Технические характеристики современных серверов
Технические характеристики современных серверов
Симметричные мультипроцессорные системы компании Bull
Группа компаний, объединенных под общим названием Bull, является одним из крупнейших производителей информационных систем на мировом компьютерном рынке и имеет свои отделения в Европе и США. Большая часть акций компании принадлежит французскому правительству. В связи с происходившей в последнем пятилетии перестройкой структуры компьютерного рынка компания объявила о своей приверженности к направлению построения открытых систем. В настоящее время компания продолжает выпускать компьютеры класса мейнфрейм (серии DPS9000/900, DPS9000/800, DPS9000/500) и среднего класса (серии DPS7000 и DPS6000), работающие под управлением фирменной операционной системы GCOS8, UNIX-системы (серии DPX/20, Escala), а также широкий ряд персональных компьютеров компании Zenith Data Systems (ZDS), входящей в группу Bull.
Активность Bull в области открытых систем сосредоточена главным образом на построении UNIX-систем. В результате технологического соглашения с компанией IBM, в 1992 году Bull анонсировала ряд компьютеров DPX/20, базирующихся на архитектуре POWER, а позднее в 1993 году на архитектуре PowerPC и работающих под управлением операционной системы AIX (версия системы UNIX компании IBM). Версия ОС AIX 4.1, разработанная совместно специалистами IBM и Bull, поддерживает симметричную многопроцесоорную обработку.
Архитектура
PowerScale, представляет собой первую
реализацию симметричной мультипроцессорной
архитектуры (SMP), разработанной Bull
специально для процессоров
PowerPC. В
начале она была реализована на процессоре
PowerPC 601, но легко модернизируется для
процессоров 604 и 620. Эта новая SMP-архитектура
используется в семействе систем Escala.
Архитектура процессоров PowerPC
Основой архитектуры PowerPC является многокристальная архитектура POWER, которая была разработана прежде всего в расчете на однопроцессорную реализацию процессора. При разработке PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) в архитектуре POWER было сделано несколько изменений в следующих направлениях:
упрощение архитектуры с целью ее приспособления для реализации дешевых однокристальных процессоров;
устранение команд, которые могут стать препятствием повышения тактовой частоты;
устранение архитектурных препятствий суперскалярной обработке и внеочередному выполнению команд;
добавление свойств, необходимых для поддержки симметричной мультипроцессорной обработки;
добавление новых свойств, считающихся необходимыми для будущих прикладных программ;
обеспечение длительного времени жизни архитектуры путем ее расширения до 64-битовой.
Архитектура PowerPC поддерживает ту же самую базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально нарушить двоичную совместимость с приложениями, написанными для архитектуры POWER, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программных средств. Такие изменения вводились, естественно, только в тех случаях, если соответствующая возможность либо использовалась не очень часто в кодах прикладных программ, либо была изолирована в библиотечных программах, которые можно просто заменить.
Микропроцессор PowerPC поддерживает мультипроцессорную обработку, в частности, модель тесно связанных вычислений в разделяемой (общей) памяти. Работа тесно связанных процессоров предполагает использование разными процессорами одной общей памяти и одной операционной системы, которая управляет всеми процессорами и аппаратурой системы. Процессоры должны конкурировать за разделяемые ресурсы.
В симметричной мультипроцессорной системе все процессоры считаются функционально эквивалентными и могут выполнять операции ввода/вывода и другие вычисления. Возможности управления подобной системой с разделяемой памятью реализованы в ОС AIX 4.1.
Разработанное Bull семейство Escala обеспечивает масштабируемость и высокую готовность систем, центральным местом которых является симметричная мультипроцессорная архитектура, названная PowerScale, позволяющая производить постепенную модернизацию и объединять в системе от 1 до 8 процессоров.
Проблемы реализации SMP-архитектуры
По определению симметричная мультипроцессорная обработка (SMP) является архитектурой, в которой несколько процессоров разделяют доступ к единственной общей памяти и работают под управлением одной копии операционной системы. В этом случае задания могут соответствующим образом планироваться для работы на разных процессорах в пределах "пула имеющихся ресурсов", допуская распараллеливание, поскольку несколько процессов в такой системе могут выполняться одновременно.
