùåñòâëÿåòñÿ îñðåäíåíèåì ýòàëîíîâ ïî ïðèçíàêàì.
V. Èñõîäíûå äàííûå äëÿ òåñòèðîâàíèÿ ïðîãðàììû è ïðîâåäåíèÿ èññëåäîâàíèé.
1é êëàññ ÒÀÁËÈÖÀ 1
|
ЭТАЛОНЫ |
|||||
|
¹ ïðèçíàêà |
1 |
2 |
3 |
4 |
5 |
|
1 |
0.95 |
0.80 |
0.90 |
0.70 |
1.00 |
|
2 |
0.54 |
0.68 |
0.47 |
0.75 |
0.80 |
|
3 |
0.80 |
0.40 |
0.90 |
0.30 |
0.50 |
|
4 |
0.65 |
0.90 |
0.80 |
0.60 |
0.70 |
|
5 |
0.81 |
0.51 |
0.91 |
0.71 |
1.00 |
|
6 |
0.42
|
0.56 |
0.14 |
0.70 |
1.00 |
|
7 |
1.00 |
0.56 |
0.78 |
0.67 |
0.34 |
|
8 |
0.60 |
0.81 |
1.00 |
0.74 |
0.88 |
|
9 |
0.64 |
0.51 |
0.77 |
0.25 |
1.00 |
|
10 |
0.50 |
0.63 |
1.00 |
0.24 |
0.76 |
|
11 |
0.51 |
1.00 |
0.25 |
0.77 |
0.64 |
2é êëàññ ÒÀÁËÈÖÀ 2
|
ЭТАЛОНЫ |
|||||
|
¹ ïðèçíàêà |
1 |
2 |
3 |
4 |
5 |
|
1 |
0.21 |
0.25 |
0.17 |
0.23 |
0.30 |
|
2 |
0.24 |
0.28 |
0.20 |
0.26 |
0.30 |
|
3 |
0.80 |
0.70 |
0.74 |
0.76 |
0.78 |
|
4 |
0.40 |
0.30 |
0.10 |
0.20 |
0.25 |
|
5 |
0.42 |
0.39 |
0.50 |
0.36 |
0.30 |
|
6 |
0.16 |
0.15 |
0.16 |
0.17 |
0.16 |
|
7 |
0.35 |
0.29 |
0.33 |
0.31 |
0.25 |
|
8 |
0.26 |
0.38 |
0.50 |
0.34 |
0.42 |
|
9 |
0.19 |
0.17 |
0.21 |
0.13 |
0.25 |
|
10 |
0.40 |
0.48 |
0.70 |
0.24 |
0.56 |
|
11 |
0.02 |
0.04 |
0.01 |
0.03 |
0.03 |
3é êëàññ ÒÀÁËÈÖÀ 3
|
ЭТАЛОНЫ |
|||||
|
¹ ïðèçíàêà |
1 |
2 |
3 |
4 |
5 |
|
1 |
0.21 |
0.25 |
0.17 |
0.23 |
0.30 |
|
2 |
0.60 |
0.80 |
0.40 |
0.70 |
1.00 |
|
3 |
1.00
|
0.80 |
0.84 |
0.86 |
0.88 |
|
4 |
1.00 |
0.90 |
0.70 |
0.80 |
0.85 |
|
5 |
0.15 |
0.12 |
0.21 |
0.09 |
0.03 |
|
6 |
0.08 |
0.06 |
0.10 |
0.14 |
0.09 |
|
7 |
0.25 |
0.20 |
0.22 |
0.21 |
0.18 |
|
8 |
0.25 |
0.34 |
0.44 |
0.31 |
0.37 |
|
9 |
0.19 |
0.17 |
0.21 |
0.13 |
0.25 |
|
10 |
0.49 |
0.57 |
0.83 |
0.33 |
0.65 |
|
11 |
0.04 |
0.06 |
0.03 |
0.05 |
0.05 |
4é êëàññ ÒÀÁËÈÖÀ 4
|
ЭТАЛОНЫ |
||||||
|
¹ ïðèçíàêà |
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
0.85 |
0.75 |
0.19 |
0.27 |
0.19 |
0.27 |
|
2 |
0.40 |
0.61 |
0.22 |
0.30 |
0.50 |
0.90 |
|
3 |
0.60 |
0.70 |
0.72 |
0.80 |
0.82 |
1.00 |
|
4 |
0.85 |
0.75 |
0.15 |
0.35 |
0.75 |
0.95 |
|
5 |
0.61 |
0.41 |
0.33 |
0.45 |
0.06 |
0.18 |
|
6 |
0.28 |
0.84 |
0.15 |
0.17 |
0.07 |
0.11 |
|
7 |
0.45 |
0.89 |
0.27 |
0.35 |
0.19 |
0.23 |
|
8 |
0.67 |
0.95 |
0.30 |
0.46 |
0.28 |
0.40 |
|
9 |
0.38 |
0.90 |
0.15 |
0.23 |
0.15 |
0.23 |
|
10 |
0.37 |
0.89 |
0.32 |
0.64 |
0.41 |
0.73 |
|
11 |
0.38 |
0.90 |
0.02 |
0.04 |
0.04 |
0.06 |
Ë È Ò Å Ð À Ò Ó Ð À
[1] Êîíñïåêò ëåêöèé ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ".
