Основні поняття й ознаки теорії складності
Основні поняття й означення теорії складності
У теоретичній криптографії існує два основних підходи до визначення стійкості криптографічних систем і протоколів – теоретично-інформаційний та теоретично-складносний.
Теоретично-інформаційний підхід передбачає, що супротивник, атакуючий криптографічну систему, не має навіть теоретичної можливості отримати інформацію, достатню для досягнення своїх цілей. Класичний приклад – шифр Вернама з одноразовими ключами, абсолютно стійкий проти пасивного супротивника. Цей шифр є абсолютно надійним.
Нагадаємо, що шифр Вернама
(одноразового блокноту) був винайдений
в 1917 році Гілбертом Вернамом. У ньому
була використана операція побітового
додавання за модулем 2. Перед шифруванням
повідомлення
 подають
у двійковій формі. Ключем
подають
у двійковій формі. Ключем
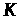 є
будь-яке двійкове слово, однакової з
довжини.
Криптотекст
є
будь-яке двійкове слово, однакової з
довжини.
Криптотекст
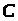 отримують таким шляхом:
отримують таким шляхом:
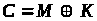 .
Розшифрування в шифрі одноразового
блокноту збігається із шифруванням
.
Розшифрування в шифрі одноразового
блокноту збігається із шифруванням
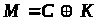 .
Це зрозуміло, оскільки
.
Це зрозуміло, оскільки
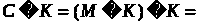
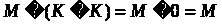
Якщо супротивник не знає
ключа
,
то з підслуханого криптотексту
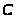 він абсолютно нічого не дізнається про
повідомлення
.
Для супротивника усі ключі є рівноймовірними.
Двійкове слово
може бути криптотекстом для будь-якого
іншого повідомлення
він абсолютно нічого не дізнається про
повідомлення
.
Для супротивника усі ключі є рівноймовірними.
Двійкове слово
може бути криптотекстом для будь-якого
іншого повідомлення
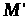 ,
якщо б шифрування відбувалось з
використанням якогось іншого ключа
,
якщо б шифрування відбувалось з
використанням якогось іншого ключа
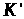 ,
а саме
,
а саме
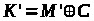 .
Наприклад, запишемо слово „БАНАН” у
двійковій формі: 000001 000000 010001 000000 010001.
.
Наприклад, запишемо слово „БАНАН” у
двійковій формі: 000001 000000 010001 000000 010001.
Нехай ключем буде двійкова послідовність
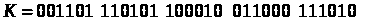 .
.
Отримуємо криптотекст
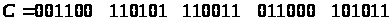 .
.
Але такий самий криптотекст ми отримаємо, якщо зашифруємо повідомлення „ГРУША” ключем
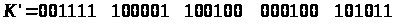 .
.
Теорія складності є методикою аналізу обчислювальної складності різних криптографічних методів і алгоритмів. Вона порівнює криптографічні методи та алгоритми і визначає їх надійність. Теорія інформації стверджує можливість злому всіх криптографічних алгоритмів (окрім одноразових блокнотів). Теорія складності повідомляє, чи можна їх зламати до того, як настане теплова загибель Всесвіту.
Складність алгоритму
визначається обчислювальними потужностями,
необхідними для його виконання.
Обчислювальну складність алгоритму
часто визначають двома параметрами: Т
(часова складність) та S (просторова
складність або вимоги до пам’яті). Як
Т так і S звичайно відображуються як
функції від
 ,
де
–
розмір вхідних даних (існують також
інші міри складності: число випадкових
бітів, наскільки широкий канал зв’язку,
об’єм даних тощо).
,
де
–
розмір вхідних даних (існують також
інші міри складності: число випадкових
бітів, наскільки широкий канал зв’язку,
об’єм даних тощо).
Обчислювальну складність
алгоритму звичайно виражають через
символ „О велике”, що вказує порядок
величини обчислювальної складності.
Це просто член розкладення функції
складності, що найшвидше зростає за
умови зростання
;
всі члени нищого порядку ігноруються.
Наприклад, якщо часова складність
порядку
 ,
то вона виражається як
,
то вона виражається як
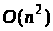 .
.
Часова складність, виміряна подібним чином, не залежить від реалізації.
Не потрібно знати ні точного часу виконання окремих інструкцій, ні числа бітів, які являють різні змінні, ні навіть швидкості процесора. Один комп’ютер може бути на 50% швидший від іншого, а в третього ширина шини даних може бути вдвічі більше, проте складність алгоритму, що оцінена порядком величини, не зміниться. І це не є хитрим трюком. Під час оцінки доволі складних алгоритмів усім іншим можна знехтувати (з точністю до постійного множника).
