Формування об’ємних зображень на основі фотографій
Затверджено
482.362.70915-28 81 59-3 ЛЗ
МІНІСТЕРСТВО ОСВІТИ ТА НАУКИ УКРАЇНИ
ЧЕРНІВЕЦЬКИЙ НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ
ІМЕНІ ЮРІЯ ФЕДЬКОВИЧА
Факультет комп’ютерних наук
Кафедра комп’ютерних систем та мереж
ФОРМУВАННЯ ОБ’ЄМНИХ ЗОБРАЖЕНЬ НА ОСНОВІ ФОТОГРАФІЙ
(курсова робота)
482.362. 70915-28 81 59-3
Сторінок 28
2008
Анотація
Пояснювальна записка складається з основних розділів, які пов’язані з аналізом й обґрунтуванням теми дипломного проекту, призначенням і областю застосування, описом функціональних можливостей програми, вибором технічних і програмних засобів, організації вхідних та вихідних результатів, розглядом очікуваних техніко – економічних показників та списком використаних джерел літератури при розробці програмного продукту.
Текст документу складається з 28 сторінок друкованого тексту та 6 рисунків.
Зміст
Вступ
1. Призначення та область застосування
2. Технічні характеристики
2.1. Постановка задачі на розробку програми
2.1.1 Класифікація моделей і методів візуалізації
2.1.2 Полігональні сітки
2.1.3 Воксельні моделі
2.1.4 Моделі, засновані на зображеннях
2.1.5 Точкове подання
2.1.6 Ієрархічні подання
2.2. Опис алгоритму і функціонування програми
2.3. Опис організації вхідних та вихідних даних
2.4. Опис організації вибору технічних і програмних засобів
3. Очікувані техніко – економічні показники
Список використаних джерел
Вступ
Назва: Формування об’ємних зображень на основі фотографій.
Призначення: Дипломний проект затверджено на Вченій Раді факультету комп’ютерних наук Чернівецького національного університету імені Юрія Федьковича від 13 листопада 2007 року протоколом №3 і призначений для формування об’ємних зображень на основі фотографій. Дипломний проект полягає у написанні програмного продукту, що реалізує перетворення двомірного зображення у тривимірне.
1. Призначення та область застосування
В даний час призначень та областей застосування програм, які орієнтовані на перетворення зображень з плоского в об’ємне дуже багато. Їх застосовують:
- при проектуванні будівель (створення моделі будинку до його зведення);
- при проектуванні літаків та космічних апаратів (дозволяє виявити неполадки на етапі розробки та дає можливість випробувати розроблену модель);
- при проектуванні друкованих плат;
- при проведенні археологічних розкопок (дає можливість видворити модель об’єкта по її частинам);
- при роботі з анімацією (створення об’ємних зображень з малюнків);
- при створенні комп’ютерних ігор.
Для перетворення зображень існують такі програми:
1. 3D Studio Max – компоненти цієї програми дозволяють проводити візуалізацію зображення.
До переваг програми можна віднести: якість створеного об’ємного зображення; дозволяють використовувати фільтри покращення зображення.
До недоліків програми можна віднести: потребує додаткового знання програми; велика ціна за програму; низька швидкість обробки зображення; складність реалізації алгоритму програми; потребує встановлення на комп’ютер додаткових компонентів; ресурсозалежна (потребує комп’ютер з великими обчислювальними можливостями).
2. Maya – ця програма є аналогом попереднього продукту.
Переваги та недоліки програми такі, як і в попередній.
3. AutoCAD – компоненти цієї програми дозволяють створювати об’ємні зображення з креслень.
До переваг програми можна віднести: точність створеного зображення; швидкість створення; не являється ресурсозалежною.
До недоліків програми можна віднести: потребує додаткового вивчення програми; ціна за програму, наявність малої кількості текстур; необхідність встановлення в операційну систему; складність реалізації алгоритму програми.
4. Realviz ImageModeler – ця програма орієнтована на створення об’ємних зображень з фотографії.
До переваг програми можна віднести: можливість відтворення з фотографії складних об’єктів, не являється ресурсозалежною.
До недоліків програми можна віднести: потребує додаткового знання програми; велика вартість програмного продукту; швидкість аналізу зображення; складність реалізації алгоритму програми, якість отриманого зображення посередня.
5. StitcherUnlimited – ця програма є аналогом попередньої.
Переваги та недоліки даної програми такі, як і в попередній.
6. Image Skulpturer - ця програма орієнтована на створення об’ємних зображень з фотографії.
До переваг програми можна віднести: простота інтерфейсу; відтворює складні зображення; потребує невелику кількість вхідних параметрів фотографії; якість відтвореного зображення; ресурсонезалежна.
До недоліків програми можна віднести: ціна за програму; складний алгоритм програми.
Розроблений програмний продукт, що орієнтований на перетворення двомірного зображення у тривимірне має великий спектр призначення, а саме:
1. Пришвидшити перетворення плоского зображення у об’ємне.
2. Перетворювати структури зображення разом з її текстурою.
3. Призначається для огляду зображення під різними кутами.
4. Призначений для огляду об’єкту з різних відстаней.
4. Програмний продукт може зберігати зображення під час огляду його з різних сторін.
Переваги створеної програми: безкоштовність; інтуїтивно простий інтерфейс; швидкість обробки зображення; простота реалізації.
Недоліки створеної програми: обмеженість вихідних форматів зображення (тільки bmp); неможливість відтворення складних об’єктів, потреба у правильному освітленні малюнку.
2. Технічні характеристики
2.1 Постановка задачі на розробку програми
В дипломному проекті поставлена задача створити програмний продукт, який орієнтовано на роботу з зображенням. А саме, перетворення двомірного зображення у тривимірне, можливість його огляду з різних сторін та збереження зображення під іншим кутом огляду. Також задача програми демонструвати студентам стадії формування тривимірного зображення
2.1.1 Класифікація моделей і методів візуалізації
На даний час відоме досить велике кількість різних методів подання тривимірних об'єктів і пов'язаних з ними методів візуалізації, у тому числі багатомасштабних. Всі подання можна розділити на кілька класів, що володіють характерними властивостями:
Поверхневі / об'ємні.
Зв'язані / дискретні.
Явні / параметричні.
Поверхневі моделі описують тільки поверхню об’єкта в тривимірному просторі. На противагу їм, об'ємні (воксельні) структури дозволяють задавати моделі, як частину тривимірного простору, розбитого деяким чином на осередки, які вважаються заповненими, якщо вони містять частину об’єкта, і порожніми – у противному випадку.
Зв'язані моделі явно або неявно містять інформацію про безперервні ділянки поверхонь моделей, тоді як дискретні подання описують тільки наближення поверхні об’єкта.
Явне завдання моделей припускає, що опис моделі об’єкта в даному поданні доступно в явній формі, а параметричне – що для його одержання необхідно додатково обчислювати деяку функцію, яка залежить від параметру.
Методи візуалізації можна умовно розділити на проекційні методи й методи трасування променів.
Проекційні методи - це методи, у яких синтез зображення виконується за допомогою афінних перетворень і перетворень проекції. Тривимірна сцена як набір примітивів візуалізації (звичайно, багатокутників, точок, ліній тощо) трансформується у двомірний масив, що і відображається на екрані монітора.
Методи трасування променів працюють на рівні пікселів вихідного зображення, розраховуючи їхні кольори на основі даних про геометрію сцени і положення віртуальної камери.
Сьогодні інтерактивну швидкість синтезу зображень надають тільки проекційні методи, часто за підтримкою апаратного забезпечення. Надалі в роботі розглядаються тільки такі методи, які в свою чергу накладають деякі обмеження на можливі подання об'єктів. Характерною рисою поставленого завдання є робота з реальними даним, тобто даними, введеними в комп'ютер за допомогою пристроїв дистанційного сканування. Такі дані, в більшості випадків, дискретні й задані явно, звичайно у вигляді набору точок або набору карт глибини. Крім того, за винятком томографів (цей випадок у роботі не розглядається), що одержують внутрішню структуру об’єкта, всі сканери працюють тільки з поверхнею об’єкта. Таким чином, подання повинне гарно описувати явно задані дискретні поверхні.
Проведемо аналіз різних подань із метою виявлення придатності їхнього використання для рішення поставленого завдання. У тексті не розглядаються різні параметричні й процедурні подання тому, що їх особливості (складність обчислень, відсутність апаратної підтримки) роблять складним використання цих подань для моделювання реальних об'єктів.
2.1.2 Полігональні сітки
Полігональні сітки є на даний момент найпоширенішим поданням, для якого створене велика кількість програмного забезпечення, що дозволяє редагувати, передавати по мережі й відображати моделі з використанням апаратної підтримки.
Характерною рисою полігональних сіток є підтримка зв’язності моделі. У силу цього полігональні подання добре пристосовані для опису великої кількості синтетичних поверхонь.
Однак, відскановані дані, споконвічно не містять інформації про зв’язність й безперервність поверхонь, а являють собою набір близько розташованих часток (sample). Такі обмеження випливають із пристрою скануючого механізму, що має дискретний крок кінцевого розширення.
Отже, для використання полігональних моделей зв’язність повинна бути введена штучно на етапі препроцесуванні. Таким чином, полігональні моделі не призначені для прямої роботи з від сканованими даними, тому що вимагають відновлення поверхні, що в загальному випадку є нетривіальним завданням і сильно залежить від класу оброблюваних об'єктів. При цьому відновлена поверхня не обов'язково буде використовуватися на етапі візуалізації (наприклад, якщо модель такої складності, що проекція трикутника на екран при типовій проекції перегляду близька по площі з одним пікселем).
З іншого боку, створена велика кількість методів, що дозволяють досить ефективно перетворювати дискретні від скановані дані в полігональні сітки. Більше того, сучасне устаткування високого класу дозволяє виконувати перетворення в сітку апаратно [1].
Набагато складніше ситуація з поданням великих обсягів даних і підтримкою різних рівнів деталізації. Структура полігональних сіток лінійна й вони не забезпечують «природної» підтримки багатомасштабності. Тому робота з великими сітками ускладнена і потребує різних, найчастіше обчислювально складних методів спрощення. Було створено безліч алгоритмів для створення багатомасштабних подань на основі сіток, що мають безпосереднє відношення до поставленого завдання.
Практично всі технології спрощення сіток використовують деякі варіації або комбінації наступних механізмів: семплюваня (sampling), проріджування (decimation), адаптивної розбивки (adaptive sub>division) і злиття вершин (vertex merging) [2].
Алгоритми семплюваня спрощують первісну геометрію моделі, використовуючи або підмножину вихідних точок, або перетинання вокселів з моделлю на тривимірній сітці. Такі алгоритми найкраще працюють на гладких поверхнях без гострих кутів.
Алгоритми, що використовують адаптивну розбивку, знаходять просту базову (base) сітку, що потім рекурсивно розбивається для апроксимації первісної моделі. Такий підхід працює добре, коли знайти базову модель відносно просто. Наприклад, базова модель для ділянки ландшафту звичайно прямокутник. Для досягнення гарних результатів на довільних моделях потрібне створення базової моделі, що відбиває важливі властивості вихідної, що може бути нетривіально.
Проріджуючи алгоритм, ітеративно видаляє вершини або грані з полігональної сітки, роблячи тріангуляцію після кожного кроку. Більшість із них використають тільки локальні зміни, що дозволяє виконувати спрощення досить швидко (рис. 2.1).

