Проблема аутентификации данных и блочные шифры
Проблема аутентификации данных и блочные шифры.
Данная статья является продолжением серии статей автора о реализациях и использовании Российского стандарта шифрования [1,2,3] и об архитектуре и режимах использования блочных шифров [4], и посвящена проблемам подтверждения подлинности и авторства сообщений. Статья была написана осенью 1995 года – почти три года назад, и подготовлена для публикации в журнале «Монитор», где у автора вышли 2 статьи по криптографии. Однако по разным причинам статья тогда не была опубликована – сначала из-за нехватки времени на ее окончательную доводку и подготовку кодов–примеров к статье, а затем из-за закрытия «Монитора».
Содержание
Введение 2
1. Задача аутентификации данных.
2. Контроль неизменности массивов данных.
2.1. Задача имитозащиты данных.
2.2. Подходы к контролю неизменности данных.
2.3. Выработка кода аутентификации сообщений.
2.4. Выработка кода обнаружения манипуляций.
3. Цифровая подпись на основе традиционных блочных шифров.
3.1. Что такое цифровая подпись.
3.2. Базовая идея Диффи и Хеллмана.
3.3. Модификация схемы Диффи–Хеллмана для подписи битовых групп.
3.4. Схема цифровой подписи на основе блочного шифра.
Заключение 24
Литература 24
Введение
Наш совсем уже близкий к своему завершению век с полным правом может считаться веком тотальной информатизации общества – роль информации в современном мире настолько велика, что информационная индустрия стала одной из ведущих отраслей наших дней, а получившие огромное распространение устройства для обработки цифровых данных – компьютеры – являются одним из символов нашей цивилизации. Информация, представленная в самых различных формах, подобно другим товарам производится, хранится, транспортируется к потребителю, продается, покупается наконец потребляется, устаревает, портится, и т.д.. На протяжении жизненного цикла информационные массивы могут подвергаться различным нежелательным для их потребителя воздействиям, проблемам борьбы с которыми и посвящена данная статья.
Так как информация имеет нематериальный характер, массивы данных не несут на себе никаких отпечатков, по которым можно было бы судить об их прошлом – о том, кто является автором, о времени создания, о фактах, времени и авторах вносимых изменений. Модификация информационного массива не оставляет осязаемых следов на нем и не может быть обнаружена обычными методами. «Следы модификации» в той или иной форме могут присутствовать только на материальных носителях информации – так, специальная экспертиза вполне способна установить, что сектор X на некоей дискете был записан позже всех остальных секторов с данными на этой же дорожке дискеты, и эта запись производилась на другом дисководе. Указанный факт, будучи установленным, может, например, означать, что в данные, хранимые на дискете, были внесены изменения. Но после того, как эти данные будут переписаны на другой носитель, их копии уже не будут содержать никаких следов модификации. Реальные компьютерные данные за время своей жизни многократно меняют физическую основу представления и постоянно кочуют с носителя на носитель, в силу чего их не обнаружимое искажение не представляет серьезных проблем. Поскольку создание и использование информационных массивов практически всегда разделены во времени и/или в пространстве, у потребителя всегда могут возникнуть обоснованные сомнения в том, что полученный им массив данных создан нужным источником и притом в точности таким, каким он дошел до него.
Таким образом, в системах обработки информации помимо обеспечения ее секретности важно гарантировать следующие свойства для каждого обрабатываемого массива данных:
подлинность – он пришел к потребителю именно таким, каким был создан источником и не претерпел на своем жизненном пути несанкционированных изменений;
авторство – он был создан именно тем источником, каким предполагает потребитель.
Обеспечение системой обработки этих двух качеств массивов информации и составляет задачу их аутентификации, а соответствующая способность системы обеспечить надежную аутентификацию данных называется ее аутентичностью.
Задача аутентификации данных.
На первый взгляд может показаться, что данная задача решается простым шифрованием. Действительно, если массив данных зашифрован с использованием стойкого шифра, такого, например, как ГОСТ 28147–89, то для него практически всегда будет справедливо следующее:
в него трудно внести изменения осмысленным образом, поскольку со степенью вероятности, незначительно отличающейся от единицы, факты модификации зашифрованных массивов данных становятся очевидными после их расшифрования – эта очевидность выражается в том, что такие данные перестают быть корректными для их интерпретатора: вместо текста на русском языке появляется белиберда, архиваторы сообщают, что целостность архива нарушена и т.д.;
только обладающие секретным ключом шифрования пользователи системы могут изготовить зашифрованное сообщение, таким образом, если к получателю приходит сообщение, зашифрованное на его секретном ключе, он может быть уверенным в его авторстве, так как кроме него самого только законный отправитель мог изготовить это сообщение.
Тем не менее, использование шифрования в системах обработки данных само по себе неспособно обеспечить их аутентичности по следующим причинам:
Изменения, внесенные в зашифрованные данные, становятся очевидными после расшифрования только в случае большой избыточности исходных данных. Эта избыточность имеет место, например, если массив информации является текстом на каком-либо человеческом языке. Однако в общем случае это требование может не выполняться – если случайная модификация данных не делает их недопустимым для интерпретации со сколько-нибудь значительной долей вероятности, то шифрование массива не обеспечивает его подлинности. Говоря языком криптологии, аутентичность и секретность суть различные свойства криптосистем. Или, более просто: свойства систем обработки информации обеспечивать секретность и подлинность обрабатываемых данных в общем случае могут не совпадать.
Факт успешного (в смысле предыдущего пункта) расшифрования зашифрованных на секретном ключе данных может подтвердить их авторство только в глазах самого получателя. Третья сторона не сможет сделать на основании этого однозначного вывода об авторстве массива информации, так как его автором может быть любой из обладателей секретного ключа, а их как минимум два – отправитель и получатель. Поэтому в данном случае споры об авторстве сообщения не могут быть разрешены независимым арбитражем. Это важно для тех систем, где между участниками нет взаимного доверия, что весьма характерно для банковских систем, связанных с управлением значительными ценностями.
Таким образом, существование проблемы подтверждения подлинности и авторства массивов данных, отдельной от задачи обеспечения их секретности, не вызывает сомнения. В последующих разделах настоящей статьи излагаются подходы к ее решению, базирующиеся на использовании классических блочных шифров. В разделе 2 рассматриваются подходы к решению задачи подтверждения подлинности данных, а в разделе 3 – к задаче подтверждения их авторства. В принципе, для решения указанных задач может быть использован любой традиционный блочный криптографический алгоритм. В компьютерных кодах, прилагаемых к настоящей статье, автор использует наиболее знакомый и близкий ему шифр – криптоалгоритм ГОСТ 28147–89.
Контроль неизменности массивов данных.
Задача имитозащиты данных.
Под имитозащитой данных в системах их обработки понимают защиту от навязывания ложных данных. Как мы уже выяснили, практически всегда на некоторых этапах своего жизненного цикла информация оказывается вне зоны непосредственного контроля за ней. Это случается, например, при передаче данных по каналам связи или при их хранении на магнитных носителях ЭВМ, физический доступ к которым посторонних лиц исключить почти никогда не представляется возможным. Только если целиком заключить линию связи в кожух из твердого металла, внутрь кожуха закачать газ под давлением и высылать роту автоматчиков прочесывать местность каждый раз, когда в секции такой системы будут зафиксированы малейшие изменения давления, как это, по слухам, делают Российские спецслужбы, ответственные за правительственную связь, будет хоть какая-то гарантия неприкосновенности передаваемых данных, не всегда, впрочем, достаточная. Но подобный подход многократно удорожает стоимость каналов связи, ведь стоимость кожуха, защищенных помещений для обработки сигнала и услуг вооруженных людей на много порядков превышает стоимость проложенной витой пары проводов. И как в этом случае быть с электромагнитным сигналом? – ведь не до всех мест можно дотянуть провод, а такой сигнал, даже если это узконаправленный лазерный пучок, не говоря об обычном радиосигнале, не спрячешь в кожух.
Таким образом, физически предотвратить внесение несанкционированных изменений в данные в подавляющем большинстве реальных систем их обработки, передачи и хранения не представляется возможным. Поэтому крайне важно своевременно обнаружить сам факт таких изменений – если подобные случайные или преднамеренные искажения будут вовремя выявлены, потери пользователей системы будут минимальны и ограничатся лишь стоимостью «пустой» передачи или хранения ложных данных, что, конечно, во всех реальных ситуациях неизмеримо меньше возможного ущерба от их использования. Целью злоумышленника, навязывающего системе ложную информацию, является выдача ее за подлинную, а это возможно только в том случае, если сам факт такого навязывания не будет вовремя обнаружен, поэтому простая фиксация этого факта сводит на нет все усилия злоумышленника. Подведем итог – под защитой данных от несанкционированных изменений в криптографии понимают не исключение самой возможности таких изменений, а набор методов, позволяющих надежно зафиксировать их факты, если они имели место.
