Разработка и отладка формального языка
Введение
В современном программировании большой популярностью пользуются языки высокого уровня. Это вызвано тем, что программировать на этих языках существенно проще и программы, написанные с их помощью нагляднее, чем эквивалентные им программы, выполненные на языках низкого уровня. Именно поэтому в данной работе необходимо разработать свой небольшой язык и осуществить его подготовку к написанию компилятора к данному языку. Этот язык должен показать некоторые возможности современных языков программирования и позволить разработчику данного языка укрепить знания, полученные ранее и более глубоко изучить предмет «Теория трансляции».
Для этого необходимо выполнить задание, описанное выше с учетом предъявляемых технических требований к разрабатываемому языку.
Данная курсовая работа имеет большое учебное значение, так как в настоящее время всё больше внимания уделяют языкам программирования высокого уровня, потому что писать программы на них намного проще (программы стали большими) и удобнее. В будущем эти знания могут пригодиться нам в разработке собственных языков или участвовать в разработке мощного языка высокого уровня. Именно поэтому большое практическое значение имеет разработка собственного языка, пусть не слишком мощного, но высокоуровневого, на котором будут видны все возможности языков современных.
Чтобы создать подобный язык в рамках данной курсовой работы необходимо в соответствии с требованиями к языку разработать грамматику, в которой будет описан синтаксис языка, а затем отладить её с помощью методов простого и параллельного предшествований.
Для метода параллельного предшествования необходимо разработать алгоритм машинного представления метода; затем провести лексический анализ, построить автоматные грамматики выделения лексем и схему сканера, описать принцип его работы.
Назначение и область применения
Разработка языка C++ несет исключительно обучающую цель и производится с целью углубить и расширить познания автора в дисциплине «Теория трансляций», а также в приобретении навыков разработке учебного языка и проведения работы, подготавливающей язык к построению транслятора.
Разрабатываемый язык позволяет мне, систематизировать и укрепить знания, полученные в прошлом и подготовиться к дальнейшему углублению их. Именно поэтому данный язык является учебным и не имеет практической области применения.
Технические характеристики
Постановка задачи на разработку
Перечень требований к разрабатываемому языку программирования:
Процедура sub>.
Оператор объявления констант.
Описание типа переменных с помощью суффикса: Sin 99gle, Integer.
Массивы фиксированного размера с макс. размерностью 2
Операторы ввода / вывода MsgBox, InputBox.
Арифметические операции: + \ ^.
Логические операции: Not, And, Or.
Операции сравнения.
Условный оператор типа If…Then
Оператор цикла типа For… Next.
Оператор присваивания.
Оператор безусловного перехода.
Функции: конкатенация строк, Cbool, Format, GetAllSettings.
Элементы управления: TextBox, CommandButton, CheckBox, PictureBox.
Описание применяемых математических методов
Введём несколько определений:
Определение 1. Контекстно-свободной грамматикой G называется четверка упорядоченных множеств:
G = {Vт, Vn, P, S}, где
Vт – словарь терминальных символов грамматики;
Vn – словарь нетерминальных символов грамматики;
P – множество правил грамматики:
P = {(A, )|A-> & AVn & V*}
S – начальный символ грамматики (SVт);
V* – множество строк, составленных из символов полного словаря
V (V=Vт Vn);
V* = {|= п ( xV) ( QV*)=Qx}
п – пустая цепочка.
Определение 2. Цепочка o порождает нетривиальным образом цепочку o (записывают o=>+W), если существует последовательность непосредственных выводов:
o =>1 =>… n, n>=1.
Определение 3. Цепочка порождает цепочку Q (записывают =>*Q), если =>+Q, или =Q.
Определение 4. Цепочка называется сентенциальной формой грамматики G, если она выводится из начального символа грамматики, т.е. если S->*.
Определение 5. Предложение языка – это сентенциальная форма, состоящая только из терминальных символов.
Определение 6. Язык L(G) – это множество предложений
L(G) = {| S->+ Vт*}.
Определение 7. Символы A, B контекстно-свободной грамматики связаны отношением FIRST, если выполняется условие
A->B,
где AVn, BV, V*.
