Теория искусственного интеллекта
Создание высокоавтоматизированных производств предполагает автоматизацию не только физического, но и умственного труда человека. В последние десятилетия складывается ситуация, в которой человек уже не в состоянии воспринять и переработать весь объем информации, необходимый для принятия решений и поэтому зачастую из носителя прогресса человек превращается в фактор, сдерживающий его.
Автоматизация интеллектуальной деятельности потребовала решения новых задач, не возникавших ранее в теории автоматического управления. К их числу относится описание и представление в ЭВМ сложной внешней среды, автоматическое планирование и выполнение комплекса разнообразных действий технических устройств, направленных на достижение заданной цели, организация общения человека с ЭВМ на языке, близком к естественному, и ряд других.
Прогресс в области информатизации практически всех сфер деятельности человека, в том числе в мехатронике и робототехнике связан с тем, что часть интеллектуальной нагрузки берут на себя компьютеры. Одним из способов достигнуть максимального прогресса в этой области, является "искусственный интеллект", когда компьютер выполняет не только однотипные, многократно повторяющиеся операции, но и сам сможет обучаться. Кроме того, создание полноценного "искусственного интеллекта" открывает перед человечеством новые горизонты развития производства, транспорта, летательных аппаратов, медицинской и бытовой техники.
Научное направление, в рамках которого решаются данные задачи, называют искусственным интеллектом.
Цель и задачи дисциплины
Цель – изучение общих понятий и терминологии искусственного интеллекта (ИИ) как прикладной науки, архитектуры систем ИИ в современном производстве, инструментальных средств реализации принципов ИИ в мехатронных и робототехнических системах, а также приобретение элементарных навыков в области автоматизации решения сложноформализуемых задач, которые до сих пор считаются прерогативой человека, в том числе при проектировании интеллектуальных систем (ИС) производственного назначения.
Задачи дисциплины.
ЗНАТЬ:
основные понятия ИИ;
принципы построения систем ИИ в технике;
модели и методы представления знаний в ИС;
моделирование нечетких множеств, нечеткая логика;
методы поиска решений и соответствующие им реализации механизма вывода как основы машинного мышления;
принципы построения и функционирования экспертных систем (ЭС);
алгоритмы распознавания образов и ситуаций;
системы машинного зрения;
нейросистемы
применение систем ИИ в мехатронике.
УМЕТЬ:
построить структуру системы ИИ для решаемой технической задачи;
сформировать базу знаний на основе различных типов представления знаний;
пользоваться методом поиска в пространстве состояний и сведения задач к подзадачам при планировании движения робота;
построить элементарную ЭС для определенной предметной области.
Учебный план. Лек. – 30 ч., лаб. – 16 ч., экз.
Общие сведения. Проблемы ИИ в робототехнике и мехатронике
Основные определения. Под интеллектом будем понимать способность мозга решать задачи путем приобретения, запоминания и целенаправленного преобразования знаний в процессе обучения на опыте и адаптации к разнообразным обстоятельствам для выполнения функии деятельности.
Интеллект –intelligence - (лат. Intellektus – познание, понимание, рассудок) –способность мышления, рационального познания, ум. Иначе – мыслительная способность, умственное начало у человека.
Рациональное познание – отражение объективной действительности в представлениях, суждениях, понятиях.
Мыслительная способность – способность, связанная с поиском решений, действий или закономерностей в нестандартных условиях, если методы, алгоритмы решения или действия априори не известны. В нашем курсе под интеллектом будем понимать способность мозга решать задачи путем приобретения, запоминания и целенаправленного преобразования знаний в процессе обучения на опыте и адаптации к разнообразным обстоятельствам для выполнения функций деятельности.
ИИ (artificial intelligence - AI) – научное направление, которое занимается проблемами имитации человеческого интеллекта в рамках которого строятся теории и модели, призванные объяснить и использовать в технических системах принципы и механизмы интеллектуальной деятельности человека. ИИ – это одно из направлений информатики, целью которого является разработка программно-аппаратных средств, позволяющих пользователю-непрограммисту ставить и решать свои, традиционно считающиеся интеллектуальными задачи, общаясь с ЭВМ на ограниченном подмножестве естественного языка. Иначе и короче – ИИ это техническая (информационная и программно-аппаратная) реализация некоторых интеллектуальных способностей человека.
ИИ – область компьютерных наук, занимающаяся исследованием и автоматизацией разумного поведения.
Под ИС понимают адаптивную систему, позволяющую строить программы целесообразной деятельности по решению поставленных перед ними задач на основании конкретной ситуации, складывающейся на данный момент времени в окружающей среде.
Дополнения:
1. к сфере решаемых ИС задач относятся задачи, обладающие, как правило, следующими особенностями:
- в них заранее неизвестен алгоритм решения задач;
- в них используется информация помимо традиционных данных в числовой форме в виде изображений, рисунков, знаков, букв, слов, звуков;
- в них предполагается наличие выбора, т.е. необходимо сделать выбор между многими вариантами в условиях неопределенности.
2. Системы ИИ отличаются от других искусственных систем, включая традиционные компьютерные программы тем, что они используют знания, а также рядом других признаков:
- способностью достигать целей, меняющихся во времени;
- способностью сопоставлять, использовать и преобразовывать знания;
- способностью ориентироваться в многообразии специальных подсистем, варьируя их методы;
- способностью самостоятельно планировать ресурсы и концентрировать их в нужном направлении;
- возможностью обеспечения интеллектуального интерфейса с пользователем и другими системами.
ИС должна в наборе фактов распознать существенные, ИС способны из имеющихся знаний и фактов сделать выводы не только с использованием дедукции, но и с помощью аналогии, индукции и т.п. Кроме того, ИС должны быть способны к самооценке - обладать рефлексией, т.е. средствами для оценки результатов собственной работы. ИС также должны улавливать сходство между имеющимися фактами.
Потенциальные возможности ИС безграничны, однако пока общей теории интеллектуальности не существует и не найдено общих методов решения проблем.
Проблемы ИИ в робототехнике и мехатронике
1 – Представление знаний. Направление связано с формализацией и представлением знаний различными моделями, языками и делением знаний по типам, а также создание программных средств для их преобразования (пополнения, обработки и т.п.). Здесь рассматриваются вопросы приобретения знаний – их источники, процедуры и приемы. Базой служат знания о проблемной области, хранящиеся в памяти интеллектуальной системы (ИС).
2 – Оперирование, манипулирование знаниями. Направление включает: построение способов пополнения знаний на основе их неполных описаний, системы классификации знаний, хранящихся в памяти ИС; обобщение знаний и формулирование на их основе абстрактных понятий; методы достоверного и правдоподобного вывода на основе имеющихся знаний, модели рассуждений. (1и 2 объединяет теория баз знаний (БЗ)).
3 – Общение. Проблема охватывает: понимание связных текстов на естественном языке, синтез связных текстов, понимание речи и ее синтез; модели коммуникаций между пользователями и ИС; формирование объяснений действий ИС; формирование методов построения лингвистических процессоров, осуществляющих перевод текстовой информации во внутреннее машинное представление, диалоговых систем и пр.
4 – Восприятие. В проблему входят: анализ зрительной, слуховой и др. видов информации, методы ее обработки и внутреннего машинного представления, распознавание образов и формирование ответных реакций на воздействие внешней среды и способов адаптации искусственных систем к среде путем обучения
5 – Обучение (воспитание)– до решения ИС новых задач, с которыми ранее не встречались. Проблема включает: методы формирования условий задачи по информации о проблемной ситуации; обучение переходу от известных решений частных задач – к решению общей; формирование модели процесса обучения. Мало пока сделано. В этом плане интересен подход к имитации мышления, предложенный А. Тьюрингом. "Пытаясь имитировать интеллект взрослого человека, — пишет Тьюринг, — мы вынуждены много размышлять о том процессе, в результате которого человеческий мозг достиг своего настоящего состояния. Почему бы нам вместо того, чтобы пытаться создать программу, имитирующую интеллект взрослого человека, не попытаться создать программу, которая имитировала бы интеллект ребенка? Ведь если интеллект ребенка получает соответствующее воспитание, он становится интеллектом взрослого человека… Наш расчет состоит в том, что устройство, ему подобное, может быть легко запрограммировано… Таким образом, мы расчленим нашу проблему на две части: на задачу построения "программы-ребенка" и задачу "воспитания" этой программы".
6 – Поведение – поведенческие процедуры адекватного взаимодействия со средой, человеком, другими ИС; функции управления действиями, в т.ч. модели целесообразного поведения, нормативного поведения; методы многоуровневого планирования и коррекции планов в динамических ситуациях при решении конкретных задач автоматического устройства, функционирующего в сложной внешней среде.
Наиболее важные причины, объясняющие вклад человечества в развитие ИИ:
1 – Создание ЭВМ новых поколений, максимально приближенных к пользователю, освобождение его от программирования решения задач. (Сложность общения с ЭВМ не должна превосходить сложности общения с современными бытовыми средствами, доведение «интеллектуального» уровня ЭВМ до способности выполнения профессиональных задач программиста.) Обладание большой суммой знаний о способах решения задач, специальных процедурах автоматического синтеза программ; максимальное приближение к общению людей.
2 – Бум информационных технологий, проникновение ЭВМ во все сферы человеческой жизни, создание локальных, глобальных и международных сетей передачи и обработки данных. Следствие – изменение стиля и, возможно, содержания человеческого общения в деловой и бытовой сферах.
3 – Коренное изменение роли человека в технологии производства (все области), замещение его функций физического, интеллектуального труда и управления автоматическими системами с т.н. «интеллектуальным управлением».
4 – ИС становятся инструментом проектирования новых, в т.ч. сверхсложных изделий, разработки технологий, изобретательства, прогнозирования и диагностирования.
Последние 2 пункта особенно важны для понимания сути мехатроники.
Таким образом, диапазон вопросов, охватываемый ИИ – от общих теоретических принципов науки ИИ до инженерных приемов создания аппаратных и программных средств решения интеллектуальных задач.
Еще некоторые определения:
Решение задачи – любая деятельность (человека или машины), связанная со следующим:
выработкой планов и действий, необходимых для достижения определенной цели;
выводами новых закономерностей;
формированием фраз на естественном или близком ему (но понятном) языке и др.
Конкретная интеллектуальная деятельность базируется на знаниях предметной области, в которой ставятся и решаются задачи. Предметной (проблемной) областью знаний называется совокупность взаимосвязанных сведений, необходимых для решения определенной задачи или совокупности задач. Эти знания включают описания (представления) объектов, их элементов и связей между ними, явлений, фактов и закономерностей.
Основные направления работ в сфере ИИ:
Робототехника и мехатроника.
Символьная обработка.
Игровые программы.
Обучающие системы.
Разработка и создание экспертных систем.
Доказательство теорем.
Машинный перевод.
Распознавание изображений.
Машинное творчество.
Структура и функции интеллектуальной системы управления
Основной функцией ИС является целенаправленное поведение в сложном плохо организованном внешнем мире. Целенаправленное поведение можно организовать путем преобразования знаний о текущем состоянии мира, полученных с помощью сенсорных систем, в последовательность действий, направленных на достижение заданной цели. Такие преобразования должны опираться на априорные знания о мире и способах его преобразования. Следовательно, центральными звеньсями ИС являются система представления знаний и развитая система планирования действий. Особенность ИС – процессы сбора и преобразования информации должны протекать в реальном режиме времени.
Обобщенная функциональная структура ИС показана на рис. . и включает три основные взаимосвязанные системы: восприятия, представления знаний, планирования и исполнения действий.
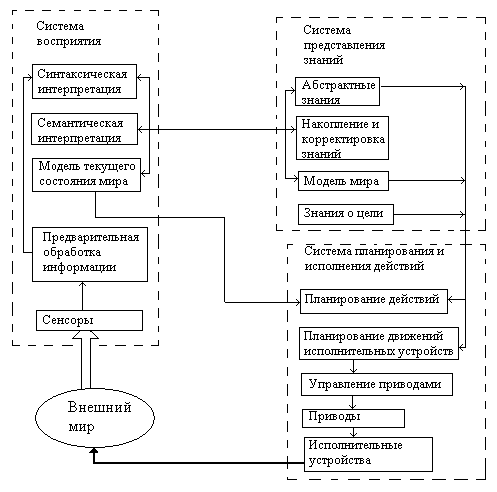
Рис.
Одной из основных является система представления знаний, две других в значительной степени опираются на нее. Представление знаний (т.е. форма их выражения) должно быть выбрано с учетом конкретного класса задач, на решение которых спроектирована ИС. Система представления знаний представляет совокупность четырех блоков: абстрактные знания; знания о целях; модель мира ИС; накопления и корректировки знаний.
Абстрактные знания – сведения об общих закономерностях, действующих как во внешнем, так и во внутреннем мире ИС, которые считают условно постоянными. Например, физические закономерности.
Знания о целях – информация о глобальных целях, которые ИС должна достигнуть в процессе функционирования, а также о способах их декомпозиции, разделения на промежуточные этапы.
Модель мира ИС – формальное описание знаний о среде, в которой функционирует система. Сведения сформированы и сообщены системе заранее.
Для повышения точности и расширения знаний о мире используется блок накопления и корректировки знаний. В нем производится накопление новых фактов о внешнем мире и их анализ на непротиворечивость с другими фактами, хранящимися в системе представления знаний. Если новый факт не противоречив, он включается в модель мира. В некоторых случаях предварительно осуществляется проверка его достоверности.
Однако, непротиворечивость не является обязательным требованием, т.к. дает возможность устойчиво функционировать в малоизученном мире.
Специфическими требованиями к системе представления знаний являются:
- «терпимость» к неполноте и противоречиям. СПЗ должна быть построена так, чтобы ИС функционировала при обнаружении неполноты или неточности в знаниях;
- критичность к новой информации - способность проверить согласованность новой информации с имеющейся и принять решение о ее достоверности;
- обучаемость и способность к корректировке знаний.
Связь с внешним миром в ИС осуществляется через систему восприятия. Система восприятия формирует ситуационные знания ИС, т.е. знания о текущей ситуации. Первичными источниками информации являются различные сенсоры. Информация от сенсоров преобразуется, обрабатывается и представляется в виде, удобном для дальнейших преобразований.
Дальнейшее преобразование связано с синтаксической и семантической интерпретацией. При синтаксической интерпретации формируется представление воспринимаемого мира на некотором внутреннем языке ИС, при этом смысл воспринимаемых явлений остается не раскрытым. Семантическая интерпретация связана с выявлением смысла воспринимаемой информации. Завершающая процедура – построение модели текущего состояния мира.
Система планирования и исполнения действий формирует и реализует программы воздействий на внешний мир, что ведет к достижению поставленной цели. Планирование действий ИС представляется как процесс решения задачи. Решение задачи – это последовательность действий, переводящая текущее состояние мира в желаемое. Для выполнения действий их необходимо расчленить на необходимые движения.
Дополнения.
Интеллектуальные роботы часто называют интегральными. Сейчас для понятия «интегральный робот» используется классификация робототехнических устройств, в основу которой положены пять групп функционально завершенных систем.:
- группа В – системы восприятия звуковой, тактильной и других видов информации о внешней среде;
- группа М – системы воздействия на объекты внешнего мира (манипуляторы);
- группа Т – системы, обеспечивающие перемещение робота;
- группа П – системы планирования действий и решения задач;
- группа Р – системы, обеспечивающие связь робота с оператором и/или другими роботами.
Любой конкретный робот может быть образован сочетанием всех или части перечисленных систем, например, ВМП – очувствленные роботы с системой планирования действий.
Научные школы в области ИИ
Тьюринг Алан (1912 - 1954) – английский математик, сформировавший основные принципы работы современных ЭВМ. В 36-37 гг. задолго предсказал возможность диалогового общения человека с компьютером, использование последнего как партнера в игровых ситуациях и пр.
Минский М. – проф. Массачусетского технологического института; исследования по моделированию головного мозга.
Ньюэелл – создатель компьютерной программы простых выводов.
Маккарти Дж. – инициатор образования научного кружка по ИИ в 1956 г.; вошли: Минский, Ньювел, Моншенон, Саймон и др. Введены понятия ИИ, распознавания образов и пр.
В середине 60-х г. создаются НИИ лаборатории по ИИ в Массачусетском технологическом институте, Стенфордском ун-те, ун-те Карнеги-Меллона. Исследования по РТС + информатике + выч.техн. + ИИ.