Попытаемся найти универсальные подходы к построению такой защиты. Прежде всего, в распоряжении получателя информации должна быть процедура проверки или аутентификации A(T), позволяющая проверить подлинность полученного массива данных T. На выходе указанная процедура должна выдавать одно из двух возможных булевых значений – массив данных опознается как подлинный, либо как ложный: A(T)Î{0,1} для любого допустимого T. Условимся, что значение 1 соответствует подлинному массиву данных, а значение 0 – ложному. Процедура аутентификации должна обладать следующими свойствами, ограничивающими возможность злоумышленника подобрать массив данных T>1>, отличающийся от подлинного массива T (T¹T>1>), который бы тем не менее был бы этой процедурой опознан как подлинный (A(T>1>)=1):
у злоумышленника не должно быть возможности найти такое сообщение иначе как путем перебора по множеству допустимых сообщений – последняя возможность есть в его распоряжении всегда;
вероятность успешно пройти проверку на подлинность у случайно выбранного сообщения T* не должна превышать заранее установленного значения p.
Теперь вспомним про универсальность конструируемой схемы защиты, которая, в частности, означает, что схема должна быть пригодной для защиты любого массива данных T из достаточно широкого класса. Однако, если реализовать схему буквально, т.е. использовать для проверки в точности то сообщение, которое отправитель должен передать получателю, принцип универсальности может придти в противоречие со вторым требованием к процедуре проверки. Действительно, исходя из этого принципа мы можем потребовать, чтобы все возможные сообщения T были допустимыми, что совершенно явно нарушит второе требование к функции проверки. Для того, чтобы их примирить, в схему необходимо ввести дополнительные шаги – преобразование данных отправителем и обратное преобразование получателем. Отправитель выполняет преобразование данных с использованием некоторого алгоритма F: T'=F(T). Тогда, помимо процедуры аутентификации, в распоряжении получателя должна быть процедура G восстановления исходных данных: T=G(T'). Весь смысл этих преобразований заключается в том, чтобы множество преобразованных сообщений {T'}, взаимно однозначно отображающееся на множество допустимых исходных сообщений {T}, было неизвестно злоумышленнику, и вероятность случайно угадать элемент из этого множества была достаточно мала для того, чтобы ее можно было не принимать во внимание.
Последнее требование в сочетанием с принципом универсальности однозначно приводит к необходимости внесения определенной избыточности в сообщение, что означает попросту тот факт, что размер преобразованного сообщения должен быть больше размера исходного сообщения на некоторую величину, как раз и составляющую степень избыточности: |T'|–|T|=D. Очевидно, что чем больше эта величина, тем меньше вероятность принять случайно взятое сообщение за подлинное – эта вероятность равна 2–D. Если бы не требование внесения избыточности, в качестве функций преобразования F и G данных могли бы использоваться функции зашифрования и расшифрования данных на некотором ключе K: F(T)=E>K>(T), G(T')=D>K>(T'). Однако при их использовании размер массива зашифрованных данных T' равен размеру массива исходных данных T: |T'|=|T|, поэтому метод здесь не подходит.
Наиболее естественно реализовать алгоритм преобразования с внесением избыточности простым добавлением к исходным данным контрольной комбинации фиксированного размера, вычисляемой как некоторая функция от этих данных: T'=F(T)=(T,C), C=f(T), |C|=D. В этом случае выделение исходных данных из преобразованного массива заключается в простом отбрасывании добавленной контрольной комбинации C: T=G(T')=G(T,C)=T. Проверка на подлинность заключается в вычислении для содержательной части T полученного массива данных T' значения контрольной комбинации C'=f(T) и сравнении его с переданным значением контрольной комбинацией C. Если они совпадают, сообщение считается подлинным, иначе – ложным:
>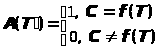 >
.
>
.
Теперь рассмотрим свойства, которым должна удовлетворять функция выработки контрольной комбинации f:
Эта функция должна быть вычислительно необратимой, то есть не должно существовать способа подобрать массив данных T под заданную контрольную комбинацию C иначе как перебором по пространству возможных значений T.
Эта функция не должна быть известна злоумышленнику – у него не должно быть способа вычислить контрольную комбинацию C ни для какого массива данных T. Это требование по сути означает, что функция f должна быть секретной, рассмотрим его подробнее:
во-первых, в соответствии с общепризнанным в криптографии принципом Кирхгоффа требование секретности функции выработки контрольной комбинации следует заменить на применение открытой функции, использующей вектор секретных параметров (ключ) – точно так же, как это делается при построении шифров: C=f(T)=f>K>(T).
во-вторых, оказывается, что в отдельных случаях это требование можно существенно ослабить. Дело в том, что истинная цель этого пункта – исключить для злоумышленника возможность отправить ложное сообщение T>1>, снабдив его корректно вычисленной контрольной комбинацией C>1>=f(T>1>). Этого можно достичь двумя следующими способами:
с помощью использованного выше требования секретности функции вычисления контрольной комбинации или зависимости ее от вектора секретных параметров (ключа);
с помощью организации такого протокола использования средств защиты, который бы исключал возможность подобного навязывания ложных данных.
Очевидно, что возможность (b) может быть реализована только если контрольная комбинация передается или хранится отдельно от защищаемых данных. Несмотря на кажущуюся экзотичность, такая возможность встречается достаточно часто, речь о ней впереди.
Рассмотрим некоторые хорошо известные способы вычисления контрольной комбинации и оценим возможность их использования в рассматриваемой системе имитозащиты данных. Простейшим примером такой комбинации является контрольная сумма блоков сообщения, взятая по модулю некоторого числа, обычно берут два в степени размера блока:
если T=(T>1>,T>2>,...,T>m>), то C=f(T)=(T>1>+T>2>+...+T>m>)mod2N,
где N=|T>1>|=|T>2>|=...=|T>m>| – размер блоков сообщения.
Однако такое преобразование не соответствует обоим вышеизложенным требованиям к функции вычисления контрольной комбинации и поэтому непригодно для использования в схеме имитозащиты:
во-первых, и это самое главное – оно не исключает возможность подбора данных под заданную контрольную комбинацию. Действительно, пусть отправитель информации передал по ненадежному каналу сообщение T и контрольную сумму C для него, вычисленную по приведенной выше формуле. В этом случае все, что потребуется злоумышленнику для навязывания получателю произвольно взятого ложного массива данных T'=(T'>1>,T'>2>,...,T'>m>>'>) – это дополнить его еще одним блоком, вычисленным по следующей формуле:
T'>m>>'>>+>>1>=C–(T'>1>+T'>2>+...+T'> m>>'>)mod2N.
Все блоки ложного сообщения, кроме одного, не обязательно последнего, злоумышленник может установить произвольными.
во-вторых, рассмотренное преобразование не является криптографическим, и для злоумышленника не составит труда изготовить контрольную комбинацию для произвольного выбранного им сообщения, что позволяет ему успешно выдать его за подлинное – если контрольная комбинация хранится или передается вместе с защищаемым массивом данных.
Подходы к контролю неизменности данных.
В настоящее время известны два подхода к решению задачи защиты данных от несанкционированного изменения, базирующихся на двух изложенных выше подходах к выработке контрольной комбинации:
Выработка MAC – Message Authentification Code – кода аутентификации сообщений. Этот подход заключается в том, что контрольная комбинация вычисляется с использованием секретного ключа с помощью некоторого блочного шифра. Важно, что на основе любого такого шифра можно создать алгоритм вычисления MAC для массивов данных произвольного размера. В литературе МАС иногда не вполне корректно называется криптографической контрольной суммой, или, что более точно, криптографической контрольной комбинацией. Данный подход к аутентификации данных общепризнан и закреплен практически во всех криптографических стандартах - имитовставка, формируемая согласно ГОСТ 28147-89 является типичным образцом MAC.
Выработка MDC – Маnipulation Detection Code – кода обнаружения манипуляций (с данными). Для вычисления MDC для блока данных используется так называемая необратимая функция сжатия информации, в литературе также называемая односторонней функцией, функцией одностороннего сжатия (преобразования) информации, криптографической хэш–функцией, или просто хэш–функцией. Понятно, что ее необратимость должна носить вычислительный характер:
вычисление прямой функции Y=f(X) легко осуществимо вычислительно;
вычисление обратной функции X=f–1(Y) неосуществимо вычислительно, то есть не может быть выполнено более эффективным путем, чем перебором по множеству возможных значений X;
Оба способа вычисления контрольной комбинации – MDC и MAC принимают в качестве аргумента блок данных произвольного размера и выдают в качестве результата блок данных фиксированного размера.