Главным преимуществом архитектуры SMP по сравнению с другими подходами к реализации мультипроцессорных систем является прозрачность для программных приложений. Этот фактор существенно улучшает время выхода на рынок и готовность традиционных коммерческих приложений на системах SMP по сравнению с другими мультипроцессорными архитектурами.
В современных системах SMP наиболее актуальным вопросом разработки является создание высокопроизводительной подсистемы памяти для обеспечения высокоскоростных RISC-процессоров данными и командами. Общее решение этой проблемы заключается в использовании большой высокоскоростной кэш-памяти, т.е. в создании иерархии памяти между процессорами и разделяемой глобальной памятью. Архитектура PowerScale предлагает новый подход к решению вопросов традиционного узкого горла, ограничивающего производительность SMP-систем, а именно, новую организацию управления кэш-памятью и доступа к памяти.
PowerScale представляет собой высоко оптимизированную разработку, которая является результатом интенсивных исследований параметров производительности современных коммерческих приложений. Обычно выполнение этих прикладных систем связано с необходимостью манипулирования огромными объемами данных и разделения доступа к этим данным между многими пользователями или программами. Такого рода рабочая нагрузка характеризуется наличием больших рабочих наборов данных с низким уровнем локализации. При моделировании прикладных систем подобного профиля на системах SMP, были замечены два особых эффекта:
Из-за малой вероятности нахождения соответствующих данных в кэш-памяти возникает весьма интенсивный трафик между системной памятью и кэшами ЦП. Поэтому очень важно сконструировать систему, обеспечивающую широкополосный доступ к памяти.
В традиционной SMP-системе по умолчанию одна из задач планировщика заключается в том, чтобы запустить следующий разрешенный для выполнения процесс на первом же процессоре, который становится свободным. Поэтому по мере того, как увеличивается число процессоров и процессов, вероятность перемещения процессов с одного процессора на другой, также увеличивается. Эта побочная миграция процессов приводит к существенному увеличению уровня трафика между кэшами ЦП. Поэтому ключевым вопросом обеспечения высокой системной производительности становится физическая реализация когерентности кэш-памяти.
В традиционной SMP-архитектуре связи между кэшами ЦП и глобальной памятью реализуются с помощью общей шины памяти, разделяемой между различными процессорами. Как правило, эта шина становится слабым местом конструкции системы и стремится к насыщению при увеличении числа инсталлированных процессоров. Это происходит потому, что увеличивается трафик пересылок между кэшами и памятью, а также между кэшами разных процессоров, которые конкурируют между собой за пропускную способность шины памяти. При рабочей нагрузке, характеризующейся интенсивной обработкой транзакций, эта проблема является даже еще более острой.
В архитектуре PowerScale компании Bull интерфейс памяти реализован с учетом указанного выше профиля приложений и рассчитан на использование нескольких поколений процессоров со все возрастающей производительностью. В действительности архитектура PowerScale с самого начала была разработана в расчете на поддержку до 8 процессоров PowerPC 620.
Описание архитектуры PowerScale
В архитектуре PowerScale (рис. 4.1) основным средством оптимизации доступа к разделяемой основной памяти является использование достаточно сложной системной шины. В действительности эта "шина" представляет собой комбинацию шины адреса/управления, реализованной классическим способом, и набора магистралей данных, которые соединяются между собой посредством высокоскоростного матричного коммутатора. Эта система межсоединений получила название MPB_SysBus. Шина памяти используется только для пересылки простых адресных тегов, а неблокируемый матричный коммутатор - для обеспечения более интенсивного трафика данных. К матричному коммутатору могут быть подсоединены до 4 двухпроцессорных портов, порт ввода/вывода и подсистема памяти.
Главным преимуществом такого подхода является то, что он позволяет каждому процессору иметь прямой доступ к подсистеме памяти. Другим важным свойством реализации является использование расслоения памяти, что позволяет многим процессорам обращаться к памяти одновременно.