Ëàáîðàòîðíàÿ ðàáîòà ¹2 ïî êóðñó “Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ”
Èññëåäîâàíèå âåðîÿòíîñòíîé ìåðû áëèçîñòè ðàñïîçíàâàåìûõ îáúåêòîâ è êëàññîâ
I. Öåëü ðàáîòû
Öåëüþ ëàáîðàòîðíîé ðàáîòû ÿâëÿåòñÿ ïðàêòè÷åñêîå îñâîåíèå ìåòîäîâ êîìïüþòåðíîé ðåàëèçàöèè âåðîÿòíîñòíîé ìåðû áëèçîñòè, ïðèìåíÿåìîé äëÿ ïðèíÿòèÿ ðåøåíèé â âåðîÿòíîñòíûõ ñèñòåìàõ ðàñïîçíàâàíèÿ.
II. Çàäà÷è ëàáîðàòîðíîé ðàáîòû
1. Ðàçðàáîòêà àëãîðèòìà ïðèíÿòèÿ ðåøåíèÿ â âåðîÿòíîñòíîé ñèñòåìå ðàñïîçíàâàíèÿ íà îñíîâå èñïîëüçîâàíèÿ èçâåñòíîé âåðîÿòíîñòíîé ìåðû áëèçîñòè - ñðåäíåãî ðèñêà.
2. Ïðîãðàììíàÿ ðåàëèçàöèÿ ðàçðàáîòàííîãî àëãîðèòìà.
3. Ââîä çàäàííûõ îïèñàíèé êëàññîâ íà ÿçûêå ïðåäëîæåííûõ ïðèçíàêîâ ðàñïîçíàâàíèÿ.
4. Îòëàäêà ïðîãðàììû.
5. Âûïîëíåíèå êîíòðîëüíûõ ðàñïîçíàâàíèé íåèçâåñòíûõ îáúåêòîâ ïî âåêòîðàì ïðèçíàêîâ, çàäàííûõ ïðåïîäàâàòåëåì.
6. Ïðîâåäåíèå èññëåäîâàíèé âëèÿíèÿ íà ðåøåíèå î ïðèíàäëåæíîñòè
- àïðèîðíûõ âåðîÿòíîñòåé êëàññîâ;
- ïëàò, íàçíà÷àåìûõ çà îøèáî÷íûå ðåøåíèÿ.
III. Òðåáîâàíèÿ ê âûïîëíåíèþ çàäà÷.
1. ×èñëî êëàññîâ ðàñïîçíàâàåìûõ îáúåêòîâ - 3.
2. Êîëè÷åñòâî ïðèçíàêîâ ðàñïîçíàâàíèÿ - 1.
3. ßçûê ïðîãðàììèðîâàíèÿ - Ïàñêàëü, Ñè.
4. Ëàáîðàòîðíàÿ ðàáîòà äîëæíà áûòü îôîðìëåíà â ñîîòâåòñòâèè ñ óñòàíîâëåííûì ïîðÿäêîì.
5. Èññëåäîâàíèÿ âûïîëíèòü â äâà ýòàïà:
Ýòàï 1 - îöåíêà âëèÿíèÿ àïðèîðíûõ âåðîÿòíîñòåé êëàññîâ íà ïðèíèìàåìûå ðåøåíèÿ î ïðèíàäëåæíîñòè;
Ýòàï 2 - îöåíêà âëèÿíèÿ ïëàò çà îøèáî÷íûå ðåøåíèÿ î ïðèíàäëåæíîñòè íà ýòè ðåøåíèÿ.
IV. Èñõîäíûå äàííûå äëÿ èññëåäîâàíèé
1. Óñëîâíûå àïðèîðíûå ïëîòíîñòè ðàñïðåäåëåíèÿ âåðîÿòíîñòåé, èñïîëüçóåìûå äëÿ îïèñàíèÿ êëàññîâ - íîðìàëüíûå ñ ìàòåìàòè÷åñêèìè îæèäàíèÿìè m>i> è ñðåäíåêâàäðàòè÷åñêèìè ðàçáðîñàìè - s>i> (Òàáëèöà 1).
2. Èçìåðåííûå çíà÷åíèÿ ïðèçíàêîâ ïî ðàñïîçíàâàåìûì îáúåêòàì
-
 (Òàáëèöà 1)
(Òàáëèöà 1)
3. Àïðèîðíûå âåðîÿòíîñòè êëàññîâ è ìàòðèöà ïëàò çà îøèáêè äëÿ ïåðâîãî èññëåäîâàíèÿ:
|
P(W>1>) |
P(W>2>) |
P(W>3>) |
|
|
1-é íàáîð |
0.1 |
0.8 |
0.1 |
|
2-é íàáîð |
0.2 |
0.6 |
0.2 |
|
3-é íàáîð |
0.3 |
0.4 |
0.3 |
|
4-é íàáîð |
0.4 |
0.2 |
0.4 |
|
5-é íàáîð |
0.4 |
0.1 |
0.5 |
4. Àïðèîðíûå âåðîÿòíîñòè êëàññîâ è ìàòðèöû ïëàò çà îøèáêè äëÿ âòîðîãî èññëåäîâàíèÿ:
P(W>1>)= 0.33, P(W>2>)= 0.33, P(W>3>)= 0.33.