Российская школа – Совет по ИИ отделения информатики, выч.техники и автоматизации АН при Институте проблем управления РАН : акад. Поспелов Гермоген Сергеевич, Поспелов Д.А., Попов Э.В.,Захаров В.Н., Хорошевский и др.
История развития систем ИИ
Исторически сложились три основных направления в ИИ. В рамках первого подхода объектом исследований являются структура и механизмы работы мозга человека, а конечная цель заключается в раскрытии тайн мышления. Необходимыми этапами исследований в этом направлении являются построение моделей на основе психофизиологических данных, проведение экспериментов с ними, выдвижение новых гипотез относительно механизмов интеллектуальной деятельности, совершенствование моделей и т. д.
Второй подход в качестве объекта исследования рассматривает ИИ. Здесь речь идет о моделировании интеллектуальной деятельности с помощью вычислительных машин. Целью работ в этом направлении является создание алгоритмического и программного обеспечения вычислительных машин, позволяющего решать интеллектуальные задачи не хуже человека.
Наконец, третий подход ориентирован на создание смешанных человеко-машинных, или, как еще говорят, интерактивных интеллектуальных систем, на симбиоз возможностей естественного и искусственного интеллекта. Важнейшими проблемами в этих исследованиях является оптимальное распределение функций между естественным и искусственным интеллектом и организация диалога между человеком и машиной.
Самыми первыми интеллектуальными задачами, которые стали решаться при помощи ЭВМ были логические игры (шашки, шахматы), доказательство теорем. Хотя, правда здесь надо отметить еще кибернетические игрушки типа "электронной мыши" Клода Шеннона, которая управлялась сложной релейной схемой. Эта мышка могла "исследовать" лабиринт, и находить выход из него. А кроме того, помещенная в уже известный ей лабиринт, она не искала выход, а сразу же, не заглядывая в тупиковые ходы, выходила из лабиринта.
Американский кибернетик А. Самуэль составил для вычислительной машины программу, которая позволяет ей играть в шашки, причем в ходе игры машина обучается или, по крайней мере, создает впечатление, что обучается, улучшая свою игру на основе накопленного опыта. В 1962 г. эта программа сразилась с Р. Нили, сильнейшим шашистом в США и победила.
Каким образом машине удалось достичь столь высокого класса игры? Естественно, что в машину были программно заложены правила игры так, что выбор очередного хода был подчинен этим правилам. На каждой стадии игры машина выбирала очередной ход из множества возможных ходов согласно некоторому критерию качества игры. В шашках (как и в шахматах) обычно невыгодно терять свои фигуры, и, напротив, выгодно брать фигуры противника. Игрок (будь он человек или машина), который сохраняет подвижность своих фигур и право выбора ходов и в то же время держит под боем большое число полей на доске, обычно играет лучше своего противника, не придающего значения этим элементам игры. Описанные критерии хорошей игры сохраняют свою силу на протяжении всей игры, но есть и другие критерии, которые относятся к отдельным ее стадиям — дебюту, миттэндшпилю, эндшпилю.
Разумно сочетая такие критерии (например, в виде линейной комбинации с экспериментально подбираемыми коэффициентами или более сложным образом), можно для оценки очередного хода машины получить некоторый числовой показатель эффективности — оценочную функцию. Тогда машина, сравнив между собой показатели эффективности очередных ходов, выберет ход, соответствующий наибольшему показателю. Подобная автоматизация выбора очередного хода не обязательно обеспечивает оптимальный выбор, но все же это какой-то выбор, и на его основе машина может продолжать игру, совершенствуя свою стратегию (образ действия) в процессе обучения на прошлом опыте. Формально обучение состоит в подстройке параметров (коэффициентов) оценочной функции на основе анализа проведенных ходов и игр с учетом их исхода.
По мнению А. Самуэля, машина, использующая этот вид обучения, может научиться играть лучше, чем средний игрок, за относительно короткий период времени.
Можно сказать, что все эти элементы интеллекта, продемонстрированные машиной в процессе игры в шашки, сообщены ей автором программы. Отчасти это так. Но не следует забывать, что программа эта не является "жесткой", заранее продуманной во всех деталях. Она совершенствует свою стратегию игры в процессе самообучения. И хотя процесс "мышления" у машины существенно отличен оттого, что происходит в мозгу играющего в шашки человека, она способна у него выиграть.
Ярким примером сложной интеллектуальной игры до недавнего времени являлись шахматы. В 1974 г. состоялся международный шахматный турнир машин, снабженных соответствующими программами. Как известно, победу на этом турнире одержала советская машина с шахматной программой "Каисса".
Почему здесь употреблено "до недавнего времени"? Дело в том, что недавние события показали, что несмотря на довольно большую сложность шахмат, и невозможность, в связи с этим произвести полный перебор ходов, возможность перебора их на большую глубину, чем обычно, очень увеличивает шансы на победу. К примеру, по сообщениям в печати, компьютер фирмы IBM, победивший Каспарова, имел 256 процессоров, каждый из которых имел 4 Гб дисковой памяти и 128 Мб оперативной. Весь этот комплекс мог просчитывать более 100'000'000 ходов в секунду. До недавнего времени редкостью был компьютер, могущий делать такое количество целочисленных операций в секунду, а здесь мы говорим о ходах, которые должны быть сгенерированы и для которых просчитаны оценочные функции. Хотя с другой стороны, этот пример говорит о могуществе и универсальности переборных алгоритмов.
В настоящее время существуют и успешно применяются программы, позволяющие машинам играть в деловые или военные игры, имеющие большое прикладное значение. Здесь также чрезвычайно важно придать программам присущие человеку способность к обучению и адаптации. Одной из наиболее интересных интеллектуальных задач, также имеющей огромное прикладное значение, является задача обучения распознаванию образов и ситуаций. Решением ее занимались и продолжают заниматься представители различных наук — физиологи, психологи, математики, инженеры. Такой интерес к задаче стимулировался фантастическими перспективами широкого практического использования результатов теоретических исследований: читающие автоматы, системы ИИ, ставящие медицинские диагнозы, проводящие криминалистическую экспертизу и т. п., а также роботы, способные распознавать и анализировать сложные сенсорные ситуации.
В 1957 г. американский физиолог Ф. Розенблатт предложил модель зрительного восприятия и распознавания — перцептрон. Появление машины, способной обучаться понятиям и распознавать предъявляемые объекты, оказалось чрезвычайно интересным не только физиологам, но и представителям других областей знания и породило большой поток теоретических и экспериментальных исследований.
Перцептрон или любая программа, имитирующая процесс распознавания, работают в двух режимах: в режиме обучения и в режиме распознавания. В режиме обучения некто (человек, машина, робот или природа), играющий роль учителя, предъявляет машине объекты и о каждом их них сообщает, к какому понятию (классу) он принадлежит. По этим данным строится решающее правило, являющееся, по существу, формальным описанием понятий. В режиме распознавания машине предъявляются новые объекты (вообще говоря, отличные от ранее предъявленных), и она должна их классифицировать, по возможности, правильно.
Проблема обучения распознаванию тесно связана с другой интеллектуальной задачей — проблемой перевода с одного языка на другой, а также обучения машины языку. При достаточно формальной обработке и классификации основных грамматических правил и приемов пользования словарем можно создать вполне удовлетворительный алгоритм для перевода, скажем научного или делового текста. Для некоторых языков такие системы были созданы еще в конце 60-г. Однако для того, чтобы связно перевести достаточно большой разговорный текст, необходимо понимать его смысл. Работы над такими программами ведутся уже давно, но до полного успеха еще далеко. Имеются также программы, обеспечивающие диалог между человеком и машиной на урезанном естественном языке.
Что же касается моделирования логического мышления, то хорошей модельной задачей здесь может служить задача автоматизации доказательства теорем. Начиная с 1960 г., был разработан ряд программ, способных находить доказательства теорем в исчислении предикатов (лог. – пропозициональная функция, т.е. выражение с неопределенными переменными) первого порядка. Эти программы обладают, по словам американского специалиста в области ИИ Дж. Маккатти, "здравым смыслом", т. е. способностью делать дедуктивные заключения.
В программе К. Грина и др., реализующей вопросно-ответную систему, знания записываются на языке логики предикатов в виде набора аксиом, а вопросы, задаваемые машине, формулируются как подлежащие доказательству теоремы. Большой интерес представляет "интеллектуальная" программа американского математика Хао Ванга. Эта программа за 3 минуты работы IBM-704 вывела 220 относительно простых лемм и теорем из фундаментальной математической монографии, а затем за 8.5 мин выдала доказательства еще 130 более сложных теорем, часть их которых еще не была выведена математиками. Правда, до сих пор ни одна программа не вывела и не доказала ни одной теоремы, которая бы, что называется "позарез" была бы нужна математикам и была бы принципиально новой.
Очень большим направлением систем ИИ является робототехника. В чем основное отличие интеллекта робота от интеллекта универсальных вычислительных машин? /К пониманию МЕХАТРОНИКИ/:
Для ответа на этот вопрос уместно вспомнить принадлежащее великому русскому физиологу И. М. Сеченову высказывание: "… все бесконечное разнообразие внешних проявлений мозговой деятельности сводится окончательно лишь к одному явлению — мышечному движению". Другими словами, вся интеллектуальная деятельность человека направлена в конечном счете на активное взаимодействие с внешним миром посредством движений. Точно так же элементы интеллекта робота служат прежде всего для организации его целенаправленных движений. В то же время основное назначение чисто компьютерных систем ИИ состоит в решении интеллектуальных задач, носящих абстрактный или вспомогательный характер, которые обычно не связаны ни с восприятием окружающей среды с помощью искусственных органов чувств, ни с организацией движений исполнительных механизмов.
Первых роботов трудно назвать интеллектуальными. Только в 60-х годах появились очуствленные роботы, которые управлялись универсальными компьютерами. К примеру в 1969 г. в Электротехнической лаборатории (Япония) началась разработка проекта "промышленный интеллектуальный робот". Цель этой разработки — создание очуствленного манипуляционного робота с элементами искусственного интеллекта для выполнения сборочно-монтажных работ с визуальным контролем.
Манипулятор робота имеет шесть степеней свободы и управляется мини-ЭВМ NEAC-3100 (объем оперативной памяти 32000 слов, объем внешней памяти на магнитных дисках 273000 слов), формирующей требуемое программное движение, которое отрабатывается следящей электрогидравлической системой. Схват манипулятора оснащен тактильными датчиками.
В качестве системы зрительного восприятия используются две телевизионные камеры, снабженные красно-зелено-синими фильтрами для распознавания цвета предметов. Поле зрения телевизионной камеры разбито на 64*64 ячеек. В результате обработки полученной информации грубо определяется область, занимаемая интересующим робота предметом. Далее, с целью детального изучения этого предмета выявленная область вновь делится на 4096 ячеек. В том случае, когда предмет не помещается в выбранное "окошко", оно автоматически перемещается, подобно тому, как человек скользит взглядом по предмету. Робот Электротехнической лаборатории был способен распознавать простые предметы, ограниченные плоскостями и цилиндрическими поверхностями при специальном освещении. Стоимость данного экспериментального образца составляла примерно 400000 долларов.
Постепенно характеристики роботов улучшались, Но до сих пор они еще далеки по понятливости от человека, хотя некоторые операции уже выполняют на уровне лучших жонглеров. К примеру удерживают на лезвии ножа шарик от настольного тенниса.
Есть еще одна проблема — проблема безопасности применения систем ИИ.
Данная проблема будоражит умы человечества еще со времен Карела Чапека, впервые употребившего термин "робот". Большую лепту в обсуждение данной проблемы внесли и другие писатели-фантасты. Как самые известные мы можем упомянуть серии рассказов писателя-фантаста и ученого Айзека Азимова, а так же довольно свежее произведение — "Терминатор". Кстати именно у Айзека Азимова мы можем найти самое проработанное, и принятое большинством людей решение проблемы безопасности. Речь идет о так называемых трех законах роботехники.
Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинен вред.
Робот должен повиноваться командам, которые ему дает человек, кроме тех случаев, когда эти команды противоречат первому закону.
Робот должен заботиться о своей безопасности, насколько это не противоречит первому и второму закону.
На первый взгляд подобные законы, при их полном соблюдении, должны обеспечить безопасность человечества. Однако при внимательном рассмотрении возникают некоторые вопросы. Во-первых, законы сформулированы на человеческом языке, который не допускает простого их перевода в алгоритмическую форму. Попробуйте, к примеру перевести на любой из известных Вам языков программирования, такой термин, как "причинить вред". Или "допустить". Попробуйте определить, что происходит в любом случае, а что он "допустил"?
Далее предположим, что мы сумели переформулировать, данные законы на язык, который понимает автоматизированная система. Теперь интересно, что будет подразумевать система ИИ под термином "вред" после долгих логических размышлений? Не решит ли она, что все существования человека это сплошной вред? Ведь он курит, пьет, с годами стареет и теряет здоровье, страдает. Не будет ли меньшим злом быстро прекратить эту цепь страданий? Конечно можно ввести некоторые дополнения, связанные с ценностью жизни, свободой волеизъявления. Но это уже будут не те простые три закона, которые были в исходнике.
Следующим вопросом будет такой. Что решит система ИИ в ситуации, когда спасение одной жизни возможно только за счет другой? Особенно интересны те случаи, когда система не имеет полной информации о том, кто есть кто.
Однако, несмотря на перечисленные проблемы, данные законы являются довольно неплохим неформальным базисом проверки надежности системы безопасности для систем ИИ.
Знания. База знаний
Интеллектуальная деятельность человека связана с поиском решений (действий, закономерностей), в новых, нестандартных ситуациях. Любая интеллектуальная деятельность опирается на знания о предметной области, в которой ставятся и решаются задачи.
Данные – это факты, сведения и идеи, представленные в формализованном виде, позволяющем передавать или обрабатывать их Ред.:Под термином "знания" подразумевается не только та информация, которая поступает в мозг через органы чувств. Такого типа знания чрезвычайно важны, но недостаточны для интеллектуальной деятельности. Дело в том, что объекты окружающей нас среды обладают свойством не только воздействовать на органы чувств, но и находиться друг с другом в определенных отношениях. Ясно, что для того, чтобы осуществлять в окружающей среде интеллектуальную деятельность (или хотя бы просто существовать), необходимо иметь в системе знаний модель этого мира. В этой информационной модели окружающей среды реальные объекты, их свойства и отношения между ними не только отображаются и запоминаются, но и могут мысленно "целенаправленно преобразовываться". При этом существенно то, что формирование модели внешней среды происходит "в процессе обучения на опыте и адаптации к разнообразным обстоятельствам".
Японский словарь - "знания" – результат, полученный познанием; система суждений, основанная на объективной закономерности.
Русский словарь - "знания"– проверенный практикой результат познания действительности, верное её отражение в мышлении человека.
Другие определения:
Знания – это совокупность сведений, образующих целостное представление, соответствующее определенному уровню осведомленности о некотором вопросе, предмете, проблеме, явлении. Знания описывают основные закономерности предметной области, позволяющие человеку решать конкретные производственные, научные и другие задачи. Знания являются основным понятием в ИС. Можно выделить еще ряд определений:
Знания – это результат, полученный познанием окружающего мира и его объектов.
Знания – это система суждений с принципиальной и единой организацией, основанная на объективной закономерности.
Знания – это формализованная информация, на которую ссылаются или которую используют в процессе логического вывода.
Под знанием понимается совокупность фактов и правил манипулирования фактами.
Проблема выделения знаний, прежде всего, относится к областям преобладания эмпирического знания, где накопление фактов опережает развитие теории. Знания важны там, где определения размыты, понятия меняются, ситуация зависит от множества контекстов, где велика неопределенность и нечеткость информации (контекст – относительно законченная в смысловом отношении часть текста высказывания). Таким образом, знания – это специальная форма представления смысловой информации, позволяющая хранить, воспроизводить и понимать эту информацию.
Знания обычно представляют в форме фактов, характерных для окружающего мира, и правил манипулирования фактами. Причем под фактом понимают элементарное высказывание с некоторой оценкой. Любую осмысленную часть факта считают данными, т.е. факты – это совокупности данных.
Данные сами по себе не несут смысловой нагрузки. Например, число 16.40 не имеет в себе смысла до тех пор, пока мы не узнаем, что это время отправления поезда или цена товара, т.е. данные нуждаются в интерпретации. В отличие от данных знания несут в себе определенную смысловую нагрузку, представляя собой нечто большее, чем просто последовательность символов. Этот смысл позволяет путем символьной обработки получать новую информацию.
