Быстрые вычисления с целыми числами и полиномами
Министерство образования Российской Федерации
Ярославский Государственный Университет им. П.Г. Демидова
Курсовая работа
По дисциплине «Алгебра»
Быстрые вычисления с целыми числами и полиномами
Выполнил: Студент группы КБ-11
Сбоев А.В.
Проверил: Дурнев В.Г.
Ярославль, 2003
Содержание
Введение. Сложность теоретико-числовых алгоритмов.
Полиномиальные алгоритмы
Алгоритм вычисления ad mod m
Дихотомический алгоритм возведения в степень
Алгоритм Евклида
Алгоритм решения уравнения ax + by = 1
Полиномиальная арифметика
Алгоритм нахождения делителей многочлена f(x) в кольце F>p>[x]
Произведение и возведение в степень многочленов, заданных массивами
Небольшие оптимизации для произведения многочленов
Вычисление полиномов
Схема Горнера
Интерполяционная формула Ньютона и табулирование значений многочлена
Дискретное логарифмирование
1. Введение. Сложность теоретико-числовых алгоритмов
Сложность алгоритмов теории чисел обычно принято измерять количеством арифметических операций (сложений, вычитаний, умножений и делений с остатком), необходимых для выполнения всех действий, предписанных алгоритмом. Впрочем, это определение не учитывает величины чисел, участвующих в вычислениях. Ясно, что перемножить два стозначных числа значительно сложнее, чем два однозначных, хотя при этом и в том, и в другом случае выполняется лишь одна арифметическая операция. Поэтому иногда учитывают ещё и величину чисел, сводя дело к так называемым побитовым операциям, т. е. Оценивая количество необходимых операций с цифрами 0 и 1, в двоичной записи чисел. Это зависит от рассматриваемой задачи, целей автора и т. д.
На первый взгляд странным также кажется, что операции умножения и деления приравниваются по сложности к операциям сложения и вычитания. Житейский опыт подсказывает, что умножать числа значительно сложнее, чем складывать их. В действительности же, вычисления можно организовать так, что на умножение или деление больших чисел понадобится не намного меньше битовых операций, чем на сложение. Существует алгоритм Шенхаге – Штрассена, основанный на так называемом быстром преобразовании Фурье, и требующий O(n ln n lnln n) битовых операций для умножения двух n-разрядных двоичных чисел. Таким же количеством битовых операций можно обойтись при выполнении деления с остатком двух двоичных чисел, записываемых не более чем n цифрами. Для сравнения отметим, что сложение n-разрядных двоичных чисел требует O(n) битовых операций.
Говоря о сложности алгоритмов, мы будем иметь в виду количество арифметических операций. При построении эффективных алгоритмов и обсуждении верхних оценок сложности обычно хватает интуитивных понятий той области математики, которой принадлежит алгоритм. Формализация же этих понятий требуется лишь тогда, когда речь идёт об отсутствии алгоритма или доказательстве нижних оценок сложности.
2. Полиномиальные алгоритмы
Четыре приведённых ниже алгоритма относятся к разряду так называемых полиномиальных алгоритмов. Это название носят алгоритмы, сложность которых оценивается сверху степенным образом в зависимости от длины записи входящих чисел. Если наибольшее из чисел, подаваемых на вход алгоритма, не превосходит m, то сложность алгоритмов этого типа оценивается величиной O(lncm), где c – некоторая абсолютная постоянная. Во всех приведённых примерах с =1.
Следующий алгоритм вычисляет admod m. При этом, конечно, предполагается, что натуральные числа a и d не превосходят по величине m.
2.1 Алгоритм вычисления ad mod m
Представим d в двоичной системе счисления d = d>0>2r+…+d>r>>-1>2+d>r>, где d>i>, цифры в двоичном представлении, равны 0 или 1, d>0> = 1.
Положим a>0 >= a и затем для i = 1,…,r вычислим a>i>> > > >a2>i>>-1>adi (mod m).
a>r> есть искомый вычет admod m.
Справедливость этого алгоритма вытекает из сравнения
a>i >> >a2>i-1>ad02^i+…+di (mod m),
легко доказываемого индукцией по i.
Так как каждое вычисление на шаге 2 требует не более трёх умножений по модулю m и этот шаг выполняется r log>2 >m раз, то сложность алгоритма может быть оценена величиной O(ln m).
2.2 Дихотомический алгоритм возведения в степень.
В общем виде дихотомический алгоритм позволяет вычислить n–ю степень в моноиде. Будучи применён к множеству целых чисел с операцией сложения, этот метод позволяет умножать два целых числа и более известен как египетское умножение.
Классический алгоритм возведения в степень посредством последовательного умножения характерен, главным образом, своей неэффективностью в обычных обстоятельствах – его время работы линейным образом зависит от показателя степени.
В озьмём
моноид М с
операцией умножения и рассмотрим
некоторый элемент x>0>
из М, а также
произвольное натуральное число n>0>.
Для того, чтобы вычислить , представим
n>0>
в двоичной системе счисления:
озьмём
моноид М с
операцией умножения и рассмотрим
некоторый элемент x>0>
из М, а также
произвольное натуральное число n>0>.
Для того, чтобы вычислить , представим
n>0>
в двоичной системе счисления:
n>0> = b>t>2t + b>t – >>1>2t – 1 + … + b>1>21 + b>0>20,
предполагая, что n>0 >содержит (t + 1)двоичных цифр (т. е. что b>t> 0 и b>t>> + >>1> = 0). В этих условиях вычисляемое выражение может быть записано:
или же .
