Информационная система университета
СпециальностьАСОИУГруппа554fgfdgfgРеферат
Отчет 91 с., 34 рисунка, 15 таблиц, источника, 3 приложения
АЛГОРИТМ, БЛОК СХЕМА, ОБЪЕКТ УПРАВЛЕНИЯ,
ИНФОРМАЦИОННАЯ СИСТЕМА УНИВЕРСИТЕТА,
ПАКЕТ, СООБЩЕНИЕ, УСТРОЙСТВО, ФУНКЦИОНАЛЬНА СХЕМА
Объект исследования представляет собой систему обмена и передачи информации между студентами, преподавателями университета и сторонними лицами. В процессе проектирования была разработана полномасштабная функциональная схема верхнего уровня и схема ее положения и внедрения в существующую Информационную Систему Университета. Представлено описание функционирования верхнего уровня ИСУ. Описана входная и выходная информация. Разработана структура и формат пакетов, циркулирующих в ИСУ. Спроектированы модульные схемы алгоритмов. Описаны все информационные массивы и переменные, используемые для четкого и надежного функционирования ИСУ. Разработаны способы и средства, обеспечивающие надежность ИСУ.
Содержание
Введение Error: Reference source not found
1. Характеристика существующей Информационной Системы Университета Error: Reference source not found
2. Описание и характеристика задач Error: Reference source not found
2.1. Краткое описание всех задач поставленных перед ИСУ Error: Reference source not found
2.2. Описание задач первой группы Error: Reference source not found
2.3. Описание задач второй группы Error: Reference source not found
2.4. Требования к программе Error: Reference source not found
2.4.1. Требования к функциональным характеристикам Error: Reference source not found
2.4.2. Требования к составу и параметрам технических средств Error: Reference source not found
2.4.3. Требования к информационной и программной совместимости Error: Reference source not found
2.5. Предварительная оценка технико–экономических показателей Error: Reference source not found
3. Полномасштабная функциональная схема верхнего уровня ИСУ Error: Reference source not found
4. Описание функционирования верхнего уровня ИСУ (Сервер) Error: Reference source not found
4.1. Инициализация системы Error: Reference source not found
4.2. Прием сообщений от нижнего уровня Error: Reference source not found
4.3. Отправка сообщений на нижний уровень Error: Reference source not found
4.4. Другие функции выполняемые в системе Error: Reference source not found
4.5. Администрирующие функции системы Error: Reference source not found
4.6. Функции работы с клиентом Error: Reference source not found
5. Описание функционирования верхнего уровня ИСУ (Клиент) Error: Reference source not found
5.1. Регистрация пользователя Error: Reference source not found
5.2. Отправка объявления Серверу Error: Reference source not found
5.3. Прием сообщений от Сервера Error: Reference source not found
6. Входная и выходная информация Error: Reference source not found
7. Формат и структура пакетов, циркулирующих в ИСУ Error: Reference source not found
8. Модульная схема алгоритмов Error: Reference source not found
8.1. Алгоритм процедуры (Control) Error: Reference source not found
8.2. Алгоритм процедуры (Order) Error: Reference source not found
8.3. Алгоритм процедуры перемещения данных (Datas_up) Error: Reference source not found
8.4. Алгоритм процедуры перемещения данных (Datas_Down) Error: Reference source not found
8.5. Алгоритм инициализации системы(Init) Error: Reference source not found
8.6. Алгоритм процедуры ожидания (Waiting) Error: Reference source not found
8.7. Алгоритм процедуры обработки объявлений (Processing) Error: Reference source not found
8.8. Алгоритм процедуры взаимодействия с удаленным клиентом (Interaction) Error: Reference source not found
8.9. Алгоритм процедуры получения приоритета (Get_priority) Error: Reference source not found
8.10. Алгоритм процедуры приема сообщения (Get_message) Error: Reference source not found
8.11. Алгоритм процедуры отправки объявления (Send_message) Error: Reference source not found
8.12. Другие процедуры ИСУ. Error: Reference source not found
9. Описание информационных массивов Error: Reference source not found
9.1. Информационные массивы Сервера Error: Reference source not found
9.1.1. Массив объявлений Error: Reference source not found
9.1.2. Динамический массив Error: Reference source not found
9.1.3. Оперативная справка Error: Reference source not found
9.1.4. Долгосрочная справка Error: Reference source not found
9.1.5. Массив сообщений в системе Error: Reference source not found
9.1.6. Массив сообщений Error: Reference source not found
9.1.7. Временный массив объявлений Error: Reference source not found
9.1.8. Массив не опубликованных объявлений Error: Reference source not found
9.1.9. Устройства Error: Reference source not found
9.1.10. База данных пользователей Error: Reference source not found
9.2. Информационные массивы Клиента Error: Reference source not found
10. Надежность ПО Error: Reference source not found
10.1. Аналитические модели надежности Error: Reference source not found
10.2. Динамические модели надежности Error: Reference source not found
10.3. Статические модели надежности Error: Reference source not found
10.4. Эмпирические модели надежности Error: Reference source not found
10.5. Количественный расчет надежности 59
Заключение Error: Reference source not found
Список использованных источников Error: Reference source not found
Приложение 1 - Функциональная схема "Сервер". Подсистемы Управления и Интерфейсная. 63
Приложение 2 - Функциональная схема "Сервер". Подсистема взаимодействия с "Клиентом". 64
Приложение 3 – Функциональная схема "Клиент". 65
Перечень условных обозначений, символов, едИниц и терминов
ID – Идентификатор присутствия (Identification)
Админ – Администратор системы
БДП – База данных пользователей
Вх – Входной
Вых – Выходной
ИСУ – Информационная Система Университета
ЛВС – Локальная вычислительная сеть
Мас (Mas) – Массив
П – Процедура
ПК – Персональный компьютер
ПО – Програмное обеспечение
Т – Таймер
Введение
Наступившее третье тысячелетие характеризуется большим потоком информации. Сейчас не секрет, что именно информация считается одним из двигателей прогресса. Она является всеобщей и универсальной производительной силой общества /1/. Применение информации снижает энтропию общественного производства. Для различных государственных и не государственных структур обладание достоверной и оперативной информацией считается, чуть ли не секретным оружием. Имея доступ к необходимой информации, осуществляется планирования производства, планов переговоров, давление на партнеров и конкурентов, повышения эффективности принятых решений. Для обычных людей обладание информацией позволяет экономить при приобретении различных видов продукции, выбирать того или иного поставщика или производителя.
Информация лежит в основе управления. Этот принцип представлен на рисунке 1.
Для ее передачи, обработки было придумано огромное количество устройств, способов, средств и алгоритмов. Несомненно, на данный момент Internet занимает первые и лидирующие позиции как источник всемирной информационной базы. Все большее совершенствование персональных компьютеров позволяет многим людям присоединиться к этой всемирной информационной сети. Предприятия, правительственные организации переходят или собираются в ближайшем будущем перейти на электронные средства предоставления информации.
Под электронными средствами понимается не только персональные компьютеры, но и различные бегущие строки, графические экраны, мониторы, информационные табло, такие как:
табло для котировок акций;
табло для казино;
табло процентных ставок;
табло для футбольных, баскетбольных и др. полей.
Все эти электронные устройства в большинстве своем оснащенные автоматическим или автоматизированным управлением позволяют упростить и повысить эффективность работу людей.
В основе диплома лежит оперативные, качественные и своевременные способы предоставления информации конечным пользователям. Для этого были выбраны выше описанные средства предоставления информации, объединенные в единую сеть с единым центром автоматизированного управления. Что позволяет в короткие сроки информировать людей, о различных аспектах работы университета.
Информационная Система Университета (ИСУ) позволяет не только опубликовывать различные объявления кафедр, деканатов, но и включает возможность размещения различных поздравлений, рекламы, экстренных сообщений. Что позволит открыть еще одну статью доходов университета. Повысит его статус и имидж.
1. Характеристика существующей Информационной Системы Университета
Что значит информационная система университета? Это способ донести информацию до ее потребителя. Информация может быть различного характера и предназначается различным потребителям. Основные потребители информации это студенты. Источники информации также различны, это могут быть кафедры, деканаты, различные другие обучающие учреждения. Также к источникам можно отнести различные торговые предприятия или предприятия, оказывающие какие либо услуги клиентам, которыми могут быть студенты или преподаватели университета.
Большое количество информации предназначено ограниченному кругу людей. Это может быть, какое либо объявление кафедры или деканата предназначенное студентам определенной группы. Деканат курирует работу всего факультета, и объявления деканата касаются всех студентов данного факультета. Кафедра действует более уже, и любые объявления касаются только студентов той специальности, к чьей кафедре они прикреплены.
Для донесения необходимой информации студентам, каждая кафедра и деканат имеют свои доски объявления. Доска объявления представляет собой квадратную или прямоугольную доску, либо рейки на которые натянута материя. На данные доски вывешиваются бумажные объявления о том или ином событии. Прикрепляться объявления могут различным способом. Это могут быть иголки, скрепки, булавки, кнопки или скотч. Объявления, вывешиваемые на длительный срок, могут помещаться под стекло.
Информация, касающаяся большинства людей, вывешивается на доску объявления находящуюся в холе университета. Любой студент или преподаватель может повесить свое объявление на данную доску. Это также верно и для различных торговых и производственных организаций.
Недостатки данной бумажной системы являются:
неконтролируемое вывешивание объявлений;
объявления, потерявшие свою актуальность, продолжают находиться на доске объявлений;
возможны случайные обрывы, в случае важности вывешенной информации возникает необходимость постоянного контроля за объявлением;
ни кто не гарантирует, что вывешенное объявление, ни кто не сорвет и не выбросит;
при потери объявления, восстановление его занимает достаточно много времени. Это связано с тем, что бумажное объявление следует написать или если оно набрано на персональном компьютере, его нужно распечатать, для того чтобы распечатать, нужен принтер и т.д.;
также большое количество бумажных объявлений можно увидеть на стеклах и стенах университета, но это зависит только от культуры студентов, преподавателей и других людей, посещающих университет;
постоянная нехватка иголок, скрепок и т.д. не всегда гарантирует своевременное вывешивание объявления.
Предлагаемая система на базе электронных средств предоставления информации не в коем случае не претендует на универсальность. У нее также есть свои недостатки и достоинства. Но она способна улучшить качество, надежность и своевременность предоставления информации потребителям.
2. Описание и характеристика задач
2.1. Краткое описание всех задач поставленных перед ИСУ
Задачи, поставленные перед Информационной Системой Университета можно разделить на 2 группы. Задачи, обеспечивающие функционирование системы и задачи, выполняемые самой системой. Данное разделение весьма условно, так как большинство задач можно отнести как к первой, так и ко второй группе.
К первой группе относятся задачи обеспечивающее надежное функционирование системы, качественное выполнение всех функций, быстрота работы системы в целом, не должно быть потерь информации во время функционирования системы, устранение ошибок взаимодействия всех частей ИСУ, минимизация исходного текста программы, способность системы однозначно реагировать на любое внешнее или внутреннее воздействие, отсутствие неопознанных или неописанных сообщений в системе.
Ко второй группе относятся задачи: корректный вывод объявлений на любое из устройств функционирующих в системе, способность удаленной подачи объявления, возможность выделения объявлений по важности, способность запрета подачи объявления, какому либо пользователю или группе пользователей, способность получения информации о функционировании системы в любой момент времени, способность определения кто, когда и сколько раз подавал свои объявления в систему, полный сбор всей статистической информации.
2.2. Описание задач первой группы
Обеспечение надежности связано с тем, что во время функционирования системы большой объем информации циркулирующей в системе находиться во временных массивах оперативной памяти, система должна в случае отключения восстановить всю исходную информацию на время выхода системы из строя. Это обеспечивается за счет введения некоторой избыточности в хранение информации, а именно все переменные, отвечающие за правильное функционирование системы, имею свои копии на жестком диске, и при восстановлении ИСУ вся информация находящаяся на диске переписывается во временные массивы, что позволяет полностью восстановить систему на момент отключения.
При выходе из строя, каких либо устройств системы, система остается работоспособной. Это осуществляется за счет четкого разграничения верхнего уровня системы и нижнего. Система остается работоспособной даже в случае отказа работы локальной сети, в которой функционирует ИСУ. В данном случае все объявления можно подавать через администратора системы или через терминал, который непосредственно подключен к серверу обеспечивающего работу ИСУ.
Задачи качества и быстродействия выполняются за счет детальной проработки всех функций выполняемых в системе. Под детальной проработкой понимаются рассмотрение всех возможных ситуаций возникающих в системе и оптимизация реакций на них. Четкое разделение задач. Слаженная и однозначная работа всех систем ИСУ.
Обеспечение отсутствия потерь информации также связано с некоторой избыточностью. Т.е. вся информация поступающая в систему сохраняется во временных массивах. Структура данных массив имеет несколько копий, при поступлении нескольких сообщений они сохраняются в данных массивах, и ожидают своей очереди, пока сервер не закончит обработку предыдущих сообщений.
Оптимизация исходного текста программы обеспечивается за счет применения методов технологии программирования и выбора языка программирования.
Способность системы однозначно реагировать на любое внешнее или внутреннее воздействие, отсутствие неопознанных или неописанных сообщений в системе обеспечиваются за счет детального рассмотрения всех возможных ситуаций возникающих в системе и вариантов реагирования на них.
2.3. Описание задач второй группы
Корректный вывод объявлений на любое из устройств, функционирующих в системе, обеспечивается за счет проработки правил взаимодействия всех устройств включенных в ИСУ.
