Прогнозирование цены компьютера Pentium 166 на 19 декабря 1997 г
Башкирский Государственный Университет
Кафедра финансов и налогообложения
КУРСОВАЯ РАБОТА
НА ТЕМУ:
Прогнозирование цены компьютера
Pentium166 на 19 декабря 1997 года.
Выполнила: студентка дн.от.
эк.ф-та,3-го курса,гр. 3.4ЭЮ
Хакимова Д.И.
Проверила: научный рук-ль,
доцент ,к.э.н.
Саяпова А.Р.
г. Уфа 1997 г.
Содержание :
ВВЕДЕНИЕ
ГЛАВА 1. Характеристика прогнозирования
1.1. Сущность методов прогнозирования
ГЛАВА 2. Постановка задачи
ГЛАВА 3. Сбор и предварительная обработка данных
3.1. Характеристика временного ряда
3.2. Источник информации
3.3. Принцип сбора данных
ГЛАВА 4. Компонентный анализ
ГЛАВА 5. Регрессионная модель
ГЛАВА 6. Прогнозирование на основе модели АРСС
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
ВВЕДЕНИЕ
В настоящее время, решением задачи дальнейшего повышения эффективности производства может быть осуществлено на основе использования достижений науки, в том числе экономико-математического моделирования и вычислительной техники. Проникновение математики в экономику, прогнозирование и управление является определяющей особенностью .
Ускорение темпов математизации в экономике объясняется сложностью экономических систем, анализ которых невозможен без точных методов.
Появление ЭВМ , новых компьютерных программ, компьютерных систем, глобальной сети Internet привлекло к расширению экономико-математических исследований, так как позволило резко сократить время, необходимое для решения сверхбольших задач. Основными направлениями экономического и социального развития на ближайшую перспективу предусматривается обеспечить значительный рост объема производства вычислительной техники, повышения ее надежности.
Экономика и ЭВМ тесно связаны между собой, хотя бы потому что нашли широкое применение в практической деятельности органов и служб снабжения и сбыта, экономисты по материально-техническому снабжению должны хорошо знать математические методы и модели, которые могут быть использованы для совершенствования деятельности сферы обеспечения народного хозяйства материальными ресурсами.
В данной курсовой работе я рассматриваю исследование динамики цен на Pentium166, ведущей компьютерной фирмы “ВИСТ-АРСЕНАЛ”, на основе различных моделей. Данный объект прогнозирования был выбран в соответствии с тем, что в настоящее время все больше предпочтение отдается компьютерам, и их роль в экономике не мало важна.
ГЛАВА 1. Характеристика прогнозирования.
В современных условиях на развитие экономики страны существенное влияние оказывает прогнозирование .
Прогноз является научным предвидением на основании имеющихся данных направления, характера каких либо явлений.
Прогнозирование:
Процесс научного предвидения будущего состояния предмета или явления на основании анализа его прошлого и настоящего ; систематическая научно обоснованная информация о качественных и количественных характеристиках развития этого предмета или явления в перспективе. Результатом прогнозирования является прогноз.
Экономическое прогнозирование - научное предвидение наиболее вероятных изменений состояния, структуры и динамики народного хозяйства, отдельных его элементов в будущем; предварительная стадия перспективного планирования. Важнейшей чертой методологии прогнозирования является системный подход.
Научно-техническое прогнозирование - система оценок возможных целей и путей развития науки и техники, ожидаемый результатов научно-технического прогресса; составная часть экономического прогнозирования. Включает в себя : прогноз проведения научно-исследовательских работ в соответствии с целями, будущими потребностями общества; программный этап прогнозирования на котором определяют меры по реализации целей развития науки и техники; организационный этап , на котором определяются конкретные условия , необходимые для выполнения различных вариантов программ.
Прогнозирование содержит в себе две главные цели: первая - это что будет в будущем, каков прогноз, и вторая - как достигнуть ожидаемого прогноза преодолев все препятствия и сделать прогноз желаемым.
