Эмуляция команды математического сопроцессора Fsub>
Содержание
информация алгоритм эмуляция сопроцессор
Введение
Анализ задания и выбор технологии, языка и среды разработки
Определение структуры программного продукта
2.1 Анализ процесса обработки информации и выбор структур данных для хранения
2.2 Выбор методов решения задачи и разработка основных алгоритмов предметной области
2.3 Построение структурной схемы программного продукта
Описание реализации программного продукта
3.1 Описание программы эмуляции команды Fsub> математического сопроцессора
3.2 Описание функции Fsub>
3.3 Описание функции FLD
3.4 Описание функции Print_st
Тестирование программы
Заключение
Приложение
Введение
Реалии нашего времени диктуют тот факт, что определяющим качеством товара является его стоимость. Это связано, в основном, с большим ассортиментом каждого устройства, какой бы не был необходим пользователю. Что вполне логично. Ни кто не станет покупать вещь если существует её дешевый аналог. Но ради справедливости надо заметить что не всегда качественный. Но русские не сдаются и по этому китайский ширпотреб и соответствующая ему культура деловых отношений будет существовать еще долго. Что логично это оказывает и характерное влияние на производимые электроне чипы, микроконтроллеры и прочие сопутствующие детали. Рядовой производитель столкнулся с условием максимально удешевления своей продукции с целью получения преимущества в конкурентной борьбе. И по этим причинам сейчас не редкость встретить всевозможные электронные устройства, такие как медиаплееры, телефоны и т.д. реализованные на материальной базе, лишенной многих функций как казалось обычных процессоров вычислительных систем и машин.
В основном вся тяжесть ложиться на разработчиков программного обеспечения для этих устройств. Программистам приходиться самостоятельно, опираясь на существующие функции реализовывать недостающие, если нет возможности обойтись без них.
Анализ задания и выбор технологии, языка и среды разработки
Для написания программы, эмулирующей работу сопроцессора необходим серьезный инструмент разработки. Так уж повелось, что в природе существует несколько способов решения поставленной задачи, тут исключения не будет. В ходе работы были просмотрены и оценены несколько языков программирования. Далее о каждом более подробно.
Pascal, достоинства :
Удобная среда разработки, включающая функциональный отладчик, доступный в любой момент.
Контекстная справочная система, по которой можно изучать язык без обращения к сторонним источникам.
Высокая скорость компиляции, высокая скорость выполнения откомпилированных программ.
Встроенная возможность использовать вставки на языке ассемблера.
Недостатки:
Компилятор рассчитан на реальный режим DOS, применение которого сходит на нет. Однако в последних версиях компилятора и среды введена поддержка защищённого режима вместе с соответствующим отладчиком (TD).
В модуле CRT имеется ошибка (некорректный подсчёт количества циклов для функции delay, не рассчитанный на быстрые процессоры, процессоры с переменной частотой и многозадачные среды), из-за которой при запуске программы на компьютерах с тактовой частотой более 200 MHz сразу происходило аварийное завершение с сообщением "Runtime error 200 at…". Существуют разные варианты исправления модуля CRT.В варианте Клауса Хартнегга ошибка 200 не возникает, но длительность Delay на быстрых компьютерах меньше желаемой, и эта проблема по незнанию иногда тоже считается недостатком Turbo Pascal.
Assembler, достоинства:
Язык ассеблера позволяет писать самый быстрый и компактный код, как минимум не хуже, чем генерируемый трансляторами языков более высокого уровня, всё зависит от способностей программиста.
Если код программы достаточно большой, данные, которыми он оперирует, не помещаются целиком в регистрах процессора, т.е. частично или полностью находятся в оперативной памяти, то искусный программист, как правило, способен значительно оптимизировать программу по сравнению с высокоуровневыми трансляторами по одному или нескольким параметрам: скорость работы (за счёт оптимизации вычислений и/или более рационального обращения к ОП, перераспределения данных), объём кода (в том числе за счёт эффективного использования промежуточных результатов).
Обеспечение максимального использования специфических возможностей конкретной платформы, что также позволяет создавать более эффективные программы с меньшими затратами ресурсов.
При программировании на ассемблере возможен непосредственный доступ к аппаратуре, в том числе портам ввода-вывода, регистрам процессора, и др.
Язык ассемблера применяется для создания драйверов оборудования и ядра операционной системы
Язык ассемблера используется для создания "прошивок" BIOS.