Способность удаленной подачи объявления обеспечивается за счет включения ИСУ в локальную сеть университета и разработке приложения отвечающего за корректное взаимодействие с сервером. Данное приложение взаимодействует с частью сервера, которая отвечает за правильный прием сообщений от клиента, обработку всех сообщений принятых от клиента и в случае обнаружения ошибок обладает возможностью информировать клиента.
Удаленная подача объявлений может быть расширенна за счет возможности подачи объявления по средствам глобальной сети Internet. Учитывая тот факт, что локальная сеть университета, имеет выход в Internet, но в целях обеспечения надежности системы нельзя непосредственно подать объявление, не находясь в стенах университета. Подача объявления возможна по средствам оформления электронного письма на имя администратора системы. После получения письма администратор принимает решения об опубликовании данного объявления в системе с соответствующим приоритетом. В противном случае администратор имеет возможность ответить отказом автору письма с обоснованием или отсутствием объяснения отказа.
Администратор системы имеет возможность в любой момент времени считать, просмотреть или распечатать необходимую статистическую информацию. Это возможно за счет постоянного слежения и запоминание системы всех своих действий.
Все эти задачи более детально будут рассмотрены и описаны по ходу проектирования системы.
2.4. Требования к программе
2.4.1. Требования к функциональным характеристикам
Требование к выполнению функций:
работа в режиме реального масштаба времени;
обеспечить надежность функционирования системы и защиту от сбоев;
должен осуществляться принцип интегральной обработки информации, т.е. полное использование АСУ для автоматического обеспечения максимального числа функций для объекта и результатов пользователя АСУ;
ввод информации должен производиться только однажды, в систему не вводились данные, которые могут быть выработаны внутри системы.
Функции, выполняемые программой.
Интуитивно понятный интерфейс. Регистрация событий на объекте, отображение всех действий выполняемых на нижнем уровне в реальном масштабе времени Запись всех событий в базу данных. Управление всей системой или отдельными объектами.
Поддерживать базу данных пользователей, Функции добавления, удаления, редактирования данных о пользователе.
Просмотр и печать отчетов по времени, проведенному сотрудником на рабочем месте, опозданиям и переработкам, выбранных по дате, типу и номеру карты, фамилии и т.д.
Требование к надежности.
Требования к надежности программного обеспечения, как к АСУ реального масштаба времени:
соблюдение рангов и приоритетов подпрограмм, где подсистема реализующая управление имеет более высокий ранг выполнения, чем остальные подсистемы;
система должна осуществлять проверку выполнения команд и передавать информацию обо всех своих действиях;
опрос состояния объекта управления и осуществление управления;
осуществление механизма проверки данных получаемых от объекта на достоверность;
программа должна вести протоколы текущего состояния, прошедших событий, аварийных ситуаций.
Протокол должен представлять собой структуру данных, хранящуюся на жестком диске компьютера хранящую в себе данные о состоянии объекта на промежутке времени. Администратору должна быть предоставлена возможность, осуществлять такие операции над протоколом: просмотр и печать.
Режим редактирования должен быть защищен паролем от несанкционированного доступа.
Новые значения должны немедленно вводиться в действие.
Программа должна также соответствовать следующим требованиям надежности:
контроль выполнения большинства операций в программе, анализ их результатов на присутствие ошибок, выяснение причины ошибок (например, с помощью анализа результатов работы процедур и функций программы, отслеживания возникновения особых случаев), исправление ошибочных ситуаций при помощи специальных процедур обработки ошибок и особых случаев;
защита от некорректных действий пользователя программы. Данный вид защиты может осуществляться с использованием некоторых специальных свойств пунктов меню программы и кнопок панели инструментов программы (а также кнопок в диалогах и формах). При невозможности выполнения какого-либо действия в определенный момент времени (это зависит от текущей выполняющейся операции) соответствующий этому действию пункт меню или кнопка должны быть отмечены "потухшим" изображением и являться недоступными пользователю в этот момент времени. Должны быть доступны только те пункты меню и кнопки, нажатие которых активизирует действия, не "конфликтующие" с текущей выполняющейся операцией или текущим режимом работы программы.
2.4.2. Требования к составу и параметрам технических средств
Для эксплуатации программы требуется IBM-совместимый персональный компьютер.
К комплектации и параметрам компьютера предъявляются следующие требования:
процессор Pentium 366;
объем ОЗУ – 64 МБ;
жесткий диск емкостью 3,2 ГБ;
видеоадаптер;
монитор SVGA;
принтер для печати отчетов.
Принимая во внимание то, что эксплуатироваться программа будет в среде операционной системы Windows NT, которая предъявляет довольно высокие требования к параметрам и быстродействию компьютера.
2.4.3. Требования к информационной и программной совместимости
Поставленная задача должна быть реализована программным путем, т.е. написана на каком-либо языке программирования, должна быть определена операционная система. Соответственно перечисленным критериям можно провести характеристику вариантов решения поставленной задачи.
Для того чтобы приступить к написанию программы обеспечивающую работоспособность будущей Информационной Системы Университета, следует рассмотреть возможные типы интерфейса программы. Среди существующих вариантов можно выделить два основных типа: на основе меню и на основе языка команд.
Интерфейсы типа меню облегчают взаимодействие пользователя с компьютером, поскольку снимают необходимость заранее изучать язык общения с системой. Такой способ особенно удобен для начинающих и непрофессиональных пользователей.
Интерфейс на основе языка команд требует знания пользователем нужных команд и их синтаксиса. Достоинство командного языка заключается в его мощности и гибкости.
Указанные два основных типа интерфейса представляют собой крайние случаи, между которыми существует множество промежуточных вариантов. Меню и командные языки дополняют друг друга, поэтому в интерфейсах многих современных систем присутствуют оба этих средства. В связи с тем, что программой, возможно, будут пользоваться люди мало знающих компьютер, но желающих опубликовать свое объявление в ИСУ, следует остановиться на интерфейсе экранная форма. Это обеспечить комфортность работы, как администратора системы, так и рядового пользователя. Основные преимущества данного интерфейса:
пользователь может отредактировать некоторый ответ перед вводом;
он может временно пропустить вопросы и возвращаться к ответу на предыдущий вопрос, т.е. пользователь может работать с формой до тех пор, пока он, удовлетворенный своей работой, не нажмет определенную клавишу, означающую конец ввода;
компьютерная система может проверить каждый ответ непосредственно после ввода или же выдавать список ошибок только после заполнения формы целиком.
В начале хотелось бы рассмотреть операционную систему MS DOS, которая соответствует интерфейсу командной строки. Преимуществами данной системы являются: низкие требования к ресурсам компьютера, простота ее устройства, что предоставляет программисту определенную свободу действий. В то же время она обладает большим количеством недостатков некоторые, из которых хотелось бы перечислить: очень неразвитый интерфейс с пользователем, поэтому большая нагрузка ложиться на программиста при реализации более развитого и понятного интерфейса, данная ОС не имеет возможности адресовать более 1 Мб оперативной памяти, что накладывает определенные ограничения при программировании. Система MS DOS не поддерживает режим многозадачности, поэтому программу защиты необходимо реализовывать в виде резидентной программы, что является кропотливой и трудной работой. Исходя из вышеперечисленного, можно сделать вывод, что реализация данного проекта в системе MS DOS /2/ не является оптимальным решением. Можно рассмотреть графическую надстройку MS DOS оболочку Windows 3.x, данная оболочка предоставляет программисту больше возможностей при построении развитого графического интерфейса, но она наследует такие недостатки, как очень неразвитую систему поддержки многозадачности, что является необходимым при реализации данного проекта.
В настоящее время наиболее распространенной операционной системой является — система Windows 95 фирмы Microsoft, эта ОС имеет ряд очень выгодных преимуществ во первых это высокоразвитый графический интерфейс, что очень ценится пользователями. Предоставляет программисту большое количество разнообразных функций API Win32, которые дают широкие возможности по построению того же интерфейса, более удобное управление памятью компьютера, которая перестала быть сегментированной и имеет ограничение при адресации 4 Гб, что вполне достаточно. Еще одним преимуществом является встроенная поддержка сетевых коммуникаций, что при реализации работы является насущной необходимостью. Предоставлены такие механизмы, передачи данных между программами, как DDE — динамический обмен данными, буфер обмена и OLE 2 — связывание и внедрение объектов. Достаточно хорошо реализован механизм не вытесняющей многозадачности и многопоточности. Операционная система Windows 95 избавила программистов от необходимости писать в программах вставки на языке Ассемблер, что является трудным занятием. Во многом эта ОС подходит для реализации работы, но в ней отсутствует возможность управлять приоритетами программ, так для обеспечения надежности при достижении необходимой частоты опроса подсистема управления должна иметь более высокий ранг приоритета выполнения по сравнению с остальной частью.
Операционная система Windows NT 4.0 /3/ включает в себя все достоинства Windows 95, и также является наиболее устойчивой к сбоям в программном обеспечении. Включает механизм рангов выполнения программ, такие как фоновый режим, обычный, высокий и реального времени. К преимуществу данной операционной системы следует отнести использование более меньшего кванта времени. Так любой другой ОС достижение частоты 50 Гц невозможно без перепрограммирования системного таймера, в Windows NT это возможно.
Ее недостатком стоит отметить высокие требования к ресурсам компьютера. Исходя из вышеизложенного стоит остановить свой выбор на системе Windows NT 4.0.
Языки программирования делятся на высокого и низкого уровня. К языкам программирования относится: язык низкого уровня - Ассемблер, и высокого - Си, Си++, Pascal /4/.
Написание программ на языке Ассемблер очень сложное и трудоемкое дело и требует высокой квалификации. Основной предпосылкой использования Ассемблера было невысокое быстродействие компьютера и недостаточный объем оперативной памяти, а данный язык позволял использовать наиболее полно все ресурсы компьютера. В настоящее время вычислительная техника имеет высокое быстродействие и низкий уровень цен на нее, что позволяет не прибегать к помощи этого сложного языка.
Распространенной средой программирования является Borland Delphi, с языком программирования Object Pascal. Данная среда программирования предоставляет широкие средства, при программировании интерфейсов и работе с базами данных, своей возможностью, как графического (визуального) построения программ так и традиционного написания программ. Delphi относят к средам быстрой разработки программ.
Программы, написанные на Delphi, являются объектно-ориентированными, что приносит свои преимущества и недостатки. Преимущество объектно-ориентированной программы в ее высокой структуризации, следовательно, более понятной. Программа строится на основе классов уже разработанных фирмой Borland, которые облегчают труд программиста, но при этом переносят нагрузку на ЭВМ. Недостатком Delphi является чрезмерное "раздувание" машинного кода программы и как следствие более высокие требования конечной программы к ресурсам и быстродействию ЭВМ.
Язык программирования Си часто называют языком среднего уровня из-за его гибкости и удобства. Данный язык предоставляет использовать во всей полноте все преимущества и возможности операционной среды, такие как управление памятью, потоками процессами. При помощи этого языка удобно осуществлять связь с аппаратными средствами компьютера, что необходимо при программировании подсистемы управления, программа написанная на Си не обладает излишним кодом, как это бы произошло в Delphi, и более быстродейственна.
С++ BUILDER – это достаточно новая среда разработки программ, в том числе и систем управления базами данных. Это сочетание языка объектно-ориентированного программирования C++ с дружественной программисту средой разработки, которая предполагает использование при разработке программ компонентов - готовых элементов интерфейса и элементов, которые обеспечивают многочисленные функции обработки данных (не относящиеся к созданию интерфейса). Большие возможности управления базами данным. BDE (Borland Database Engine) является встроенным средством работы с базами данных. BDE является стандартным программным средством промежуточного уровня для доступа ко всем популярным форматам баз данных. BDE также имеет широкие возможности доступа к базам данных архитектуры клиент-сервер, возможности управления базами данных с помощью языка структурированных запросов SQL (Structured Query Language). Поэтому разработку системы более удобно проводить в среде С++ BUILDER.
2.5. Предварительная оценка технико– экономических показателей
Так как Информационная Система Университета будет работать в системе реального времени и в то же время центральный компьютер будет обрабатывать большое количество информации, то компьютер должен быть максимальным по быстродействию, иметь большой объем памяти и дисковое пространство. В качестве системных ресурсов машины администратора рекомендуется взять процессор – PC Pentium 366, память – 64 Мбайт оперативной памяти, жесткий диск – 3,2 Гбайт, монитор – SVGA или более мощный. Компьютер с такой конфигурацией обойдется университету в 15 тыс. рублей. В качестве операционной системы рекомендуется установить – Windows NT. Покупка операционной системы, такой как Windows NT, обойдется в 5 тыс. рублей.
При правильно построенной политике подачи объявления: преподавателям и студентам бесплатно, объявления рекламного характера сторонних лиц оплачиваются по некоторой тарифной сетке, позволит открыть новую статью доходов университета и окупить все затраты на построение ИСУ.
3. Полномасштабная функциональная схема верхнего уровня ИСУ
Прежде чем разрабатывать функциональную схему следует определить место и положение Информационной Системы Университета в системе обмена информации существующей на данный момент. На сегодняшний день большинство рутинной работы и процесс обучения в университете выполняются на персональных компьютерах. Они расположены в деканатах, кафедрах, учебных аудиториях, почти все компьютеры в университете связаны в одну многофункциональную локальную сеть, или будут связаны в обозримом будущем, которая имеет доступ к глобальной информационной сети Internet /5-8/. Что позволяет быстро и качественно, не прибегая к бумажным технологиям, обмениваться информацией как внутри университета, так и за его пределами.
В одну из основных задач входит определение рационального и обоснованного места ИСУ в данной существующей системе. Учитывая ранее описанные задачи ИСУ и существующую схему обмена информации /9,10/, была разработана схема представленная на рисунке 2.