Ниже приведена схема, иллюстрирующая общую организацию доступа к памяти (рис. 4.2) Каждый процессорный модуль имеет свой собственный выделенный порт памяти для пересылки данных. При этом общая шина адреса и управления гарантирует, что на уровне системы все адреса являются когерентными.
Вопросы балансировки нагрузки
В процессе разработки системы был сделан выбор в направлении использования больших кэшей второго уровня (L2), дополняющих кэши первого уровня (L1), интегрированные в процессорах PowerPC. Это решение породило необходимость более глубокого рассмотрения работы системы в целом. Чтобы получить полное преимущество от использования пространственной локальности данных, присутствующих в кэшах L2, необходимо иметь возможность снова назначить ранее отложенный процесс на процессор, на котором он ранее выполнялся, даже если этот процессор не является следующим свободным процессором. Подобная "настройка" системы является основой для балансировки нагрузки и аналогична процессу планирования.
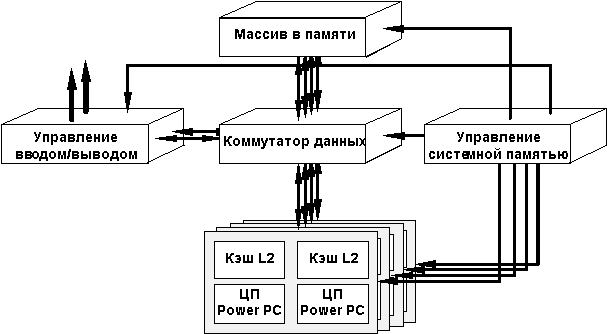
Рис. 4.1. Архитектура PowerScale
Очевидно, что всегда полезно выполнять процесс на одном и том же процессоре и иметь более высокий коэффициент попаданий в кэш, чем при выполнении процесса на следующем доступном процессоре. Используя алгоритмы, базирующиеся на средствах ядра системы, можно определить наиболее подходящее использование пула процессоров с учетом текущего коэффициента попаданий в кэш. Это позволяет оптимизировать уровень миграции процессов между процессорами и увеличивает общую пропускную способность системы.
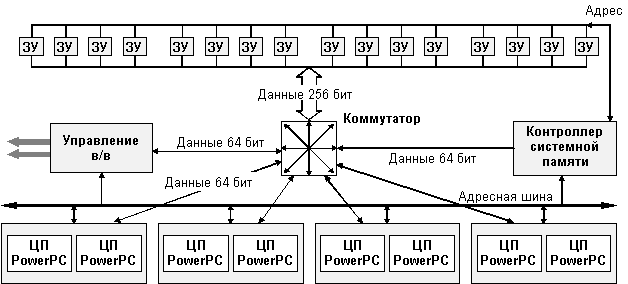
Рис. 4.2. Схема организации доступа к памяти
Модель памяти
Процессор PowerPC определяет слабо упорядоченную модель памяти, которая позволяет оптимизировать использование пропускной способности памяти системы. Это достигается за счет того, что аппаратуре разрешается переупорядочивать операции загрузки и записи так, что требующие длительного времени операции загрузки могут выполняться ранее определенных операций записи. Такой подход позволяет уменьшить действительную задержку операций загрузки. Архитектура PowerScale полностью поддерживает эту модель памяти как на уровне процессора за счет набора команд PowerPC, так и глобально путем реализации следующих ограничений:
Обращения к глобальным переменным синхронизации выполняются строго последовательно.
Никакое обращение к переменной синхронизации не выдается процессором до завершения выполнения всех обращений к глобальным данным.
Никакие обращения к глобальным данным не выдаются процессором до завершения выполнения предыдущих обращений к переменной синхронизации.
Для обеспечения подобной модели упорядоченных обращений к памяти на уровне каждого процессора системы используются определенная аппаратная поддержка и явные команды синхронизации. Кроме того, на системном уровне соблюдение необходимых протоколов для обеспечения упорядочивания обращений между процессорами или между процессорами и подсистемой ввода/вывода возложено на программное обеспечение.
