Информационные технологии в эконометрике
Реферат
По эконометрике
Эконометрические информационные технологии
СОДЕРЖАНИЕ
Проблема множественных проверок статистических гипотез 3
Методы статистических испытаний (Монте-Карло) и датчики псевдослучайных чисел 25
Методы размножения выборок (бутстреп-методы) 30
Эконометрика в контроллинге 35
Литература 41
Проблема множественных проверок статистических гипотез
Практика применения эконометрических методов часто выходит за границы классической математико-статистической теории. В качестве примера рассмотрим проверку статистических гипотез.
Базовая теоретическая модель касается проверки одной-единственной статистической гипотезы. На практике же при выполнении того или иного прикладного исследования гипотезы зачастую проверяют неоднократно. При этом, как правило, остается неясным, как влияют результаты предыдущих проверок на характеристики (уровень значимости, мощность) последующих проверок. Есть ли вообще влияние? Как его оценить? Как его учесть при формулировке окончательных выводов?
Изучены лишь некоторые схемы множественных проверок, например, схема последовательного анализа А. Вальда или схема оценивания степени полинома в регрессии путем последовательной проверки адекватности модели (см. главу 5 выше). В таких исключительных постановках удается рассчитать характеристики статистических процедур, включающих множественные проверки статистических гипотез.
Однако в большинстве важных для практики случаев статистические свойства процедур анализа данных, основанных на множественных проверках, остаются пока неизвестными. Примерами являются процедуры нахождения информативных подмножеств признаков (коэффициенты для таких и только таких признаков отличны от 0) в регрессионном анализе или выявления отклонений параметров в автоматизированных системах управления.
В таких системах происходит слежение за большим числом параметров. Резкое изменение значения параметра свидетельствует об изменении режима работы системы, что, как правило, требует управляющего воздействия. Существует теория для определения границ допустимых колебаний одного или фиксированного числа параметров. Например, можно использовать контрольные карты Шухарта или кумулятивных сумм, а также их многомерные аналоги (см. главу 13). В подавляющем большинстве постановок, согласно обычно используемым вероятностным моделям, для каждого параметра, находящемся в стабильном ("налаженном") состоянии, существует хотя и малая, но положительная вероятность того, что его значение выйдет за заданные границы. Тогда система зафиксирует резкое изменение значения параметра ("ложная разладка"). При достаточно большом числе параметров с вероятностью, близкой к 1, будет обнаружено несколько "случайных сбоев", среди которых могут "затеряться" и реальные отказы подсистем. Можно доказать, что при большом числе параметров имеется два крайних случая - независимых (в совокупности) параметров и функционально связанных параметров, а для всех остальных систем вероятность обнаружения резкого отклонения хотя бы у одного параметра лежит между соответствующими вероятностями для этих двух крайних случаев.
Почему трудно изучать статистические процедуры, использующие множественные проверки гипотез? Причина состоит в том, что результаты последовательно проводящихся проверок, как правило, не являются независимыми (в смысле независимости случайных величин). Более того, последовательность проверок зачастую задается исследователем произвольно.
Проблема множественных проверок статистических гипотез - часть более общей проблемы "стыковки" (сопряжения) статистических процедур. Дело в том, что каждая процедура может применяться лишь при некоторых условиях, а в результате применения предыдущих процедур эти условия могут нарушаться. Например, часто рекомендуют перед восстановлением зависимости (регрессионным анализом) разбить данные на однородные группы с помощью какого-либо алгоритма классификации, а затем строить зависимости для каждой из выделенных групп отдельно. Здесь идет речь о "стыковке" алгоритмов классификации и регрессии. Как вытекает из рассмотрений главы 5 выше, попадающие в одну однородную группу результаты наблюдений зависимы и их распределение не является нормальным (гауссовым), поскольку они лежат в ограниченной по некоторым направлениям области, а границы зависят от всей совокупности результатов наблюдений. При этом при росте объема выборки зависимость уменьшается, но ненормальность остается Распределение результатов наблюдений, попавших в одну группу, приближается не к нормальному, а к усеченному нормальному. Следовательно, алгоритмами регрессионного анализа, основанными на "нормальной теории", пользоваться некорректно. Согласно рекомендациям главы 10 целесообразно применять робастную регрессию.
Проблема "стыковки" статистических процедур обсуждается давно. По проблеме "стыковки" был проведен ряд исследований, результаты некоторые из которых упомянуты выше, но сколько-нибудь окончательных результатов получено не было. По нашему мнению, на скорое решение проблемы "стыковки" рассчитывать нельзя. Возможно, она является столь же "вечной", как и проблема выбора между средним арифметическим и медианой как характеристиками "центра" выборки.
В качестве примера обсудим одно интересное исследование по проблеме повторных проверок статистических гипотез - работу С.Г. Корнилова [1].
Как уже отмечалось, теоретическое исследование является весьма сложным, сколько-нибудь интересные результаты удается получить лишь для отдельных постановок. Поэтому вполне естественно, что С.Г. Корнилов применил метод статистического моделирования на ЭВМ. Однако нельзя забывать о проблеме качества псевдослучайных чисел. Достоинства и недостатки различных алгоритмов получения псевдослучайных чисел много лет обсуждаются в различных изданиях (см. ниже).
В работе С.Г. Корнилова хорошо моделируется мышление статистика-прикладника. Видно, насколько мешает устаревшее представление о том, что для проверки гипотез необходимо задавать определенный уровень значимости. Особенно оно мешает, если в дальнейшем понадобятся дальнейшие проверки. Гораздо удобнее использовать "достигаемый уровень значимости", т.е. вероятность того, что статистика критерия покажет большее отклонение от нулевой гипотезы, чем то, что соответствует имеющимся экспериментальным данным (см. терминологическое приложение 1 в конце книги). Если есть желание, можно сравнивать "достигаемый уровень значимости" с заданными значениями 0,05 или 0,01. Так, если "достигаемый уровень значимости" меньше 0,01, то нулевая гипотеза отвергается на уровне значимости 0,01, в противном случае - принимается. Следует рассчитывать "достигаемый уровень значимости" всегда, когда для этого есть вычислительные возможности.
Переход к "достигаемому уровню значимости" может избавить прикладника от еще одной трудности, связанной с использованием непараметрических критериев. Дело в том, что их распределения, как правило, дискретны, поскольку эти критерии используют только ранги наблюдений. Поэтому невозможно построить критерий с заданным номинальным уровнем значимости, реальный уровень значимости может принимать лишь конечное число значений, среди которых, как правило, нет ни 0,05, ни 0,01, ни других популярных номинальных значений.
Невозможность построения критических областей критериев с заданными уровнями значимости затрудняет сравнение критериев по мощности, как это продемонстрировано в работе [2]. Есть формальный способ достичь заданного номинального уровня значимости - провести рандомизацию, т.е. при определенном (граничном) значении статистики критерия провести независимый случайный эксперимент, в котором одни исходы (с заданной суммарной вероятностью) приводят к принятию гипотезы, а остальные - к ее отклонению. Однако подобную процедуру рандомизации прикладнику трудно принять - как оправдать то, что одни и те же экспериментальные данные могут быть основанием как для принятия гипотезы, так и для ее отклонения? Вспоминается обложка журнала "Крокодил", на которой один хозяйственник говорит другому: "Бросим монетку. Упадет гербом - будем строить завод, а упадет решкой - нет". Описанная процедура рандомизации имеет практический смысл лишь при массовой рутинной проверке гипотез, например, при статистическом контроле больших выборок изделий или деталей (см. главу 13, посвященную эконометрике качества).
У все еще распространенных критерия Стьюдента и других параметрических статистических критериев - свои проблемы. Они исходят из предположения о том, что функции распределения результатов наблюдений входят в определенные параметрические семейства небольшой размерности. Наиболее распространена гипотеза нормальности распределения. Однако давно известно, что подавляющее большинство реальных распределений результатов измерений не являются нормальными. Об этом говорится, например, в классической для инженеров и организаторов производства монографии проф.В. В. Налимова [3]. Ряд недавно полученных конкретных экспериментальных фактов и теоретических соображений рассмотрен в главе 4.
Как же быть? Проверять нормальность распределения своих данных? Но это дело непростое, можно допустить те или иные ошибки, в частности, применяя критерии типа Колмогорова или омега-квадрат (одна из наиболее распространенных ошибок состоит в том, что в статистики вместо неизвестных параметров подставляют их оценки, но при этом пользуются критическими значениями, рассчитанными для случая, когда параметры полностью известны [4]). Кроме того, для сколько-нибудь надежной проверки нормальности нужны тысячи наблюдений (см. главу 4). Поэтому в подавляющем большинстве реальных задач нет оснований принимать гипотезу нормальности. В лучшем случае можно говорить о том, что распределение результатов наблюдений мало отличается от нормального.