В следующей ниже таблице 1 приведены сравнительные характеристики обоих подходов:
Таблица 1. Сравнительные характеристики подходов к решению задачи контроля неизменности массивов данных.
|
№ |
Параметр сравнения |
Подход |
|
|
вычисление MAC |
вычисление MDC |
||
|
|
Используемое преобразование данных |
Криптографическое преобразование (функция зашифрования) |
Односторонняя функция, функция необратимого сжатия информации |
|
|
Используемая секретная информация |
Секретный ключ |
Не используется |
|
|
Возможность для третьей стороны вычислить контрольную комбинацию |
Злоумышленник не может вычислить контрольную комбинацию, если ему не известен секретный ключ |
Злоумышленник может вычислить контрольную комбинацию для произвольного блока данных |
|
|
Хранение и передача контрольной комбинации |
Контрольная комбинация может храниться и передаваться вместе с защищаемым массивом данных |
Контрольная комбинация должна храниться и передаваться отдельно от защищаемого массива данных |
|
|
Дополнительные условия |
Требует предварительного распределения ключей между участниками информационного обмена |
Не требует предварительных действий |
|
|
Области, в которых подход имеет преимущество |
Защита от несанкционированных изменений данных при их передаче |
Разовая передача массивов данных, контроль неизменности файлов данных и программ |
Прокомментируем отличия: подход на основе MAC требует для вычисления контрольной комбинации секретного ключа, для второго это не нужно. Потенциальный злоумышленник не сможет вычислить MAC для произвольного сфабрикованного им сообщения, но сможет вычислить MDC, так как для этого не требуется никаких секретных данных, поэтому MAC может передаваться от источника к приемнику по открытому каналу, тогда как для передачи MDC требуется защищенный канал.
Казалось бы, преимущества первого подхода настолько очевидны, что второй подход не сможет найти себе применения. Однако это не так – использование MAC требует, чтобы предварительно между участниками информационного обмена были распределены ключи. Если же этого не произошло, для его реализации необходим специальный канал, обеспечивающий секретность и подлинность передаваемой информации, по которому параллельно с передачей данных по незащищенному каналу будут передаваться ключи. Для передачи же MDC требуется канал, обеспечивающий только подлинность передаваемых данных, требование секретности отсутствует, и это делает данный метод предпочтительным при одноразовой передаче данных: основная информация передается по обычному незащищенному каналу, а MDC сообщается отправителем получателю по каналу, который может прослушиваться но не может быть использован для навязывания ложных данных – например, голосом по телефону – если участники обмена лично знакомы и хорошо знают голоса друг друга. Кроме того, подход на основе выработки MDC более прост и удобен для систем, где создание и использование информационных массивов разделены во времени, но не в пространстве, то есть для контроля целостности хранимой, а не передаваемой информации – например, для контроля неизменности программ и данных в компьютерных системах. При этом контрольная комбинация (MDC) должна храниться в системе таким образом, чтобы исключить возможность ее модификации злоумышленником.
Оба подхода допускают возможность реализации на основе любого классического блочного шифра. При этом надежность полученной системы имитозащиты, конечно при условии ее корректной реализации, будет определяться стойкостью использованного блочного шифра – это утверждение исключительно легко доказывается. В двух последующих разделах будут рассмотрены оба подхода к контролю неизменности массивов данных.
Выработка кода аутентификации сообщений.
Выработка кода аутентификации сообщений с использованием процедуры криптографического преобразования данных официально или полуофициально закреплена во многих стандартах на алгоритмы шифрования. Так, например, в различных комментариях к стандарту шифрования США рекомендуется использовать DES для выработки контрольной комбинации [5]. Российский стандарт шифрования ГОСТ 28147 89 [6] явным образом предусматривает режим выработки имитовставки, которая является не чем иным, как образцом MAC.
Схема использования криптографического преобразования E>K> для выработки кода аутентификации весьма проста: все исходное сообщение разбивается на блоки, затем последовательно для каждого блока находится результат преобразования по алгоритму E>K> побитовой суммы блока по модулю 2 с результатом выполнения предыдущего шага. Таким образом, получаем следующее уравнение для выработки контрольной комбинации:
C=C>K>(T)=E>K>(T>1>ÅE>K>(T>2>ÅE>K>(...ÅE>K>(T>m>)))).
Схема алгоритма выработки MAC приведена на рисунке 1.
Входные данные – массив данных T, разбитый на m блоков фиксированного размера, равного размеру блока данных использованного шифра (для большинства наиболее известных шифров – 64 бита): T=(T>1>,T>2>,...,T>m>). Последний блок данных T>m> каким-либо способом дополняется до полного блока данных, если имеет меньший размер.
MAC получает нулевое начальное значение.
Следующий шаг алгоритма 2 выполняются последовательного для каждого блока исходных данных в порядке их следования.
Побитовая сумма по модулю 2 очередного блока исходных данных T>i> c текущим значением MAC S подвергается преобразованию по алгоритму зашифрования, результат становится новым текущим значением MAC.
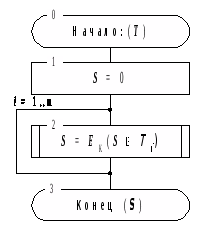
Рис. 1. Алгоритм выработки кода аутентификации для массива данных.
Результатом работы алгоритма – MAC для входного массива данных – является последнее текущее значение MAC, полученное на шаге 2.Рассмотрим свойства криптографических преобразований E>K>, используемых для шифрования данных, и определим те из них, которые необходимы при выработке MAC:
Преобразование данных должно использовать в качестве параметра секретный ключ K. Его секретность определяет секретность зашифрованных данных.
Преобразование данных должно быть криптографически стойким, то есть не должно существовать иной возможности определить входной блок алгоритма при известном выходном и неизвестном ключе, или определить ключ при известных входном и выходном блоках иначе как перебором по возможным значениям входного блока и ключа в первом и во втором случаях соответственно.
Преобразование данных должно быть обратимым – для того, чтобы была осуществима процедура расшифрования.
Если шифрующее преобразование E>K> предполагается использовать для выработки кода аутентификации, выполнение третьего свойства не требуется, так как при этом преобразование всегда выполняется в одну сторону. Кроме того криптостойкость алгоритма преобразования может быть несколько ниже, чем при шифровании, и это не приведет к снижению надежности всей схемы. Действительно, при выработке MAC в распоряжении криптоаналитика есть только один блок данных – MAC, который является функцией сразу всех блоков исходного текста, а при зашифровании в его распоряжении есть набор блоков шифротекста, каждый из которых зависит только от одного блока исходного текста. Очевидно, в первом случае его задача существенно сложнее. Именно по этой причине в ГОСТе 28147–89 для выработки имитовставки используется упрощенный 16-раундовый цикл преобразования, тогда как для шифрования – полный 32-раундовый.
Выработка кода обнаружения манипуляций.
Подход к выработке контрольной комбинации массива данных с помощью вычислительно необратимых функций получил развитие только в последнее время в связи с появлением практических схем цифровой подписи, так как по своей сути он является способом вычисления хэш-функции, которая используется во всех схемах цифровой подписи.
Существует большое количество возможных подходов к построению вычислительно необратимых функций, практически всегда самым трудным является обоснование свойства необратимости предложенной функции. Однако есть класс способов, где такое свойство не нуждается в доказательстве, оно просто следует из характеристик примененного метода – это построение функций одностороннего преобразования на основе классических блочных шифров. Данный подход известен достаточно давно и изложен в ряде работ, из русскоязычных отметим [7], в его основе лежит тот факт, что уравнение зашифрования блока данных по циклу простой замены Y=E>K>(X) вычислительно неразрешимо относительно ключа K – это является неотъемлемым свойством любого действительно стойкого шифра. Даже при известных открытом (X) и зашифрованном (Y) блоках ключ K не может быть определен иначе как перебором по множеству возможных значений. Алгоритм выработки контрольной комбинации для массива данных T следующий:
массив данных T разбивается на блоки фиксированного размера, равного размеру ключа используемого шифра:
T=(T>1>,T>2>,...,T>m>);
|T>1>|=|T>2>|=...=|T>m>>–>>1>|=|K|, 0<|T>m>|£|K|.
при необходимости последний (неполный) блок дополняется каким-либо образом до блока полного размера;
MDC или хэш сообщения вычисляется по следующей формуле:
C=H(T)=E>T>>m>(E>T>>m>>–1>(...E>T>>1>(S))),
где S – начальное заполнение алгоритма – может выбираться произвольно, обычно полагают S=0;
Несложно доказать, что задача подбора массива данных T'=(T'>1>,T'>2>,...,T'>m>>'>) под заданную контрольную комбинацию C эквивалентна следующей системе уравнений подбора ключа для заданных входного и выходного блоков данных криптоалгоритма:
E>T>>'>>1>(S)=S>1>,
E>T>>'>>2>(S>1>)=S>2>,
...
E>T>>'>>m>>'>(S>m>>'>>–1>)=C,
Нет необходимости решать сразу все эти уравнения относительно ключа T>i>' – все блоки массива данных T', кроме одного, могут быть выбраны произвольными – это определит, все значения S>i>, и лишь один, любой из них, должен быть определен решением соответствующего уравнения E>T>>'>>i>(S>i>>–1>)=S>i> относительно T'>i>. Так как данная задача вычислительно неразрешима в силу использования криптостойкого алгоритма шифрования, предложенная схема вычисления MDC обладает гарантированной стойкостью, равной стойкости используемого шифра.
Однако данная схема не учитывает проблему побочных ключей шифра, которая заключается в следующем: может существовать несколько ключей, с использованием которых при зашифровании одинаковые блоки открытого текста переводятся в одинаковые блоки шифротекста:
E>K>>1>(X)=E>K>>2>(X) при некоторых X и K>1>¹K>2>.