Оцінка обчислювальної складності наочно демонструє, як об’єм вхідних даних впливає на вимоги до часу та об’єму пам’яті.
Наприклад, якщо
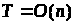 ,
подвоєння вхідних даних подвоїть і час
виконання алгоритму. Якщо
,
подвоєння вхідних даних подвоїть і час
виконання алгоритму. Якщо
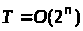 ,
додання лише одного біту до вхідних
даних подвоїть час виконання алгоритму.
,
додання лише одного біту до вхідних
даних подвоїть час виконання алгоритму.
Головною ціллю теорії складності є забезпечення механізмів класифікації обчислювальних задач згідно з ресурсами, необхідних для їх розв’язання. Класифікація не має залежати від конкретної обчислювальної моделі, а скоріше оцінювати внутрішню складність задачі.
Ресурси, що оцінюються, як уже було зазначено раніше, можуть бути такими: час, простір пам’яті, випадкові біти, кількість процесорів, тощо, але зазвичай головним фактором є час, а іноді й простір.
Теорія розглядає мінімальний час і об’єм пам’яті для розв’язання найскладнішого варіанта задачі на теоретичному комп'ютері, відомому як машина Тьюринга. Машина Тьюрінга є кінцевим автоматом з безкінечною магнітною стрічкою пам’яті для читання/запису. Це означає, що машина Тьюрінга – реалістична обчислювальна модель.
Задачі, які можна розв’язати за допомогою алгоритмів з поліноміальним часом, називають такими, що можуть бути розв’язані, оскільки за умов нормальних вхідних даних вони можуть бути розв’язані за прийнятний час (точне визначення "прийнятності" залежить від конкретних умов).
Задачі, які можуть бути
вирішені тільки за допомогою
суперполіноміальних алгоритмів з
поліноміальним часом, є обчислювально
складними навіть за відносно малими
значеннями
.
Що ще гірше, Алан Тьюрінг доказав, що деякі задачі неможливо розв’язати. Навіть без урахування часової складності алгоритму, створити алгоритм для їх розв’язання неможливо.
Задачі можна розбити на класи у відповідності зі складністю їх розв'язання. Найважливіші класи й очікувані співвідношення між ними показані на рис. 1.
Клас
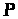 ,
що є найнижчим, містить усі задачі, які
можна розв’язати за поліноміальний
час. До класу
,
що є найнижчим, містить усі задачі, які
можна розв’язати за поліноміальний
час. До класу
 входять усі задачі, які можна розв’язати
за поліноміальний час тільки на
недетермінованій машині Тьюрінга (це
варіант звичайної машини Тьюрінга, що
може робити припущення). Така машина
робить припущення щодо розв’язку задачі
– чи „вдачно вгадуючи”, чи перебираючи
усі припущення паралельно – та перевіряє
своє припущення за поліноміальний час.
входять усі задачі, які можна розв’язати
за поліноміальний час тільки на
недетермінованій машині Тьюрінга (це
варіант звичайної машини Тьюрінга, що
може робити припущення). Така машина
робить припущення щодо розв’язку задачі
– чи „вдачно вгадуючи”, чи перебираючи
усі припущення паралельно – та перевіряє
своє припущення за поліноміальний час.
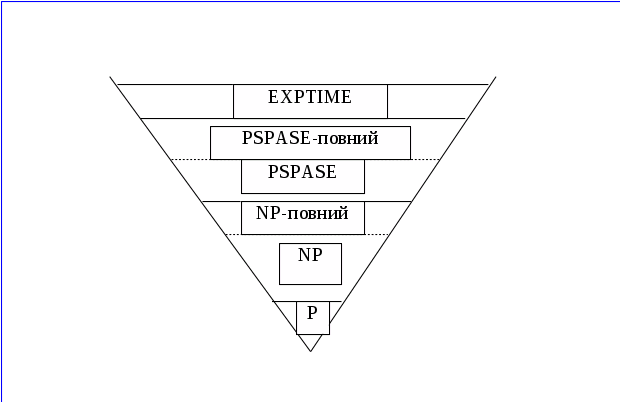
 Рисунок
1 – Класи складності
Рисунок
1 – Класи складності
Важливість
– задач у криптографії визначається
умовою, що за недетермінований
поліноміальний час можна зламати багато
симетричних алгоритмів та алгоритмів
з відкритим ключем. Для даного шифротексту
,
криптоаналітик просто вгадує відкритий
текст
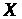 і ключ
і ключ
 ,
потім поліноміальний час виконує
алгоритм шифрування по входах
і
та перевіряє, чи рівний результат
.
