Композиции шифров
МПС РФ
Московский Государственный Университет
Путей Сообщения (МИИТ)
Кафедра «Электроника и защита информации»
Курсовая работа
по дисциплине: «Криптографические методы
защиты информации»
На тему: «Композиции шифров»
Выполнил: Ефалов П.А.
Студент гр. АКБ-311
ИСУТЭ
Проверил: Титов Е.В.
Москва-2003
СОДЕРЖАНИЕ:
Введение…………………………………………………..…………………….4
1. Комбинированные методы шифрования
Комбинирование простых способов шифрования..………………………5
2. Теория проектирования блочных шифров…...……………………………8
2.1. Сети Файстеля………………………………………………………..8
2.2. Простые соотношения……………………………………………….9
2.3. Групповая структура………………………………………………...9
2.4. Слабые ключи………………………………………………………10
2.5. Устойчивость алгоритма к дифференциальному и
линейному криптоанализу…………………………………………10
2.6. Проектирование S-блоков…………………………………………11
2.7. Проектирование блочного шифра………………………………...13
3. Блочные шифры……………………………………………………………14
3.1. Алгоритм Lucifer……………………………………………………14
3.2. Алгоритм Madryga………………………………………………….15
3.2.1. Описание алгоритма Madryga………………………………16
3.2.1. Криптоанализ алгоритма Madryga………………………….17
3.3. Алгоритм REDOC…………………………………………………..18
3.3.1. Алгоритм REDOC III………………………………………..18
3.4. Алгоритм LOKI……………………………………………………..19
3.4.1. Алгоритм LOKI91…………………………………………...19
3.4.2. Описание алгоритма LOKI91……………………………… 21
3.4.3. Криптоанализ алгоритма LOKI91………………………….21
3.5. Алгоритм Knufu и Knafre…………………………………………..22
3.5.1. Алгоритм Knufu…………………………………………..…23
3.5.2. Алгоритм Knafre………………………………………….....23
3.6. Алгоритм ММВ…………………………………………………….24
3.6.1. Стойкость алгоритма ММВ………………………………...25
3.7. Алгоритм Blowfish…………………………………………………26
3.7.1. Описание алгоритма Blowfish……………………………...26
3.7.2. Стойкость алгоритма Blowfish……………………………..29
3.8. Алгоритм RC5………………………………………………………29
4. Объединение блочных шифров…………………………………………....32
4.1. Двойное шифрование………………………………………………32
4.2. Тройное шифрование……………………………………………....33
4.2.1. Тройное шифрование с двумя ключами…………………..33
4.2.2. Тройное шифрование с тремя ключами…………………...35
4.2.3. Тройное шифрование с минимальным ключом…………..35
4.2.4. Режимы тройного шифрования……………………………35
4.2.5. Варианты тройного шифрования………………………….37
4.3. Удвоение длины блока…………………………………………… 38
4.4. Другие схемы многократного шифрования……………………...39
4.4.1. Двойной режим OFB/счетчика…………………………….39
4.4.2. Режим ECB+OFB…………………………………………...39
4.4.3. Схема xDESi………………………………………………...40
4.4.4. Пятикратное шифрование………………………………….41
4.5. Уменьшение длины ключа в CDMF……………………………...42
4.6. Отбеливание………………………………………………………..42
4.7. Каскадное применение блочных алгоритмов……………………43
4.8. Объединение нескольких блочных алгоритмов…………………44
Заключение…...……………………………………………………………….45
Список литературы…………...………………………………………………46
ВВЕДЕНИЕ
Шифрсистемы классифицируются по различным признакам: по видам защищаемой информации (текст, речь, видеоинформация), по криптографической стойкости, по принципам обеспечения защиты информации (симметричные, ассиметричные, гибридные), по конструктивным принципам (блочные и поточные) и др. При построении отображений шифра используются с математической точки зрения два вида отображений: перестановки элементов открытого текста и замены элементов открытого текста на элементы некоторого множества. В связи с этим множество шифров делится на 3 вида: шифры перестановки, шифры замены и композиционные шифры, использующие сочетание перестановок и замен. Рассмотрим последний класс шифров, то есть шифры композиции.
На практике обычно используют два общих принципа шифрования: рассеивание и перемешивание. Рассеивание заключается в распространении влияния одного символа открытого текста на много символов шифртекста: это позволяет скрыть статистические свойства открытого текста. Развитием этого принципа является распространение влияния одного символа ключа на много символов шифрограммы, что позволяет исключить восстановление ключа по частям. Перемешивание состоит в использовании таких шифрующих преобразований, которые исключают восстановление взаимосвязи статистических свойств открытого и шифрованного текста. Распространенный способ достижения хорошего рассеивания состоит в использовании составного шифра, который может быть реализован в виде некоторой последовательности простых шифров, каждый из которых вносит небольшой вклад в значительное суммарное рассеивание и перемешивание. В качестве простых шифров чаще всего используют простые подстановки и перестановки. Известны также методы аналитического преобразования, гаммирования, а также метод комбинированного шифрования.
Примерно до конца 19 века все используемые шифры практически представляли собой различные комбинации шифров замены и перестановки, причем часто весьма изощренных. Например, использовались шифры с несколькими таблицами простой замены, выбор которых осуществлялся в зависимости от шифрования предыдущего знака, в шифрах замены перестановки строились с использованием специальных правил и т.д. Особенно надежными шифрами отличался российский «Черный кабинет» - организация занимавшаяся разработкой собственных шифров и дешифрованием шифров зарубежных. При отсутствии современных методов, а главное вычислительной техники, данные шифры могли считаться вполне надежными. Некоторые из них просуществовали вплоть до второй мировой войны, например, широко известный шифр «Два квадрата» применялся немцами вплоть до 1945 года (метод дешифрования данного шифра был разработан советскими криптографами и активно использовался во время войны).
1. Комбинированные методы шифрования
Важнейшим требованием к системе шифрования является стойкость данной системы. К сожалению, повышение стойкости при помощи любого метода приводит, как правило, к трудностям и при шифровании открытого текста и при его расшифровке. Одним из наиболее эффективных методов повышения стойкости шифртекста является метод комбинированного шифрования. Этот метод заключается в использовании и комбинировании нескольких простых способов шифрования. Шифрование комбинированными методами основывается на результатах, полученных К.Шенноном. Наиболее часто применяются такие комбинации, как подстановка и гамма, перестановка и гамма, подстановка и перестановка, гамма и гамма. Так, например, можно использовать метод шифрования простой перестановкой в сочетании с методом аналитических преобразований или текст, зашифрованный методом гаммирования, дополнительно защитить при помощи подстановки.
Рассмотрим несколько примеров:
Пример 1. Возьмем в качестве открытого текста сообщение: «Я пишу курсовую».
Защитим этот текст методом простой перестановки, используя в качестве ключа слово "зачет" и обозначая пробел буквой "ь". Выписываем буквы открытого текста под буквами ключа. Затем буквы ключа расставляем в алфавитном порядке. Выписываем буквы по столбцам и получаем шифртекст: ььоиууяусшрюпкв.
Полученное сообщение зашифруем с помощью метода подстановки:
Пусть каждому символу русского алфавита соответствует число от 0 до 32. То есть букве А будет соответствовать 0, букве Б - 1 и т.д. Возьмем также некое число, например, 2, которое будет ключом шифра. Прибавляя к числу, соответствующему определенному символу 2, мы получим новый символ, например, если А соответствует 0, то при прибавлении 2 получаем В и так далее. Пользуясь этим, получаем новый шифртекст: ююркххбхуьтасмд.
Итак, имея открытый текст: «Я пишу курсовую», после преобразований получаем шифртекст: ююркххбхуьтасмд, используя методы перестановки и замены. Раскрыть текст расшифровщик сможет, зная, что ключами являются число 2 и слово "зачет" и соответственно последовательность их применения.
Пример 2. В качестве примера также рассмотрим шифр, предложенный Д. Френдбергом, который комбинирует многоалфавитную подстановку с генератором псевдослучайных чисел. Особенность данного алгоритма состоит в том, что при большом объеме шифртекста частотные характеристики символов шифртекста близки к равномерному распределению независимо от содержания открытого текста.
1. Установление начального состояния генератора псевдослучайных чисел.
2. Установление начального списка подстановки.
3. Все символы открытого текста зашифрованы?
4. Если да - конец работы, если нет - продолжить.
5. Осуществление замены.
6. Генерация случайного числа.
7. Перестановка местами знаков в списке замены.
8. Переход на шаг 4.
Пример 3. Открытый текст: "АБРАКАДАБРА".
Используем одноалфавитную замену согласно таблице 1.
Таблица 1:
|
А |
Б |
Д |
К |
Р |
|
X |
V |
N |
R |
S |
Последовательность чисел, вырабатываемая датчиком: 31412543125.
1. у>1>=Х.
После перестановки символов исходного алфавита получаем таблицу 2 (h>1>=3).
Таблица 2:
|
Д |
Б |
А |
К |
Р |
|
X |
V |
N |
R |
S |
2. у>2>=V. Таблица 2 после перестановки (h>2>=1) принимает вид, представленный в таблице 3.
Таблица 3:
|
Б |
Д |
А |
К |
Р |
|
X |
V |
N |
R |
S |
Осуществляя дальнейшие преобразования в соответствии с алгоритмом Френдберга, получаем шифртекст: "XVSNSXXSSSN".
Одной из разновидностей метода гаммирования является наиболее часто применяемый метод многократного наложения гамм. Необходимо отметить, что если у>i>=Г>k>(Г>1>(x>i>)), то Г>k>(Г>1>(x>i>))=Г>1>(Г>k>(x>i>)). (1*)
Тождество (1*) называют основным свойством гаммы.
Пример 4. Открытый текст: "ШИФРЫ"(25 09 21 17 28");
Г>1>> >= "ГАММА" ("04 01 13 13 01");
Г>2 >= "ТЕКСТ" ("19 06 11 18 19"), согласно таблице 1.
Используемая операция: сложение по mod 2.
1. Y1>i>=x>i > H2>i>
11001 01001 10101 10001 11100
00100 00001 01101 01101 00001
=
11101 01000 11000 11100 11101.
2. У2>i>=y1>i > H3>i>
11101 01000 11000 11100 11101
10011 00110 01011 10010 10011
=
01110 01110 10011 01110 01110.
Проведем операцию шифрования, поменяв порядок применения гамм.
1. У1>i> =x>i>> > h2>i>
11001 01001 10101 10001 11100
10011 00110 01011 10010 10011
=
01010 01111 11110 00011 01111.
2. У2>i'>=y1>i' > H2>i>
01010 01111 11110 00011 01111
00100 00001 01101 01101 00001
=
01110 01110 10011 01110 01110.
Таким образом, y2>i>=y2>i'>, что является подтверждением основного свойства гаммы.
При составлении комбинированных шифров необходимо проявлять осторожность, так как неправильный выбор составлявших шифров может привести к исходному открытому тексту. Простейшим примером служит наложение одной гаммы дважды.
Пример 5. Открытый текст: "ШИФРЫ"("25 09 21 17 28");
Г>1 >= Г>2>= "ГАММА" ("04 01 13 13 01"), согласно таблице 1.
Используемая операция: сложение по mod 2:
11001 01001 10101 10001 11100
00100 00001 01101 01101 00001
00100 00001 01101 01101 00001
=
11001 01001 10101 10001 11100.
Таким образом, результат шифрования представляет собой открытый текст.
2. Теория проектирования блочных шифров
К. Шеннон выдвинул понятия рассеивания и перемешивания. Спустя пятьдесят лет после формулирования этих принципов, они остаются краеугольным камнем проектирования хороших блочных шифров.
Перемешивание маскирует взаимосвязи между открытым текстом, шифртекстом и ключом. Даже незначительная зависимость между этими тремя составляющими может быть использована в дифференциальном и линейном криптоанализе. Хорошее перемешивание настолько усложняет статистику взаимосвязей, что пасуют даже мощные криптоаналитические средства.
Рассеивание распространяет влияние отдельных битов открытого текста на возможно больший объем шифртекста. Это тоже маскирует статистические взаимосвязи и усложняет криптоанализ.
Для обеспечения надежности достаточно только перемешивания. Алгоритм, состоящий из единственной, зависимой от ключа таблицы подстановок 64 бит открытого текста в 64 бит шифртекста был бы достаточно надежным. Недостаток в том, что для хранения такой таблицы потребовалось бы слишком много памяти: 1020 байт. Смысл создания блочного шифра и состоит в создании чего-то подобного такой таблице, но предъявляющего к памяти более умеренные требования.