Внедрение ИСУ в сеть передачи данных


Под центральным компьютером понимается некоторый персональный компьютер на котором работает программа управления и взаимодействия как с нижним уровнем ИСУ так и с удаленными ПК. Данная программа будет именоваться в дальнейшем - "Сервер". Программа, работающая на удаленных ПК в локальной сети – "Клиент".
Следует также четко разграничить верхний и нижний уровень. Под верхним уровнем понимается система управления всей ИСУ. Верхний уровень реализуется в виде программы управления и включает в себя функции управления, слежения и взаимодействия всех частей ИСУ. Нижний уровень, представляет из себя набор устройств, аппаратный интерфейс взаимодействия с верхним уровнем, алгоритмы работы устройств и способы вывода информации.
Как уже было сказано выше, верхний уровень в свою очередь делится на две подсистемы "Сервер" и "Клиент". "Сервер" делится на три уровня.
подсистема управления;
интерфейсная подсистема взаимодействия "Сервера" с администратором системы;
подсистема взаимодействия с "Клиентом".
В приложении 1 представлена функциональная схема с подсистемами управления и интерфейсной подсистемой взаимодействия "Сервера" и администратора системы.
Подсистема взаимодействия с "Клиентом" представлена отдельной схемой в приложении 2.
Функциональная схема "Клиент" представлена в приложении 3.
Задачи подсистемы управления включают надежное функционирование ИСУ, ее устойчивость к различным возмущением из вне, своевременное выполнение всех необходимых функций управления, исключение возможностей потери пакетов, качественное выполнение всех задач реализованных в системе, возможность работы в автономном режиме без вмешательства администратора системы.
Интерфейсная подсистема взаимодействия "Сервера" с администратором системы реализует возможность вмешательства в функционирование работы ИСУ администратора системы, изменение параметров работы ИСУ, получение различной справочной информации, предоставление администратору выполнение функций добавления, удаления и редактирования списка пользователей ИСУ.
Подсистема взаимодействия с "Клиентом" реализовывает функции подачи объявления с удаленной машины их правильный и надежный прием, возможность пользователей, если они зарегистрированы в системе, узнать свой приоритет, список и описание устройств функционирующих в системе.
Подсистема Клиент работающая на удаленной машине реализовывает функции связи с Сервером, а точнее с подсистемой взаимодействия с "Клиентом", получение от сервера списка и описание устройств функционирующих в ИСУ, возможность удаленной отправки объявления в ИСУ.
4. Описание функционирования верхнего уровня ИСУ (Сервер)
4.1. Инициализация системы
Во время запуска системы управление передается процедуре Init, функция которой привести в однозначное соответствие данные, хранящиеся на диске и данные, расположенные в оперативной памяти системы. Все основные переменные, используемые в системе, имеют свои копии на жестком диске, при изменении данных изменения также происходят и на диске, что позволяет при аварийном отключении восстановить ее состояние на момент выхода системы из строя.
Инициализации подлежат следующие переменные:
массив устройств, который содержит данные об устройствах не способных выполнять свои функции на данный момент времени;
так как отключение системы могло произойти во время некоторого сбоя, процедура Init должна выяснить, чем в данный момент занимается каждое устройство нижнего уровня. И произвести инициализацию динамического массива, который в каждый момент времени отображает текущее состояние нижнего уровня. Для этого процедура Init последовательно вызывает процедуру Order;
временный массив объявлений содержит объявления принятых от пользователя или администратора, но не успевших обработаться системой.
4.2. Прием сообщений от нижнего уровня
Любое сообщение, полученное от нижнего уровня, поступает во входной буфер.
После приема сообщения генерируется прерывание, которое вызывает процедуру Datas_up. Задача данной процедуры состоит в обработке сообщения и заполнения массива "Входящих сообщений". Массив представляет собой следующую структуру данных представленную в таблице 1.
Таблица 1 - Структура массива входящих сообщений
|
Переменная |
Тип переменной |
|
Номер устройства |
Integer |
|
Тип сообщения |
Integer |
|
Ошибка |
Integer |
|
Ответ |
Integer |
|
Номер объявления |
Integer |
|
Идентификатор присутствия |
Boolean 0-нет 1-есть |
Для каждого устройства существует свой массив.
Переменные "Тип сообщения", "Ошибка", "Ответ", "Номер объявления" заполняется в зависимости от типа сообщения. "Номер устройства" это не что иное, как адрес источника. Также проверяется "Контрольная сумма" принятого сообщения и переменная "Идентификатор присутствия" принимает логическое значение истина.
Процедура Control постоянно проверяет переменную "Идентификатор присутстви" . Как только данная переменная принимает значение истина, процедура проверяет "Тип сообщени". В зависимости от "Типа сообщения" Control выполняет следующие действия :
"Тип сообщения" = 01.
Control вызывает процедуру Order с параметром "Номер устройств". Order проверяет по "Динамической модел", чем в данный момент должно заниматься это устройство. Если устройство должно выводить некоторое сообщение, то Order формирует сообщение с "Типом сообщения" = 02 и помещает его в массив исходящих сообщений. Если устройство не должно ни чего делать, то Order также формирует сообщение с "Типом сообщения" = 02 но поле "Текст" остается пустым.
"Тип сообщения" = 02.
Если переменная "Ошибка" = 0, то Control обнуляет все переменные в массиве исходящих сообщений. "Массив исходящих объявлений" обнуляются.
Если "Ошибка" =1, переменная "Повтор" в массиве исходящих сообщений принимает значение = 1 и время = 60.
После массив входящих объявлений обнуляется.
"Тип сообщения" = 03.
Если переменная "Ответ" = 0, то переменная "Занят" в "Динамической модели" принимает значение 0.
Если переменная "Ответ" =1, то переменная "Занят" в "Динамической модели" принимает значение =1 и переменная "Номер объявления" в "Динамической модели" = "Номер объявления" в массиве входящих сообщений.
После массивы входящих и исходящих объявлений обнуляются.
"Тип сообщения" = 04.
Переменная "Повтор" в массиве исходящих сообщений принимает значение = 1 и время = 60.
"Массив входящих объявлений" обнуляется.
4.3. Отправка сообщений на нижний уровень
Для отправки сообщения на нижний уровень системы служит процедура Datas_down, которая постоянно проверяет значения переменных "Идентификатор присутствия" в массиве исходящих сообщений. Если данная переменная имеет значение истина, то Datas_down формирует пакет в зависимости от "Типа сообщения" и помещает его в выходной буфер.
"Массив исходящих сообщений" имеет следующую структуру данных представленную в таблице 2.
Таблица 2 - Структура массива исходящих сообщений
|
Переменная |
Тип переменной |
|
Номер устройства |
Integer |
|
Тип сообщения |
Integer |
|
Текст объявления |
String |
|
Номер объявления |
Integer |
|
Идентификатор присутствия |
Boolean 0-нет 1-есть |
|
Повтор |
Integer принимает значения 0,1 или 2 |
|
Время |
Integer принимает значения от 60 до 0 |
Для каждого устройства существует свой массив.
Если пришло время вывода объявления находящегося в массиве не опубликованных объявлений, то процедура Control формирует сообщение с "Типом сообщения" 02. Формирование сообщения происходит путем считывания данных из массива неопубликованных объявлений и заполнение массива исходящих сообщений. Переменной "Повтор" в массиве исходящих сообщений присваивается значение = 0, а переменной "Время" значение = 60. Также переменной "Идентификатор присутствия" присваивается значение истина.
4.4. Другие функции выполняемые в системе
В системе могут быть случаи, когда устройство нижнего уровня не отвечает на запросы. Чтобы распознать данные устройства и впредь к ним не обращаться следует контролировать все пакеты уходящие на нижний уровень. Данную функцию выполняет процедура Waiting. После того как система сформировала сообщение и записала его в массив исходящих сообщений, процедура Waiting начинает каждую секунду уменьшать значение переменной "Время" в массиве исходящих сообщений, от 60 до 0. Как только значение достигло 0, происходит проверка переменной "Повтор". Если данная переменная < 3, то ее значение увеличивается на 1 и значение "Время" = 60. В случае если переменная "Повтор" достигло значения = 3, то Waiting обнуляет массив исходящих сообщений и делает соответствующую пометку в массиве не работающих устройств.
Обработкой поступивших сообщений занимается процедура Processing. Она берет поступившие сообщения из временного массива объявлений, обрабатывает их и добавляет в массив всех объявлений находящийся на диске. В случае если пользователь или администратор системы выбрали устройство, которое помечено как неработающее, Processing формирует сообщение с типом сообщения = 06 для удаленного пользователя или выводит его на экран для администратора системы. Далее данная процедура просматривает объявления в массиве всех объявлений, и если подошло время, для вывода объявления, помещает данное объявление в массив неопубликованных объявлений.
При отправки сообщения с "типом сообщения" = 06, Processing проверяет устройства, которые выбрал "Клиент". Устройства, на которые клиент хочет передать свое объявление представляет собой 2 байтное число (см. рис. 3).
Кодирование устройств
2-х байтная строка устройств
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Рис. 3
По битам, которые помечены 1, процедура определяет номера устройств выбранных клиентом, сравнивает их с массивом устройств. Если устройство на которое необходимо вывести объявление является не работоспособным, то в соответствующие биты переменной "Не работающие устройства" массива исходящих сообщений клиенту принимают значение истинно, т.е. = 1. После этого объявление исправляется и посылается в массив неопубликованных объявлений и записывается на диск.
4.5. Администрирующие функции системы
Во время работы ИСУ человек исполняющий функции администратора способен внести некоторые коррективы в функционирование системы. В частности в его задачу входит изменение, дополнение и удаление пользователей в системе, проводить контроль функционирования устройств нижнего уровня, подключение и отключение данных устройств, оформление объявления с самым высоким приоритетом вывода. Только администратор может получить справочную информацию о состоянии системы в любой момент времени.
За получение справки отвечает процедура Inquiry. В ее функцию входит получение запроса от администратора системы и выдачу информации в некотором структурированном виде. Inquiry имеет доступ ко всем информационным массивам ИСУ хранящимся как на диске так и в оперативной памяти.
Для проведения диагностики нижнего уровня системы по заданию администратора служит процедура Diagnostics. Она формирует сообщения на нижний уровень системы с "Типом сообщения" = 03 и помещает его в массив исходящих сообщений. После посылки сообщения каждому устройству нижнего уровня Diagnostics, выдает сообщение администратору системы о том, что информация, о функционировании системы будет выдана через 4 минуты. Т.к. в случае неправильной работы будет автоматически осуществлены 3 запроса на нижний уровень и ожидание ответа на каждый из них в течении 60 секунд, за правильную работу данной функции отвечает процедура Waiting. После 4 минут процедура Diagnostics выводит содержание массива устройств на экран монитора. Процедура Diagnostics может выводить быструю диагностику устройств нижнего уровня. В этом случае она не формирует сообщения на нижний уровень, а просто выводит содержание массива устройств на экран. Можно принудительно запретить работу некоторого устройства или добавить новое, изменив содержание массива устройств.
Оформление заявки на подачу объявления осуществляет процедура Application. После принятия объявления Application сохраняет его во временном массиве объявлений.
Процедура Work_DB осуществляет полный доступ к базе данных пользователей и позволяет редактировать, удалять и добавлять записи пользователей.
4.6. Функции работы с клиентом
Также как и с нижним уровнем, все сообщения приходящие от "Клиента" помещаются во входной буфер. После чего с помощью процедуры Datas_up2, которая активизируется прерыванием, данные разбиваются и помещаются во входящий массив сообщений клиента. Данный массив имеет следующую структуру представленную в таблице 3.
Таблица 3 - Структура массива входящих сообщений клиента
|
Переменная |
Тип переменной |
|
Тип сообщения |
Integer |
|
Текст объявления |
String |
|
Сетевое имя |
String |
|
Пароль |
String |
|
Контрольная сумма |
Boolean 0-правильная 1-неправильная |
|
Идентификатор присутствия |
Boolean 0-нет 1-есть |
|
Приоритет |
Integer |
|
Устройство |
Integer |
|
Адрес источника |
Integer |
Все переменные заполняются в зависимости от типа сообщения, т.к. каждый тип сообщения имеет свой формат пакета. Также вычисляется "Контрольная сумма" принятого сообщения и переменная "Идентификатор присутствия" принимает логическое значение истина.
Массив имеет 5 копий для сообщений принятых, но не обработанных Interaction. Массив имеет циклическую структуру.
Всю работу по обработке сообщений клиента и ответ на них берет на себя процедура Interaction. Она постоянно опрашивает переменную "Идентификатор присутствия" на наличие истинного значения. Как только данная переменна, принимает значение истинно, Interaction определяет значение переменной "Тип сообщения" и в зависимости от ее значения выполняет необходимые действия.
"Тип сообщения" = 05.
Interaction обращается к "Базе Данных Пользователей" (БДП) и сравнивает имя пользователя и пароль, полученные от "Клиента". В случае если имя пользователя существует в базе данных, и пароль совпадает, Interaction считывает значения приоритета и формирует сообщение Клиенту с Типом сообщения – 05. Переменная "Ошибка" в массиве исходящих сообщений клиенту, значение 0, Сетевое имя – имя переданное "Клиентом", "Приоритет" – приоритет из базы данных.
Если данное "Сетевое имя" не обнаружено в БДП, то процедура формирует сообщение с "Типом сообщения" 05. В поле "Ошибка" значение 1. В поле "Сетевое имя" значение "Гость", "Приоритет" наименьший.