Отличия знаний от данных:
Интерпретируемость. Данные в ЭВМ могут интерпретироваться только соответствующей программой. Знания отличаются тем, что в них присутствует возможность содержательной интерпретации.
Наличие классификационных отношений. Разнообразные формы хранения данных не обеспечивают возможности компактного описания всех связей между различными типами данных. При переходе к знаниям между отдельными единицами знаний можно установить такие отношения как «элемент-множество», «тип-подтип», «ситуация-подситуация», отражающие характер их взаимосвязей.
Наличие ситуативных связей, которые определяют ситуативную совместимость отдельных событий или фактов, хранимых или вводимых в память.
Четыре важнейших свойства, которые отличают знания от данных:
1 – высокая структурированность;
2 – внутренняя интерпретируемость (истолкование, объяснение) знаний и их связей;
3 – семантическая (смысловая) компактность – кластеризованность;
4 – взаимозависимость и взаимоактивность.
Для того чтобы данные превратились в знания, они должны быть определенным образом структурированы. Знание с этих позиций - некоторая организационная форма мышления, отражающая существенные свойства, связи и отношения предметов и явлений. Полезные знания – это данные, организованные в понятия.
Знания представляют собой иерархические структуры. Общие знания, касающиеся целых подобластей данной предметной области, включают в себя более узкие, касающиеся каких-то отдельных признаков или специальных вопросов из предметной области.
Между элементами и объектами знаний существуют функциональные и каузальные (причинностные) отношения. Функциональные отношения несут процедурную информацию, позволяющую определять или вычислять одни объекты через другие. Каузальные отношения задают причинно-следственные связи.
Семантика (смысловое значение, содержание) отношений между объектами может носить декларативный (данные) или процедурный (программы) характер
Классификация знаний
Знания делятся на формализованные и неформализованные. Формализованные знания выражаются в виде законов, формул, алгоритмов, моделей и т.п. Такие знания описываются в книгах и руководствах и отражают точные и универсальные знания в виде строгих суждений.
Неформализованные знания (вербальные - словесные) субъективны и приблизительны. Они являются результатом обобщения многолетнего опыта работы и интуиции специалиста и представляют собой некоторое множество эмпирических приемов и правил логического вывода. Это - ключевые понятия для ИИ.
Типы знаний
Поверхностные знания - это в основном приблизительные знания, эвристики и некоторые закономерности, устанавливаемые опытным путем. Такие знания в силу их приблизительности называют также экспертными.
Глубинные – отражают наиболее общие принципы, в соответствии с которыми развиваются все процессы в предметной области и свойства этих процессов. К глубинным относятся знания, основанные на теориях, абстракциях и аналогиях, в которых отражается понимание структуры предметной области. Для получения глубинных знаний необходимо понять внутренние механизмы, действующие в предметной области, и, прежде всего, основные закономерности, которые обуславливают принятие правильных решений. Глубинные знания используются прежде всего при решении неординарных ситуаций.
Процедурные знания – это знания, которые могут быть представлены процедурой или процессом. В компьютерной программе эти знания хранятся как код, а не как данные. Программные алгоритмы являются формой процедурных знаний, т.к. они содержат информацию о том, как решить конкретную задачу.
Декларативные – это знания, которые хранятся как данные. В декларативном представлении легко добавлять или изменять знания, т.к. они независимы от программы.
Статистические – тип знаний, которые не изменяются в процессе решения задачи.
Динамические – могут приобретаться с течением времени.
Жесткие знания позволяют получать однозначные четкие рекомендации при заданных начальных условиях.
Мягкие знания допускают множественные, расплывчатые решения и различные варианты рекомендаций.
Кроме указанных понятий используется понятие метазнания (знания о знаниях). Оно используется для обозначения знаний о способах использования знаний и свойств знаний.
В общем виде знания в ЭВМ представляются некоторой знаковой (семиотической) системой. С понятием «знак» непосредственно связаны понятия денотат и концент. Денотат – это объект, обозначаемый данным знаком. Концент – свойства денотата.
Экстенсионал знака определяет класс всех его допустимых денотатов. Интенсионал знака определяет содержание связанных с ним понятий.
Интенсиональные знания описывают абстрактные объекты, события, отношения. Например, поставщик, потребитель, транспорт. Экстенсиональные знания представляют собой данные, характеризующие конкретные объекты, их состояние, значения параметров в определенные отрезки времени. Экстенсионалом поставщика может быть завод, потребителя – предприятие, транспорта – автомобиль.
В семиотической (знаковой) системе выделяют три аспекта: синтаксический, семантический и прагматический.
Синтаксис описывает внутреннее устройство знаковой системы, т.е. правила построения и преобразования сложных знаковых выражений. Семантика определяет отношения между знаками и их концентами, т.е. задает смысл или обозначения конкретных знаков. Прагматика определяет знак с точки зрения конкретной сферы применения, либо субъекта, использующего данную знаковую систему.
Для хранения данных и знаний используются базы данных и базы знаний. База данных – это совокупность связанных данных, хранящихся с минимальной избыточностью и используемых различными приложениями посредством системы управления базами данных. База знаний – это совокупность описывающих предметную область правил и фактов, позволяющих с помощью механизма вывода решать вопросы, ответ на которые в явном виде в базе отсутствует. БЗ как программное средство обеспечивает поиск, хранение, преобразование и запись в память ПК сложно структурированных информационных единиц – знаний.
Совокупность модели представления знаний и связанных с ней процедур образуют систему представления знаний. База знаний и база данных рассматриваются как разные уровни информации, хранящейся в интеллектуальном банке информации. Системы управления базами знаний являются развитием систем управления базами данных..
Знания в ИС можно представить следующей схемой преобразования.
СХЕМА ПРЕОБРАЗОВАНИЯ ЗНАНИЙ
ВшП ВтП ВтП ВшП

Блок представления знаний БПЗ связан с внешним миром (окружающей средой) двумя блоками преобразователей БП1 и БП2, которые преобразуют знания о предметной области из внешнего представления ВшП во внутреннее ВтП и наоборот.
Б
БИ
БО
БЗ
БД
БВР



 П3 имеет
информационную модель следующего вида.
П3 имеет
информационную модель следующего вида.
МОДЕЛЬ БЛОКА ПРЕДСТАВЛЕНИЯ ЗНАНИЙ
Б
 ПЗ
ПЗ
ИБД
Где БИ – блок интерпретаций, ИБД – интелл. банк данных,
БО – блок обучения, БЗ, БД – база знаний, база данных.
БВР – блок вывода решений,
Инженерия знаний
Проблемами проектирования баз знаний занимается инженерия знаний. В задачи инженерии знаний входит получение и структурирование знаний о некоторой предметной области, формирование для нее поля знаний и разработка баз знаний.
Поле знаний – это условное неформальное описание основных понятий и взаимосвязей между понятиями предметной области, выявленных из различных источников, в том числе, полученных от экспертов, в виде графов, диаграмм, таблиц, текстов и т.п.
Если для естественных наук достаточно аппарата классической математики, то в инженерии знаний разработчики имеют дело с «мягкими» предметными областями. Здесь классический математический аппарат не обеспечивает выразительной адекватности, здесь важна эффективность представления, его компактность, ясность интерпретации, наглядность и т.п.
Специалист, способный делать заключения по проблемам определенной области называется экспертом. Он накапливает знания в этой предметной области в результате многолетней практики, что позволяет распознавать и оценивать ситуации.
Средний специалист в конкретной предметной области помнит от 50 до 100 тыс. чанков и использует их для решения задач и проблем. Здесь чанк – (англ. chank – большой кусок) символьные образы, объединенные в человеческом мозге в блоки, запоминаемые и извлекаемые как единое целое.
Всем этим объясняется представление знаний в ИС в виде БЗ как сложных иерархических структур с соответствующими связями между этими структурами.
Требования к специалисту-эксперту:
Применять знания и опыт для «оптимального» решения задач, делать достоверные выводы, исходя из неполных и ненадежных данных.
Уметь обосновать сделанные выводы.
Приобретать новые знания, в т.ч. путем общения с другими экспертами.
Периодически систематизировать свои знания.
Находить новые правила принятия решений, в т.ч. эвристики (эмпирические правила вплоть до угадывания).
Оценивать степень своей компетентности и обращаться за консультацией к другим источникам.
Представление знаний в ИС –это проблема науки «инженерии знаний».
Инженер по знаниям – специалист, проектирующий БЗ на основе модели представления знаний и наполнения их знаниями из предметной области.
Представление знаний – процесс формализованного описания для ввода знаний в БЗ, структуризация знаний для облегчения поиска решений.
Описание проводится с помощью языка представления знаний (ЯПЗ). ЯПЗ – знаковая система, в которой описываются объекты и явления (или обобщения) согласно принятому множеству соглашений по знакам, синтаксису (построение, порядок, способ соединения слов и предложений) и семантике (смысловое значение). ЯПЗ обеспечивает возможность формальной записи знаний + оперирование знаниями.
Программист – специалист, призванный воплотить разрабатываемую ИС в виде программного средства.
Требуемые личные качества:
Общительность,
Способность отказаться от традиционных навыков и осваивать новые методы,
Интерес к разработке.
Профессиональные качества:
Иметь опыт и навыки самостоятельной разработки программ,
Знакомство с основными структурами представления знаний и механизмами выводов,
Знакомство с состоянием рынка программных продуктов для разработки ИС и диалоговых интерфейсов.
Процесс формирования поля знаний экспертом и инженером по знаниям может быть представлен следующим алгоритмом:
Восприятие и интерпретация действительности предметной области некоторым экспертом, в результате образуется некоторая модель как семантическое представление действительности и его личного опыта.
вербализация опыта некоторого эксперта, когда он объясняет свои рассуждения и передает свои знания инженеру по знаниям. В результате образуется некоторое текстовое или речевое сообщение. Именно в процессе объяснения эксперт на размытые ассоциативные образы в лабиринтах своей памяти «надевает» четкие словесные ярлыки, т.е. вербализирует знания.
Восприятие и интерпретация некоторого сообщения инженером по знаниям. В результате в памяти инженера образуется некоторая модель предметной области.
Кодирование и вербализация модели в форме некоторого поля знаний, спроектированного инженером по знаниям для реализации в базе знаний.
Это трудная задача – добиться максимального соответствия между действительным состоянием предметной области и некоторым полем знаний. Поле знаний может быть представлено как пирамида, где следующий уровень служит для восхождения на новую ступень обобщения и углубления знаний.
В искусственном интеллекте используется термин – формирование знаний, который обозначает процесс анализа данных и выявления скрытых закономерностей с использованием специального математического аппарата и программных средств ЭВМ. Основные методы извлечения знаний представлены на рис.
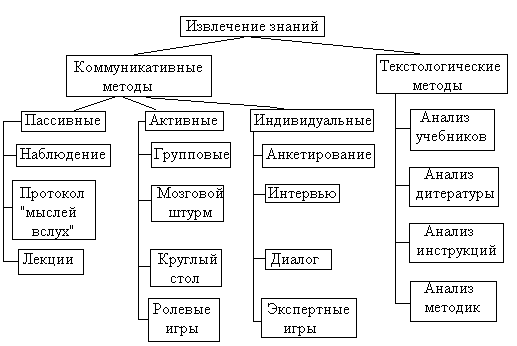
Все эти методы позволяют сформировать поле знаний на основании следующего алгоритма:
1.Определение входных и выходных данных, структура которых существенно влияет на форму и содержание поля знаний.
2.Составление словаря терминов и наборов ключевых фраз, при этом особенно важен словарь терминов.
3.Выявление объектов и понятий, выбор значимых понятий и их признаков.
4.Выявление связей между понятиями, построение сети ситуаций, где связи только намечены, но пока не поименованы.
5.Структуризация понятий с выявлением понятий более высокого уровня обобщенгия и детализацией на более низком уровне.
6.Построение пирамиды знаний с иерархической лестницей понятий по уровню общности.
7.Определение временных, причинно-следственных и других отношений с их обозначением путем присвоения имен свеем связям.
8.Определение стратегий принятия решений. Выявление цепочек рассуждений связывает все сформированные ранее понятия и отношения в динамическую систему поля знаний.
Модели представления знаний
От формы представления знаний зависит характеристика и свойства систем искусственного интеллекта. В отличие от знаний, используемых человеком, в компьютере используется моделирование знаний. Под моделью знаний понимается способ описания знаний в базе знаний.
В общем случае модели представления знаний могут быть условно разделены на декларативные и процедурные. Декларативная модель основывается на предположении, что проблема представления некоторой предметной области решается независимо от того, как эти знания будут использоваться. Поэтому модель состоит как бы из двух частей: структур, описывающих знания и механизма вывода, оперирующего этими структурами, независимо от содержательного наполнения структур. При этом синтаксические и семантические аспекты разделены. Описания выполняемых процедур не содержатся в явном виде. Предметная область представляется в виде описания ее состояния, а вывод решения основывается в основном на процедурах поиска в пространстве состояний.
Процедурная модель основывается не небольших программах (процедурах), которые определяют, как поступать в конкретных ситуациях. В этой модели семантика заложена непосредственно в описании элементов базы знаний. Общие правила представлены в виде специальных целенаправленных процедур.
Требования к моделям представления знаний:
- однородность представления;
- простота понимания;
- упрощение механизма управления выводом.
Наиболее распространенными являются четыре модели представления знаний в интеллектуальных системах и их комбинации:
- логическая или логика предикатов;
- продукционная;
- семантические сети;
- фреймовая модель.
Представление знаний с помощью логики предикатов
Логика предикатов используется как один из языков представления знаний. В любом языке для создания языковых форм должно быть определено следующее:
- множество знаков, которое можно в нем использовать;
- полное определение слов через знаковые последовательности;
- грамматические правила образования предложений из слов (синтаксические правила).
Каждое слово из предложения соответствует объектам и действиям того реального мира, который описывается этим языком. Таким образом в языке присутствуют слова, которые описывают сущности, и слова, которые описывают атрибуты сущностей и действия над ними.
Для формулировки знаний о некоторой предметной области средствами логики предикатов в проблемной области выделяют два основных типа понятий:
- дискретные объекты, которые называют сущностями;
- отношения между сущностями.
Именам отношений соответствует термин «предикат», а сущностям – аргументы. Символы, используемые для обозначения высказываний, называют атомами. Таблицей истинности формулы называется таблица, содержащая истинностные значения формулы при всех возможных комбинациях истинностных значений входящих в нее атомов..
Логика предикатов (исчислений) основана на логике (исчислении) высказываний. Высказыванием (суждением) называют предложение, принимающее только два значения – «истина» или «ложь». Логический вывод (силлогизм) в классической логике строится двумя путями: дедукцией и индукцией. В современной логике вывод строится также абдукцией. Индукция и абдукция называются вероятностными силлогизмами.
Дедукция – вывод, позволяющий получать заключение из большой или малой посылки. Большая посылка называется дедуктивным правилом, малая – фактическим заявлением (декларацией).
Пример: Большая посылка: рыба – живое существо, умеющее плавать.
Малая посылка: карась – рыба.
Вывод: карась – живое существо, умеющее плавать.
Большая и малая посылка называются данными о знаниях или просто знаниями и их объем должен быть достаточно большим.. Упорядоченное множество таких знаний составляет базу знаний..
Дедуктивное правило позволяет детализировать и формализовать причинно-следственные связи явлений (процессов) и дел (предметов), т.е. это знания, необходимые для выполнения алгоритма принятия решений. Основная часть знаний кодируется не только арифметическими, но и логическими символами. Таким образом требуется специальный язык для ЭВМ.
Индукция – получение большой посылки из заключения ее малой посылки. Можно ли считать правомерным определение «рыба – это живое существо, умеющее плавать»» в качестве большой посылки, исходя из того, что известны многие виды рыб? Вывод неправомерен, т.к. могут быть неизвестные виды рыб, перемещающиеся по суше. По мере накопления наблюдений повышается достоверность большой посылки.
Абдукция – получение малой посылки из заключения и большой посылки. На основании факта, что некоторые из живых существ умеют плавать, делается заключение, что это живое существо – рыба. Однако этот вывод нельзя считать безусловно достоверным. Человек в обыденной жизни имеет постоянно дело с нечеткими, вероятностными оценками.
Пример силлогизма:
- Все металлы электропроводны;
- медь – металл;
Заключение: медь электропроводна.
Предикатом или логической функцией называется функция от любого числа аргументов, принимающая истинностные значения «истина» или «ложь». Аргументы принимают значения из произвольного конечного или бесконечного множества М, называемого предметной областью. Предикат от n аргументов является n-местным предикатом.