Тонкость, состоит в том, что в одном шифре следует периодически перемежать в различных комбинациях перемешивание (с гораздо меньшими таблицами) и рассеивание. Такой шифр называют составным шифром (product cipher). Иногда блочный шифр, который использует последовательные перестановки и подстановки, называют сетью перестановок-подстановок, или SP-сетью.
Рассмотрим функцию f алгоритма DES. Перестановка с расширением и Р-блок реализуют рассеивание, а S-блоки - перемешивание. Перестановка с расширением и Р-блок линейны, S-блоки - нелинейны. Каждая операция сама по себе очень проста, но вместе они работают превосходно.
Кроме того, на примере DES можно продемонстрировать еще несколько принципов проектирования блочных шифров. Первый принцип реализует идею итеративного блочного шифра. При этом предполагается, что простая функция раунда последовательно используется несколько раз. Двухраундовый алгоритм DES слишком ненадежен, чтобы все биты результата зависели от всех битов ключа и всех битов исходных данных. Для этого необходимо 5 раундов. Весьма надежен 16-раундовый алгоритм DES, а 32-раундовый DES еще более стоек.
2.1. Сети Файстеля
Большинство блочных алгоритмов относятся к так называемым сетям Файстеля. Идея этих сетей датируется началом семидесятых годов. Возьмем блок длиной п и разделим его на две половины длиной n/2: L и R. Разумеется, число п должно быть четным. Можно определить итеративный блочный шифр, в котором результат j-го раунда определяется результатом предыдущего раунда:
L>i> = R>i>>-1>
R>i> = L>i>>-1 > f(R>i>>-1>, K>i>)
K>i>> >- подключ j-го раунда, а f - произвольная функция раунда.
Применение этой концепции можно встретить в алгоритмах DES, Lucifer, FEAL, Khufu, Khafre, LOKI, ГОСТ, CAST, Blowfish и других. Этим гарантируется обратимость функции. Так как для объединения левой половины с результатом функции раунда используется операция XOR, всегда истинно следующее выражение:
L>i>>-1 > f(R>i>>-1>, K>i >) L>i>>-1 > f(R>i>>-1>, K>i>) = L>i>>-1>
Шифр, использующий такую конструкцию, гарантированно обратим, если можно восстановить исходные данные f на каждом раунде. Сама функция f не важна, она не обязательно обратима. Мы можем спроектировать сколь угодно сложную функцию f, но нам не понадобится реализовывать два разных алгоритма - один для зашифрования, а другой для расшифрования. Об этом автоматически позаботится структура сети Файстеля.
2.2. Простые соотношения
Алгоритм DES характеризуется следующим свойством: если Е>К>(Р) = С, то Е>K>>' >(Р') = С', где Р', С' и K' - побитовые дополнения Р, С и K. Это свойство вдвое уменьшает сложность лобового вскрытия. Свойства комплементарности в 256 раз упрощают лобовое вскрытие алгоритма LOKI.
Простое соотношение можно определить так:
Если Е>K>(Р) = С, то E>f>>(>>K>>)>(g(P,K)) = h(C,K)
где f, g и h - простые функции. Под «простыми функциями» подразумевают функции, вычисление которых несложно, намного проще итерации блочного шифра. В алгоритме DES функция f представляет собой побитовое дополнение K, g - побитовое дополнение Р, a h - побитовое дополнение C. Это - следствие сложения ключа и текста операцией XOR. Для хорошего блочного шифра простых соотношений нет.
2.3. Групповая структура
При изучении алгоритма возникает вопрос, не образует ли он группу. Элементами группы служат блоки шифртекста для каждого возможного ключа, а групповой операцией служит композиция. Изучение групповой структуры алгоритма представляет собой попытку понять, насколько возрастает дополнительное скрытие текста при многократном шифровании.
Важен, однако, вопрос не о том, действительно ли алгоритм - группа, а о том, насколько он близок к таковому. Если не хватает только одного элемента, алгоритм не образует группу, но двойное шифрование было бы, с точки зрения статистики, просто потерей времени. Работа над DES показала, что этот алгоритм весьма далек от группы. Существует также ряд интересных вопросов о полугруппе, получаемой при шифровании DES. Содержит ли она тождество, то есть, не образует ли она группу? Иными словами, не генерирует ли, в конце концов, некоторая комбинация операций зашифрования (не расшифрования) тождественную функцию? Если так, какова длина самой короткой из таких комбинаций?
Цель исследования состоит в оценке пространства ключей для теоретического лобового вскрытия, а результат представляет собой наибольшую нижнюю границу энтропии пространства ключей.
2.4. Слабые ключи
В хорошем блочном шифре все ключи одинаково сильны. Как правило, нет проблем и с алгоритмами, включающими небольшое число слабых ключей, например, DES. Вероятность случайного выбора одного из них очень мала, и такой ключ легко проверить и, при необходимости, отбросить. Однако если блочный шифр используется как однонаправленная хэш-функция, эти слабые ключи иногда могут быть задействованы.
2.5. Устойчивость алгоритма к дифференциальному и
линейному криптоанализу
Исследования дифференциального и линейного криптоанализа значительно прояснили теорию проектирования надежных блочных шифров. Авторы алгоритма IDEA ввели понятие дифференциалов, обобщение основной идеи характеристик. Они утверждали, что можно создавать блочные шифры, устойчивые к атакам такого типа. В результате подобного проектирования появился алгоритм IDEA. Позднее это понятие было формализовано в работах Кайса Ниберг (Kaisa Nyberg) и Ларе Кнудсен, которые описали метод создания блочных шифров, доказуемо устойчивых к дифференциальному криптоанализу. Эта теория была расширена на дифференциалы высших порядков и частные дифференциалы. Как представляется, дифференциалы высших порядков применимы только к шифрам с малым числом раундов, но частные дифференциалы прекрасно объединяются с дифференциалами.
Линейный криптоанализ появился сравнительно недавно, и продолжает совершенствоваться. Были определены понятия ранжирования ключей и многократных аппроксимаций. Кем-то была предпринята попытка объединения в одной атаке дифференциального и линейного методов криптоанализа. Пока неясно, какая методика проектирования сможет противостоять подобным атакам.
Кнудсен добился известного успеха, рассматривая некоторые необходимые (но, возможно, недостаточные) критерии того, что он назвал практически стойкими сетями Файстеля - шифров, устойчивых как к дифференциальному, так и к линейному криптоанализу. Ниберг ввел для линейного криптоанализа аналог понятия дифференциалов в дифференциальном криптоанализе.
Достаточно интересна, как представляется, двойственность дифференциального и линейного методов криптоанализа. Эта двойственность становится очевидной как при разработке методики создания хороших дифференциальных характеристик и линейных приближений, так и при разработке критерия проектирования, обеспечивающего устойчивость алгоритмов к обоим типам вскрытия. Пока точно неизвестно, куда заведет это направление исследований. Для начала Дэймен разработала стратегию проектирования алгоритма, основанную на дифференциальном и линейном криптоанализе.
2.6. Проектирование S-блоков
Мощь большинства сетей Файстеля, а особенно их устойчивость к дифференциальному и линейному криптоанализу, напрямую связана с их S-блоками. Поэтому вопрос о том, что же образует хороший S-блок, стал объектом многочисленных исследований.
S-блок - это просто подстановка: отображение m-битовых входов на n-битовые выходы. Применяется большая таблица подстановок 64-битовых входов на 64-битовые выходы. Такая таблица представляет собой S-блок размером 64*64 бит. S-блок с m-битовым входом и n-битовым выходом называется m*n-битовым S-блоком. Как правило, обработка в S-блоках - единственная нелинейная операция в алгоритме. Именно S-блоки обеспечивают стойкость блочного шифра. В общем случае, чем больше S-блоки, тем лучше.
В алгоритме DES используются восемь различных 6*4-битовых S-блоков. В алгоритмах Khufu и Khafre предусмотрен единственный 8*32-битовый S-блок, в LOKI – 12*8-битовый S-блок, а в Blowfish и CAST – 8*32-битовые S-блоки. В IDEA S-блоком, по сути, служит умножение по модулю, это 16+16-битовый S-блок. Чем больше S-блок, тем труднее обнаружить статистические данные, нужные для вскрытия методами дифференциального или линейного криптоанализа. Кроме того, хотя случайные S-блоки обычно не оптимальны с точки зрения устойчивости к дифференциальному и линейному криптоанализу, стойкие S-блоки легче найти среди S-блоков большего размера. Большинство случайных S-блоков нелинейны, невырождены и характеризуются высокой устойчивостью к линейному криптоанализу, причем с уменьшением числа входных битов устойчивость снижается достаточно медленно.
Размер т важнее размера п. Увеличение размера п снижает эффективность дифференциального криптоанализа, но значительно повышает эффективность линейного криптоанализа. Действительно, если п ≥ 2m - т, наверняка существует линейная зависимость между входными и выходными битами S-блока. А если п ≥ 2m , линейная зависимость существует даже только между выходными битами. Заметная доля работ по проектированию S-блоков состоит в изучении булевых функций. Для обеспечения безопасности, булевы функции S-блоков должны отвечать определенным требованиям. Они не должны быть ни линейными, ни аффинными, ни даже близкими к линейным или аффинным функциям. Число нулей и единиц должно быть сбалансированным, и между различными комбинациями битов не должно быть никаких корреляций. При изменении значения любого входного бита на противоположное выходные биты должны вести себя независимо. Эти критерии проектирования так же связаны с изучением бент-функций (bent functions): функций, которые, как можно показать, оптимально нелинейны. Хотя они определены просто и естественно, их изучение очень трудно.
По-видимому, очень важное свойство S-блоков - лавинный эффект: сколько выходных битов S-блока изменяется при изменении некоторого подмножества входных битов. Нетрудно задать для булевых функций условия, выполнение которых обеспечивает определенный лавинный эффект, но проектирование таких функций задача сложная. Строгий лавинный критерий (Strict Avalanche Criteria - SAC) гарантирует изменение ровно половины выходных битов при изменении единственного входного бита. В одной из работ эти критерии рассматриваются с точки зрения утечки информации.
Несколько лет назад крипгографы предложили выбирать S-блоки так, чтобы таблица распределения различий для каждого S-блока была однородной. Это обеспечило бы устойчивость к дифференциальному криптоанализу за счет сглаживания дифференциалов на любом отдельном раунде. В качестве примера такого проектирования можно назвать алгоритм LOKI. Однако такой подход иногда облегчает дифференциальный криптоанализ. На самом деле, удачнее подход, гарантирующий наименьшее значение максимального дифференциала. Кванджо Ким (Kwangjo Kim) выдвинул пять критериев проектирования S-блоков, напоминающих критерии проектирования S-блоков DES.
Выбор хороших S-блоков - нелегкая задача. Известно множество конкурирующих подходов ее решения; среди hих можно выделить четыре основных.
Случайный выбор. Ясно, что небольшие случайные S-блоки ненадежны, но крупные случайные S-блоки могут оказаться достаточно хорошими. Случайные S-блоки с восемью и более входами достаточно стойки, еще лучше 12-битовые S-блоки. Стойкость S-блоков возрастает, если они одновременно и случайны, и зависят от ключа.
Выбор с последующим тестированием. В некоторых шифрах сначала генерируются случайные S-блоки, а затеи их свойства тестируются на соответствие требованиям.
Разработка вручную. При этом математический аппарат используется крайне незначительно: S-блоки создаются с использованием интуитивных приемов. Барт Пренел (Bart Preneel) заявил, что «... теоретически интересные критерии недостаточны (для выбора булевых функций S-блоков)...», и «... необходимы специальные критерии проектирования».
Математическая разработка. S-блоки создаются в соответствии с законами математики, поэтому обладают гарантированной устойчивостью к дифференциальному и линейному криптоанализу и хорошими рассеивающими свойствами.
Раздавались призывы объединить «математический» и «ручной» подходы, но реально, по-видимому, конкурируют случайно выбранные S-блоки и S-блоки с определенными свойствами. К преимуществам последнего подхода можно отнести оптимизацию против известных методов вскрытия — дифференциального и линейного криптоанализа. Однако в этом случае неясна степень защиты от неизвестных методов вскрытия. Разработчики DES знали о дифференциальном криптоанализе, поэтому S-блоки DES оптимизированы надлежащим образом. Но, вероятнее всего, о линейном криптоанализе они не знали, и S-блоки DES очень слабы по отношению к такой атаке. Случайно выбранные S-блоки в DES были бы слабее к дифференциальному криптоанализу, но устойчивее к линейному криптоанализу.