Е сли
задана последовательность (x>i>)>0
>>>>
>>i>>
>>>>
>>t>,
первый элемент которой есть x>0>
и x>i>
для i
[1,t]
определено соотношением x>i>
= x>i>>
– >>1>2,
то можно записать = {x>i>
| 0
i
t,
b>i>
0}. Чтобы завершить построение алгоритма
и иметь возможность получить значение
предыдущего произведения, необходимо
вычислить биты b>i>
числа n>0>.
Для последовательности (n>i>)
>0 >>>>
>>i>>
>>>>
>>t>>+1>
(с начальным элементом n>0>),
определённой соотношением n>i>
= [n>i>>–>>1>/2]
для любого i
[1, t
+ 1], бит b>i>
равен нулю, если n>i>
чётно, и равен единице в противном
случае. Первое значение индекса i,
для которого n>i>
равно нулю, есть t
+ 1.
сли
задана последовательность (x>i>)>0
>>>>
>>i>>
>>>>
>>t>,
первый элемент которой есть x>0>
и x>i>
для i
[1,t]
определено соотношением x>i>
= x>i>>
– >>1>2,
то можно записать = {x>i>
| 0
i
t,
b>i>
0}. Чтобы завершить построение алгоритма
и иметь возможность получить значение
предыдущего произведения, необходимо
вычислить биты b>i>
числа n>0>.
Для последовательности (n>i>)
>0 >>>>
>>i>>
>>>>
>>t>>+1>
(с начальным элементом n>0>),
определённой соотношением n>i>
= [n>i>>–>>1>/2]
для любого i
[1, t
+ 1], бит b>i>
равен нулю, если n>i>
чётно, и равен единице в противном
случае. Первое значение индекса i,
для которого n>i>
равно нулю, есть t
+ 1.
Ясно, что число итераций, необходимых для выполнения алгоритма, зависит только от показателя n.
2t n 2t + 1 или t log>2>n < t + 1.
Первая часть этого свойства может быть выражена следующим образом: [n/2t + 1] = 0 и [n/2t] 0, что позволяет точно определить число совершаемых делений n, равное числу итераций алгоритма при заданном значении n. Очевидно, нужно совершить t + 1 итераций, чтобы выполнить алгоритм, т. е. [log>2>n] + 1 итераций. Следовательно, трудоёмкость алгоритма есть O(log n).
Третий алгоритм – это классический алгоритм Евклида вычисления наибольшего общего делителя целых чисел. Мы предполагаем заданными два натуральных числа a и b и вычисляем их наибольший общий делитель (a,b).
2.3 Алгоритм Евклида
Вычислим r – остаток от деления числа a на b, a = bq+r, 0 r < b.
Если r = 0, то b есть искомое число.
Если r 0, то заменим пару чисел (a,b) парой (b,r) и перейдём к шагу1.
Не останавливаясь на объяснении, почему алгоритм действительно находит (a,b), докажем некоторую оценку его сложности.
Теорема 1. При вычислении наибольшего общего делителя (a,b) с помощью алгоритма Евклида будет выполнено не более 5p операций деления с остатком, где p есть количество цифр в десятичной записи меньшего из чисел a и b.
Доказательство. Положим r>0> = a > b и определим r>1>,r>2>,…,r>n> - последовательность делителей, появляющихся в процессе выполнения шага 1 алгоритма Евклида. Тогда
r>1> = b,…, 0 r>i+1> < r>i>, i = 0,1,…,n - 1.
Пусть также u>0> = 1, u>1> = 1, u>k>>+1> = u>k>+u>k>>-1>, k 1, - последовательность Фибоначчи. Индукцией по i от i = n - 1 до i = 0 легко доказывается неравенство r>i>>+1> u>n>>->>i>. А так как u>n> 10(n-1)/5, то имеем неравенства 10p > b = r>1> u>n> 10(n-1)/5 и n < 5p+1.
Немного подправив алгоритм Евклида, можно достаточно быстро решать сравнения ax 1 (mod m) при условии, что (a,b) = 1. Эта задача равносильна поиску целых решений уравнения ax + by = 1.
2 .4
Алгоритм решения уравнения ax
+ by
= 1
.4
Алгоритм решения уравнения ax
+ by
= 1
Определим матрицу E =
Вычислим r – остаток от деления числа a на b, a = bq + r, 0 r < b.
Е сли
r
= 0, то второй столбец матрицы Е
даёт вектор (x
y)
решений уравнения.
сли
r
= 0, то второй столбец матрицы Е
даёт вектор (x
y)
решений уравнения.
Если r 0, то заменим матрицу Е матрицей
Заменим пару чисел (a,b) парой (b,r) и перейдём к шагу 1.
Если обозначить через Е>k> матрицу Е, возникающую в процессе работы алгоритма перед шагом 2 после k делений с остатком (шаг 1), то в обозначениях из доказательства теоремы 1 в этот момент выполняется векторное равенство (a,b)E>k> = (r>k>>-1>,r>k>). Его легко доказать индукцией по k. Поскольку числа a и b взаимно просты, имеем r>n>> >= 1, и это доказывает, что алгоритм действительно даёт решение уравнения ax + by = 1. Буквой n мы обозначили количество делений с остатком, которое в точности такое же, как и в алгоритме Евклида.
Полиномиальные алгоритмы в теории чисел – большая редкость. Да и оценки сложности алгоритмов чаще всего опираются на какие-либо не доказанные, но правдоподобные гипотезы, обычно относящиеся к аналитической теории чисел.