Один из этих ключей – тот, на котором проводилось зашифрование – «истинный», а другой – «побочный». Таким образом, побочным ключом для некоторого блока данных X и некоторого истинного ключа K называется ключ K', который дает точно такой же результат зашифрования блока X, что и истинный ключ K: E>K>>'>(X)=E>K>(X). Ясно, что для различных блоков исходного массива данных побочные ключи также в общем случае различны – вероятность встретить пару ключей, переводящих одновременно несколько пар одинаковых блоков открытых текстов в пары одинаковых блоков шифротекстов стремительно убывает с ростом числа этих пар. Поэтому обнаружение побочного ключа криптоаналитиком при дешифровании сообщения не является его особым успехом, так как с вероятностью, незначительно отличающейся от 1, на этом найденном ключе он не сможет правильно расшифровать никаких других блоков шифротекста. Совершенно иное дело в алгоритме выработки MDC – здесь обнаружение побочного ключа означает, что злоумышленник подобрал такой ложный, то есть отсутствующий в сообщении блок данных, использование которого приводит к истинному MDC исходного массива данных.
Для того, чтобы уменьшить вероятность навязывания ложных данных через нахождение побочных ключей, в шагах криптографического преобразования применяются не сами блоки исходного сообщения, а результат их расширения по некоторой схеме. Под схемой расширениея здесь понимается процедура построения блоков данных большего размера из блоков данных меньшего размера. Примером может служить, например, функция расширения, в которой выходной блок строится из байтов (или 2-,4-,... и т.д. -байтовых слов) исходного блока, перечисляемых в различном порядке. Указанное расширение стоит применять, если размер ключа использованного шифра в несколько раз превышает размер его блока данных. Так, для алгоритма DES, с размером блока данных 64 бита и ключа 56 бит в расширении нет необходимости. Если в схеме используется алгоритм ГОСТ 28147–89 с размером блока 64 бита и размером ключа 256 бит, стоит использовать 64- или 128-битные блоки исходного текста и расширять их до размеров 256 бит. Пример функции расширения 128-битового блока в 256-битовый может быть, например, следующим:
Исходный блок: T=(B>1>, B>2>, B>3>, B>4>, B>5>, B>6>, B>7>, B>8>, B>9>, B>10>, B>11>, B>12>, B>13>, B>14>, B>15>, B>16>),
После расширения: P(T)=(B>1>, B>2>, B>3>, B>4>, B>5>, B>6>, B>7>, B>8>, B>9>, B>10>, B>11>, B>12>, B>13>, B>14>, B>15>, B>16>,
B>1>, B>4>, B>7>, B>10>, B>13>, B>16>, B>3>, B>6>, B>9>, B>12>, B>15>, B>2>, B>5>, B>8>, B>11>, B>14>),
где B>i> – байты блока данных, |B>i>|=8.
Схема алгоритма выработки MDC (хэш–кода) с использованием классического блочного шифра приведена на рисунке 2.
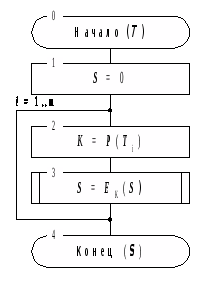
Входные данные – массив данных T, разбитый на m блоков фиксированного размера, не превышающего размер ключа использованного криптоалгоритма и, как правило, делящего его нацело: T=(T>1>,T>2>,...,T>m>). Последний блок данных T>m> каким-либо способом дополняется до полного блока данных, если имеет меньший размер.
MDC получает нулевое начальное значение (это значение может быть, в принципе, любым).
Последующие шаги 2 и 3 алгоритма выполняются последовательного для каждого блока исходных данных в порядке их следования.
Выполняется расширение очередного блока T>i> данных с помощью функции расширения P до размера ключа шифра.
Выполняется зашифрование текущего значения MDC на ключе, полученном на шаге 2, результат становится новым текущим значением MDC.
Результатом работы алгоритма (т.е. MDC для всего входного массива данных) является последнее текущее значение MDC, полученное на шаге 3.
Рассмотренный алгоритм также может быть использован для выработки хэш–кода в схемах цифровой подписи.
Цифровая подпись на основе традиционных блочных шифров.
На первый взгляд, сама эта идея может показаться абсурдом. Действительно, общеизвестно, что так называемая «современная», она же двухключевая криптография возникла и стала быстро развиваться в последние десятилетия именно потому, что ряд новых криптографических протоколов типа протокола цифровой подписи, в которых возникла острая необходимость в связи с проникновением электронных технологий в новые сферы, не удалось реализовать на базе традиционных криптоалгоритмов, широко известных и хорошо изученных к тому времени. Тем не менее, это возможно. И первые, кто обратил внимание на такую возможность, были … родоначальники криптографии с открытым ключом У.Диффи (W.Diffie) и М.Е.Хеллман (M.E.Hellman). В своей работе [8] они опубликовали описание подхода, позволяющего выполнять процедуру цифровой подписи одного бита с помощью блочного шифра. Прежде чем изложить эту изящную идею, сделаем несколько замечаний о сути и реализациях цифровой подписи.
Что такое цифровая подпись.
Итак, схема цифровой подписи или электронно-цифровой подписи – это набор алгоритмов и протоколов1, позволяющих построить информационное взаимодействие между двумя и более участниками таким образом, чтобы факт авторства переданного массива данных, «подписанного» одним из участников, мог быть надежно подтвержден или опровергнут третьей стороной, «независимым арбитражем». Подобная схема необходима для всех систем электронной обработки данных, где нет полного взаимного доверия между участниками информационного процесса, прежде всего это касается финансовой сферы. Любая схема цифровой подписи предполагает добавление к «подписываемому» массиву данных дополнительного кода – собственно «цифровой подписи», выработать который может только автор сообщения, обладающий секретным ключом подписи, а все остальные могут лишь проверить соответствие этой «подписи» подписанным данным. Поэтому каждая схема должна предусмотреть, как минимум, определение трех следующих алгоритмов:
Алгоритм G>K> выработки пары ключей – подписи K>S> и проверки подписи K>C> с использованием вектора случайных параметров R: (K>S>,K>C>)=G>K>(R), здесь:
K>S> – ключ подписи, он должен быть известен только подписывающему;
K>C> – ключ проверки подписи, он не является секретным и доступен каждому, кто должен иметь возможность проверять авторство сообщений.
Алгоритм S подписи сообщения T с использованием секретного ключа подписи K>S>:
s=S(T,K>S>),
где s – цифровая подпись сообщения;
Алгоритм V проверки подписи с использованием ключа проверки подписи K>C>, выдающий в качестве результата булево значение – подтверждается или не подтверждается авторство сообщения:
V(T,s,K>C>)Î{0,1}.
На практике логический результат всегда получают как результат сравнения двух чисел, или кодов, или блоков данных – речь об одном и том же. Практически во всех известных схемах цифровой подписи это сравнение производят следующим образом:
вычисляют контрольную комбинацию по некоторому алгоритму C с использованием подписанного сообщения и цифровой подписи:
c=C(T,s);
сравнивают контрольную комбинацию c и ключ проверки подписи K>C>, если они совпадают, то подпись признается верной, а данные – подлинными, в противном случае данные считаются ложными.
>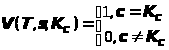 >
>
Собственно говоря, указанных трех алгоритмов достаточно для реализации схемы цифровой подписи, однако на практике в схемы добавляют еще один алгоритм – функцию выработки хэш–блока для подписываемого массива данных T. Большинство криптографических алгоритмов оперируют блоками данных фиксированного размера, а массивы большего размера обрабатывают по частям, что необходимо для обеспечения эффективности и надежности этих схем. Если такой же подход использовался при выработке цифровой подписи, блоки массивов информации подписывались бы отдельно друг от друга, и размер подписи оказался бы сравнимым с размером подписываемого массива данных, что по вполне понятным причинам не удобно. Поэтому в практических схемах ЭЦП подписывается не само сообщение, а его хэш–код, то есть результат вычисления функции необратимого сжатия для этого массива, который имеет фиксированный размер. Таким образом, в схему ЭЦП добавляется четвертый алгоритм:
Алгоритм H вычисления необратимой хэш–функции для подписываемых массивов:
h=H(T).
Алгоритм вычисления хэш–функции и прочие алгоритмы схемы не зависят друг от друга и согласуются только по размеру блоков, которыми они оперируют. Это позволяет при необходимости менять в схеме подписи способ вычисления хэш–значений.
Для работоспособной схемы электронно-цифровой подписи необходимо выполнение следующих условий:
никто, кроме лица, обладающего секретным ключом подписи K>S>, не может корректно подписать заданное сообщение T;
Поскольку сторона, проверяющая подпись, обладает открытым ключом K>C> проверки подписи, из указанного свойства следует, что не должно существовать вычислительно эффективного алгоритма вычисления секретного ключа K>S> по открытому K>C>.
никто, включая лицо, обладающее ключом подписи, не в состоянии построить сообщение T', подходящее под наперед заданную подпись s.