Рис.2.1. Об’єднання ребер (процес тріангуляції)
Схеми зі злиттям вершин працюють за допомогою об’єднання двох або більше вершин деталізованої моделі в одну, котра у свою чергу може бути сполучена з іншими вершинами. Злиття вершин трикутника знищує його, зменшуючи загальне число трикутників моделі. Звичайно алгоритми використовують складні методи визначення, які вершини потрібно об’єднати разом і у якому порядку. Методи, що використовують злиття ребер (edge collapse), завжди зливають вершини, що розділяють одну грань. Такі методи зберігають локальну топологію і, крім того, при деяких умовах можуть працювати в реальному часі.
Складність обчислень у цих методах висока і їхнє використання не завжди виправдане при роботі з дискретними даними, оскільки складність з'являється насамперед через необхідність підтримувати зв’язаність моделі. Іншою причиною високої складності методів є лінійна структура сітки, яку необхідно відновлювати для візуалізації за допомогою графічних API.
Переваги даного алгоритму: розповсюджене представлення; апаратна підтримка.
Недоліки алгоритму: неефективні для роботи з дискретними даними через штучну підтримку зв’язності, складного препроцесінга; неефективні для більших моделей через труднощі з організацією багатомасштабності.
2.1.3 Воксельні моделі
Класичні воксельні (voxel) моделі являють собою тривимірний масив, кожному елементу якого зіставлений колір й коефіцієнт прозорості. Такий масив задає наближення об’єкта з точністю, обумовленої обмеженням масиву.
Воксельні (або об'ємними) методами візуалізації називаються методи візуалізації тривимірних функцій, у дискретному випадку заданих, наприклад, за допомогою описаного вище масиву.
Типові методи воксельної візуалізації обробляють масив, і формують проекцію кожного його елемента на видову площину. Вихідний масив являє собою регулярну структуру даних, що істотно використовується в методах візуалізації. Звичайно елемент масиву з’являється на екрані у вигляді деякого примітиву, так званого відбитку (footprint) або сплату (splat). Різні методи відрізняються способами обчислень форми й розмірів зображення[3].
Обсяги даних у воксельних поданнях значні, навіть для невеликих моделей. Єдиною реальною можливістю працювати зі складними об'єктами є використання деревоподібних ієрархій. У роботі Лаур Д. та Ханрахана П. на основі вихідного масиву будується багатомасштабне подання у вигляді восьмеричного дерева. Кожен вузол дерева містить усереднене значення кольорів і прозорості всіх своїх нащадків. Крім того, кожен вузол дерева містить змінну, що показує середню помилку, асоційовану з даним вузлом. Ця змінна показує помилку, що виникає при заміні оригінального набору вокселів в даній області простору на константну функцію, рівну середньому значенню кольорів всіх нащадків даного вузла. Надалі це значення використовується для керування якістю візуалізації й рівнем деталей.
Незважаючи на те, що воксельні методи орієнтовані в першу чергу на наукову візуалізацію, багато ідей, що використовується в цих методах, знаходять своє застосування в інших областях. Наприклад, ідея решітки використається при роботі із точковими поданнями, а також з поданнями, заснованими на зображеннях.
Переваги даного алгоритму: простота регулярної структури; апаратна підтримка.
Недоліки даного алгоритму: великий обсяг даних, тому необхідно використовувати спеціальні багатомаштабні структури для роботи зі складними об'єктами; використовувані структури даних зберігають внутрішньої, невидимі, частини об’єкта, тоді як для поставленого завдання достатній опис поверхні.
2.1.4 Моделі, засновані на зображеннях
Моделювання й візуалізація, засновані на зображеннях (Image-Based Modeling and Rendering, далі IBMR) являють собою альтернативний підхід до рішення завдань синтезу зображення [4].
Такі методи не використовують проміжні структури даних, і синтезують підсумкову картинку, ґрунтуючись на вихідних даних - як правило, зображеннях або зображеннях з глибиною. Більш формально метод візуалізації, заснований на зображеннях, можна визначити як алгоритм, що визначає, як по кінцевому наборі вихідних (reference) зображень сцени одержати нове, результуюче (resulting) зображення для заданої точки спостереження й заданих параметрів віртуальної камери.
Структури даних, використовувані для такого алгоритму візуалізації, можуть сильно відрізнятися, незмінним залишається орієнтація методів на безпосередню роботу з вихідними даними, що робить методи IBMR концептуально близькими до поставленого завдання.
Зображення з картами глибини
Однієї з найпростіших структур даних, використовуваних в IBMR є набори зображень із картами глибини. Визначимо пари зображення плюс карта глибини як кольорове зображення, якій зіставлене напівтонові зображення відповідного розміру, інтенсивність у кожній точці якого відповідає відстані від камери до поверхні об’єкта.
Примітною властивістю подання є те, що сучасні дистанційні сканери дозволяють прямо одержувати дані у вигляді карт глибини, а найбільш дорогі моделі одержують і колірну інформацію про об'єкт. Отже, таке подання максимально підходить для роботи зі складними реальними даними, а завдання полягає в розробці методу візуалізації.
Варто помітити, що пари зображення плюс карта глибини однозначно визначає дискретне наближення поверхні в тривимірному просторі, при цьому якість наближення залежить від роздільної здатності зображення й обраного положення камери.
Одна карта глибини зберігає тільки видиму частину об’єкта, тому для відновлення повного об’єкта необхідно використати набір з декількох карт глибини, залежно від складності сцени (рис. 2.2).

