Программное обеспечение удалённого доступа к технической документации
ÔÀÉË: VDV-1.INF #ÒÅÌÀ:Ïðîãðàììíîå îáåñïå÷åíèå óäàë¸ííîãî äîñòóïà ê òåõíè÷åñêîé äîêóìåíòàöèè #ÐÀÇÄÅË: #ÍÀÇÍÀ×ÅÍÈÅ:Äèïëîì #ÔÎÐÌÀÒ: WinWord 2000 #ÀÂÒÎÐ: Â. Ìàìàåâ #ÑÄÀÂÀËÑß: â ÌÃÈÝÒå íà êàôåäðå ÏÊÈÌÑ â 2000 ã. #ÏÐÈÌÅ×ÀÍÈß: ñ ïðîãðàììîé è ïðèìåðàìè
МИНИСТЕРСТВО
ОБЩЕГО И ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
РФ
МОСКОВСКИЙ
ГОСУДАРСТВЕННЫЙ ИНСТИТУТ ЭЛЕКТРОННОЙ
ТЕХНИКИ (ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ)
КНИЖКА ДИПЛОМНИКА.
Ф.И.О. _Мамаев Василий Александрович ____________________
Факультет ____ ЭКТ _______ Индекс группы _____52_______
Специальность N_ 22.03 ______________
Специализация (кафедра) _ПКИМС___________________________
Начало дипломного проектирования _ 21.01.2000 _____
Контрольные сроки просмотра проекта на кафедре:
1 просмотр _16.02.2000 2 просмотр _20.03.2000
дата дата
3 просмотр _15.04.2000 4 просмотр _18.05.2000
дата дата
Окончание дипломного проектирования _05.06.2000__________
Срок представления на рецензию ______01.06.2000__________
Защита проекта на заседании ГЭК _____07.06.2000__________
ЗАДАНИЕ НА ДИПЛОМНЫЙ ПРОЕКТ
Наименование темы: _ Программное обеспечение удалённого доступа к технической документации.
Цель проекта: _Разработка метода создания программ трансляторов различных текстовых форматов с использованием генераторов программ Lex и Yacc путем создания программы-транслятора из текстового формата nroff в гипертекстовый формат HTML.
Назначение разрабатываемого изделия (процесса): Обеспечение возможности работы с документацией и справочной информацией для пользователей САПР ИМС на основе унифицированных средств удалённого доступа.
Технические требования.
А) требования, предъявляемые к объектам проектирования:
___Разрабатываемое
программное обеспечение должно
функционировать на компьютерах под
управлением операционной системы UNIX и
различных ее разновидностей (SunOS, Solaris,
FreeBSD, Linux, Intel Solaris).
Требования
к конечному формату текста:
• Тексты
в конечном формате должны быть доступны
для чтения на компьютерах, работающих
как под управлением Windows 95 (NT), так
и под управлением системы UNIX и ее
разновидностей, вне зависимости от
реализации от графического интерфейса
пользователя.
• Тексты
в конечном формате должны быть доступны
для чтения как в режиме удаленного
доступа, так и непосредственно на
компьютере пользователя.
Необходимые
функциональные возможности
программы транслятора:
• Преобразование
стандартного набора команд текстового
формата nroff в команды формата HTML.
• Максимально
полное сохранение исходного форматирования
текста.
• Замена
используемых шрифтов X Window System на
шрифты операционной системы Windows.
• Добавление
гипертекстовых ссылок.
Требования
к количественным параметрам
программы-транслятора:
• Не
должно быть ограничений на объем входного
файла.
• Время
обработки файла длиной 1000 строк текста
не должно превышать 10 секунд.
Б)
содержание специального раздела проекта
(указываются отдельно части, разрабатываемые
как эскизный, технический и рабочий
проекты, графические работы: чертежи и
плакаты, требования к выполнению
расчетно-пояснительной записки): На
уровне эскизного проекта
дать описание структуры программно-аппаратного
комплекса САПР.
Глава пояснительной
записки.
Плакат №1 – Общая
структура программно-аппаратного
комплекса САПР ИМС.
На
уровне технического проекта
рассмотреть и сопоставить применяемые
в настоящее время технические решения
по организации удалённого доступа к
технической документации.
Глава
пояснительной записки.
Плакат
№2 - Схема удалённого доступа к
документации.
Плакат №3 - Схема
доступа к гипертекстовой документации.
На
уровне рабочего проекта
разработать и реализовать программу транслятор
из текстового формата nroff в гипертекстовый
формат HTML на основе генераторов программ
Lex и Yacc.
Глава пояснительной
записки.
Плакаты в составе,
необходимом для иллюстрации содержания
выполненных работ.
В) задание на технологический раздел проекта: Технология создания трансляторов с применением генераторов программ Lex и Yacc.
Г) задание на организационно-экономический раздел проекта: _Экономическое обоснование разработки НИОКР.
Д) задание на раздел «Производственная и экологическая безопасность»: Обеспечение комфортных условий труда при работе на ПЭВМ.
Основная
литература:
1. Беляков М.И.,
Рабовер Ю.И., Фридман А.Л. Мобильная
операционная система. – Москва: Радио
и связь, 1991. – 206 с.
2. Topham D.W., Troung H.V., Unix and Xenix: A
Step-by-Step Guide. – Bowie: Brady Communication Company, Inc.
1985. – 352 c.
3. Гончаров
А.А., HTML в примерах. - Петербург: Питер,
1997. - 230 с.
4. Ф.
Льюис, Д. Розенкранц, Р. Стирнз.,
Теоретические основы проектирования
компиляторов. - Москва: Мир, 1979. - 120 с.
5. Р.
Петерсен., LINUX. Полное руководство. Киев:
BHV, 1998. - 300 с.
(подписи)
Руководитель дипломного проекта Авдеев Ю.В. _____________
Нач. отд. 26 з-д Микрон.
Консультанты по разделам проекта:
Специальному Авдеев Ю.В. _____________
Нач. отд. 26 з-д Микрон.
Технологическому Адрианов М.В. _____________
Нач. лаб. 261 з-д Микрон.
Организационно-экономическому Короткова Т.Л. _____________
Доцент каф. Маркетинга МГИЭТ(ТУ).
Производственной и экологической Привалов В.П. _____________
безопасности К.Т.Н., доцент каф. ПЭБ МГИЭТ(ТУ).
Заведующий кафедрой Казенов Г.Г. _____________
Задание получил 16.02.2000 Мамаев В.А.
Рецензент Наумов Н.М. _____________
Ст. науч. сотрудник НИИМЭ и з-д Микрон.
СПРАВКА ОБ УСПЕВАЕМОСТИ.
Студент Мамаев В.А. за время пребывания в МИЭТ с 1992г. по 2000г. полностью выполнил учебный план специальности со следующими оценками:
отлично - ____________________________________________________
хорошо - ____________________________________________________
удовлетворительно -___________________________________________
Секретарь факультета ______________________________________________
(подпись)
Заключение руководителя дипломного проекта:
Студент _____________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
_____________________________________________________________________
Руководитель Авдеев Ю.В. (подпись)
Заключение о дипломном проекте:
Дипломный проект просмотрен, и студент Мамаев В.А. может быть допущен к защите этого проекта в Государственной экзаменационной комиссии.
Заведующий учебным центром _________________________________(подпись)
Заведующий кафедрой Казенов Г.Г. (подпись)
Введение. 4
1. Постановка задачи. 9
1.1 Требования, предъявляемые к транслятору. 9
1.2 Оценка достоинств и недостатков существующих трансляторов. 11
Заключение. 15
2. Проектирование транслятора 16
2.1 Схема разработки транслятора. 16
2.2 Принципы построения лексических анализаторов. 18
2.3 Грамматики.
Принципы построения грамматических
анализаторов. 21
Заключение. 34
3. Технология реализации транслятора с помощью генераторов программ Lex и Yacc. 35
3.1 Определение лексем, встречающихся в формате nroff 35
3.2 Описание грамматических правил преобразования из формата nroff в формат HTML. 40
3.3 Соответствие
между командами форматов
nroff и HTML. 43
3.4 Отладка лексического и грамматического анализаторов. 48
Заключение. 49
4. Экономическое обоснование разработки НИОКР. 50
4.1 Расчет затрат времени на разработку транслятора. 50
4.2 Расчет стоимости основных фондов, используемых для разработки транслятора. 52
4.3 Расчет затрат на разработку транслятора. 56
Наименование фонда 60
4.4 Формирование расчетной (остаточной) прибыли предприятия и определение эффективности произведенных затрат на разработку транслятора. 60
4.5 Оценка значимости разработки транслятора. 65
Заключение. 68
5. Обеспечение комфортных условий труда при работе на ПЭВМ. 69
5.1 Характеристика условий труда оператора ЭВМ 69
5.2 Требования к защите от шума и вибраций. 69
5.3 Требования к микроклимату, содержанию аэроионов и вредных химических веществ в воздухе помещений эксплуатации ПЭВМ 71
5.4 Требования к интенсивности электромагнитных полей, рентгеновского, видимого, ультрафиолетового и инфракрасного излучений. 73
5.5 Требования к освещению помещений и рабочих мест с ПЭВМ. 74
5.6 Расчет освещенности рабочего места программиста. 78
Заключение. 84
Список литературы: 85
Приложения. 86
Фрагмент кода лексического анализатора. 86
Фрагмент кода грамматического анализатора. 87
Код головной программы. 89
Введение.
Одним из основополагающих моментов организации САПР является выбор архитектуры вычислительного комплекса и технологии доступа к прикладным программным средствам. В настоящее время наиболее распространенным является подход, получивший наименование «технологии клиент-сервер». Этот подход состоит в сосредоточении вычислительных и прикладных ресурсов на выделенных компьютерах - серверах и организации доступа к ним с рабочих мест - клиентов.
Так как обязательным компонентом САПР является информационное обеспечение (различные базы данных, проектные библиотеки и все виды документации), то при использовании технологии клиент-сервер целесообразно разместить эти составляющие на выделенных серверах.
Главным препятствием при создании таких информационных серверов оказывается большое количество форматов текста, в которых хранится техническая информация и различная документация, способов и средств доступа к данным, их разнородность, различие требований к аппаратным средствам и системной среде.
Например, документация о системе UNIX и функциях языка «c++» (или его аналога «g++») представлена в виде так называемых «manual pages». Она просматривается с помощью команды системы UNIX «man» либо с помощью утилиты просмотра «Xman». Справочные файлы САПР «Compass» используют формат «Iview», просматриваемый с помощью специальных утилит просмотра. А САПР «Cadence» предоставляет информацию пользователю в формате «Open Book», также требующем специальных средств просмотра.
Кроме того, при использовании в качестве рабочего места X терминала, доступ к некоторым документам становится невозможен в принципе, так как, например, программе просмотра «Iview» требуется для работы графический клиент X Window версии 6, а многие из находящихся в эксплуатации Х терминалов имеют аппаратно реализованную версию X Window 5.
Для выхода из создавшейся ситуации можно предложить следующее: необходимо привести всю документацию к единому формату данных и сосредоточить ее в одном месте, удобном для доступа всех пользователей. Это даст возможность оснастить всех пользователей унифицированными средствами доступа ко всем информационным ресурсам.
Единый формат для документации должен отвечать следующим требованиям:
Тексты, записанные в выбранном формате, должны быть доступны для чтения как на персональном компьютере под управлением операционной системы Windows 95(NT), так и на сервере, работающим под управлением UNIX, а также на Х терминале.