При предложении какой-либо схемы подписи оба эти свойства необходимо доказывать, что делается обычно доказательством равносильности соответствующей задачи вскрытия схемы какой-либо другой, о которой известно, что она вычислительно неразрешима. Практически все современные алгоритмы цифровой подписи и прочие схемы «современной криптографии» основаны на так называемых «сложных математических задачах» типа факторизации больших чисел или логарифмирования в дискретных полях. Однако доказательство невозможности эффективного вычислительного решения этих задач отсутствует, и нет никаких гарантий, что они не будут решены в ближайшем будущем, а соответствующие схемы взломаны – как это произошло с «ранцевой» схемой цифровой подписи [9]. Более того, с бурным прогрессом средств вычислительных техники «границы надежности» методов отодвигаются в область все больших размеров блока. Всего пару десятилетий назад, на заре криптографии с открытым ключом считалось, что для реализации схемы подписи RSA достаточно 128- или даже битовых чисел. Сейчас эта граница отодвинута до 1024-битовых чисел – практически на порядок, – и это далеко еще не предел. Надо ли объяснять, что с каждой такой «подвижкой» приходится перепроектировать аппаратуру и переписывать программы, реализующие схему. Ничего подобного нет в области классических блочных шифров, если не считать изначально ущербного и непонятного решения комитета по стандартам США ограничить размер ключа алгоритма DES 56-ю битами, тогда как еще во время обсуждения алгоритма предлагалось использовать ключ большего размера [5]. Схемы подписи, основанные на классических блочных шифрах, свободны от указанных недостатков:
во-первых, их стойкость к попыткам взлома вытекает из стойкости использованного блочного шифра;
Надо ли говорить, что классические методы шифрования изучены гораздо больше, а их надежность обоснована неизмеримо лучше, чем надежность методов «современной криптографии».
во-вторых, даже если стойкость использованного в схеме подписи шифра окажется недостаточной в свете прогресса вычислительной техники, его легко можно будет заменить на другой, более устойчивый, с тем же размером блока данных и ключа, без необходимости менять основные характеристики всей схемы – это потребует только минимальной модификации программного обеспечения;
Базовая идея Диффи и Хеллмана.
Итак, вернемся к схеме Диффи и Хеллмана подписи одного бита сообщения с помощью алгоритма, базирующегося на любом классическом блочном шифре. Предположим, в нашем распоряжении есть алгоритм зашифрования E>K>, оперирующий блоками данных X размера n и использующий ключ размером n>K>: |X|=n, |K|=n>K>. Структура ключевой информации в схеме следующая:
секретный ключ подписи K>S> выбирается как произвольная пара ключей K>0>, K>1> используемого блочного шифра:
K>S>=(K>0>,K>1>);
Таким образом, размер ключа подписи равен удвоенному размеру ключа использованного блочного шифра:
|K>S>|=2|K|=2n>K>
ключ проверки вычисляется как пара блоков криптоалгоритма по следующим уравнениям:
K>C>=(C>0>,C>1>), где:
C>0>=E>K>>0>(X>0>), C>1>=E>K>>1>(X>1>),
где являющиеся параметром схемы блоки данных X>0> и X>1> несекретны и известны проверяющей подпись стороне.
Таким образом, размер ключа проверки подписи равен удвоенному размеру блока использованного блочного шифра:
|K>C>|=2|X|=2n.
Алгоритмы схемы цифровой подписи Диффи и Хеллмана следующие:
Алгоритм G выработки ключевой пары:
Берем случайный блок данных размера 2n>K>, это и будет секретный ключ подписи:
K>S>=(K>0>,K>1>)=R.
Ключ проверки подписи вычисляем как результат двух циклов зашифрования по алгоритму E>K>:
K>C>=(C>0>,C>1>)=(E>K>>0>(X>0>),E>K>>1>(X>1>)).
Алгоритм S выработки цифровой подписи для бита t (t Î{0,1}) заключается просто в выборе соответствующей половины из пары, составляющей секретный ключ подписи:
s=S(t)=K>t>.
Алгоритм V проверки подписи состоит в проверке уравнения E>K>>t>(X>t>)=C>t>, которое, очевидно, должно выполняться для нашего t. Получателю известны все используемые величины:
K>t>=s – цифровая подпись бита,
C>t> – соответствующая половина ключа проверки,
X>t> – несекретный параметр алгоритма.
Таким образом, функция проверки подписи будет следующей:
>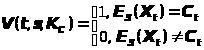 >.
>.
Не правда ли, все три алгоритма этой схемы изумительно простоты в сравнении со схемами RSA и эль-Гамаля?! Покажем, что данная схема работоспособна, для чего проверим выполнение необходимых свойств схемы цифровой подписи:
Невозможность подписать бит t, если неизвестен ключ подписи.
Действительно, для выполнения этого злоумышленнику потребовалось бы решить уравнение E>s>(X>t>)=C>t> относительно s, эта задача эквивалентна определению ключа для известных блока шифротекста и соответствующего ему открытого текста, что вычислительно невозможно в силу использования стойкого шифра.
Невозможность подобрать другое значение бита t, которое подходило бы под заданную подпись очевидна, потому что число возможных значений бита всего два и вероятность выполнения двух следующих условий одновременно пренебрежимо мала в просто в силу использования криптостойкого алгоритма:
E>s>(X>0>)=C>0>,
E>s>(X>1>)=C>1>.
Таким образом, предложенная Диффи и Хеллманом схема цифровой подписи на основе классического блочного шифра криптостойка настолько, насколько стоек использованный шифр, и при этом весьма проста. Теперь самое время рассказать, почему же эта замечательная схема не нашла сколько-нибудь значительного практического применения. Все дело в том, что у нее есть два недостатка. Всего два, но каких!
Первый недостаток сразу бросается в глаза – он заключается в том, что данная схема позволяет подписать лишь один бит информации. В блоке большего размера придется отдельно подписывать каждый бит, поэтому даже с учетом хеширования сообщения все компоненты подписи – секретный ключ, проверочная комбинация и собственно подпись получаются довольно большими по размеру и более чем на два порядка превосходят размер подписываемого блока. Предположим, что в схеме используется криптографический алгоритм E>K> с размером блока и ключа, выраженными в битах, соответственно n и n>K>. Предположим также что размер хэш–блока в схеме равен n>H>. Тогда размеры основных рабочих блоков будут следующими:
размер ключа подписи:
n>S>=n>H>×2n>K>=2n>H>n>K>.
размер ключа проверки подписи:
n>С>=n>H>×2n=2n>H>n.
размер подписи:
n>S>>g>=n>H>×n>K>=n>H>n>K>.
Если, например, в качестве основы в данной схеме будет использован шифр ГОСТ 28147–89 с размером блока n=64 бита и размером ключа n>K>=256 бит, и для выработки хэш–блоков будет использован тот же самый шифр в режиме выработки MDC, что даст размер хэш–блока n>H>=64 то размеры рабочих блоков будут следующими:
размер ключа подписи:
n>S>=n>H>×2n>K>=2n>H>n>K>=2×64×256=215 бит = 4096 байт.
размер ключа проверки подписи:
n>С>=n>H>×2n=2n>H>n=2×64×64=213 бит = 1024 байта.
размер подписи:
n>S>>g>=n>H>×n>K>=n>H>n>K>=64×256=214 бит = 2048 байт.
Согласитесь, довольно тяжелые ключики.
Второй недостаток данной схемы, быть может, менее заметен, но зато гораздо более серьезен. Дело в том, что пара ключей подписи и проверки в ней одноразовая! Действительно, выполнение процедуры подписи бита сообщения приводит к раскрытию половины секретного ключа, после чего он уже не является полностью секретным и не может быть использован повторно. Поэтому для каждого подписываемого сообщения необходим свой комплект ключей подписи и проверки. Это исключает возможность практического использования рассмотренной схемы Диффи–Хеллмана в первоначально предложенном варианте в реальных системах ЭЦП.
В силу указанных двух недостатков предложенная схемы до сравнительно недавнего времени рассматривалась лишь как курьезная теоретическая возможность, никто всерьез не рассматривал возможность ее практического использования. Однако несколько лет назад в работе [7] была предложена модификация схемы Диффи–Хеллмана, фактически устраняющая ее недостатки. В настоящей работе данная схема не рассматривается во всех деталях, здесь изложены только основные принципы подхода к модификации исходной схемы Диффи–Хеллмана и описания работающих алгоритмов.
Модификация схемы Диффи–Хеллмана для подписи битовых групп.
В данном разделе изложены идеи авторов [7], позволившие перейти от подписи отдельных битов в исходной схемы Диффи–Хеллмана к подписи битовых групп. Центральным в этом подходе является алгоритм «односторонней криптографической прокрутки», который в некотором роде может служить аналогом операции возведения в степень. Как обычно, предположим, что в нашем распоряжении имеется криптографический алгоритм E>K> с размером блока данных и ключа соответственно n и n>K> битов, причем размер блока данных не превышает размера ключа: n£n>K>. Пусть в нашем распоряжении также имеется некоторая функция «расширения» n–битовых блоков данных в n>K>–битовые Y=P>n>>®>>nK>(X), |X|=n, |Y|=n>K>. Определим функцию R>k> «односторонней прокрутки» блока данных T размером n бит k раз (k³0) с помощью следующей рекурсивной формулы:
>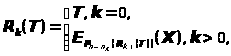 >
>
где X – произвольный несекретный n-битовый блок данных, являющийся параметром процедуры прокрутки. По своей идее функция односторонней прокрутки чрезвычайно проста, надо всего лишь нужное количество раз (k) выполнить следующие действия: расширить n-битовый блок данных T до размера ключа использованного криптоалгоритма (n>K>), на полученном расширенном блоке как на ключе зашифровать блок данных X, результат зашифрования занести на место исходного блока данных (T). В силу определения операция R>k>(T) обладает двумя крайне важными для нас свойствами:
Аддитивность по числу прокручиваний:
R>k>>+>>k>>'>(T)=R>k>>'>(R>k>(T)).