С другой стороны, случайные S-блоки могут быть и неоптимальны к данным атакам, но они могут быть достаточно большими и, следовательно, достаточно стойкими. Кроме того, они, скорее всего, окажутся достаточно устойчивыми к неизвестным методам вскрытия. Споры все еще кипят, но лично мне кажется, что S-блоки должны быть такими большими, насколько это возможно, случайными и зависящими от ключа.
2.7. Проектирование блочного шифра
Спроектировать блочный шифр нетрудно. Если рассматривать 64-битовый блочный шифр как перестановку 64-битовых чисел, ясно, что почти все эти перестановки безопасны. Трудно спроектировать такой блочный шифр, который не только стоек, но также может быть легко описан и реализован.
Нетрудно спроектировать блочный шифр, если объем памяти достаточен для размещения 48*32-битовых S-блоков. Трудно спроектировать нестойкий вариант алгоритма DES, если нужно использовать в нем 128 раундов. При длине ключа 512 битов нет нужды беспокоиться о какой-либо зависящей от ключа комплементарности.
Настоящий фокус - и причина, почему на самом деле очень трудно спроектировать блочный шифр - это разработать алгоритм с возможно наименьшим ключом, требованиям к памяти и максимальной скоростью работы.
3. Блочные шифры
3.1. Алгоритм Lucifer
В конце шестидесятых годов корпорация IBM запустила исследовательскую программу по компьютерной криптографии, названную Lucifer (Люцифер) и руководимую сначала Хорстом Файстелем (Horst Feistel), а затем Уолтом Тачменом (Walt Tuchman). Такое же имя - Lucifer - получил блочный алгоритм, появившийся в результате этой программы в начале семидесятых годов. В действительности существует, по меньшей мере, два различных алгоритма с таким именем. Один из них содержит ряд пробелов в спецификации алгоритма. Все это привело к заметной путанице.
Алгоритм Lucifer представляет собой сеть перестановок и подстановок, его основные блоки напоминают блоки алгоритма DES. В DES результат функции f складывается операцией XOR с входом предыдущего раунда, образуя вход следующего раунда. У S-блоков алгоритма Lucifer 4-битовые входы и выходы, вход S-блоков представляет собой перетасованный выход S-блоков предыдущего раунда, входом S-блоков первого раунда служит открытый текст. Для выбора используемого S-блока из двух возможных используется бит ключа. (Lucifer реализует все это в едином Т-блоке с 9 битами на входе и 8 битами на выходе). В отличие от алгоритма DES, половины блока между раундами не переставляются, да и само понятие половины блока в алгоритме Lucifer не используется. У этого алгоритма 16 раундов, 128-битовые блоки и более простая, чем в DES, схема развертки ключа.
Применив дифференциальный криптоанализ к первой реализации алгоритма Lucifer, Бихам и Шамир показали, что Lucifer с 32-битовыми блоками и 8 раундами можно взломать с помощью 40 подобранных открытых текстов за 229 операций. Этот же метод позволяет вскрыть Lucifer с 128-битовыми блоками и 8 раундами с помощью 60 подобранных открытых текстов за 253 шагов. Другая дифференциальная атака вскрывает 18-раундовый, 128-битовый Lucifer с помощью 24 подобранных открытых текстов за 221 операций. Во всех этих вскрытиях использовались стойкие S-блоки алгоритма DES. Применив дифференциальный криптоанализ ко второй реализации Lucifer, Бихам и Шамир обнаружили, что его S-блоки намного слабее, чем в алгоритме DES. Дальнейший анализ показал нестойкость более половины возможных ключей. Криптоанализ на основе связанных ключей позволяет взломать 128-битовый Lucifer с любым числом раундов с помощью 233 подобранных открытых текстов для подобранных ключей или 265 известных открытых текстов для подобранных ключей. Вторая реализация Lucifer еще слабее.
Некоторые полагают, что Lucifer надежнее DES из-за большей длины ключа и малочисленности опубликованных сведений. Но очевидно, что это не так. На алгоритм Lucifer выданы нескольких патентов США. Сроки действия всех этих патентов уже истекли.
3.2. Алгоритм Madryga
В. Е. Мадрига (W. E. Madryga) предложил этот блочный алгоритм в 1984 году. Его можно эффективно реализовать программным путем: в алгоритме нет раздражающих перестановок, и все операции выполняются над байтами.
Стоит перечислить задачи, которые решал автор при проектировании алгоритма:
Без помощи ключа открытый текст невозможно получить из шифртекста. (Это означает только то, что алгоритм стоек).
Число операций, необходимых для восстановления ключа по образцу шифртекста и открытого текста, должно быть статистически равно произведению числа операций при шифровании на число возможных ключей. (Это означает, что никакое вскрытие с открытым текстом не может быть эффективнее лобового вскрытия).
Опубликование алгоритма не влияет на стойкость шифра. (Безопасность полностью определяется ключом).
Изменение одного бита ключа должно радикально изменять шифртекст одного и того же открытого текста, а изменение одного бита открытого текста должно радикально изменять шифртекст для того же ключа (лавинный эффект).
Алгоритм должен содержать некоммутативную комбинацию подстановок и перестановок.
Подстановки и перестановки, используемые в алгоритме, должны определяться как входными данными, так и ключом.
Избыточные группы битов открытого текста должны быть полностью замаскированы в шифртексте.
Длина шифртекста должна совпадать с длиной открытого текста.
Между любыми возможными ключами и особенностями шифртекста недопустимы простые взаимосвязи.
Все возможные ключи должны обеспечивать стойкость шифра. (Не должно быть слабых ключей).
Длина ключа и текст должны иметь возможность варьирования для реализации различных требований к безопасности.
Алгоритм должен допускать эффективную программную реализацию на мэйнфреймах, мини- и микрокомпыотерах и с помощью дискретной логики. (По существу, число функций, используемых в алгоритме, ограничено операциями XOR и битовым сдвигом).
Алгоритм DES удовлетворял первым девяти требованиям, но последние три появились впервые. Если допустить, что лучший способ взлома алгоритма - лобовое вскрытие, переменная длина ключа, конечно же, заставит замолчать тех, кто считает, что 56 битов - слишком малая величина. Такие люди могут реализовать этот алгоритм с любой длиной ключа. А любой, кто когда-нибудь пытался реализовать DES программными средствами, обрадуется алгоритму, который учитывает особенности программных реализаций.
3.3.1. Описание алгоритма Madryga
Алгоритм Madryga состоит из двух вложенных циклов. Внешний цикл повторяется восемь раз (для гарантии надежности число циклов можно увеличить) и заключается в применении внутреннего цикла к открытому тексту. Внутренний цикл превращает открытый текст в шифртекст и выполняется однократно над каждым 8-битовым блоком (байтом) открытого текста. Таким образом, весь открытый текст последовательно восемь раз обрабатывается алгоритмом.
Итерация внутреннего цикла оперирует с 3-байтовым окном данных, называемым рабочим кадром (Рис. 1.). Это окно сдвигается на 1 байт за итерацию. (При работе с последними 2 байтами данные полагаются циклически замкнутыми). Первые два байта рабочего кадра циклически сдвигаются на переменное число позиций, а для последнего байта исполняется операция XOR с несколькими битами ключа. По мере перемещения рабочего кадра все байты последовательно циклически сдвигаются и подвергаются операции XOR с частями ключа. Последовательные циклические сдвиги перемешивают результаты предыдущих операций XOR и циклического сдвига, причем на циклический сдвиг влияют результаты XOR. Благодаря этому процесс в целом обратим.
|
Текст |
1 |
2 |
3 |
4 |
5 |
6 |
… |
TL-2 |
TL-1 |
TL |
||
|
Движущийся рабочий кадр |
WF(1) |
WF(2) |
WF(3) |
|||||||||
|
8 битов |
8 битов |
8 битов |
||||||||||
|
ROT |
||||||||||||
|
Перемещение |
Объект сдвига |
Счетчик сдвига |
||||||||||
|
16 бит |
3 бита |
|||||||||||
|
Преобразование |
Объект преобразования |
|||||||||||
|
8 битов XOR |
||||||||||||
|
Ключ |
1 |
2 |
3 |
… |
KL |
|||||||
|
XOR |
||||||||||||
|
Хэш ключа |
1 |
2 |
3 |
… |
KL |
|||||||
Рис. 1. Одна итерация алгоритма Madryga
Поскольку каждый байт данных влияет на два байта слева и на один байт справа от себя, после восьми проходов каждый байт шифртекста зависит от 16 байтов слева и 8 байтов справа.
При зашифровании каждая итерация внутреннего цикла устанавливает рабочий кадр на предпоследний байт открытого текста и циклически перемещает его к третьему с конца байту открытого текста. Сначала весь ключ подвергается операции XOR со случайной константой и затем циклически сдвигается вправо на 3 бита (ключ и данные двигаются в разных направлениях, чтобы минимизировать избыточные операции с битами ключа). Младшие три бита младшего байта рабочего кадра сохраняются, они определяют циклический сдвиг остальных двух байтов. Далее конкатенация двух старших байтом циклически сдвигается влево на переменное число битов (от 0 до 7). Затем над младшим байтом рабочего кадра выполняется операция XOR с младшим байтом ключа. Наконец рабочий кадр смещается вправо на один байт и весь процесс повторяется.
Случайная константа предназначена для превращения ключа в псевдослучайную последовательность. Длина константы должна быть равной длине ключа. При обмене данными абоненты должны пользоваться одной и той же константой. Для 64-битового ключа Мадрига рекомендует константу 0x0fle2d3c4b5a6978.
При расшифровании процесс повторяется в обратном порядке. В каждой итерации внутреннего цикла рабочий кадр устанавливается на байт, третий слева от последнего байта шифртекста, и циклически сдвигается в обратном направлении до байта, расположенного на 2 байта левее последнего байта шифртекста. 2 байта шифртекста в процессе циклически сдвигаются вправо, а ключ - влево. После циклических сдвигов выполняется операция XOR.
3.2.2. Криптоанализ алгоритма Madryga
Ученые Квинслендского технического университета (Queensland University of Technology) исследовали алгоритм Madryga и некоторые другие блочные шифры. Они обнаружили, что лавинный эффект при преобразовании открытого текста в шифртекст в этом алгоритме не проявляется. Кроме того, во многих шифртекстах доля единиц превышала доли нулей.
Формальный анализ этого алгоритма не производит впечатления особо надежного. При поверхностном знакомстве с ним Эли Бихам пришел к следующим выводам:
Алгоритм состоит только из линейных операций (циклический сдвиг и XOR), незначительно изменяемых в зависимости от данных.
Это ничуть не напоминает мощь S-блоков DES.
Четность всех битов шифртекста и открытого текста неизменна и зависит только от ключа. Поэтому, обладая открытым текстом и соответствующим шифртекстом, можно предсказать четность шифртекста для любого открытого текста.
Само по себе ни одно из этих замечаний нельзя назвать убийственным, однако этот алгоритм не вызывает у многих криптоаналитиков положительных эмоций. Некоторые вообще не рекомендуют использовать алгоритм Madryga.
3.3. Алгоритм REDOC
REDOC II представляет собой еще один блочный алгоритм, разработанный Майклом Вудом (Michael Wood) для корпорации Cryptech. В нем используются 20-байтовый (160-битовый) ключ и 80-битовый блок.
Алгоритм REDOC II выполняет все манипуляции - перестановки, подстановки и операции XOR с ключом - с байтами. Этот алгоритм удобен для программной реализации. В REDOC II использованы переменные таблицы функций. В отличие от алгоритма DES, имеющего фиксированный (хотя и оптимизированный с точки зрения стойкости) набор таблиц подстановок и перестановок, в REDOC II используются зависимые от ключа и открытого текста наборы таблиц (по сути, S-блоки). В REDOC II 10 раундов, каждый раунд состоит из сложной последовательности манипуляций с блоком.
Другая уникальная особенность REDOC II — использование масок. Это числа - производные таблицы ключей, которые используются для выбора таблиц данной функции для данного раунда. Для выбора таблиц функций используются как значение данных, так и маски.
При условии, что самое эффективное средство взлома этого алгоритма - лобовое вскрытие, REDOC II весьма надежен: для восстановления ключа требуется 2160 операций. Томас Кузик (Thomas Cusick) выполнил криптоанализ одного раунда REDOC II, но расширить вскрытие на несколько раундов ему не удалось. Используя дифференциальный криптоанализ, Бихам и Шамир успешно выполнили криптоанализ одного раунда REDOC II с помощью 2300 подобранных открытых текстов. Они не сумели расширить эту атаку на несколько раундов, но им удалось получить три значения маски после четырех раундов. Были и другие попытки криптоанализа.