Прогнозирование можно разделить на три формы предвидения:
Гипотеза - предположение, истинность которого недоказана. Доказанная гипотеза становится истиной. Различают гипотезу как метод развития научного знания, включающий выдвижение и предстоящую экспериментальную проверку предположения, и как структурный элемент научной теории.
Прогноз - вносит большую определенность в экспериментальную проверку, определяет более точное состояние объекта.
План - раннее составленный порядок действий, включающий заранее предшествующих гипотез и прогнозов, которые сочетаются различными способами. План может составляться до прогноза, а также следовать за прогнозом, прогноз может развиваться одновременно с разработкой плана.
В основе прогнозирования лежит предпосылка, что зависимость в потреблении , существующая в прошлом, сохраниться и в будущем.
Возможные разновидности прогнозов можно представить в виде следующего ряда:
1. Экономические прогнозы - носят преимущественно общий характер и служат для описания состояния экономики в целом по компании или по конкретным изделиям.
2. Прогнозы развития конкуренции - характеризуют возможную стратегию и практику конкурентов, их долю на рынке и так далее.
3. Прогнозы развития технологии - ориентируют пользователя относительно перспектив развития технологий.
4. Прогнозы состояния рынка - используются для анализа рынка товаров.
5. Социальное прогнозирование - исследует вопросы, связанные с отношением людей к тем или иным общественным явлениям.
Экономические прогнозы можно подразделить на три части:
По масштабности объекта прогнозирования (глобальные прогнозы, макропрогнозы, межотраслевые и межрегиональные прогнозы, региональные прогнозы, прогнозы развития народнохозяйственного комплекса, отраслевые прогнозы, микропрогнозы).
По времени упреждения (долгосрочные прогнозы (от 5 до 20 лет и более), среднесрочные прогнозы (от 1 до 5 лет), краткосрочные (от нескольких месяцев до 1 года), оперативные (до одного месяца)).
По цели прогнозирования (поисковый прогноз, нормативный прогноз).
В современных условиях в силу динамичности процессов, возрастание неопределенности информацией, наиболее актуальным делом и реальным делом, становится краткосрочное прогнозирование. при краткосрочном прогнозировании наиболее важным являются последние данные исследуемого процесса, а не тенденции сложившиеся на всем периоде предыстории.
1.1. Сущность методов прогнозирования
В настоящее время существует множество методов прогнозирования, каждый метод содержит множество приемов мышления , имеет свою отличительную особенность. Более эффективными методами прогнозирования, являются те , которые учитывают неравноценность различных уровней ряда.
Для прогнозирования используются различные математические методы от давно изученных и применяемых в математической статистике корреляционных и регрессионных моделей до новых методов экспоненциального сглаживания.
Разработка прогнозов опирается на следующие группы методов прогнозирования:
Качественные методы, Анализирузируя деятельность предприятия, составляя прогноз его функционирования, аналитик не всегда располагает информацией, достаточной для количественных методов прогнозирования, а иной раз высшее руководство фирмы попросту не понимает сложных методов количественного прогнозирования, что, в любом случае, требует применения качественных методов прогнозирования.
Качественные методы прогнозирования предполагают обращение к мнению экспертов - людей наиболее компетентных по исследуемым вопросам.
К качественным методам прогнозирования можно отнести следующие:
Мнение жюри, как правило, сводится к обобщению мнений экспертов с дальнейшим их усреднением;
Модель ожидания потребностей - метод, являющийся в определенной степени обратным методу совокупного мнения, производится опрос клиентов;
Метод экспертных оценок - отобранные и пользующиеся доверием эксперты заполняют опросный лист.
Из всей совокупности возможных методов анализа, вероятно, одним из наиболее перспективных является балловый метод. Его можно использовать не только для прогнозирования, но и для планирования и для анализа. Этот метод позволяет объективизировать совокупность субъективных мнений.
Впервые балловый метод был разработан и использован аналитиками из США для оценки оборонной мощи Советского Союза.
В настоящее время балловый метод широко используется при решении множества задач планирования и прогнозирования в условиях ограниченности исходных данных, например определение возможных вариантов решения управленческой задачи с количественным исчислением предпочтительности каждого из вариантов, количественной оценки степени влияния на анализируемый объект различных факторов и многих других.