Односторонность или необратимость прокрутки: если известно только некоторое значение функции R>k>(T), то вычислительно невозможно найти значение R>k>>'>(T) для любого k'<k – если бы это было возможно, в нашем распоряжении был бы способ определить ключ шифрования по известному входному и выходному блоку криптоалгоритма E>K>. что противоречит предположению о стойкости шифра.
Теперь покажем, как указанную операцию можно использовать для подписи группы битов: изложим описание схемы подписи блока T, состоящего из n>T> битов, по точно такой же схеме, по которой в предыдущем разделе описывается схема подписи одного бита.
секретный ключ подписи K>S> выбирается как произвольная пара блоков K>0>, K>1>, имеющих размер блока данных используемого блочного шифра:
K>S>=(K>0>,K>1>);
Таким образом, размер ключа подписи равен удвоенному размеру блока данных использованного блочного шифра:
|K>S>|=2n;
ключ проверки вычисляется как пара блоков, имеющих размер блоков данных использованного криптоалгоритма по следующим формулам:
K>C>=(C>0>,C>1>), где:
C>0>=R>2>>n>>T>>–>>1>(K>0>), C>1>=R>2>>n>>T>>–>>1>(K>1>).
В этих вычислениях также используются несекретные блоки данных X>0> и X>1>, являющиеся параметрами функции «односторонней прокрутки», они обязательно должны быть различными.
Таким образом, размер ключа проверки подписи равен удвоенному размеру блока данных использованного блочного шифра:
|K>C>|=2n.
Алгоритмы модифицированной авторами [7] схемы цифровой подписи Диффи и Хеллмана следующие:
Алгоритм G выработки ключевой пары:
Берем случайный блок данных подходящего размера 2n, это и будет секретный ключ подписи:
K>S>=(K>0>,K>1>)=R.
Ключ проверки подписи вычисляем как результат «односторонней прокрутки» двух соответствующих половин секретного ключа подписи на число, равное максимальному возможному числовому значению n>T>-битового блока данных, то есть на 2nT–1.
K>C>=(C>0>,C>1>)=(R>2>>n>>T–1>(K>0>), R>2>>n>>T–1>(K>1>)).
Алгоритм S>n>>T> выработки цифровой подписи для n>T>-битового блока T, ограниченного, по своему значению, условием 0£T£2nT–1, заключается в выполнении «односторонней прокрутки» обеих половин ключа подписи T и 2nT–1–T раз соответственно:
s=S>n>>T>(T)=(s>0>,s>1>)=(R>T>(K>0>), R>2>>n>>T–1–>>T>(K>1>)).
Алгоритм V>n>>T> проверки подписи состоит в проверке истинности соотношений:
R>2>>n>>T–1–>>T>(s>0>)=C>0>, R>T>(s>1>)=C>1>, которые, очевидно, должны выполняться для подлинного блока данных T:
R>2>>n>>T–1–>>T>(s>0>)=R>2>>n>>T–1–>>T>(R>T>(K>0>))=R>2>>n>>T–1–>>T>>+>>T>(K>0>)=R>2>>n>>T–1>(K>0>)=C>0>,
R>T>(s>1>)=R>T>(R>2>>n>>T–1–>>T>(K>1>))=R>T>>+>>2>>n>>T–1–>>T>(K>1>)=R>2>>n>>T–1>(K>1>)=C>1>.
Таким образом, функция проверки подписи будет следующей:
>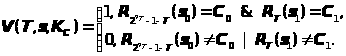 >
>
Покажем, что для данной схемы выполняются необходимые условия работоспособности схемы подписи:
Предположим, что в распоряжении злоумышленника есть n>T>-битовый блок T, его подпись s=(s>0>,s>1>), и ключ проверки K>C>=(C>0>,C>1>). Пользуясь этой информацией, злоумышленник пытается найти правильную подпись s'=(s'>0>,s'>1>) для другого n>T>-битового блока T'. Для этого ему надо решить следующие уравнения относительно s'>0> и s'>1>:
R>2>>n>>T–1–>>T>>'>(s'>0>)=C>0>,
R>T>>'>(s'>1>)=C>1>.
В распоряжении злоумышленника есть блок данных T с подписью s=(s>0>,s>1>), и это позволяет ему вычислить одно из значений s'>0>,s'>1>, даже не владея ключом подписи:
если T<T', то s'>0>=R>T'>(K>0>)=R>T'>>–>>T>(R>T>(K>0>))=R>T'>>–>>T>(s>0>),
если T>T', то s'>1>=R>2>>n>>T–1–>>T'>(K>1>)=R>T>>–>>T'>(R>2>>n>>T–1–>>T>(K>1>))=R>T>>–>>T'>(s>1>).
Однако для нахождения второй половины подписи (s'>1> в случае (a) и s'>0> в случае (b)) ему необходимо выполнить прокрутку в обратную сторону, т.е. найти R>k>(X), располагая только значением для большего k: R>k>>'>(X), k'>k, что является вычислительно невозможным. Таким образом, злоумышленник не может подделать подпись под сообщением, если не располагает секретным ключом подписи.
Второе требование также выполняется: вероятность подобрать блок данных T', отличный от блока T, но обладающий такой же цифровой подписью, чрезвычайно мала и может не приниматься во внимание. Действительно, пусть цифровая подпись блоков T и T' совпадает. Тогда подписи обоих блоков будут равны соответственно:
s=S>n>>T>(T)=(s>0>,s>1>)=(R>T>(K>0>), R>2>>n>>T–1–>>T>(K>1>)),
s'=S>n>>T>(T')=(s'>0>,s'>1>)=(R>T>>'>(K>0>), R>2>>n>>T–1–>>T>>'>(K>1>)),
s=s', следовательно:
R>T>(K>0>)=R>T>>'>(K>0>) & R>2>>n>>T–1–>>T>(K>1>)=R>2>>n>>T–1–>>T>>'>(K>1>).
Положим для определенности T£T', тогда справедливо следующее:
R>T'>>–>>T>(K>0>*)=K>0>*,R>T'>>–>>T>(K>1>*)=K>1>*,где K>0>*=R>T>(K>0>), K>1>*=R>2>>n>>T–1–>>T>>'>(K>1>)
Последнее условие означает, что прокручивание двух различных блоков данных одно и то же число раз оставляет их значения неизменными. Вероятность такого события чрезвычайно мала и может не приниматься во внимание.
Таким образом рассмотренная модификация схемы Диффи–Хеллмана делает возможным подпись не одного бита, а целой битовой группы. Это позволяет в несколько раз уменьшить размер подписи и ключей подписи/проверки данной схемы. Однако надо понимать, что увеличение размера подписываемых битовых групп приводит к экспоненциальному росту объема необходимых вычислений и начиная с некоторого значения делает работу схемы недопустимо неэффективной. Граница «разумного размера» подписываемой группы находится где-то рядом с восемью битами, и блоки большего размера все равно необходимо подписывать «по частям».
Теперь найдем размеры ключей и подписи, а также объем необходимых для реализации схемы вычислений. Пусть размер хэш–блока и блока используемого шифра одинаковы и равны n, а размер подписываемых битовых групп равен n>T>. Предположим также, что если последняя группа содержит меньшее число битов, обрабатывается она все равно как полная n>T>-битовая группа. Тогда размеры ключей подписи/проверки и самой подписи совпадают и равны следующей величине:
>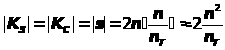 >
бит,
>
бит,
где éxù обозначает округление числа x до ближайшего целого в сторону возрастания. Число операций шифрования E>K>(X), требуемое для реализации процедур схемы, определяются нижеследующими соотношениями:
при выработке ключевой информации оно равно:
>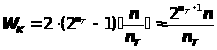 >,
>,
при подписи и проверке подписи оно вдвое меньше:
>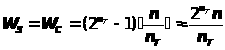 >.
>.
В следующей ниже таблице 2 приведены рассчитанные значения размеров ключей и подписи, и числа требуемых операций шифрования в зависимости от размера подписываемых битовых групп при условии использования блочного криптоалгоритма с размером блока n=64 бита:
Таблица 2. Числовые показатели схемы подписи в зависимости от размера битовых групп.
-
n>T>
Число бит.