Если "Сетевое имя" существует в базе данных, но пароль не совпадает с паролем отправленным "Клиентом", то Interaction отправляет то же самое сообщение, но в поле "Ошибка" значение 2. "Сетевое имя" также получает значение "Гость" с наименьшим "Приоритетом".
Структура массива исходящих сообщений клиенту представлена в таблице 4.
Таблица 4 - Структура массива исходящих сообщений клиенту
|
Переменная |
Тип переменной |
|
Тип сообщения |
Integer |
|
Текст |
String |
|
Сетевое имя |
String |
|
Приоритет |
Integer |
|
Ошибка |
Integer |
|
Идентификатор присутствия |
Boolean 0-нет 1-есть |
|
Не работающие устройства |
Integer |
|
Адрес приемника |
Integer |
Массив имеет 5 копий для уменьшения периода ожидания во время отправки сообщения "Клиенту".
"Тип сообщения" = 06.
При получении "Сервером" данного сообщения от "Клиента", процедура Interaction заполняет временный массив объявлений, значение переменных данного массива берутся из массива входящих сообщений клиента.
"Тип сообщения" = 07.
Если от "Клиента" пришло сообщение с неправильной контрольной суммой, то "Сервер" формирует сообщение с данным "Типом сообщения", т.е. 07.
"Тип сообщения" =08.
Сообщение посылается "Клиентом" и представляет собой запрос на описание устройств существующих в системе. Interaction считывает из массива устройств, все значения, и формирует сообщение с "Типом сообщения" = 08.
5. Описание функционирования верхнего уровня ИСУ (Клиент)
5.1. Регистрация пользователя
Для того чтобы пользователь имел возможность отправлять объявления, ему следует получить свой приоритет, если он зарегистрирован в системе. Пользователь, не зарегистрированный в системе, получает "Сетевое имя" "Гость" с наименьшим приоритетом.
При запуске "Клиентской" части системы пользователь имеет возможность послать сообщение "Серверу" с "Типом сообщения" = 05. За получение приоритета от сервера отвечает процедура Get_priority. Она запрашивает у пользователя его "Сетевое имя" и "Пароль". После формирует сообщение и посылает его "Серверу".
Get_priority позволяет пользователю получить "Сетевое имя" "Гость" и наименьший приоритет, не устанавливая связи с "Сервером". переменная "Ок", которая говорит о том, что пользователь имеет право отправлять сообщения принимает значение истинно.
Для отправки сообщения "Серверу" Get_priority заполняет массив исходящих сообщений серверу, и устанавливает переменную "Идентификатор присутствия" в истинно. Данный массив имеет следующую структуру представленную в таблице 5.
Таблица 5 - Структура массива исходящих сообщений серверу
|
Переменная |
Тип переменной |
|
Тип сообщения |
Integer |
|
Текст объявления |
String |
|
Сетевое имя |
String |
|
Пароль |
String |
|
Идентификатор присутствия |
Boolean 0-нет 1-есть |
|
Приоритет |
Integer |
|
Устройства |
Integer |
|
Адрес источника |
Integer |
Процедура Datas_down3 постоянно проверяет значение переменной Идентификатор присутствия, если она приняла значение, истинно формирует пакет и помещает его в выходной буфер 3.
5.2. Отправка объявления Серверу
За данную функцию отвечает процедура Send_message. Она запрашивает у пользователя информацию о том когда, на какое устройство и какое объявление надо вывести. Также она проверяет переменную "Ок", в случае истинного значения пользователю разрешено отправлять объявление. После получения всех необходимых данных процедура заполняет массив исходящих сообщений серверу с типом сообщения = 06. И устанавливает переменную "Идентификатор присутствия" в истинное значение.
Информацию об устройствах процедура берет из массива устройств.
Если пользователь хочет обновить свою информацию в массиве устройств, то Send_message формирует сообщение серверу с "Типом сообщения" 08.
5.3. Прием сообщений от Сервера
Любое сообщение, пришедшее от "Сервера" помещается во "Входной буфер3". И генерируется прерывание, которое вызывает процедуру Datas_up 3. данная процедура разбивает принятый пакет и инициализирует переменные в массиве входящих сообщений от сервера. Переменная "Идентификатор присутствия" принимает значение истинно. В задачу данной процедуры включается функция по проверке контрольной суммы принятого пакета. Если контрольная сумма не верна, то переменная "Контрольная сумма" в массиве входящих сообщений от сервера принимает значение истинно. "Массив входящих сообщений от сервера" имеет следующую структуру представленную в таблице 6.
Таблица 6 - Структура массива входящих сообщений от сервера
|
Переменная |
Тип переменной |
|
Тип сообщения |
Integer |
|
Текст |
String |
|
Сетевое имя |
String |
|
Приоритет |
Integer |
|
Ошибка |
Integer |
|
Идентификатор присутствия |
Boolean 0-нет 1-есть |
|
Не работающие устройства |
Integer |
|
Контрольная сумма |
Boolean |
За прием сообщений отвечает процедура Get_message. Она постоянно проверяет переменную "Идентификатор присутствия" в массиве входящих сообщений от сервера. Если данная переменная принимает значение истинно, то процедура проверяет значение "Тип сообщения" и в зависимости от него выполняет определенные действия.
"Тип сообщения" = 05.
Get_message проверяет значение переменной "Ошибка" в массиве входящих сообщений от сервера. Если "Ошибка" = 0, пользователь получает информацию о том, что его "Сетевое имя" и "Пароль" приняты системой и ему разрешено посылать объявления с зарегистрированным заранее приоритетом. "Ошибка" =1, пользователь информируется о том, что его "Сетевое имя" не обнаружено в базе данных пользователей. "Ошибка" = 2, пароль введенный пользователем не верен. В двух последних случаях пользователю будет разрешено посылать сообщения под "Сетевым именем" "Гость" и минимальным приоритетом. Переменная "Ок" принимает значение истинно.
"Тип сообщения" = 06.
Если переменная "Неработающие устройства" в массиве входящих сообщений от сервера = 0, то выводится сообщение пользователю на экран, что его объявление было успешно принято и обработано системой.
Если данная переменная не равна 0, то вычисляется номера бинарных единиц и по массиву устройств определяется не работающие устройства. Выводятся данные устройства, и сообщается пользователю, что его объявление не будет на них выведено.
"Тип сообщения" = 07.
"Сервер" сообщает клиенту, что система приняла сообщение от данного пользователя, но контрольная сумма у принятого сообщения неправильная и просит пользователя повторить сообщение. Get_message выводит соответствующую информацию на экран пользователя.
"Тип сообщения" = 08.
В зависимости от переменной "Текст" в массиве входящих сообщений от сервера процедура Get_message заполняет массив устройств. И информирует об этом пользователя.
6. Входная и выходная информация
Вся информация, циркулирующая в системе, представляет собой некоторые символьные выражения. Всю входную и выходную информацию можно подразделить на информацию обеспечивающую управление, осуществляющую запрос и справочную информацию. Входная и выходная информация группируется по типам и представляет собой пакеты/11/, с помощью которых и осуществляется связь между различными частями системы. В связи с тем, что в системе не должно возникать ни каких непредсказуемых ситуаций, т.е. система должна однозначно реагировать на все типы сообщений полученных ею, были разработаны типы пакетов, которые имеют строгую структуру и представлены в пункте "Формат и структура пакетов циркулирующих в системе". Были рассмотрены и определены все возможные ситуации, возникающие в системе и на каждую ситуацию, определено строгое поведение ИСУ.
Информация и команды, возникающая в системе, зависят от того, что пользователь требует от ИСУ. Основная информация, получаемая от пользователя, это текстовые объявления, которые он хочет опубликовать в системе. В зависимости от того, на какое из устройств произойдет вывод данного объявления, ИСУ преобразовывает его в нужный формат и выводит на устройство вывода /12/.
Существуют различные устройства вывода. Некоторые из них представлены на рисунке 4.
Устройства вывода


Устройства вывода бегущая строка (см. рис. 5), позволяет выводить строчные объявления, при выводе которых возникает иллюзия движения. Движение осуществляется с лева на право, с некоторой установленной скоростью.
Бегущая строка

Текстовое табло

Текстовое табло (см. рис. 6) позволяет выводить текст в любой части экрана, смещать его и создавать иллюзию движения, как и бегущая строка. Основное достоинство текстового табло - позволяет выводить большее количество строк за единицу времени.
Графическое табло

Графическое табло (см. рис. 7) позволяет выводить не только текстовые сообщения но и простую графику. Формирование рисунка может происходить в любом месте табло и зависит только от фантазии создателя объявления и от разрешающей способности графического табло.
Помимо рассмотренных устройств, существует огромное количество приспособлений и устройств для вывода различной информации, как специализированной так и универсальной.
К универсальным относятся все устройства рассмотренные выше. Их особенность заключается в том, что они могут выводить любую информацию, поступающую на входы данных устройств. Эта особенность делает их немного сложнее и дороже, но в тоже время позволяет использовать в полной мере все возможности и приспосабливать их к меняющимся целям и запросам потребителя.
К специализированным устройствам вывода можно отнести устройства, которые выводят только определенную информацию. Примером может служить временные табло, отображающие текущее время. Табло для котировок акций, табло процентных ставок, табло отображающие температуру, влажность. Во время футбольных или баскетбольных матчей, специализированные табло выводят информацию о текущем счете игры. Еще одна особенностей специализированных устройств заключается в том, что они не требуют удаленного управления. Это можно охарактеризовать на примере: измерение температуры воздуха, оцифровывание этого значения и вывод его на табло, осуществляется автоматически в самом устройстве, и не требует ни какого вмешательства из вне.
Любое из данных устройств может быть помещено в систему. Управление может быть централизованно. То есть информация может быть получена из внешних источников, обработана системой и выведена на устройства вывода. Либо как в случае со специализированными устройствами, информация может быть получена самим устройством, им обработана и им же выведена.
7. Формат и структура пакетов, циркулирующих в ИСУ
На рисунке 8 изображен общий формат пакетов, используемых при обмене информацией.
Формат пакета
|
Заголовок пакета |
Адрес источника |
Адрес приемника |
Тип сообщения |
Текст |
Контрольная сумма |
Префикс пакета |
Рис. 8
"Заголовок пакета" и "Префикс пакета" предназначен для выделения пакета из информационного потока и синхронизации приемника и источника.
"Адрес приемника" – это адрес того устройства, которому предназначен пакет.
"Адрес источника" – это адрес того устройства, где был создан пакет.
"Тип сообщения" – информирует приемник о структуре поля "Текст".
"Текст" – текст сообщения.
"Контрольная сумма" – служит для обнаружения ошибок при приеме пакета. Для вычисления контрольной суммы необходимо найти сумму всех байтов полей "Место назначения", "Адрес отправителя", "Тип сообщения" и "Сообщение". Если полученная контрольная сумма будет совпадать с числом заголовок пакета или префикс пакета, то ее нужно инвертировать.
Далее перечислены все типы сообщений существующих в системе.
01 – Нижний уровень информирует верхний о том, что в процессе, каких либо сбоев информация, хранящаяся в оперативной памяти устройства нижнего уровня, имеет неправильную контрольную сумму. Поле "Текст" имеет нулевую длину.
02 – Если сообщение пришло от верхнего уровня, то в поле Текст первые 2 байта номер выводимого объявления, все последующее объявление, которое следует вывести устройством нижнего уровня. Если длина поля "Текст" = 0 то устройство ни чего не должно выводить.
Сообщение, посылаемое устройством нижнего уровня, информирует верхний уровень о правильном приеме сообщения. Поле "Текст" имеет длину в 1 байт. Если значение данного байта = 0, то устройство нижнего уровня правильно приняло сообщения и приступило к его выводу. Если значение данного байта = 1, то сообщение было принято с ошибкой.
03 – Верхний уровень требует информацию о работе данного устройства нижнего уровня. Поле "Текст" имеет нулевую длину.
Сообщение нижнего уровня является ответом за запрос верхнего уровня. Поле "Текст" имеет длину 3 байта. Если значение первого байта = 0, то устройство свободно, 2 и 3 байт также = 0. Если значение первого байта = 1, устройство в данный момент выводит объявление, номер которого помещается во второй и третий байт.
04 – Говорит о том, что было принято сообщение с неправильной контрольной суммой и является запросом для повторной передачи сообщения. Поле "Текст" имеет нулевую длину.
05 – Клиент посылает запрос серверу с просьбой проверить пользователя и выслать его приоритет. Поле "Текст" состоит из 20 байт, в первых 10 байтах находиться "Сетевое имя" пользователя, во вторых 10 байтах находиться его пароль.
Ответ "Сервера" на запрос клиента. В поле Текст 13 байт.1 байт – ошибка, 0 - ошибки нет , 1 - не существует данного сетевого имени в базе данных пользователя, 2 - сетевое имя обнаружено, но пароль не совпадает. 10 байт "Сетевое имя", 2 байта приоритет.
06 – "Клиент" посылает "Серверу" объявление, которое он хочет опубликовать. Поле "Текст" 2 байта приоритет, 2 байта устройства, 2 байта время, остальное под текст объявления.
Ответ "Cервера". Поле "Текст" из 2 байт. Если значение в данных байтах = 0, то объявление было успешно принято и будет опубликовано. Если не = 0 то смотрится по бинарной 1 и говорит о том что данное устройство не работоспособно.
07 – Посылается только "Сервером" и говорит о том, что было принято сообщение с неправильной контрольной суммой и является запросом для повторной передачи сообщения. Поле "Текст" имеет нулевую длину.
08 – "Клиент" требует список устройств и описание их. Поле "Текст" пусто.