Все операции исчисления высказываний переносятся в исчисления предикатов и используются для связывания предикатов и формул, т.е. позволяют получить из простых высказываний сложные. Основные операции алгебры логики:
Отрицание. Высказывание истинно, если высказывание А ложно. А ложно, если А истинно.
Конъюнкция. А ^ В (А*В) – логическое умножение. Высказывание истинно только в тех случаях, когда истинны А и В.
Дизъюнкция. А В – логическое сложение А+В. Высказывание истинно только в случае, если истинно хотя бы одно из слагаемых.
А В (А В) Импликация или следование В из А. Читается также «если А, то В». Высказывание ложно только в том случае, если А истинно и В ложно.
А В – эквивалентность. «А тогда и только тогда, когда В». Высказывание истинно тогда и только тогда, когда А и В имеют одно и то же истинное значение.
В логике предикатов используются основные свойства логических операций: свойства ассоциативности, коммутативности, дистрибутивности, законы идемпотентности и де Моргана.
В логике предикатов для компактной
записи высказываний типа « для любого
x
истинно F(x)»
и «существует такое x,
для которого истинно F(x)»,
дополнительно вводятся две операции –
квантор общности
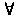 и квантор существования
и квантор существования
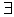 .
Вышеприведенные высказывания можно
записать в следующем виде:
.
Вышеприведенные высказывания можно
записать в следующем виде:
xF(x)
– высказывание истинно, когда F(x)
истинно для всех x
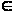 M и
ложно в противоположном случае.
M и
ложно в противоположном случае.
xF(x)
– высказывание истинно, когда существует
элемент x
M,
для которого F(x)
истинно и ложно в противоположном
случае.
В логике предикатов обычно используются шесть типов символов:
А) Предикатные переменные x, y, z, u, v, w или те же буквы с индексами.
Б) Предметные константы a, b, c, d, e или те же буквы с индексами.
В) Функциональные символы – f, g, h или те же буквы с индексами.
С) Предикатные символы p, q, r, s, t или те же буквы с индексами.
Д) Логические символы
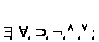
Е) Вспомогательные символы – круглые скобки, запятые и т.п.
Вывод, дающий заключение из двух посылок можно представить следующим образом:
Предпосылка 1. Все металлы электропроводны.
Предпосылка 2. Медь металл.
Заключение: медь электропроводна.
Если вместо имен субъектов поставить переменные x, y, z, то можно получить логическую формулу:
Предпосылка 1. металл (x) электропроводен (x)
Предпосылка 2. металл (медь)
Заключение: электропроводна (медь).
Логика предикатов рассматривает вопрос, можно ли, представляя предложения в виде логических формул, с помощью выводов получить из нескольких логических формул некоторую конечную логическую формулу.
Таким образом в логике предикатов основным объектом исследования является формула. При ее определении используется понятие «терм» (некоторая сущность), объединяющая название элементарных функций, к которым применима предикатная буква. Терм определяется следующим образом:
- всякая предметная переменная или предметная константа являются термами;
- если f – n-местная функция из n аргументов и t>1> …..t>n> – термы, то f(t>1>…..t>n>) есть терм;
Выражение p (t>1>…..t>n>), где p – предикатный символ m аргументов и t>1>…..t>m> – термы называется атомарной функцией или атомом.
Атомы и всякие выражения из них есть правильно построенные формулы (ППФ).
Пример;
Предпосылка 1. (логическая формула) x (p(x)) q(x)
Предпосылка 2. (атом) p(a)
Заключение (атом) q(a)
Здесь p – металл, q – электропроводность, a – медь.
Интерпретация. Формула имеет определенный смысл, т.е. обозначает определенное высказывание, если существует какая-либо интерпретация.. Интерпретировать формулу – значит связать с ней определенное множество М, т.е. конкретизировать предметную область, называемую областью интерпретации и указать соответствие, относящееся:
- каждой предметной константе в формуле конкретный элемент из М;
- каждой n-местной функциональной букве в формуле – конкретную n-местную функцию на М;
- каждой n-местной предикатной букве в формуле конкретное отношение между n элементами из М.
Иными словами – интерпретирование формул исчисления предикатов это конкретизация предметной области М и соответствия между символами, входящими в формулы с одной стороны, и элементами, функциями и отношениями на М с другой.
Пример: элементарная формула G(f(a,b), g(f,b))
Интерпретация: М – множество действительных чисел; a,b –числа 2 и 3 соответственно; f – функция сложения (f(a,b) = a+b); g – функция умножения (g(a,ba0 =ab); G - отношение «не меньше» . Формула обозначает высказывание « сумма 2+3 не меньше произведения 2*3». Результат «ложь». Если изменить интерпретацию, b = 1 или b = 2, то результатом будет «истина».
Другая формула при той же интерпретации:
G(f(g(x,x),g(y,y),g(a,g(x,y)))
Формула обозначает высказывание
x2 + y2> 2xy
Высказывание верно при любом x и y из М и всегда истинно.
Для описания высказываний на языке предикатов в заданной предметной области часто для обозначения предикатных букв и констант используются слова или сокращения, которые являются названиями определяемых ими свойств, отношений, объектов.
( x) [ Дельфин (x) умный (x)]
Дельфин наделен умственными способностями
( x) [Слон (x) --- цвет (x, серый)]
Все слоны имеют серую окраску.
Логика предикатов применяется для решения сравнительно простых задач.
Продукционные модели знаний
Продукционные модели занимают особое положение, т.к. они являются наиболее декларативным способом представления знаний. Продукционная модель представления знаний – это набор правил вида
ЕСЛИ «условие, ТО «действие»,
где «условие» образец для поиска в базе данных (утверждение о состоянии базы данных); «действие» - действие, выполняемое при успешном исходе поиска в базе (процедуры, которые могут изменять состояние базы данных). Действия могут быть промежуточными, выступающие далее как условия и целевыми, завершающими работу системы.
В продукционных моделях используются некоторые элементы логических моделей, что позволяет организовать из них эффективные процедуры вывода, а с другой стороны, более наглядно отражают знания, чем классические логические модели. Правила вывода в этих моделях называются продукциями.
Системы продукций – это набор правил, используемый как база знаний, поэтому его еще называют базой правил. Продукции соответствуют навыкам в долгосрочной памяти человека. Подобно навыкам в долгосрочной памяти эти продукции не изменяются при работе системы. Они вызываются «по образцу» для решения данной проблемы.. Рабочая память продукционной системы соответствует краткосрочной памяти или текущей области внимания человека. Содержание рабочей области после решения задачи не сохраняется.
Примеры фактов и правил.
Факт 1. Зажженная плита – горячая.
Правило 1. Если положить руку на зажженную плиту, то можно обжечься.
В общем виде под продукцией понимается выражение следующего вида:
( I ); Q; P; A B; N
Здесь I – имя продукции, с помощью которого эта продукция выделяется из всего множества продукций. В качестве имени может выступать какое-то словосочетание или порядковый номер продукции. Q - характеризует сферу применения продукции. Примерами сфер применения могут быть «роботизированный участок», «приготовление пищи» и другие. Разделение знаний на отдельные сферы позволяет экономить время на поиск нужных знаний.
Основным элементом продукции является ее ядро А В. Интерпретация ядра продукции может быть различной, но чаще всего звучит так: ЕСЛИ А, ТО В1, ИНАЧЕ В2. Элемент Р – условие применимости. Обычно Р представляет собой логическое выражение. Когда Р принимает значение «истина» ядро активизируется. Если Р «ложно», то ядро не может быть использовано. Элемент N описывает постусловия продукции. Это действия, которые выполняются только в том случае, если ядро продукции реализовалось.
В системе продукций должны быть заданы специальные процедуры управления продукциями, с помощью которых происходит активизация продукций и выбор для выполнения той или иной продукции из числа активизированных. Продукционные системы имеют давнюю историю. Их ограничение – в применении к крупномасштабным задачам, т.к. большое число правил приводит к замедлению скорости вывода. Кроме того, продукционная модель не имеет механизма вывода из тупиковых состояний в процессе поиска. Она продолжает работать, пока не будут исчерпаны все допустимые продукции.
Преимущества продукционной модели представления знаний:
- простота и гибкость выделения знаний;
- отделение знаний от программы поиска;
- модульность продукционных правил (правила не могут вызывать другие правила);
- простота пополнения и модификации;
- возможность эвристического управления поиском;
- возможность трассировки «цепочки рассуждений»;
- простота механизма вывода;
- независимость от выбора языка программирования;
- для ПК это простой и точный механизм использования знаний с высокой однородностью, описанных по одному синтаксису;
- продукционные правила являются правдоподобной моделью решения задачи человеком.
Фрагмент управления транспортным роботом:
Правило 1: Если i-й накопитель пуст – перейти к i+1 накопителю.
Правило 2: Если в i-том накопителе есть детали И тележка робота не заполнена, то освободить накопитель и перейти к i+1 накопителю.
Правило 3: Если тележка робота заполнена, то отвезти детали на склад и вернуться к i-тому накопителю.
Продукционная система имеет три компонента. Это знания, представленные в виде системы продукций в базе правил (БП), образцы условий в рабочей памяти (РП) и механизм вывода (МВ) (рис. ).
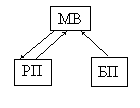
Машина (механизм) вывода.
Программа, управляющая перебором правил называется машиной вывода (интерпретатором правил). МВ выполняет две функции: а) просмотр существующих фактов из рабочей памяти (базы данных) и правил из базы знаний с добавлением (по мере возможности) в рабочую память новых фактов; б) определение порядка просмотра и применения правил.
Этот механизм управляет процессом консультации, сохраняя для пользователя информацию о полученных заключениях, и запрашивает у него информацию, когда для срабатывания очередного правила в РП оказывается недостаточно данных.
МВ представляет собой небольшую по объему программу и включает два компонента – один реализует вывод, второй управляет этим процессом.
Действие компонента вывода основано на применении правила, называемого modus ponens. «Если известно, что истинно утверждение А и существует правило ЕСЛИ А ,ТО В, тогда утверждение В также истинно». Правила срабатывают, когда находятся факты, удовлетворяющие их левой части. «Если истинна посылка, то должно быть истинно и заключение». Компонент вывода должен функционировать даже при недостатке информации.
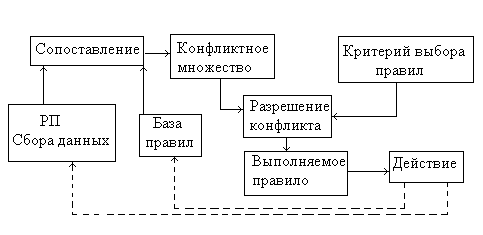
Управляющий компонент определяет порядок применения правил и выполняет четыре функции:
1. Сопоставление = образец правила сопоставляется с известным фактом.
2. Выбор – если в конкретной ситуации может быть применено сразу несколько правил, то из них выбирается одно, наиболее подходящее по заданному критерию (разрешение конфликтов).
3. Срабатывание – если образец правила при сопоставлении совпал с каким-либо фактом из РП, то правило срабатывает.
4. Действие – РП подвергается изменению путем добавления в нее заключения сработавшего правила. Если в правой части правила содержится указание на какое-либо действие, то оно выполняется.
Интерпретатор (МВ) работает циклически. В каждом цикле он просматривает все правила, чтобы выявить те, которые совпадают с известными на данный момент фактами из РП. После выбора правило срабатывает, его заключение заносится в РП, и цикл повторяется снова. В одном цикле может сработать только одно правило.
Если несколько правил успешно сопоставлены с фактами, то МВ производит выбор по определенному критерию единственного правила, которое срабатывает в данном цикле.
Цикл работы МВ показан на рис.
Работа МВ зависит только от состояния РП и от состава базы знаний. На практике обычно учитывается история работы, т.е поведение МВ запоминается в памяти состояний, которая содержит протокол системы. (рис. ).
Пример:
П1. Если (отдых летом) И (человек активный)
ТО (ехать в горы)
П2. Если (любит солнце) ТО (отдых летом)
Предположим, что в систему поступили факты: человек активный и любит солнце.
1-проход.
Шаг 1. Пробуем П!, не работает (не хватает данных – отдых летом)
Шаг 2. Пробуем П2, работает, б базу поступает факт – отдых летом.
2-й проход.
Шаг 3. Пробуем П1, работает. Активизируется цель (ехать в горы), которая выступает как совет.
Стратегия управления выводом.
От метода поиска зависит порядок применения и срабатывания правил. Процедура выбора сводится к определению направления поиска и способа его осуществления.
Прямой и обратный вывод. В системах с прямым выводом по известным фактам отыскивается заключение, которое следует из этих фактов. Если такое заключение найдено, то оно заносится в РП. Такой вывод называют выводом, управляемым данными.
При обратном выводе вначале выдвигается гипотеза, а затем МВ как бы возвращается назад, переходя к фактам, пытаясь найти те, которые подтверждают гипотезу. Если она правильна, то выдвигается следующая гипотеза, детализирующая первую и являющуюся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями. Применяется в тех случаях, когда цели известны и их сравнительно немного.
В системах с более сотен правил желательно использовать стратегию управления выводом, позволяющую минимизировать время поиска решения и тем самым повысить эффективность работы системы. К числу таких стратегий относятся поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета стратегия.
При поиске в глубину в качестве подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи.
При поиске в ширину анализируются все начальные варианты. Разбиение на подзадачи заключается в выделении подзадач, решение которых рассматривается как достижение промежуточных целей. Альфа-бета стратегия заключается в удалении ветвей, неперспективных для успешного поиска.
Работа продукционной системы инициируется начальным описанием (состоянием) задачи. Из продукционного множества правил выбираются правила, пригодные для применения на очередном шаге. Эти правила могут создавать так называемое конфликтное множество. Для выбора правил из конфликтного множества существуют стратегии разрешения конфликтов, которые могут быть достаточно простыми, например, выбор первого правила. Могут быть и сложными эвристическими правилами. Следует отметить, что конфликтные множества представляют собой простейшие базы целей.
Кроме базовой структуры продукционных систем необходимы дополнительные средства – управление данными, уточняющими смысл:
Триплет: объект – атрибут (необходимый признак) – значение;
Пример; робот – степень подвижности – 4.
Четверка: – атрибут (необходимый признак) – значение – степень достоверности.
Пример: сверло – материал Р!* - стойкость 25 мин. – достоверность 0,7.
Условная часть может состоять из одного или нескольких условий, соединенных связкой И. Заключительная часть показывает данные, которыми следует пополнить РП при выполнении условной части. На практике при необходимости расширяют эти правила. Например, используют связку ИЛИ. В условной части, вводят условную часть с вычислениями на основании содержимого РП, либо вводят заключительную часть с пометкой – не дополнять содержимое РП.
Визуально такое отношение можно представить в виде графа с древовидной структурой (рис. ).
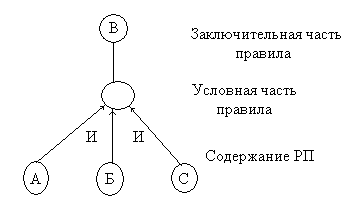
Если существует множество правил, из которых выводится одно и то же заключение, то выполняется процедура ИЛИ над всеми заключениями из этих правил. Таким образом всю систему продукций можно представить в виде одного графа И/ИЛИ (рис. ).
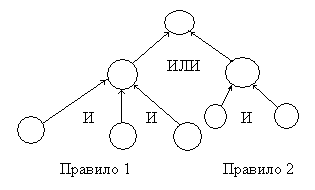
Система, реализующая прямую цепочку рассуждений, на основании имеющихся условий делает возможным логические выводы. Система, реализующая обратную цепочку рассуждений по имеющимся выводам, ищет необходимые для них условия.
По такому графу обратный вывод – это поиск пути на графе. Управление последовательностью поиска осуществляется механизмом вывода. Могут быть использованы различные стратегии поиска. Используются также системы с двунаправленными выводами, где сначала оценивается небольшой объем полученных данных и выбирается гипотеза (прямой вывод), а затем запрашиваются данные для принятия решения о пригодности данной гипотезы.
Для повышения эффективности функционирования ИС в проблемной области с увеличением числа правил используются методы группирования, упорядочения информации в РП, предварительной компиляции правил в виде графа.
Пример работы продукционной системы. Рассматривается роботизированный участок.
