Принципи мережевого аналізу та оптимізації
Принципи мережевого аналізу та оптимізації
1. СУТНІСТЬ ТА ШЛЯХИ ОПТИМІЗАЦІЇ МЕРЕЖЕВОГО АНАЛІЗУ
Для підвищення ефективності роботи будь-якої транспортної інфокомунікаційної мережі необхідно:
1. Сформулювати критерії ефективності роботи мережі. Найчастіше такими критеріями стають продуктивність і надійність, для яких, у свою чергу, потрібно обрати конкретні показники оцінки, наприклад, час реакції і коефіцієнт готовності, відповідно.
2. Обмежити безліч варійованих параметрів мережі, що прямо або побічно впливають на критерії ефективності визначеною множиною. Ці параметри дійсно повинні бути варійованими, тобто потрібно переконатися в тому, що їх можна змінювати в деяких межах за нашим бажанням. Так, якщо розмір пакету якого-небудь протоколу в конкретній операційній системі встановлюється автоматично і не може бути змінений шляхом налаштування, то цей параметр в даному випадку не є варійованим, хоча в іншій операційній системі він може відноситься до змінних за бажанням адміністратора, а значить і варійованим. Іншим прикладом може служити пропускна спроможність внутрішньої шини маршрутизатора - вона може розглядатися, як параметр оптимізації тільки в тому випадку, якщо допускаємо можливість заміни обладнання в мережі.
Всі варійовані параметри можуть бути згруповані різним чином.
3. Визначити поріг чутливості для значень критерію ефективності. Так, продуктивність мережі можна оцінювати логічними значеннями "Працює"/"Не працює", і тоді оптимізація зводиться до діагностики несправностей і приведення мережі в будь-який працездатний стан. Іншим крайнім випадком є тонке налаштування мережі, при якій параметри працюючої мережі (наприклад, розмір кадру або величина вікна непідтверджених пакетів) можуть варіюватися з метою підвищення продуктивності (наприклад, середнього значення часу реакції) хоч би на декілька відсотків. Як правило, під оптимізацією мережі розуміють деякий проміжний варіант, при якому потрібно вибрати такі значення параметрів мережі, щоб показники її ефективності істотно покращилися, наприклад, користувачі в комп'ютерній мережі отримували відповіді на свої запити до сервера баз даних не за 10 секунд, а за 3 секунди, а передача файлу на віддалений комп'ютер виконувалася не за 2 хвилини, а за 30 секунд.
Таким чином, можна запропонувати три різні трактування завдання оптимізації:
1. Приведення мережі в будь-який працездатний стан. Зазвичай це завдання вирішується першим, і включає:
• пошук несправних елементів мережі - кабелів, роз'ємів, адаптерів, комп'ютерів;
• перевірку сумісності устаткування і програмного забезпечення;
• вибір коректних значень ключових параметрів програм і пристроїв, що забезпечують проходження повідомлень між всіма вузлами мережі, - адрес мереж і вузлів, використовуваних протоколів, типів кадрів Ethernet і т.п.
2. Грубе налаштування - вибір параметрів та конфігурації, що різко впливають на характеристики (надійність, продуктивність) мережі. Якщо мережа працездатна, але обмін даними відбувається дуже поволі (час очікування складає десятки секунд або хвилини) або ж сеанс зв'язку часто розривається без видимих причин, то працездатною таку мережу можна назвати тільки умовно, і вона безумовно потребує грубого налаштування. На цьому етапі необхідно знайти ключові причини істотних затримок проходження пакетів в мережі. Зазвичай причина серйозного уповільнення або нестійкої роботи мережі криється в одному невірно працюючому елементі або некоректно встановленому параметрі, але через велику кількість можливих винуватців пошук може зажадати тривалого спостереження за роботою мережі і громіздкого перебору варіантів. Грубе налаштування багато в чому схоже на приведення мережі в працездатний стан. Тут також зазвичай задається деяке порогове значення показника ефективності і потрібно знайти такий варіант мережі, у якого це значення було б не гірше порогового. Наприклад, потрібно побудувати транспортну мережу так, шоб пропускна здатність задовольнила субпровайдерів з деяким запасом на майбутнє.