В каждом конкретном случае этапы и последовательность их проведения имеют свою специфику, тем не менее существует общая методология баллового метода, которую в формализованном варианте можно представить следующим образом:
формулирование цели проведения экспертного анализа;
определение группы специалистов , обеспечивающей проведение экспертизы;
разработка и обеспечение проведения экспертного анализа;
формирование группы экспертов, участвующих в экспертизе;
разработка анкеты с формулированием вопросов, исключающих их двоякую трактовку и ориентированных на количественную оценку;
проведение анкетирования;
анализ анкет;
проведение анкетирования во второй, третий, четвертый раз, в зависимости от сложности исследования и требуемой точности;
обобщение результатов.
В основном исполнение практически всех этапов носит технический характер. Полученные результаты могут быть использованы для принятия управленческих решений. Следует еще раз отметить, что метод экспертных оценок универсален и пригоден для решения различных проблем. Все виды экспертных оценок, кроме индивидуального интервьюирования экспертов, предполагают коллективное участие экспертов в работе.
Метод Дельфы представляет набор процедур, выполняемых в определенной очередности и имеющих целью формирования группового мнения по проблеме, характеризующейся недостаточностью информации для использования других методов. Метод Дельфы - это типичный представитель методов группового анкетирования. Опрос экспертов осуществляется либо через внешние устройства ЭВМ, либо с помощью опросных листов, ка правило в несколько туров. Результаты опросов обрабатываются, с целью получения среднего из крайних мнений. От тура к туру ответы экспертов носят более устойчивый характер, перестают изменятся. Такое положение служит основанием для прекращения опросов.
Методы экстраполяции представляют предположение о неизменности факторов, определяющих развитие изучаемого объекта , и заключаются в распространении закономерностей развития объекта в прошлом на его будущее. Сущность этих методов заключается в том, что на основе статистической обработки и анализа динамического ряда определяется его тенденция, так называемый тренд ряда. Группу простых методов экстраполяции, составляют методы прогнозирования , основанные на предположении относительного постоянства в будущем абсолютных значений уровней, среднего уровня ряда, среднего абсолютного прироста, среднего темпа роста. Группа сложных методов экстраполяции, основана на выявлении основной тенденции, т.е. применении статистических формул, описывающих тренд.
Методы многофакторного моделирования подразделяются на методы логического, информационного, статистического моделирования. Логическое моделирование представляет собой метод исторической аналогии, основанный на установлении и использовании аналогии объекта прогнозирования с другим одинаковым объектом , опережающим первым в своем развитии. Методы информационного моделирования составляют специфическую область в прогнозировании. методы статистического прогнозирования описывают взаимосвязи признаков-факторов и результативных признаков, систему уравнений взаимосвязанных рядов динамики.
Нормативный метод прогнозирования устанавливает определенный отрезок времени фиксированной системы норм. Инструментами нормативного метода служат теория графов, матричный подход.
Неформальные методы прогнозирования Наглядная информация - информация получаемая от средств массовой информации (кроме печатных органов), а также смежников, поставщиков, конкурентов. Материальные расходы получения такой информации незначительны, однако требуют большого количества времени. Письменная информация - информация, получаемая из печатных источников периодической печати. Так же, как и наглядная, письменная информация не имеет глубокого характера и быстро устаревает. Промышленный шпионаж - информация, полученная посредством промышленного шпионажа, изначально, как важнейшая, находится под защитой пользователя. Такая информация является наиболее ценной.
Количественные методы прогнозирования Применение таких методов целесообразно в случаях устойчивой экстраполяционной направленности исследуемого явления. Иначе говоря, лишь тогда, когда можно предположить, что деятельность в прошлом имела определенную тенденцию, которую можно ожидать и в перспективе, имеющейся информации достаточно для внесения возможных корректив и выявления статистически достоверных зависимостей.
ГЛАВА 2. Постановка задачи.