Тексты должны сохранять исходное форматирование.
Учитывая, что часто документация содержит перекрестные ссылки, важной чертой, влияющей на выбор формата, становится возможность создания в тексте таких ссылок.
Кроме того, требуется, чтобы твердые копии документации изготавливались бы одним методом и выглядели бы одинаково вне зависимости от метода доступа к удаленному серверу технической документации.
Представляется оптимальным выбор формата HTML. Этот формат просматривается с помощью программ, версии которых работают как под управлением Windows, так и под управлением UNIX. Формат HTML поддерживает широкие возможности форматирования. Кроме того, этот формат является стандартным форматом для текстов в технологиях Internet, и его использование позволяет легко решить проблему общедоступности документации при помощи использовании этих технологий. Используя формат HTML, можно сделать документацию, преобразованную из того или иного формата, общедоступной, поместив ее в один из узлов сети. Следует заметить, что в настоящее время большинство локальных сетей строятся на тех же принципах и с использованием того же инструментария, что и сети Internet. Формат HTML удобен еще и тем, что форматирование текста в нем, как и в формате nroff (наиболее распространенном в среде UNIX), осуществляется простыми текстовыми командами, что позволяет его легко редактировать в случае надобности с помощью любого текстового редактора.
Проект посвящен разработке метода создания программ трансляторов различных форматов текста. Рассмотрены существующие программы трансляторы, оценены их достоинства и недостатки. Выбран унифицированный подход к разработке программ трансляторов, разработан маршрут разработки таких программ.
Рассмотрены экономические аспекты разработки программы транслятора, произведена оценка значимости разработки транслятора.
1. Постановка задачи.
Существует множество путей создания программы-транслятора, работающей в среде UNIX. Конкретная реализация программы зависит, прежде всего, от требований, предъявляемых к программе и конечному формату. Кроме того, возможна ситуация, при которой разработка новой программы может просто не иметь смысла, так как в среде UNIX существует большое количество свободно распространяемых программ предназначенных для решения самого широкого спектра задач.
1.1 Требования, предъявляемые к транслятору.
Согласно условиям технического задания программа должна функционировать в вычислительных системах под управлением ОС "Unix" и совместимых с ней (“SunOS”, “Linux”, “FreeBSD”, и др.). Проблема состоит в том, что исполняемые файлы ОС “UNIX” могут быть неработоспособны в среде “Linux”. В то же время, многие из UNIX-подобных систем поставляются пользователю в виде исходных файлов, предназначенных для компилирования. Так же и в данном случае можно передавать программу в виде исходных текстов, снабженных программой компиляции. Это, с одной стороны, повысит переносимость программы, а с другой - позволит вносить достаточно опытному пользователю необходимые поправки и корректировки, расширяя возможности транслятора в соответствии с потребностями пользователя. При этом необходимым условием становится написание программы при помощи таких средств, которые присутствовали бы в любой UNIX-подобной операционной системе.
Полученный же в результате работы программы должен поддерживаться как в операционной системе UNIX, так и в операционной системе Windows 95 (NT). Программа, предназначенная для просмотра текста в конечном формате должна быть распространенной и общедоступной. Оптимальным вариантом было бы, если бы программа являлась неотъемлемой частью операционных систем или же в любой системе существовали способы просмотра текста в данном формате.
Важным условием является сохранение в конечном формате текста всего форматирования, имевшегося в исходном формате и, возможно, добавление элементов форматирования, облегчающих работу пользователя с документом.
Следует учитывать, что большинство имеющихся форматов используют при выводе текста различные шрифты. При этом в разных операционных системах шрифты различны и, в большинстве случаев, не совместимы. При преобразовании текста следует провести адекватную замену используемых в исходном тексте шрифтов.
1.2 Оценка достоинств и недостатков существующих трансляторов.
Прежде всего, следует выяснить, имеет ли смысл создавать новую программу, так как в настоящее время уже существуют различные программы-трансляторы из формата nroff в формат HTML. Рассмотрим характеристики этих программ, выясняя их преимущества и их недостатки.
Наиболее известными и распространенными программами в настоящее время являются следующие:
Программа “nroff2HTML” (автор Р. Ричи).
Программа написана на языке “C”, работает под управлением ОС “UNIX”.
Работает с исходными текстами в формате nroff. При конвертировании вставляет в текст конечного файла обязательные теги формата HTML (такие, как <HTML></HTML>, <HEAD></HEAD>, <BODY></BODY>) и затем копирует исходный текст, уничтожая все команды nroff, предварительно отформатировав его с помощью тега <PRE></PRE>. В результате получается сплошной текст.
Программа “gnome-man2html”, входящая в графический интерфейс пользователя “GNOME”.
Программа написана на языке "C", работает под управлением операционной системы "Linux", тесно интегрирована с графическим интерфейсом пользователя "GNOME".
Данная программа работает не с реальными файлами, а выступает как фильтр при выводе текста с помощью программы “man” на экран компьютера, перенаправляя вывод в окно HTML-броузера и снабжая его при этом всеми командами, необходимыми для форматирования. Полученный на экране текст выглядит наилучшим образом, т.к. в нем сохраняются все необходимые виды форматирования и поддерживаются перекрестные ссылки. Но данная программа не может работать без пакета “GNOME”, для работы которого, в свою очередь, необходима ОС “Linux”.
Программа “hypernroff” (автор К. Садовски).
Программа написана на языке “C”, работает под управлением ОС “UNIX”.
В качестве входного и выходного потоков используется стандартный поток ввода вывода. Позволяет принимать информацию из файлов и выводить ее в файл посредством перенаправления потоков, доступном в среде UNIX. Вставляет в текст конечного файла обязательные теги формата HTML. Поддерживает некоторые виды управления текстом, такие, как выравнивание (по левому и правому краям, по центру). Все форматирование осуществляется заменой пробелов, при помощи которых форматируется текст в формате nroff, на символ формата HTML “nbsp” - неразрывный пробел. Изменение шрифтов, подчеркивание, курсив не поддерживаются.
Программа “man2html” (автор Р. Верховен).
Программа написана на языке “C”, работает под управлением ОС “FreeBSD”. Под управлением других разновидностей ОС “UNIX” не полностью работоспособна. Существует cgi-скрипт “vh-man2html” (автор М. Гамильтон), обеспечивающий вызов программы и выдачу результатов ее работы в html-броузере.
Работает с исходными текстами в формате nroff. Поддерживает макросы man-1.4 и формат BSD-mandoc (разновидность nroff). Вставляет в текст конечного файла обязательные теги формата HTML. Поддерживает различные виды управления текстом, в том числе таблицы. Замена шрифтов не производится. Не вставляются перекрестные ссылки, хотя скрипт “vh-man2html” сильно облегчает поиск необходимых файлов.
Ни одна из этих программ не удовлетворяет нашим требованиям, так как нам необходимо сохранять максимально полный объем форматирования (что дает нам программа “gnome-man2htmnl”), добившись переносимости программы и максимальной ее независимости от наполнения операционной среды (программа “gnome-man2htmnl” является непереносимой, она функционирует только под управлением системы Linux). Главным недостатком всех рассмотренных программ является их ориентация на работу непосредственно на одном рабочем месте, без использования сетевых технологий. Этим объясняется, например то, что ни одно из программ не поддерживает замену шрифтов X Window System на шрифты операционной системы Windows.
При создании проекта в первую очередь следует решить второй вопрос (независимость от наполнения операционной среды), и, затем, выбрав принципы реализации проекта, приступить к созданию программы, способной адекватно обработать, как минимум, весь объем стандартных команд и операций формата nroff.
1.3 Выбор способа реализации транслятора.
Первым очевидным элементом, присутствующим во всех таких ОС, является компилятор языка “С”, на котором, собственно, и написана операционная система “UNIX”. Но язык “С” является достаточно сложным языком и не все пользователи знакомы с ним. В тоже время, в ОС “UNIX” существуют другие средства написания программ: это генераторы программ LEX и YACC. Описание их команд настолько просто и логично, что позволяет вносить коррективы в существующую программу не имея специальной подготовки, и, возможно, даже не будучи знакомым с описанием этих средств, имея только текст исходной программы.
Заключение.
Выявлена необходимость создания программы транслятора, так как существующие на данный момент программы не удовлетворяет предъявляемым требованиям. В качестве конечного формата выбран гипертекстовый формат HTML, как наиболее полно соответствующий нашим целям, широко распространенный и простой в использовании. В качестве средства создания программ выбраны генераторы программ Lex и Yacc благодаря легкости освоения и полной переносимости программ, написанных на их основе, в среде UNIX.
2. Проектирование транслятора
Проектирование программы транслятора с использованием генераторов программ Lex и Yacc имеет свои особенности, независящие от конкретных форматов, с которыми будет работать разрабатываемый транслятор.
Разработав общий маршрут проектирования на основе этих средств программирования, можно впоследствии проектировать подобные задачи быстро и без лишних затрат.
2.1 Схема разработки транслятора.
Сначала с помощью генератора программ Lex строится лексический анализатор. В задачу лексического анализатора входит полное поглощение входного файла (потока) и передача в синтаксический анализатор найденных лексем, а также некоторых необходимых данных. Например, может быть найдена некоторая лексема NUMBER, а в качестве данных будет передано числовое значение найденного числа или цифры, либо возможна ситуация при которой в качестве лексемы выбирается команда, а данные, сопутствующие этой команде, передаются не как лексемы, а каким-либо другим путем.
Затем строится синтаксический анализатор с помощью генератора программ YACC. В синтаксическом анализаторе описываются правила, с помощью которых будет происходить преобразование текста. Правила опираются на полученные из лексического анализатора лексемы.
Кроме того, возможно, что в формате, в который происходит преобразование, могут требоваться какие-либо элементы, не зависящие от текста, например, заголовок формата и команды, завершающие текст. Эти элементы должны быть вставлены либо на этапе синтаксического анализа, и процедура их вставки будет частью синтаксического анализатора, либо они будут вставляться головной программой, которая и будет вызывать программу синтаксического анализа.
Компиляция модулей (лексического анализатора, синтаксического анализатора и головной программы) происходит в следующем порядке:
Спецификация синтаксического анализатора с помощью генератора программ Yacc преобразуется в программу на языке C. При этом создается файл с описанием лексем, обрабатываемых синтаксическим анализатором.
Спецификация лексического анализатора с помощью генератора программ Lex преобразуется в программу на языке C. Имена лексем определяются в подключаемом файле, полученном на предыдущем этапе.
Компилируется с помощью компилятора языка C головная программа, вызывающая синтаксический анализатор. При компиляции подключаются лексический анализатор и синтаксический анализатор (программы на языке C). Компиляция происходит с использованием стандартных библиотек.
2.2 Принципы построения лексических анализаторов.
Лексический анализатор выполняет первую стадию трансляции - читает строки транслируемого текста, выделяет лексемы и передает их на дальнейшие стадии трансляции (грамматический разбор, синтаксический анализ).
Основным элементом лексического анализатора являются правила. Правила – это расширенные регулярные выражения и действия. Действия могут быть записаны как с помощью команд «языка» Lex, так и на языке C. Регулярные выражения – это описания возможных наборов символов из входного потока, называемые в дальнейшем лексемами.
Лексический анализатор распознает тип каждой лексемы и соответствующим образом помечает ее. Лексический анализатор должен не только выделить лексему, но и выполнить некоторые преобразования. Например, если лексема - число, то его необходимо перевести во внутреннюю форму записи.
