Програмування універсальних мікропроцесорів на мовах Асемблер
Полтавський Військовий Інститут Зв’язку
Кафедра схемотехніки радіоелектронних систем
ОБЧИСЛЮВАЛЬНА ТЕХНІКА ТА МІКРОПРОЦЕСОРИ
Програмне забезпечення мікропроцесорних систем.
Програмування універсальних мікропроцесорів на мовах Асемблер.
Система команд МП IA-32.
Лекція обговорена і схвалена на засіданні
предметно-методичної комісії
Протокол № ____ від ________
Полтава – 2006
Навчальна література
Юров В. Assembler -- СПб: Издательство „Питер”, 2001, с. 57-66.
Мікропроцесорна техніка: Підручник/ Ю.І. Якименко та інш. – К.: ІВЦ Політехніка; Кондор, 2004. с. 49-53, 105-118.
ВСТУП
Як і вся інформація, що збережена в пам'яті ЕОМ, команди подаються двійковим кодом. Як говорилося раніше, двійкове подання інформації є оптимальним для ЕОМ, але незручно для сприйняття людиною. Тому при програмуванні МП застосовується мова асемблер, а для подання адресної інформації (а по більшій частині і для подання даних) використовується шістнадцяткова система числення. Однак, шістнадцяткові коди команд також не занадто зручні для запам'ятовування, тим більше, що в деяких випадках та сама команда може мати різне шістнадцяткове подання. Тому система команд МП представляється у вигляді мнемокодів асемблера.
По-справжньому вирішити проблеми, зв'язані з апаратурою (або навіть, більш того, що залежать від апаратури як, наприклад, підвищення швидкодії програми), неможливо без знання асемблера.
Програміст або будь-який інший користувач може використовувати будь-які високорівневі засоби, аж до програм побудови віртуальних світів і навіть не підозрювати, що насправді комп'ютер виконує не команди мови, на якій написана його програма, а їхнє трансформоване (а точніше, відтрансльоване) подання у формі послідовності команд зовсім іншої мови - машинної. А тепер уявимо, що в такого користувача виникла нестандартна проблема. Наприклад, його програма повинна працювати з деяким незвичайним пристроєм або виконувати інші дії, що вимагають знання принципів роботи апаратури комп'ютера. І отут без знання асемблера не обійтися. І не випадково практично всі компілятори мов високого рівня містять засоби зв'язку своїх модулів з модулями на асемблері або підтримують вихід на асемблерний рівень програмування.
Програми, написані мовою асемблер, вимагають значно меншого обсягу пам'яті і часу виконання в порівнянні з програмами, написаними на будь-якій мові високого рівня. Саме тому асемблер широко використовується при створенні системних програм, особливо драйверів різних пристроїв, основними вимогами до яких є висока швидкодія і компактність.
Знання мови асемблер і результуючого машинного коду дає розуміння архітектури ЕОМ, що не забезпечується при програмуванні мовою високого рівня. Мови високого рівня створювалися для того, щоб програмувати переважно без обліку технічних особливостей конкретних комп'ютерів, асемблер же орієнтований саме на специфіку комп'ютера або, точніше, на специфіку процесора. Мікропроцесори, що належать до різних сімейств, мають, відповідно, свої, системи команд, що істотно розрізняються.
Програмування на асемблері -- це дуже трудомісткій, потребуючий великої уваги і практичного досвіду процес. Тому реально на асемблері пишуть, в основному програми, що повинні забезпечити ефективну роботу з апаратною частиною. Іноді на асемблері пишуться критичні за часом виконання або витратами пам'яті ділянки програми. Згодом вони оформляються у вигляді підпрограм і сполучаються з кодом на мові високого рівня.
На попередніх лекціях (тема 6) ми з’ясували особливості реального та захищеного режимів роботи МП, розглянули принцип формування адреси пам’яті МП архітектури IA-32 у реальному та захищеному режимах. Для створення ефективних та компактних програм існує достатньо широкий вибір типу адресації операндів. Розвинута система команд в свою чергу дозволяє програмісту складати практично будь-які системні та прикладні програми, використовуючи мнемокоди асемблера.
Типи адресації операндів МП IA-32.
Існують такі способи адресації:
Пряма адресація. При такій адресації адреса операнда вказана безпосередньо в команді.
Непряма адресація. При такій адресації у форматі команди вказується номер (ім’я) регістра, у якому зберігається адреса комірки пам’яті, яка містить операнд.