Определение 8. Символы A и B грамматики связаны отношением.=., если в грамматике имеется правило вида:
WAВ.
Определение 9. Отношение >. Между символами A и B грамматики находится из правила:
(>.)=(LAST+)T (.=.).
Определение 10. Отношение <. Между символами A и B грамматики находится из правила:
(<.)=(.=.) (FIRST+).
Разработка грамматики по неформальному описанию языка
В соответствии с техническим заданием на разработку языка напишем грамматику, листинг которой приведен в Приложении 1.
Чтобы проверить ее корректность составим контрольный пример:
sub> D11 ()
Dim A As Integer,
B% As Integer
Const D As Single
Dim M (2) As Integer A = (B*2 + 9)^10
If ((IsNumeric (A) <>0 and A>0) Then
MsgBox («A is number», vbOkOnly) EndI
Text. Text = A
End sub>
Дерево к данному примеру приведено на листе А1.
Разработка сканера
Лексический анализ проводится сканером (лексическим анализатором). Сканер выделяет простейшие языковые конструкции (лексемы) и классифицирует их тип.
Сканер работает с таблицами, которые являються базой данных сканера.
Таблицы делятся на постоянные и временные.
Постоянные таблицы создаются разработчиком сканера и включают в себя:
ТТС1 – таблица терминальных символов (однолитерных).
ТТС2 – таблица терминальных символов (двулитерных).
ТКС – таблица ключевых слов.
Временные таблицы создаются в процессе работы сканера и зависят от исходного модуля (программы, проверяемой сканером). Временные таблицы включают в себя:
ТИ – таблица идентификаторов.
ТК – таблица констант.
ТФ – таблица функций.
ТСС – таблица стандартных символов.
ТСС является результатом работы сканера. Это взаимно-однозначное отображение исходного модуля.
Формальное определение лексем.
Лексические единицы:
арифметические операции: «+», «/», «^».
операции сравнения: «>», «<», «=», «>=», «<=», «<>»
операция присваивания: «=»
скобка открывающая «(«
скобка закрывающая «)»
служебные слова:
«Dim», «As», «Private», «Public», «sub>», «End», «goto», «Optional», «MsgBox», «InputBox».
условный оператор: «If», «Then»
оператор цикла: «For», «Next»
типы данных: «Single», «Byte»,» Date», «Integer», «Boolean», «String», «Variant», «Object».
элементы управления: «TextBox», «ComandButton», «CheckBox», «PictureBox»
свойства элементов управления: «Caption», «Text», «With», «Height», «Visible»
специальные константы: «VbOkOnly», «VbOkCansel», «VbAbortRetryIgnore»,
«VbCritical»
логические функции: «Not», «And», «Or»
функции: «Format», «CBool», «GetAllSettings». нижнее подчеркивание: «_»
точка: «.»
кавычки: «@»
десятичные целые константы
идентификатор
Разрабатываем структуры данных, которые будут использоваться сканером.
Таблица 1. Однолитерные терминальные символы TTC1:
|
Адрес |
Символ |
KTL |
|
1 26 27 54 |
a … z A … Z |
1 |
|
55 … 64 |
0 … 9 |
2 |
|
65 |
= |
3 |
|
66 |
> |
3 |
|
67 |
< |
3 |
|
68 |
^ |
3 |
|
69 |
* |
3 |
|
70 |
- |
3 |
|
71 |
\ |
3 |
|
72 |
# |
3 |
|
73 |
% |
3 |
|
74 |
. |
3 |
|
75 |
_ |
3 |
|
76 |
@ |
3 |
|
77 |
( |
3 |
|
78 |
) |
3 |
Таблица 2. Двулитерные терминальные символы
|
Адрес |
Символ |
KTL |
|
1 |
<= |
3 |
|
2 |
>= |
3 |
|
3 |
<> |
3 |
Таблица 3. Классы текущих литер
|
Символ |
Класс |
|
Буква |
1 |
|
Цифра |
2 |
|
Допустимый символ |
3 |
Таблица 4. Функции
|
Логические ф-и (адрес) |
|
Not(1) |
|
And(2) |
|
Or(3) |
|
Функции (адрес) |
|
CBool (5) |
|
Format (6) |
|
GetAllSettings (7) |
|
Concat (8) |
Таблица 5. Тип лексической единицы
|
Лексическая единица |
Тип |
|
операция «=» |
1 |
|
операция «–» |
2 |
|
операция «*» |
3 |
|
операция «^» |
4 |
|
операция «\» |
5 |
|
операция «mod « |
6 |
|
разделители «.»,», « |
7 |
|
нижнее подчеркивание «_» |
8 |
|
кавычки «@» |
9 |
|
операции сравнения |
10 |
|
служебные слова |
11 |
|
условный оператор |
12 |
|
оператор цикла |
13 |
|
тип данных |
14 |
|
элементы управления |
15 |
|
оператор цикла |
16 |
|
события элементов управления |
17 |
|
свойства элементов управления |
18 |
|
специальные константы |
19 |
|
логические функции |
20 |
|
функции |
21 |
|
десятичная целая константа |
22 |
|
идентификатор |
23 |
|
название функции |
24 |
|
псевдоним функции |
25 |
|
библиотек |
26 |
|
открывающая скобка «(« |
27 |
|
закрывающая скобка «)» |
28 |
Для каждой лексической единицы составляем автоматную грамматику.
И дентификатор:
дентификатор:
S = бK
K = бK|цК|%F |#F
Десятичная целая константа:

S = «ц» D
D = «ц» D | e2 F
С тепень:
тепень:
S = «^» F
Д еление:
еление:
S = «\» F
C ложение:
ложение:
S = «+» F
Знаки отношения:
S


<
e3
= «<» A | «>» B | «=» F
A



A
= «=» D |«>«D| e3 F
B







=/>
e5
= «=» D | e4 F
D





S
D
F
>
=
= e5 F



Скобка открывающая «(»:

S = «(«F
Скобка закрывающая»)»:
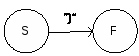
S = «)» F
Операция «=»:
S = «=» F
= «=» F
Точка «.»:
S = «.» F
= «.» F
Нижнее подчеркивание «_»:

S = «_» F
Функции, служебные слова, специальные константы, логические функции, элементы управления, события, свойства элементов управления, псевдоним функций резервируем, поэтому для них автоматной грамматики не строим.
Схема обобщенного конечного автомата
Сканер выполняет следующие действия:
1. Выделяет лексические единицы.
2. Классифицирует лексические единицы.
3. Определяет лексические ошибки;
4. Создает некоторые внутренние формы представления – таблицы стандартных символов (ТСС).
Построим обобщенный автомат для всего сканера (схема сканера). Для этого объединим начальные символы описания всех лексем в стартовую вершину. Схема сканера приведена нa Рис. 12.
В данном сканере использованы следующие сокращения:
A – входная цепочка;
NA – количество символов входной цепочки;
TL – текущая литера;
NTL – номер текущей литеры;
KTL – класс текущей литеры;
TLE – тип лексической единицы;
LE – лексическая единица;
MDLE – максимальная длина лексической единицы;
NLE – текущая длинна LE;
ALE – компонента записи ТСС, которая определяет адрес лексической единицы в соответствующей таблице.
На рис. 12 изображена схема сканера