Рис. 2.2. Створення карти глибин по пікселям
Було запропоновано досить багато методів візуалізації й використання подібних структур даних. Наприклад, Леонардо-Макмиллан використовує систему обробки зображень для деформації (warping) вихідного зображення з обліком вихідної й результуючої (поточної) камер таким чином, щоб результат, відображений на екрані, створював ілюзію тривимірності [5].
У роботі Мартіна Олів’єрі також використовується деформація зображень, однак результатом роботи алгоритму є текстури створені з карт глибини для поточного положення віртуальної камери й накладені на просту (плоску) полігональну сітку - так називані рельєфні текстури (relief textures) [6].
Однак ці методи мають серйозні недоліки. З одного боку, в умовах недостатньої точності вихідних даних й або великому відхиленні віртуальної камери від вихідної, у результуючому зображенні можлива поява дірок (holes), тобто погіршення якості візуалізації. З іншого боку, результатом роботи дистанційних сканерів часто є набори даних з 50-70 карт глибини, які в описаних вище алгоритмах будуть оброблятися сепаратно, створюючи додаткові погрішності візуалізації. Крім того, час візуалізації однієї карти глибини розміром 512x512 по методу Олів’єрі на комп'ютері із процесором Pentium III 866 і відео картою NVidia GeForce2 Pro становить близько 70 мс. Обробка 50-ти зображень займе біля 4-х секунд.
Іншим можливим варіантом є пряме відновлення тривимірних координат семплів (sample) і їхня візуалізація прямо за допомогою проекції на видову площину віртуальної камери. Такий підхід дозволяє використати апаратне прискорення тому, що пікселі вихідних зображень у просторі можуть бути представлені крапками або багатокутниками. Однак, на практиці такий метод працює тільки для досить невеликих наборів даних.
Головною перешкодою для створення багатошарових методів візуалізації карт глибини є відсутність чіткої просторової структури пари зображення плюс карта глибини.
Багатошарові зображення із глибиною
Останнім часом було почато кілька спроб використання багатомасштабних методів разом із заснованими на зображеннях поданнями. Одна з них описана в роботі Чанга й Бішопа й як базове подання використовує багатошарові зображення із глибиною (Layered Depth Images - LDI), у перше описані в статі Гортлера С. Солена М. (Візуалізація багатошарових глибин зображення
Багатошарові зображення із глибиною зберігають для кожного пікселя карти кольорів всі перетинання відповідного променя з моделлю. Одного багатошарового зображення досить для опису повного об’єкта (рис. 2.3).