,
потім поліноміальний час виконує
алгоритм шифрування по входах
і
та перевіряє, чи рівний результат
.
Приклад – криптосистема з відкритим ключем. Вам уже відомо, що вона визначається трьома алгоритмами: алгоритмом генерації ключів, алгоритмом шифрування та алгоритмом розшифрування. Алгоритм генерації є загальнодоступним. Хто завгодно може подати на вхід алгоритму рядок r належної довжини й отримати пару ключей (K>1>,K>2>). Відкритий ключ K>1> публікується, а секретний ключ K>2 >і випадковий рядок r – зберігаються в секреті. Нагадаємо, що криптосистема RSA запропонована в 1977 році, і є однією з найбільш популярних криптосистем з відкритим ключем. Назва системи утворена з перших букв прізвищ її творців – Рональда Райвеста, Аді Шаміра і Леонарда Адлемана.
Генерування ключів. Обирають
два достатньо великих простих числа
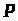 і
і
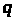 .
.
Для їх добутку
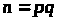 функція Ейлера буде дорівнювати
функція Ейлера буде дорівнювати
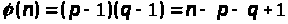 (в теорії чисел використовують поняття
функції Ойлера
(в теорії чисел використовують поняття
функції Ойлера
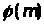 ,
під якою розуміють кількість чисел
менших від
,
під якою розуміють кількість чисел
менших від
 і взаємопростих з
).
Потім випадковим чином вибирають число
е, яке
не перевищує значення
і взаємопростих з
).
Потім випадковим чином вибирають число
е, яке
не перевищує значення
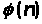 і буде взаємопростим з ним. Для цього
числа е за
алгоритмом Евкліда знаходять елемент
d,
зворотний до е, тобто
такий, що
і буде взаємопростим з ним. Для цього
числа е за
алгоритмом Евкліда знаходять елемент
d,
зворотний до е, тобто
такий, що
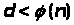 і
і
 .
.
Цей запис у теорії чисел
означає, що добуток
 при діленні на число
дає залишок рівний 1 (читається
порівнян з одиницею за модулем
).
при діленні на число
дає залишок рівний 1 (читається
порівнян з одиницею за модулем
).
У результаті:
Як відкритий
ключ пара чисел
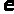 та
та
 .
.
Як секретний ключ – число d.
Шифрування виконується
блоками. Для цього повідомлення записують
у цифровому вигляді та розбивають на
блоки так, що кожний блок являє число,
яке не перевищує
.
Скажімо, якщо блок М
записаний у двійковому
вигляді довжини
,
то має виконуватися
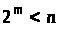 .
.
Алгоритм шифрування Е
в системі RSA полягає в піднесенні
двійкового числа М
до степеня
.
Запишемо це так
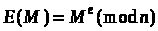 .
.
У результаті виходить шифроблок
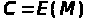 .
.
Дешифрування.
Алгоритм дешифрування
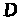 шифроблоку
шифроблоку
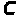 полягає у піднесенні двійкового числа
С до
степеня
полягає у піднесенні двійкового числа
С до
степеня
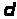 ,
тобто
,
тобто
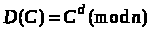 .
.
Для простоти викладення припустимо, що відкритий текст і криптограма мають однакову довжину n. Крім того, вважаємо, що відкритий текст, криптограма й обидва ключі – рядки в двійковому алфавіті.
Припустимо, що супротивник
атакує цю криптосистему. Йому відомий
відкритий ключ K>1>.
Він перехопив криптограму d
і намагається знайти повідомлення М,
де
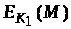 .
Оскільки алгоритм загальновідомий,
супротивник може послідовно перебирати
всі повідомлення довжини n,
обчислювати для кожного такого
повідомлення
.
Оскільки алгоритм загальновідомий,
супротивник може послідовно перебирати
всі повідомлення довжини n,
обчислювати для кожного такого
повідомлення
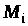 криптограму
криптограму
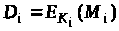 і порівнювати D>і>
з D.
Якщо D>і>
D, то
M>і >
шуканий текст. Якщо пощастить, то
відкритий текст буде знайдений швидко.