Целью работы служит исследование изменений цен на компьютер начального уровня модификации Pentium166, базирующегося на платформе Triton (430VX Chipset), с процессором ADM в корпусе MiniTower, в комплект также входит клавиатура, мышь Mitsumi, монитор Sumsung-14”3Ne. Наблюдение производится с 14.10.96 г. по 15.12.97г., прогнозирование цены на 19.12.97г.
Краткие сведения о компьютерах и выбранной модели.
Сегодня трудно, даже невозможно представить себе такую область человеческой деятельности, где бы не использовались компьютеры.
Компьютер - это машина для обработки информации. Поэтому у любого компьютера должны быть устройства, через которые в него поступает информация; устройства где она хранится и обрабатывается, и , наконец , устройства для вывода результатов.
Данная конфигурация модели Pentium166 содержит все необходимые компоненты, для работы на компьютере. Ведь без мыши, клавиатуры и монитора он не представляет собой ничего, потому что вводить информацию без указанных конфигураций становится невозможным. Конфигурация модели Pentium166: платформа Triton (430VX Chipset), с процессором ADM в корпусе MiniTower, клавиатура, мышь Mitsumi, монитор Sumsung-14”3Ne; на сегодняшний день устарела, хотя еще в прошлом году стояла в ряду первых и дорогих. И будет не удивительно, если через некоторое время вовсе пропадет из числа окупаемых себя моделей. Время не стоит на месте и на смену данной модели прийдет другая, более сильная и современная.
ГЛАВА 3. Сбор и предварительная обработка данных.
3.1. Характеристика временного ряда.
Временным рядом называется последовательность наблюдений упорядоченная во времени. Основной чертой выделяющей анализ временных рядов среди других видов статистического анализа, является существенность порядка, в котором производится наблюдение. Если во многих задачах наблюдение статистически независимо, то во временных рядах, они как правило зависимы и характер этой зависимости может определяться положением наблюдений в последовательности; природа ряда и структура порождающая ряд процессов, могут предопределять порядок образования последовательности . Почти в каждой области встречаются явления, которые интересно изучать, их развитие, изменение во времени. В повседневной жизни могут быть примером : метеорологические условия, цены на тот или иной товар, с течением времени изменяется деловая активность, режим протекания того или иного процесса и т.д.
Характерная черта временных рядов - это особенности трактовки понятие непрерывности и дискретности. Существует непрерывность во времени и непрерывность переменной. Измерение цены на Pentium166 может производится непрерывно, при этом наблюдение можно фиксировать в виде графика. Я ограничиваюсь только временными рядами, представляющие собой дискретную последовательность наблюдений, происходимые через регулярные промежутки, т.е. через равные промежутки времени. Календарные неприятности не возникали, т.к. фирма “ВИСТ-АРСЕНАЛ”, любезно предоставила “прайс-листы” составленные в дни после получения товара, а товар поставлялся машиной независимо от “выходных” и “празднуемых” дней, в каждое Воскресение недели.
Общий вид временного ряда выглядит следующим образом:
U(t) = y(1) + y(2) + ... +y(n),
где t - порядковый номер наблюдения ( t = 1, 2, ... n )
n - уровни временного ряда
Формально задача прогнозирования сводится к получению оценок значений ряда на некотором периоде будущего, т.е. к получению значения вида:
Y(t), t = n + 1, n + 2...
При использовании методов экстраполяции исходят из предположения о сохранении закономерностей прошлого развития на период прогнозирования. Во многих случаях при разработке оперативного и краткосрочного прогноза эти предположения являются справедливыми.
Статистические методы исследования исходят из предположения о возможности представления уровней временного ряда в виде суммы нескольких компонент, отражающих закономерность и случайность развития.
Классической моделью временных рядов является четырех компонентная модель:
U(t) = f(t) + S(t) + n(t) + e(t) ,
где f(t) - тренд (долговременная тенденция развития);
S(t) - сезонная компонента;
n(t) - колебания относительно тренда с большей или меньшей регулярностью;
e(t) - случайная (нерегулярная, несистематическая) компонента;
m ( et ) = 0
cov (et1,et2)=0
("t1 и t2)
Случайная компонента удовлетворяющая этим условиям называется “белым шумом”, т.к. ее спектр похож на спектр белого цвета.