Как влияют отклонения от нормальности на свойства статистических процедур? Для разных процедур - разный ответ. Если речь идет об отбраковке выбросов - влияние отклонений от нормальности настолько велико, что делает процедуру отбраковки с практической точки зрения эвристической, а не научно обоснованной (см. главу 4). Если же речь идет о проверке однородности двух выборок с помощью критерия Стьюдента (при априорном предположении о равенстве дисперсий) или Крамера-Уэлча (при отсутствии такого предположения), то при росте объемов выборок влияние отклонений от нормальности убывает, как это подробно показано в главе 4). Это вытекает из Центральной Предельной Теоремы. Правда, при этом оказывается, что процентные точки распределения Стьюдента не приносят реальной пользы, достаточно использовать процентные точки предельного нормального распределения.
Весьма важна обсуждаемая, в частности, в работе [1] постоянно встающая перед эконометриком проблема выбора того или иного статистического критерия для решения конкретной прикладной задачи. Например, как проверять однородность двух независимых выборок числовых результатов наблюдений? Известны параметрические критерии: Стьюдента, Лорда; непараметрические: Крамера-Уэлча, Вилкоксона, Ван-дер-Вардена, Сэвиджа, Мартынова, Смирнова, типа омега-квадрат (Лемана-Розенблатта) и многие другие (см., например, главу 4 и справочник [5]). Какой из них выбрать для конкретных расчетов?
Некоторые авторы предлагают формировать технологию принятия статистического решения, согласно которой решающее правило формируется на основе комбинации нескольких критериев. Например, технология может предусматривать проведение "голосования": если из 5 критериев большинство "высказывается" за отклонение гипотезы, то итоговое решение - отвергнуть ее, в противном случае - принять. Эти авторы не всегда понимают, что в их подходе нет ничего принципиально нового, просто к уже имеющимся критериям они добавляют их комбинации - очередные варианты, тем или иным образом выделяющие критические области в пространствах возможных значений результатов измерений, т.е. увеличивают число рассматриваемых критериев.
Итак, имеется некоторая совокупность критериев. У каждого - свой набор значений уровней значимости и мощностей на возможных альтернативах. Математическая статистика демонстрирует в этой ситуации виртуозную математическую технику для анализа частных случаев и полную беспомощность при выдаче практических рекомендаций. Так, оказывается, что практически каждый из известных критериев является оптимальным в том или ином смысле для какого-то набора нулевых гипотез и альтернатив. Математики изучают асимптотическую эффективность в разных смыслах - по Питмену, по Бахадуру и т.д., но - для узкого класса альтернативных гипотез, обычно для альтернативы сдвига. При попытке переноса асимптотических результатов на конечные объемы выборок возникают новые нерешенные проблемы, связанные, в частности, с численным оцениванием скорости сходимости (см. главу 10). В целом эта область математической статистики может активно развиваться еще многие десятилетия, выдавая "на гора" превосходные теоремы (которые могут послужить основанием для защит кандидатских и докторских диссертаций, выборов в академики РАН и т.д.), но не давая ничего практике. Хорошо бы, чтобы этот пессимистический прогноз не вполне оправдался!
С точки зрения эконометрики и прикладной статистики необходимо изучать проблему выбора критерия проверки однородности двух независимых выборок. Такое изучение было проведено, в том числе методом статистических испытаний, и в результате был получен вывод о том, что наиболее целесообразно применять критерий Лемана-Розенблатта типа омега-квадрат (см. главу 4).
В литературе по прикладным статистическим методам, как справедливо замечает С.Г. Корнилов в работе [1], имеется масса ошибочных рекомендаций. Чего стоят хотя бы принципиально неверные государственные стандарты СССР по статистическим методам, а также соответствующие им стандарты СЭВ и ИСО, т.е. Международной организации по стандартизации. Особо выделяются своим количеством ошибочные рекомендации по применению критерия Колмогорова для проверки нормальности (см. ссылки в работе [4]). Ошибки есть и в научных статьях, и в нормативных документах (государственных стандартах), и в методических разработках, и даже в вузовских учебниках. К сожалению, нет способа оградить инженера и научного работника, экономиста и менеджера, нуждающихся в применении эконометрических и статистических методов, от литературных источников и нормативно-технических и инструктивно-методических документов с ошибками, неточностями и погрешностями. Единственный способ - либо постоянно поддерживать профессиональные контакты с квалифицированными специалистами в эконометрике, либо самому стать таким специалистом.
Как оценить достигаемый уровень значимости конкретного критерия, предусматривающего повторные проверки? Сразу ясно, что в большинстве случаев никакая современная теория математической статистики не поможет. Остается использовать современные компьютеры. Методика статистического моделирования, описанная в работе [1], может стать ежедневным рабочим инструментом специалиста, занимающегося применением эконометрических методов. Для этого она должна быть реализована в виде соответствующей диалоговой программной системы. Современные персональные компьютеры позволяют проводить статистическое моделирование весьма быстро (за доли секунд). Можно использовать различные модификации бутстрепа - одного из вариантов применения статистического моделирования (см. ниже).
Проведенное обсуждение показывает, как много нерешенных проблем стоит перед специалистом, занимающимся, казалось бы, рутинным применением стандартных статистических процедур. Эконометрика - молодая наука, ее основные проблемы, по нашему мнению, еще не до конца решены. Много работы как в сравнительно новых областях, например, в анализе нечисловых и интервальных данных (см. главы 8 и 9 выше), так и в классических.
Проблемы разработки и обоснования статистических технологий
В настоящем пункте рассматриваются проблемы практического использования эконометрических методов для системного анализа конкретных экономических данных. При этом применяются не отдельные методы описания данных, оценивания, проверки гипотез, а развернутые цельные процедуры - так называемые "статистические технологии". Понятия "статистические технологии" или "эконометрические технологии" аналогичны понятию "технологический процесс" в теории организации производства.
Статистические технологии. Поскольку термин "технология" сравнительно редко используется применительно к эконометрике и статистике, поясним суть рассматриваемой проблемы. Статистический анализ конкретных экономических данных, как правило, включает в себя целый ряд процедур и алгоритмов, выполняемых последовательно, параллельно или по более сложной схеме. В частности, с точки зрения менеджера эконометрического проекта можно выделить следующие этапы:
- планирование статистического исследования (включая разработку форм учета, их апробацию; подготовку сценариев интервью и анализа данных и т.п.);
- организация сбора необходимых статистических данных по оптимальной или рациональной программе (планирование выборки, создание организационной структуры и подбор команды статистиков, подготовка кадров, которые будут заниматься сбором данных, а также контролеров данных и т.п.);
- непосредственный сбор данных и их фиксация на тех или иных носителях (с контролем качества сбора и отбраковкой ошибочных данных по соображениям предметной области);
- первичное описание данных (расчет различных выборочных характеристик, функций распределения, непараметрических оценок плотности, построение гистограмм, корреляционных полей, различных таблиц и диаграмм и т.д.),
- оценивание тех или иных числовых или нечисловых характеристик и параметров распределений (например, непараметрическое интервальное оценивание коэффициента вариации или восстановление зависимости между откликом и факторами, т.е. оценивание функции),
- проверка статистических гипотез (иногда их цепочек - после проверки предыдущей гипотезы принимается решение о проверке той или иной последующей гипотезы; например, после проверки адекватности линейной регрессионной модели и отклонения этой гипотезы может проверяться адекватность квадратичной модели),
- более углубленное изучение, т.е. одновременное применение различных алгоритмов многомерного статистического анализа, алгоритмов диагностики и построения классификации, статистики нечисловых и интервальных данных, анализа временных рядов и др.;
- проверка устойчивости полученных оценок и выводов относительно допустимых отклонений исходных данных и предпосылок используемых вероятностно-статистических моделей, в частности, изучение свойств оценок методом размножения выборок и другими численными методами;
- применение полученных статистических результатов в прикладных целях, т.е. для формулировки выводов в терминах содержательной области (например, для диагностики конкретных материалов, построения прогнозов, выбора инвестиционного проекта из предложенных вариантов, нахождения оптимальных режима осуществления технологического процесса, подведения итогов испытаний образцов технических устройств и др.),
- составление итоговых отчетов, в частности, предназначенных для тех, кто не является специалистами в статистических методах анализа данных, в том числе для руководства - "лиц, принимающих решения".