С помощью языка ассемблера создаются компиляторы и интерпретаторы языков высокого уровня, а также реализуется совместимость платформ.
Существует возможность исследования других программ с отсутствующим исходным кодом с помощью дизассемблера.
Недостатки:
Главное преимущество ассемблера практически полностью нивелируется хорошей оптимизацией в современных компиляторах языков высокого уровня.
В силу своей машинной ориентации ("низкого" уровня) человеку по сравнению с языками программирования высокого уровня сложнее читать и понимать программу, она состоит из слишком "мелких" элементов — машинных команд, соответственно усложняются программирование и отладка, растет трудоемкость, велика вероятность внесения ошибок. В значительной степени возрастает сложность совместной разработки.
Как правило, меньшее количество доступных библиотек по сравнению с современными индустриальными языками программирования.
Отсутствует переносимость программ на компьютеры с другой архитектурой и системой команд (кроме двоично-совместимых).
С++, достоинства:
C++ — чрезвычайно мощный язык, содержащий средства создания эффективных программ практически любого назначения, от низкоуровневых утилит и драйверов до сложных программных комплексов самого различного назначения. В частности:
Поддерживаются различные стили и технологии программирования, включая традиционное директивное программирование, ООП, обобщенное программирование, метапрограммирование (шаблоны, макросы).
Поддержка инвариантов "всегда сначала А, потом В" при помощи деструкторов. Это позволяет захватывать и особождать ресурсы, начинать и завершать операции, блокировать и разблокировать доступ к чему-либо автоматически. Например, для чтения файла достаточно объявления переменной типа ifstream. Файл будет закрыт автоматически, когда переменная перестанет быть видимой. Многие языки требуют явного написания кода в таком случае. С++ корректно обрабатывает такие ситуации и в случае возникновения исключений.
Возможность создания обобщённых контейнеров и алгоритмов для разных типов данных, их специализация и вычисления на этапе компиляции, используя шаблоны.
Кроссплатформенность. Доступны компиляторы для большого количества платформ, на языке C++ разрабатывают программы для самых различных платформ и систем.
Эффективность. Язык спроектирован так, чтобы дать программисту максимальный контроль над всеми аспектами структуры и порядка исполнения программы. Ни одна из языковых возможностей, приводящая к дополнительным накладным расходам, не является обязательной для использования — при необходимости язык позволяет обеспечить максимальную эффективность программы.
Имеется возможность работы на низком уровне с памятью, адресами.
Высокая совместимость с языком С, позволяющая использовать весь существующий С-код (код С может быть с минимальными переделками скомпилирован компилятором С++; библиотеки, написанные на С, обычно могут быть вызваны из С++ непосредственно без каких-либо дополнительных затрат, в том числе и на уровне функций обратного вызова, позволяя библиотекам, написанным на С, вызывать код, написанный на С++).
Недостатки:
Отчасти недостатки C++ унаследованы от языка-предка — Си, — и вызваны изначально заданным требованием возможно большей совместимости с Си. Это такие недостатки, как:
Синтаксис, провоцирующий ошибки:
Операция присваивания обозначается как = , а операция сравнения как ==. Их легко спутать, при этом операция присваивания возвращает значение, поэтому присваивание на месте выражения является синтаксически корректным, а в конструкциях цикла и ветвления появление числа на месте логического значения также допустимо, так что ошибочная конструкция оказывается синтаксически правильной. Типичный пример подобной ошибки:
if (x=0) { операторы }
Здесь в условном операторе по ошибке написано присваивание вместо сравнения. В результате, вместо того, чтобы сравнить текущее значение x с нулём, программа присвоит x нулевое значение, а потом интерпретирует его как значение условия в операторе if. Так как нуль соответствует логическому значению "ложь" (false), блок операторов в условной конструкции не выполнится никогда. Ошибки такого рода трудно выявлять, но во многих современных компиляторах предлагается диагностика некоторых подобных конструкций.
Операции присваивания (=), инкрементации (++), декрементации (--) и другие возвращают значение. В сочетании с обилием операций это позволяет, хотя и не обязывает, создавать трудночитаемые выражения. Наличие этих операций в Си было вызвано желанием получить инструмент ручной оптимизации кода, но в настоящее время оптимизирующие компиляторы обычно генерируют оптимальный код и на традиционных выражениях. С другой стороны, один из основных принципов языков C и C++ — позволять программисту писать в любом стиле, а не навязывать "хороший" стиль.