Для некоторых задач эффективные алгоритмы вообще не известны. Иногда в таких случаях всё же можно предложить последовательность действий, которая, «если повезёт», быстро приводит к требуемому результату. Существует класс так называемых вероятностных алгоритмов, которые дают правильный результат, но имеют вероятностную оценку времени работы. Обычно работа этих алгоритмов зависит от одного или нескольких параметров. В худшем случае они работают достаточно долго. Но удачный выбор параметра определяет быстрое завершение работы. Такие алгоритмы, если множество «хороших» значений параметров велико, на практике работают достаточно эффективно, хотя и не имеют хороших оценок сложности.
3. Полиномиальная арифметика
Рассмотрим вероятностный алгоритм, позволяющий эффективно находить решения полиномиальных сравнений по простому модулю. Пусть p – простое число, которое предполагается большим, и f(x)Z[x] – многочлен, степень которого предполагается ограниченной. Задача состоит в отыскании решений сравнения
f(x) 0 (mod p). (1)
Например, речь может идти о решении квадратичных сравнений, если степень многочлена f(x) равна 2. Другими словами, мы должны отыскать в поле F>p> = Z/pZ все элементы, удовлетворяющие уравнению f(x) = 0.
Согласно малой теореме Ферма, все элементы поля F>p> являются однократными корнями многочлена xp - x. Поэтому, вычислив наибольший общий делитель d(x) = (xp - x, f(x)), мы найдём многочлен d(x), множество корней которого в поле F>p> совпадает с множеством корней многочлена f(x), причём все эти корни однократны. Если окажется, что многочлен d(x) имеет нулевую степень, т. е. лежит в поле F>p>, это будет означать, что сравнение (1) не имеет решений.
Для вычисления многочлена d(x) удобно сначала вычислить многочлен c(x)xp (mod f(x)), пользуясь алгоритмом, подобным описанному выше алгоритму возведения в степень (напомним, что число p предполагается большим). А затем с помощью аналога алгоритма Евклида вычислить d(x) = (c(x) – x, f(x)). Всё это выполняется за полиномиальное количество арифметических операций.
Таким образом, обсуждая далее задачу нахождения решений сравнения (1) мы можем предполагать, что в кольце многочленов F>p>[x] справедливо равенство
f(x) = (x – a>1>)…(x – a>n>), a>i>F>p>, a>i> a>j>.
3. 1 Алгоритм нахождения делителей многочлена f(x) в кольце F>p>[x]
Выберем каким-либо способом элемент F>p>.
Вычислим наибольший общий делитель
g(x) = ( f(x), (x + )(p-1)/2 – 1).
Если многочлен g(x) окажется собственным делителем f(x), то многочлен f(x) распадается на два множителя и с каждым из них независимо нужно будет проделать все операции, предписываемые настоящим алгоритмом для многочлена f(x).
Если окажется, что g(x) = 1 или g(x) = f(x), следует перейти к шагу 1 и, выбрав новое значение , продолжить выполнение алгоритма.
Количество операций на шаге 2 оценивается величиной O(ln p), если вычисления проводить так, как это указывалось выше при нахождении d(x). Выясним теперь, сколь долго придётся выбирать числа , пока на шаге 2 не будет найден собственный делитель f(x).
Количество решений уравнения (t + a>1>)(p – 1)/2 = (t + a>2>)(p – 1)/2 в поле F>p>> >не превосходит (p-3)/2. Это означает, что подмножество D F>p>, состоящее из элементов , удовлетворяющих условиям
( + a>1>)(p – 1)/ 2 ( + a>2>)(p – 1)/ 2, -a>1>, -a>2>,
состоит не менее чем (p – 1)/2 из элементов. Учитывая теперь, что каждый ненулевой элемент bF>p> удовлетворяет одному из равенств b(p – 1)/2 = 1, либо b(p – 1)/2 = –1, заключаем, что для D одно из чисел a>1>, a>2> будет корнем многочлена (x + ) (p – 1)/2 – 1, а другое – нет. Для таких элементов многочлен, определённый на шаге 2 алгоритма, будет собственным делителем многочлена f(x).
Итак, существует не менее (p –1)/2 «удачных» выборов элемента , при которых на шаге 2 алгоритма многочлен f(x) распадается на два собственных множителя. Следовательно, при «случайном» выборе элемента F>p>, вероятность того, что многочлен не разложится на множители после k повторений шагов алгоритма 1-4, не превосходит 2-k. Вероятность с ростом k убывает очень быстро. И действительно, на практике этот алгоритм работает достаточно эффективно.
Заметим, что при оценке вероятности мы использовали только два корня многочлена f(x). При n > 2 эта вероятность, конечно, ещё меньше. Более тонкий анализ с использованием оценок А. Вейля для сумм характеров показывает, что вероятность для многочлена f(x) не распасться на множители при однократном проходе шагов алгоритма 1-4 не превосходит 2-n + O(p-1/2). Здесь постоянная в O(.) зависит от n. В настоящее время известно элементарное доказательство оценки А. Вейля.
Если в сравнении (1) заменить простой модуль p составным модулем m, то задача нахождения решений соответствующего сравнения становится намного более сложной. Известные алгоритмы её решения основаны на сведении сравнения к совокупности сравнений (1) по простым модулям – делителям m, и, следовательно, они требуют разложения числа m на простые сомножители, что, как уже указывалось, является достаточно трудоёмкой задачей.