Сервер отвечает на запрос. Поле "Текст" – 1 байт работает или не работает устройство, 1 байта номер устройства в массиве устройств. В данном случае под массивом устройств понимают 2 байтное число, которое как бы кодирует список устройств.200 байт на описание, данная структура может повторяться столько раз, сколько устройств в системе, но не больше 16. Данная информация находится в массиве устройств.
8. Модульная схема алгоритмов
8.1. Алгоритм процедуры (Control)
Алгоритм /13,14/ представлен на рисунках 9 - 12.
Алгоритм процедуры (Control)
 Рис. 9
Рис. 9
Данная процедура является основным звеном для связи верхнего уровня ИСУ с нижним уровнем. В ее задачу входит обработка всех сообщений принятых от нижнего уровня и формирование и отправка сообщений на нижний уровень.
Описание переменных присутствующих на блок схеме:
i – счетчик(Номер устройства);
id[i](вх) – "Идентификатор присутствия" по номеру записи в массиве входящих сообщений;
id[i](вых)
– "Идентификатор присутствия" по
номеру записи в массиве исходящих
сообщений;
n – количество устройств нижнего уровня в ИСУ .
Рис. 10
Рис. 11
Рис. 12
8.2. Алгоритм процедуры (Order)
Данная процедура вызывается в том случае, если по каким либо причинам, система считает, что нижний и верхний уровень действуют не синхронно. Т.е. информация, хранящаяся в динамическом массиве верхнего уровня, не соответствует действительности. Для того чтобы восстановить правдивую информацию вызывается данная процедура с параметром "Номер устройства". Order формирует пакет на нижний уровень с запросом, чем занимается данное устройство. Если необходимо опросить все устройства нижнего уровня, процедура вызывается в цикле с новым параметром.
Процедура вызывается с параметром:
i – Переданный параметр ("Номер устройства").
Алгоритм представлен на рисунке 13.
Алгоритм
процедуры (Order)
Рис. 13
8.3. Алгоритм процедуры перемещения данных (Datas_up)
Во входном буфере находиться принятый пакет сообщения. Его формат и структура описаны в пункте "Формат и структура пакетов циркулирующих в системе". Задача данной процедуры идентифицировать данный пакет, разбить его и заполнить массив входящих сообщений.
Описание переменных присутствующих на блок схеме:
N – "Номер сообщения" (служит для заполнения массива сообщения в системе).
Алгоритм представлен на рисунке 14.
Алгоритм
процедуры перемещения данных (Datas_up)
Рис. 14
8.4. Алгоритм процедуры перемещения данных (Datas_Down)
Данная процедура занимается формированием пакетов и отправкой их на нижний уровень (см. рис. 15). Как только в массиве исходящих сообщений появилось сообщение, которое необходимо направить на нижний уровень, процедура формирует текстовую строку и помещает ее в выходной буфер.
Формат и структура пакетов циркулирующих в ИСУ описана в одноименном пункте. Для простоты описания алгоритма были введены следующие обозначения:
N –
Количество устройств вывода в ИСУ; 1 -
"Заголовок пакета"; 2 - "Адрес
источника"; 3 - "Адрес приемника";
4 - "Тип сообщения"; 5 - "Текст";
6 - "Контрольная сумма"; 7 - "Префикс
пакета".
Алгоритм процедуры перемещения данных (Datas_Down)
Рис. 15
8.5. Алгоритм инициализации системы(Init)
Алгоритм представлен на рисунке 16.
Алгоритм
инициализации системы(Init)
Рис. 16
8.6. Алгоритм процедуры ожидания (Waiting)
Алгоритм представлен на рисунке 17.
Алгоритм процедуры ожидания (Waiting)
Рис. 17
8.7. Алгоритм процедуры обработки объявлений (Processing)
Все объявления принятые системой помещаются во временный массив объявлений. После чего с помощью процедуры Processing (см. рис. 18 - 21) они обрабатываются и помещаются в базу данных объявлений (массив объявлений). Также процедура выполняет одну из важнейших функций, а именно определяет время вывода сообщения и помещает его в массив неопубликованных объявлений. Исключает коллизии, т.е. если два разных сообщения должны быть опубликованы в одно и тоже время, данная процедура определяет приоритеты и принимает решение о первоочередном выводе того или иного объявления.
Переменные используемые в процедуре:
временный массив представляет собой массив записей, состоящий из 16 элементов. В каждой записи находиться два поля 1- "Номер устройства" и 2 – "Номер объявления". Причем 1-вая строка в каждой записи содержит значение количества объявлений, время опубликования которых наступило, но по каким либо причинам они не были опубликованы;
J – номер временного массива;
К- номер строки;
Мах – максимальный приоритет;
МахК – строка где находится максимальный приоритет.
Алгоритм
процедуры обработки объявлений
(Processing)
Рис. 18
Рис. 19
Рис. 20
Рис. 21
8.8. Алгоритм процедуры взаимодействия с удаленным клиентом (Interaction)
Алгоритм представлен на рисунках 22 - 26.
Условное обозначение:
Mas1=Массив входящих сообщений клиента;
Mas2=Массив исходящих сообщений клиенту;
Mas=Временный массив объявлений.
Алгоритм процедуры взаимодействия с удаленным клиентом (Interaction)
Рис. 22
Послать
сообщение с Типом сообщения =07
Рис. 23
Обработать сообщение с Типом сообщения =05
Рис. 24
Рис. 25
Рис. 26
8.9. Алгоритм процедуры получения приоритета (Get_priority)
Алгоритм представлен на рисунке 27.
Условные обозначения:
Mas1=Массив исходящих сообщений серверу;
Mas2=Массив входящих сообщений от сервера.
Алгоритм
процедуры получения приоритета
(Get_priority)
Рис. 27
8.10. Алгоритм процедуры приема сообщения (Get_message)
Алгоритм представлен на рисунках 28 - 31.
Алгоритм
процедуры приема сообщения (Get_message)
Рис. 28
Рис. 29
Рис. 30
Рис. 31
8.11. Алгоритм процедуры отправки объявления (Send_message)
Алгоритм
процедуры отправки объявления
(Send_message)
Алгоритм представлен на рисунке 32.
8.12. Другие процедуры ИСУ
Алгоритмы процедур Datas_up2, Datas_up3, Datas_Down2 и Datas_Down3 по своим выполняемым действиям аналогичны процедурам Datas_up и Datas_Down, по этой причине были выпущены из рассмотрения. Описание выполняемых функций и способов их реализации без построения модульной схемы представлены в выше лежащих главах дипломного проекта.
Проверка на завершение представлена на рисунке 33.
Рис. 33
9. Описание информационных массивов
9.1. Информационные массивы "Сервера"
Некоторые информационные массивы, существующие в системе, были описаны выше. Помимо них в системе представлены следующие структуры данных.
9.1.1. Массив объявлений
Структура массива "Массив объявлений" представлена в таблице 7.
Таблица 7 - Массив объявлений
|
Название поля |
Условное обозначение |
Размерность |
|
Идентификатор устройств |
Status_bar |
Integer |
|
Время начала вывода сообщения |
Time_B |
Data |
|
Текст сообщения |
Text |
Blob |
|
Приоритет сообщения |
Priority |
Integer |
|
Адрес источника |
Login |
String |
"Идентификатор устройств" - представляет собой двух байтовую структуру, которая кодирует все устройства в системе. Если пользователь выбрал то или иное устройство, то некоторый бит Идентификатора устройств, принимает значение бинарной единицы.
9.1.2. Динамический массив
Данный массив содержит информацию о функционировании нижнего уровня в любой момент времени. В случае любого сбоя или по запросу, можно обновить или получить необходимую информации о функционировании устройства нижнего уровня в любой момент времени. Структура динамического массива представлена в таблице 8.
Таблица 8 - Структура динамического массива
|
Название поля |
Размерность |
|
Номер устройства |
Integer |
|
Занят |
Boolean |
|
Номер объявления |
Integer |
Данный массив представляет собой массив записей по количеству имеющихся устройств. Номер устройства идентифицирует устройство нижнего уровня. Переменная "Занят" говорит о функционировании устройства в данный момент времени. Если переменная "Занят" имеет значение истинно в "Номер объявления" находится номер объявления, которое устройство выводит в данный момент времени.
9.1.3. Оперативная справка
Содержит массив, состоящий из 60 элементов динамического массива. Данный массив служит для оперативной выдачи информации о функционировании системы за последний час. Оперативная справка имеет циклическую структуру. При начале каждого цикла вся информация, содержащаяся в массиве, сохраняется на диске, в долгосрочной справке.
9.1.4. Долгосрочная справка
Массив, содержащий сведения, о функционировании нижнего уровня системы начиная с начала жизненного цикла ИСУ. Служит для анализа функционирования системы в любой момент времени или за некоторый промежуток.
9.1.5. Массив сообщений в системе
Любое сообщение, входящее в систему или исходящее из нее преобразуется в тип String и помещается в массив сообщений в системе. Который имеет циклическую структуру и содержит 100 элементов. При заполнении всех 100 элементов, массив копируется на диск и добавляется к массиву сообщений. После чего заполнение массива сообщений в системе начинается заново.
9.1.6. Массив сообщений
Содержит все сообщения в системе начиная с момента запуска системы и служит для анализа функционирования системы в любой момент времени на протяжении всего жизненного цикла ИСУ.
9.1.7. Временный массив объявлений
Все объявления принятые системой помещаются во временный массив объявлений и имеет такую же структуру, как и массив объявлений представленную в таблице 7. Данный массив состоит из 5 записей и служит для исключения возможности потери объявления принятых системой. Т.е. если система на данный момент времени выполняет, какую либо функцию, и не имеет возможности обработать объявления пришедшее в ИСУ, то данное объявление помещается во временный массив объявлений для последующей обработки. Массив имеет циклическую структуру и по мере обработки принятого объявления, объявление удаляется или точнее переносится в массив "Массив объявлений".
9.1.8. Массив не опубликованных объявлений
Данный массив содержит информацию об объявлениях, которые следует выводить в данный момент времени. Имеет структуру представленную в таблице 9.
Таблица 9 - Массив не опубликованных объявлений
|
Название поля |
Размерность |
|
Номер устройства |
Integer |
|
Номер объявления |
Integer |
|
Идентификатор присутствия |
Boolean |
Количество записей в данном массиве равно количеству устройств в системе. Процедура Processing отвечает за заполнения массива не опубликованных объявлений. Как только приходит время опубликования какого либо объявления, она помещает номер объявления в "Номер объявления" и переменная "Идентификатор присутствия" принимает значение истинно.
9.1.9. Устройства
Данный массив описывает все устройства существующие в системе. Структура его представлена в таблице 10.
Таблица 10 - Устройства
|
Название поля |
Размерность |
|
Номер устройства |
Integer |
|
Физический адрес устройства в сети |
Long Integer |
|
Не работает |
Boolean |
|
Описание |
String |
"Номер устройства" однозначно идентифицирует устройство в системе. "Не работает" показывает способно устройство выполнять свои функции на данный момент времени. Описание содержит краткую характеристику устройства. В данную переменную можно поместить ответы на вопросы : Что за устройство, где расположено и др.
На диске содержится копия массива "Устройства". Это позволяет в случае, каких либо неполадок оперативно восстановить массив "Устройства".
9.1.10. База данных пользователей
База данных пользователей служит для хранения информации обо всех клиентах, которые пользуются услугами ИСУ. Изменение, удаление, добавление записей к "Базе данных пользователя" имеет право только администратор системы. База данных может быть как текстовый файл с необходимой информацией так и специализированной базой данных доступ к которой возможен только по средствам предоставляемым Системой Управления Базой Данных или SQL запросами.
Структура Базы данных пользователей представлена в таблице 11.
Таблица 11 - База данных пользователей
|
Название поля |
Условное обозначение |
Размерность |
|
№ |
Number |
Integer |
|
Фамилия |
Last_name |
String |
|
Имя |
Firs_name |
String |
|
Отчество |
Patronymic |
String |
|
Имя в сети |
Login |
String |
|
Приоритет |
Priority |
Integer |
|
Пароль |
Password |
String |
|
Запретить подачу объявлений |
Forbid |
Boolean |
9.2. Информационные массивы Клиента
Массивы, входящие сообщения от сервера и исходящие сообщения серверу описаны в главе "Описание функционирования верхнего уровня ИСУ (Клиент) ".
Как и "Сервер", "Клиент" имеет массив "Устройств". Данный массив копируется с "Сервера" с помощью запроса с "Типом сообщения" 08.
Клиент также постоянно оперирует с переменными "Сетевое имя", "Приоритет", "Пароль", "Ок". Они служат для получения права опубликования своих объявлений в системе, и для отправки и получения пакетов от сервера.
10. Надежность ПО
10.1. Аналитические модели надежности
Аналитическое /15-17/ моделирование НПС включает четыре шага:
определение предположений, связанных с процедурой тестирования ПС;
разработка или выбор аналитической модели, базирующейся на предположениях о процедуре тестирования;
выбор параметров моделей с использованием полученных данных;
применение модели - расчет количественных показателей надежности по модели.
10.2. Динамические модели надежности
Модель Шумана. Исходные данные для модели Шумана, которая относится к динамическим моделям дискретного времени, собираются в процессе тестирования ПС в течение фиксированных или случайных временных интервалов. Каждый интервал - это стадия, на которой выполняется последовательность тестов и фиксируется некоторое число ошибок.