Хотя лексический анализ по своей идее прост, тем не менее эта фаза работы транслятора часто занимает больше времени, чем любая другая. Частично это происходит из-за необходимости просматривать и анализировать исходный текст символ за символом. Иногда даже бывает необходимо вернуть прочитанный символ во входной поток с тем, чтобы повторить просмотр и анализ. Происходит это потому, что часто бывает трудно определить, где проходят границы лексемы. Например, могут существовать две лексемы: “make” и “makefile”. При анализе входного потока символов может быть выделена лексема “make”, хотя правильно было бы выделить лексему “makefile”. Единственный способ преодолеть это затруднение - просмотр полученной цепочки символов назад и вперед. В нашем примере при выделении лексемы “make” мы должны просмотреть следующий поступающий символ и, если он будет символом "f", то вполне возможно, что поступает лексема “makefile”.
Вообще говоря, в общем случае программы лексического анализа, построенные с помощью генератора программ Lex, всегда просматривают входной поток вперед. При этом из входного потока выбирается лексема, соответствующая правилам, с наибольшей длиной. Это несколько замедляет работу, но помогает избежать ошибок.
Также в общем случае предполагается, что лексема может находиться в любом месте входного потока. Но при этом предусмотрены способы учитывать контекст. Во первых, для этого применяются так называемые «состояния» лексического анализатора. Переход в состояние осуществляется при срабатывании какого либо правила по специальной команде. Исходным состоянием анализатора является состояние «0». Возможна ситуация, когда одно и тоже правило может выполняться в нескольких состояниях. Во вторых, существует оператор определения контекста: «/». Например, выражение «ab/cd» удовлетворяет строке ab только в том случае, если за ней следует cd.
Кроме того, в Lex существуют инструменты, использующие просмотр вперед и назад: в правиле при определении лексемы могут использоваться спецсимволы «^» и «$», говорящие, что лексема должна находится в начале строки или в конце. Последний, на самом деле, является частным случаем оператора «/», так как для определения конца строки используется выражение
\”\n”
При использовании лексического анализатора совместно с синтаксическим, от лексического анализатора требуется полное поглощение входного потока и передача в синтаксический анализатор найденных лексем и данных, им соответствующих. Для того, чтобы весь входной поток был полностью поглощен и в конечный файл не попали необработанные фрагменты входного формата, лексемы, содержащиеся в спецификации лексического анализатора должны полностью описывать все возможные наборы символов.
Для передачи данных из лексического анализатора в синтаксический существует несколько путей. Наиболее простым является метод передачи данных при помощи глобальных переменных – текстовой yytext и числовой yylval.
Для упрощения написания спецификаций можно применять так называемые «подстановки». Какой-либо часто используемый шаблон описывается и сопоставляется с некоторым именем. В дальнейшем это имя можно использовать в правилах вместо данного шаблона. При этом, если возникнет необходимость изменения шаблона, не надо будет искать вхождения шаблона на протяжении всей спецификации – достаточно будет изменить шаблон в определении подстановки.
2.3 Грамматики.
Принципы построения грамматических
анализаторов.
Спецификация Yacc (грамматика) описывается как набор правил в виде, близком к форме Бэкуса Наура (БНФ). Каждое правило описывает грамматическую конструкцию, называемую нетерминальным символом, и сопоставляет ей имя. С точки зрения грамматического разбора правила рассматриваются как правила вывода (подстановки). Грамматические правила описываются в терминах некоторых исходных конструкций, которые называются лексическими единицами, или лексемами. Как правило, имена сопоставляются лексемам, соответствующим классам объектов, конкретное значение которых не существенно для целей грамматического анализа.
Прежде, чем говорить о конкретных принципах построения синтаксических анализаторов с использованием генератора программ Yacc, необходимо разобраться в том, какие грамматики существуют и чем они отличаются.
Прежде всего стоит отметить, что различают два основных типа грамматик: контекстно-зависимые и контекстно-независимые.
Если порождающее правило имеет следующий вид:
A ::= ,
где A – нетерминальный символ, а - терминальный или нетерминальный, то порождающее правило называется контекстно-зависимым, то есть замена нетерминального символа A на последовательность может иметь место только в контекстах и . Соответственно, и грамматика, содержащая подобное правило, называется контекстно-зависимой.
Если порождающее правило имеет вид:
A ::= ,
то есть, если левая часть порождающего правила состоит из одного нетерминального символа, который в итоге (через ряд промежуточных шагов) может заменяться на последовательность , стоящую в правой части, независимо от контекста, в котором этот нетерминальный символ встречается, то такое правило и, соответственно, грамматика называются контекстно-независимыми (или контекстно-свободными).
Контекстно независимые грамматики более универсальны. Для разработки универсальных принципов проектирования трансляторов следует использовать их, так как они позволяют обработать практически любой входной язык.
Контекстно-свободные грамматики.
Существует несколько основополагающих терминов в теории грамматик. Нетерминальный символ (нетерминал) – описываемые элементы. Например, при определении языков программирования нетерминалами служат <оператор>, <арифметическое выражение> и т.п. В контекстно-свободной грамматике может быть любое конечное число нетерминалов.
Слова из словаря языка играют роль терминальных символов (терминалов). Контекстно-свободная грамматика может также содержать любое конечное число терминалов. В языках программирования терминалами являются фактически используемые в них слова и символы: «do», «else», «+» и т.п.
Правила грамматики иногда называются продукциями и в общем виде выглядят так:
Один_нетерминал любая конечная цепочка из терминалов и нетерминалов.
При этом цепочка справа от стрелки может быть и пустой. Например,
<A>
Иногда подобные правила называют эпсилон правилами. Контекстно-свободная грамматика может содержать любое конечное множество продукций. В качестве иллюстрации опять приведем пример из описания языка программирования. Продукция тогда выглядит так:
<оператор> IF <логическое_выражение> THEN <оператор>
Один из нетерминалов выделен как начальный нетерминал или начальный символ, с которого должны начинаться выводы цепочек языка. Для языков программирования таким нетерминалом может быть, например, <программа>. Обычно начальный символ обозначают <S>.
Итак, контекстно-свободная грамматика будет задаваться:
конечным множеством нетерминалов;
конечным множеством терминалов, которое не пересекается с множеством нетерминалов;
конечным множеством правил вида <A> , где A – нетерминал, а - цепочка терминалов и нетерминалов (возможно, пустая); нетерминал <A> называется левой частью правила, а - правой частью;
одним нетерминальным символом, выделенным в качестве начального.
Если множество правил приводится без специального указания множества терминальных и нетерминальных символов, то предполагается, что грамматика содержит в точности те терминалы и нетерминалы, которые встречаются в правилах.
Для описания грамматик очень часто используют способ записи, получивший название формы Бэкуса-Науэра или БНФ. Здесь символ заменяется символом ::=, за которым может следовать любое число правых частей, разделенных вертикальной чертой |. Здесь также нетерминалы заключаются в угловые скобки.
Правила грамматики используют для того, чтобы задавать способы подстановки или замены цепочек. Подстановка осуществляется путем замены некоторого нетерминала в какой-нибудь заданной цепочке терминалов и нетерминалов на правую часть правила, левой частью которого является этот нетерминал. Иногда говорят, что в таком случае правило применяется к нетерминалу цепочки.
Последовательность некоторых подстановок называется выводом. Каждая цепочка, встречающаяся в выводе, называется промежуточной цепочкой этого вывода.
Множество терминальных цепочек, которые можно вывести из начального символа грамматики, называется языком. Говорят, что язык определяется, грамматикой, порождается ею или выводится в ней. Язык, порождаемый контекстно-свободной грамматикой, также называется контекстно-свободным языком.
В случае, когда на каждом шаге подстановок заменяется самый левый нетерминальный символ, такой вывод называется левосторонним или левым выводом. Для каждого дерева существует единственный левый вывод, так как благодаря условию выбора самого левого нетерминала место каждой подстановки устанавливается единственным образом. Аналогично, для дерева существует единственный правосторонний или правый вывод, который получается если заменять всегда самый правый нетерминал.
Описать дерево вывода цепочки контекстно-свободного языка проще на примере.
Пусть дана следующая грамматика (начальный нетерминал <S>):
1. <S> a<A><B>c
2. <S>
3. <A> c<S><B>
4. <A> <A>b
5. <B> b<B>
6. <B> a
Пусть дана цепочка: a<A><B>c, тогда вывод будет выглядеть следующим образом:
<S> (1) ==> a<A><B>c (2) ==> a<A>b<B>c (3) ==> ac<S><B>b<B>c (4) ==> ac<S>ab<B>c (5) ==> acab<B>c (6) ==> acabac (7).
Теперь для каждой из семи пронумерованных цепочек можно построить дерево.
-
(1)
<S>
-
(2)
<S>
a <A> <B> c
-
(3)
<S>
a <A> <B> c
<A> b
-
(4)
<S>
a <A> <B> c
<A> b
c <S> <B>
-
(5)
<S>
a <A> <B> c
<A> b
c <S> <B>
a
-
(6)
<S>
a <A> <B> c
<A> b
c <S> <B>
a
-
(7)
<S>
a <A> <B> c
<A> b a
c <S> <B>
a
Окончательный вариант дерева называется деревом вывода терминальной цепочки acabac.
Когда одна цепочка может иметь несколько деревьев вывода, говорят, что соответствующая грамматика неоднозначна.
Таким образом, резюмируя вышесказанное, можно подытожить:
Каждой цепочке, выводимой в данной контекстно-свободной грамматике, соответствует одно или несколько деревьев вывода.
Каждому дереву соответствует один или более выводов.
Каждому дереву соответствует единственный правый и единственный левый выводы.
Если каждой цепочке, выводимой в данной контекстно-свободной грамматике, соответствует единственное дерево вывода, эта грамматика называется однозначной; в противном случае ее называют неоднозначной.
Если правая часть каждого правила грамматики содержит не более одного нетерминала, причем этот нетерминал является самым правым символом правой части, грамматика называется праволинейной.
Нетерминалы, которые не порождают ни одной терминальной цепочки, называются бесплодными или мертвыми. Они могут быть исключены из грамматики со всеми правилами, в которые входят.
Нетерминалы, которые не появляются ни в одной цепочке, выводимой из начального символа, называются недостижимыми нетерминалами.
Нетерминалы, которые бесплодны или недостижимы, называются бесполезными. При составлении грамматик велика вероятность появления бесполезных нетерминалов и загромождение грамматик лишними правилами. Для поиска подобных нетерминалов существует конкретная процедура, разбитая на две части: обнаружение бесплодных нетерминалов и обнаружение недостижимых нетерминалов. Сначала нужно выполнить процедуру для бесплодных нетерминалов, так как при их удалении из грамматик другие нетерминалы могут стать недостижимыми.
Терминальный символ называется продуктивным (или живым), если из него выводится какая-нибудь терминальная цепочка, то есть если он не является бесплодным нетерминалом. Процедура обнаружения бесплодных нетерминалов основана на следующем свойстве продуктивных символов: Если все символы правой части правила продуктивны, то продуктивен и символ, стоящий в ее левой части.
Символ называется достижимым в грамматике, если он может появиться в какой-нибудь цепочке, выводимой из начального нетерминала, то есть если он не является недостижимым. Процедура обнаружения недостижимых символов грамматики основана на следующем свойстве достижимых символов:
Если нетерминал в левой части правила является достижимым, то достижимы и все символы правой части этого правила.
Теперь, исходя из вышеописанных свойств грамматик, можно сформулировать принципы построения синтаксического анализатора.