3.2 Произведение и возведение в степень многочленов, заданных массивами
Условимся представлять многочлены массивами, индексированными, начиная с 0, в которых элемент с индексом i означает коэффициент многочлена степени i
type
Polynome=array[1..Nmax] of Ring_Element;
Следующий алгоритм даёт функцию умножения двух многочленов и , где многочлен степени (который даёт результат в конце алгоритма) должен быть предварительно инициализирован нулём.
for i:= 0 to degP do
for j:= 0 to degQ do
R[i+j]:=R[i+j]+P[i]Q[i];
Изучая предыдущий алгоритм, устанавливаем, что его сложность как по числу перемножений, так и сложений, равна произведению высот двух многочленов: (deg P + 1)(degQ + 1), но в этом алгоритме, который не учитывает случай нулевых коэффициентов, можно рассматривать высоту многочлена как число всех коэффициентов. Значит, возможно улучшить предыдущий алгоритм, исключив все ненужные перемножения:
for i:= 0 to degP do
if P[i] 0 then
for j:= 0 to degQ do
if Q[j] 0 then
R[i+j]:=R[i+j]+P[i]Q[i];
Очень просто вычислить сложность алгоритма возведения в степень последовательными умножениями, если заметить, что когда P – многочлен степени d, то Pi – многочлен степени id. Если обозначить C>mul>(n) сложность вычисления Pn, то рекуррентное соотношение C>mul>(i + 1) = C>mul>(i) + (d +1)(id +1) даёт нам:
C>mul>(n) = =
Ч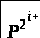
 то
касается возведения в степень с помощью
дихотомии (т.е. повторяющимися возведениями
в квадрат), вычисления несколько сложнее:
зная , вычисляем с мультипликативной
сложностью. Как следствие имеем:
то
касается возведения в степень с помощью
дихотомии (т.е. повторяющимися возведениями
в квадрат), вычисления несколько сложнее:
зная , вычисляем с мультипликативной
сложностью. Как следствие имеем:
C>sqr>(2l) = = =

=
Предварительное заключение, которое можно вывести из предыдущих вычислений, складывается в пользу дихотомического возведения в степень: если n есть степень двойки (гипотеза ad hoc), этот алгоритм ещё выдерживает конкуренцию, даже если эта победа гораздо скромнее в данном контексте (n2d2/3 против n2d2/2), чем когда работаем в Z/pZ (2log>2> n против n).
Н
 о
мы не учли корректирующие перемножения,
которые должны быть выполнены, когда
показатель не является степенью двойки.
Если n = 2l+1
– 1, нужно добавить к последовательным
возведениям в квадрат перемножения
всех полученных многочленов. Умножение
многочлена степени (2i-1)d
на многочлен степени 2id
вносит свой вклад из ((2i
– 1)d + 1)( 2i
d + 1) умножений, которые,
будучи собранными по всем корректирующим
вычислениям, дают дополнительную
сложность:
о
мы не учли корректирующие перемножения,
которые должны быть выполнены, когда
показатель не является степенью двойки.
Если n = 2l+1
– 1, нужно добавить к последовательным
возведениям в квадрат перемножения
всех полученных многочленов. Умножение
многочлена степени (2i-1)d
на многочлен степени 2id
вносит свой вклад из ((2i
– 1)d + 1)( 2i
d + 1) умножений, которые,
будучи собранными по всем корректирующим
вычислениям, дают дополнительную
сложность:
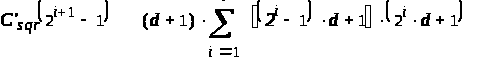
= =

=
Т

 еперь
можно заключить, что дихотомическое
возведение в степень не всегда является
лучшим способом для вычисления степени
многочлена с помощью перемножений
многочленов. Число перемножений базисного
кольца, которые необходимы, C>sqr>(n),
- в действительности заключено между
( ) и т.е. между n2d2/3
и 2n2d2/3,
тогда как простой алгоритм требует
всегда n2d2/2
перемножений. В частности, если исходный
многочлен имеет степень, большую или
равную 4, возведение в степень наивным
методом требует меньше перемножений в
базисном кольце, чем бинарное возведение
в степень, когда n
имеет форму 2l
– 1.
еперь
можно заключить, что дихотомическое
возведение в степень не всегда является
лучшим способом для вычисления степени
многочлена с помощью перемножений
многочленов. Число перемножений базисного
кольца, которые необходимы, C>sqr>(n),
- в действительности заключено между
( ) и т.е. между n2d2/3
и 2n2d2/3,
тогда как простой алгоритм требует
всегда n2d2/2
перемножений. В частности, если исходный
многочлен имеет степень, большую или
равную 4, возведение в степень наивным
методом требует меньше перемножений в
базисном кольце, чем бинарное возведение
в степень, когда n
имеет форму 2l
– 1.
Можно довольно просто доказать, что если n имеет вид 2l +2l – 1 + c (выражения, представляющие двоичное разложение n), то метод вычисления последовательными перемножениями лучше метода, использующего возведение в квадрат (этот последний метод требует корректирующего счёта ценой, по крайней мере, n2d2/9). Всё это доказывает, что наивный способ является лучшим для этого класса алгоритмов, по крайней мере, в половине случаев.
Действительно, МакКарти [3] доказал, что дихотомический алгоритм возведения в степень оптимален среди алгоритмов, оперирующих повторными умножениями, если действуют с плотными многочленами (антоним к разреженным) по модулю m, или с целыми и при условии оптимизации возведения в квадрат для сокращения его сложности наполовину (в этом случае сложность действительно падает приблизительно до n2d2/6 + n2d2/3 = n2d2/2).
3.3 Небольшие оптимизации для произведений многочленов
В принципе вычисление произведения двух многочленов степеней n и m соответственно требует (n +1)( m +1) элементарных перемножений. Алгоритм оптимизации возведения в квадрат состоит просто в применении формулы квадрата суммы:
что даёт n +1 умножений для первого члена и n( n +1)/2 – для второго, или в целом (n +1)( n +2)/2 умножений, что близко к половине предусмотренных умножений, когда n большое.