Правило 1: ЕСЛИ (станок без заготовки) (1)
И (заготовка на накопителе) (2)
ТО (робот подает заготовку на станок) (3)
Правило 2: ЕСЛИ (накопитель подал заготовку в загрузочную позицию) (4)
ТО (заготовка в загрузочной позиции)
Действия:
Допустим, в РП вносятся 1 и 4 образцы и рассматривается возможность применения правил. Сначала МВ сопоставляет образцы из условной части правил с образцами в РП.
Если все образцы имеются в РП, то условная часть считается истинной, в противном случае – ложной. Т.к. в условной части (2) отсутствует, то условная часть правила 1 считается ложной. Но правило 2 выполняется, т.к. посылка (4) верна, поэтому МВ выполняет его заключительную часть, и образец (2) заносится в РП.
3. Вторично применяется правило 1, т.к. правило 2 уже было применено и выбыло из числа кандидатов. Т.к. (1) истина и (2) истина, то (3) – вывод. В итоге правил, которые можно было бы применить не остается и система останавливается.
4. Для описания задач часто используют дерево решений.
Семантические сети
В бытовом понимании семантика означает смысл слова, действия, художественного произведения и т.п. Семантическая сеть – это граф, вершинам которого сопоставляются понятия (объекты, процессы, явления), дуги графа – это отношения между вершинами.
Возможные отношения в семантических сетях (не полный список):
Агент – это то, что (тот, кто) вызывает действие. Агент часто является подлежащим в предложении. Например, «Иванов ударил мяч».
Объект – это то, на что (на кого) направлено действие. В предложении объект часто выполняет роль прямого дополнения. Например, «Робот взял пирамиду».
Инструмент – это средство, которое используется агентом для выполнения действия. Например, «Иванов открыл дверь с помощью ключа».
Соагент – служит как подчиненный партнер главному агенту. Например, «Иванов сдал экзамен с помощью Петрова».
Пункт отправления и пункт назначения – это отправная и конечная позиция при перемещении агента или объекта. Например, «Робот переместился от одного станка к другому».
Траектория – это перемещение от пункта отправления к пункту назначения. Например, «Они прошли через дверь по ступенькам на лестницу».
Средство доставки – то в чем или на чем происходит перемещение. Например, «Иванов всегда едет домой на машине».
Местоположение – то место, где произошло (происходит, будет происходить) действие. Например, «Он работал за столом».
Потребитель – то лицо, для которого выполняется действие. Например, «Иванов собрал шпаргалки для Кати».
Сырье – это, как правило, материал из которого что-то сделано или состоит. Обычно сырье вводится предлогом из. Например, «Иванов собрал робот из интегральных схем».
Время – указывает на момент совершения действия. Например, «Он закончил работу поздно вечером».
Пример семантической сети: Поставщик осуществил поставку изделий по заказу клиента до 1 июня 2008 г. в количестве 1000 шт.
Поиск в семантической сети: Какой объект находится на желтом блоке?
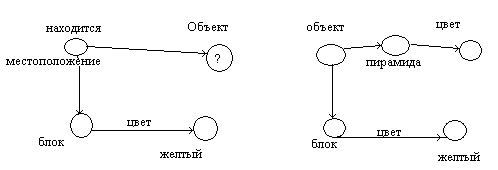
Совместив запрос с сетью получим ответ – пирамида.
Классификация сетей.
По структуре:
Сети простого типа – у которых вершины не имеют собственной внутренней структуры.
Однородные сети – при одинаковых отношениях между вершинами.
Сети иерархического типа – таким сетям свойственны структуры с вершинами разного ранга, имеющими разный уровень или подчиненность от низших к высшим.
По характеру отношений, приписываемых дугам сети:
Функциональные сети. Дуги отражают тот факт, что вершина, из которой выходит дуга, играет по отношению к вершине, куда идет дуга, роль аргумента. Описания, соответствующие вершине – функции, задают процедуру нахождения результата.
Сценарии – однородные сети, в которых в качестве единственного отношения выступает отношение нестрогого порядка (например, отношение «не раньше, чем»), которое допускает одновременность. Чаще всего эти отношения определяют все возможные последовательности событий.
Семантические сети – в отличие от двух первых – неоднородны и иерархичны.
Семантические сети делятся на интенсиональные и экстенсиональные. Интенсиональная сеть содержит интенсиональные знания и описывает общую структуру модернизируемой предметной области на основе абстрактных объектов и отношений, т.е. обобщенных представителей некоторых классов объектов и отношений. Например, такие объекты как Производственный участок, груз, деталь могут являться обобщенными понятиями множества значений от которых образуется множество имен конкретных производственных участков (токарный, прессовый и т.п.), множество имен грузов (заготовка, кассета), множество классов деталей (болт, вал, гайка и т.п.).
Экстенсиональная семантическая сеть описывает экстенсиональные знания о модернизируемых объектах, являясь как бы «фотографией» его текущего состояния.
Интенсиональная сеть предложения «Робот сверлит отверстие в детали сверлом диаметром 10 мм.
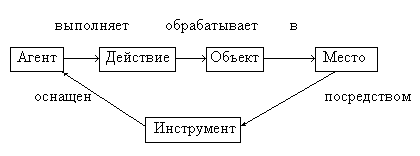
Рис. Интенсиональная сеть.
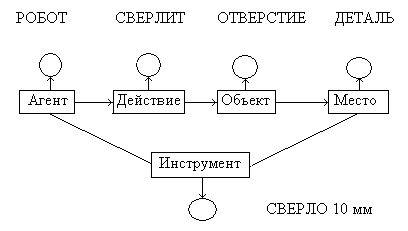
Рис. Экстенсиональная сеть.
В семантических сетях используются три основных типа объектов: понятия, события, свойства.
Понятие – это сведения об абстрактных или физических объектах предметной области. Общие понятия интерпретируются как множество параметров или констант.
События – это действия, которые могут внести изменения в предметную область .Результатом события является некоторое новое состояние предметной области. Можно задать желаемое (целевое) состояние предметной области и поставить задачу отыскания в семантической сети последовательности событий, приводящей к новому состоянию.
Свойства – используются для уточнения понятий или событий. Для понятий это особенности или характеристики (цвет, размеры, качество). Для свойств - продолжительность, время, место.
Семантические отношения делят на четыре класса: лингвинистические, логические, теоретико-множественные и квантифицированные.
Лингвинистические – наиболее употребительные – падежные, к которым относятся агент и т.п. Другой тип – это характеризация глаголов и атрибутивных отношений. К характеризации глаголов относятся наклонение, время, род, число, залог. Атрибутивные отношения – цвет, форма, размер. Например: «Большие красные шары».
Логические отношения представляют собой операции алгебры логики..
Теоретико-множественные – это подмножество, супермножество, элемент множества, отношение части и целого и др. Этот класс отношений используется для построения иерархических соподчиненных структур, для представления обобщенной информации.
Квантифицированные отношения – это логические кванторы общности и существования.. Логические кванторы применяются для представления знаний декларативного типа. Например: «каждый станок требует профилактического ремонта», «Существует робот А, который может обслуживать станки группы В».
Важным понятием в семантических сетях является десигнат – уникальное внутрисистемное имя, которое ставится в соответствие некоторому объекту в предметной области, если о нем в данный момент времени нет полной информации. Например, «Станок С1 имеет накопитель». Это предложение имеет неопределенность относительно характеристик накопителя. По мере поступления информации будут уточняться емкость накопителя и другие данные.
(F1: имеет агент Станок объект D1)
(D1: имя накопитель)
(D1: габарит ______)
(D1: емкость _______)
F1 – метка факта, D1 – метка десигната.
В момент первого напоминания вводится информация, которая используется в дальнейшем. В семантических сетях информация может представляться в фреймовом виде..
При построении интеллектуальных банков данных на основе семантических сетей основным принципом их организации является разделение экстенсиональных и интенсиональных знаний, при этом экстенсиональные семантические сети являются основой базы данных, а интенсиональные сети – основой базы знаний.
Особенности представления знаний в семантических сетях состоят в следующем:
- в семантической сети могут быть представлены такие виды объектов как понятия, события, специализированные методы решения. Увеличение номенклатуры объектов снижает однородность сети и приводит к необходимости увеличения набора механизмов и методов вывода.
- многомерность семантических сетей позволяет представить в них сложные семантические отношения, связывающие отдельные понятия, понятия и события в предложении, а также предложения в текстах.
- на каждой стадии формирования решения можно четко разделить полное знание системы (полная семантическая сеть) и текущее знание – возбуждаемый участок сети, в котором производятся некоторые операции (процесс вывода, понимания и т.п.).
Известны многие варианты семантических сетей, общие характеристики которых сводятся к следующему:
- описание объектов предметной области происходит на уровне естественного языка;
- все знания, включая вновь поступающие факты, а также специализированные методы решения, накапливаются в относительно однородной структуре памяти;
- определяется ряд более или менее унифицированных семантических отношений между объектами, которым ставятся в соответствие унифицированные методы вывода;
- запросы вместе с методами вывода определяют участки знания (семантической сети), имеющие отношение к поставленной задаче, фиксируя тем самым понимание запроса и вытекающую из него цепь выводов, соответствующих решению задачи; выводы в семантических сетях отличаются значительной полнотой.
Управление выводом.
Механизм вывода использует метод генерации выводов, так называемый «метод распространяющейся активности и техники пересечений». Процесс осуществляется построением на основе введенных высказываний цепочек возможных выводов во всех направлениях до тех пор, пока в сети не обнаружится пересечение или не найден фрагмент, отражающий поставленный запрос к базе знаний. Недостаток – сложность организации процедуры вывода. Область применения семантических сетей – системы обработки естественного языка, системы технического зрения и другие.
Фреймовое представление знаний
Все типы моделей знаний перед их применением в конкретной системе необходимо заполнить информацией, уточняющей используемые общие символы и понятия. Модель без наполнения информацией до уровня соответствия единичной реальной системе называется абстрактной.
В обычном диалоге значительная часть информации не выражается собеседником определенно и ясно (умалчивается). Предполагается, что оба собеседника хорошо знают тему разговора и нет смысла лишний раз описывать очевидные детали, которые являются стандартными для данной ситуации.
Термин фрейм (frame – рамка, остов) предложен в 1975 г. Марвеллом Минским. Фрейм – это единица представления знаний, заполненная в прошлом, детали которой могут быть изменены согласно текущей ситуации, т.е. это минимальное описание, которое еще сохраняет сущность описываемого явления и такое, что дальнейшее ее сокращение приводит к потере сущности. Получается, что фрейм – это абстрактный образ, объект или ситуация.
Фрейм отражает основные свойства объекта или явления. Информация в фреймах записывается в виде списка свойств, называемых во фрейме слотами (slot – паз, щель), таким образом, слот является основной структурной единицей фрейма.
Пример. Слова «комната» порождает у слушателя образ комнаты «жилое помещение» с четырьмя стенами, окнами и дверью, площадью 12-30 м2. Из этого описания ничего нельзя убрать (убрав окна, получаем чулан), но в нем есть «дырки» или «слоты» - это незаполненные значения некоторых атрибутов. Например, количество окон, высота потолка и т.п. В теории фреймов такой образ называется фреймом комнаты.
Слот представляет собой пару: имя слота и его значение. В качестве значения слота могут выступать константы (факты), выражения с переменными, ссылки на другие слоты и т.п.
Слот может иметь структуру, элементы которой сами являются слотами. Фрейм состоит из конечного значения слотов. Слотам фреймов могут быть приписаны по умолчанию некоторые стандартные значения. Значения, присвоенные по умолчанию, могут быть заменены значениями, подходящими для обрабатываемой ситуации.
Различают фреймы-образцы или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных фактических ситуаций на основе поступающих данных. Фрейм-прототип – это интенсиональное описание некоторого множества фреймов-примеров.
Пример фрейма-прототипа: ДАТА
(ДАТА) (месяц)(имя)(день)(целые числа){1,2…31}(год)(функция) (день недели)(перечень {понед.,….,воскр.} (функция)
В слоте (месяц) на месте значения записано ИМЯ, т.е. значением слота может быть любое буквенное выражение. Значение слота ДЕНЬ являются целые числа, причем перечень их приводится в слоте.
В качестве функции могут быть использованы любые функции языка LISP. Так, в слоте ГОД с использованием языка LISP могут быть организованы следующие процедуры. Если во входном предложении указан ГОД, то он вносится в поле значения фрейма-примера; если год не указан, то активизируется процедура, которая заполняет значение текущим годом. Такого рода функция называется «по умолчанию».
В слоте «день недели» можно организовать процедуры, которые при обработке входного сообщения будут вызываться автоматически, для проверки на непротиворечивость значения дня недели, указанного пользователем, либо вычисления этого значения.
Конкретный пример может выглядеть следующим образом:
(ISA) ДАТА)(месяц)(июнь)(день)(вторн.)
Метка ISA обозначает, что данный слот является фреймом-примером.
Модель фрейма является достаточно универсальной, т.к. существуют не только фреймы для обозначения объектов и понятий, но и другие типы:
- фреймы-сценарии, используемые для обозначения объектов и понятий (лекция, собрание, заем);
- фреймы-роли (отец, мать, менеджер, кассир, клиент);
- фреймы-сценарии (собрание акционеров, празднование дня рождения)ж
- фреймы-ситуации (тревога, авария, рабочий режим работы устройства) и другие.
Формально как модуль для отображения образа структура фрейма может быть представлена следующим образом:
(имя фрейма)
(имя 1-го слота); (значение 1-го слота)
(имя 2-го слота); (значение 2-го слота)
………………………………………….
………………………………………….
(имя N-го слота); (значение N-го слота)
Ту же запись можно представить в виде таблицы
-
Имя фрейма
Имя слота
Значение слота
Способ получения
слота
Присоединенная процедура
Иногда применяют другой вариант:
-
Имя фрейма
Имя слота
Указатель
типа данных
значение
слота
Присоединенная процедура
Значения столбцов этой таблицы:
1. Имя слота – идентификатор, присваиваемый фрейму; это имя – единственное в данной системе, т.е. уникальное имя.
2. Имя слота – идентификатор, присваиваемый слоту; это уникальное имя во фрейме, к которому он принадлежит. Обычно имя слота не несет никакой смысловой нагрузки, но в ряде случаев может иметь специфический смысл. В их число входят слоты IS-A или A KIND OF (орел), показывающие фрейм-родитель данного фрейма (АКО-связи), слот указателей дочерних фреймов, слоты дат изменения, имен пользователей , текста комментариев и др. Такие слоты называются системными и используются при редактировании БЗ и управлении выводом.
3.Указатель типа данных, показывает, что за значение хранится в слоте. Возможные типы значений: INTEGER – целый, REAL – действительный, BOOL – булев, указатель на другой фрейм, LISP – вызываемая процедура.
4. Значение слота – должно совпадать с указанным типом данных этого слота.
Дополнительные столбцы предназначены для описания способа получения слотом его значения и возможного присоединения к тому или иному слоту специальных процедур, которые выполняются, когда информация в слотах (значения атрибутов) меняется. С каждым слотом можно связать любое число процедур.
Процедуры должны решать следующие задачи:
1.поместить новую информацию в слот;
2.удалить информацию из слота;
3.обработать обращение к информации пока не заполненного слота.
Конкретные процедуры, включаемые в слот, делят на два типа:
- процедуры-демоны – активизируются автоматически каждый раз, когда данные попадают в соответствующий фрейм-пример или удаляются из него.
С помощью процедур этого типа автоматически выполняются все рутинные операции, связанные с ведением баз данных и знаний (обновление).
- процедуры-слуги – активизируются только по запросу. Например, если пользователь не указал год, то активизируется процедура-слуга.
Фреймы и слоты описывают ситуацию в семантических форматах. С каждым слотом фрейма связаны описания условий, которые должны быть соблюдены, чтобы могло произойти означивание слота. В более сложных случаях условия могут касаться отношения между значениями, выбираемыми сразу для нескольких слотов.
В качестве значения слота может выступать имя другого фрейма, так образуются сети фреймов.
Существуют несколько способов получения слотом значений во фрейме-экземпляре:
- по умолчанию от фрейма-образца (Delauf – значение);
- через наследование свойств от фрейма, указанного в слоте АКО;
- по формуле, указанной в слоте;
- через присоединенную процедуру;
- явно из диалога с пользователем;
- из базы данных.
Важнейшим свойством теории фреймов является заимствование из теории семантических сетей наследование свойств. Такое наследование происходит по АКО-связям (A-King-Of – это). Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно наследуются, т.е. переносятся, значения аналогичных слотов.