Таким образом задача анализа временных рядов сводится к определенности наличия той или иной компоненты, расчленения на отдельные компоненты синтезу модели, использование модели для прогнозирования и управления процесса.
3.2. Источник информации.
Данные для моделирования были взяты из “прайс-листов” ведущей компьютерной фирмы “ВИСТ-АРСЕНАЛ”. Объектом моделирования выступает компьютер модели Pentium166, базирующегося на платформе Triton (430VX Chipset), с процессором ADM в корпусе MiniTower, в комплект также входит клавиатура, мышь Mitsumi, монитор Sumsung-14”3Ne.
-
Дата
Pentium166
T
Дата
Pentium166
T
14.10.96
6.509
1
19.05.97
5.450
32
21.10.96
6.468
2
26.05.97
5.442
33
28.10.96
6.351
3
02.06.97
5.431
34
04.11.96
6.289
4
09.06.97
5.422
35
11.11.96
6.193
5
16.06.97
5.410
36
18.11.96
6.115
6
23.06.97
5.342
37
25.11.96
6.103
7
30.06.97
5.298
38
02.12.96
5.989
8
07.07.97
4.899
39
09.12.96
5.973
9
14.07.97
4.585
40
16.12.96
5.889
10
21.07.97
4.422
41
23.12.96
5.861
11
28.07.97
4.395
42
30.12.96
5.689
12
04.08.97
4.297
43
06.01.97
5.601
13
11.08.97
4.215
44
13.01.97
5.632
14
18.08.97
3.985
45
20.01.97
5.590
15
25.08.97
3.765
46
27.01.97
5.588
16
01.09.97
3.653
47
03.02.97
5.580
17
08.09.97
3.672
48
10.02.97
5.571
18
15.09.97
3.665
49
17.02.97
5.563
19
22.09.97
3.660
50
24.02.97
5.571
20
29.09.97
3.652
51
03.03.97
5.569
21
06.10.97
3.650
52
10.03.97
5.563
22
13.10.97
3.643
53
17.03.97
5.552
23
20.10.97
3.640
54
24.03.97
5.542
24
27.10.97
3.632
55
31.03.97
5.531
25
03.11.97
3.612
56
07.04.97
5.530
26
10.11.97
3.593
57
14.04.97
5.522
27
17.11.97
3.564
58
21.04.97
5.502
28
24.11.97
3.514
59
28.04.97
5.500
29
01.12.97
3.510
60
05.05.97
5.480
30
08.12.97
3.508
61
12.05.97
5.463
31
15.12.97
3.498
62
3.3 Принцип сбора данных.
Данные были собраны путем просмотра “прайс-листов” за период с 14.10.97 по 15.12.97 , которые фирма хранила как в базе данных компьютера, в глобальной сети Internet, а так же и в “подшитом” виде.
График исходных данных.

ГЛАВА 4. Компонентный анализ.
Оценка Тренда.
Тренд - это некоторая функция времени. Тренд характеризует основную закономерность движения во времени, свободную в основном (но не полностью) от случайных воздействий.
Обычно полученная траектория связывается исключительно со временем. Предполагается, что рассматривая любое явление как функцию времени, можно выразить влияние всех остальных факторов. Механизм их влияния в явном виде не учитывается. Исходя из вышесказанного под трендом понимается регрессия на время. Более общее понятие тренда весьма удобное на практике, - это детерминированная составляющая динамики развития, определяемая влиянием постоянно действующих факторов. Отклонения от тренда являются случайной составляющей.
Оценка тренда возможна на основе двух подходов:
оценка на основе гладких функций х = f(x); (параметрические методы)
на основе разного рода скользящих средних (непараметрические методы)
Я оценивала тренд методом вторых разностей.