Во-первых, должно существовать правило, описывающее любой входной поток, который может быть обработан анализатором. Для большинства текстов таким правилом может быть следующее:
text: text string
Такое правило описывает входной поток рекурсивно как набор строк, образующих текст. В некоторых форматах (например, таких, как RTF) начальным правилом было бы
text: text word
Следует различать обработку команд и обработку непосредственно содержащегося текста. В большинстве случаев команды производят некоторое действие, а текст подлежит выводу в существующих условиях.
Команды могут располагаться как в определенных местах потока (в определенном контексте), так и быть расположены среди текстовых строк. В любом случае, команды каким-либо образом отличаются от текстовых строк. Зарезервированных слов в текстовых форматах не бывает, обычно для выделения команд применяются те или иные спецсимволы.
Команды могут иметь аргументы, описание аргументов также подчиняется определенным правилам.
Можно сказать, что такие элементы, как команды, аргументы, текстовые и пустые строки представляют собой лексемы - минимальный объект, которым оперирует анализатор при синтаксическом анализе.
Следует заметить, что использование в качестве построителя лексического анализатора генератора программ Lex, а в качестве построителя синтаксического анализатора генератора программ Yacc удобно еще и потому, что эти инструменты создавались с учетом возможности их совместного использования и имеют удобные способы совмещения.
Заключение.
Рассмотрены общие принципы проектирования трансляторов текстовых форматов. Разобраны принципы создания лексических анализаторов. Исследованы грамматики и разобраны общие принципы построения синтаксических анализаторов. Лексические и синтаксические анализаторы удобно строить именно с помощью генераторов программ Lex и Yacc, так как они создавались для совместной работы.
3. Технология реализации транслятора с помощью генераторов программ Lex и Yacc.
При построении транслятора сначала строится лексический анализатор и происходит его отладка. На этом этапе лексемы определяются, но передачи их куда-либо не происходит. После отладки (когда есть уверенность, что тексты на лексическом уровне обрабатываются достаточно полно) в правила лексического анализатора добавляется возврат лексем командой return(). Естественно, что на этом этапе лексический анализатор самостоятельно может принять из потока и обработать не более одной лексемы. Начинается построение синтаксического анализатора, который каждый раз для получения лексемы вызывает лексический анализатор. Затем также происходит отладка анализаторов. Окончательным этапом является создание головной программы и отладка взаимодействия всех частей транслятора.
3.1 Определение лексем, встречающихся в формате nroff
Прежде всего, в формате nroff можно выделить четыре группы лексем: текст, команды, аргументы команд и переменные.
Команды всегда находятся в начале строки и начинаются с точки. Все команды состоят из одной или двух букв латинского алфавита. Команды могут иметь один или несколько аргументов.
Аргументы команд следуют через один или несколько пробелов (или табуляций) после команды. Аргумент может быть числом со знаком или без знака, символом или строкой. После аргумента могут следовать пробельные символы.
Переменные могут располагаться в любом месте текста. Все переменные сначала объявляются при помощи специальной команды.
Текстовые строки выводятся сплошным потоком, то есть если текст располагается на нескольких строках, но между ними нет команды перевода строки в формате nroff, то этот текст, по возможности, будет выведен без перевода строк.
Если строка не содержит никаких символов (кроме конца строки), то происходит вывод пустой строки и выдается команда перевода строки.
Состояния, имеющиеся в формате nroff.
|
Состояние |
Описание |
Переходы |
|
0 |
Начальное состояние |
Возможен переход в состояние приема команды или текста. |
|
TEXT |
Состояние приема текста |
После приема одной текстовой строки происходит переход в начальное состояние. |
|
COMMAND |
Состояние приема команд |
После приема команды происходит переход в состояние приема аргумента. |
|
COMARG |
Состояние приема аргумента команды |
Вне зависимости от того, был принят аргумент или нет, происходит переход в начальное состояние. |
Основные лексемы, встречающиеся в формате nroff.
|
Лексема |
Значение |
|
TEXTSTR |
Строка текста |
|
EMPTYSTR |
Пустая строка |
|
FONT |
Команды управления |
|
SIZE |
шрифтами |
|
ADJUST |
Команды управления |
|
NOADJUST |
расположением |
|
SCENTER |
текста |
|
IN |
Команды управления |
|
TIN |
отступами |
|
SUNDERLINE |
Команды управления |
|
UNDERLINE |
видом |
|
BOLD |
текста |
|
BREAKLINE |
Команды вывода |
|
SPACE |
символов разрыва строк и |
|
LINESPACE |
пробельных символов |
|
UNKNOW |
Все неизвестные команды |
|
EXIT |
Команда прекращения обработки текста |
|
DARG |
Аргументы |
|
CARG |
команд |
|
SARG |
Лексический анализатор разбирает входной поток следующим образом:
В начальном состоянии считывается первый символ из потока.
Если символ является точкой, то анализатор переходит в состояние ожидания команды.
Иначе предполагается, что взят первый символ из текстовой строки. Анализатор переходит в состояние приема текста, причем при последующем действии взятые из потока данные будут добавлены к символу, находящемуся в буфере – так обеспечивается целостность текста.
Если же символ взять не удалось - была встречена пустая строка – то синтаксическому анализатору передается лексема, означающая пустую строку.
В состоянии приема текста строка из потока принимается целиком, до символа конца строки. Лексический анализатор возвращает синтаксическому анализатору лексему, означающую текст, предварительно перейдя в начальное состояние.
В состоянии приема команды из потока принимается две латинских буквы, за которыми могут следовать один или более пробелов.
В соответствии с полученными символами выбирается лексема и передается синтаксическому анализатору.
Если полученные символы не подходят под шаблон ни одной из команд, то команда объявляется неизвестной. Перед возвращением лексемы в синтаксический анализатор, лексический анализатор переходит в состояние ожидания аргумента команды.
Предполагается, что аргументы команд могут быть трех типов – слово (например, название шрифта у команды .ft); символьный (например, тип выравнивания у команды .ad) или числовой (например, количество строк у команды .br). После определения лексемы, лексический анализатор переходит в начальное состояние и передает лексему синтаксическому анализатору.
Следует учитывать, что лексический анализатор, построенный с помощью генератора программ Lex, принимая символы, берет их не по порядку следования правил, а выбирает правило, удовлетворяющее наибольшей длине принимаемой строки. Поэтому лексический анализатор определит аргумент как символьный только в случае, если он действительно содержит только один символ.
В противоположном случае аргумент определяется как слово.
Если аргумент состоит из одной и более цифр, то он передается как число.
3.2 Описание грамматических правил преобразования из формата nroff в формат HTML.
В нашем случае наиболее общим правилом является описание входного файла как списка списков строк. Строки могут быть двух типов - команды и текст. Команды могут иметь аргумент либо не иметь аргумента. Текст может быть текстовой строкой и пустой строкой. Такие элементы, как команды, аргументы, текстовые и пустые строки представляют собой лексемы - минимальный объект, которым оперирует анализатор при синтаксическом анализе.
Если синтаксический анализатор получает от лексического анализатора лексему "текст", то он выводит в выходной поток содержимое буфера yytext, используя для этого специально определенную функцию textout().
Если получена лексема "пустая строка", то в выходной поток выводится тэг HTML <br> при помощи функции breakline().
Если получена лексема, соответствующая одной из команд, то, возможно, запрашивается лексема аргумента и выполняются необходимые операции.
Так как во всех командах аргумент является вторым элементом правила, то для доступа к его значению всегда используется псевдопеременная $2.
Обработка большинства команд приводит к тому, что в выходной поток записывается открывающий тэг, возможно с теми или иными аргументами. Так как формат HTML требует закрытия тэга до его повторного открытия, то для контроля закрытия предусмотрены переменные-триггеры. Они принимают значение, равное единице, при выводе в выходной поток открывающего тэга и каждый раз перед выводом нового открывающего тэга проводится проверка на включение триггера. Если триггер включен, то перед выводом стартового тэга будет выведен закрывающий тэг.
В формате nroff принята такая система команд, при которой у большинства команд аргументом является количество строк, на которые будет распространятся действие этой команды. В HTML же область действия команды определяется местоположением открывающего и закрывающего тэгов. Для того, что бы определить место вывода закрывающего тэга, введены переменные-счетчики. В момент получения команды им присваивается значение аргумента, и затем оно уменьшается при выводе в выходной поток очередной порции текста. При достижении счетчиком значения "ноль", в выходной поток выводится закрывающий тэг. Если значение счетчика меньше нуля, то это значит, что он сейчас неактивен.
При выводе текста функцией textout() происходит анализ на содержание в тексте переменных. Если переменные найдены, то происходит подстановка их значений в выводимый текст.
Для вывода в выходной поток тэга <br> - команда перевода строки – применяется специальная функция breakline(). Необходимость такого шага обусловлена тем, что в nroff существует команда ".ls", которая определяет, сколько пустых строк выводится по команде ".br" (аналогом которой является тег <br>). При поступлении лексемы, соответствующей команде ".ls" значение ее аргумента присваивается переменной LS, которая определяет сколько раз подряд выведется тэг <br> в выходной файл.
Замена шрифтов осуществляется при помощи функции fontchange(). В качестве аргумента ей передается имя шрифта, используемого в исходном документе. Имя шрифта, на который будет заменен данный шрифт определяется по специально созданной таблице, хранящейся во внешнем файле. В случае, если замена не определена, подставляется шрифт по умолчанию.
Особо надо оговорить обработку команды nroff ".ex". При получении лексемы, соответствующей этой команде, синтаксический анализатор завершает свою работу, возвращая в головную функцию значение "0", свидетельствующее о нормальном завершении работы.
3.3 Соответствие
между командами форматов
nroff и HTML.
Точного соответствия между текстовым форматом nroff и гипертекстовым форматом HTML нет.
Главным отличием является то, что формат HTML ориентирован на использование его в локальных или глобальных сетях, а формат nroff - на использование только для чтения документов.
Формат HTML поддерживает больше видов форматирования текстов, гипертекстовые ссылки, включение в текст графики, запуск внешних программ и многое другое.
Формат nroff подразумевает постраничный вывод на экран, а формат HTML - вывод сплошным потоком с возможностью последующей прокрутки окна просмотра.