3.3.1 Алгоритм REDOC III
Алгоритм REDOC III представляет собой упрощенную версию REDOC II, тоже разработанную Майклом Вудом. Он оперирует с 80-битовым блоком. Длина ключа может изменяться и достигать 2560 байт (204800 бит). Алгоритм состоит только из операций XOR над байтами ключа и открытого текста, перестановки и подстановки не используются.
1) Создают таблицу ключей из 256 10-байтовых ключей, используя секретный ключ.
2) Создают два 10-байтовых блока масок M1 и М2. M1 представляет собой результат операции XOR первых 128 10-байтовых ключей, а М2 - результат операции XOR вторых 128 10-байтовых ключей.
3) Для шифрования 10-байтового блока:
Выполняют операцию XOR с первым байтом блока данных и первым байтом M1. Выбирают ключ в таблице ключей, рассчитанной в раунде 1. Используют вычисленное значение XOR в качестве индекса таблицы. Выполняют операцию XOR с каждым, кроме первого, байтом блока данных и соответствующим байтом выбранного ключа.
Выполняют операцию XOR со вторым байтом блока данных и вторым байтом M1. Выбирают ключ в таблице ключей, рассчитанной в раунде 1. Используют вычисленное значение XOR в качестве индекса таблицы. Выполните операцию ХОR с каждым, кроме второго, байтом блока данных и соответствующим байтом выбранного ключа.
Продолжают эти действия со всем блоком данных (с 3-10 байтами), пока не будет использован каждый байт для выбора ключа из таблицы после выполнения операции XOR с ним и соответствующим значением M1. Затем выполняют операцию XOR с каждым, кроме использованного для выбора ключа, байтом, и ключом.
Повторяют этапы а-с для М2.
Это несложный и скоростной алгоритм. На процессоре 80386 с тактовой частотой 33МГц он шифрует данные со скоростью 2.75 Мбит/сек. По оценке Вуда, конвейеризированный процессор с трактом данных 64 бит и тактовой частотой 20 МГц может шифровать данные со скоростью свыше 1.28 Гбиг/сек.
Алгоритм REDOC III нестоек. Он уязвим к дифференциальному криптоанализу. Для восстановления обеих масок достаточно около 223 подобранных открытых текстов.
3.4. Алгоритм LOKI
Алгоритм LOKI разработан в Австралии и впервые представлен в 1990 году в качестве возможной замены DES. В нем используются 64-битовый блок и 64-битовый ключ.
Используя дифференциальный криптоанализ, Бихам и Шамир взламывали алгоритм LOKI с 11 и менее раундами быстрее, чем лобовым вскрытием [170]. Более того, алгоритм характеризуется 8-битовой комплементарностью, что упрощает лобовое вскрытие в 256 раз.
Как показал Ларе Кнудсен (Lars Knudsen), алгоритм LOKI с 14 и менее раундами уязвим дифференциальному криптоанализу. Кроме того, если в LOKI используются альтернативные S-блоки, то полученный шифр, вероятно, тоже уязвим дифференциальному криптоанализу.
3.4.1. Алгоритм LOKI91
В ответ на описанные выше вскрытия разработчики LOKI вернулись за чертежную доску и пересмотрели свой алгоритм. В результате появился алгоритм LOKI91. (Предыдущая версия LOKI была переименована в LOKI89).
Чтобы повысить устойчивость алгоритма к дифференциальному криптоанализу и избавиться от комплементарности, в исходный проект были внесены следующие изменения:
Алгоритм генерации подключей модифицирован с тем, чтобы половины переставлялись не после каждого, а после каждого второго раунда.
Алгоритм генерации подключей модифицирован так, что число позиций циклического сдвига левого подключа составляло то 12, то 13 битов.
Исключены начальная и заключительная операции XOR с блоком и ключом.
Изменена функция S-блока с целью сгладить профили XOR S-блоков (чтобы повысить их устойчивость к дифференциальному криптоанализу), и исключить все значения х, для которых f(x) = 0, где f - комбинация Е-, S- и Р-блоков.
Алгоритм LOKI не запатентован - реализовать и использовать LOKI может кто угодно.
3.4.2. Описание алгоритма LOKI91
Механизм алгоритма LOKI91 подобен DES (Рис. 2). Блок данных расщепляется на левую и правую половины и проходит 16 раундов, что весьма напоминает DES. В каждом раунде правая половина сначала подвергается операции XOR с частью ключа, а затем расширяющей перестановке (Табл. 3).
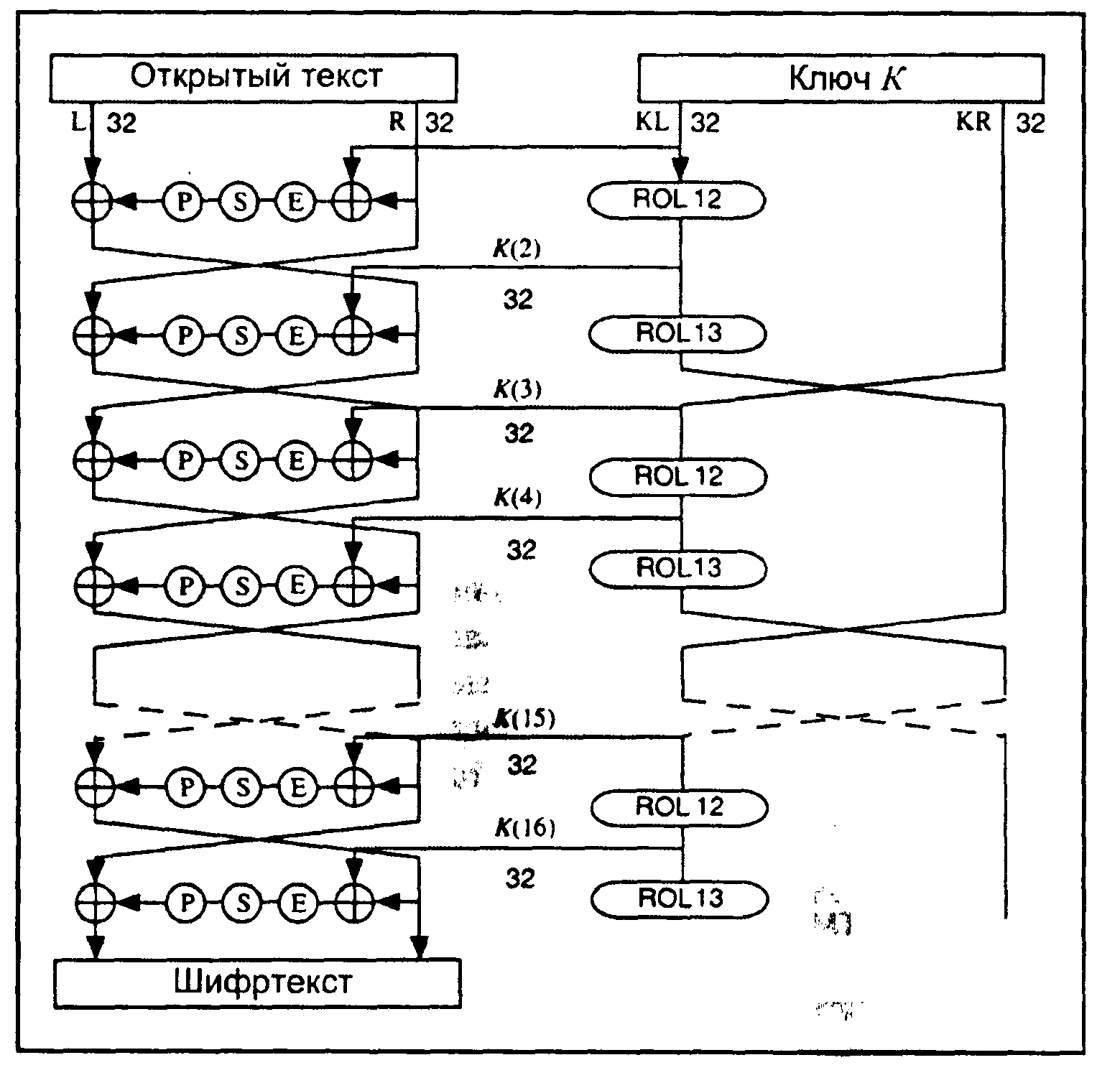
Рис. 2. Алгоритм LOKI91
Таблица 3. Перестановка с расширением
|
4, |
3, |
2, |
1, |
32, |
31, |
30, |
29, |
28, |
27, |
26, |
25, |
|
28, |
27, |
26, |
25, |
24, |
23, |
22, |
21, |
20, |
19, |
18, |
17, |
|
20, |
19, |
18, |
17, |
16, |
15, |
14, |
13, |
12, |
11, |
10, |
9, |
|
12, |
11, |
10, |
9, |
8, |
7, |
6, |
5, |
4, |
3, |
2, |
1 |
48-битовый выход разделяется на четыре 12-битовых блока. В каждом блоке выполняется такая подстановка с использованием S-блока: берется каждый 12-битовый вход, 2 старших и 2 младших бита используются для образования номера r, а восемь внутренних битов образуют номер с. Выход S-блока, О, имеет следующее значение:
О(r,с) = (с + ((r*17) 0xff) & 0xff)31 mod P>r>
Таблица 4. Значения P>r>
|
r |
1, |
2, |
3, |
4, |
5, |
6, |
7, |
8, |
9, |
10, |
11, |
12, |
13, |
14, |
15, |
16 |
|
P>r> |
375, |
379, |
391, |
395, |
397, |
415, |
419, |
425, |
433, |
445, |
451, |
463, |
471, |
477, |
487, |
499 |
Затем четыре 8-битовых результата снова объединяются, образуя 32-битовое число, которое подвергается операции перестановки, описанной в табл. 3. Наконец, для получения новой левой половины выполняется операция XOR правой половины с прежней левой половиной, а левая половина становится новой правой половиной. После 16 раундов для получения окончательного шифртекста снова выполняется операция XOR над блоком и ключом.
Таблица 5. Перестановка с помощью Р-блока
|
32, |
24, |
16, |
8, |
31, |
23, |
15, |
7, |
30, |
22, |
14, |
6, |
29, |
21, |
13, |
5, |
|
28, |
20, |
12, |
4, |
27, |
19, |
11, |
3, |
26, |
18, |
10, |
2, |
25, |
17, |
9, |
1 |
Подключи генерируются из ключа достаточно прямолинейно. 64-битовый ключ разбивается на левую и правую половины. На каждом раунде подключом служит левая половина. Далее она циклически сдвигается влево на 12 или 1 3 битов, затем после каждых двух раундов левая и правая половины меняются местами. Как и в DES, для зашифрования и расшифрования используется один и тот же алгоритм с некоторыми изменениями в использовании подключей.
3.4.3. Криптоанализ алгоритма LOKI91
Кнудсен предпринял попытку криптоанализа LOKI91, но нашел, что этот алгоритм устойчив к дифференциальному криптоанализу. Все же он обнаружил метод атаки на основе связанных ключей для подобранных открытых текстов, который упрощает лобовое вскрытие почти вчетверо. Это метод опирается на слабость схемы развертки ключей. Кроме того, этот метод пригоден и в том случае, когда алгоритм используется в качестве однонаправленной хэш-функции.
Другая атака со связанными ключами позволяет вскрыть алгоритм LOKI91 с помощью 232 подобранных открытых текстов для выбранных ключей или с помощью 248 известных открытых текстов для выбранных ключей. Эффективность атаки не зависит от числа раундов алгоритма. (В той же работе Бихам вскрывает LOKI89 криптоанализом со связанными ключами, используя 217 подобранных открытых текстов для выбранных ключей или 233 известных открытых текстов для выбранных ключей). Усложнив схему развертки ключа, несложно повысить устойчивость LOKI91 к подобной атаке.
3.5. Алгоритмы Khufu и Khafre
В 1990 году Ральф Меркл (Ralph Merkle) предложил два алгоритма. В основу конструкции заложены следующие принципы:
56-битовый размер ключа DES слишком мал. Так как стоимость увеличения размера ключа пренебрежимо мала (компьютерная память недорога и доступна), длину ключа следует увеличить.
Широкое использование в DES перестановок, хотя и удобно для аппаратных реализаций, чрезвычайно затрудняет программные реализации. Самые скоростные реализации DES выполняют перестановки с помощью таблиц подстановок. Таблицы подстановок могут обеспечить те же характеристики «рассеивания», что и собственно перестановки, и намного повысить гибкость реализации.