Безпосередня адресація. У першому байті команди з безпосередньою адресацією розміщується код операції. Значення операндів заносяться в команду під час програмування і знаходяться у другому і третьому байтах. Цими значеннями зазвичай є деякі константи. У процесі виконання програми значення операндів залишаються незмінними, оскільки вони разом із командою розміщуються в ПЗП. Використання такого способу не потребує адреси операндів.
Автоінкрементна (автодекрементна) адресація. Адреса операнда обчислюється так само, як і при непрямій адресації, а потім здійснюється збільшення вмісту регістра: на один-для звернення до наступного байта, на два – для звернення до наступного слова. Розмір операнда визначається кодом операції.
Сторінкова адресація. Під час використання сторінкової адресації пам'ять поділяється на ряд сторінок однакової довжини. Адресація сторінок здійснюється або з програмного лічильника, або з окремого регістра сторінок. Адресація пам'яті всередині сторінок здійснюється адресою, що міститься в команді.
Індексна адресація. Для утворення адреси операнда до значення адресного поля команди додається значення вмісту індексного регістра (SI або DI), яке називається індексом.
Відносна адресація. При відносній адресації адреса операнда визначається додаванням вмісту програмного лічильника або іншого регістра із зазначеним у команді числом.
Базова адресація. Ефективна адреса операнда ЕА обчислюється складанням вмісту базових регістрів ВХ або ВР і зміщенням (8- або 16-розряднє число).
Базова-індексна адресація. Ефективна адреса операнда ЕА дорівнює сумі вмісту базових регістрів ВХ або ВР, індексних регістрів SI або DI та зміщення. Базова та індексна адресація застосовуються для звернення до елементів одновимірного масиву, Базова – індексна – до двовимірного масиву.
Дотепер ми вживали терміни "виконавча (або ефективна) адреса" і "внутрішньосегментний зсув" як синоніми, що є вірним лише для єдиного, найпростішого режиму адресації, що називається прямою адресацією. У дійсності ж система команд МП ІA 32 передбачає 11 режимів адресації, у більшості з яких зсув є лише одним з компонентів, використовуваних для обчислення ефективної адреси. При цьому тільки в двох випадках операнди не зв'язані з пам'яттю. Це операнд - вміст регістра, що береться з будь-якого регістра процесора і безпосередній операнд, що утримується в самій команді. Інші дев'ять режимів так чи інакше звертаються до пам'яті.
При звертанні до пам'яті ефективна адреса ЕА обчислюється по формулі:
EA = Base +Index* Scale +Disp
з використанням наступних компонентів:
- Зсув (Dіsplacement або Dіsp) - 8, 16 або 32-бітне число, включене у команду;
- База (Base) - вміст базового регістра. Звичайно використовується для вказівки на початок деякого масиву;
- Індекс (Іndex) - вміст індексного регістра. Звичайно використовується для вибору елемента масиву;
- Масштаб (Scale) - множник (1, 2, 4 або 8), зазначений у коді інструкції. Цей елемент використовується для вказівки розміру елемента масиву, доступний тільки при 32-бітній адресації.
Окремі доданки в цій формулі можуть бути відсутніми.
Обчислення ефективної адреси пояснюється схемою, представленої на рис. 1. Можливі режими адресації представлені в таблиці 1.
Процесори ІA-32 можуть працювати з 32-бітною або 16-бітною адресацією. 16-бітна адресація функціонує так само, як у МП І8086, при цьому як компоненти адреси використовуються молодші 16 біт відповідних регістрів. Як говорилося вище, у реальному режимі за замовчуванням використовується 16-бітна адресація, однак є можливість для поточної інструкції переключитися на 32-бітну. При 32-бітній адресації застосовуються розширені 32-розрядні регістри і додаткові режими з масштабуванням індексу. Однак значення ефективної адреси, що обчислюється, усе рівно не може вийти за 64-килобайтний бар'єр - при спробі використання ЕА, що виходить за межу сегмента генерується виключення #GP (General Protectіon Fault).

ЕА
Рис. 1. Обчислення ефективної адреси
Таблиця 1
|
Режим |
Адреса |
|
Пряма адресація |
EA = Disp |
|
Непряма регістрова адресація |
EA = Base |
|
Базова адресація |
EA = Base +Disp |
|
Індексна адресація |
EA = Index +Disp |
|
Масштабована індексна адресація |
EA = Index* Scale +Disp (*) |
|
Базово-індексна адресація |
EA = Base +Index |
|
Масштабована базово-індексна адресація |
EA = Base +Index* Scale (*) |
|
Базово-індексна адресація зі зсувом |
EA = Base +Index +Disp (*) |
|
Масштабована базово-індексная адресація зі зсувом |
EA = Base +Index* Scale +Disp |
(*)- масштабування індексу можливо тільки при 32-бітній адресації.