Рис. 2.3. Багатошарове зображення
Відмінність багатошарових зображень із глибиною від простих полягає в тім, що одне зображення дозволяє зберігати інформацію не тільки про видиму з даної вихідної камери частини поверхні об’єкта, а повну інформацію про об'єкт. По суті, LDI – це тривимірна структура даних, що представляє собою прямокутну матрицю, кожним елементом якої є список крапок. Кожна крапка містить глибину (відстань до опорної площини) і атрибути, у найпростішому випадку – кольори. Для подання всього об’єкта можна використати єдине багатошарове зображення, що використовує шість перспективних LDI з єдиним центром проекції (3).
Така структура дозволяє проводити візуалізацію як описаними вище методами Макмілана й Олів’єрі, так і просто використати збережену інформацію як скупчення точок і відображати його прямо за допомогою одного із графічних API (наприклад, OpenGL).
З використанням LDI-подібних структур зв'язані деякі обмеження на візуалізацію, обумовлені тим, що всі крапки в зображенні орієнтовані на одну базову площину. Крім того, LDI не можуть бути прямо отримані із пристроїв введення й для створення такої структури необхідне використання додаткових алгоритмів, наприклад, деформуючи зображення із глибиною по методу Макмілана таким чином, щоб площина результуючого зображення збігалася з базовою площиною LDI. Відзначимо, що процес формування LDI відбувається до безпосередньої візуалізації, і тому його ефективність не відбивається на швидкості візуалізації.
Однак LDI не дозволяє прямо відображати об'єкт із різними ступенями деталізації. Але була почата спроба створити багатосштабне подання на основі LDI з використанням так називаного дерева LDI (LDI tree).
Сутність методу полягає в наступному: замість одного LDI формується восьмеричне дерево, у кожному вузлі якого перебуває свій LDI і посилання на інші вузли, у яких перебуває LDI меншого розміру (в одиницях сцени), але того ж дозволу. Також для кожного вузла є обмежуючий паралелепіпед.
Всі LDI у дереві мають однаковий дозвіл. Висота дерева залежить від дозволу LDI. Чим менше дозвіл LDI, тим більше висота дерева. Кожен LDI у дереві містить інформацію тільки про ту частину сцени, що втримується в його обмежуючому паралелепіпеді. Обмежуючі паралелепіпеди вузлів наступного рівня дерева виходять дробленням обмежуючого паралелепіпеда поточного рівня на вісім рівних частин (рис. 2.4).