Макросы (#define) являются мощным, но опасным средством. Они сохранены в C++ несмотря на то, что необходимость в них, благодаря шаблонам и встроенным функциям, не так уж велика. В унаследованных стандартных С-библиотеках много потенциально опасных макросов.
Некоторые преобразования типов неинтуитивны. В частности, операция над беззнаковым и знаковым числами выдаёт беззнаковый результат.
Необходимость записывать break в каждой ветви оператора switch и возможность последовательного выполнения нескольких ветвей при его отсутствии провоцирует ошибки из-за пропуска break. Эта же особенность позволяет делать сомнительные "трюки", базирующиеся на избирательном неприменении break и затрудняющие понимание кода.
Препроцессор, унаследованный от С, очень примитивен. Это приводит с одной стороны к тому, что с его помощью нельзя (или тяжело) осуществлять некоторые задачи метапрограммирования, а с другой, вследствие своей примитивности, он часто приводит к ошибкам и требует много действий по обходу потенциальных проблем. Некоторые языки программирования (например, Scheme и Nemerle) имеют намного более мощные и более безопасные системы метапрограммирования (также называемые макросами, но мало напоминающие макросы С/С++).
Плохая поддержка модульности (по сути, в классическом Си модульность на уровне языка отсутствует, её обеспечение переложено на компоновщик). Подключение интерфейса внешнего модуля через препроцессорную вставку заголовочного файла (#include) серьёзно замедляет компиляцию при подключении большого количества модулей (потому что результирующий файл, который обрабатывается компилятором, оказывается очень велик). Эта схема без изменений скопирована в C++. Для устранения этого недостатка, многие компиляторы реализуют механизм прекомпиляции заголовочных файлов Precompiled Headers.
К собственным недостаткам C++ можно отнести:
Сложность и избыточность, из-за которых C++ трудно изучать, а построение компилятора сопряжено с большим количеством проблем. В частности:
В языке практически полностью сохранён набор конструкций Си, к которому добавлены новые средства. Во многих случаях новые средства и механизмы позволяют делать то же самое, что и старые, но в языке сохраняются оба варианта.
Поддержка множественного наследования реализации в ООП-подсистеме языка вызывает целый ряд логических проблем, а также создаёт дополнительные трудности в реализации компилятора. Например, указатель на класс, имеющий несколько родителей, больше не может рассматриваться (с использованием приведения типа в стиле C) как указатель на одного из своих родителей, поскольку родительская часть объекта может быть расположена с некоторым смещением относительно начала объекта (т. е. значения указателя). По этой же причине нельзя приводить указатель на родительский класс к указателю на производный без использования специальных синтаксических средств (оператора dynamic_cast).
Шаблоны в своём исходном виде приводят к порождению кода очень большого объёма, а введённая позже в язык возможность частичной спецификации шаблонов трудно реализуема и не поддерживается многими существующими компиляторами.
Метапрограммирование на основе шаблонов C++ сложно и при этом ограничено в возможностях. Оно состоит в реализации средствами шаблонов C++ интерпретатора примитивного функционального языка программирования выполняющегося во время компиляции. Сама по себе данная возможность весьма привлекательна, но такой код весьма трудно воспринимать и отлаживать. Языки Lisp/Scheme, Nemerle и некоторые другие имеют более мощные и одновременно более простые для восприятия подсистемы метапрограммирования. Кроме того, в языке D реализована сравнимая по мощности, но значительно более простая в применении подсистема шаблонного метапрограммирования.
Хотя декларируется, что С++ мультипарадигменный язык, реально в языке отсутствует поддержка функционального программирования. Отчасти, данный пробел устраняется различными библиотеками (Loki, Boost) использующими средства метапрограммирования для расширения языка функциональными конструкциями (например, поддержкой лямбд/анонимных методов), но качество подобных решений значительно уступает качеству встроенных в функциональные языки решений. Такие возможности функциональных языков, как сопоставление с образцом, вообще крайне сложно эмулировать средствами метапрограммирования.
Некоторые считают недостатком языка C++ отсутствие встроенной системы сборки мусора. С другой стороны, в C++ имеется достаточно средств, позволяющих почти исключить использование опасных указателей, нет принципиальных проблем и в реализации и использовании сборки мусора (на уровне библиотек, а не языка). Отсутствие встроенной сборки мусора позволяет пользователю самому выбрать стратегию управления ресурсами.