3. Тонке налаштування параметрів мережі (власне оптимізація). Якщо мережа працює задовільно, то подальше підвищення її продуктивності або надійності навряд чи можна досягти зміною тільки якого-небудь одного параметра, як це було у разі повністю непрацездатної мережі або ж у разі її грубого налаштування. У разі нормальної працюючої мережі подальше підвищення її якості зазвичай вимагає знаходження деякого вдалого поєднання значень великої кількості параметрів, тому цей процес і отримав назву "Тонкого налаштування".
Навіть при тонкому налаштуванні мережі оптимальне поєднання її параметрів (у строгому математичному розумінні терміну "оптимальність") отримати неможливо, та і не потрібно. Немає сенсу витрачати колосальні зусилля по знаходженню строгого оптимуму, що відрізняється від близьких до нього режимів роботи на величини такого ж порядку, що і точність вимірювань трафіку в мережі. Досить знайти будь-яке з близьких до оптимального рішень, щоб рахувати завдання оптимізації мережі вирішеної. Такі близькі до оптимального рішення зазвичай називають раціональними варіантами, і саме їх пошук цікавить на практиці адміністратора мережі або мережевого інтегратора.
Пошук несправностей в мережі - це поєднання аналізу (вимірювання, діагностика і локалізація помилок) і синтезу (ухвалення рішення про те, які зміни треба внести до роботи мережі, щоб виправити її роботу).
■ Аналіз - визначення значення критерію ефективності (або, що одне і те ж, критерію оптимізації) системи для даного поєднання параметрів мережі. Іноді з цього етапу виділяють підетап моніторингу, на якому виконується простіша процедура, - процедура збору первинних даних про роботу мережі: статистики про кількість циркулюючих в мережі кадрів і пакетів різних протоколів, стан портів концентраторів, комутаторів і маршрутизаторів і т.п. Далі виконується етап власне аналізу, під яким в цьому випадку розуміється складніший і інтелектуальний процес осмислення зібраної на етапі моніторингу інформації, зіставлення її з даними, отриманими раніше, і вироблення припущень про можливі причини сповільненої або ненадійної роботи мережі. Завдання моніторингу вирішується програмними і апаратними вимірниками, тестерами, мережевими аналізаторами і вбудованими засобами моніторингу систем управління мережами і системами. Завдання аналізу вимагає активнішої участі людини, а також використання таких складних засобів як експертні системи, що акумулюють практичний досвід багатьох мережевих фахівців.
■ Синтез - вибір значень варійованих параметрів, при яких показник ефективності має якнайкраще значення. Якщо задано порогове значення показника ефективності, то результатом синтезу повинен бути один з варіантів мережі, що перевершує заданий поріг. Приведення мережі в працездатний стан - це також синтез, при якому знаходиться будь-який варіант мережі, для якого значення показника ефективності відрізняється від стану "не працює". Синтез раціонального варіанту мережі - процедура найчастіше неформальна, оскільки вона пов'язана з вибором дуже великого і дуже різнорідної безлічі параметрів мережі - типів вживаного комунікаційного устаткування, моделей цього устаткування, числа серверів, типів комп'ютерів, використовуваних як сервери, типи та виробник транспортних систем, параметри цих транспортних систем, стеки комунікаційних протоколів, їх параметри і т.д. і т.п. Дуже часто мотиви, що впливають на вибір "в цілому", тобто вибір типа або моделі обладнання, стека протоколів або операційної системи, не носять технічного характеру, а приймаються з інших міркувань - комерційних, "політичних" і т.п. Тому формалізувати постановку завдання оптимізації в таких випадках просто неможливо. Тут основна увага приділяється етапам моніторингу і аналізу мережі, як формальнішим процедурам, що автоматизуються. У тих випадках, коли це можливо, у даній роботі даються рекомендації з виконання деяких послідовностей дій по знаходженню раціонального варіанту мережі або приводяться міркування, що полегшують його пошук.
2. КРИТЕРІЇ ЕФЕКТИВНОСТІ РОБОТИ МЕРЕЖІ
Вся множина найбільш часто використовуваних критеріїв ефективності роботи мережі може бути розділена на дві групи. Одна група характеризує продуктивність роботи мережі, друга, - надійність.