У найгіршому випадку перебір буде
виконаний за час приблизно 2n
T(n),
де T(n)
час, потрібний на обчислення функції
E>1>
від повідомлення довжини n.
Якщо повідомлення мають довжину біля
1000 бітів, то такий перебіру є на практиці,
навіть за допомогою найпотужніших
комп’ютерів. Наведений алгоритм пошуку
відкритого тексту називають алгоритмом
повного перебору або „метод брутальної
сили”.
і порівнювати D>і>
з D.
Якщо D>і>
D, то
M>і >
шуканий текст. Якщо пощастить, то
відкритий текст буде знайдений швидко.
У найгіршому випадку перебір буде
виконаний за час приблизно 2n
T(n),
де T(n)
час, потрібний на обчислення функції
E>1>
від повідомлення довжини n.
Якщо повідомлення мають довжину біля
1000 бітів, то такий перебіру є на практиці,
навіть за допомогою найпотужніших
комп’ютерів. Наведений алгоритм пошуку
відкритого тексту називають алгоритмом
повного перебору або „метод брутальної
сили”.
Одним з інших найпростіших алгоритмів пошуку відкритого тексту – угадування. Цей алгоритм потребує малої кількості обчислень, але спрацьовує знехтовно низькою вірогідністю.
Насправді супротивник може намагатися атакувати криптосистему різними шляхами, використовувати різноманітні, більш складні алгоритми пошуку відкритого тексту.
Клас
містить у собі клас
,
оскільки будь-яку задачу, що можна
розв’язати за поліноміальний час на
детермінованій машині Тьюрінга, можна
розв’язати й на недетермінованій машині
Тьюрінга за поліноміальний час, просто
етап припущення опускається.
Якщо всі задачі класу
розв’язуються за поліноміальний час
і на детермінованій машині Тьюрінга,
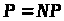 .
Хоч здається очевидним, що деякі
задачі набагато складніші від інших
(лобове розкриття алгоритму шифрування
проти шифрування випадкового блоку
шифротексту), ніхто не доказав, що
.
Хоч здається очевидним, що деякі
задачі набагато складніші від інших
(лобове розкриття алгоритму шифрування
проти шифрування випадкового блоку
шифротексту), ніхто не доказав, що
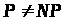 (чи
).
Однак більшість спеціалістів, що
займаються теорією складності, переконані,
що ці класи нерівні. Можна навести
приклади. Майкл Кері та Девід Джонсон
склали перелік більш ніж 300
-повних
задач. Ось деякі з них:
(чи
).
Однак більшість спеціалістів, що
займаються теорією складності, переконані,
що ці класи нерівні. Можна навести
приклади. Майкл Кері та Девід Джонсон
склали перелік більш ніж 300
-повних
задач. Ось деякі з них:
– Задача комівояжера.
Комівояжер повинен об’їхати
різних міст, використовуючи тільки один
бак з пальним (задано максимальну
відстань, яку він може проїхати). Чи
існує такий маршрут, що дозволяє йому
відвідати кожне місто лише один раз,
використовуючи цей єдиний бак з пальним?
– Задача про трійні шлюби. У
кімнаті
чоловіків,
жінок і
священиків (жерців, равінів тощо). Окрім
того існує список припустимих шлюбів,
записи яких містять одного чоловіка,
одну жінку й одного священика, що згоден
провести обряд. Чи можливо, за умов цього
списку, побудувати
шлюбів так, щоб кожен чи вступав у шлюб
тільки з однією людиною, чи реєстрував
тільки один шлюб.
Наступним у ієрархії складності
йде клас
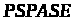 .
Задачі класу
можна розв’язати в поліноміальному
просторі. До класу
входить клас
,
але ряд задач
вважають більш складним ніж задачі
.
Звісно, це поки що не може бути доведено.
Відомий клас т.з.
-повних
задач, що мають таку властивість: якщо
будь-яка з них є
-задачею,
то
.
Задачі класу
можна розв’язати в поліноміальному
просторі. До класу
входить клас
,
але ряд задач
вважають більш складним ніж задачі
.
Звісно, це поки що не може бути доведено.
Відомий клас т.з.
-повних
задач, що мають таку властивість: якщо
будь-яка з них є
-задачею,
то
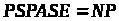 і якщо будь-яка з них є
-
задачею, то
і якщо будь-яка з них є
-
задачею, то
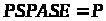 .
.
І, нарешті, існує клас
 .