X - 0.000-1.00*X(t-1); X-0.000-1.00*x(t-1)
Удаление Тренда
Иногда из некоторых временных рядов нужно удалить линейный ил медленно меняющийся тренд . Такого рода тренды наблюдаются в рядах, например, при суммировании одной или нескольких компонент, приводящим к ошибкам двух типов. Во-первых при неправильной калибровке нулевой точки каждый момент отбора данных будет возникать небольшая ошибка. После суммирования эта постоянная величина даст прямую. Такой линейный тренд может привести к большим ошибкам при определении плотности спектра мощности и в связанных с этим вычислениях . Ошибка второго типа возникает из-за возрастания в процессе суммирования мощности, соответствующей низкочастотному шуму. Как правило такой шум в данных всегда есть. При суммировании он обретает форму случайного, но медленно меняющегося тренда. Насколько быстро меняется такой тренд, до некоторой степени зависит от интервала квантования.
Наилучшим способом удаления тренда служит применение высокочастотных фильтров. Полимиальный тренд можно удалять методом наименьших квадратов. Если требуется удаление многочленов только низких порядков, то решение соответствующей системы методом обратной матрицы можно свести к непосредственному вычислению коэффициентов с использованием памяти ЭВМ.
После того как удалили тренд, то получили стационарный ряд.
На графике можно увидеть остатки после удаления тренда.

Стационарный ряд выглядит как не совсем регулярные колебания, около некоторого среднего уровня.
Стационарный случайный процесс может быть представлен в виде суммы гармонических колебаний различных частот, называемых гармониками.
Функция, описывающая распределение амплитуд этого процесса по различным частотам, называется спектральной плотностью. График называется спектром.
Спектр (периодическая шкала).

Спектр показывает, какого рода колебания преобладают в данном процессе, какова его внутренняя структура.
Стационарная случайная функция Х(t) может быть представлена ввиде канонического разложения:
¥
X(t) = å (UkCOSWkT + VkSINWkT)
k=0
где Uk,Vk - некоррелированные случайные величины с математическими ожиданиями, равными нулю, и одинаковыми дисперсиями, т.е.
D(Uk) = D(Vk ) = Dk.
Такое разложение называется спектральным разложением стационарного случайного процесса X = Х(t). Спектр стационарной случайной функции описывает распределение дисперсий по различным частотам.
Дисперсия стационарной случайной функции равна сумме дисперсий всех гармоник ее спектрального разложения.
Отсюда делаем вывод, что дисперсия величины Х(t) определенным образом распределена по различным частотам: одним частотам соответствует большая дисперсия, другим - меньшая дисперсия.
Функция x(w) = Dk/W называется спектральной плотностью дисперсии или спектральной плотностью стационарной случайной функци Х(t).
При анализе временных рядов применяется спектральный анализ стационарных случайных функций.
Целью спектрального анализа временных рядов является оценка спектра ряда. Спектром временного ряда, является разложение дисперсии ряда по частотам для определения существенных гармонических составляющих.
Значение спектра оценивается по формуле:
m
f (Wj ) = 1/2p {hoco+ 2 å hk ck cos Wj k }
k=1
где Wj - частоты, для которых оцениваются спектры:
Wj =p j/ ; j = 1,2,...m;
где ck - автоковариационная функция;
hk - специально подобранные веса значений ковариационной функции,
зависящие от частоты m;
hk - еще называют кореляционным окном;
m - целое число называемое точкой усечения или числом
используемых сдвигов и представляющее собой число частотных
полос, для которых оценивается спектр.
Чем больше m , тем больше точек оцениваемого спектра, а следовательно, и больше дисперсия оценки в каждой точке.
Чем меньше m, тем лучше оценка.
Величина m зависит от длины временного ряда.
На графике где изображен спектр можно проследить возрастание и убывание спектра, на графике также можно наблюдать пики т.е. отклонения от тренда.
Но также исходя из этого, можно увидеть что временной ряд не имеет периодичности, т. е. нет исходных повторяющихся особенностей ряда.
Кроме того, спектральный анализ можно еще рассмотреть путем изучения сезонных колебаний. Это бы позволило выявить периодические составляющие исследуемого ряда с целью повышения точности прогнозирования.