5. Âàðèàíòû çàäàíèé
Òàáëèöà 1
|
Âàðèàíò |
M>i> |
s>i> |
|
||||
|
Êëàññ 1 |
Êëàññ 2 |
Êëàññ 3 |
Êëàññ 1 |
Êëàññ 2 |
Êëàññ 3 |
||
|
1 |
17 |
19 |
23 |
3 |
1.5 |
4 |
20 |
|
2 |
27 |
29 |
33 |
2.9 |
1.6 |
3.8 |
30 |
|
3 |
37 |
39 |
43 |
3.2 |
1.4 |
4.1 |
40 |
|
4 |
32 |
34 |
38 |
3 |
1.5 |
4 |
35 |
|
5 |
28 |
39 |
34 |
2.9 |
1.6 |
3.8 |
31 |
|
6 |
47 |
49 |
53 |
3.2 |
1.4 |
4.1 |
50 |
|
7 |
42 |
44 |
48 |
3 |
1.5 |
4 |
45 |
|
8 |
39 |
41 |
45 |
2.9 |
1.6 |
3.8 |
42 |
|
9 |
36 |
38 |
42 |
3.2 |
1.4 |
4.1 |
39 |
|
10 |
46 |
48 |
52 |
3 |
1.5 |
4 |
49 |
|
11 |
22 |
24 |
28 |
2.9 |
1.6 |
3.8 |
25 |
|
12 |
51 |
53 |
57 |
3.2 |
1.4 |
4.1 |
54 |
|
13 |
24 |
26 |
30 |
3 |
1.5 |
4 |
27 |
|
14 |
15 |
17 |
21 |
2.9 |
1.6 |
3.8 |
18 |
|
15 |
25 |
27 |
31 |
3.2 |
1.4 |
4.1 |
28 |
Ë È Ò Å Ð À Ò Ó Ð À
[1 ] Êîíñïåêò ëåêöèé ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ".
Ëàáîðàòîðíàÿ ðàáîòà ¹ 3-1 ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ"
Îöåíêà ýôôåêòèâíîñòè âåðîÿòíîñòíîé ñèñòåìû ðàñïîçíàâàíèÿ
I. Öåëü ðàáîòû
Öåëüþ ëàáîðàòîðíîé ðàáîòû ÿâëÿåòñÿ ïðàêòè÷åñêîå îñâîåíèå ìåòîäîâ êîìïüþòåðíîé ðåàëèçàöèè àëãîðèòìîâ îöåíêè ýôôåêòèâíîñòè ÑÐ. Ëàáîðàòîðíàÿ ðàáîòà âûïîëíÿåòñÿ â ïðîöåññå ðåøåíèÿ êîíêðåòíîé çàäà÷è.
II.Çàäà÷è ëàáîðàòîðíîé ðàáîòû
2.1. Ðàçðàáîòàòü àëãîðèòì ðåøåíèÿ çàäà÷è ñëåäóþùåãî ñîäåðæàíèÿ:
â ïðîöåññå äåìîíòàæà ïðèâîäîâ íåêîòîðûõ óñòðîéñòâ, ïðîâîäèìîãî â öåëÿõ èõ ðåìîíòíî-âîññòàíîâèòåëüíûõ ðàáîò, àâòîìàòè÷åñêè êëàññèôèöèðóþòñÿ è êîìïëåêòóþòñÿ ìóôòû âðàùàþùèõñÿ ñî÷ëåíåíèé ïî èõ âíóòðåííåìó äèàìåòðó. Ïðèíÿòûé òåõíîëîãè÷åñêèé ïðîöåññ äåìîíòàæà îáóñëîâëèâàåò ñëó÷àéíûé õàðàêòåð äåìîíòàæà ìóôòû êàæäîãî òèïîðàçìåðà è ïåðåäà÷ó åå íà êëàññèôèêàöèþ è êîìïëåêòîâàíèå.
Ñðåäíåêâàäðàòè÷åñêàÿ îøèáêà èçìåðåíèé âíóòðåííåãî äèàìåòðà ìóôòû ñïåöèàëüíîé ýëåêòðîìåõàíè÷åñêîé ñèñòåìîé ñîñòàâëÿåò 3 ìì.
Âñåãî â äåìîíòèðóåìûõ èçäåëèÿõ èñïîëüçóåòñÿ 5 òèïîðàçìåðîâ ìóôò, âíóòðåííèå äèàìåòðû êîòîðûõ è êîëè÷åñòâî ïðèâåäåíû â òàáëèöå
|
Êîë-âî ìóôò |
Äèàìåòðû ìóôò ïî âàðèàíòàì |
||||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
|
100 |
3 |
7 |
18 |
35 |
4 |
17 |
8 |
11 |
5 |
20 |
6 |
10 |
19 |
|
100 |
6 |
10 |
21 |
38 |
7 |
20 |
11 |
14 |
8 |
23 |
9 |
13 |
22 |
|
100 |
9 |
13 |
24 |
41 |
10 |
23 |
14 |
17 |
11 |
26 |
12 |
16 |
25 |
|
100 |
12 |
16 |
27 |
44 |
13 |
26 |
17 |
20 |
14 |
29 |
15 |
19 |
28 |
|
100 |
15 |
19 |
30 |
47 |
16 |
29 |
20 |
23 |
17 |
32 |
18 |
22 |
31 |
2.2. ðåçóëüòàòå ðàçðàáîòêè:
2.2.1. Îïèñàòü êëàññû ñèñòåìû ðàñïîçíàâàíèÿ, ó÷èòûâàÿ ÷òî îøèáêè èçìåðåíèé â òåõíè÷åñêèõ óñòðîéñòâàõ ïðèâîäÿò, êàê ïðàâèëî, ê íîðìàëüíîìó çàêîíó ðàñïðåäåëåíèÿ âåðîÿòíîñòåé îöåíèâàåìîãî ïàðàìåòðà.