Возможны и многие иные структуризации различных статистических технологий (см., например, аналогичную схему для процедур экспертных оценок в главе 12). Важно подчеркнуть, что квалифицированное и результативное применение статистических методов - это отнюдь не проверка одной отдельно взятой статистической гипотезы или оценка характеристик или параметров одного заданного распределения из фиксированного семейства. Подобного рода операции - только отдельные кирпичики, из которых складывается статистическая технология. Между тем учебники и монографии по статистике обычно рассказывают только об отдельных кирпичиках, но не обсуждают проблемы их организации в технологию, предназначенную для прикладного использования.
Итак, процедура статистического анализа данных – это информационный технологический процесс, другими словами, та или иная информационная технология. Статистическая информация подвергается разнообразным операциям (последовательно, параллельно или по более сложным схемам). В настоящее время об автоматизации всего процесса статистического анализа данных говорить было бы несерьезно, поскольку имеется слишком много нерешенных проблем, вызывающих дискуссии среди эконометриков и статистиков. Так называемые "экспертные системы" в области статистического анализа данных пока не стали рабочим инструментом статистиков. Ясно, что и не могли стать. Можно сказать и жестче - это пока научная фантастика или даже вредная утопия.
Проблема "стыковки" алгоритмов. В литературе статистические технологии рассматриваются явно недостаточно. В частности, обычно все внимание сосредотачивается на том или ином элементе технологической цепочки, а переход от одного элемента к другому остается в тени. Между тем проблема "стыковки" статистических алгоритмов, как известно, требует специального рассмотрения (см. предыдущий пункт настоящей главы), поскольку в результате использования предыдущего алгоритма зачастую нарушаются условия применимости последующего. В частности, результаты наблюдений могут перестать быть независимыми, может измениться их распределение и т.п.
Так, вполне резонной выглядит рекомендация: сначала разбейте данные на однородные группы, а потом в каждой из групп проводите статистическую обработку, например, регрессионный анализ. Однако эта рекомендация под кажущейся прозрачностью содержит подводные камни. Действительно, как поставить задачу в вероятностно-статистических терминах? Если, как обычно, примем, что исходные данные - это выборка, т.е. совокупность независимых одинаково распределенных случайных элементов, то классификация приведет к разбиению этих элементов на группы. В каждой группе элементы будут зависимы между собой, а их распределение будет зависеть от группы, куда они попали. Отметим, что в типовых ситуациях границы классов стабилизируются, а это значит, что асимптотически элементы кластеров статновятся независимыми. Однако их распределение не может быть нормальным. Например, если исходное распределение было нормальным, то распределения в классах будет усеченным нормальным. Это означает, что необходимо пользоваться непараметрическими методами, о чем уже не раз говорилось в главах 4 и 5 (подробнее этот пример разобран в работе [7]).
Разберем другой пример При проверке статистических гипотез большое значение имеют такие хорошо известные характеристики статистических критериев, как уровень значимости и мощность. Методы их расчета и использования при проверке одной гипотезы обычно хорошо известны. Если же сначала проверяется одна гипотеза, а потом с учетом результатов ее проверки (конкретнее, если первая гипотеза принята) - вторая, то итоговая процедура, которую также можно рассматривать как проверку некоторой (более сложной) статистической гипотезы, имеет характеристики (уровень значимости и мощность), которые, как правило, нельзя простыми формулами выразить через характеристики двух составляющих гипотез, а потому они обычно неизвестны. Лишь в некоторых простых случаях характеристики итоговой процедуры можно рассчитать (см. примеры в главе 13). В результате итоговую процедуру нельзя рассматривать как научно обоснованную, она относится к эвристическим алгоритмам. Конечно, после соответствующего изучения, например, методом Монте-Карло, она может войти в число научно обоснованных процедур эконометрики или прикладной статистики.
О термине "высокие статистические технологии". Как понятно, технологии бывают разные. Бывают адекватные и неадекватные, современные и устаревшие. Обратим внимание на термин "высокие технологии". Он популярен в современной научно-технической литературе и используется для обозначения наиболее передовых технологий, опирающихся на последние достижения научно-технического прогресса. Есть такие технологии и среди технологий эконометрического и статистического анализа данных - как в любой интенсивно развивающейся научно-практической области.
Примеры высоких эконометрических и статистических технологий и входящих в них алгоритмов анализа экономических данных постоянно обсуждаются на страницах настоящей книги. Подробный анализ современного состояния и перспектив развития эконометрики дан в главе 15 при обсуждении “точек роста” нашей научно-практической дисциплины. В этой главе в качестве примеров "высоких статистических технологий" выделены технологии непараметрического анализа данных (см. главы 4, 5 и 6); устойчивые (робастные) технологии (см. главу 10); технологии, основанные на размножении выборок (см. ниже в настоящей главе), на использовании достижений статистики нечисловых данных (см. главы 8 и 12) и статистики интервальных данных (см. главу 9).
Подробнее обсудим здесь пока не вполне привычный термин "высокие статистические технологии". Каждое из трех слов несет свою смысловую нагрузку.
"Высокие", как и в других научно-технических областях, означает, что статистическая технология опирается на современные научные достижения и передовой опыт реальной деятельности, а именно, достижения эконометрической и статистической теории и практики, в частности, на современные результаты теории вероятностей и прикладной математической статистики. При этом формулировка "опирается на современные научные достижения" означает, во-первых, что математическая основа технологии получена сравнительно недавно в рамках соответствующей научной дисциплины, во-вторых, что алгоритмы расчетов разработаны и обоснованы в соответствии с нею (а не являются т. н. "эвристическими"). Со временем, если новые подходы и результаты не заставляют пересмотреть оценку применимости и возможностей технологии, заменить ее на более современную, "высокие статистические технологии" переходят в "классические статистические технологии", такие, как метод наименьших квадратов. Как известно, несмотря на солидный возраст (более 200 лет), метод наименьших квадратов остается одним из наиболее часто используемых эконометрических методов. Итак, высокие статистические технологии - плоды недавних серьезных научных исследований. Здесь два ключевых понятия - "молодость" технологии (во всяком случае, не старше 50 лет, а лучше - не старше 10 или 30 лет), и опора на "высокую науку".
Термин "статистические" привычен, но разъяснить его нелегко. Во всяком случае, к деятельности Государственного комитета РФ по статистике высокие статистические технологии непосредственного отношения не имеют. В главе 1 уже шла речь о том разрыве между различными группами лиц, употребляющих термин "статистика", который имеется в нашей стране. Впрочем, сам термин "статистика" пррошел долгий путь. Как известно, сотрудники проф.В. В. Налимова, одного из наиболее известных отечественных статистиков ХХ в., собрали более 200 определений термина "статистика" [8]. Полемика вокруг терминологии иногда принимает весьма острые формы (см., например, редакционные замечания к статье [9], написанные в стиле известных высказываний о генетике и кибернетике 1940-х годов - впрочем, каких-либо организационных выводов не последовало). Современное представление о терминологии в области теории вероятностей и прикладной математической статистики отражено в приложении 1 к настоящей книге, подготовленной в противовес распространенным ошибкам и неточностям в этой области. В частности, с точки зрения эконометрики статистические данные – это результаты измерений, наблюдений, испытаний, анализов, опытов, а "статистические технологии" - это технологии анализа статистических данных.
Всегда ли нужны "высокие статистические технологии"? "Высоким статистическим технологиям" противостоят, естественно, "низкие статистические технологии" (а между ними расположены "классические статистические технологии"). Это те технологии, которые не соответствуют современному уровню науки и практики. Обычно они одновременно и устарели, и не вполне адекватны сути решаемых эконометрических и статистических задач.
Примеры таких технологий неоднократно критически рассматривались, в том числе и на страницах этой книги. Достаточно вспомнить критику использования критерия Стьюдента для проверки однородности при отсутствии нормальности и равенства дисперсии или критику применения классических процентных точек критериев Колмогорова и омега-квадрат в ситуациях, когда параметры оцениваются по выборке и эти оценки подставляются в "теоретическую" функцию распределения (подробный разбор проведен, например, в работе [4]). Приходилось констатировать широкое распространение таких порочных технологий и конкретных алгоритмов, в том числе в государственных и международных стандартах (перечень ошибочных стандартов дан в работе [10]), учебниках и распространенных пособиях. Тиражирование ошибок происходит обычно в процессе обучения в вузах или путем самообразования при использовании недоброкачественной литературы.
На первый взгляд вызывает удивление устойчивость "низких статистических технологий", их постоянное возрождение во все новых статьях, монографиях, учебниках. Поэтому, как ни странно, наиболее "долгоживущими" оказываются не работы, посвященные новым научным результатам, а публикации, разоблачающие ошибки, типа статьи [4]. Прошло больше 15 лет с момента ее публикации, но она по-прежнему актуальна, поскольку ошибочное применение критериев Колмогорова и омега-квадрат по-прежнему распространено.