В данной работе удаление сезонной компоненты не представляет возможности, так как исследуемый ряд не имеет сезонности.
Башкирский Государственный Университет
Кафедра финансов и налогообложения
ПРИЛОЖЕНИЕ
к курсовой работе на тему:
Прогнозирование цены на
комьютер Pentium 166
на 19 декабря 1997 года.
Выполнила: студентка дн.от.
эк.ф-та,3-го курса,гр. 3.4ЭЮ
Хакимова Д.И.
Проверила: научный рук-ль,
доцент ,к.э.н.
Саяпова А.Р.
г. Уфа 1997 г.
Содержание приложения:
Удаление тренда различными способами используемые программой Statistika версии 4.3
Модель Holt (a =0.300,a=0.800)
Модель Winters (a =0.300,a=0.800)
Модель Брауна (a =0.300,a=0.800)
Регрессионная модель
Удаление тренда различными способами используемые программой Statistika версии 4.3
Я работала в программе Statistica 4.3 которая позволяет удалить тренд, исходя из ниже предложенных графиков можно увидеть различные способы для его удаления. Но эти способы не явились более подходящими, и поэтому представлены для анализа проделанной курсовой работе.

На этом графике использовался метод Trend sub>tract
(x=x-(a+b*t)), где а= 6.606, b = -0.52 .
Тренд в данном случае неудалился, так как сам тренд не линейный.
Сделав вывод, что тренд не линейный, я проделала попытку удалить тренд в Nonlinear Estimatoin получила следущее:
-
Model: PENTIUM = b1+b2/t+b3/t**2
N=62
Dep.var: PENTIUM loss (OBS - PRED)**2
FINAL loss:31.852464424 R=.67433
variance explained: 45.473%
b1
b2
b3
Estimate
4.34597
11.85681
-10.0804
График удаления тренда не линейным способом:

Выше описанным способом тренд тоже не удалился.
Модель Holt (a =0.300,a=0.800)
Примером адаптивной модели предназначенной для прогнозирования сезонных процессов, является модель Хольта. Эта модель предполагает мультипликативное объединение линейного тренда и сезонные составляющие во временном ряду.
Модель Хольта при a = 0.300
Exp.smoothing: SO=6.534 TO = 0.49
-
TIME
SERIES
Summury of error
Lin.trend; no season;
Alpha= 0.300 Gamma=0.1
PENTIUM
Error
Mean error
.00731672825436
Mean absolute error
.13134104302219
Sums of squares
1.96424677027454
Mean squares
.03168139952056
Mean percentage error
.26328877539247
Mean abs. pers.
3.01698849598955
График по Хольту с a = 0.300

Exp.smoothing: SO=6.534 TO = 0.49
-
CASE
SMOOTHED SERIES
16.12.97
3.379367
17.12.97
3.343613
18.12.97
3.307860
19.12.97
3.272107
Модель Хольта при a = 0.800
Exp.smoothing: SO=6.534 TO = 0.49
-
TIME
SERIES
Summury of error
Lin.trend; no season;
Alpha= 0.800 Gamma=0.1
PENTIUM
Error
Mean error
.00315177373958
Mean absolute error
.05706002635321
Sums of squares
.48259413419920
Mean squares
.00778377635805
Mean percentage error
.12944834490985
Mean abs. pers.
1.26337346085392
График по Хольту с a = 0.800

Exp.smoothing: SO=6.534 TO = 0.49
-
CASE
SMOOTHED SERIES
16.12.97
3.457111
17.12.97
3.423383
18.12.97
3.398655
19.12.97
3.355927
Модель Winters (a =0.300,a=0.800)
Модель Уйнтерса при a = 0.300
Exp.smoothing:Multipl.season(12) SO=6.433 TO = 0.52
-
TIME
SERIES
Summury of error
Lin.trend; no season; Alpha= 0.300 Delta=.100; Gamma=0.1
PENTIUM
Error
Mean error
.00850967552279
Mean absolute error
.13196744584935
Sums of squares
2.02519074270767
Mean squares
.03266436817876
Mean percentage error
.27239869561423
Mean abs. pers.