Для произведения двух многочленов первой степени P = aX + b и Q = cX + d достаточно легко находим формулы U = ac, W = bd, V = (a + b)(c + d) и PQ = =UX2 + (V – U – W)X +W, в которых появляются только три элементарных умножения, но четыре сложения. Можно рекурсивно применить этот процесс для умножения двух многочленов P и Q степени 2l – 1, представляя их в виде и применяя предыдущие формулы для вычисления PQ в зависимости от A, B, C и D, где каждое произведение AB, CD и (A + B)(C + D) вычисляется с помощью рекурсивного применения данного метода (это метод Карацубы). Всё это даёт мультипликативную сложность (2l) и аддитивную сложность (2l) такие, что:
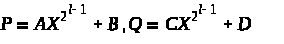 (2l)
= 3(2l
– 1),…, (2)
= 3(1),
(1)
= 1,
(2l)
= 3(2l
– 1),…, (2)
= 3(1),
(1)
= 1,
(2l) = 3(2l – 1) + 32l,…, (2) = 3(1) + 6, (1) = 1.
В этой последней формуле член 32l представляет собой число элементарных сложений, необходимых, чтобы сделать два сложения многочленов степени 2l – 1 – 1 (a + b и c + d) и два вычитания многочленов степени 2l – 1 (U – V – W). Суммируя каждое из этих выражений, находим для n, являющегося степенью двойки:
(n) = nlog3/log2 n1,585 и (2) =7 nlog3/log2 – 6n.
К сожалению, этот принцип остаётся теоретическим, и на его основе нужно построить итерационный алгоритм, чтобы получить разумную эффективность (цена управления рекурсией очень велика).
3.4 Вычисление многочленов
Рассмотрим общую задачу вычисления многочлена n-й степени
u(x) = u>n>xn + u>n – >>1>xn – 1 + ... + u>1>x + u>0>, u>n> 0, (1)
3.4.1 Схема Горнера
u(x) = (…(u>n>x + u>n>> – 1>)x + …)x + u>0>. (2)
Весь этот процесс требует n умножений и n сложений.
Было предложено несколько обобщений схемы Горнера. Посмотрим сначала, как вычисляется в случае, когда – комплексное число, а коэффициенты вещественны. Комплексное сложение и умножение можно очевидным образом свести к последовательности обычных операций над вещественными числами:
вещественное + комплексное требует 1 сложение,
комплексное + комплексное требует 2 сложения,
вещественное комплексное требует 2 умножения,
комплексное комплексное требует 4 умножения и 2 сложения
или 3 умножения и 5 сложений.
Следовательно, схема Горнера (2) требует 4n – 2 умножений и 3n – 2 сложений или 3n – 1 умножений и 6n – 5 сложений для вычисления u(z), когда z комплексное. Вот другая процедура для вычисления u(x + iy):
a>1> = u>n>, b>1> = u>n – >>1>, r = x + x, s = x2 + y2; (3)
a>j> = b>j – >>1> + ra>j –>>1>, b>j >> >= u>n – j> – sa>j>> –1>, 1 < j n.
Легко доказать индукцией по n, что u(z) = za>n> + b>n>. Эта схема требует 2n + 2 умножений и 2n + 1 сложений, так что при n 3 она лучше схемы Горнера.
Рассмотрим процесс деления многочлена u(x) на многочлен x – x>0>. В результате такого деления мы получаем u(x) = (x – x>0>)q(x) + r(x); здесь deg(r) < 1, поэтому r(x) есть постоянная, не зависящая от x и u(x>0>) = 0q(x>0>) + r = r. Анализ этого процесса деления показывает, что вычисления почти те же самые, что в схеме Горнера для определения u(x>0>). Аналогично, когда мы делим u(z) на многочлен (z – z>0>)(z – z>0>) = z2 – 2x>0>z + x>0>2 + y>0>2, то соответствующие вычисления эквивалентны процедуре (3); мы получаем
u (z)
= (z
– z>0>)(z
– z>0>)q(z)
+ a>n>z
+ b>n>;
(z)
= (z
– z>0>)(z
– z>0>)q(z)
+ a>n>z
+ b>n>;
следовательно,
u(z>0>) = a>n>z>0> + b>n>.
Вообще, когда мы делим u(x) на, f(x) получая u(x) = f(x) q(x) + r(x), то из равенства f(x>0>) = 0 следует u(x>0>) = r(x>0>); это наблюдение ведёт к дальнейшим обобщениям правила Горнера. Мы можем положить, например, f(x) = x2 – x>0>2; это даст нам схему Горнера «второго порядка»
u(x) = (…(u>2>>>> >>n>>/2 >>> x2 + u>2>>>> >>n>>/2 >>>> – 2>)x2 + u>0 >+
+((….u>2>>>> >>n>>/2 >>>> >> - 1 >x2 + u>2>>>> >>n>>/2 >>>> - 3>)x2 + … +)x2u>1>)> >x. (4)
3.4.2 Интерполяционная формула Ньютона и табулирование значений многочлена
Рассмотрим специальный случай вычисления многочлена. Интерполяционный многочлен Ньютона степени n, определяемый формулой
u[n](x) = >n>(x – x>0>) (x – x>1>)…(x – x>n>> – 1>) +…+ >n> (x – x>0>) (x – x>1>) + >1> (x – x>0>) + >0>, (5)
является единственным многочленом степени n от x, который принимает предписанные значения y>0>, y>1>, …, y>n> в заданных n + 1 различных точках x>0>, x>1>, …, x>n> соответственно. После того, как значения постоянных найдены, интерполяционная формула Ньютона становится удобной для вычислений, так как мы можем, обобщив правило Горнера, записать
u[n](x) = ((…(>n>(x – x>n>> – 1>) + >n>> – 1>)(x – x>n>> – 2>) + …)(x – x>1>) + >1>)
(x – x>0>) + >0>. (6)
Теперь рассмотрим, как находятся постоянные в формуле Ньютона. Их можно определить, находя «разделённые разности» и сводя вычисления в следующую таблицу (иллюстрирующую случай n = 3):
y>0>
(y>1> – y>0>)/(x>1> – x>0>) = y>1>
y>1> (y>2> – y’>1>)/(x>2> – x>0>) = y>2>
(y>2> – y>1>)/(x>2> – x>1>) = y>2> (y’’>3> – y’’>2>)/(x>3> – x>0>) = y>3>
y>2> (y>3> – y’>2>)/(x>3> – x>1>) = y>3>
(y>3> – y>2>)/(x>3> – x>2>) = y>3>
y>3> (7)
Можно доказать, что >0> = y>0>, >1> = y’>1>, >2> = y’>2>, и т. д. Следовательно, для нахождения величин может быть использована следующая вычислительная процедура (соответствующая таблице (7)):
Начать с того, что установить (>0>, >1>, …, >n>) (y>0>, y>1>, … , y>n>); затем для k = 1, 2, …, n (именно в таком порядке) установить y>j> (y>j> – y>j>> – >>1>)/(x>j> – x>j>> – >>k>) для j = n, n – 1, …, k (именно в таком порядке).