Продуктивність мережі вимірюється за допомогою показників двох типів - тимчасових, таких, що оцінюють затримку, що вноситься мережею при виконанні обміну даними, і показників пропускної спроможності, що відображають кількість інформації, переданою мережею в одиницю часу. Ці два типи показників є взаємно зворотними, і, знаючи один з них, можна обчислити інший.
2.1 ЧАС РЕАКЦІЇ
Зазвичай, як тимчасова характеристика продуктивності мережі використовується такий показник як час реакції. Термін "час реакції" може використовуватися в дуже широкому сенсі, тому у кожному конкретному випадку необхідно уточнити, що розуміється під цим терміном.
У загальному випадку, час реакції визначається як інтервал часу між виникненням запиту користувача до будь-якого мережевому сервісу і отриманням відповіді на цей запит. Очевидно, що сенс і значення цього показника залежать від типу сервісу, до якого звертається користувач, від того, який користувач і до якого сервера звертається, а також від поточного стану інших елементів мережі - завантаженості сегментів, через які проходить запит, завантаженості сервера і т.п.
Для кінцевого користувача таким чином певний час реакції є зрозумілим і найбільш природним показником продуктивності мережі (розмір файлу, який вносить деяку невизначеність до цього показника, можна зафіксувати, оцінюючи час реакції при передачі, наприклад, одного мегабайта даних). Проте, мережевого фахівця цікавить в першу чергу продуктивність власне мережі, тому для точнішої її оцінки доцільно відокремити з часу реакції складові, відповідні етапам немережевої обробки даних - пошуку потрібної інформації на диску, записи її на диск і т.п. Отриманий в результаті таких скорочень час можна вважати іншим визначенням часу реакції мережі на прикладному рівні.
При оцінці продуктивності мережі не по відношенню до окремих пар вузлів, а до всіх вузлів в цілому використовуються критерії двох типів: середньо-зважені і порогові.
Середньо-зважений критерій є сумою часів реакції всіх або деяких вузлів при взаємодії зі всіма або деякими серверами мережі за певним сервісом, тобто сумою вигляду
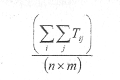
де Тij - час реакції і-го клієнта при зверненні до j-ro сервера, n - число клієнтів, m - число серверів. Якщо усереднювання проводиться і за сервісами, то в приведеному виразі додасться ще одне підсумовування - по кількості сервісів, що враховуються. Оптимізація мережі за даним критерієм полягає в знаходженні значень параметрів, при яких критерій має мінімальне значення або принаймні не перевищує деяке задане число.
Пороговий критерій відображає найгірший час реакції за всіма можливими поєднаннями клієнтів, серверів і сервісів:
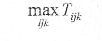
де і і j мають той же сенс, що і у попередньому випадку, а k позначає тип сервісу. Оптимізація також може виконуватися з метою мінімізації критерію, або ж з метою досягнення їм деякої заданої величини, розумної, що визнається, з практичної точки зору.
Частіше застосовуються порогові критерії оптимізації, оскільки вони гарантують всім користувачам деякий задовільний рівень реакції мережі на їх запити. Середньо-зважені критерії можуть дискримінувати деяких користувачів, для яких час реакції дуже великий при тому, що при усереднюванні отриманий цілком прийнятний результат.
Можна застосовувати і більш диференційовані за категоріями користувачів і ситуаціями критерії. Наприклад, можна поставити перед собою мету гарантувати будь-якому користувачеві доступ до сервера, що знаходиться в його сегменті, за час, що не перевищує 5 секунд, до серверів, що знаходяться в його мережі, але в сегментах, відокремлених від його сегменту комутаторами, за час, не що перевищує 10 секунд, а до серверів інших мереж - за час до 1 хвилини.
2.2 ПРОПУСКНА ЗДАТНІСТЬ
Основне завдання, для вирішення якої будується будь-яка мережа - швидка передача інформації між комп'ютерами. Тому критерії, пов'язані з пропускною спроможністю мережі або частини мережі, добре відображають якість виконання мережею її основної функції.