Целесообразно рассмотреть здесь по крайней мере четыре обстоятельства, которые определяют эту устойчивость ошибок.
Во-первых, прочно закрепившаяся традиция. Учебники по т. н. "Общей теории статистики", написанные "чистыми" экономистами (поскольку учебная дисциплина "Статистика" официально относится к экономике), если беспристрастно проанализировать их содержание, состоят в основном из введения в прикладную статистику, изложенного в стиле "низких статистических технологий", т.е. на уровне 1950-х годов, а во многом и на уровне начала ХХ в. . К "низкой" прикладной статистике добавлена некоторая информация о деятельности органов Госкомстата РФ. Некорректно обвинять только экономистов - примерно таково же положение со статистическими методами в медицине: одни и те же "низкие статистические технологии" переписываются из книги в книгу. Новое поколение, обучившись ошибочным подходам, идеям, алгоритмам, их использует, а с течением времени и достижением должностей, ученых званий и степеней – пишет новые учебники со старыми ошибками.
Второе обстоятельство связано с большими трудностями при оценке экономической эффективности применения статистических методов вообще и при оценке вреда от применения ошибочных методов в частности. (А без такой оценки как докажешь, что "высокие статистические технологии" лучше "низких"?) Некоторые соображения по первому из этих вопросов приведены в статье [9], содержащей оценки экономической эффективности ряда работ по применению статистических методов (см. также главу 13, посвященную эконометрике качества). При оценке вреда от применения ошибочных методов приходится учитывать, что общий успех в конкретной инженерной или научной работе вполне мог быть достигнут вопреки применению ошибочных методов, за счет "запаса прочности" других составляющих общей работы. Например, преимущество одного технологического приема над другим можно продемонстрировать как с помощью критерия Крамера-Уэлча проверки равенства математических ожиданий (что правильно), так и с помощью двухвыборочного критерия Стьюдента (что, вообще говоря, неверно, т. к. обычно не выполняются условия применимости этого критерия - нет ни нормальности распределения, ни равенства дисперсий). Кроме того, приходится выдерживать натиск невежд, защищающих свои ошибочные работы, например, государственные стандарты. Вместо исправления ошибок применяются самые разные приемы бюрократической борьбы с теми, кто разоблачает ошибки.
Третье существенное обстоятельство – трудности со знакомством с высокими статистическими технологиями. В нашей стране в силу ряда исторических обстоятельств развития статистических методов и эконометрики (см. главу 1) в течение последних 10 лет только журнал "Заводская лаборатория" предоставлял такие возможности. К сожалению, поток современных отечественных и переводных статистических книг, выпускавшихся ранее, в частности, издательствами "Наука", "Мир", “Финансы и статистика”, практически превратился в узкий ручеек… Возможно, более существенным является влияние естественной задержки во времени между созданием "новых статистических технологий" и написанием полноценной и объемной учебной и методической литературы. Она должна позволять знакомиться с новой методологией, новыми методами, теоремами, алгоритмами, методами расчетов и интерпретации ихъ результатов, статистическими технологиями в целом не по кратким оригинальным статьям, а при обычном вузовском и последипломном обучении.
И, наконец, наиболее важное. Всегда ли нужны высокие статистические технологии? Приведем аналогию - нужна ли современная сельскохозяйственная техника для обработки приусадебногоучастка? Нужны ли трактора и комбайны? Может быть, достаточно технологий, основанных на использовании лопаты? Вернемся к данным государственной статистики. Применяются статистические технологии первичной обработки (описания) данных, основанные на построении разнообразных таблиц, диаграмм, графиков. Большинство потребителей статистической информации это представление данных удовлетворяет. Итак, чтобы высокие статистические технологии успешно использовались, необходимы два условия: чтобы они были объективно нужны для решения практической задачи и чтобы потенциальный пользователь технологий субъективно понимал это.
Таким образом, весь арсенал реально используемых в настоящее время эконометрических и статистических технологий можно распределить по трем потокам:
- высокие статистические технологии;
- классические статистические технологии,
низкие статистические технологии.
Под классическими статистическими технологиями, как уже отмечалось, понимаем технологии почтенного возраста, сохранившие свое значение для современной статистической практики. Таковы технололгии на основе метода наименьших квадратов (включая методы точечного оценивания параметров прогностической функции, непараметрические методы доверительного оценивания параметров, прогностической функции, проверок различных гипотез о них - см. главу 5), статистик типа Колмогорова, Смирнова, омега-квадрат, непараметрических коэффициентов корреляции Спирмена и Кендалла (относить их только к методам анализа ранжировок - значит делать уступку "низким статистическим технологиям", см. главу 5) и многих других статистических процедур.
Основная современная проблема в области эконометрических и статистических технологий состоит в том, чтобы в конкретных эконометрических исследованиях использовались только технологии первых двух типов.
Каковы возможные пути решения основной современной проблемы в области статистических технологий?
Бороться с конкретными невеждами - дело почти безнадежное. Отстаивая свое положение и должности, они либо нагло игнорируют информацию о своих ошибках, как это обычно делают авторы учебников по "Общей теории статистики" и их издатели, либо с помощью различных бюрократических приемов уходят и от ответственности, и от исправления ошибок по существу (как это было со стандартами по статистическим методам - см. статью [10]). Третий вариант - признание и исправление ошибок - встречается, увы, редко. Но встречается.
Конечно, необходима демонстрация квалифицированного применения высоких статистических технологий. В 1960-70-х годах этим занималась Лаборатория статистических методов акад.А.Н. Колмогорова в МГУ им. М.В. Ломоносова. Секция "Математические методы исследования" журнала "Заволская лаборатория" опубликовала за последние 40 лет более 1000 статей в стиле "высоких статистических технологий". В настоящее время действует Институт высоких статистических технологий и эконометрики МГТУ им. Н.Э. Баумана. Есть, конечно, целый ряд других научных коллективов, работающих на уровне "высоких статистических технологий".
Очевидно, самое основное - это обучение. Какие бы новые научные результаты ни были получены, если они остаются неизвестными студентам, то новое поколение экономистов ии менеджеров, исследователей и инженеров вынуждено осваивать их поодиночке, в порядке самообразования, а то и переоткрывать.Т. е. практически новые научные результаты почти исчезают, едва появившись. Как ни странно это может показаться, избыток научных публикаций превратился в тормоз развития науки. По нашим данным, к настоящему времени по эконометрическим и статистическим технологиям опубликовано не менее миллиона статей и книг, в основном во второй половине ХХ в., из них не менее 100 тысяч являются актуальными для современного специалиста. При этом реальное число публикаций, которые способен освоить исследователь за свою проофессиональную жизнь, по нашей оценке, не превышает 2-3 тысяч. Во всяком случае, в наиболее "толстом" на русском языке трехтомнике по статистике М. Дж. Кендалла и А. Стьюарта приведено около 2 тысяч литературных ссылок. Итак, каждый исследователь-эконометрик знаком не более чем с 2-3% актуальных для него литературных источников. Поскольку существенная часть публикаций заражена "низкими статистическими технологиями", то исследователь-самоучка, увы, имеет мало шансов выйти на уровень "высоких статистических технологий". С подтверждениями этого печального вывода постоянно приходится сталкиваться. Одновременно приходится констатировать, что масса полезных результатов погребена в изданиях прошлых десятилетий и имеет мало шансов пробиться в ряды используемых в настоящее время "высоких статистических технологий" без специально организованных усилий современных специалистов.
Итак, основное - обучение. Несколько огрубляя, можно сказать так: что попало в учебные курсы и соответствующие учебные пособия - то сохраняется, что не попало - то пропадает.
Необходимость высоких статистических технологий. Может возникнуть естественный вопрос: зачем нужны высокие статистические технологии, разве недостаточно обычных статистических методов? Специалисты по эконометрике справедливо считают и доказывают своими теоретическими и прикладными работами, что совершенно недостаточно. Так, совершенно очевидно, что многие данные в информационных системах имеют нечисловой характер, например, являются словами или принимают значения из конечных множеств. Нечисловой характер имеют и упорядочения, которые дают эксперты или менеджеры, например, выбирая главную цель, следующую по важности и т.д. Значит, нужна статистика нечисловых данных. Мы ее построили. Далее, многие величины известны не абсолютно точно, а с некоторой погрешностью - от и до. Другими словами, исходные данные - не числа, а интервалы. Нужна статистика интервальных данных. Мы ее развиваем. В широко известной монографии по контроллингу [11] на с.138 хорошо сказано: "Нечеткая логика - мощный элегантный инструмент современной науки, который на Западе (и на Востоке - в Японии, Китае - А. О) можно встретить в десятках изделий - от бытовых видеокамер до систем управления вооружениями, - у нас до самого последнего времени был практически неизвестен". Напомним, первая монография российского автора по теории нечеткости содержит основы высоких статистических технологий анализа выборок нечетких множеств (см. книгу [12]). Ни статистики нечисловых данных, ни статистики интервальных данных, ни статистики нечетких данных нет и не могло быть в классической статистике. Все это - высокие статистические технологии. Они разработаны за последние 10-30-50 лет. А обычные вузовские курсы по общей теории статистики и по математической статистике разбирают научные результаты, полученные в первой половине ХХ века.