Ці задачі розв’язуються за експоненційний
час. На теперішній час можна довести,
що
-повні
задачі неможливо розв’язати за
детермінований поліноміальний час.
Крім того доведено, що
.
Ці задачі розв’язуються за експоненційний
час. На теперішній час можна довести,
що
-повні
задачі неможливо розв’язати за
детермінований поліноміальний час.
Крім того доведено, що
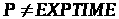 .
.
Дамо деякі визначення. Ми говоритимемо про алгоритми.
Алгоритм – це чітко задана обчислювальна процедура, що приймає змінні вхідні дані і зупиняється з видачею вихідних даних.
Звичайно, термін „чітко задана обчислювальна процедура” є математично неточною. Вона може бути зроблена точною за допомогою формальних обчислювальних моделей, таких як машини Тьюрінга, машини випадкового доступу чи булеві схеми. Однак, чим мати справу з технічними складностями таких моделей, краще розглядати алгоритм як комп’ютерну програму, записану на деякій конкретній мові програмування для конкретного комп’ютера, яка приймає змінні вхідні дані і зупиняється з видачею вихідних даних.
Зазвичай цікавим є знаходження найефективнішого (тобто, найшвидшого) алгоритму для вирішення даної обчислювальної задачі. Час, який витрачає алгоритм до зупинки, залежить від ”розміру” конкретної задачі. Крім того, одиниця часу, що використовується, має бути точною, особливо при порівнянні ефективності двох алгоритмів.
Якщо ми маємо справу з алгоритмом, то вважають зафіксованими два алфавіти: вхідний – А і вихідний – В. Робота алгоритму полягає у тому, що він отримує на вхід слово вхідного алфавіту, і як результат виконання послідовності елементарних операцій, подає на вихід слово у вихідному алфавіті.
Залежно від типу алгоритму говорять, що алгоритм обчислює функцію, розрізнює множину чи мову, знаходить елемент з певними властивостями.
Час виконання алгоритму на конкретних вхідних даних визначається як кількість елементарних операцій чи „кроків”, що виконуються. Часто крок використовується для визначення бітової операції. Для деяких алгоритмів буде більш зручним використовувати крок для маркування чогось ще, наприклад, порівняння, машинної команди, машинного тактового циклу, модулярного множення тощо.
Якщо t (n) cnc для деякої константи с, то алгоритм вирішує задачу за поліноміальний (від довжини входу) час.
Такий алгоритм називають поліноміальним, а задачу такою, що вирішується поліноміально.
Поняття поліноміального часу є центральною концепцією теорії складності обчислень. У рамках цієї концепції вважається, що поліноміальні алгоритми відповідають швидким, ефективним на практиці алгоритмам, а такі, що вирішуються поліноміально, відповідають легким задачам.
Алгоритм, що на безкінечній
послідовності входів робить більш ніж
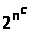 кроків,
де n –
довжина входу, а с > 0 – деяка константа,
називається експоненційним.
кроків,
де n –
довжина входу, а с > 0 – деяка константа,
називається експоненційним.
Про такий алгоритм говорять, що він потребує експоненційного часу. Експоненційні алгоритми відповідають загальним поняттям про неефективні на практиці алгоритми.
Так, наприклад, реалізація
ідеї несиметричного шифрування базується
на понятті однобічної взаємно однозначної
функції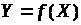 ,
такої, що при відомому
порівняно просто обчислити
,
такої, що при відомому
порівняно просто обчислити
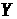 ,
однак зворотню функцію
,
однак зворотню функцію
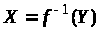 обчислити (за прийнятний час) неможливо.
Цю властивість називають практичною
незворотністю. Зазвичай обчислення
прямої функції має поліноміальну
складність, а зворотної – у кращому
випадку експоненційну. У криптосистемі
RSA достатньо просто знайти добуток двох
простих чисел (поліноміальна складність),
але задача розкладання великого числа
на прості співмножники є дуже складною
(як мінімум експоненційної складності).
Сьогодні не існує жодної однобічної
функції, для якої математично була б
доведена її практична незворотність
або експоненційна складність. Ті функції,
що знайшли довгострокове застосування
в криптографії, вважаються однобічними.
При цьому можна лише стверджувати, що
на сьогодні відомі алгоритми обчислення
зворотної функції зі складністю, що
практично може бути реалізована (в
рамках заданих параметрів).
обчислити (за прийнятний час) неможливо.