2.2.2. Ðàññ÷èòàòü âåðîÿòíîñòè îøèáîê ëîæíîé êëàññèôèêàöèè ìóôò ïðåäëàãàåìîé ñèñòåìîé .
2.2.3. Îïðåäåëèòü àïðèîðíûé ðèñê ðàñïîçíàâàíèÿ â ñèñòåìå ïðè ðàâíûõ ïëàòàõ çà îøèáêè.(Ãðàíèöû ìåæäó i-ûì è i+1-ûì êëàññàìè óñòàíàâëèâàþòñÿ ïî ðàâåíñòâó ïëîòíîñòåé ðàñïðåäåëåíèÿ âåðîÿòíîñòåé ñîñåäíèõ êëàññîâ, òî åñòü:
m>i >+ m>i+1>
à>i,i+1> = ¾¾¾¾
2
ãäå m>i> è m>i+1> - ìàòåìàòè÷åñêèå îæèäàíèÿ îïèñàíèé ñîñåäíèõ êëàññîâ.)
2.3. Âûïîëíèòü ïðîãðàììíóþ ðåàëèçàöèþ ðàçðàáîòàííîãî àëãîðèòìà.
2.4. Îòëàäèòü ïðîãðàììó.
2.5. Âûïîëíèòü ðàñ÷åòû.
2.6. Ïðîâåñòè àíàëèç è îôîðìëåíèå ðåçóëüòàòîâ.
III. Ìåòîäè÷åñêèå óêàçàíèÿ ê âûïîëíåíèþ çàäàíèÿ.
3.1. Ïðîãðàììà ðàñ÷åòà è àíàëèçà ýôôåêòèâíîñòè ìîæåò áûòü âûïîëíåíà íà ëþáîì ÿçûêå âûñîêîãî óðîâíÿ.
3.2. Çàâèñèìîñòè âåðîÿòíîñòåé îøèáîê êëàññèôèêàöèè è ñðåäíåãî ðèñêà îò ÑÊÎ èçìåðåíèé îôîðìèòü ãðàôè÷åñêè.
3.3. Äëÿ èñïîëüçîâàíèÿ ïðè ðåøåíèè èíòåãðàëà Ëàïëàñà íåîáõîäèìî ðàçðàáîòàòü ïðîãðàììíóþ ôóíêöèþ íà îñíîâå åãî ðàçëîæåíèÿ â ðÿä.
3.4.Ïðè èíòåãðèðîâàíèè íîðìàëüíîé ïëîòíîñòè ðàñïðåäåëåíèÿ âåðîÿòíîñòåé èñïîëüçîâàòü ñëåäóþùåå çíà÷åíèå èíòåãðàëà Ëàïëàñà
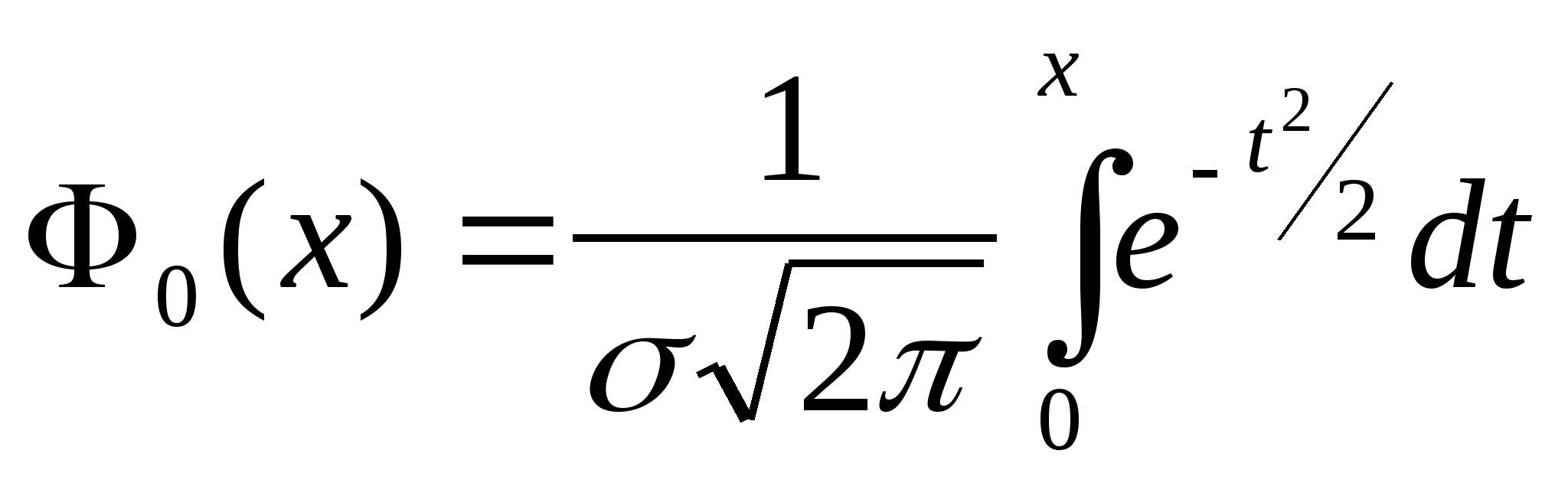
Ë È Ò Å Ð À Ò Ó Ð À
[1] Êîíñïåêò ëåêöèé ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ".