Подсистема памяти
С реализацией архитектуры глобальной памяти в мультипроцессорной системе обычно связан очень важный вопрос. Как объединить преимущества "логически" локальной для каждого процессора памяти, имеющей малую задержку доступа, с требованиями реализации разделяемой глобальной памяти?
Компания Bull разработала патентованную архитектуру, в которой массив памяти полностью расслоен до уровня длины строки системного кэша (32 байта). Такая организация обеспечивает минимум конфликтов между процессорами при работе подсистемы памяти и гарантирует минимальную задержку. Требование реализации глобальной памяти обеспечивается тем, что массив памяти для программных средств всегда представляется непрерывным.
Предложенная конструкция решает также проблему, часто возникающую в других системах, в которых использование методов расслоения для организации последовательного доступа к различным областям памяти возможно только, если платы памяти устанавливаются сбалансировано. Этот, кажущийся тривиальным, вопрос может приводить к излишним закупкам дополнительных ресурсов и связан исключительно с возможностями конструкции системы. PowerScale позволяет обойти эту проблему.
Архитектура PowerScale автоматически оптимизирует степень расслоения памяти в зависимости от того, какие платы памяти инсталлированы в системе. В зависимости от конкретной конфигурации она будет использовать низкую или высокую степень расслоения или их комбинацию. Все это полностью прозрачно для программного обеспечения и, что более важно, для пользователя.
Архитектура матричного коммутатора
Архитектура коммутатора реализована с помощью аппаратной сети, которая осуществляет индивидуальные соединения типа точка-точка процессора с процессором, процессора с основной памятью и процессора с магистралью данных ввода/вывода. Эта сеть работает совместно с разделяемой адресной шиной. Такой сбалансированный подход позволяет использовать лучшие свойства каждого из этих методов организации соединений.
Разделяемая адресная шина упрощает реализацию наблюдения (snooping) за адресами, которое необходимо для аппаратной поддержки когерентности памяти. Адресные транзакции конвейеризованы, выполняются асинхронно (расщеплено) по отношению к пересылкам данных и требуют относительно небольшой полосы пропускания, гарантируя, что этот ресурс никогда войдет в состояние насыщения.
Организация пересылок данных требует больше внимания, поскольку уровень трафика и время занятости ресурсов физического межсоединения здесь существенно выше, чем это требуется для пересылки адресной информации. Операция пересылки адреса представляет собой одиночную пересылку, в то время как операция пересылки данных должна удовлетворять требованию многобайтной пересылки в соответствии с размером строки кэша ЦП. При реализации отдельных магистралей данных появляется ряд дополнительных возможностей, которые обеспечивают:
максимальную скорость передачи данных посредством соединений точка-точка на более высоких тактовых частотах;
параллельную пересылку данных посредством организации выделенного пути для каждого соединения;
разделение адресных транзакций и транзакций данных. Поэтому архитектуру PowerScale компании Bull можно назвать многопотоковой аппаратной архитектурой (multi-threaded hardware architecture) с возможностями параллельных операций.
На рис. 4.3 показаны основные режимы и операции, выполняемые матричным коммутатором.
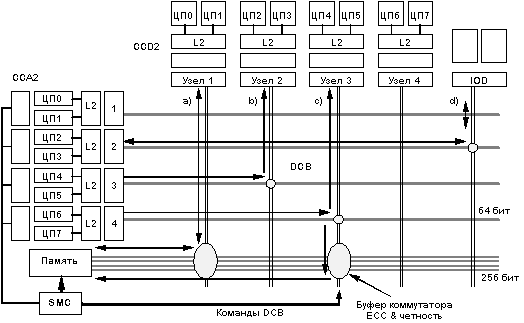
Рис.
4.3. Матричный коммутатор. ССA2 - сдвоенный
контроллер адресов кэш-памяти;
CCD2 -
сдвоенный контроллер данных кэш-памяти;
IOD - дочерняя плата ввода/вывода;
DCB -
матричный коммутатор данных; SMC -
контроллер системной памяти
Режим обращения к памяти - Memory mode: (a)
Процессорный узел или узел в/в коммутируется с массивом памяти (MA). Такое соединение используется для организации операций чтения памяти или записи в память.