Пример:
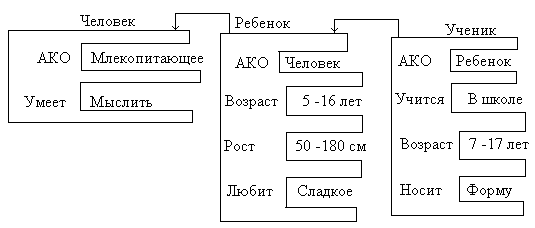
Рис.
Понятие «ученик» наследует свойства фреймов «ребенок» и «человек», которые находятся на более высоком уровне иерархии, На вопрос: «любят ли ученики сладкое?» следует ответ - «да», т.к. этим свойством обладают все дети, указанные во фрейме «ребенок».
Пример из области машиностроения:
-
Станок
АКО
Изделие
Функция
Резание
Серийность
производства
Серийное, индивидуальное
-
Обрабатывающий центр
АКО
Станок
Группа
Сверлильно-расточной
Операции
Сверление, фрезерование,
растачивание
Управление
УЧПУ
-
Модель 2204 ВМФ4
АКО
Обрабатывающий центр
Рабочая зона
Размеры, мм
250*250*400
Тип системы ЧПУ
Контурно-позиционная
Устройство ЧПУ
Модель
2С42
Инструмент. магазин
Кол-во инструментов
30
«Модель 2204 ВМФ4» наследует свойства фреймов «обрабатывающий центр» и «станок», находящиеся на более высоком уровне иерархии.
Наследование свойств может быть частичным, т.к. возраст для учеников не наследуется из фрейма «ребенок», поскольку указан в собственном фрейме.
Основным преимуществом фреймов как модели представления знаний является то, что они отражают концептуальную основу организации памяти человека, а также ее гибкость и наглядность. Концепция фреймов позволяет строить иерархические структуры фреймов. Допускается до пяти уровней вложения, что важно для организации механизма наследования.
Одна из вершин выделяется для предикатного (функционального) символа, остальные – для аргументов определенного символа. Для каждой аргументной вершины дана область допустимых значений, что позволяет интерпретировать вершину как слот. Такое определение близко к понятию факт в семантических сетях.
Конкретные фреймы:
Фрейм соединение предназначен для описания различных типов соединений, встречающихся в технических системах. «Субъект Х соединяет объект У с объектом Z способом W».
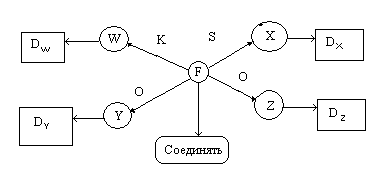
Дуги имеют метки падежных отношений: S – субъект, О – объект, К – отношение «посредством чего», D>j> – области допустимых значений действующего аргумента.
Фрейм-назначение служит для описания процессов через назначение отдельных элементов, участвующих в них. «Насос (Н) перекачивает газ (Г) от источника тепла (ИТ) к теплообменнику (ТО)»
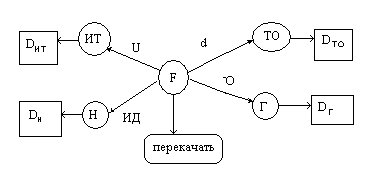
Символами И и d обозначаются падежные отношения соответственно «источник действия» и «приемник действия».
Фрейм-закон функционирования предназначен для описания аналитических законов изменения отдельных параметров во времени. Ситуация: Вычислить параметр в момент времени t с использованием функции f, имеющей аргументы a>1>, a>2>, …….a>n>. Метки дуг V>f> вид функции, - время, Гц = результат применения функции.
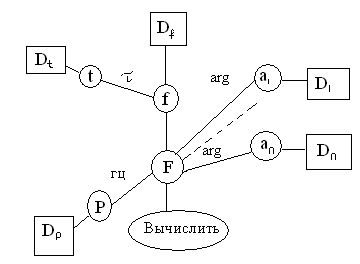
Можно выделить три основных процесса, происходящих во фреймовых системах:
1.Создание экземпляра фрейма. Для создания необходимо найти подходящий фрейм и заполнить его слоты информацией, описывающей специфику рассматриваемой ситуации.
3.Активация фреймов.
3.Организация вывода, заключающегося в процессе поиска и активации в сети фреймов до нахождения наиболее соответствующего и построение на его основе экземпляра фрейма.
В системах представления знаний, основанных на фреймах, используют три основных подхода для организации процессов обработки информации:
1) информационно-вычислительный процесс организуется пользователем с привлечением языка программирования (например LISP).
2) Для систем фреймов вводится единый вычислительный процесс, основой которого является выбор фреймов, управляющих дальнейшими вычислениями.
3) Определяются подклассы фреймов, для которых разрабатываются специфические алгоритмы, опирающиеся на индивидуальные свойства подклассов.
Специальные языки представления знаний в сетях фреймов: FRL, KRL, экспертные системы МОДУС, TRISTAN и др.
План
1. Нечеткие знания. Общие положения (Инженерия знаний и нечёткость).
1.1 Определение. Причины нечеткости знаний.
1.2 Нечёткая логика.
1.3 Нечеткие множества.
Введение
Пожалуй, наиболее поразительным свойством человеческого интеллекта является способность принимать правильные решения в обстановке неполной и нечеткой информации. Построение моделей приближенных рассуждений человека и использование их в компьютерных системах будущих поколений представляет сегодня одну из важнейших проблем науки.
Значительное продвижение в этом направлении сделано 30 лет тому назад профессором Калифорнийского университета (Беркли) Лотфи А. Заде (Lotfi A. Zadeh). Его работа "Fuzzy Sets", появившаяся в 1965 году в журнале Information and Control, № 8, заложила основы моделирования интеллектуальной деятельности человека и явилась начальным толчком к развитию новой математической теории.
Что же предложил Заде? Во-первых, он расширил классическое канторовское понятие множества, допустив, что характеристическая функция (функция принадлежности элемента множеству) может принимать любые значения в интервале (0;1), а не только значения 0 либо 1. Такие множества были названы им нечеткими (fuzzy). Л.Заде определил также ряд операций над нечеткими множествами и предложил обобщение известных методов логического вывода modus ponens и modus tollens.
Введя затем понятие лингвистической переменной и допустив, что в качестве ее значений (термов) выступают нечеткие множества, Л.Заде создал аппарат для описания процессов интеллектуальной деятельности, включая нечеткость и неопределенность выражений.
Дальнейшие работы профессора Л.Заде и его последователей заложили прочный фундамент новой теории и создали предпосылки для внедрения методов нечеткого управления в инженерную практику.
Уже к 1990 году по этой проблематике опубликовано свыше 10000 работ, а число исследователей достигло 10000, причем в США, Европе и СССР по 200-300 человек, около 1000 - в Японии, 2000-3000 - в Индии и около 5000 исследователей в Китае.
В последние 5-7 лет началось использование новых методов и моделей в промышленности. И хотя первые применения нечетких систем управления состоялись в Европе, наиболее интенсивно внедряются такие системы в Японии. Спектр приложений их широк: от управления процессом отправления и остановки поезда метрополитена, управления грузовыми лифтами и доменной печью до стиральных машин, пылесосов и СВЧ-печей. При этом нечеткие системы позволяют повысить качество продукции при уменьшении ресурсов и энергозатрат и обеспечивают более высокую устойчивость к воздействию мешающих факторов по сравнению с традиционными системами автоматического управления.
Другими словами, новые подходы позволяют расширить сферу приложения систем автоматизации за пределы применимости классической теории. В этом плане любопытна точка зрения Л.Заде: "Я считаю, что излишнее стремление к точности стало оказывать действие, сводящее на нет теорию управления и теорию систем, так как оно приводит к тому, что исследования в этой области сосредоточиваются на тех и только тех проблемах, которые поддаются точному решению. В результате многие классы важных проблем, в которых данные, цели и ограничения являются слишком сложными или плохо определенными для того, чтобы допустить точный математический анализ, оставались и остаются в стороне по той причине, что они не поддаются математической трактовке. Для того чтобы сказать что-либо существенное для проблем подобного рода, мы должны отказаться от наших требований точности и допустить результаты, которые являются несколько размытыми или неопределенными".
Смещение центра исследований нечетких систем в сторону практических приложений привело к постановке целого ряда проблем таких, как новые архитектуры компьютеров для нечетких вычислений, элементная база нечетких компьютеров и контроллеров, инструментальные средства разработки, инженерные методы расчета и разработки нечетких систем управления и многое другое.
1. Нечеткие знания
Обширной областью эффективного применения интеллектуальных систем как средства построения информационных систем нового поколения является область нечетких знаний. Это связано с тем, что во всех предметных областях существенное место занимают некорректные, нечетко формулируемые задачи и реальный человеческий способ рассуждения (опирающийся на естественный язык) не может быть описан в рамках традиционных математических формализмов, предполагающих однозначность интерпретации. Другими словами, знания чаще всего нечетки. «Для того, чтобы ИС вышли за рамки простых символьных выводов и приблизились к мышлению человека, необходимы методы представления нечетких знаний и механизмы выводов, работающие в их среде.» Исии. Возникла необходимость создания теории, позволяющей формально описывать нестрогие, нечеткие понятия и моделировать рассуждения, содержащие такие понятия.
Все недоопределённости в знаниях можно классифицировать следующим образом:
недетерминированность выводов,
многозначность,
ненадежность,
неполнота,
нечеткость или неточность. Именно этому классу уделяется внимание ниже.
1.1 Определение. Причины нечеткости знаний
Нечеткими называются такие знания, которые допускают суждения об относительной степени истинности или ложности.
Типы, источники, причины нечеткости знаний:
присутствие неопределенности в фактическом знании,
неточность языка представления знаний,
знания, основанные на неполной информации,
неопределенность, появляющаяся при агрегации (объединении в одну систему) знаний, полученных из разных источников и пр.
В последнее десятилетие всё больше внимания уделяется подходу, основанному на теории нечетких множеств. Эту теорию предложил ам. ученый Лофти Заде в 1965 году. Главная идея подхода Заде заключается в использовании для моделирования рассуждений нечеткой логики. Заде ввел одно из главных понятий в нечеткой логике – понятие лингвистической переменной.
Использование этого подхода позволяет построить «нечёткие» аналоги основных математических понятий и создать формальный аппарат для моделирования человеческого способа решения задач.
1.2 Нечёткая логика
Лингвистическая переменная (ЛП) – это переменная, значение которой определяется набором вербальных (словесных) характеристик некоторого свойства. Например, ЛП «рост» определяется набором {карликовый, низкий, средний…}.
В нечёткой логике степень истинности или степень ложности каждого нечеткого высказывания (или ЛП) принимает значения из отрезка от 0 до 1, причем 0 и 1 совпадают с понятиями ложь и истина для чётких высказываний. Степень истинности 0,7, например, это не вероятность в статистическом смысле, а некоторое произвольное субъективное значение.
Составные высказывания (как и в обычной логике высказываний) образуются из простых с помощью логических операций отрицания (не), конъюнкции (и), дизъюнкции (или), импликации /замещения/ ( ), эквиваленции ( ). Так степень истинности комбинации высказываний s1 и s2, имеющих соответственно степени истинности p1 и p2, в нечеткой логике может быть определена следующим образом.
Конъюнкция: высказывание s1 «И» s2 имеет истинность слайд
p = min (p1, p2).
Дизъюнкция: высказывание s1 «ИЛИ» s2 имеет истинность
p = max (p1, p2).
Отрицание: высказывание «НЕ» s1 имеет истинность
p = 1 - p1.
Импликация: s1 s2 можно представить логической формулой
(«НЕ» s1) “ИЛИ” s2,
то истинность импликации нечётких высказываний может быть определена как
p = max (1 - p1, p2).
Эквивалентность: s1 s2 можно представить логической формулой (s1 s2) “И” (s2 s1) или при нечётких высказываниях
p = min (max (1 - p1, p2), max (p1, 1 - p2)).
Здесь истина эквиваленции р = 1 при р1 = р2 = 0 и р1 =р2 = 1,
р = 0,5 при р1 = р2 = 0,5.
Л8.ПРИМЕР – нечеткая логика.
s1: Иванов – успешный студент, степень истинности р1 = 0,7,
s2: Петров – успешный студент, степень истинности р2 = 0,4.
1. Оба успешные студенты
И – конъюнкция р = мин (0.7, 0.4) = 0.4 – истинность решения.
2. s1 ИЛИ s2- дизъюнкция (кто-то из них успешный)
степень истинности р = мах (0.7, 0.4) = 0.7.
3. НЕ - s1 – отрицание (не Иванов)
степень истинности р = 1 – р1 = 1 – 0.7 = 0.3.
4. s1 s2 - Замещение – импликация
степень истинности р = мах (1 – 0.7, 0.4) = 0.4 или если р1 = 0,5, а р2 = 0.4, то
р = мах (1 – 0.5, 0.4) = 0.5.
5. s1 s2 - Эквиваленция - они равноценны степень истинности р = мин( мах( 1 – р1, р2), мах (р1, 1 – р2)) = мин( мах (1-0.7, 0.4), мах(0.7, 1-0.4)) = мин(0.4, 0.7) = 0.4.
1.3 Нечёткие множества
Нечёткое множество отличается от обычного множества тем, что относительно любых его элементов можно сделать не два, а три вывода:
элемент принадлежит данному множеству;
элемент не принадлежит данному множеству;
элемент принадлежит данному множеству со степенью уверенности
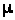 (далее
будем называть коэффициентом достоверности
или принадлежности);
(далее
будем называть коэффициентом достоверности
или принадлежности);
Очевидно, первые два
случая соответствуют третьему при
значениях коэффициента достоверности
= 1 и
= 0 соответственно. Таким образом, нечёткое
множество определяется путем введения
обобщенного понятия принадлежности.
Как определить и смоделировать следующее множество? «Когда мы говорим «старик», то не ясно, что мы имеем в виду: больше 50? больше 60? больше 70?». Подход, сформированный Заде, основывается на нижеприведённом представлении.
Пусть U
полное множество, охватывающее всю
проблемную область. Нечёткое (под)
множество F
множества U
определяется через функцию принадлежности
>F>(u)
(u
- элемент множества U).
Эта функция отображает элементы u
множества на множество чисел в отрезке
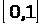 ,
которые указывают степень принадлежности
каждого элемента нечеткому множеству
F.
,
которые указывают степень принадлежности
каждого элемента нечеткому множеству
F.
Если полное множество U состоит из конечного числа множеств u>1>, u>2>, …, u>n>, то нечёткое множество F можно представить в следующем виде:
F =
>F>(u>1>)/u>1>
+
>F>(u>2>)/u>2
>+ … +>F>(u>n>)/u>n>
=
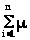 >F>(u>i>)/
u>i>.
>F>(u>i>)/
u>i>.
*Знак + не есть сложение,
а скорее обозначает совокупность
элементов множества (знаменатель) с их
принадлежностью (числитель). Знаки
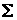 и
и
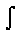 имеют
поэтому несколько отличный от традиционного
смысл.
имеют
поэтому несколько отличный от традиционного
смысл.
Например, если полное множество – это множество людей в возрасте от 0 до 100 лет, то функция принадлежности нечётких множеств, означающих возраст «молодой», «средний», «старый» можно определить так, как на рис. 10.1.
При записи через 10 лет получим приблизительно следующее:
*Молодой =
>м
>(u)
= 1/0 + 1/10 + 0,8/20 + 0,3/30.
Средний =
>ср
>(u)
= 0,5/30 + 1/40 +0,5/50.
Старый =
>ст
>(u)
= 0,4/50 + 0,8/60 + 1/70 + 1/80 + 1/90.
*Члены с коэффициентом принадлежности 0 не записываются.
П онятия
дополнение, объединение и пересечение
множеств (по рис.).
онятия
дополнение, объединение и пересечение
множеств (по рис.).
>м
>(u)
>ср
>(u)
>ст
>(u)





 1
1


 Молодой Средний Старый
Молодой Средний Старый



 0
0
0 10 20 30 40 50 60 70 80 90 u (возраст)
Рис. 10.1. Нечёткие множества и функции принадлежности категорий возраста.
Фаззификация (переход к нечеткости)
Точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно - при помощи определенных функций принадлежности.
Рассмотрим этот этап подробнее. Прежде всего, введем понятие «лингвистической переменной» и «функции принадлежности».
Лингвистические переменные
В нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются ТЕРМАМИ. Так, значением лингвистической переменной ДИСТАНЦИЯ являются термы ДАЛЕКО, БЛИЗКО и т. д.