Ëàáîðàòîðíàÿ ðàáîòà ¹ 3-2 ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ"
Èññëåäîâàíèå âëèÿíèÿ îøèáîê ðàñïîçíàâàíèÿ íà ýôôåêòèâíîñòü âåðîÿòíîñòíîé ñèñòåìû
I. Öåëü ðàáîòû
Öåëüþ ëàáîðàòîðíîé ðàáîòû ÿâëÿåòñÿ ïðàêòè÷åñêîå îñâîåíèå ìåòîäîâ êîìïüþòåðíîé ðåàëèçàöèè àëãîðèòìîâ îöåíêè ýôôåêòèâíîñòè ÑÐ. Íàñòîÿùàÿ ëàáîðàòîðíàÿ ðàáîòà îñíîâûâàåòñÿ íà âûïîëíåííîé ëàáîðàòîðíîé ðàáîòå N 3-1 è ÿâëÿåòñÿ åå ïðîäîëæåíèåì.
II. Çàäà÷è ëàáîðàòîðíîé ðàáîòû
2.1.  êà÷åñòâå àëãîðèòìà äëÿ âûïîëíåíèÿ íàñòîÿùåé ðàáîòû èñïîëüçîâàòü àëãîðèòì, ðàçðàáîòàííûé â ëàáîðàòîðíîé ðàáîòå ¹ 3-1.
2.2. Èñõîäíûå äàííûå äëÿ ðàñ÷åòîâ îñòàâèòü òåìè æå, ÷òî áûëè âûáðàíû ïî ïðåäëîæåííîìó âàðèàíòó â ëàáîðàòîðíîé ðàáîòå ¹ 3-1.
2.3. Òðåáóåòñÿ:
2.3.1. Ñðåäè îøèáîê êëàññèôèêàöèè ìóôò (ñì. ëàáîðàòîðíóþ ðàáîòó № 3-1) найти такую, которая имеет максимальную вероятность
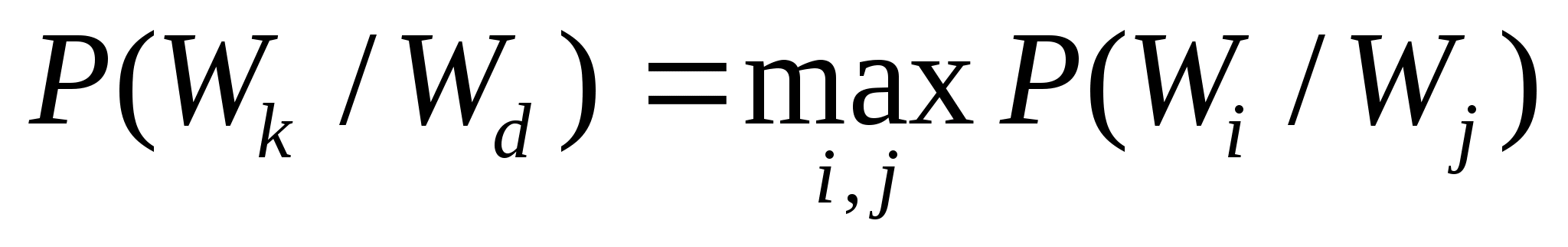
2.3.2. Èñïîëüçóÿ ñîçäàííóþ â ëàáîðàòîðíîé ðàáîòå ¹ 3-1 ïðîãðàììó, ðàññ÷èòàòü çàâèñèìîñòü ìàêñèìàëüíîé ïî âåðîÿòíîñòè îøèáêè êëàññèôèêàöèè P(W>k>/W>d>) îò âåëè÷èíû ÑÊÎ îøèáêè èçìåðåíèé äèàìåòðà ïðè äèñêðåòíîì ïîâûøåíèè òî÷íîñòè èçìåðèòåëÿ äèàìåòðà s = 3 ìì, 2.5 ìì, 2 ìì, 1.5 ìì, 1 ìì è 0.5 ìì:
P(W>k> /W>d>)= F>1>( s ).
2.3.3. Äëÿ òåõ æå çíà÷åíèé îøèáêè èçìåðåíèé (ï.2) ðàññ÷èòàòü çàâèñèìîñòü ñðåäíåãî ðèñêà ðàñïîçíàâàíèÿ:
_
R = F>2>( s).
2.3.4. Ïî ðåçóëüòàòàì îïðåäåëåíèÿ â ï 2. çàâèñèìîñòè P(W>k> /W>d> )=F>1>( s) ïðåäúÿâèòü òðåáîâàíèå ê òî÷íîñòè ñèñòåìû èçìåðåíèé âíóòðåííåãî äèàìåòðà ìóôò (ÑÊÎ) äëÿ âûïîëíåíèÿ òðåáîâàíèÿ òåõíè÷åñêîãî çàäàíèÿ íà ñèñòåìó ðàñïîçíàâàíèÿ - íå áîëåå äâóõ îøèáî÷íûõ êëàññèôèêàöèé íà 500 ìóôò .
2.4. Âûïîëíèòü ðàñ÷åòû.