Рис. 12. Схема сканера
Семантические подпрограммы сканера
Конечный автомат необходимо доопределить семантическими подпрограммами для того, чтобы он был преобразован в сканер.
В основе работы семантических подпрограмм лежат простейшие действия по преобразованию строк:
1) выделение текущей литеры;
2) объединение строк;
3) выполнение арифметических операций.
В данном сканере задействованы следующие подпрограммы:
Подпрограмма PODGOT (подготовка):
NTL = 0;
NLE = 0;
TLE = A[NTL];
KTL = KLASS(TL); {определяем класс TL}
STRCOPY (LE, "»);
Подпрограмма TIP (определение типа):
IF KTL = 2 {цифра}
THEN {можно определить тип лексической единицы}
TLE = 2;
MDLE = 7;
ELSE ERROR («ошибка»);
Подпрограмма BKL (включение):
NLE++;
IF NLE>MDLE
THEN ERROR («ошибка»)
ELSE LE = LE || TL;
Подпрограмма SLL (следующая литера)
NTL++;
TL=A [NTL];
KTL = klass (TL);
Подпрограмма ZAPTAB (LE, TLE, ALE, REZ):
Осуществляет поиск лексической единицы в ТК. Для постоянных таблиц эта подпрограмма только определяет адрес LE, однако, во временные таблицы она еще и записывает лексическую единицу.
Запись элемента в ТСС можно осуществить с помощью процедуры OUT (TLE, ALE).
Таблицы сканера для тестовой цепочки
Private sub> D11 () Dim A As Integer, B% As Integer Const D As Single Dim M (2) As Integer A = (B/2 + 9)^10 If ((IsNumeric (A) <>0 and A>0) Then MsgBox («A is number», vbOkOnly) EndIf Text. Text = A End sub>
Таблица 6. Константы
|
Константа |
Атрибуты |
|||
|
Тип |
Запятая |
Точность представления |
Основание системы счисления |
|
|
2 |
integer |
Нет |
1 |
10 |
|
9 |
integer |
Нет |
1 |
10 |
|
0 |
integer |
Нет |
1 |
10 |
|
10 |
integer |
Нет |
1 |
10 |
Таблица 7. Идентификаторы
|
Идентификатор |
Атрибуты |
Адрес идентификатора |
||
|
Тип |
Запятая |
Основание системы счисления |
||
|
A |
integer |
нет |
10 |
1 |
|
B% |
integer |
нет |
10 |
2 |
|
C |
integer |
нет |
10 |
3 |
|
D |
Single |
нет |
10 |
4 |
Таблица 8. Стандартные символы
|
Лексическая единица |
Тип лексической единицы |
Адрес лексической единицы |
|
Private |
10 |
10 |
|
sub> |
10 |
10 |
|
D11 |
21 |
21 |
|
( |
22 |
77 |
|
) |
23 |
78 |
|
Dim |
10 |
10 |
|
A |
21 |
1 |
|
As |
10 |
10 |
|
Integer |
13 |
13 |
|
, |
6 |
74 |
|
B% |
21 |
2 |
|
As |
10 |
10 |
|
Integer |
13 |
13 |
|
Const |
10 |
10 |
|
D |
21 |
3 |
|
As |
10 |
10 |
|
Single |
13 |
13 |
|
A |
21 |
1 |
|
= |
1 |
65 |
|
( |
22 |
77 |
|
B% |
21 |
2 |
|
, |
6 |
74 |
|
B% |
21 |
2 |
|
/ |
5 |
70 |
|
2 |
20 |
2 |
|
+ |
2 |
69 |
|
9 |
20 |
4 |
|
) |
23 |
78 |
|
^ |
3 |
68 |
|
10 |
20 |
3 |
|
If |
11 |
11 |
|
( |
22 |
78 |
|
( |
22 |
78 |
|
IsNumeric |
19 |
2 |
|
( |
22 |
77 |
|
A |
21 |
1 |
|
) |
23 |
78 |
|
<> |
9 |
67 |
|
0 |
20 |
3 |
|
and |
18 |
1 |
|
A |
21 |
1 |
|
> |
9 |
66 |
|
0 |
20 |
3 |
|
) |
23 |
78 |
|
Then |
11 |
11 |
|
A |
21 |
1 |
|
= |
1 |
65 |
|
B |
21 |
2 |
|
EndIf |
11 |
11 |
|
Text |
14 |
14 |
|
. |
6 |
74 |
|
Text |
16 |
16 |
|
= |
1 |
65 |
|
A |
21 |
1 |
|
End |
10 |
10 |
|
sub> |
10 |
10 |
Отладка формальной грамматики
Отладка грамматики – это процесс преобразования грамматики к виду, удовлетворяющему используемый метод синтаксического анализа.
В исходной грамматике 42 конфликта. Среди них встречаются конфликты трех типов:
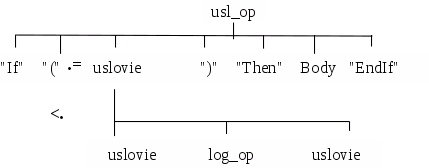
Конфликты типа =<
|
uslovie |
|
|
( |
=< |
Рис. 13. Конфликт типа =<
Для того, чтобы показать как отладить этот конфликт, рассмотрим его на примере:
Из рисунка 3.13 видно, что между терминальным символом «(» и нетерминальным uslovie конфликт типа =<. Чтобы его отладить необходимо опустить нетерминал uslovie вниз по дереву.
Таким образом, между символами «(» и uslovie осталось только отношение <.
Все остальные конфликты этого типа разрешаются аналогично.
Конфликт типа =>
Чтобы показать как разрешаются конфликты этого типа, разрешим конфликт между символами Вody и Еnd. Этот конфликт изображен на рисунке 15.