Рис. 2.4. Дерево із LDI
Дерево LDI дозволяє вирішувати проблему візуалізації дуже великих структур даних, використовуючи наступну ідею: при візуалізації немає необхідності обробляти нащадків вузла, якщо сам вузол забезпечує достатній ступінь деталізації. Автори використають наступний критерій ступеня деталізації: вважається, що LDI забезпечує достатній рівень деталізації, якщо "відбиток" (footprint, splat) його пікселя на результуючому зображенні покриває не більше одного пікселя екрана.
З іншого боку, використання того ж підходу дозволяє доповнити дані низької роздільної здатності штучно відновленими додатковими рівнями дерева, створюючи ефект фільтрації одержуваного зображення.
Візуалізація виробляється за допомогою обходу дерева від кореня до листів і малювання LDI методом Макмілана. При цьому обробка всіх вузлів дерева не потрібно, і обхід вітки дерева завершується на першому LDI, що забезпечує достатню точність.
Алгоритм має високу якість візуалізації, можливість прогресивної передачі даних. Однак його ефективність, як за часом, так і по пам'яті, досить низька. Час одержання зображення в дозволі 512х512 для LDI середньої складності на графічній станції SGI Onyx2 (16Гбайт оперативної пам'яті, 32 процесора MIPS R1000 250Mhz) зайняло більше трьох секунд.
Переваги даних алгоритмів: орієнтація на проблемну область; легкість одержання й моделювання.
Недоліки даних алгоритмів: складні, не завжди якісні методи візуалізації; труднощі з підтримкою багатомасштабності; робота тільки з дифузійними поверхнями.
2.1.5 Точкове подання
Класичні подання, засновані на зображеннях, спрямовані на використання зображень як примітиви візуалізації. Підвищення ефективності візуалізації досягається за рахунок того, що час візуалізації в них пропорційно не складності геометрії, як у традиційних системах, заснованих на полігональних сітках, а числу пікселів у вихідних зображеннях. Хоча такі підходи досить добре працюють для візуалізації складних об'єктів, вони, як правило, вимагають значних обсягів пам'яті, візуалізація страждає від появи артефактів у результуючому зображенні, а також від неможливості роботи з динамічним освітленням. Крім того, на сьогодні не розроблено ефективних багатомасштабних алгоритмів.
Клас точкових (point sample) алгоритмів компенсують недоліки IBМ при частковому збереженні описаних вище переваг [7].
Об'єкти моделюються, як щільний набір точок поверхні, які відновлюються з вихідних зображень і зберігаються разом з кольорами, глибиною й інформацією про нормалі, уможливлюючи використання Z-буфера для видалення невидимих поверхонь, затінення по Фонгу, і інші ефекти, наприклад, тіні (рис. 2.5).