Режим вмешательства (чтение): (b)
Читающий узел коммутируется с другим узлом (вмешивающимся узлом) и шиной данных MA. Этот режим используется тогда, когда при выполнении операции чтения строки от механизма наблюдения за когерентным состоянием памяти поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются читающему узлу и одновременно записываются в MA. Если читающий и вмешивающийся ЦП находятся внутри одного и того же узла, то данные заворачиваются назад на уровне узла и одновременно записываются в память.
Режим вмешательства (чтение с намерением модификации - RWITM):(c)
Процессорный узел или узел в/в (читающий узел) коммутируется с другим процессорным узлом или узлом в/в. Этот режим используется тогда, когда при выполнении операция RWITM от механизма наблюдения поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются только читающему узлу и не записываются в память.
Режим программируемого ввода/вывода (PIO): (d)
Процессорный узел коммутируется с узлом в/в. Это случай операций PIO, при котором данные обмениваются только между процессором и узлом в/в.
Режим в/в с отображением в памяти (memory mapped):
Главный узел коммутируется с узлами в/в (подчиненными узлами), вовлеченными в транзакцию. Это случай операций с памятью.
Параметры производительности
Вслед за установочной фазой транзакции (например, после установки адреса на адресной шине) данные могут пересылаться через коммутатор на полной скорости синхронизации. Это возможно благодаря организации соединению точка-точка, которое создается для каждой отдельной транзакции. Поэтому в дальнейшем какие-либо помехи отсутствуют. Возможно также выполнять параллельно несколько операций, например, множественный доступ к памяти или пересылки между кэшами.
Для того чтобы уменьшить задержку памяти, операции чтения начинаются до выполнения каких-либо действий по обеспечению глобальной когерентности на уровне системы. Ответы когерентности полностью синхронизированы, разрешаются за фиксированное время и поступают всегда прежде, чем будет захвачен разделяемый ресурс - шина памяти. Это помогает избежать ненужных захватов шины. Любые транзакции, которые не разрешаются когерентно за данное фиксированное время, позднее будут повторены системой.
Используемая в системе внутренняя частота синхронизации равна 75 МГц, что позволяет оценить уровень производительности разработанной архитектуры. Интерфейс физической памяти имеет ширину 32 байта и, учитывая арбитраж шины, позволяет пересылать 32 байта каждые 3 такта синхронизации. Это дает скорость передачи данных 800 Мбайт/с, поддерживаемую на уровне интерфейса памяти. Каждый порт ЦП имеет ширину 8 байт и способен передавать по 8 байт за такт, т.е. со скоростью 600 Мбайт/с. Следует отметить, что это скорость, достигаемая как при пересылке ЦП-память, так и при пересылке кэш-кэш. Скорость 800 Мбайт/с для памяти поддерживается с помощью буферов в коммутаторе, которые позволяют конвейеризовать несколько операций.
Поскольку несколько операций могут выполняться через коммутатор на полной скорости параллельно, то для оптимальной смеси операций (две пересылки из ЦП в память, плюс пересылка кэш-кэш), пропускная способность может достигать пикового значения 1400 Мбайт/с. Таким образом, максимальная пропускная способность будет варьироваться в диапазоне от 800 до 1400 Мбайт/с в зависимости от коэффициента попаданий кэш-памяти.
Когерентность кэш-памяти
Известно, что требования, предъявляемые современными процессорами к полосе пропускания памяти, можно существенно сократить путем применения больших многоуровневых кэшей. Проблема когерентности памяти в мультипроцессорной системе возникает из-за того, что значение элемента данных, хранящееся в кэш-памяти разных процессоров, доступно этим процессорам только через их индивидуальные кэши. При этом определенные операции одного из процессоров могут влиять на достоверность данных, хранящихся в кэшах других процессоров. Поэтому в подобных системах жизненно необходим механизм обеспечения когерентного (согласованного) состояния кэшей. С этой целью в архитектуре PowerScale используется стратегия обратной записи, реализованная следующим образом.