S-блоки DES, содержащие всего 64 4-битовых элементов, слишком малы. Теперь, с увеличением объема памяти, должны возрасти и S-блоки. Более того, все восемь S-блоков в DES используются одновременно. Хотя это и удобнее для аппаратуры, для программной реализации это представляется ненужным ограничением. Должны быть реализованы больший размер S-блоков и последовательное (а не параллельное) их использование.
Общепризнанно, что начальная и заключительная перестановки криптографически бессмысленны, а поэтому должны быть исключены.
Все скоростные реализации DES заранее вычисляют ключи для каждого раунда. Отсюда, нет причин не сделать эти вычисления более сложными.
В отличие от DES, критерии проектирования S-блоков должны быть общедоступны.
В настоящее время к этому перечню Меркл, возможно, добавил бы «устойчивость к дифференциальному и линейному криптоанализу, ведь в то время эти методы вскрытия не были известны.
3.5.1 Алгоритм Khufu
Khufu - это 64-битовый блочный шифр. 64-битовый открытый тест сначала расщепляется на две 32-битовые половины, L и R. Над обеими половинами и определенными частями ключа выполняется операция XOR. Затем, аналогично DES, результаты проходят некоторую последовательность раундов. В каждом раунде младший значащий байт L используется как вход S-блока. У каждого S-блока 8 входных битов и 32 выходных бита. Далее выбранный в S-блоке 32-битовый элемент подвергается операции XOR с R. Затем L циклически сдвигается на число, кратное восьми битам, L и R меняются местами, и раунд завершается. Сам S-блок не статичен, он меняется каждые восемь раундов. Наконец, по окончании последнего раунда, над L и R выполняется операция XOR с другими частями ключа, и половины объединяются, образуя блок шифртекста.
Хотя части ключа используются для операции XOR с блоком шифрования в начале и конце исполнения алгоритма, главное назначение ключа - генерация S-блоков. Эти S-блоки секретны, по существу, это часть ключа. Полный размер ключа алгоритма Khufu равен 512 бит (64 байт), алгоритм предоставляет способ генерации S-блоков по ключу. Вопрос о достаточном числе раундов остается открытым. Как указывает Меркл, 8-раундовый алгоритм Khufu уязвим к вскрытию с подобранным открытым текстом. Он рекомендует использовать 16, 24 или 32 раунда. (Меркл ограничивает количество раундов числами, кратными восьми).
Поскольку S-блоки Khufu зависят от ключа и секретны, алгоритм устойчив к дифференциальному криптоанализу. Известна дифференциальная атака на 16-раундовый Khufu, которая восстанавливает ключ с помощью 231 подобранных открытых текстов, однако этот метод не удалось расширить на большее число раундов. Если принять, что лучший метод взлома Khufu - лобовое вскрытие, стойкость алгоритма впечатляет. 512-би-овый ключ обеспечивает сложность вскрытия 2512 - это огромное число в любом случае.
3.5.2. Алгоритм Khafre
Khafre - это вторая криптосистема, предложенная Мерклом. (Khufu (Хуфу) и Khafre (Хафр) - имена египетских фараонов). Конструкция этого алгоритма близка Khufu, однако он спроектирован для приложений, где невозможны предварительные вычисления. S-блоки не зависят от ключа. Вместо этого в Khafre используются фиксированные S-блоки. Блок шифрования подвергается операции XOR с ключом не только перед первым раундом и после последнего, но и после каждых восьми раундов шифрования.
Меркл предполагал, что в алгоритме Khafre следует использовать 64- или 128-битовые ключи и что в этом алгоритме понадобится большее число раундов, чем в Khufu. Это, наряду с тем, что каждый раунд Khafre сложнее раунда Khufu, делает Khafre менее скоростным. Зато алгоритму Khafre не нужны никакие предварительные расчеты, что ускорит шифрование небольших порций данных.
В 1990 году Бихам и Шамир применили свой метод дифференциального криптоанализа к алгоритму Khafre. Им удалось взломать 16-раундовый Khafre атакой с подобранным открытым текстом, используя около 1500 различных шифрований. На их персональном компьютере это заняло около часа. Преобразование этой атаки в атаку с известным открытым текстом потребует около 238 шифрований. Алгоритм Khafre с 24 раундами можно взломать с помощью атаки с подобранным открытым текстом за 253 шифрования, а с помощью атаки с известным открытым текстом – за 259 шифрования.
Алгоритмы Khufu и Khafre запатентованы. Исходный код этих алгоритмов приведен в патенте.
3.6. Алгоритм ММВ
Недовольство использованием в одном из криптоалгоритмов 64-битового блока шифрования привело к созданию Джоаной Дэймен алгоритма под названием ММВ (Modular Multiplication-based Block cipher - модулярный мультипликативный блочный шифр). В основе ММВ лежит смешивание операций различных алгебраических групп. ММВ - итеративный алгоритм, главным образом состоящий из линейных действий (XOR и использование ключа) и параллельного применения четырех крупных обратимых нелинейных подстановок. Эти подстановки определяются с помощью умножения по модулю 232-1 с постоянными множителями. В итоге появляется алгоритм, использующий 128-битовый ключ и 128-битовый блок.
Алгоритм ММВ оперирует 32-битовыми подблоками текста (х>0>, х>1>, х>2>, x>3>) и 32-битовыми подблоками ключа (k>0>, k>1>, k>2>, k>3>). Это упрощает реализацию алгоритма на современных 32-битовых процессорах. Чередуясь с операцией XOR, шесть раз используется нелинейная функция f. Вот этот алгоритм (все операции с индексами выполняются по модулю 4):
x>i>> >= x>i> k>i> для i = 0..3
f(х>0>, х>1>, х>2>, x>3>)
x>i>> >= x>i> k>i>>+1> для i = 0..3
f(х>0>, х>1>, х>2>, x>3>)
x>i>> >= x>i> k>i>>+2> для i = 0..3
f(х>0>, х>1>, х>2>, x>3>)
x>i>> >= x>i> k>i> для i = 0..3
f(х>0>, х>1>, х>2>, x>3>)
x>i>> >= x>i> k>i>>+1> для i = 0..3
f(х>0>, х>1>, х>2>, x>3>)
x>i>> >= x>i> k>i>>+2> для i = 0..3
f(х>0>, х>1>, х>2>, x>3>)
Функция f исполняется в три шага:
x>i> = с>i>> >* x>i> для i = 0..3 (Если на входе умножения одни единицы, то на выходе - тоже одни единицы).
Если младший значащий бит х>0> = 1, то x>0> = х>0> С. Если младший значащий байт х>3> = 0, то х>3> = х>3> С.
x>i> = х>i>>-1 > x>i>> > х>i>>+1> для i = 0..3.
Все операции с индексами выполняются по модулю 4. Операция умножения на шаге 1 выполняется по модулю 232-1. Специальный случай для данного алгоритма: если второй операнд равен 232-1, результат тоже равен 232-1. В алгоритме используются следующие константы:
С = 2ааааааа
c>0> = 025f1cdb
c>1 >= 2*c>0>
с>2>=23 *с>0>
с>3>=27 *с>0>
> >Константа С - «простейшая» константа без круговой симметрии, высоким троичным весом и нулевым младшим значащим битом. У константы с>0> есть другие особые характеристики. Константы c>1>, с>2> и с>3> - сдвинутые версии с>0>, и служат для предотвращения атак, основанных на симметрии.
Расшифрование выполняется в обратном порядке, Этапы 2 и 3 инверсны им самим. На этапе 1 вместо с>i> используется с>i>-1 . Значение с>0>-1 = 0dad4694 .
Стойкость алгоритма ММВ
Схема алгоритма ММВ обеспечивает на каждом раунде значительное и независимое от ключа рассеивание. ММВ изначально проектировался в расчете на отсутствие слабых ключей.
ММВ – это уже мертвый алгоритм. Это утверждение справедливо по многим причинам, хотя криптоанализ ММВ и не был опубликован. Во-первых, алгоритм проектировался без учета требования устойчивости к линейному криптоанализу. Устойчивость к дифференциальному криптоанализу обеспечил выбор мультипликативных множителей, но о существовании линейного криптоанализа авторы не знали.
Во-вторых, Эли Бихам реализовал эффективную атаку с подобранным ключом, использующую тот факт, что все раунды идентичны, а развертка ключа – просто циклический сдвиг на 32 бита. В третьих, несмотря на эффективность программной реализации ММВ, аппаратное исполнение менее эффективно по сравнению с DES.
Дэймен предлагает желающим улучшить алгоритм ММВ сначала проанализировать умножение по модулю с помощью линейного криптоанализа и подобрать новый множитель, а затем сделать константу С различной на каждом раунде. Затем улучшить развертку ключа, добавляя к ключам раундов константы с целью устранения смещения. Однако сам он не стал заниматься этим, а разработал алгоритм 3-Way.
3.7. Алгоритм Blowfish
Blowfish - это алгоритм, разработанный Брюсом Шнайером специально для реализации на больших микропроцессорах. Алгоритм Blowfish не запатентован. При проектировании алгоритма Blowfish Шнайер пытался удовлетворить следующим критериям:
Скорость. Программа, реализующая алгоритм Blowfish на 32-битовых микропроцессорах, шифрует данные со скоростью 26 тактов на байт.
Компактность. Для исполнения программной реализации алгоритма Blowfish достаточно 5 Кбайт памяти.
Простота. В алгоритме Blowfish используются только простые операции: сложение, XOR и подстановка из таблицы по 32-битовому операнду. Анализ его схемы несложен, что снижает риск ошибок реализации алгоритма.
Настраиваемая стойкость. Длина ключа Blowfish переменна и может достигать 448 бит.
Алгоритм Blowfish оптимизирован для применения в системах, не практикующих частой смены ключей, например, в линиях связи и программах автоматического шифрования файлов. При реализации на 32-битовых микропроцессорах с большим размером кэша данных, например, процессорах Pentium и PowerPC, алгоритм Blowfish заметно быстрее DES. Алгоритм Blowfish не годится для применения в случаях, где требуется частая смена ключей, например, в коммутаторах пакетов, или в качестве однонаправленной хэш-функции. Большие требования к памяти не позволяют использовать этот алгоритм в смарт-картах.
3.7.1. Описание алгоритма Blowfish
Blowfish представляет собой 64-битовый блочный алгоритм шифрования с ключом переменной длины. Алгоритм состоит из двух частей: расширения ключа и шифрования данных. Расширение ключа преобразует ключ длиной до 448 битов в несколько массивов подключей общим размером 4168 байт.
Шифрование данных заключается в последовательном исполнении простой функции 16 раз. На каждом раунде выполняются зависимая от ключа перестановка и зависимая от ключа и данных подстановка. Используются только операции сложения и XOR над 32-битовыми словами. Единственные дополнительные операции каждого раунда - четыре взятия данных из индексированного массива.
В алгоритме Blowfish используется множество подключей. Эти подключи должны быть вычислены до начала зашифрования или расшифрования данных.

Рис 3. Алгоритм Blowfish
Р-массив состоит из восемнадцати 32-битовых подключей:
Р>1>,Р>2>,...,Р>18>
Каждый из четырех 32-битовых S-блоков содержит 256 элементов:
S>1,0>, S>1,1>,…, S>1,255>
> >S>2,0>, S>2,2>,…, S>2,255>
> >S>3,0>, S>3,3>,…, S>3,255>
> >S>4,0>, S>4,4>,…, S>4,255>
Алгоритм Blowfish представляет собой сеть Файстеля, состоящей из 16 раундов. На вход подается 64-битовый элемент данных х. Для зашифрования данных:
Разбить х на две 32-битовых половины: x>L>, x>R>
Для i от 1 до 16:
x>L >= x>L > P>i>
> >x>R >= F> >(x>L>) x>R>
> >Переставить x>L>> >и x>R>
> >Переставить x>L> и x>R> (отнять последнюю перестановку)
x>R> = x>R > P>17>
> >x>L> = x>L > P>18>
> >Объединить x>L >и x>R>
> >
>
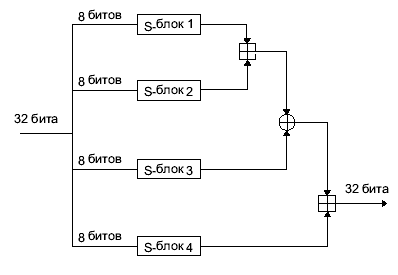
Рис. 4. Функция F
Функция F рассчитывается следующим образом ( Рис. 4.):
Разделить x>L> на четыре 8-битовых фрагмента: а, b, с и d
F(x>L>) = ((S>1,>>a> + S>2,>>b>mod232) S>3,>>c>) + S>4,>>d>mod232
Расшифрование выполняется точно так же, как и зашифрование, но Р>1>,Р>2>,...,Р>18> используются в обратном порядке.