Рис. 2.5. Дірки при візуалізації крапкових моделей
Метод візуалізації таких даних нагадує класичні методи деформацій (warping), але з тим розходженням, що точки містять додаткову інформацію про геометрію, і вони видонезалежні (view independent), тобто кольори точки не залежить від напрямку, з якого вона була відновлена. Подібний підхід використався для реалістичної візуалізації дерев [2].
Основною проблемою візуалізації моделей у таких поданнях є відновлення безперервних поверхонь, тобто гарантія відсутності дірок після того, як положення кожної крапки буде наведено до віконних координат. Одним з можливих практичних рішень є решітка (splatting), тобто обчислення форми «відбитка» точки на площині екрана. Решітка також часто використається в методах, заснованих на зображеннях. Можливі також інші підходи, наприклад комбінація ресемплінгу й ієрархічного z-буфера, недоліками яких є недостатнє використання сучасних апаратних прискорювачів, що виражається в часі візуалізації близько 3-5 секунд на кадр для нескладних сцен.
Головним недоліком точкових подань, як і багатьох інших, є складність із поданням великих обсягів даних. Використання неструктурованого набору крапок дозволяє досягти певної гнучкості при візуалізації, але при збільшенні обсягу на перший план виходять методи відео залежного спрощення, використати які в реальному часі не представляється можливим без введення додаткових структур даних.
Переваги даного алгоритму: орієнтація на проблемну область; легкість одержання й моделювання; значна гнучкість у методах візуалізації.
Недоліки даного алгоритму: труднощі з підтримкою багатомасштабності; неякісна або повільна візуалізація.
2.1.6 Ієрархічні подання
Як правило, ієрархічні подання будуються на базі одного з подань, розглянутих вище. У переважній більшості випадків для побудови ієрархій використовуються деревоподібні структури, наприклад, восьмеричні дерева, або kd-дерева. Також використаються загальні види тривимірних дерев на основі ієрархій що описують сфери та куби. Властивості ієрархій можуть сильно розрізнятися залежно від базового подання, однак загальні принципи побудови й візуалізації ієрархічних структур подібні між собою.
Нижній рівень дерева, тобто сукупність листових вершин, являє собою максимально деталізовану модель. Далі, піднімаючись до кореня, атрибути усередняться, структура спрощується до виродження в один примітив на вершині дерева. Візуалізація, навпаки, виробляється за допомогою рекурсивного обходу дерева від вершини до листів.
Ієрархічні структури на базі полігональних сіток використаються для динамічного контролю за рівнем деталізації й складністю моделі. У методі злиття вершин з вузлом дерева асоційована вершина сітки, і перехід до вище поставленого вузла дерева здійснюється за допомогою злиття вершин.
Точкові семпли - це точки, що володіють кінцевим розміром і положенням у просторі, тобто вони є аналогом нерівномірно розподілених у просторі вокселів. На їхній основі будується ієрархія сфер, таких що, сфера, асоційована із внутрішнім вузлом дерева, містить безліч своїх нащадків.
Переваги даного алгоритму: підтримка багатомасштабності; можливість прогресивної обробки й передачі по мережі; можливість динамічного контролю над рівнем деталізації.
Недоліки даного алгоритму: необхідність у попередній обробці, або перетворенні з іншого подання; у загальному випадку більша вартість обробки примітива, чим у лінійних поданнях; часте збільшення обсягу через необхідність підтримки багатомасштабності (для зберігання показників тощо).
2.2 Опис алгоритму і функціонування програми
Згідно оглянутих вище методів та алгоритмів, ми в даному проекті будемо розглядати перетворення зображення по карті глибин. Оскільки даний алгоритм надає нам простіший спосіб реалізації та добрі часові показники. Процес побудови карти глибин розраховується наступним чином:
визначається колір пікселя (в процесі беруть участь три основні коліра червони, зелений та синій);
потім визначається середнє значення серед цих трьох кольорів (шумується значення кольорів Ч + З + С та ділиться на кількість кольорів);
у наступному етапі задається значення відносно якого буде підніматися піксель (це значення залишається однаковим для всіх пікселів зображення);
такі дії будуть проводитись відносно кожного пікселя зображення.
Загальний алгоритм роботи програми по перетворенню двомірного зображення в об’ємне виглядає наступним чином. Алгоритм програми зображено на блок-схемі(рис. 2.6).