2.5. Ïðîâåñòè àíàëèç è îôîðìèòü ðåçóëüòàòû.
III. Ìåòîäè÷åñêèå óêàçàíèÿ ê âûïîëíåíèþ çàäàíèÿ.
3.1. Çàâèñèìîñòè âåðîÿòíîñòåé îøèáîê êëàññèôèêàöèè è ñðåäíåãî ðèñêà îò ÑÊÎ èçìåðåíèé îôîðìèòü ãðàôè÷åñêè.
3.2. Ïðè âûïîëíåíèè ï. 2.3.4 âîñïîëüçîâàòüñÿ ëèíåéíîé èíòåðïîëÿöèåé .
Ë È Ò Å Ð À Ò Ó Ð À
[1] Êîíñïåêò ëåêöèé ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ".
Ëàáîðàòîðíàÿ ðàáîòà ¹ 3-3 ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ"
Îöåíêà âëèÿíèÿ ÷èñëà êëàññîâ íà ýôôåêòèâíîñòü âåðîÿòíîñòíîé ñèñòåìû ðàñïîçíàâàíèÿ
I. Öåëü ðàáîòû
Öåëüþ ëàáîðàòîðíîé ðàáîòû ÿâëÿåòñÿ ïðàêòè÷åñêîå îñâîåíèå ìåòîäîâ îöåíêè ýôôåêòèâíîñòè ÑÐ. Íàñòîÿùàÿ ëàáîðàòîðíàÿ ðàáîòà âûïîëíÿåòñÿ êàê ïðîäîëæåíèå ëàáîðàòîðíûõ ðàáîò ¹¹ 3-1, 3-2.
II.Çàäà÷è ëàáîðàòîðíîé ðàáîòû
2.1. Íà îñíîâå ðàçðàáîòàííîé ïðîãðàììû è ðåçóëüòàòîâ ðàñ÷åòîâ ïî ëàáîðàòîðíûì ðàáîòàì ¹¹ 3-1, 3-2 ïîâòîðèòü âûïîëíåíèå èõ òðåáîâàíèé, ïðåäâàðèòåëüíî èñêëþ÷èâ èç ñîñòàâà êëàññèôèöèðóåìûõ ìóôò 100 øòóê ñëåäóþùèõ äèàìåòðîâ ïî âàðèàíòàì:
Äèàìåòðû èñêëþ÷àåìûõ ìóôò â ìì ïî âàðèàíòàì
|
Âàðèàíò |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
Äèàìåòð |
9 |
13 |
24 |
41 |
10 |
23 |
14 |
17 |
11 |
26 |
12 |
16 |
25 |
2.2. Ñðàâíèòü çàâèñèìîñòü àïðèîðíîãî ðèñêà îò òî÷íîñòåé èçìåðåíèÿ ïðèçíàêà ðàñïîçíàâàíèÿ ñ çàâèñèìîñòüþ, ïîëó÷åííîé â ïåðâîì èññëåäîâàíèè (ëàáîðàòîðíàÿ ðàáîòà ¹ 3-2).
2.3. Ñðàâíèòü çàâèñèìîñòü ìàêñèìàëüíîé îøèáêè ðàñïîçíàâàíèÿ êëàññîâ îò òî÷íîñòåé èçìåðåíèÿ ïðèçíàêà ðàñïîçíàâàíèÿ ñ çàâèñèìîñòüþ, ïîëó÷åííîé â ïåðâîì èññëåäîâàíèè, è ïîÿñíèòü ðåçóëüòàò.
Ë È Ò Å Ð À Ò Ó Ð À
[1] Êîíñïåêò ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ".

Â Î Ï Ð Î Ñ Û
ÏÐÀÊÒÈ×ÅÑÊÈÕ ÇÀÍßÒÈÉ ÏÎ ÊÓÐÑÓ
"Îñíîâû ïîñòðîåíèÿ
ñèñòåì ðàñïîçíàâàíèÿ
îáðàçîâ"
Ç À Í ß Ò È Å ¹ 1
Îñîáåííîñòè çàäà÷ ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ
1.Îñíîâíûå îïðåäåëåíèÿ òåîðèè (îáúåêò, îáðàç, ðàñïîçíàâàíèå, ñèñòåìà ðàñïîçíàâàíèÿ).
2.Èíâàðèàíòíîñòü çàäà÷ ïîñòðîåíèÿ ÑÐ îòíîñèòåëüíî ïðèìåíåíèé è óçêàÿ ñïåöèôè÷íîñòü òåõíè÷åñêèõ ÑÐ.
3.Ñîäåðæàíèå è îñîáåííîñòè I ýòàïà ñîçäàíèÿ ÑÐ. Îïðåäåëåíèå ïîëíîãî ïåðå÷íÿ ïðèçíàêîâ ðàñïîçíàâàíèÿ.
4.Ñîäåðæàíèå è îñîáåííîñòè II ýòàïà ñîçäàíèÿ ÑÐ. Ðàçðàáîòêà àïðèîðíîãî àëôàâèòà êëàññîâ.
5.Ñîäåðæàíèå è îñîáåííîñòè III è IV ýòàïîâ ñîçäàíèÿ ÑÐ. Ðàçðàáîòêà àïðèîðíîãî ñëîâàðÿ ïðèçíàêîâ è îïèñàíèå êëàññîâ.