В реализациях Blowfish, в которых требуется очень высокая скорость, цикл должен быть развернут, а все ключи храниться в кэше.
Подключи рассчитываются с помощью самого алгоритма Blowfish. Вот какова точная последовательность действий.
Сначала Р-массив, а затем четыре S-блока по порядку инициализируются фиксированной строкой. Эта строка состоит из шестнадцатеричных цифр π.
Выполняется операция XOR над Р>1> с первыми 32 битами ключа, XOR над Р>2> со вторыми 32 битами ключа, и т.д. для всех битов ключа (вплоть до Р>18>). Операция XOR выполняется циклически над битами ключа до тех пор, пока весь Р-массив не будет инициализирован.
Используя подключи, полученные на этапах 1 и 2, алгоритм Blowfish шифрует строку из одних нулей.
Р>1 >и Р>2 >заменяются результатом этапа 3.
Результат этапа 3 шифруется с помощью алгоритма Blowfish и модифицированных подключей.
Р>3 >и Р>4> заменяются результатом этапа 5.
Далее по ходу процесса все элементы Р-массива, а затем все четыре S-блока по порядку заменяются выходом постоянно меняющегося алгоритма Blowfish.
Всего для генерации всех необходимых подключей требуется 521 итерация. Приложения могут сохранять подключи - нет необходимости выполнять процесс их получения многократно.
3.7.2. Стойкость алгоритма Blowfish
Серж Воденэ (Serge Vaudenay) исследовал алгоритм Blowfish с известными S-блоками и r раундами. Как оказалось, дифференциальный криптоанализ может восстановить Р-массив с помощью 28r+1 подобранных открытых текстов. Для некоторых слабых ключей, которые генерируют плохие S-блоки (вероятность выбора такого ключа составляет 1/214), эта же атака восстанавливает Р-массив с помощью всего 24г+1 подобранных открытых текстов. При неизвестных S-блоках эта атака может обнаружить использование слабого ключа, но не может восстановить сам ключ (и также S-блоки и Р-массив). Эта атака эффективна только против вариантов с уменьшенным числом раундов и совершенно безнадежна против 16-раундового алгоритма Blowfish. Разумеется, важно и открытие слабых ключей, хотя они, вероятно, использоваться не будут. Слабым называют ключ, для которого два элемента данного S-блока идентичны. До выполнения расширения ключа невозможно установить факт слабости ключа.
Не известны факты успешного криптоанализа алгоритма Blowfish. В целях безопасности не следует реализовывать Blowfish с уменьшенным числом раундов. Компания Kent Marsh Ltd. встроила алгоритм Blowfish в свой продукт FolderBolt, предназначенный для обеспечения защиты Microsoft Windows и Macintosh. Кроме того, алгоритм входит в Nautilus и PGPfone.
3.8. Алгоритм RC5
RC5 представляет собой блочный шифр с множеством параметров: размером блока, размером ключа и числом раундов. Он изобретен Роном Ривестом и проанализирован в RSA Laboratories.
В алгоритме RC5 предусмотрены три операции: XOR, сложение и циклические сдвиги. На большинстве процессоров операции циклического сдвига выполняются за постоянное время, переменные циклические сдвиги представляют собой нелинейную функцию. Эти циклические сдвиги, зависящие как от ключа, так и от данных - интересная операция.
В RC5 используется блок переменной длины, но в приводимом примере будет рассмотрен 64-битовый блок данных. Шифрование использует 2r+2 зависящих от ключа 32-битовых слов - S>0>, S>1>, S>2>,... S>2r>>+1> - где r - число раундов. Для зашифрования сначала нужно разделить блок открытого текста на два 32-битовых слова: А и В. (При упаковке байтов в слова в алгоритме RC5 соблюдается соглашение о прямом порядке (little-endian) байтов: первый байт занимает младшие биты регистра А и т.д.) Затем:
A=A + S>0 >
B = B + S>0>
Для i от 1 до r:
A = ((A B) <<< B) + S>2i>
> >В = ((В А) <<< А) + S>2>>i>>+1>
Выход находится в регистрах А и В.
Расшифрование тоже несложно. Нужно разбить блок открытого текста на два слова, А и В, а затем:
Для i от r до 1 с шагом -1:
B = ((B - S>2i>>+1>) >>> A) A
A = ((A - S>2i>) >>> B) B
B = B – S>i>
A = A - S>0>
Символом «>>>» обозначен циклический сдвиг вправо. Конечно же, все сложения и вычитания выполняются по модулю 232.
Создание массива ключей сложнее, но тоже прямолинейно. Сначала байты ключа копируются в массив L из с 32-битовых слов, дополняя при необходимости заключительное слово нулями. Затем массив S инициализируется при помощи линейного конгруэнтного генератора по модулю 232:
S>0 >= Р
Для i от 1 до 2(r + 1) - 1:
S>i> = (S>i>>-1 >+ Q) mod 232
где P = 0xb7e15163 и Q = 0x9e3779b9, эти константы основываются на двоичном представлении е и phi.
Наконец, нужно подставить L в S:
i = j = 0
A = B = 0
Выполнить 3n раз (где п - максимум от 2(r + 1) и с):
A = S >i>= (S>i> + A + B) <<< 3
B= L>i >= (L>i> + A + B) <<< (A + B)
i = (i + 1) mod 2(r +1)
i = (j +1) mod с
В действительности RC5 представляет собой семейство алгоритмов. Выше был определен RC5 с 32-битовым словом и 64-битовым блоком, но нет причин, запрещающих использовать этот же алгоритм с 64-битовым словом и 128-битовым блоком. Для w=64, Р и Q равны 0xb7e151628aed2a6b и 0x9e3779b97f4a7c15, соответственно. Ривест обозначил различные реализации RC5 как RC5-w/r/b, где w - размер слова, r - число раундов, a b - длина ключа в байтах.
RC5 - новый алгоритм, но RSA Laboratories потратила достаточно много времени, анализируя его работу с 64-битовым блоком. После 5 раундов статистика выглядит очень убедительно. После 8 раундов каждый бит открытого текста влияет не менее чем на один циклический сдвиг. Дифференциальная атака требует 224 подобранных открытых текстов для 5 раундов, 2 - для 10 раундов, 253 - для 12 раундов и 268 - для 15 раундов. Конечно же, существует только 264 возможных открытых текстов, поэтому такая атака неприменима к алгоритму с 15 и более раундами. Оценка возможности линейного криптоанализа показывает, что алгоритм устойчив к нему после 6 раундов. Ривест рекомендует использовать не менее 12, а лучше 16, раундов. Это число может меняться.
Компания RSADSI в настоящее время патентует RC5, и его название заявлено как торговая марка. Компания утверждает, что плата за лицензию будет очень мала, но эти данные нуждаются в проверке.
4. Объединение блочных шифров
Известно множество путей объединения блочных алгоритмов для получения новых алгоритмов. Создание подобных схем стимулируется желанием повысить безопасность, избежав трудности проектирования нового алгоритма. Так, алгоритм DES относится к надежным алгоритмам, он подвергался криптоанализу добрых 20 лет и, тем не менее, наилучшим способом взлома остается лобовое вскрытие. Однако ключ DES слишком короток. Разве не плохо было бы использовать DES в качестве компонента другого алгоритма с более длинным ключом? Это позволило бы воспользоваться преимуществами обоих систем: устойчивостью, гарантированной двумя десятилетиям криптоанализа, и длинным ключом.
Один из методов объединения - многократное шифрование. В этом случае для шифрования одного и того же блока открытого текста алгоритм шифрования используется несколько раз с несколькими ключами. Каскадное шифрование подобно многократному шифрованию, но использует различные алгоритмы. Известны и другие методы.
Повторное шифрование блока открытого текста одним и тем же ключом с помощью того же или другого алгоритма неэффективно. Повторное использование того же алгоритма не повышает сложность лобового вскрытия. (Мы предполагаем, что криптоаналитику известны алгоритм и число операций шифрования). При использовании различных алгоритмов сложность лобового вскрытия может, как возрастать, так и оставаться неизменной. При этом нужно убедиться в том, что ключи для последовательных шифрований различны и независимы.
4.1. Двойное шифрование
К наивным способам повышения надежности алгоритма относится шифрование блока дважды с двумя различными ключами. Сначала блок зашифровывается первым ключом, а получившийся шифртекст - вторым ключом. Расшифрование выполняется в обратном порядке.
С = Е>К1>(E>k>>2>(Р))
P = D>K>>1>(D>K>>1>(C))
Если блочный алгоритм образует группу, всегда существует такой К3, для которого:
С = Е>К2>(Е>К1>(Р)) = Е>К3>(Р)
Если алгоритм не образует группу, взломать итоговый дважды зашифрованный блок шифртекста с помощью полного перебора намного сложнее. Вместо 2n (где п – длина ключа в битах), потребуется 22n попыток. Если алгоритм использует 64-битовый ключ, для обнаружения ключей, которыми дважды зашифрован шифртекст, понадобится 2128 попыток.
Однако при атаке с известным открытым текстом это не так. Меркл и Хеллман предложили способ согласования памяти и времени, который позволяет вскрыть такую схему двойного шифрования за 2n+1 шифрований, а не за 22n. (Они использовали эту схему против DES, но результаты можно обобщить на все блочные алгоритмы). Такая атака называется «встреча посередине»: с одной стороны выполняется зашифрование, а с другой - расшифрование, а полученные посередине результаты сравниваются.
В этой атаке криптоаналитику известны значения P>1>, С>1>, Р>2> и С>2>, такие что:
C>1>=E>K>>2>(E>K>>1>(P>t>>)>)
С>2>=Е>К2>(Е>К1>(Р>2>))
Для каждого возможного К криптоаналитик рассчитывает Е>К>(Р>1>) и сохраняет результат в памяти. Собрав все результаты, он для каждого К вычисляет D>K>(C>1>) и ищет в памяти такой же результат. Если такой результат обнаружен, то, возможно, что текущий ключ – К>2>, а ключ для результата в памяти – К>1>. Затем криптоаналитик зашифровывает Р>2> ключами К>1> и К>2>. Если он получает С>2>, он может почти быть убежденным (с вероятностью 1 к 22m-2n, где т - размер блока), что он восстановил и К>1> и К>2>. В противном случае он продолжает поиск. Максимальное количество попыток шифрования, которое ему придется предпринять, составляет 2*2n, т.е. 2n+1. Если вероятность ошибки слишком велика, криптоаналитик может использовать третий блок шифртекста, обеспечивая вероятность успеха 1 к 23m-2n. Существуют и другие способы оптимизации.
Для такого вскрытия нужен большой объем памяти: 2n блоков. Для 56-битового ключа нужно хранить 256 64-битовых блоков, или 1017 байт. Такой объем памяти пока еще трудно себе представить, но этого хватает, чтобы убедить самых осторожных криптографов в ненадежности двойного шифрования.
При 128-битовом ключе для хранения промежуточных результатов потребуется огромная память в 1039 байт. Если предположить, что каждый бит информации хранится на единственном атоме алюминия, запоминающее устройство, нужное для такого вскрытия, будет представлять собой алюминиевый куб с ребром 1 км. Кроме того, понадобится куда-то его поставить. Так что атака «встреча посередине» при ключах такого размера представляется невозможной.
Другой способ двойного шифрования, который иногда называют методом Дэвиса-Прайса (Davies-Price), представляет собой вариант режима шифрования СВС.
С>i >=E>k1>(P>i> E>k2>(C>i-1>))
P>i>=D>k1>(C>i>) E>k2>(C>i-1>)
Утверждается, что «у этого режима нет никаких особых достоинств», к тому же он, по-видимому, столь же уязвим к атаке «встреча посередине», как и другие режимы двойного шифрования.
4.2. Тройное шифрование
4.2.1. Тройное шифрование с двумя ключами
В более удачном методе, предложенном Тачменом, блок обрабатывается три раза с использованием двух ключей: первым ключом, вторым ключом и снова первым ключом. Тачмен предлагает, чтобы отправитель сначала зашифровал сообщение первым ключом, затем расшифровал вторым, и окончательно зашифровал первым ключом. Получатель расшифровывает сообщение первым ключом, затем зашифровывает вторым и, наконец, расшифровывает первым.