Модель Шумана может быть использована при определенным образом организованной процедуре тестирования. Использование модели Шумана предполагает, что тестирование проводится в несколько этапов. Каждый этап представляет собой выполнение программы на полном комплексе разработанных тестовых данных. Выявленные ошибки регистрируются (собирается статистика об ошибках), но не исправляются. По завершении этапа на основе собранных данных о поведении ПС на очередном этапе тестирования может быть использована модель Шумана для расчета количественных показателей надежности. После этого исправляются ошибки, обнаруженные на предыдущем этапе, при необходимости корректируются тестовые наборы и проводится новый этап тестирования. При использовании модели Шумана предполагается, что исходное количество ошибок в программе постоянно и в процессе тестирования может уменьшаться по мере того, как ошибки выявляются и исправляются. Новые ошибки при корректировке не вносятся. Скорость обнаружения ошибок пропорциональна числу оставшихся ошибок. Общее число машинных инструкций в рамках одного этапа тестирования постоянно.
Предполагается, что до начала тестирования в ПС имеется Е>т> ошибок. В течение времени тестирования t обнаруживается e>c> ошибок в расчете на команду в машинном языке.
Таким образом, удельное число ошибок на одну машинную команду, оставшихся в системе после т времени тестирования, равно:
>
 >,
(1)
>,
(1)
где I>T> — общее число машинных команд, которое предполагается постоянным в рамках этапа тестирования.
Автор предполагает, что значение функции частоты отказов Z(t) пропорционально числу ошибок, оставшихся в ПС после израсходованного на тестирование времени t:
> >,
(2)
>,
(2)
где С — некоторая константа;
t — время работы ПС без отказа.
Тогда, если время работы ПС без отказа 1 отсчитывается от точки t = 0, а t остается фиксированным, функция надежности, или вероятность безотказной работы на интервале времени от 0 до t, равна:
> >;
(3)
>;
(3)
>
 >.
(4)
>.
(4)
Из величин, входящих в формулы
(3) и (4), не известны начальное значение
ошибок в ПС (Е>T>) и коэффициент
пропорциональности - С. Для их
определения прибегают к следующим
рассуждениям. В процессе тестирования
собирается информация о времени и
количестве ошибок на каждом прогоне,
т.е. общее время тестирования> >t
складывается из времени каждого прогона:
>t
складывается из времени каждого прогона:
> >.
(5)
>.
(5)
Предполагая, что интенсивность появления ошибок постоянна и равна l, можно вычислить ее как число ошибок в единицу времени:
> >,
(6)
>,
(6)
где А>i> — количество ошибок на i-м прогоне.
> >.
(7)
>.
(7)
Имея данные для двух различных моментов тестирования t>a> и t>b>, которые выбираются произвольно с учетом требования, чтобы e>c>(t>b>)<e> c>(t>A>) можно сопоставить уравнения (4) и (7) при:
> >
, (8)
>
, (8)
> >.
(9)
>.
(9)
Вычисляя отношения (8) и (9), получим:
> >.
(10)
>.
(10)
Подставив полученную оценку параметров E>T>, в выражение (8), получим оценку для второго неизвестного параметра:
> >.
(11)
>.
(11)
Получив неизвестные Еt и С, можно рассчитать надежность программы по формуле (3).
Позднее автором предложена модифицированная модель, не учитывающая число машинных команд, т.е. независимая от I>T>
Функция частоты отказов в течение 1-го интервала тестирования остается постоянной и равна:
> >,
t³0,
i=1,2,…m. (12)
>,
t³0,
i=1,2,…m. (12)
Известные параметры модели Е>T> и С автор предлагает вычислять из следующих соотношений:
> >,
(13)
>,
(13)
> >,
(14)
>,
(14)
где t>i>( — время i-го прогона (время i-го интервала);
m>i>’ — число прогонов, завершившихся отказом в i-ом интервале (число ошибок в i-м интервале);
m — общее число тестовых интервалов;
n>i> — общее число ошибок, обнаруженных (но не включенных) к i-му интервалу.
Все эти данные можно получить в ходе тестирования. Вычислив значения параметров Е>t> и С, можно определить показатели:
число оставшихся ошибок в ПС;
N>T>=Е>T>-n; (15)
надежность:
> >,
t>0. (16)
>,
t>0. (16)
Достоинство этой модели по сравнению с предыдущей заключается в том, что можно исправлять ошибки, внося изменения в текст программы в ходе тестирования, не разбивая процесс на этапы, чтобы удовлетворить требованию постоянства числа машинных инструкций.
Модель Lа Раdula. По этой модели выполнение последовательности тестов производится в т этапов. Каждый этап заканчивается внесением изменений (исправлений) в ПС. Возрастающая функция надежности базируется на числе ошибок, обнаруженных в ходе каждого тестового прогона.
Надежность ПС в течение i-го этапа:
> >,
i = 1,2,3,…, (17)
>,
i = 1,2,3,…, (17)
где А—параметр роста;
> >
при i ® ¥.Т.е
R(¥) - предельная
надежность ПС.
>
при i ® ¥.Т.е
R(¥) - предельная
надежность ПС.
Эти неизвестные величины автор предлагает вычислить, решив следующие уравнения:
> >,
(18)
>,
(18)
> >,
(19)
>,
(19)
где S>i>. — число тестов;
m>i>, — число отказов во время i-го этапа:
т — число этапов;
i=1,2, ...,т.
Определяемый по этой модели показатель есть надежность ПС на i-м этапе:
> >,
i = m+1, m+2 … (20)
>,
i = m+1, m+2 … (20)
Преимущество модели заключается в том, что она является прогнозной и, основываясь на данных, полученных в ходе тестирования, дает возможность предсказать вероятность безотказной работы программы на последующих этапах ее выполнения.
Модель Джелинского-Моранды. относится к динамическим моделям непрерывного времени. Исходные данные для использования этой модели собираются в процессе тестирования ПС. При этом фиксируется время до очередного отказа. Основное положение, на котором базируется модель, заключается в том, что значение интервалов времени тестирования между обнаружением двух ошибок имеет экспоненциальное распределение с частотой ошибок (или интенсивностью отказов), пропорциональной числу еще не выявленных ошибок. Каждая обнаруженная ошибка устраняется, число оставшихся ошибок уменьшается на единицу.
Функция плотности распределения времени обнаружения 1-й ошибки, отсчитываемого от момента выявления 1-1-и ошибки, имеет вид:
> >,
(21)
>,
(21)
где l>i> — частота отказов (интенсивность отказов), которая пропорциональна числу еще не выявленных ошибок в программе:
> >
(22)
>
(22)
где N — число ошибок, первоначально присутствующих в программе; С — коэффициент пропорциональности.
Наиболее вероятные значения
величин >
 >
и >
>
и >
 >(оценка
максимального правдоподобия) можно
определить на основе данных, полученных
при тестировании. Для этого фиксируют
время выполнения программы до очередного
отказа (t>1>, t>2>, t>3>, … t>k>,).
>(оценка
максимального правдоподобия) можно
определить на основе данных, полученных
при тестировании. Для этого фиксируют
время выполнения программы до очередного
отказа (t>1>, t>2>, t>3>, … t>k>,).
Значения >
>
и >
>
предлагается получить, решив систему
уравнений:
> >,
(23)
>,
(23)
> >,
(24)
>,
(24)
где
Q=В/АК;> >;>
>;> >.
(25)
>.
(25)
Поскольку полученные значения
>
>
и >
>
- вероятностные и точность их зависит
от количества интервалов тестирования
(или количества ошибок), найденных к
моменту оценки надежности,
асимптотические оценки дисперсий авторы
предлагают определить с помощью следующих
формул:
> >,
(26)
>,
(26)
> >,
(27)
>,
(27)
где
D = KS/C2 и >
 >.
(28)
>.
(28)
Чтобы получить числовые значения
l>i> нужно подставить
вместо N и С их возможные значения >
>
и >
>.
Рассчитав К значений по формуле (22)
и подставив их в формулу (21), можно
определить вероятность безотказной
работы на различных временных
интервалах. На основе полученных
расчетных данных строится график
зависимости вероятности безотказной
работы от времени.
Модель Шика-Волвертона. Модификация модели Джелинского-Моранды для случая возникновения на рассматриваемом интервале более одной ошибки предложена Волвертоном и Шиком. При этом считается, что исправление ошибок производится лишь после истечения интервала времени, на котором они возникли. В основе модели Шика-Волвертона лежит предположение, согласно которому частота ошибок пропорциональна не только количеству ошибок в программах, но и времени тестирования, т.е. вероятность обнаружения ошибок с течением времени возрастает. Частота ошибок (интенсивность обнаружения ошибок) l>i>, предполагается постоянной в течение интервала времени t>i>, и пропорциональна числу ошибок, оставшихся в программе по истечении (i - 1)-го интервала; но она пропорциональна также и суммарному времени, уже затраченному на тестирование (включая среднее время выполнения программы в текущем интервале):
> >.
(29)
>.
(29)
В данной модели наблюдаемым событием является число ошибок, обнаруживаемых в заданном временном интервале, а не время ожидания каждой ошибки, как это было для модели Желинского-Моранды. В связи с этим модель относят к группе дискретных динамических моделей, а уравнения для определения С и N имеют несколько иной вид:
> >
, (30)
>
, (30)
где
> >,
(31)
>,
(31)
> >.
(32)
>.
(32)
t>i> — продолжительность временного интервала, в котором наблюдается М>i> ошибок;
Т>i-1> — время, накопленное за (i—1) интервалов:
> >,
T>0>=0 . (33)
>,
T>0>=0 . (33)
n>i-1> — суммарное число ошибок, обнаруженных за период от первого до (i -1)-го интервала времени включительно:
> >,
n>0>=0 . (34)
>,
n>0>=0 . (34)
М — общее число временных интервалов;
> >
— суммарное число обнаруженных
ошибок. (35)
>
— суммарное число обнаруженных
ошибок. (35)
При М = 1 уравнения (30) приобретают вид уравнений (21).
Таким образом, модель Джелинского-Моранды является частным случаем модели Шика-Волвертона для случая, когда при тестировании фиксируется время до появления очередной ошибки.
Модель Муса. Модель Муса относят к динамическим моделям непрерывного времени. Это значит, что в процессе тестирования фиксируется время выполнения программы (тестового прогона) до очередного отказа. Но считается, что не всякая ошибка ПС может вызвать отказ, поэтому допускается обнаружение более одной ошибки при выполнении программы до возникновения очередного отказа.
Считается, что на протяжении всего жизненного цикла ПС может произойти М>0> отказов и при этом будут выявлены все N>0> ошибки, которые присутствовали в ПС до начала тестирования.
Общее число отказов Мо связано с первоначальным числом ошибок N>0> соотношением
N>0> = ВМ>0>, (36)
где В — коэффициент уменьшения числя ошибок.
В момент, когда производится оценка надежности, после проведения тестирования, на которое потрачено определенное время t, зафиксировано m отказов и выявлено п ошибок.
Тогда из соотношения:
п=Вт (15) , (37)
можно определить коэффициент уменьшения числа ошибок В как число, характеризующее количество устраненных ошибок, приходящихся на один отказ.
В модели Муса различают два вида времени:
1) суммарное время функционирования t, которое учитывает чистое время тестирования до контрольного момента, когда производится оценка надежности;
2) оперативное время t- время выполнения программы, планируемое от контрольного момента и далее, при условии, что дальнейшего устранения ошибок не будет (время безотказной работы в процессе эксплуатации).
Для суммарного времени функционирования t предполагается:
интенсивность отказов пропорциональна числу не устраненных ошибок;
скорость изменения числа устраненных ошибок, измеряемая относительно суммарного времени функционирования,. пропорциональна интенсивности отказов.
Один из основных показателей надежности, который рассчитывается по модели Муса, - средняя наработка на отказ. Этот показатель определяется как математическое ожидание временного интервала между последовательными отказами и связан с надежностью:
> >,
(38)
>,
(38)
где t — время работы до отказа.
Если интенсивность отказов постоянна (т.е. когда длительность интервалов между последовательными отказами имеет экспоненциальное распределение), то средняя наработка на отказ обратно пропорциональна интенсивности отказов. По модели Муса средняя наработка на отказ зависит от суммарного времени функционирования t:
> >,
(39)
>,
(39)
где T>0> — средняя наработка на отказ в начале испытаний (тестирования);
С - коэффициент сжатия тестов, который вводится для устранения избыточности при тестировании. Если, например, один час тестирования соответствует 12 ч работы в реальных условиях, то коэффициент сжатия тестов равен 12.
Параметр То - средняя наработка на отказ до начала тестирования, можно предсказать из следующего соотношения:
> >,
(40)
>,
(40)
где f — средняя скорость исполнения программы, отнесенная к числу команд (операторов);
К — коэффициент проявления ошибок, связывающий частоту возникновения ошибок со "скоростью ошибок", которая представляет собой скорость, с которой бы встречались ошибки программы, если бы программа выполнялась линейно (последовательно по командам). В настоящее время значение К приходится определять эмпирическим путем по однотипным программам. Его значение изменяется от 1.54*10-7 до 3.99*10-7;
N>0> — начальное число ошибок — можно рассчитать с помощью другой модели, позволяющей определить эту величину на основе статистических данных, полученных при тестировании (например, модель Шумана). Надежность R для оперативного периода t выражается равенством:
> >.
(41)
>.
(41)
Если в договоре с заказчиком оговорена требуемая величина наработки на отказ Т>F>, то можно определить число отказов Dm и дополнительное время функционирования (тестирования) D t, обеспечивающее заданное Т>F>. Их можно рассчитать по формулам:
> >,
(42)
>,
(42)
> >.
(43)
>.