Важная и весьма перспективная часть эконометрики - применение высоких статистических технологий к анализу конкретных экономических данных, что зачастую требует дополнительной теоретической работы по доработке статистических технологий применительно к конкретной ситуации. Большое значение имеют конкретные эконометрические модели, например, модели экспертных оценок или эконометрики качества. И конечно, такие конкретные применения, как расчет и прогнозирование индекса инфляции. Сейчас уже многих ясно, что годовой бухгалтерский баланс предприятия может быть использован для оценки его финансово-хозяйственной деятельности только с привлечением данных об инфляции (см. главу 7).
О подготовке специалистов по высоким статистическим технологиям. Приходится с сожалением констатировать, что в России практически отсутствует подготовка специалистов по высоким статистическим технологиям. В курсах по теории вероятностей и математической статистике обычно даются лишь классические основы этих дисциплин, разработанные в первой половине ХХ в., а преподаватели-математики свою научную деятельность предпочитают посвящать доказательству теорем, имеющих лишь внутриматематическое значение, а не развитию высоких статистических технологий. В настоящее время появилась надежда на эконометрику. В России начинают развертываться эконометрические исследования и преподавание эконометрики. Экономисты, менеджеры и инженеры, прежде всего специалисты по контроллингу, должны быть вооружены современными средствами информационной поддержки, в том числе высокими статистическими технологиями и эконометрикой. Очевидно, преподавание должно идти впереди практического применения. Ведь как применять то, чего не знаешь?
Приведем два примера - отрицательный и положительный, - показывающие связь преподавания с внедрением передовых технологий.
Один раз - в 1990-1992 гг. мы уже обожглись на недооценке необходимости предварительной подготовки тех, для кого предназначены современные программные продукты. Наш коллектив (Всесоюзный центр статистических методов и информатики Центрального Правления Всесоюзного экономического общества) разработал систему диалоговых программных систем обеспечения качества продукции. Их созданием руководили ведущие специалисты страны. Но распространение программных продуктов шло на 1-2 порядка медленнее, чем мы ожидали. Причина стала ясна не сразу. Как оказалось, работники предприятий просто не понимали возможностей разработанных систем, не знали, какие задачи можно решать с их помощью, какой экономический эффект они дадут. А не понимали и не знали потому, что в вузах никто их не учил статистическим методам управления качеством. Без такого систематического обучения нельзя обойтись - сложные концепции "на пальцах" за 5 минут не объяснишь.
Есть и противоположный пример - положительный. В середине 1980-х годов в советской средней школе ввели новый предмет "Информатика". И сейчас молодое поколение превосходно владеет компьютерами, мгновенно осваивая быстро появляющиеся новинки, и этим заметно отличается от тех, кому за 30-40 лет.
Если бы удалось ввести в средней школе курс теории вероятностей и статистики - а такой курс есть в Японии и США, Швейцарии, Кении и Ботсване, почти во всех странах (и ЮНЕСКО проводит всемирные конференции по преподаванию математической статистики в средней школе - см сборник докладов [13]) - то ситуация с внедрением высоких статистических технологий могла бы быть резко улучшена. Надо, конечно, добиться того, чтобы такой курс был построен на высоких статистических технологиях, а не на низких. Другими словами, он должен отражать современные достижения, а не концепции пятидесятилетней или столетней давности.
Методы статистических испытаний (Монте-Карло) и датчики псевдослучайных чисел
Многие эконометрические информационные технологии опираются на использование методов статистических испытаний. Этот термин применяется для обозначения компьютерных технологий, в которых в эконометрическую модель искусственно вводится большое число случайных элементов. Обычно моделируется последовательность независимых одинаково распределенных случайных величин или же последовательность, построенная на основе такой, например, последовательность накапливающихся (кумулятивных) сумм.
Необходимость в методе статистических испытаний возникает потому, что чисто теоретические методы дают точное решение, как правило, лишь в исключительных случаях. Либо тогда, когда исходные случайные величины имеют вполне определенные функции распределения, например, нормальные, чего, как правило, не бывает. Либо когда объемы выборок очень велики (с практической точки зрения - бесконечны). Эта проблема уже обсуждалась в главе 10.
Не только в чисто эконометрических задачах обработки статистических данных возникает необходимость в методе статистических испытаний. Она не менее актуальна и при экономико-математическом моделировании технико-экономических и торговых процессов. Представим себе всем знакомый объект - торговый зал самообслуживания по продаже продовольственных товаров. Сколько нужно работников в зале, сколько касс? Необходимо просчитать загрузку в разное время суток, в разные сезоны года, с учетом замены товаров и смены сотрудников. Нетрудно увидеть, что теоретическому анализу подобная система не поддается, а компьютерному - вполне.
Методы статистических испытаний стали развиваться после второй мировой войны с появлением компьютеров. Второе название - методы Монте-Карло - они получили по наиболее известному игорному дому, а точнее, по его рулетке, поскольку исходный материал для получения случайных чисел с произвольным распределением - это случайные натуральные числа.
В методах статистических испытаний можно выделить две составляющие. Базой являются датчики псевдослучайных чисел. Результатом работы таких датчиков являются последовательности чисел, которые обладают некоторыми свойствами последовательностей случайных величин (в смысле теории вероятностей). Надстройкой являются различные алгоритмы, использующие последовательности псевдослучайных чисел.
Что же это могут быть за алгоритмы? Приведем примеры. Пусть мы изучаем распределение некоторой статистики при заданном объеме выборки. Тогда естественно много раз (например, 100000 раз) смоделировать выборку заданного объема (т.е. набор независимых одинаково распределенных случайных величин) и рассчитать значение статистики. Затем по 100000 значениям статистики можно достаточно точно построить функцию распределения изучаемой статистики, оценить ее характеристики. Однако эта схема годится лишь для так называемой "свободной от распределения" статистики, распределение которой не зависит от распределения элементов выборки. Если же такая зависимость есть, то одной точкой моделирования не обойдешься, придется много раз моделировать выборку, беря различные распределения, меняя параметры. Чтобы общее время моделирования было приемлемым, возможно, придется сократить число моделирований в одной точке, зато увеличив общее число точек. Точность моделирования может быть оценена по общим правилам выборочных обследований (см. главу 2).
Второй пример - частично описанное выше моделирование работы торгового зала самообслуживания по продаже продовольственных товаров. Здесь одна последовательность псевдослучайных чисел описывает интервалы между появлениями покупателей, вторая, третья и т.д. связаны с выбором ими первого, второго и т.д. товаров в зале (например, число - номер в перечне товаров). Короче, все действия покупателей, продавцов, работников предприятия разбиты на операции, каждая операция, в продолжительности или иной характеристике которой имеется случайность, моделируется с помощью соответствующей последовательности псевдослучайных чисел. Затем итоги работы сотрудников торговой организации и зала в целом выражаются через характеристики случайных величин. Формулируется критерий оптимальности, решается задача оптимизации и находятся оптимальные значения параметров.
Оптимальные планы статистического контроля, построенные на основе вероятностно-статистических моделей, строятся в главе 13.
Теперь обсудим свойства датчиков псевдослучайных чисел. Здесь стоит слово "псевдослучайные", а не "случайные". Это весьма важно.
Дело в том, что за последние 50 лет обсуждались в основном три принципиально разных варианта получения последовательностей чисел, которые в дальнейшем использовались в методах статистических испытаний.
Первый - таблица случайных чисел. К сожалению, объем любой таблицы конечен, и сколько-нибудь сложные расчеты с ее помощью невозможны. Через некоторое время приходится повторяться. Кроме того, обычно обнаруживались те или иные отклонения от случайности (см. об этом в работе [9]).
Второй - физические датчики случайных чисел. Основной недостаток - нестабильность, непредсказуемые отклонения от заданного распределения (обычно - равномерного).
Третий - расчетный. В простейшем случае каждый следующий член последовательности рассчитывается по предыдущему. Например, так:

где z0 - начальное
значение (заданное целое положительное
число) M - параметр алгоритма (заданное
целое положительное число), P=2m, где m -
число двоичных разрядов представления
чисел, с которыми манипулирует компьютер.