С = E>K>>1>(D>K>>2>(E>K>>1>(P)))
P = D>K>>1>(E>K>>1>(D>K>>1>(С)))
Иногда такой режим называют режимом зашифрование-расшифрование-зашифрование (Encrypt-Decrypt-Encrypt - EDE). Если блочный алгоритм использует n-битовый ключ, длина ключа описанной схемы составляет 2п бит. Эта остроумная связка ключей (зашифрования-расшифрования-зашифрования) разработана в корпорации IBM для совместимости с существующими реализациями алгоритма: задание двух одинаковых ключей эквивалентно одинарному шифрованию. Такая схема EDE сама по себе не обеспечивает заведомую безопасность, однако этот режим использовался для улучшения алгоритма DES в стандартах Х9.17 и ISO 8732.
Для предотвращения описанной выше атаки «встреча посередине», использование ключей ki и K2 чередуется. Если С=Е>K>>2>(Е>К1>(Е>К1>(Р))), то криптоаналитик может заранее вычислить Е>К1>(Е>К1>(Р))) для любого возможного K1, а затем выполнить вскрытие. Для этого потребуется только 2n+2 шифрований.
Тройное шифрование с двумя ключами устойчиво к такой атаке. Но Меркл и Хеллман разработали другой способ согласования памяти и времени, который позволяет взломать и этот алгоритм шифрования за 2n-1 действий, используя 2n блоков памяти.
Для каждого возможного К2 расшифровывают 0 и сохраняют результат в памяти. Затем расшифровывают 0 для каждого возможного К1, чтобы получить Р. Выполняют тройное зашифрование Р, чтобы получить С, и затем расшифровывают С ключом К1. Если полученное значение совпадает со значением (хранящимся в памяти), полученным при расшифровании 0 ключом К2, то, возможно, пара K1K2 и будет искомым результатом. Проверяют, так ли это. Если нет, продолжают поиск.
Для выполнения этого вскрытия с подобранным открытым текстом нужна память огромного объема. Понадобится 2n времени и памяти, а также 2m подобранных открытых текстов. Атака не слишком практична, но все же указывает на некоторую слабость этого метода.
Пауль ван Оорсчот (Paul van Oorschot) и Майкл Винер (Michael Wiener) преобразовали эту атаку к атаке на основе открытых текстов, для которой их нужно р штук. В примере предполагается использование режима EDE.
1) Предположить первое промежуточное значение а.
2) Используя известный открытый текст, свести в таблицу для каждого возможного К1 второе промежуточное значение b при первом промежуточном значении, равном а:
b=D>K>>1>(С)
где С - шифртекст, полученный по известному открытому тексту.
3) Для каждого возможного K2 найти в таблице элементы с совпадающим вторым промежуточным значением b:
b = E>K>>2>(a)
4) Вероятность успеха равна р/т, где р - число известных открытых текстов, а т -размер блока. Если совпадения не обнаружены, нужно выбрать другое значение а и начать сначала.
Атака требует 2n+m/р времени и р - памяти. Для алгоритма DES это составляет 2120/р. При р, больших 256, эта атака выполняется быстрее, чем полный перебор.
4.2.2. Тройное шифрование с тремя ключами
Если используют тройное шифрование, рекомендуется использовать три разных ключа. Общая длина ключа станет больше, но хранение ключа обычно не вызывает затруднений. Биты дешевы.
С = E>K>>3>(D>K>>2>(E>K>>1>(P)))
P = D>K1>(E>K>>2>(D>K>>3>(С)))
Для наилучшего вскрытия с согласованием памяти и времени, примером которого служит «встреча посередине», понадобятся 22n операций и 2n блоков памяти. Тройное шифрование с тремя независимыми ключами настолько надежно, насколько на первый взгляд кажется надежным двойное шифрование.
4.2.3. Тройное шифрование с минимальным ключом
Известен более надежный метод использования тройного шифрования с двумя ключами, препятствующий описанной атаке и называемый тройным шифрованием с минимальным ключом (Triple Encryption with Minimum Key - TEMK). Фокус в том, чтобы получить три ключа из двух: Х1 и Х2.
K>1>=E>X1>(D>X2>(E>X1>(T>1>)))
K>2> = E>X1>(D>X2>(E>X1>(T>2>)))
K>3>=E>X>>1>(D>X>>1>(E>X>>1>(T>3>)))
Здесь T>1>, T>2> и Т>3> - константы, которые необязательно хранить в секрете. Эта схема гарантирует, что для любой конкретной пары ключей наилучшим методом взлома будет вскрытие с известным открытым текстом.
4.2.4. Режимы тройного шифрования
Недостаточно просто определить тройное шифрование, его можно выполнить несколькими методами. Решение зависит от требуемых безопасности и эффективности.
Вот два возможных режима тройного шифрования:
Внутренний СВС: Файл зашифровывается в режиме СВС три раза (Рис. 1а). Для этого нужны три различных вектора инициализации (ВИ).
C>i>=E>K3>(S>i> C>i-1>); S>i>=D>K2>(T S>i-1>); T>i>=E>K1>(P>i> T>i-1>)
P>i>=T>i-1> D>K1>(T>i>); T>i>=S>i-1> E>K2>(S>i>); S>i>=C>i-1> D>K3>(C>i>)
Где С>0>, S>0> и T>0> - векторы инициализации.
Внешний СВС: Файл шифруется с помощью тройного шифрования (один раз) в режиме СВС (Рис. 5). Для этого нужен один вектор ВИ.
C>i>=E>K3>(D>K2>(E>K1>(P>i> C>i-1>)))
P>i>=C>i-1> D>K1>(E>K2>(D>K3>(C>i>)))

Рис. 5. Тройное шифрование в режиме СВС
Оба режима требуют больше ресурсов, чем однократное шифрование: больше аппаратуры или больше времени. Однако при установке трех шифровальных микросхем производительность внутреннего СВС не меньше, чем при однократном шифровании. Так как три шифрования СВС независимы, три микросхемы могут быть загружены постоянно, подавая свой выход себе на вход.
Напротив, во внешнем СВС обратная связь лежит вне трех процессов шифрования. Это означает, что даже при использовании трех микросхем производительность составит только треть производительности однократного шифрования. Чтобы получить ту же производительность для внешнего СВС, потребуется чередование векторов ВИ.
С>i >= E>K3>(D>K2>(E>K1>(P>i> C>i-3>)))
где С>0>, C>-1> и С>-2>> >- векторы инициализации. Это не поможет при программной реализации, разве только при использовании параллельного компьютера.
К сожалению, менее сложный режим также и менее безопасен. Бихам проанализировал устойчивость различных режимов к дифференциальному криптоанализу с подобранными шифртекстами и обнаружил, что внутренний СВС только незначительно надежнее однократного шифрования. Если рассматривать тройное шифрование как большой единый алгоритм, его внутренние обратные связи позволяют вводить внешнюю и известную информацию во внутреннюю структуру алгоритма, что облегчает криптоанализ. Для дифференциальных атак нужно огромное количество подобранных шифртекстов, что делает эти вскрытия не слишком практичными, но этих результатов должно хватить, чтобы насторожить скептически настроенных пользователей. Анализ устойчивости алгоритмов к вскрытиям «в лоб» и «встречей посередине» показал, что и этом отношении оба варианта одинаково надежны.
Кроме перечисленных, известны и другие режимы. Можно зашифровать файл один раз и режиме ЕСВ, затем дважды в СВС, или один раз в СВС, один в ЕСВ и еще раз в СВС, или дважды в СВС и один раз в ЕСВ. Бихам показал, что эти варианты отнюдь не устойчивее однократного DES при вскрытии методом дифференциального криптоанализа с подобранным открытым текстом. Он не оставил больших надежд и для других вариантов. Если вы собираетесь применять тройное шифрование, используйте режимы с внешней обратной связью.
4.2.5. Варианты тройного шифрования
Прежде чем было доказано, что DES не образует группу, предлагались различные схемы многократного шифрования. Одним из способов гарантировать, что тройное шифрование не выродится в однократное, было изменение эффективной длины блока. Простой метод предполагает дополнять блок битами. С этой целью между первым и вторым, а также между вторым и третьим шифрованиями текст дополняется строкой случайных битов длиной в полблока (Рис. 6). Если p - это функция дополнения, то:
С = Е>K>>3>(р(Е>К2>(р(Е>К1>(Р)))))
Дополнение не только маскирует структуру текста, но и обеспечивает перекрытие блоков шифрования, примерно как кирпичи в стене. Длина сообщения увеличивается только на один блок.

Рис. 6. Тройное шифрование с дополнением
В другом методе, предложенном Карлом Эллисоном (Carl Ellison), между тремя шифрованиями используется некоторая бесключевая функция перестановки. Перестановка должна работать с большими блоками - 8 Кбайт или около этого, что делает эффективный размер блока для этого варианта равным 8 Кбайт. Если перестановка выполняется быстро, этот вариант ненамного медленнее, чем базовое тройное шифрование.
C = E>K1>(T(E>K2>(T(E>K1>(P)))))
Т собирает входной (длиной> >до 8 Кбайт) и использует генератор псевдослучайных чисел для его перемешивания. Изменение одного входного бита приводит к изменению восьми байтов результата первого шифрования, до 64 байтов - результата второго шифрования и до 512 байтов - результата третьего шифрования. Если каждый блочный алгоритм работает в режиме СВС, как предполагалось первоначально, изменение единичного входного бита, скорее всего, приведет к изменению всего 8-килобайтового блока, даже если это не первый блок.
Новейший вариант этой схемы противодействует атаке на внутренний СВС, предложенной Бихамом, добавлением процедуры отбеливания, позволяющей замаскировать структуру открытых текстов. Эта процедура представляет собой потоковую операцию XOR с криптографически надежным генератором псевдослучайных чисел и обозначена ниже как R. Т мешает криптоаналитику определить априорно ключ, использованный для шифрования любого заданного входного байта последнего шифрования. Второе шифрование обозначено пЕ (шифрование с циклическим использованием п различных ключей):
С = Е>К3>(R(Т(пЕ>К2>(Т(Е>К1>(R))))))
Все шифрования выполняются в режиме ЕСВ, используется не меньше п+2 ключей шифрования и криптографически стойкий генератор псевдослучайных чисел.
В этой схеме предлагалось использование алгоритма DES, однако она работает с любым блочным алгоритмом. Мне неизвестны факты анализа надежности этой схемы.
4.3. Удвоение длины блока
В академических кругах давно спорят на тему, достаточна ли 64-битовая длина блока. С одной стороны, 64-битовый блок обеспечивает рассеивание открытого текста только на 8 байтов шифртекста. С другой стороны, более длинный блок затрудняет надежную маскировку структуры, а, кроме того, увеличивает вероятность ошибок.
Выдвигались предложения удваивать длину блока алгоритма с помощью многократного шифрования. Прежде, чем реализовывать одно из них, можно оценить возможность вскрытия «встреча посередине». Схема Ричарда Аутбриджа (Richard Outerbridge), показанная на рис. 7, ничуть не безопаснее тройного шифрования с одинарным блоком и двумя ключами.

Рис. 7. Удвоение длины блока
Однако подобный прием не быстрее обычного тройного шифрования: для шифрования двух блоков данных все так же нужно шесть шифрований. Характеристики обычного тройного шифрования известны, а за новыми конструкциями часто скрываются новые проблемы.
4.4. Другие схемы многократного шифрования
Недостаток тройного шифрования с двумя ключами заключается в том, что при увеличении вдвое пространства ключей нужно выполнять три шифрования каждого блока открытого текста. Поэтому существуют хитрые способы объединения двух шифрований, которые удвоили бы пространство ключей.
4.4.1 Двойной режим OFB/счетчика
Этот метод использует блочный алгоритм для генерации двух гамм, которые используются для шифрования открытого текста.
S>i >= E>K1>(S>i-1> I>1>); I>1 >= I>1>+1
T>i >= E>K2>(T>i->>1> I>2>); I>2 >= I>2>+1
C>i> = P>i> S>i> T
где S>i> и T>i> - внутренние переменные, а I>1>, и I>2> - счетчики. Две копии блочного алгоритма работают в некотором гибридном режиме OFB/счетчика, а открытый текст, S>i>, и Т>i> объединяются операцией XOR. При этом ключи К1 и К2 независимы.