Взвесив все за и против было принято решение писать на языке программирования С++. Во многом благодаря тому что данный язык является самым мощным средством разработки на данное время. Также не малую роль сыграл тот факт что самая удобная среда разработки Visual Studio также поддерживаетс С++.
Определение структуры программного продукта
2.1 Анализ процесса обработки информации и выбор структур данных для хранения
Процесс обработки информации приближен к процессам, проводимым в математическом сопроцессоре Intel 80x87. В программе на диалоговом уровне реализована возможность задания числового значения, которое нужно будет вычесть из вершиной стека эмулированного математического сопроцессора, и вычитание разных элементов стека. В том числе и идущих не по порядку. В процессе работы эмуляции сопроцессора часто необходимо быстрое обращение к битам отдельного числа для этого используется следующая структура bits, представленная в таблице 2.1
Таблица 2.1
|
тип |
имя переменной |
размер(бит) |
|
unsigned char |
b0 |
1 |
|
unsigned char |
b1 |
1 |
|
unsigned char |
b2 |
1 |
|
unsigned char |
b3 |
1 |
|
unsigned char |
b4 |
1 |
|
unsigned char |
b5 |
1 |
|
unsigned char |
b6 |
1 |
|
unsigned char |
b7 |
1 |
Структура bits объединенa в структур bait_tabс полями в таблице 2.2
Таблица 2.2
|
тип |
название |
|
bits |
bit |
|
unsigned char |
bait |
Определим структуры для мантиссы и порядка:
Структура ud16 с полями в таблице 2.3
Таблица 2.3
|
тип |
название |
|
bait_tab |
data[2] |
|
short |
val |
Структура ud64 с полями в таблице 2.4
Таблица 2.4
|
тип |
название |
|
bait_tab |
data[8] |
|
_int64 |
val |
Структура ud80 с полями в таблице 2.5
Таблица 2.5
|
тип |
название |
|
ud64 |
mant |
|
ud16 |
exp |
В самом же сопроцессоре стековые регистры имеют вид структуры str с полями, преставленной в таблице 2.6
Таблица 2.6
|
типа |
название |
|
bait_tab |
data[10] |
|
ud80 |
val |
Также в программе определены регистры состояния, тегов и контроля.
Структура regs представлена в таблице 2.7
Таблица 2.7
|
тип |
имя переменной |
размер(бит) |
|
unsigned |
IE |
1 |
|
unsigned |
DE |
1 |
|
unsigned |
ZE |
1 |
|
unsigned |
OE |
1 |
|
unsigned |
UE |
1 |
|
unsigned |
PE |
1 |
|
unsigned |
SF |
1 |
|
unsigned |
ES |
1 |
|
unsigned |
C0 |
1 |
|
unsigned |
C1 |
1 |
|
unsigned |
C2 |
1 |
|
unsigned |
TOP |
3 |
|
unsigned |
C3 |
1 |
|
unsigned |
B |
1 |
Структура _sreg с полями в таблице 2.8
Таблица 2.8
|
тип |
название |
|
regs |
data |
|
unsigned short int |
sreg |
Структура _creg, включает в себя следующую структуру:
Таблица 2.9
|
тип |
имя переменной |
размер(бит) |
|
unsigned |
IM |
1 |
|
unsigned |
DM |
1 |
|
unsigned |
ZM |
1 |
|
unsigned |
OM |
1 |
|
unsigned |
UM |
1 |
|
unsigned |
PM |
1 |
|
unsigned |
PC |
2 |
|
unsigned |
RC |
2 |
Таблица 2.10
|
тип |
название |
|
unsigned short int |
creg |
Структура _twr, включает в себя следующую структуру:
Таблица 2.11
|
тип |
имя переменной |
размер(бит) |
|
unsigned char |
pr0 |
2 |
структура _twr с полями в таблице 2.12
Таблица 2.12
|
типа |
название |
|
unsigned short int |
twr |
2.2 Выбор методов решения задачи и разработка основных алгоритмов предметной области
Для вычитания двух стековых регистров, приводим порядок к одному значению и вычитаем мантиссы. Далее если необходимо производим нормализацию. Если в результате произошло переполнение мантиссы или порядка, устанавливаем флаги и возвращаем 0.