Если мы хотим вычислить многочлен u(x) степени n сразу для многих значений x, образующих арифметическую прогрессию (т. е. хотим вычислить u(x>0>), u(x>0> + h), u(x>0> + 2h),…), то весь процесс можно после нескольких первых шагов свести к одному только сложению вследствие того факта, что n-я разность от многочлена есть постоянная.
Найти коэффициенты >n>, …, >1>, >0> представления нашего многочлена в виде интерполяционного многочлена Ньютона
u(x) = >n >/ n! hn(x – x>0> – (n – 1)h)…(x – x>0> – h)(x – x>0>) +…+ >2>> >/ 2! h2 (x – x>0> – h)(x – x>0>) + >1>> >/ h2 (x – x>0>) + >0>. (8)
(Это можно сделать, беря повторные разности, в точности так же, как мы определяли выше постоянные в (5) (надо принять x>j> = x>0> + jh), с тем исключением, что все деления на x>j> – x>j>> – >>k>> > из вычислительной процедуры устраняются.)
Установить x x>0>.
Теперь значением u(x) является >0>.
Установить >j> >j> + >j>> + 1> для j = 0, 1, …, n – 1 (именно в таком порядке). Увеличить x на h и вернуться в шаг 3.
4. Дискретное логарифмирование
Пусть p – простое число. Ещё Эйлер знал, что мультипликативная группа кольца циклична, т. е. существуют такие целые числа а, что сравнение
ax b (mod p) (2)
разрешимо относительно x при любом bZ, не делящимся на p. Числа а с этим свойством называются первообразными корнями, и количество их равно (p – 1), где – функция Эйлера. Целое х, удовлетворяющее сравнению (2), называется индексом или дискретным логарифмом числа b.
Выше мы описали алгоритм, позволяющий по заданному числу x достаточно быстро вычислять ах mod p. Обратная же операция – вычисление по заданному b его дискретного логарифма, вообще говоря, является очень сложной в вычислительном отношении задачей. Именно это свойство дискретного логарифма и используется в его многочисленных криптографических применениях. Наиболее быстрые (из известных) алгоритмы решения этой задачи, основанные на так называемом методе решета числового поля, требуют выполнения exp(c(ln p)1/3(ln ln p)2/3) арифметических операций, где c – некоторая положительная постоянная. Это сравнимо со сложностью наиболее быстрых алгоритмов разложения чисел на множители. Конечно, указанная оценка сложности получена при условии справедливости ряда достаточно правдоподобных гипотез.
Говоря о сложности задачи дискретного логарифмирования, мы имели в виду «общий случай». Ведь и большое целое число легко может быть разложено на простые сомножители, если все эти сомножители не очень велики. Известен алгоритм, позволяющий быстро решать задачу дискретного логарифмирования, если p – 1 есть произведение малых простых чисел.
Пусть q – простое число, делящее р – 1. Обозначим с а(p – 1)/q (mod p), тогда классы вычетов 1, с, с2, … , сq – 1 все различны и образуют полное множество решений уравнения хq = 1 в поле F>p> = Z/Z>p>. Если q не велико и целое число d удовлетворяет сравнению хq 1 (mod p), то показатель k, 0 k < q, для которого выполняется d ck (mod p), легко может быть найден, например, с помощью перебора. Именно на этом свойстве основан упомянутый выше алгоритм.
Д опустим,
что р – 1 = qkh,
(q,h)
= 1. Алгоритм последовательно строит
целые числа u>j>,
j
= 0,1,…,k,
для которых выполняется сравнение
опустим,
что р – 1 = qkh,
(q,h)
= 1. Алгоритм последовательно строит
целые числа u>j>,
j
= 0,1,…,k,
для которых выполняется сравнение

1 (mod
p).
(3)
1 (mod
p).
(3)
Т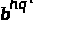
 ак
как выполняется сравнение
1 (mod
p),
то найдётся целое число u>0>,
для которого
(mod
p).
При таком выборе сравнение (3) с j
= 0, очевидно, выполняется. Предположим,
что найдено число u>j>,
удовлетворяющее сравнению (3). Тогда
определим t
с помощью сравнения
ак
как выполняется сравнение
1 (mod
p),
то найдётся целое число u>0>,
для которого
(mod
p).