3.02001823889308
График по Уинтерсу с a = 0.300

Exp.smoothing:Multipl.season(12) SO=6.433 TO = 0.52
-
CASE
SMOOTHED SERIES
16.12.97
3.373012
17.12.97
3.337162
18.12.97
3.309019
19.12.97
3.283079
Модель Уйнтерса при a = 0.800
Exp.smoothing:Multipl.season(12) SO=6.433 TO = 0.52
-
TIME
SERIES
Summury of error
Lin.trend; no season; Alpha= 0.800 Delta=.100; Gamma=0.1
PENTIUM
Error
Mean error
.00387269483310
Mean absolute error
.06040575200437
Sums of squares
.54276104822497
Mean squares
.00875421046649
Mean percentage error
.14058659957529
Mean abs. pers.
1.32624409579650
График по Уинтерсу с a = 0.800

Exp.smoothing:Multipl.season(12) SO=6.433 TO = 0.52
-
CASE
SMOOTHED SERIES
16.12.97
3.453841
17.12.97
3.429777
18.12.97
3.407928
19.12.97
3.380729
Модель Брауна (a =0.300,a=0.800)
Модель Брауна может отображать развитие не только в виде линейной тенденции, нои в виде случайного процесса, не имеющего тенденции, а также ввиде изиеняющейся параболической тенденции.
Модель Брауна при a = 0.300
Exp.smoothing: SO=4.982
-
TIME
SERIES
Summury of error
Lin.trend; no season;
Alpha= 0.300
PENTIUM
Error
Mean error
-.0780414476807
Mean absolute error
.1978141110028
Sums of squares
6.8610393089365
Mean squares
.1106619243377
Mean percentage error
-2.2104491142263
Mean abs. pers.
4.0726990990745
График по Брауну с a = 0.300
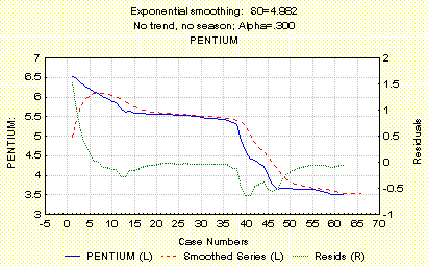
Exp.smoothing: SO=4.982
-
CASE
SMOOTHED SERIES
16.12.97
3.530736
17.12.97
3.530736
18.12.97
3.530736
19.12.97
3.530736
Модель Брауна при a = 0.800
Exp.smoothing: SO=4.982
-
TIME
SERIES
Summury of error
Lin.trend; no season;
Alpha= 0.300
PENTIUM
Error
Mean error
-.0298811251614
Mean absolute error
.08804695430620
Sums of squares
3.1058602054085
Mean squares
.05009465809765
Mean percentage error
-.90807550618029
Mean abs. pers.
1.70449937474829
График по Брауну с a = 0.800

Exp.smoothing: SO=4.982
-
CASE
SMOOTHED SERIES
16.12.97
3.500203
17.12.97
3.500203
18.12.97
3.500203
19.12.97
3.500203
Прогнозирование по вышеуказанным моделям получается не совсем стабильным.
Регрессионная модель
В экономической деятельности очень часто требуется не только получать прогнозные оценки исследуемого показателя, но и количественно охарактеризовать степень влияния на него других факторов.
Рассматривая зависимость цены на компьютер Pentium166 и инфляции я получаю:
REGRESSION SUMMARY for Dependent Variable: PENTIUM
|
R=.68998993 RI=.47608611 Abjusted RI=.45593557 F(1,26)=23.626 p<.00005 std. Err of estimate |
||||||
|
N = 28 |
BETA |
St.Err. of BETA |
B |
St.Err. of B |
t(26) |
p-level |
|
Intercpt |
6.701069 |
.537806 |
12.46001 |
.000000 |
||
|
Inf |
-6.89990 |
1.41953 |
-.345470 |
.071074 |
-4.86071 |
.000049 |