6.Ñîäåðæàíèå è îñîáåííîñòè V ýòàïà ñîçäàíèÿ ÑÐ. Ðàçáèåíèå àïðèîðíîãî ïðîñòðàíñòâà ïðèçíàêîâ íà îáëàñòè, ñîîòâåòñòâóþùèå àëôàâèòó êëàññîâ. Âûáîð àëãîðèòìà êëàññèôèêàöèè.
7.Ñîäåðæàíèå è îñîáåííîñòè VI ýòàïà ñîçäàíèÿ ÑÐ. Îïðåäåëåíèå ðàáî÷åãî àëôàâèòà êëàññîâ è ðàáî÷åãî ñëîâàðÿ ïðèçíàêîâ.
Ç À Í ß Ò È Å № 2
Êëàññèôèêàöèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ
1.Êëàññèôèêàöèÿ ñèñòåì ðàñïîçíàâàíèÿ (ïðîñòûå è ñëîæíûå).
2.Êëàññèôèêàöèÿ ñèñòåì ðàñïîçíàâàíèÿ (ñèñòåìû áåç îáó÷åíèÿ, îáó÷àþùèåñÿ è ñàìîîáó÷àþùèåñÿ).
3.Êëàññèôèêàöèÿ ñèñòåì ðàñïîçíàâàíèÿ (îáùèå ïðåäñòàâëåíèÿ î ëîãè÷åñêèõ è ñòðóêòóðíûõ ñèñòåìàõ).
4.Êëàññèôèêàöèÿ ñèñòåì ðàñïîçíàâàíèÿ (äåòåðìèíèðîâàííûå è âåðîÿòíîñòíûå ñèñòåìû).
Ç À Í ß Ò È Å ¹ 3
Îñíîâíûå îñîáåííîñòè äåòåðìèíèðîâàííûõ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ
1.Îïèñàíèå êëàññîâ íà ÿçûêå äåòåðìèíèðîâàííûõ ïðèçíàêîâ.
2.Ìåðû áëèçîñòè, èñïîëüçóåìûå äëÿ îöåíêè ïðèíàäëåæíîñòè îáðàçîâ â äåòåðìèíèðîâàííûõ ñèñòåìàõ ðàñïîçíàâàíèÿ.
3.Ðåøàþùåå ïðàâèëî äëÿ êëàññèôèêàöèè îáúåêòîâ, îïèñàííûõ íà ÿçûêå äåòåðìèíèðîâàííûõ ïðèçíàêîâ.
Ç À Í ß Ò È Å ¹ 4
Îñíîâíûå îñîáåííîñòè âåðîÿòíîñòíûõ ñèñòåì
ðàñïîçíàâàíèÿ îáðàçîâ
1.Îïèñàíèå êëàññîâ íà ÿçûêå âåðîÿòíîñòíûõ ïðèçíàêîâ ðàñïîçíàâàíèÿ.
2.Ïîðÿäîê íàçíà÷åíèÿ ïëàò çà îøèáî÷íûå ðåøåíèÿ.
3.Ìåðû áëèçîñòè, èñïîëüçóåìûå äëÿ îöåíêè ïðèíàäëåæíîñòè îáðàçîâ â âåðîÿòíîñòíûõ ñèñòåìàõ.
4.Îïðåäåëåíèå àïîñòåðèîðíûõ âåðîÿòíîñòåé êëàññîâ.
5.Ðåøàþùåå ïðàâèëî äëÿ êëàññèôèêàöèè îáúåêòîâ, îïèñàííûõ íà ÿçûêå âåðîÿòíîñòíûõ ïðèçíàêîâ ðàñïîçíàâàíèÿ. Àïîñòåðèîðíûé ðèñê.
Ç À Í ß Ò È Å № 5
Îñîáåííîñòè ýâðèñòè÷åñêèõ âûáîðîâ ïðèçíàêîâ è êëàññîâ
1.Àïðèîðíàÿ îöåíêà ýôôåêòèâíîñòè âåðîÿòíîñòíîé ñèñòåìû ðàñïîçíàâàíèÿ. Àïðèîðíûé ðèñê.
2.Îïðåäåëåíèå âåðîÿòíîñòè îøèáêè ïðè îöåíêå ñðåäíåãî àïðèîðíîãî ðèñêà. Îñîáåííîñòè îïðåäåëåíèÿ îøèáîê ïðè îïèñàíèè êëàññîâ íîðìàëüíîé ïëîòíîñòüþ ðàñïðåäåëåíèÿ âåðîÿòíîñòåé.
3.Äîêàçàòåëüñòâî âëèÿíèÿ ÷èñëà ïðèçíàêîâ íà ýôôåêòèâíîñòü ðàñïîçíàâàíèÿ.
4.Äîêàçàòåëüñòâî âëèÿíèÿ ÷èñëà êëàññîâ íà ýôôåêòèâíîñòü ðàñïîçíàâàíèÿ.
Ç À Í ß Ò È Å ¹ 6
Îñíîâû ìàòåìàòè÷åñêîãî ìîäåëèðîâàíèÿ ñëîæíûõ
òåõíè÷åñêèõ ñèñòåì
1.Îñíîâíûå îïðåäåëåíèÿ òåîðèè ìîäåëèðîâàíèÿ ñèñòåì (ìîäåëü, ìîäåëèðîâàíèå, îïèñàíèå ñèñòåìû, èçîìîðôíîñòü ìîäåëè è ñèñòåìû).