Вертикальная когерентность кэшей
Каждый процессор для своей работы использует двухуровневый кэш со свойствами охвата. Это означает, что кроме внутреннего кэша первого уровня (кэша L1), встроенного в каждый процессор PowerPC, имеется связанный с ним кэш второго уровня (кэш L2). При этом каждая строка в кэше L1 имеется также и в кэше L2. В настоящее время объем кэша L2 составляет 1 Мбайт на каждый процессор, а в будущих реализациях предполагается его расширение до 4 Мбайт. Сама по себе кэш-память второго уровня позволяет существенно уменьшить число обращений к памяти и увеличить степень локализации данных. Для повышения быстродействия кэш L2 построен на принципах прямого отображения. Длина строки равна 32 байт (размеру когерентной гранулированности системы). Следует отметить, что, хотя с точки зрения физической реализации процессора PowerPC, 32 байта составляют только половину строки кэша L1, это не меняет протокол когерентности, который управляет операциями кэша L1 и гарантирует что кэш L2 всегда содержит данные кэша L1.
Кэш L2 имеет внешний набор тегов. Таким образом, любая активность механизма наблюдения за когерентным состоянием кэш-памяти может быть связана с кэшем второго уровня, в то время как большинство обращений со стороны процессора могут обрабатываться первичным кэшем. Если механизм наблюдения обнаруживает попадание в кэш второго уровня, то он должен выполнить арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Поэтому глобальная память может работать на уровне тегов кэша L2, что позволяет существенно ограничить количество операций наблюдения, генерируемых системой в направлении данного процессора. Это, в свою очередь, существенно увеличивает производительность системы, поскольку любая операция наблюдения в направлении процессора сама по себе может приводить к приостановке его работы.
Вторичная когерентность кэш-памяти
Вторичная когерентность кэш-памяти требуется для поддержки когерентности кэшей L1&L2 различных процессорных узлов, т.е. для обеспечения когерентного состояния всех имеющихся в мультипроцессорной системе распределенных кэшей (естественно включая поддержку когерентной буферизации ввода/вывода как по чтению, так и по записи).
Вторичная когерентность обеспечивается с помощью проверки каждой транзакции, возникающей на шине MPB_SysBus. Такая проверка позволяет обнаружить, что запрашиваемая по шине строка уже кэширована в процессорном узле, и обеспечивает выполнение необходимых операций. Это делается с помощью тегов кэша L2 и логически поддерживается тем фактом, что L1 является подмножеством L2.
Протокол MESI и функция вмешательства
В рамках архитектуры PowerScale используется протокол MESI, который представляет собой стандартный способ реализации вторичной когерентности кэш-памяти. Одной из основных задач протокола MESI является откладывание на максимально возможный срок операции обратной записи кэшированных данных в глобальную память системы. Это позволяет улучшить производительность системы за счет минимизации ненужного трафика данных между кэшами и основной памятью. Протокол MESI определяет четыре состояния, в которых может находиться каждая строка каждого кэша системы. Эта информация используется для определения соответствующих последующих операций (рис. 4.4).
Состояние строки "Единственная" (Exclusive):
Данные этой строки достоверны в данном кэше и недостоверны в любом другом кэше. Данные не модифицированы по отношению к памяти.
Состояние строки "Разделяемая" (Shared):
Данные этой строки достоверны в данном кэше, а также в одном или нескольких удаленных кэшах.
Состояние строки "Модифицированная" (Modified):
Данные этой строки достоверны только в данном кэше и были модифицированы. Данные недостоверны в памяти.
Состояние строки "Недостоверная" (Invalid):
Достоверные данные не были найдены в данном кэше.
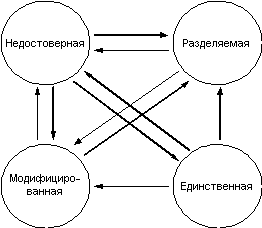
Рис. 4.4. Диаграмм переходов состояний протокола MESI
Для поддержки мультипроцессорной организации были реализованы несколько примитивов адресной шины. Это позволяет одному главному устройству шины передавать, а другим устройствам обнаруживать (или наблюдать) появление этих примитивов на шине. Устройство-владелец кэша наблюдает за адресной шиной во время глобального запроса и сравнивает целевой адрес с адресами тегов в своем кэше L2. Если происходит попадание, то выполняемые действия определяются природой запроса.