Размер подписи и ключей, байт
Число операций шифрования
групп
|K>S>|=|K>C>|=|s|
W>K>
W>S>=W>C>
64
1024
128
64
32
512
192
96
22
352
308
154
16
256
480
240
13
208
806
403
11
176
1386
693
10
160
2540
1270
8
128
4080
2040
8
128
8176
4088
7
112
14322
7161
6
96
24564
12282
6
96
49140
24570
5
80
81910
40955
5
80
163830
81915
5
80
327670
163835
4
64
524280
262140
Размер ключа подписи и проверки подписи можно дополнительно уменьшить следующими приемами:
Нет необходимости хранить ключи подписи отдельных битовых групп, их можно динамически вырабатывать в нужный момент времени с помощью генератора криптостойкой гаммы. Ключом подписи в этом случае будет являться обычный ключ использованного в схеме подписи блочного шифра. Для ГОСТа 28147–89 этот размер равен 256 битам, поэтому если схема подписи будет построена на ГОСТе, размер ключа подписи будет равен тем же 256 битам.
Точно так же, нет необходимости хранить массив ключей проверки подписи отдельных битовых групп блока, достаточно хранить его хэш-комбинацию. При этом алгоритм выработки ключа подписи и алгоритм проверки подписи будут дополнены еще одним шагом – вычислением хэш-кода для массива проверочных комбинаций отдельных битовых групп.
Таким образом, проблема размера ключей и подписи полностью решена, однако, главный недостаток схемы – одноразовость ключей – не преодолен, поскольку это невозможно в рамках подхода Диффи–Хеллмана. Для практического использования такой схемы, рассчитанной на подпись N сообщений, отправителю необходимо хранить N ключей подписи, а получателю – N ключей проверки, что достаточно неудобно. Однако эта проблема может быть решена в точности так же, как была решена проблема ключей для множественных битовых групп – генерацией ключей подписи для всех N сообщений из одного мастер-ключа и свертывание всех проверочных комбинаций в одну контрольную комбинацию с помощью алгоритма выработки хэш-кода. Такой подход решил бы проблему размера хранимых ключей, однако привел бы к необходимости вместе подписью каждого сообщения высылать недостающие N–1 проверочных комбинаций, необходимых для вычисления хэш-кода от массива всех контрольных комбинаций отдельных сообщений. Ясно, что такой вариант не обладает преимуществами по сравнению с исходным. Однако в [7] был предложен механизм, позволяющий значительно снизить остроту проблемы. Его основная идея – вычислять контрольную комбинацию (ключ проверки подписи) не как хэш от линейного массива проверочных комбинаций всех сообщений, а попарно – с помощью бинарного дерева. На каждом уровне проверочная комбинация вычисляется как хэш от двух проверочных комбинаций младшего уровня. Чем выше уровень комбинации, тем больше отдельных ключей проверки в ней «учтено». Предположим, что наша схема рассчитана на 2L сообщений. Обозначим через C>i>(l) i-тую комбинацию l-того уровня. Если нумерацию комбинаций и уровней начинать с нуля, то справедливо следующее условие: 0£i<2L–l, а i-тая проверочная комбинация l-того уровня рассчитана на 2l сообщений с номерами от i×2l до (i+1)×2l–1 включительно. Число комбинаций нижнего, нулевого уровня равно 2L, а самого верхнего, L-того уровня – одна, она и является контрольной комбинацией всех 2L сообщений, на которые рассчитана схема. На каждом уровне, начиная с первого, проверочные комбинации рассчитываются по следующей формуле:
C>i>(l+1)=H(C>2>(>i>l)||C>2>(>i>l)>+>>1>),
где через A||B обозначен результат конкатенации двух блоков данных – A и B, а через H(X) – процедура вычисления хэш-кода блока данных X.
При использовании указанного подхода вместе с подписью сообщения необходимо передать не N–1, как в исходном варианте, а только log>2>N контрольных комбинаций. Передаваться должны комбинации, соответствующие смежным ветвям дерева на пути от конечной вершины, соответствующей номеру использованной подписи, к корню.
Уровень

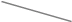 3: C>0>(3)
3: C>0>(3)


 2: C>0>(2)> >C>1>(2)
2: C>0>(2)> >C>1>(2)




 1: C>0>(1)> >C>1>(1)> >C>2>(1)> >C>3>(1)
1: C>0>(1)> >C>1>(1)> >C>2>(1)> >C>3>(1)
0: C>0>(0)> >C>1>(0)> >C>2>(0)> >C>3>(0)> >C>4>(0)> >C>5>(0)> >C>6>(0)> >C>7>(0)
Рис. 3. Схема попарного хеширования проверочных комбинаций при выработке общего ключа проверки подписи.
Схема попарного хеширования проверочных комбинаций при выработке общего ключа проверки подписи на восемь сообщений приведена на рисунке 3. Так, в схеме на 8 сообщений при передаче сообщения №5 (контрольная комбинация выделена рамкой) вместе с его подписью должны быть переданы контрольная комбинация сообщения №4 (C>4>(0)), общая для сообщений №№6–7 (C>3>(1)) и общая для сообщений №№0–3 (C>0>(2)), все они выделены на рисунке другим фоном. При проверке подписи значение C>5>(0) будет вычислено из сообщения и его подписи, а итоговая контрольная комбинация, подлежащая сравнению с эталонной, по следующей формуле:C=C>0>(3)=H(C>0>(2)||H(H(C>4>(0)||C>5>(0))||C>3>(1))).
Номера контрольных комбинаций каждого уровня, которые должны быть переданы вместе с подписью сообщения с номером i (0£i<2L), вычисляются по следующей формуле: C>ë> (>i>l>/>)>2>>l>>û>>Å>>1>, l=0,...,L–1, где xÅ1 означает число, получающееся в результате инвертирования младшего бита в числе x.
Необходимость отправлять вместе с подписью сообщения дополнительную информацию, нужную для проверки подписи, на самом деле не очень обременительна. Действительно, в системе на 1024=210 подписей вместе с сообщением и его подписью необходимо дополнительно передавать 10 контрольных комбинаций, а в системе на 1048576=220 подписей – всего 20 комбинаций. Однако при большом числе подписей, на которые рассчитана система, возникает другая проблема – хранение дополнительных комбинаций, если они рассчитаны предварительно, или их выработка в момент формирования подписи.
Дополнительные контрольные комбинации, которые передаются вместе с подписью и используются при ее проверке, вырабатываются при формировании ключа проверки по ключу подписи и могут храниться в системе и использоваться в момент формирования подписи, либо вычисляться заново в этот момент. Первый подход предполагает затраты дисковой памяти, так как необходимо хранить 2L+1–2 хэш-комбинаций всех уровней, а второй требует большого объема вычислений в момент формирования подписи. Можно использовать и компромиссный подход – хранить все хэш-комбинации начиная с некоторого уровня l*, а комбинации меньшего уровня вычислять при формировании подписи. В рассмотренной выше схеме подписи на 8 сообщений можно хранить все 14 контрольных комбинаций, используемых при проверки (всего их 15, но самая верхняя не используется), тогда при проверке подписи их не надо будет вычислять заново. Можно хранить 6 комбинаций начиная с уровня 1 (C>0>(1), C>1>(1), C>2>(1), C>3>(1), C>0>(2), C>1>(2)), тогда при проверке подписи сообщения №5 необходимо будет заново вычислить комбинацию C>4>(0), а остальные (C>0>(2),C>3>(1)) взять из «хранилища», и т.д.. Указанный подход позволяет достичь компромисса между быстродействием и требованиям к занимаемому количеству дискового пространства. Надо отметить, что отказ от хранения комбинаций одного уровня приводит к экономии памяти и росту вычислительных затрат примерно вдвое, то есть зависимость носит экспоненциальный характер.
Схема цифровой подписи на основе блочного шифра.
Ниже приведены числовые параметры и используемые вспомогательные алгоритмы рассматриваемой схемы цифровой подписи:
E>K> – алгоритм зашифрования с размером блока данных и ключа n и n>K> битов соответственно;
Г>m>(s,K) – алгоритм выработки m битов криптостойкой гаммы с использованием n-битового вектора начальных параметров (синхропосылки) s и n>K>–битового ключа K, представляет собой рекуррентный алгоритм выработки n-битовых блоков данных и их последующего зашифрования по алгоритму E>K>;
P>m>>®>>n>>K> – набор функций расширения m-битовых блоков данных до n>K>-битовых для различных m (типично – для кратных n, меньших n>K>);
L – фактор количества подписей (система рассчитана на N=2L подписей);
n>T>
– число битов в подписываемых битовых
группах, тогда число групп равно >
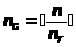 >.
>.
Ниже изложены алгоритмы схемы подписи:
Алгоритм формирования ключей подписи и проверки подписи.
Формирования ключа подписи.
Ключ подписи формируется как n>K>-битовый блок данных с помощью аппаратного генератора случайных кодов или криптостойкого программного генератора псевдослучайных кодов K>S>=G>n>>T>(...). Биты ключа должны быть независимы и с равной вероятностью принимать оба возможных значения – 0 и 1.
Формирования ключа проверки подписи. Схема алгоритма формирования ключа проверки подписи изображена на рисунке 4.
Исходные данные алгоритма – n>K>–битовый массив данных K>S> – ключ подписи.
Вычисляем n>G> – количество n>T>-битовых групп в подписываемых блоках.