2.3 Построение структурной схемы программного продукта
Для работы программы необходимы следующие функции:
int main() – главная функция программы в ней вызываеться функция инициализации, заполнение стека сопроцессора, а также в диалоговом режиме вызываеться Fsub>.
int fld(str reg[],_sreg &sreg,_creg creg,_twr twr,int st0 ,int stimm)– заполнение стека сопроцессора.
int print_st(str reg[],_sreg sreg,_creg creg,_twr twr, int id)– печатает 1-й элемент стека сопроцессора.
int fsub>(str reg[],_sreg &sreg,_creg creg,_twr twr,int fl, int s1,int s2)– функция выполняющаяя сложение двух стековых регистров и выталкивает вершину стека.
Структурная схема программного продукта:
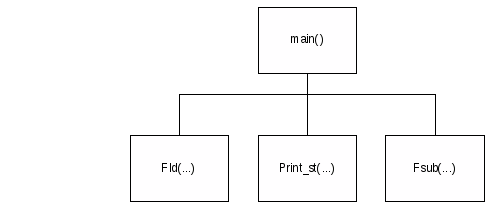
Рис.1. Структурная схема программного продукта
Описание реализации программного продукта
3.1 Описание программы эмуляции команды Fsub> математического сопроцессора
В функции void main(), с которой начинается выполнение программы, производится инициализация эмулятора сопроцессора, заполнение стека первоначальными значениями, после этого предлагается в диалоговом режиме ввести значение:
1 - fsub>
2 - fsub> n
3 - fsub> st(n), st(n)
4 - fld
0 - выход
В случае если пользователь введет 1, программа вычтет из вершины стека значение, находящееся на следующей позиции, 2 – вычтет из вершины стека переменную, введенную пользователем, 3 – произведет вычитание указанных пользователем значений стека, 4 – поместит на вершину стека новое значение.
3.2 Описание функции Fsub>
Логика работы функции представлена блок-схемой на рис.3.1.

Рис.3.1. Лист 1

Рис.3.1. Лист 2
3.3 Описание функции FLD
Логика работы функции представлена блок-схемой на рис.3.2.

Рис.3.2. Лист 1

Рис.3.2. Лист 2
3.4 Описание функции Print_st
Логика работы функции представлена блок-схемой на рис.3.3.

Рис.3.3. Лист 1
Тестирование программы
4.1 Выбор стратегии тестирования и разработка тестов
Для проверки работоспособности программы необходимо разработать такой тест, чтобы он проверил все возможные случаи, которые могут возникнуть при пользовании этой программой. Для этого составим набор тестов:
План тестирования:
Вычтем регистры st0 и st1 командой fsub>
Вычтем регистр st0 и переменную n командой fsub> n
Вычтем регистры st1 и st5 командой fsub> st1, st5
Вычтем регистры st0 и st2 командой fsub> st0, st2
Вычтем регистры st0 и st3 командой fsub> st0, st3
Вычтем регистры st0 и st6 командой fsub> st0, st6
Вычтем регистры st0 и st7 командой fsub> st0, st7
Вычтем регистры st0 и st7 командой fsub> st0, st4
Результаты тестов: Перед тестированием.
twr =98B; swr =E; cwr =D
Таблица 4.1
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
5,54 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
0 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 1 теста ( fsub>) регистры не изменяются.
Таблица 4.2
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
-4,008 |
3 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 2 теста ( fsub> n, n = -5000,52), регистры не изменяются.
Таблица 4.3
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
9,9252 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 3 теста ( fsub> st1, st5), регистры не изменяются.
Таблица 4.4
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
8,7952 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 4 теста ( fsub> st0, st2).
twr =98B
swr =400E (флаг IE = 1, DE = 1)
cwr =D
Таблица 4.5
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
8,7952 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 5 теста ( fsub> st0, st3), регистры неизменны.