Рис. 2.6. Робота алгоритму перетворення зображення по карті висот
2.3 Опис організації вхідних та вихідних даних
Програма дає можливість використовувати зображення різного типу, а саме: від скановані, фотографії та малюнки. В якості вхідних даних можливо використовувати лише зображення формату bmp.
Результат перетворення зображення можливо обертати під різними кутами, віддаляти та наближати. Отримане зображення після перетворення можливо зберегти. Формат збереження отриманого файлу bmp.
2.4 Опис організації вибору технічних і програмних засобів
Розроблений програмний продукт орієнтований на роботу в ОС Windows /XP/Vista, тому для коректної роботи програми необхідне стабільне функціонування ОС. Під час виконання, програма не звертається до інших
програмних продуктів, таких як Microsoft Office та ін., але звертається до реєстру ОС.
Мінімальними вимогами, за яких програма працюватиме та буде видавати достовірні результати, до апаратної частини ПК, можна вважати:
• процесор 6-го покоління Intel Celeron 1.1 ГГц;
• об’єм оперативної пам’яті 128 Мб.;
• графічний адаптер S3 Savage 64 Мб.;
• жорсткий диск ємністю 10 Гб.;
• привід гнучких дисків (дисковод).
3. Очікувані техніко-економічні показники
Проведемо оцінку
витрат праці на розробку програмного
забезпечення для комплексу, при цьому
виходимо з того, що розмір вихідного
тексту запису алгоритму і даних в
основному визначає затрати праці
 та час розробки
та час розробки
 програмного продукту:
програмного продукту:
 (1)
(1)
де
 — кількість вихідних команд в тисячах.
— кількість вихідних команд в тисячах.
У якості вихідної команди приймаємо рядок програми.
Загальний об'єм вихідного тексту програм складає приблизно 900 рядків. Тоді:

Продуктивність праці розробників програмного забезпечення визначається наступним чином:
 (2)
(2)
Тоді ми отримуємо, що продуктивність праці розробника:
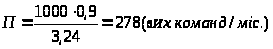
Час необхідний для розробки програмного продукту, можна визначити за формулою (3):
 (3)
(3)
де
 — строк розробки програмного продукту;
— строк розробки програмного продукту;
 — коефіцієнт вірності
постановки завдання;
— коефіцієнт вірності
постановки завдання;
 — час розробки
алгоритму;
— час розробки
алгоритму;
 — час настройки та
тестування;
— час настройки та
тестування;
 — час на підготовку
тексту;
— час на підготовку
тексту;
 — час на розробку
документації.
— час на розробку
документації.
Останні величини обчислюються за наступними формулами:
 (4)
(4)
 (5)
(5)
 (6)
(6)
 (7)
(7)
 (8)
(8)
 (9)
(9)
де К — залежить від ступеня підготовки програміста;
 — кількість рядків
програми (в тис.).
— кількість рядків
програми (в тис.).
Підставляємо значення у формули (4-9) враховуючи, що К=0,8 (стаж роботи до 2-х років).