Знак
 здесь
означает теоретико-числовую операцию
сравнения, т.е. взятие дробной части от
здесь
означает теоретико-числовую операцию
сравнения, т.е. взятие дробной части от
 и отбрасывание целой.
и отбрасывание целой.
В настоящее время применяется именно третий вариант. Совершенно ясно, что он не соответствует интуитивному представлению о случайности. Например, интуитивно очевидно, что по предыдущему элементу случайной последовательности с независимыми элементами нельзя предсказать значение следующего элемента. Расчетный путь получения последовательности псевдослучайных чисел противоречит не только интуиции, но и подходу к определению случайности на основе теории алгоритмов, развитому акад.А.Н. Колмогоровым и его учениками в 1960-х годах. Однако во многих прикладных задачах он работает, и это основное.
Методу статистических испытаний посвящена обширная литература (см., например, монографии [14-16]). Время от времени обнаруживаются недостатки у популярных датчиков псевдослучайных чисел. Так, например, в середине 1980-х годов выяснилось, что для одного из наиболее известных датчиков

После этого в 1985 г. в журнале "Заводская лаборатория" началась дискуссия о качестве датчиков псевдослучайных чисел, которая продолжалась до 1993 г. и закончилась статьей проф.С.М. Ермакова [17] и нашим комментарием.
Итоги можно подвести так. Во многих случаях решаемая методом статистических испытаний задача сводится к оценке вероятности попадания в некоторую область в многомерном пространстве фиксированной размерности. Тогда из чисто математических соображений теории чисел следует, что с помощью датчиков псевдослучайных чисел поставленная задача решается корректно. Сводка соответствующих математических обоснований приведена, например, в работе С.М. Ермакова [17].
В других случаях приходится рассматривать вероятности попадания в области в пространствах переменной размерности. Типичным примером является ситуация, когда на каждом шагу проводится проверка, и по ее результатам либо остаемся в данном пространстве, либо переходим в пространство большей размерности. Например, в главе 5 при оценивании степени многочлена либо останавливались на данной степени, либо увеличивали степень, переходя в параметрическое пространство большей размерности. Так вот, вопрос об обоснованности применения метода статистических испытаний (а точнее, о свойствах датчиков псевдослучайных чисел) в случае пространств переменной размерности остается в настоящее время открытым. О важности этой проблемы говорил академик РАН Ю.В. Прохоров на Первом Всемирном Конгрессе Общества математической статистики и теории вероятностей им. Бернулли (Ташкент, 1986 г).
Имитационное моделирование. Поскольку постоянно говорим о моделировании, приведем несколько общих формулировок.
Модель в общем смысле (обобщенная модель) - это создаваемый с целью получения и (или) хранения информации специфический объект (в форме мысленного образа, описания знаковыми средствами либо материальной системы), отражающей свойства, характеристики и связи объекта-оригинала произвольной природы, существенные для задачи, решаемой субъектом (это определение взято из монографии [18, с.44]).
Например, в менеджменте производственных систем используют:
- модели технологических процессов (контроль и управление по технико-экономическим критериям, АСУ ТП - автоматизированные системы управления технологическими процессами);
- модели управления качеством продукции (в частности, модели оценки и контроля надежности);
- модели массового обслуживания (теории очередей);
- модели управления запасами (в современной терминологии - модели логистики, т.е. теории и практики управления материальными, финансовыми и информационными потоками);
- имитационные и эконометрические модели деятельности предприятия (как единого целого) и управления им (АСУ предприятием) и др.
Согласно академику РАН Н.Н. Моисееву [19, с.213], имитационная система - это совокупность моделей, имитирующих протекание изучаемого процесса, объединенная со специальной системой вспомогательных программ и информационной базой, позволяющих достаточно просто и оперативно реализовать вариантные расчеты. Другими словами, имитационная система - это совокупность имитационных моделей. А имитационная модель предназначена для ответов на вопросы типа: "Что будет, если…" Что будет, если параметры примут те или иные значения? Что будет с ценой на продукцию, если спрос будет падать, а число конкурентов расти? Что будет, если государство резко усилит вмешательство в экономику? Что будет, если остановку общественного транспорта перенесут на 100 м дальше от входа в торговый зал, о котором шла речь выше, и поток покупателей резко упадет? Кроме компьютерных моделей, на вопросы подобного типа часто отвечают эксперты при использовании метода сценариев (см. главу 12).
При имитационном моделировании часто используется метод статистических испытаний (Монте-Карло). Теорию и практику машинных имитационных экспериментов с моделями экономических систем еще 30 лет назад подробно разобрал Т. Нейлор в обширной классической монографии [20]. Вернемся к внутриэконометрическому применению датчиков псевдослучайных чисел.
Методы размножения выборок (бутстреп-методы)
Эконометрика и прикладная статистика бурно развиваются последние десятилетия. Серьезным (хотя, разумеется, не единственным и не главным) стимулом является стремительно растущая производительность вычислительных средств. Поэтому понятен острый интерес к статистическим методам, интенсивно использующим компьютеры. Одним из таких методов является так называемый "бутстреп", предложенный в 1977 г.Б. Эфроном из Станфордского университета (США).
Сам термин "бутстреп" - это "bootstrap" русскими буквами и буквально означает что-то вроде: "вытягивание себя (из болота) за шнурки от ботинок". Термин специально придуман и заставляет вспомнить о подвигах барона Мюнхгаузена.
В истории эконометрики было несколько более или менее успешно осуществленных рекламных кампаний. В каждой из них "раскручивался" тот или иной метод, который, как правило, отвечал нескольким условиям:
- по мнению его пропагандистов, полностью решал актуальную научную задачу;
- был понятен (при постановке задачи, при ее решении и при интерпретации результатов) широким массам потенциальных пользователей;
- использовал современные возможности вычислительной техники.
Пропагандисты метода, как правило, избегали беспристрастного сравнения его возможностей с возможностями иных эконометрических методов. Если сравнения и проводились, то с заведомо слабым "противником".
В нашей стране в условиях отсутствия систематического эконометрического образования подобные рекламные кампании находили особо благоприятную почву, поскольку у большинства затронутых ими специалистов не было достаточных знаний в области методологии построения эконометрических моделей для того, чтобы составить самостоятельное квалифицированное мнение.
Речь идет о таких методах как бутстреп, нейронные сети, метод группового учета аргументов, робастные оценки по Тьюки-Хуберу (см. главу 10), асимптотика пропорционального роста числа параметров и объема данных и др. Бывают локальные всплески энтузиазма, например, московские социологи в 1980-х годах пропагандировали так называемый "детерминационный анализ" - простой эвристический метод анализа таблиц сопряженности, хотя в Новосибирске в это время давно уже было разработано продвинутое программное обеспечение анализа векторов разнотипных признаков (см. главу 8).
Однако даже на фоне всех остальных рекламных кампаний судьба бутстрепа исключительна. Во-первых, признанный его автор Б. Эфрон с самого начала признавался, что он ничего принципиально нового не сделал. Его исходная статья (первая в сборнике [21]) называлась: "Бутстреп-методы: новый взгляд на методы складного ножа". Во вторых, сразу появились статьи и дискуссии в научных изданиях, публикации рекламного характера, и даже в научно-популярных журналах. Бурные обсуждения на конференциях, спешный выпуск книг. В 1980-е годы финансовая подоплека всей этой активности, связанная с выбиванием грантов на научную деятельность, содержание учебных заведений и т.п. была мало понятна отечественным специалистам.
В чем основная идея группы методов "размножения выборок", наиболее известным представителем которых является бутстреп?
Пусть дана выборка
 .
В вероятностно-статистической теории
предполагаем, что это - набор независимых
одинаково распределенных случайных
величин. Пусть эконометрика интересует
некоторая статистика
.