(43)
По результатам тестовых испытаний можно определить значение коэффициента В из соотношения (37) и М>0> - из соотношения (34). По договорной величине требуемой средней наработки на отказ Т>F> и рассчитанной по модели Муса текущей средней наработки на отказ Т можно сделать заключение о необходимости продолжать или, возможно, закончить тестирование программ. В случае необходимости продолжения работ по тестированию для достижения требуемой средней наработки на отказ модель дает возможность предсказать число возможных отказов Dm (формула (42)) и дополнительное время тестирования D t (формула (43)).
Модель переходных вероятностей. Эта модель основана на марковском процессе, протекающем в дискретной системе с непрерывным временем.
Процесс, протекающий в системе, называется марковским (или процессом без последствий), если для каждого момента времени вероятность любого состояния системы в будущем зависит только от состояния системы в настоящее время t>0> и не зависит от того, каким образом система пришла в это состояние. Процесс тестирования ПС рассматривается как марковский процесс.
В начальный момент тестирования (t=0) в ПС было n ошибок. Предполагается, что в процессе тестирования выявляется по одной ошибке. Тогда последовательность состояний системы (n, n-1, n-2, n-3} и т.д. соответствует периодам времени, когда предыдущая ошибка уже исправлена, а новая еще не обнаружена. Например, в состоянии n-5 пятая ошибка уже исправлена, а шестая еще не обнаружена.
Последовательность состояний {т, т-1, т-2, т-3 и т.д.} соответствует периодам времени, когда ошибки исправляются. Например, в состоянии т-1 вторая ошибка уже обнаружена, но еще не исправлена. Ошибки обнаруживаются с интенсивностью l, а исправляются с интенсивностью m.
Предположим, в какой-то момент времени процесс тестирования остановился. Совокупность возможных состояний системы будет: 5={ n, т, n-1, n-1, n-2, m-2, . . . }.
Система может переходить из одного состояния в другое с определенной вероятностью P>ij>. Время перехода системы из одного состояния в другое бесконечно мало.
Вероятность перехода из состояния n-k в состояние m-k есть l>n-k>>D>>t> ( для k = 0, 1, 2, ... . Соответственно вероятность перехода из состояния m-k в состояние n-k-1 будет m>m-k>>D>>t> для k=0,1,2,....
Общая схема модели представлена на рисунке 34. Если считать, что l>1> и m>1> зависят от текущего состояния системы, то можно составить матрицу переходных вероятностей представленной в таблице 12.
Общая схема модели

Рис. 34
Таблица 12 - Модель многих состояний ПС
|
1-l>n>Dt |
l>n>Dt |
0 |
0 |
0 … |
0 … |
|
|
0 |
1-m>m>Dt |
m>m>Dt |
0 |
0 … |
0 … |
|
|
0 |
0 |
1-l>n-1>Dt |
l>n-1>Dt |
|||
|
0 |
0 |
0 |
1-m>m-1>Dt |
|||
|
……………… |
……………… |
……………… |
……………… |
……………. |
1-l>n-k>Dt |
l>n-k>Dt |
|
0 |
1-m>m-k>Dt |
Пусть S'(t) - случайная переменная, которой обозначено состояние системы в момент времени t.
В любой момент времени система может находиться в двух возможных состояниях: работоспособном либо неработоспособном (момент исправления очередной ошибки).
Вероятности нахождения системы в том или ином состоянии определяются как:
Pn-k(t) = P(S’(t)=n-k), k=1,2,3,… (44)
Pm-k(t) = P(S’(t)=m-k), k=1,2,3,… (45)
Готовность системы определяется как сумма вероятностей нахождения ее в работоспособном состоянии:
> >.
(46)
>.
(46)
Под готовностью системы к моменту времени t понимается вероятность того, что система находится в рабочем состоянии во время t.
Надежность системы после t (времени отладки, за которое уже выявлено К ошибок, т.е. система находится в состоянии n-k (К-я ошибка исправлена, а (К+1)-я еще не обнаружена), может быть определена из состояния:
> >,
(47)
>,
(47)
где >
 >
— интервал времени, когда может
появиться (К+ 1)-я ошибка;
>
— интервал времени, когда может
появиться (К+ 1)-я ошибка;
> >
— принятая постоянная интенсивность
проявления ошибок.
>
— принятая постоянная интенсивность
проявления ошибок.
Рассмотрим решение модели для случая, когда интенсивность появления ошибок l и интенсивность их исправления m- постоянные величины. Составляется система дифференциальных уравнений:
> >;
>;
> >,
k=1,2,3,… (48)
>,
k=1,2,3,… (48)
> >,
k=0,1,2,3,…
>,
k=0,1,2,3,…
Начальными условиями для решения системы могут являться:
P>n>(0) = 1;
P>n-k>(0) = 0; k=1,2,3,… (49)
P>m-k>(0) = 0; k=1,2,3,…
При имеющихся начальных условиях система уравнений может быть решена классически или с использованием преобразований Лапласа.
В результате решения определяются P>n-k> и P>m-k> для случая, когда l и m - константы.
Для общего случая отбросим ограничение постоянства интенсивностей появления и исправления ошибок и предположим, что
> >,
k=1,2,3,…, (50)
>,
k=1,2,3,…, (50)
т.е. являются функциями числа ошибок, найденных к этому времени в ПС. Система дифференциальных уравнений для такого случая имеет вид:
> >
>
> >,
K=1,2,3, … (51)
>,
K=1,2,3, … (51)
>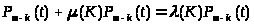 >,
K=1,2,3, …
>,
K=1,2,3, …
Начальные условия для решения системы будут:
P>n>(0)=1;
P>n-k>(0)=0; k=1,2,3,… (52)
P>m-k>(0)=0; k=1,2,3,…
Система может быть решена методом итераций Эйлера. Предполагается, что в начальный период использования модели значения Х и р должны быть получены на основе предыдущего опыта разработчика. В свою очередь, модель позволяет накапливать данные об ошибках, что дает возможность повышения точности анализа на основе предыдущего моделирования. Практическое использование модели требует громоздких вычислений и делает необходимым наличие ее программной поддержки.
10.3. Статические модели надежности
Статические модели принципиально отличаются от динамических прежде всего тем, что в них не учитывается время появления ошибок в процессе тестирования и не используется никаких предположений о поведении функции риска А..((). Эти модели строятся на твердом статистическом фундаменте.
Модель Миллса. Использование этой модели предполагает необходимость перед началом тестирования искусственно вносить в программу ("засорять") некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как естественные, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования.
Тестируя программу в течение некоторого времени, собирается статистика об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные. Соотношение:
>>> >,
(53)
>,
(53)
дает возможность оценить N - первоначальное число ошибок в программе. В данном соотношении, которое называется формулой Миллса, S - количество искусственно внесенных ошибок, n - число найденных собственных ошибок, V - число обнаруженных к моменту оценки искусственных ошибок. Например, если в программу внесено 50 ошибок и к некоторому моменту тестирования обнаружено 25 собственных и 5 внесенных ошибок, то по формуле Миллса делается предположение, что первоначально в программе было 250 ошибок.
Вторая часть модели связана с проверкой гипотезы от N Предположим, что в программе имеется К собственных ошибок| и внесем в нее еще S ошибок. В процессе тестирования были обнаружены все S внесенных ошибок и n собственных ошибок.
Тогда по формуле Миллса мы предполагаем, что первоначально в программе было N = n ошибок. Вероятность, с которой можно высказать такое предположение, возможно рассчитать по следующему соотношению:
 1, если
n<K;
1, если
n<K;
С = >
 >;
если n£K .
(54)
>;
если n£K .
(54)
Например, если утверждается, что в программе нет ошибок (К=0), и при внесении в программу 10 ошибок все они в процессе тестирования обнаружены, но при этом не выявлено ни одной собственной, то С=0,9. То есть с вероятностью 0,9 можно утверждать, что в программе нет ошибок. Но если в процессе тестирования была обнаружена одна собственная ошибка, то С=1, так как n > К, и наше предположение о том, что в программе нет ошибок, на 100% не подтвердилось.
Таким образом, величина С является мерой доверия к модели и показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель ошибок: первое предсказывает возможное число первоначально имевшихся в программе ошибок, а второе используется для установления доверительного уровня прогноза. Однако формула (54) для расчета С не может быть использована в случае, когда не обнаружены все искусственно рассеянные ошибки. Для этого случая, когда оценка надежности производится до момента обнаружения всех 5 рассеянных ошибок, величина С рассчитывается по модифицированной формуле (55):
 1, если n>K
1, если n>K
C= >
>> >,
если n£K,
(55)
>,
если n£K,
(55)
где числитель и знаменатель формулы при n < К являются биноминальными коэффициентами вида:
> >.
(56)
>.
(56)
В действительности модель Миллса можно использовать для оценки N после каждой найденной ошибки. Предлагается во время всего периода тестирования отмечать на графике число найденных ошибок и, текущие значения для N. Достоинством модели являются простота применяемого математического аппарата, наглядность и возможность использования в процессе тестирования.
Однако она не лишена и ряда недостатков, самые существенные из которых - это необходимость внесения искусственных ошибок (этот процесс плохо формализуем) и достаточно вольное допущение величины К, которое основывается исключительно на интуиции и опыте человека, проводящего оценку, т.е. допускает большое влияние субъективного фактора.
Модель Липова. Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа тестов. Если сделать то же предположение, что и в модели Миллса, т.е. что собственные и искусственные ошибки имеют равную вероятность быть найденными, то вероятность обнаружения п собственных и V внесенных ошибок равна:
> >
, (57)
>
, (57)
где m — количество тестов, используеиых при тестировании;
q — вероятность обнаружения ошибки в каждом из т тестов, рассчитанная по формуле:
> >,
(58)
>,
(58)
S - общее количество искусственно внесенных ошибок;
N-количество собственных ошибок, имеющихся в ПС до начала тестирования.
Для использования модели Лилова должны выполняться следующие условия:
N³n³0;
S³V³0; (59)
m³n+V³0.
Оценки максимального правдоподобия (наиболее вероятное значение) для N задаются соотношениями:
 >
>
 >
при n³1, V³1;
>
при n³1, V³1;
N = >
 >
при V = 0; (60)
>
при V = 0; (60)
0 при n = 0.
Модель Лилова дополняет модель Миллса, дав возможность оценить вероятность обнаружения определенного количества ошибок к моменту оценки.
Простая интуитивная модель. Использование этой модели предполагает проведение тестирования двумя группами программистов (или двумя программистами в зависимости от величины программы) независимо друг от друга, использующими независимые тестовые наборы. В процессе тестирования каждая из групп фиксирует все найденные ею ошибки. При оценке числа оставшихся в программе ошибок результаты тестирования обеих групп собираются и сравниваются.
Получается, что первая группа обнаружила N1 ошибок, вторая – N2, а N12 - это ошибки, обнаруженные обеими группами.
Если обозначить через N неизвестное количество ошибок, присутствовавших в программе до начала тестирования, то можно эффективность тестирования каждой из групп определить как:
> >;
>
>;
>
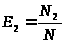 >.
(61)
>.
(61)
Предполагая, что возможность обнаружения всех ошибок одинакова для обеих групп, можно допустить, что, если первая группа обнаружила определенное количество всех ошибок, она могла бы определить то же количество любого случайным образом выбранного подмножества. В частности, можно допустить, что:
> >.
(62)
>.
(62)
>>
Из формулы (25) N>2> = Е>2>N, подставив в (26), получим:
> >,
(63)
>,
(63)
или
> >.
(64)
>.
(64)
Значение N12 известно, а E>1> и E>2> можно определить как N>12>/N>1> и N>12>/N>1>. Развивая эту модель и опираясь на предположение, что обе группы, проводящие тестирование, имеют равную вероятность обнаружения "общих" ошибок, ее можно рассчитать по следующей формуле:
> >
, (65)
>
, (65)
где Р(N>12>) — вероятность обнаружения N>12> "общих" ошибок тестирования программы двумя независимыми группами.
Модель Коркорэна. Модель Коркорэна относится к статическим моделям надежности ПС, так как в ней не используются параметры времени тестирования и учитывается только результат N испытаний, в которых выявлено N1 ошибок i-го типа. Модель использует изменяющиеся вероятности отказов для различных типов сшибок.
В отличие от двух рассмотренных выше статических моделей, где оценивалось количество первоначальных ошибок в программе, а также их количество, оставшееся после некоторого периода тестирования, по модели Коркорэна оценивается вероятность безотказного выполнения программы на момент оценки.
> >,
(66)
>,
(66)
где N>0> — число безотказных выполнений программы;
N — общее число прогонов;
К — априориорно известное число типов

a>i>, если N>i>>0;
Y>i>= (67)
0, если N>i> = 0;
a>i> — вероятность выявления при тестировании ошибки 1-го типа.
В этой модели вероятность a>i>, должна оцениваться на основании априорной информации или данных предшествующего периода функционирования однотипных программных средств. Наиболее часто встречающиеся ошибки и вероятности их выявлений при тестировании ПС прикладного назначения приводятся в таблице 13 (пример).
Таблица 13 - Ошибки программы по категориям и вероятности их появления
|
Тип ошибки |
Вероятность появления ошибки |
|
Ошибки вычислений |
0,09 |
|
Логические ошибки |
0,26 |
|
Ошибки ввода-вывода |
0,16 |
|
Ошибки манипулирования данными |
0,18 |
|
Ошибки сопряжения |
0,17 |
|
Ошибки определения данных |
0,08 |
|
Ошибки в БД |
0,06 |
Модель Нельсона. Данная модель была создана в фирме TRW (аэрокосмическая компания США), при расчете надежности ПС учитывает вероятность выбора определенного тестового набора для очередного выполнения программы.