Нагадаємо, у цій ситуації при 16-бітній адресації просто ігнорується перенос у розряд А16 і сегмент "звертається в кільце".
Засоби контролю стежать і за переходом через границю сегмента під час звертання до "прикордонної" адресі. При спробі адресації до слова, що має зсув FFFF>16> або до подвійного слову зі зсувом FFFD>16> - FFFF>16> (їх старші байти виходять за межу сегмента), або виконання інструкції, хоча б один байт якої не уміщається в даному сегменті, процесор також виробляє виключення #GP.
У захищеному режимі також можливе переключення 16-и і 32-бітної адресації.
Розходження між режимами адресації при використанні 16-и і 32-бітної адресації показані в таблиці 2.
Таблиця 2.
|
Компонент |
16-бітна адресація |
32-бітна адресація |
|
Базовий регістр |
ВХ або ВР |
Будь-який 32-бітний регістр загального призначення. |
|
Індексний регістр |
SI або DI |
Будь-який 32-бітний регістр загального призначення, крім ESP |
|
Масштаб |
Немає (завжди 1) |
1, 2, 4, 8 |
|
Зсув |
0, 8, 16 біт |
0, 8, 32 біт |
Як видно з таблиці, при 32-бітній адресації функціональне призначення регістрів МП фіксовано менш жорстко.
2. Класифікація і формати команд МП IA-32
Сукупність команд, що можуть бути виконані конкретним мікропроцесором, називається системою команд мікропроцесора.
Команда визначає операцію, яку має виконати МП над даними. Команда містить у явній або неявній формах інформацію про те, де буде розміщений результат операції, а також про адресу наступної команди. Обсяг, займаний командою в пам'яті, складає декілька байт і залежить від призначення команди. У загальному випадку формат команди містить операційну та адресну частини. Команди містять однобайтний або двохбайтний код інструкції, за яким можуть випливати декілька байт, що визначають режим виконання команди, і операнди (об'єкти, над якими або за допомогою яких виконується команда). Команди можуть використовувати від нуля до трьох операндів. Нагадаємо, що операнд – це об'єкт у вигляді значення даних, вмісту регістрів або вмісту комірок пам'яті, з яким оперує команда.
Система команд МП сімейства Іntel 80X86 містить кілька сотень інструкцій, що мають різне функціональне призначення.
Можна навести таку класифікацію команд МП сімейства Іntel 80X86:
- інструкції пересилання даних,
- інструкції введення-виведення,
- інструкції двійкової арифметики,
- інструкції десяткової арифметики,
- інструкції логічних операцій,
- зсуви й обертання (циклічні зсуви),
- інструкції обробки біт і байт,
- команди передачі керування,
- умовні переходи,
- інструкції виклику процедури,
- строкові операції,
- операції з прапорами,
- інструкції завантаження покажчиків,
- інструкції математичного співпроцесора,
- інструкції пакетів мультимєдійних розширень (MMX, SSE),
- системні інструкції.
Програма на асемблері являє собою сукупність блоків пам'яті, які називаються сегментами пам'яті. Програма може складатися з одного або декількох таких блоків-сегментів. Кожен сегмент містить сукупність речень мови, кожне з яких займає окремий рядок коду програми.
Речення, що складають програму, можуть являти собою синтаксичну конструкцію, що відповідає команді, макрокоманді, директиві або коментареві:
- команди або інструкції являють собою символічні аналоги машинних команд. У процесі трансляції інструкції асемблера перетворяться у відповідні команди мікропроцесора;
- макрокоманди -- оформлені певним чином речення тексту програми, що заміщаються під час трансляції іншими реченнями -- як правило, істотно великими за обсягом;
- директиви є вказівкою трансляторові асемблера на виконання деяких дій. У директив немає аналогів у машинному поданні;
- рядки коментарів, що містять будь-які символи, у тому числі і літери російського алфавіту. Коментарі ігноруються транслятором.
Д ля
того щоб транслятор асемблера міг
розпізнати речення, вони повинні
формуватися по визначеним синтаксичним
правилам. Ці правила можуть бути
формалізовані на зразок правил граматики.