В вероятностно-статистической теории
предполагаем, что это - набор независимых
одинаково распределенных случайных
величин. Пусть эконометрика интересует
некоторая статистика
 Как изучить ее свойства? Подобными
проблемами мы занимались на протяжении
всей книги и знаем, насколько это
непросто. Идея, которую предложил в 1949
г.М. Кенуй (это и есть "метод складного
ножа") состоит в том, чтобы из одной
выборки сделать много, исключая по
одному наблюдению (и возвращая ранее
исключенные). Перечислим выборки, которые
получаются из исходной:
Как изучить ее свойства? Подобными
проблемами мы занимались на протяжении
всей книги и знаем, насколько это
непросто. Идея, которую предложил в 1949
г.М. Кенуй (это и есть "метод складного
ножа") состоит в том, чтобы из одной
выборки сделать много, исключая по
одному наблюдению (и возвращая ранее
исключенные). Перечислим выборки, которые
получаются из исходной:


 ;
;
…
 ;
;
…
 ;
;

Всего n новых (размноженных) выборок объемом (n-1) каждая. По каждой из них можно рассчитать значение интересующей эконометрика статистики (с уменьшенным на 1 объемом выборки):



…

…


Полученные значения статистики
позволяют судить о ее распределении и
о характеристиках распределения - о
математическом ожидании, медиане,
квантилях, разбросе, среднем квадратическом
отклонении. Значения статистики,
построенные по размноженным подвыборкам,
не являются независимыми, однако, как
мы видели в главе 5 на примере ряда
статистик, возникающих в методе наименьших
квадратов и в кластер-анализе (при
обсуждении возможности объединения
двух кластеров), при росте объема выборки
влияние зависимости может ослабевать
и со значениями статистик типа
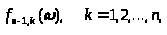 можно
обращаться как с независимыми случайными
величинами.
можно
обращаться как с независимыми случайными
величинами.
Однако и без всякой
вероятностно-статистической теории
разброс величин
дает
наглядное представление о том, какую
точность может дать рассматриваемая
статистическая оценка.
Сам М. Кенуй и его последователи
использовали размножение выборок в
основном для построения оценок с
уменьшенным смещением. А вот Б. Эфрон
преложил новый способ размножения
выборок, существенно использующий
датчики псевдослучайных чисел. А именно,
он предложил строить новые выборки,
моделируя выборки из эмпирического
распределения (см. определения в
терминологическом Приложении 1 в конце
книги). Другими словами, Б. Эфрон предложил
взять конечную совокупность из n элементов
исходной выборки
и с помощью датчика случайных чисел
сформировать из нее любое число
размноженных выборок. Процедура, хотя
и нереальна без ЭВМ, проста с точки
зрения программирования. По сравнению
с описанной выше процедурой появляются
новые недостатки - неизбежные совпадения
элементов размноженных выборок и
зависимость от качества датчиков
псевдослучайных чисел (см. выше). Однако
существует математическая теория,
позволяющая (при некоторых предположениях
и безграничном росте объема выборки)
обосновать процедуры бутстрепа (см.
сборник статей [21]).
Есть много способов развития
идеи размножения выборок (см., например,
статью [22]). Можно по исходной выборке
построить эмпирическую функцию
распределения, а затем каким-либо образом
от кусочно-постоянной функции перейти
к непрерывной функции распределения,
например, соединив точки
 отрезками прямых. Другой вариант -
перейти к непрерывному распределению,
построив непараметрическую оценку
плотности. После этого рекомендуется
брать размноженные выборки из этого
непрерывного распределения (являющегося
состоятельной оценкой исходного),
непрерывность защитит от совпадений
элементов в этих выборках.
отрезками прямых. Другой вариант -
перейти к непрерывному распределению,
построив непараметрическую оценку
плотности. После этого рекомендуется
брать размноженные выборки из этого
непрерывного распределения (являющегося
состоятельной оценкой исходного),
непрерывность защитит от совпадений
элементов в этих выборках.
Другой вариант построения размноженных выборок - более прямой. Исходные данные не могут быть определены совершенно точно и однозначно. Поэтому предлагается к исходным данным добавлять малые независимые одинаково распределенные погрешности. При таком подходе одновременно соединяем вместе идеи устойчивости (см. главу 10) и бутстрепа. При внимательном анализе многие идеи эконометрики тесно друг с другом связаны (см. статью [22]).
В каких случаях целесообразно применять бутстреп, а в каких - другие эконометрические методы? В период рекламной кампании встречались, в том числе в научно-популярных журналах, утверждения о том, что и для оценивания математического ожидания полезен бутстреп. Как показано в статье [22], это совершенно не так. При росте числа испытаний методом Монте-Карло бутстреп-оценка приближается к классической оценке - среднему арифметическому результатов наблюдений. Другими словами, бутстреп-оценка отличается от классической только шумом псевдослучайных чисел.
Аналогичной является ситуация и в ряде других случаев. Там, где эконометрическая теория хорошо развита, где найдены методы анализа данных, в том или иной смысле близкие к оптимальным, бутстрепу делать нечего. А вот в новых областях со сложными алгоритмами, свойства которых недостаточно ясны, он представляет собой ценный инструмент для изучения ситуации.
Эконометрика в контроллинге
Контроллеру и сотрудничающему с ним эконометрику нужна разнообразная экономическая и управленческая информация, не менее нужны удобные инструменты ее анализа. Следовательно, информационная поддержка контроллинга необходима для успешной работы контроллера. Без современных компьютерных инструментов анализа и управления, основанных на продвинутых эконометрических и экономико-математических методах и моделях, невозможно эффективно принимать управленческие решения. Недаром специалисты по контроллингу большое внимание уделяют проблемам создания, развития и применения компьютерных систем поддержки принятия решений. Высокие статистические технологии и эконометрика - неотъемлемые части любой современной системы поддержки принятия экономических и управленческих решений.
Важная часть эконометрики - применение высоких статистических технологий к анализу конкретных экономических данных. Такие исследования зачастую требуют дополнительной теоретической работы по "доводке" статистических технологий применительно к конкретной ситуации. Большое значение для контроллинга имеют не только общие методы, но и конкретные эконометрические модели, например, вероятностно-статистические модели тех или иных процедур экспертных оценок (глава 12) или эконометрики качества (глава 13), имитационные модели деятельности организации, прогнозирования в условиях риска (глава 14). И конечно, такие конкретные применения, как расчет и прогнозирование индекса инфляции. Сейчас уже многим специалистам ясно, что годовой бухгалтерский баланс предприятия может быть использован для оценки его финансово-хозяйственной деятельности только с привлечением данных об инфляции. Различные области экономической теории и практики в настоящее время еще далеко не согласованы. При оценке и сравнении инвестиционных проектов принято использовать такие характеристики, как чистая текущая стоимость, внутренняя норма доходности, основанные на введении в рассмотрение изменения стоимости денежной единицы во времени (это осуществляется с помощью дисконтирования). А при анализе финансово-хозяйственной деятельности организации на основе данных бухгалтерской отчетности изменение стоимости денежной единицы во времени по традиции не учитывают.
Специалисты по контроллингу должны быть вооружены современными средствами информационной поддержки, в том числе средствами на основе высоких статистических технологий и эконометрики. Очевидно, преподавание должно идти впереди практического применения. Ведь как применять то, чего не знаешь?
Статистические технологии применяют для анализа данных двух принципиально различных типов. Один из них - это результаты измерений (наблюдений, испытаний, анализов, опытов и др.) различных видов, например, результаты управленческого или бухгалтерского учета, данные Госкомстата и др. Короче, речь идет об объективной информации. Другой - это оценки экспертов, на основе своего опыта и интуиции делающих заключения относительно экономических явлений и процессов. Очевидно, это - субъективная информация. В стабильной экономической ситуации, позволяющей рассматривать длинные временные ряды тех или иных экономических величин, полученных в сопоставимых условиях, данные первого типа вполне адекватны. В быстро меняющихся условиях приходятся опираться на экспертные оценки. Такая новейшая часть эконометрики, как статистика нечисловых данных, была создана как ответ на запросы теории и практики экспертных оценок (см. главы 8 и 12).
Для решения каких экономических задач может быть полезна эконометрика? Практически для всех, использующих конкретную информацию о реальном мире. Только чисто абстрактные, отвлеченные от реальности исследования могут обойтись без нее. В частности, эконометрика необходима для прогнозирования, в том числе поведения потребителей, а потому и для планирования. Выборочные исследования, в том числе выборочный контроль, основаны на эконометрике. Но планирование и контроль - основа контроллинга. Поэтому эконометрика - важная составляющая инструментария контроллера, воплощенного в компьютерной системе поддержки принятия решений. Прежде всего оптимальных решений, которые предполагают опору на адекватные эконометрические модели. В производственном менеджменте это может означать, например, использование моделей экстремального планирования эксперимента (судя по накопленному опыту их практического использования, такие модели позволяют повысить выход полезного продукта на 30-300%).
Высокие статистические технологии в эконометрике предполагают адаптацию применяемых методов к меняющейся ситуации. Например, параметры прогностического индекса меняются вслед за изменением характеристик используемых для прогнозирования величин. Таков метод экспоненциального сглаживания. В соответствующем алгоритме расчетов значения временного ряда используются с весами. Веса уменьшаются по мере удаления в прошлое. Многие методы дискриминантного анализа основаны на применении обучающих выборок. Например, для построения рейтинга надежности банков можно с помощью экспертов составить две обучающие выборки - надежных и ненадежных банков. А затем с их помощью решать для вновь рассматриваемого банка, каков он - надежный или ненадежный, а также оценивать его надежность численно, т.е. вычислять значение рейтинга.