Предполагается, что область данных, необходимых для выполнения тестирования программного средства, разделяется на К взаимоисключающих подобластей Z>i>, i= 1,2, .... k. Пусть Р>i> - вероятность того, что набор данных Z>i> будет выбран для очередного выполнения программы. Предполагая, что к моменту оценки надежности было выполнено N>i> прогонов программы на Z>i> наборе данных и из них n>i>, количество прогонов закончилось отказом, надежность ПС в этом случае равна:
> >.
(68)
>.
(68)
На практике вероятность выбора очередного набора данных для прогона (Р>i>) определяется путем разбиения всего множества значений входных данных на подмножества и нахождения вероятностей того, что выбранный для очередного прогона набор данных будет принадлежать конкретному подмножеству. Определение этих вероятностей основано на эмпирической оценке вероятности появления тех или иных входов в реальных условиях функционирования.
10.4. Эмпирические модели надежности
Эмпирические модели в основном базируются на анализе структурных особенностей программного средства (или программы). Как указывалось ранее, эмпирические модели часто не дают конечных результатов показателей надежности, однако их использование на этапе проектирования ПС полезно для прогнозирования требующихся ресурсов тестирования, уточнения плановых сроков завершения проекта и т.д.
Модель сложности. В литературе неоднократно подчеркивается тесная взаимосвязь между сложностью и надежностью ПС. Если придерживаться упрощенного понимания сложности ПС, то она может быть описана такими характеристиками, как размер ПС (количество программных модулей), количество и сложность межмодульных интерфейсов.
Под программным модулем в данном случае следует понимать программную единицу, выполняющую определенную функцию (ввод, вывод, вычисление и т.д.) и взаимосвязанную с другими модулями ПС.
Некоторые базовые понятия для определения характеристик сложности даны в таблице 14.
Сложность модуля ПС может быть описана, если рассматривать структуру программы как последовательность узлов, дуг и петель в виде направленного графа.
Таблица 14 - Определение характеристик сложности
|
Связь |
Для модуля |
Для ПС (многомодульная программа) |
|
Узел |
Точка ветвления модуля |
Модуль, имеющий более одного выхода |
|
Дуга |
Последовательные участки модуля |
Последовательность нескольких модулей, имеющих один выход |
|
Петля |
Циклические участки модуля |
Циклические участки, состоящие из нескольких модулей |
В качестве структурных характеристик модуля ПС используются:
1) отношение действительного числа дуг к максимально возможному числу дуг, получаемому искусственным соединением каждого узла с любым другим узлом дугой;
2) отношение числа узлов к числу дуг;
3) отношение числа петель к общему числу дуг.
Для сложных модулей и для больших многомодульных программ составляется имитационная модель, программа которой "засоряется" ошибками и тестируется по случайным входам. Оценка надежности осуществляется по модели Миллса.
При проведении тестирования известна структура программы, имитирующей действия основной, но не известен конкретный путь, который будет выполняться при вводе определенного тестового входа. Кроме того, выбор очередного тестового набора из множества тест-входов случаен, т.е. в процессе тестирования не обосновывается выбор очередного тестового входа. Эти условия вполне соответствуют реальным условиям тестирования больших программ.
Полученные данные анализируются, проводится расчет показателей надежности по модели Миллса (или любой другой из описанных выше), и считается, что реальное ПС, выполняющее аналогичные функции, с подобными характеристиками и в реальных условиях должно вести себя аналогичным или похожим образом.
Преимущества оценки показателей надежности по имитационной модели, создаваемой на основе анализа структуры будущего реального ПС, заключаются в следующем:
модель позволяет на этапе проектирования ПС принимать оптимальные проектные решения, опираясь на характеристики ошибок, оцениваемые с помощью имитационной модели;
позволяет прогнозировать требуемые ресурсы тестирования;
дает возможность определить меру сложности программ и предсказать возможное число ошибок и т.д.
К недостаткам можно отнести высокую стоимость метода, так как он требует дополнительных затрат на составление имитационной модели, и приблизительный характер получаемых показателей.
Модель, определяющая время доводки программ. Эта модель используется для ПС, которые имеют иерархическую структуру, т.е. ПС как система может содержать подсистемы, которые состоят из компонентов, а те, в свою очередь, состоят из V модулей. Таким образом, ПС может иметь V различных уровней композиции. На любом уровне иерархии возможна взаимная зависимость между любыми парами объектов системы. Все взаимозависимости рассматриваются в терминах зависимости между парами модулей.
Анализ модульных связей строится на том, что каждая пара модулей имеет конечную (возможно, нулевую) вероятность, что изменения в одном модуле вызовут изменения в другом модуле.
Пусть ПС состоит из n модулей.
Р>ij> есть вероятность того, что изменения в модуле вызовут необходимость внесения изменений в модуль;.
Для ПС, состоящего из n модулей, будет ne таких парных отношений.
Р - матрица размерностью n * т с элементами Р>ij>. Допустим, что при тестовой сборке ПС в i-м модуле выявлено А>i>, ошибок, или в модуле i должно быть сделано А>i> изменений.
Обозначим через А вектор размерностью n с элементами А>i>,. Тогда А - общее число изменений, требуемых при интеграции модулей в систему на нулевом шаге.
Общее число изменений на первом шаге, требуемых в результате изменений, сделанных на нулевом шаге, будет равно А * Р.
Обозначим через Р2 матрицу размерностью n * m, элементы которой равны:
> >,
(69)
>,
(69)
и представляют собой сумму вероятностей, что изменения в модуле i распространяются в модуль К и затем в модуль j. Следовательно, i-й, и j-й элементы матрицы Р2 - это двушаговая вероятность, что изменение в модуле ш распространится в модуль j.
Общее число изменений ПС с учетом двушагового распространения будет равно А * Р2. Очевидно, что число изменений, требуемых в системе, с учетом k-шагового распространения начальных изменений будет равно А * Рk..
Величины, которые используются в модели для получения нужных оценок, - это вектор начальных изменений А и матрица вероятности межмодульных связей Р. По мере развития проекта ПС эти величины могут уточняться при появлении реальных данных тестирования. Значения элементов вектора А становятся очевидными при присоединении очередного модуля к системе в процессе тестовой сборки.
Для уточнения элементов матрицы достаточно фиксировать для каждого модуля данные о проведенных изменениях, их причинах и последствиях в форме следующей таблицы (см. табл. 15).
Таблица 15- Сбор данных, необходимых для расчета матрицы вероятностей р
|
Описание ошибки |
Каким модулем вызвана |
Действие на другие модули |
После получения относительно большой выборки данных их можно использовать для коррекции элементов матрицы Р следующим образом:
Число измерений в модуле i, вызванных модулем j
 P>ij >=
. (70)
P>ij >=
. (70)
Общее число измерений в модуле j
Рассмотренная модель позволяет на этапе тестирования, а точнее при тестовой сборке системы, определять возможное число необходимых исправлений и время, необходимое для доведения ПС до рабочего состояния.
Основываясь на описанной процедуре оценки общего числа изменений, требуемых для доводки ПС, можно построить две различные стратегии корректировки ошибок:
фиксировать все ошибки в одном выбранном модуле и устранить все побочные эффекты, вызванные изменениями этого модуля, отрабатывая таким образом последовательно все модули;
фиксировать все ошибки нулевого порядка в каждом модуле, затем фиксировать все ошибки первого порядка и т.д.
Исследование этих стратегий доказывает, что время корректировки ошибок на каждом шаге тестирования определяется максимальным числом изменений, вносимых в ПС на этом шаге, а общее время - суммой максимальных времен на каждом шаге.
Это подтверждает известный факт, что тестирование обычно является последовательным процессом и обладает значительными возможностями для параллельного исправления ошибок, что часто приводит к превышению затрачиваемых на него ресурсов над запланированными.
10.5. Количественный расчет надежности
Для количественной оценки надежности был выбран метод La Padula, так как он позволяет вычислить прогнозное значение надежности.
Для расчета надежности был реализован алгоритм Процедура обработки объявления (Processing). Данный модуль был протестирован в 3 этапа по 10 тестов в каждом. Количественный расчет делался в пакете Mathcad, и имеет следующий вид:
Si - число тестов на этапе;
mi - число отказов на i-ом этапе;
m - число этапов;
Rf - предельное значение надежности;
A - параметр роста;
R(i)=Rf-A/i - надежность на i-ом этапе.
> >
>
> >
>
>
 >
>
> >
>
> >
>
> >
>
> >
>
> >
>
> >
>
> >
>
> >
>
> >
>
>График надежности представлен на рисунке 35.>
График надежности
> >
>
Рис. 35
Из графика видно, что в процессе проведенных тестов прогнозируемое значение надежности приближается к 1.
Заключение
В результате выполненной работы была спроектирована полномасштабная функциональная схема верхнего уровня Информационной Системы Университета обеспечивающая качественный и оперативный вывод информации. Верхний уровень системы не зависит от топологии нижнего уровня, что увеличивает гибкость системы и обеспечивает размещение устройств вывода в любой точке университетского городка, это позволяет охватить все учебные корпуса АмГУ и обеспечивает донесение необходимой информации до конечных потребителей информации в минимальный срок.
Спроектирована схема положения ИСУ в существующей системе передачи информации и схема взаимодействия основных частей ИСУ. Разработаны и описаны все информационные массивы участвующие в функционировании верхнего уровня. При этом большой акцент сделан на уменьшение избыточности данных. Также ИСУ исключает возможность ввода данных способных выработаться внутри нее.
Представлено полное описание функционирования верхнего уровня с разработанными алгоритмами, обеспечивающими уменьшение времени реакции на возникновение какого либо события, сохранение всей статистической информации о функционировании системы для ее последующего анализа. Обеспечено однозначное реагирование на любое событие, возникшее в системе, это достигнуто за счет детальной проработки всех возможных ситуаций способных возникнуть как на верхнем, так и на нижнем уровне ИСУ. С позиции обеспечения надежности системы была введена некоторая избыточность данных, а именно - все переменные и массивы, используемые в системе, имеют свои копии на жестком диске, это позволяет при отказе системы полностью восстановить ее на момент отключения.
При анализе входной и выходной информации были спроектированы все пакеты, необходимые для обеспечения работоспособности и выполнения всех поставленных задач и функций перед ИСУ. Структура пакетов полностью отвечает требованиям уменьшения избыточности и уменьшения времени обработки сообщений при передаче между различными частями ИСУ. Введение контрольной суммы обеспечивает защиту от ошибок при передаче пакетов.
Разработана и описана клиентская часть верхнего уровня, со всеми правилами взаимодействия с серверной частью. Определены все пакеты и возможные сообщения для полной работоспособности "Клиента". Правила построения основаны на тех же принципах, что и "Сервер", а именно - уменьшение избыточности данных, увеличение надежности, защита от ошибок и др. Клиентская часть позволяет пользователям опубликовывать свои объявления в системе непосредственно со своего рабочего места. Это позволяет улучшить оперативность и качество предоставления информации конечному потребителю. При этом введена иерархия пользователей: каждый пользователь, принадлежит к своей группе, с определенным приоритетом, сформированной администратором системы. Это позволяет более важные объявления опубликовывать в первую очередь.
В системе заложена возможность опубликования различных объявлений, сообщений и другой текстовой и графической информации, которая позволяет привлечь государственные и не государственные предприятия для опубликования объявлений рекламного характера. Это дает возможность открыть еще одну статью доходов университета и окупить все затраты на создание и поддержание работоспособности системы.
Внедрение разработанной информационной системы позволит повысить статус и имидж университета, что является одной из задач поставленной перед ИСУ.
Список использованных источников
Бирник А.С. Информация и управление. – М., 1994. – 240 с.
www.citforum.ru Дьяконов В.П. 95 вопросов по серийной Windows 95.
www.citforum.ru Олифер Н.А. Сетевые операционные системы.
www.citforum.ru Громов Ю.Ю. Программирование на языке СИ.
www.citforum.ru Брежнев А.Ф. Семейство протоколов TCP/IP.
www.citforum.ru Комер Д.А. Протоколы TCP/IP. Том 1. Принципы, протоколы и архитектура.
www.citforum.ru Олифер В.С. Введение в IP-сети.
Робачевский А.М. Операционная система UNIX.-СПб.: BHV – Санкт-Петербург, 1998. – 528 с.
Труфанов В.А. Производственная практика по специальности "Автоматизированные системы обработки информации и управления": Учебно-методическое пособие / Амурский гос. ун-т. – Благовещенск, 1997. – 12 с.
Е.Л.Еремин, А.Д.Плутенко. Учебно-методическое пособие по дипломному проектированию для студентов специальности "Автоматизированные системы обработки информации и управления" – 2202. Благовещенск, 1997. – 48 с.
Араманов И.Н. Пакеты и сообщения в сетях TCP/IP, IPX/SPX, NetBios и др. –М.: Известия. 1998. – 286 с.
www.elec.ru
Удавиченко М.Ф. Строим алгоритмы. – М.: СТУ. 1990. – 78 с.
Боэм Б.У. Инженерное проектирование программного обеспечения: Пер. с англ./Под ред А.А.Красилова. – М.: Радио и связь. 1985. - 512 с.
Гласс Р. Руководство по надежному программированию: Пер. с англ. –М.: Финансы и статистика, 1982. - 280 с.
Липаев В.В. Тестирование программ. – М.: Радио и связь, 1986 - 292 с.
Шураков В.В. Надежность программного обеспечения систем обработки данных. –М.: Статистика, 1981. - 215 с
Приложение 1. Функциональная схема "Сервер". Подсистемы Управления и Интерфейсная

Приложение 2. Функциональная схема "Сервер". Подсистема взаимодействия с "Клиентом"

Приложение 3. Функциональная схема "Клиент"