Найбільш розповсюджений і зрозумілий
спосіб такого опису мови програмування
- синтаксичні діаграми. Наприклад,
синтаксис речень асемблера можна описати
за допомогою синтаксичної діаграми,
представленої на рис.2.
ля
того щоб транслятор асемблера міг
розпізнати речення, вони повинні
формуватися по визначеним синтаксичним
правилам. Ці правила можуть бути
формалізовані на зразок правил граматики.
Найбільш розповсюджений і зрозумілий
спосіб такого опису мови програмування
- синтаксичні діаграми. Наприклад,
синтаксис речень асемблера можна описати
за допомогою синтаксичної діаграми,
представленої на рис.2.
Рис. 2. Формат речень асемблера.
Синтаксичні діаграми, що пояснюють формат директив, команд і макрокоманд асемблера, представлені на рис. 3 і 4 відповідно.
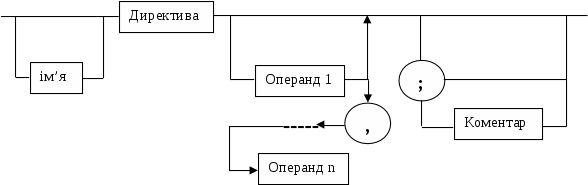
Рис. 3. Формат директив асемблера.

Рис. 4. Формат команд і макрокоманд
На цих рисунках:
- ім'я мітки - ідентифікатор, значенням якого є адреса першого байта того речення тексту програми, що він позначає;
- ім'я -- ідентифікатор, що відрізняє дану директиву від інших директив;
- код операції (КОП) і директива -- це мнемонічні позначення відповідної машинної команди, макрокоманди або директиви транслятора;
- операнди -- описуються виразами з числовими і текстовими константами, мітками і ідентифікаторами змінних з використанням знаків операцій і деяких зарезервованих слів.
Використовувати синтаксичні діаграми дуже просто: для цього потрібно знайти шлях від входу діаграми (ліворуч) до її виходу (праворуч). Якщо такий шлях існує, то речення або конструкція синтаксично правильні. Якщо такого шляху немає, цю конструкцію компілятор не прийме. По суті, синтаксичні діаграми відповідають логіці роботи транслятора при розборі вхідних речень програми.
Припустимими символами при написанні тексту програм є:
1. усі латинські букви: A-Z, a-z. При цьому заголовні і малі літери вважаються еквівалентними;
2. цифри від 0 до 9;
3. знаки ?, @, $, _, &;
4. роздільники , . [ ] ( ) < > { } + / * % ! ' " ? \ = # ^.
Речення асемблера формуються з лексем, що представляють собою синтаксично нероздільні послідовності припустимих символів мови, що мають зміст для транслятора.
Лексемами є:
- ідентифікатори - послідовності припустимих символів, що використовуються для позначення таких об'єктів програми, як коди операцій, імена змінних і назви міток. Правило запису ідентифікаторів полягає в наступному: ідентифікатор може складатися з одного або декількох символів; як символи можна використовувати букви латинського алфавіту, цифри і деякі спеціальні знаки - _, ?, $, @. Ідентифікатор не може починатися символом цифри. Довжина ідентифікатора може бути до 255 символів, хоча транслятор сприймає лише перші 32, а інші ігнорує.
- ланцюжки символів - послідовності символів, укладені в одинарних або подвійних лапках;
- цілі числа в одній з наступних систем числення: двійкової, десяткової, шістнадцяткової.
Ототожнення чисел при записі їх у програмах на асемблері виконується за визначеними правилами:
- Десяткові числа не вимагають для свого ототожнення вказівки яких-небудь додаткових символів, наприклад 25 або 139.
- Для ототожнення у вихідному тексті програми двійкових чисел необхідно після запису нулів і одиниць, що входять у їхній склад, поставити латинське "b", наприклад 10010101b.
- Шістнадцяткові числа мають більше умовностей при своєму записі. У транслятора можуть виникнути труднощі з розпізнаванням шістнадцяткових чисел через те, що вони можуть складатися як з одних цифр 0...9 (наприклад 190845), так і починатися з букви латинського алфавіту (наприклад ef15). Для того щоб "пояснити" трансляторові, що дана лексема не є десятковим числом або ідентифікатором, програміст повинний спеціальним образом виділяти шістнадцяткове число. Для цього на кінці послідовності цифр, що складають шістнадцяткове число, записують латинську букву "h". Якщо шістнадцяткове число починається з літери, то перед ним записується ведучий нуль: 0ef15h.