4.4.2. Режим ECB + OFB
Этот метод разработан для шифрования нескольких сообщений фиксированной длины, например, блоков диска. Используются два ключа: К1 и К2. Сначала для генерации маски блока нужной длины используется выбранный алгоритм и ключ К1. Эта маска впоследствии используется повторно для шифрования сообщений теми же ключами. Затем выполняется операция XOR над открытым текстом сообщения и маской. Наконец результат этой операции шифруется с помощью выбранного алгоритма и ключа К2 в режиме ЕСВ.
Этот метод анализировался только в той работе, в которой он и был опубликован. Понятно, что он не слабее одинарного шифрования ЕСВ, и, возможно, столь же устойчив, как и двойное применение алгоритма. Вероятно, криптоаналитик может выполнять независимый поиск двух ключей, если получит несколько файлов открытого текста, зашифрованных одним ключом.
Чтобы затруднить анализ идентичных блоков в одних и тех же местах различных сообщений, можно использовать вектор инициализации (ВИ). В отличие от использования векторов ВИ в других режимах, в данном случае перед шифрованием ЕСВ выполняется операция XOR над каждым блоком сообщения и вектором ВИ.
Мэтт Блейз (Matt Blaze) разработал этот режим для своей криптографической файловой системы (Cryptographic File System - CFS) UNIX. Это удачный режим, поскольку задержку вызывает только одно шифрование в режиме ЕСВ - маску можно генерировать только один раз и сохранить. В CFS в качестве блочного алгоритма используется DES.
4.4.3. Схема xDESi
DES может использоваться, как компонент ряда блочных алгоритмов с увеличенными размерами ключей и блоков. Эти схемы никак не зависят от DES, и в них может использоваться любой блочный алгоритм.
Первый, xDES1, представляет собой схему Любы-Ракоффа с блочным шифром в качестве базовой функции. Размер блока вдвое больше размера блока используемого блочного шифра, а размер ключа втрое больше, чем у используемого блочного шифра. В каждом из трех раундов правая половина шифруется блочным алгоритмом и одним из ключей, затем выполняется операция XOR результата с левой половиной, и половины переставляются.
Это быстрее обычного тройного шифрования, так как тремя шифрованиями шифруется блок, длина которого вдвое больше длины блока используемого блочного алгоритма. Но при этом возможна простая атака «встреча посередине», которая позволяет найти ключ с помощью таблицы размером 2k, где k - размер ключа блочного алгоритма. Правая половина блока открытого текста шифруется с помощью всех возможных значений К1, и выполняется операция XOR с левой половиной открытого текста, и полученные значения сохраняются в таблице. Затем правая половина шифртекста шифруется с помощью всех возможных значений K3, и выполняется поиск совпадений в таблице. При совпадении пара ключей К1 и К3 - возможный вариант правого ключа. После нескольких попыток вскрытия останется только один кандидат. Таким образом, xDES1 нельзя назвать идеальным решением. Более того, известно вскрытие с подобранным открытым текстом, доказывающее, что xDES1 ненамного прочнее используемого в нем блочного алгоритма.
В xDES2 эта идея расширяется до 5-раундового алгоритма, размер блока которого в 4, а размер ключа - в 10 раз превышают размеры блока и ключа используемого блочного шифра. На Рис. 8. показан один этап xDES2, каждый из четырех подблоков по размеру равен блоку используемого блочного шифра, а все 10 ключей независимы.

Рис. 8. Один этап xDES2
Эта схема также быстрее тройного шифрования: для шифрования блока, который в четыре раза больше блока используемого блочного шифра, нужно 10 шифрований. Однако этот метод уязвим к дифференциальному криптоанализу, и использовать его не стоит. Такая схема остается чувствительной к дифференциальному криптоанализу, даже если используется DES с независимыми ключами раундов.
При i 3 xDESi вероятно слишком громоздок, чтобы использовать его в качестве блочного алгоритма. Например, размер блока xDES3 в 6 раз больше, чем у лежащего и основе блочного шифра, ключ в 21 раз длиннее, а для шифрования блока, который в 6 раз длиннее блока, лежащего в основе блочного шифра, нужно 21 шифрование. Тройное шифрование выполняется быстрее.
4.4.4. Пятикратное шифрование
Если тройное шифрование недостаточно надежно – к примеру, хотят зашифровать ключи тройного шифрования еще более сильным алгоритмом - кратность шифрования можно увеличить. Очень устойчиво к вскрытию «встреча посередине» пятикратное шифрование. (Аргументы, аналогичные рассмотренным для двойного шифрования, показывают, что четырехкратное шифрование по сравнению с тройным лишь незначительно повышает надежность).
С = Е>К1>(D>K>>2>(E>K>>3>(D>K>>2>(E>K>>1>(P)))))
P = D>K1>(E>K2>(D>K3>(E>K2>(D>K1>(C)))))
Эта конструкция обратно совместима с тройным шифрованием, если К2=К3, и с однократным шифрованием, если К1=К2=К3. Конечно, она будет еще надежней, если использовать пять независимых ключей.
4.5. Уменьшение длины ключа в CDMF
Этот метод разработан в IBM для продукта CDMF (Commercial Data Masking Facility -аппаратура закрытия коммерческих данных). Он предназначен для преобразования 56-битового ключа DES в 40-битовый ключ, разрешенный для экспорта. Предполагается, что в первоначальный ключ DES включены биты четности.
1. Обнуляются биты четности: биты 8, 16, 24, 32, 40, 48, 56, 64.
2. Результат этапа 1 шифруется с помощью DES ключом 0xc408b0540ba1e0ae, результат шифрования объединяется операцией XOR с результатом этапа 1.
3. В результате этапа 2 обнуляются следующие биты: 1, 2, 3, 4, 8, 16, 17, 18, 19, 20, 24, 32, 33, 34, 35, 36, 40, 48, 49, 50, 51, 52, 56, 64.
4. Результат этапа 3 шифруется с помощью DES ключом 0xef2c041ce6382fe6.
Полученный ключ используется для шифрования сообщения.
Но не следует забывать, что этот метод укорачивает ключ и, следовательно, ослабляет алгоритм.
4.6. Отбеливание
Отбеливанием (whitening) называют такое преобразование, при котором выполняется операция XOR над входом блочного алгоритма и частью ключа и XOR над выходом блочного алгоритма и другой частью ключа. Впервые этот метод применен для варианта DESX, разработанного в RSA Data Security, Inc., а затем (по-видимому, независимо) в Khufu и Khafre. (Необычное имя методу дано Ривестом).
Смысл этих действий в том, чтобы помешать криптоаналитику восстановить пары «открытый текст/шифртекст» для исследуемого блочного алгоритма. Метод заставляет криптоаналитика угадывать не только ключ алгоритма, но и одно из значений отбеливания. Так как операция XOR выполняется и до, и после исполнения блочного алгоритма, этот метод считается устойчивым к атаке «встреча посередине».
C = K3 E>K1>(P K1)
P = K1 D>K2>(C K3)
Если K1=K3, то для вскрытия «в лоб» потребуется 2n+m/p операций, где п - размер ключа, m - размер блока, a р - число известных открытых текстов. Если К1 и К3. различны, то для вскрытия «в лоб» с тремя известными открытыми текстами потребуется 2n+m+1 операций. Против дифференциального и линейного криптоанализа такие меры обеспечивают защиту на уровне всего нескольких битов ключа. Но с вычислительной точки зрения это очень дешевый способ повышения надежности блочного алгоритма.
4.7. Каскадное применение блочных алгоритмов
Есть вариант шифрования сначала алгоритмом А и ключом К>A>, а затем еще раз алгоритмом В и ключом K>B>? Может быть, у Алисы и Боба различные мнения о том, какой алгоритм надежнее: Алиса хочет пользоваться алгоритмом А, а Боб - алгоритмом В. Этот прием, иногда называемый каскадным применением, можно распространить и на большее количество алгоритмов и ключей.
Пессимисты утверждают, что совместное использование двух алгоритмов не гарантирует повышения безопасности. Алгоритмы могут взаимодействовать каким-то хитрым способом, что на самом деле их надежность даже уменьшится. Даже тройное шифрование тремя различными алгоритмами может оказаться не столь безопасным, как вы рассчитываете. Криптография - довольно тонкое искусство, поэтому если не совсем понимать, что и как делать, то можете легко попасть впросак.
Действительность намного светлее. Упомянутые предостережения верны, только если различные ключи зависят друг от друга. Если все используемые ключи независимы, сложность взлома последовательности алгоритмов, по крайней мере, не меньше сложности взлома первого из применяемых алгоритмов. Если второй алгоритм уязвим к атаке с подобранным открытым текстом, то первый алгоритм может облегчить эту атаку и при каскадном применении может сделать второй алгоритм уязвимым к атаке с известным открытым текстом. Такое возможное облегчение вскрытия не ограничивается только алгоритмами шифрования: если вы позволите кому-то другому определить любой из алгоритмов, делающих что-то с вашим сообщением до шифрования, стоит удостовериться, что ваше шифрование устойчиво по отношению к атаке с подобранным открытым текстом. Можно заметить, что наиболее часто используемым алгоритмом для сжатия и оцифровки речи до модемных скоростей, применяемым перед любым алгоритмом шифрования, служит CELP, разработанный в АНБ.
Это можно сформулировать и иначе: при вскрытии с подобранным открытым текстом каскад шифров взломать не легче, чем любой из шифров каскада. Предыдущий результат показал, что взломать каскад, по крайней мере, не легче, чем самый прочный из шифров каскада. Однако в основе этих результатов лежат некоторые не сформулированные предположения. Только если алгоритмы коммутативны, как в случае каскадных потоковых шифров (или блочных шифров в режиме OFB), надежность их каскада не меньше, чем у сильнейшего из используемых алгоритмов.
Если Алиса и Боб не доверяют алгоритмам друг друга, они могут использовать их каскадом. Для потоковых алгоритмов порядок шифрования значения не имеет. При использовании блочных алгоритмов Алиса может сначала использовать алгоритм А, а затем алгоритм В. Боб, который больше доверяет алгоритму В, может использовать алгоритм В перед алгоритмом А. Между алгоритмами они могут вставить хороший потоковый шифр. Это не причинит вреда и может значительно повысить безопасность.
Ключи для каждого алгоритма в каскаде должны быть независимыми. Если алгоритм А использует 64-битовый ключ, а алгоритм В - 128-битовый ключ, то получившийся каскад должен использовать 192-битовый ключ. При использовании зависимых ключей у пессимистов гораздо больше шансов оказаться правыми.
4.8. Объединение нескольких блочных алгоритмов
Есть еще один способ объединения нескольких блочных алгоритмов, надежность которого с гарантией не хуже надежности обоих алгоритмов. Для двух алгоритмов (и двух независимых ключей):
1. Генерируется строка случайных битов R того же размера, что и сообщение М.
2. Зашифровывается R первым алгоритмом.
3. Зашифровывается МR вторым алгоритмом.
4. Шифртекст сообщения представляет собой объединение результатов этапов 2 и 3.
При условии, что строка случайных битов действительно случайна, этот метод шифрует M с помощью одноразового блокнота, а затем содержимое блокнота и получившееся сообщение шифруются каждым из двух алгоритмов. Так как для восстановления М необходимо и то, и другое, криптоаналитику придется взламывать оба алгоритма. К недостаткам относится удвоение размера шифртекста по сравнению с открытым текстом.
Этот метод можно расширить для нескольких алгоритмов, но добавление каждого алгоритма увеличивает размер шифртекста. Сама по себе идея неплоха, но не слишком практична.
ЗАКЛЮЧЕНИЕ
Известны два основных типа шифров, комбинации которых образуют классические криптографические системы. Главная идея, положенная в основу их конструирования, состоит в комбинации функций, преобразующих исходные сообщения в текст шифровки, то есть превращающих эти исходные сообщения с помощью секретных ключей в нечитаемый вид. Но непосредственное применение функций сразу ко всему сообщению реализуется очень редко. Все практически применяемые криптографические методы связаны с разбиением сообщения на большое число частей фиксированного размера, каждая из которых шифруется отдельно, если не независимо.
Базовые криптографические методы являются "кирпичами" для создания прикладных систем. На сегодняшний день криптографические методы применяются для идентификации и аутентификации пользователей, защиты каналов передачи данных от навязывания ложных данных, защиты электронных документов от копирования и подделки.
СПИСОК ЛИТЕРАТУРЫ:
Шнайер Б. «Прикладная криптография», М.: Издательство Триумф, 2003 г.
Фомичев В.М. «Дискретная математика и криптология», М.: Диалог-МИФИ, 2003 г.
Ященко В.В. «Введение в криптографию». М., 1988 г.
Cryptography.ru. Статьи Интернет-сайтов.