Как уже было отмечено, одной из функций тегов L2 является уменьшение накладных расходов, связанных с ответами на запросы механизма наблюдения. Доступ к тегам L2 разделяется между процессорами и адресной шиной. Теги L2 практически выполняют роль фильтров по отношению к активностям наблюдения. Это позволяет процессорам продолжать обработку вместо того, чтобы отвечать на каждый запрос наблюдения. Хотя теги L2 представляют собой разделяемый между процессором и шиной ресурс, его захват настолько кратковременен, что практически не приводит ни к каким конфликтам.
Состояние строки кэш-памяти "модифицированная" означает в частности то, что кэш, хранящий такие данные, несет ответственность за правильность этих данных перед системой в целом. Поскольку в основной памяти эти данные недостоверны, это означает, что владелец такого кэша должен каким-либо способом гарантировать, что никакой другой модуль системы не прочитает эти недостоверные данные. Обычно для описания такой ответственности используется термин "вмешательство" (intervention), которое представляет собой действие, выполняемое устройством-владельцем модифицированных кэшированных данных при обнаружении запроса наблюдения за этими данными. Вмешательство сигнализируется с помощью ответа состоянием "строка модифицирована" протокола MESI, за которым следуют пересылаемые запросчику, а также потенциально в память, данные.
Для увеличения пропускной способности системы в PowerScale реализованы два способа выполнения функции вмешательства:
Немедленная кроссировка (Cross Immediate), которая используется когда канал данных источника и получателя свободны и можно пересылать данные через коммутатор на полной скорости.
Поздняя кроссировка (Cross Late), когда ресурс (магистраль данных) занят, поэтому данные будут записываться в буфер коммутатора и позднее пересылаться запросчику.
Физическая реализация архитектуры
Ниже на рис. 4.5 показана схема, представляющая системные платы, разработанные компанией Bull, которые используются для физической реализации архитектуры PowerScale.
Многопроцессорная плата:
Многопроцессорная материнская плата, которая используется также в качестве монтажной панели для установки модулей ЦП, модулей основной памяти и одной платы в/в (IOD).
Модуль ЦП (дочерняя процессорная плата):
Каждый модуль ЦП, построенный на базе PowerPC 601/604, включает два микропроцессора и связанные с ними кэши. Имеется возможность модернизации системы, построенной на базе процессоров 601, путем установки модулей ЦП с процессорами 604. Смешанные конфигурации 601/604 не поддерживаются.
Дочерняя плата ввода/вывода: (IOD)
IOD работает в качестве моста между шинами MCA и комплексом ЦП и памяти. Поддерживаются 2 канала MCA со скоростью передачи 160 Мбайт/с каждый. Хотя поставляемая сегодня подсистема в/в базируется на технологии MCA, это не является принципиальным элементом архитектуры PowerScale. В настоящее время проводятся исследования возможностей реализации нескольких альтернативных шин ввода/вывода, например, PCI.
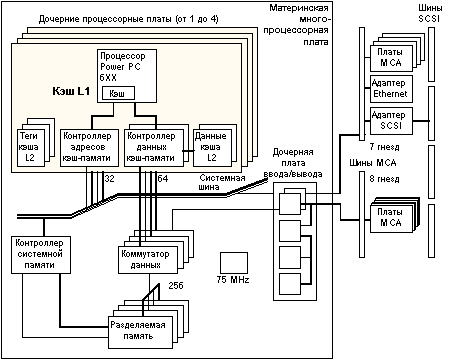
Рис. 4.5. Физическая реализация PowerScale
Платы памяти:
Каждая плата памяти состоит из четного числа банков. Максимальное число банков равно 16. Объем памяти на каждой плате может быть 64, 256 или 512 Мбайт.