Практично кожне речення мовою асемблер містить опис одного або декількох операндів.
Можливо провести наступну класифікацію операндів:
- постійні або безпосередні операнди,
- адресні операнди,
- переміщувані операнди,
- лічильник адреси,
- регістровий операнд,
- базовий і індексний операнди,
- структурні операнди,
- записи.
Перелічимо тепер можливі типи операторів асемблера.
- арифметичні оператори,
- оператори зсуву,
- оператори порівняння,
- логічні оператори,
- індексний оператор,
- оператор перевизначення типу,
- оператор перевизначення сегмента,
- оператор іменування типу структури,
- оператор одержання сегментної складової адреси виразу,
- оператор одержання зсуву виразу.
Операнди та операнди – це складові частини виразів. Вирази являють собою комбінації операндів і операторів, розглянуті як єдине ціле.
Результатом обчислення виразу може бути адреса деякої комірки пам'яті або деяке константне (абсолютне) значення.Як і в мовах високого рівня, виконання операторів асемблера при обчисленні виразів здійснюється відповідно до їх пріоритетів. Операції з однаковими пріоритетами виконуються послідовно зліва на право. Зміна порядку виконання можлива шляхом розміщення круглих дужок, що мають найвищий пріоритет.
Розглянемо декілька базових операторів найбільш простих і розповсюджених типів, що дозволяють створювати найпростіші програми. Усі приклади подані для реального режиму роботи МП ІA-32. Крім того, усі числа в цих прикладах є шістнадцятковими, однак буква h наприкінці числа опущена, а також не використовуються мітки й імена констант і змінних.
1. mov < операнд призначення (приймач) >, < операнд – джерело >. Це -- основна команда пересилання даних загального призначення. Вона реалізує найрізноманітніші варіанти пересилання.
Наприклад:
MOV AL,03 - помістити число 03 у молодшу половину (байт) регістра АХ. Тут 03 - безпосередній операнд, а AL - регістровий операнд. Регістровий операнд -- це просте ім'я регістра. У програмі на асемблері можна використовувати імена всіх регістрів загального призначення і більшості системних регістрів.
MOV AХ,DX -- пересилання значення з регістра DX у AX. Тут обоє операнди -- регістрові.
MOV AХ,0000 -- очищення акумулятора.
MOV [0023],AХ -- пересилання вмісту акумулятора в комірку пам'яті за адресою DS:0023. Зверніть увагу на те, що без використання прямокутних дужок ця команда була б безглуздою і транслятор у цьому випадку видав би повідомлення про помилку. Саме використання таких дужок дає можливість трансляторові інтерпретувати перший операнд не як безпосереднє число, а як вміст комірки пам'яті, розташованої за адресою DS:0023. Тобто , число в прямокутних дужках сприймається як зсув логічної адреси комірки пам'яті.
MOV СХ,[0023] -- пересилання вмісту комірки пам'яті за адресою DS:0023 у CX.
2. add < приймач >,< джерело >. Ця команда призначена для додавання двох цілочисельних операндів (джерело і приймач) розмірністю байт, слово або подвійне слово. При цьому результат додавання міститься за адресою першого операнда (приймач).
Наприклад:
ADD DX,03 -- збільшує на 3 значення регістра DX. Операнди тут, як у попередній команді, можуть бути безпосередніми, регістровими і т.д.
3. sub> < приймач >,< джерело >. Ця команда призначена для виконання цілочисельного віднімання першого операнда з другого, результат міститься в приймач.
Приклад:
sub> DX,AX - значення регістра DX віднімається з AX, результат міститься в DX.
4. mul <множник_1>. Ця команда виконує множення двох цілих чисел без обліку знака. Алгоритм залежить від формату операнда команди і вимагає явної вказівки місця розташування тільки одного співмножника, що може бути розташований у пам'яті або в регістрі. Місце розташування другого співмножника фіксоване і залежить від розміру першого співмножника:
- якщо операнд, зазначений у команді - байт, то другий співмножник повинний розташовуватися в AL (молодшій половині акумулятора);
- якщо операнд, зазначений у команді - слово, то другий співмножник повинний розташовуватися в AX.