При таком выборе сравнение (3) с j
= 0, очевидно, выполняется. Предположим,
что найдено число u>j>,
удовлетворяющее сравнению (3). Тогда
определим t
с помощью сравнения

ct (mod p), (4)
и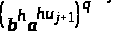
 положим. Имеют место сравнения
положим. Имеют место сравнения
1 (mod p), (5)
о значающие
справедливость (3) при j
+ 1.
значающие
справедливость (3) при j
+ 1.
При j = k сравнение означает в силу (2), что 1 (mod p). Целое число а есть первообразный корень по модулю р, поэтому имеем (x – u>k>)h 0 (mod p – 1) и
x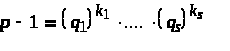
u>k>
(mod qk).
u>k>
(mod qk).
Е сли ,
где все простые числа q>j>
малы, то указанная процедура позволяет
найти вычеты x
mod
,
i
= 1,…,s,
и, с помощью китайской теоремы об
остатках, вычет x
mod
p
– 1, т. е. решить сравнение (2).
сли ,
где все простые числа q>j>
малы, то указанная процедура позволяет
найти вычеты x
mod
,
i
= 1,…,s,
и, с помощью китайской теоремы об
остатках, вычет x
mod
p
– 1, т. е. решить сравнение (2).
В случае обычных логарифмов в поле действительных чисел имеется специальное основание e = 2,171828…, позволяющее достаточно быстро вычислять логарифмы с произвольной точностью. Например, это можно делать с помощью быстро сходящегося ряда
ln(1+x)/(1 – x) = 2(x + x3/3 + x5/5 + …), |x| < 1. (6)
Логарифмы по произвольному основанию с могут быть вычислены с помощью тождества
log>c >x = ln x/ ln c. (7)
В случае дискретных логарифмов нет основания, по которому логарифмы вычислялись бы столь же быстро, как натуральные в поле действительных чисел. Вместе с тем, последняя формула, связывающая логарифмы с различными основаниями, остаётся справедливой и позволяет выбирать основание удобным способом. Единственное условие для этого состоит в том, чтобы логарифм нового основания Log c был взаимно прост c p - 1. Тогда в формуле (7) возможно деление по модулю р – 1. Заметим, что это условие будет выполнено, если и только если с – первообразный корень. Из расширенной гипотезы Римана следует, что наименьший первообразный корень по модулю р ограничен величиной O(log6 p). Поэтому в дальнейшем для простоты изложения мы будем предполагать, что основание а в (2) невелико, именно а = O(log6 p).
Т
 ак
как поле Fp
неполно, вычисление дискретных логарифмов
не может использовать предельный переход
и основано на иных принципах. Прежде
всего, нужный дискретный логарифм log
b
вычисляется не сам по себе, а вместе с
совокупностью логарифмов ряда других
чисел. Заметим, что всякое сравнение
вида
ак
как поле Fp
неполно, вычисление дискретных логарифмов
не может использовать предельный переход
и основано на иных принципах. Прежде
всего, нужный дискретный логарифм log
b
вычисляется не сам по себе, а вместе с
совокупностью логарифмов ряда других
чисел. Заметим, что всякое сравнение
вида
(mod p), (8)
где q>i>, k>i>, m>i> Z приводит к соотношению между логарифмами
(k>1> – m>1>)Log q>1> + … + (k>s> – m>s>)Log q>s> 0 (mod p – 1). (9)
А
 если выполняются сравнения
если выполняются сравнения
a (mod p – 1) b (mod p),
то
r>1>Log q>1> +…+ r>s>Log q>s> 1 (mod p – 1) (10)
и
Log b x>1>Log q>1> +…+ x>s>Log q>s> (mod p – 1) (11)
Имея достаточно много векторов k>1>,…,k>s>, m>1>,…,m>s> с условием (8), можно найти решение соответствующей системы сравнений (9), (10). Если эта система имеет единственное решение, то им как раз и будет набор логарифмов Log q>1,>…,Log q>s>. Затем с помощью (11) можно найти Log b.
М ы
опишем ниже реализацию этой идеи, взятую
из работы [1]. Эвристические соображения
позволили авторам этой работы утверждать,
что предложенный ими алгоритм требует
L1 + ,
где L = , арифметических операций для
вычисления Log b.
ы
опишем ниже реализацию этой идеи, взятую
из работы [1]. Эвристические соображения
позволили авторам этой работы утверждать,
что предложенный ими алгоритм требует
L1 + ,
где L = , арифметических операций для
вычисления Log b.
П оложим
оложим
H
= [ ] + 1, J = H2
– q.
Тогда 0 < J < 2 + 1, и, как легко проверить, для любой пары целых чисел с>1>, с>2> выполняется сравнение
(H + c>1>) (H + c>2>) J + (c>1> + c>2>)H + c>1>c>2> (mod p). (12)
Если числа c>i >не очень велики, скажем c>i> L1/2 + при некотором > 0, то правая часть сравнения (12) не превосходит p1/2 + /2. Можно доказать, что случайно выбранное натуральное число x < p1/2 + /2 раскладывается в произведение простых чисел, меньших с вероятностью, большей, чем L-1/2 - /2.
Обозначим через S = {q>1>,…,q>s>} совокупность всех простых чисел q < L1/2, а также всех простых чисел вида H + c при 0 < c < L1/2 + . Тогда s = O(L1/2 + ). Будем теперь перебирать случайным образом числа и для каждой такой пары пытаться разложить на множители соответствующее выражение из правой части (12). Для разложения можно воспользоваться, например, делением на все простые числа, меньшие, чем L1/2. Перебрав все (L1/2 + )2/2 = O(L1 + 2 ) указанных пар с1, с2 мы найдём, как это следует из указанных выше вероятностных соображений, не менее
L-1/2 - /2 *O(L1 + 2 ) = O(L1/2 + 3/2) (13)
пар, для которых правая часть сравнения (12) полностью раскладывается на простые сомножители, меньшие L1/2. Сравнение (12), таким образом, принимает вид (8). Так строится система уравнений типа (9).