Таблица 4.6
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
8,7952 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 6 теста ( fsub> st0, st6); twr =98B; swr =600E (флаг IE = 1)
cwr =D
Таблица 4.7
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
8,7952 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 7 теста ( fsub> st0, st7).
twr =98B
swr =410E (флаг IE = 1, SF = 1)
cwr =D
Таблица 4.8
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
8,7952 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
После 8 теста ( fsub> st0, st4).
twr =98B
swr =600E (флаг IE = 1)
cwr =D
Таблица 4.9
|
Название регистра |
Мантисса |
Порядок |
|
St0 |
8,7952 |
2 |
|
St1 |
4,562 |
3 |
|
St2 |
денормализованый операнд |
0 |
|
St3 |
0 |
0 |
|
St4 |
бесконечность |
5 |
|
St5 |
1,12 |
1 |
|
St6 |
нечисло |
0 |
|
St7 |
пусто |
0 |
Заключение
В результате проделанной работы была написана программа, по своей сути, дублирующая команду математического сопроцессора fsub>, а также её вариации. Были изучены и применены на практике в виде эмуляции 3 регистра. Регистор тегов, регистр команд и регистр состояний.
Была изучена система команд процессора 80х87 и принципы работы процессоров. Было получено представление и содержании такого устройства как процессор, что до не давнего времени было известно на уровне "черного ящика".
Приложение
П.1. Текст программы
#include<iostream>
#include<string>
#include<windows.h>
struct bits
{
unsigned char b0 : 1;
unsigned char b1 : 1;
unsigned char b2 : 1;
unsigned char b3 : 1;
unsigned char b4 : 1;
unsigned char b5 : 1;
unsigned char b6 : 1;
unsigned char b7 : 1;
};
union bait_tab
{
bits bit;
unsigned char bait;
};
struct regs
{
unsigned IE: 1; // Ошибка недействительной операции;
unsigned DE: 1; // Ошибка денормализованного операнда;
unsigned ZE: 1; // Ошибка деления на ноль;
unsigned OE: 1; // Ошибка антипереполнения;
unsigned UE: 1; // Ошибка переполнения;
unsigned PE: 1; // Ошибка точности;
unsigned SF: 1; // Бит ошибки работы со стеком;
unsigned ES: 1; // Бит суммарной ошибки;
unsigned C0: 1; // Бит признака (Condition Code);
unsigned C1: 1; // Бит признака (Condition Code);
unsigned C2: 1; // Бит признака (Condition Code);
unsigned TOP:3; // Указатель регистра текущей вершины стека;
unsigned C3: 1; // Бит признака (Condition Code);
unsigned B: 1; // Бит занятости.
};
union _sreg
{
regs data;
unsigned short int sreg;
};
union _creg
{
struct
{
//маски
unsigned IM: 1; // Маска недействительной операции;
unsigned DM: 1; // Маска денормализованного операнда;
unsigned ZM: 1; // Маска деления на ноль;
unsigned OM: 1; // Маска антипереполнения;
unsigned UM: 1; // Маска переполнения;
unsigned PM: 1; // Маска точности;
unsigned PC: 2; // Поле управления точностью;
unsigned RC: 2; // Поле управления округлением.
} data;
unsigned short int creg;
};
union _twr
{
struct
{
unsigned char pr0:2;// 00 - занят допустимым не нулевым значением
//unsigned char pr1:2;// 01 - содержит нулевое значение
//unsigned char pr2:2;// 10 - содержит специальное численное значение
//unsigned char pr3:2;// 11 - регистр пуст
//unsigned char pr4:2;
//unsigned char pr5:2;
//unsigned char pr6:2;
//unsigned char pr7:2;
} data[8];
unsigned short int twr;
};
union ud16
{
bait_tab data[2];
short val;
};
union ud32
{
bait_tab data[4];
int val;
};
union ud64
{
bait_tab data[8];
_int64 val;
};
struct ud80
{