Следующие шаги 2–9 выполняются столько раз, на сколько подписей рассчитана схема, т.е. для каждого номера подписи системы.
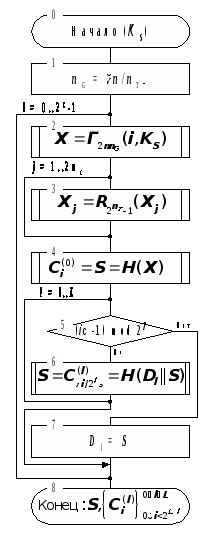
Рис. 4. Алгоритм выработки ключа проверки подписи.
Выработать блок гаммы размером 2nn>G> бит с помощью генератора криптостойкой гаммы на ключе K>S> с начальным заполнением i (номером подписи) и поместить его в 2nn>G>–битовый массив X.2nn>G>–битовый массив X интерпретируется как массив из 2n>G> n-битовых элементов X>j>, X=(X>1>,X>2>,...,X>2>>n>>G>), |X>j>|=n,
затем для каждого элемента этого массива вычисляется результат его «односторонней прокрутки» 2nT–1 раз.
Для массива X вычисляется и записывается в блок данных S его хэш-код, который является индивидуальной проверочной комбинацией для подписи номер i.
Следующие шаги 5,6 выполняются количество раз, равное фактору количества подписей L.
Если l младших бит номера подписи – единицы, переход к шагу 6, иначе – выполнение цикла прекращается и управление передается на шаг 7.
Текущая хэш-комбинация S объединяется c текущей хэш-комбинацией D>l> уровня l, и для полученного массива вычисляется хэш–значение, которое становится новой текущей хэш–комбинацией.
Текущая хэш-комбинация S заменяет хэш-комбинацию D>l> уровня l.
Последняя
вычисленная при выполнении алгоритма
текущая хэш-комбинация S
и будет являться результатом работы
алгоритма – ключом проверки подписи.
Кроме того, в ходе выполнения алгоритма
будут последовательно выработаны
хэш-комбинации всех уровней от 0 до L
>
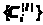 >,
0£l£L,
0£i<2L–l,
которые могут храниться в системе и
использоваться при формировании
подписи.
>,
0£l£L,
0£i<2L–l,
которые могут храниться в системе и
использоваться при формировании
подписи.
Алгоритм подписи хэш-блока массива данных.
Схема алгоритма подписи хэш-блока массива данных изображена на рисунке 5.
Исходные данные алгоритма:
T – подписываемый – n-битовый хэш-блок массива данных;
K>S> – ключ подписи – n>K>-битовый массив данных;
i – порядковый номер подписи.
Вычисляем n>G> – число n>T>-битовых групп в подписываемом n-битном хэш-блоке.
Выработать блок гаммы размером 2nn>G> бит с помощью генератора криптостойкой гаммы на ключе K>S> с начальным заполнением i (номером подписи) и поместить его в 2nn>G>-битовый массив X.
2nn>G>-битовый массив X интерпретируется как массив из n>G> пар n-битовых элементов X=((X>1>,X>2>),...,(X>2>>n>>G>>–1>,X>2>>n>>G>)), |X>j>|=n,
затем для каждой составляющей каждого элемента этого массива, соответствующего определенной битовой группе хэш-блока, нужное число раз выполняется процедура «односторонней прокрутки».

Рис. 5. Алгоритм подписи хэш-кода сообщения.
К индивидуальной проверочной комбинации последовательно добавляется попарные хэш-комбинации, по одной комбинации с каждого уровня от 0 до L–1, которые необходимы при вычислении проверочной комбинации самого верхнего уровня (L), общей для всех сообщений. Номер добавляемой комбинации каждого уровня определяется отбрасыванием количества последних бит в номере подписи, равного номеру уровня, и в инвертировании младшего бита полученного числа.В результате получаем цифровую подпись хэш-блока сообщения S=(X,D), состоящую из массива подписей битовых групп блока X=(X>1>,X>2>,...,X>2>>n>>G>) и из массива дополнительных проверочных комбинаций D=(D>0>,D>1>,...,D>L>>–1>), необходимых для выполнения процедуры проверки подписи и используемых при вычислении попарных проверочных комбинаций.
Алгоритм проверки подписи хэш-блока массива данных.
Схема алгоритма проверки подписи хэш-блока массива данных изображена на рисунке 6.
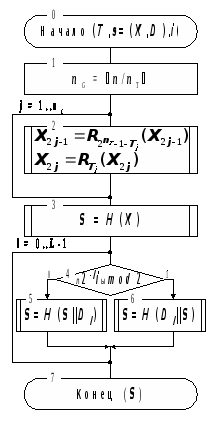 Рис.
6. Алгоритм проверки
подписи.
Рис.
6. Алгоритм проверки
подписи.
T – подписанный – n-битовый хэш-блок массива данных;
s – подпись хэш–блока, состоит из массива X, содержащего 2n>G> n-битовых элементов подписи битовых групп, и массива D, содержащего L n-битовых хэш–комбинаций;
i – порядковый номер подписи.
Вычисляем n>G> – число n>T>–битовых групп в подписываемом хэш–блоке, имеющем размер n бит.
В соответствии с правилами проверки подписи производится «односторонняя прокрутка» элементов подписи битовых групп, содержащихся в массиве X, по два элемента на каждую группу.
Для массива X вычисляется и записывается в S его хэш-код, который должен быть равен индивидуальной проверочной комбинацией для i-той подписи.
Следующие шаги 4–6 выполняются количество раз, равное фактору количества подписей L.
Производится выбор по значению l-того бита (нумерация с 0 со стороны младшего бита) номера подписи.
Если значение бита равно 0, то к коду справа добавляется очередная хэш-комбинация, содержащаяся в подписи, для полученного блока вычисляется хэш-функция, которая замещает предыдущее содержимое S.
Если значение бита равно 1, то выполняется то же самое, только хэш-комбинация добавляется к коду слева.
В конце выполнения алгоритма в S содержится код, который должен быть сравнен с ключом проверки подписи, если коды одинаковы, подпись считается верной, иначе – неверной.
Заключение.
Стойкость предложенной схемы цифровой подписи определяется стойкостью использованного блочного шифра, а устойчивость ко вскрытию переборными методами –наименьшим из чисел n, n>K>. Ключевой комплект в данной схеме рассчитан на определенное число подписей, что, с одной стороны, может восприниматься как недостаток схемы, но с другой позволяет лицензировать количество подписей, облегчая тем самым ее коммерческое использование. Рассматриваемая схема подписи не соответствует стандарту России на цифровую подпись, а алгоритм вычисления MDC – стандарту на выработку хэш-кода массива данных, что делает невозможным аттестацию в соответствующих организациях устройств и программных продуктов, их реализующих. Однако изложенные схемы вполне могут быть использованы там, где спорные вопросы не могут быть вынесены на уровень арбитражных и судебных разбирательств, например, в системах автоматизации внутреннего документооборота учреждений, особенно если электронный документооборот не заменяет бумажный, а существует в дополнение к нему для ускорения прохождения документов.
В качестве приложения к настоящей статье приведены исходные тексты на языке ассемблера для процессоров клона Intel 8086 функции вычисления MDC для блоков данных и функции, реализующие алгоритмы описанной схемы цифровой подписи. Функция выработки хэш-кода (MDC) написана таким образом, что позволяет обрабатывать блоки данных по частям, то есть за несколько вызовов. Все функции используют в качестве основы алгоритм зашифрования по ГОСТ 28147–89. Также прилагаются тексты тестовых программ на языке Си для проверки неизменности файлов на основе MDC и цифровой подписи.
Литература.
А.Ю.Винокуров. ГОСТ не прост...,а очень прост, М., Монитор.–1995.–N1.
А.Ю.Винокуров. Еще раз про ГОСТ., М., Монитор.–1995.–N5.
А.Ю.Винокуров. Алгоритм шифрования ГОСТ 28147-89, его использование и реализация для компьютеров платформы Intel x86., Рукопись, 1997.
А.Ю.Винокуров. Как устроен блочный шифр?, Рукопись, 1995.
М.Э.Смид, Д.К.Бранстед. Стандарт шифрования данных: прошлое и будущее. /пер. с англ./ М., Мир, ТИИЭР.–1988.–т.76.–N5.
Системы обработки информации. Защита криптографическая. Алгоритм криптографического преобразования ГОСТ 28147–89, М., Госстандарт, 1989.
Б.В.Березин, П.В.Дорошкевич. Цифровая подпись на основе традиционной криптографии//Защита информации, вып.2.,М.: МП "Ирбис-II",1992.
W.Diffie,M.E.Hellman. New Directions in cryptography// IEEE Trans. Inform. Theory, IT-22, vol 6 (Nov. 1976), pp. 644-654.
У.Диффи. Первые десять лет криптографии с открытым ключом. /пер. с англ./ М., Мир, ТИИЭР.–1988.–т.76.–N5.
1 Протоколов в криптографии называется набор правил и алгоритмов более высокого порядка, регламентирующих использование алгоритмов низшего порядка. Его основное назначение – гарантировать правильное использование криптографических алгоритмов.