Існує велика кількість варіантів визначення критеріїв цього вигляду, точно таких, як і у разі критеріїв класу "час реакції". Ці варіанти можуть відрізнятися один від одного: вибраною одиницею вимірювання кількості передаваної інформації, характером даних, що враховуються, - тільки призначені для користувача або ж призначені для користувача разом із службовими, кількістю точок вимірювання передаваного трафіку, способом усереднювання результатів на мережу в цілому. Розглянемо різні способи побудови критерію пропускної спроможності детальніше.
А) Критерії вимірювання, які відрізняються одиницею інформації, шо передається:
В якості одиниці вимірювання інформації, шо передається зазвичай використовуються пакети (або кадри, далі ці терміни використовуватимуться як синоніми) або біти. Відповідно, пропускна спроможність вимірюється в пакетах в секунду або ж в бітах в секунду.
Оскільки обчислювальні мережі працюють за принципом комутації пакетів (або кадрів), тo вимірювання кількості переданої інформації в пакетах має сенс, тим більше що пропускна спроможність комунікаційного устаткування, що працює на канальному рівні і вище, також найчастіше вимірюється в пакетах в секунду. Проте, внаслідок змінного розміру пакету (це характерно для всіх протоколів за виключенням ATM, що має фіксований розмір пакету в 53 байти), вимірювання пропускної спроможності в пакетах в секунду пов'язане з деякою невизначеністю - пакети якого протоколу і якого розміру маємо на увазі? Найчастіше розглядають пакети протоколу Ethernet, як найпоширенішого, що мають мінімальний для протоколу розмір в 64 байти (без преамбули). Пакети мінімальної довжини вибрані як еталонні через те, що вони створюють для комунікаційного устаткування найбільш важкий режим роботи - обчислювальні операції, вироблювані з кожним пакетом, що прийшов, в дуже слабкій мірі залежать від його розміру, тому на одиницю переносимої інформації обробка пакету мінімальної довжини вимагає виконання значно більше операцій, чим для пакету максимальної довжини.
Вимірювання пропускної спроможності в бітах на секунду (для локальних мереж характерніші швидкості, вимірювані в мільйонах біт на секунду, - Мбіт/с) дає точнішу оцінку швидкості передаваної інформації, ніж при використанні пакетів.
Б) Критерії, що відрізняються врахуванням службової інформації:
У будь-якому протоколі є заголовок, що переносить службову інформацію, і поле даних, в якому переноситься інформація, що вважається для даного протоколу призначеної для користувача. Наприклад, в кадрі протоколу Ethernet мінімального розміру 46 байт (з 64) є поле даних, а що залишилися 18 є службовою інформацією. При вимірюванні пропускної спроможності в пакетах в секунду відокремити призначену для користувача інформацію від службової неможливо, а при побітовому вимірюванні - можна.
Якщо пропускна спроможність вимірюється без ділення інформації на призначену для користувача і службову, то в цьому випадку не можна ставити завдання вибору протоколу або стека протоколів для даної мережі. Це пояснюється тим, що навіть якщо при заміні одного протоколу на іншій ми отримаємо вищу пропускну спроможність мережі, то це не означає, що для кінцевих користувачів мережа працюватиме швидше - якщо частка службової інформації, що доводиться на одиницю призначених для користувача даних, у цих протоколів різна (а в загальному випадку це так), то можна у якості оптимального вибрати повільніший варіант мережі. Якщо ж тип протоколу не змінюється при налаштуванні мережі, то можна використовувати і критерії, що не виділяють призначені для користувача дані із загального потоку.
При тестуванні пропускної спроможності мережі на прикладному рівні найлегше вимірювати якраз пропускну спроможність за призначеними для користувача даними. Для цього досить виміряти час передачі файлу певного розміру між сервером і клієнтом і розділити розмір файлу на отриманий час. Для вимірювання загальної пропускної спроможності необхідні спеціальні інструменти вимірювання - аналізатори протоколів або SNMP або RMON агенти, вбудовані в операційні системи, мережеві адаптери або комунікаційне устаткування.
В) Критерії, що відрізняються кількістю і розташуванням точок вимірювання:
Пропускну спроможність можна вимірювати між будь-якими двома вузлами або точками мережі, наприклад, між клієнтським комп'ютером і сервером. При цьому значення пропускної спроможності, що отримуються, змінюватимуться за одних і тих же умов роботи мережі залежно від того, між якими двома точками проводяться вимірювання. Оскільки в мережі одночасно працює велике число призначених для користувача комп'ютерів і серверів, то повну характеристику пропускної спроможності мережі дає набір пропускних спроможностей, зміряних для різних поєднань взаємодіючих комп'ютерів, - так звана матриця трафіку вузлів мережі. Існують спеціальні засоби вимірювання, які фіксують матрицю трафіку для кожного вузла мережі.