Коммутатор данных (DCB) интегрирован в нескольких СБИС (4х16 бит) и функционально соединяет магистраль данных MPB_SysBus с подсистемой памяти, модулями ЦП и платой в/в. Ширина магистрали данных DCB на уровне массива памяти составляет 256 + 32 бит, а ширина магистрали данных для каждого порта ЦП и порта в/в равна 64 + 8 бит. Операции DCB управляются контроллером системной памяти (SMC) с помощью командной шины, обеспечивающей необходимую коммутацию устройств.
Семейство UNIX-серверов Escala
На российский рынок в настоящее время активно продвигаются UNIX-серверы семейства Escala - многопроцессорные системы с архитектурой PowerScale, построенные на базе микропроцессора PowerPC 601. Они предлагаются для работы в качестве нескольких типов серверов приложений: сервера транзакций (Transation Server) при использовании мониторов обработки транзакций подобных Tuxedo, сервера базы данных (Database Server) на основе таких известных систем как Oracle или Informix, а также управляющего сервера (System Management Server), обеспечивающего управление инфраструктурой предприятия и существенно упрощающего администрирование гетерогенными системами и сетями. Серверы Escala двоично совместимы с системами Bull DPX/20, а их архитектура разработана с учетом возможности применения новейших процессоров PowerPC 604 и 620.
Основные характеристики серверов Escala в зависимости от применяемого конструктива даны в таблице 4.1. Системы семейства Escala обеспечивают подключение следующих коммуникационных адаптеров: 8-, 16- и 128-входовых адаптеров асинхронных последовательных портов, 1- или 4-входовых адаптеров портов 2 Мбит/с X.25, а также адаптеров Token-Ring, Ethernet и FDDI.
Таблица 4.1
|
МОДЕЛЬ Escala |
M101 |
M201D201 D401 R201 |
|
|
Mini-Tower |
DesksideRack-Mounted |
|
ЦП |
||
|
Тип процессора |
PowerPC 601 |
|
|
Тактовая частота (МГц) |
75 |
7575 75 75 |
|
Число процессоров |
1/4 |
2/42/8 4/8 2/8 |
|
Размер кэша второго уровня (Кб) |
512 |
5121024 1024 1024 |
|
ПАМЯТЬ |
||
|
Стандартный объем (Мб) |
32 |
6464 64 64 |
|
Максимальный объем (Мб) |
512 |
5122048 2048 2048 |
|
ВВОД/ВЫВОД |
||
|
Тип шины |
MCA |
MCAMCA MCA MCA |
|
Пропускная способность (Мб/с) |
160 |
160160 2x160 2x160 |
|
Количество слотов |
6 |
615 15 16 |
|
Количество посадочных мест |
|
|
|
3.5" |
4 |
47 7 7 |
|
5.25" |
2 |
23 3 3 |
|
Емкость
внутренней |
1/18 |
1/182/36 4/99 - |
|
Емкость внешней |
738 |
7381899 1899 2569 |
|
Количество сетевых адаптеров |
1/4 |
1/41/12 1/12 1/13 |
|
ПРОИЗВОДИТЕЛЬНОСТЬ (число процессоров 2/4) |
||
|
SPECint92 |
77 |
7777 77 77 |
|
SPECfp92 |
84 |
8484 84 84 |
|
SPECrate_int92 |
3600/6789 |
3600/67893600/6789 - /6789 3600/6789 |
|
SPECrate_fp92 |
3900/7520 |
3900/75203900/7520 - /7520 3900/7520 |
|
Tpm-C |
750/1350 |
750/1350750/1350 750/1350 750/1350 |
Заключение
При разработке PowerScale Bull удалось создать архитектуру с достаточно высокими характеристиками производительности в расчете на удовлетворение нужд приложений пользователей сегодня и завтра. И обеспечивается это не только увеличением числа процессоров в системе, но и возможностью модернизации поколений процессоров PowerPC. Разработанная архитектура привлекательна как для разработчиков систем, так и пользователей, поскольку в ее основе лежит одна из главных процессорных архитектур в компьютерной промышленности - PowerPC.