Так как нас интересует, прежде всего, преобразование команд формата nroff в команды формата HTML, то имеет смысл рассмотреть команды исходного формата и определить, какие команды им будут соответствовать в конечном формате:
|
nroff |
HTML |
Описание |
|
Комментарии |
||
|
\” |
<COMMENT> </COMMENT> |
Комментарий |
|
Команды для управления шрифтом |
||
|
.bd |
<b> </b> |
Жирный шрифт |
|
.ul |
<u> </u> |
Подчеркивание |
|
.ft font_name |
<font face="font_name"> </font> |
Устанавливает шрифт |
|
.ps n |
<font size="n"> </font> |
Устанавливает размер символа |
|
nroff |
HTML |
Описание |
|
Команды управления текстом |
||
|
.br |
<br> |
Следующая строка |
|
.ce |
<center> </center> |
Центрирование |
|
.ad x |
<div adjust="x"> </div> |
Выравнивание текста |
|
.na |
<pre> </pre> |
Нет управления текстом |
|
.sp |
<spacer> </spacer> |
Пустое пространство |
В HTML не поддерживаются следующие команды, имеющиеся в формате nroff:
|
nroff |
Описание |
|
Команды управления страницами |
|
|
.bp |
начать новую страницу |
|
.pl |
установить длину страницы |
|
.pn |
установить номер страницы |
|
.ll |
длина строки |
Для вывода текста в виде, максимально близко к исходному, в конечном формате иногда необходимо использовать не одну команду, а комбинацию команд:
|
Nroff |
HTML |
Описание |
|
.rt |
<table border=0> <tr> <td> </td> ……… </tr> ……… </table> |
вертикальный возврат для столбцов |
|
.nf |
<br> |
нет заполнения |
|
.in |
… |
отступ |
|
.ti |
… |
временный отступ |
|
.ls |
<br> |
пропуск строки |
При создании документа в формате HTML необходимо вставлять обязательные тэги:
|
HTML |
Комментарий |
|
<HTML> </HTML> |
Признак HTML-документа. Весь текст, помещенный между этими тэгами обрабатывается в соответствии с форматом HTML. Закрывающий тэг служит признаком конца документа и выводится при нахождении команды nroff .ex |
|
<HEAD> </HEAD> |
Область заголовка HTML-документа, служит для формирования общей структуры документа. |
|
<TITLE> </TITLE> |
Заголовок HTML-документа. Вставляется имя конвертируемого файла. |
|
<BODY> </BODY> |
Заключает в себе гипертекст, который, собственно и выводится в окне броузера. |
|
<A> </A> |
Гиперссылка. Этими тэгами обрамляются ссылки на другие документы. Предполагается, что они располагаются в том же каталоге, что и открытый документ и имена файлов имеют расширение .html |
|
<BASE> |
Элемент для создания базового адреса для ссылок. Если документы и программа транслятор находятся в разных каталогах, то это тэг определяет местонахождение каталога с документами. |
3.4 Отладка лексического и грамматического анализаторов.
Отладка происходит в два этапа – отладка лексического анализатора и отладка системы из лексического и синтаксического анализаторов.
Для отладки используется метод пошагового просмотра работы анализаторов. Для этого создан специальный оператор (посредством команды #define языка С), выводящий сообщение о состоянии анализатора (имя обрабатываемой лексемы и состояние различных переменных).
При отладки лексического анализатора возможно использование тестовых пакетов – текстов в формате nroff, а также интерактивное тестирование, когда анализатор принимает информацию из стандартного ввода (с клавиатуры) и выдает результаты на стандартный вывод (экран монитора).
Для проверки правильности написания правил синтаксического анализатора генератор программ Yacc на этапе тестирования запускается с ключом d по которому создается файл с деревом разбора.
Заключение.
Создана программа-транслятор из формата nroff в гипертекстовый формат HTML.
Программа выводит пустые обязательные теги формата HTML и преобразует текст из формата nroff в формат HTML. Полностью поддерживается стандартный набор команд формата nroff. Реализована большая часть команд различных пакетов макросов, наиболее полно реализован пакет макросов “man”.
Порядок работы с программой-транслятором ut4all таков: на вход программы подается текстовый файл в формате nroff, а на выходе получаем текстовый файл в формате HTML. Имена текстовых файлов передаются в качестве аргумента, причем первым аргументом является имя входного файла, а вторым – имя выходного. В случае отсутствия одного или обоих аргументов в качестве входного и выходного потоков используются стандартные потоки. Если входного файла не существует, то выдается сообщение об ошибке, если не существует выходного файла, то он создается.
Сообщения об ошибках направляются в стандартный поток ошибок.
4. Экономическое обоснование разработки НИОКР.
4.1 Расчет затрат времени на разработку транслятора.
4.1.1. Для начала необходимо определить продолжительность создания транслятора. Определим весь перечень работ по всем этапам разработки информационной системы.
Этапы создания транслятора:
|
Этап 1: |
Техническое задание. |
|
Получение задания, его обработка, а также согласование задания и его деталей с консультантом. |
|
|
Этап 2: |
Техническое предложение. |
|
Изучение ОС Unix и ее компонент – lex, yacc. |
|
|
Этап 3: |
Эскизное проектирование. |
|
Изучение подходов к написанию трансляторов. |
|
|
Этап 4: |
Техническое проектирование. |
|
Разработка алгоритмов решения задачи. |
|
|
Этап 5: |
Рабочий проект. |
|
Разработка структуры программного обеспечения. |
|
|
Этап 6: |
Изготовление опытного образца. |
|
Непосредственно программирование. |
|
|
Этап 7: |
Испытание опытного образца. |
|
Отладка программы |
|
|
Этап 8: |
Оформление документации. |
|
Оформление документации. |
По формуле 1.1 рассчитывается
ожидаемое время выполнения каждой
работы
 .
.
(1.1)
 ,
где
,
где
 - минимальная
продолжительность работы, т.е. время,
необходимое для выполнения работы при
наиболее благоприятном стечении
обстоятельств (час, дни, недели и т.д. );
- минимальная
продолжительность работы, т.е. время,
необходимое для выполнения работы при
наиболее благоприятном стечении
обстоятельств (час, дни, недели и т.д. );
 - максимальная
продолжительность работы т.е. время,
необходимое для выполнения работы при
наиболее неблагоприятном стечении
обстоятельств (час, дни, недели и т.д. )
- максимальная
продолжительность работы т.е. время,
необходимое для выполнения работы при
наиболее неблагоприятном стечении
обстоятельств (час, дни, недели и т.д. )
Для определения возможного
разброса ожидаемого времени определяется
дисперсия (рассеивание)

(1.2)

Составим таблицу значений
 по каждой работе каждого этапа:
по каждой работе каждого этапа:
Таблица 1.1.
|
Этапы |
дн |
дн |
дн |
|
|
1 |
5 |
10 |
7 |
1 |
|
2 |
40 |
50 |
44 |
4 |
|
3 |
4 |
5 |
4,4 |
0,04 |
|
4 |
5 |
8 |
6,2 |
0,36 |
|
5 |
4 |
6 |
4,8 |
0,16 |
|
6 |
50 |
60 |
54 |
4 |
|
7 |
17 |
21 |
18,6 |
0,64 |
|
8 |
6 |
7 |
6,4 |
0,04 |
|
Всего |
131 |
167 |
145,4 |
Исполнитель для всех этапов один, т.е. возможно только последовательное выполнение всех работ.
4.2 Расчет стоимости основных фондов, используемых для разработки транслятора.
Первоначальная (балансовая) стоимость складывается из всех затрат, связанных с приобретением, сооружением и строительством основных производственных фондов.
К основным фондам при разработке транслятора можно отнести то оборудование, на котором выполнялась данная разработка:
Таблица 2.1
|
Оборудование |
Стоимость в $ |
|
|
Компьютер |
Процессор |
150 |
|
Материнская плата |
120 |
|
|
Оперативная память |
160 |
|
|
Видеокарта |
35 |
|
|
Модем |
165 |
|
|
Винчестер |
200 |
|
|
CD-rom |
110 |
|
|
Дисковод |
25 |
|
|
Корпус |
36 |
|
|
Клавиатура |
12 |
|
|
Мышь |
7 |
|
|
Принтер |
300 |
|
|
Монитор |
480 |
Первоначальная (балансовая) стоимость основных фондов в соответствии с данными, приведенными в таблице 2.1, составит 1800$ или 50400 рублей (по курсу 1$ 28 руб. – на апрель 2000 г.).
Первоначальная (остаточная) стоимость характеризует оценку основных производственных фондов по первоначальной (балансовой) стоимости за минусом общей суммы амортизационных отчислений на данный момент.
Общую сумму амортизационных отчислений на время начала выполнения дипломного проекта определим по формуле:
K*H>a>*t
 A
= (2.1)
A
= (2.1)
Ф>д>
где
K - первоначальная балансовая стоимость основных фондов, руб.;
H>a>- норма годовых амортизационных отчислений, % (таблица 2.2.);
t - реально использованное машинное время, час.;
Ф>д> - действительный фонд времени работы оборудования за год, час.
Таблица 2.2
Нормы амортизационных отчислений по отдельным видам спец. оборудования (% от балансовой стоимости).
|
НАИМЕНОВАНИЕ ОБОРУДОВАНИЯ |
Норма амортизационных отчислений |
|
Физико-термическое оборудование для производства изделий микроэлектроники и полупроводниковых приборов |
28.2 |
|
Контрольно-измерительное и испытательно-тренировочное оборудование для производства электронной техники |
27.5 |
|
Оборудование для измерения электрофизических параметров полупроводниковых приборов |
27.3 |
|
Оборудование для механической обработки полупроводниковых материалов |
23.9 |
|
Вакуумное технологическое оборудование для нанесения тонких пленок |
24.3 |
|
Оборудование для производства фотошаблонов |
23.4 |
|
Сборочное оборудование для производства полупроводниковых и электровакуумных приборов |
23.8 |
|
Электронные генераторы, стабилизированные источники питания, тиристорные выпрямители, регуляторы напряжения |
15.5 |
|
Прочее спецтехнологическое оборудование для производства изделий электронной техники |
13.1 |
|
Контрольно-измерительная и испытательная аппаратура связи, сигнализации и блокировки: |
|
|
Переносная |
14.2 |
|
Стационарная |
8.5 |
|
Лабораторное оборудование и приборы |
20.0 |
|
Электронные цифровые вычислительные машины общего назначения, специализированные и управляющие |
12.0 |
Сумма амортизационных отчислений составит:
50400* 0.12* 1000
A = 2360 = 2563
руб.
= 2360 = 2563
руб.
Первоначальная (остаточная) стоимость составит:
45000 - 2563 = 42437 руб.
4.3 Расчет затрат на разработку транслятора.
4.3.1. Расчет затрат на разработку транслятора.
Таблица 3.1
-
Материальные ресурсы
Цена, руб.
Книги
"LINUX"
120
HTML
15
DEMOS32
50
Программное обеспечение
ОС Windows 95
625
OS LINUX
190
Суммарные затраты составляют 1000 руб.
4.3.2. Заработная плата.
К основной зарплате при выполнении НИОКР относятся зарплата научных, инженерно-технических работников и рабочих НИИ и КБ. Их зарплата определяется по формуле 3.1.
 ,
,
(3.1)
где
 -
тарифная ставка работника I-ого разряда,
=
83,49 руб;
-
тарифная ставка работника I-ого разряда,
=
83,49 руб;
 -
тарифный коэффициент работника
соответствующего разряда (таблица
3.2.);
-
тарифный коэффициент работника
соответствующего разряда (таблица
3.2.);
 -
фактически отработанное работником
время, чел-месяц..
-
фактически отработанное работником
время, чел-месяц..
Таблица 3.2.
Единая тарифная сетка по оплате труда работников бюджетной сферы.
|
Разряды оплаты труда |
Тарифные коэффициенты |
Разряды оплаты труда |
Тарифные коэффициенты |
|
1 |
1.00 |
10 |
2.98 |
|
2 |
1.12 |
11 |
3.37 |
|
3 |
1.27 |
12 |
3.38 |
|
4 |
1.44 |
13 |
4.31 |
|
5 |
1.62 |
14 |
4.81 |
|
6 |
1.83 |
15 |
5.50 |
|
7 |
2.07 |
16 |
6.11 |
|
8 |
2.34 |
17 |
6.78 |
|
9 |
2.64 |
18 |
7.54 |
И>з.п.>= 83,49 * 1.62 * (145,4 / 21,8) =
= 902 руб.
4.3.3. Дополнительная заработная плата составляет 10-20% от основной. Дополнительная зарплата с основной зарплатой образуют фонд оплаты труда.