Оскільки в мережах дані на шляху до вузла призначення зазвичай проходять через декілька транзитних проміжних етапів обробки, то як критерій ефективності може розглядатися пропускна спроможність окремого проміжного елементу мережі - окремого каналу, сегменту або комунікаційного пристрою.
Знання загальної пропускної спроможності між двома вузлами не може дати повної інформації про можливі шляхи її підвищення, оскільки із загальної цифри не можна зрозуміти, яким з проміжних етапів обробки пакетів найбільшою мірою гальмує роботу мережі. Тому дані про пропускну спроможність окремих елементів мережі можуть бути корисні для ухвалення рішення про способи її оптимізашї.
Має сенс визначити загальну пропускну спроможність мережі як середню кількість інформації, переданої між всіма вузлами мережі в одиницю часу. Загальна пропускна спроможність мережі може вимірюватися як в пакетах в секунду, так і в бітах в секунду. При діленні мережі на сегменти або підмережі загальна пропускна спроможність мережі рівна сумі пропускних спроможностей підмереж плюс пропускна спроможність міжсегментних або міжмережевих зв'язків.
Для аналізу пропускної спроможності можна користуватися як методами, що утворені на основі розбиття на під мережі та визначення мінімального перерізу за теоремою Форда-Фолкерсона, так і за моделлю, побудованою на основі теореми Котлярова для сукупності систем масового обслуговування.
2.3 ПОКАЗНИКИ НАДІЙНОСТІ ТА ВІДМОВОСТІЙКОСТІ
Найважливішою характеристикою транспортної магістральної мережі є надійність - здатність правильно функціонувати протягом тривалого періоду часу. Ця властивість має три складових: власне надійність, готовність і зручність обслуговування.
Підвищення надійності полягає в запобіганні несправностям, відмовам і збоям за рахунок застосування електронних схем і компонентів з високим ступенем інтеграції, зниження рівня перешкод, полегшених режимів роботи схем, забезпечення теплових режимів їх роботи, а також за рахунок вдосконалення методів збірки апаратури. Надійність вимірюється інтенсивністю відмов і середнім часом напрацювання на відмову. Надійність мереж як розподілених систем багато в чому визначається надійністю кабельних систем і комутаційної апаратури - роз'ємів, кросових панелей, комутаційних шаф і т.п., що забезпечують власне електричну або оптичну зв'язність окремих вузлів між собою.
Підвищення готовності передбачає придушення в певних межах впливу відмов і збоїв на роботу системи за допомогою засобів контролю і корекції помилок, а також засобів автоматичного відновлення циркуляції інформації в мережі після виявлення несправності. Підвищення готовності є боротьбою за зниження часу простою системи.
Критерієм оцінки готовності є коефіцієнт готовності, який може інтерпретуватися, як вірогідність знаходження системи в працездатному стані. Коефіцієнт готовності обчислюється як відношення середнього часу напрацювання на відмову до суми цієї ж величини і середнього часу відновлення. Системи з високою готовністю називають також відмовостійкими.
Основним способом підвищення готовності є надмірність, на основі якої реалізуються різні варіанти відмовостійкої архітектури. Обчислювальні мережі включають велику кількість елементів різних типів, і для забезпечення відмовостійкості необхідна надмірність по кожному з ключових елементів мережі. Якщо розглядати мережу тільки як транспортну систему, то надмірність повинна існувати для всіх магістральних маршрутів мережі, тобто маршрутів, що є загальними для великої кількості клієнтів мережі. Такими маршрутами зазвичай є маршрути до корпоративних серверів - серверів баз даних, Web-серверів, поштових серверів і т.п. Тому для організації відмовостійкої роботи всі елементи мережі, через які проходять такі маршрути, повинні бути зарезервовані: повинні бути резервні кабельні зв'язки, якими можна скористатися при відмові одного з основних кабелів, всі комунікаційні пристрої на магістральних шляхах повинні або самі бути реалізовані по відмовостійкій схемі з резервуванням всіх основних своїх компонентів, або для кожного комунікаційного пристрою повинен бути резервний аналогічний пристрій.