Конечно, для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Пусть, например, переменная ДИСТАНЦИЯ может принимать любое значение из диапазона от 0 до 60 метров. Как же нам поступить? Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет СТЕПЕНЬ ПРИНАДЛЕЖНОСТИ данного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной ДИСТАНЦИЯ. В нашем случае расстоянию в 50 метров можно задать степень принадлежности к терму ДАЛЕКО, равную 0,85, а к терму БЛИЗКО - 0,15. Конкретное определение степени принадлежности возможно только при работе с экспертами. При обсуждении вопроса о термах лингвистической переменной интересно прикинуть, сколько всего термов в переменной необходимо для достаточно точного представления физической величины. В настоящее время сложилось мнение, что для большинства приложений достаточно 3-7 термов на каждую переменную. Минимальное значение числа термов вполне оправданно. Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Для большинства применений этого вполне достаточно. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число же 7 обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
В заключение дадим два совета, которые помогут в определении числа термов:
А) исходите из стоящей перед вами задачи и необходимой точности описания, помните, что для большинства приложений вполне достаточно трех термов в переменной;
Б) составляемые нечеткие правила функционирования системы должны быть понятны, вы не должны испытывать существенных трудностей при их разработке; в противном случае, если не хватает словарного запаса в термах, следует увеличить их число.
Фаззификация (переход к нечеткости)
Точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно - при помощи определенных функций принадлежности.
Рассмотрим этот этап подробнее. Прежде всего, введем понятие «лингвистической переменной» и «функции принадлежности».
Лингвистические переменные
В нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются ТЕРМАМИ. Так, значением лингвистической переменной ДИСТАНЦИЯ являются термы ДАЛЕКО, БЛИЗКО и т. д.
Конечно, для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Пусть, например, переменная ДИСТАНЦИЯ может принимать любое значение из диапазона от 0 до 60 метров. Как же нам поступить? Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет СТЕПЕНЬ ПРИНАДЛЕЖНОСТИ данного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной ДИСТАНЦИЯ. В нашем случае расстоянию в 50 метров можно задать степень принадлежности к терму ДАЛЕКО, равную 0,85, а к терму БЛИЗКО - 0,15. Конкретное определение степени принадлежности возможно только при работе с экспертами. При обсуждении вопроса о термах лингвистической переменной интересно прикинуть, сколько всего термов в переменной необходимо для достаточно точного представления физической величины. В настоящее время сложилось мнение, что для большинства приложений достаточно 3-7 термов на каждую переменную. Минимальное значение числа термов вполне оправданно. Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Для большинства применений этого вполне достаточно. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число же 7 обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
В заключение дадим два совета, которые помогут в определении числа термов:
n исходите из стоящей перед вами задачи и необходимой точности описания, помните, что для большинства приложений вполне достаточно трех термов в переменной;
n составляемые нечеткие правила функционирования системы должны быть понятны, вы не должны испытывать существенных трудностей при их разработке; в противном случае, если не хватает словарного запаса в термах, следует увеличить их число.
Функции принадлежности
Как уже говорилось, принадлежность каждого точного значения к одному из термов лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рис. 3).
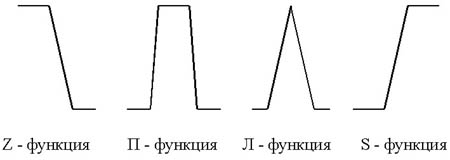
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Подведем некоторый итог этапа фаззификации и дадим некое подобие алгоритма по формализации задачи в терминах нечеткой логики.
Шаг 1. Для каждого терма взятой лингвистической переменной найти числовое значение или диапазон значений, наилучшим образом характеризующих данный терм. Так как это значение или значения являются «прототипом» нашего терма, то для них выбирается единичное значение функции принадлежности.
Шаг 2. После определения значений с единичной принадлежностью необходимо определить значение параметра с принадлежностью «0» к данному терму. Это значение может быть выбрано как значение с принадлежностью «1» к другому терму из числа определенных ранее.
Шаг 3. После определения экстремальных значений нужно определить промежуточные значения. Для них выбираются П- или Л-функции из числа стандартных функций принадлежности.
Шаг 4. Для значений, соответствующих экстремальным значениям параметра, выбираются S- или Z-функции принадлежности.
Если удалось подобным образом описать стоящую перед вами задачу, вы уже целиком погрузились в мир нечеткости. Теперь необходимо что-то, что поможет найти верный путь в этом лабиринте. Таким путеводителем вполне может стать база нечетких правил. О методах их составления мы поговорим ниже.
Разработка нечетких правил
На этом этапе определяются продукционные правила, связывающие лингвистические переменные. Совокупность таких правил описывает стратегию управления, применяемую в данной задаче.
Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (часть ЕСЛИ …) и консеквента (часть ТО …). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок И или ИЛИ.
Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение.
Пусть мы имеем следующее правило:
ЕСЛИ ДИСТАНЦИЯ=средняя И
УГОЛ=малый, ТО МОЩНОСТЬ=средняя.
Обратимся к примеру с контейнерным краном и рассмотрим ситуацию, когда расстояние до платформы равно 20 метрам, а угол отклонения контейнера на тросе крана равен четырем градусам. После фаззификации исходных данных получим, что степень принадлежности расстояния в 20 метров к терму СРЕДНЯЯ лингвистической переменной ДИСТАНЦИЯ равна 0,9, а степень принадлежности угла в 4 градуса к терму МАЛЫЙ лингвистической переменной УГОЛ равна 0,8.
На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: MIN(…) и MAX(…). Первый вычисляет минимальное значение степени принадлежности, а второй - максимальное значение. Когда применять тот или иной оператор, зависит от того, какой связкой соединены посылки в правиле. Если использована связка И, применяется оператор MIN(…). Если же посылки объединены связкой ИЛИ, необходимо применить оператор MAX(…). Ну а если в правиле всего одна посылка, операторы вовсе не нужны. Для нашего примера применим оператор MIN(…), так как использована связка И. Получим следующее:
MIN(0,9;0,8)=0,8.
Следовательно, степень принадлежности антецедента такого правила равна 0,8. Операция, описанная выше, отрабатывается для каждого правила в базе нечетких правил.
Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов MIN/MAX вычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил.
После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией.
Дефаззификация (устранение нечеткости)
На этом этапе осуществляется переход от нечетких значений величин к определенным физическим параметрам, которые могут служить командами исполнительному устройству.
Результат нечеткого вывода, конечно же, будет нечетким. В примере с краном команда для электромотора крана будет представлена термом СРЕДНЯЯ (мощность), но для исполнительного устройства это ровно ничего не значит.
Для устранения нечеткости окончательного результата существует несколько методов. Рассмотрим некоторые из них. Аббревиатура, стоящая после названия метода, происходит от сокращения его английского эквивалента.
Метод центра максимума (СоМ)
Так как результатом нечеткого логического вывода может быть несколько термов выходной переменной, то правило дефаззификации должно определить, какой из термов выбрать. Работа правила СоМ показана на рис. 4.
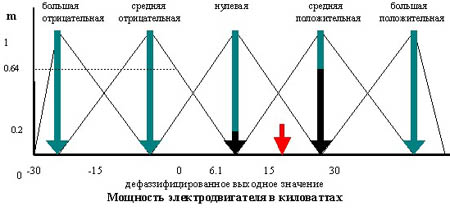
Метод наибольшего значения (МоМ)
При использовании этого метода правило дефаззификации выбирает максимальное из полученных значений выходной переменной. Работа метода ясна из рис. 5.
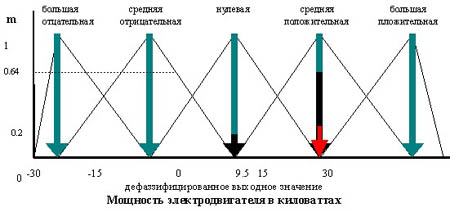
Метод центроида (СоА)
В этом методе окончательное значение определяется как проекция центра тяжести фигуры, ограниченной функциями принадлежности выходной переменной с допустимыми значениями. Работу правила можно видеть на рис. 6.
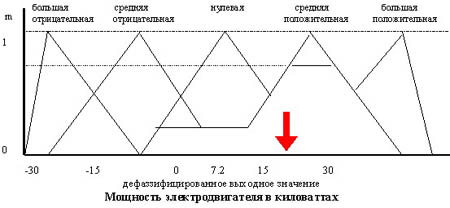
Применение: MYCIN, Fuzzy CLIPS, AM, HEARSAY-11, PROSPECTOR. «Экспертные системы»
В современном обществе при решении задач управления сложными многопараметрическими и сильно связанными системами, объектами и производственными и технологическими процессами приходится сталкиваться с решением неформализуемых и трудноформализуемых задач. Такие задачи часто возникают в следующих областях: авиация, космос и оборона, нефтеперерабатывающая промышленность и транспортировка нефтепродуктов, энергетика, металлургия, машиностроительная промышленность, медицина, прогнозирование и мониторинг и другие.
В начале 60-х годов в рамках исследований по искусственному интеллекту (ИИ) сформировалось самостоятельное направление - экспертные системы (ЭС). В задачу этого направления входит исследование и разработка программ (устройств), использующих знания и процедуры вывода для решения задач, ранее решавшихся только человеком-экспертом. Области применения ЭС включают широкий проблемный спектр от медицинской диагностики и определения курса лечения до систем управления различного рода, планирования и контроля процесса производства.
Экспертная система — система, объединяющая возможности компьютера со знаниями и опытом эксперта в такой форме, что система способна предложить разумный совет или осуществить разумное решение. Дополнительно желаемой характеристикой такой системы является способность пояснять ход своих рассуждений в понятной для человека форме.
Данное определение ЭС одобрено комитетом группы специалистов по экспертным системам Британского компьютерного общества.
Под экспертной системой понимают программу, которая, используя знания специалистов (экспертов) о некоторой конкретной узко специализированной предметной области и в пределах этой области, способна принять решение на уровне эксперта-профессионала.
Можно отметить двойственность толкования названия ЭС, т.к. во-первых, в них используется знания экспертов, а во-вторых, ЭС сами могут выступать в качестве экспертов.
Огромный интерес к экспертным системам со стороны пользователя вызван следующими причинами:
1. Специалисты, не знающие программирования, с помощью экспертных систем могут самостоятельно разрабатывать интересующие их приложения, что позволяет резко расширить сферу использования вычислительной техники.
2. Экспертные системы при решении практических задач достигают результатов, не уступающих, а иногда и превосходящих возможности людей экспертов, не оснащенных ЭС.
3. Решаемые экспертными системами задачи являются неформализованными и используют эвристические, экспериментальные, субъективные знания экспертов в определенной предметной области.
4. В экспертных системах знания отделены от данных, и мощность ЭС обусловлена в первую очередь мощностью базы знаний и только во вторую очередь используемыми методами решения задач.
Обычно к экспертным системам относят системы, основанные на знаниях, т.е. системы, функциональные возможности которых являются в первую очередь следствием их наращиваемой базы знаний (БЗ) и только во вторую очередь определяется используемыми методами принятия решения.
Правильное функционирование ЭС, как систем основанных на знаниях, зависит от качества и количества знаний, хранимых в их БЗ. Поэтому приобретение знаний для ЭС является очень важным процессом.
Приобретение (извлечение) знаний — получение информации о проблемной области различными способами, в том числе от специалистов, и выражение её на языке представления знаний с целью построения БЗ. Необходимо умело «скопировать» образ мышления эксперта.
Знания для ЭС могут быть получены из различных источников: книг, отчетов, баз данных, эмпирических правил, персонального опыта эксперта и т. п. Возможны 3 способа получения знаний от эксперта: протокольный анализ, интервью и игровая имитация профессиональной деятельности
Классификация экспертных систем
По назначению: экспертные системы общего назначения; специализированные: а) проблемно-ориентированные для задач диагностики, проектирования, прогнозирования; б) предметно-ориентированные для решения специфических задач, например, контроль ситуации на АЭС.
По степени зависимости от внешней среды:
-статические экспертные системы, не зависящие от внешней среды;
- динамические, учитывающие динамику внешней среды и предназначенные для решения задач в реальном времени.
По типу использования:
- изолированные экспертные системы;
- экспертные системы на входе/выходе других систем;
- гибридные экспертные системы, интегрированные с базами данных и другими программными средствами.
По сложности решаемых задач:
- простые экспертные системы, имеющие до 1000 простых правил;
- средние системы, имеющие от 1000 до 10000 правил;
- сложные, имеющие более 10000 правил.
По стадии создания:
- исследовательский образец, разработанный за 1-2 месяца с минимальной базой знаний;
- демонстрационный образец, разработанный за 3-4 месяца на языках LISP, PROLOG и др.;
- промышленный образец, разработанный за 4-8 месяцев с полной базой знаний на языках типа CLIPS;
- коммерческий образец, разработанный за 1,5 – 2 года на современных языках с полной базой знаний.
Области применения ЭС
В настоящее время ЭС используются при решении задач следующих типов:
принятие решений в условиях неопределенности (неполноты) информации о внешнем мире,
интерпретация символов и сигналов (например, системы оптического распознавания),
прогнозирование (погоды, месторождений полезных ископаемых),
диагностика (заболеваний, состояния технических устройств),
конструирование (например, технических устройств), планирование (например, банковских операций),
обучение,
управление, контроль и др.
Функциональная структура экс пертной системы
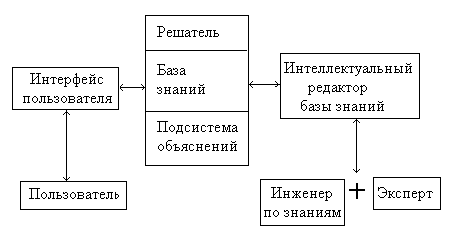
Рис. 13.1.Структура ЭС
*Типичная экспертная система состоит из следующих основных компонентов: модуля принятия решения (интерпретатора), БД, БЗ, пользовательского интерфейса.
Ввод входных данных и информации о текущей задаче – через пользователя.
База данных предназначена для хранения исходных и промежуточных данных, необходимых для решения текущей задачи. Термин база данных совпадает по названию, но не по значению с термином, используемым в информационно-поисковых системах и системах управления БД, где он обозначает список однотипных единиц информации.
Пример содержимого базы данных ЭС обработки детали на станке.
База знаний (БЗ) — совокупность описывающих предметную область правил и фактов, позволяющих с помощью механизма вывода выводить суждения в рамках этой предметной области, которые в явном виде в базе не присутствуют.
Решатель, используя информацию из БД и знания из БЗ, формирует такую последовательность правил, которые, будучи примененными к данным из БД, приводят к решению задачи. Этот модуль используется и на этапе обучения системы и на этапе проведения экспертизы. В начале обучения база знаний системы пуста. Используя данные из БД, решатель пытается выработать какое-то суждение. Поскольку в БЗ отсутствуют какие-либо правила, требуемые для решения задачи, суждение будет неверным, на что системе будет указано человеком-экспертом, а так же будет введен правильный ответ. Используя полученную от человека информацию (правильное суждение), решатель дополнит БЗ соответствующими правилами. Затем модуль принятия решений попытается вывести новое суждение. Если ответ, полученный системой в результате ее работы, является верным, модуль принятия решений еще раз подтвердит правила, участвовавшие в принятии ответа. Такой процесс обучения продолжается до тех пор, пока ЭС не начнет выводить только правильные суждения. К моменту проведения экспертизы база знаний уже заполнена при помощи модуля принятия решений необходимыми для решения поставленной задачи правилами. Применяя проверенные правила к данным из БД, модуль принятия решения выведет требуемое суждение.
Интерфейс пользователя предназначен для осуществления процесса взаимодействия между человеком-экспертом и экспертной системой. Он обеспечивает возможность высокоуровневого общения с ЭС, преобразуя входные данные, представленные на естественном языке, во внутреннее представление ЭС, а сообщения ЭС — в обратном направлении.
Таким образом, данные определяют объекты, их характеристики и значения, существующие в области экспертизы. Правила определяют способы преобразования данных, характерные для рассматриваемой проблемной области. Эксперт, используя интерфейс пользователя, наполняет систему знаниями, которые позволяют ЭС в режиме решения самостоятельно (без эксперта) решать задачи из проблемной области.
Режимы работы ЭС
Существует 2 режима работы ЭС: режим приобретения знаний и режим решения задач. В режиме приобретения знаний ЭС заполняется знаниями при помощи инженера по знаниям и эксперта в какой-то проблемной области. Эксперт описывает проблемную область в виде совокупности данных и правил, которые инженер по знаниям заносит в том или ином виде в базу знаний.