Дополнительная заработная плата составит:
0.2 * 902 = 180,4 руб.
Фонд оплаты труда составит:
902 + 180,4 = 1082,4 руб.
4.3.4. Амортизационные отчисления (без учета амортизационных отчислений на полное восстановление) определяются по формуле 3.2.
(3.2.)
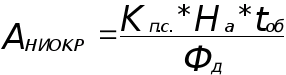 , где
, где
 -
первоначальная (балансовая) стоимость
основных фондов на начало года, руб.;
-
первоначальная (балансовая) стоимость
основных фондов на начало года, руб.;
 -
норма годовых амортизационных отчислений,
% (таблица 2.2);
-
норма годовых амортизационных отчислений,
% (таблица 2.2);
 -
машинное время, необходимое для выполнения
НИОКР, час.;
-
машинное время, необходимое для выполнения
НИОКР, час.;
 -
действительный фонд времени работы
оборудования за год, час.
-
действительный фонд времени работы
оборудования за год, час.
Амортизационные отчисления составят:
42437 * 0.12 * 400
А >НИОКР
>
=
= 863,13 руб.
>НИОКР
>
=
= 863,13 руб.
2360
4.3.5. Косвенные расходы.
Косвенные расходы составляют 50-100% от фонда оплаты труда.
Косвенные расходы составят:
0.7 * 1082,4 = 757,68 руб.
4.3.6. Расчет налогов.
Обязательные отчисления в государственные внебюджетные фонды.
Таблица 3.3
|
>п/п> |
>Наименование фонда> |
Ставка налога (%) |
>Объект налогообложения> |
|
>1> |
>Пенсионный фонд> |
>28.0> |
Фонд оплаты труда и другие выплаты |
|
>1.0> |
>Зарплата работающих> |
||
|
>2> |
Фонд обязательного медицинского страхования |
>3.6> |
>Фонд оплаты труда> |
|
>3> |
Государственный фонд занятости |
>1.5> |
>Фонд оплаты труда> |
|
>4> |
>Фонд социального страхования> |
>5.40> |
Фонд оплаты труда, доходы от ценных бумаг и банковских вкладов. Добровольные взносы граждан и юридических лиц, ассигнования из бюджета РФ на пособия, компенсации |
Учитывая, что фонд оплаты труда составляет 1082,4 руб., зарплата работника составляет 902 руб., имеем следующие отчисления в государственные внебюджетные фонды:
Таблица 3.4
|
п/п |
Наименование фонда |
Ставка налога (%) |
ОтчисленияРуб. |
|
1 |
Пенсионный фонд |
28.0 1.0 |
303,07 9.02 |
|
2 |
Фонд обязательного медицинского страхования |
3.6 |
38,97 |
|
3 |
Государственный фонд занятости |
1.5 |
16,24 |
|
4 |
Фонд социального страхования |
5.40 |
58,43 |
Суммарный налог в государственные внебюджетные фонды составит:
303,07 + 38,97 + 58,43 = 400,47 руб.
4.4 Формирование расчетной (остаточной) прибыли предприятия и определение эффективности произведенных затрат на разработку транслятора.
Для оценки и анализа эффективности произведенных затрат используется следующие показатели:
договорная цена;
доход (выручка) предприятия;
прибыль;
срок окупаемости затрат;
коэффициент эффективности (рентабельность).
Договорная цена НИОКР - цена, устанавливаемая непосредственно предприятием-исполнителем по договоренности с предприятием-потребителем с учетом конъюнктуры рынка на основе сложившегося спроса и предложения.
Формируют договорную цену НИОКР затраты на их выполнение и прибыль, величина которой определяется исполнителем.
Установим договорную цену на разработанный транслятор в размере 1250 руб. Предположим, что доход (выручка) от реализации данного транслятора составила 1250*15=18750 руб.
Из дохода изымаются налоги на содержание жил. фонда и объектов социально-культурной сферы, на имущество и на цели образования. Ставки данных налогов приведены в таблице 4.1.
Таблица 4.1.
Налоги.
|
>п/п> |
>Вид налога> |
Ставка налога (%) |
>Объект налогообложения> |
|
>1> |
Налог на прибыль предприятий |
>35.0> |
>Балансовая прибыль> |
|
2 |
Налог на прибыль от посреднических операций предприятий |
38.0 |
>Прибыль от посреднических операций> |
|
>3> |
>Налог на имущество> |
>2.0> |
Основные фонды, материальные активы |
|
>4> |
Налог на цели образования |
>1.0> |
>Фонд оплаты труда> |
|
>5> |
Налог на содержание жилищного фонда и объектов социально-культурной сферы |
>1.5> |
>Объем реализации товаров и услуг> |
Учитывая, что стоимость основных фондов составляет 42437 руб., фонд оплаты труда – 1082,4 руб., объем реализации - 18750 руб., имеем:
Таблица 4.2.
|
Вид налога |
Ставка налога (%) |
Величина налога |
|
1.Налог на имущество |
2.0 |
848,74 |
|
2.Налог на цели образования |
1.0 |
10,82 |
|
3. Налог на содержание жилищного фонда и объектов социально-культурной сферы |
1.5 |
281,25 |
Доход за вычетом налогов составляет:
37500 – (848,74 + 10,82 + 281,25 ) – 400,47 = 35958,72 руб.
Выручка от реализации транслятора за вычетом его себестоимости и всех вышеперечисленных налогов образуют балансовую прибыль.
Себестоимость складывается из материальных затрат, заработной платы, амортизационных отчислений и косвенных расходов. Себестоимость транслятора составляет:
С = Ио(1+К>д.>)(K>к.>+K>с.н.>)+S>мат.>+A>об.>=
= 1082*(1+0,7)*(1+0,37)+1000+863,13 =
= 4383,11 руб.
Балансовая прибыль составляет:
18750 – 4383,11 = 14366,89 руб./год
Балансовая прибыль, уменьшенная на налог на прибыль, образует расчетную (остаточную) прибыл. Ставка налога на прибыль составляет 35%:
 =
14366,89 - (0,35*14366,89) – 848,74
–
10,82 – 562,5 – 16,24 = 7900,18 руб.
=
14366,89 - (0,35*14366,89) – 848,74
–
10,82 – 562,5 – 16,24 = 7900,18 руб.
Срок окупаемости затрат на выполнение НИОКР определяется по формуле:
(4.1.)
 (лет), где
(лет), где
 -
себестоимость НИОКР, руб.;
-
себестоимость НИОКР, руб.;
-
расчетная прибыль, руб.
Срок окупаемости транслятора составит:
t>ок >= 4383,11 / 7900,18 = 0,55 года
Коэффициент эффективности произведенных затрат на выполнение НИОКР определяется по формуле 4.2.
(4.2.)

Коэффициент эффективности произведенных затрат на разработку транслятора:
1
К >эф-ти>
= *100% = 181,8%
>эф-ти>
= *100% = 181,8%
0,55
4.5 Оценка значимости разработки транслятора.
Для оценки значимости выполненной работы можно воспользоваться оценочными коэффициентами, учитывающими степень положительного эффекта от выполнения дипломного проекта:
объем выполненных исследований,
сложность решения задачи,
уровень технической подготовки студента
полноту использования современных методов выполнения исследований и разработок.
Значимость выполненных исследований и разработок можно выразить через коэффициент значимости Dзн, который определяется по формуле:
i
Dзн = ,
max
где i=1,2,3,4; max = 40,0.
Величина коэффициента исследования или разработки изменяется в пределах от 0,1 до 1, т.е. 0,1≤ Dзн ≤1
Чем ближе к единице значение Dзн , тем более весома выполненная работа.
Определим значение коэффициента значимости дипломной работы.
В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5.
В ходе работы над дипломным проектом была освоена возможность создания программ-трансляторов с помощью генераторов программ lex и yacc. Это можно считать выполнением основной части исследования. Таким образом объем выполненных исследований и разработок 2=4,0.
Сложность решения задачи в дипломной работе научно-исследовательского характера 3=7,0.
В ходе работы над дипломным проектом использовались современные средства электронно-вычислительой техники (персональный компьютер Pentium 120 с операционной системой Windows-95). Поэтому уровень научно-технической подготовки студента 4=6,0.
Коэффициент значимости равен :
I 6,5 + 4,0 + 7,0 + 6,0
Dзн = = = 0,59
max 40,0
Полученный коэффициент значимости указывает на достаточно высокий уровень выполненных исследований и разработок.
Заключение.
Выполнен расчет затрат на разработку транслятора. Оценена прибыль от реализации транслятора и определена эффективность произведенных затрат. Коэффициент эффективности составляет 181,8%
Кроме того, произведена оценка значимости разработки транслятора и он указывает на достаточно высокий уровень выполненных исследований и разработок.
5. Обеспечение комфортных условий труда при работе на ПЭВМ.
5.1 Характеристика условий труда оператора ЭВМ
Условия труда оператора характеризуются возможностью воздействия на них комплекса опасных и вредных факторов: шума, тепловыделений, вредных веществ, радиоактивных, электромагнитных излучений, недостаточной или избыточной освещенности рабочих мест, высокого напряжения, давлений, существенно отличных от атмосферного, нервно-психические перегрузки (умственное перенапряжение, перенапряжение анализаторов, эмоциональные перегрузки) и т.д. Вредные факторы могут влиять на оператора не только непосредственно, вызывая функциональные изменения в организме и, как следствие, профессиональные заболевания, но и воздействуют опосредованно на психику человека, снижая скорость реакции, ухудшая внимание: шум снижает концентрацию внимания, оказывает эмоциональное воздействие, вибрации вызывают уменьшение разрешающей способности и остроты зрения.
5.2 Требования к защите от шума и вибраций.
Фоновый уровень шума не должен превышать 40 дБА, (при работе систем воздушного отопления, вентиляции и кондиционирования - 35 дБА), а во время работы на ПЭВМ 50 дБА (таблица 1). Нормативные уровни шума обеспечиваются использованием малошумного оборудования, применением звукопоглощающих материалов для облицовки помещений, а также различных звукоизолирующих устройств.
Таблица 1.
Допустимые уровни звука, эквивалентные уровни звука и уровни звукового давления в октавных полосах частот при работе на ПЭВМ
|
Уровни звукового давления, дБ |
Средне-геометрические частоты октавных полос, Гц |
Уровни звука, эквивалентные уровни звука, дБА |
|
86 |
31.5 |
|
|
71 |
63 |
|
|
61 |
125 |
50 |
|
54 |
500 |
|
|
49 |
1000 |
|
|
45 |
2000 |
|
|
40 |
4000 |
|
|
38 |
8000 |
50 |
Время реверберации в помещениях с ПЭВМ не должно быть более 1 с. Частотная характеристика времени реверберации в диапазоне частот 250-4000 Гц должна быть ровной, а на частоте 125 Гц спад времени реверберации должен составлять не более 15%.
Вибрация не должна превышать нормируемых значений (таблица 2).
Таблица 2.