ud64 mant;
ud16 exp;
};
union str
{
bait_tab data[10];
ud80 val;
};
int fld(str reg[],_sreg &sreg,_creg creg,_twr twr,int st0 ,int stimm);
int print_st(str reg[],_sreg sreg,_creg creg,_twr twr,int id);
int fsub>(str reg[],_sreg &sreg,_creg creg,_twr twr,int fl,int s1, int s2);
int main()
{
str reg[9]={};
_sreg sreg;
_creg creg;
_twr twr;
setlocale(LC_ALL,"Russian");
int d = -1;
sreg.sreg = 0;
creg.creg = 0;
sreg.data.TOP = 7;
creg.data.PC = 3;
twr.twr = 0xffff;
memset(reg,0,sizeof(reg));
while(d != 0)
{
printf("1 - fsub>\n2 - fsub> n\n3 - fsub> st(n), st(n)\n4 - fld\n0 - выход\n");
scanf("%d",&d);
switch (d)
{
case 1:// fsub>========================================================================================
fsub>(reg,sreg,creg,twr,1,0,0);
//print_st(reg,sreg,creg,twr,0);
break;
case 2:
printf("Введите непосредственный операнд: \n");
fld(reg,sreg,creg,twr,0,9);
print_st(reg,sreg,creg,twr,0);
break;
case 3:
int s1;
int s2;
printf("Введите номера регистров, которые вы хотите использовать: \n");
scanf("%d %d",&s1,&s2);
//fld(reg,sreg,creg,twr,s1,0);
//fld(reg,sreg,creg,twr,s2,0);
fsub>(reg,sreg,creg,twr,1,s1,s2);
break;
case 4:
printf("Добовлнение значения в стек: \n");
fld(reg,sreg,creg,twr,0,0);
break;
}
}
}
int fld(str reg[],_sreg &sreg,_creg creg,_twr twr,int st0 ,int stimm)
{
short p = 0;
char l[10];
_int64 i = 0;
scanf("%s",&l);
for(int m = 0; m <= strlen(l); m++)
{
if ((l[m] == '0')&&(p <= 0))
{
p--;
}
else
{
if ((i == 0)&&(l[m] != ','))p++;
}
if (l[m] == ',')
{
for(int e = m; e < strlen(l); e++)
{
l[e] = l[e+1];
}
char* ends;
i = strtol(l,&ends,10);
if (l[m] != '0')break;
}
}
/*if (p > 0)
{p++;}
else
{p--;}*/
if (i != 0)
{
twr.data[st0].pr0 &= 0;
}
else
{twr.data[st0].pr0 |= 1;}
p--;
if (stimm == 0)
{
if (st0 != 0)
{
reg[st0].val.mant.val = i;
reg[st0].val.exp.val = p;
}
else
{
reg[sreg.data.TOP].val.mant.val = i;
reg[sreg.data.TOP].val.exp.val = p;
sreg.data.TOP =sreg.data.TOP - 1;
}
}
else
{
reg[8].val.mant.val = i;
reg[8].val.exp.val = p;
fsub>(reg,sreg,creg,twr,2,0,0);
}
return 0;
}
int print_st(str reg[],_sreg sreg,_creg creg,_twr twr, int id)
{
int ssn;
if (id != 0)
{
ssn = id;
}
else
{
ssn = sreg.data.TOP;
}
double a = (double)reg[ssn].val.mant.val;
short b = reg[ssn].val.exp.val;
for (int i = 0; i <= abs(b); i++)
{
a /=10;
}
printf("%10.5f\n",a);
return 0;
}
int fsub>(str reg[],_sreg &sreg,_creg creg,_twr twr,int fl, int s1,int s2)
{
_int64 a;
short am;
_int64 b;
short bm;
int sn1;
int sn2;
if (fl == 1)
{
if ((s2 == 0)&&(s1 == 0))
{
//sn1 = sreg.data.TOP + 2;
//sn2 = sreg.data.TOP + 1 ;
sn1 = 7;
sn2 = 6;
}
else
{
sn1 = sreg.data.TOP + s1;
sn2 = sreg.data.TOP + s2;
}
a = reg[sn1].val.mant.val;
am = reg[sn1].val.exp.val;
b = reg[sn2].val.mant.val;
bm = reg[sn2].val.exp.val;
}
else
{
a = reg[sreg.data.TOP +1].val.mant.val;
am = reg[sreg.data.TOP +1].val.exp.val;
b = reg[8].val.mant.val;
bm = reg[8].val.exp.val;
}
short dm = am - bm;
if (a > b)
{
for(int i = 0; i < dm; i++)
{
a *= 10;
}
//reg[sn1].val.exp.val+=dm;
}
else
{
for(short n = 0; n <= (-1)*dm; n++)
{
b *= 10;
}
if (fl == 1)
{
reg[sn1].val.exp.val += (-1)*dm;
}
else
{
reg[sreg.data.TOP +1].val.exp.val += (-1)*dm;
}
}
a-= b;
//printf("%d\n",a);
if (fl == 1)
{
reg[sn1].val.mant.val = a;
//sreg.data.TOP+=2;
print_st(reg,sreg,creg,twr,sn1);
}
else
{
reg[sreg.data.TOP].val.mant.val = a;
//sreg.data.TOP+=1;
}
return 0;
}