|
End |
|
|
Вody |
=> |
Рис. 15. Конфликт типа =>
Синтаксический анализ
В процессе синтаксического анализа требуется для нескольких предложений входного языка построить синтаксическое дерево, провести синтаксический разбор методом простого предшествования.
Задачи синтаксического анализатора:
1) выделение синтаксических единиц;
2) определение всех синтаксических ошибок (если они есть);
3) преобразование таблицы стандартных символов (ТСС) в некоторую внутреннюю форму представления программы(ВФПП).
Схема программы синтаксического анализатора
Схема программы синтаксического анализа методом простого предшествования приведена в графическом приложении (лист1).
Принятые обозначения:
X – массив символов анализируемой цепочки;
MP – матрица простого предшествованя;
P – множество правил грамматики, которые описывают язык;
ST – стек для определения хвоста основы;
ST1 – стек для определения головы основы;
TL – текущая литера;
NTL – номер текущей литеры;
OSN – массив, в котором будет накапливаться основа;
NOSN – количество символов в массиве OSN (текущее количество символов в основе);
A->, где – правая часть правила, которая совпадает с массивом OSN, A – левая часть правила, на которую заменяется основа;
REZ – результат.
Чтобы выделить основу необходимо сначала найти конец основы, а затем ее начало, после чего выделяется основа (блоки J2 – O8).
Если после выделения строки OSN находится правило, у которого правая часть правила совпадает с OSN то, переменной REZ присваивается 1, если такого правила нет – ошибка, синтаксический анализ может быть прекращен или нужно исправить ошибку (блок R8).
Операции выполняемые над строковыми переменными:
st.push(i) – поместить элемент i в стек;
st.pop() – удалить элемент из стека;
st.top() – получить доступ к вершине стека;
st.nst() – определить количество элементов в стеке.
Работа данного алгоритма представлена в таблице синтаксического анализа в графическом приложении (лист1).
Заключение
В процессе выполнения курсовой работы были разработаны синтаксический и лексический анализаторы, семантические процедуры для сканера, а также был разработан алгоритм, реализующий синтаксический анализ методом простого предшествования. В целом язык оправдал надежды, возложенные на него в начале работы, и получился довольно стройным и гибким.