Тоді час, який необхідний для розробки програмного продукту дорівнює

Визначимо собівартість години роботи ПК.
Для цього розраховуються поточні витрати на експлуатацію комп'ютера.
До їх складу включаються витрати на електроенергію і амортизаційні відрахування на реновацію від вартості комп'ютера та інше.
Витрати на електроенергію визначають множенням витрати електроенергії за одну годину на вартість 1 кВт/год електроенергії і на час роботи комп'ютера за рік. Час роботи комп'ютера за рік визначається множенням кількості робочих днів у рік на час роботи комп'ютера за день:
 (10)
(10)
де
 — середня кількість робочих днів у рік.
— середня кількість робочих днів у рік.
Середня кількість робочих днів у рік буде рівна:

Тоді, час роботи ПК за рік дорівнює:

Витрати енергії визначаються за формулою:
 (11)
(11)
де
 — витрати електроенергії за одну годину;
— витрати електроенергії за одну годину;
 — вартість 1 кВт/год електроенергії;
— вартість 1 кВт/год електроенергії;
 — час роботи комп’ютера за рік.
— час роботи комп’ютера за рік.
Тоді витрати енергії складають:

Амортизаційні відрахування визначаються множенням вартості комплексу на норму амортизаційних відрахувань 10%:

Приблизна річна заробітна плата обслуговуючого персоналу складає:

Відрахування на соціальне страхування, складають 3% від загальної заробітної плати за рік:

Вартість витрачених матеріалів складає 2% від вартості обчислювальної техніки:

Утримання на ремонт приміщень, в яких знаходяться засоби обчислювальної техніки, складає 3% від вартості обчислювальної техніки:

Кількість комплексів, що реалізовують зв’язок:

Собівартість години роботи на комп'ютері визначається наступним співвідношенням:
 (12)
(12)
Підставляємо значення в останню формулу й отримаємо:

Рахуємо прямі витрати на виконання курсової роботи, які визначаються наступним добутком:
 (13)
(13)
де
 — собівартість години роботи на
комп’ютері;
—
час необхідний для розробки програмного
продукту. Підставляємо значення й
одержуємо:
— собівартість години роботи на
комп’ютері;
—
час необхідний для розробки програмного
продукту. Підставляємо значення й
одержуємо:

Накладні витрати, що включають витрати на освітлення, опалення та ін. приймаються в розмірі 40-50% від суми прямих витрат:

Загальні витрати на виконання курсової роботи:
 (14)
(14)
Підставляємо дані й одержуємо:

Ціна на програмний продукт визначається наступним співвідношенням:
 (15)
(15)
де В — витрати на виконання курсового проекту;
P — рівень рентабельності, в нашому випадку P = 30;
K — коефіцієнт, що залежить від науково-технічного рівня К = 0,9.
Підставляємо ці значення й отримаємо ціну програмного продукту, яка дорівнює:

Список використаних джерел
1. Turk, G., Levoy, M., Zippered Polygon Meshes from Range Images. Proc. SIGGRAPH '94.
2. Luebke, David P. A Developer's Survey of Polygonal Simplification Algorithms. IEEE Computer Graphics & Applications, 2001.
3. Роджерс Д., Адаме Дж. Математические основы машинной графики: Пер. с англ. — М.: Мир, 2001. —604 с.
4. Curless, B., Levoy, M., Volumetric Method for Building Complex Models from Range Images. Proc. SIGGRAPH '96.
5. McMillan, L. An Image-Based Approach to Three-Dimensional Computer Graphics. Ph.D. Dissertation. UNC Computer Science Technical Report TR97-013, University of North Carolina, 1997
6. Bishop, G., Oliveira M.M., "Relief Textures" Proc. SIGGRAPH'2000
7. Роджерс Д. Алгоритмические основы машинной графики: Пер. с англ. - М.: Мир, 1989. – 512 с.
8. Божко А, Жук Д.М., Маничев В.Б. Комп’ютерна графіка. - М.: МГТУ им. Баумана, 2007. - 392 с.