Один из способов построения адаптивных эконометрических моделей - нейронные сети (см., например, монографию [23]). При этом упор делается не на формулировку адаптивных алгоритмов анализа данных, а - в большинстве случаев - на построение виртуальной адаптивной структуры. Термин "виртуальная" означает, что "нейронная сеть" - это специализированная компьютерная программа, "нейроны" используются лишь при общении человека с компьютером. Методология нейронных сетей идет от идей кибернетики 1940-х годов. В компьютере создается модель мозга человека (весьма примитивная с точки зрения физиолога). Основа модели - весьма простые базовые элементы, называемые нейронами. Они соединены между собой, так что нейронные сети можно сравнить с хорошо знакомыми экономистам и инженерам блок-схемами. Каждый нейрон находится в одном из заданного множества состояний. Он получает импульсы от соседей по сети, изменяет свое состояние и сам рассылает импульсы. В результате состояние множества нейтронов изменяется, что соответствует проведению эконометрических вычислений.
Нейроны обычно объединяются в слои (как правило, два-три). Среди них выделяются входной и выходной слои. Перед началом решения той или иной задачи производится настройка. Во-первых, устанавливаются связи между нейронами, соответствующие решаемой задаче. Во-вторых, проводится обучение, т.е. через нейронную сеть пропускаются обучающие выборки, для элементов которых требуемые результаты расчетов известны. Затем параметры сети модифицируются так, чтобы получить максимальное соответствие выходных значений заданным величинам.
С точки зрения точности расчетов (и оптимальности в том или ином эконометрическом смысле) нейронные сети не имеют преимуществ перед другими адаптивными эконометрическими системами. Однако они более просты для восприятия. Надо отметить, что в эконометрике используются и модели, промежуточные между нейронными сетями и "обычными" системами регрессионных уравнений (одновременных и с лагами). Они тоже используют блок-схемы, как, например, универсальный метод моделирования связей экономических факторов ЖОК (этот метод описан в работе [24]).
Заметное место в математико-компьютерном обеспечении принятия решений в контроллинге занимают методы теории нечеткости (по-английски - fuzzy theory, причем термин fuzzy переводят на русский язык по-разному: нечеткий, размытый, расплывчатый, туманный, пушистый и др.). Начало современной теории нечеткости положено работой Л.А. Заде 1965г., хотя истоки прослеживаются со времен Древней Греции (об истории теории нечеткости см., например, книгу [12]). Это направление прикладной математики в последней трети ХХ в. получило бурное развитие. К настоящему времени по теории нечеткости опубликованы тысячи книг и статей, издается несколько международных журналов (половина - в Китае и Японии), постоянно проводятся международные конференции, выполнено достаточно много как теоретических, так и прикладных научных работ, практические приложения дали ощутимый технико-экономический эффект.
Основоположник рассматриваемого научного направления Лотфи А. Заде рассматривал теорию нечетких множеств как аппарат анализа и моделирования гуманистических систем, т.е. систем, в которых участвует человек. Его подход опирается на предпосылку о том, что элементами мышления человека являются не числа, а элементы некоторых нечетких множеств или классов объектов, для которых переход от "принадлежности" к "непринадлежности" не скачкообразен, а непрерывен. В настоящее время методы теории нечеткости используются почти во всех прикладных областях, в том числе при управлении качеством продукции и технологическими процессами.
Нечеткая математика и логика - мощный элегантный инструмент современной науки, который на Западе и на Востоке (в Японии, Китае, Корее) можно встретить в программном обеспечении сотен видов изделий - от игрушек и бытовых видеокамер до систем управления предприятиями. В России он был достаточно хорошо известен с начала 1970-х годов. Однако первая монография российского автора по теории нечеткости [12] была опубликована лишь в 1980 г. В дальнейшем проводившиеся раз в год всесоюзные конференции собирали около 100 участников - по мировым меркам немного. В настоящее время интерес к теории нечеткости среди экономистов и менеджеров растет.
При изложении теории нечетких множеств обычно не подчеркивается связь с вероятностными моделями. Между тем еще в середине 1970-х годов установлено (цикл соответствующих теорем приведен, в частности, в монографии [12], но это отнюдь не первая публикация), что теория нечеткости в определенном смысле сводится к теории случайных множеств, хотя эта связь и имеет, возможно, лишь теоретическое значение. В США подобные работы появились лет на пять позже.
Профессионалу в области контроллинга полезны многочисленные интеллектуальные инструменты анализа данных, относящиеся к высоким статистическим технологиям и эконометрике.
Литература
1. Корнилов С.Г. Накопление ошибки первого рода при повторной проверке статистических гипотез. Регламент повторных проверок. // Заводская лаборатория. 1996. Т.62. Nо.5. С.45-51.
2. Камень Ю.Э., Камень Я.Э., Орлов А.И. Реальные и номинальные уровни значимости в задачах проверки статистических гипотез. // Заводская лаборатория. 1986. Т.52. No.12. С.55-57.
3. Налимов В.В. Применение математической статистики при анализе вещества. - М.: Физматгиз, 1960. - 430 с.
4. Орлов А.И. Распространенная ошибка при использовании критериев Колмогорова и омега-квадрат. // Заводская лаборатория. 1985. Т.51. No.1. С.60-62.
5. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. Изд.3-е. - М.: Наука, 1983. - 416 с.
6. Орлов А.И. О современных проблемах внедрения прикладной статистики и других статистических методов. // Заводская лаборатория. 1992. Т.58. No.1. С.67-74.
7. Орлов А.И. Некоторые вероятностные вопросы теории классификации. – В сб.: Прикладная статистика. Ученые записки по статистике, т.45. - М.: Наука, 1983. С.166-179.
8. Никитина Е.П., Фрейдлина В.Д., Ярхо А.В. Коллекция определений термина "статистика" / Межфакультетская лаборатория статистических методов. Вып.37. - М.: Изд-во Московского государственного университета им. М.В. Ломоносова, 1972. - 46 с.
9. Орлов А.И. Что дает прикладная статистика народному хозяйству? // Вестник статистики. - 1986. - No.8. - С.52-56.
10. Орлов А.И. Сертификация и статистические методы (обобщающая статья). // Заводская лаборатория. - 1997. - Т.63. - No.З. - С.55-62.
11. Контроллинг в бизнесе. Методологические и практические основы построения контроллинга в организациях / А.М. Карминский, Н.И. Оленев, А.Г. Примак, С.Г. Фалько. - М.: Финансы и статистика, 1998. - 256 с.
12. Орлов А.И. Задачи оптимизации и нечеткие переменные. - М.: Знание, 1980. - 64 с.
13. The teaching of statistics / Studies in mathematics education. Vol.7. - Paris, UNESCO, 1989. - 258 pp.
14. Ермаков С.М. Метод Монте-Карло и смежные вопросы. - М.: Наука, 1975. - 471 с.
15. Ермаков С.М., Михайлов Г.А. Статистическое моделирование. - М.: Наука, 1982. - 296 с.
16. Иванова И.М. Случайные числа и их применения. - М.: Финансы и статистика, 1984. - 111 с.
17. Ермаков С.М. О датчиках случайных чисел. // Заводская лаборатория. 1993. Т.59. No.7. С.48-50.
18. Неуймин Я.Г. Модели в науке и технике. История, теория, практика. - Л.: Наука, 1984. - 190 с.
19. Моисеев Н.Н. Математические задачи системного анализа. - М.: Наука, 1981. - 488 с.
20. Нейлор Т. Машинные имитационные эксперименты с моделями экономических систем. - М.: Мир, 1975. - 500 с.
21. Эфрон Б. Нетрадиционные методы многомерного статистического анализа. - М.: Финансы и статистика, 1988. - 263 с.
22. Орлов А.И. О реальных возможностях бутстрепа как статистического метода. // Заводская лаборатория. 1987. Т.53. No.10. С.82-85.
23. Бэстенс Д.Э., Берт В.М. ван дер, Вуд Д. Нейронные сети и финансовые рынки: принятие решений в торговых операциях. - М.: ТВП, 1998.
24. Орлов А.И., Жихарев В.Н., Кольцов В.Г. Новый эконометрический метод "ЖОК" оценки результатов взаимовлияний факторов в инженерном менеджменте // Проблемы технологии, управления и экономики / Под общей редакцией к. э. н. Панкова В.А. Ч.1. Краматорск: Донбасская государственная машиностроительная академия, 1999. С.87-89.