Результат множення міститься також у фіксованому місці, обумовленому розміром співмножників:
- при множенні байтів результат міститься в AX;
- при множенні слів результат міститься в пару DX:AX;
Наприклад:
MUL BL - робить цілочисельне множення без обліку знака вмісту молодшої половини регістра BX на вміст молодшої половини акумулятора. Результат міститься в акумуляторі.
5. dіv < дільник >. Команда виконує операцію цілочисельного ділення двох двійкових беззнакових значень с видачею результату у вигляді частки і залишку від ділення. Для виконання команди необхідне завдання двох операндів - діленого і дільника. Ділене задається неявно і розмір його залежить від розміру дільника, що вказується в команді:
- якщо дільник розміром у байт, то ділене повинно бути розташоване в регістрі AX. Після операції частка міститься в AL, а залишок - у AH;
- якщо дільник розміром у слово, то ділене повинно бути розташоване в парі регістрів DX:AX, причому молодша частина діленого знаходиться в AX. Після операції частка міститься в AX, а залишок - у DX.
Наприклад:
DІV 08 - робить цілочисельне ділення без знака вмісту акумулятора на 08.
Варто пам'ятати, що при виконанні операції ділення можливе виникнення виняткової ситуації: 0 - помилка ділення. Ця ситуація виникає в одному з двох випадків: дільник дорівнює 0 або частка занадто велика для його розміщення в регістрі AX/AL.
6. іnc < операнд >. Команда робить збільшення значення операнда в пам'яті або регістрі на 1. Наприклад:
ІNC BL - збільшує значення, що утримується в молодшій половині регістра BX на 1. Команда може бути корисна при організації циклів.
7. dec < операнд >. Команда робить зменшення значення операнда в пам'яті або регістрі на 1. Наприклад:
DEC BL - зменшує значення, що утримується в молодшій половині регістра BX на 1.
8. pop <приймач>. Команда призначена для добування слова зі стека (вмісту вершини стека) у комірку пам'яті або регістр. Алгоритм роботи:
- завантажити в приймач вміст вершини стека (адресується парою SS:SP);
- збільшити вміст SP на 2 байти.
Варто пам'ятати, що неприпустимий добування слова в сегментний регістр CS.
9. push <джерело>. Команда призначена для розміщення вмісту операнда "джерело" у стеці. Використовується разом з командою РОР для запису значень у стек і добування їх зі стека Алгоритм роботи:
- зменшити значення покажчика стека SP на 2;
- записати джерело у вершину стека (яка адресується парою SS:SP).
У стек можна записувати як вміст регістрів або комірок пам'яті, так і безпосередні значення. На відміну від команди РОР у стек можна включати значення сегментного регістра CS. При записі в стек 8-бітних значень для них усе рівно виділяється слово.
10. ret. Призначена для повернення керування з процедури викликаючої програми. Команда досить багатофункціональна і може мати числовий операнд. У найпростішому випадку може використовуватися без додаткових параметрів як команда завершення програми.
У заключній частині заняття лектор підводить підсумки заняття відповідає на питання курсантів, звертає їх увагу на основні визначення та поняття, які були розглянуті на лекційному занятті, рекомендує, які питання буде доцільно додатково розглянути на самостійній підготовці та повідомляє перелік рекомендованої літератури. Крім того, лектор повідомляє курсантам тему наступного заняття та форму проведення поточного контролю на ньому.
В И С Н О В О К
Усі процеси в машині на найнижчому, апаратному рівні приводяться в дію тільки командами (інструкціями) машинної мови. Сукупність команд, що можуть бути виконані конкретним мікропроцесором, називається системою команд мікропроцесора.
Мікропроцесори, що належать до різних сімейств, мають, відповідно, свої, що істотно розрізняються системи команд. Система команд МП ІA 32 передбачає 11 режимів адресації, у більшості з яких зсув є лише одним з компонентів, використовуваних для обчислення ефективної адреси.
При цьому тільки в двох випадках операнди не зв'язані з пам'яттю. Це операнд - вміст регістра, що береться з будь-якого регістра процесора і безпосередній операнд, що утримується в самій команді. Інші дев'ять режимів так чи інакше звертаються до пам'яті.
Мова асемблер для кожного типу комп'ютера своя. Знання мови асемблер і результуючого машинного коду дає розуміння архітектури ЕОМ, що не забезпечується при програмуванні мовою високого рівня. Мови високого рівня створювалися для того, щоб програмувати переважно без обліку технічних особливостей конкретних комп'ютерів, асемблер же орієнтований саме на специфіку комп'ютера або, точніше, на специфіку процесора.