В режиме решения задач необходимо посредством интерфейса пользователя заполнить БД данными о задаче. При этом данные пользователя о задаче, представленные на привычном для пользователя языке, преобразуются во внутренний язык системы.
Итак, на основе входных данных из БД и данных и правил о проблемной области из БЗ модуль принятия решения выводит суждение, являющееся решением поставленной перед ЭС задачи. Если ответ ЭС не понятен пользователю, то он может потребовать объяснения, как этот ответ получен.
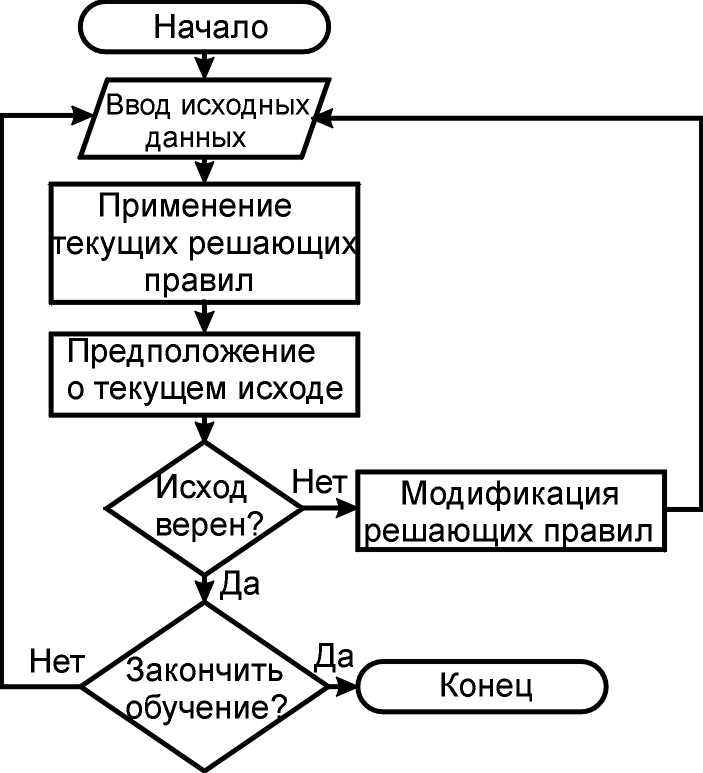
Рис. 13.2. Алгоритм работы ЭС в режиме обучения
Технология проектирования и разработки ЭС
Разработка ЭС имеет существенные отличия от разработки обычного программного продукта. Опыт создания ЭС показал, что использование при их разработке методологии, принятой в традиционном программировании, либо чрезмерно затягивает процесс создания ЭС, либо вообще приводит к отрицательному результату.
Создавать ЭС следует только тогда, когда разработка ЭС возможна, оправдана и методы инженерии знаний соответствуют решаемой задаче.
Чтобы разработка ЭС была возможной для данной проблемной области, необходимо одновременное выполнение, по крайней мере следующих требований:
1. К экспертам:
существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты;
эксперты сходятся в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС;
эксперты способны вербализовать (выразить на естественном языке) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС;
решение задачи требует только рассуждений, а не действий;
5. Задача не должна быть слишком трудной (т.е. ее решение должно занимать у эксперта несколько часов или дней, а не недель);
6. Задача хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения между ними и известные (хотя бы эксперту) способы получения решения задачи.
7. решение задачи не должно в значительной степени использовать «здравый смысл» (т.е.широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), т.к. подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта.
Использование ЭС в данном приложении может быть возможно, но не оправдано. Применение ЭС может быть оправдано одним из следующих факторов:
1. решение задачи принесет значительный эффект, например экономический;
2. использование человека-эксперта невозможно либо из-за недостаточного количества экспертов, либо из-за необходимости выполнять экспертизу одновременно в различных местах;
3. использование ЭС целесообразно в тех случаях, когда при передаче информации эксперту происходит недопустимая потеря времени или информации;
4. использование ЭС целесообразно при необходимости решать задачу в окружении, враждебном для человека.
Приложение соответствует методам инженерии знаний, если решаемая задача обладает совокупностью следующих характеристик:
1) задача может быть решена посредством манипуляции с символами (т.е. с помощью символических рассуждений), а не манипуляций с числами, как принято в математических методах и в традиционном программировании;
2) задача должна иметь эвристическую, а не алгоритмическую природу, т.е. ее решение должно требовать применения эвристических правил. Задачи, которые могут быть гарантированно решены (с соблюдением заданных ограничений) с помощью некоторых формальных процедур, не подходят для применения ЭС;
3) задача должна быть достаточно сложна, чтобы оправдать затраты на разработку ЭС. Однако она не должна быть чрезмерно сложной (решение занимает у эксперта часы, а не недели), чтобы ЭС могла ее решать;
4) задача должна быть достаточно узкой, чтобы решаться методами ЭС, и практически значимой.
При разработке ЭС, как правило, используется концепция "быстрого прототипа". Смысл ее состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования.
Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия ЭС, так и уменьшение требуемой памяти. Трудоемкость и время создания ЭС в значительной степени зависят от типа используемого инструментария.
В ходе работ по созданию ЭС сложилась технология их разработки, включающая шесть следующих этапов (рис. 1.4):
идентификацию, концептуализацию, формализацию, выполнение, тестирование, опытную эксплуатацию. На этапе идентификации определяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей.
На этапе концептуализации проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач.
На этапе формализации выбираются ИС и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями.
На этапе выполнения осуществляется наполнение экспертом базы знаний. В связи с тем, что основой ЭС являются знания, данный этап является наиболее важным и наиболее трудоемким этапом разработки ЭС. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном ЭС. Процесс приобретения знаний осуществляется инженером по знаниям на основе анализа деятельности эксперта по решению реальных задач.
Трудности при разработке экспертных систем
Разработка ЭС связана с определенными трудностями, к числу которых можно отнести следующие:
1. Проблема извлечения знаний экспертов.Ни один специалист никогда просто так не откроет секреты своего профессионального мастерства, свои сокровенные знания в профессиональной области. Он должен быть заинтересован материально или морально. Часто такой специалист опасается, что раскрыв свои секреты, он будет не нужен компании. Вместо него будет работать экспертная система. Необходимо выбирать высококвалифицированного специалиста, заинтересованного в сотрудничестве.
2. Проблема формализации знаний экспертов. Эксперты-специалисты в определенной области, как правило, не в состоянии формализовать свои знания. Часто они принимают правильные решения на интуитивном уровне и не могут аргументировано объяснить, почему принято то или иное решение. Иногда эксперты не могут прийти к взаимопониманию. В таких ситуациях поможет выбор эксперта, умеющего ясно формулировать свои мысли и легко объяснять другим свои идеи.
3. Проблема нехватки времени у экспертов. Выбранный для разработки эксперт не может найти достаточно времени для выполнения проекта. Чтобы избежать такой ситуации, необходимо получить от эксперта, прежде чем начнется проект, согласие тратить на проект время в определенном фиксированном объеме.
4. Правила, формализованные экспертом, не дают требуемой точности. Проблему можно избежать, если решать вместе с экспертом реальные задачи. Эксперт, как правило, легче понимает правила, записанные на языке, близком к естественному.
5. Недостаток ресурсов. В качестве ресурсов выступают персонал (инженеры знаний, разработчики инструментальных средств, эксперты) и средства построения ЭС (средства разработки и средства поддержки). Удвоение персонала не сокращает время разработки наполовину, т.к. процесс создания ЭС – это процесс со множеством обратных связей.
6. Неадекватность инструментальных средств решаемой задаче. Часто определенные типы знаний (например, временные или пространственные) не могут быть легко представлены на одном ЯПЗ, так же как и разные схемы представления (например, фреймы и продукции) не могут быть достаточно эффективно реализованы на одном ЯПЗ. Некоторые задачи могут быть непригодными для решения по технологии ЭС (например, отдельные задачи по анализу сцен). Необходим тщательный анализ решаемых задач, чтобы определить пригодность предлагаемых инструментальных средств и сделать правильный выбор.
Методология построения экспертных систем. Рассмотрим методику формализации экспертных знаний на примере создания экспертных диагностических систем. Целью создания таких систем является определение состояния объекта диагностирования (ОД) и имеющихся в нем неисправностей.
Состояниями ОД могут быть: исправно, неисправно, работоспособно. Неисправностями, например, радиоэлектронных ОД являются: обрыв связи, замыкание проводников, неправильное функционирование элементов и т.п. Число неисправностей может быть велико. В ОД могут быть одновременно несколько неисправностей.
Разные неисправности ОД проявляются во внешней среде информационными параметрами. Совокупность значений информационных параметров определяет «информационный образ» (ИО) неисправности ОД. ИО может быть полным, т.е. содержать всю необходимую информацию для постановки диагноза, или, соответственно, неполным. В последнем случае постановка диагноза носит вероятностный характер.
Основой для построения эффективных экспертных диагностических систем являются знания эксперта для постановки диагноза, записанные в виде информационных образов, и система представления знаний, встраиваемая в информационные системы обеспечения функционирования и контроля ОД, интегрируемые с соответствующей технической аппаратурой.
Для описания своих знаний эксперт с помощью инженера по знаниям должен выполнить следующее.
1.Выделить множество всех неисправностей ОД, которые должна различать система.
2. Выделить множество информативных (существенных) параметров, значения которых позволяют различить каждую неисправность ОД и поставить диагноз с некоторой вероятностью.
3.Для выбранных параметров следует выделить информативные значения или информативные диапазоны значений, которые могут быть как количественными, так и качественными. Например, точные количественные значения могут быть записаны: задержка 25 нсек, задержка 30 нсек и т. Д. Количественный диапазон значений может быть записан: задержка 25-49 нсек, 40-50 нсек, 50 нсек и выше. Качественный диапазон значений может быть записан: индикаторная лампа светится ярко, светится слабо, не светится. Для более удобного дальнейшего использования диапазон значений может быть закодирован.
4. Процедура создания полных или неполных ИО каждой неисправности в алфавите значений информационных параметров может быть определена следующим образом. Составляются диагностические правила, определяющие вероятный диагноз на основе различных сочетаний диапазонов значений выбранных параметров ОД. Правила могут быть записаны в различной форме. Механизм записи последовательности проведения тестовых процедур в виде правил реализуется, например, следующим образом:
ЕСЛИ: Р» = 1
ТО: таст = Т1, Т3, Т7,
Где Т1, Т3, Т7 – тестовые процедуры, подаваемые на ОД при активизации (срабатывании) соответствующей продукции. В ЭС приоритет отдается прежде всего знаниям и опыту, а лишь затем логическому выводу.
Оболочки ЭС
К настоящему времени ЭС стали одной из серьезных отраслей информационной индустрии. Программное обеспечение в этой области быстро расширяется. При создании первых ЭС было отмечено, что механизм логического вывода и язык представления знаний могут быть отделены от конкретных знаний и использованы в различных проблемных областях. "Пустые" проблемно-независимые ЭС с незаполненной базой знаний называются оболочками ЭС.
Внутренние средства оболочки ЭС обеспечивают манипуляцию знаниями, генерацию объяснений, а также сервис разработки и отладки базы знаний. Для создания прикладной ЭС пользователь должен написать свою собственную базу знаний, используя предлагаемый оболочкой язык представления знаний.
Несмотря на обилие оболочек ЭС — CxPERT, Exsys, GoldWorks, Guru, KDS3, KnowledgePro, Nexpert, Rule Master, VP Expert — можно выделить ограниченное число методов построения механизмов вывода ЭС: применение правил продукций, использование механизма исчисления предикатов, символьная обработка знаний, представленных в текстовой форме, использование вероятностного подхода к обработке знаний.
Вывод заключения может быть произведен экспертной системой двумя способами:
Прямой ход — определяются все входные данные и на их основании выводится заключение.
Обратный ход — выбирается гипотеза и проверяются на истинность ее признаки. Если они истинны, то верна и гипотеза, если нет — проверяется следующая гипотеза.
Применение ЭС на основе нейронных сетей
За рубежом интерес к нейронным сетям стремительно растет. На нейронной технологии в сочетании с использованием проводящих полимеров основано устройство распознавания запахов, разработанное совместно фирмами Neotronics и Neoral Technologies. Системы на основе одного из типов нейронной сети осуществляют контроль за энергоустановками в некоторых городах США. Сеть РАРNЕТ после пробного рассмотрения нескольких тысяч образцов определяет пораженные раком клетки быстрее и точнее, чем это делает лаборант. "Гибридная" система анализа данных Clementine, разработанная ISL, применяется банком Чейз Манхэттен (Chase Manhattan Bank) для изучения вкусов и склонностей части своей клиентуры. Датский институт мясной промышленности приспособил нейронную сеть для анализа качества свинины. Фирма АЕА Technology разработала на основе нейронной сети средство определения идентичности подписи.
Опыт показал, что применение нейронных сетей оправданно там, где закономерности не изучены, а входные данные избыточны, иногда противоречивы и засорены случайной информацией.
Языки представления знаний
Стремление к эффективной программной реализации моделей представления знаний привело к разработке большого числа языков представления знаний от простых, предназначенных для решения отдельных специальных задач, до мощных универсальных.
Общими свойствами ЯПЗ высокого уровня являются следующие;
- наличие средств описания типов данных и процедур управления более сложных, чем в универсальных языках программирования;
- наличие встроенных механизмов представления поиска и обработки информации;
- наличие средств построения дедуктивных алгоритмов.
ЯПЗ условно можно разделить на три группы:
1.Языки обработки символьной информации. Характерными представителями этой группы являются LISP, РЕФАЛ, SNOBOL.
2.Языки, ориентированные на поиск решения в пространстве состояний и доказательства теорем. К ним относятся, например, PLANNER,QLISP.
3.Языки, представления знаний общего назначения. Характерными представителями являются KRL, FRL.
Наиболее распространенным языком обработки символьной информации является LISP. Основными единицами информации в этом языке являются атомы и списки. Атом – любая последовательность алфавитно-цифровых символов и специальных знаков, заключенных между ограничениями. Атомы могут использоваться для представления имен, отношений, действий, свойств, переменных, а также для представления синтаксических признаков, семантических маркеров.
Список – это упорядоченная совокупность элементов, в качестве которых могут выступать либо атомы, либо другие списки. Под выражением в LISP понимается либо атом, либо список. Выражение (6, 8, SPM, B) представляет собой список из четырех элементов, каждый из которых является атомом; выражение (PUT (NHE PEN) (IN (THE TABLE))) – список из трех элементов. Первый элемент – атом, второй – список из двух атомов, третий – двухэлементный список со вторым элементом в виде списка.
В LISP есть аппарат интерпретации списков, называемый вычислением. Первый элемент интерпретируется как имя функции, остальная часть рассматривается как множество аргументов функции. Примеры: Список (PLUS 2 4) вырабатывает значение 6 = 2 + 4. Список (TIMES 9 3 ) вырабатывает значение 27=9х3. LISP имеет целый ряд встроенных стандартных функций, но может строить и вводить свои функции.
Для присвоения значения переменной используется функция SETQ. Например, (SETQ R 4) переменная R получает значение 4. Для обработки списков в LISP используется ряд элементарных функций, таких, как CAR, CDR, CONS и др.
Литература
1 – Тугенгольд А.К., Рубанчик В.Б. Искусственный интеллект в машиностроительных технологических системах: Учеб. пособие. Ростов-на-Дону, Изд. центр ДГТУ, 1996. – 140 с.
2 – Базы знаний интеллектуальных систем/ Т.А. Гаврилова, В.Ф. Хорошевский – СПб. Питер, 2000. – 384 с.
3 – Статические и динамические экспертные системы: Учеб. Пособие / Э.В. Попов и др. – М.: Финансы и статистика, 1996. – 320 с.
4 - Фу К., Гонсалес Р., Ли К. Робототехника. – М.: Мир, 1989. – 624 с.
5 – Накано Э. Введение в робототехнику. - М.: Мир, 1988. – 334 с.
6. Робототехника и гибкие автоматизированные производства. Кн. 6. Техническая имитация интеллекта. Назаретов В.М., Ким Д.П. Высшая школа, 1986. – 144 с.
7. Интеллектуальные робототехнические системы. Уч. пособие. В.Л. Афонин, В.А. Макушин. Москва, 2005. Интернет университет информационных технологий. – 208 с.
8. Введение в мехатронику. Кн.2.