Допустимые нормы вибрации на рабочих местах с ПЭВМ.
|
Средне-геометрические частоты октавных полос, Гц |
Допустимые значения |
|||
|
по виброскорости |
по виброускорению |
|||
|
м/с2 |
дБ |
м/с |
дБ |
|
|
2 |
5,310 |
25 |
4,510 |
79 |
|
4 |
5,310 |
25 |
2,210 |
73 |
|
8 |
5,310 |
25 |
1,110 |
67 |
|
16 |
1,110 |
31 |
1,110 |
67 |
|
31.5 |
2,110 |
37 |
1,110 |
67 |
|
63 |
4,210 |
43 |
1,110 |
67 |
5.3 Требования к микроклимату, содержанию аэроионов и вредных химических веществ в воздухе помещений эксплуатации ПЭВМ
В производственных помещениях, в которых работа на ПЭВМ является основной (диспетчерские, операторские, расчетные, кабины и посты управления, залы вычислительной техники и др.), должны обеспечиваться оптимальные параметры микроклимата (таблица 3). Интенсивность теплового облучения оператора от осветительных приборов, инсоляции на постоянных и непостоянных рабочих местах не должна превышать 35Вт/м2 при облучении 50% поверхности тела и более , 70Вт/м2 при облучении от 25 до 50% и 100Вт/м2 - при облучении не более 25% поверхности тела. Тепловыделение регулируется устройством эффективных систем вентиляции и кондиционирования.
Таблица 3.
Оптимальные нормы микроклимата для помещений с ПЭВМ.
|
Период года |
Катего-рия работ |
Темпера-тура воздуха, оС не более |
Относи-тельная влажность воздуха, % |
Скорость движения воздуха, м/с |
|
Холодный |
легкая-1а легкая-1б |
22-24 21-23 |
40-60 40-60 |
0,1 0,1 |
|
Теплый |
легкая-1а легкая-1б |
23-25 22-24 |
40-60 40-60 |
0,1 0,2 |
Примечания: к категории 1а относятся работы, производимые сидя и не требующие физического напряжения, при которых расход энергии составляет до 120 ккал/ч; к категории 1б относятся работы, производимые сидя, стоя или связанные с ходьбой и сопровождающиеся некоторым физическим напряжением, при которых расход энергии составляет от 120 до 150 ккал/ч.
Уровни положительных и отрицательных аэроионов в воздухе помещений с ПЭВМ должны соответствовать нормам, приведенным в таблице 4.
Таблица 4.
Уровни ионизации воздуха помещений при работе на ПЭВМ
|
Уровни |
Число ионов в 1 см воздуха |
|
|
n+ |
n- |
|
|
Минимально необходимые |
400 |
600 |
|
Оптимальные |
1500-3000 |
3000-5000 |
|
Максимально допустимые |
50000 |
5000 |
Содержание вредных химических веществ в производственных помещениях, работа на ПЭВМ в которых является основной (диспетчерские, операторские, расчетные, кабины и посты управления, залы вычислительной техники и др.), не должно превышать "Предельно допустимых концентраций загрязняющих веществ в атмосферном воздухе населенных мест". В качестве средств защиты используется рациональная система вентиляции рабочих мест, дополненная очистными устройствами.
5.4 Требования к интенсивности электромагнитных полей, рентгеновского, видимого, ультрафиолетового и инфракрасного излучений.
Мощность экспозиционной дозы рентгеновского излучения в любой точке на расстоянии 0.05м от экрана и корпуса ПЭВМ при любых положениях регулировочных устройств не должна превышать 7.74*10-12 А/кг, что соответствует эквивалентной дозе, равной 0.1 мбэр/час.
Уровень ультрафиолетового излучения на рабочем месте пользователя в длинноволновой области (400-315 нм) должен быть не более 10 Вт/м, в средневолновой области (315-280 нм) не более 0,01Вт/м и отсутствовать в коротковолновой области (280-200 нм).
Предельно допустимые уровни напряженности электромагнитного поля на рабочем месте пользователя по электрической составляющей в диапазоне до 300 МГц должны быть не более 50 В/м и по магнитной составляющей не более 5 А/м.
На частотах более высокого диапазона (300МГц...300ГГц) устанавливаются предельно допустимые значения плотности потока энергии электромагнитного поля. Максимальное значение ППЭ>ПДУ> не должно превышать 10 Вт/м2.
Напряженность электростатических полей на поверхностях ПЭВМ не более 20 кВ/м.
5.5 Требования к освещению помещений и рабочих мест с ПЭВМ.
Нормативным документом в качестве основных параметров, регламентирующих световую среду, определяются для естественного освещения коэффициент естественного освещения е. и для искусственного - освещенность рабочего места оператора Е>р.м.>, лк.
Естественное освещение должно осуществляться через светопроемы, ориентированные преимущественно на север и северо-восток и обеспечивать коэффициент естественной освещенности (КЕО) не ниже 1.2% в зонах с устойчивым снежным покровом и не ниже 1.5% на остальной территории. Указанные значения КЕО нормируются для зданий, расположенных в III климатическом поясе. Для внутренней отделки интерьера помещений с ПЭВМ должны использоваться диффузно-отражающие материалы с коэффициентом отражения для потолка - 0.7-0.8; для стен - 0.5-0.6; для пола - 0.3-0.5.
Искусственное освещение в помещениях эксплуатации ПЭВМ должно осуществляться системой общего равномерного освещения и обеспечивать освещенность не ниже нормируемых значений (таблица 5).
Таблица 5.
Нормы освещенности в помещениях с ПЭВМ
|
Характеристика работы |
Рабочая поверхность |
Плос-кость |
Освещенность, лк |
|
Работа преимущественно с ПЭВМ (50% и более рабочего времени) |
экран клавиатура документ стол |
В Г Г Г |
200 400 400 400 |
|
Работа преимущественно с документами, с и ПЭВМ (менее 50% рабочего времени) |
экран клавиатура документ стол |
В Г Г Г |
200 400 500* 500* |
Примечание: В - вертикальная плоскость, Г - горизонтальная плоскость;
* - допускается установка светильников местного освещения для подсветки документов; местное освещение не должно создавать бликов на поверхности экрана и увеличивать освещенность экрана более 300 лк.
Яркость светящихся поверхностей (окна, светильники и др.), находящихся в поле зрения, должна быть не более 200 кд/м.
Следует ограничивать отраженную блескость на рабочих поверхностях (экран, стол, клавиатура и др.) за счет правильного выбора типов светильников и расположения рабочих мест по отношению к источникам естественного и искусственного освещения, при этом яркость бликов на экране ПЭВМ не должна превышать 40 кд/м и яркость потолка, при применении системы отраженного освещения, не должна превышать 200 кд/м.
Показатель ослепленности для источников общего искусственного освещения в производственных помещениях должен быть не более 20, показатель дискомфорта в административно-общественных помещениях не более 40.
Соотношение яркости между рабочими поверхностями не должно превышать 3:1-5:1, а между рабочими поверхностями и поверхностями стен и оборудования 10:1.
Яркость светильников общего освещения в зоне углов излучения от 50 град. до 90 град. с вертикалью в продольной и поперечной плоскостях должна составлять не более 200 кд/м, защитный угол светильников должен быть не менее 40 град.
Светильники местного освещения должны иметь не просвечивающий отражатель с защитным углом не менее 40град.
Коэффициент запаса (Кз) для осветительных установок общего освещения должен приниматься равным 1.4.
Величина коэффициента пульсации не должна превышать 5%, что должно обеспечиваться применением газоразрядных ламп в светильниках общего и местного освещения с высокочастотными пускорегулирующими аппаратами (ВЧ ПРА). При отсутствии светильников с ВЧ ПРА лампы многоламповых светильников или рядом расположенные светильники общего освещения следует включать на разные фазы трехфазной сети и использовать преимущественно люминесцентные лампы типа ЛБ.
5.6 Расчет освещенности рабочего места программиста.
При любом виде освещения необходимо следить за равномерностью освещения рабочего места. В противном случае, при неравномерном освещении, перевод взгляда с более освещенного в менее освещенное, или наоборот, будет вызывать у пользователя сужение и расширение зрачка. Это, в свою очередь, повлечет напряжение глазных мышц и общую усталость.
Освещение рабочего места обеспечивается за счет применения общего искусственного освещения помещения и местного освещения рабочего места (система комбинированного освещения) — не ниже 750 лк (СН 4559-88). Источники общего и местного освещения — люминесцентные лампы. Нормированные значения освещенности в помещении представлены в таблице 6:
Таблица 6
|
Плоскость, в которой нормируется освещение |
Разряд и подразряд зрительных работ по СН и П 23.05.95 |
Освещенность, лк (комбинированное освещение) |
Коэффициент
пульсации, |
|
|
Горизонтальная |
1 Г |
всего |
от общего |
КП % не |
|
1500 |
300 |
более 20/10 |
Оптимальный уровень яркости, отображаемой на экране дисплея информации, должен лежать в пределах от десятка до сотен Кд/м2. Размер объекта различения не менее 0.6 мм (тип монитора - VGA). Контрастность изображения (объект/фон) не менее 0.8. Низкочастотное дрожание изображения на экране монитора должно находиться в пределах 0.1 мм. ( требования к вычислительной технике по СН 4559-88). Время непрерывной работы с экраном в большинстве случаев не должно превышать 1.5 — 2 часа, длительность перерывов для отдыха должна составлять 5 — 15 мин.
Для освещения помещения искусственным светом из всех существующих источников света, наиболее целесообразно использовать люминесцентные лампы (лампы дневного света), так как они экономичны, и их спектр близок к дневному свету.
Расположение источников света.
Общее освещение реализуется с помощью простых и распространенных светильников таких, как открытые двухламповые светильники УСП35. Они используются для освещения нормальных помещений с отражением потолка и стен, а также при умеренной влажности и запыленности. При выборе расположения светильников необходимо руководствоваться двумя критериями:
обеспечение высокого качества освещения, ограничения ослепляемости и необходимой направленности света на рабочее место;
наиболее экономичное создание нормированной освещенности.
Характеристики помещения:
высота помещения H = 3.0 м;
длина помещения l = 4.8 м;
ширина помещения a = 3.5 м.
Для рабочего стола пользователя уровень рабочей поверхности над полом составляет 0.7 м. Тогда:
h = H - 0.7 = 2.3 м.
У светильников УСП35 коэффициент запаса k>з> = 1.3 . Отсюда расстояние между светильниками L:
L = k>з> * h = 1.3 * 2.3 = 2.99 м 3.0 м.
Располагаем светильники вдоль стороны помещения с окном. Расстояние между стенами и крайним рядом светильников считаем по формуле:
Lст = 0.3 * L = 0.3 * 3.0 = 0.897 м 0.9 м.
Для равномерного общего освещения светильники располагаются рядами, параллельными стенам с окнами. Количество светильников в одном ряду равно 2.
Расчет светового потока.
Расчет требуемого светового потока F производится по формуле:
F = En * S * z * k>з> / (n * N), где:
Eн — нормированная минимальная освещенность, лк;
S — площадь освещаемого помещения;
z — коэффициент минимальной освещенности, равный отношению средней освещенности к минимальной. При использовании люминесцентных ламп z = 1.1;
k>з> — коэффициент запаса, учитывающий запыление светильников и износ источников света. Для помещений ВЦ, освещенных люминесцентными лампами, k>з> = 1.4.
N — число светильников;
n — коэффициент использования светового потока, который показывает, какая часть от общего светового потока приходится на рассчитываемую плоскость. Он зависит от типа светильников, коэффициентов отражения светового потока от стен Qс, потолка Qп, пола Qпола, геометрических размеров помещения и высоты подвеса светильников, что учитывается индексом помещения i:
i = S / ( h * ( l + a ) ) = 17.5 / ( 2.3 * ( 4.8 + 3.5 ) ) = 0.92.
С учетом отражения стен и потолка выбираем n = 0.5.
Итак, Ен = 300 лк; S = 16.8 м2; k>з> = 1.4; z = 1.1; N = 4; n = 0.5.