Перехід з основного зв'язку на резервний або з основного пристрою на резервний може відбуватися як в автоматичному режимі, так і вручну, за участю адміністратора. Очевидно, що автоматичний перехід підвищує коефіцієнт готовності системи, оскільки час простою мережі в цьому випадку буде істотно менший, ніж при втручанні людини. Для виконання автоматичних процедур реконфігурації необхідно мати в мережі інтелектуальні комунікаційні пристрої, а також централізовану систему управління, що допомагає пристроям розпізнавати відмови в мережі і адекватно на них реагувати.
Високий ступінь готовності мережі можна забезпечити у тому випадку, коли процедури тестування працездатності елементів мережі і переходу на резервні елементи вбудовані в комунікаційні протоколи. Прикладом такого типу протоколів може служити протокол FDDI, в якому постійно тестуються фізичні зв'язки між вузлами і концентраторами мережі, а у разі їх відмови виконується автоматична реконфігурація зв'язків за рахунок вторинного резервного кільця. Існують і спеціальні протоколи, що підтримують відмовостійкість мережі, наприклад, протокол SpanningTree, що виконує автоматичний перехід на резервні зв'язки в мережі, побудованій на основі мостів і комутаторів.
Існують різні градації відмовостійких комп'ютерних систем, до яких відносяться і обчислювальні мережі. Приведемо декілька загальноприйнятих визначень:
• висока готовність (highavailability) - характеризує системи, що виконані за звичайною комп'ютерною технологією, використовують надмірні апаратні і програмні засоби і відновлення, що допускають час, в інтервалі від 2 до 20 хвилин;
• стійкість до відмов (faulttolerance) - характеристика таких систем, які мають в гарячому резерві надмірну апаратуру для всіх функціональних блоків, включаючи процесори, джерела живлення, підсистеми введення/висновку, підсистеми дискової пам'яті, причому час відновлення при відмові не перевищує однієї секунди;
• безперервна готовність (continuousavailability) - це властивість систем, які також забезпечують час відновлення в межах однієї секунди, але на відміну від систем стійких до відмов, системи безперервної готовності усувають не тільки простої, що виникли в результаті відмов, але і планові простої, пов'язані з модернізацією або обслуговуванням системи. Всі ці роботи проводяться в режимі online. Додатковою вимогою до систем безперервної готовності є відсутність деградації, тобто система повинна підтримувати постійний рівень функціональних можливостей і продуктивності незалежно від виникнення відмов.
Оскільки мережі обслуговують одночасно велику кількість користувачів, то при розрахунку коефіцієнта готовності необхідно враховувати цю обставину. Коефіцієнт готовності мережі повинен відповідати довшому часу, протягом якого мережа виконувала з належною якістю свої функції для всіх користувачів. Очевидно, що у великих мережах дуже важко забезпечити значення коефіцієнта готовності, близькі до одиниці.
Між показниками продуктивності і надійності мережі існує тісний зв'язок. Ненадійна робота мережі дуже часто призводить до істотного зниження її продуктивності. Це пояснюється тим, що збої і відмови каналів зв'язку і комунікаційного устаткування приводять до втрати або спотворення деякої частини пакетів, внаслідок чого комунікаційні протоколи вимушені організовувати повторну передачу загублених даних. Оскільки, для прикладу, в локальних мережах відновленням загублених даних займаються як правило протоколи транспортного або прикладного рівня, шо працюють з тайм-аутами в декілька десятків секунд, то втрати продуктивності внаслідок низької надійності мережі можуть складати сотні відсотків.
3. ІНСТРУМЕНТИ МОНІТОРИНГУ І АНАЛІЗУ МЕРЕЖІ
Все різноманіття засобів, вживаних для моніторингу і аналізу обчислювальних мереж, можна розділити на декілька великих класів:
Системи управління мережею (NetworkManagementSystems) централізовані програмні системи, які збирають дані про стан вузлів і комунікаційних пристроїв мережі, а також дані про трафік, циркулюючий в мережі. Ці системи не тільки здійснюють моніторинг і аналіз мережі, але і виконують в автоматичному або напівавтоматичному режимі дії по управлінню мережею - включення і відключення портів пристроїв, зміна параметрів мостів адресних таблиць мостів, комутаторів і маршрутизаторів і т.п. Прикладами систем управління можуть служити популярні системи HPOpenView, SunNetManager, IBMNetView.