Напомним, что число а, согласно нашему предположению, существенно меньше, чем L1/2. Поэтому оно раскладывается в произведение простых чисел, входящих во множество {q>1>,…,q>s>}, и это приводит к сравнению (10).
Заметим, что количество (13) найденных сравнений типа (9) превосходит число s. Следовательно, построенная система неоднородных линейных сравнений относительно Log q>i>> > содержит сравнений больше, чем неизвестных. Конечно, множество её решений может при этом быть бесконечным. Одна из правдоподобных гипотез состоит в том, что система имеет всё-таки единственное решение, и, решив её, можно определить дискретные логарифмы всех чисел q>i>. На этом завершается первый этап работы алгоритма из [1].
Как было отмечено, каждое из чисел, стоящих в правой части сравнения (12), не превосходит p1/2 + /2. Поэтому оно раскладывается в произведение не более O(ln p) простых сомножителей и, следовательно, каждое из сравнений (9) построенной системы содержит лишь O(ln p) отличных от нуля коэффициентов. Матрица системы сравнений будет разреженной, что позволяет применять для её решения специальные методы с меньшей оценкой сложности, чем обычный гауссов метод исключения переменных.
Вместо перебора всех допустимых значений c>i> в [1] предлагается использовать так называемое решето, отбрасывающее все пары этих чисел, для которых правая часть (12) заведомо не раскладывается в произведение малых простых сомножителей. Для каждого c>1> и каждой малой простой степени q' < L1/2 можно найти все решения c2 < L1/2 линейного сравнения
J + (c>1> + c>2>)H + c>1>c>2> 0 (mod q').
Организованная правильным образом, эта процедура одновременно отбирает все нужные пары чисел c>1,>c>2 >и даёт разложение на простые сомножители правых частей сравнений (12).
И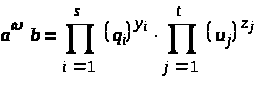 так,
после первого этапа работы алгоритма
в нашем распоряжении оказываются
дискретные логарифмы всех чисел из
множества S. Второй этап алгоритма сводит
поиск дискретного логарифма числа b
к поиску логарифмов некоторого множества
чисел u,
не превосходящих по величине L2.
Выбирая случайным образом число
не более L1/4
раз, можно, как показывают вероятностные
соображения, найти такое ,
что вычет ab
mod p
раскладывается в произведение простых
чисел, меньших L2.
Пусть
так,
после первого этапа работы алгоритма
в нашем распоряжении оказываются
дискретные логарифмы всех чисел из
множества S. Второй этап алгоритма сводит
поиск дискретного логарифма числа b
к поиску логарифмов некоторого множества
чисел u,
не превосходящих по величине L2.
Выбирая случайным образом число
не более L1/4
раз, можно, как показывают вероятностные
соображения, найти такое ,
что вычет ab
mod p
раскладывается в произведение простых
чисел, меньших L2.
Пусть
(mod p)
такое разложение, где u>1>,…,u>t> – некоторые простые числа с условием L1/2 < u < < L2. На поиск этого сравнения потребуется O(L1/2)арифметических операций. В результате вычисление дискретного логарифма числа b сводится к вычислению t дискретных логарифмов для чисел u>j>, 1 j t среднего размера.
Наконец, на последнем этапе производится вычисление логарифмов всех чисел u>j>. Пусть u – простое число из интервала условием L1/2 < u < L2. Обозначим
G
= [p
/ u],
I = HGu
– p.
Для любых целых чисел c>1>, c>2> < L1/2 + выполняется сравнение
(H + c>1>) (H + c>2>)u I + (c>1>G+ c>2>H + c>1>c>2> )u (mod p). (14)
Отметим, что правая часть этого сравнения не превосходит p1/2 L5/2 + . Просеивая все числа c>1>, c>2> из указанного интервала, можно найти такие, что числа G+ c>2 >и правая часть сравнения (14) состоят из простых сомножителей, не превосходящих L1/2. Тогда сравнение (14) позволяет вычислить Log u. Вычисление Log b при известных уже значениях Log q>1> требует L1/2 + арифметических операций.
Существуют и другие способы построения соотношений (8). В [2] для этого используются вычисления в полях алгебраических чисел. В качестве множителей в соотношения типа (8) используются не только простые числа, но и простые идеалы с небольшой нормой.
Задача вычисления дискретных логарифмов может рассматриваться также и в полях Fpn, состоящих из pn элементов, в мультипликативных группах классов вычетов (Z/mZ)*, в группах точек эллиптических кривых и вообще в произвольных группах.
Список литературы
Введение в криптографию под общей редакцией Ященко, М.: МЦНМО: «Черо», 1999.
Алгебраическая алгоритмика, Ноден П., Китте К., М.: «Мир», 1999.
Coppersmith D., Odlyzko A. M., Schroeppel R. Descrete logarithms in GF(p) // Algorithmica. V. 1,1986. P. 1-15.
Lenstra A. K, Lenstra H. W. (jr.) The Development of the Number Field Siev. Lect. Notes in Math. V. 1554. Springer, 1993.
McCarthy D. P. “The optimal algorithm to evaluate xn using elementary multiplication methods”, Math. Comp., vol. 31, no 137, 1977, pp. 251 – 256.