Тогда, F = 300 * 16.8 * 1.4 * 1.1 / (0.5 * 4) = 3881 лм. Учитывая, что расчёт производится для двухлампового светильника, выбираем лампы ЛБ 30, которые имеют: световой поток Ел = 2100 лм, потребляемая мощность P>пот> = 30 Вт.
Рассчитаем общую потребляемую мощность системы освещения и минимальную освещённость, которые вычисляются по формулам:
Р>е> = P>пот> * N = 2 * 30 * 4 = 240 Вт,
Е>min> = E>н> * (F>выбр >/ F>расч>) = 300 * (4200 / 3881) = 325 лк.
Схема размещения светильников приведена на рисунке:
Рис 1
 Схема
размещения светильников в рабочем
помещении.
Схема
размещения светильников в рабочем
помещении.
Заключение.
Рассмотрены требования, необходимые для создания комфортных условий работы на ПЭВМ.
Для того, чтобы удовлетворить приведенным требованиям по шуму, вибрациям и т.п., рекомендовано проводить закупки оборудования с небольшой вибрацией, пониженным шумом и так далее. В качестве конкретных мер можно предложить пользоваться нематричными (лазерными или струйными) принтерами, а систему вентиляции, снабдив звукопоглощателями и, по возможности, виброгасителями, вынести за пределы рабочего помещения.
Рассчитана освещенность рабочего места оператора ПЭВМ, определены мощность и месторасположения источников света.
Список литературы:
Беляков М.И., Рабовер Ю.И., Фридман А.Л. Мобильная операционная система. – Москва: Радио и связь, 1991. – 206 с.
Topham D.W., Troung H.V., Unix and Xenix: A Step-by-Step Guide. – Bowie: Brady Communication Company, Inc. 1985. – 352 c.
Кутузов Е.И., Диалоговая Единая Мобильная Операционная Система ДЕМОС. – Москва: Высшая школа, 1987. – 380 с.
Гончаров А.А., HTML в примерах. - Петербург: Питер, 1997. - 230 с.
Р. Петерсен., LINUX. Полное руководство. Киев: BHV, 1998. - 300 с.
Ф. Льюис, Д. Розенкранц, Р. Стирнз., Теоретические основы проектирования компиляторов. - Москва: Мир, 1979. - 120 с.
Тихомиров, Давидов., ОС Демос. - Москва: Наука, 1989. - 230 с.
Э. Н. Сванидзе., Технико-экономическое обоснование эффективности НИОКР. - Москва, 1998. - 80 с.
Константинова Л.А., Ларионов Н.М., Писеев В.М., Методические указания по выполнению раздела "Охрана труда" в дипломных проектах для студентов МИЭТ. - Москва: издательство МИЭТ, 1988г. - 30 с.
Давыдов Б.И., Тихончук В.С., Биологические воздействия, нормирование и защита от электромагнитных излучений. - Москва: "Энергоиздат", 1984г. - 55 с.
Юдин Е.Я., Белов С.В., Охрана труда в машиностроении. — Москва: “Машиностроение”, 1983. -60с.
ГОСТ 12.1.045-84. Электрические поля. Допустимые уровни на рабочих местах и требования к проведению контроля. — Москва: “Стандарты”, 1978. - 95 с.
ГОСТ 12.1.003-83 ССБТ. Шум. Общие требования безопасности. — Mосква: “Стандарты”, 1978. - 40с.
Приложения.
Фрагмент кода лексического анализатора.
%START TEXT COMMAND COMARG
%{
#include <math.h>
#include <stdio.h>
%}
%%
^[^"."\n] {yymore();
BEGIN TEXT;};
^"." {BEGIN COMMAND;};
^\n {return (EMPTYSTR);};
^[^"."\n]$ {return (TEXTSTR);};
<TEXT>.+ {BEGIN 0;
return (TEXTSTR);};
<COMMAND>br[ \t]* {BEGIN COMARG;
return (BREAKLINE);};
<COMMAND>sp[ \t]* {BEGIN COMARG;
return (SPACE);};
<COMMAND>bd[ \t]* {BEGIN COMARG;
return (BOLD);};
<COMMAND>ul[ \t]* {BEGIN COMARG;
return (UNDERLINE);};
<COMMAND>ft[ \t]+ {BEGIN COMARG;
return (FONT);};
<COMMAND>ps[ \t]+ {BEGIN COMARG;
return (SIZE);};
<COMMAND>ad[ \t]+ {BEGIN COMARG;
return (ADJUST);};
<COMMAND>na[ \t]* {BEGIN COMARG;
return (NOADJUST);};
<COMMAND>fi[ \t]* {BEGIN COMARG;
return (FILL);};
<COMMAND>nf[ \t]* {BEGIN COMARG;
return (NOFILL);};
<COMMAND>in[ \t]+ {BEGIN COMARG;
return (IN);};
<COMMAND>ti[ \t]+ {BEGIN COMARG;
return (TIN);};
<COMMAND>ex[ \t].* {BEGIN COMARG;
return (EXIT);};
<COMMAND>[A-Za-z]{1,2}[ \t]* {BEGIN COMARG;
return (UNKNOW);};
<COMARG>[ \t]*$ {BEGIN 0;};
<COMARG>[0-9]+ {BEGIN 0;
return (DARG);};
<COMARG>[A-Za-z] {BEGIN 0;
return (CARG);};
<COMARG>[A-Za-z][^ \t\n]+ {BEGIN 0;
return (SARG);};
%%
Фрагмент кода грамматического анализатора.
%start list
%token UNKNOW
%token EXIT
%token FONT SIZE
%token SCENTER SUNDERLINE UNDERLINE BOLD
%token ADJUST NOADJUST LINELENGHT IN TIN
%token BREAKLINE SPACE LINESPACE
%token FILL NOFILL
%token DARG CARG SARG
%token TEXTSTR EMPTYSTR
%{
#include "lex.yy.c"
#define printT(STR) fprintf(yyout,(STR))
#define printD(STR,D) fprintf(yyout,(STR),(D))
int cb=-1,cu=-1,cc=-1,cl=-1;
int co=-1;
int ta=0,tf=0,tb=0,tu=0,tc=0,tp=0;
int tFILL=0,cIN,cTIN,LS=0;
char nhtext[YYLMAX];
int i;
%}
%%
list: | list string
string: text
| command
;
command: BREAKLINE
{breakline();}
| SPACE comarg
{printD("<spacer type=\"vertical\" size=%d>",$2*30);}
| LINESPACE comarg
{LS=$2;}
| BOLD comarg
{if (!tb) {tb=1;
printT("<b>");}
cb=$2;}
| UNDERLINE comarg
{if (!tu) {tu=1;
printT("<u>");}
cu=$2;}
| FONT comarg
{if (tf) printT("</font>");
fontchange(nhtext);
tf=1;}
| SIZE comarg
{if (tf) printT("</font>");
printD("<font size=%d>",$2);
tf=1;}
| ADJUST comarg
{if (tp) {tp=0;printT("</pre>");};
if (ta) printT("</div>");
ta=1;
printT("<div align=\"");
switch (nhtext[0])
{
case 'l': printT("left");break;
case 'r': printT("right");break;
case 'c': printT("center");break;
default : printT("left");break;
}
printT("\">");};
| IN comarg
{cIN=$2;};
| TIN comarg
{cTIN=$2;};
| FILL
{tFILL=1;};
| NOFILL
{tFILL=0;};
| UNKNOW comarg
{fprintf(stderr,"unknow nroff command before arg
'%s'\n",yytext);}
| UNKNOW
{fprintf(stderr,"unknow nroff command: .%s\n",yytext);}
| EXIT
{return(0);}
;
comarg: DARG
{$$=atoi(yytext);}
| CARG
{nhtext[0]=yytext[0];}
| SARG
{for(i=0;yytext[i]!=0;i++) nhtext[i]=yytext[i];
nhtext[i++]=0;}
;
text: TEXTSTR
{if (cTIN) {for(i=0;i<cTIN;i++)
printT(" ");
cTIN=0;}
else for(i=0;i<cIN;i++)
printT(" ");
printD("%s",yytext);
if (!tFILL) breakline();
if (!(cb<0)) cb--;
if (!cb) {tb=0;printT("</b>");};}
| EMPTYSTR
{breakline();}
;
%%
Код головной программы.
#include "y.tab.c"
int main(int argc, char *argv[])
{
++argv, --argc; /* skip over program name */
if (argc > 0)
yyin = fopen(argv[0], "r");
else
yyin = stdin;
++argv, --argc; /* skip over input file name */
if (argc > 0)
yyout = fopen(argv[0], "w");
else
yyout = stdout;
fprintf(yyout,
"<HTML>\n <HEAD>\n <TITLE>\n </TITLE>\n </HEAD>\n\n <BODY>\n");
yyparse();
fprintf(yyout,
"\n </BODY>\n</HTML>\n\n");
}
Государственный комитет РФ по высшему образованию
Московский Государственный институт электронной техники
(технический университет)
Факультет: |
ЭКТ |
|
Кафедра: |
ПКИМС |
Пояснительная записка
к дипломному проекту на тему:
«Программное обеспечение удаленного доступа к технической документации»
Дипломник |
Мамаев В.А. |
/ / |
|
Руководитель проекта |
Авдеев Ю.В. |
/ / |
|
Консультант |
Авдеев Ю.В. |
/ / |
|
Консультант по технологической части |
Адрианов М.В. |
/ / |
|
Консультант по организационно-экономической части |
Короткова Т.Л. |
/ / |
|
Консультант по производственной и экологической безопасности |
Привалов В.П. |
/ / |
Москва
2000г.
РЕЦЕНЗИЯ
на дипломный проект студента
Московского Государственного Института Электронной Техники,
факультета ЭКТ
Мамаева В.А.
на тему: «Программное обеспечение удалённого доступа к технической документации»
Дипломный проект посвящён разработке программы трансляции форматированного текста из формата Nroff в гипертекстовый формат HTML. Цель разработки состоит в освоении и опробовании технологии автоматической генерации трансляторов для организации сервера технической и проектной документации предприятия. Актуальность задачи обусловлена реальными потребностями базового предприятия.
Пояснительная записка состоит из специальной части, технологического раздела, организационно-экономического раздела, раздела производственно-экологической безопасности, списка литературы и приложений.
В специальной части проекта приведена постановка задачи; рассмотрены и проанализированы требования к форматам разнородной технической документации при организации удалённого доступа; проанализированы существующие программные средства конвертирования форматов; обоснована необходимость разработки программы и применения инструментальных средств Lex и Yacc. Представлены формализованные описания обрабатываемых форматов и результаты разработки.
В технологическом разделе рассмотрены технологические аспекты создания трансляторов путём автоматической генерации с применением указанных инструментальных средств.
К достоинствам настоящего проекта следует отнести использование передовых технологий и инструментов создания программного обеспечения. Особая ценность проекта состоит в его соответствии непосредственным потребностям предприятия. Результаты проекта представляют собой необходимый этап работ по созданию информационной инфраструктуры САПР и находятся на этапе внедрения.
В качестве замечания к проекту считаю возможным обратить внимание на недостаточное количество графических иллюстративных материалов, что впрочем может быть обусловлено спецификой задачи.
Дипломный проект отвечает предъявляемым требованиям, и заслуживает оценки «отлично», а Мамаев В.А.. - присвоения ему квалификации инженера.
Ведущий научный сотрудник
АООТ "НИИМЭ и завод "Микрон", к.т.н. _________________ Н.М.Наумов