Засоби управління системою (SystemManagement). Засоби управління системою часто виконують функції, аналогічні функціям систем управління, але по відношенню до інших об'єктів. У першому випадку об'єктом управління є програмне і апаратне забезпечення комп'ютерів мережі, а в другому - комунікаційне устаткування. Разом з тим, деякі функції цих двох видів систем управління можуть дублюватися, наприклад, засоби управління системою можуть виконувати простий аналіз мережевого трафіку.
Вбудовані системи діагностики і управління
• (Embeddedsystems). Ці системи виконуються у вигляді програмно-апаратних модулів, що встановлюються в комунікаційне устаткування, а також у вигляді програмних модулів, вбудованих в операційні системи. Вони виконують функції діагностики і управління тільки одним пристроєм, і в цьому їх основна відмінність від централізованих систем управління. Прикладом засобів цього класу може служити модуль управління концентратором Distrebuted 5000, що реалізовує функції автосегментації портів при виявленні несправностей, приписування портів внутрішнім сегментам концентратора і деякі інші. Як правило, вбудовані модулі управління "за сумісництвом" виконують роль SNMP-агентів, що поставляють дані про стан пристрої для систем управління.
• Аналізатори протоколів (Protocolanalyzers). Є програмними або апаратно-програмними системами, які обмежуються на відміну від систем управління лише функціями моніторингу і аналізу трафіку в мережах. Хороший аналізатор протоколів може захоплювати і декодувати пакети великої кількості протоколів, вживаних в мережах, - звичайні декілька десятків. Аналізатори протоколів дозволяють встановити деякі логічні умови для захоплення окремих пакетів і виконують повне декодування захоплених пакетів, тобто показують в зручній для фахівця формі вкладеність пакетів протоколів різних рівнів один в одного з розшифровкою змісту окремих полів кожного пакету.
Устаткування для діагностики і сертифікації кабельних систем.
Умовно це устаткування можна поділити на чотири основні групи: мережеві монітори, прилади для сертифікації кабельних систем, кабельні сканери і тестери (мультиметри).
• Мережеві монітори (звані також мережевими аналізаторами) призначені для тестування кабелів різних категорій. Слід розрізняти мережеві монітори і аналізатори протоколів. Мережеві монітори збирають дані тільки про статистичні показники трафіку - середню інтенсивність загального трафіку мережі, середній інтенсивності потоку пакетів з певним типом помилки і т.п.
• Призначення пристроїв для сертифікації кабельних систем, безпосередньо виходить з їх назви. Сертифікація виконується відповідно до вимог одного з міжнародних стандартів на кабельні системи.
• Кабельні сканери використовуються для діагностики мідних кабельних систем.
• Тестери призначені для перевірки кабелів на відсутність фізичного розриву.
• Експертні системи. Цей вид систем акумулює людські знання про виявлення причин аномальної роботи мереж і можливі способи приведення мережі в працездатний стан. Експертні системи часто реалізуються у вигляді окремих підсистем різних засобів моніторингу і аналізу мереж: систем управління мережами, аналізаторів протоколів, мережевих аналізаторів. Простим варіантом експертної системи є контекстно-залежна help-система. Складніші експертні системи є так звані бази знань, що володіють елементами штучного інтелекту. Прикладом такої системи є експертна система, вбудована в систему управління Spectrum компанії Cabletron.
• Багатофункціональні пристрої аналізу і діагностики. Останніми роками, у зв'язку з повсюдним розповсюдженням локальних мереж виникла необхідність розробки недорогих портативних приладів, що суміщають функції декількох пристроїв: аналізаторів протоколів, кабельних сканерів і, навіть, деяких можливостей ПЗ мережевого управління. Як приклад такого роду пристроїв можна привести Compas компанії MicrotestInc. або 675 LANMeter компании FlukeCorp.