2.Õàðàêòåðíûå îñîáåííîñòè ñëîæíûõ ñèñòåì. Ïðèíöèïû ïîñòðîåíèÿ ìîäåëåé ñëîæíîé ñèñòåìû (äåêîìïîçèöèè, äîïóñòèìûõ óïðîùåíèé).
3.Íàçíà÷åíèå è ñóùíîñòü îïûòíî-òåîðåòè÷åñêîãî ìåòîäà èñïûòàíèé ñëîæíûõ ñèñòåì.
4.Íàçíà÷åíèå ÷àñòíûõ è ñèñòåìíûõ ìîäåëåé â èñïûòàíèÿõ ñëîæíûõ ñèñòåì.
Ç À Í ß Ò È Å № 7
Ìåòîä ñòàòèñòè÷åñêèõ èñïûòàíèé (Ìîíòå-Êàðëî)
1.Ñóùíîñòü ìåòîäà ñòàòèñòè÷åñêèõ èñïûòàíèé è åãî äîñòîèíñòâà.
2.Ïîíÿòèå ïñåâäîñëó÷àéíîãî ÷èñëà. Îñîáåííîñòè êâàçèñëó÷àéíûõ âåëè÷èí, ïîëó÷àåìûõ íà ÝÂÌ.
3.Ïðèíöèïû ñòàòèñòè÷åñêîãî ìîäåëèðîâàíèÿ íåçàâèñèìûõ ñëó÷àéíûõ ñîáûòèé.
4.Ñïîñîáû ïîëó÷åíèÿ íà ÝÂÌ ñëó÷àéíûõ ÷èñåë ñ çàäàííûì çàêîíîì ðàñïðåäåëåíèÿ.
Ç À Í ß Ò È Å ¹ 8
Ìàòåìàòè÷åñêîå ìîäåëèðîâàíèå ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ
1.Öåëü êîìïüþòåðíîãî ìîäåëèðîâàíèÿ ÑÐ.
2.Îñîáåííîñòè ìîäåëèðîâàíèÿ ðàñïîçíàâàåìîãî îáúåêòà.
3.Ìîäåëèðîâàíèå ñðåäñòâ îïðåäåëåíèÿ õàðàêòåðèñòèê ðàñïîçíàâàåìûõ îáúåêòîâ.
4.Ìîäåëèðîâàíèå êàíàëîâ ñâÿçè è ïåðåäà÷è èíôîðìàöèè.
5.Îöåíêà ýôôåêòèâíîñòè ðàñïîçíàâàíèÿ ïðè ìîäåëèðîâàíèè ÑÐ.
6.Çàäà÷è óïðàâëåíèÿ ïðè ìîäåëèðîâàíèè.
7.Îñîáåííîñòè ïðèìåíåíèÿ îïûòíî-òåîðåòè÷åñêîãî ìåòîäà èñïûòàíèé ñëîæíûõ ñèñòåì ê ìîäåëèðîâàíèþ ÑÐ.
8.Èñïîëüçîâàíèå ìîäåëèðîâàíèÿ ÑÐ íà ýòàïàõ èõ ñîçäàíèÿ è îïòèìèçàöèè.
Ë È Ò Å Ð À Ò Ó Ð À
[1] Êîíñïåêò ëåêöèé ïî êóðñó "Îñíîâû ïîñòðîåíèÿ ñèñòåì ðàñïîçíàâàíèÿ îáðàçîâ".
[2] Ãîðåëèê À.Ë. Ìåòîäû ðàñïîçíàâàíèÿ. М., "Высшая школа", 1986 г.
[3] Аркадьев А.Г., Браверман Э.М. "Обучение машины распознаванию образов" М., "Наука", 1964 г.
[4] Ëåâèí Á.Ð."Òåîðåòè÷åñêèå îñíîâû ñòàòèñòè÷åñêîé ðàäèîòåõíèêè"
Ì. , "Ñîâ.ðàäèî", 1968 ã.
[5] Âåíòöåëü Å.Ñ . "Òåîðèÿ âåðîÿòíîñòåé" М."Физматгиз", 1969 г.
[6] Ìàðòèí Ô. "Ìîäåëèðîâàíèå íà âû÷èñëèòåëüíûõ ìàøèíàõ" М., "Сов.радио", 1972 г.
[7] Ïîëëÿê Þ.Ñ. "Âåðîÿòíîñòíîå ìîäåëèðîâàíèå" М., "Сов.радио", 1971 г.
[8] Áóñëåíêî Í.Ï., Ãîëåíêî Ä.È., Ñîáîëü È.Ì. è äð "Ìåòîä ñòàòèñòè÷åñêèõ èñïûòàíèé. (Ìåòîä Ìîíòå- Êàðëî)" Ì., ÃÈÔÌË, 1962 ã.
[9] Âàñèëüåâ Â.È. "Ðàñïîçíàþùèå ñèñòåìû. Ñïðàâî÷íèê" Êèåâ, Íàóêîâà äóìêà, 1983 ã.
[10] Áàðàáàø Þ.Ë., Çèíîâüåâ Á.Â. è äð. "Âîïðîñû ñòàòèñòè÷åñêîé òåîðèè ðàñïîçíàâàíèÿ" Ì., Ñîâ. ðàäèî, 1967 ã.
[11]"Ôèçèêà âèçóàëèçàöèè èçîáðàæåíèé â ìåäèöèíå" ò.2., Ì., Ìèð, 1991 ã.