Цю властивість називають практичною
незворотністю. Зазвичай обчислення
прямої функції має поліноміальну
складність, а зворотної – у кращому
випадку експоненційну. У криптосистемі
RSA достатньо просто знайти добуток двох
простих чисел (поліноміальна складність),
але задача розкладання великого числа
на прості співмножники є дуже складною
(як мінімум експоненційної складності).
Сьогодні не існує жодної однобічної
функції, для якої математично була б
доведена її практична незворотність
або експоненційна складність. Ті функції,
що знайшли довгострокове застосування
в криптографії, вважаються однобічними.
При цьому можна лише стверджувати, що
на сьогодні відомі алгоритми обчислення
зворотної функції зі складністю, що
практично може бути реалізована (в
рамках заданих параметрів).
Часто буває складно отримати час виконання алгоритму. У таких випадках змушені погодитися на апроксимацію часу виконання, зазвичай можна отримати асимптотичний час виконання, тобто досліджується, як збільшується час виконання алгоритму з безмежним збільшенням розміру вхідних даних. Розглядаються тільки ті функції, що задані на додатних цілих числах і приймають дійсні значення.
Нехай f та g будуть двома такими функціями.
Запис f(n) O( g(n)) означає, що f асимптотично зростає не швидше, ніж g(n), з точністю до постійного кратного, у той час як f(n) (g(n)) означає, що f(n) зростає, принаймні, також асимптотично швидко, як зростає g(n), з точністю до постійного множника.
f(n) O(g(n)) означає, що функція f(n) стає несуттєвою відносно g(n) по мірі зростання n.
При цьому для будь-яких функцій f(n), g(n), h(n) і l(n) справедливі такі властивості і співвідношення:
f (n) O(g(n)), у випадку. якщо g(n) = (f (n)).
f(n) (g(n)), у випадку. якщо f (n) O(g(n)) і (f)n (g(n)).
Якщо f (n) O(h(n)) і (g)n O(h(n)), то ( f g)(n) O(h(n)).
Якщо f (n) O( h(n)) і g(n) O(l(n)), то ( f g)( n) O(h(n)l(n)).
Рефлексивність f(n) O(f(n)).
Транзитивність. Якщо f(n) O(g(n)) і g(n) O(h(n)), то f(n) O(h(n)).
Складність алгоритмів вимірюють кількістю арифметичних операцій (додавань, віднімань, множень і ділень із залишком), необхідних для виконання всіх дій. Однак це визначення не бере до уваги величини чисел, що беруть участь в обчисленнях. Тому, часто беруть до уваги ще й величину чисел, зводячи обчислення до бітових операцій, тобто оцінюючи кількість необхідних операцій із цифрами 0 і 1, у двійковому записі чисел. Це залежить від задачі, що розглядаються.
Даний підхід зручний з таких
міркувань. По-перше, у комп’ютерах дані
подаються і обробляються у двійковому
вигляді, а інші подання в основному
використовують під час введення даних
і під час виведення результатів. По-друге,
перевід числа
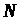 від однієї основи системи обчислень до
іншої виконується швидко і потребує
виконання
від однієї основи системи обчислень до
іншої виконується швидко і потребує
виконання
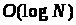 арифметичних операцій (ділення з
залишком, множення або додаваня чисел),
де
арифметичних операцій (ділення з
залишком, множення або додаваня чисел),
де
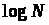 – довжина запису числа
(основу логарифмам не вказуємо, оскільки
воно не впливає на вид оцінки складності).
Перехід до іншої основи є рідкісною
операцією, затратами на її виконання
можна знехтувати. Нарешті, бітова оцінка
непогано відображує реальну складність
операцій, оскільки, як правило, оцінки
складності для інших основ систем
обчислень призводять лише до змін у
константному множнику функції оцінки
складності. При оцінці складності
обчислювальних задач, звичайно,
застосовують методи редукції і піднесення
до інших задач з відомими оцінками
складності.
– довжина запису числа
(основу логарифмам не вказуємо, оскільки
воно не впливає на вид оцінки складності).
Перехід до іншої основи є рідкісною
операцією, затратами на її виконання
можна знехтувати. Нарешті, бітова оцінка
непогано відображує реальну складність
операцій, оскільки, як правило, оцінки
складності для інших основ систем
обчислень призводять лише до змін у
константному множнику функції оцінки
складності. При оцінці складності
обчислювальних задач, звичайно,
застосовують методи редукції і піднесення
до інших задач з відомими оцінками
складності.